X 4159:2005
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
まえがき
この規格は,工業標準化法第14条によって準用する工業標準化法第12条第1項の規定に基づき,財団
法人日本規格協会から工業標準原案を具して日本工業規格を改正すべきとの申出があり,日本工業標準調
査会の審議を経て,経済産業大臣が改正した日本工業規格である。これによってJIS X 4159:2002は改正さ
れ,この規格に置き換えられる。
今回の改正では,空白の取扱いの規定に対する注意事項,適合性の規定に対する注意事項,参考文献及
び参考文献を参照するためのURIの変更などについて,改正を行った。
この規格の一部が,技術的性質をもつ特許権,出願公開後の特許出願,実用新案権,又は出願公開後の
実用新案登録出願に抵触する可能性があることに注意を喚起する。経済産業大臣及び日本工業標準調査会
は,このような技術的性質をもつ特許権,出願公開後の特許出願,実用新案権,又は出願公開後の実用新
案登録出願にかかわる確認について,責任はもたない。
JIS X 4159:2005には,次に示す附属書がある。
附属書A(規定)文献
附属書B(規定)文字クラス
附属書C(参考)XML及びSGML
附属書D(参考)実体参照及び文字参照の展開
附属書E(参考)決定的内容モデル
附属書F(参考)文字符号化の自動検出
附属書G(参考)W3C XML作業グループ
附属書H(参考)W3C XMLコア作業グループ
附属書I(参考)文書作成に関する備考
原勧告の標題及びまえがきの翻訳
拡張可能なマーク付け言語 (XML) 1.0 (Third Edition)
W3C勧告 2004年2月4日
この版の掲載場所
http://www.w3.org/TR/2004/REC-xml-20040204
最新版の掲載場所
http://www.w3.org/TR/REC-xml
以前の版の掲載場所
http://www.w3.org/TR/2003/WD-xml-20031030
編者
Tim Bray, Textuality and Netscape <tbray@textuality.com>
Jean Paoli, Microsoft <jeanpa@microsoft.com>
C. M. Sperberg-McQueen, University of Illinois at Chicago and Text Encoding Initiative <cmsmcq@uic.edu>
Eve Maler, Sun Microsystems, Inc. <eve.maler@east.sun.com> - Second Edition
X 4159:2005
(2)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
François Yergeu <francois@yergeru.com> - Third Edition
規定の訂正を含む可能性があるこの勧告に関する正誤表を参照されたい。
この勧告には,XML及び改訂箇所を色分けしたXHTMLの参考様式も用意されている。
翻訳もある。
著作権 © 2000 W3C® (MIT, INRIA, 慶應)が,すべての権利を保有する。免責, 商標, 文書の使
用,及びソフトウェアの使用許諾に関するW3Cの規則を適用する。
要約 拡張可能なマーク付け言語(XML)はSGMLのサブセットであって,この勧告で,そのすべて
を規定する。XMLの目標は,現在HTMLがWWW上で配布,受信及び処理可能であるのと同様に,一
般的なSGMLをWWW上で配布,受信及び処理可能にすることとする。XMLは実装が容易であって,
SGML及びHTMLのどちらに対しても相互運用性を保つ設計がなされている。
この文書の状態 ここでは,この勧告の公表時における状態を示す。他の文書がこの勧告に置き
換わることがある。現在のW3C出版物の一覧及びこの勧告の最新の改訂(revision)は,
http://www.w3.org/TR/ のW3C技術文書索引で見ることができる。
この文書は,W3Cの勧告である。この勧告は,W3C会員企業及び関連する団体によって閲読さ
れており,技術統括責任者によってW3C勧告として承認されている。これは安定した文書であり,
参考資料として使用してよく,他の文書から引用規定として引用してもよい。W3Cはこの勧告を
制定することによって,この規定への注目を喚起し,広い普及を促進するという役割を果たす。
この結果,Webの機能及び相互運用性が高まる。
この勧告は,現在広範囲に使用されている国際的な文書処理の規格(Standard Generalized
Markup Language, ISO 8879:1986に修正を加えたもの) をWWW上で使用するためにサブセット化
した構文を規定する。この勧告は,XMLコア作業グループのW3CにおけるXML活動の一部として作
成された。この規定は,英語版だけを正式とする。しかし,この勧告の翻訳については
http://www.w3.org/2003/03/Translations/byTechnology?tecnology=REC-xml を参照されたい。
このThird Editionは, XMLの新しい版(version)ではない。読者の便宜のため,2000年10月6
日に発行されたSecond Editionについての累積された正誤表
(http://www.w3.org/XML/xml-V10-2e-errata から入手可能)に示された変更を本文に組み入れて
いる。さらに,MUST,SHOULD,MAYなどの用語遣いのキーワードをIETF RFC 2119が定義する正式
な意味で用いる場合を明確にするために,規定の用語遣いの重要な部分にマーク付けが導入され
た。読者の便宜のため,改訂箇所を色分けしたXHTML版も用意されている。この版は,正誤表に
公開された誤りに基づく各変更を強調すると共に,正誤表の誤りへのリンクをもつ。正誤表の中
の多くの誤りには,変更の理由が示されている。
この勧告の実装に関する報告は,http://www.w3.org/2003/09/Xml10-3eimplementation.htmlか
ら入手できる。
この勧告に関する知的所有権に関する文書は,作業グループのIPR公開ページから見つけること
ができるだろう。
この勧告に誤りがあれば xml-editor@w3.org に報告されたい。このThird Editionについての
正誤表は,http://www.w3.org/XML/xml-V10-3e-errata から入手できる。
X 4159:2005
(3)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
この規定への適合性を審査支援するために,試験項目群が保守されている。
X 4159:2005
(4)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
目 次
序文
1. 一般
1.0 適用範囲
1.1 経緯及び目標
1.2 定義
2. 文書
2.1 整形式のXML文書
2.2 文字
2.3 共通の構文構成子
2.4 文字データ及びマーク付け
2.5 コメント
2.6 処理命令
2.7 CDATAセクション
2.8 前書き及び文書型宣言
2.9 非依存文書宣言
2.10 空白の取扱い
2.11 行末の取扱い
2.12 言語識別
3. 論理構造
3.1 開始タグ,終了タグ及び空要素タグ
3.2 要素型宣言
3.2.1 要素内容
3.2.2 混合内容
3.3 属性リスト宣言
3.3.1 属性の型
3.3.2 属性のデフォルト
3.3.3 属性値の正規化
3.4 条件付きセクション
4. 物理構造
4.1 文字参照及び実体参照
4.2 実体宣言
4.2.1 内部実体
4.2.2 外部実体
4.3 解析対象実体
4.3.1 テキスト宣言
X 4159:2005
(5)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
4.3.2 整形式の解析対象実体
4.3.3 実体における文字符号化
4.4 XMLプロセサによる実体及び参照の扱い
4.4.1 “認識しない”
4.4.2 “取込み”
4.4.3 “検証のために取込み”
4.4.4 “禁止”
4.4.5 リテラル内での取込み
4.4.6 “通知”
4.4.7 “処理しない”
4.4.8 “PEとして取込み”
4.5 内部実体置換テキストの構築
4.6 定義済み実体
4.7 記法宣言
4.8 文書実体
5. 適合性
5.1 妥当性を検証するプロセサ及び検証しないプロセサ
5.2 XMLプロセサの使用
6. 記法
附属書A(規定) 文献
附属書B(規定) 文字クラス
附属書C(参考) XML及びSGML
附属書D(参考) 実体参照及び文字参照の展開
附属書E(参考) 決定的内容モデル
附属書F(参考) 文字符号化の自動検出
附属書G(参考) W3C XML作業グループ
附属書H(参考) W3C XMLコア作業グループ
附属書I(参考) 文書作成に関する備考
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
日本工業規格 JIS
X 4159:2005
拡張可能なマーク付け言語 (XML) 1.0
Extensible Markup Language (XML)1.0
序文 この規格は,2004年2月に3rd EditionとしてWorld Wide Web Consortium(W3C)から公表された勧告
Extensible Markup Language (XML)1.0を翻訳し,技術的内容を変更することなく作成した日本工業規格であ
る。
なお,この規格で側線又は点線の下線を施してある箇所は,原勧告に編集上の変更をしている事項又は
原勧告にない参考である。
1. 一般
1.0
適用範囲 この規格[拡張可能なマーク付け言語XML(Extensible Markup Language)]は,XML文書
というデータオブジェクトのクラスを規定し,XML文書を処理するプログラムの動作の一部を規定する。
XMLは,JIS X 4151:1992[SGML(Standard Generalized Markup Language)]の制限したサブセットとする。
XML文書は,必ずSGML規格に適合する。
XML文書は実体という記憶単位から成り,実体は構文解析されるデータ又は構文解析されないデータか
ら成る。構文解析されるデータは,文字から成り,その一部は文字データを構成し,一部はマーク付けを
構成する。マーク付けは,文書の記憶レイアウト及び論理構造を記述する符号とする。XMLは,記憶レイ
アウト及び論理構造についての制約条件を記述する機構を提供する。
XMLプロセサというソフトウェアモジュールは,XML文書を読み込み,その内容及び構造へのアクセ
スを提供するために用いる。 XMLプロセサは,他のモジュールのために動作することを前提としており,
そのモジュールを応用プログラムという。この規格は,XMLプロセサに要求される振る舞いを規定する。
つまり,XMLデータの読込み方法を規定し,応用プログラムに提供する情報を規定する。
1.1
経緯及び目標 1996年にWorld Wide Web Consortium(W3C)の中に設立されたXML作業グループ(以
前は,SGML編集レビュー委員会と呼ばれた。)がXMLを開発した。この作業グループの議長を,Sun
MicrosystemsのJon Bosakが務めた。W3Cが組織し,以前はSGML作業グループと呼ばれたXML SIG(Special
Interest Group)も,XMLの制定に活発に参画した。XML作業グループのメンバを附属書Gに示す。Dan
Connollyは,作業グループとW3Cとの調整役を務めた。
XMLの設計目標を次に示す。
a) XMLは,インタネット上でそのまま使用できる
b) XMLは,広範囲の応用プログラムを支援する。
c) XMLは,SGMLと互換性をもつ。
d) XML文書を処理するプログラムは容易に書ける。
e) XMLでは,任意選択の機能はできるだけ少なくし,理想的には一つも存在しない。
f)
XML文書は,人間にとって読みやすく,十分に理解しやすいことが望ましい。
2
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
g) XMLの設計は,すみやかに行うことが望ましい。
h) XMLの設計は,厳密で,しかも簡潔なものとする。
i)
XML文書は,容易に作成できる。
j)
XMLでは,マーク付けの数を減らすことは重要ではない。
XML第1.0版を理解し,それを処理する計算機プログラムを書くために十分な情報は,この規格,関連
する規格など(文字についてはUnicode及びJIS X 0221-1,言語識別タグについてはIETF RFC 3066,言語
コードについてはISO 639,並びに国名コードについてはJIS X 0304。)によってすべて示す。
参考 この版のXMLの原規定は,テキスト及び法律上の注意を一切改変しない限り,自由に配布し
てもよい。
1.2
定義
1.2.1
用語定義 XML文書を規定するために使用する用語は,この規格内で定義する。次に示す語句は,
それらの用語を定義するため,及びXMLプロセサの動きを規定するために使用する。
1.2.1.1 誤り(error) この規格が規定する規則に対する違反。結果は定義しない。適合するソフトウェアは,
誤りを検出して報告してもよく,誤りから回復してもよい。
1.2.1.2 致命的誤り(fatal error) 適合するXMLプロセサが検出し,応用プログラムに報告しなければなら
ない誤り。プロセサは,致命的な誤りを発見したあとも,それ以降の誤りを探すためにデータ処理を続行
し,見つかった誤りを応用プログラムに報告してもよい。誤り訂正をサポートするために,プロセサは,
処理していないデータ(文字データ及びマーク付けの混在したもの。)を文書から取り出し,応用プログラ
ムに渡してもよい。しかし,プロセサは,致命的な誤りを1度でも検出したならば,通常の処理を続行し
てはならない。つまり,プロセサは,文字データと文書の論理構造についての情報とを,通常の方法で応
用プログラムに渡し続けてはならない。
1.2.1.3 利用者の任意選択によっては(at user option) 適合するソフトウエアは,記述されたとおりに振る
舞ってもよい(may),又は振る舞わなくてはならない(must)(文中の助動詞による。)。そのとおりに振る舞
う場合は,記述された振る舞いを選択又は拒否する手段を利用者に提供しなければならない。
1.2.1.4 妥当性制約(validity constraint) すべての妥当な XML文書に適用する規則。妥当性制約への違反
は,誤りとする。利用者の任意選択によっては,検証を行うXMLプロセサは,この誤りを報告しなけれ
ばならない。
1.2.1.5 整形式制約(well-formedness constraint) すべての整形式のXML文書に適用する規則。整形式制約
への違反は致命的な誤りとする。
1.2.1.6 マッチする(match) (文字列又は名前がマッチする)比較する二つの文字列又は名前は,同一でなけ
ればならない。JIS X 0221-1において,複数の表現が可能な文字[例えば,合成形式及び基底文字+ダイア
クリティカルマーク(ダイアクリティカルマーク)形式]は,いずれの文字列も同じ表現のときに限り,マ
ッチする。比較のとき ,大文字と小文字との区別をする。(文字列と文法中の規則とがマッチする)ある生
成規則から生成する言語に,ある文字列が属するとき,この文字列は,この生成規則にマッチするという。
(内容と内容モデルとがマッチする)ある要素が,制約[妥当性制約: 要素の妥当性]に示す意味で宣言に適合
するとき,この要素は,マッチするという。
1.2.1.7 互換性のためには(for compatibility) XMLの機能であって,XMLがSGMLと互換であることを保
証するためだけに導入されるものについて記述する文を示す。
1.2.1.8 相互運用性のためには(for interoperability) 拘束力はもたない推奨事項について記述する文を示
す。ISO 8879へのWebSGML適用附属書以前から存在するSGMLプロセサが,XML文書を処理できる可
3
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
能性を高めるために,これらの推奨事項を取り入れる。
1.2.2
用語遣い
1.2.2.1 してもよい(may) 適合する文書又はXMLプロセサは,記述されたとおりに動作してもよいが,そ
のとおりにする必要はない。
1.2.2.2 しなければならない(must) 適合する文書又はXMLプロセサは,記述されたとおりに動作するこ
とが要求される。そうでなければ,誤りとする。
2. 文書 この規格で定義する意味で,整形式のデータオブジェクトをXML文書という。整形式のXML
文書が,ある制約条件を満足すれば,妥当なXML文書という。
XML文書は,論理構造及び物理構造をもつ。物理的には,文書は,実体という単位からなる。実体が他
の実体を参照すれば,参照された実体も文書の一部になる。文書は,“ルート”すなわち文書実体から始ま
る。論理的には,文書は,宣言・要素・コメント・文字参照・処理命令を含み,これらすべては,文書内
で明示的なマーク付けによって示す。論理構造及び物理構造は,4.3.2 整形式の解析対象実体に示すとお
りに,厳密に入れ子になっていなければならない。
2.1
整形式のXML文書 あるテキストオブジェクトが,次の条件を満たすとき,そのテキストオブジ
ェクトを整形式のXML文書と呼ぶ。
a) 全体として,documentというラベルをもつ生成規則にマッチする。
b) この規格で定義するすべての整形式制約に従う。
c) 文書内で直接的又は間接的に参照されるそれぞれの解析対象実体 が整形式となる。
文書
[1]
document
::= prolog element Misc*
生成規則documentにマッチするとは,次を意味する。
a) 一つ以上の要素を含む。
b) ルート又は文書要素という要素が一つだけ存在し,これは,他の要素の内容に含まれない。 これ以外
のすべての要素は,その開始タグが他の要素の内容に含まれれば,対応する終了タグも同じ要素の内
容に含まれる。つまり,要素は,開始タグ及び終了タグによって区切られ,入れ子構造をなす。
これらの結果として,文書内のどの非ルート要素Cに対しても,ある要素Pが存在し,Cは,Pの内容
に含まれるが,Pの内容に含まれる他の要素に含まれることはない。このとき,PをCの親といい,CをP
の子という。
2.2
文字 解析対象実体は,テキスト(文字の並びであって,マーク付け又は文字データを表す。)を含む。
文字は,テキストの最小単位であって,JIS X 0221-1:2001に規定されている。使用できる文字は,タブ・
復帰・改行・(Unicode及びJIS X 0221-1に規定する)文字とする。 附属書A 文献のA.1 引用規定で引用さ
れるこれらの規格の版は,この規格の原勧告が作成された時点で最新のものとする。補遺又は新版によっ
て,これらの規格には新しい文字が追加されることがある。したがって,XMLプロセサは,Charで指定し
た範囲のすべての文字を受け付けなければならない。
文字の範囲
[2]
Char
::= #x9 | #xA | #xD | [#x20-#xD7FF] | [#xE000-#xFFFD] | [#x10000-#x10FFFF]
4
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
/* 任意のUnicode文字。ただし,S領域,FFFE及びFFFFは除く。*/
文字符号位置をビットパタンに符号化する機構は,実体ごとに違ってもよい。すべてのXMLプロセサ
は,Unicode 3.1 のUTF-8符号化及びUTF-16符号化を受け付けなければならない。二つのどちらが用いら
れているかを明示するため又は他の符号化を利用するための機構は,4.3.3 実体における文字符号化に記
述する。
備考 文書作成者は,Unicodeの6.8(Unicode3の3.6のD21も参照すること。)で定義される互換文字を
避けることが推奨される。次の範囲に定義される文字も避けることが推奨される。これらは,制御
文字であるか又は永久に定義されないUnicode文字であるかのどちらかとする。
[#x7F-#x84], [#x86-#x9F], [#xFDD0-#xFDDF],
[#x1FFFE-#x1FFFF], [#x2FFFE-#x2FFFF], [#x3FFFE-#x3FFFF],
[#x4FFFE-#x4FFFF], [#x5FFFE-#x5FFFF], [#x6FFFE-#x6FFFF],
[#x7FFFE-#x7FFFF], [#x8FFFE-#x8FFFF], [#x9FFFE-#x9FFFF],
[#xAFFFE-#xAFFFF], [#xBFFFE-#xBFFFF], [#xCFFFE-#xCFFFF],
[#xDFFFE-#xDFFFF], [#xEFFFE-#xEFFFF], [#xFFFFE-#xFFFFF],
[#x10FFFE-#x10FFFF].
