Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
まえがき
この規格は,工業標準化法に基づいて,日本工業標準調査会の審議を経て,通商産業大臣が制定した日
本工業規格である。これによって,JIS Z 8101 : 1981は廃止され,この規格に置き換えられる。
今回の制定では,1999年にFDISとして発行されたISO/FDIS 3534-3を基礎として用いた。
JIS Z 8101 : 1999は,一般名称を“統計−用語と記号−”として,次の各部によって構成される。
第1部:確率及び一般統計 (Part 1:Probability and general statistical terms)
第2部:統計的品質管理用語 (Part 2:Statistical quality control terms)
第3部:実験計画法 (Part 3:Design of experiments)
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
目次
ページ
序文 ··································································································································· 1
適用範囲 ····························································································································· 2
1. 一般用語 ························································································································ 2
2. 実験の配置 ···················································································································· 12
3. 解析の方法 ···················································································································· 28
参考文献 ···························································································································· 34
索引 ································································································································· 38
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
日本工業規格 JIS
Z 8101-3 : 1999
(ISO/FDIS 3534-3 : 1999)
統計−用語と記号−
第3部:実験計画法
Statistics−Vocabulary and symbols−
Part 3:Design of experiments
序文
この規格は,1999年にFDISとして発行されたISO/FDIS 3534-3, Statistics−Vocabulary and symbols−Part 3:
Design of experimentsを翻訳し,技術的内容及び規格票の様式を変更することなく作成した日本工業規格で
ある。
なお,この規格で点線の下線を施してある箇所は,原国際規格にはない事項である。
本質的に実験計画法は,効率的かつ経済的に,妥当で適切な結論に到達できるような実験を計画する方策
である。どの実験計画を選択するかは,提示された問題のタイプ,結論の一般性の程度,実験に用いるこ
とのできる資源(実験に用いる資材,要員,時間),に依存するであろう。適切に計画され実行された実験
では,結果の統計的な分析と結果の解釈が,往々にして簡単になる。
近年,とりわけ製品やサービスの品質改善に実験計画法が必須であるという認識によって,実験計画法が
盛んに適用されるようになってきた。統計的品質管理や,経営的な意志決定,検査,さらに他の品質に関
するツールも,この目的のために用いられているが,実験計画法は複雑で変化に富み相互に作用する状況
での選択の方法論という意義がある。歴史的には,実験計画法は農学の分野で成功し発達してきた。医学
でも,入念な実験計画法との協調関係が長く続いている。現在は,手軽に始められるようにするための工
夫(ユーザーフレンドリーなソフトウェアパッケージ)や,トレーニングの改善,影響力のある提唱者,
実験計画法の成功例の蓄積などにより,各種の産業の場で,この方法論によって注目に値する効果があが
ることが立証されている。
要因実験(2.1参照)は,実験者が興味を持っている複数の因子の間の相互関係を検討するための方法論で
ある。この種の実験は,一度に一つの因子だけを取り上げる直感的な実験よりも,はるかに効果的であり,
また効率的である。他の因子の水準が異なるときに,その因子の(実験の応答で表される)振る舞いが異
なるかどうかを判断するためには,要因実験は特に適している。交互作用(1.17参照)の検討で確認され
た相乗効果を利用することにより,しばしば品質の“大進歩”が達成される。多数の因子を検討したいと
きには,要因実験は実行不可能なほど大きくなってしまう。そのような場合には,一部実施要因実験(2.1.1
参照)が可能な折衷案となる。実際に,当初の目的が後の段階でさらに調査をすべき因子を識別すること
であるのならば,スクリーニング計画(2.2参照)が有用である。
実験の計画に当たっては,実験条件や実験単位への処理の割りあてによって引き起こされるかたよりを制
限することが必要になる。無作為化(1.29参照)やブロック化(1.28参照)といったトピックは,邪魔な,
又は外部の要素の影響の最小化を扱っている。特別なブロック化の方策には,乱塊法(2.3.1参照),ラテ
2
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ン方格法(2.3.2参照)やその変形,釣合い型不完備ブロック計画(2.3.4.1参照)などがある。
継続的な改善を目標とする展開的なプロセスとして実験計画法を考える場合には,応答曲面計画(2.4参照)
が重要な役割を果たす。重要ないくつかの因子について複数の水準を考慮すると,応答曲面法が最適点の
付近に2次効果をぴったりと適応させる。
配合計画(2.5参照)は,合金中の成分のように複数の因子が部分として全体を構成している状況での問題
を扱う。枝分れ計画(2.6参照)は試験室間共同実験で特に有用である。
実験が計画に従って実行されたのであれば,得られたデータの解析の方法は,わかりやすい。グラフィカ
ルな方法(3.1参照)は総合的な結論を明らかにするとき特に効果的に用いられる。モデル(1.1,及びそ
の続きを参照)のパラメータの推定は,ふつう回帰分析(3.3参照)によって行われる。回帰分析は欠測値,
外れ値の識別などの困難な状況も扱うことができる。
良い実験計画とは,
a) 因子や水準の選択,及び前提条件の記述に,事前の知識や経験を組み入れるものであり,
b) 最小の努力で,適切な情報をもたらすものであり,
c) 実験を始める前に,その計画ならば,必要とされる精度で実験の目的に達することができることを保
証するものであり,
d) 多くの研究と同じように,継続的に行われる性格のものであり,
e) 実験の進行中に誤解を避けるために配置と実験処理の順序を明確にするもの,
であろう。
適用範囲
この規格のこの部は,実験計画法の分野で用いられ,日本工業規格を作成する際に用いられ得る用
語を規定する。
1. 一般用語
1.1
(統計)モデル,模型 (とうけい)もでる,もけい
model
応答変数と説明変数との関係及びそれに付随する仮定に関する記述。
備考1. モデルには,三つの要素がある。第一の要素は,モデル化される応答変数(1.2)である。第二
は,説明変数(1.3)に依存したモデルの決定論的あるいは系統的な変動を記述する要素である。
最後は,モデルのランダムな要素,すなわち,誤差あるいは確率的な部分である。ランダム
な要素として,非常に精緻なものを用いることがある。例えば誤差項に,応答変数の実現値
が大きくなるにつれて,変動が増大するようなばらつきの効果(1.14)を取り込むこともできよ
う。1.2,1.3を参照されたい。
例1. 部品の寿命は,部品の周囲の環境条件に依存する。
例2. モデルを更に数式化すると,次のようになる。
yij=μ+αi+βj+εij
ここで,yijは,因子Aの第i水準,因子Bの第j水準での応答変数,μは応答変数の総平均,
αiは,因子Aの第i水準による上乗せ効果,βjは,因子Bの第j水準による上乗せ効果,εijは,
誤差項である。
この場合,モデルの応答変数に関する要素は,単にyijである。モデルの決定論的あるいは系
統的な変動を記述する要素は,μ+αi+βjであり,総平均項と要因効果に関する二つの項からな
3
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
る。モデルのランダムな要素あるいは誤差の部分は,εijからなり,応答変数を生成するプロセ
スに固有な変動を記述している。
例3. 広く用いられるモデルとして次のようなものがある。
yijk=αi+βj+τij+εijk
ここで,yijkは応答変数,αiは,因子1による調整量,βjは,因子2による調整量,τijはこれ
らの因子の交互作用に起因する調整量,εijkは誤差項である。
ここでは,“調整量”という用語を例2.の“上乗せされた効果”の代わりに用いている。その
理由は,例3.の数式モデルには,総平均項が含まれないからである。また,例2.のyijとεijの代
わりに,例3.でyijkとεijkをそれぞれ用いたのは,実験に繰返しが存在することを暗黙の前提と
しているからである。
例4. 次のような数式モデルもある。
yi=eβ0+β1xi+β2xi2+εi
ここで,yiは,説明変数がxiのときの応答変数である。eβ0+β1xi+β2xi2は,説明変数がxiのとき
の応答変数の平均を表現し,εiは誤差項である。
備考2. 上記のモデルに関する記述は,加法的な誤差をもつ古典的な線形モデルだけではなく,一般
化線形モデルに対しても適用される。一般化線形モデルでは,誤差は,2項分布,ポアソン分
布,指数分布,ガンマ分布,正規分布など様々な確率分布によって表される。
1.2
応答変数,目的変数 おうとうへんすう,もくてきへんすう
response variable
実験の結果を表す変数。
備考1. 一般的な同義語として,出力変数 (output variable) がある。
2. 従属変数という用語は,独立 (JIS Z 8101-1 : 1999, 1.7) という用語との混乱の可能性がある
ので,同義語として使うことを奨めない。
3. 各実験単位で複数の応答変数が記録されている場合には,応答変数がベクトル値となること
もある。
1.3
説明変数 せつめいへんすう
predictor variable
実験の結果を説明するのに役立つ可能性のある変数。
備考1. 一般的な同義語として,“入力変数 (input variable)”,“予測変数 (predictor variable)”があ
る。
2. 与えられた説明変数の制御可能性の程度によって,その説明変数が実験計画の中で果たす役
割が規定される。説明変数は,制御可能(固定可能),あるいは準制御可能(短期間ならば制
御可能,又は,それ相当のコストを払えば制御可能),もしくは制御不能(ランダム)な場合
がある。
3. 説明変数にランダムな要素が内在する場合もある。一方,質的な区分を表す場合のように,
誤差なく観測される説明変数,あるいは,割りつけが可能な説明変数もある。
4. 独立変数という用語は,独立 (JIS Z 8101-1 : 1999, 1.7) という用語との混乱の可能性がある
ので,同義語として使うことをすすめない。
1.4
計画空間 けいかくくうかん
design region,design space
4
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
説明変数の値として,許される値の集合。
参考 実験の場ともいう。
1.5
因子,要因 いんし,よういん
factor
応答変数に対する効果を評価することを意図して,変動させている説明変数。
備考1. 因子は,実験結果に対する見逃せない変動原因となる場合がある。
2. ここでは“因子”という用語を説明変数(1.3)の同義語としており,一般用語としての“因子
(factor)”よりは,限定的に用いている。
3. 因子はブロック(1.11)の構成にも関連する場合がある。
参考 最適の水準を選ぶ目的でとり上げる因子を制御因子という。最適水準を選ぶことを目的とせず,
他の制御因子との交互作用を調べることを目的としてとり上げる因子を標示因子という。
1.6
水準 すいじゅん
level
因子の設定可能な値あるいは設定可能な割りつけ。
備考1. “説明変数の値”が,同義語である。
2. “水準”という用語は,通常は量的特性に対して使う。しかし,質的特性の設定を識別する
のにも用いる。
例 触媒に関する二つの水準は,例えば“用いる”か“用いない”かである。熱処理の四つの水準は,
例えば100℃,120℃,140℃,160℃である。試験室に関する質的変数としては,例えば3種の分
析機器に応じて,水準をA,B,Cとすることができよう。
備考3. 一つの因子の様々な水準に対して応答変数を観測すれば,実験の水準範囲内での因子の効果
を定める情報が得られる。水準範囲を超えた外挿は,仮定したモデル式に対して確証がない
限り,通常不適切である。水準範囲内での内挿の妥当性は,水準数と水準間隔に依存するこ
とがある。実験水準の範囲内に,極端な変動を引き起こすような不連続な関係や多峰性が生
じていない限り,内挿は通常妥当である。水準は,選択された規定値(値自体は,既知の場
合も未知の場合もある)に限定される場合もある。また,水準が研究範囲からの純粋にラン
ダムな選択で与えられる場合もある。
1.7
実験誤差 じっけんごさ
experimental error
応答変数の変動の中で,因子やブロック,若しくは,実験実施に関するその他の寄与として説明できな
い変動。
備考1. 実験の材料や環境条件,実験操作を注意深く制御しても,実験を繰り返せば,各試行ごとに
