X 3003-1993
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
まえがき
国際標準化機構 (ISO) と国際電気標準会議 (IEC) は,世界規模の標準化のための専門組織である。ISO
又はIECの会員である各国機関は,専門委員会 (TC) を通じて国際規格の開発に参加する。専門委員会は,
技術的活動の特定の分野を対象として,それぞれの組織が設立する。ISOとIECとの専門委員会は,相互
の関心のある分野について協力する。これら以外の政府又は非政府の国際組織もまた,ISO及びIECの連
絡会員になって,作業に参加している。
情報処理技術の分野では,ISOとIECは連合技術会議ISO/IEC JTC1を結成した。この連合技術会議で
採択された国際規格原案 (DIS) は,各国機関に回付され,投票される。投票した各国機関の75パーセン
ト以上の承認が得られれば,国際規格 (International Standard) として発行される。
国際規格ISO/IEC 10279は,ISO/IEC JTC1(情報処理技術)が作成した。
国際規格ISO/IEC 10279の附属書は,参考である。
X 3003-1993
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
目次
ページ
1. 適用範囲,適用分野,引用規格等 ······················································································· 1
1.1 適用範囲 ······················································································································ 1
1.2 適用分野 ······················································································································ 1
1.3 引用規格等 ··················································································································· 2
1.3.1 引用規格 ···················································································································· 2
1.3.2 対応国際規格 ·············································································································· 2
1.3.3 関連規格 ···················································································································· 2
2. 規格への合致 ·················································································································· 2
2.0 機能単位及び規格合致性·································································································· 2
2.1 規格合致プログラム ······································································································· 4
2.2 規格合致処理系 ············································································································· 4
2.3 誤り ···························································································································· 5
2.4 例外状態 ······················································································································ 5
3. 構文の記述法及び用語の定義 ····························································································· 6
3.1 構文の記述法 ················································································································ 6
3.2 用語の定義 ··················································································································· 8
4. プログラム要素 ·············································································································· 12
4.0 概要 ··························································································································· 12
4.1 文字 ··························································································································· 12
4.2 プログラム,行及び区···································································································· 13
4.3 プログラムの注釈 ········································································································· 15
4.4 識別名 ························································································································ 16
5. 数値 ····························································································································· 19
5.0 概要 ··························································································································· 19
5.1 数値定数 ····················································································································· 19
5.2 数値変数 ····················································································································· 20
5.3 数値式 ························································································································ 21
5.4 数値組込み関数 ············································································································ 22
5.5 数値let文 ···················································································································· 25
5.6 数値の扱い及び角度 ······································································································ 26
6. 文字列 ·························································································································· 28
6.0 概要 ··························································································································· 28
6.1 文字列定数 ·················································································································· 28
6.2 文字列変数 ·················································································································· 28
6.3 文字列式 ····················································································································· 30
X 3003-1993 目次
(2)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ページ
6.4 文字列組込み関数 ········································································································· 31
6.5 文字列let文 ················································································································· 33
6.6 文字列宣言 ·················································································································· 34
7. 配列 ····························································································································· 35
7.0 概要 ··························································································································· 35
7.1 配列宣言 ····················································································································· 35
7.2 数値配列 ····················································································································· 37
7.3 文字列配列 ·················································································································· 39
8. 制御構造 ······················································································································· 41
8.0 概要 ··························································································································· 41
8.1 論理式 ························································································································ 41
8.2 制御文 ························································································································ 43
8.3 繰返し構造 ·················································································································· 44
8.4 判定構造 ····················································································································· 47
9. プログラム分割 ·············································································································· 50
9.0 概要 ··························································································································· 50
9.1 利用者定義関数 ············································································································ 50
9.2 副プログラム ··············································································································· 55
9.3 プログラム連鎖 ············································································································ 60
10. 入出力 ························································································································ 61
10.0 概要 ·························································································································· 61
10.1 内部データ ················································································································· 61
10.2 入力 ·························································································································· 63
10.3 出力 ·························································································································· 66
10.4 書式付き出力 ·············································································································· 69
10.5 配列入出力 ················································································································· 73
11. ファイル ····················································································································· 77
11.0 ファイル編成及び記録形式 ···························································································· 77
11.1 ファイル操作 ·············································································································· 81
11.2 ファイル指示子の操作 ·································································································· 91
11.3 ファイルへのデータ生成 ······························································································· 94
11.4 ファイルからのデータ入力 ··························································································· 101
11.5 ファイルにおけるデータ変更 ························································································ 107
12. 例外状態処理及びデバッグ····························································································· 110
12.1 例外状態処理 ············································································································· 110
12.2 デバッグ ··················································································································· 115
13. 図形 ·························································································································· 117
13.0 機能単位 ··················································································································· 117
13.1 座標系 ······················································································································ 118
X 3003-1993 目次
(3)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ページ
13.2 属性及び画面制御 ······································································································· 121
13.3 図形出力 ··················································································································· 127
13.4 図形入力 ··················································································································· 130
13.5 絵及び描点出力 ·········································································································· 135
14. 実時間 ······················································································································· 141
14.0 概要 ························································································································· 141
14.1 実時間プログラム ······································································································· 141
14.2 実時間宣言 ················································································································ 143
14.3 並行動作制御 ············································································································· 146
14.4 処理入出力 ················································································································ 149
14.5 共用データ ················································································································ 150
14.6 通報の受け渡し ·········································································································· 151
14.7 ビット列操作 ············································································································· 154
14.8 資源管理 ··················································································································· 155
15. 固定小数点10進数 ······································································································· 157
15.0 概要 ························································································································· 157
15.1 固定小数点10進数の精度····························································································· 157
15.2 固定小数点10進数のプログラム分割 ·············································································· 159
16. 編集 ·························································································································· 161
16.0 概要 ························································································································· 161
16.1 未整列プログラム ······································································································· 161
16.2 編集用指令 ················································································································ 161
附属書A(参考) 規格の構成 ····························································································· 171
附属書B(参考) 有効範囲································································································· 172
附属書C(参考) 処理系定義の機能 ····················································································· 173
附属書D(参考) 構文要素索 ····························································································· 177
附属書E(参考) 生成規則一覧 ··························································································· 178
附属書F(参考) GKS水準0bのためのBASICの拡張····························································· 195
附属書G(参考) 基本BASICとFull BASICとの相違点 ·························································· 207
附属書H(参考) 将来の削除を考慮している言語要素 ····························································· 209
附属書I(参考) モジュール及び単文字入力 ·········································································· 210
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
日本工業規格 JIS
X 3003-1993
電子計算機プログラム言語
Full BASIC
The Programming Language Full BASIC
日本工業規格としてのまえがき
この規格は,1991年に第1版として発行されたISO/IEC 10279 (Information technology−Programming
languages−Full BASIC) に基づいて,その技術的内容を変更することなく作成した日本工業規格である。
ISO/IEC 10279の技術的内容は,ANSI X3.113から導出されたものである。構文及び意味の具体的な規定
は,ANSI X3.113を引用する。ISO/IEC 10279は,簡易図形出力の規定についてECMA-116 BASICも引用
する。ECMA-116 BASICの技術的内容はANSI X3.113から導出されたものである。
この日本工業規格の構成,箇条番号及び文章表現は,ANSI X3.113に合わせてある。ISO/IEC 10279の技
術的内容及び文章表現は,それぞれの箇所に配分し,調整してある。ANSI X3.113にあってISO/IEC 10279
で削除されている文章は,備考又は参考とした。
1. 適用範囲,適用分野,引用規格等
1.1
適用範囲 この規格は,次のとおり,プログラム言語Full BASIC及びその部分集合を定める。
(1) Full BASIC,その中核機能単位又はその種々の拡張に従って書かれたプログラムの構文
(2) Full BASICで書かれたプログラムによって制御される自動データ処理系が,入力として受け入れるこ
とのできるデータの形式,最低保証される,数値表現の精度と範囲及び最低保証される,文字列の長
さと文字集合
(3) Full BASICで書かれたプログラムによって制御される自動データ処理系が,出力として作り出すこと
のできるデータの形式,最低保証される,数値表現の精度と範囲及び最低保証される,文字列の長さ
と文字集合
(4) Full BASICで書かれたプログラムの意味を解釈する意味規則
(5) 検出されるべき誤り及び例外状態並びにそれらの誤り及び例外状態が処理される仕方
参考 更にこの規格は,Full BASICプログラムを編集する機能を含む選択機能単位を定める。
BASIC言語は,元来,主として対話方式で用いるように設計されたものであるが,この規格
は,そのように限定されてはいない言語を定める。この規格は,インタプリタ,逐次形翻訳系,
1回通読翻訳系など,どの特定の処理系実現手法を採用することをも妨げるつもりはない。
1.2
適用分野 この規格は,さまざまな種類の自動データ処理系の間での,BASICプログラムの移植可
能性を高めるために,Full BASIC言語を定める。
参考 この規格に合致したプログラムは,規格Full BASICで書かれているという。
この規格は,ISO/IEC 10279に従い,部分集合の規格合致性について独自に規定する。これ
2
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,ANSI X3.113のものとECMA-116のものとの双方を許すように構成されている。
1.3
引用規格等
1.3.1
引用規格 引用規格を,次に示す。
JIS X 0201 情報交換用符号
JIS X 0301 日付及び時刻の表記
1.3.2
対応国際規格 対応国際規格を,次に示す。
ISO/TEC 10279 : 1991 (E) Information technology−Programming languages−Full BASIC
ANSI X3.113-1987 Information Systems−Programming Languages−Full BASIC
ANSI X3J2/TIB-1 BASIC Technical Information Bulletin Number 1
Interpretations of ANSI X3.113-1987 (1991-07-15),
ISO/IEC JTC1/SC22 N1187 (1992-07)
備考 以下の引用箇所では,これを解釈文書又はTIBと略称することがある。アメリカ規格協会
(ANSI) は,このTIBは規格の一つの解釈を与えるものであり,規格を変更するものではない
と注意を述べている。
ECMA-116 BASIC−ECMA BASIC-1, ECMA BASIC-2, ECMA Graphics Module (1986)
1.3.3
関連規格 関連規格を,次に示す。
JIS X 0210 情報交換用文字列による数値表現
JIS X 3003-1982 電子計算機プログラム言語基本BASIC
ISO 7942 : 1985 Information processing systems−Computer graphics−Graphical Kernel System
(GKS) functional description
備考 JIS X 4201[コンピュータグラフィクス中核系 (GKS) 機能記述]-1990がこの国際規格に対応
している。
ANSI X3.124-1985 Computer Graphics−Graphical Kernel System (GKS), Functional Description
ANSI/IEEE 726-1982 Real−time BASIC for CAMAC
ANSI X3.113A-1989 Information Systems−Programming Languages−Full BASIC−Addendum for
individual character input and modules, DIS 10279 1991 Addendum 1
2. 規格への合致
2.0
機能単位及び規格合致性 機能単位及び規格合致性は,次による。
参考 ISO/IEC 10279においては,規格合致性の規定以外の技術的内容は,ANSI X3.113の3.〜16.に
よる。ANSI X3.113の3.2にある予約語は,規定ではなく参考とする。部分集合中核機能単位
を構成要素とする機能単位の予約語は,ANSI X3.113の4.4.2にあるものを,JISの4.4.2(11)に
示すもので置き換える。簡易図形出力機能単位の技術的内容は,ECMA-116の13.による。
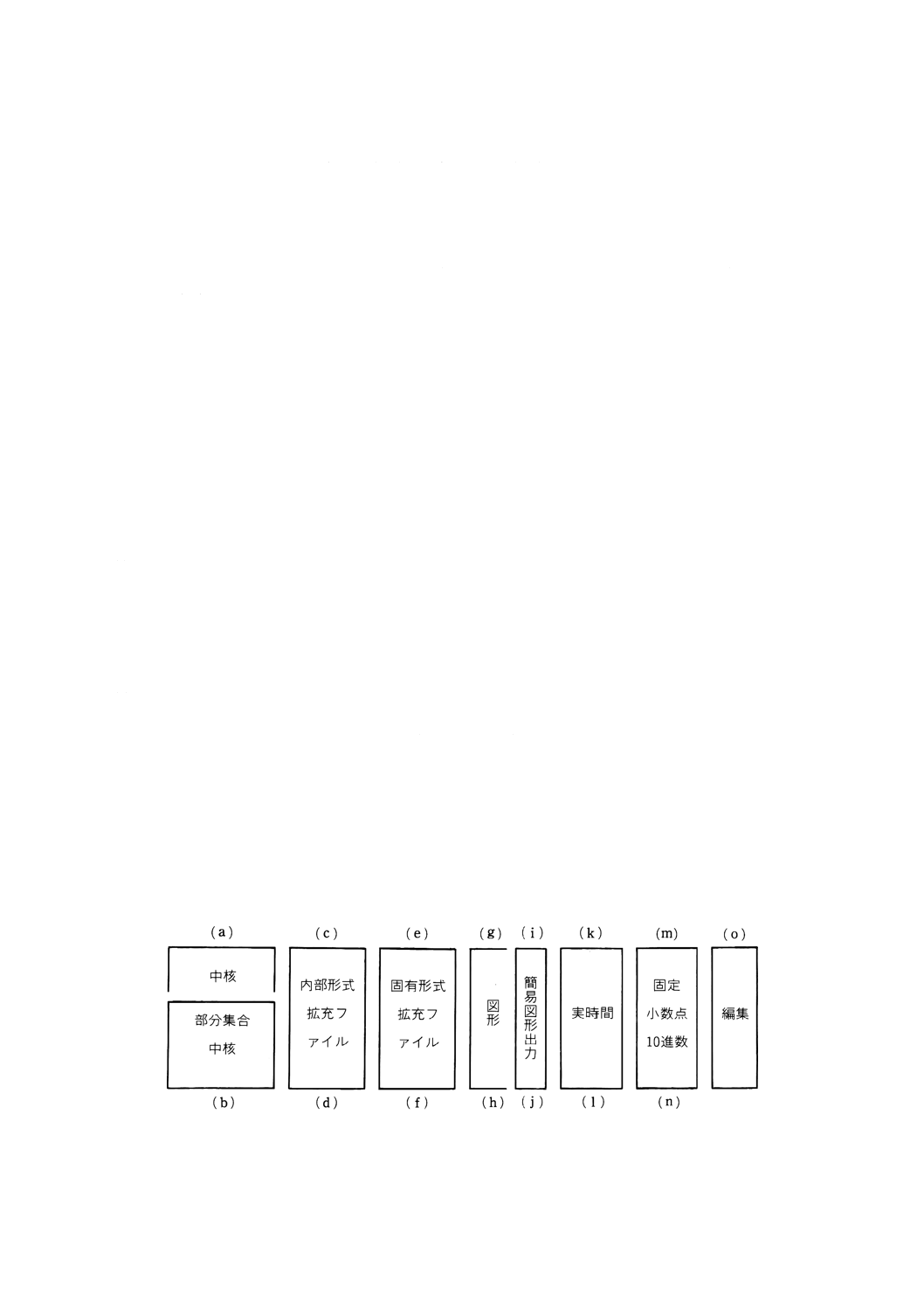
(1) 機能単位 このFull BASIC言語は,機能単位 (module) によって構成する。規格への合致は,次の15
個の機能単位の特定の組について定義する(図2.1参照)。
参考 これらの機能単位は,ANSI X3.113の2.及びECMA-116の2.にあるものを含む。
(a) 中核機能単位 (core module)。11.の中の拡充ファイルの規定を除いた4.〜12.の構文に従うすべての
プログラムを範囲とする。
(b) 部分集合中核機能単位 (subset core module)。4.4.2(11)の予約語の規定を含め,11.の中の拡充ファイ
ルの規定を除いた4.〜11.及び12.2の構文に従うすべてのプログラムを範囲とする。部分集合中核機
3
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
能単位は,予約語が多く,例外状態処理(12.1参照)がないこと以外は,中核機能単位と同じであ
る。
(c) 内部形式拡充ファイル機能単位 (enhanced-internal file module)。中核の規定及び11.の中の内部形式
記録の(“固”と指定されていない)拡充ファイルの生成規則の構文に従うすべてのプログラムを範
囲とする。
(d) 内部形式拡充ファイル部分集合機能単位 (enhanced-internal file subset module)。部分集合中核の規定
及び11.の中の内部形式記録の(“固”と指定されていない)拡充ファイルの生成規則の構文に従う
すべてのプログラムを範囲とする。
(e) 固有形式拡充ファイル機能単位 (enhanced-native file module)。中核の規定及び11.の中の固有形式記
録の(“固”と指定されている)拡充ファイルの生成規則の構文に従うすべてのプログラムを範囲と
する。
(f) 固有形式拡充ファイル部分集合機能単位 (enhanced-native file subset module)。部分集合中核の規定及
び11.の中の固有形式記録の(“固”と指定されている)拡充ファイルの生成規則の構文に従うすべ
てのプログラムを範囲とする。
(g) 図形機能単位 (graphics module)。中核の規定及び13.の構文に従うすべてのプログラムを範囲とする。
(h) 図形部分集合機能単位 (graphics subset module)。部分集合中核の規定及び13.の構文に従うすべての
プログラムを範囲とする。
(i) 簡易図形出力機能単位 (mini graphics module)。中核の規定及び13.1〜13.3の括弧【 】で囲まれてい
ない構文に従うすべてのプログラムを範囲とする。
参考 この構文は,ECMA-116の13.による。
(j) 簡易図形出力部分集合機能単位 (mini graphics subset module)。部分集合中核の規定及び13.1〜13.3
の括弧【 】で囲まれていない構文に従うすべてのプログラムを範囲とする。
参考 この構文は,ECMA-116の13.による。
(k) 実時間機能単位 (real-time module)。中核の規定及び14.の構文に従うすべてのプログラムを範囲とす
る。
(l) 実時間部分集合機能単位 (real-time subset module)。部分集合中核の規定及び14.の構文に従うすべて
のプログラムを範囲とする。
(m) 固定小数点10進数機能単位 (fixed decimal module)。中核の規定及び15.の構文に従うすべてのプロ
グラムを範囲とする。
(n) 固定小数点10進数部分集合機能単位 (fixed decimal subset module)。部分集合中核の規定及び15.の
構文に従うすべてのプログラムを範囲とする。
(o) 編集機能単位 (editing module)。16.の構文に従うすべての未整列プログラム及び編集用指令を範囲と
する。
(2) 規格合致性 機能単位の特定の組に対する二つの規格合致性 (conformance) を定める。一つはBASIC
言語で書かれたプログラムの規格合致性とし,もう一つはそのようなプログラムを処理する処理系の
規格合致性とする。機能単位のある特定の組に規格合致する任意のプログラムが,その同じ組又はそ
れらの機能単位を包含する組に規格合致するどの処理系で実行されても,同じ結果を生成するように,
規格合致性の要件が構成されている。ただし,処理系定義の機能が幾つかある(附属書C参照)。
参考 ISO/IEC 10279及びこの規格の意図は,プログラム又は処理系がANSI X3.113 (Full BASIC) 又
はECMA-116 (ECMA BASIC) のどちらかに規格合致するならば,そのまま自動的にISO/IEC
4
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
10279及びこの規格に規格合致することにある。
更に,上の(1)に15個の機能単位を定める。機能単位は,ANSI X3.113及びECMA-116の9
個の部分に基づく。これらの機能単位を構成する部分を,参考表に示す。
ANSI X3.113に定める中核機能単位及び6個の選択機能単位は,(a),(c),(e),(g),(k),(m)
及び(o)に対応する。ECMA-116に定める4個の機能単位は,参考表に示すとおりである。
2.1
規格合致プログラム プログラムは,次の条件のすべてを満たすときに限り,機能単位のその組に
対して規格合致とする。
(1) プログラム及びその中に含まれるおのおのの文その他の構文要素が,規格のその機能単位の構文規則
に正しく従っている。
(2) 全体としてのプログラムが,構文規則の適用に関して,規格のその機能単位で定めるどの広域的制約
(global constraint) にも違反しない。
2.2
規格合致処理系 規格合致処理系の要件は,次による。
(1) 処理系 (implementation) は,次のすべての条件を満たすときに限り,その機能単位の組に対して規格
合致とする。
(a) その機能単位の組に対する規格合致プログラムを受け入れて処理する。
(b) その機能単位の組に規格合致しないプログラムを受け入れない場合に,その理由を報告する。
(c) 誤り及び例外状態を,規格の定めるところに従って解釈する。
(d) 規格合致プログラム中のおのおのの文の意味を,規格の定めるところに従って解釈する。
(e) 規格合致プログラムの全体としての意味を,規格の定めるところに従って解釈する。
(f) 少なくとも規格で定められた精度と範囲の数値を,入力,処理及び出力する。
(g) 少なくとも規格で定められた長さと文字集合の文字列を,入力,処理及び出力する。
(h) 規格の中で“規定しない”又は“処理系定義 (implementation-defined)”とされている機能に対する
動作を記述した,利用者のための文書 (documentation) がある。
(i) 規格で定義された言語に対する拡張 (enhancement) のすべてを記述し識別した,利用者のための文
書がある。
(2) 編集機能単位に規格合致するには,更に次の条件がある。
処理系は,16.の規定に従って,未整列プログラム及び編集用指令を受け入れて処理する。
(3) この規格は,規格に合致しない文及び全体として規格に合致しないプログラムの意味の解釈に関して,
処理系に対して何も要求しない。
図2.1 機能単位[2.0(1)参照]

5
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
参考表 機能単位の構成
機能単位
[2.0(1)参照]
中核 部分
集合
内部 固有 図形 簡易
図形
実時
間
固定 編集
(a)
○
(b)
○
(c)
○
○
(d)
○
○
(e)
○
○
(f)
○
○
(g)
○
○
(h)
○
○
(i)
○
○
(j)
○
○
(k)
○
○
(l)
○
○
(m)
○
○
(n)
○
○
(o)
○
○
(1)
○
(2)
○
○
(3)
○
○
○
○
(4)
○
○
○
○
○
注(1) ECMA BASIC-1
(2) ECMA BASIC-1とECMA Graphics Module
(3) ECMA BASIC̲2
(4) ECMA BASIC-2とECMA Graphics Module
2.3
誤り この規格は,プログラムの本文中の構文上の誤り (error) をいちいち報告することは,処理系
に対して要求しない。
ある機能単位の組に対する規格合致処理系は,拡張された言語で書かれたプログラムを受け入れてもよ
い。この場合に,プログラム中でその機能単位の組に規格合致していない部分をいちいち報告する必要は
ない。
文その他の要素がこの規格に定める構文規則に合致していなくて,かつその文又はその要素が十分に文
書化されて明確な,処理系定義の意味をもたないときには,処理系は,誤りを報告しなければならない。
処理系による誤りの報告は,十分に文書化されて明確なやり方によらなければならない。可能ならば処理
系は,誤りのある文及びその文中の誤りの位置を示すことが望ましい。
2.4
例外状態 例外状態 (exception) は,プログラムの実行中にこの規格の意味規則どおりに動作できな
いこと又は何らかの資源の制限を超えそうになったことを,処理系が認識したときの状態とする。
(1) 処理系は,規格の定めるすべての例外状態を検出,報告及び処理しなければならない。ただし,12.1
に定める機構又は拡張によって備えられた機構が,例外状態の処理のために利用者によって呼び出さ
れる場合を除く。
(2) 処理系は,回復手続き (recovery procedure) がプログラム中に指定されていない例外状態を,規格の定
める回復手続きによって処理しなければならない。規格が回復手続きを定めていない例外状態,及び
処理系のハードウェア又は操作環境の制約によって,規格の定めた回復手続きがとれない例外状態の
処理は,その例外状態がプログラム中のどこで発生したかによる。
(a) 関数,絵又は副プログラムの呼出し中に起こったときには,例外状態は,呼出し側のプログラム単
6
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
位中のその呼び出した文に“伝達”される(12.1参照)。
(b) (a)の伝達が主プログラム若しくは並行単位に到達したとき又は例外状態が主プログラム中若しく
は並行単位中で起こったときには,その例外状態によって,そのプログラム又は(実時間プログラ
ムの場合には)その並行単位の実行が終了される。
(3) 組込みの例外処理機構が例外状態を報告する方法は,処理系定義とする。ただし,処理系は報告の内
容として,少なくともその例外状態種別及び例外状態の起こった当初の行の行番号を識別しなければ
ならない。
(4) プログラム中の一つの文の実行が複数個の例外状態を引き起こす場合,この規格は,ファイルの場合
を除いて,それらを検出,報告又は処理する順序を規定しない。
備考 一般に,入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効
果及びその入出力装置の状態は,処理系定義とする。この規定は,10.及び11.の入出力全般に
適用する。
参考 ANSI X3.113では,この備考が明示的には書いてないが,TIB(1.3.2参照)によって補った。
(5) 規格合致プログラム中に,実行すれば必ず例外状態になる文がある場合に,処理系は,利用者に警告
してもよい。しかし,その場合でも処理系は,そのプログラムを,規格の定める通常の意味規則に従
って,受け入れて実行しなければならない。
3. 構文の記述法及び用語の定義
3.1
構文の記述法
3.1.1
生成規則 構文 (syntax) は,生成規則 (production) と呼ぶ書換え規則 (rewriting rule) の集まりに
よって記述する。これは,プログラムや式などのさまざまの構文上の単位の形を定義し,どういう記号の
列がその形に適合するかを定める。
(1) 構文単位名 生成規則においては,日本語の語[日本語の文字及び太字(ボールド体)の英小文字か
らなる語],英大文字及び数字を構文単位名 (metaname) すなわち構文上の単位の名称として用いる。
構文単位名の多くは,他の構文単位名への書換えによって定義する。ある種の構文単位名を,終端
構文単位名 (terminal metaname) という。これに対する書換えの規則は,生成規則の中にはなく,書換
えは,そこで終結する。
備考 構文上の単位の名称は,次のとおりである。
終端構文単位名でない構文単位名
構文単位名
英大文字
終端構文単位名である構文単位名
数字
特殊文字の名称
[処理系定義]のもの
終端構文単位名のうち,英大文字,数字及び特殊文字の名称は,すべて4.1で定義する。英大文字は,
英大文字自身及びそれに対応する英小文字の双方を指す終端構文単位名とする。ただし,“英大文字”及び
“英小文字”の生成規則 [4.1.2(9)(10)] においては,英大文字は英大文字自身だけを,英小文字は英小文字
自身だけを指す。数字は,それ自身を指す終端構文単位名とする。
[処理系定義] (implementation-defined) は,固有の構文単位を指すものではなく,それぞれの生成規則
ごとに,処理系がその構文単位に対して適切なやり方で定める。[処理系定義]の一部については,対応す
る“注意”の項で,その構文単位に対する表現を推奨する。
7
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) 等号 例を用いて,生成規則の詳細を規定する。5.1に次のような生成規則がある。
小数部=小数点 符号なし整数
これは,“小数部”というものを,小数点の次に符号なし整数をおいたものとすることを定める。
“小数点”は,終端構文単位名であり,これを左辺とする生成規則はない。4.1の“意味”の項で,
小数点の具体的な文字を定義する。
(3) 星印 “符号なし整数”とは何かの定義として,次のような生成規則がある。
符号なし整数=数字 数字*
これは,“符号なし整数”というものを,1個の数字の後ろに0個以上の数字をつないだものとする
ことを定める。星印“*”は,反復を表す構文演算子 (syntactic operator) とし,その直前の構文単位が
0回以上何回繰り返されてもよいことを示す。
(4) 縦線 “数字”とは何かの定義として,4.1に次のような生成規則がある。
数字=0|1|2|3|4|5|6|7|8|9
これは,“数字”というものを,“0”,“1”,…,“9”のどれか一つとすることを定める。縦線“|”
は,“又は”を表す構文演算子とし,左辺の構文単位名を右辺のどれか一つで書き換えることを示す。
右辺の“0”〜“9”は,もはやどの生成規則の左辺にも現れない終端構文単位名であるから,“小数
部”に関する書換えは,これで終結する。4.1の“意味”の項で,“0”〜“9”の具体的な文字を定義
する。
(5) 疑問符 疑問符“?”は,星印と似て省略可能を表す構文演算子とし,その直前の構文単位があって
もなくてもよいことを示す。例えば,次のような生成規則がある。
指数部=E 符号? 符号なし整数
これは,“指数部”というものを,英字“E”又は“e”の後ろに0個又は1個の符号をおき,その
後ろに符号なし整数をおいたものとすることを定める。
(6) 波括弧 波括弧“{”,“}”は,構文単位名の列を一まとめにして扱うことを示す。例えば,次のよう
な生成規則がある。
変数名並び=変数名 {コンマ 変数名}*
これは,“変数名並び”というものを,1個の変数名の後ろに0個以上の変数名をコンマで区切って
つないだものとすることを定める。構文単位をまとめるためでなく,文字の列の中に波括弧を実際に
書きたい場合には,“左波括弧”又は“右波括弧”という終端構文単位名によって示す。
(7) 優先順位 一つの生成規則の中に幾つもの構文演算子を用いた場合には,優先順位を次のとおりに定
める。疑問符“?”及び星印“*”は,その直前の日本語の語である一つの構文単位名,英大文字から
なる一つの英単語(例 NOT,REST)又は波括弧でくくられた一つの構文式に対して適用する。縦線
“|”は,空白で分けて並べられた語及び構文式の列に対して適用する。その列の左端は,等号,縦
線又はまだ閉じられていない左波括弧のうちの最も近いものとする。例えば,
有効数字部=符号なし整数 小数点?|符号なし整数? 小数部
は,
有効数字部={符号なし整数{小数点}?}|{{符号なし整数}? 小数部}
と同等とする。
(8) 空白 生成規則中の空白は,構文単位名を区切るのに用いる。BASICプログラム中の空白の用法に関
しては,特別に規定する(4.1参照)。
(9) 含号 ある種の構文単位名は,二つ以上の生成規則によって定義される。例えば,5.2に次のような生
8
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
成規則がある。
単純変数名⊃数値単純変数名
更に,6.2に次のような生成規則がある。
単純変数名⊃文字列単純変数名
この二つの生成規則は,(ほかに単純変数名の定義が存在しないならば)次のようなただ一つの生成
規則と同等とする。
単純変数名=数値単純変数名|文字列単純変数名
複数個の構文定義を含む等号“=”は,すべて含号“⊃”で置き換えることができる。含号による
構文定義は,それぞれの右辺を縦線“|”で区切って並べた形の一つの右辺をもつ,等号による構文
定義と同等とする。
3.1.2
例示 構文の記述法の例として,この記述法自身の生成規則を示す。ここで現れる終端構文単位名
は,その名前の表す文字とする。
(1) 生成規則=日本語の構文単位名 空白列 {等号|含号} 空白列 構文式
(2) 日本語の構文単位名={英小文字|日本文字} 構文文字*
(3) 構文文字=英小文字|日本文字|ハイフン
(4) 空白列=空白* 行末? 空白* 空白
(5) 構文式=構文項 {空白列? 縦線 空白列? 構文項}*
(6) 構文項=構文因子 {空白列 構文因子}*
(7) 構文因子=構文一次子 構文反復?