2.3
共通の構文構成子 この章では,文法内で広く使用する幾つかの記号を定義する。
S (空白)は,一つ以上のスペース文字(#x20),復帰,改行又はタブから成る。
空白
[3]
S
::= (#x20 | #x9 | #xD | #xA)+
参考 直前の生成規則に#xDが含まれているのは,First Editionとの後方互換性だけを目的としている。
2.11で説明されているとおり,XML文書中にそのまま現れる#xD文字すべては,削除されるか
#xA文字によって置き換えられた後に他の処理が適用される。この規則にマッチする#xD文字
を得る唯一の方法は,実体値リテラルにおいて文字参照を用いることとする。
便宜上,文字を,字(letter)・数字・他の文字に分類する。一つの字(letter)は,アルファベット的若しくは
音節文字である基底文字又は漢字のような文字とする。各クラスにおける実際の文字についての完全な定
義は,附属書B 文字クラスに示す。
Nameは,字(letter)又は幾つかの区切り文字の一つで始まり,その後に字(letter),数字,ハイフン,下線,
コロン又はピリオドが続く。これらの文字を名前文字という。文字列"xml"で始まる名前,又は正規表現
(('X'|'x') ('M'|'m') ('L'|'l'))にマッチする任意の文字列で始まる名前は,この規格の現在の版又は将来の版での
標準化のために予約する。
備考 XML名前空間勧告(TR X 0023)は,コロン文字を含む名前に意味を与えている。そのため作者
は,名前空間の用途以外で名前にコロンを使用しないことが望ましい。XMLプロセサは,コロ
ンを名前文字として受け付けなければならない。
Nmtoken(名前トークン)は,名前文字の列とする。
名前及びトークン
5
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
[4]
NameChar
::= Letter | Digit | '.' | '-' | '̲' | ':' | CombiningChar | Extender
[5]
Name
::= (Letter | '̲' | ':') (NameChar)*
[6]
Names
::= Name (S Name)*
[7]
Nmtoken
::= (NameChar)+
[8]
Nmtokens
::= Nmtoken (S Nmtoken)*
備考 生成規則Names及び Nmtokensは,トークン化された属性値が正規化されたあとの妥当性を定義
するために使用する(3.3.1 属性の型を参照すること。)。
リテラルデータは,引用符で囲まれた文字列とし,その列を区切る引用符は含まない。リテラルは,内
部実体の内容(EntityValue),属性値(AttValue),外部識別子(SystemLiteral)の指定に使用する。SystemLiteral
はマーク付けの走査を行わずに解析できることに注意せよ。
リテラル
[9]
EntityValue
::= '"' ([^%&"] | PEReference | Reference)* '"'
| "'" ([^%&'] | PEReference | Reference)* "'"
[10] AttValue
::= '"' ([^<&"] | Reference)* '"'
| "'" ([^<&'] | Reference)* "'"
[11] SystemLiteral ::= ('"' [^"]* '"') | ("'" [^']* "'")
[12] PubidLiteral
::= '"' PubidChar* '"' | "'" (PubidChar - "'")* "'"
[13] PubidChar
::= #x20 | #xD | #xA | [a-zA-Z0-9] | [-'()+,./:=?;!*#@$̲%]
備考 生成規則EntityValueは,リテラルに単独の<を明示的に指定する実体定義(例えば <!ENTITY
mylt "<">)を認めている。この実体を参照すると整形式誤りが生じるため,この実体定義を避け
ることを強く勧める。
2.4
文字データ及びマーク付け テキストは,文字データ及びマーク付けから成る。マーク付けは,開
始タグ,終了タグ,空要素タグ,実体参照,文字参照,コメント,CDATAセクション の区切り子,文書
型宣言,処理命令及びXML宣言,テキスト宣言,文書の最上位レベルにあるすべての空白文字(つまり文
書要素の外側で他のマーク付けの内側でないもの)の形をとる。
マーク付けではないすべてのテキストは,文書の文字データを構成する。
アンパサンド(&)及び不等号(より小) (<)は,マーク付けの区切り子として使用する場合,又はコメント,
処理命令若しくはCDATAセクション 内で使用する場合にだけ,そのままの形で出現してよい。 これらの
文字が他の部分で必要な場合,番号による文字参照又は文字列"&"及び文字列"<"を用いて別扱いし
なければならない。不等号(より大) (>)は,文字列">"を用いて表現してもよい。内容の中で列"]]>"を使
用するときは,それが,CDATAセクションの終了をマーク付けしない限り,互換性のため,">"又は文
字参照を用いて別扱いしなければならない。
要素の内容では,いかなるマーク付けの開始区切り子も含まない任意の文字列が,文字データを構成す
る。CDATAセクションでは,CDATAセクションの終了区切り子"]]>"を含まない任意の文字列が,文字デ
ータを構成する。
属性値が一重引用符及び二重引用符を含むためには,アポストロフィ又は一重引用符(')は,"'"と
して表現し,二重引用符(")は,"""として表現する。
6
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
文字データ
[14] CharData
::= [^<&]* - ([^<&]* ']]>' [^<&]*)
2.5
コメント コメント は,他のマーク付けの外ならば,文書のどこに現れてもよい。さらに,文書型
宣言の中で,文法が許す場所に現れてもよい。コメントは,文書の文字データの一部ではない。XMLプロ
セサは,応用プログラムがコメントのテキストを取り出すことを可能としてもよいが,そうしなくともよ
い。 互換性のためには,文字列 "--"(二連ハイフン)は,コメント内で現れてはならない。パラメタ実体参
照は,コメントの内部では認識されない。
コメント
[15] Comment ::= '<!--' ((Char - '-') | ('-' (Char - '-')))* '-->'
コメントの例を次に示す。
<!-- declarations for <head> & <body> -->
この文法は,--->で終わるコメントを許さないことに注意すること。次に,整形式でない例を示す。
<!-- B+,B,or B--->
2.6
処理命令 処理命令(PI)によって,応用プログラムのための命令を文書に入れることができる。
処理命令
[16] PI
::= '<?' PITarget (S (Char* - (Char* '?>' Char*)))? '?>'
[17] PITarget
::= Name - (('X' | 'x') ('M' | 'm') ('L' | 'l'))
PIは,文書の文字データの一部ではないが,応用プログラムに渡されなければならない。PIは,命令が
渡される応用プログラムを特定するために使用するターゲット(PITarget)で始まる。ターゲット名"XML",
"xml"などは,この規格の現在の版又は将来の版の標準化のために予約する。XMLの記法機構を,PIのタ
ーゲットを宣言するために用いてもよい。パラメタ実体参照は,処理命令の内部では認識されない。
2.7
CDATAセクション CDATAセクションは,文字データが出現するところであれば,どこに出現し
てもよい。CDATAセクションで囲まなければマーク付けとして認識されてしまう文字を含むテキストを別
扱いするのにCDATAセクションを使用する。CDATAセクションは,文字列"<![CDATA["で始まり,文字
列"]]>"で終わる。
CDATAセクション
[18] CDSect
::= CDStart CData CDEnd
[19] CDStart
::= '<![CDATA['
[20] CData
::= (Char* - (Char* '))>' Char*))
[21] CDEnd
::= ']]>'
CDATAセクション内では,文字列CDEndだけをマーク付けとして認識するので,不等号(より小)及び
アンパサンドは,そのままの形で出現してよい。"<"及び"&"を用いて別扱いする必要はない(別扱い
7
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
できない。)。CDATAセクションは入れ子にはできない。
"<greeting>"及び"</greeting>"を,マーク付けではなく,文字データとして認識するためのCDATAセクシ
ョンの例を次に示す。
<![CDATA[<greeting>Hello,world!</greeting>]]>
2.8
前書き及び文書型宣言 XML文書は,使用するXMLの版を指定するXML宣言で始めることが望
ましい。 例えば,次に示す完全なXML文書は,整形式であるが 妥当ではない。
<?xml version="1.0"?>
<greeting>Hello,world!</greeting>
同じことが次の文書にもあてはまる。
<greeting>Hello,world!</greeting>
XML文書内のマーク付けの機能は,記憶構造及び論理構造を記述すること,並びに属性名及び属性値の
対を論理構造に関連づけることにある。XMLは,論理構造についての制約条件を定義するため,及びあら
かじめ定義された記憶単位を使用するための機構として文書型宣言を提供する。妥当なXML文書とは,
文書型宣言をもち,その文書型宣言に示す制約条件を満たすXML文書とする。
文書型宣言は,文書の最初の要素の前に現れなければならない。
前書き
[22] prolog
::= XMLDecl? Misc* (doctypedecl Misc*)?
[23] XMLDecl
::= '<?xml' VersionInfo EncodingDecl? SDDecl? S? '?>'
[24] VersionInfo
::= S 'version' Eq ("'" VersionNum "'" | '"' VersionNum '"')
[25] Eq
::= S? '=' S?
[26] VersionNum ::= '1.0'
[27] Misc
::= Comment | PI | S
XMLの文書型宣言は,ある文書クラスのための文法を記述するマーク付け宣言を含むか,参照する。こ
の文法を,文書型定義又はDTDという。文書型宣言は,マーク付け宣言を含んだ外部サブセット(特別な
種類の外部実体)を参照することができ,又は内部サブセットにマーク付け宣言を直接含むこともできる。
外部サブセットと内部サブセットの両方を使うこともできる。ある文書のDTDは,両方のサブセットを
まとめたものとして構成される。
マーク付け宣言は,要素型宣言,属性リスト宣言,実体宣言又は記法宣言とする。次に示す整形式制約
及び妥当性制約に規定するとおり,これらの宣言は,パラメタ実体内に全体又は一部が含まれてもよい。
より詳しい情報は,4. 物理構造を参照のこと。
文書型定義
[28] doctypedecl ::= '<!DOCTYPE' S Name (S ExternalID)? S? ('[' intSubset ']' S?)? '>'
[妥当性制約: ルート要素型]
[整形式制約: 外部サブセット]
[28a] DeclSep
::= PEReference | S
[整形式制約: 宣言間のパラメタ実体]
[28b] intSubset
::= markupdecl | DeclSep
8
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
[29] markupdecl
::= elementdecl | AttlistDecl | EntityDecl | NotationDecl | PI | Comment
[妥当性制約: 宣言及びパラメタ実体が厳密に入れ子をなすこと]
[整形式制約: 内部サブセット内のパラメタ実体]
外部サブセットを参照せず,内部サブセットを含まないdoctypedeclをもつ整形式文書を作成できること
に注意すること。
マーク付け宣言は,その全体又は一部を,パラメタ実体の置換テキストで構成してもよい。各々の非終
端記号 (elementdecl,AttlistDeclなど)のための生成規則は,この規格の後半にあり,すべてのパラメタ実体
を取り込んだ後の宣言について記述する。
パラメタ実体参照は,DTD(内部及び外部サブセット並びに外部パラメタ実体)のどの場所でも認識され
る。ただし,リテラル,処理命令,コメント及び無視される条件セクション(3.4 条件付きセクションを参
照すること)を除く。パラメタ実体は,実体値リテラルでも同様に認識される。内部サブセットで使用され
るパラメタ実体は,次に示す制限を受ける。
妥当性制約: ルート要素型
文書型宣言におけるNameは,ルート要素の型とマッチしなければならない。
妥当性制約: 宣言及びパラメタ実体が厳密に入れ子をなすこと
パラメタ実体の置換テキストは,マーク付け宣言内において,厳密に入れ子になっていなければなら
ない。つまり,マーク付け宣言(markupdecl)の最初又は最後の文字が,パラメタ実体参照の指し示す置
換テキストに含まれれば,両方とも同じ置換テキストに含まれなければならない。
整形式制約: 内部サブセット内のパラメタ実体
DTDの内部サブセットでは,パラメタ実体参照は,マーク付け宣言が出現可能な場所だけに出現でき
る。マーク付け宣言の一部としては出現できない。この制約は,外部パラメタ実体又は外部サブセッ
トでの参照には適用しない。
整形式制約: 外部サブセット
外部サブセットがある場合,その外部サブセットは,生成規則 extSubsetにマッチしなければならない。
整形式制約: 宣言間のパラメタ実体
DeclSepでのパラメタ実体参照の置換テキストは,生成規則extSubsetDeclにマッチしなければならない。
内部サブセットのときと同様に,外部サブセットと,DeclSepにおいて参照する任意の外部パラメタ実体
とは,非終端記号markupdeclによって許される型の完全なマーク付け宣言を幾つか並べたものでなければ
ならない。マーク付け宣言の間には,空白又はパラメタ実体参照を置いてもよい。外部サブセット又はこ
れらの外部パラメタ実体の内容の一部は,条件付きセクションを用いて無視してもよい。内部サブセット
ではこれは許されないが,内部サブセットから参照される外部パラメタ実体では許される。
外部サブセット
[30] extSubset
::= TextDecl? extSubsetDecl
[31] extSubsetDecl ::= ( markupdecl | conditionalSect | DeclSep)*
外部サブセット及び外部パラメタ実体の中では,パラメタ実体参照がマーク付け宣言の間だけでなく,
マーク付け宣言の中でも認められる。この点でも,外部サブセット及び外部パラメタ実体は,内部サブセ
ットと異なる。
9
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
文書型宣言付きのXML文書の例を,次に示す。
<?xml version="1.0"?>
<!DOCTYPE greeting SYSTEM "hello.dtd">
<greeting>Hello,world!</greeting>
システム識別子"hello.dtd"が,文書のDTDのアドレス(統一資源識別子(URI)参照)となる。
次の例のとおりに宣言を局所的に与えることもできる。
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE greeting [
<!ELEMENT greeting (#PCDATA)>
]>
<greeting>Hello,world!</greeting>
外部サブセット及び内部サブセットの両方を使用するときは,内部サブセットが外部サブセットより先
に出現したと見なす。これは,内部サブセットの実体及び属性リスト宣言が,外部サブセットの実体及び
属性リスト宣言に優先するという効果をもたらす。
2.9
非依存文書宣言 XMLプロセサは,応用プログラムに文書の内容を渡すが,マーク付け宣言は,こ