その結果が変動することは,実験の一般的な特性である。したがって,実験誤差が生じるこ
とが,一般的である。この変動が,実験結果から得られる結論にある程度の不確実性を生じ
させる。このため,結論に至る際には,この変動を考慮すべきである。
2. 個々の応答変数の誤差に関するこの漠然とした概念的枠組みを具体的なものに進化させるた
めに,残差(1.21),確率変数としての誤差(1.22),純誤差(1.23) といった用語が用意されてい
る。
3. 実際の実験が,“併行条件 (JIS Z 8101-2 : 1999, 2.12)”や“再現条件 (JIS Z 8101-2 : 1999,
2.15)”で行われるならば,それらの実験条件で求められる“併行標準偏差 (JIS Z 8101-2 : 1999,
5
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2.13)”や“再現標準偏差 (JIS Z 8101-2 : 1999, 2.16)”が,それぞれの実験誤差と関連して興
味の対象となる。
1.8
分散成分 ぶんさんせいぶん
variance component
要因効果あるいは実験誤差を表す確率変数の分散。
備考1. モデルyij=μ+τi+εijで,ここで,τiは,それが取り得る値の無限集合からランダムに抽出さ
れた水準であり,τiとεijの分布は独立である。τiもεijも確率変数である。可能な水準からなる
無限集合からのランダムな選択がなされた後には,解析はτiの実現値に基づいて行われる。
確率構造の観点からは,分散を含む方程式
Var (yij) =Var (τi) +Var (εij)
を考えることに意味がある。ここで右辺をστ2+σε2と表す。στ2,σε2はyijの分散成分を表す
記号である。
2. 枝分れ実験や要因実験への拡張も可能である。
1.9
実験単位 じっけんたんい
experimental unit
特定の処理を受ける単位体。
参考 実験単位に対する処理の結果として,応答変数の値が生成される。
1.10 処理 しょり
treatment
各因子の特定の水準設定。
1.11 ブロック ぶろっく
block
実験単位の全体集合よりは均一となるように実験単位(1.9)を集めたもの。(1.28も参照)
備考1. “ブロック”という用語は,元来農場を風当たり,地下水への近さ,耕地層の厚さといった
共通条件で分割する農事試験に起因する。ブロックとして用いられる他の例は,原材料のバ
ッチ,オペレータ,一日の内で検討される対象単位の数などである。
2. ブロックの存在を意識することで,実験単位に処理を割り付ける方法が,変更されるのが一
般的である。
1.12 1因子実験 いちいんしじっけん
one-factor experiment
単一の因子について,その因子が応答変数に効果があるか否かを調べる実験。
参考 一因子実験と表記してもよい。
例 次のモデルを考える。
y=μi+ε
ここで,yは応答変数,μiは因子の第i水準の平均応答,εは他のすべての効果と変動の原因を
表現する確率変数。
この理論モデルによって,応答変数yと,因子の水準に依る効果μi及び誤差項εとが関連付けら
れる。応答変数に対する因子の効果が,μi間の差違に反映する。この場合,応答変数の平均は,
因子の水準の関数となる。
このモデルの別の表記法は,次のようになる。
6
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
y=μ+αi+ε
ここで,yは応答変数,μは,応答変数の総平均,αiは因子の第i水準により上乗せされる調整
量,εは他のすべての効果と変動の原因とを表現する確率変数である。
1.13 主効果 しゅこうか
main effect
応答変数の平均に対する単一因子の影響。
備考 水準の因子については,主効果は一つの水準からもう一つの水準へ移ったときの応答変数の変
化と関連する。水準を−1(例えば,“低い”)と+1(例えば,“高い”)で表せば,因子の主効
果の推定値は,因子が+1のときの応答の平均値から,因子が−1のときの応答の平均値を引い
たものである。次のモデルを考えよう。
y=μ+βX+ε
ここで,y,μ,εは1.12と同様であり,Xは上記したように+1か−1である。また,βは因
子Xによる調整量を表す。βは,因子Xの主効果の1/2に等しくなることに注意されたい。βが
0の場合には,Xは,Xの水準にかかわらず応答変数の平均に対して影響を及ぼさない。すなわ
ち,Xの主効果は0ということになる。
1.14 ばらつきの効果 ばらつきのこうか
dispersion effect
応答変数の分散に対する単一因子の影響。
備考 因子が応答変数の平均にそれほど影響を与えなくても,応答変数のばらつきには大変な影響を
与える可能性を認識することが大切である。そのような状況では,因子の特定の水準が応答変
数の変動を低くさせる,あるいは一貫させるといった意味で,非常に好ましいことがある。な
お,応答変数の平均と分散の両方に影響を与える因子の存在もあり得る。
1.15 2因子実験 にいんしじっけん
two-factor experiment
応答変数に影響を与え得る二つの異なる因子を同時に検討する実験。
備考 二つの因子が互いに干渉しなければ,“主効果”という用語を適用すべきである。すなわち,個々
の因子に対して主効果とは,応答変数の平均に対するそれぞれの因子の寄与である。
参考 二因子実験と表記してもよい。
1.16 k因子実験 けーいんしじっけん
k factor experiment
応答変数に影響を与え得るk個 (k≧2) の異なる因子を同時に検討する実験。
備考 一般的な同義語として,多因子実験 (multi-factor experiment) がある。
1.17 交互作用 こうごさよう
interaction
応答変数に対する一つの因子の影響が,ほかのいくつかの因子に依存している程度を表す効果。
備考1. 交互作用は,応答に対して一つの因子の主効果では表せず,もう一つの因子の水準に依存す
る程度を示す。交互作用は差の効果とも言われる。以下の図でこれらの現象を示す。
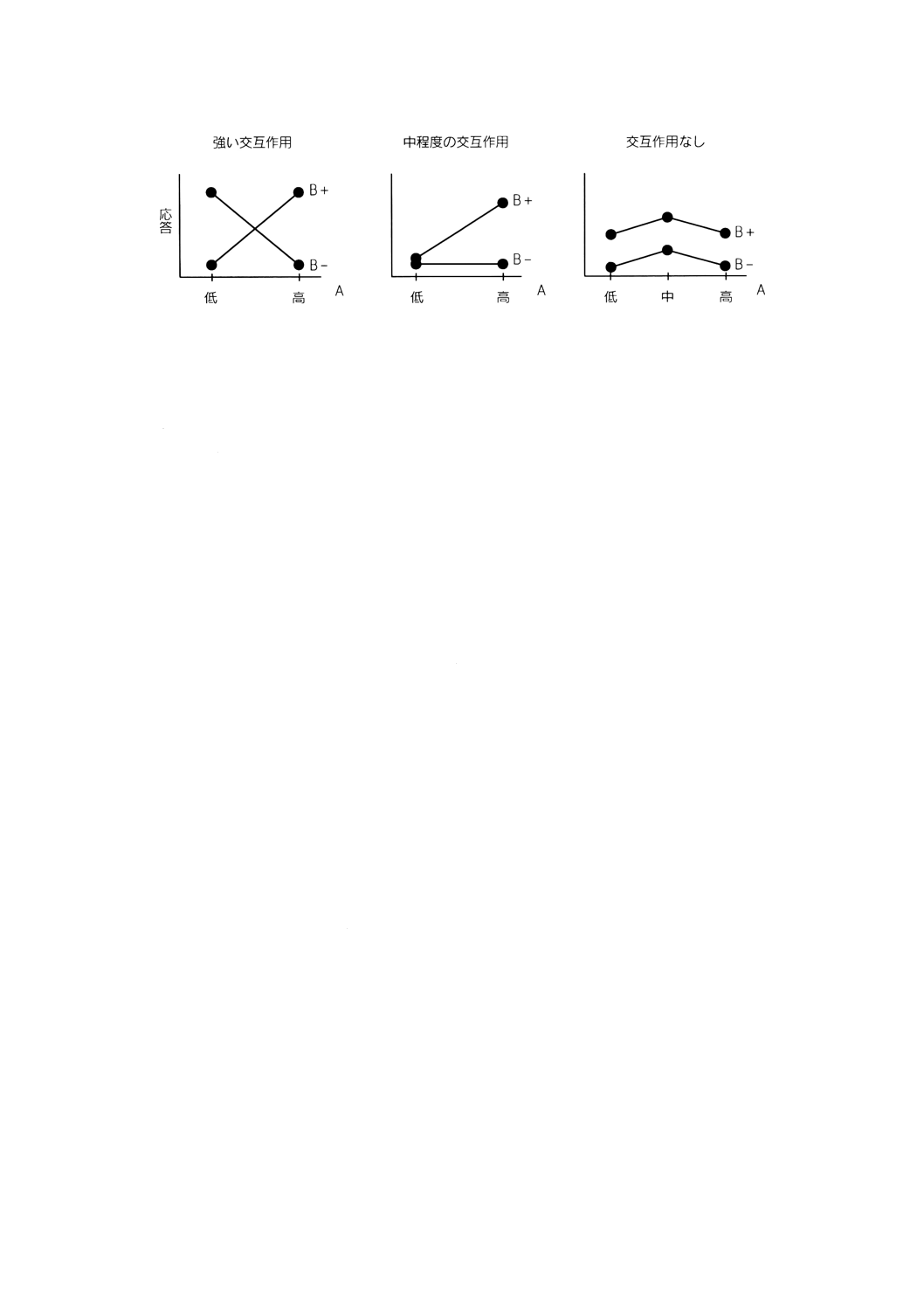
7
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2. 一般に交互作用は二つの因子について考える。より正確には,それは2因子交互作用あるい
は1次の交互作用と言われる。もちろん,三つの因子,例えばA,B,Cにおいて,1次の交
互作用ABが因子Cの水準に依存するという交互作用を考えることもできる。この場合,2
次の交互作用があるという。同様に,3次,4次,より高次の交互作用を考えることもできる。
3. 1.1の例3.において,二つの因子とそれらの2因子あるいは1次の交互作用τijを含んだ実験の
モデルが与えられている。
参考 主効果と交互作用とを総称して要因効果という。
1.18 交絡 こうらく
confounding
二つ以上の要因効果(主効果及び/又は交互作用)が区別できないように計画的に組み合わせること。
備考 交絡は重要なテクニックの一つで,例えば実験において特定のブロックを効率的に利用するこ
とを可能にする。これは,検討の対象でない効果(主効果あるいは交互作用)を前もって選び
ブロック効果に交絡させ,他の重要な効果がそのような交絡から免れるように,計画を立てる
ことによって行われる。交絡は実験の実施計画(1.30)の試行回数を減らすためにも計画的に用い
られる。しかし時に,実験を行っている最中に計画が不注意で変わったり,不完全な計画から
交絡が生じ,実験の効率が落ちたり,あるいは実験が無効になることさえある。
1.19 別名 べつめい
alias
<統計>実験の性質のため,他の主効果や交互作用が完全に交絡している効果(主効果あるいは交互作用)。
1.20 曲線関係,曲線性 きょくせんかんけい,きょくせんせい
curvature
予測変数と応答変数の直線関係からの乖離(かいり)。
備考1. 曲線関係は名義的な,又は順序的な,若しくは質的な説明変数ではなく,量的な説明変数に
対して意味がある。曲線関係を見つけるために因子は3水準以上でなければならない。例えば,
反復された中心点(因子の高と低の中央)は曲線関係の発見や評価を可能にする。また,因
子の水準の範囲を拡げることが曲線関係を観測するために必要になることもある。
2. 1.12の例で示したモデルに戻れば,曲線関係は
Y=μ+βX+γX2+ε
のような形で簡単にモデル化することができる。もし,γが0からずれているならば,直線
関係に比べて曲線関係があるということになる。
1.21 残差 ざんさ
residual
応答変数における観測値と予測値との差。
8
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考 応答変数の予測値は想定したモデルに基づき,そのモデルのパラメータはデータから推定され
る。
例1.
j
i
ij
a
y
β
μ
)
)
)
−
−
−
は,1.1の例2.のモデルを用いたAの第i水準,Bの第j水準の実験単位の残差
である。
2.
ij
j
i
ijk
a
y
τ
β
)
)
)
−
−
−
は,1.1の例3.のモデルに対する残差である。
3.
2
2
1
0
ˆ
ˆ
ˆ
xi
xi
e
yi
β
β
β
+
+
−
は,1.1の例4.のモデルに対する残差である。
1.22 (確率変数としての)残差,実験上の残差 (かくりつへんすうとしての)ざんさ,じっけんじょ
うのざんさ
residual error
応答変数の観測値と,想定したモデルに基づき求めた応答変数の予測値との差を表す確率変数。
備考1. この定義のために,応答変数の予測値という用語は,想定したモデルを用いて実験のデータ
から導かれた経験的なモデルによって定められた処理に対して求めた応答変数の推定値と解
釈される。
例 μ)とβ)がそれぞれ,1.13の備考におけるμとβの推定量ならば,
x
y
β
μ)
)−
−
は予測変数の値がxの
ときのyの観測値が与えられたときの(確率変数としての)残差である。
備考2. (確率変数としての)残差は実験誤差とモデルによって考慮されていない避けられない原因
の変動を含んでいる。
3. (確率変数としての)残差の分散は通常,一つの実験において総平方和から想定したモデル
に含まれる項に関してプールされた平方和を引き,対応する差の自由度で割ることによって
推定される。(3.3の例1.と3.4の例を参照。)
参考 複数の平方和を合算して一つの平方和にすることをプーリングという。プーリング後の平方和
の自由度は対応する平方和の自由度の和になる。
1.23 純誤差,純粋な誤差 じゅんごさ,じゅんすいなごさ
pure error
固定した処理組合せで観測を反復した際の観測値の変動を表す確率変数。
備考1. 計画の中心点のみで反復が行われた場合,中心点の応答に関する標本分散は,純誤差の分散
の推定値を与える。もし,複数の処理組合せで反復が行われた場合,純誤差の分散の総合的
な推定値は,処理組合せごとに推定値を求め,それらをプールすることによって求められる。
例 1.1の例3.に戻ると,固定した (i, j) に対する純誤差の分散の推定値は
(
)2
1
1
1
−
=
∑
−
ij
ijk
ij
ij
y
y
k
n
n
とな
る。ここで,
ijk
ij
ij
ij
y
k
n
n
y
1
1
=
∑
=
である。もし,各 (i, j) の組合せで反復が生じた場合,純誤差の分
散のプールした推定値は
(
)2
,
,
1
−
∑
−
ij
ijk
y
y
k
j
i
IJ
N
,ここで,i=1,…,I ; j=1,…,J ; k=1,…,nijと
いう形になる。
備考2. 純誤差という用語は,実際には二つの異なった意味で使われる。一つは数学モデルに関係し
て母分散(σ2)を指す。もう一つは,推定された(確率変数としての)残差に関連して,モ
デルのあてはまりの不足を検定するための基準を与える標本純誤差あるいは経験的な純誤差
9
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
を指す。1.1でモデルを示している例の中で,例3.だけが純誤差の直接の推定を可能にする反
復をもっている。数学的にみれば,純誤差は例2.ではVar (εij) ,例3.ではVar(εijk) ,例4.では
Var(εi) と解釈される。
1.24 対比 たいひ
contrast
〈統計〉係数のすべてが0でなく,係数の和が0である応答変数の線形関数。
参考 係数の一部に0でないものがあればよい。
備考 観測値y1,y2,…,ynについて,aiのすべてが0でなく,a1+a2+…+an=0を満たすとき,線
形関数a1y1+a2y2+…+anynは対比である。
例1. 一つの因子が3水準で,その結果がy1,y2,y3と表されている。この実験の第1水準と第3水準で
応答の差に興味がある(一時的に中間の水準は無視する)とする。この問題を評価するための
適切な対比は以下に与えられ(質問1参照),それには,y1とy3の値が必要である。水準の間隔
が等しいならば,2番目の疑問(質問2)は応答のパターンが線形な傾向よりも(2次の)曲線関
係を示している証拠があるかということである。これには,y1とy3の平均とy2を比較すること
になる。(曲線関係がなければ,y2はy1とy3を結んだ直線の近くになり,言い換えればy1とy3
の平均にほぼ等しくなるはずである。)
応答
y1
y2
y3
質問1の対比の係数
−1
0
+1
対比1
−y1
+y3
質問2の対比の係数
−1/2
+1
−1/2
対比2
−1/2y1
y2
−1/2y3
この例は連続変数に対する回帰分析的な問題を示している。より便利にするために,しばし
ば対比の係数として分数ではなく整数が用いられる。この場合,対比2の係数は (−1,+2,
−1) となる。
例2. 一つの因子の離散的な水準を扱う例では,異なった組合せの疑問が生じることがある。三つの
供給者があり,一つを新しい製造技術を使っているA1,他の二つA2とA3は従来のものを使っ
ていると仮定する。第1に,新しい技術を使っているA1が古いものを使っているA2とA3と差が
見られるかどうか?y1と,y2とy3の平均を比べる。第2に,従来の技術を使っている二つの供給元
に差があるかどうか?y2とy3を比べる。対比の係数のパターンは先の問題の場合と同じようにな
るが,結果の解釈は異なる。
応答
y1
y2
y3
質問1の対比の係数
−2
+1
+1
対比1
−2y1
+y2
+y3
質問2の対比の係数
0
−1
+1
対比2
−y2
+y3
10
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1.25 直交対比 ちょっこうたいひ
orthogonal contrast
係数について対応するペアを掛け算し,それらの積和が0になるという条件を満たす対比の集合。
例1.