(8) 構文一次子= 日本語の構文単位名|数字 数字*|英大文字 英大文字*|左波括弧 空白* 構文式
空白* 右波括弧
(9) 構文反復=星印|疑問符
3.2
用語の定義 この規格で用いる主な用語の定義は,次による。
(1) BASIC ある類似の構文と意味をもった言語の族に対して与えられた名称。Beginnerʼs All-purpose
Symbolic Instruction Codeの頭文字をとった頭字語である。
(2) あふれ (overflow) 数値演算の場合,前の演算で絶対値がMAXNUM(5.4.4参照)を超える結果又
は固定小数点宣言の精度指定によって表現することのできる最大値を超える結果を生成しようとした
状態。
文字列演算の場合,前の演算が処理系定義の最大長より長い文字列の結果を生成しようとした状態。
文字列代入の場合,前の演算が文字列変数又は文字列関数の宣言された最大長又は省略時想定によ
る最大長より長い結果を代入しようとした状態。
(3) 誤り (error) プログラムが正しくなくなるような,プログラムの構文上の欠陥。
(4) 一括方式 (batch mode) 利用者との対話によらない環境でプログラムを処理する方式。
(5) 印字欄 (print zone) 印字出力行中のある連続した文字位置。print文による一つの印字項目を評価し
た結果を,ここに配置することができる。
(6) 下位けたあふれ (underflow) 数値演算において,前の演算で絶対値が機械最小値よりも小さく,か
つゼロでない結果を生成しようとした状態。
(7) 外部 (external) 構文的に,より大きいプログラム単位に含まれていない手続きを指す修飾語。
(8) 機械最小値 (machine infinitesimal) BASIC処理系が表現でき,かつ処理できる最小の(ゼロでない)
正の値。
9
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(9) 機能語 (keyword) プログラム言語で用いる文又は文の構成要素を識別する文字の列。通常,よく使
われる単語や記憶しやすい単語でつづる。
この規格の定めるすべての機能語を表3.1に示す。この規格は,機能単位によって構成されている
ので,必要な機能語は機能単位ごとに異なる。各機能語がどの機能単位に含まれるかをも示す。
機能語のつづりの英大文字の一部又は全部を,英小文字で書いてもよい。
(10) 行 (line) プログラムの行を2通りの観点で規定する。一つは物理行 (physical line) とし,もう一つ
は論理行 (logical line) とする。物理行は,順番に並んでいる文字の列とする。行番号又はアンド記号
で始まり,行末で終わる。論理行は,行番号の後ろにBASIC言語の本文を順番に並べたものとする。
行継続 (line-continuation) は,論理的に,1文字の空白で置き換える。
(11) 行末 (end-of-line) 行の終りを識別する文字,文字の列又は指示。
行には,プログラムの行,印字の行及び入力応答の行の3種類の行がある。行末は,行の種類や環
境に応じて異なっていてもよい。例えばある処理系で,入力応答の行末が,対話方式や一括方式で用
いる入力源に応じて異なっていてもかまわない。
行末の代表的な例としては,復帰 (carriage-return),復改 (carriage-return line-feed) 又はカードの終端
などの記録末 (end of record) がある。
(12) 切捨て (truncation) 高精度の数値表現から低精度の数値表現を得る方法の一つ。もとの表現中の不
必要な下位のけたを単に取り除く。
(13) 固有 (native) 記録形式において,記録中で欄が特定の構造をもち,同じシステム内の別の言語が生
成した記録と互換性があることを指す修飾語。
数値データや文字列データにおいて,親ハードウェアが直接に実現できるように,ある種の意味規
則(例えば,精度や文字の大小順序)の実現方法が処理系定義に任されていることを指す修飾語。
(14) 識別名 (identifier) 変数,配列,配列値,例外処理区,関数,絵,副プログラム及びプログラムを
命名する文字の列。実時間プログラムにおいては,識別名は,並行単位,事象,構造,処理域,共用
域及び通報域を命名するのにも用いる。
(15) してもよい (may) この用語は,処理系に対する許容の意味で用いる。すなわち,規格合致処理系
(standard-conforming implementation) が,ある機能を実現してもよいし,実現しなくてもよいことを示
す。
(16) しなければならない (shall) この用語は,要求の意味で用いる。すなわち,規格合致しているとい
えるために,プログラムがとらなければならない形及び処理系がとらなければならない動作を規定す
ることを示す。
(17) 対話方式 (interactive mode) プログラムを対話的に処理する方式。利用者は,個々のプログラムの
動作に対して直接に応答ができ,更に,プログラムの実行の開始と終了を制御することができる。
(18) できる (can) この用語は,プログラムに対する許容の意味で用いる。すなわち,規格合致プログラ
ム (standard-conforming program) の中に,ある形式を書いてもよく,規格合致処理系がこのプログラ
ムを正しく処理しなければならないことを示す。
(19) 内部 (internal) 記録形式において,データの型及び正確な値を保持して生成し,後の読込み操作で
そのとおりに再入力できるデータ表現を指す修飾語。
手続きにおいて,構文的に,より大きいプログラム単位に含まれて,データを共用する手続きを指
す修飾語。
(20) プログラム単位 (program unit) BASICプログラムの独立した部分。主プログラム(end文の行まで
10
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
の行の列),外部副プログラム定義,外部関数定義,外部絵定義又は並行単位。
(21) 丸め (rounding) 高精度の数値表現から低精度の数値表現を得る方法の一つ。もとの数値のうちの
除去される部分の大きさによって,結果の下位のけたを調整する。例えば,Xを最も近い整数値に丸
めるには,INT (X+0.5) とすることができる(5.4参照)。
(22) 有効数字 (significant digits) 数値表現中の,ゼロでない最高位の数字から最低位の数字までの数字
の列。小数点の位置には無関係である。通常,正規化浮動小数点表現においては,数値表現中の有効
数字だけが,内部表現の仮数部に保持される。固定小数点表現においては,最低位の数字が明示的に
最右端のけたに位置付けられ,有効数字の左側のゼロも保持されることがある。
(23) 予約語 (reserved word) BASICプログラム中で,ルーチン識別名,文字列識別名又は数値識別名と
して用いてはならない文字の列。4.4.2(11)参照。次のものがある。
(a) 引き数のない組込み関数名
(b) 配列値の識別名
(c) ある種の機能語
(24) 例外状態 (exception) プログラムの実行中に,規格の意味規則どおりに動作できないこと又は何ら
かの資源の制限を超えそうになったことを,処理系が認識したときの状態。ある種の例外状態[続行
可能 (nonfatal) な例外状態]は,規格の定める自動回復手続きで処理することができる。これらも含
めてすべての例外状態は,プログラムで指定する回復手続き (recovery procedure) で処理することもで
きる(12.1参照)。規格が回復手続を定めていない例外状態[続行不能 (fatal) な例外状態]及び処理
系のハードウェア又は操作環境の制約によって規格の定めた回復手続きがとれない例外状態は,プロ
グラム中に回復手続きの指定がなければ,その例外状態の発生した環境に従って,次のとおり処理さ
れる。
(a) 関数,絵又は副プログラムの呼出し中に起こったときには,例外状態は,呼出し側のプログラム単
位中のその呼び出した文に“伝達”される(12.1参照)。
(b) (a)の伝達が主プログラム若しくは並行単位に到達したとき又は例外状態が主プログラム中若しく
は並行単位中で起こったときには,その例外状態が,そのプログラム又は(実時間プログラムの場
合には)その並行単位の実行を終了させる。

11
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表3.1 機能語一覧[3.2(9)参照]
機能単位は,次の略号によって示す。
中:中核,フ:拡充ファイル,図:図形,実:実時間,小:固定小数点,編:編集
ACCESS 中
EVENT 実
NEXT 中
SELECT 中実
AND 中
EXCEPTION 中
NOT 中
SEND 実
ANGLE 中図
EXIT 中図実
NUMERIC 中フ実小
SEQUENTIAL 中
AREA 図
EXTERNAL 中図小
OF フ実
SET 中
ARITHMETIC 中小
EXTRACT 編
OFF 中
SETTER 中
ARRAY 図
FILETYPE 中
ON 中実
SHARED 実
ASK 中図
FIRST 編
OPEN 中
SIGNAL 実
AT 図編
FIXED 小
OPTION 中
SIZE 中図
BASE 中
FOR 中
OR 中
SKIP 中フ
BEGIN 中
FROM 実
ORGANIZATION 中
STANDARD 中フ
BREAK 中
FUNCTION 中小
OUT 実
START 実
CALL 中
GET 図実
OUTIN 中実
STATUS 図
CASE 中実
GO 中
OUTPUT 中実
STEP 中編
CAUSE 中
GOSUB 中
PARACT 実
STOP 中
CELLS 図
GOTO 中
PARSTOP 実
STREAM 中
CHAIN 中
GRAPH 図
PICTURE 図
STRING 中フ実
CHOICE 図
HANDLER 中
PIXEL 図
STRUCTURE 実
CLEAR 図
HEIGHT 図
PLOT 図
STYLE 図
CLIP 図
IF 中
POINT 図
SUB 中
CLOSE 中
IMAGE 中
POINTER 中
TAB 中
COLLATE 中フ
IN 中図実
POINTS 図
TEMPLATE フ
COLOR 図
INPUT 中実
PORT 実
TEXT 図
CONNECT 実
INTERNAL 中
PRINT 中
THEN 中
CONTINUE 中
IS 中
PROCESS 実
THERE 中
DATA 中
JUSTIFY 図
PROGRAM 中
TIME 実
DATUM 中
KEY フ
PROMPT 中
TIMEOUT 中実
DEBUG 中
KEYED フ
PUT 実
TO 中図実編
DECIMAL 中
LAST 編
RADIANS 中
TRACE 中
DECLARE 中実
LENGTH 中
RANDOMIZE 中
UNTIL 中
DEF 中小
LET 中
RANGE 図
URGENCY 実
DEGREES 中
LIMIT 図
READ 中
USE 中
DELAY 実
LINE 中図
RECEIVE 実
USING 中図
DELETE フ編
LINES 図
RECORD フ
VALUE 図
DEVICE 図
LIST 編
RECSIZE 中
VARIABLE 中
DIM 中
LOCATE 図
RECTYPE 中
VIEWPORT 図
DISCONNECT 実
LOOP 中
RELATIVE フ
WAIT 実
DISPLAY 中
MARGIN 中
REM 中
WHEN 中
DO 中
MAT 中フ図
RENUMBER 編
WHILE 中
DRAW
MAX 図
REST 中
WINDOW 図
ELAPSED 中
MESSAGE 実
RESTORE 中
WITH 中フ図
ELSE 中
MISSING 中
RETRY 中
WRITE 中
ELSEIF 中
MIX 図
RETURN 中
ZONEWIDTH 中
END 中図実
MULTIPOINT 図
REWRITE フ
ERASABLE 中
NAME 中
SAME 中
ERASE 中
NATIVE 中フ
SEIZE 実
参考 ANSI X3.113には語MAXがないが,誤りと考えられるので補った。
12
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
4. プログラム要素
4.0
概要 BASICプログラムは,行 (line) の列とする。行は,文 (statement) を含む。各行自体は,文
字 (character) の列とする。
4.1
文字
4.1.1
概要 BASIC用の文字集合 (character set) は,JIS X 0201の文字で構成する。
4.1.2
構文 構文は,次による。
(1) プログラム文字=引用符|非引用符文字
(2) 引用文字=二連引用符|非引用符文字
(3) 非引用符文字= 感嘆符|番号記号|ドル記号|パーセント記号|アンド記号|アポストロフィ|
左括弧|右括弧|星印|コンマ|斜線|コロン|セミコロン|小号|等号|大号|
疑問符|山記号|下線|単純文字
(4) 二連引用符=引用符 引用符
(5) 単純文字=空白|単語文字
(6) 単語文字=数字|英字|小数点|正号|負号
(7) 数字=0|1|2|3|4|5|6|7|8|9
(8) 英字=英大文字|英小文字
(9) 英大文字= A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|W|
X|Y|Z
(10) 英小文字= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
(11) 非プログラム文字=[処理系定義]
(12) 構文の生成規則によって生成されるプログラムは,次の場合にだけ空白を含む。
(a) 注釈文字列の中
(b) 引用文字列,単純文字列及び即値文字列の中
(c) 構文単位名“空白”によって,空白の存在が明示的に示されているところ
(13) 更に,次の場所以外なら,どこに空白を用いてもよい。これは,プログラムの実行には何も影響を与
えない。プログラムの外観を整え,読みやすくするために用いる。空白をおいてはならない場所は,
次のとおりとする。
(a) 行番号の直前
(b) 行番号の途中
(c) 機能語のつづりの途中
(d) 識別名のつづりの途中
(e) 数値定数の途中
(f) 2文字の比較記号の途中
(g) 行継続における行末とアンド記号との間
参考 この(g)項は,TIBによる。
(14) 引用文字列,単純文字列及び書式文字列の中の空白は,意味をもつ。単純文字列に先行又は後続する
空白の列は,その文字列の一部とはみなさない。
(15) プログラム中の機能語の直前及び直後の文字は,英字,数字,下線又はドル記号であってはならない。
機能語の直後が行末 (end-of-line) であってもよい。
4.1.3
例 なし。
13
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
4.1.4
意味 意味は,次による。
(1) 英字 (letter) は,情報交換用符号 (JIS X 0201) の位置4/1〜5/10にあるローマ文字の英大文字及び位
置6/1〜7/10にあるローマ文字の英小文字を用いる。
備考 これらの規定がJIS X 0201を引用するのは,文字を明確に指定するためである。符号を定める
趣旨ではない。
(2) 数字 (digit) は,情報交換用符号の位置3/0〜3/9にある数字を用いる。
(3) その他のプログラム文字は,情報交換用符号の位置2/0〜2/15,3/10〜3/15,5/14及び5/15にある図形
文字を用いる。
(4) 文字の名称は,表4.1(163ページ)による。文字の標準の大小順序 (collating sequence) は,表4.1に
よる。標準 (standard) の大小順序は,省略時想定の場合及びcollate選択子で明示的にSTANDARDを
指定した場合に用いる(6.4,6.6及び8.1参照)。固有 (native) の大小順序は,処理系定義とする。
(5) 英字以外の文字は,それ自身を表す。英字は,引用文字列,単純文字列及び行入力応答の中ではそれ
自身を表す。識別名及び機能語において,対応する英大文字と英小文字は等価とする。引用文字列中
の非引用符文字は,それ自身を表す。引用文字列中の二連引用符は,文字列の値としては1文字の引
用符を表す。
4.1.5
例外状態 なし。
4.1.6
注意 注意は,次による。
(1) 4.1.2(11)の非プログラム文字 (other-character) は,処理系が定めて,BASIC用の文字集合に含めること
ができる。非プログラム文字は,入力の要求に対するデータとして供給したり,関数CHR$(6.4参照)
の値として生成したりして,文字列の値中に用いることができる。これらの非プログラム文字の効果
は,処理系定義とする。
(2) 非プログラム文字(行末を示す文字は除く。)を含むプログラムは,規格合致プログラムではない。
4.2
プログラム,行及び区
4.2.1
概要 プログラムの構成は,次による。
(1) BASICプログラムは,行 (line) の列とする。各行は,一意な行番号 (line-number) を含まなければな
らない。行番号は,プログラムの編集用及びその行に含まれる文 (statement) の名札 (label) として使
用される。
(2) 一つのBASICプログラムは,幾つかのプログラム単位 (program-unit) からなる。先頭のプログラム単
位を主プログラム (main-program) という。主プログラムの最後の行は,end行 (end-line) でなければ
ならない。主プログラムに続いて,0個以上の外部副プログラム定義(external-sub-def,9.2参照),外
部関数定義(external-function-def,9.1参照)又は外部絵定義(external-picture-def,13.5参照)を書く。
一つのBASICプログラムは,並行単位(parallel-section,14.1参照)の一つの列を含んでいてもよい。
この場合,各並行単位は,独立したプログラム単位とする。
(3) BASICプログラム中で,ある種の行の論理的な集まりを区 (block) という。
4.2.2
構文 構文は,次による。
(1) プログラム⊃program行? 主プログラム 外部手続き単位*
(2) program行=行番号 PROGRAM プログラム名 値仮引き数部? 行末部
(3) プログラム名=ルーチン識別名
(4) 主プログラム=手続き区* end行
(5) 手続き区=内部手続き定義|区
14
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(6) 内部手続き定義⊃内部関数定義|内部副プログラム定義|handler区
(7) 区⊃単純行|繰返し区|if区|select-case区|image行|保護区
(8) 単純行=行番号 単純文 行末部
(9) 行番号=数字 数字*
(10) 単純文⊃宣言文|単純実行文|条件文
(11) 宣言文⊃空文|data文|declare文|dim文|option文|rem文
(12) 単純実行文⊃数値関数定義let文|文字列関数定義let文|例外処理区戻り文|ask文|break文|
call文|cause-exception文|chain文|close文|debug文|erase文|exit-do文|exit-for文|
exit-function文|exit-handler文|exit-sub文|gosub文|goto文|input文|let文|line-input文|
mat文|mat-input文|mat-line-input文|mat-print文|mat-read文|mat-write文|open文|
print文|randomize文|read文|restore文|return文|set文|stop文|trace文|write文
(13) stop文=STOP
(14) 条件文=if文|on-gosub文|on-goto文
(15) 行末部=行末注釈? 行末
(16) 行末=[処理系定義]
(17) end行=行番号 end文 行末部
(18) end文=END
(19) 外部手続き単位=注釈行* 外部手続き定義
(20) 外部手続き定義⊃外部関数定義|外部副プログラム定義
(21) 注釈行=行番号 {空文|rem文}行末
(22) 行⊃単純行|注釈行|case行|case-else行|def行|do行|else行|elseif行|end行|
end-function行|end-handler行|end-if行|end-select行|end-sub行|end-when行|
external-function行|external-sub行|for行|内部function行|handler行|if-then行|image行|
loop行|next行|program行|select-case行|内部sub行|use行|when-in行|when-use行
(23) プログラム単位⊃主プログラム|外部手続き定義
(24) 行継続=アンド記号 空白* 行末部 アンド記号
(25) プログラムは,行の列とする。実時間プログラム以外のプログラムでは,行のうちの一つだけは,end
行でなければならない。先頭からend行までの行(end行を含む。)が主プログラムを構成する。
(26) 行番号は,ゼロであってはならない。先行するゼロ列は,何も効果をもたない。行は,行番号の値の
昇順に並んでいなければならない(16.参照)。プログラム単位中で行番号を引用するときには,その
プログラム単位中の行の行番号を参照しなければならない。行番号の数字は,1〜5文字とする。行番
号の値は,1〜50000とする。
(27) 行末 (end-of-line) の検出方法は,処理系定義とする。行末は,例えば復帰文字,復帰文字と改行文字
の連なり,物理記録の終りなどとしてもよい。
(28) プログラム中の一つの物理行は,132個以下の文字からなる。行末の指示は,この文字の個数には数
えない。
(29) 空白を用いてよい場所では,空白を行継続 (line-continuation) で置き換えてもよい。この場合,空白と
しての効果しかもたない。ただし,引用文字列,単純文字列,即値文字列,注釈文字列(4.1及び4.3
参照)及び行継続の中の空白は除く。
参考 この“行継続”という言葉は,TIBによる。
15
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(30) program行 (program-name-line) の値仮引き数を,主プログラム中又は実時間プログラムの先頭の並行
単位(14.1参照)中のdim文又はdeclare文で,明示的に宣言してはならない。
4.2.3
例 構文の例を次に示す。
100 PROGRAM Graphit & ! This program draws a graph
& (x, & ! x is x-coordinate
(2)
& y) ! y is y-coordinate
999 END
(15)
4.2.4
意味 意味は,次による。
(1) program行は,chain文の作用対象 (operand) となる(9.3参照)。プログラム名と,chain文中のプロ
グラム指示名 (program-designator) との間の対応付けは,処理系定義とする。program行の値仮引き
数部の評価は,9.1による。その有効範囲は,主プログラム又は先頭の並行単位(14.1参照)とする。
単独で実行されるプログラムのプログラム名は,何も効果をもたない。単独で実行されるプログラム
のprogram行の値仮引き数部の効果は,処理系定義とする。
(2) プログラムは,その先頭の行から始め,次のいずれかになるまで,順番に実行される。
(a) 行の実行によって,他の動作が指示される。
(b) 例外状態になる。ただし,続行可能な例外状態であって,利用者がそれに対して例外処理区を定義
していない場合を除く。
(c) chain文が実行される。
(d) stop文又はend文が実行される。
(3) end文 (end-statement) は,主プログラムの物理的な終りを示す。これを実行すると,プログラムの実
行が終了する。stop文 (stop-statement) を実行すると,プログラムの実行が終了する。
4.2.5
例外状態 なし。
4.2.6
注意 プログラム単位中にない行番号の参照は,構文誤りとする。処理系は,これを例外状態とし
て扱ってもよい。その場合には,このことを文書化しておかなければならない。
4.3
プログラムの注釈
4.3.1
概要 BASICプログラムには,プログラムの行の終りに,又は独立したrem文 (remark-statement)
によって,注釈 (comment) を付けることができる。
4.3.2
構文 構文は,次による。
(1) rem文=REM 注釈文字列
(2) 注釈文字列=プログラム文字*
(3) 空文=行末注釈
(4) 行末注釈=感嘆符 注釈文字列
(5) 注釈文字列の中では,行継続をしてはならない。
4.3.3
例 構文の例を次に示す。
REM FINAL CHECK
(1)
!COMPUTE AVERAGE
(4)
4.3.4
意味 意味は,次による。
(1) プログラムの実行がrem文又は空文 (null-statement) の行に到達すると,何もしないで次の行に進む。
(2) 行末注釈 (tail-comment) は,それを含む行の実行には何も効果を与えない。行末注釈中の注釈文字列
16
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(remark-string) は,ただその行の注釈としての意味をもつだけとする。
4.3.5
例外状態 なし。
4.3.6
注意 なし。
4.4
識別名
4.4.1
概要 識別名 (identifier) は,変数,配列,配列値,関数,プログラム,副プログラム,例外処理
区及び絵を命名する。実時間プログラム (real-time-program) においては,並行単位,事象,構造及び域を
も命名する(14.参照)。
4.4.2
構文 構文は,次による。
(1) 識別名⊃数値識別名|文字列識別名|ルーチン識別名
(2) 数値識別名=英字 識別名文字*
(3) 識別名文字=英字|数字|下線
(4) 文字列識別名=英字 識別名文字* ドル記号
(5) ルーチン識別名=英字 識別名文字*
(6) 識別名は,文字列識別名の場合のドル記号をも含めて,31文字以内とする。
(7) 数値識別名 (numeric-identifier) は,数値単純変数,1〜3次元の数値配列,数値関数又は数値配列値を
命名する。一つのプログラム単位中では,一つの数値識別名でこれらのうちの二つ以上の対象を命名
してはならない。同様に文字列識別名 (string-identifier) は,文字列単純変数,1〜3次元の文字列配列,
文字列関数又は文字列配列値を命名する。一つのプログラム単位中では,一つの文字列識別名でこれ
らのうちの二つ以上の対象を命名してはならない。
(8) 識別名は,内部副プログラム定義,内部関数定義,handler区又は内部絵定義を命名する。一つのプ
ログラム単位中では,一つの識別名でこれらのうちの二つ以上の対象を命名してはならない。
(9) 一つのプログラム中では,一つのルーチン識別名 (routine-identifier) は,外部関数定義,外部副プログ
ラム定義,外部絵定義,主プログラム又は並行単位の二つ以上の対象を命名してはならない。
(10) 外部関数定義を命名する数値識別名を,ルーチン識別名として使ってはならない。
参考 この規格中の“ルーチン識別名”という用語は,“数値識別名”という用語と完全に使い分けら
れているわけではない。
(11) 引き数のない組込み関数又は配列値の名前CON,DATH,EXLINE,EXTYPE,IDN,MAXNUM,PI,
RND,TIME,TRANSFORM及びZERは,ほかの対象を命名する数値識別名として使ってはならない。
引き数のない組込み関数又は配列値の名前DATE$,NUL$及びTIME$は,ほかの対象を命名する文字
列識別名として使ってはならない。
機能語NOT,ELSE,PRINT及びREMは,識別名として使ってはならない。
更に,部分集合中核機能単位においては,次の機能語もまた,識別名として使ってはならない。
ACCESS, AND, ANGLE, AREA, ARITHMETIC, ASK, AT, BASE, BEGIN, BREAK, CALL, CASE,
CHAIN, CLEAR, CLIP, CLOSE, COLLATE, COLOR, DATA, DATUM, DEBUG, DECIMAL, DECLARE,
DEF, DEGREES, DEVICE, DIM, DISPLAY, DO, ELAPSED, ELSEIF, END, ERASE, ERASABLE, EXIT,
EXTERNAL, FILETYPE, FOR, FUNCTION, GO, GOSUB, GOTO, GRAPH, IF, IMAGE, INPUT,
INTERNAL, IS, LENGTH, LET, LINE, LINES, LOOP, MARGIN, MAT, MISSING, NAME, NATIVE, NEXT,
NUMERIC, OFF, ON, OPEN, OPTION, OR, ORGANIZATION, OUTIN, OUTPUT, POINT, POINTER,
POINTS, PROGRAM, PROMPT, RADIANS, RANDOMIZE, READ, RECSIZE, RECTYPE, REST,
RESTORE, RETURN, SAME, SELECT, SEQUENTIAL, SET, SETTER, SIZE, SKIP, STANDARD, STATUS,
17
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
STEP, STOP, STREAM, STRING, STYLE, SUB, TAB, TEXT, THEN, THERE, TIMEOUT, TO, TRACE,
UNTIL, USING, VARIABLE, VIEWPORT, WHILE, WINDOW, WITH, WRITE, ZONEWIDTH
4.4.3
例 構文の例を次に示す。
X
(2)
sum
(2)
A$
(4)
last̲name$ (4)
INVERT
(5)
4.4.4
意味 意味は,次による。
(1) プログラム単位中で定義された変数,配列,handler区,内部関数定義,内部副プログラム定義又は
内部絵定義(13.5参照)を命名する識別名は,それを含むプログラム単位が呼び出されるたびに局所
的 (local) とする。その意味で,各プログラム単位は,他と区別される実体 (entity) とする。これら
の識別名は,別のプログラム単位中では別の対象を命名し,同一プログラム単位の別の回の呼出しで
も別の対象を命名する。ただし,組込み関数又はプログラム単位を命名する識別名は,プログラム全
体に対して広域的 (global) とする。すなわち,それらの識別名は,どこにあっても同じ対象を指名す
る。
参考 あるプログラム単位の名前を,別のプログラム単位の内部で,変数の名前として用いるような
ことはできる。
(2) 組込み関数の名前又は機能語TABと同じつづりの名前を,利用者定義関数,配列又は変数の識別名と
して,暗黙的に又は明示的に定義・宣言してもよい。その定義・宣言の有効範囲の中では,指定され
た解釈が,規格であらかじめ規定した解釈に優先する。したがって,その有効範囲の中では,この組
込み関数又は印字の位置指定TABは,利用できなくなる。
(3) 一つのプログラム単位中で,英大文字と英小文字が違うだけの識別名は,同じ対象を指示する。例え
ば,X1は,x1と同じ対象を識別する。その他の違いのある識別名は,別の対象を指示する。
参考 別の種類の対象であれば,同じつづりの識別名をもつことがありうる[4.4.2,4.4.6(4)参照]。
4.4.5
例外状態 なし。
4.4.6
注意 注意は,次による。
(1) この規格に対して,単純変数名として使用できない単語を増やすような処理系定義の拡張をしてはな
らない。
配列や定義関数を引用するプログラム単位中では,すべての配列は宣言しなければならず(7.1参照),
すべての定義関数もまた宣言・定義しなければならない。したがって,プログラム中におけるこれら
の識別名に対する宣言が,処理系組込みの解釈に優先するのならば,処理系は,この規格で規定され
ている以外の組込み関数を提供することができる。
しかし,処理系が拡張して提供する組込み関数に引き数がなくて,それを使う場合,その名前が単
純変数名と構文的に区別できないことがありうる。そのような組込み関数を提供する処理系は,それ
らの名前を組込み関数名として識別する構文的な手段を提供しなければならない。構文の例としては,
次のようなものが考えられる。
(a) これらの関数を引用するプログラム単位は,この関数名を明示的に宣言しなければならないことに
する。
18
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) NEWFUNCTION ( ) というふうに,これらの関数の引用には,空の括弧を書かなければならないこ
とにする。
(2) オペレーティングシステムは,主プログラムとは独立に翻訳される手続きの識別名の長さ及び形につ
いて,追加の制限を課してもよい。
(3) 組込み関数は,同じつづりの名前の利用者定義関数又は単純変数が定義された場合には,無視される。
識別名は,機能語と同じつづりであってもよい。ただし,機能語PRINT,ELSE,REM又はNOTと同
じであってはならない。
(4) 同じつづりの識別名が,二つ以上の別の対象を命名してもよい場合及び命名してはならない場合は,
次のようにまとめることができる。
参考 この(4)項は,TIBによる。
(a) 一つの文字列識別名は,その有効範囲の中では,二つ以上の文字列対象を命名するのに用いてはな
らない。そして例えば,そのプログラム単位の中で,declare文のexternal-function宣言で宣言し,
引用するのでないならば,外部関数と同じつづりの文字列識別名で内部の対象を命名してもよい。
(b) 一つの数値識別名は,その有効範囲の中では,二つ以上の数値対象を命名するのに用いてはならな
い。そして例えば,そのプログラム単位の中で,declare文のexternal-function宣言で宣言し,引用
するのでないならば,外部関数と同じつづりの数値識別名で内部の対象を命名してもよい。
(c) ある内部ルーチン(内部副プログラム,内部関数,内部絵及びhandler区)を命名するのに用いた
ルーチン識別名は,そのプログラム単位の有効範囲の中では,ほかの内部ルーチンを命名するのに
用いてはならない。
(d) 内部副プログラム,内部関数又は内部絵を命名するのに用いたルーチン識別名は,そのプログラム
単位の有効範囲の中では,それぞれ外部副プログラム,外部関数又は外部絵を命名するのに用いて
はならない。
(e) 一つのルーチン識別名は,一つのプログラムの中で,二つ以上の外部ルーチン,プログラム又は並
行単位を命名するのに用いてはならない。
(f) 次の対象は,同じルーチン識別名で重ねて命名してもよい。
外部副プログラムと内部関数
外部副プログラムと内部絵
外部副プログラムと内部のhandler区
外部絵と内部副プログラム
外部絵と内部関数
外部絵と内部のhandler区
主プログラムと内部副プログラム
主プログラムと内部関数
主プログラムと内部絵
主プログラムと内部のhandler区
並行単位と内部副プログラム
並行単位と内部関数
並行単位と内部絵
並行単位と内部のhandler区
19
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5. 数値
5.0
概要 数値 (nunber) は,BASICの基本的な二つのデータ型 (data type) の一つとする(他の一つは,
文字列とする)。数値は,定数,変数及び組込み関数に結び付けられ,それらによって数値式が構成される。
5.1
数値定数
5.1.1
概要 数値定数 (numeric-contant) は,スカラ数値 (scalar numeric value) を表す。数値定数は,位
取り10進数で表現する。数値定数には,次の四つの形式がある。
形式1 小数点なし指数部なし (implicit point unscaled) 形式 sd…d
形式2 小数点あり指数部なし (explicit point unscaled) 形式 sd…drd…d
形式3 小数点あり指数部あり (explicit point scaled) 形式 sd…drd…dEsd…d
形式4 小数点なし指数部あり (implicit point scaled) 形式 sd…dEsd…d
ここで,
d:10進数字
r:小数点
s:省略可能な符号
E:英字E又はe
とする。符号の先行していない数値定数は,正とみなす。
5.1.2
構文 構文は,次による。
(1) 定数⊃数値定数
(2) 数値定数=符号? 符号なし数値定数
(3) 符号=正号|負号
(4) 符号なし数値定数=有効数字部 指数部?
(5) 有効数字部=符号なし整数 小数点?|符号なし整数? 小数部
(6) 符号なし整数=数字 数字*
(7) 小数部=小数点 符号なし整数
(8) 指数部=E 符号? 符号なし整数
5.1.3
例 構文の例を次に示す。
−21.
(2)
1E10
(4)
5e−1
(4)
.4E+1 (4)
500.