の内容に影響を与えることがある。例えば,属性のデフォルト値及び実体宣言は影響を与える。非依存文
書宣言は,XML宣言の一部分として出現することができ,影響を与えるマーク付け宣言が文書実体の外部
又はパラメタ実体の中に出現するかどうかを示す。外部マーク付け宣言は外部サブセット又はパラメタ実
体の中に出現するマーク付け宣言として定義される(パラメタ実体は,外部でも内部でもよい。妥当性を検
証しないプロセサが内部パラメタ実体を読むことを義務付けないために,内部パラメタ実体も含める。)。
非依存文書宣言
[32] SDDecl ::= S 'standalone' Eq (("'" ('yes' | 'no') "'") | ('"' ('yes' | 'no') '"'))
[妥当性制約: 非依存文書宣言]
非依存文書宣言では,値"yes"は,XMLプロセサから応用プログラムへと渡される情報に影響する外部
マーク付け宣言が存在しないことを意味する。値"no"は,影響する外部マーク付け宣言が存在するか,又
は存在する可能性があることを意味する。非依存文書宣言は,外部宣言が存在するかどうかだけを示すこ
とに注意すること。外部実体への参照が文書内に存在していても,その実体が内部で宣言されているとき
は,文書の非依存の値には影響を与えない。
外部マーク付け宣言が存在しなければ,非依存文書宣言は意味をもたない。外部マーク付け宣言は存在
するが,非依存文書宣言が存在しない場合は,"no"の値が設定されているものとする。
XML文書で standalone="no" が設定されているものは,あるアルゴリズムでstandalone="yes"の文書
に変換できる。変換後の文書のほうがネットワークによる配信には望ましいかもしれない。
妥当性制約: 非依存文書宣言
非依存文書宣言は,何らかの外部マーク付け宣言が次のいずれかを宣言しているときは,値"no"を取
らなければならない。
a) デフォルト値付きの属性であって,この属性が適用される要素が,属性値を 指定せずに文書内に現
れるもの。
b) amp,lt,gt,apos,quot以外の実体であって,その実体に対する参照が文書内に出現するもの。
10
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
c) トークン化された型をもつ属性であって,文書中で出現するときの属性値は,この値から正規化が
生成する値と,宣言がないとしたときに正規化が生成する値とが異なるもの。
d) 要素内容をもつ要素型であって,空白がその要素型のいずれかのインスタンス内に直接現れるもの。
非依存文書宣言付きのXML宣言の例を,次に示す。
<?xml version="1.0" standalone='yes'?>
2.10 空白の取扱い XML文書を編集するときは,マーク付けを目立たせ読みやすくするために,“空
白”(スペース,タブ及び空白行)を使うと便利なことが多い。これらの空白は,配布する版の文書の一部に
含めることを普通は意図していない。しかし,“意味のある”空白であって,配布する版に保持されなけれ
ばならないものも多い。例えば,詩及びソースコードにおける空白がこれにあたる。
XMLプロセサは,文書内のマーク付け以外のすべての文字を,変更せずにそのまま応用プログラムに渡
さなければならない。妥当性を検証するXMLプロセサは,これらの文字の中でどの文字が要素内容に出
現する空白を構成するかを応用プログラム側に伝えなければならない。
xml:spaceという特別な属性を要素に加えることによって,応用プログラムはこの要素の中の空白を保
存することが望ましいという意図を示してもよい。妥当な文書では,この属性を使用する場合は,他の属
性と同じように宣言しなければならない。宣言するときは,取り得る値を"default","preserve"のいずれか
又は両方に限る列挙型でなければならない。例を次に示す。
<!ATTLIST poem xml:space (default|preserve) 'preserve'>
<!ATTLIST pre xml:space (preserve) #FIXED 'preserve'>
値"default"は,応用プログラムのデフォルトの空白処理モードがその要素に適用できることを意味する。
値"preserve"は,すべての空白を応用プログラムが保存することを意味する。この宣言の意図は,xml:space"
属性の別の指定で上書きしない限り,要素の内容に現れるすべての要素に適用すると解釈する。この規格
は,xml:spaceに"default"及び"preserve"以外の値を指定したときの意味は定義しない。他の値を指定するこ
とは誤りとする。XMLプロセサは,この誤りを報告してもよく,この属性指定を無視することによって回
復してもよく,応用プログラムに誤った値を報告することによって回復してもよい。応用プログラムは,
誤った値を無視しても拒絶してもよい。
文書のルート要素については,この属性の値を指定するか,又はこの属性のデフォルト値が宣言されて
いる場合を除いては,応用プログラムによる空白の取扱いについて,いかなる意図も示さないと解釈する。
2.11 行末の取扱い XMLの解析対象実体は,通常コンピュータのファイル内に保存され,編集の便宜の
ために複数の行に分けることが多い。これらの行は,普通は,復帰(#xD)コード及び改行(#xA)コードの何
らかの組合せによって分けられる。
応用プログラムの仕事を簡単にするため,XMLプロセサは,次の処理をした場合と同一の文字を,応用
プログラムに渡さなければならない。入力された(文書実体を含む)外部解析対象実体の中のすべての行末
(連続する2文字#xD #xA,及び#xAを後ろにともなわない#xD)を,解析を行う前にXMLプロセサが単一
の#xAに変換することによって正規化する処理とする。
2.12 言語識別 文書処理においては,その文書の中身がどんな自然言語又は形式言語で書かれているか
明示することが,役に立つことが多い。XML文書内の要素のもつ内容又は属性値において使用する言語を
指定するために,xml:langという名前の特別な属性を,文書内に挿入してもよい。妥当な文書においてこ
の属性を使用する場合は,他の属性と同様に宣言しなくてはならない。この属性の値は, IETF RFC 3066(言
語識別のためのタグ)又は後継規定で定義される言語識別コードとする。さらに,空白文字列も許す。
11
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(生成規則33から38は削除された。)
例を次に示す。
<p xml:lang="en">The quick brown fox jumps over the lazy dog.</p>
<p xml:lang="en-GB">What colour is it?</p>
<p xml:lang="en-US">What color is it?</p>
<sp who="Faust" desc='leise' xml:lang="de">
<l>Habe nun,ach! Philosophie,</l>
<l>Juristerei,und Medizin</l>
<l>und leider auch Theologie</l>
<l>durchaus studiert mit heisem Bemuh'n.</l>
</sp>
xml:langで宣言した意図は,この要素の内容の中に現れる他の要素のxml:lang属性で上書きされない限
り,指定した要素のすべての属性と内容に適用される。特に,要素Bでxml:langとして空文字列を指定す
ることによって,特定の言語を指定することなく,上位の要素Aで指定されたxml:langを打ち消すことが
できる。Bの中では,有効な言語情報は存在しないと見なされる。これは,B及びその祖先においてxml:lang
が指定されなかったときと同様とする。
備考 言語情報は,外部の転送プロトコル(HTTP,MIMEなど)によって与えられることもある。与え
られた場合,XML応用プログラムはこの情報を利用してもよいが,xml:langによって与えられる
より局所的な情報がこれを上書きすると見なすことが望ましい。
xml:langを次に示すとおりに簡単に宣言してもよい。
xml:lang CDATA #IMPLIED
必要ならば,特定のデフォルト値を与えてもよい。英語を母語とする学生用のフランス語の詩集では,
説明及び注を英語で記述すれば,属性xml:langを次のとおりに宣言することとなる。
<!ATTLIST poem xml:lang CDATA 'fr'>
<!ATTLIST gloss xml:lang CDATA 'en'>
<!ATTLIST note xml:lang CDATA 'en'>
3. 論理構造 いかなるXML文書も,一つ以上の要素を含む。要素の境界は,開始タグ及び終了タグによ
って区切る。要素が空要素のときは,空要素タグで示す。各々の要素は型をもつ。要素型は名前[共通識
別子(generic identifier)又はGIと呼ぶことがある。]によって特定される。要素は幾つかの属性をもつこと
ができる。属性は名前及び値をもつ。
要素
[39] element
::= EmptyElemTag
| STag content ETag
[整形式制約: 要素型のマッチ]
[妥当性制約: 要素の妥当性]
この規格は,要素型及び属性の意味,使用方法,又は(構文に関することを除き)名前に制約を与えない。
ただし,正規表現(('X'|'x')('M'|'m')('L'|'l'))にマッチする文字列で始まる名前は,この版又は今後の版のこの規
12
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
格での標準化のために予約する。
整形式制約: 要素型のマッチ
要素の終了タグの名前は,その要素の開始タグにおける要素型とマッチしなければならない。
妥当性制約: 要素の妥当性
要素が妥当とは,その要素型とマッチするNameをもつ宣言(elementdeclにマッチするもの)が存在し,
さらに次のいずれかの条件を満たす場合とする。
a) 宣言がEMPTYにマッチし,要素が 内容をもたない(実体参照・コメント・PI・空白も,もたない。)。
b) 宣言がchildrenにマッチし,要素の 子要素の並びが(実体参照を置換テキストで置き換えた後で),
内容モデル中の正規表現によって生成される言語に属する。開始タグ及び最初の子要素の間,子要素
の間,又は最後の子要素及び終了タグの間に空白・コメント・PI (すなわち,Miscにマッチするもの。)
が,あってもよい。空白文字だけを含むCDATAセクション,及び空白に展開される文字参照を置換
テキストとしてもつ実体への参照は,非終端記号Sにマッチせず,そのためこれらの位置に出現でき
ないことに注意すること。しかし,空白に展開される文字参照だけから構成されるリテラル値をもつ
内部実体への参照は,文字参照の展開により置換テキストが空白になるので,非終端記号Sにマッチ
する。
c) 宣言がMixedにマッチし,要素の内容は,(実体参照を置換テキストで置き換えた後に)文字データ,
空白,PI及び 子要素からなる。子要素の要素型は,内容モデルに出現する名前にマッチする。
d) 宣言がANYにマッチし,(実体参照を置換テキストで置き換えた後の)内容は文字データ及び子要
素から成り,どの子要素の要素型も宣言されている。
3.1
開始タグ,終了タグ及び空要素タグ 空でない任意のXML要素の始まりは,開始タグによってマー
ク付けする。
開始タグ
[40] STag
::= '<' Name (S Attribute)* S? '>'
[整形式制約: 属性指定の一意性]
[41] Attribute
::= Name Eq AttValue
[妥当性制約: 属性値の型]
[整形式制約: 外部実体への参照がないこと]
[整形式制約: 属性値に<を含まないこと]
開始タグ及び終了タグ内のNameは,要素の型を表す。Name及びAttValueの対を要素の属性指定といい,
個々の対におけるNameを属性名といい,AttValueの内容(区切り子' 又は"の間のテキスト)を属性値という。
開始タグ又は空要素タグにおける属性指定の順序には意味がないことに注意すること。
整形式制約: 属性指定の一意性
開始タグ又は空要素タグでは,同一の属性名が2回以上出現してはならない。
妥当性制約: 属性値の型
属性は宣言されていなければならない。属性値は,その属性に対して宣言した型に属さなければなら
ない(属性の型については,3.3 属性リスト宣言を参照。)。
整形式制約: 外部実体への参照がないこと
属性値には,外部実体への直接的又は間接的な参照を含むことはできない。
13
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
整形式制約: 属性値に<を含まないこと
属性値内で直接的又は間接的に参照する実体の置換テキストには,<を含んではならない。
開始タグの例を次に示す。
<termdef id="dt-dog" term="dog">
開始タグで始まる要素の終わりは,終了タグでマーク付けしなければならない。この終了タグは,対応
する開始タグの要素型と同じ名前をもつ。
終了タグ
[42] ETag
::= '</' Name S? '>'
終了タグの例を,次に示す。
</termdef>
要素の開始タグと終了タグとの間のテキストをその要素の内容という。
要素の内容
[43] content
::= CharData? ((element | Reference | CDSect | PI | Comment) CharData?)*
内容をもたない要素は空であるという。空要素は,終了タグを直後にともなう開始タグによって表現さ
れるか,又は空要素タグによって表現される。 空要素タグは,次の特別な形式をとる。
空要素のためのタグ
[44] EmptyElemTag
::= '<' Name (S Attribute)* S? '/>'
[整形式制約: 属性指定の一意性]
空要素タグは,内容をもたない任意の要素の表現に利用できる。空要素タグで表現する要素を,キーワ
ードEMPTYを用いて宣言しなくてもよい。 相互運用性のためには,空要素タグは,EMPTYとして宣言
された要素に使用すべきであり,またこれ以外の要素に使用すべきではない。
空要素の例を,次に示す。
<IMG align="left"
src="http://www.w3.org/Icons/WWW/w3c̲home" />
<br></br>
<br/>
3.2
要素型宣言 妥当性を保証するため,要素型宣言及び属性リスト宣言を用いてXML文書の要素の構
造に制約を加えることができる。要素型宣言は,要素の内容についての制約とする。
要素型宣言は,要素の子として出現可能な要素型について,制約を加えることが多い。利用者の任意選
択によっては,要素型宣言をもたない要素型が他の要素型宣言によって参照されれば,XMLプロセサは警
告を出してもよい。しかし,これは誤りとはしない。
要素型宣言は次の形式をとる。
要素型宣言
14
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
[45] elementdecl ::= '<!ELEMENT' S Name S contentspec S? '>'
[妥当性制約: 要素型宣言の一意性]
[46] contentspec ::= 'EMPTY' | 'ANY' | Mixed | children
ここで,Nameは宣言されている要素の型を示す。
妥当性制約: 要素型宣言の一意性
一つの要素型を2回以上宣言できない。
要素型宣言の例を次に示す。
<!ELEMENT br EMPTY>
<!ELEMENT p (#PCDATA|emph)* >
<!ELEMENT %name.para; %content.para; >
<!ELEMENT container ANY>
3.2.1
要素内容 ある型の要素が,必ず子要素だけを含み(文字データを含まない。),それらの間には空
白(非終端記号Sにマッチする文字)だけしか現れないとき,その要素型は,要素内容をもつという。 この
場合,内容モデルが制約となる。内容モデルは,子要素の型及び子要素の出現順序を制御する簡単な文法
とする。この文法は,内容素子(cp)から成る。内容素子は,名前,内容素子の選択リスト又は内容素子の
列リストから構成される。
要素内容モデル
[47] children
::= (choice | seq) ('?' | '*' | '+')?
[48] cp
::= (Name | choice | seq) ('?' | '*' | '+')?