y1
y2
y3
ai1
対比1
−1
0
+1
ai2
対比2
0
−1
+1
ai1ai2
0
0
+1
Σai1ai2=1なので直交していない
例2.
y1
y2
y3
ai1
対比1
−1
0
+1
ai2
対比2
−1
+2
−1
ai1ai2
+1
0
−1
Σai1ai2=0なので直交している
1.26 直交配列,直交配列表 ちょっこうはいれつ,ちょっこうはいれつひょう
orthogonal array
因子のすべてのペアに対して,因子の水準について考えられる処理組合せが同数回現れるような処理組
合せの集合。
備考 直交配列における強さという概念は,直交配列の一つの可能な利用法であるスクリーニング計
画(2.2)に関係がある。強さdの計画は任意のd個の因子における完全な要因計画である。強さ
1は,各因子の水準が同数回現れること(これはバランスした因子とも呼ばれる)を意味する。
直交配列表は強さ2である。部分集合の大きさdが強さである。
1.27 反復 はんぷく
replication
説明変数に関する所与の設定について,複数回の実験を実施すること。
参考 反復の回数を反復数という。
備考 この定義は,JIS Z 8101-1 : 1999, 2.64を実験計画法に合わせた表現に改めたものである。種々
の制約により,反復はランダムな順序ではなく逐次的に実施しなければならないことがある。
このような状況は,繰返しに対応するともいえるが,この用語についての普遍的な合意は得ら
れていない。
また,旧版のISO 3534-3 : 1985で定義されていた重複 (duplication) は,繰返し (repetition) の
基礎となる考え方と重なっている。したがって,JIS Z 8101のこの部においては,反復とは説
明変数がある水準のときに応答変数について複数個の値が得られることを意味する用語とする。
重複,繰返しについては,ISO 10241 : 1992の4節に従いここでは定義しない。
参考 ISO 10241 : 1992は用語の定義方法を規定しており,4節には概念が重なるものは統合すること
が望ましいとしている。この規格は,ISO 3534-3第2版の最終国際規格案 (FDIS;Final Draft
International Standard) の翻訳規格であり,ISO 3534-3第1版 (1985) の翻訳規格は存在しない。
11
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1.28 ブロック化 ぶろっくか
blocking
比較的均一なブロックに実験単位 (experimental unit) を配置すること。
ブロック化により,それぞれのブロック内での実験誤差が,同じ数の実験単位を処理(1.11,2.3参照)
にランダムに割り付ける場合と比べて小さくなることが期待できる。
備考1. 効果を検討するために導入される因子(主因子,principal factors)の他に,すべての実験単位
で一定に保つことが困難または不可能で実験全体では見逃せない原因になるものの影響を考
慮してブロックが選ばれる。これらの見逃せない原因による効果はブロック内では最小化さ
れ,より等質な実験の部分空間が得られる。実験結果の解析においては,ブロックの効果を
評価せねばならない。
2. すべての処理が含まれているブロックは“完備ブロック”と呼ばれる。処理の集合のうち一
部の処理のみが含まれているブロックは“不完備ブロック”と呼ばれる。処理が対 (pair) と
して扱われる場合には,これらの対はブロックとなる。
1.29 ランダム化,無作為化 らんだむか,むさくいか
randomization
処理を実験単位に割り付ける際,それぞれの実験単位にどの処理も等しい確率で割り付けられるように
する方法。
備考 ランダム化は,実験に取り上げていない因子が原因で生じるかたよりを予防することを狙いと
している。ランダム化は,時間・空間的に潜在する影響を減らすであろう。(JIS Z 8101-1 : 1999,
2.65参照)
1.30 実験の実施計画 じっけんのじっしけいかく
experimental plan
処理の実験単位への割りつけと実施の時間的順序。
1.31 計画された実験 けいかくされたじっけん
designed experiment
その目的に適合するように選ばれた実験の実施計画。
備考 実験を計画することの目的は,正当で妥当な結論を効率的かつ経済的に実験の結果から導き出
す方法を,明らかにすることである。適切な実験計画の選択は,取り扱う問題の種類,出す結
論の一般性の度合,高確率で検出したい効果の大きさ(検出力),実験単位の均一性,実験遂行
のコストなどの考慮に依存する。適切に計画された実験の場合には,統計解析,そしてその結
果の解釈は簡単なものになる。
1.32 EVOP いぼっぷ
evolutionary operation, EVOP
日常の生産の中で製造設備を用いて実施される逐次的な実験。
備考 EVOPの主たる目的は,工程改善のための知識を実際の生産時に得ることと,最小のコストで
(生産の許容範囲内での)比較的小規模な水準変更により実験を計画することである。EVOP
においては,因子の水準の変動幅は通常はとても小さく,これは水準変更により規格外品が出
てしまうのを避けるためである。このため偶然変動を減らすために多くの反復が必要になるで
あろう。
12
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1.33 完全ランダム化計画,完全無作為化計画 かんぜんらんだむかけいかく,かんぜんむさくいかけい
かく
completely randomized design
処理がすべての実験単位に対してランダムに割り付けられた計画。
備考 完全ランダム化計画は,すべての実験単位が適度に等質(系統的な差はない)あるいは不均一
性に関する情報がないという仮定のもとでのみ適切な計画となる。
1.34 キューブポイント,頂点 きゅーぶぽいんと,ちょうてん
cube point
水準をコード化して考えたときに,因子の水準からなるベクトル (a1,a2,…,ak) において,すべての
要素が+1または−1であるベクトルで表される点。
備考 これらの点は,2水準要因計画,又はその一部実施計画によって求めることができる(2.1参照)。
2k個の頂点は中心複合計画の中で用いられる(2.4,例1.)。
1.35 スターポイント,星型点 すたーぽいんと,ほしがたてん
star point
水準をコード化して考えたときに,因子の水準からなるベクトル (a1,a2,…,ak) において,一つの要
素だけがαまたは−αに等しく残りは0であるベクトルで表される点。
備考 明らかに,すべてのスターポイントは唯一の非零成分αまたは−αを持つ。中心複合計画におい
ては,典型的には2k個のスターポイントを持つ。
1.36 センターポイント,中心点 せんたーぽいんと,ちゅうしんてん
center point
水準をコード化して考えた場合に,因子の水準からなるベクトル (a1,a2,…,ak) において,すべての
要素が0であるベクトルで表される点。
備考 計画における水準をコード化して考えた場合に,中心点のすべての要素は0で,これをベクト
ルで表現すると (0,0,…,0) となり,この点は計画の中心に対応する。この点の数はn0で表
され,この値は応答曲面計画の様々な目的を達成するために選ばれる。実験を行う場の純誤差
を推定するためにしばしば中心点での反復が行われる。
1.37 回転可能性 かいてんかのうせい
rotatability
あてはめたモデルに基づく予測値の分散が,計画のセンターポイントから等距離ならば等しくなるとい
う,計画についての性質。
2. 実験の配置
2.1
要因実験 よういんじっけん
full factorial experiment ; factorial experiment
二つ以上の水準で探求される二つ以上の因子のすべての可能な処理から構成される実験。
備考1. 要因実験では,すべての交互作用と主効果を推定することができる。
2. 要因実験は,各因子の水準数の積として表現されることが多い。例えば,3水準の因子Aと
2水準の因子Bと4水準の因子Cによる実験は,3×2×4要因実験と表現される。これらの
数の積は処理の総数を表している。
3. 水準数が同じである因子を含む場合は,因子の数(例えばk)を肩に上げて累乗の形で表現
13
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
することが多い。2因子とも3水準である実験は32実験と表され(このときkは2である),
異なる処理が与えられる9個の実験単位を必要とする。
4. 要因実験は(因子が)クロスした計画と呼ばれることもある。
2.1.1
一部実施要因実験 いちぶじっしよういんじっけん
fractional factorial experiment
要因実験の部分集合で構成される実験。
備考 よく使われるものは,実施割合は可能な処理組合せすべての簡単な比になっている。例えば1/2
や1/4などがよく使われる。
2.1.2
2水準実験 にすいじゅんじっけん
two-level experiment
すべての因子が2水準である実験。
2.1.2.1
2k要因実験 にのけーじょうよういんじっけん
2k factorial experiment
k個の因子からなる要因実験で,すべての因子が2水準のもの。
例 圧力,温度,触媒,オペレータの4因子の収量への効果を調べるには,24要因実験が適切である。
Aは圧力(低い高い),Bは温度(低い,高い),Cは触媒(有り,無し)でDはオペレータ(1
人,2人)とする。
実験単位
処理
A
B
C
D
1
(1)
−
−
−
−
2
a
+
−
−
−
3
b
−
+
−
−
4
ab
+
+
−
−
5
c
−
−
+
−
6
ac
+
−
+
−
7
bc
−
+
+
−
8
abc
+
+
+
−
9
d
−
−
−
+
10
ad
+
−
−
+
11
bd
−
+
−
+
12
abd
+
+
−
+
13
cd
−
−
+
+
14
acd
+
−
+
+
15
bcd
−
+
+
+
16
abcd
+
+
+
+
24実験は,上の表に示されているように16の異なる処理からなる。“−”と“+”の記号は各
因子の可能な2水準を表す。多くの場合マイナス記号は因子の低い方の水準を,プラス記号は高
い方の水準を表すが,水準を表す記号は任意でよい。
この表の列の順番は標準イェーツ順序 (standard Yateʼs order) と呼ばれるもので,解析のときに
都合がよい。これらの処理を実際に行う順番は,無作為化(1.29参照)して決定されなければな
14
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
らない。最初の因子Aは符号が交互に(−,+,−,+,のように)なっている。2番目の因子
Bは二つのマイナスと二つのプラスが交互になっている。因子Cは四つのマイナスと四つのプラ
スが交互になっている。最後に,因子Dは実験1から8まではマイナスで,9〜16まではプラス
である。JIS Z 8101のこの部の以降の部分では,マイナスは−1とプラスは+1と解釈する。
参考 田口の直交配列表と標準イェーツ順序の表は,本質的には同じものであり,行の入れ換えの操
作によって相互に変換することができる。標準イェーツ順序の表の実験単位番号1〜16の各行
を,上から順に16,8,12,4,14,6,10,2,15,7,11,3,13,5,9,1と並べ替えると田