(5)
1.2
(5)
.255
(7)
5.1.4
意味 意味は,次による。
(1) 数値定数の値は,その定数によって表現される数値とする。英字E及びeは,10のべき乗を意味する。
ここで,E又はeの後ろの符号を省略すると,正号が想定される。
(2) プログラム中では,数値定数の有効数字部 (significand) の数字のけた数は,何けたあってもよい。処
理系は,その数値定数の正確な値,又はそれを処理系定義の精度 (precision) に丸めた値を保持する。
数値定数の処理系定義の精度は,有効なarithmetic選択子がDECIMALであるかNATIVEであるかに
対応して,それぞれ10進10けた以上又は10進6けた以上とする(5.6参照)。
20
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
数値定数の指数部 (exrad) の数字のけた数は,何けたあってもよい。ただし,ゼロでない定数の絶
対値が,処理系定義の範囲の外にある場合には,例外状態になりうる(5.6参照)。絶対値が機械最小
値 (machine infinitesimal) よりも小さい定数は,ゼロで置き換えられる。絶対値が関数MAXNUMの
値よりも大きい定数は,あふれ (overflow) を報告される。
5.1.5
例外状態 例外状態は,次による。
(1) 数値定数の評価があふれを起こす。(1001,続行不能。)
5.1.6
注意 注意は,次による。
(1) ゼロでなく,かつ絶対値が機械最小値よりも小さい定数は,処理系が下位けたあふれ (underflow) の
例外状態(1501,続行可能。ゼロで置き換えて処理を続ける。)として報告し,例外処理区による処理
を許すことを推奨する。
(2) この規格には,名前付き定数の機能はない。しかし,それは,引き数のない利用者定義関数(9.1参照)
を用いて書くことができる。
5.2
数値変数
5.2.1
概要 数値変数名 (numeric-variable) は,数値単純変数 (simple numeric variable) 又は数値配列
(numeric array) の要素に対する参照とする。
5.2.2
構文 構文は,次による。
(1) 変数名⊃数値変数名
(2) 数値変数名=数値単純変数名|数値配列要素名
(3) 数値単純変数名=数値識別名
(4) 数値配列要素名=数値配列名 添字部
(5) 数値配列名=数値識別名
(6) 添字部=左括弧 添字 {コンマ 添字}* 右括弧
(7) 添字=指標
(8) 指標=数値式
(9) 単純変数名⊃数値単純変数名
(10) 配列名⊃数値配列名
(11) 添字部の添字の個数は,1〜3とする。
5.2.3
例 構文の例を次に示す。
X
(3)
sum
(3)
V(4)
(4)
table(i,j+1) (4)
5.2.4
意味 意味は,次による。
(1) プログラムの実行中はいつも,一つの数値変数は一つの数値に結び付いている。数値変数に結び付い
た値は,プログラム中で文を実行して,変更することができる。
(2) 数値単純変数名 (simple-numeric-variable) は,単にプログラム単位中に書くだけで暗黙的に宣言される。
数値変数名の有効範囲は,それの書いてあるプログラム単位とする。ただし,内部手続き定義の仮引
き数の場合を除く(9.1及び9.2参照)。
参考 ANSI X3.113では,ここが“内部関数定義”となっているが,誤りであるので,TIBによって
訂正した。
21
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3) 指標 (index) は,数値式とし,その値は,最も近い整数値に丸められる。xを丸めた値は,INT (x+.
5) で定義する。
(4) 数値配列要素名 (numeric-array-element) は,添字付き数値変数名ともいい,配列中の要素を添字の値
によって選択して参照する。参照可能な添字の値の範囲は,dim文又はdeclare文によって明示的に宣
言しなければならない(7.1参照)。添字の値は,正しい範囲の中になければならない。
(5) 実行を開始する時に数値変数に結び付ける初期値は,処理系定義とする。
5.2.5
例外状態 例外状態は,次による。
(1) 添字の値が,宣言された上下限指定の範囲の中にない。(2001,続行不能。)
5.2.6
注意 注意は,次による。
(1) 変数の初期値については規定しないので,処理系によって異なりうる。したがって,プログラムを移
植可能にするには,変数を含む式の評価に先立って,それらの変数に値を明示的に代入しておくこと
が望ましい。
(2) 初期値を変数に結び付けるには,処理系定義の多くの方式がある。すべての変数の初期値を未定義で
あることがわかるようにしておき,値が明示的に代入されることなしにその変数の値を利用しようと
すると,例外状態(3101,続行可能。処理系定義の値を用いて処理を続ける。)になる方式を推奨する。
5.3
数値式
5.3.1
概要 数値式 (numeric-expression) は,加算,減算,乗算,除算及びべき乗の演算を用いて,数値
変数名,符号なし数値定数及び数値関数引用で構成する。
5.3.2
構文 構文は,次による。
(1) 式⊃数値式
(2) 数値式=符号? 数値項 {符号 数値項}*
(3) 数値項=数値因子 {乗除算演算子 数値因子}*
(4) 数値因子=数値一次子 {山記号 数値一次子}*
(5) 数値一次子=符号なし数値定数|数値変数名|数値関数引用|左括弧 数値式 右括弧
(6) 数値関数引用⊃数値関数名 値実引き数部?
(7) 数値関数名=数値定義関数名|数値組込み関数名
(8) 値実引き数部=左括弧 値実引き数 {コンマ 値実引き数}* 右括弧
(9) 値実引き数=式|実配列名
(10) 実配列名=配列名
(11) 乗除算演算子=星印|斜線
(12) 数値関数引用中の値実引き数の個数及び型は,その数値関数の定義における値仮引き数の個数及び型
と一致していなければならない。実配列は,対応する値仮引き数と同じ次元数をもたなければならな
い。
(13) 数値型の値実引き数を外部関数定義に渡す場合,外部関数定義及びそれを呼び出すプログラム単位に
おいて有効なarithmetic選択子は,一致していなければならない。
(14) プログラム単位中の式の中で引用されるすべての数値関数名は,組込み関数名であるか,又はそのプ
ログラム単位中のより早い位置に,内部関数定義による定義若しくはdeclare文による宣言がなけれ
ばならない。
5.3.3
例 構文の例を次に示す。
3*X−Y^2
(2)
22
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
cost*quantity+overhead (2)
2^(−X)
(4)
SQR(X^2+Y^2)
(5)
value(X,Y,a$)
(6)
minimum(Xvector)
(6)
5.3.4
意味 意味は,次による。
(1) 数値式の構成及び評価 (evaluation) は,通常の代数の規則に従う。山記号(^),星印(*),斜線(/),
正号(+)及び負号(−)は,それぞれ,べき乗,乗算,除算,加算及び減算又は符号反転を表す。
括弧がない限り,最初にべき乗を行い,次に乗算及び除算を行い,最後に加算,減算及び符号反転を
行う。括弧のないときには,同順位の演算は左から右に評価する。
例
書き方
解釈
A−B−C
(A−B)−C
A^B^C
(A^B)^C
A/B/C
(A/B)/C
−A+B
(−A)+B
−A^B
−(A^B)
(2) 演算子の数学における用法が結合律や交換律を満たすものであれば,処理系は,括弧を用いることで
規制されていない限り,これらの性質を利用して式の評価の順序を変更してもよい。
(3) 数値式を評価する途中で下位けたあふれになると,その演算の結果の値は,ゼロで置き換えられる。
(4) 0^0の値は,1と定義する。
(5) 数値関数引用 (numeric-function-ref) は,あらかじめ定められた算法 (algorithm) を呼び出す記法とす
る。関数定義に仮引き数(parameter,5.4,6.4及び9.1参照)があれば,それは実引き数 (argument) の
値で置き換えられる。数値関数を評価すると,定義されている算法を実行し,一つのスカラ数値が結
果として与えられ,これが数値式の中の数値関数引用の値になる。
5.3.5
例外状態 例外状態は,次による。
(1) 数値式を評価すると,ゼロによる除算になる。(3001,続行不能。)
(2) 数値式を評価すると,あふれになる。(1002,続行不能。)
(3) べき乗の演算を評価すると,負数の非整数乗になる。(3002,続行不能。)
(4) べき乗の演算を評価すると,ゼロの負数乗になる。(3003,続行不能。)
5.3.6
注意 注意は,次による。
(1) 数値式を評価するときの精度は,5.6の制約のもとで,処理系によって異なりうる。
(2) 下位けたあふれは,処理系が例外状態(1502,続行可能。ゼロで置き換えて処理を続ける。)として報
告し,例外処理区による処理を許すことを推奨する。
(3) 処理系は,数値式の中の数値一次子及び演算を,5.3.4の意味規定に合致する任意の順序で評価してよ
い。もちろん,演算子の評価に先立って,その作用対象を評価しなければならない。例えば,数値式
A+B+C+D * Eでは,数値一次子及び加算は,それぞれどんな順序で評価してもよい。しかしここ
で,積D * Eは加算の作用対象である。したがって,この乗算は,3番Eの正号の示す加算に先立っ
て行わなければならない。
5.4
数値組込み関数

23
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5.4.1
概要 一般的に使用される数値関数 (numeric function) の評価に対し,あらかじめ定められた算法
(algorithm) が処理系から提供される。数値以外の機能に関連する関数については,6.4,7.1,7.2,12.1,
13.5及び14.7で規定する。
5.4.2
構文 構文は,次による。
(1) 数値組込み関数名⊃ ABS|ACOS|ANGLE|ASIN|ATN|CEIL|COS|COSH|COT|CSC|
DATE|DEG|EPS|EXP|FP|INT|IP|LOG|LOG10|LOG2|MAX|
MAXNUM|MIN|MOD|PI|RAD|REMAINDER|RND|ROUND|SEC|
SGN|SIN|SINH|SQR|TAN|TANH|TIME|TRUNCATE
(2) randomize文=RANDOMIZE
5.4.3
例 構文の例を次に示す。
RANDOMIZE (2)
5.4.4
意味 意味は,次による。
(1) 数値組込み関数 (numeric-supplied-function) の値及び値実引き数の個数は,表5.1による。各関数の数
値型実引き数は,特に断らない限り,最大の正数から絶対値最大の負数までの範囲の値とする。
角度を返す関数(ANGLE,ASIN及びATN)の値の単位は,ラジアンとする。ただし,option文の
angle選択子でDEGREESが有効な場合(5.6参照)には,度とする。πは,円周率 (=3.14159…) の真
値とする。
表5.1 数値関数
x,y:数値式;n:指標,すなわち数値式を丸めた整数値
関数
関数値
ABS (x)
xの絶対値。
ACOS (x)
xの逆余弦(単位は,ラジアン又は度。5.6参照)。関数値の範囲(ラジアンの場合)及びx
の範囲は,次のとおりとする。
0≦ACOS (x)≦π, −1≦x≦1
ANGLE (x, y)
原点と座標 (x, y) とを結ぶベクトルが正のx軸となす角(単位は,ラジアン又は度。5.6参
照)。関数値の範囲(ラジアンの場合)は,次のとおりとする。
−π<ANGLE (x, y)≦π
x=y=0であってはならない。逆時計回りを正とする。
例 ANGLE (1, 1)=45度
ASIN (x)
xの逆正弦(単位は,ラジアン又は度。5.6参照)。関数値の範囲(ラジアンの場合)及びx
の範囲は,次のとおりとする。
−π/2≦ASIN (x)≦π/2, −1≦x≦1
ATN (x)
xの逆正接(単位は,ラジアン又は度。5.6参照)。関数値の範囲(ラジアンの場合)は,
次のとおりとする。
−π/2<ATN (x)<π/2
CEIL (x)
x以上の最小の整数。
COS (x)
x(単位は,ラジアン又は度。5.6参照)の余弦。
COSH (x)
xの双曲線余弦。
COT (x)
x(単位は,ラジアン又は度。5.6参照)の余接。
CSC (x)
x(単位は,ラジアン又は度。5.6参照)の余割。
DATE
10進数表示の今日の日付yyddd。ここで,yyは西暦年数の下2けたを,dddは年の中の通
日を表す。
例 1977年5月9日のDATEの値は,77129である。
日付機能がない場合のDATEの値は,−1とする。
DEG (x)
x(単位はラジアン)を,度を単位として表した値。
EPS (x)
x−x',x"−x及びσのうちの最大値,。ここで,x'及びx"は,それぞれxの直前の値及び直後
24
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
関数
関数値
の値とする。σは,表現可能な最小の正数とする。xに直前の値がない場合には,x'=x,x
に直後の値がない場合には,x"=xとする。EPS (0) は,処理系によって表現可能な最小の
正数とし,値は,処理系定義とする。option文のarithmetic選択子で,異なった指定を書
いた場合には,関数EPSの値は異なりうる(5.6参照)。
EXP (x)
指数関数,すなわち,自然対数の底e (=2.71828…) のx乗。関数値が機械最小値より小さ
いときには,ゼロで置き換えられる。
FP (x)
xの小数部,すなわち,x−IP (x)。
INT (x)
を超えない最大の整数。
例 INT (1.3)=1
INT (−1.3)=−2
IP (x)
xの整数部,すなわち,SGN (x) * INT (ABS (x))。
LOG (x)
xの自然対数。xは正でなければならない。
LOG10 (x)
xの常用対数。xは正でなければならない。
LOG2 (x)
2を底とするxの対数。xは正でなければならない。
MAX (x, y)
xとyの代数的に大きいほうの値。
MAXNUM
処理系が表現及び操作できる有限の最大の正数。値は,処理系定義とする。option文の
arithmetic選択子で,異なった指定を書いた場合には,関数MAXNUMの値は異なりうる
(5.6参照)。
MIN (x, y)
xと,yの代数的に小さいほうの値。
MOD (x, y)
yを法とするxの値,すなわち,x−y * INT (x/y)。yは,ゼロであってはならない。
PI
円周率π (=3.14159…)。
RAD (x)
x(単位は度)を,ラジアンを単位として表した値。
REMAINDER (x, y)
xをyで割った余り,すなわち,x−y * IP (x/y)。yは,ゼロであってはならない。
RND
処理系定義の擬似乱数列における次の擬似乱数。これは,0≦RND<1の一様擬似乱数とす
る。
ROUND (x, n)
xの値を小数点以下10進nけたに丸めた値。nが負ならば,小数点の左側−nけたに丸め
る。すなわち,INT (x * 10^n+.5) /10^n。
SEC (x)
x(単位は,ラジアン又は度。5.6参照)の正割。
SGN (x)
xの符号。これは,
xが負であれば −1
xがゼロであれば 0
xが正であれば +1
とする。
SIN (x)
x(単位は,ラジアン又は度。5.6参照)の正弦。
SINH (x)
xの双曲線正弦。
SQR (x)
xの非負の平方根。xは,負であってはならない。
TAN (x)
x(単位は,ラジアン又は度。5.6参照)の正接。
TANH (x)
xの双曲線正接。
TIME
その日の午前0時からの経過秒数。
例 午前11時15分のTIMEの値は,40500である。
時計機能がない場合のTIMEの値は,−1とする。午前0時の関数TIMEの値は,
0とする。86400ではない。
TRUNCATE (x, n)
xの値の小数点以下10進nけたより後を切り捨てた値。nが負ならば,小数点の左側−n
けたより後を切り捨てる。すなわち,IP (x*10^n) /10^n。
(2) 表5.1の関数値の欄における“ラジアン又は度”の説明は,option文のangle選択子でDEGREESが有
効な場合,度の意味とする。RADIANSが有効な場合,ラジアンの意味とする。
(3) 周期的な三角関数SIN,COS,TAN,SEC,CSC及びCOTに対する10進m+1けたの正確度の要求(5.6.4
参照)は,実引き数が−2πから2πまでの範囲にあるときだけ適用する。実引き数がこの範囲の外にあ
り,関数値を計算するために実引き数の値の範囲を調整する必要があるとき,関数値の正確度の損失
25
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,この調整の際の精度落ちによるものだけが許される。
例 処理系は,SIN (x) を,SIN (MOD (x, 2π)) として評価してもよい。ほかの関数も同様である。
(4) randomize文 (randomize-statement) を実行してないとき,関数RNDの引用は,プログラムの実行のた
びごとに同じ擬似乱数列を生成する。randomize文を実行すると,この処理系定義の擬似乱数列が無
効になり,擬似乱数列の中から新たに予測できない出発点が選ばれ,以後の関数RNDで使われる。
擬似乱数列は,プログラム全体に広域的とし,個々のプログラム単位に局所的ではない。
5.4.5
例外状態 例外状態は,次による。
(1) 関数LOG,LOG10又はLOG2の実引き数の値が,ゼロ又は負である。(3004,続行不能。)
(2) 関数SQRの実引き数の値が,負である。(3005,続行不能。)
(3) 数値組込み関数の値の絶対値が,MAXNUMよりも大きい,又は数学的に無限大になる。(1003,続行
不能。)
(4) 関数MOD又はREMAINDERの第2実引き数の値が,ゼロである。(3006,続行不能。)
(5) 関数ACOS又はASINの実引き数の値が,−1より小さい又は1より大きい。(3007,続行不能。)
(6) ANGLE (0, 0) を評価しようとした。(3008,続行不能。)
5.4.6
注意 注意は,次による。
(1) 処理系は,実時間時計機能 (real-time clock) のような乱数発生の手掛かりになる機構をもたない場合
に,利用者との対話などの方法によってrandomize文を処理してもよい。
(2) この規格は,数値組込み関数を評価した結果の最終的な値に対してだけ,処理系があふれを報告する
ことを要求する。すなわち,関数の値を評価する過程で起こる例外状態を報告する必要はない。しか
し,その場合でも関数の最終的な値の正確度を保証するために,処理系は,適切な処置をとらなけれ
ばならない。数値組込み関数の最終的な値に対してあふれを報告する場合には,あふれを起こした関
数の名前も報告することを推奨する。
(3) 数値組込み関数の値がゼロでなく,かつ絶対値が機械最小値よりも小さい場合,処理系が下位けたあ
ふれの例外状態(1503,続行可能。ゼロで置き換えて処理を続ける。)として報告し,例外処理区によ
る処理を許すことを推奨する。
(4) 関数DATE及びTIMEで用いる基準時間帯 (time zone) は,処理系定義とする。
(5) 関数DATEでは,西暦年数を4けたで表すことはできない。それが必要な場合には,文字列関数
DATE$を利用する。
5.5
数値let文
5.5.1
概要 let文 (let-statement) は,数値式の値を計算し,数値変数の並びに対して同時的に代入する。
5.5.2
構文 構文は,次による。
(1) let文⊃数値let文
(2) 数値let文=LET 数値変数名並び 等号 数値式
(3) 数値変数名並び=数値変数名 {コンマ 数値変数名}*
5.5.3
例 構文の例を次に示す。
LET P=3.14159
(2)
LET A(X,3)=SIN(X)* Y+1
(2)
LET A,Y(I),Z=I+1
(2)
LET T(I,J),I,J=I+J
(2)
26
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5.5.4
意味 数値変数名並びの変数名に添字がある場合,それは左から右に順に評価される。次いで,右
辺の数値式(5.3参照)が評価される。最後に,数値式の値が,必要ならば変数の保持できる最も近い近似
値に丸められた上で,数値変数名並びの各数値変数に左から右に順に代入される。
5.5.5
例外状態 なし。
5.5.6
注意 次の2文,
LET A=1
LET A,B(A)=2
を実行することは,次の3文,
LET A=1
LET A=2
LET B(A)=2
を実行することと等価ではない。
5.6
数値の扱い及び角度
5.6.1
概要 特に指定しない限り,すべての数値変数の値は,論理的に浮動小数点10進数として扱われ,
10進10けた以上の処理系定義の精度 (precision) をもつ。option文 (option-statement) で指定することによ
って,精度は下がるかもしれないがより効率のよい数値表現を選ぶことができる。
特に指定しない限り,三角関数(5.4参照)及び図形変形関数(13.5参照)の引き数及び値の単位は,ラ
ジアン (radian) とする。option文で指定することによって,これらの関数の角度の単位を度 (degree) に変
えることができる。
5.6.2
構文 構文は,次による。
(1) option文=OPTION 選択子並び
(2) 選択子並び=選択子 {コンマ 選択子}*
(3) 選択子⊃ARITHMETIC {DECIMAL|NATIVE|ANGLE{DEGREES|RADIANS}
(4) declare文=DECLARE 宣言指定
(5) 宣言指定⊃numeric宣言
(6) numeric宣言⊃NUMERIC 数値宣言 {コンマ 数値宣言}*
(7) 数値宣言⊃数値単純変数名
(8) arithmetic選択子のあるoption文を書く場合には,同じプログラム単位中のどの数値式よりも早い位
置,かつ数値配列名又は数値変数名を指定した,どのdim文及びdeclare文よりも早い位置に書かな
ければならない。
参考 ANSI X3.113では,“数値配列名又は固定小数点宣言”とあるが,誤りと考えられるので訂正し
た。
(9) arithmetic選択子は,一つのプログラム単位中では,たかだか1回だけ書くことができる。
(10) angle選択子のあるoption文を書く場合には,同じプログラム単位中の,数値組込み関数名及び変形
関数名に対するどの引用よりも早い位置に書かなければならない。
(11) angle選択子は,一つのプログラム単位中では,たかだか1回だけ書くことができる。
(12) declare文を書く場合には,そこで宣言される変数名に対するどの参照よりも早い位置に書かなければ
ならない。
5.6.3
例 構文の例を次に示す。
OPTION ARITHMETIC DECIMAL,ANGLE DEGREES (1)
27
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5.6.4
意味 意味は,次による。
(1) arithmetic選択子は,その選択子 (option) を含むプログラム単位中での数値の論理的な振舞いを制御
する。
(2) arithmetic選択子でDECIMALを指定するか,又はarithmetic選択子を指定しない場合,数値変数の
値は,論理的に浮動小数点10進数として扱われ,処理系定義の精度(これをmけたとする。)及び範
囲をもつ。この精度は少なくとも10進数10けた (m≧10) とし,範囲は少なくとも10−38から10+38
までとする。
(3) 10進数演算の結果は,少なくとも10進m+1けたの精度をもつ浮動小数点10進数の中間結果の概念
によって規定する(処理系は,これと同等な別の方法で実現してもよい)。数値変数は,厳密に正確
(exact) な値をとる。数値定数は,少なくとも10進解けたの精度で正確に評価される。数値演算及び
数値関数は,その作用対象や引き数(これら自体,計算された中間結果であることもある。)から計算
された値について,少なくとも10進m+1けたの精度で正確に評価される。すべての場合に,評価の
中間結果は,少なくとも10進m+1けたの精度をもつ浮動小数点10進数として表現される。したが
って,真の結果がm+1けたの有効数字をもつ10進数で表現できるとき,計算された結果は,厳密に
正確である。個々の定数,演算及び関数の評価における誤差は,有効数字のm+2けた日において5
を超えない。処理系は,(真の結果に対する)絶対誤差が,これらの規定によって得られる結果の絶対
誤差よりも,常に大きくならない,いかなる数値の評価方法をとってもよい。
(4) arithmetic選択子でNATIVEを指定した場合,数値変数及び数値定数の値は,少なくとも10進6けた
の処理系定義の精度及び少なくとも2×10−38から10+38までの処理系定義の範囲をもつ処理系定義の
方法で表現され,扱われる。処理系は,誤差がこの精度の限度内である限り,10進数の値を必ずしも
正確に表現しなくてよい。
(5) angle選択子は,その選択子を含むプログラム単位中での三角関数の評価を制御する。angle選択子で
RADIANSを指定するか,又はangle選択子を指定しない場合,数値組込み関数COS,COT,CSC,
SEC,SIN及びTAN,並びに図形変形関数ROTATE及びSHEARは引き数の単位をラジアンとし,数
値組込み関数ACOS,ANGLE,ASIN及びATNは結果の単位をラジアンとする。
(6) angle選択子でDEGREESを指定した場合,数値組込み関数COS,COT,CSC,SEC,SIN及びTAN,
並びに図形変形関数ROTATH及びSHEARは引き数の単位を度とし,数値組込み関数ACOS,ANGLE,
ASIN及びATNは結果の単位を度とする。
(7) プログラムの実行がoption文の行に到達すると,何もしないで次の行に進む。
(8) numeric宣言に数値単純変数名を書くと,その変数は数値単純変数になる。
(9) プログラムの実行がdeclare文の行に到達すると,何もしないで次の行に進む。
5.6.5
例外状態 なし。
5.6.6
注意 注意は,次による。
(1) arithmetic選択子でNATIVEを指定した場合に処理系が選択する数値の表現は,DECIMALを指定し
たときと同じであってもよい。
(2) arithmetic選択子でNATIVEを指定した場合,数値式及び数値関数の評価における最小の精度は規定
しないが,処理系は少なくとも10進6けた以上の精度を保つことを推奨する。
(3) arithmetic選択子でNATIVEを指定した場合,処理系定義の正数の下限は,2×10−38以下である。こ
の値は,IEEE標準の浮動小数点2進数を採用する処理系を規格合致とするために定めた。
28
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
6. 文字列
6.0
概要 文字列は,BASICの基本的な二つのデータ型 (data type) の一つとする(他の一つは,数値と
する)。文字列 (string) は,文字の任意の連なりとする。その長さは,固定長でなく可変長であるが,ある
文字列に対して最大の長さを指定することもできる。文字列は,定数,変数及び組込み関数に結び付けら
れ,それらによって文字列式が構成される。
6.1
文字列定数
6.1.1
概要 文字列定数 (string-constant) は,引用符でくくられた固定長の文字の列とする。引用符それ
自身を文字列定数の中に含めるには,連続した二つの引用符で一つの引用符を表現する。
6.1.2
構文 構文は,次による。
(1) 定数⊃文字列定数
(2) 文字列定数=引用文字列
(3) 引用文字列=引用符 引用文字* 引用符
(4) 文字列定数の長さとは,引用符でくくられた引用文字の個数とする。これは二つの行末の間に書くこ
とのできる文字数の処理系定義の最大数(少なくとも132)によってだけ制限される。
6.1.3
例 構文の例を次に示す。
”XYZ”
(2)
”1E10”
(2)
”He said,””Donʼt””.”
(2)
6.1.4
意味 文字列定数の値は,先頭と末尾の引用符でくくられたすべての引用文字の並びとする。引用
文字列の中の二連引用符 (double-quote) は,二つの記号からなるが,一つの引用符を表す。文字列定数中
の空白は,先頭及び末尾の空白列も含めて,意味をもつ。先頭の引用符と末尾の引用符とを続けて書いた
引用文字列 (” ”) は,空文字列を表す。文字列定数中の英大文字と英小文字とは,区別される。
6.1.5
例外状態 なし。
6.1.6
注意 文字列定数の最大長は,物理行の最大長によって制限される。したがって,文字列定数の最
大長は,行の長さ−3である。3というのは,行継続のアンド記号 (&),先頭の引用符及び末尾の引用符の
分である。例を示す。
100 LET A$=&
&”abc...unseen characters here...xyz”
物理行の最大長は132以上であるから,処理系は文字列定数の最大長を129以上としなければならない。
6.2
文字列変数
6.2.1
概要 文字列変数名 (string-variable) は,文字列単純変数 (simple string variable) 又は1〜3次元の
文字列配列 (string array) の要素に対する参照とする。
文字列単純変数を明示的に宣言する必要はない。文字列変数名は,ドル記号によって数値変数名と区別
される。
6.2.2
構文 構文は,次による。
(1) 変数名⊃文字列変数名
(2) 文字列変数名={文字列単純変数名|文字列配列要素名} 部分文字列指定?
(3) 文字列単純変数名=文字列識別名
(4) 文字列配列要素名=文字列配列名 添字部
(5) 文字列配列名=文字列識別名
29
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(6) 部分文字列指定=左括弧 指標 コロン 指標 右括弧
(7) 単純変数名⊃文字列単純変数名
(8) 配列名⊃文字列配列名
6.2.3
例 構文の例を次に示す。
K$
(2)
name$(X:Y)
(2)
ITEM$(1,n)(z:z+5)
(2)
A$(4)
(4)
table$(I,J)
(4)
6.2.4
意味 意味は,次による。
(1) プログラムの実行中はいつも,一つの文字列変数は一つの文字列値に結び付いている。文字列変数に
結び付いた値は,プログラム中で文を実行して,変更することができる。
(2) 文字列変数に結び付いている文字列の長さは,プログラムの実行中に,0文字(空文字列を意味する。)
から,文字列変数に許される最大長(6.6.4参照)まで変わりうる。
(3) 文字列単純変数名 (simple-string-variable) は,明示的に宣言する(6.6参照)ことも,また,プログラ
ム単位中に書くだけで暗黙的に宣言することもできる。文字列変数名の有効範囲は,それの書いてあ
るプログラム単位とする。ただし,内部手続き定義の仮引き数の場合には,有効範囲はその定義の中
とする。
(4) 文字列配列要素名 (string-array-element) は,添字付き文字列変数名ともいい,1〜3次元の配列中の要
素を添字の値によって選択して参照する。添字の値は,正しい範囲の中になければならない(7.1参照)。
(5) 部分文字列指定 (substring-qualifier) は,文字列変数に結び付いた値の一部を指定する手段を与える。
a$ (m : n) は,a$に結び付いた文字列値のm文字目からn文字目(m及びnは,指標とする。)までの
部分文字列を指定する。文字列中の文字は,左から右に,1から順に番号付けられる。部分文字列指
定に関する例外状態はない。m又はnが1からLEN (a$) までの範囲の中になければ,mはMAX (m, 1),
nはMIN (n, LEN (a$))とみなす。この調整後もm>nであれば,次のとおりとする。
(a) n<m≦LEN (a$) の場合,a$ (m : n) は,m番目の文字の前にある空文字列とする。
(b) LEN (a$) <mの場合,a$ (m : n) は,略の直後の空文字列とする。
例 A$=“1234”とすると,次のとおりになる。
A$ (1 : 1) =“1”
A$ (1 : 3) =“123”
A$ (0 : 3) =“123”
A$ (2 : 5) =“234”
A$ (3 : 2) =A$の3番目の文字の前の空文字列
A$ (5 : 7) =A$の直後の空文字列
(6) 実行を開始する時に文字列変数に結び付ける初期値は,処理系定義とする。
6.2.5
例外状態 例外状態は,次による。
(1) 添字の値が,宣言された上下限指定の範囲の中にない。(2001,続行不能。)
6.2.6
注意 注意は,次による。
(1) 変数の初期値については規定しないので,処理系によって異なりうる。したがって,プログラムを移
植可能にするには,変数を含む式の評価に先立って,プログラム中でそれらの変数に値を明示的に代
30
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
入しておくことが望ましい。
(2) 初期値を変数に結び付けるには,処理系定義の多くの方式がある。処理系がすべての変数の初期値を
未定義であることがわかるようにしておき,プログラム中で値を明示的に代入することなしにその変
数の値を利用しようとすると,例外状態(3102,続行可能。処理系定義の値を用いて処理を続ける。)
になる方式を推奨する。
6.3
文字列式
6.3.1
概要 文字列式 (string-expression) は,文字列変数名,文字列定数,文字列関数引用又はこれらの
連結 (concatenation) で構成する。
6.3.2
構文 構文は、次による。
(1) 式⊃文字列式
(2) 文字列式=文字列一次子 {連結演算子 文字列一次子}*
(3) 文字列一次子=文字列定数|文字列変数名|文字列関数引用|左括弧 文字列式 右括弧
(4) 文字列関数引用=文字列関数名 値実引き数部?