[49] choice
::= '(' S? cp ( S? '|' S? cp )+ S? ')'
[妥当性制約: グループ及びパラメタ実体が厳密な入れ子をなしていること]
[50] seq
::= '(' S? cp ( S? ',' S? cp )* S? ')'
[妥当性制約: グループ及びパラメタ実体が厳密な入れ子をなしていること]
ここで,Nameは,子として出現してよい要素の型を示す。この文法で選択リストが現れる位置では,選
択リスト内のいずれの内容素子も要素内容の中に現れてよい。列リストに現れる内容素子は,リストで指
定する順番のとおりに,要素内容に現れなければならない。名前又はリストの後に出現する任意選択の文
字は,要素又はリスト内の内容素子が,1回以上任意の回数(+),0回以上任意の回数(*)又は0回若しくは
1回(?)出現可能なことを規定する。この演算子がない場合は要素又は内容素子が正確に1度だけ現われな
くてはならないことを意味する。 ここで示す構文及び意味は,この規格における生成規則で用いるものと
同一とする。
要素の内容が内容モデルにマッチするのは,列,選択及び繰返し演算子に従って,内容の中の要素と内
容モデル内の要素型とをマッチさせながら,内容モデル内の一つのパスをたどれるときに限る。互換性の
ため,要素が,内容モデルにおける要素型の複数の出現位置とマッチする内容モデルは,誤りとする。詳
細な規定については,附属書E 決定的内容モデルを参照。
妥当性制約: グループ及びパラメタ実体が厳密な入れ子をなしていること
パラメタ実体の置換テキストは,括弧で囲まれたグループによって,厳密な入れ子を構成しなければ
ならない。つまり,choice,seq又はMixedに含まれる左小括弧又は右小括弧のいずれか一方がパラメ
15
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
タ実体の置換テキストに含れれば,他方も同じ置換テキストに含まれなければならない。
相互運用性のためには,choice,seq又はMixedの中にパラメタ実体が現れた場合,その置換テキス
トは少なくとも一つの空でない文字を含むことが望ましく,置換テキストの最初と最後の空でない文
字は接続子( |又は,)でないことが望ましい。
要素内容モデルの幾つかの例を次に示す。
<!ELEMENT spec (front,body,back?)>
<!ELEMENT div1 (head,(p | list | note)*,div2*)>
<!ELEMENT dictionary-body (%div.mix; | %dict.mix;)*>
3.2.2
混合内容 ある要素型の要素が文字データを含むことができるとき,その要素型は,混合内容をも
つという(文字データに子要素が混在しても構わない。)。 この場合,子要素の型についての制約が存在し
てもよいが,子要素の順序又は出現回数についての制約は存在しない。
混合内容宣言
[51] Mixed
::= '(' S? '#PCDATA' (S? '|' S? Name)* S? ')*'
| '(' S? '#PCDATA' S? ')'
[妥当性制約: グループ及びパラメタ実体が厳密な入れ子をなしていること]
[妥当性制約: 要素型の重複の禁止]
ここで,Nameは子として出現してもよい要素の型を示す。キーワード #PCDATA は,歴史的には"解析
対象文字データ(parsed character data)"に由来する。
妥当性制約: 要素型の重複の禁止
一つの混合内容宣言内に,同じ名前が複数回出現してはならない。
混合内容宣言の例を次に示す。
<!ELEMENT p (#PCDATA|a|ul|b|i|em)*>
<!ELEMENT p (#PCDATA | %font; | %phrase; | %special; | %form;)* >
<!ELEMENT b (#PCDATA)>
3.3
属性リスト宣言 属性は,名前及び値の対を要素に関連付けるために用いる。属性指定は,開始タ
グ又は空要素タグ内でだけ可能とする。したがって,属性指定を認識するための生成規則は,3.1 開始タ
グ,終了タグ及び空要素タグに示されている。属性リスト宣言は,次の目的で用いる。
a) ある要素型に適用する属性の集合を規定する。
b) 属性への型制約を設定する。
c) 属性のデフォルト値を規定する。
属性リスト宣言は,ある要素型と関連付けられた各属性に対し,名前,データ型及び(存在すれば)デフ
ォルト値を規定する。
属性リスト宣言
[52] AttlistDecl
::= '<!ATTLIST' S Name AttDef* S? '>'
[53] AttDef
::= S Name S AttType S DefaultDecl
16
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
AttlistDecl規則に含まれるNameは,要素型の名前とする。利用者の任意選択によっては,宣言していな
い要素型に対して属性を宣言したならば,XMLプロセサは,警告を出してもよい。しかし,これは誤りと
はしない。 AttDef規則におけるNameは,属性の名前とする。
ある要素型に対して,複数のAttlistDeclがある場合,これらすべての内容を繋ぎ合わせる。ある要素型の
同じ属性に,複数の定義がある場合には,最初の宣言を有効とし,他の宣言は無視する。相互運用性のた
めには,DTDの作成者は,ある要素型には高々一つの属性リスト宣言しか与えない,ある属性名には高々
一つの属性定義しか与えない,及びすべての属性リスト宣言には少なくとも一つの属性定義を与える,と
いう選択をしてもよい。相互運用性のためには,XMLプロセサは,利用者の任意選択によっては,ある要
素型に複数の属性リスト宣言を与えたり,ある属性に複数の属性定義を与えたりしたときに,警告を出し
てもよい。しかし,これは,誤りとはしない。
3.3.1
属性の型 XMLの属性の型は,文字列型・トークン化型・列挙型の3種類とする。文字列型は,
値として任意のリテラル文字列をとる。トークン化型は,字句及び意味に関して,次に示す様々な制約を
もつ。文法中で書かれている妥当性制約は,3.3.3 属性値の正規化で記述されるとおりに属性値が正規化
された後で適用される。
属性の型
[54] AttType
::= StringType | TokenizedType | EnumeratedType
[55] StringType
::= 'CDATA'
[56] TokenizedType ::= 'ID'
[妥当性制約: ID]
[妥当性制約: 一つの要素ごとに一つのID]
[妥当性制約: ID属性のデフォルト]
| 'IDREF' [妥当性制約: IDREF]
| 'IDREFS' [妥当性制約: IDREF]
| 'ENTITY' [妥当性制約: 実体名]
| 'ENTITIES' [妥当性制約: 実体名]
| 'NMTOKEN' [妥当性制約: 名前トークン]
| 'NMTOKENS' [妥当性制約: 名前トークン]
妥当性制約: ID
ID型の値は,生成規則Nameにマッチしなければならない。一つのXML文書内では,一つの名前が,
この型の値として複数回現れてはならない。つまり,IDの値は,要素を一意に特定しなければならな
い。
妥当性制約: 一つの要素ごとに一つのID
要素型は,複数のID属性をもってはならない。
妥当性制約: ID属性のデフォルト
ID属性は,デフォルトとして,#IMPLIED又は#REQUIREDを宣言しなければならない。
妥当性制約: IDREF
IDREF型の値は,生成規則Nameにマッチしなければならない。IDREFS型の値は,Namesにマッチし
17
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
なければならない。各々のNameは,XML文書内に存在する要素のID属性の値とマッチしなければな
らない。つまり,IDREFの値は,あるID属性の値とマッチしなければならない。
妥当性制約: 実体名
ENTITY型の値は,生成規則Nameにマッチしなければならない。ENTITIES型の値は,Namesにマッ
チしなければならない。各々のNameは,DTDで宣言する解析対象外実体とマッチしなければならない。
妥当性制約: 名前トークン
NMTOKEN型の値は,生成規則Nmtokenにマッチしなければならない。NMTOKENS型の値は,
Nmtokensにマッチしなければならない。
列挙型の属性は,宣言した幾つかの値の一つをとることができる。列挙型には,2種類ある。
列挙属性の型
[57] EnumeratedType ::= NotationType | Enumeration
[58] NotationType
::= 'NOTATION' S '(' S? Name (S? '|' S? Name)* S? ')'
[妥当性制約: 記法属性]
[妥当性制約: 一つの要素型に一つの記法]
[妥当性制約: 空要素に記法なし]
[妥当性制約: トークンの重複なし]
[59] Enumeration
::= '(' S? Nmtoken (S? '|' S? Nmtoken)* S? ')'
[妥当性制約: 列挙]
[妥当性制約: トークンの重複なし]
NOTATION属性は,その属性が付与されている要素を解釈するのに使用する記法を特定する。記法は,
DTD内で宣言され,システム識別子及び/又は公開識別子に関連付けられる。
妥当性制約: 記法属性
この型の値は,宣言に含まれる幾つかの記法の名前の一つとマッチしなければならない。つまり,宣
言に含まれる記法名は,すべて宣言されていなければならない。
妥当性制約: 一つの要素型に一つの記法
一つの要素型には,一つ以下のNOTATION属性しか指定できない。
妥当性制約: 空要素に記法なし
相互運用性のためには ,NOTATION型の属性をEMPTYと宣言された要素に対して宣言してはなら
ない。
妥当性制約: トークンの重複なし
単一のNotationType属性宣言における記法名は,すべて異なるものとする。同様に,単一のEnumeration
属性宣言におけるすべての Nmtokenは,すべて異なるものとする。
妥当性制約: 列挙
この型の値は,宣言に含まれる幾つかのNmtokenトークンの一つとマッチしなければならない。
相互運用性のためには,同じNmtokenは,一つの要素型の幾つかの列挙型の属性として,複数回現れな
いことが望ましい。
3.3.2
属性のデフォルト 属性宣言は,属性の指定が必すかどうかについての情報を与える。必すでない
場合には,文書内で属性が指定されていないとき,XMLプロセサがどう処理するかという情報も与える。
18
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
属性のデフォルト
[60] DefaultDecl ::= '#REQUIRED' | '#IMPLIED'
| (('#FIXED' S)? AttValue)
[妥当性制約: 必す属性]
[妥当性制約: 属性デフォルトの構文的な正しさ]
[整形式制約: 属性値に<を含まないこと]
[妥当性制約: 固定の属性デフォルト]
属性宣言において,#REQUIREDはその属性が必すであること,#IMPLIEDはデフォルト値がないこと
を意味する。 宣言が#REQUIREDでも#IMPLIEDでもないときには,AttValueの値が,デフォルト値とな
る。#FIXEDキーワードは,その属性の値がデフォルト値と常に同一でなければならないことを示す。デ
フォルト値が宣言されている属性が省略されている要素をXMLプロセサが見つけた場合は,宣言された
デフォルト値を応用プログラムに報告しなければならない。
妥当性制約: 必す属性
デフォルトの宣言が#REQUIREDキーワードの場合,属性リスト宣言で参照した要素型のすべての要
素で,その属性を指定しなければならない。
妥当性制約: 属性デフォルトの構文的な正しさ
宣言したデフォルト値は,宣言した属性型の構文的な制約を満たさなければならない。
型についての構文的な制約だけが要求されていることに注意。他の制約(例えばENTITY型の属性の
値は,宣言された解析対象外実体の名前であること。)は,宣言されたデフォルト値が実際に使われた
とき(この属性を指定しない要素が現れたとき。)に有効になる。
妥当性制約: 固定の属性デフォルト
属性が#FIXEDキーワードで宣言されたデフォルト値をもつ場合,その属性のインスタンスはデフォ
ルト値にマッチしなければならない。
属性リスト宣言の例を,次に示す。
<!ATTLIST termdef
id ID #REQUIRED
name CDATA #IMPLIED>
<!ATTLIST list
type (bullets|ordered|glossary) "ordered">
<!ATTLIST form
method CDATA #FIXED "POST">
3.3.3
属性値の正規化 属性値を応用プログラムに渡す前,又は妥当性を検証する前に,XMLプロセサ
は,次に示すアルゴリズムを適用することによって,属性値を正規化しなければならない。ただし,この
アルゴリズムと同じ結果を応用プログラムに渡すなら,他の方法によって正規化してもよい。
a) すべての改行は入力の際に,2.11 行末の取扱いで記述されるとおりに#xAに正規化されなければなら
ない。このアルゴリズムの残りの操作はこの方法で正規化されたテキストに対して行う。
b) 正規化された値は,空文字列であるとして処理を始める。
c) 正規化前の属性値にある,文字,実体参照及び文字参照に対して,先頭から最後まで次の処理を行う。
19
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1) 文字参照については,正規化された値に参照された文字を追加する。
2) 実体参照については,このアルゴリズムのステップc)を実体の置換テキストに再帰的に適用する。
3) 空白文字(#x20,#xD,#xA,#x9)については,正規化された値にスペース文字(#x20)を追加する。
4) そのほかの文字については,その文字を正規化された値に追加する。
属性の型がCDATAでない場合は,XMLプロセサは正規化された属性値に対して,さらに次の処理をし
なければならない。まず,先頭又は末尾にあるスペース文字(#x20)をすべて取り除く。次に,連続するス
ペース文字(#x20)を一つのスペース文字(#x20)に置き換える。
正規化前の属性値が,スペース(#x20)以外の空白文字への文字参照を含んでいるなら,正規化された値
は参照された文字(#xD,#xA又は #x9)をそのまま含む。正規化前の値が,空白文字(参照ではなく)を含ん
でいるときは異なる結果になる。この場合,各空白文字は,正規化された値では,スペース文字(#x20)に
置き換えられる。置換テキストがスペース文字を含む実体が,正規化前の値で参照されているときも異な
る結果になる。この場合,正規化された値では,再帰的な処理によって,空白文字はスペース文字(#x20)
に置き換えられる。
妥当性を検証しないプロセサは,宣言が見つからない属性は,すべて,CDATAと宣言しているとして扱
うものとする。
属性値が,宣言を読み込んでいない実体への参照を含むときは,誤りとする。これは,妥当性を検証し
ないプロセサを用いるときに限って起こりうる。
次に,属性の正規化についての例を示す。次の宣言がある場合を考える。
<!ENTITY d "
">
<!ENTITY a "
">
<!ENTITY da "
">
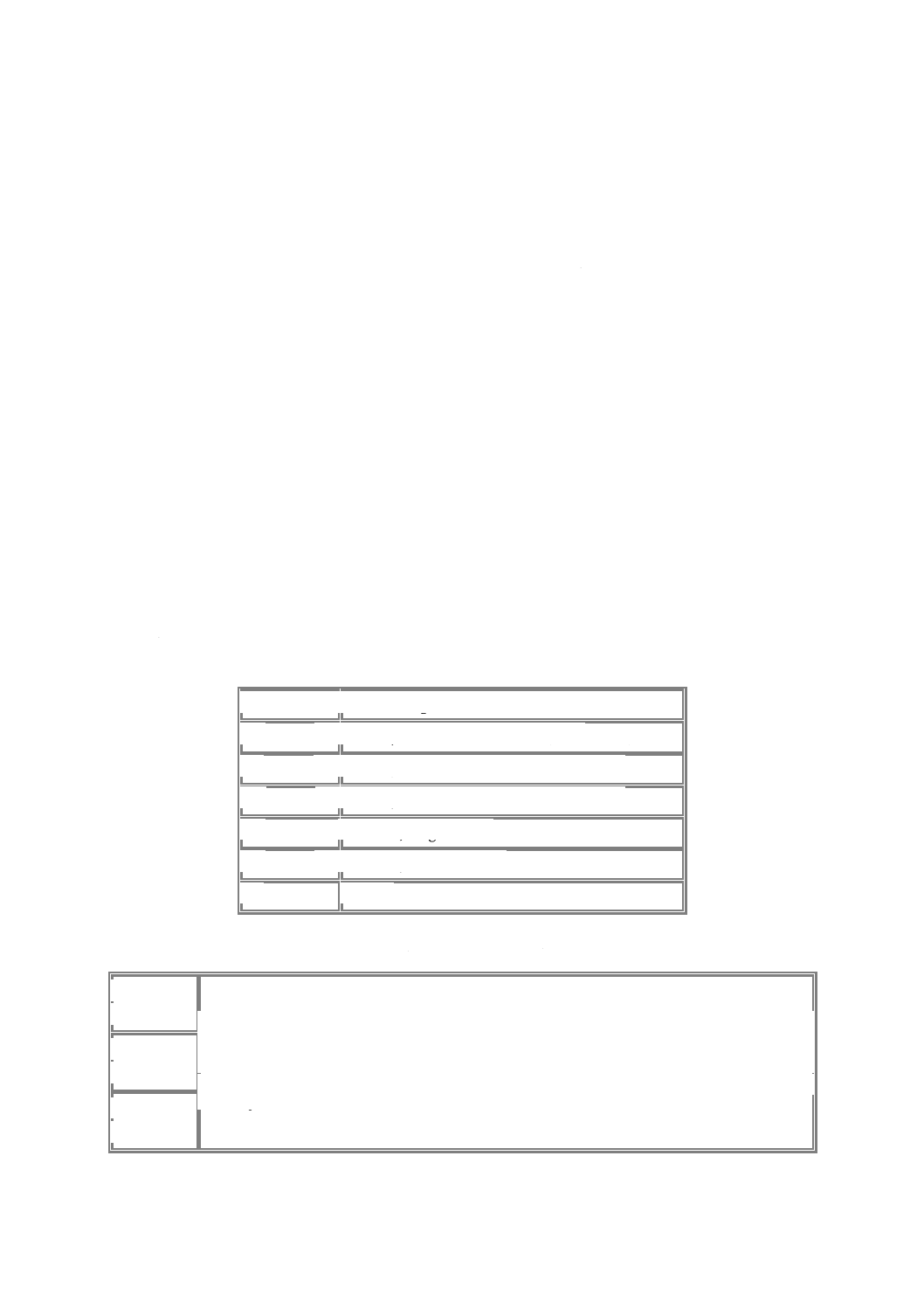
属性aがNMTOKENSとして宣言されていれば,表1の左欄の属性指定は,中欄の文字の並びに正規化
される。属性aが CDATAとして宣言されていれば,右欄の内容に正規化される。
表 1 属性値の正規化の例
属性指定
aが NMTOKENS
aが CDATA
a="
xyz"
x y z
#x20 #x20 x y z
a="&d;&d;A&a; &a;B&da;"
A #x20 B
#x20 #x20 A #x20 #x20 #x20 B
#x20 #x20
a=
"

A

B
&#
xa;"
#xD #xD A #xA #xA B
#xD #xA
#xD #xD A #xA #xA B #xD #xA
aがNMTOKENS型として宣言された場合,最後の例は,整形式ではあるが妥当ではないことに注意。
3.4
条件付きセクション 条件付きセクションとは,文書型宣言の外部サブセットの一部又は外部パラ
メタ実体の一部であって,制御キーワードの指定によって,DTDの論理構造に含まれるか又は除かれるか
が変わる部分とする。
20
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
条件付きセクション
[61] conditionalSect
::= includeSect | ignoreSect
[妥当性制約: 条件付きセクション/パラメタ実体が厳密に入れ子をなすこと ]
[62] includeSect
::= '<![' S? 'INCLUDE' S? '[' extSubsetDecl ']]>'
[63] ignoreSect
::= '<![' S? 'IGNORE' S? '[' ignoreSectContents* ']]>'
[妥当性制約: 条件付きセクション/パラメタ実体が厳密に入れ子をなすこと ]
[64] ignoreSectContents ::= Ignore ('<![' ignoreSectContents '])>' Ignore)*
[65] Ignore
::= Char* - (Char* ('<![' | ']]>') Char*)
妥当性制約: 条件付きセクション/パラメタ実体が厳密に入れ子をなすこと
条件付セクションの"<![","["又は"]]>"のいずれかがパラメタ実体参照の置換テキストに含まれるなら,
すべてが同一のパラメタ実体の置換テキスト に含まれなければならない。
条件付きセクションは,DTDの内部サブセット及び外部サブセットと同様に,完全な宣言,コメント,
処理命令又は入れ子になった条件付きセクションを,幾つか含んでよい。これらの間に,空白が現れても
よい。
条件付きセクションのキーワードがINCLUDEならば,条件付きセクションの内容はDTDの一部である。