口のL16直交配列表が生成される。
表の第2列は,処理の内容を簡潔に表現したものである。小文字が存在する場合には,対応
する大文字で表される因子が高い水準であることを示している。文字がない場合は,その文字
に対応する因子は低い水準である。すべての因子が低い水準である処理は “(1)” と表現する。
要因実験ではすべての主効果と交互作用を推定できる。24の例では,四つの主効果 (A,B,
C,D),六つの2因子(1次の)交互作用 (AB,AC,AD,BC,BD,CD),四つの3因子(2
次の)交互作用 (ABC,ABD,ACD,BCD) と,一つの4因子(3次の)交互作用 (ABCD) が
ある。
各効果は(例えば,Aによる効果,AとBの交互作用,さらにはA,B,C,Dによる4因子
交互作用など),対比の係数を用いて即座に推定できる。このことについては,3.3で議論する。
2.1.2.2
2k−P一部実施要因実験 にのけーまいなすぴーじょういちぶじっしよういんじっけん
2k-p fractional factorial experiment
2k要因実験から注意深く選ばれた (2−P) 部分集合を用いる実験。
備考1. 因子が多いとき,2k要因実験は実施可能でないほどの処理を必要とすることがある。全処理
の部分集合を注意深く選ぶことによって,要因実験とほぼ等しい情報を一部実施実験で集め
ることができる。特に,重要と思われる効果や交互作用は,無視できると思われる交互作用
とだけ交絡するように選ぶ。
2. Pが1のとき結果として得られる一部実施要因実験は1/2(半分)実施 (half-fraction) と呼ば
れ,Pが2のときは1/4実施 (quarter-fraction) と呼ばれる。以下,同様である。
3. 2k−P実験はk個の因子をk−P個の第1グループとP個の第2グループの二つに分けて構成
できる。第1グループのk−P因子は2k−Pの実験単位からなる要因実験として割り当てられ
る。この実験単位数は全体の実験数となる。第2グループの各因子の水準は第1グループの
因子の水準で決定される。第2グループの各因子の水準を第1グループの因子の水準で表す
P個の等式の集まりは,計画を生成することから生成関係 (generating relation) と呼ばれる。
生成関係のP個の方程式は計画の性質を定義する2P−1個の定義関係 (defining relation) を求
めるのに使われる。
参考 原国際規格案では定義関係の個数を2k−P−1個と誤って記述している。
例 16処理の6因子実験を考える。これは,26−2一部実施要因実験を意味している。4因子 (A,B,
C,D) で要因実験を行うように組むことができる。残りのEとFの2因子はA,B,C,Dの水
準から決定できる。一つの可能な表現は,E=ABCとF=BCDである(この構成法から得られる
4文字の記号列ABCEとBCDFはワード(“語”)と呼ばれる。同様に,ABCは3文字語でACDEG
は5文字語である)。因子の水準として+1と−1を用いることで,A,B,Cの水準が(積ABC
で)対応するEの水準を決定する。同様にB,C,Dの水準が(積BCDで)Fの水準を決定する。
15
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
例えば第1番目の実験単位の場合,AからDは2.1.2.1にある例の表のとおりである。第1実験単
位ではEとFも低い水準である。主効果Eは3因子交互作用ABCと交絡し,FはBCDと交絡す
る。完全な別名または交絡関係は定義関係I=ABCE=BCDF=ADEFから求めることができる。
2.1.3
計画のレゾリューション,計画の分解能 けいかくのれぞりゅーしょん,けいかくのぶんかいのう
design resolution
定義関係の中でもっとも短い記号列の長さ。
備考1. 計画のレゾリューションはその計画の別名関係の程度を表している。長さは普通大文字のロ
ーマ数字で表す。最もよく用いられるのは,レゾリューションIII,IV,Vの三つである。
レゾリューション(分解能)IIIの計画では,最も短い記号列の長さは3である(Iは考え
ない)。これは,この計画では主効果が他の主効果と別名関係にならないことを示している。
少なくとも一つの主効果はどれかの2因子交互作用と別名関係になる。
レゾリューション(分解能)IVの計画では,主効果は他の主効果およびどの2因子交互作
用とも別名関係にならない。少なくとも一つの2因子交互作用はどれか他の2因子交互作用
と別名関係になる。
レゾリューション(分解能)Vの計画では,主効果と2因子交互作用は他のどの主効果や
2因子交互作用とも別名関係にならない。
2. レゾリューションが高いほど,多くの効果(主効果や交互作用など)があいまいなく推定で
きる。因子数も実験数も同じ二つの計画からひとつ選ぶときには,レゾリューションが高い
ほうを選択すべきである。幸いにも,実際に用いる多くのkやPに対しては,最も適当と思
われる定義関係が与えられている。(例えば,参考文献[3]p.410を参照。)
例 2.1.2.2の例を続ける。この26−2一部実施要因実験における計画のレゾリューションは定義関係か
ら求められる。正確には,定義関係での最短の記号列(Iを除く)の長さが計画のレゾリューシ
ョンである。IA=AI=A,IB=BI=B,I=A2=B2=C2などの関係を使うと,関係式E=ABCは
EE=ABCEとなり,さらにI=ABCEと書ける。同様にF=BCDからはI=BCDF導ける。定義関
係は一般化交互作用ABCE×BCDF=ADEFを評価することで完結する。(I以外で)最も短い語の
長さは4なのでレゾリューションIVである。
備考3. これらの計画生成子はボックス・ハンター生成子と呼ばれるが,その起源はさらにさかのぼ
ることができる。
2.2
スクリーニング計画 すくりーにんぐけいかく
screening design
引き続く探求のために因子の部分集合を特定するための実験。
参考 この“因子の部分集合”は重要と思われる因子の集合を意味している。
備考1. このような実験は,一般に主効果の探求に焦点を当てているが,交互作用の存在が分析を複
雑にするので,この曖昧さを解くために追加実験が必要になることがある。
例1. 前の2.1.2.2で与えた2k−P一部実施要因実験(特に実施割合が低いもの)は,スクリーニング計
画とみることができる。
例2. プラケットとバーマン[4]は処理数が4の倍数である一連の2水準スクリーニング計画を提案し
た。彼らの計画は,探索する主効果の数が(繰返しなしの)処理数に近いときに選ばれること
が多い。例えば,下のような処理数12のプラケット・バーマン計画は11効果までスクリーニン
グすることができる。この計画では,2因子交互作用(例えばAB)の存在は,主効果C,D,
16
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…,Kの推定に影響を及ぼす。
実験単位
A
B
C
D
E
F
G
H
I
J
K
1
+
−
+
−
−
−
+
+
+
−
+
2
+
+
−
+
−
−
−
+
+
+
−
3
−
+
+
−
+
−
−
−
+
+
+
4
+
−
+
+
−
+
−
−
−
+
+
5
+
+
−
+
+
−
+
−
−
−
+
6
+
+
+
−
+
+
−
+
−
−
−
7
−
+
+
+
−
+
+
−
+
−
−
8
−
−
+
+
+
−
+
+
−
+
−
9
−
−
−
+
+
+
−
+
+
−
+
10
+
−
−
−
+
+
+
−
+
+
−
11
−
+
−
−
−
+
+
+
−
+
+
12
−
−
−
−
−
−
−
−
−
−
−
備考2. 多くのプラケット・バーマン計画はアダマール行列と関連がある。アダマール行列は初期に
は理論的観点で研究されていたが,その後実験計画に有効であることが分かった。アダマー
ル行列は一つの列(同じことであるが,行でもよい)の知識だけで簡単に構成できる。一つ
の構成法は,一番下の行をすべてマイナス符号とする。残りの列の要素は,第1列の要素を一
行下げながら右に移動し,11番目の要素を一番上に持っていく。の手順を行列が完成するま
で続ける。この行列の例を下に示す。構成法から,第1列のプラス符号のある場所を示せば十
分である。
n
第1列のプラス符号の行番号
12
1, 2, 4, 5, 6, 10
20
1, 2, 5, 6, 7, 8, 10, 12, 17, 18
24
1, 2, 3, 4, 5, 7, 9, 10, 13, 14, 17, 19
上のn=12で示した行番号は,例2.で詳細に示した計画と一致していることに注意する。
プラケット・バーマン計画の多くは,一列の要素の情報をもとにしてこの一般的方法で構成
できる。しかし,n=28,52,76,92,100についてはこの簡単な方法では作成できない。詳
細は参考文献[5]を参照のこと。
3. 田口玄一は,使いやすい工夫を施すことでプラケット・バーマン計画を普及させた。配列L12
は上に示した実験数12のプラケット・バーマン計画と同じものである。L20は実験数20の
プラケット・バーマン計画と同じものである。L配列は計画行列の要素をアダマール行列の
構成とは異なる順番で並べていることに注意する必要がある。
参考 2.1.2.1の参考を参照。
備考4. プラケット・バーマン計画は,過飽和実験(実験数よりも因子の方が多い実験)の水準設定
にも用いられている。詳細は参考文献[6]及び[7]を参照のこと。
2.3
ブロック計画 ぶろっくけいかく
block design
実験単位全体が均一な部分集合に分割できることが分かっている場合に,この均一性に関する情報を積
極的に利用する実験計画。
17
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考 実験単位間の不均一性を実験計画において無視すると,観測値の変動が増加し,実験から得ら
れる情報量が減少することになる。このことを計画段階において考慮することにより,実験を
目的にかなったものにすることができる。
2.3.1
乱塊法 らんかいほう
randomized block design
P個の処理を含むn個のブロックから構成される実験計画。
P個の処理はランダム化により各ブロック内の実験単位に割り当てられる。
備考 乱塊法では,ブロック内の実験単位の方がブロック間の実験単位よりも均一になるように,実
験単位がいくつかのブロックにグループ分けされる。各ブロック内では,処理はランダムに実
験単位に割り当てられる。処理間の相対的な効果は,異なるブロック間の効果に影響されるこ
となく,効率的に推定される。
2.3.2
ラテン方格法 らてんほうかくほう
Latin square design
すべてh水準の三つの因子を含み,任意の2因子のすべての水準組合せが1回だけ現れるような大きさ
h2の実験計画。
備考1. ラテン方格法は三つの因子,すなわち,処理に関連する主要な因子とブロック効果に関連す
る2次的な二つの因子とを含む。これらの因子はいずれも同じ水準数をもつ。h2個(hは2以
上の整数)の実験単位は,2種類のブロック因子(行因子と列因子)によって分類される。主
要な因子のh水準は,各行・各列に1回だけ各水準が現れるという制約のもとに,ランダムに
h2個の実験単位に割り当てられる。したがってラテン方格法は,二つのブロック化変数(二
つの外的変動要因)を含むように乱塊法を拡張したものである。この設定において,主要な
因子の水準数はブロック因子の水準数と等しくなければならない。
三つの4×4ラテン方格を下に示す。これらはいずれも,ラテン方格法の基になる。四つの