(5) 文字列関数名=文字列定義関数名|文字列組込み関数名
(6) 連結演算子=アンド記号
(7) 文字列関数引用中の値実引き数の個数及び型は,その文字列関数の定義における値仮引き数の個数及
び型と一致していなければならない。実配列は,対応する値仮引き数と同じ次元数をもたなければな
らない。
(8) プログラム単位中の式の中で引用されるすべての文字列関数名は,組込み関数名であるか,又はその
プログラム単位中のより早い位置に,内部関数定義による定義若しくはdeclare文による宣言がなけ
ればならない。
6.3.3
例 構文の例を次に示す。
A2$ & B$(4:22)&”223”
(2)
X$(1,3)(I:J)
(3)
6.3.4
意味 意味は,次による。
(1) 文字列式の値は,その文字列式中の文字列一次子 (string-primary) の値を連結したものとする。
例 A$=“COME”及びB$=“IN”とすると,次のとおりになる。
A$ & B$=“COME IN”
B$ & A$=“INCOME”
(2) 文字列一次子は,文字列式の中で左から右に順に評価される。各文字列一次子ごとに,添字があれば
最初に添字が評価され,次に部分文字列指定が,最後にその文字列一次子自身の値が評価される。
(3) 文字列関数引用 (string-function-ref) は,あらかじめ定められた算法 (algorithm) を呼び出す記法とす
る。関数定義に仮引き数(parameter,6.4及び9.1参照)があれば,それは実引き数 (argument) の値
で置き換えられる。文字列関数を評価すると,定義されている算法を実行し,一つのスカラ文字列値
が結果として与えられ,これが文字列式の中の文字列関数引用の値になる。
6.3.5
例外状態 例外状態は,次による。
(1) 文字列式の評価が文字列あふれを起こす。(1051,続行不能。)
6.3.6
注意 アンド記号は,連結と行継続の両方に使う。だから,次の文は,文字の列ABCXYZを印字
する。
100 PRINT ”ABC” &&

31
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
& ”XYZ”
6.4
文字列組込み関数
6.4.1
概要 一般的に使用される文字列関数 (string function) 及び実引き数が文字列であるような数値関
数 (numeric function) の評価に対し,あらかじめ定められた算法 (algorithm) が処理系から提供される。
6.4.2
構文 構文は,次による。
(1) 文字列組込み関数名⊃ {CHR|DATE|LCASE|LTRIM|REPEAT|RTRIM|STR|TIME|UCASE|
USING} ドル記号
(2) 数値組込み関数名⊃LEN|ORD|POS|VAL
(3) 数値関数引用⊃MAXLEN 左括弧 {文字列単純変数名|文字列配列名} 右括弧
6.4.3
例 なし。
6.4.4
意味 組込み関数 (implementation-supplied function) の値,値実引き数の個数及び値実引き数の型
は,表6.1による。
表6.1 文字列関数
m:指標,すなわち数値式を丸めた整数値; x:数値式;
v$:文字列単純変数名又は文字列配列名; a$, b$:文字列式
関数
関数値
CHR$ (m)
宣言された文字集合の文字の大小順序における順序位置m+1の文字からなる長さ1文字
の文字列。文字集合の最初の文字は,引き数ゼロによって得られる。mは,ゼロ以上かつ
宣言された文字集合中の文字数未満でなければならない[表4.1(163ページ)参照]。
例 標準文字集合においては,次のとおりになる。
CHR$ (53) = “5”, CHR$ (65) =“A”
固有文字集合におけるCHR$の値は,処理系定義とする。
DATE$
JIS X 0301に従った日付yyyymmddの文字列表現。
例 1977年5月9日のDATE$は,“19770509”である。
日付機能がない場合のDATE$の値は,“00000000”とする。
LCASE$ (a$)
a$に結び付いた値の中の英大文字を,すべて対応する英小文字で置き換えて得られる文字
列。
LEN (a$)
a$に結び付いた値の中の文字の個数。
例 次の文字列定数の値は1個の引用符であるから,関数値は1である。
LEN ( ” ” ” ” ) =1
LTRIM$ (a$)
a$に結び付いた値の中の先行するすべての空白を削除して得られる文字列。
MAXLEN (v$)
その文字列単純変数又は文字列配列の文字列の最大長(6.6参照)。有効な文字列長の制限
がないときは,値MAXNUMを返す。
ORD (a$)
a$に結び付いた文字列によって指名された文字の,宣言された文字集合における順序位置。
文字集合の最初の文字の順序位置は,ゼロとする。a$として許される値は,その文字集合
中の1文字及び長さ2〜3文字の呼び名 (mnemonic) とする。呼び名において,英大文字と
英小文字は同じに扱う。標準文字集合で許される値は,表4.1(163ページ)による。固有
文字集合で許される値は,処理系定義とする。
例 標準文字集合においては,次のようになる。
ORD (”BS”) =8
ORD (”A”) =65
ORD (”a”) =97
ORD (”5”) =53
ORD (”SOH”) =1
ORD (”Soh”) =1
ORD (”ABC”) ……例外状態
POS (a$, b$)
a$に結び付いた文字列中で,b$に結び付いた値と一致する最初のものの先頭の,a$におけ
32
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
関数
関数値
る文字位置。一致する部分がないときは,POS (a$, b$) はゼロとする。POS (a$, ” ”) は,a$の
すべての値に対して1とする。
POS (a$, b$, m)
a$に結び付いた値の第m文字目以降の文字列中で,b$に結び付いた値と一致する最初のも
のの先頭の,a$における文字位置。b$に結び付いた値がa$に結び付いた値のmで指定され
た部分中にないとき,又はm>LEN (a$) であるとき,ゼロを返す。それ以外は,次の算法
によって定められるPOSの値を返す。
LET temp1=MAX (1, MIN (m, LEN (a$) +1))
LET temp2$=a$ (temp1 : LEN (a$))
LET temp3=POS (temp2$, b$)
IF temp3=0 THEN
LET POS=0
ELSE
LET POS=temp3+temp1−1
END IF
例 a$=“GRANDSTANDING”とすると,次のとおりになる。
POS (a$, ”AN”, 1) =3
POS (a$, ”AN”, 4) =8
POS (a$, ”AN”, 9) =0
POS (a$, ” ”, m) は,m≦LEN (a$) のとき,MAX (m, 1) になる。
REPEAT$ (a$, m)
a$に結び付いた値をm回繰り返して連結した文字列値。mは,ゼロ以上とする。
RTRIM$ (a$)
a$に結び付いた値の中の後続するすべての空白を削除して得られる文字列。
STR$ (x)
xに結び付いた値がprint文によって出力されるときの数値定数の形をした文字列。この数
値定数の前後の空白は,除かれる。
例 STR$ (123.5) =“123.5”
STR$ (−3.14) =“−3.14”
TIME$
JIS X 0302に従った24時間表示の時刻hh : mm : ssの文字列表現。
例 午前11時15分のTIME$の値は,“11 : 15 : 00”である。
時計機能がない場合のTIME$の値は,“99 : 99 : 99”とする。午前0時のTIME$の値は“00 :
00 : 00”とする。
UCASE$ (a$)
a$に結び付いた値の中の英小文字を,すべて対応する英大文字で置き換えて得られる文字
列。
USING$ (a$, x)
a$に結び付いた値を書式項目として用いて,数値式xの値を書式化した文字列表現(10.4
参照)。書式付き出力の例外状態についての規定(10.4.5参照)も適用する。
VAL (a$)
a$に結び付いた文字列が数値定数の形であるとき,その数値定数の値。文字列の前後の空
白は,無視される。数値定数を評価した結果が下位けたあふれになったときは,ゼロを返
す。
例 VAL (”123.5”) =123.5
VAL (”2E−99”) ……ゼロになりうる
VAL (”MCMXVII”) ……例外状態
6.4.5
例外状態 例外状態は,次による。
(1) VALの実引き数の値が正しい数値定数の形でない。(4001,続行不能。)
(2) VALの実引き数の値が正しい数値定数の形であるが,その評価があふれを起こす。(1004,続行不能。)
(3) CHR$の実引き数の値が適切な範囲の中にない。(4002,続行不能。)
(4) ORDの実引き数の値が正しい1文字でも正しい呼び名でもない。(4003,続行不能。)
(5) REPEAT$の第2実引き数の指標の値吻が負である。(4010,続行不能。)
参考 ANSI X3.113では,“第2実引き数の値が負である”となっているが,誤りと考えられるので訂
正した。
6.4.6
注意 注意は,次による。
33
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(1) 関数VALの絶対値がゼロでなく,かつ絶対値が機械最小値よりも小さい場合,処理系が下位けたあふ
れの例外状態(1504,続行可能。ゼロで置き換えて処理を続ける。)として報告し,例外処理区による
処理を許すことを推奨する。
(2) DATE$及びTIME$で用いる基準時間帯 (time zone) は,処理系定義とする。
(3) 関数UCASE$及びLCASE$の効果は,英字についてだけ,完全に定義する。アクセント記号付きの文
字のような非プログラム文字に対する効果は,処理系定義とする。
参考 Full BASICの規格の各国版は,地域的なアルファベットの利用に適合するために,この効果を
規定してもよい。
6.5
文字列let文
6.5.1
概要 let文 (let-statement) は,文字列式 (string-expression) の値を計算し,文字列変数の並びに対
して同時的に代入する。
6.5.2
構文 構文は,次による。
(1) let文⊃文字列let文
(2) 文字列let文=LET 文字列変数名並び 等号 文字列式
(3) 文字列変数名並び=文字列変数名 {コンマ 文字列変数名}*
6.5.3
例 構文の例を次に示す。
LET A$=”ABC”
(2)
LET A$(I)=B$(3:4)
(2)
LHT A$,B$=”NEGATIVE DISCRIMINANT”
(2)
LET C$(7:10)=”wxyz”
(2)
LET A$=”ABCD” &&
(2)
& ”XYZ”
6.5.4
意味 意味は,次による。
(1) 文字列変数名並びの文字列変数名に添字や部分文字列指定がある場合,それらは左から右に順に評価
される。次いで,右辺の文字列式(6.3参照)が評価される。最後に,文字列式の値が,文字列変数名
並びの各文字列変数に左から右に順に代入される。
(2) 左辺の文字列変数名に部分文字列指定があるときは,その文字列変数の値のうち,部分文字列指定で
指定された部分文字列が,右辺の値で置換される。この置換の結果,文字列変数の値の長さが,変わ
ることもありうる。
例 A$=“1234”であるとき,A$ (m, n) への代入は,次のようになる。
代入するlet文
結果の値
LET A$(2:3)=”32”
“1324”
LET A$(2:3)=” ”
“14”
LET A$(2:3)=A$(1:2)
“1124”
LET A$(2:1)=”5”
“15234”
6.5.5
例外状態 例外状態は,次による。
(1) 文字列変数に対する値の代入が文字列あふれを起こす。(1106,続行不能。)
6.5.6
注意 文字列変数名並びにおける文字列変数への代入の順序は,重要である。例えば,次の文で代
入の順序が規格と異なるときには,結果が異なりうる。
LET A$(1:2), A$(2:5)=”X”
34
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
6.6
文字列宣言
6.6.1
概要 option文 (option-statement) は,文字集合における文字の大小順序を指定する。
declare文 (declare-statement) は,プログラム単位における個々の文字列変数の値の最大長を設定する。
6.6.2
構文 構文は,次による。
(1) 選択子⊃COLLATE {NATIVE|STANDARD}
(2) 宣言指定⊃string宣言
(3) string宣言=STRING 最大長指定? 文字列宣言 {コンマ 文字列宣言}*
(4) 最大長指定=星印 符号なし整数
(5) 文字列宣言⊃文字列単純宣言
(6) 文字列単純宣言=文字列単純変数名 最大長指定?
(7) collate選択子のあるoption文を書く場合には,同じプログラム単位中のどの文字列式よりも早い位置,
どのdata文よりも早い位置,かつ文字列配列名又は文字列変数名を指定した,どのdim文及びdeclare
文よりも早い位置に書かなければならない。
参考 ANSI X3.113には,data文に関する規定がないが,誤りであるので,TIBによって訂正した。
(8) collate選択子は,一つのプログラム単位中では,たかだか1回だけ書くことができる。
(9) 一つの文字列単純変数名は,一つのプログラム単位中では,たかだか1回だけdeclare文で宣言でき
る。仮引き数である文字列単純変数名を,declare文で宣言してはならない。
6.6.3
例 構文の例を次に示す。
COLLATE NATIVE
(1)
STRING*8 last name$*20,first name$,middle name$ (3)
6.6.4
意味 意味は,次による。
(1) collate選択子は,文字列を比較したり(8.1参照),関数CHR$や関数ORDの値を計算したり(6.4参
照)するのにプログラム単位中で用いる文字の大小順序を指定する。OPTION COLLATE NATIVEは,
親システム固有の大小順序を用いることを指定する。OPTION COLLATE STANDARDは,表4.1(163
ページ)にある文字の順序を用いることを指定する。プログラム単位中にcollate選択子がないときに
は,STANDARDが想定される。
(2) string宣言で宣言された文字列単純変数は,処理系定義の値以下の最大長をもつことができる。最大
長は,次の優先順位で決められる。
(a) その変数名の文字列宣言における最大長指定
(b) その変数名を含むdeclare文の機能語STRINGの直後に書く最大長指定
(c) 処理系定義の最大長
(3) 文字列の最大長は,文字列変数に代入できる文字列の値の最大文字数を保証し,それより長い値を代
入しようとすると,文字列あふれの例外状態になることを指定する。処理系は,省略時想定の最大長
を,132文字以上としなければならない。
(4) 最大長を0と宣言すると,その文字列変数の保持できる値の最大長が,ゼロになる。すなわち,空文
字列だけを保持する。
6.6.5
例外状態 なし。
6.6.6
注意 固有の大小順序は,標準の大小順序と同じであってもよい。
参考 Full BASICの規格の各国版は,地域的なアルファベットの特定の利用に適合するために,collate
選択子を拡張して規定してもよい。
35
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
7. 配列
7.0 概要 配列 (array) は,数値又は文字列の指標付けられた集まりとする。配列要素 (array-element) は,
数値用又は文字列用のスカラ演算で操作できる(5.及び6.参照)。更に,配列全体は,配列用の文で操作で
きる。
7.1
配列宣言
7.1.1
概要 dim文 (dimension-statement) 又はdeclare文 (declare-statement) によって,配列を宣言する。
(1) option文 (option-statement) のbase選択子は,一つのプログラム単位の中の,下限値 (lower bound) が
明示的に宣言されていないすべての配列の添字 (subscript) に対して,暗黙の下限値を定義する。option
文で宣言して,すべてのそのような配列の添字の下限値を,ゼロ又は1にできる。option文による宣
言がない場合には,暗黙の下限値は1とする。
(2) 配列の次元 (dimension) は,1〜3次元とする。次元数及び各次元の添字の上下限は,declare文又は
dim文で宣言する。仮配列以外のすべての配列名は,これらの文でただ1回だけ宣言しなければなら
ない。添字の下限値は,明示的に宣言しないと,base選択子によって1又はゼロとなる。添字の上限
値 (upper bound) は,必ず明示的に宣言しなければならない。
例えば,1〜10,1980〜1989又は−9〜0の添字をもつ1次元の配列は,いずれも10個の要素からな
る。各次元に対して1〜10の添字をもつ3次元の配列は,1 000個の要素からなる。
(3) dedare文は,文字列変数・文字列配列 (string array) の文字列の最大長の宣言及び文字列配列・数値配
列 (numeric array) の配列宣言に用いることができる。dim文は,配列宣言に用いることはできるが,
文字列配列の文字列の最大長を宣言することはできない。
7.1.2
構文 構文は,次による。
(1) dim文=DIM 配列宣言並び
(2) 配列宣言並び=配列宣言 {コンマ 配列宣言}*
(3) 配列宣言=数値配列宣言|文字列配列宣言
(4) 数値配列宣言=数値配列名 上下限指定部
(5) 上下限指定部=左括弧 上下限指定 {コンマ 上下限指定}* 右括弧
(6) 上下限指定=整数 TO 整数|整数
(7) 整数=符号? 符号なし整数
(8) 文字列配列宣言=文字列配列名 上下限指定部
(9) 選択子⊃BASE {0|1}
(10) 文字列宣言⊃文字列配列宣言 最大長指定?
(11) 数値宣言⊃数値配列宣言
(12) 数値関数引用⊃ MAXSIZE 最大寸法実引き数部|SIZE 上下限実引き数部|
LBOUND 上下限実引き数部|UBOUND 上下限実引き数部
(13) 最大寸法実引き数部=左括弧 実配列名 右括弧
(14) 上下限実引き数部=左括弧 実配列名 {コンマ 指標}? 右括弧
(15) 上下限指定部の中の上下限の個数は,1〜3とする。
(16) 定義関数副プログラム,プログラム又は絵定義の仮配列となっている配列を,declare文又はdim文で
宣言してはならない。仮配列は,仮引き数部に書くことによって宣言される。仮配列以外のすべての
配列は,その配列又はその配列の要素を参照するどの文よりも早い位置のdeclare文又はdim文で宣
言しなければならない。配列及びその要素への参照は,declare文,dim文又は仮引き数におけるその
36
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
配列の宣言と,次元数が一致しなければならない。
(17) 一つの配列に対する配列宣言は,一つのプログラム単位の中に,ただ1回だけ書かなければならない。
(18) 上下限指定において下限値を書く場合には,下限値(第1番目の整数)は,上限値(第2番目の整数)
以下の値でなければならない。
下限値を書かない場合には,上限値は,base選択子によるゼロ又は1の暗黙の下限値未満であって
はならない。
(19) base選択子のあるoption文を書く場合には,同じプログラム単位の中の,どのdeclare文,どのdim
文及び数値配列値又は文字列配列値を用いるどのmat文よりも早い位置に書かなければならない。
(20) base選択子は,一つのプログラム単位の中では,たかだか1回だけ書くことができる。
(21) 実配列が1次元として宣言されている場合にだけ,上下限実引き数部の指標を省略することができる。
7.1.3
例 構文の例を次に示す。
DIM A(6),B(10, 10),B$(100),D(1 TO 5,1980 TO 1989)
(1)
DIM A$(4, 4),C(−5 TO 10)
(1)
A$(3 TO 21) * 8
(10)
SIZE(A,1)
(12)
SIZE(B$,2)
(12)
SIZE(X)
(12)
LBOUND(A)
(12)
UBOUND(C$,2)
(12)
7.1.4
意味 意味は,次による。
(1) 配列宣言 (array-declaration) は,上下限指定部 (bounds) に書いた上下限指定 (bounds-range) の個数1
〜3に従って,その配列が1〜3次元であることを宣言する。更に,上下限指定部は,その配列の添字
がとりうる最大値(及び指定されれば最小値)を指定する。添字の最小値が明示的に宣言されておら
ず,プログラム単位中にbase選択子もない場合には,添字の最小値は暗黙的に1と宣言される。
(2) option文のbase選択子は,プログラム単位に対して局所的とする。base選択子は,それを含むプログ
ラム単位中のすべての配列の添字に対して共通の最小値を宣言する。ただし,添字の最小値が明示的
に宣言されているものは除く。
(3) プログラムの実行がdim文の行に到達すると,何もしないで次の行に進む。
(4) 文字列宣言の文字列配列宣言に,最大長指定を書くことができる。このとき,最大長指定は,文字列
配列の各要素の最大長を定める。文字列宣言に最大長指定を書かなければ,文字列単純変数の場合
(6.6.4) と同様に,string宣言の最大長指定が有効になる。これらの明示的な最大長指定がない場合に
は,処理系定義の最大長が有効になる。
(5) aを配列名としnを指標とするとき,SIZE (a, n) の値は,aのn番目の添字に対する参照可能な値の
現在の個数とする。このとき,nは,最も近い整数値に丸められる。aの添字は,左から右に,1から
順に番号付けられる。SIZE (a) の値は,配列aの全要素の現在の個数とする。
(6) MAXSIZE (a) の値は,配列aの配列宣言によって許される全要素の個数とする。
(7) aを配列名としnを指標とするとき,LBOUND (a, n) の値は,aのn番目の添字に許される現在の最
小値とする。同じくUBOUND (a, n) の値は,aのn番目の添字に許される現在の最大値とする。関数
SIZEの場合と同様に,nは,最も近い整数値に丸められ,aの添字は,左から右に,1から順に番号
付けられる。関数LBOUND及び関数UBOUNDは,実引き数がベクトル(1次元配列)である場合に
37
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,配列名を実引き数に書くだけで呼び出すことができる。その場合,LBOUND及びUBOUNDの値
は,それぞれ,ベクトルの添字に許される現在の最小値及び最大値とする。以下で,“ベクトル”とは
1次元の配列,“行列”とは2次元の配列をいう。
7.1.5
例外状態 例外状態は,次による。
(1) 関数SIZEを引用したときの指標の値が,1より小さい又は配列の次元数より大きい。(4004,続行不
能。)
(2) 関数LBOUNDを引用したときの指標の値が,1より小さい又は配列の次元数より大きい。(4008,続
行不能。)
(3) 関数UBOUNDを引用したときの指標の値が,1より小さい又は配列の次元数より大きい。(4009,続
行不能。)
7.1.6
注意 注意は,次による。
(1) dim文は,基本BASIC (JIS X 3003-1982) との互換性のために採用された。その機能は,すべてdeclare
文に含まれている。
(2) 処理系が4次元以上の配列を許す場合,関数SIZE,LBOUND及びUBOUNDがそれらの次元に対し
ても機能し,例外状態は,宣言された次元数を超える次元に対してだけ起こさせることを推奨する。
7.2
数値配列
7.2.1
概要 BASICでは,数値配列 (numeric array) は要素ごとに扱うこともできる。しかし,数値配列
を指標付きの要素の集まりとみるだけでなく,一つのものとみなして,全体を一度に操作するほうが便利
な場合がある。BASICは,このような操作を行うための幾つかの標準操作を備える。
7.2.2
構文 構文は,次による。
(1) mat文⊃数値mat文
(2) 数値mat文=MAT 数値配列名 等号 数値配列式
(3) 数値配列式= {数値配列名 数値配列演算子}? 数値配列名|スカラ乗数 数値配列名|数値配列
値|数値配列関数引用
(4) 数値配列演算子=符号|星印
(5) スカラ乗数=数値一次子 星印
(6) 数値配列値⊃スカラ乗数? {CON|IDN|ZER} 再定義上下限指定部?
(7) 再定義上下限指定部=左括弧 再定義上下限指定 {コンマ 再定義上下限指定}* 右括弧
(8) 再定義上下限指定={指標 TO}? 指標
(9) 数値配列関数引用= {TRN|INV} 左括弧 数値配列名 右括弧
(10) 数値関数引用⊃ DET 左括弧 数値配列名 右括弧|DOT 左括弧 数値配列名 コンマ 数値配
列名 右括弧
(11) 再定義上下限指定部の中の再定義上下限指定の個数は,1〜3とする。
(12) 数値mat文によって値が代入される左辺の数値配列の次元数は,その数値配列式の値の次元数と同じ
でなければならない。
(13) 関数DOTの実引き数として書く数値配列は,1次元でなければならない。
(14) 関数IDNに書く再定義上下限指定部の中の再定義上下限指定の個数は,1又は2とする。
(15) 加算又は減算で用いる二つの数値配列は,同じ次元数をもたなければならない。関数DET,INC又は
TRNの実引き数として書く数値配列は,2次元でなければならない。
(16) 数値配列演算子の星印(行列の乗算)を書くとき,その作用対象の数値配列は,1次元又は2次元と
38
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する。その少なくとも方は,2次元でなければならない。
7.2.3
例 構文の例を次に示す。ここで,A,B及びCは2次元数値配列,X,Y及びZは1次元数値配
列,Wは数値一次子とする。
参考 ANSI X3.113では,“数値一次子”のところが数値式となっているが,誤りであるので,TIBに
よって訂正した。
例1. 構文規則(2)の例
MAT A=B
MAT X=Y
MAT A=B+C
MAT X=Y−Z
MAT A=B * C
MAT X=A * Y
MAT X=Y * A
MAT A=W * B
MAT X=W * CON
MAT A=ZER(4,3)
MAT X=ZER
MAT A=INV(B)
MAT A=TRN(B)
例2. 構文規則(10)の例
DET(B)
DOT(X,Y)
7.2.4
意味 意味は,次による。
(1) mat文と上下限の再定義
(1.1) 数値mat文 (numeric-array-assignment) を実行すると,数値配列式 (numeric-array-expression) が評価
され,その値が等号の左辺の配列に代入される。必要ならば,この配列の寸法 (size) が動的に変更
される。次元数は,変更されない。各次元の寸法が,右辺の数値配列式の値の寸法と同じになる。
(1.2) 数値配列の寸法が動的に変更されるとき,その添字の現在の上限値だけが,新しい寸法に合わせて
次のとおり変更される。
新しい下限値=もとの下限値
新しい上限値=もとの下限値+新しい寸法−1
各次元の新しい寸法は,その数値配列を宣言する配列宣言で指定した寸法を超えてもよい。しか
し,その数値配列の要素の新しい総数は,配列宣言で指定した要素の総数を超えてはならない。
(2) 配列式
(2.1) 数値配列式の評価は,通常の行列代数の規則に従う。星印“*”,正号“+”,負号“−”は,それぞ
れ乗算,加算,減算を表す。
(2.2) 数値配列式の中の数値配列の寸法は,行列代数の規則に適合していなければならない。加算又は減
算される二つの数値配列は,各次元の寸法が同じでなければならない。乗算される二つの数値配列
は,あるl,m,nに対して,次のいずれかでなければならない。
(a) l×m行列及びm×n行列である。この結果は,l×n行列となる。
(b) m要素ベクトル及びm×n行列である。この結果は,n要素ベクトルとなる。
(c) l×m行列及びm要素ベクトルである。この結果は,l要素ベクトルとなる。
(2.3) 数値配列を評価すると,数値配列の全要素が使用される。すなわち,一つの数値配列は,一つのも
のとして扱われる。
(2.4) 数値配列式の中にスカラ乗数 (scalar-multiplier) があるときには,まずスカラ乗数の数値一次子が評
価され,次にその値が数値配列の各要素に掛けられる。
(2.5) 数値配列式を評価する途中で下位けたあふれになると,その演算の結果の値は,ゼロで置き換えら
39
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
れる。
(3) 配列値
(3.1) 数値配列値 (numeric-array-value) が,等号の左辺の数値配列に代入される。再定義上下限指定部が
ない場合には,等号の左辺の数値配列と同じ寸法の数値配列が生成される。再定義上下限指定部が
ある場合には,指定された寸法をもつ数値配列が生成され,等号の左辺の数値配列も(1)の規定に従
って再定義 (redimensioning) される。再定義上下限指定の二つの指標は,その配列値の対応する次
元の上限及び下限を表す。
再定義上下限指定に指標を一つだけ書いたときには,それは上限を表す。下限は,そこで有効な
暗黙の値になる。配列値IDNに再定義上下限指定部を書くときには,それは正方行列(以下,行数
と列数が同じ行列をいう。)を生成するものでなければならない。配列値IDNに再定義上下限指定
部を書かないときには,等号の左辺の数値配列は正方行列でなければならない。
(3.2) 配列値ZERは,すべての要素がゼロである数値配列を生成する。配列値CONは,すべての要素が
1である数値配列を生成する。配列値IDNは,単位行列すなわち主対角要素は1,それ以外の要素
はゼロの正方行列を生成する。配列値IDNに再定義上下限指定を一つだけ書くと,同じ再定義上下
限指定を二つ書いたようにみなされる。
(3.3) 配列値IDN,ZER又はCONスカラ乗数を作用させると,その数値一次子(5.3参照)が評価され,
結果の行列は,配列値IDN,ZER又はCONの各非ゼロ要素をその数値一次子の値で置き換えた値
をもつ。
(4) 配列関数
(4.1) 関数TRNは,実引き数の転置行列を生成する。m×n行列の実引き数に対して,n×m行列を返す。
(4.2) 関数INVは,実引き数の逆行列を生成する。実引き数は,正方行列でなければならない。
(4.3) 関数DETは,実引き数の行列式の値を返す。実引き数は,正方行列でなければならない。
(4.4) DOT (x, y) の値は,1次元の数値ベクトルx,yの内積であるスカラ値とする。
7.2.5. 例外状態 例外状態は,次による。
(1) 数値配列式中の数値配列の寸法が,行列代数の規則に合わない。(6001,続行不能。)
(2) 再定義後の配列で必要な要素の総数が,もとの配列宣言で確保された要素数を超える。(5001,続行不
能。)
(3) 再定義上下限指定の1番目の指標の値が,2番目の指標の値より大きい。(6005,続行不能。)
(4) 再定義上下限指定に指標が一つだけ書いてあって,その値が有効な暗黙の下限の値未満である。(6005,
続行不能。)
(5) 配列値IDNに続く再定義上下限指定部が,正方行列を指定していない。又は,再定義上下限指定部が
書いてなくて,受取り側の行列が正方行列でない。(6004,続行不能。)
(6) 関数DETの実引き数が,正方数値行列でない。(6002,続行不能。)
(7) 関数INVの実引き数が,正方数値行列でない。(6003,続行不能。)
(8) 数値配列式の評価が,あふれを起こす。(1005,続行不能。)
(9) 関数DET又はDOTの評価が,あふれを起こす。(1009,続行不能。)
(10) 関数INVの実引き数が,特異行列である。又は,有効数字が,すべて失われた。(3009,続行不能。)
7.2.6
注意 処理系が,下位けたあふれを例外状態(1505,続行可能。値をゼロで置き換えて,処理を続
ける。)として報告し,例外処理区による処理を許すことを推奨する。
7.3
文字列配列
40
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
7.3.1
概要 文字列配列 (string array) は,数値配列と同様に,指標付きの要素の集まりとみるだけでな
く,全体として一つのものとみなすこともできる。BASICは,文字列配列全体を連結 (concatenate) した
り,代入したりする機能を備える。
7.3.2
構文 構文は,次による。
(1) mat文⊃文字列mat文
(2) 文字列mat文=MAT 文字列配列名 部分文字列指定? 等号 文字列配列式
(3) 文字列配列式= 文字列配列一次子 {連結演算子 文字列配列一次子}?|文字列一次子 連結演算
子 文字列配列一次子|文字列配列一次子 連結演算子 文字列一次子|文字列配
列値
(4) 文字列配列一次子=文字列配列名 部分文字列指定?
(5) 文字列配列値={文字列一次子 連結演算子}? NUL ドル記号 再定義上下限指定部?