条件付きセクションのキーワードがIGNOREならば,条件付きセクションの内容は論理的にはDTDの一
部ではない。キーワードをINCLUDEとする条件付きセクションが,キーワードをIGNOREとするより大
きな条件付きセクションに含まれるならば,外側及び内側の条件付きセクションの両方とも無視する。無
視される条件付きセクションの内容を解析するとき,キーワードに続く"["の後のすべての文字は,条件付
きセクションを開始する"<!["と終了する"]]>"を除き,この条件付きセクションの終了が見つかるまで無視
する。この処理において,パラメタ実体参照は認識されない。
条件付きセクションのキーワードがパラメタ実体参照ならば,XMLプロセサは条件付きセクションを取
り込むか無視するかを判断する前に,このパラメタ実体を展開しなければならない。
例を次に示す。
<!ENTITY % draft 'INCLUDE' >
<!ENTITY % final 'IGNORE' >
<![%draft;[
<!ELEMENT book (comments*,title,body,supplements?)>
]]>
<![%final;[
<!ELEMENT book (title,body,supplements?)>
]]>
4. 物理構造 XML文書は,一つ以上の記憶単位から構成する。これらの記憶単位を,実体という。すべ
ての実体は,内容 をもつ。文書実体及び外部DTDサブセットを除くすべての実体は,実体 名によって
特定する。 各XML文書は,文書実体と呼ぶ実体を一つもつ。XMLプロセサは,この文書実体から処理
を開始する。文書実体が,文書のすべてを含んでもよい。
実体は,解析対象実体又は解析対象外実体とする。解析対象実体の内容は,解析対象実体の置換テキス
21
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
トと呼ぶ。このテキストは,文書の本体の一部として解釈する。
解析対象外実体は,内容がテキストでもそうでなくともよい資源とする。テキストの場合,XMLでなく
ともよい。各解析対象外実体には,記法が関連付けられ,この記法は,名前で特定する。XMLプロセサが
実体や記法の識別子を応用プログラムに渡すという要件以外は,XMLは解析対象外実体の内容を制限しな
い。
解析対象実体は,実体参照によって名前で呼び出す。解析対象外実体は,ENTITY型又はENTITIES型
の属性の値として,名前で呼び出す。
一般実体は,文書内容の中で使用する実体とする。あいまいにならない限り,この規格では,一般実体
を単に実体と呼ぶ。パラメタ実体は,DTD内で使用する解析対象実体とする。これらの2種類の実体は,
異なる書式で参照し,異なる文脈で認識される。さらに,それらは異なる名前空間にある。したがって,
同じ名前のパラメタ実体と一般実体は,ふたつの異なった実体である。
4.1
文字参照及び実体参照 文字参照は,JIS X 0221-1文字集合の特定の文字,例えば,入力機器から直
接入力不可能な文字を参照する。
文字参照
[66] CharRef ::= '&#' [0-9]+ ';'
| '&#x' [0-9a-fA-F]+ ';'
[整形式制約: 使用できる文字]
整形式制約: 使用できる文字
文字参照を用いて参照する文字は,生成規則Charにマッチしなければならない。
文字参照が"&#x"で始まれば,終端の;までの数字及び字(letter)は,JIS X 0221-1の文字符号位置を16進
数で表現する。文字が "&#" で始まれば,終端の;までの数字は,文字符号位置を10進数で表現する。
実体参照は,名前の付いた実体の内容を参照する。一般解析対象実体への参照は,アンド記号(&)及びセ
ミコロン記号(;)を区切り子として用いる。パラメタ実体への参照は,パーセント記号(%)及びセミコロン(;)
を区切り子として用いる。
実体参照
[67] Reference ::= EntityRef | CharRef
[68] EntityRef ::= '&' Name ';'
[整形式制約: 実体が宣言されていること]
[妥当性制約: 実体が宣言されていること]
[整形式制約: 解析対象実体]
[整形式制約: 再帰なし]
[69] PEReference ::= '%' Name ';'
[妥当性制約: 実体が宣言されていること]
[整形式制約: 再帰なし]
[整形式制約: DTDの中]
整形式制約: 実体が宣言されていること
DTDをもたない文書,パラメタ実体参照を含まない内部DTDサブセットだけをもつ文書又は
22
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
"standalone='yes'"をもつ文書において,外部サブセット又はパラメタ実体中に出現しない実体参照で
は,その実体参照のNameは,外部サブセット又はパラメタ実体で出現しない実体宣言にマッチしなけ
ればならない。ただし,整形式の文書は,実体amp,lt,gt,apos,quotを宣言する必要はない。 一
般実体の場合は,属性リスト宣言のデフォルト値内での参照より先に,宣言が現れなければならない。
パラメタ実体又は外部サブセットで出現する実体宣言の読み込み・処理を,妥当性を検証しないプ
ロセサに義務付けてはいないことに注意。それらの文書では,実体は宣言されなければならないとい
う規則は,standalone='yes'の場合だけ,整形式制約となる。
妥当性制約: 実体が宣言されていること
外部サブセット又は外部パラメタ実体をもち,さらに "standalone='no'"をもつ文書において,実体参
照で用いる Name は,ある実体宣言に含まれる名前とマッチしなければならない。相互運用性のため
には,妥当な文書は4.6 定義済み実体で指定した書式によって,実体 amp,lt,gt,apos,quotを宣
言することが望ましい。パラメタ実体の場合は,宣言は,参照より先に現れなければならない。同様
に,一般実体の場合は,その一般実体への直接又は間接的な参照をともなったデフォルト値を含む属
性リスト宣言よりも先に,宣言が現れなければならない。
整形式制約: 解析対象実体 実体参照は,解析対象外実体の名前を含んでいてはならない。解析対象
外実体は,ENTITY型又はENTITIES型として宣言した属性値としてだけ参照できる。
整形式制約: 再帰なし
解析対象実体は,それ自体への参照を,直接にも間接にも含んではならない。
整形式制約: DTDの中
パラメタ実体参照は,DTD内にだけ,出現してよい。
文字参照及び実体参照の例を,次に示す。
Type <key>less-than</key> (<) to save options.
This document was prepared on &docdate; and
is classified &security-level;.
パラメタ実体参照の例を,次に示す。
<!-- declare the parameter entity "ISOLat2"... -->
<!ENTITY % ISOLat2
SYSTEM "http://www.xml.com/iso/isolat2-xml.entities" >
<!-- ... now reference it. -->
%ISOLat2;
4.2
実体宣言 実体は,次のとおりに宣言する。
実体宣言
[70] EntityDecl ::= GEDecl| PEDecl
[71] GEDecl
::= '<!ENTITY' S Name S EntityDef S? '>'
[72] PEDecl
::= '<!ENTITY' S '%' S Name S PEDef S? '>'
[73] EntityDef
::= EntityValue | (ExternalID NDataDecl?)
[74] PEDef
::= EntityValue | ExternalID
Nameは,実体参照において実体を特定する。解析対象外実体ならば,ENTITY 型又はENTITIES型の属
23
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
性値において,Nameは実体を特定する。同一の実体が複数回宣言されれば,最初の宣言を用いる。利用者
の任意選択によっては,複数回宣言される実体に関し,XMLプロセサは,警告を出してもよい。
4.2.1
内部実体 実体の定義が EntityValueのとき,これを内部実体という。これは,別個の物理的記憶
単位をもたず,実体の内容は宣言内で与える。正しく置換テキストを生成するには,リテラル実体値内で
の実体参照及び文字参照の処理が必要となるかもしれないことに注意する。詳細は,4.5 内部実体置換テ
キストの構築を参照。
内部実体は,解析対象実体とする。
内部実体宣言の例を,次に示す。
<!ENTITY Pub-Status "This is a pre-release of the specification.">
4.2.2
外部実体 内部実体でない実体は外部実体であって,次のとおりに宣言する。
外部実体宣言
[75] ExternalID ::= 'SYSTEM' S SystemLiteral
| 'PUBLIC' S PubidLiteral S SystemLiteral
[76] NDataDecl
::= S 'NDATA' S Name [妥当性制約: 記法が宣言されていること]
NDataDecl が存在すれば,この実体は,一般解析対象外実体とし,そうでなければ,解析対象実体とす
る。
妥当性制約: 記法が宣言されていること
Name は,宣言した記法の名前とマッチしなければならない。
SystemLiteral を,実体のシステム識別子と呼ぶ。XMLプロセサが,実体の置換テキストを生成するに
は,入力を必要とする。入力を得るためにシステム識別子を参照する処理の一部として,統一資源識別子
(URI)参照(IETF RFC 2396で定義され,IETF RFC 2732で改訂された。) に変換してから参照することが意
図されている。 素片識別子(#文字で始まるもの。)がシステム識別子に含まれることは誤りとする。 この
規格の適用範囲外の情報(例えば,ある特定のDTDの特別なXML要素又は特定の応用プログラムの仕様
によって定義された処理命令)によって上書きされない限り,相対的な統一資源識別子(URI)は,その実体
の位置,すなわち,その実体宣言が現れる資源に相対的とする。実体宣言が現れる資源とは,この実体宣
言を宣言として構文解析した時点で,先頭の'<'を含む外部実体とする。 したがって,統一資源識別子(URI)
は,文書実体・外部DTDサブセットを含む実体・なんらかの外部パラメタ実体に対して相対的とする。
統一資源識別子(URI)によって特定される資源を得ようとするとき,パーサのレベルでリダイレクトされて
もよく(例えば,実体リゾルバ),下位プロトコルのレベル(例えば,HTTPのLocation:ヘッダ)によってリダ
イレクトされてもよい。この規格の適用範囲外の付加的な情報が資源の中に存在しない限り必ず,資源の
基底統一資源識別子(base URI)は実際に返された資源の統一資源識別子(URI)とする。言い換えれば,すべ
てのリダイレクションが起こったあとで得られる資源の統一資源識別子(URI)とする。
システム識別子(及び他の統一資源識別子(URI)参照として使用されるXML文字列)が含む文字の幾つか
は,IETF RFC 2396及びIETF RFC 2732に従えば,参照された資源を得るために統一資源識別子(URI)を使用
する前に別扱いする必要がある。これらの別扱いが必要な文字は,#x0から #x1Fまでの制御文字及び#x7F
の制御文字(そのほとんどはXMLでは出現できない。),スペース#x20,区切り子('<' #x3C,'>' #x3E及び
'"' #x22),unwise文字( '{' #x7B,'}' #x7D,'|' #x7C,'\' #x5C(バックスラッシュ),'^' #x5E及び '̀' #x60)並
びに #x7Fを超える文字とする。 別扱いは常にまったく可逆的な処理であるというわけではないので,絶
24
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
対に必要なときに限って,できるだけ後の段階で別扱いを行うものとする。特に,相対的な統一資源識別
子(URI)を絶対的なものに変換する処理は,別扱いを起動しないことが望ましい。統一資源識別子(URI)参
照を参照するプロセス又はソフトウェア部品に統一資源識別子(URI)参照を渡す処理も,別扱いを起動しな
いことが望ましい。別扱いが本当に起きるときは,次のとおりに行わなければならない。
a) 別扱いされる各文字は,UTF-8では1バイト以上のバイトとして表現される。
b) a)で表現されたバイト列はすべて,統一資源識別子(URI)の別扱い機構によって別扱いする(つま
り,%HH に変換される。ここでHHはバイト値の16進表記とする。)。
c) (別扱い対象の)元の文字を,b)の別扱いの結果として得られる文字列に置き換える。
システム識別子以外に,外部識別子は,公開識別子を含んでもよい。 実体の内容を取り出すXMLプロ
セサは,公開識別子及びシステム識別子並びにこの仕様の範囲外の付加的な情報をどのように組み合わせ
て,代わりの統一資源識別子(URI)参照の生成を試みてもよい。XMLプロセサがこれに失敗した場合は,
システムリテラルとして指定した統一資源識別子(URI)参照を用いなければならない。マッチする前に,公
開識別子内にある空白文字からなる文字列は,すべて単一のスペース文字(#x20)に正規化しなければなら
ず,先頭及び末尾の空白文字はすべて削除しなければならない。
外部実体宣言の例を,次に示す。
<!ENTITY open-hatch
SYSTEM "http://www.textuality.com/boilerplate/OpenHatch.xml">
<!ENTITY open-hatch
PUBLIC "-//Textuality//TEXT Standard open-hatch boilerplate//EN"
"http://www.textuality.com/boilerplate/OpenHatch.xml">
<!ENTITY hatch-pic
SYSTEM "../grafix/OpenHatch.gif"
NDATA gif >
4.3
解析対象実体
4.3.1
テキスト宣言 外部解析対象実体は,テキスト宣言で始まることが望ましい。
テキスト宣言
[77] TextDecl
::= '<?xml' VersionInfo? EncodingDecl S? '?>'
テキスト宣言は,そのままの形で現れなければならず,解析対象実体への参照を経由してはならない。
外部解析対象実体において,テキスト宣言は,先頭以外のいかなる位置にも出現しない。外部解析対象実
体中のテキスト宣言は,置換テキストに含まれるとは見なさない。
4.3.2 整形式の解析対象実体 ラベルdocumentをもつ生成規則にマッチすれば,文書実体は整形式とする。
ラベルextParsedEntをもつ生成規則にマッチすれば,外部の一般解析対象実体は,整形式とする。すべての
外部パラメタ実体は整形式になるように定義されていることに注意。
整形式の外部解析対象実体
[78] extParsedEnt ::= TextDecl? content
置換テキストが,ラベルcontentをもつ生成規則にマッチすれば,内部の一般解析対象実体は,整形式と
25
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する。すべての内部のパラメタ実体は,定義から整形式になる。
一般実体はすべて整形式なので,XML文書の論理的及び物理的構造は,厳密に入れ子となる。開始タグ,
終了タグ,空要素タグ,要素,コメント,処理命令,文字参照及び実体参照が,一つの実体で開始し,別
の実体で終了することはない。
4.3.3
実体における文字符号化 XML文書内の外部解析対象実体は,それぞれ別の文字符号化を用いて
もよい。すべてのXMLプロセサは,UTF-8で符号化した実体,及びUTF-16で符号化した実体を処理でき
なければならない。この規定での"UTF-8"及び"UTF-16"という用語は,他のラベルをもつ符号化には適用
されない。その符号化がどれほど "UTF-8"又は"UTF-16"に類似していても,適用されない。
UTF-16で符号化した実体は,JIS X 0221-1:2001の附属書H,Unicodeの2.4又はUnicode3の2.7で規定す
る“印”(しるし)(ZERO WIDTH NO-BREAK SPACE文字,#xFEFF)で始まらなければならない。UTF-8で符
号化した実体は,“印”(しるし)で始まってもよい。これは,符号化の印であって,XML文書のマーク付け
の一部でも,文字データの一部でもない。XMLプロセサは,この文字を用いて,UTF-8で符号化した文書
とUTF-16で符号化した文書との区別を行えなければならない。
XMLプロセサは,UTF-8及びUTF-16で符号化した実体を読めなければならない。他の符号化が世界で
は用いられることも多く,それらの符号化を用いる実体をXMLプロセサは処理できることが望ましい。
外部の文字符号化情報(MIMEヘッダなど)がない場合,UTF-8又はUTF-16以外の符号化を用いて格納する
解析対象実体は,符号化宣言を含むテキスト宣言 (4.3.1 テキスト宣言を参照のこと。)で始めなければな
らない。
符号化宣言
[80] EncodingDecl ::= S 'encoding' Eq ('"' EncName '"' | "'" EncName "'")
[81] EncName
::= [A-Za-z] ([A-Za-z0-9.̲] | '-')*
/* ラテン文字だけを含む符号化名 */
文書実体では,符号化宣言は,XML宣言の一部として含まれる。EncNameは,使用する符号化の名前と
する。
符号化宣言では,値"UTF-8","UTF-16","ISO-10646-UCS-2"及び"ISO-10646-UCS-4"は,Unicode及び
JIS X 0221-1の各種符号化のために用いることが望ましい。値 "ISO-8859-1","ISO-8859-2",...