行は一方のブロック因子の水準を与え,四つの列は他方のブロック因子の水準を与える。主
要な因子の四つの処理水準はA,B,C,Dである。
ABCD
ABCD
ABCD
BADC
DCBA
CDAB
CDAB
BADC
DCBA
DCBA
CDAB
BADC
2. ラテン方格法は一般に,その実験において興味の対象ではない2種類のブロック効果の影響
を,“バランスを取る (balancing out)”ことによって取り除くために使われる。ブロック化
(1.28)を参照せよ。2種類のブロックは,慣例的に方格の行と列とによって表される。例えば,
各行を実験日に対応させ,各列をオペレータに対応させる。主要な因子の水準数 (h) は,各
ブロック因子の水準数に等しい。ランダム化は次の手順で行う。主要な因子の水準をランダ
ムにラテン文字に割り当てる。ラテン方格の一覧表から一つをランダムに選ぶか, “Statistical
Tables” [8]に説明されている手順でラテン方格を一つ選ぶ。二つのブロック因子の水準を方格
の行と列にランダムに配置する。[ラテン方格の数は,1 (2×2) ; 12 (3×3) ; 576 (4×4) ; 161,
280 (5×5) である。このうち,1 (2×2) ; 1 (3×3) ; 4 (4×4) ; 56 (5×5) 個が“標準 (standard) ラ
テン方格”である。標準ラテン方格とは,第1行と第1列がアルファベット順に並んでいる
ものをいう。他のラテン方格は,標準ラテン方格の行と列を並べ替えることによって構成す
18
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ることができる。]
3. これらブロック因子は,互いに,また主要な因子との間に交互作用をもたないことが基本的
な前提条件である。もしこの前提条件が成り立たなければ,実験上の残差の値は増加し,因
子の効果はそのような交互作用と交絡することになる。上記の前提条件が成り立つとき,こ
の計画は特に実験の規模を最小化することに有効である。ときには,ブロック因子の代わり
に他の主要な因子を用いて,三つの主要な因子を取り上げる場合もある。これは,交互作用
がないという前提条件のもとでの,一部実施要因実験と同値である。一部実施要因実験の計
画にはラテン方格法を構成するものがある。交互作用に関する前提条件をより完全に理解す
るためには,一部実施要因実験の観点からこの問題に接近する方が望ましい。
参考 因子の水準数をそろえるために同じ水準を他の水準名でも重複して用いる時,それを擬水準と
いう。擬水準を用いた実験では,解析法に工夫を要する。
2.3.3
グレコラテン方格法 ぐれこらてんほうかくほう
Graeco−Latin square design
すべてh水準の四つの因子を含み,任意の2因子のすべての水準組合せが1回だけ現れるような大きさ
h2の実験計画。
備考1. グレコラテン方格法は四つの因子を含む。h2個(hは3以上の整数)の実験単位は,h水準を
もつ3種類のブロック因子(例えば,行因子,列因子,ギリシャ文字)によって分類される。
主要な因子のh水準は,ランダムにh2個の実験単位に割り当てられる。
ただし,各処理水準は,各行・各列に1回だけ現れるとともに,各ギリシャ文字とも1回
だけ一緒に現れなければならない。
2. 二つのラテン方格は,一方の方格の各ラテン文字が,他方の方格の各ラテン文字と1回だけ
同時に現れるとき,直交しているといわれる。二つの直交するラテン方格法を組み合わせて
グレコラテン方格法を構成することができる。
3. グレコラテン方格法は,主要な因子の水準数と同じ水準数をもつ三つのブロック化変数を取
り上げることができる。
例 4×4グレコラテン方格法の一例は次のとおりである。
Aα
Bβ
Cγ
Dδ
Bδ
Aγ
Dβ
Cα
Cβ
Dα
Aδ
Bγ
Dγ
Cδ
Bα
Aβ
因子1は行,因子2は列で与えられる。因子3はギリシャ文字で表される。主要な因子(第4
の因子)はラテン文字で表されている。
参考 互いに直交する3個以上のラテン方格を組み合わせた計画を超方格 (hyper square) という。
2.3.4
不完備型ブロック計画 ふかんびがたぶろっくけいかく
incomplete block design
実験単位をいくつかのブロックに分割するけれども,各ブロックで処理の完全な一組を実施することが
できないような実験計画。
備考 実際,乱塊法(2.3.1)は,各ブロックにおいてすべての処理を実施するのに十分な数の実験単位
が用いられることを強調して,“完備型ブロック計画 (complete block design)”と考えることが
できる。

19
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2.3.4.1
釣合い型不完備ブロック計画,BIBD つりあいがたふかんびぶろっくけいかく,びーあいびー
でぃー
balanced incomplete block design, BIBD
主要な因子のl個の水準を,各ブロックが等しくk個の異なる水準を含むb個のブロックに配置した不
完備型ブロック計画。
水準のすべてのペアは等しくλ個のブロックに現れる。
参考 λを会合数という。
備考1. “釣合い (balanced)”という用語は各ペアの実現数が等しいことを表し,“不完備
(incomplete)”は各ブロックで主要な因子のすべての水準を実施することができないことを表
している。“ブロック (block)”は,実験単位の均一な部分集合上で実験を実施することを表
している。
例1. 4処理,6ブロック,各ブロック2処理(l=4,k=2,b=6,λ=1)の状況を考える。具体的には,
主要な因子の4水準 (T1,T2,T3,T4) を取り上げるけれども,1日に二つの水準しか実施できな
いものとする。6日間でこの実験を実施するとすれば,次の計画が適切である。
日
T1
T2
T3
T4
1
*
*
2
*
*
3
*
*
4
*
*
5
*
*
6
*
*
この例では,処理水準の各ペアは1回ずつ同じブロックに現れている。
例2. 主要な因子の6水準,10ブロック,各ブロック3水準(l=6,k=3,b=10,λ=2)の状況を考え
る。この場合,6水準から3水準の組を選ぶ可能な組合せの数は20なので,20個のブロックが必
要であると考えるのは自然である。次の処理組合せを考えよ。ここで,三つの処理水準の組が
各ブロックを表している。
(T1, T2, T3), (T1, T2, T4), (T1, T3, T5), (T1, T4, T6), (T1, T5, T6)
(T2, T3, T6), (T2, T4, T5), (T2, T5, T6), (T3, T4, T5), (T3, T4, T6)
ここで,水準の各ペアは正確に2回ずつ同じブロックに現れている。このことは,10ブロッ
クで十分なことを意味している。
例3
7水準,7ブロック,各ブロック4水準(l=7,k=4,b=7,λ=2)の状況を考える。
主要な因子の水準
ブロック
1
1
2
3
6
2
2
3
4
7
3
3
4
5
1
4
4
5
6
2
5
5
6
7
3
6
6
7
1
4
7
7
1
2
5
備考2. 釣合い型不完備ブロック計画では,主要な因子の各水準は実験において等しくr回現れる。
そして,次の関係が成り立つ。
20
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
b・k=l・h, b≧l, h (k−1) =λ (l−1)
上の数式において各記号は整数を意味しているので,(l,k,b,h,λ)の組合せのうち限
られたものだけから不完備型ブロック計画を構成することができる。しかし,与えられた五
つの整数(l,k,b,h,λ)が上記の三つの条件を満足しても,必ずしもBIBDが存在すると
は限らない。
3. ランダム化のためには,各ブロックをランダムに配置し,ブロック内で独立に処理水準をラ
ンダムに配置する。
2.3.4.2
部分釣合い型不完備ブロック計画,PBIB ぶぶんつりあいがたふかんびぶろっくけいかく,ぴ
ーびーあいびー
partially balanced incomplete block design, PBIB
主要な因子のl個の水準を,各ブロックが等しくk個の異なる水準を含むb個のブロックに配置した不
完備型ブロック計画。
水準のペアが同じブロックに一緒に現れる回数は,ペアによって異なる。
備考1. l個の水準とb個のブロックからなる不完備型ブロック計画は,次の条件を満たすとき,m (≧
2) クラスのアソシエートをもつPBIBという。
a) 各ブロックはk (<l) 個の異なる水準を含む。
b) 各水準はh個のブロックに現れる。
c) 水準間に次の関係が存在する。
− 任意の二つの水準は,第1種,第2種,…,第m種のアソシエートのいずれかである。この
関係は対称的である(水準αが水準βの第i種アソシエートならば,水準βは水準αの第i種ア
ソシエートである)。
− 各水準はni個の第i種アソシエートをもつ (i=1,2,…,m) 。数値niは選ばれた水準には
依存しない。
− 第i種のアソシエート関係にある水準のペアαとβが与えられたとき,αの第j種アソシエート
であり,βの第k種アソシエートである水準の数はPjki (i,j,k=1,2,…,m) である。数値
Pjkiは第i種のアソシエートにあるペア (α,β) に依存しない。
d) 互いに第i種アソシエートの関係にある任意の二つの水準は,λi (i=1,2,…,m) 個のブ
ロックで一緒に現れる。すべてのλiが等しいとは限らない。
2. 整数l,b,h,k,λ1,λ2,…λm,n1,n2,…nm,Pjki (i=1,2,…,m) には次の関係がある。
l・h=b・k
n1λ1+n2λ2+…+nmλm=h (k−1)
n1+n2+…+nm=l−1
niPjki=
ik
i
jP
n
=
ij
k
kP
n
例 次の表に示されるl=6,k=4,b=6,h=4,n1=1,n2=4,λ1=4,λ2=2の状況を考える。
主要な因子の水準
ブロック
1
1
4
2
5
2
2
5
3
6
3
3
6
1
4
4
4
1
5
2
5
5
2
6
3

21
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
6
6
3
4
1
この計画で,各水準はh=4回実施され,任意の水準(例えば,水準1)から始めると,n1=1
個の水準(例えば,水準4)がλ1=4個のブロックにおいて水準1と共に現れ,n2=4個の水準(水
準2,3,5,6)はλ2=2個のブロックにおいて水準1と共に現れる。どの水準から始めても,こ
れらのパラメータn1,n2,λ1,λ2は,同じである。
2.3.5
ユーデン方格 ゆーでんほうかく
Youden square
ラテン方格から,行または列を取り除いたり,あるいは加えたりすることによって導かれるブロック計
画で,一方のブロック因子に関しては乱塊法,他方のブロック因子に関しては釣合い型不完備ブロック計
画になっている計画。
備考 ユーデン方格は,行列の行と列とによって表される二つのブロック因子をもつ計画と考えるこ
とができる。行列の各要素は主要な因子の水準を表している。例えば,次の配置において列の
数が水準の数と等しく,行の数は列の数より少ないとする。行ブロック因子に関しては乱塊法
となるように,各水準は各行において1回現れる。これに対して,列ブロック因子に注目すれ
ば,釣合い型不完備ブロック計画となる。4×4ラテン方格から第4行を除去することによって,
3×4ユーデン方格が得られる。
例1.