(6) 文字列mat文によって値が代入される左辺の文字列配列の次元数は,その文字列配列式の値の次元数
と同じでなければならない。
(7) 連結する二つの文字列配列は,次元数が同じでなければならない。
7.3.3
例 構文の例を次に示す。
MAT A$=A$ & B$
(2)
MAT A$=NUL$ (5,6)
(2)
MAT A$=(”Number”)& B$
(2)
MAT A$(4:6)=(””)& B$
(2)
7.3.4
意味 意味は,次による。
(1) 文字列mat文 (string-array-assignment) を実行すると,文字列配列式 (string-array-expression) が評価さ
れ,その値が等号の左辺の配列に代入される。必要ならば,この配列の寸法 (size) が動的に変更され
る。次元数は,変更されない。各次元の寸法が,右辺の文字列配列式の値の寸法と同じになる。
(2) 文字列配列の寸法が動的に変更されるとき,その添字の現在の上限値だけが,新しい寸法に合わせて
次のとおり変更される。
新しい下限値=もとの下限値
新しい上限値=もとの下限値+新しい寸法−1
各次元の新しい寸法は,その文字列配列を宣言する配列宣言で指定した寸法を超えてもよい。しか
し,その文字列配列の要素の新しい総数は,配列宣言で指定した要素の総数を超えてはならない。
(3) 文字列mat文の左辺の文字列配列に部分文字列指定があるときは,各要素の値のうち部分文字列指定
で指定された部分文字列を置き換える。左辺の部分文字列指定を先に評価し,それから右辺の文字列
配列式を評価する。
(4) 文字列配列式では,連結及び部分文字列の抽出操作も行う。連結する二つの文字列配列は,各次元の
寸法が同じでなければならない。連結は,要素ごとに行われる。文字列一次子を連結するときは,こ
の文字列一次子が文字列配列のすべての要素の,(構文に従って)先頭又は末尾に連結される。文字列
配列に部分文字列指定があるときは,指定した部分文字列を配列の各要素から抽出する。
参考 ANSI X3.113では,“文字列一次子”のところがスカラとなっているが,誤りであるので,TIB
によって訂正した。
(5) 評価及び代入の順序は,次による。
(a) 左辺の配列の部分文字列指定を評価する。
41
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) 文字列配列式を左から右に順に評価する。個々の文字列一次子又は文字列配列一次子は,次のとお
り評価する。最初に添字を評価する。次に部分文字列指定を評価する。最後に文字列一次子そのも
のの値を評価する。
(c) 連結する。
(d) 代入する。
(6) 文字列配列値NUL$は,すべての要素が空文字列である配列を生成する。再定義上下限指定部がない
場合には,等号の左辺の文字列配列と同じ寸法の文字列配列が生成される。再定義上下限指定部があ
る場合には,指定された寸法をもつ文字列配列が生成され,等号の左辺の文字列配列も(2)の規定に従
って再定義される。数値配列値の再定義上下限指定部についての7.2.4の規定を,NUL$にも適用する。
(7) 部分文字列指定をもった文字列配列への代入が上下限を再定義するときの効果は,処理系定義とする。
これは,例えば,文字列mat文の左辺に部分文字列指定があり,右辺に再定義上下限指定部をもった
文字列配列値がある場合である。
参考 この(7)の項は,TIBによる。
7.3.5
例外状態 例外状態は,次による。
(1) 文字列配列式中の配列の寸法が異なる。(6101,続行不能。)
(2) 再定義上下限指定の1番目の指標の値が,2番目の指標の値より大きい。(6005,続行不能。)
(3) 再定義上下限指定に指標が一つだけ書いてあって,その値が有効な暗黙の下限の値未満である。(6005,
続行不能。)
(4) 再定義後の配列で必要な要素の総数が,もとの配列宣言で確保された要素数を超える。(5001,続行不
能。)
(5) 文字列配列式の評価が,文字列あふれを起こす。(1052,続行不能。)
(6) 左辺の文字列配列への代入が,文字列あふれを起こす。(1106,続行不能。)
7.3.6
注意 なし。
8. 制御構造
8.0
概要 制御構造 (control structure) は,プログラム中の行の実行の順序を制御する。それは,行番号
を明示的に参照する文,行番号を参照せずに明示的に構成された繰返し構造 (loop structure) 及び行番号を
参照せずに明示的に構成された判定構造 (decision structure) の両方によって行われる。
8.1
論理式
8.1.1
概要 論理式 (relational-expression) は,プログラム中の制御の流れを変更するために式の値を比較
する。
8.1.2
構文 構文は,次による。
(1) 論理式=論理和
(2) 論理和=論理積 {OR 論理積}*
(3) 論理積=論理項 {AND 論理項}*
(4) 論理項=NOT? 論理一次子
(5) 論理一次子=比較式|左括弧 論理式 右括弧
(6) 比較式=数値式 比較演算子 数値式|文字列式 比較演算子 文字列式
(7) 比較演算子=等値比較|大号|小号|非大|非小
(8) 等値比較=等号|非等
42
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(9) 非等=小号 大号|大号 小号
(10) 非小=大号 等号|等号 大号
(11) 非大=小号 等号|等号 小号
8.1.3
例 構文の例を次に示す。
NOT X<Y OR A$=B$ AND B$=C$
(2)
A<=X AND X<=B
(3)
1<=I AND I<=10 AND A(I)=X
(3)
I<N AND (J>M OR A(I)<B(J))
(3)
8.1.4
意味 意味は,次による。
(1) “小さいか等しい”は,非大で表す。“大きいか等しい”は,非小で表す。“等しくない”は,非等で
表す。“大きい”,“小さい”及び“等しい”は,それぞれ大号,小号及び等号で表す。
(2) 二つの数値式は,同じ値のときだけ,等値とする。
(3) 二つの文字列式は,その両方の値の長さが同じで,かつ対応する位置の文字がすべて同じであるとき
だけ,等値とする。
(4) 文字列式を含む論理式の評価で,比較の“小さい”は,“大小順序 (collating sequence) においてより
早く現れる”ことと定義し,他の比較もそれと同様に定義する。詳しくは,次による。
(a) 二つの文字列が同じ長さであって等値でない場合,両方の異なる文字のうちで最左端の文字位置を
比べ,一方の文字が指定された大小順序(6.6参照)においてより早く現れれば,それを含む文字列
は他方の文字列より小さいとする。
(b) 二つの文字列の長さが異なる場合,一方の長さが0文字であるか,又は一方が他方の先頭からの部
分文字列であるとき,長さの短いほうがもう一方に比べて“小さい”とする。
(c) それ以外で長さの異なる二つの文字列の大小関係は,短いほうの文字列の内容と,長いほうの文字
列の先頭から短いほうと同じ長さ分だけ取り出した文字列の内容との比較によって定義する。
(5) 演算子AND,OR及びNOTの優先順位は,構文の規定に従う。すなわち,NOTは直後の論理一次子
(relational-primary) に作用し,ANDは直前及び直後の論理項 (relational-term) に作用し,ORは直前及
び直後の論理積 (conjunction) に作用する。
(6) 論理式の評価の順序は,次のとおりとする。
(a) 論理式は,それを構成する論理和 (disjunction) の真理値をとる。
(b) 論理和に直接含まれる論理積は,真である論理積が見つかるか,又はすべての論理積の評価が終わ
るまで,左から右に順に評価される。そして,真である論理積が見つかったところで論理和全体が
真と評価され,残りの論理積は評価されない。真である論理積が見つからないと,その論理和は,
偽となる。
(c) それぞれの論理積において,その中に直接に含まれる論理項は,偽である論理項が見つかるか,又
はすべての論理項の評価が終わるまで,左から右に順に評価される。そして,偽である論理項が見
つかったところで論理積全体が偽と評価され,残りの論理項は評価されない。すべての論理項が真
であれば,その論理積は,真となる。
(d) それぞれの論理項において,その中に直接に含まれる論理一次子が評価され,NOTが直接に含まれ
るときは,論理一次子の真理値が逆転する。結果の値がその論理項の値となる。
(e) 比較式 (comparison) である論理一次子は,各種の比較について(4)の規定に従って評価される。比較
式でない論理一次子は,その中に直接に含まれる論理式の真理値をとる。この論理式は,(6)の規定
43
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
を再び適用して評価される。
8.1.5
例外状態 なし。
8.1.6
注意 論理式においては,式の評価に必要な部分だけを評価する。例えば,配列Aの上下限が1
から10までとすると,
1<=X AND X=10 AND A(X)=KEY
は,範囲外添字の例外状態には決してならない。
8.2
制御文
8.2.1
概要 制御文 (control statement) は,文の通常の実行順序を変更し,その文の次の行からではなく,
指定された行から実行を続ける。
(1) goto文 (goto-statement) は,無条件分岐 (unconditional transfer) を行う。
(2) on-goto文 (on-goto-statement) は,選ばれた行から実行を続ける。
(3) gosub文 (gosub-statement) とreturn文 (return-statement) は,サブルーチン呼出しに用いる。
(4) on-gosub文 (on-gosub-statement) とreturn文は,選択的なサブルーチン呼出しに用いる。
8.2.2
構文 構文は,次による。
(1) 行番号分岐=gosub文|goto文|if文|データ存否|on-gosub文|on-goto文
(2) goto文= {GOTO|GO TO} 行番号
(3) on-goto文=ON 指標 {GOTO|GO TO} 行番号 {コンマ 行番号}*{ELSE 単純実行文}?
(4) gosub文= {GOSUB|GO SUB} 行番号
(5) return文=RETURN
(6) on-gosub文=ON 指標 {GOSUB|GO SUB} 行番号 {コンマ 行番号}*{ELSE 単純実行
文}?
8.2.3
例 構文の例を次に示す。
GO TO 999
(2)
GOTO 999
(2)
ON L+I GO TO 400,400,500
(3)
ON X GO TO 100,200,150,9999 ELSE LET A=1
(3)
GO SUB 5000
(4)
GOSUB 5160
(4)
ON A+7 GOSUB 1000,2000,7000,4000
(6)
ON F1−2 GOSUB 4360,4460,4660 ELSE PRINT F$ (6)
8.2.4
意味 意味は,次による。
(1) goto文は,指定された行番号の行から実行を続ける。
(2) on-goto文を実行すると,指標が評価され,その値が最も近い整数に丸められる。この整数の値を使っ
て,GOTOに続く行番号の並びの中から,この整数番目の行番号を選ぶ(このとき,並び中の左端の
行番号を1番目とする)。そして,その選ばれた行番号の行から実行を続ける。
on-goto文がelse句をもち,かつその指標の丸められた値が1より小さいか又は並び中の行番号の個
数より大きいときには,ELSEに続く単純実行文を実行する。その単純実行文で別の行へ分岐するこ
とがなければ,通常の実行順序でon-goto文の次の行から実行を続ける。
(3) gosub文,on-gosub文及びreturn文の実行は,行番号の棚 (stack) の概念を用いて説明する。(行番号
の棚は概念上のものであって,この規格は,処理系がこの方法を用いることを要求しない。処理系は,
44
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ほかの方法で実現してもよい。)
(a) 行番号の棚は,プログラム単位又は内部手続き定義の各回の呼出しごとに一つずつ想定される。プ
ログラム単位又は内部手続き定義の各回の呼出しで,最初にgosub文又はon-gosub文を実行するま
では,その呼出しに対する棚は空とする。
(b) gosub文を実行するたびに,gosub文自身の行番号が棚のいちばん上に積まれ,gosub文で指定した
行番号の行から,そのプログラム単位又は内部手続き定義の実行を続ける。
(c) on-gosub文を実行すると,指標が評価され,その値が最も近い整数に丸められる。この整数の値を
使って,GOSUBに続く行番号の並びの中からこの整数番目の行番号を選ぶ(このとき,並び中の
左端の行番号を1番目とする。)。そして,on-gosub文自身の行番号が棚のいちばん上に積まれ,指
標で選ばれた行番号の行から,そのプログラム単位又は内部手続き定義の実行を続ける。
(d) on-gosub文がelse句をもち,かつその指標の丸められた値が1より小さいか又は並び中の行番号の
個数より大きいときには,ELSEに続く単純実行文を実行する。このときには,行番号の棚は変わ
らない。その単純実行文で別の行へ分岐することがなければ,通常の実行順序でon-gosub文の次の
行から実行を続ける。
(e) return文を実行するたびに,棚のいちばん上にある行番号を取り除き,その行番号の行の次の行か
ら,そのプログラム単位又は内部手続き定義の実行を続ける。
(f) 内部手続き定義中のgosub文,on-gosub文及びreturn文は,その内部手続き定義の棚だけを使用す
る。それ以外のgosub文,on-gosub文及びreturn文は,その文を含むプログラム単位の棚だけを使
用する。
(g) プログラム単位又は内部手続き定義の実行を終了する時に,gosub文及びon-gosub文の実行回数と,
return文の実行回数とが等しくなっている必要はない。プログラム単位又は内部手続き定義のその
回の呼出しに想定された行番号の棚は,それぞれの実行の終了時に空にされる。
8.2.5
例外状態 例外状態は,次による。
(1) else句のないon-goto文又はon-gosub文の指標の丸められた値が,1より小さい又は並び中の行番号
の個数より大きい。(10001,続行不能。)
(2) 同じプログラム単位又は内部手続き定義の中で,対応するgosub文又はon-gosub文を実行していない
のに,return文を実行しようとする。(10002,続行不能。)
8.2.6
注意 注意は,次による。
(1) 行番号分岐という構文単位名は,行番号を参照する分岐を表すときにだけ用いる。それ以外の分岐を
表す生成規則に用いることはない。
(2) 行番号分岐中で,プログラム単位中にない行番号を参照すると,それは構文誤りとする(4.2参照)。
したがって,この規格は,そのような参照に対する例外状態を規定しない。しかし,処理系は,これ
を例外状態として扱ってもよい。その場合には,規格に合致しないそのようなプログラムの効果を,
文書化しておかなければならない。
8.3
繰返し構造
8.3.1
概要 繰返し区 (loop) は,一連の文を反復実行する。do区 (do-loop) は,任意の出口条件
(exit-condition) のある繰返し区を構成する。for文 (for-statement) とnext文 (next-statement) は,回数制御
される繰返し区を構成する。
8.3.2
構文 構文は,次による。
(1) 繰返し区=do区|for区
45
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) do区=do行 do本体
(3) do行=行番号 do文 行末部
(4) do文=DO 出口条件?
(5) 出口条件= {WHILE|UNTIL} 論理式
(6) do本体=区* loop行
(7) exit-do文=EXIT DO
(8) loop行=行番号 loop文 行末部
(9) loop文=LOOP 出口条件?
(10) for区=for行 for本体
(11) for行=行番号 for文 行末部
(12) for文=FOR 制御変数名 等号 始値 TO 限界 {STEP 増分}?
(13) 制御変数名=数値単純変数名
(14) 始値=数値式
(15) 限界=数値式
(16) 増分=数値式
(17) for本体=区* next行
(18) exit-for文=EXIT FOR
(19) next行=行番号 next文 行末部
(20) next文=NEXT 制御変数名
(21) for区 (for-loop) の末尾のnext文の制御変数名 (control-variable) は,そのfor区の先頭のfor文の制御
変数名と同じものとする。
(22) あるfor区のfor本体 (for-body) に含まれる内側のfor区には,外側のfor区と同じ制御変数名を用い
てはならない。
(23) ある繰返し区の外部に書く行番号分岐中の行番号は,その繰返し区のfor本体又はdo本体 (do-body)
の内部にある行を参照してはならない。
(24) exit-do文は,do区の中にだけ書くことができる。exit-for文は,for区の中にだけ書くことができる。
8.3.3
例 構文の例を次に示す。
10 DO WHILE I<=N AND A(I) <> 0
20 LET I=I+1
(2)
30 LOOP
46
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
100 DO
110 LET I=I+1
120 PRINT ”MORE ENTRIES (ENTER ʼNOʼ IF NONE)”
(2)
130 INPUT A$(I)
140 LOOP UNTIL A$(I)=”NO”
10 DO
20 INPUT X
30 IF 0<X AND X <7 AND X=INT(X) THEN EXIT DO
(2)
40 PRINT ”INPUT AN INTEGER BETWEEN 1 AND 7”
50 LOOP
100 FOR I=1 TO 10
150 LET A(I)=I
(10)
200 NEXT I
FOR I=A TO B STEP −1
(12)
NEXT C7
(20)
8.3.4
意味 意味は,次による。
(1) 出口条件は,機能語WHILEに続く論理式の値が偽であるか,又は機能語UNTILに続く論理式の値が
真であれば,繰返し区から出ることを指示する。
(2) プログラムの実行がdo行に達した時,do行の中に出口条件があれば,それが評価される。出口条件
がないとき,又は出口条件が繰返し区から出ることを指示しないときには,次の行から実行を続ける。
出口条件が繰返し区から出ることを指示するときには,対応するloop行の次の行から実行を続ける。
プログラムの実行がloop行に達した時,loop行の中に出口条件があれば,それが評価される。出口
条件がないとき,又は出口条件が繰返し区から出ることを指示しないときには,対応するdo行から
実行を続ける。出口条件が繰返し区から出ることを指示するときには,loop行の次の行から実行を続
ける。
(3) for文とnext文の動作は,他の文に置き換えて次のとおり規定する。
110 FOR v=始値 TO 限界 STEP 増分
(一連の行)
150 NEXT v
は,次と同等とする。
110 LET own1=限界
120 LET own2=増分
130 LET v=始値
140 DO UNTIL (v−own1)* SGN (own2)>0
(一連の行)
150 LET v=v+own2
47
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
160 LOOP
ここで,vは,数値単純変数名とする。own1とown2は,そのfor区に関係付けられている変数と
し,利用者からは参照できない。同様に,行番号120,130,140及び160は図示するためだけのもの
であって,for区が実際にそのような行番号を生成するわけではない。変数own1とown2は,他のfor
区に関係付けられている同様の変数とは別のものとする。
この置換えにおいて,for行への行番号分岐は最初のlet文(行番号110の行)への行番号分岐と解
釈され,next行への行番号分岐は最後のlet文(行番号150の行)への行番号分岐と解釈される。
(4) for文においてstep句を省略すると,増分 (increment) として+1が想定される。
(5) exit-do文 (exit-do-statement) を実行すると,そのexit-do文を含む最も内側のdo区のloop行の次の行
から実行を続ける。exit-for文 (exit-for-statement) を実行すると,そのexit-for文を含む最も内側のfor
区のnext行の次の行から実行を続ける。
8.3.5
例外状態 なし。
8.3.6
注意 next文を経由してfor区を出たときには,制御変数の値は繰返し区の中で最後に使われた値
の“次の値”(使われなかった最初の値)となる。それ以外でfor区を出たときには,制御変数の値はその
ときの値となる。
例 FOR I=1 TO J STEP 2
(一連の文)
NEXT I
例に示すfor区において,Jがゼロである場合には,一連の文を実行しないでfor区から出る。このとき,
制御変数Iの値は1(使われなかった最初の値)となる。Jが10である場合,next文を経由してfor本体
を出たときには,制御変数Iの値は11(最後に使われた値9の“次の値”)となる。next文を経由しない
で,例えば3回目の実行中にfor本体を出たときには,制御変数Iの値は5(そのときの値)となる。
8.4
判定構造
8.4.1
概要 if文 (if-statement) は,条件分岐,一つの単純実行文の条件付き実行,又は二つの単純実行
文の一方の実行を行う。
if区 (if-block) は,行の連なりの条件付き実行,又は幾つかの行の連なりのうちの一つの条件付き実行
を行う。
select-case区 (select-block) は,式の値に基づいて,幾つかの行の連なりのうちのどれか一つの実行を行
う。
8.4.2
構文 構文は,次による。
(1) if文=IF 論理式 THEN 単純実行動作 {ELSE 単純実行動作}?
(2) 単純実行動作=単純実行文|行番号
(3) if区=if-then行 then本体 elseif区* else区? end-if行
(4) if-then行=行番号 IF 論理式 THEN 行末部
(5) then本体=区*
(6) elseif区=elseif行 区*
(7) elseif行=行番号 ELSEIF 論理式 THEN 行末部
(8) else区=else行 区*
(9) else行=行番号 ELSE 行末部
(10) end-if行=行番号 END IF 行末部
48
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(11) select-case区=select-case行 注釈行* case区 case区* case-else区? end-select行
(12) select-case行=行番号 select-case文 行末部
(13) select-case文=SELECT CASE 式
(14) case区=case行 区*
(15) case行=行番号 case文 行末部
(16) case文=CASE 照合項目並び
(17) 照合項目並び=照合項目 {コンマ 照合項目}*
(18) 照合項目=定数|範囲指定
(19) 範囲指定={定数 TO|IS 比較演算子} 定数
(20) case-else区=case-else行 区*
(21) case-else行=行番号 CASE ELSE 行末部
(22) end-select行=行番号 END SELECT 行末部
(23) select-case区中のcase文の中に書く定数は,select-case文中の式と同じ型(すなわち,数値又は文字
列のどちらか)でなければならない。
(24) select-case区中の照合項目並びで指定する範囲及び定数は,重複してはならない。
(25) if区,then本体,elseif区,else区,select-case区,case区及びcase-else区において,それらの外部に
書く行番号分岐中の行番号は,内部にある行を参照してはならない。ただし,if区のif-then行及び
select-case区のselect-case行は,参照してもよい。
(26) elseif区,else区,case区及びcase-else区の内部に書く行番号分岐中の行番号は,それらに対応する
elseif行,else行,case行及びcase-else行を参照してはならない。
8.4.3
例 構文の例を次に示す。
IF X=>Y2 THEN GOSUB 900 ELSE GOSUB 2000
(1)
IF X$=”NO” OR X$=”STOP” THEN LET A=1
(1)
IF A=B THEN 100
(1)
IF A$=B$ THEN 200 ELSE 300
(1)
10 IF X=INT(X) THEN
20 PRINT X;”IS AN INTEGER”
30 ELSE
(3)
40 PRINT X;”IS NOT AN INTEGER”
50 END IF
100 IF A=0 THEN
110 PRINT ”ONE ROOT”
120 ELSEIF DISC<0 THEN
130 PRINT ”COMPLEX ROOTS”
(3)
140 ELSE
150 PRINT ”REAL ROOTS”
160 END IF
49
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
10 SELECT CASE A$ (1:1)
20 CASE ”A”TO”Z”, ”a”TO”z”
30 PRINT A$;”starts with a letter”
40 CASE ”0”TO“9”
(11)
50 PRINT A$;”starts with a digit”
60 CASE ELSE
70 PRINT A$;”doesn't start with a letter or a digit”
80 END SELECT
10 SELECT CASE X
20 CASE IS<0
30 PRINT X;”is negative”
40 CASE IS>0
(11)
50 PRINT X;”is positive”
60 CASE ELSE
70 PRINT X;”is zero”
80 END SELECT
8.4.4
意味 意味は,次による。
(1) if文は,論理式の値が真である場合,機能語THENの後ろに単純実行文があれば,その単純実行文を
実行し,THENの後ろに行番号があれば,その行番号の行からプログラムの実行を続ける。論理式の
値が偽である場合,機能語ELSEの後ろに単純実行文があれば,その単純実行文を実行し,ELSEの
後ろに行番号があれば,その行番号の行からプログラムの実行を続け,ELSEがなければ,順序どお
りに,すなわちif文の次の行から実行を続ける。
(2) if区の実行は,次による。
(a) then本体,elseif区又はelse区が,区を一つも含んでいなくても,結果は,注釈行1行からなる区
を一つ含んでいる場合と同じとする。
(b) if-then行の中の論理式の値が真である場合,then本体の1行目から実行を続ける。
if-then行の論理式の値が偽である場合,elseif区があれば,それらのelseif行の論理式を順に評価
する。真である論理式が最初に見つかったところで,そのelseif区中の区の1行目から実行を続け
る。
真である論理式を含むelseif行がない場合,else区があれば,そのelse区中の区の1行目から実行
を続け,else区がなければ,end-if行の次の行から実行を続ける。
(c) then本体,elseif区又はelse区の最後まで実行した後は,end-if行の次の行から実行を続ける。
(3) select-case区では,select-case文 (select-statement) 中の式を評価し,その値をcase文 (case-statement) 中
の照合項目と一致するまで順に比較する。式の値が次のいずれかであるときに,“一致”したという。
(a) 定数の照合項目と等しい。
(b) TOを含む範囲指定の,第の定数の値以上で第二の定数の値以下である。
(c) 範囲指定の中の,比較演算子と定数によって示される関係を満足する。
一致すると,そのcase文を含むcase区中の区を実行する。一致しないとき,case-else区があれば,
それを実行する。case区又はcase-else区の最後まで実行した後は,end-select行の次の行から実行
50
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
を続ける。
(4) 二つ以上の区を入れ子構造にすることができる。この場合,for区と同じ制限が適用される[すなわ
ち,外側の区は,内側の区を完全に含んでいなければならない(8.3.2参照)]。
8.4.5
例外状態 例外状態は,次による。
(1) case-else区のないselect-case区の実行で,どの照合項目でも一致しない。(10004,続行不能。)
8.4.6
注意 なし。
9. プログラム分割
9.0
概要 BASICプログラムは,複数の論理的な構造に分割 (segmentation) して書くことができる。
(1) BASICは,プログラムの分割のために,四つの機構を提供する。
(a) 利用者定義関数 (user-defined function) 関数の値は,数値式及び文字列式の中で使用することがで
きる。
(b) 副プログラム (subprogram) の定義 副プログラムは,call文によって呼び出され,参照引き数を介
して情報伝達を行う。
(c) プログラム連鎖 (chaining) 別々のプログラムを,利用者の介入なしに逐次的に実行させる。
(d) 図形絵 (graphical picture) の定義 13.5参照。
(2) 関数及び副プログラム(両者を合わせてルーチンと呼ぶ。)には,内部及び外部の2種類がある。この
区別は,13.5で規定する絵定義にも適用する。外部ルーチンは,主プログラムの後ろに続けて書く独
立したプログラム単位である。内部ルーチンは,プログラム単位(主プログラム,外部ルーチン又は
並行単位)の中に含まれ,そのプログラム単位の一部とみなされる。内部ルーチンの中に更に内部ル
ーチンを書くことはできない。
(3) 一般に,外部ルーチンは,他のプログラム単位とは何も(例えば,変数,data文,内部ルーチン,選
択子,デバッグ状態などを)共有しない。外部ルーチンと他のプログラム単位との情報交換は,引き
数又は(外部関数の場合には)関数値によって行う。
一方,内部ルーチンは,それを含むプログラム単位とすべてのものを共有する。ただし,その内部
ルーチンの仮引き数及びそのgosub用の行番号の棚は,共有しない。内部ルーチンに局所変数は,存
在しない。
参考 有効範囲については,附属書B(参考)に一覧を示す。ANSI X3.113では,行番号の棚に触れ
ていないが,誤りであるので,TIBによって訂正した。
(4) 一つのプログラム単位中で,ルーチンは,それを呼び出すどの文よりも早い位置に定義又は宣言がな
ければならない。ルーチンを定義又は宣言だけしておいて,それを一度も呼び出さなくても誤りでは
ない。
外部ルーチンは,プログラム全体のどこからでも呼び出すことができる。内部ルーチンは,それを
含むプログラム単位の中からだけ呼び出すことができる。
(5) 内部ルチン及び外部ルーチンの中にある行番号分岐で,ルーチンの外部の行番号を参照することはで
きない。ルーチンの外部にある行番号分岐で,ルーチンの内部の行番号を参照することもできない。
9.1
利用者定義関数
9.1.1
概要 BASICは,プログラマの便宜のために組込み関数を提供する(5.4,6.4,その他参照)。組
込み関数に加えて,プログラマが,プログラム単位又はプログラムの内部で新しい関数を定義することも
できる。
51
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
9.1.2
構文 構文は,次による。
(1) 関数定義=内部関数定義|外部関数定義
(2) 内部関数定義=def行|内部function行 区* end-function行
(3) def行=行番号 def文 行末部
(4) def文=数値def文|文字列def文
(5) 数値def文⊃DEF 数値定義関数名 値仮引き数部? 等号 数値式
(6) 数値定義関数名=数値識別名
(7) 文字列def文=DEF 文字列定義関数名 最大長指定? 値仮引き数部? 等号 文字列式
(8) 文字列定義関数名=文字列識別名
(9) 値仮引き数部=左括弧 値仮引き数 {コンマ 値仮引き数}* 右括弧
(10) 値仮引き数⊃単純変数名|仮配列宣言
(11) 仮配列宣言=配列名 左括弧 コンマ* 右括弧
(12) 内部function行⊃ 行番号 FUNCTION {数値定義関数名|文字列定義関数名 最大長指定?}
値仮引き数部? 行末部
(13) end-function行=行番号 END FUNCTION 行末部
(14) 外部関数定義=external-function行 手続き区* end-function行
(15) external-function行⊃ 行番号 EXTERNAL FUNCTION {数値定義関数名|文字列定義関数名
最大長指定?} 値仮引き数部? 行末部
(16) 数値関数定義let文=LET 数値定義関数名 等号 数値式
(17) 文字列関数定義let文=LET 文字列定義関数名 等号 文字列式
(18) exit-function文=EXIT FUNCTION
(19) 宣言指定⊃def宣言|内部function宣言|external-function宣言
(20) def宣言=DEF 定義関数名並び
(21) 内部function宣言=FUNCTION 定義関数名並び
(22) external-function宣言=EXTERNAL FUNCTION 定義関数名並び
(23) 定義関数名並び=定義関数名 {コンマ 定義関数名}*
(24) 定義関数名⊃数値定義関数名|文字列定義関数名
(25) 内部関数定義の外部の行番号分岐中の行番号は,内部関数定義の内部にある行を参照してはならない。
ただし,内部function行は,参照してもよい。内部関数定義の内部の行番号分岐中の行番号は,その
内部関数定義の外部にある行及びその先頭の内部function行を参照してはならない。
(26) 外部関数定義の内部の行番号分岐中の行番号は,その外部関数定義の先頭のexternal-function行を参
照してはならない。
(27) 一つのプログラム中で,同じ名前の外部関数定義を2回以上定義してはならない。一つのプログラム
単位中で,同じ名前の内部関数定義を2回以上定義してはならない。
(28) 一つのプログラム単位中で,同じ名前の(内部又は外部)関数を2回以上宣言したり定義したりして
はならない。
(29) 定義関数名が外部関数定義によって定義されている場合,プログラム単位中でその定義関数名を引用
するどの文よりも早い位置に,その定義関数名を含むextern-function宣言のdeclare文を書かなけれ
ばならない。
(30) 定義関数名がdef行以外の内部関数定義によって定義されている場合,そのプログラム単位中でその

52
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
定義関数名を引用するどの文よりも早い位置に,その内部関数定義,又はその定義関数名を含む内部
function宣言のdeclare文のどちらかを書かなければならない。
(31) 定義関数名がdef行によって定義されている場合,そのプログラム単位中でその定義関数名を引用す
るどの文よりも早い位置に,そのdef行,又はその定義関数名を含むdef宣言のdeclare文のどちらか
を書かなければならない。
(32) 再帰的な関数定義の中では,その関数自身を宣言する必要がない。すなわち,ある関数定義が,定義
しようとしている関数自身の引用を含む場合,その定義関数名を含む宣言指定を書く必要がない。
(33) exit-function文は,関数定義の中にだけ書くことができる。
(34) def行を除くすべての関数定義の中には,数値関数定義let文又は文字列関数定義let文を少なくとも1
回以上書かなければならない。この数値関数定義let文又は文字列関数定義let文の中の定義関数名は,
その関数定義の内部function行又はexternal-function行に書いた定義関数名と同じでなければならな
い。
(35) 数値関数引用及び文字列関数引用の中に書く値実引き数の個数及び型は,対応する関数定義における
値仮引き数の個数及び型に一致していなければならない。すなわち,
(a) 値実引き数の個数は,値仮引き数の個数と同じでなければならない。
(b) 値実引き数部の中の値実引き数は,値仮引き数部の中の対応する値仮引き数に結び付けられる(対
応付けは,最初の実引き数は最初の仮引き数に,2番目の実引き数は2番目の仮引き数に,という
ように行われる。)。型の対応は,表のとおりでなければならない。
仮引き数
実引き数
数値単純変数名
数値式
文字列単純変数名
文字列式
仮配列宣言(数値)
実配列名(数値)
仮配列宣言(文字列) 実配列名(文字列)
(36) 実配列の次元数は,対応する仮配列の次元数と同じでなければならない。仮配列の次元数は,その仮
配列宣言中のコンマの個数より1だけ大きい数とする。仮配列の次元数は,3次元まで(すなわち,
コンマ2個まで)とする。
(37) 数値型の実引き数を,別のプログラム単位の対応する仮引き数に渡す場合,両方のプログラム単位に
おいて有効なarithmetic選択子は,一致していなければならない。
(38) 数値型の外部関数定義のarithmetic選択子は,それを呼び出すプログラム単位のarithmetic選択子と
一致していなければならない。
(39) 同じ値仮引き数の名前を,一つの値仮引き数部に,2回以上書いてはならない。
値仮引き数を,その内部関数定義又は外部関数定義の中で,declare文やdim文に書いてはならない。
(40) def宣言及び内部function宣言に書く定義関数名は,同じプログラム単位中のどこか別の場所で,内
部関数定義によって定義しておかなければならない。
(41) external-function宣言に書く定義関数名は,プログラム中のどこか別の場所で,外部関数定義によっ
て定義しておかなければならない。
9.1.3
例 構文の例を次に示す。
DEF E=2.7182818
(5)
DEF AVERAGE(X,Y)=(X+Y)/2
(5)
DEF FNA$(S$,T$)=S$ & T$
(7)
DEF Right$(A$, n)=A$(Len(A$)−n+1:Len(A$))
(7)
53
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
100 EXTERNAL FUNCTION ANSWER(A$)
120 SELECT CASE UCASE$(As)
130 CASE ”YES”
140 LET ANSWER=1
150 CASE ”NO”
(14)
160 LET ANSWER=2
170 CASE ELSE
180 LET ANSWER=3
190 END SELECT
200 END FUNCTION
FUNCTION AVERAGE, REVERSE$
(21)
9.1.4
意味 関数定義 (function-def) は,関数の値を,値仮引き数 (function-parameter) 及び必要ならその
他の変数や定数を含む式の値として定義する。
(1) 関数の引き数
(1.1) 定義関数 (defined function) を引用すると,値実引き数 (function-argument) があればそれは左から右
に順に評価され,その値が関数定義の対応する値仮引き数に代入される。すなわち,値実引き数は,
値仮引き数に値によって (by value) 渡される。
(1.2) 仮配列 (formal array) の次元数は,仮配列宣言に書いたコンマの個数より1だけ大きい数とする。
関数定義が呼ばれる際には,仮配列は,対応する実配列 (actual array) と同じ上下限をもつ。値仮
引き数の文字列単純変数及び文字列配列は,文字列の最大長として処理系定義の省略時想定値をも
つ。
(2) 関数の評価
(2.1) 関数がdef文 (def-statement) で定義されている場合,def文の式が評価され,その値が関数の値とな
る。
(2.2) 関数が内部関数定義 (internal-function-def) 又は外部関数定義 (external-function-def) で定義されて
いる場合,内部function行又はexternal-function行に続く行が,次のいずれかになるまで,順番に
実行される。
(a) 行の実行によって,他の動作が指示される。
(b) 続行不能な例外状態になる。
(c) chain文又はstop文が実行される。
(d) exit-function文が実行される。
(e) end-function行に到達する。
(2.3) 定義関数の値は,数値関数定義let文 (numeric-function-let-statement) 又は文字列関数定義let文
(string-function-let-statement) の実行によって定められ,関数定義の実行が終了する時点でその定義
関数名に最後に代入された値となる。その時点で値が代入されていない場合は,処理系定義とする。
ただし,その処理系の定義は,初期設定されていない変数の引用と同様に,一貫していなければな
らない。
(2.4) 関数定義から返される文字列値の最大長は,文字列定義関数名に続けて書いた最大長指定によって
54
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
定められる。最大長指定を書かない場合,最大長は,最大長指定をもたない文字列変数に対する長
さと同じになる。
(2.5) exit-function文 (exit-function-statement) を実行すると,その関数定義の実行が終了する。end-function
行は,関数定義の物理的な終りを示すとともに,関数定義の実行も終了させる。関数定義の中でstop
文を実行すると,プログラム全体の実行が終了する。
(2.6) 関数定義は,直接又は間接に自分自身を引用してもよい。すなわち,再帰的な関数呼出しが許され
る。
(2.7) 関数定義中の行は,その関数が引用されない限り,実行されることはない。プログラムの実行がdef
行に到達すると,何もしないで次の行に進む。プログラムの実行が内部function行に到達すると,
何もしないで対応するend-function行の次の行に進む。
(3) 変数,配列,経路番号及び内部データの有効範囲
(3.1) 関数定義の値仮引き数部に書く仮引き数は,その関数定義の毎回の呼出しに対して局所的とする。
すなわち,関数定義の外部で使われている同じ名前の変数や配列とは,別のものとする。
(3.2) 関数定義において仮引き数に指定されていない変数と配列の扱いは,その関数定義が内部関数定義
か外部関数定義かによって異なる。
関数定義が外部関数定義である場合,これらの変数と配列は,そのプログラム単位の毎回の呼出
しに対して局所的とする。すなわち,その関数定義の外部で使われている名前,又は,それ以前の
その関数定義の呼出しのときにその中で使われた名前とは,たとえ同じつづりであっても別のもの
とする。更に,これらの変数や配列が関数定義の呼出しのたびに初期化されるか否かは,処理系定
義とする。ただし,その処理系の定義は,主プログラム又は並行単位における変数や配列の初期化
と,一貫していなければならない。
関数定義が内部関数定義である場合,これらの変数と配列とはそのプログラム単位に広域的とし,
代入された値は関数定義の呼出しのたびに保存される。すなわち,これらの値が内部関数定義の実
行中に変えられたならば,呼び出したプログラム単位に戻った後でもこの変更は有効とする。
(3.3) 経路番号(channel-number,9.2参照)の有効範囲は,(ゼロ番の経路を除き)常にプログラム単位と
する。ゼロ番でない経路番号は,外部関数定義においては毎日の呼出しに対して局所的とし,内部
関数定義においてはその関数定義を含むプログラム単位に広域的とする。
ゼロ番の経路は,プログラム全体に広域的とする。
ファイルは,使用する前にあらかじめopen文によって,プログラム単位中のゼロ番でない経路
に割り当てられていなければならない。関数定義に対して局所的な経路に割り当てられたファイル
は,その関数定義の実行が終了する時点で自動的に閉じられる。
(3.4) 内部データの有効範囲は,常にプログラム単位とする。
外部関数定義中のdata文のデータ要素は,そのプログラム単位の毎日の呼出しに対して局所的と
する。したがって,このような関数定義中のread文及びrestore文は,その関数定義中のdata文の
データ要素だけを参照し,他のプログラム単位中のデータ要素を参照することはない。このような
関数定義中のデータ列に対する指示子は,関数定義が呼び出されるたびにデータ列の先頭に戻され
る(10.1参照)。
内部関数定義中のdata文のデータ要素は,そのプログラム単位におけるデータ列の一部分とする。
そして,このような関数定義中のread文やrestore文は,そのプログラム単位のデータ列全体を参
照する。
55
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
9.1.5
例外状態 例外状態は,次による。
(1) 文字列関数定義let文を用いて,文字列定義関数にその文字列の最大長より長い値を代入しようとす
る。(1106,続行不能。)
9.1.6
注意 注意は,次による。
(1) 呼び出すプログラム単位と呼び出されるプログラム単位との間で,collate選択子が異なる指定をして
いてもよい。そのとき,その間で文字列型引き数の受け渡しをしてもよい。collate選択子は,文字列
の内部表現を指定するものではなく,文字列比較における大小順序及び関数CHR$や関数ORDの結果
を指定するだけのものとする。
(2) 内部関数定義で定義したりdeclare文で宣言したりした関数を,そのプログラム単位で一度も引用し
なくても誤りではない。
(3) 内部関数定義を,その内部関数の名前を含むdef宣言や内部function宣言をもつdeclare文より前に書
いても誤りではない。
(4) ある内部関数に対するどの引用よりも早い位置にその関数に対する定義を書けば,その定義関数名に
対する内部function宣言又はdef宣言を省略してもよい。
(5) 内部関数及び外部関数の両方に対して,関数が引用されるより前に宣言又は定義しなければならない
という規定は,プログラム中の幾つかのプログラム単位が外部関数と同じ名前の内部関数を含むこと
を許す。これによって,プログラマがライブラリ中の関数を使うときに,すべての外部関数の名前を
知らなくても使えるようになる。
9.2
副プログラム
9.2.1
概要 副プログラム (subprogram) は,プログラムを論理的に分割する。論理的に分割されたプロ
グラム間では,引き数の受け渡しができる。定義関数と同様に,副プログラムには,プログラム単位内部
のものとプログラム単位外部のものとがある。
9.2.2
構文 構文は,次による。
(1) 副プログラム定義=内部副プログラム定義|外部副プログラム定義
(2) 内部副プログラム定義=内部sub行 区* end-sub行
(3) 内部sub行=行番号 sub文 行末部
(4) sub文=SUB 副プログラム名 参照仮引き数部?