"ISO-8859-n"(ここでnはパート番号とする。)は,ISO 8859の対応するパートのために用いる。値
"ISO-2022-JP","Shift̲JIS"及び"EUC-JP"は,JIS X 0208-1997の各種符号化のために用いることが望まし
い。インタネット割当て番号主体(Internet Assigned Numbers Authority)が定めたIANA-CHARSETS(附属書A
のA.1引用規定を参照。)に,(charsetsとして)登録された文字符号化については,ここに挙げたもの以外
についても,登録された名前で参照することが望ましい。それ以外の符号化は,接頭辞"x-"で始まる名前
を使うことが望ましい。XMLプロセサは,文字符号化の名前を大文字・小文字の区別をせずにマッチをと
ることが望ましい。IANAに登録された名前は,IANAにその名前で登録された符号化を示すと解釈する,
又は不明であるとして扱うことが望ましい(もちろん,IANAに登録されたすべての符号化の実装をプロセ
サ に要求するものではない。)。
外部の伝送プロトコル(すなわち,HTTP,MIMEなど)で与えられる情報が存在しない場合,XMLプロ
セサに渡された実体が,符号化宣言を含むにもかかわらず,宣言で示したもの以外の方式で符号化されて
いるとき,又は“印”(しるし)でも符号化宣言でも始まらない実体が,UTF-8以外の符号化を使用したとき

26
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,致命的誤りとする。ASCIIはUTF-8のサブセットなので,通常のASCIIの実体は厳密には符号化宣言
を必要としないことに注意。
TextDeclが外部実体の先頭以外の場所に出現することは,致命的な誤りとする。
処理できない符号化を使用した実体をXMLプロセサが発見したときは,致命的な誤りとする。XML実
体が(デフォルトで,符号化宣言によって,又はより高次のプロトコルによって)ある符号化であると確定
されるが,その符号化としては正しくないバイト列を含む場合は,致命的な誤りとする。特に,UTF-8で
符号化された実体が,不正であるとUnicode 3.1で定義されたコードユニット列を含むことは致命的な誤り
とする。上位のプロトコルによって符号化が決まらない場合,符号化宣言を含まないXML 実体が,正し
いUTF-8又はUTF-16の内容をもたないときも,致命的な誤りとする。
符号化宣言を含むテキスト宣言の例を次に示す。
<?xml encoding='UTF-8'?>
<?xml encoding='EUC-JP'?>
4.4
XMLプロセサによる実体及び参照の扱い 次の表に,文字参照,実体参照及び解析対象外実体の呼
出しが現れる文脈,並びに,それぞれの場合におけるXMLプロセサに要求される振る舞いを要約する。一
番左の列のラベルは,参照が現れる文脈を示す。
内容における参照
要素の開始タグ及び終了タグの間の任意の場所での参照。非終端記号contentに対応する。
属性値における参照
開始タグの属性の値,又は属性宣言におけるデフォルト値のいずれかでの参照。非終端記号AttValue
に対応する。
属性値として出現
参照ではなく,Nameとして出現。ENTITY型として宣言した属性の値として出現するか,又は
ENTITIES型として宣言した属性の値におけるスペースで区切られたトークンの一つとして出現する。
実体値における参照
実体の宣言における,パラメタ実体又は内部実体のリテラル実体値の中での参照。非終端記号
EntityValueに対応する。
DTDにおける参照
DTDの内部又は外部サブセットのいずれかの中に現われる参照。ただし,EntityValue,AttValue,PI,
Comment,SystemLiteral,PubidLiteral又は無視される条件付きセクションの内容の外側にあるもの(3.4
条件付きセクションを参照)に限る。
表 2 実体及び参照の扱い
実体の型
文字
パラメタ
内部一般
外部解析対象
実体一般
解析対象外
実体
内容での参照 認識 しない
取込み
検証のために
取込み
禁止
取込み
属性値での参照 認識 しない リテラル内で
の取込み
禁止
禁止
取込み
属性値として出現 認識 しない
禁止
禁止
通知
認識しない
27
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
実体値での参照
リテラル内
での取込み
処理しない
処理しない
誤り
取込み
DTDでの参照
PEとして
取込み
禁止
禁止
禁止
禁止
4.4.1
“認識しない” DTDの外では,%文字は,いかなる特別な意味ももたない。したがって,DTD
の中ではパラメタ実体参照として認識するものであっても,contentの中ではマーク付けとしては認識しな
い。同様に,適切に宣言した属性の値の中に現れる場合を除き,解析対象外実体の名前は認識しない。
4.4.2
“取込み” 実体参照を処理するには,その置換テキストを取り出し,処理する。参照自体の代わ
りに,参照があった位置で,文書の一部として含まれるものとして取り込む。置換テキストは,文字デー
タ及び(パラメタ実体以外の)マーク付けのいずれを含んでもよく,これらは,通常の方法で認識されなけ
ればならない (文字列"AT&T;"は,"AT&T;"に展開され,残されたアンパサンドは,実体参照の区切り
子としては認識しない。)。文字参照は,番号で示した文字を参照自体の代わりに取り込む。
4.4.3
“検証のために取込み” 文書の妥当性を検証するには,XMLプロセサは,解析対象実体への参
照を認識したとき,その置換テキストを取り込まなければならない。実体が外部実体であって,XML文書
の妥当性を検証しないときは,実体の置換テキストを取り込んでもよいが,取り込むことを義務づけられ
てはいない。妥当性を検証しないプロセサが置換テキストを取り込まない場合,実体を認識したが,読み
込まなかったことを応用プログラムに通知しなければならない。
この取決めは,SGML及びXMLの実体の機構が提供する自動取込み機能が,文書作成時のモジュール
化を主な目的として設計されており,その他の応用プログラム(特に,文書のブラウジング)には,必ずし
も適切ではない,という認識による。例えば,ブラウザは外部解析対象実体への参照を見つけると,その
実体が存在するという表示だけを行い,表示を要求されたときにだけ,内容を取り出すかもしれない。
4.4.4
“禁止” 次のものは禁止されており,致命的な誤りとする。
a) 解析対象外実体への参照の出現。ただし実体宣言におけるEntityValueにおける出現は除く。
b) DTDのEntityValue又はAttValue以外の部分における,文字参照又は一般実体への参照の出現。
c) 属性値内の外部実体への参照の出現。
4.4.5
リテラル内での取込み 実体参照が属性値の中で現れたとき,又は,パラメタ実体への参照がリテ
ラル実体値の中で現れたとき,置換テキストは,参照自体の代わりに,参照があった位置に文書の一部と
してあったものとして処理される。ただし,置換テキストの中の一重引用符又は二重引用符文字は,常に
通常の文字データとして扱われ,リテラルを終了させることはない。例えば,次の文書例は整形式である。
<!ENTITY % YN '"Yes"' >
<!ENTITY WhatHeSaid "He said %YN;" >
一方,次の例は整形式ではない。
<!ENTITY EndAttr "27'" >
<element attribute='a-&EndAttr;>
4.4.6
“通知” 解析対象外実体の名前が,ENTITY型又はENTITIES型の属性値においてトークンとし
て現れたとき,妥当性を検証するプロセサは,応用プログラムに対して,その実体及び関連する記法のシ
ステム識別子並びに(存在すれば)公開識別子を通知しなければならない。
4.4.7
“処理しない” 一般実体参照が,実体宣言におけるEntityValue内に現れるとき,一般実体参照は
処理されないで,そのまま残る。
28
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
4.4.8
“PEとして取込み” 外部解析対象実体の場合と同様に,パラメタ実体は,妥当性を検証すると
きだけ取り込む必要がある。パラメタ実体参照をDTD内に認識して取り込むとき,その置換テキストは,
その前後に一つのスペース文字(#x20)の付加によって引き伸ばされる。パラメタ実体の置換テキストが
DTD内の文法的トークンを完全に含むようにすることを,この規定は意図している。この振る舞いは,実
体値の中でのパラメタ実体参照には適用されない。この場合については4.4.5 リテラル内での取込みで記
述する。
4.4.9
“誤り” 実体宣言におけるEntityValueにおいて解析対象外実体への参照が出現することは,誤り
とする。
4.5
実体置換テキストの構築 実体の取扱いの規定で,実体値を二つの形式に区別することは役に立つ。
内部実体の場合,リテラル実体値は,実体宣言内に実際に存在する,引用符で囲まれた文字列とする。こ
れは,非終端記号EntityValueとマッチする。外部実体の場合,リテラル実体値は,その実体に含まれるテ
キストそのままとする。 内部実体の場合,置換テキストは,文字参照及びパラメタ実体参照の置換え後に
おける,実体の内容とする。外部実体の場合,置換テキストは,実体の内容とする。ただし,テキスト宣
言は(もしあるなら)取り除く(周辺の空白文字は除かない。)。しかし,文字参照又はパラメタ実体参照は置
き換えないものとする。
内部実体宣言内で与えるリテラル実体値(EntityValue)は,文字参照,パラメタ実体参照及び一般実体参照
を含んでもよい。これらの参照は,リテラル実体値内に完全に含まれていなければならない。先に示した
とおりに取り込まれる(又は リテラル内で取込まれる)実際の置換テキストは,参照されるパラメタ実体の
置換テキストを含み,リテラル実体値に含まれる文字参照の代わりにそれが表す文字を含む。しかし,一
般実体参照はそのまま残し,展開してはならない。例えば,次の宣言を与えたとする。
<!ENTITY % pub "Éditions Gallimard" >
<!ENTITY rights "All rights reserved" >
<!ENTITY book "La Peste: Albert Camus,
© 1947 %pub;. &rights;" >
実体の置換テキスト"book"は,次のとおりとなる。
La Peste: Albert Camus,
c 1947 Editions Gallimard. &rights;
参照"&book;"が文書の内容又は属性値内に出現すれば,一般実体参照"&rights;"は展開される。
これらの単純な規則は,複雑な相互作用をもちうる。 難しい例についての詳細は,附属書4. 実体参照
及び文字参照の展開を参照のこと。
4.6
定義済み実体 不等号(より小),アンパサンド及び他の区切り子を別扱いするには実体参照及び文字
参照のどちらも使用できる。幾つかの一般実体(amp,lt,gt,apos,quot)をこの目的のために使用する。
番号による文字参照も,この目的のために用意されている。文字参照は,認識されると直ちに展開され,
文字データとして扱われるので,番号による文字参照"<"及び "&"は,文字データ内に出現する <
及び&を別扱いするために使用できる。
すべてのXMLプロセサは,宣言されているかどうかに関係なく,これらの実体を認識しなくてはなら
ない。相互運用性のためには,妥当なXML文書は,これらの実体を使用する前に他の実体と同様に宣言
することが望ましい。実体 lt又はampを宣言する場合,内部実体として宣言し,その置換テキストは,
別扱いされる文字(不等号(より小)又はアンパサンド) への文字参照としなければならない。これらの実体
を参照しても結果が整形式となるためには,二重の別扱いを必要とする。実体gt,apos又は quotを宣言
29
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する場合,これらの実体を内部実体として宣言し,その置換テキストは,別扱いされる単一の文字(又はそ
の文字への文字参照)としなければならない。この場合,二重の別扱いは不要であるが,有害ではないこと
に注意。次にその例を示す。
<!ENTITY lt "&#60;">
<!ENTITY gt ">">
<!ENTITY amp "&#38;">
<!ENTITY apos "'">
<!ENTITY quot """>
4.7
記法宣言 記法は,解析対象外実体の形式,記法属性をもつ要素の形式又は処理命令の対象とする
応用プログラムを特定する名前とする。
記法宣言は,記法の名前及び外部識別子を提供する。この名前は,外部実体宣言及び属性リスト宣言並
びに属性指定に用いる。外部識別子は,与えられた記法のデータを処理できるプログラム(helper application)
を,XMLプロセサ又は応用プログラムが探すために利用できる。
記法宣言
[82] NotationDecl ::= '<!NOTATION' S Name S (ExternalID | PublicID) S? '>'
[妥当性制約: 記法名の一意性]
[83] PublicID
::= 'PUBLIC' S PubidLiteral
妥当性制約: 記法名の一意性
あるNameを宣言できるのは,ただ一つの記法宣言とする。
宣言されていて,属性値・属性定義・実体宣言で参照されているすべての記法について,XMLプロセサ
は,記法の名前及び外部識別子を応用プログラムに提供しなければならない。さらに,外部識別子を,シ
ステム識別子,ファイル名又はその他の情報(その記法のデータを処理するプロセサを応用プログラムが起
動するために必要なもの)に展開してもよい。しかし,XMLプロセサ又は応用プログラムが動作するシス
テムでは利用できない記法を,XML文書が宣言し,参照しても,誤りとはしない。
4.8
文書実体 文書実体は,実体の成す木構造のルートであって,XMLプロセサが処理を開始する対象
とする。この規格は,XMLプロセサが,文書実体の存在する場所をどのように見つけるかは規定しない。
他の実体と異なり,文書実体は名前をもたず,いかなる識別子もなしにプロセサへの入力ストリームに出
現してもよい。
5. 適合性
5.1
妥当性を検証するプロセサ及び検証しないプロセサ 適合XMLプロセサは,妥当性を検証するもの
及び妥当性を検証しないものの二つに分類される。
妥当性を検証するプロセサも妥当性を検証しないプロセサも,読み込んだ文書実体及び他のすべての解
析対象実体において,この規格の整形式制約への違反を報告しなければならない。
利用者の任意選択によっては,妥当性を検証するプロセサは,DTD内の宣言によって示された制約への
違反と,この規格が規定する妥当性制約への違反とを,すべて報告しなければならない。 これを実現する
ために,妥当性を検証するXMLプロセサは,DTD全体と文書内で参照されているすべての外部解析対象
実体とを読み込んで処理しなければならない。
30
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
妥当性を検証しないプロセサは,整形式であることを確認するために,DTDの内部サブセット全体を
含めた文書実体を調べることだけが義務付けられている。文書の妥当性を確認する必要はないが,読
み込んでいないパラメタ実体への参照が最初に起きるまでに読み込んだDTDの内部サブセットとパ
ラメタ実体とに現れるすべての宣言を処理しなければならない。すなわち,属性値を正規化し,内部
実体の置換テキストを取込み,デフォルトの属性値を与えるために,これらの宣言にある情報を使用
しなければならない。 実体の宣言は上書きされる可能性があるので,妥当性を検証しないプロセサは,
読み込んでいないパラメタ実体への参照より後に現れた実体宣言及び属性リスト宣言を処理してはな
らない。ただし,standalone="yes" のときは処理しなければならない。
妥当性を検証しないプロセサで,妥当でない文書を処理するとき,応用プログラムは一貫性のある
情報を受け取るとは限らないことに注意されたい。例えば,文書中において一意であるという幾つか
の要件は,満足されるとは限らない。これは,一つ以上の要素が同じidをもつこと,同じ名前の要素
型宣言又は記法宣言が重複することなどがある。これらの場合,応用プログラムにこのような情報を
報告する点に関するパーサの振る舞いは,定義しない。
5.2
XMLプロセサの使用 妥当性を検証するXMLプロセサの振る舞いはほとんど予測可能である。す
なわち,文書のすべての断片を読み込み,整形式及び妥当性に対するすべての違反を報告しなければなら
ない。妥当性を検証しないプロセサに必要とされることはそれより少ない。すなわち,文書実体以外の文
書の断片を読み込む必要はない。したがって,XMLプロセサの利用者に対して重要な二つの効果をもつ。
a) ある種の整形式の誤り,特に外部実体を読まなければ検出できない誤りを検出することに,妥当性を
検証しないプロセサは失敗してもよい。実体が宣言されていること,解析対象実体及び再帰なしとい
う見出しが付けられた制約,並びに4.4 XMLプロセサによる実体及び参照の扱いで禁止として説明さ
れている幾つかの場合が,この種の誤りに相当する。
b) プロセサから応用プログラムに渡される情報は,プロセサがパラメタ実体及び外部実体を読み込むか
どうかで異なる。例えば,妥当性を検証しないプロセサは,属性値を正規化したり,内部実体の置換
テキストを取り込んだり,デフォルトの属性値を与えることに失敗してもよい。失敗してよいかどう
かは,外部実体及びパラメタ実体内での宣言を既に読み込んでいるかどうかによって決まる。
異なるXMLプロセサ間での相互運用性を最も高めるためには,妥当性を検証しないプロセサを使用す
る応用プログラムは,そのようなプロセサでは必要とされない振る舞いに依存すべきではない。DTD機能
のうち検証に関係しないもの(デフォルトをもつ属性の宣言及び内部実体の宣言など)であって、外部実体
に定義されている又は定義されている可能性があるものを必要とする応用プログラムは,妥当性を検証す
るプロセサを使用することが望ましい。
6. 記法 XMLの形式的な文法は,簡単な拡張Backus-Naur Form(EBNF)記法によって与える。文法の各
規則は,次の形式で記号を定義する。
symbol ::= expression
記号は,正規言語の開始記号であるときは大文字で始め,そうでなければ小文字で始める。リテラル文
字列は引用符で囲む。
規則の右辺では,一つ以上の文字からなる文字列とマッチするために,次の式を使用する。
#xN
ここで,Nは16進の整数とする。この式は,JIS X 0221-1における値(コード位置)がNである文字と
マッチする。
31
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
[a-zA-Z],[#xN-#xN]
指定した範囲の値(両端の値を含む。)をもつ任意のCharとマッチする。
[abc],[#xN#xN#xN]
列挙された複数の文字のうち,いずれかの値をともなうCharとマッチする。列挙指定及び範囲指定を,
ひと組の角カッコの中に混在させることができる。
[^a-z],[^#xN-#xN]
指定した範囲外の値をもつ任意のCharとマッチする。
[^abc],[^#xN#xN#xN]
指定した文字以外の値をもつ任意のCharとマッチする。禁止される値の列挙指定と範囲指定を,ひと
組の角カッコの中に混在させることができる。
"string"
二重引用符で囲むリテラル文字列とマッチする。
'string'
一重引用符で囲むリテラル文字列とマッチする。
これらの記号を,次のとおりに組み合わせて,複合パターンを作ってもよい。ここで,A及びBは式と
する。
(expression)
ここに示す組合せによる式(expression)を,一つのまとまりとして扱うために使う。
A?