ブロック因子2(列)
ブロック因子1
(行)
1
2
3
4
1
A
D
C
B
2
B
A
D
C
3
C
B
A
D
D
/
C
/
B
/
A
/
ラテン方格から除去
A,B,C,Dは主要な因子の4水準を示している。
例2. 次の配列は4×7ユーデン方格を示す。
3
4
5
6
7
1
2
5
6
7
1
2
3
4
6
7
1
2
3
4
5
7
1
2
3
4
5
6
この例において,四つの行は乱塊法であり,七つの列はパラメータl=b=7,h=k=4,λ=2
のBIBDであることが分かる。
2.3.6
分割法 ぶんかつほう
split-plot design
主要な因子の同じ水準が割り当てられている実験単位の一群(プロット,plot)を分割 (split) し,他の
いくつかの主要な因子の効果を最初の主要な因子の各水準内で検討することができるようにした計画。
例 因子Aの3水準を2反復で試験する。
Aの各水準内で因子Bの同じ2水準を研究する。
反復I
反復II
プロット
A1
A1B2
A1B1
A1B2
A1B1
A2
A2B1
A2B2
A2B1
A2B2
A3
A3B1
A3B2
A3B2
A3B1
22
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考1. この例で,反復は1次因子 (A) に対してブロックの役割を果たしている。Aの3水準の一つが
割り当てられた各プロットは,2次因子B(プロット内因子)に対してブロックの役割を果た
す。Bの効果はAの水準内で調べられることになる。したがって,プロット内因子Bについ
て残差の推定値は,実験全体の残差の推定値よりも小さくなるはずである。分割法では,プ
ロット内効果とプロット間効果に対して異なる残差の値が得られる。この計画を拡張して,2
次因子の水準内で比較されるような3次因子を導入することも可能である。分割法がよく用い
られるのは,一つの因子に関しては,その水準を変えることが容易ではないので一連の広い
実験領域に水準が割り当てられるのに対して,他の因子に関しては一連の実験領域の中で容
易に水準を変えることができる場合である。
参考 1次因子,2次因子を,一次因子,二次因子と表記してもよい。
備考2. この実験配置は,農業実験[ここに,分割法 (split-plot design) の名前が由来している。]と
ともに,工業実験においても普通に用いられる。しばしば,ある因子の一連の水準が大きな
実験単位を必要とするのに対して,他の因子の一連の水準は,より小さな実験単位で比較す
ることができる。例えば,合金を製造するための異なるタイプの炉の比較は,異なるタイプ
の鋳型の比較よりも多くの合金材料を必要とするであろう。炉のタイプは1次因子の水準,鋳
型のタイプは2次因子(プロット内因子)の水準と考えることができる。別の例は,大きな機
械を用いる場合である。その作業速度を変えるには,一連の歯車を交換するという時間とコ
ストのかかる仕事が必要なので,この因子の水準を頻繁に変化させることは望ましくない。
各速度で製造された材料は,いくつかの手法で熱処理されたり,異なる圧力のもとで成形さ
れたり,異なる光沢剤で磨かれたりする。これら三つの因子の水準を変えることは比較的容
易である。後者がプロット内因子(2次因子)となり,作業速度がプロット間因子(1次因子)
となる。
参考 一次因子の主効果は一次誤差 (first order error) で検定し,二次因子の主効果は二次誤差
(second order error) で検定する。1次誤差,2次誤差を,一次誤差,二次誤差と表記してもよ
い。
2.3.7
2方分割法 にほうぶんかつほう
two-way split-plot design, split-block design
2次因子の水準が,各プロットで独立にランダム化されるのではなく,各反復におけるプロットにまた
がって帯状に配置されている分割法。したがって,二つの異なる方向への分割法と考えることができる。
参考 二方分割法と表記してもよい。
例 3×4計画において,ランダム化後の適切な配置は次のようになる。
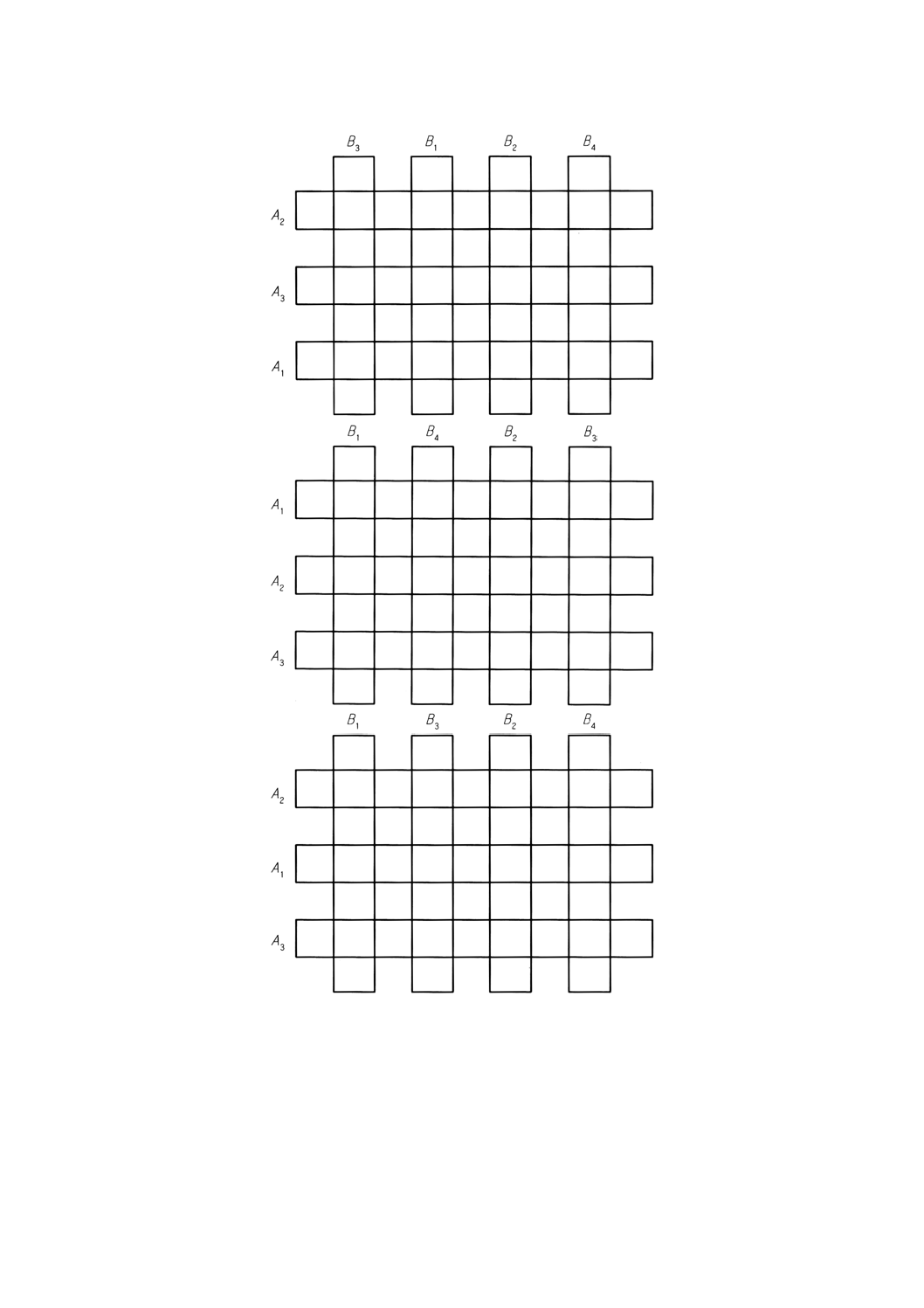
23
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考 2方分割法は,AとBの主効果(平均効果)の精度を犠牲にして,交互作用(差の効果)の精
度を高くしている。一般に交互作用に関しては,乱塊法や通常の分割法よりも正確に調べるこ
とができる。
工場実験では,実際上の見地からこの計画が必要になる。例えば繊維工業において,因子A
は二酸化塩素による漂白工程の異なる処理法,因子Bは冷却工程における異なる過酸化水素添
加量である。
24
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2.4
応答曲面計画 おうとうきょくめんけいかく
response surface design
応答変数と説明変数群の関係を研究することをねらいとした実験計画。
備考1. これらの計画を用いることの明らかな利点は,応答変数を改善するため,説明変数に関する
連続的な調節についての示唆が得られる点である。
例1. 中心複合計画 (central composite design) の例を示す。
これは効率的な計画(典型的には回転可能)となるように選ばれた頂点,星型点,中心点か
らなる処理の組合せである。三つの説明変数について,次の組合せは中心複合計画となる。
実験単位
x1
x2
x3
1
−1
−1
−1
2
1
−1
−1
3
−1
1
−1
4
1
1
−1
5
−1
−1
1
6
1
−1
1
7
−1
1
1
8
1
1
1
9
0
0
0
10
0
0
0
11
−2
0
0
12
2
0
0
13
0
−2
0
14
0
2
0
15
0
0
−2
16
0
0
2
実験単位1−8は計画の頂点への配置であり,これは23要因計画に等しい。説明変数の水準
はコード化して示している。実験点9,10は中心点,実験点11−16は星型点である。最初の8
個の実験点についてまずは一つのグループとして実験が行われ,その後に残りの実験点が行わ
れると推察される。(実際の実験順序は無作為化されるべきである。)中心複合計画では計画を
逐次的に組み合わせることが容易である。この計画によって収集されたデータに対するモデル
は,
線形 (x1, x2, x3) ,2乗 (x12, x22, x32) ,2因子交互作用 (x1x2, x1x3, x2x3) からなる。
備考2. 中心複合計画の変形として,ある因子(群)の水準数を減らした面中心型中心複合計画があ
り,これはすべての星型点をα=1とすることによって導かれる。因子の水準数を減らすこと
によって,回転可能性が損なわれることがある(因子の数に依存する)。
例2. ボックス−ベーンケン計画 (Box−Behnken design) は,2k要因計画に釣合い型不完備ブロック
計画を組合わせることにより構成される。次は3変数のBox−Behnken計画である。
25
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
実験単位
x1
x2
x3
1
0
−1
−1
2
0
1
−1
3
0
−1
1
4
0
1
1
5
−1
0
−1
6
1
0
−1
7
−1
0
1
8
1
0
1
9
−1
−1
0
10
1
−1
0
11
−1
1
0
12
1
1
0
13
0
0
0
14
0
0
0
15
0
0
0
例3. 五角形計画 (pentagon design) は,2因子で単位円(水準をコード化した場合)上に等距離に位
置する五つの点からなる計画で,可能ならば中心点を反復する。この定義を満たす五つの点は:
(1,0), (0.309,0.951), (−0.809,0.588), (−0.809,−0.588), (0.309,−0.951) である。
これらの値は,cos (72°) =0.309,sin (72°) =0.951のようになっている。
例4. 六角形計画 (hexagon design) は,2因子で単位円(水準をコード化した場合)上に等距離に位置
する六つの点からなる計画である。可能ならば中心点で反復を実施する。この定義を満たす六
つの点は: (1,0), (0.5,0.866), (−0.5,0.866), (−1.0,0), (−0.5,−0.866), (0.5,−
0.866) である。これらの値は,cos (60°) =0.5,sin (60°) =0.866のようになっている。
備考3. 単位円に内接する任意の正多角形は,応答曲面計画のクラスの中で基礎となる回転可能計画
となる。
2.5
配合計画,混合計画 はいごうけいかく,こんごうけいかく
mixture design
説明変数の総和がある一定量という制約がある場合の実験計画。
備考 配合計画の最も典型的な例は,合金要素の混合の比率を因子として取り上げた場合である。こ
の計画空間はX1+X2+…+Xk=1を満たさなければならない。例えば,それぞれの要素に最低
レベルがある場合のように,他の制約も取り入れる場合の計画もいくつか用意されている。配
合実験の取り扱いについては参考文献[9]に包括的に述べられている。
2.6
枝分れ計画 えだわかれけいかく
nested design, hierarchical design
ある因子のすべての水準が,他のすべての因子の一つの水準だけに現れる実験の計画。
備考1. この計画は主として因子の分散成分を評価するために用いられる。三つの因子をA,B,C
とするとき,Bの全水準が因子Aの一つの水準だけに現れ,同様にCの全水準が因子Bの一
つの水準だけに現れる。k因子 (k≧2) の枝分れ計画は,k段枝分れ計画 (k-stage nested design)
と呼ばれることがある。
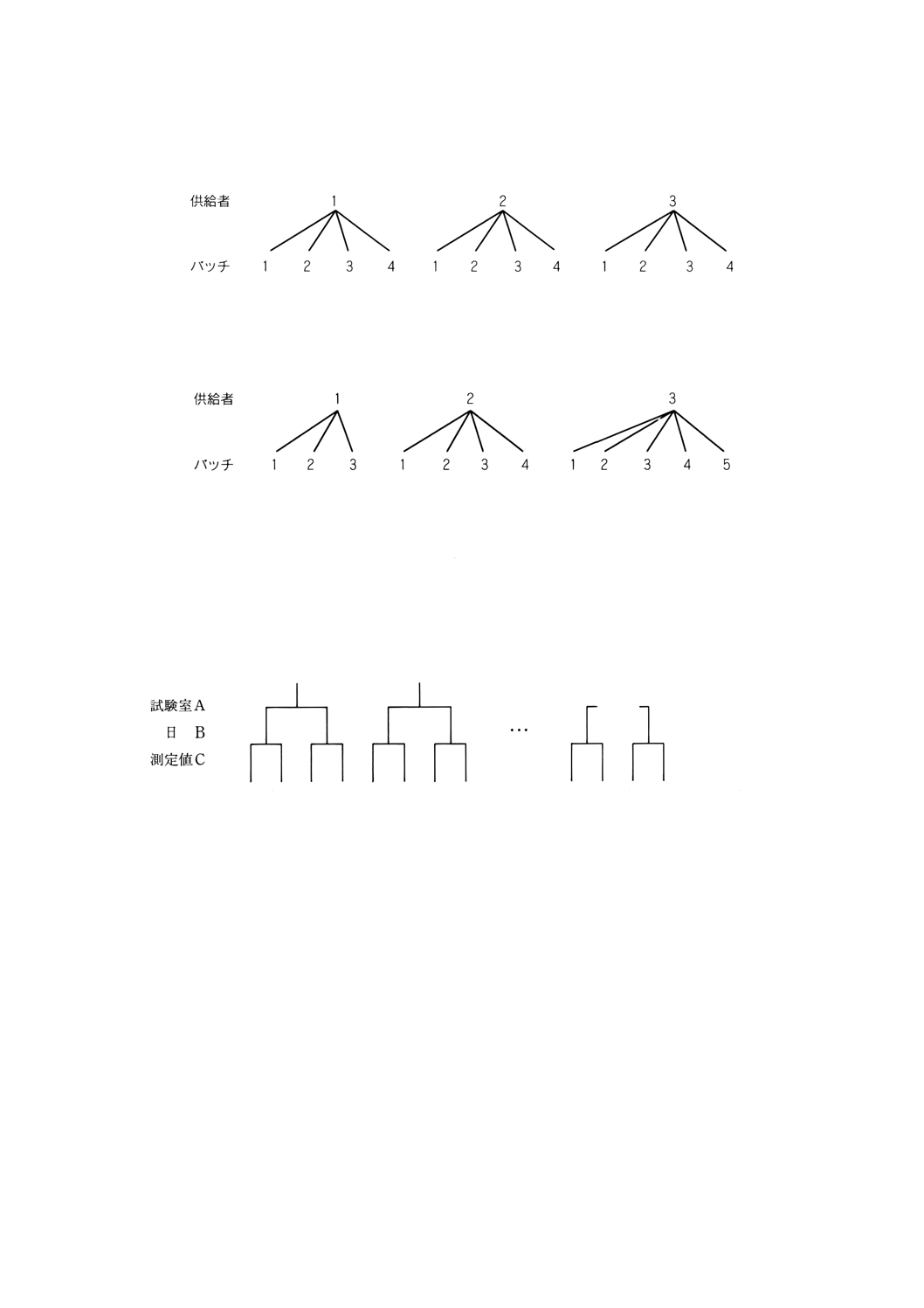
26
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
例 三つの異なる供給者が四バッチの原材料を,ある会社に納品し,バッチの純度を評価するという
状況を想定する。
図に表したように,例えば,供給者1のバッチ1と供給者2のバッチ1は区別されるため,バ
ッチは各供給者から枝分れしている。バッチという因子名は同じであるが,バッチという因子と
供給者という因子は交差していない。この例で,供給者からのバッチ数がそれぞれ異なっていて
も枝分れ計画である。次の構成もまた枝分れ計画である。
しかし,各供給者からのバッチ数が一定であれば,解析はずっと簡単になる。
備考2. 一般に枝分れ計画では,水準の差や予測モデルではなく,分散成分として結果を評価するた
めに用いられる。
2.6.1
バランス型枝分れ計画,完全枝分れ計画 ばらんすがたえだわかれけいかく,かんぜんえだわかれ
けいかく
balanced nested design,fully nested design
上位の因子内での水準数が一定の枝分れ計画。
例 次の図はバランス型枝分れ計画を示している。
この計画は,各試験室が2日(因子Bの水準数が2)にわたり,各日とも2回測定(因子Cの
水準数が2)を行うので,バランス型枝分れ計画である。日は,与えられた測定環境の中ではラ
ンダムに選ばれたものと考え得るので,各試験室で実験を行った日は異なっているであろう。
備考 構造を変えることで問題がより深い意味を持つようになる場合には,下位の因子の水準が他の
因子と交差するように因子の定義を調整できることがある。B1を月曜日にし,B2を金曜日とし