(5) 副プログラム名=ルーチン識別名
(6) 参照仮引き数部=左括弧 参照仮引き数 {コンマ 参照仮引き数}* 右括弧
(7) 参照仮引き数⊃単純変数名|仮配列宣言|経路番号
(8) 経路番号=番号記号 符号なし整数
(9) end-sub行=行番号 end-sub文 行末部
(10) end-sub文=END SUB
(11) exit-sub文=EXIT SUB
(12) 外部副プログラム定義=external-sub行 手続区* end-sub行
(13) external-sub行=行番号 EXTERNAL sub文 行末部
(14) call文=CALL 副プログラム名 参照実引き数部?
(15) 参照実引き数部=左括弧 参照実引き数 {コンマ 参照実引き数}* 右括弧
(16) 参照実引き数=式|実配列名|経路式
(17) 宣言指定⊃内部sub宣言|external-sub宣言

56
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(18) 内部sub宣言=SUB 副プログラム名並び
(19) external-sub宣言=EXTERNAL SUB 副プログラム名並び
(20) 副プログラム名並び=副プログラム名 {コンマ 副プログラム名}*
(21) 内部副プログラム定義の外部の行番号分岐中の行番号は,内部副プログラム定義の内部にある行を参
照してはならない。ただし,内部sub行は,参照してもよい。内部副プログラム定義の内部の行番号
分岐中の行番号は,その内部副プログラム定義の外部にある行及びその先頭の内部sub行を参照して
はならない。
(22) 外部副プログラム定義の内部の行番号分岐中の行番号は,その先頭のexternal-sub行を参照してはな
らない。
(23) 一つのプログラム中で,同じ名前の外部副プログラムを2回以上定義してはならない。一つのプログ
ラム単位中で,同じ名前の内部副プログラムを2回以上定義してはならない。
(24) 一つのプログラム単位中で,同じ名前の(内部又は外部)副プログラムを2回以上宣言したり定義し
たりしてはならない。
(25) 副プログラム名が外部副プログラム定義によって定義されている場合,プログラム単位中でその副プ
ログラム名を引用するどのcall文よりも早い位置に,その副プログラム名を含むexternal-sub宣言の
declare文を書かなければならない。
(26) 副プログラム名が内部副プログラム定義によって定義されている場合,そのプログラム単位中でその
副プログラム名を引用するどの文よりも早い位置に,その内部副プログラム定義,又はその副プログ
ラム名を含む内部sub宣言のdeclare文のどちらかを書かなければならない。
(27) 再帰的な副プログラム定義の中では,その副プログラム自身を宣言する必要がない。すなわち,ある
副プログラム定義が,定義しようとしている副プログラム自身を引用するcall文を含む場合,その副
プログラム名を含む宣言指定を書く必要がない。
(28) exit-sub文は,副プログラム定義の中にだけ書くことができる。
(29) call文中に書く参照実引き数の個数及び型は,対応する副プログラム定義における参照仮引き数の個
数及び型に一致していなければならない。すなわち,
(a) 参照実引き数の個数は,参照仮引き数の個数と同じでなければならない。
(b) 参照実引き数部の中の参照実引き数は,参照仮引き数部の中の対応する参照仮引き数に結び付けら
れる(対応付けは,最初の実引き数は最初の仮引き数に,2番目の実引き数は2番目の仮引き数に,
というように行われる。)。型の対応は,表のとおりでなければならない。
仮引き数
実引き数
数値単純変数名
数値式
文字列単純変数名
文字列式
仮配列宣言(数値)
実配列名(数値)
仮配列宣言(文字列) 実配列名(文字列)
経路番号
経路式
(30) 実配列の次元数は,対応する仮配列の次元数と同じでなければならない。その仮配列の次元数は,仮
配列宣言中のコンマの個数より1だけ大きい数とする。
(31) 数値型の実引き数を,別のプログラム単位の対応する仮引き数に渡す場合,両方のプログラム単位に
おいて有効なarithmetic選択子は,一致していなければならない。
(32) 一つの参照仮引き数に,同じ参照仮引き数の名前を,2回以上書いてはならない。
参照仮引き数を,その内部副プログラム定義又は外部副プログラム定義の内部で,declare文又は
57
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
dim文に書いてはならない。
(33) 参照仮引き数としてゼロ番の経路を書いてはならない。
(34) 内部sub宣言に書く副プログラム名は,同じプログラム単位中のどこか別の場所で内部副プログラム
定義によって定義しておかなければならない。
(35) external-sub宣言に書く副プログラム名は,プログラム中のどこか別の場所で,外部副プログラム定
義によって定義しておかなければならない。
9.2.3
例 構文の例を次に示す。
100 SUB exchange(a,b)
110 LET t=a
120 LET a=b
(2)
130 LET b=t
140 END SUB
SUB CALC(X,Y,Z$)
(4)
SUB SORT(A(),B(,),A$,#3)
(4)
2000 EXTERNAL SUB OPEN (#1, fname$, result)
(13)
CALL CALC (3*A+2, 7715, ”NO”)
(14)
CALL SORT (Zvect, Ymat, (L$), #N)
(14)
9.2.4
意味 意味は,次による。
(1) 副プログラムの実行
(1.1) call文 (call-statement) を実行すると,call文で指名された副プログラムに制御が移る。副プログラ
ムの実行は,sub文の次の行から開始され,次のいずれかになるまで,順番に続けられる。
(a) 行の実行によって,他の動作が指示される。
(b) 続行不能な例外状態になる。
(c) chain文が実行される。
(d) stop文又はexit-sub文が実行される。
(e) end-sub行に到達する。
(1.2) end-sub行は,副プログラムの物理的な終りを示すとともに,この行を実行すると,副プログラム
の実行を終了させる。exit-sub文 (exit-sub-statement) を実行すると,その文を含む最も内側の副プ
ログラムの実行が終了する。副プログラムの実行が終了すると,その副プログラムの実行を開始さ
せたcall文の次の行から実行を続ける。
(1.3) 副プログラム中でstop文を実行すると,そのプログラム全体の実行が終了する。
(1.4) 副プログラムは,直接に又は他の手続きを通して間接に,自分自身を呼び出してもよい。すなわち,
再帰的な副プログラム呼出しが許される。
(1.5) 副プログラム定義中の行は,その副プログラムがcall文によって引用されない限り実行されること
はない。プログラムの実行がsub文の行に到達すると,何もしないで対応するend-sub行の次の行
に進む。
(2) 副プログラムの引き数
(2.1) call文を実行すると,その参照実引き数 (procedure-argument) が左から右に順に,呼び出される副プ
ログラムのsub文 (sub-statement) 中の対応する参照仮引き数 (procedure-parameter) と同一のもので
58
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
あるとされる。
(2.2) 参照実引き数のうち数値変数名及び部分文字列指定を伴わない文字列変数名は,参照によって (by
reference) 渡される。すなわち,副プログラム中の参照仮引き数のすべての引用は,対応する参照
実引き数の引用になり,その参照仮引き数への代入は,対応する参照実引き数への代入になる。
(2.3) 参照実引き数が配列要素名である場合には,その添字は,副プログラムが呼び出されるたびに入口
で1回だけ評価される。
(2.4) 参照実引き数が式であり,数値変数名ではなく,部分文字列指定を伴わない文字列変数名でもない
場合,その参照実引き数は,副プログラムが呼び出されるたびに入口で1回だけ評価される。得ら
れた値が,その副プログラムに対して局所的な場所に割り当てられる。この局所的な値は,対応す
る参照仮引き数の値として使用される。その参照仮引き数への代入は,この局所的な場所への代入
となる。
参照実引き数のこの評価は,左から右に順に評価される。
(2.5) 仮配列 (formal array) である参照仮引き数を参照すると,参照実引き数部の対応する配列を参照す
ることになる。同様に,そのような配列に対して代入や上下限の再定義 (redimensioning) を行うと,
参照実引き数部の対応する配列に対して代入や上下限の再定義を行うことになる。副プログラムの
入口では,参照仮引き数の仮配列は,対応する参照実引き数と同じ上下限をもつ。
(2.6) 文字列単純変数名又は文字列配列名である参照仮引き数の文字列の最大長は,それらの引き数が値
によって (by value) 渡される場合は処理系定義の省略時想定値とし,参照によって渡される場合は
対応する参照実引き数の文字列の最大長とする。
(2.7) ある配列とその要素の両方が一つのcall文の参照実引き数として使用され,その配列が副プログラ
ムの実行中に上下限を再定義されたとき,配列要素に対応する参照仮引き数に対するそれ以降の参
照の結果は,処理系定義とする。
(2.8) 参照実引き数が経路式 (channel-expression) である場合,その経路式は,副プログラムが呼び出され
るたびに入口で1回だけ評価される。副プログラム中で対応する参照仮引き数の値を参照すると,
評価された結果の経路が使用される。この経路に割り当てられたファイルの性質(11.1.4参照)は,
そのまま副プログラムに渡される。副プログラム中でファイルの性質及び内容を変更した場合,そ
の変更は,どの経路番号で参照したとしても直ちに有効とし,副プログラムから出た後もそのまま
有効とする。
(2.9) call文が実行されるときに,参照実引き数で示される経路にファイルが割り当てられていなくても
よい。副プログラム中のopen文でその経路にファイルを割り当てたとき,その割当ては,副プロ
グラムから出た後もそのまま有効とする。
(3) 変数,配列,経路番号及び内部データの有効範囲
(3.1) 副プログラム定義の参照仮引き数部に書く参照仮引き数のうち,値によって渡される参照仮引き数
は,その副プログラム定義の毎回の呼出しに対して局所的とする。すなわち,副プログラム定義の
外部で使われている同じ名前の変数や配列とは,別のものとする。
参照によって (by reference) 渡される参照仮引き数に関しては,その名前は副プログラム定義の
毎回の呼出しに対して局所的とするが,その名前が参照する対象は対応する参照実引き数と同じも
のとする[9.2.4(2)参照]。
(3.2) 副プログラム定義において仮引き数に指定されていない変数と配列の扱いは,その副プログラム定
義が内部副プログラム定義か外部副プログラム定義かによって異なる。
59
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
副プログラム定義が外部副プログラム定義である場合,これらの変数と配列は,そのプログラム
単位の毎回の呼出しに対して局所的とする。すなわち,その副プログラム定義の外部で使われてい
る名前,又は,それ以前のその副プログラム定義の呼出しのときにその中で使われた名前とは,た
とえ同じつづりであっても別のものとする。更に,これらの変数や配列が副プログラム定義の呼出
しのたびに初期化されるか否かは,処理系定義とする。ただし,その処理系定義は,主プログラム
及び並行単位における変数や配列の初期化と同様に,一貫していなければならない。
副プログラム定義が内部副プログラム定義である場合,これらの変数と配列とはそのプログラム
単位に広域的とし,代入された値は副プログラム定義の呼出しのたびに保存される。すなわち,こ
れらの値が内部副プログラム定義の実行中に変えられたならば,呼び出したプログラム単位に戻っ
た後でもこの変更は有効とする。
(3.3) 参照仮引き数でない経路番号の有効範囲は,(ゼロ番の経路を除き)常にプログラム単位とする。副
プログラム定義中のゼロ番でない経路番号は,外部副プログラム定義においては毎回の呼出しに対
して局所的とし,内部副プログラム定義においてはその副プログラム定義を含むプログラム単位に
広域的とする。
ゼロ番の経路は,プログラム全体に広域的とする。
ファイルは,使用する前にあらかじめopen文によって,プログラム単位中のゼロ番でない経路
に割り当てられていなければならない。副プログラム定義に対して局所的な経路に割り当てられた
ファイルは,その副プログラム定義の実行が終了する時点で自動的に閉じられる。
(3.4) 内部データの有効範囲は,常にプログラム単位とする。
外部副プログラム定義中のdata文のデータ要素は,そのプログラム単位の毎回の呼出しに対して
局所的とする。したがって,このような副プログラム定義中のread文及びrestore文は,その副プ
ログラム定義中のdata文のデータ要素だけを参照し,他のプログラム単位中のデータ要素を参照す
ることはない。このような副プログラム定義中のデータ列に対する指示子は,副プログラム定義が
呼び出されるたびにデータ列の先頭に戻される(10.1参照)。
内部副プログラム定義中のdata文のデータ要素は,そのプログラム単位におけるデータ列の一部
分とする。そして,このような副プログラム定義中のread文やrestore文は,そのプログラム単位
のデータ列全体を参照する。
9.2.5
例外状態 なし。
9.2.6
注意 注意は,次による。
(1) call文があって,それが引用する内部副プログラム定義がそれより後に書いてある場合に,処理系は,
内部sub宣言を省略できるように拡張してもよい。
(2) 別名
(2.1) ある対象に対して,同じ有効範囲をもつ二つ以上の異なる名前が存在するとき,別名 (alias) がある
という。仮引き数が参照によって渡されるときに,ある状況下で別名が作られる。仮引き数が値に
よって渡される場合は,それぞれの仮引き数に対して別の対象が生成されるので,別名が作られる
ことはない。
(2.2) 次の状況下でcall文によって別名が作られる。
(a) 値を丸めた結果が同じ整数値になる経路式を,経路番号である複数の仮引き数に渡す。
(b) 同じ実配列名を複数の仮配列宣言に渡す。
(c) 同じ単純変数名又は配列要素名を,単純変数名である複数の仮引き数に渡す。
60
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(d) ある配列を仮配列宣言に渡し,かつ,その配列の要素を単純変数名である仮引き数に渡す。
(e) 経路式を内部副プログラムに渡す。
(f) 経路式でない実引き数を,参照によって内部副プログラムに渡す。
(2.3) (2.1)の(a)〜(d)では,二つ以上の仮引き数が同じ対象又は同じ対象の一部を指名するので別名が生じ
る。(e)及び(f)では,一つの対象が,仮引き数として,及びプログラム単位全体に対して広域的な対
象としての両方の形で,内部副プログラムから“見える”ので別名が生じる。
(2.4) 別名のある参照仮引き数を使って対象の状態を変更すると,その変更は,それ以後のすべての参照
において,どの名前を使って参照するかに関係なく直ちに有効となる。参照仮引き数によって参照
される対象の状態を変える事象は,代入,入出力操作及び配列上下限の再定義である。
(2.5) 規格合致処理系では,次のプログラムのprint文は実行されない。
100 DECLARE INTERNAL SUB S
110 LET A=0
120 CALL S(A,A)
130 SUB S(B,C)
140 LET A=1
150 LET B=2
160 LET C=3
170 IF A<>B OR B<>C OR A<>C THEN
180 PRINT ”This shouldnʼt happen.”
190 END IF
200 END SUB
210 END
(3) 次の事項に関する9.1.6の注意は,副プログラムに対しても同様に適用する。
(a) 異なるcollate選択子をもつプログラム単位は,誤りとはしない[9.1.6(1)参照]。
(b) 定義又は宣言されていながら引用されない関数名は,誤りとはしない[9.1.6(2)参照]。
(c) 定義が宣言に先行する関数名は,内部関数定義では誤りとはしない[9.1.6(3)参照]。
(d) プログラム単位中で引用する外部関数名は,そのプログラム単位中で必ず宣言しなければならない。
内部関数名は,必ずしも宣言しなくてもよい[9.1.6(4)参照]。
(e) 外部関数と同じ名前の内部関数を使ってもよい[9.1.6(5)参照]。
参考 ANSI X3.113では,ここが“異なったプログラム単位においては”となっているが,誤りであ
るので,TIBによって訂正した。
9.3
プログラム連鎖
9.3.1
概要 chain文 (chain-statement) は,別々のプログラムを利用者の介入なしに連続して実行させる。
このような機能は,大きなプログラムを分割するのに有効である。
9.3.2
構文 構文は,次による。
(1) chain文=CHAIN プログラム指示名 {WITH 値実引き数部}?
(2) プログラム指示名=文字列式
(3) chain文中の値実引き数部に書く値実引き数とprogram行中の値仮引き数部に書く値仮引き数との結
合は,定義関数に対する規定と同じ規則を適用する(9.1参照)。
9.3.3
例 構文の例を次に示す。
61
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
CHAIN ”PROG2”
(1)
CHAIN A$ WITH(X,FILENAME$)
(1)
9.3.4
意味 意味は,次による。
(1) chain文は,現在のプログラムの実行を終了し,すべてのファイルを閉じ,プログラム指示名
(program-designator) によって指示されたプログラムの実行を開始する。プログラムを関連付ける方法
は,処理系定義とする。
(2) chain文によって実行されるプログラムがprogram行 (program-name-line) を含む場合には,chain文
の値実引き数が評価され,その値がprogram行の対応する値仮引き数に代入される。すなわち,値実
引き数は,値仮引き数に値によって (by value) 渡される。
仮配列の上下限は,関数に対して配列引き数を渡す場合の規則(9.1参照)に従って,対応する実配
列の上下限に等しくなるように調整される。
(3) プログラム指示名において,対応する英大文字と英小文字を等価なものとするか否かは,処理系定義
とする。
(4) chain文によって実行されるプログラム中の変数の初期値は,処理系定義とする。
9.3.5
例外状態 例外状態は,次による。
(1) プログラム指示名によって識別されたプログラムが利用可能でない。(10005,続行不能。)
(2) chain文の値実引き数の個数及び型が,chain文によって実行されるプログラムのprogram行の対応す
る値仮引き数の個数及び型と一致しないか,又は値仮引き数部をもつprogram行が存在しない。(4301,
続行不能。)
(3) 実配列の次元数が,対応する仮配列の次元数と同じでない。(4302,続行不能。)
(4) 有効なarithmetic選択子の一致しないプログラム間で,chain文によって数値型の引き数を渡す。
(4303,続行不能。)
9.3.6
注意 注意は,次による。
(1) 通常の処理系においては,プログラム指示名は,そのプログラムが収められているファイルの名称で
ある。chain文によって実行されるプログラムは,BASICプログラムである必要はない。
(2) 4301,4302及び4303の例外状態の報告は,chain文のあるプログラム,chain文によって実行される
プログラム又はその他の中間のシステムプログラムのいずれが行ってもよい。
10. 入出力
10.0 概要 入出力機能によって,BASICプログラムがデータの集まりを入出力する。プログラムは,入
力データをそのプログラムのdata文 (data-statement) から得ることもできるし,プログラムの外部の標準
入力源 (standard source) 又は指名した入力源(11.4参照)から得ることもできる。出力データを,プログ
ラムの外部の標準出力先 (standard destination) 又は指名した出力先(11.3及び11.5参照)に送り出すこと
ができる。
10.1 内部データ
10.1.1 概要 read文 (read-statement) は,data文 (data-statement) によって作られたデータ列 (data
sequence) にある値を変数に代入する。restore文 (restore-statement) は,プログラム中の同じデータを,再
び読めるようにする。
10.1.2 構文 構文は,次による。
(1) read文⊃READ {if-missing句 コロン}? 変数名並び
62
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) 変数名並び=変数名 {コンマ 変数名}*
(3) if-missing句=IF MISSING THEN データ存否動作
(4) データ存否動作=exit-do文|exit-for文|行番号
(5) restore文=RESTORE 行番号?
(6) data文=DATA データ要素並び
(7) データ要素並び=データ要素 {コンマ データ要素}*
(8) データ要素=定数|単純文字列
(9) 単純文字列=単語文字|単語文字 単純文字* 単語文字
(10) データ存否動作のexit-for文は,for本体の中にだけ書くことができる。データ存否動作のexit-do文
は,do本体の中にだけ書くことができる。
(11) restore文の行番号は,data文を含む行を参照するものでなければならない。
10.1.3 例 構文の例を次に示す。
READ X,Y,Z
(1)
READ IF MISSING THEN 1350:X(1), A$
(1)
RESTORE
(5)
RESTORE 1000
(5)
DATA 3.14159,PI, 5E-30,”,”
(6)
COMMAS CANNOT OCCUR IN UNQUOTED STRINGS
(9)
10.1.4 意味 意味は,次による。
(1) 一つのプログラム単位中のdata文のデータ要素は,全体で一つのデータ列を構成する。一つのプログ
ラム単位の中にあるすべてのdata文に書いたすべてのデータ要素が,その書いた順番に,一つの列に
なる。
(2) プログラムの実行がdata文の行に到達すると,何もしないで次の行に進む。
(3) read文を実行すると,そのread文を含むプログラム単位のデータ列にある値が,順番に変数並び中
の変数に代入される。データ列に対して,一つの指示子 (pointer) を想定し関係付ける。プログラム単
位の実行を開始すると,指示子は,データ列にある先頭のデータ要素を指す。read文を実行するたび
に,指示子の指すデータ要素の値が変数並び中の変数に代入され,指示子はそのデータ要素の次を指
す。
(4) データ列の終りを越えてデータ要素を読もうとしたとき,そのread文の中にif-missing句がなければ,
例外状態になる。if-missing句があれば,そのデータ存否動作 (io-recovery-action) を実行する。データ
存否動作がexit-do文又はexit-for文であれば,その文は通常と同じ効果をもつ(8.3参照)。データ存
否動作が行番号であれば,その行番号の行から実行を続ける。
(5) データ列にあるそれぞれのデータ要素の型は,代入される変数の型に一致していなければならない。
すなわち,数値変数に対するデータ要素は,数値定数でなければならず,文字列変数に対するデータ
要素は,文字列定数又は単純文字列でなければならない。数値定数の形になっている単純文字列は,
read文によって文字列変数にも数値変数にも代入できる。
(6) 数値データを評価した結果が下位けたあふれになると,その値は,ゼロで置き換えられる。
(7) 変数名並び中の添字及び部分文字列指定は,その変数名並び中の先行する(すなわち左側の)変数が
すべて値を代入されてから,評価される。
(8) 行番号を指定しないでrestore文を実行すると,そのrestore文を含むプログラム単位中のデータ列へ
63
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
の指示子を,データ列の先頭に戻す。次に実行されるread文は,データ列の先頭からデータ要素を読
むことになる。restore文に行番号があれば,そのrestore文を含むプログラム単位中のデータ列への
指示子は,その行番号のdata文中の先頭のデータ要素を指す。そして,次に実行されるread文は,
指示されたdata文の先頭からデータ要素を読むことになる。
(9) 一般に,入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及び
その入出力装置の状態は,処理系定義とする。この規定は,10.及び11.の入出力全般に適用する。
参考 ANSI X3.113にはこの(9)項がないが,TIBによって補った。
10.1.5 例外状態 例外状態は,次による。
(1) read文の変数名並び中の変数がデータ要素を要求したが,データ列が尽きてしまって,かつif-missing
句が指定されていない。(8001,続行不能。)
参考 ANSI X3.113の文章は不十分であるので,TIBによって訂正した。
(2) 数値定数でないデータ要素を数値変数に代入しようとした。(8101,続行不能。)
(3) 数値データの評価があふれを起こす。(1006,続行不能。)
(4) 文字列変数に対するデータ要素の代入が文字列あふれを起こす。(1053,続行不能。)
10.1.6 注意 処理系は,下位けたあふれを例外状態(1506,続行可能。ゼロで置き換え,処理を続ける。)
としてもよい。この場合,下位けたあふれを例外処理区で処理することができる(12.1参照)。
10.2 入力
10.2.1 概要 input文 (input-statement) 又はline-input文 (line-input-statement) によって,データを入力す
る。
(1) input文は,プログラムの外部の入力源 (source) から値を変数に代入することによって,実行中のプ
ログラムと利用者との対話を可能にする。一つの入力応答 (input-reply) の中に文字列データと数値デ
ータが混在していてもよい。それぞれのデータの項目は,コンマで区切る。
(2) 処理系定義の通常の入力要求 (input-prompt) を,指定によって別の入力要求に置き換えることができ
る。
(3) line-input文は,空白やコンマを含む一つの入力応答の行全体を,文字列変数の値として代入する。
10.2.2 構文 構文は,次による。
(1) input文⊃INPUT 入力修飾? 変数名並び
(2) 入力修飾=入力修飾項目 {コンマ 入力修飾項目}* コロン
(3) 入力修飾項目=prompt句|timeout句|elapsed句
(4) prompt句=PROMPT 文字列式
(5) timeout句=TIMEOUT 数値時間式
(6) 数値時間式=数値式
(7) elapsed句=ELAPSED 数値変数名
(8) line-input文⊃LINE INPUT 入力修飾? 文字列変数名並び
(9) 入力要求=[処理系定義]
(10) 入力応答=データ要素並び コンマ? 行末
(11) 行入力応答=プログラム文字* 行末
(12) prompt句,timeout句及びelapsed句は,一つの入力修飾の中に,それぞれたかだか1回だけ書くこ
とができる。これらは,どのような順序で書いてもよい。
10.2.3 例 構文の例を次に示す。
64
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
INPUT X
(1)
INPUT X, A$, Y(2)
(1)
INPUT PROMPT ”What is your name?”:N$
(1)
INPUT TIMEOUT 3*N, ELAPSED T, PROMPT Pstring$:N$
(1)
LINE INPUT A$
(8)
LINE INPUT PROMPT ””:A$, B$
(8)
2, SMITH, −3
(10)
25, 0, −10.2
(10)
He said ”Don't”.