A又は空列とマッチする(任意選択のA)。
A B
Aの次にBが出現するものとマッチする。このオペレータは,選択よりも高い優先度をもつ。したが
って,A B | C Dと(A B) | (C D)は等しい。
A | B
A又はBのどちらかとマッチする。
A - B
AとマッチするがBとはマッチしない任意の文字列とマッチする。
A+
Aの1回以上の繰返しとマッチする。連結は選択より高いも優先度をもつ。したがって,A+ | B+は (A+)
| (B+)と等しい。
A*
Aの0回以上の繰返しとマッチする。連結は選択より高いも優先度をもつ。したがって,A* | B*は (A*)
| (B*)と等しい。
生成規則内で使用する他の記法を次に示す。
/* ... */
コメント。
[ 整形式制約: ... ]
整形式制約。生成規則に関連した,整形式の文書に関する制約を名前によって特定する。
[妥当性制約 ... ]
妥当性制約。生成規則に関連した,妥当な文書に関する制約を名前によって特定する。
32
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書A(規定)文献
A.1 引用規定
IANA-CHARSETS
(インタネット割当て番号主体(Internet Assigned Numbers Authority)) Official Names for Character Sets, ed.
Keld Simonsen et al. (http://www.iana.org/assignments/character-setsを参照。)
IETF RFC 2396
IETF (Internet Engineering Task Force). RFC 2396: Uniform Resource Identifiers (URI): Generic Syntax. T.
Berners-Lee, R. Fielding, L. Masinter. 1998.(http://www.ietf.org/rfc/rfc2396.txtを参照。)
IETF RFC 2732
IETF (Internet Engineering Task Force). RFC 2732: Format for Literal IPv6 Addresses in URL's. R. Hinden, B.
Carpenter, L. Masinter. 1999.(http://www.ietf.org/rfc/rfc2732.txtを参照。)
IETF RFC 3066
IETF (Internet Engineering Task Force). RFC 3066: Tags for the Identification of Languages, ed. H. Alvestrand.
2001. (http://www.ietf.org/rfc/rfc3066.txtを参照。)
ISO/IEC 10646
JIS X 0221-1:2001 国際符号化文字集合(UCS) 第1部 体系及び基本多言語面及びISO/IEC
10646-2:2001 Information technology−Universal Multiple-Octet Coded Character Set (UCS)−Part 2:
Supplementary Planes
備考 ISO/IEC 10646の新版による修正及び置換,並びに新しい部分の追加による拡張を適用する。
最新版については,http://www.iso.chを参照。
参考 ISO/IEC 10646-1:2000 Information technology−Universal Multiple-Octet Coded Character Set (UCS)
−Part 1: Architecture and Basic Multilingual Plane が,JIS X 0221-1:2001に対応している。
ISO/IEC 10646:2000
JIS X 0221-1:2001 国際符号化文字集合(UCS) 第1部 体系及び基本多言語面
備考 ISO/IEC 10646:2000 Information technology -- Universal Multiple-Octet Coded Character Set (UCS) --
Part 1: Architecture and Basic Multilingual Plane が,この規格に対応している。
Unicode
The Unicode Consortium. The Unicode Standard, Version 2.0. Reading, Mass.: Addison-Wesley Developers
Press, 1996.
Unicode3
The Unicode Consortium. The Unicode Standard, Version 3.2はThe Unicode Standard, Version 3.0 (Reading,
MA, Addison-Wesley, 2000. ISBN 0-201-61633-5)によって定義され,Unicode Standard Annex #27: Unicode
3.1
(http://www.unicode.org/reports/tr27)
及
び
Unicode
Standard
Annex
#28:
Unicode
3.2(http://www.unicode.org/reports/tr28)によって補遺された。
A.2 参考文献
Aho/Ullman
Aho, Alfred V., Ravi Sethi, and Jeffrey D. Ullman. Compilers: Principles, Techniques, and Tools. Reading:
33
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
Addison-Wesley, 1986(改訂新版は1988。).
Brüggemann-Klein
Brüggemann-Klein, Anne. Regular Expressions into Finite Automata. extended abstractが収録されているの
はI. Simon, Hrsg., LATIN 1992, S. 97-98. Springer-Verlag, Berlin 1992, ジャーナル論文が収録されている
のはTheoretical Computer Science 120: 197-213, 1993.
Brüggemann-Klein and Wood
Brüggemann-Klein, Anne, and Derick Wood. Deterministic Regular Languages. Universität Freiburg, Institut
für Informatik, Bericht 38, Oktober 1991. Extended abstractが収録されているのはA. Finkel, M. Jantzen,
Hrsg., STACS 1992, S. 173-184. Springer-Verlag, Berlin 1992. Lecture Notes in Computer Science 577, ジャ
ーナル論文はOne-Unambiguous Regular Languages in Information and Computation 140 (2): 229-253,
February 1998.
Clark
James Clark. Comparison of SGML and XML. http://www.w3.org/TR/NOTE-sgml-xml-971215を参照。
IANA-LANGCODES
(インタネット割当て番号主体(Internet Assigned Numbers Authority)) Registry of Language Tags, ed. Keld
Simonsen et al.( http://www.iana.org/assignments/language-tagsを参照。)
IETF RFC 2141
IETF (Internet Engineering Task Force). RFC 2141: URN Syntax, ed. R. Moats. 1997.
(http://www.ietf.org/rfc/rfc2141.txtを参照。)
IETF RFC 2781
IETF (Internet Engineering Task Force). RFC 2781: UTF-16, an encoding of ISO 10646, ed. P. Hoffman, F.
Yergeau. 2000.(http://www.ietf.org/rfc/rfc2781.txtを参照。)
ISO 639:1988 Code for the representation of names of languages
JIS X 0304:1999 国名コード
備考 ISO 3166-1:1997 Codes for the representation of names of countries and their subdivisions -- Part 1:
Country codesが,この規格に一致している。
IETF RFC 3023
IETF (Internet Engineering Task Force). RFC 3023: XML Media Types. ed. M. Murata, S. St.Laurent, D. Kohn.
2001.(http://www.ietf.org/rfc/rfc3023.txtを参照。)
JIS X 4151-1992 文書記述言語SGML
備考 ISO 8879-1986 Information processing -- Text and Office Systems -- Standard Generalized Markup
Language (SGML) が,この規格に対応している。
JIS X 4155:2000 ハイパメディア及び時間依存情報の構造化言語(HyTime)
備考 ISO/IEC 10744:1997 Information technology -- Hypermedia/Time-based Structuring Language
(HyTime) が,この規格に一致している。
JIS X 4151:2001 文書記述言語SGML(追補2)
備考 ISO 8879:1986/Cor.2:1999 Technical Corrigendum 2 to SGML が,この規格に一致している。
IETF RFC 3023
Tim Bray, Dave Hollander, and Andrew Layman, editors. Namespaces in XML. Textuality, Hewlett-Packard,
and Microsoft. World Wide Web Consortium, 1999.( http://www.w3.org/TR/REC-xml-names/を参照。)
34
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
参考TR X 0023:1999 XML名前空間が,この規格に一致している。
35
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書B(規定)文字クラス
Unicode標準に定義するプロパティに従って,文字は基底文字(BaseChar)(これらは,ラテンアルファベ
ットのアルファベット文字を含む。),漢字などの文字(ideographic) 及び結合文字(CombiningChar)(このク
ラスはほとんどのダイアクリティカルマークを含む。)にクラス分けする。10進数値 (Digit)及びエクステ
ンダ(Extender)のクラスもある。
文字
[84] Letter
::= BaseChar | Ideographic
[85] BaseChar
::= [#x0041-#x005A] | [#x0061-#x007A] | [#x00C0-#x00D6] | [#x00D8-#x00F6]
| [#x00F8-#x00FF] | [#x0100-#x0131] | [#x0134-#x013E] | [#x0141-#x0148]
| [#x014A-#x017E] | [#x0180-#x01C3] | [#x01CD-#x01F0] | [#x01F4-#x01F5]
| [#x01FA-#x0217]
| [#x0250-#x02A8]
| [#x02BB-#x02C1]
| #x0386
| [#x0388-#x038A]
| #x038C
| [#x038E-#x03A1]
| [#x03A3-#x03CE]
| [#x03D0-#x03D6] | #x03DA | #x03DC | #x03DE | #x03E0 | [#x03E2-#x03F3]
| [#x0401-#x040C] | [#x040E-#x044F] | [#x0451-#x045C] | [#x045E-#x0481]
| [#x0490-#x04C4]
| [#x04C7-#x04C8]
| [#x04CB-#x04CC]
| [#x04D0-#x04EB] | [#x04EE-#x04F5] | [#x04F8-#x04F9] | [#x0531-#x0556]
| #x0559
| [#x0561-#x0586]
| [#x05D0-#x05EA]
| [#x05F0-#x05F2]
| [#x0621-#x063A] | [#x0641-#x064A] | [#x0671-#x06B7] | [#x06BA-#x06BE]
| [#x06C0-#x06CE]
| [#x06D0-#x06D3]
| #x06D5
| [#x06E5-#x06E6]
| [#x0905-#x0939]
| #x093D
| [#x0958-#x0961]
| [#x0985-#x098C]
| [#x098F-#x0990]
| [#x0993-#x09A8]
| [#x09AA-#x09B0]
| #x09B2
| [#x09B6-#x09B9] | [#x09DC-#x09DD] | [#x09DF-#x09E1] | [#x09F0-#x09F1]
| [#x0A05-#x0A0A] | [#x0A0F-#x0A10] | [#x0A13-#x0A28] | [#x0A2A-#x0A30]
| [#x0A32-#x0A33] | [#x0A35-#x0A36] | [#x0A38-#x0A39] | [#x0A59-#x0A5C]
| #x0A5E | [#x0A72-#x0A74] | [#x0A85-#x0A8B] | #x0A8D | [#x0A8F-#x0A91]
| [#x0A93-#x0AA8]
| [#x0AAA-#x0AB0]
| [#x0AB2-#x0AB3]
| [#x0AB5-#x0AB9]
| #x0ABD
| #x0AE0
| [#x0B05-#x0B0C]
| [#x0B0F-#x0B10] | [#x0B13-#x0B28] | [#x0B2A-#x0B30] | [#x0B32-#x0B33]
| [#x0B36-#x0B39]
| #x0B3D
| [#x0B5C-#x0B5D]
| [#x0B5F-#x0B61]
| [#x0B85-#x0B8A] | [#x0B8E-#x0B90] | [#x0B92-#x0B95] | [#x0B99-#x0B9A]
| #x0B9C
| [#x0B9E-#x0B9F]
| [#x0BA3-#x0BA4]
| [#x0BA8-#x0BAA]
| [#x0BAE-#x0BB5]
| [#x0BB7-#x0BB9]
| [#x0C05-#x0C0C]
| [#x0C0E-#x0C10]
| [#x0C12-#x0C28]
| [#x0C2A-#x0C33]
| [#x0C35-#x0C39]
| [#x0C60-#x0C61]
| [#x0C85-#x0C8C]
| [#x0C8E-#x0C90]
| [#x0C92-#x0CA8]
| [#x0CAA-#x0CB3]
36
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
| [#x0CB5-#x0CB9]
| #x0CDE
| [#x0CE0-#x0CE1]
| [#x0D05-#x0D0C]
| [#x0D0E-#x0D10]
| [#x0D12-#x0D28]
| [#x0D2A-#x0D39]
| [#x0D60-#x0D61]
| [#x0E01-#x0E2E]
| #x0E30
| [#x0E32-#x0E33]
| [#x0E40-#x0E45] | [#x0E81-#x0E82] | #x0E84 | [#x0E87-#x0E88] | #x0E8A
| #x0E8D | [#x0E94-#x0E97] | [#x0E99-#x0E9F] | [#x0EA1-#x0EA3] | #x0EA5
| #x0EA7
| [#x0EAA-#x0EAB]
| [#x0EAD-#x0EAE]
| #x0EB0
| [#x0EB2-#x0EB3]
| #x0EBD
| [#x0EC0-#x0EC4]
| [#x0F40-#x0F47]
| [#x0F49-#x0F69]
| [#x10A0-#x10C5]
| [#x10D0-#x10F6]
| #x1100
| [#x1102-#x1103]
| [#x1105-#x1107]
| #x1109
| [#x110B-#x110C]
| [#x110E-#x1112] | #x113C | #x113E | #x1140 | #x114C | #x114E | #x1150
| [#x1154-#x1155] | #x1159 | [#x115F-#x1161] | #x1163 | #x1165 | #x1167
| #x1169 | [#x116D-#x116E] | [#x1172-#x1173] | #x1175 | #x119E | #x11A8
| #x11AB | [#x11AE-#x11AF] | [#x11B7-#x11B8] | #x11BA | [#x11BC-#x11C2]
| #x11EB
| #x11F0
| #x11F9
| [#x1E00-#x1E9B]
| [#x1EA0-#x1EF9]
| [#x1F00-#x1F15] | [#x1F18-#x1F1D] | [#x1F20-#x1F45] | [#x1F48-#x1F4D]
| [#x1F50-#x1F57]
| #x1F59
| #x1F5B
| #x1F5D
| [#x1F5F-#x1F7D]
| [#x1F80-#x1FB4]
| [#x1FB6-#x1FBC]
| #x1FBE
| [#x1FC2-#x1FC4]
| [#x1FC6-#x1FCC]
| [#x1FD0-#x1FD3]
| [#x1FD6-#x1FDB]
| [#x1FE0-#x1FEC]
| [#x1FF2-#x1FF4]
| [#x1FF6-#x1FFC]
| #x2126
| [#x212A-#x212B]
| #x212E
| [#x2180-#x2182]
| [#x3041-#x3094]
| [#x30A1-#x30FA] | [#x3105-#x312C] | [#xAC00-#xD7A3]
[86] Ideographic
::= [#x4E00-#x9FA5] | #x3007 | [#x3021-#x3029]
[87] CombiningCh
ar
::= [#x0300-#x0345] | [#x0360-#x0361] | [#x0483-#x0486] | [#x0591-#x05A1]
| [#x05A3-#x05B9] | [#x05BB-#x05BD] | #x05BF | [#x05C1-#x05C2] | #x05C4
| [#x064B-#x0652]
| #x0670
| [#x06D6-#x06DC]
| [#x06DD-#x06DF]
| [#x06E0-#x06E4] | [#x06E7-#x06E8] | [#x06EA-#x06ED] | [#x0901-#x0903]
| #x093C | [#x093E-#x094C] | #x094D | [#x0951-#x0954] | [#x0962-#x0963]
| [#x0981-#x0983]
| #x09BC
| #x09BE
| #x09BF
| [#x09C0-#x09C4]
| [#x09C7-#x09C8] | [#x09CB-#x09CD] | #x09D7 | [#x09E2-#x09E3] | #x0A02
| #x0A3C
| #x0A3E
| #x0A3F
| [#x0A40-#x0A42]
| [#x0A47-#x0A48]
| [#x0A4B-#x0A4D]
| [#x0A70-#x0A71]
| [#x0A81-#x0A83]
| #x0ABC
| [#x0ABE-#x0AC5]
| [#x0AC7-#x0AC9]
| [#x0ACB-#x0ACD]
| [#x0B01-#x0B03]
| #x0B3C
| [#x0B3E-#x0B43]
| [#x0B47-#x0B48]
| [#x0B4B-#x0B4D]
| [#x0B56-#x0B57]
| [#x0B82-#x0B83]
| [#x0BBE-#x0BC2]
| [#x0BC6-#x0BC8]
| [#x0BCA-#x0BCD]
| #x0BD7
| [#x0C01-#x0C03]
| [#x0C3E-#x0C44]
| [#x0C46-#x0C48]
| [#x0C4A-#x0C4D]
| [#x0C55-#x0C56]
| [#x0C82-#x0C83]
| [#x0CBE-#x0CC4]
| [#x0CC6-#x0CC8]
| [#x0CCA-#x0CCD]
| [#x0CD5-#x0CD6]
| [#x0D02-#x0D03]
| [#x0D3E-#x0D43]

37
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
| [#x0D46-#x0D48]
| [#x0D4A-#x0D4D]
| #x0D57
| #x0E31
| [#x0E34-#x0E3A]
| [#x0E47-#x0E4E]
| #x0EB1
| [#x0EB4-#x0EB9]
| [#x0EBB-#x0EBC]
| [#x0EC8-#x0ECD]
| [#x0F18-#x0F19]
| #x0F35
| #x0F37 | #x0F39 | #x0F3E | #x0F3F | [#x0F71-#x0F84] | [#x0F86-#x0F8B]
| [#x0F90-#x0F95] | #x0F97 | [#x0F99-#x0FAD] | [#x0FB1-#x0FB7] | #x0FB9
| [#x20D0-#x20DC] | #x20E1 | [#x302A-#x302F] | #x3099 | #x309A
[88] Digit
::= [#x0030-#x0039] | [#x0660-#x0669] | [#x06F0-#x06F9] | [#x0966-#x096F]
| [#x09E6-#x09EF] | [#x0A66-#x0A6F] | [#x0AE6-#x0AEF] | [#x0B66-#x0B6F]
| [#x0BE7-#x0BEF]
| [#x0C66-#x0C6F]
| [#x0CE6-#x0CEF]
| [#x0D66-#x0D6F] | [#x0E50-#x0E59] | [#x0ED0-#x0ED9] | [#x0F20-#x0F29]
[89] Extender
::= #x00B7 | #x02D0 | #x02D1 | #x0387 | #x0640 | #x0E46 | #x0EC6 | #x3005
| [#x3031-#x3035] | [#x309D-#x309E] | [#x30FC-#x30FE]
ここで定義する文字クラスは,Unicode 2.0の文字データベースから,次のとおりに得ることができる。
a) 名前開始文字は,Ll,Lu,Lo,Lt又はNlカテゴリの一つに属さなければならない。
b) 名前開始文字以外の名前文字は,Mc,Me,Mn,Lm又はNdカテゴリの一つに属さなければならない。
c) 互換用領域にある文字(文字符号で#xF900より大きく#xFFFEより小さい文字)は,XMLにおける名前
としては許されない。
d) フォント分解か互換用分解をもつ文字(つまり,データベース内の5番目のフィールドに"compatibility
formatting tag"があるもの。これは,5番目のフィールドが,"<"で始まることによって示される。)は
許されない。
e) 次の文字は,名前開始文字として扱う。これは,プロパティファイルが,これらの文字をアルファベ
ットに類似すると見なすことによる。それらは [#x02BB-#x02C1],#x0559,#x06E5及び#x06E6とす
る。
f)
文字#x20DDから#x20E0までは,(Unicode 2.0の5.14に従って)除外する。
g) 文字#x00B7は,プロパティリストにしたがって,エクステンダ(extender)に分類する。
h) 文字#x0387は,これに相当する正準形(canonical quivalent)が #x00B7なので,名前文字に追加する。
i)
文字':'及び'̲'は,名前開始文字として使ってよい。
j)
文字'-'及び'.'は,名前文字として使ってよい。
38
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書C(参考)XML及びSGML
XMLは,SGMLのサブセットとして設計されている。すなわち,すべてのXML文書は,規格に適合す
るSGML文書にもなる。SGMLが文書に課す制限以外に,XMLがいかなる制限を課すかについての詳細
は,Clark(附属書AのA.2参考文献の“Clark”を参照。)を参照のこと。
39
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書D(参考)実体参照及び文字参照の展開
この附属書は,4.4 XMLプロセサによる実体及び参照の扱いで規定されている,実体参照及び文字参照
を認識し展開する一連の流れを例によって示す。
DTDが,次の宣言を含む場合を考える。
<!ENTITY example "<p>An ampersand (&#38;) may be escaped
numerically (&#38;#38;) or with a general entity
(&amp;).</p>" >
XMLプロセサは,実体の宣言を構文解析した時点で文字参照を認識し,これを解決する。実体"example"
の値として,次の文字列を保存する。
<p>An ampersand (&) may be escaped
numerically (&#38;) or with a general entity
(&amp;).</p>
文書内で"&example;"を参照すると,このテキストは再び構文解析される。このとき,要素"p"の開始タ
グ及び終了タグを認識し,三つの参照を認識し展開する。その結果,要素"p"は,次の内容(すべてデータ
であって,区切り子又はマーク付けは存在しない。)をもつ。
An ampersand (&) may be escaped
numerically (&) or with a general entity
(&).