よう。こうすることによって,試験室ごとに無関係な日の割り当てが,試験室を通じて共通の
設定となるので,一つの興味ある問題として月曜日と金曜日の測定結果の比較ができるように
なる。この計画の形状は,もはや枝分れ的ではなく二元的(すなわち,一つの因子の水準が他
の因子のすべての水準と組み合わせられている)な意味を持ち,要因実験とみることができる。
2.6.2
スタッガード型枝分れ計画 すたっがーどがたえだわかれけいかく
staggered nested design
2番目に枝分れしている因子が,1番目に枝分れしている因子の片方の水準では2水準をもち,1番目に
枝分れしている因子の他方の水準では1水準だけもつ枝分れ計画。

27
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
例
備考 スタッガード型計画では,すべての因子の影響がほぼ等しい自由度で推定される。
参考 スタッガード型計画の分散分析では,各平方和の自由度がほぼ等しくなる。しかし,分散成分
として推定される因子の効果の自由度までが等しくなるわけではないので,原国際規格の備考
は不正確である。
2.7
最適計画 さいてきけいかく
optimal design
ある基準,典型的には計画行列の関数を最適化するように因子の水準を設定した実験計画。
備考 取り上げた基準を最適化する計画を求める際,モデルが正しいという前提で求められているこ
とを注意しておく。もしモデルが正しくない場合には,最適計画は理論的には(すなわち数学
的には)最適かもしれないが,実践的な意味で有用ではないかもしれない。ここに示すいくつ
かの計画は最適計画として考慮することができる。
2.7.1
計画行列 けいかくぎょうれつ
design matrix
行が個々の処理(可能ならば仮定したモデルに従って変換したもの)を表現し,仮定したモデルに基づ
く処理の水準から導かれる水準(交互作用,2乗項など)によって構成されている行列。
備考1. ある与えられた実験の実施計画に対して,仮定したモデルに応じて複数の計画行列を想定す
ることができる。
2. 計画行列は一般的にはXと表記される。Xのそれぞれの行は実験の一つの処理に対応する。
もし総平均項μがモデルに含まれているならば,Xの第1列は全要素が1である。それ以外の
列は,因子,又は説明変数の関数として表すことができる。
2.7.1.1
D−最適計画 でぃ−さいてきけいかく
D−optimal design
X'Xの行列式を最大化する計画。
参考 X'で行列Xの転置行列を表している。
備考 D−最適計画のための基準は,計画行列Xを用いた場合の回帰係数の信頼楕円の体積に関連す
る。2.2で紹介したプラケット・バーマン (Placket−Burman) 計画は主効果のみのモデルに対し
てD−最適計画である。
2.7.1.2
A−最適計画 えー−さいてきけいかく
A−optimal design
X'Xのトレース(対角要素の和)を最大化する計画。
備考 A−最適基準は回帰係数の信頼楕円の体積の真球への近さに関連している。
2.7.1.3
G−最適計画 じーさいてきけいかく
G−optimal design
計画空間において応答変数の分散の最大値を最小化する計画。
28
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考 G−最適基準は直接的あるいは明示的にXを含んではいない。しかしながら,数学的にD−最
適性とG−最適性は同値であることが導かれており,D−最適計画を求めるために最適化の過
程を容易にするG−最適基準を利用することができる。
2.8
直交計画 ちょっこうけいかく
orthogonal design
任意の二つの因子が直交する計画。
備考 直交性とはnij= (ni. ×n. j) /Nがすべての (i, j) 水準の組合せについて,そしてすべての列の組
合せについて成立することである。ただし,
nij
= ある2列において水準 (i, j) が出現する数。
ni. = ある列において水準iが出現する数。
n. j
= もう一方の列において水準jが出現する数。
N
= 総実験単位回数
である。
2.9
飽和計画 ほうわけいかく
saturated design
計画行列の列の数が実験の処理数に等しい計画。
備考 実験単位の総数よりも多くの数の母数 (parameter) をあいまいさを残さずに推定するのは不可
能である。
3. 解析の方法
3.1
図による方法,グラフィカルな方法 ずによるほうほう,ぐらふぃかるなほうほう
graphical methods
実験結果の図による描写に基づく解析。
備考 計画された実験の結果を単純にプロットすることで,とりあえずの効果的な評価を行うことが
できる。
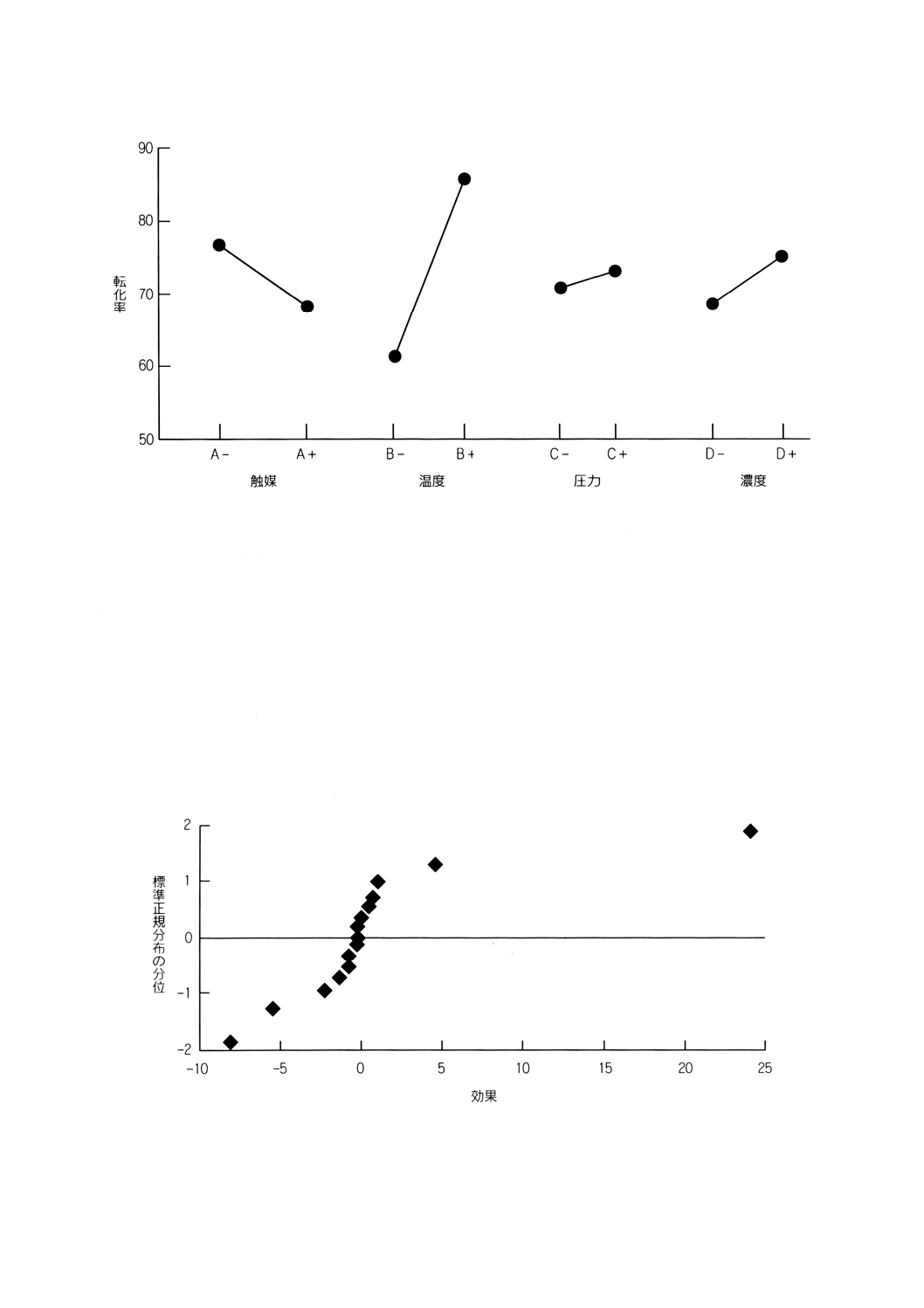
3.1.1
主効果プロット しゅこうかぷろっと
main effects plot
個々の因子について,各水準の平均応答をプロットしたもの。
備考1. 参考文献[3]の10.8節の例を図に示す。応答変数は転化率,説明変数は触媒量 (A),温度 (B),
圧力 (C),濃度 (D) である。各説明変数は2水準で,低い水準を“−”,高い水準を“+”で
表す。24の要因実験が行われた。図から,温度が転化に対して最も実質的な効果があり,触
媒が2番目で,残りの二つの因子はほとんど同等である。打点を結んだ線の傾きが0に対して
有意な差があるかということを評価するためには,追加の解析が必要であろう。
29
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
備考2. 主効果プロットは,個々の因子について,各水準の平均応答を与える。応答に対する各因子
の影響の性質や大きさをはっきりと理解できる。交互作用の存在により各因子の効果が隠れ
ることがある。
3.1.2
交互作用プロット こうごさようぷろっと
interaction plot
二つの異なった因子の水準で平均応答をプロットしたもの。交互作用(1.17)を参照。
備考 交互作用プロットは交互作用を説明するための図による検出ツールである。平行性からの乖離
が交互作用の指標となる。
3.1.3
効果の分位点プロット こうかのぶんいてんぷろっと
quantile plot of effect
要因実験や一部実施法において推定された効果に対する標準正規分位点のプロット。
例 図は3.1.1の例で示したデータについてのものである。
例 反復が行われていない実験に対して,このプロットが主要な効果を示唆するであろう(打点の大
部分を通るように引いた“ガイドライン”から右や左に大きく離れている点がそれに当たる。)。
上の例では,効果の値が24である右上方の点は温度の効果に対応する。
30
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
3.1.4
残差プロット ざんさぷろっと
residual plot
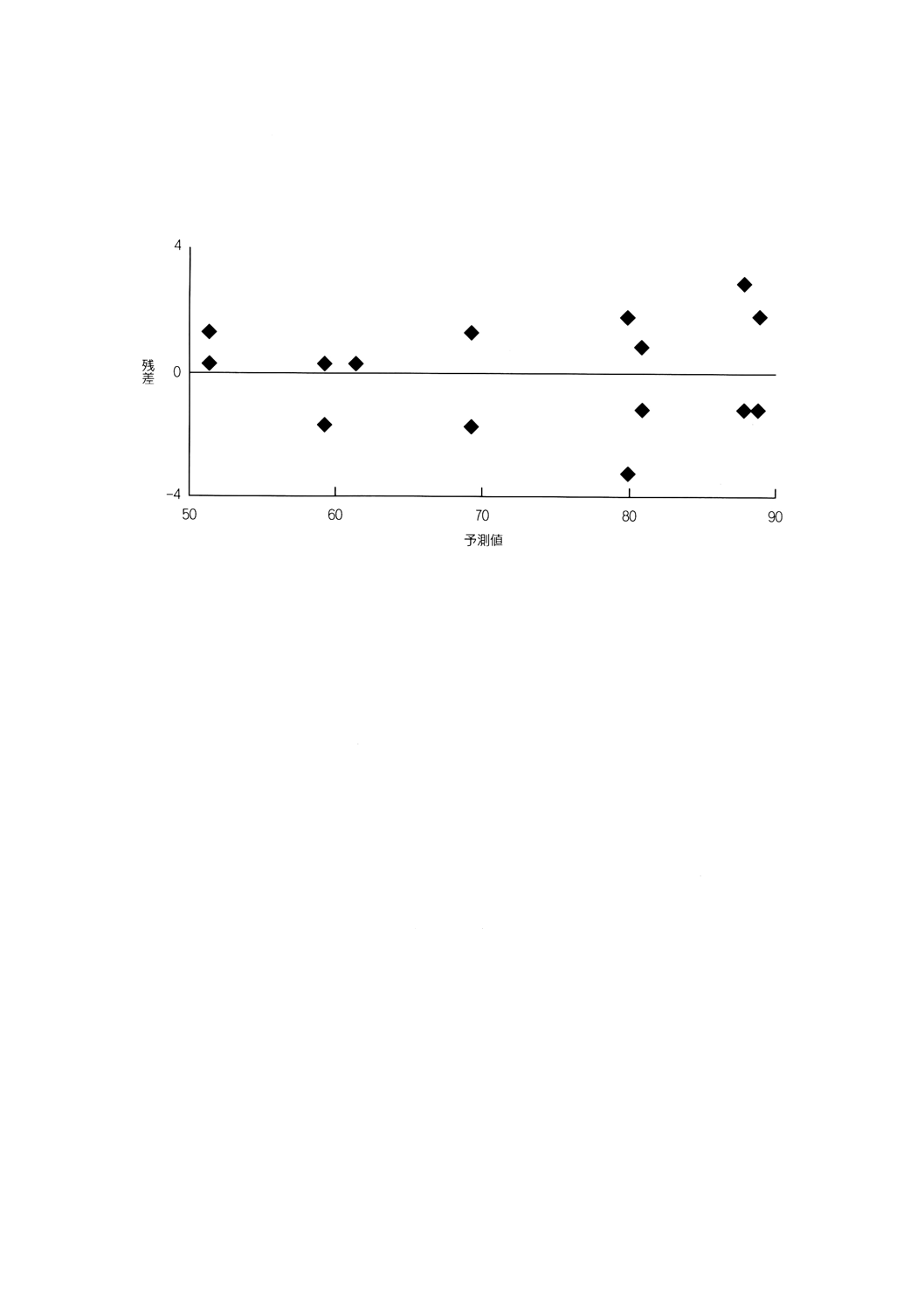
特定の因子の水準あるいは予測値に対して残差をプロットしたもの。
例 3.1.1の例について,四つの主効果とBDの交互作用をもつモデルを用いて図示する。
3.2
最小二乗法 さいしょうじじょうほう
metbod of least square
Σe2を最小にするパラメータ推定の技法。ここで,eは観測値と仮定されたモデルによる予測値との差で
あり,和はすべての処理についてとる。
備考 一般に,個々の観測値の実験誤差は独立であることが仮定されているけれども,誤差に相関が
ある場合に推定の方法を調整することは可能である。普通の分散分析,回帰分析及び共分散分
析はすべて最小二乗法を基礎としており,それぞれ異なった計算上及び解釈上の利点がある。
それは実験の配置の中でデータの群分けを可能にするある種のバランスに由来する。
3.3
回帰分析 かいきぶんせき
regression analysis
応答変数に説明変数を結びつけるモデルを評価するための手続きの集まり。
備考1. 回帰分析には,ある目的関数の値を最適化すること(例えば,観測値と仮定されたモデルに
よる予測値との差の二乗和を最小化すること)によって,仮定されたモデルのパラメータを
推定する過程が付随している。統計のソフトウェアがあるため,パラメータの推定値やその
標準誤差を求めること,及び,多くのモデル診断を行うことが容易になった。また,回帰分
析は応答の他の尺度を考慮することを容易にしている。例えば,繰返しのある要因実験にお
いてばらつきの効果に関心がある場合,Si2(ここで,Si2は繰返し点の試料分散である)の対
数は,応答変数そのものより解析及び解釈に適している。
参考 標本分散の記号にSi2を用いているが,この規格の第1部2.19ではsi2を用いている。
備考2. 回帰分析は,分散分析と似たような役割を果たしているが,因子の水準が連続的であり,ま
た,明示的な予測モデルに重点が置かれている場合に特に適切である。分散分析の一般的な
使用に要求されるバランスが,回帰分析には要求されないことから,欠測値のある計画され
た実験にとって,回帰分析は有用である。しかし,バランスがとれていないことによって,
仮説検定の次数依存性(最初の相関項に共通的な要素が含まれ,次の項に含まれないこと)
31
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
が増すとともに,バランスした実験の他の有利な点がなくなってしまう。バランスした実験
においては,この二つの技法は単に最小二乗法の変形であり,同様の結果を与える。
参考 予定した実験の割り付けにおいて,何らかの事故のため得られなかった値を欠測値 (missing
values) という。
例1. 23の要因実験で,三つの量的な因子を持った直交計画(2.8参照)を考える。
ここで,繰返し1回で,各実験単位に対して仮定されたモデルは,
Y=b0X0+b1X1+b2X2+b3X3+e
である。ここで
X0=1
X1は因子Aの水準
X2は因子Bの水準
X3は因子Cの水準
eは偶然誤差
である。
このモデルは,−1及び+1でコード化された水準をもつ三つの質的因子に対しても適用可能
である。
例1.の回帰分析表
(記号:
,i
ji
ji
X
X
x
−
=
,ここで
4
/
1
4
ji
i
X
j
X
=
∑
=
)
要因
回帰係数
平方和 (S. S.)
自由度 (D. F.)
平均平方 (M. S.)
合計
2
i
Y
Sr ∑
=
8
−
定数 (X0)
i
i
i
x
Y
x
2
0
0
0
∑
∑
=
β
Sx0=β0Σx0iYi
1
Sx0
X1 (A) の回帰
i
i
i
x
Y
x
2
1
1
1
∑
∑
=
β
Sx1=β1Σx1iYi
1
Sx1
X2 (B) の回帰
i
i
i
x
Y
x
2
2
2
2
∑
∑
=
β
Sx2=β2Σx2iYi
1
Sx2
X3 (C) の回帰
i
i
i
x
Y
x
2
3
3
3
∑
∑
=
β
Sx3=β3Σx3iYi
1
Sx3
残差
SE=ST−Sx0−Sx1−Sx2−Sx3
4
SE/4
備考3. もし,23の要因実験が同じブロック内で繰り返されたとしたら,“合計”(1行目)の自由度は
16に,“残差”の自由度は12になる。“残差”の平方和は,“繰返し”と“あてはまりの悪さ”
の二つの要素に分けられることになる。そのそれぞれは8及び4の自由度を持つ。
例1.の回帰分析表−繰返しのある実験のための補遺
ばらつきの要因
平方和 (S. S.)
自由度 (D. F.)
平均平方 (M. S.)