(11)
10.2.4 意味 意味は,次による。
(1) input文 input文を実行すると,プログラムの実行は,(4)に定める正しい入力応答がなされるまで待
たされる。input文は,入力応答にある値を順番に,変数名並び中の変数に代入する。
(2) 入力応答の取得 対話方式 (interactive mode) の場合,プログラムの利用者は,データを入力する必要
のあることを,入力要求 (input-prompt) によって知らされる。
一括方式 (batch mode) の場合,入力応答は,処理系定義の手段によって外部の入力源から与えられ
る。
(3) 入力修飾
(3.1) 入力修飾にprompt句を書くと,処理系定義の入力要求は出力されず,代わりにprompt句の文字列
式の値が出力される。ただし,入力応答がコンマで終わっている場合については,(4.6)による。
(3.2) 入力修飾にtimeout句を書くと,その数値時間式が評価され,秒数s(整数とは限らない。)が定め
られる。s秒以内に正しい入力応答又は行入力応答 (line-input-reply) が与えられなければ,例外状
態になる。
(3.3) 入力修飾にelapsed句を書くと,処理系が入力要求を出してから,そのinput文に対する最後の入力
応答の行末又はそのline-input文に対する最後の行入力応答の行末を受け取るまでに経過した秒数
(整数とは限らない。)の値が,elapsed句の数値変数に代入される。
(3.4) 処理系に時計機能 (clock) がないとき,timeout句は何も効果をもたない。elapsed句の結果は−1
とする。時計機能があるとき,elapsed句の結果は常に正とする。timeout句及びelapsed句の値の
範囲(最小値及び最大値)及び分解能は,処理系定義とする。
(4) 値の代入
(4.1) 入力応答中の一つの項目に対して,データ要素の型及び許容される値の範囲について正しいことが
確認されたところで,その都度対応する変数に値が代入される。
(4.2) 変数名並び又は文字列変数名並び中の添字及び部分文字列指定は,その変数名並び又は文字列変数
名並び中の先行する(すなわち左側の)変数がすべて値を代入されてから,評価される。
(4.3) 入力応答にあるそれぞれのデータ要素の型は,代入される変数の型に一致していなければならない。
すなわち,数値変数に対する入力は数値定数でなければならず,文字列変数に対する入力は文字列
定数又は単純文字列でなければならない。数値定数の形になっている単純文字列は,input文によっ
て文字列変数にも数値変数にも代入できる。
(4.4) 数値データを評価した結果が下位けたあふれになると,その値は,ゼロで置き換えられる。
(4.5) 入力要求に対する入力応答がコンマで終わっていないときには,それまでに与えられたすべての入
力応答中のデータ要素の個数が,値を要求している変数名の個数と等しくなければならない。
65
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(4.6) 入力応答の,行末の前の空白でない最後の文字がコンマであるときには,更にデータが与えられる
ことを意味する。この場合,入力応答中に含まれている個数だけの値が,変数名並び中の変数に代
入される。その後,入力要求(ただし,prompt句が指定されていてもその文字列式の値ではない。)
が再度出力され,続きの正しい入力応答が与えられるまで,プログラムの実行が待たされる。正し
い入力応答が与えられると,そこからデータの続きが得られる。
(5) line-input文
(5.1) line-input文を実行すると,文字列変数名並び中の各文字列変数名ごとに一つの行入力応答が,input
文の入力要求と同じやり方で要求される。
すなわち,1番目の行入力応答の値が文字列変数名並びの1番目の変数に代入される。文字列変
数名並びに更に変数名がある場合には,入力要求(ただし,prompt句が指定されていてもその文字
列式の値ではない。)が再度出力され,2番目の正しい行入力応答が与えられるまで,プログラムの
実行が待たされる。正しい行入力応答が与えられると,その値が文字列変数名並びの2番目の変数
に代入される。この過程が,文字列変数名並びのすべての変数に正しい行入力応答が与えられるま
で続く。
(5.2) 行入力応答中の文字は,前後の空白も含めて一続きの文字列とされ,対応する文字列変数の値にな
る。行入力応答の末尾の行末は,この文字列には含まれない。行入力応答中の引用符は,そのまま
の文字として扱われる。すなわち,連続する二つの引用符は,1文字ではなく,2文字として数える。
(6) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(6)項がないが,TIBによって補った。
10.2.5 例外状態 例外状態は,次による。
(1) 入力要求に対する応答として与えられた行が,構文的に正しい入力応答でない。(8102,続行可能。新
たな入力応答を要求する。)
(2) 数値変数名に対する入力として与えられたデータ要素が,数値定数でない。(8103,続行可能。現在の
入力応答の再送を要求する。)
(3) 入力応答中のデータ要素の個数が不足しており,かつ最後がコンマで終わっていない。(8002,続行可
能。現在の入力応答の再送を要求する。)
(4) 入力応答中のデータ要素の個数が多すぎる。又は,要求されている個数のデータ要素があるにもかか
わらず,入力応答がコンマで終わっている。(8003,続行可能。現在の入力応答の再送を要求する。)
(5) 数値データの評価があふれを起こす。(1007,続行可能。現在の入力応答の再送を要求する。)
(6) 文字列変数に対する,データ要素又は行入力応答の代入が文字列あふれを起こす。(1054,続行可能。
現在の入力応答又は行入力応答の再送を要求する。)
(7) 数値時間式として使用された数値式の値がゼロより小さい。(8402,続行不能。)
(8) 入力修飾中のtimeout句で指定された秒数以内に,正しい入力応答又は行入力応答がなかった。(8401,
続行不能。)
10.2.6 注意 注意は,次による。
(1) この規格は,対話方式の利用者が入力応答を誤ったときに,それを再送できる機能を処理系に対して
要求する。一括方式では,これを続行不能の例外状態としてもよい。この規格は,誤った入力応答を
修正する機能を処理系に対して要求しないが,処理系は,そのような機能を用意してもよい。
(2) prompt句が指定されない場合の入力要求は,疑問符に1文字の空白を付けた2文字とすることを推奨
66
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する。
(3) 処理系は,入力応答又は行入力応答を出力(すなわちエコー表示)しなくてもよい。
(4) 処理系は,下位けたあふれを例外状態(1507,続行可能。ゼロで置き換えて処理を続行する。)として
もよい。この場合,下位けたあふれを例外処理区で処理することができる(12.1参照)。
(5) 入力データが単純文字列である場合には,その前後の空白列は無視される(4.1参照)。引用文字列で
ある場合には,引用符でくくられた内部の空白は,すべて意味をもつ(6.1参照)。
(6) 入力応答の単純文字列は,構文規則10.1.2(9)に規定してある。処理系は,入力応答の単純文字列用の
文字の組を拡張して,10.2.5(1)に規定する例外状態8102を起こさずに利用できることにしてもよい。
参考 ANSI X3.113にはこの(6)項がないが,TIBによって補った。
10.3 出力
10.3.1 概要 print文 (print-statement) は,一定の書式で作表出力を行う。margin句のあるset文
(set-statement) は,出力行 (output line) の幅を指定する。zonewidth句のあるset文は,印字行 (print line) 中
の印字欄 (print zone) の幅を指定する。ask文 (ask-statement) によって,出力行の幅又は印字欄の幅の現
在の値を問い合わせる。
機能を拡充したprint文は,10.4,10.5及び11.3で規定する。
10.3.2 構文 構文は,次による。
(1) print文⊃PRINT 印字項目並び
(2) 印字項目並び={印字項目? 印字区切り}* 印字項目?
(3) 印字項目=式|位置指定
(4) 位置指定=TAB 左括弧 指標 右括弧
(5) 印字区切り=コンマ|セミコロン
(6) set文=SET 設定対象
(7) 設定対象⊃ {MARGIN|ZONEWIDTH} 指標
(8) ask文⊃ASK 出力質問項目並び
(9) 出力質問項目並び=出力質問項目 {コンマ 出力質問項目}*
(10) 出力質問項目= {MARGIN|ZONEWIDTH} 数値変数名
(11) 一つの出力質問項目は,一つのask文の中では,たかだか1回だけ書くことができる。
10.3.3 例 構文の例を次に示す。
PRINT X
(1)
PRINT X, Y
(1)
PRINT X, Y, Z,
(1)
PRINT ,,,X
(1)
PRINT
(1)
PRINT ”X EQUALS”, 10
(1)
PRINT X;(Y+Z)/2
(1)
PRINT TAB(10);A$;”IS DONE.”
(1)
SET MARGIN 120
(6)
SET ZONEWIDTH 20
(6)
10.3.4 意味 意味は,次による。
(1) print文 print文は,文字の列と行末を生成して,外部の装置に送り出す。この文字の列は,印字項
67
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
目並び (print-list) 中の印字項目 (print-item) と印字区切り (print-separator) を順番に評価して生成さ
れる。
(2) print文の副作用 印字項目並び中の式である関数を呼び出し,その関数がもとのprint文と同じ装置
に対するprint文を実行するとき,その実行の効果は処理系定義とする。
(3) 数値の印字 印字項目並び中の数値式を評価すると,正又はゼロならば1文字の空白,負ならば1文
字の負号の直後に,その数値の絶対値の10進表現,その直後に1文字の空白をおいた文字の列になる。
数値の10進表現の形式は,数値定数の規定(5.1参照)に従い,次のとおりとする。
(3.1) 処理系は,有効数字部の幅 (significance width) dと指数部の整数の幅 (exrad width) eを定める。幅d
は,出力する数値の表現のうち,有効数字部 (significand) の10進けた数を制御する。幅eは,指
数部 (exrad) の整数のけた数を制御する。dの値は6以上,eの値は2以上とする (d≧6, e≧2)。
(3.2) dけた以下の整数として正確に表現できる数値は,小数点なし指数部なし形式で出力される。
(3.3) 他のすべての数値は,小数点あり指数部なし形式か,小数点あり指数部あり形式で出力される。指
数部あり形式による場合と比べて,精度を落とさずにdけた以下の指数部なし形式で表現できる数
値は,指数部なし形式で出力される。
例えば,d=6のとき,10−6は,.000001と出力され,10−7は,1.E−7と出力される。
(3.4) 小数点あり指数部なし形式による数値は,dけた以内の10進数字と,小数点1文字で出力される。
処理系は,小数部の後続するゼロ列を,省略して出力してもよい。
絶対値が1未満の数値の場合,小数点の左側に数字は生成されない。この形式は,符号,小数点
及び後続の1文字の空白を含めて,最大d+3文字の幅を必要とする。
(3.5) 小数点あり指数部あり形式による数値は,次の形で出力される。
有効数字部 E 符号 符号なし整数
ここで,有効数字部の値xは,1≦x<10の範囲とし,ちょうどdけたの精度で表現される。指数
部の符号なし整数は,1〜eけたとする。処理系は,有効数字部中の小数部の後続するゼロ列及び指
数部の先行するゼロ列を,省略して出力してもよい。小数点は,有効数字部の一部分として必ず生
成される。この形式は,二つの符号,小数点,英字E及び後続する1文字の空白を含めて,最大d
+e+5文字の幅を必要とする。
(4) 文字列の印字 文字列式を評価すると,対応する文字の列になる。
(5) 印字区切りと位置指定
(5.1) 印字区切りセミコロンを評価すると,空文字列すなわち長さ0文字の文字の列になる。
(5.2) 位置指定TAB及び印字区切りコンマの評価の結果は,現在又は先行のprint文によって生成された
文字の列に依存する。現在行 (current line) とは,実行の開始以後又は最後に生成された行末以後に
生成された文字の列(空でありうる。)とする。
(5.3) 現在行の印字位置 (columnar position) とは,その行へ次に生成される文字が位置付けられる文字位
置とする。印字位置は,左から右に,1から順に番号付けられる。表4.1(標準文字集合,163ペー
ジ)の位置2/0から7/14までにある文字が1文字生成されるたびに,印字位置の番号は1増える。
行末を生成すると,印字位置は1に戻る。印字位置に対するその他の文字の効果は,処理系定義と
する。
(5.4) 行幅 (margin) とは,印字可能な最大の印字位置とする。margin句のあるset文を実行するまでの行
幅は,処理系定義とする。処理系定義のこの行幅は,省略時想定の印字欄幅 (zone width) 以上でな
ければならない。行幅としてMAXNUMを指定すると,印字位置は,任意に大きくてもよい。
68
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(5.5) 印字の行は,一定の個数の印字欄 (print zone) に分割される。zonewidth句のあるset文を実行する
までの印字欄の幅と個数は,処理系定義とする。右端以外の印字欄の幅は,すべて同じとする。端
数があるとき,右端の印字欄が短くなる。省略時想定の印字欄幅は,d+e+6以上とする。印字欄
幅は,zonewidth句のあるset文を実行して変更できる。印字欄幅は,1以上現在の行幅以下の任意
の値に設定してよい。
(5.6) 位置指定 (tab-call) TABは,次の印字項目に対する印字位置を次のとおり設定する。
(a) 位置指定TABの式が評価され,その値が最も近い整数値nに丸められる。nが1よりも小さい場合
には,例外状態になる。nが行幅mよりも大きい場合には,mの整数倍をnから引いて,1≦n≦m
にする。すなわちnは,MOD (n−1, m)+1に等しくされる。
(b) 現在行の印字位置がn以下であるときには,必要ならば空白を生成して,印字位置をnにする。現
在行の印字位置がnを越えているときには,行末を生成して次の行に移り,n−1個の空白を生成し
て,印字位置をnにする。
(5.7) 印字区切りコンマの評価の結果は,印字位置に依存する。
(a) 次の(b)と(c)の場合を除いて,通常,1文字以上の空白を生成して,印字位置を現在行中の次の印字
欄の先頭にする。
(b) 印字位置が行の右端の印字欄中にあるときには,行末を生成する。
(c) 印字位置が行幅を越えているときにも,行末を生成する。
備考 書式なし出力の実行によって,印字位置が行幅を越えるのは,最後の印字項目を出力した結果
がちょうど行幅を満たしているときだけである。
(6) 行幅を超える出力行
(6.1) 現在行に既に文字が生成されていて(すなわち,印字位置≧2),かつ次の印字項目を評価すると行
幅を越えて(すなわち,印字位置≧行幅+2になって)しまう場合には,まず行末を生成してから,
その印字項目に対する文字の列を生成する。
(6.2) 一つの印字項目を評価出力している途中で,次の文字を生成すると行幅を越えてしまうことになっ
たときには,そこで行末を生成し,印字位置を1に戻してから,その文字を生成する。
(7) 印字項目並びの終り
(7.1) 印字項目並びの評価が完了した時,印字項目並びが印字区切りで終わっていない場合には,最後に
行末が生成される。印字項目並びが印字区切りで終わっている場合には,そのような行末は生成さ
れない。
(7.2) 完全に空の印字項目並びをもったprint文は,行末を生成して,現在行の出力を完了する。現在行
が文字を含んでいないときには,空白行ができる。
(8) 行幅の設定 margin句のあるset文を実行すると,その指標が評価され,この値が新たな行幅になる。
出力行が部分的に生成されていたとしても,行幅の変更は直ちに有効になる。margin句のあるset文
は,書式なし出力だけに影響を与える。
(9) 印字欄幅の設定 zonewidth句のあるset文を実行すると,その指標が評価され,この値が新たな印字
欄幅になる。出力行が部分的に生成されていたとしても,印字欄幅の変更は直ちに有効になる。
zonewidth句のあるset文は,書式なし出力だけに影響を与える。
(10) ask文 ask文を実行すると,出力質問項目並び中の変数に,margin句の場合には現在の行幅の値,
zonewidth句の場合には現在の印字欄幅の値が代入される。印字位置が任意に大きくてよい場合には,
margin句の数値変数に値MAXNUMが代入される。
69
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(11) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(11)項がないが,TIBによって補った。
10.3.5 例外状態 例外状態は,次による。
(1) 位置指定TABの指標の値が1より小さい。(4005,続行可能。値を1として処理を続ける。)
(2) set文のmargin句の指標の値が,現在の印字欄幅の値より小さい。(4006,続行不能。)
(3) set文のzonewidth句の指標の値が,1より小さい又は現在の行幅の値より大きい。(4007,続行不能。)
10.3.6 注意 注意は,次による。
(1) 数値式を評価して生成される文字の列は,右端に1文字の空白を含む。この空白まで生成しようとす
ると,ちょうど行幅を越えることになる(すなわち,印字位置=行幅+2になる。)場合には,処理系
は,その空白の生成を省略し,その数値を現在行の右端の印字欄に出力してもよい。
(2) 小数点あり指数部あり形式 [10.3.4(3.5)] で数値を印字するときに,処理系は英小文字eを使用するこ
とにしてもよい。
(3) 位置指定TABに続く印字区切りは,それが式に続く場合と同じ効果をもつ。
10.4 書式付き出力
10.4.1 概要 print文 (print-statement) は,書式 (image) を指定して出力の形式を制御することができる。
書式は,そのprint文中又は別のimage行中で指定する。
10.4.2 構文 構文は,次による。
(1) print文⊃PRINT 書式付き印字指定
(2) 書式付き印字指定=USING 書式引用 {コロン 書式印字式並び}?
(3) 書式引用=行番号|文字列式
(4) 書式印字式並び=式 {コンマ 式}* セミコロン?
(5) image行=行番号 IMAGE コロン 書式文字列 行末
(6) 書式文字列=即値文字列{書式項目 即値文字列}*
(7) 即値文字列=即値文字*
(8) 即値文字= 英字|数字|空白|感嘆符|アポストロフィ|左括弧|右括弧|斜線|コロン|
セミコロン|等号|疑問符|下線
(9) 書式項目=けた寄せ? 浮動文字列 {整数書式項目|小数書式項目|指数書式項目}1けた寄せ
(10) けた寄せ=大号|小号
(11) 浮動文字列={正号*|負号*} ドル記号?|ドル記号* {正号|負号}?
(12) 整数書式項目=数字位置 数字位置* {コンマ 数字位置 数字位置*}*
(13) 数字位置=星印|番号記号|パーセント記号
(14) 小数書式項目=小数点 番号記号 番号記号*|整数書式項目 小数点 番号記号*
(15) 指数書式項目={整数書式項目|小数書式項目} 山記号 山記号 山記号 山記号*
(16) 書式引用の行番号は,そのプログラム単位中のimage行を参照しなければならない。
(17) image行中のコロンに続く空白列は,書式文字列の一部とする。
(18) 一つの整数書式項目中のすべての数字位置は,同一の文字でなければならない。すなわち,すべて番
号記号とするか,すべてパーセント記号とするか,又はすべて星印とする。
10.4.3 例 構文の例を次に示す。
70
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(1) 10 LET sum=20
は,
20 PRINT USING”The answer is ###.#”:sum
The answer is 20.0
を生成する。
(2) 30 PRINT USING 40:342,42.021
は,
40 IMAGE:RATE OF LOSS #### EQUALS ####.## POUNDS
RATE OF LOSS 342 EQUALS 42.02 POUNDS を生成する。
(3) 10 LET A$=”<##### ####.#### ####.####^^^^” は,
20 PRINT USING A$:1,1, 1
1 1.0000 1000.0000E−03
を生成する。
(4) 60 PRINT USING 70:”ONE”,”TWO”,”THREE” は,
70 IMAGE:Z<####>#### ########Z
ZONE TWO THREE Z
を生成する。
(5) 80 LET A$= ”Pay $**.## on ### %% 19%%” は,
90 PRINT USING A$:1, “May”, 2,83
Pay $*1.00 on May 02 1983
を生成する。
(6) 10 PRINT USING”<%%.##>---$##.## $$$+***”:3.1,−1234.567,2は,
003.10 -$1234.57 $+**2 を生成する。
(7) 10 PRINT USING”<$$$$.## $$$$.###^^^^^”:−.02, −.02 は,
$-.02 $-.200E-001
を生成する。
(8) 10 PRINT USING”$***,***.##”:1234.7777 は,
$**1,234.78
を生成する。
10.4.4 意味 意味は,次による。
(1) 書式文字列の選択 書式付き印字指定 (formatted-print-list) のあるprint文は,書式印字式並びを評価
して出力を生成する際に,書式文字列 (format-string) を識別し,書式文字列を用いて出力の制御を行
う。書式引用 (image) が行番号であるときには,書式文字列は,指定された行番号のimage行中に含
まれている。書式引用が文字列式であるときには,書式文字列はその文字列式の値とする。
(2) 書式文字列の解析
(2.1) 選択された書式文字列は,0文字以上の即値文字列 (literal-string) によって分離された幾つかの書式
項目 (format-item) に分解される。
書式項目は,書式文字列中の文字を左から右に走査して定められる。構文的に正しい書式項目の
最初の文字が探され,その文字から始まる最も長い書式項目が識別される。新しい書式項目の探索
は,前の書式項目が識別されるたびに,そのすぐ次の文字から始まる。書式項目に対する走査は,
このような方法で書式文字列の最後まで続けられる。
71
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2.2) 一つの書式項目にはそれぞれ一つの出力欄 (output field) が対応する。出力欄の長さは,書式項目中
の文字[けた寄せ (justifier),浮動文字列 (floating-characters),数字位置 (digit-place),コンマ,小数
点,番号記号及び山記号を含む。]の個数に等しい。書式項目の一部でない文字は,即値文字でなけ
ればならない。
(2.3) image行中に定義された書式文字列は,その行における空白でも行末でもない最後の文字で終わる。
(3) 即値文字列と出力欄 出力すべき値の列は,書式印字式並び (output-list) の中の各式を順番に評価し
て生成される。各値が生成される際に,まず,書式文字列の中の次の書式項目の前にある即値文字列
が,生成中の文字の列の中にそのまま複写される。次に,数値式の場合は(4)に,文字列式の場合は(5)
に従って,出力欄の長さに等しい個数の文字が書式項目によって定められ生成される。
(4) 書式付き数値出力 数値は丸められ,用いられている書式項目に対応したやり方で表現される。
(4.1) 書式項目の中にけた寄せがある場合,けた寄せば,その右隣の文字で置き換えられる。右隣の文字
が小数点である場合及びその書式項目がけた寄せだけからなる場合,けた寄せば,番号記号で置き
換えられる。
(4.2) 最初に,値の絶対値の表現が生成される。
(a) 整数書式項目 (i-format-item) の場合,値は最も近い整数に丸められ,小数点なし指数部なし形式で
表現される。
(b) 小数書式項目 (f-format-item) の場合,値は小数点あり指数部なし形式で表現され,書式項目の中の
小数点に続く番号記号の個数に応じて丸められるか右にゼロが補われる。
(c) 整数書式項目の場合も小数書式項目の場合も,意味上の小数点の左側では先行のゼロ列は生成され
ない。ただし,生成しないと出力欄に数字が一つもなくなってしまうときは,意味上の小数点の左
隣に1文字のゼロが生成される。その後,その整数中又は小数点の左側にまだ満たされていない数
字位置があれば,数字位置として,パーセント記号が用いられているときには先行のゼロ列が,星
印が用いられているときには先行の星印列が,番号記号が用いられているときには先行の空白列が
生成される。その結果,意味上の小数点の左側に生成される文字の個数は,書式項目中の数字位置
の個数と等しくなる。
(d) 指数書式項目 (e-format-item) の場合,値は,その指数書式項目中に小数書式項目を用いたか整数書
式項目を用いたかに応じて,小数点あり指数部あり形式又は小数点なし指数部あり形式で表現され
る。
ゼロでない値の有効数字部は,最も左の数字位置又は番号記号の位置にゼロ以外の数字が来るよ
うに,10のべき乗を乗じて調整される。それ以外の点では,有効数字部は,整数書式項目及び小数
書式項目の場合と同じ規則に従って生成される。
指数書式項目の中の山記号の個数は,指数部の文字数を定める。指数部の最初の文字は英字E,
次の文字は正号又は負号,残りは指数部の整数の絶対値の表現となる。指数部の整数の絶対値の表
現では,指数部の文字数が書式項目中の山記号の個数と等しくなるように,必要ならば先行のゼロ
列が生成される。指数がゼロであるとき,指数部の符号は正号とする。値がゼロであるとき,その
指数はゼロとする。
(4.3) 2番目に,書式項目の中にコンマがあれば,この数値表現のその位置にコンマが挿入される。挿入
点の左側に少なくとも1けたの数字が生成されていれば,このコンマがそのまま生成される。挿入
点の左側に数字が1けたも生成されていないときには,左隣の数字位置が星印であればコンマは星
印に置き換えられ,数字位置が番号記号であればコンマは空白に置き換えられる。

72
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(4.4) 3番目に,符号,ドル記号及び空白からなる先行文字列が表10.1のとおり生成される。
表10.1 浮動文字列の効果
書式項目中の浮動文字列(先頭の文字は,複数個あってもよい。)
に対応して生成される長さ0〜2の先行文字列を示す。
指定した浮動文字列
生成される先行文字列
先頭
末尾
非負値
負値
−
$
“$”
“−$”
$
−
“$”
“$−”
−
なし
“ ”
“−”
+
$
“+$”
“−$”
$
+
“$+”
“$−”
+
なし
“+”
“−”
$
なし
“$”
“$−”
なし
なし
“”
例外状態
参考 ANSI X3.113では,例外状態のところが“−”となっている
が,誤りであるので,TIBによって訂正した。
(4.5) 最後に,数値の表現の長さが書式項目の長さと等しくなるように,左側に空白が補われる。これは,
出力欄の中で数値表現を右寄せする効果をもつ。
(5) 書式付き文字列出力 文字列値は,どの種類の書式項目を用いて出力することもできる。文字列は,
その長さが書式項目の長さと等しくなるように,空白を補われる。これらの空白は,書式項目が大号
で始まる場合は(右寄せのために)左側に付加され,小号で始まる場合は(左寄せのために)右側に
付加され,それ以外の場合は(中央に置くために)左右に同じだけ付加される。最後の場合に,必要
な空白の個数が奇数ならば,余分の空白は右側に付加される。
(6) 書式付き出力の終了
(6.1) 出力する値の個数が書式文字列の中の書式項目の個数より多ければ,書式文字列の末端に到達する
たびに,行末が生成され,残りの式に対してその書式文字列が再び用いられる。
(6.2) すべての値が出力された後,次の即値文字列があればそれが出力される。その即値文字列の文字の
出力は,書式文字列中に書式項目が残っていれば,用いられなかった最初の書式項目の直前で終了
する。
(6.3) 書式印字式並びがセミコロンで終わっていない場合には,すべての文字の生成が終わった後で最後
に行末が生成される。書式印字式並びがセミコロンで終わっている場合には,そのような行末は生
成されない。
(7) 行幅の効果 現在の行幅は,出力に影響を及ぼさない。特に,書式付き出力においては,行幅を越え
たからといって行末が生成されることはない。
(8) image行 プログラムの実行がimage行に到達すると,何もしないで次の行に進む。
(9) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(9)項がないが,TIBによって補った。
10.4.5 例外状態 例外状態は,次による。
(1) 書式付き印字指定の中で正しくない書式文字列が指定されている。(8201,続行不能。)
(2) 書式付き印字指定が書式印字式並びを含んでいるのに,書式文字列の中に書式項目がない。(8202,続
行不能。)
73
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3) 文字列式又は数値式によって生成された出力文字列が,それに対応する書式項目より長い。(8203,続
行可能。その出力欄を星印で埋め,次の行に書式なし出力の表現で値を報告し,その次の行の,例外
状態にならなかったときに続行するのと同じ文字位置から印字を続行する。)
(4) 数値出力の指数部が,書式文字列中の山記号で確保した幅を越える。(8204,続行可能。その出力欄を
星印で埋め,次の行に書式なし出力の表現で値を報告し,その次の行の,例外状態にならなかったと
きに続行するのと同じ文字位置から印字を続行する。)
参考 ANSI X3.113の文章は不十分であるので,TIBによって訂正した。
10.4.6 注意 注意は,次による。
(1) 処理系は書式文字列を実行時に評価してもよいので,その中の誤りは,(たとえそれがimage行の中
にあり,実行前に判明していても,)例外状態として扱ってもよい。
(2) 小数点なし指数部あり形式又は小数点あり指数部あり形式で数値を印字するときに,処理系は英小文
字eを使用することにしてもよい。
参考 ANSI X3.113では,“小数点あり”のほうだけを記述してあるが,誤りであるので,TIBによっ
て訂正した。
(3) 浮動文字列を指定した書式項目においては,整数書式項目又は小数書式項目を用いて生成される数値
の整数部は,書式項目中の数字位置の個数より多くの数字を含むことができる。
(4) 負の数値には,常に負号が付く。すべての数字位置は,数字又は先行の空白列,ゼロ列若しくは星印
列で埋められるので,負の数値に対応する書式項目は,負号の分の場所を浮動文字列で確保しておか
なければならない。特に,浮動文字列を含まない書式項目又は浮動文字列が1文字のドル記号だけか
らなる書式項目の出力欄に負の数値を出力しようとすると,例外状態8203になる。
(5) 即値文字列及び即値文字は,構文規則10.4.2(7)及び(8)に規定してある。処理系は,即値文字列用の文
字の組を拡張して,10.4.5(1)に規定する例外状態8102を起こさずに利用できることにしてもよい。
参考 ANSI X3.113にはこの(5)項がないが,TIBによって補った。
10.5 配列入出力
10.5.1 概要 配列全体に入力又は配列全体を出力する文を定める。これらの文は,単一の値を扱う入出力
文の機能を拡充したものである(10.1〜10.4参照)。
10.5.2 構文 構文は,次による。
(1) mat-read文⊃MAT READ {if-missing句 コロン}? 再定義配列並び
(2) 再定義配列並び=再定義配列 {コンマ 再定義配列}*
(3) 再定義配列=配列名 再定義上下限指定部?
(4) mat-input文⊃MAT INPUT 入力修飾? {再定義配列並び|不定長ベクトル}
(5) 不定長ベクトル=配列名 左括弧 疑問符 右括弧
(6) mat-line-input文⊃MAT LINE INPUT 入力修飾? 再定義文字列配列並び
(7) 再定義文字列配列並び=再定義文字列配列 {コンマ 再定義文字列配列}*
(8) 再定義文字列配列=文字列配列名 再定義上下限指定部?
(9) mat-print文⊃MAT PRINT {印字配列名並び|USING 書式引用 コロン 書式印字配列名並び}
(10) 印字配列名並び=配列名 {印字区切り 配列名}* 印字区切り?
(11) 書式印字配列名並び=配列名 {コンマ 配列名}* セミコロン?
(12) 再定義配列におけるその配列と再定義上下限指定部とは,同じ次元数でなければならない。
(13) 不定長ベクトルの配列は,1次元でなければならない。
74
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
10.5.3 例 構文の例を次に示す。
MAT READ A
(1)
MAT READ A(M,N), B
(1)
MAT INPUT A$(3,4)
(4)
MAT INPUT X(?)
(4)
MAT INPUT PROMPT ”Enter data:”:X(?)