規則及びその効果をより詳細に示すため,さらに複雑な例を示す。次の例で,行番号は参照の便宜のた
めだけに付ける。
1 <?xml version='1.0'?>
2 <!DOCTYPE test [
3 <!ELEMENT test (#PCDATA) >
4 <!ENTITY % xx '%zz;'>
5 <!ENTITY % zz '<!ENTITY tricky "error-prone" >' >
6 %xx;
7 ]>
8 <test>This sample shows a &tricky; method.</test>
これを処理すると,次のとおりとなる。
a) 4行目で,37番の文字への参照を直ちに展開し,パラメタ実体"xx"を,シンボルテーブルに"%zz;"と
いう値とともに保存する。置換テキストを再び走査することはないので,パラメタ実体"zz"への参照
は認識しない。"zz"は,まだ宣言されていないので,走査されれば誤りとなる。
b) 5行目で,文字参照"<"を直ちに展開し,パラメタ実体"zz"を"<!ENTITY tricky "error-prone" >"とい
う置換テキストとともに保存する。これは,整形式の実体宣言になる。
c) 6行目で,"xx"への参照を認識し,"xx"の置換テキスト(すなわち,"%zz;")を構文解析する。"zz"への
参照を続いて認識し,置換テキスト("<!ENTITY tricky "error-prone" >")を構文解析する。一般実体
"tricky"は,この時点で宣言され,その置換テキストは"error-prone"になる。
d) 8行目で,一般実体"tricky"への参照を認識し,展開する。要素"test"の完全な内容は,次の自己記述的
40
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
な(非文法的な)文字列となる。つまり,This sample shows a error-prone method.
41
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書E(参考)決定的内容モデル
3.2.1 要素内容で示したとおり,要素型宣言中の内容モデルは決定的である必要がある。この要求は,
SGMLとの互換性のために導入する(SGMLでは,決定的内容モデルを"非曖昧"と呼ぶ。)。 SGMLシステ
ムを用いて作成したXMLプロセサは,非決定的内容モデルを誤りとしてもよい。
例えば,内容モデル((b,c) | (b,d))は非決定的となる。これは,最初にbを与えたとき,モデル内のい
ずれのbとマッチするのか,その次の要素を先読みすることなしには,XMLプロセサは知ることができ
ないことによる。この場合は,bの二つの出現は,一つにまとめることができ,モデルは(b,(c | d))とな
る。こうすれば,明らかに最初のbは,内容モデル内の一つの名前とだけマッチする。プロセサは先読み
して,次にくるものを知る必要がない。cもdも受理される。
形式的に示せば次のとおり。Aho,Sethi,and Ullman(附属書AのA.2参考文献の“Aho/Ullman”を参
照。)の3.9のアルゴリズム3.5などの標準的なアルゴリズムを用いて,内容モデルから有限オートマトン
を構成することができる。この種の多くのアルゴリズムでは,正規表現における各々の位置(つまり,正規
表現の構文木における各々の末端ノード)に対して,follow setを構成する。ある位置に対するfollow setに
おいて,複数の位置が同じ要素型名でラベル付けされていれば,その内容モデルは誤りとなり,誤りとし
て報告してもよい。
すべての非決定的内容モデルを等価な決定的内容モデルに変換することはできないが,多くの非決定的
内容モデルを変換するアルゴリズムが存在する。Bruggemann-Klein 1991(附属書AのA.2参考文献の
“Bruggemann-Klein”を参照。)を参照のこと。
42
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書F(参考)文字符号化の自動検出
XMLの符号化宣言は,各実体の内部ラベルとして機能し,どの文字符号化を使用するかを示す。しかし,
XMLプロセサは内部ラベルを読む前にどの文字符号化を使われているかを知る必要があり,これが,内部
ラベルが示そうとしていることに他ならない。一般的には,これは絶望的な状態となる。しかし,XML
においては,完全には絶望的ではない。これは,一般的な場合に対する次の二つの制限を,XMLが加えて
いることによる。一つの制限は,どの実装も有限個の文字符号化だけをサポートするものと見なす。他の
一つは,XMLの符号化宣言の位置及び内容を制限して,各実体で使用する文字符号化の自動検出を可能に
する。また,多くの場合に,XMLのデータストリームに加え,他の情報が利用できる。ここでは,XML
の実体がプロセサに渡されるとき,(外部)情報を伴うかどうかによって,二つの場合に分ける。まず最初
の場合を示す。
F.1 外部の符号化情報がない場合の検出
外部の符号化情報をともなわず,UTF-8又はUTF-16符号化ではないXML実体は,最初の文字列を'<?xml'
とするXML符号化宣言で始めなければならないので,どの適合したプロセサも,入力にある2オクテッ
ト又は4オクテットを調べれば,次のどの場合があてはまるかを検出できる。このリストを読む際には,
UCS-4の'<'が"#x0000003C",'?'が"#x0000003F",及びUTF-16のデータストリームの必要とする“印”(し
るし)が"#xFEFF"ということを知っておくと役立つ。 ##記法は任意のバイト値を表すが,連続する二つの
## が両方とも00であることはないという例外がある。
附属書F表 1 “印”(しるし)がある場合
00 00 FE FF UCS-4,big-endianマシン (1234 order)
FF FE 00 00 UCS-4,little-endianマシン(4321 order)
00 00 FF FE UCS-4,普通でないオクテット順(2143)
FE FF 00 00 UCS-4,普通でないオクテット順(3412)
FE FF ## ## UTF-16,big-endian
FF FE ## ## UTF-16,little-endian
EF BB BF
UTF-8
附属書F表 2 “印”(しるし)がない場合
00 00 00 3
C
UCS-4。又は,他の符号化であって,32ビットのコード単位をもち,ASCII 文字をASCII
コード値として符号化するもの。それぞれ,big-endian (1234),little-endian (4321),
二つの普通ではないオクテット順 (2143と 3412)とする。 UCS-4とその他の32ビッ
トの符号化とのどちらであるかを決定するためには,符号化宣言を読み込まなくてはな
らない。
3C 00 00
00
00 00 3C
00

43
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
00 3C 00
00
00 3C 00
3F
UTF-16BEかbig-endianの ISO-10646-UCS-2。又は,その他の16ビットのコード単
位をもつbig-endianの符号化方式であって,ASCII文字をASCIIコード値として符号
化するもの。(これらのうちどの符号化方式であるかを判定するためには,符号化宣言を
読み込まなくてはならない。)
3C 00 3F
00
UTF-16LEかlittle-endianの ISO-10646-UCS-2。又は,その他の16ビットのコード
単位をもつlittle-endianの符号化方式であって,ASCII文字をASCIIコード値として符
号化するもの。(これらのうちどの符号化方式であるかを判定するためには,符号化宣言
を読み込まなくてはならない。)
3C 3F 78
6D
UTF-8,ISO 646,ASCII,ISO 8859の各パート,Shift-JIS,EUC,並びに任意の他の
7ビット,8ビット又は混在幅の符号化方式であって,ASCII文字を通常の位置,幅及び
値とすることを保証するもの。これらのどれが使われているかを検出するためには,実
際の符号化宣言を読み込まなければならない。しかし,これらすべての符号化方式は,
関係するASCII文字に対して同じビットパターンを使用するので,符号化宣言自体は,
正確に読込むことができる。
4C 6F A7
94
EBCDIC (又はその変種。どのコードページを使用するかを知るためには,符号化宣言全
体を読み込まれなければならない。)
その他
符号化宣言なしのUTF-8。そうでないときには,データストリームに誤ったラベルが付
されている(必要な符号化宣言が欠落している)か,損傷しているか,文書の断片であるか,
何らかの形式に従って埋め込まれている。
備考 これらの場合のうち,符号化を決めるために符号化宣言を読む必要がない場合においても,本
体の4.3.3は,符号化宣言(もし存在するなら)を読み込むことを要求しており,符号化の名前が
実体の実際の符号化とマッチすることを確かめることを要求している。また,符号化を決める
ために符号化宣言を用いる必要が現在はなくても,新しい文字符号化 が発明されることによっ
て符号化宣言を用いることが必要になることもあり得る。
この程度の自動判別でも,XMLの符号化宣言を読み込み,文字符号化の識別子を十分解析できる。識別
子の解析は,類似する各々の符号化の一つ一つを区別するために必要になる(例えば,UTF-8をISO 8859
から区別するため,若しくはISO 8859の各パートを区別するため,又は用いている特定のEBCDICコー
ドページを区別するため。)。
符号化宣言の内容を ASCIIレパートリーにある文字(どのように符号化される場合であっても)に限定し
ているので,どの系統の符号化が使用されているかを検出すれば,プロセサは符号化宣言全体を正確に読
み込むことができる。現実問題として,広く使用されている文字符号化は前述の系統のいずれかにあては
まるので,オペレーティングシステム又は伝送プロトコルが与える外部情報を信頼できないときでも,内
部ラベルで文字符号化をかなり正確に示すことがXML符号化宣言によって可能となる。 ASCIIのコード
値をもつバイトを過度に用いる文字符号化(例えばUTF-7) は,確実に検出できないことがある。
プロセサが文書の符号化を検出しさえすれば,それぞれの場合に対して別の入力ルーチンを呼び出すか,
又は入力する各文字に対し適切な変換関数を呼び出すことによって,適切に動作することができる。
自分自体にラベル付けをするいかなるシステムでも同様だが,ソフトウェアが,符号化宣言を更新せず
に実体の文字集合又は符号化を変えれば,XMLの符号化宣言は機能しない。文字符号化ルーチンの実装者
は,実体のラベル付けに使用する内部及び外部の情報の正確さの保証に注意すべきである。
44
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
F.2 外部の符号化情報が存在するときの優先順位
2番目の場合は,XMLの実体の他に,符号化についての情報が存在するときである。幾つかのファイル
システム及びネットワークプロトコルでは,その符号化についての情報が存在する。複数の情報が利用で
きるとき,それらの相対的な優先度と,それらが矛盾したときの望ましい処理方法とは,XMLの配送に使
用するより高水準のプロトコルの一部として規定するのがよい。特に,IETF RFC 3023又はその後継RFC
を参照されたい。このRFCはMIMEタイプtext/xmlと application/xmlを定義しており,幾つかの有用な
指示を与えている。相互運用性のため,次の規則を推奨する。
a) XMLの実体がファイルに存在すれば,“印”(しるし)及び符号化宣言は,(存在すれば)文字符号化を決
定するために使用する。
45
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書G(参考)W3C XML作業グループ
この規格の原勧告は,W3C XML作業グループ(WG)が準備し,公開を承認した。WGがこの規格の原勧
告を承認するということは,WGのすべての委員が承認投票を行ったということを必ずしも意味しない。
XML WGの現在の委員及び以前の委員を次に示す。
Jon Bosak,Sun (Chair)
James Clark (Technical Lead)
Tim Bray,Textuality and Netscape (XML Co-editor)
Jean Paoli,Microsoft (XML Co-editor)
C. M. Sperberg-McQueen,U. of Ill. (XML Co-editor)
Dan Connolly,W3C (W3C Liaison)
Paula Angerstein,Texcel
Steve DeRose,INSO
Dave Hollander,HP
Eliot Kimber,ISOGEN
Eve Maler,ArborText
Tom Magliery,NCSA
Murray Maloney,SoftQuad,Grif SA,Muzmo and Veo Systems
村田 真,富士ゼロックス情報システム(株)
Joel Nava,Adobe
Conleth O'Connell,Vignette
Peter Sharpe,SoftQuad
John Tigue,DataChannel
46
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書H(参考)W3C XMLコア作業グループ
この規格の原勧告の3rd Editionは,W3C XML Core Working Group(WG)によって準備された。公表時に
おける委員を次に示す。
Leonid Arbouzov, Sun Microsystems
Mary Brady
John Cowan
John Evdemon, Microsoft
Andrew Fang, Arbortext
Paul Grosso, Arbortext (Co-Chair)
Arnaud Le Hors, IBM
Dmitry Lenkov, Oracle
Anjana Manian, Oracle
Glenn Marcy, IBM
Jonathan Marsh, Microsoft
Sandra Martinez, NIST
Liam Quin, W3C (Staff Contact)
Lew Shannon
Richard Tobin, University of Edinburgh
Daniel Veillard
Norman Walsh, Sun Microsystems (Co-Chair)
François Yergeau (Third Edition Editor)
47
X 4159:2005
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書I(参考)文書作成に関する備考
この規格の原勧告の3rd Editionは,XMLspec DTD,v2.5の部分的修正版で符号化された。XHTML版は,
XSLTスタイルシートxmlspec.xsl,diffspec.xsl,及びREC-xml-3e.xslを組み合わせることによって生成され
た。