F
期待値
残差
SE
12
SE/12
繰り返し
(
)
−
∑
=
i
ij
j
R
Y
Y
S
8
SR/8
あてはまりの悪さ SL=SE−SR
4
SL/4
それぞれの要因の統計的な有意性は,適切な正規性の仮定の下で,その要因及び適切な誤
32
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
差項の平均平方に対するF−統計量を用いて検定される。繰返しのない場合,“回帰”項は“残
差”項によって検定される。繰返し2回の場合,モデルが不適切であるか否かを決定するた
めに,“あてはまりの悪さ”項は“繰返し”(“実験誤差”)項によって検定される。“繰返し”
項は,“残差”項に含まれ得るモデルの不適切さによる潜在的な影響を除いた実験誤差の指標
を表している。
3.4
分散分析試 ぶんさんぶんせき
analysis of variance ANOVA
応答変数の全変動を,特定のばらつきの要因に伴う意味ある要素に分ける技法。
備考1. 分散分析は,分散成分(1.8参照)の推定及びモデルのパラメータに対する仮説の検定に用い
られる。
分散分析表は一般に次の列を含んでいる。
− ばらつきの要因
− 平方和,sum of squares (SS)
− 自由度,degrees of freedom (DF)
− 平均平方,mean square (MS)(平方和を自由度で割ったもの)
− F(その行の平均平方の誤差に付随した平均平方に対する比)
− 平均平方の期待値(モデルのパラメータの項で表される平方和の数学的期待値)
表の行は特定の要因効果又は交互作用,ブロック(ブロックが実験計画に含まれている場
合),又は誤差(モデル又はブロックによって説明されずに残った効果)を表している。“合
計”の行は,一般にサンプルサイズから1を引いた自由度を持った全平均まわりの全平方和
を表している
参考 平方和の計算で用いられる(
)
観測値の総数
総合計2
を修正項という。
例 乱塊法において,r個のうちj番目のブロックで,因子Aのt水準のうちi番目の水準により得ら
れる観測値をYij (i=1,2,…t,j=1,2,…r) と表す。主要な因子Aは母数因子,因子Bはブロ
ック因子である。このとき,次の分散分析表が計算される。
分散分析 (ANOVA) 表
要因
平方和
(S. S.)
自由度
(D. F.)
平均平方
(M. S.)
F
平均平方の期待
値 (E [M. S.])
合計
(
)2
Y
Y
Sr
ij
j
i
−
∑
∑
=
νT=hl−1
−
−
−
因子
A
(処理)
(
)2
i
ij
i
A
Y
Y
h
S
−
∑
=
νA=l−1
A
A
A
v
S
MS=
(
)
A
e
A
S
M
MS
v
v
F
=
,
σ2+hK2A
因子
B
(ブロッ
ク)
(
)2
i
ij
i
B
Y
Y
l
S
−
∑
=
νB=h−1
B
B
B
v
S
MS=
(
)
e
B
e
B
S
M
MS
v
v
F
=
,
σ2+lK2B
誤差
(
)2
Y
Y
Y
Y
Se
j
i
ij
j
i
+
−
−
∑
∑
=
νe= (l−1) (h−1)
e
e
e
v
S
MS=
−
σ2
参考 フランス語では平方和の記号をS. C.,自由度をD. L.,平均平方をC. M. と表す。
分散分析表において
ST=SA+SB+SC
33
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
νT=νA+νB+νC
F(ν1,ν2)はF統計量である。
観測値の一つのモデルは次式で与えられる。
Yij=μ+αi+βj+eij ; i=1, 2…, l ; j=1, 2…, h
ここで
Σαi=Σβj=0 ; eij〜N (0, σ2)
(
)
(
)1
;
1
2
2
2
2
−
∑
=
−
∑
=
h
K
l
a
K
j
B
i
A
β
また
μは一般平均
αiはi番目の処理の効果
βjはj番目のブロック効果
eijは実験誤差。
である
この例では,母数模型が仮定されている。μ,α,βj及びσ2の最小二乗推定値は次のように与
えられる。
hl
Y
Y
ij
j
i
/
∑
∑
=
=
μ)
Y
h
Y
Y
Y
a
ij
j
i
i
−
∑
=
−
=
/
)
Y
l
Y
Y
Y
ij
i
j
j
−
∑
=
−
=
/
β)
(
)
(
)(
)
[
]
e
j
i
ij
j
i
S
h
l
Y
Y
Y
Y
2
2
2
1
1
=
−
−
+
−
−
∑
∑
=
σ)
例に示した簡単な公式は乱塊法のセルの中の観測値が同数である場合のものである。
備考2. 基本的な仮定は次のとおりである。すなわち,すべてのばらつきの要因による効果は加法的
であること,また,実験誤差は独立で,平均値は0,同じ分散(等分散性)をもって正規分布
していること,である。F比に関連して,この技法は,これらの要因の効果の有意性検定,
及び/又は,これらの要因による分散の推定のために使われる。正規分布の仮定は有意性検
定及び信頼区間のために必要である。平均値及び交互作用は二元(又はk元)表に要約する
ことによって見ることができる。この例は,母数模型(モデル1)(3.4.1参照)を仮定してい
る。誤差の正規分布の仮定ができない場合には,応答変数の変換(例えば対数変換)を行う
こと,または,ノンパラメトリックな方法を適用することが可能なこともある。
参考 要因効果の推定量の分散σ2/neで表したとき,neを有効反復数という。
3.4.1
母数模型の分散分析 ぼすうもけいのぶんさんぶんせき
fixed effects analysis of variance
因子の水準が,各因子の値の範囲内でそれぞれ予め一定値に定められた場合の分散分析。
備考 母数模型の場合,分散成分を計算することは不適切である。この模型は,分散分析モデル1と
も呼ばれる。
34
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
3.4.2
変量模型の分散分析 へんりょうもけいのぶんさんぶんせき
random effects analysis of variance
因子の水準が,それぞれの因子の水準の母集団からサンプルされたものと仮定される場合の分散分析。
備考 変量模型の場合,分散成分の推定値を得ることが主要な目的である。この模型は,分散分析モ
デル2とも呼ばれる。
例 原材料の複数のバッチを処理している場合を仮定する。因子“バッチ”は実験のためにいくつか
のバッチを選ぶことによって実現される。そのバッチそのものは,すべてのバッチの母集団の中
からランダムに選ばれる。
3.4.3
混合模型の分散分析 こんごうもけいのぶんさんぶんせき
mixed model analysis of variance
いくつかの因子の水準は予めそれぞれ一定値に選定されており,他の因子の水準はその母集団からサン
プルされた場合の分散分析。
備考 分散成分は,変量因子にのみ意味がある。同様に,効果の推定値は母数因子だけに適用される。
この模型は,分散分析モデル3とも呼ばれる。
3.5
共分散分析 きょうぶんさんぶんせき
analysis of covariance (ANCOVA)
一つあるいは複数の付随変数(共変量ともいう)が応答変数に影響するときに,処理の効果を推定し,
検定する技法。
備考1. 共分散分析は,回帰分析と分散分析の組合わせと見ることができる。
2. 一般に,付随変数は実験の計画の中に設定できず,結果に与えるその効果は解析の中で検討
される。例えば,実験単位があって,測定は可能であるが調整は不可能なある化学成分の量
が,それぞれの実験単位で異なっているような場合である。
参考文献
[1] JIS Z 8101-1 統計−用語と記号−第1部 確率及び一般統計用語
[2] ISO 10241 : 1992, International terminology standards−Preparation and layout
[3] BOX G. E. P., HUNTER W. G. and HUNTER J. S. Statistics for Experimenters. An Introduction to Design, Data
Analysis, and Model Building. John Wiley & Sons, New York, 1978.
[4] PLACKETT R. L. and BURMAN J. P. The design of optimum multifactorial experiments, Biometrika, 33, 1946,
pp. 305-325.
[5] JOHN P. W. M. Statistical Design and Analysis of Experiments. The Macmillan Company, NewYork, 1971.
[6] LIN D. K. J. A new class of supersaturated designs. Technometrics, 35, 1993, pp. 28-31.
[7] WU C. F. J. Construction of supersaturated designs through partially aliased interactions. Biometrika, 80, (3),
1993, pp. 661-669.
[8] FISHER R. A. and YATES F. Statistical Tables for Biological, Agricultural, and Medical Research. Oliver and
Boyd, Edinburgh, 4th edition, 1953.
[9] CORNELL J. A. Experiments With Mixtures. 2nd ed. John Wiley, New York, 1990.
[10] JIS Z 8101-2 統計−用語と記号−第2部 統計的品質管理用語
[ll] JIS Z 8402-1 測定方法及び測定結果の精確さ(真度及び精度)−第1部 一般的な原理及び定義
[12] BOX G. E. P. and DRAPER N. R. Empirical Model−Building and Response Surfaces. John Wiley & Sons,
New York, 1987.
35
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
用語分科会 構成表
主査
石 田 保 士
東京芝浦電気株式会社
幹事
東 秀 彦
工業技術院標準部
委員
相 羽 弘 一
工業技術院標準部
石 川 馨
東京大学工学部
芽 野 健
電気通信省電気通信研究所
桑 原 善 一
電気通信省電気通信研究所
坂 元 平 八
神戸大学経済学部
園 部 進
日本電気株式会社玉川事業本部
田 口 玄 一
電気通信省電気通信研究所
中 岡 幸 男
早稲田大学工学部
松 島 康 夫
通商産業省機械局
事務局
白 崎 文 雄
日本規格協会
藤 田 満 一
日本規格協会
上 山 忠 夫
日本規格協会
尾 上 清治郎
日本規格協会
基本部会 品質管理用語専門委員会 構成表
委員長
石 田 保 士
東京芝浦電気株式会社
委員
石 川 馨
東京大学(サンプリング担当)
奧 津 晋
富士フイルム株式会社(実験計画担当)
金 岡 幸 二
東光電気株式会社(検査担当)
木 暮 正 夫
東京工業大学(一般担当)
小 柳 賢 一
日本科学技術連盟
園 部 進
日本電気株式会社
高 山 敏 夫
日本規格協会
田 口 玄 一
日本電信電話公社
田 中 輝 臣
工業技術院
古 川 光
早稲田大学
三 浦 新
三井化学工業株式会社(管理図担当)
三 浦 光 男
いすゞ自動車株式会社
森 口 繁 一
東京大学(数理担当)
山 内 二 郎
東京大学
事務局
東 秀 彦
工業技術院
松 川 安 一
工業技術院
加 島 良 一
工業技術院
36
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
日本規格協会管理方式研究会JIS Z 8101改正原案作成委員会
委員長
三 浦 新
玉川大学工学部
委員
大 場 興 一
東京理科大学工学部
尾 関 和 夫
日本精工株式会社
岸 暁 男
武蔵工業大学
佐々木 脩
玉川大学工学部
廣 津 千 尋
東京大学工学部
藤 田 董
川崎製鉄株式会社
藤 森 利 美
東京理科大学工学部
宮 津 隆
日本鋼管株式会社
山 本 太 郎
日本電信電話公社
横 尾 恒 雄
東洋カーボン株式会社
鷲 尾 泰 俊
慶應義塾大学工学部
吉 枝 正 明
工業技術院標準部
事務局
川 村 正 信
日本規格協会
竹 下 正 生
日本規格協会
若 園 叔 邦
日本規格協会
日本工業標準調査会 基本部会 品質管理専門委員会
委員会長
朝 香 鐵 一
東京理科大学工学部
委員
石 川 馨
武蔵工業大学
奥 野 忠 一
東京大学工学部
尾 関 和 夫
日本精工株式会社
川 村 正 信
財団法人日本規格協会
木 暮 正 夫
玉川大学工学部
瀬 倉 久 男
防衛庁装備局
田 口 玄 一
青山学院大学理工学部
角 田 克 彦
日本電信電話公社検査部
中 村 晴 佳
日産自動車株式会社
林 俊 太
工業技術院標準部
東 秀 彦
財団法人日本規格協会
藤 田 董
川鐵コンティナー株式会社
藤 森 利 美
東京理科大学工学部
真 壁 肇
東京工業大学
升 山 義 久
日本国有鉄道資材局
三 浦 新
玉川大学工学部
宮 津 隆
日本鋼管株式会社
森 秀太郎
東京芝浦電気株式会社
森 口 繁 一
電気通信大学工学部
山 口 啓 一
新日本製鉄株式会社
山 本 太 郎
日本電気株式会社
横 尾 恒 雄
東洋カーボン株式会社
鷲 尾 泰 俊
慶應義塾大学理工学部
事務局
藤 田 富 男
工業技術院標準部材料規格課
津 金 秀 幸
工業技術院標準部材料規格課
37
Z 8101-3 : 1999 (ISO/FDIS 3534-3 : 1999)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
品質管理分野国際整合化分科会
(主査)
○ 尾 島 善 一
東京理科大学理工学部
(委員)
青 木 茂 雄
財団法人日本科学技術連盟
今 井 秀 孝
工業技術院計量研究所
柿 田 和 俊
社団法人日本鉄鋼連盟
○ 加 藤 洋 一
日本電信電話株式会社
門 山 允
東京国際大学
兼 子 毅
武蔵工業大学工学部
○ 椿 広 計
筑波大学社会工学系
○ 仁 科 健
名古屋工業大学工学部
野 澤 昌 弘
東京理科大学経営学部
三佐尾 武 雄
QCコンサルタント
宮 津 隆
帝京科学大学理工学部
山 田 秀
東京都立科学技術大学工学部
横 尾 恒 雄
QCコンサルタント
大 嶋 清 治
工業技術院標準部
(事務局)
竹 下 正 生
財団法人日本規格協会
安 田 順 子
財団法人日本規格協会
備考 ○印は用語JIS原案作成WGの委員を兼ねる。
JIS Z 8101“品質管理用語”改正原案委員会WG1
(主査)
廣 津 千 尋
東京大学工学部
(委員)
尾 島 善 一
東京理科大学理工学部
加 藤 洋 一
日本電信電話株式会社
椿 広 計
慶應義塾大学理工学部
仁 科 健
名古屋工業大学工学部
大 嶋 清 治
工業技術院標準部
(事務局)
竹 下 正 生
財団法人日本規格協会
小野寺 勉
財団法人日本規格協会
JIS Z 8101-3原案作成委員会
(主査)
尾 島 善 一
東京理科大学理工学部
(委員)
飯 田 孝 久
慶應義塾大学理工学部
小 池 昌 義
工業技術院計量研究所
椿 広 計
筑波大学社会工学系
野 澤 昌 弘
東京理科大学経営学部
三 輪 哲 久
農業環境技術研究所
山 田 秀
東京理科大学工学部
浅 川 敏 郎
工業技術院標準部
(事務局)
橋 本 進
財団法人日本規格協会
安 田 順 子
財団法人日本規格協会