(4)
MAT LINE INPUT A$
(8)
MAT PRINT A;B, C;
(9)
10.5.4 意味 意味は,次による。
(1) mat-read文
(1.1) mat-read文 (array-read-statement) を実行すると,その文を含むプログラム単位のdata文によって生
成されたデータ列 (data sequence) にある値が,順番に再定義配列並び中の配列に代入される。
(1.2) 各配列のすべての要素が,行方向の順番(最後の添字が最も早く変わる順番)で,データ列の中の
データ要素にある値を代入される。代入される値は,データ列の指示子 (pointer) によって指示され
るデータ要素から順番に得られる。指示子は,それらのデータ要素の次を指す。
(1.3) データ列にある各データ要素の型は,それが代入される配列要素の型に一致していなければならな
い(10.1参照)。
(1.4) 再定義上下限指定部 (redim) を書くと,値がその再定義配列に代入される前に動的に上下限の再定
義 (redimensioning) が行われる。上下限の再定義は,配列宣言での上下限の規則に従って行われる。
再定義上下限指定の指標の値が,配列の新しい上下限になる。配列の上下限の再定義を行っている
時に例外状態になると,もとの上下限が残る。
(1.5) 再定義配列 (redim-array) 中の再定義上下限指定部は,再定義配列並び中の先行する(すなわち左側
の)配列が値を代入されてから,評価される。
(1.6) データ要素の個数が不足している場合の扱いは,if-missing句のあるときもないときも,10.1による。
(1.7) 数値データを評価した結果が下位けたあふれになると,その値は,ゼロで置き換えられる。
(2) mat-input文
(2.1) mat-input文 (array-imput-statement) を実行すると,プログラムの実行は,(2)及び(3)に定める正しい
入力応答 (input-reply) がなされるまで待たされる。mat-input文は,入力応答にある値を順番に,
再定義配列並びにある配列に代入する。値は,各配列のすべての要素に対して行方向に代入される。
(2.2) 対話方式の場合,プログラムの利用者は,データを入力する必要のあることを,入力要求
(input-prompt) によって知らされる。この入力要求は,input文の入力要求と同じものとする。
(2.3) 入力修飾の効果は,10.2による。
(2.4) 入力応答にあるそれぞれのデータ要素の型は,代入される配列要素の型に一致していなければなら
ない。
(2.5) 再定義上下限指定部を書くと,mat-read文に対して(1.4)で規定したとおり,値がその再定義配列に
代入される前に動的に上下限の再定義が行われる。
(2.6) 再定義配列中の再定義上下限指定部は,再定義配列並び中の先行する(すなわち左側の)配列が値
を代入されてから,評価される。
(2.7) 入力データが代入されてから配列の上下限が再定義され,続いて入力に関する例外状態の回復手続
きによってその配列に入力データを再入力することになったときの効果は,処理系定義とする。
75
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2.8) 配列入力の要求に対する応答において,データを単一の入力応答で供給する必要はない。配列並び
に対するデータ要素の個数が不足し,かつ入力応答の末尾がコンマであれば,入力要求が再び表示
され,更にデータ要素を供給するように入力応答が要求される。
(2.9) 数値データを評価した結果が下位けたあふれになると,その値は,ゼロで置き換えられる。
(3) 不定長ベクトルの入力
(3.1) mat-input文に不定長ベクトル (variable-length-vector) があれば,全入力応答(すなわち,コンマで
終わらない入力応答までの入力応答の列)中にあるだけの個数のデータ要素が入力として,そのベ
クトルに供給される。データの代入は,そのベクトルの現在の下限値のところがら始まる。代入後
にベクトルは,最後のデータ要素を受け取った要素のもつ添字に等しい添字を上限値として設定し
て,動的に再定義される。不定長ベクトルに代入されるデータ値の個数は,配列宣言の中で指定さ
れたときのそのベクトルに対するもとの寸法を超えてはならない。
(3.2) 入力応答にある各データ要素の型は,配列の型に一致していなければならない。
(4) mat-line-input文
(4.1) mat-line-input文 (array-line-input-statement) を実行すると,文字列配列並び中の文字列配列の一つの
要素ごとに一つの行入力応答が,入力応答の要求と同じ方法で要求される。幾つかの行入力応答の
全体の内容(それらの行末は除く。)が,文字列配列並び中の文字列配列の要素に対して,行方向に
代入される。要求される行入力応答の個数は,値を要求する要素の個数に等しい。
(4.2) 対話方式の場合,プログラムの利用者は,データを入力する必要のあることを,入力要求によって
知らされる。
(4.3) 入力修飾の効果は,10.2による。
(4.4) 再定義上下限指定部を書くと,mat-read文に対して(1.4)で規定したとおり,値がその再定義配列に
代入される前に動的に上下限の再定義が行われる。
(4.5) 再定義配列中の再定義上下限指定部は,再定義配列並び中の先行する(すなわち左側の)配列が値
を代入されてから,評価される。
(5) mat-print文
(5.1) mat-print文 (array-primt-statement) を実行すると,配列印字並び中にあるすべての配列の全要素の
値が印字される。
(5.2) 現在の出力行が空でないときにmat-print文を実行すると,まず始めに行末が生成される。
(5.3) 印字配列名並びのあるmat-print文において,一つの2次元配列の印字によって生成され外部の装
置に転送される文字の列は,次による。すなわち,その配列の要素が行方向の順番に,一つのprint
文の印字項目並びになっているとする(行別の昇順)。そして,各要素は,もとのmat-print文のそ
の配列名に続く印字区切りによって(又は印字区切りがないときにはコンマによって)区切られて
並んでいるとする。そのように想定して文字の列が生成される。ただし,配列の一つの行が印字さ
れる都度,行末(そのような行末がまだ生成されていないならば)が生成される。
3次元配列は,一連の2次元配列が,1番目の添字の値ごとに一つずつ並んだものであるかのよう
に印字され,添字の各値の間で追加の行末が生成される。
1次元配列は,行ベクトルとして扱われ,1×n配列であるかのように印字される。
更に,一つの印字配列名並び中の後続する配列との間にも,行末が生成される。
(5.4) 書式印字配列名並びのあるmat-print文において,生成され外部の装置に転送される文字の列は,
次による。すなわち,全配列の全要素が配列ごとに行方向の順番に並んで,一つのprint文の書式
76
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
印字式並びになっているとする。更に,mat-print文に指定したのと同じ書式指定が指定されている
とする。そのように想定して文字の列が生成される。追加の行末は,生成されない。
書式指定を用いるprint文の場合と同様に,書式印字配列名並びがセミコロンで終わっていない
場合には,そのmat-print文の他のすべての出力が終わった後で最後に行末が生成される。書式印
字配列名並びがセミコロンで終わっている場合には,そのような行末は生成されない。
(6) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(6)項がないが,TIBによって補った。
10.5.5 例外状態 例外状態は,次による。
(1) mat-read文の再定義配列並びの要求するデータ要素の個数が,データ列の残りにあるデータ要素の個
数より多く,かつif-missing句が指定されていない。(8001,続行不能。)
(2) データ列中の数値定数でないデータ要素を数値配列の要素に代入しようとする。(8101,続行不能。)
(3) mat-read文の実行中に,データの代入が文字列あふれを起こす。(1053,続行不能。)
(4) データ要素並び中の数値データの評価があふれを起こす。(1006,続行不能。)
(5) 配列入力の要求に対する応答として与えられた行が,構文的に正しい入力応答でない。(8102,続行可
能。新しい入力応答を要求する。)
(6) 数値配列に対する入力として与えられたデータ要素が,数値定数でない。(8103,続行可能。現在の入
力応答の再送を要求する。)
(7) 入力応答中のデータ要素の個数が不足しており,かつ最後がコンマで終わっていない。(8002,続行可
能。現在の入力応答の再送を要求する。)
(8) 入力応答中のデータ要素の個数が多すぎる。又は,要求されている個数のデータ要素があるにもかか
わらず,入力応答がコンマで終わっている。(8003,続行可能。現在の入力応答の再送を要求する。)
(9) 入力応答中の数値データの評価があふれを起こす。(1007,続行可能。現在の入力応答の再送を要求す
る。)
(10) mat-input文又はmat-line-input文の実行中,文字列データの代入が文字列あふれを起こす。(1054,
続行可能。現在の入力応答又は行入力応答の再送を要求する。)
(11)上下限の再定義後の配列で必要な要素の総数が,もとの配列宣言で確保された要素数を超える。(5001,
続行不能。)
(12) 再定義上下限指定の1番目の指標の値が,2番目の指標の値より大きい。(6005,続行不能。)
(13)再定義上下限指定に指標が一つだけ書いてあって,その値が有効な暗黙の下限の値未満である。(6005,
続行不能。)
(14) 入力修飾にあるtimeout句によって指定された秒数以内に,正しい入力応答又は行入力応答が与えら
れない。(8401,続行不能。)
(15) 数値時間式として使用された数値式の値がゼロより小さい。(8402,続行不能。)
(16) mat-print文の中で正しくない書式文字列が指定されている。(8401,続行不能。)
(17) mat-print文が書式印字配列名並びを含んでいるのに,書式文字列の中に書式項目がない。(8402,続
行不能。)
10.5.6 注意 注意は,次による。
(1) 処理系は,入力応答又は行入力応答を出力(すなわちエコー表示)しなくてもよい。
(2) この規格は,誤った入力応答を修正する機能を処理系に対して要求しないが,処理系は,そのような
77
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
機能を用意してもよい。
(3) 処理系は,下位けたあふれを例外状態(1507,続行可能。ゼロで置き換えて処理を続ける。)としても
よい。この場合,下位けたあふれを例外処理区で処理することができる(12.1参照)。
11. ファイル
11.0 ファイル編成及び記録形式 ファイル編成及び記録形式は,次による。
(1) ファイル (file) は,BASICプログラムの外部にあるデータの構造化された集まりである。ファイルは,
BASICプログラムの実行中に生成されたデータを保存し,後の実行時にそのデータを取り出したり,
修正したりする手段を利用者に提供する。外部データをプログラムに転送する処理を入力 (input),プ
ログラムから転送する処理を出力 (output) という。
処理系は,ファイルの生成,保存及び取出しの機能を提供しなければならない。その手段は,処理
系定義とする。ファイルに対する入出力操作は,ここで規定されているとおりに実行されなければな
らない。
(2) この箇条11.では,ファイル及び装置のBASICプログラムに対する論理的な見え方を規定する。ある
場合には物理的な特性を反映することもあるが,一般的にこの規格は,ファイル及び装置の物理的な
表現及び構造については何も前提としていない。
(3) ファイル編成 (file-organization) は,次の四つとする。
順編成ファイル及び索引編成ファイルは,記録 (record) の列とする。相対編成ファイルは,記録領
域 (record-area) の列とする。この記録領域には,記録があることもあるし,ないこともある。流れ編
成ファイルは,値 (value) の列とする。
(a) 順編成 (sequential)
(b) 流れ編成 (stream)
(c) 相対編成 (relative)
(d) 索引編成 (keyed)
(4) 記録形式 (record-type) は,次の三つとする。
表示形式記録は,文字の列とする。内部形式記録は,型をもった値の列とする。固有形式記録は,
プログラムで指定した枠 (template) によって記述される欄 (field) の列とする。
表示形式記録は,数値及び文字列値に対して異なる内部表現を用いるシステム相互の間でデータを
交換する手段を与え,人間の目に見える形でデータを扱う。内部形式記録は,一つのシステムの内部
でデータを効率よく操作する手段を与える。固有形式記録は,一つのシステムの内部の異なる言語処
理系間でデータを交換する手段を与える。
(a) 表示形式 (display)
(b) 内部形式 (internal)
(c) 固有形式 (native)
(5) ファイルに関連して六つの機能単位 (module) をおく。これらは,ファイル編成と記録形式のある特
定の組合せを支援する(表11.4参照)。
(a) 中核機能単位及び部分集合中核機能単位は,表示形式順編成ファイル,内部形式順編成ファイル及
び内部形式流れ編成ファイルを支援する。
(b) 内部形式拡充ファイル機能単位及び内部形式拡充ファイル部分集合機能単位は,内部形式相対編成
ファイル及び内部形式索引編成ファイルを支援する。
78
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(c) 固有形式拡充ファイル機能単位及び固有形式拡充ファイル部分集合機能単位は,固有形式順編成フ
ァイル,固有形式相対編成ファイル及び固有形式索引編成ファイルを支援する。
(d) その他のファイル編成と記録形式の組合せは,処理系定義とする。
備考 六つの機能単位は,上のとおり二つずつ3組に分かれる。各組の二つの機能単位に対する11.
の規定は,それぞれ同じ(2.0参照)である。以下ではこれらを,“部分集合”の付かない名前
で併せて呼ぶ。
(6) 機能単位の区別は,構文の生成規則にも反映されている。それぞれの箇条では,最初に中核機能単位
の構文規則を示す。次に,拡充ファイル機能単位に関する追加の構文の生成規則を示す。固有形式拡
充ファイル機能単位に関してだけ適用される拡充の生成規則に対しては,番号の前に“固”と表示す
る。
(7) 箇条11.で使う用語の定義は,次による。
(7.1) ファイルは,“ファイル要素 (file element)”の列とする。すなわち,索引編成ファイル及び順編成フ
ァイルのファイル要素は記録,相対編成ファイルのファイル要素は記録領域,流れ編成ファイルの
ファイル要素は値とする。
(7.2) 実行中に,一つのファイルには一つの“ファイル指示子 (file pointer)”が,関連付けられる。文の
実行が完了した時,ファイル指示子は一つのファイル要素又はファイルの終りを指す。ファイル指
示子がファイルの始めにあるときには,それは,もし存在するならば先頭のファイル要素を指す。
ファイルが空列である場合には,ファイルの始めと終りは同じとし,ファイル指示子はこの位置を
指す。
(7.3) “次のファイル要素 (next file element)”というとき,そのようなファイル要素が存在しないならば,
それはファイルの終りを指す。
(7.4) “ファイルの終り (end of file)”は,順編成ファイル,流れ編成ファイル及び索引編成ファイルでは,
末尾のファイル要素の直後の位置とする。相対編成ファイルでは,存在する最後の記録の直後の空
の記録領域とする。
(7.5) ファイルを全体的に操作する文を“ファイル操作 (file operation)”といい,次の五つとする。
(a) open文
(b) close文
(c) erase文
(d) set文
(e) ask文
(7.6) 個々のファイル要素に適用する文を“記録操作 (record operation)”といい,次の七つとする。
これらには,機能語MAT及びLINEを前置した文をも含む。input操作,write操作などという場合,
その機能語を用いた文すべてを指す。例えば,write操作は,write文とmat-write文とを含む。
(a) input操作
(b) print操作
(c) read操作
(d) write操作
(e) rewrite操作
(f) delete文
(g) 指示子制御を指定したset文
79
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(7.7) 七つの記録操作は,次の対象に作用する。
(a) ファイル中のデータ
(b) プログラム中の変数
(c) ファイル指示子
(7.8) print操作,write操作,rewrite操作及びdelete文は,ファイル中のデータ及びファイル指示子に作
用する。read操作及びinput操作は,プログラム中の変数及びファイル指示子に作用する。指示子
制御を指定したset文は,ファイル指示子だけに作用する。
(7.9) 入力及び出力は,上に規定したようなファイルに対する転送だけではない。処理系は,ファイルを
処理する文を,端末装置,行印字装置,通信回線などの装置 (device) に対しても適用してよい。
この箇条11.における“ファイル (file)”という用語は,外部データの入力源 (source) 又は出力先
(destination) を全般的に意味する。すなわち,狭義のファイル又は装置を意味する。この規格中で二
つを区別する必要がある場合には,用語として“狭義ファイル (true file)”と“装置 (device)”とを使
い分ける。
(8) 装置は,次の点で狭義ファイルとは異なる。
(a) 個々の装置に書き出したデータが,そのまま保存されて後の入力操作で取り出せるか否かは,処理
系定義とする(11.1参照)。
(b) 個々の装置が消去の能力をもつか否かは,処理系定義とする(11.1参照)。
(c) 装置のファイル編成としては,相対編成及び索引編成は許されない(11.1参照)。
(d) 装置は,すべての入出力方向 (access-mode) 属性を支援しなくてもよい(11.1参照)。
(e) 装置は,132以上の記録長を保証しなくてもよい(11.1参照)。ただし,処理系は,各装置で保証さ
れる最低限の記録長を文書で示さなければならない。
(f) 個々の装置が記録設定の能力をもつか否かは,処理系定義とする(11.2参照)。
(g) 個々の装置のデータ存在状態が真になったり偽になったりするための条件は,処理系定義とする
(11.2参照)。
(h) 入力制御項目の,prompt句,timeout句及びelapsed句の意味規則は,対話方式の端末装置の場合
にだけ適用される。処理系は,(もしあれば)どの装置が対話方式の端末装置であるかを定義しなけ
ればならない。これらの入力制御項目の,他の装置及び狭義ファイルに対する効果は,処理系定義
とする(11.4参照)。
(i) 装置に対するinput操作中に,表11.1に示す条件が発生したとき,それを,11.4に規定されたとお
り続行不能な例外状態として扱うか,10.2に規定されたとおり続行可能な例外状態として扱いその
回復手続きを適用するか否かは,処理系定義とする(11.4参照)。
(9) 表11.2〜表11.4は,さまざまなファイル機能の概要を示す。詳細な仕様は,11.1〜11.5による。
80
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表11.1 端末とファイルとで異なる例外状態
11.4での
例外状態種別
10.2での
例外状態種別
条件
8105
8102
入力応答の構文誤り
8101
8103
数値変数に対応するデータ要素が数値定数で
ない
8012
8002
入力応答のデータ要素が足りない
8013
8003
入力応答のデータ要素が多すぎる
1008
1007
入力中の数値あふれ
1105
1054
入力中の文字列あふれ
表11.2 ファイル編成に対する操作及び記録設定
この表は,それぞれのファイル編成に対して有効な記録操作と記録設定の組合せを示す。編成は,許され
る記録操作の能力によって定義される。表にない記録操作と記録設定との組合せは,構文誤りとする。例え
ば,key句を指定したinput文は,構文誤りとする。
○:規格によって規定される,×:例外状態,△:処理系定義
記録操作
記録設定
ファイル編成
順編成
流れ編成
順編成
索引編成
input操作
なし
○
△(2)
△(2)
△(2)
NEXT
○
△(2)
△(2)
△(2)
BEGIN
○
△(2)
△(2)
△(2)
END
○(4)
△(2)
△(2)
△(2)
SAME
○
△(2)
△(2)
△(2)
print操作
なし
○
△(2)
△(2)
△(2)
NEXT
○
△(2)
△(2)
△(2)
BEGIN
○
△(2)
△(2)
△(2)
END
○
△(2)
△(2)
△(2)
SAME
○
△(2)
△(2)
△(2)
read操作
なし
○
○
○
○
NEXT
○
○
○
○
BEGIN
○
○
○
○
END
○(4)
○(4)
○(4)
○(4)
SAME
○
○
○
○
RECORD
×(1)
×(1)
○
×(1)
KEY
×(1)
×(1)
×(1)
○(2)
write操作
なし
○
○
○
×(3)
NEXT
○
○
○
×(3)
BEGIN
○
○
○
×(3)
END
○
○
○
×(3)
SAME
○
○
○
×(3)
RECORD
×(1)
×(1)
○
×(1)(3)
KEY(等値)
×(1)
×(1)
×(1)
○
rewrite操作及び
delete文
なし
△(5)
△(5)
○
○
NEXT
△(5)
△(5)
○
○
BEGIN
△(5)
△(5)
○
○
END
△(5)
△(5)
○(4)
○(4)
SAME
△(5)
△(5)
○
○
RECORD
△(5)
△(5)
○
×(1)
KEY
△(5)
△(5)
×(1)
○
81
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
記録操作
記録設定
ファイル編成
順編成
流れ編成
順編成
索引編成
指示子制御を指
定したset文
なし
○
○
○
○
NEXT
○
○
○
○
BEGIN
○
○
○
○
END
○
○
○
○
SAME
○
○
○
○
RECORD
×(1)
×(1)
○
×(1)
KEY
×(1)
×(1)
×(1)
○
注(1) RECORDは,相対編成ファイルにだけ有効とする。KEYは,索引編成ファイルにだけ有効とする。
(2) input操作及びprint操作は,表示形式記録に対してだけ定義する。表示形式記録は,順編成ファイル
に対してだけ定義する。
(3) 索引編成ファイルに対するwrite操作には,等値探索を指定しなければならない。
(4) ENDによってデータ存在状態は,偽となる。
(5) 相対編成及び索引編成以外のファイル編成に対するrewrite操作及びdelete文は,処理系定義とする。
表11.3 記録操作及び制御
この表は,記録操作に対して構文上許される制御機能を示す。○印は,許される制御機能を示す。
記録操作
制御
記録設定
データ存否
書式と枠
中核記録設
定(1)
すべての記
録設定
if-missing句 if-there句
書式引用
枠引用
input操作
○
○
print操作
○
○
○
read操作
○
○
○
write操作
○
○
○
rewrite操作
○
○
○
delete文
○
○
set文(2)
○
○
○
注(1) 中核記録設定=NEXT|BEGIN|END|SAME
(2) set文は,指示子制御を指定したものとする。
表11.4 ファイル編成及び記録形式
この表は,規格の規定するファイル編成と記録形式との組合せ及びそれを支援する機能単位を示す。
ファイル編成
記録形式
表示形式
内部形式
固有形式
順編成
中核
中核
固有形式拡充ファイル
流れ編成
中核
相対編成
内部形式拡充ファイル 固有形式拡充ファイル
索引編成
内部形式拡充ファイル 固有形式拡充ファイル
11.1 ファイル操作
11.1.1 概要 ファイル全体に作用する文として,次の四つ及びset文(11.3参照)がある。
(1) open文 (open-statement) は,ファイルとプログラムとの接続を行い,ファイルをプログラムから参照
可能にする。ファイルの識別に用いられる形式は,オペレーティングシステムに依存する。したがっ
て,この規格では,ファイルにはそれぞれ名前と呼ばれる文字の列が関連付けられ,その名前によっ
てオペレーティングシステムがファイルを識別することだけを想定する。プログラム中では,ファイ
ルの識別には,そのファイルの参照に使用する経路 (channel) の番号を用いる。
(2) close文 (close-statement) は,open文によって参照可能にされたファイルを,参照不能にする。
(3) erase文 (erase-statement) は,狭義ファイル中のデータの全部又は一部を削除する。装置には,何の効
82
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
果も及ぼさないことがある。
(4) ask文 (ask-statement) は,ファイルの現在の状態を問い合わせる。
11.1.2 構文 構文は,次による。ここで,(1)〜(22)は中核の生成規則,(23)〜(31)は拡充ファイルの生成
規則,(32)〜(34)は両方の機能単位に適用する構文,“固”は固有形式拡充ファイルの生成規則とする。
中核の生成規則
(1) open文=OPEN 経路指定 NAME ファイル名 ファイル属性並び
(2) 経路指定=経路式 コロン
(3) 経路式=番号記号 指標
(4) ファイル名=文字列式
(5) ファイル属性並び={コンマ ファイル属性}*
(6) ファイル属性⊃中核ファイル属性
(7) 中核ファイル属性=access句|organization句|rectype句|recsize句
(8) access句=ACCESS {INPUT|OUTPUT|OUTIN|文字列式}
(9) organization句=ORGANIZATION {ファイル編成値|文字列式}
(10) ファイル編成値⊃中核ファイル編成値
(11) 中核ファイル編成値=SEQUENTIAL|STREAM
(12) rectype句=RECTYPE {記録形式値|文字列式}
(13) 記録形式値⊃中核記録形式値
(14) 中核記録形式値=DISPLAY|INTERNAL
(15) recsize句=RECSIZE {VARIABLE|文字列式} {LENGTH 指標}?
(16) close文=CLOSE 経路式
(17) erase文=ERASE REST? 経路式
(18) ask文⊃ASK 経路指定 質問項目並び
(19) 質問項目並び=質問項目 {コンマ 質問項目}*
(20) 質問項目=属性名 変数名 変数名*
(21) 属性名⊃中核属性名
(22) 中核属性名= ACCESS|DATUM|ERASABLE|FILETYPE|MARGIN|NAME|
ORGANIZATION|POINTER|RECSIZE|RECTYPE|SETTER|
ZONEWIDTH
拡充ファイルの生成規則
(23) ファイル編成値⊃拡充ファイル編成値
(24) 拡充ファイル編成値=RELATIVE|KEYED
固(25) 記録形式値⊃拡充記録形式値
固(26) 拡充記録形式値=NATIVE
(27) ファイル属性⊃拡充ファイル属性
(28) 拡充ファイル属性=collate句
(29) collate句=COLLATE {STANDARD|NATIVE|文字列式}
(30) 属性名⊃拡充属性名
(31) 拡充属性名=RECORD|KEY|COLLATE
(32) 一つのファイル属性は,一つのファイル属性並び中では,たかだか1回だけ書くことができる。
83
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(33) 一つの属性名は,一つの質問項目並び中では,たかだか1回だけ書くことができる。
(34) 質問項目中の変数の個数及び型は,表11.5 [11.1.4(10)] に従っていなければならない。
11.1.3 例 構文の例を次に示す。
OPEN #3:NAME ”myfile”
(1)
OPEN #N:NAME A$, ACCESS OUTIN, ORGANIZATION KEYED,
RECTYPE INTERNAL, RECSIZE VARIABLE LENGTH L
(1)
OPEN #N+H1:NAME ”MY” & F$, ORGANIZATION ORG$
(1)
CLOSE #N
(16)
ERASE #3
(17)
ERASE REST #4
(17)
ASK #3:ACCESS AC$, DATUM DT$, NAME NM$, ORGANIZATION ORG$,
POINTER P$, RECSIZE RS$ NUMCHARS, RECTYPE RT$
(18)
ASK #N:KEY K$
(18)
11.1.4 意味 意味は,次による。
(1) ファイルと経路 ファイルは,プログラム単位の実行中に割り当てられる経路 (channel) を通じて参
照する。
(1.1) 経路は,BASICプログラムとの間で外部データを転送するための論理的な路とする。プログラム単
位中では,経路は,そのプログラム単位に局所的な経路番号によって識別する。経路番号は,ゼロ
以上かつ処理系定義の最大値以下の整数とする。この最大値は,99以上でなければならない。ファ
イルは,ファイル名 (file-name) によって識別する。
(1.2) 経路に割り当てられている状態のファイルは“開いている (open)”といい,割り当てられていない
状態のファイルは“閉じている (closed)”という。ファイルが割り当てられている状態の経路は“活
性状態にある (active)”といい,割り当てられていない状態の経路は“不活性状態にある (inactive)”
という。
プログラムの実行開始時点では,ゼロ番以外のすべての経路は,不活性状態とする。ゼロ番の経
路は,常に活性状態とする。ゼロ番の経路に対してopen文,close文又はerase文を実行すると,
続行可能な例外状態になる。
(1.3) ゼロ番の経路による入力及び出力は,それぞれ経路式 (channel-expression) を含まないinput操作及
びprint操作と同じ入力源及び出力先をもつ。ゼロ番の経路は,ファイル属性としてSEQUENTIAL,
DISPLAY及びOUTINをもち,記録設定及び消去の能力をもたない装置として動作する。
(2) open文 open文 (open-statement) は,ファイルを参照可能にする。
(2.1) open文は,ファイル名によって識別されるファイルを,経路式によって指定した経路番号を通じて,
プログラムから参照できるようにする。英字の大文字と小文字の別だけが異なるファイル名を,同
じファイルを表すものとするか否かは,処理系定義とする。open文の実行が成功すると,指定した
経路は活性状態になり,指定したファイルは開かれる。
既に活性状態にある経路によってファイルを開こうとすると,例外状態になる。既に開いている
ファイルを開こうとした場合の効果は,処理系定義とする。同時に活性状態になりうるゼロ番以外
の経路の個数は,中核機能単位に合致する処理系の場合には1以上,拡充ファイル機能単位に合致
する処理系の場合には2以上とする。
(2.2) open文の実行が成功すると,狭義ファイル (true file) は,それ以降,明示的な指定又は省略時想定
84
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
によって関連付けられたファイル属性に従って参照できるようになる。参照可能とは,ある種のフ
ァイル操作が可能なこと及びある種のファイル指示子 (file pointer) 操作が可能なことの二つを意
味する。ファイル属性 (file attribute) と,それに対して許される文の関係の概要は,11.0による。フ
ァイルを開こうとして,open文の要求する属性によってはそのファイルを参照可能にすることがで
きない場合,すなわち,関連する操作のうちで実行できないものがそのファイルにある場合には,
例外状態になる。
(2.3) 装置に対するopen文の実行が成功すると,二つの例外を除いて,すべてのファイル処理文は,狭
義ファイルに対するのと同じ効果をもつようになる。特に,出力の場合には同じデータが生成され,
入力の場合には値及び文字は同様に解釈され同様に変数に代入される。しかし,装置には,記録設
定(11.2参照)又はerase文[(9)参照]に関連付けられた意味を,必ずしも適用できない。個々の
装置がこれらの能力をもつか否かは,ask文によって知ることができる。
(2.4) あるファイル編成属性,記録形式属性及び記録長属性でファイルを開くことに成功した後に,その
ファイルを閉じ,その後,これらのファイル属性に関して以前と異なる値でそのファイルを開いた
場合,そのファイルがそのようなファイル属性によって参照可能になるか否かは,処理系定義とす
る。同様に,内部形式又は固有形式の記録形式属性をもつファイルに対する2回のopen文の実行
の間で,有効なarithmetic選択子が異なっている場合,そのファイルがそのようにして参照可能に
なるか否かは,処理系定義とする。
逆に,狭義ファイルを後で再び開くときに次の三つの条件が満たされている場合には,利用者が
処理系定義の手段でその間にファイルを不変に保っていたならば,そのファイルは参照可能になり,
ファイルの内容は正しく保存される。
(a) これらの三つのファイル属性の値が以前と同じである。
(b) 大小順序属性の値も以前と同じである。
(c) 内部形式又は固有形式のファイルについては,有効なarithmetic選択子も以前と同じである。ただ
し,同じarithmetic選択子とは,ここではDECIMAL, NATIVE又はFIXED(15.1参照)のこととす
る。FIXEDの後ろの省略時想定の精度指定のことではない。
装置は,必ずしもデータを保存しない。索引編成ファイルを,異なる大小順序属性のもとで再び
開くと,例外状態になる。
(2.5) 内部形式又は固有形式のファイルを,arithmetic選択子が異なる,別のプログラム単位で参照した
場合,その結果は処理系定義とする。
(2.6) 処理系は,すべての入出力方向属性の利用可能な狭義ファイルを提供しなければならない。更に,
利用できない入出力方向属性のある狭義ファイルを提供してもよい。装置は,すべての入出力方向
属性が利用可能であるとは限らない。
(2.7) 中核機能単位に合致する処理系は,ファイル編成値と記録形式値に関して,次の3種類の組合せを
受け入れ,処理しなければならない。これら以外の組合せの効果は,処理系定義とする。
(a) 順編成・表示形式
(b) 順編成・内部形式
(c) 流れ編成・内部形式
(2.8) 内部形式拡充ファイル機能単位に合致する処理系は,(2.7)の3種類に加えて,次の2種類の組合せ
をも受け入れ,処理しなければならない。
(a) 相対編成・内部形式
85
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) 索引編成・内部形式
(2.9) 固有形式拡充ファイル機能単位に合致する処理系は,(2.7)の3種類に加えて,次の3種類の組合せ
をも受け入れ,処理しなければならない。
(a) 順編成・固有形式
(b) 相対編成・固有形式
(c) 索引編成・固有形式
(2.10) 属性の値として文字列式を用いた場合,その値は,その属性に関連付けられた機能語のうちのいず
れかでなければならない。この文字列値の中では,英大文字と英小文字は,等価とする。処理系は,
ファイル属性の値を追加定義してもよい。
(3) access句 access句 (access-mode) は,データをファイルから入力転送するかファイルに出力転送する
かの方向を指示する入出力方向 (access mode) 属性を与える。この属性は,access句のもつ機能語
INPUT(入力専用),OUTPUT(出力専用),OUTIN(入出力両用)のいずれか又は値がこれらの機能
語のいずれかになる文字列式によって指定する。
(3.1) 入出力方向属性がINPUTであれば,ファイルからデータを読み込むことはできるが,そのファイル
を変更することはできない。具体的には,機能語MAT又はLINEのあるものも含め,read操作,
指示子制御を指定したset文及びinput操作は許されるが,print操作,write操作,rewrite操作及
びdelete文は許されない。
(3.2) 入出力方向属性がOUTPUTであれば,ファイルに新たなデータを加えることはできるが,ファイル
中に既に存在するデータを変更したり,ファイルからデータを取り出したりすることはできない。
具体的には,print操作,指示子制御を指定したset文及びwrite操作は許されるが,read操作,rewrite
操作,delete文及びinput操作は許されない。
(3.3) 入出力方向属性がOUTINであれば,rewrite操作及びdelete文も含めて,そのファイルに対するす
べての記録操作が許される。
(3.4) erase文は,入出力方向属性がOUTINであるファイルに対してだけ許される。
(3.5) ファイル属性並び中にaccess句を書かなかったときの入出力方向属性は,そのファイルが入出力可
能であればOUTINが与えられ,入力だけ可能であればINPUTが与えられ,出力だけ可能であれば
OUTPUTが与えられる。ゼロ番の経路は,OUTINを与えて開かれたかのように動作する。
(3.6) open文を実行すると,ファイル指示子は,出力専用として開いたファイルではファイルの終りに設
定され,その他のファイルではファイルの始めに設定される。
(4) organization句 organization句 (file-organization) は,ファイル要素間の論理的関係と,要素を識別
するためのファイル指示子の操作手段とを指定するファイル編成 (file organization) 属性を与える。こ
の属性は,organization句のもつ機能語SEQUENTIAL(順編成),STREAM(流れ編成),RELATIVE
(相対編成),KEYED(索引編成)のいずれか又は値がこれらの機能語のいずれかになる文字列式に
よって指定する。
(4.1) 装置は,順編成又は流れ編成として参照される。相対編成及び索引編成は,狭義ファイルにだけ許
される。
(4.2) 順編成ファイルは,記録 (record) の列とする。記録の順序は,記録が出力された順序になる。記録
は,ファイルの終りにだけ追加することができる。ファイル指示子によって記録を識別する手段は,
ファイル指示子の現在の位置に対する相対的な位置,特別な位置BEGIN及び特別な位置ENDだけ
を可能とする。ここで,BEGINは記録の列(もしあれば)の先頭の記録を識別し,ENDは末尾の
86
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
記録の直後の位置(記録を追加できるただ一つの位置)を識別する。1回の記録操作によって,表
示形式記録は複数個操作できるが,内部形式又は固有形式の記録はたかだか1個しか操作できない。
(4.3) 流れ編成ファイルは,記録ではなく個々の値 (value) の列であるという点を除けば,順編成ファイ
ルとほとんど同じとする。値の順序は,値が出力された順序になる。値は,ファイルの終りにだけ
追加することができる。値を識別する手段は,ファイル指示子の現在の位置に対する相対的な位置,
特別な位置BEGIN及び特別な位置ENDだけを可能とする。ここで,BEGINは値の列(もしあれば)
の先頭の値を識別し,ENDは末尾の値の直後の位置を識別する。1回の記録操作では,通常,流れ
編成ファイル中の一連の値を入力又は出力する。
(4.4) 相対編成ファイルは,記録領域 (record-area) の列とする。この記録領域は,記録を含むことも含ま
ないこともある。記録領域には,1から始まる一連の番号が与えられている。したがって,記録領
域及びその中に含まれる記録の順序は,記録領域に関連付けられた整数を識別することによって定
まる。順編成ファイルに与えられている手段のほかに,この記録番号 (record number) を使用するこ
とによってもファイル指示子を操作することができる。相対編成ファイルでは,ファイルの始めは,
記録領域中の記録の有無にかかわらず先頭の記録領域とする。ファイルの終りは,既に存在してい
る最後の記録の直後の位置とする。したがって,例えば既存の記録の最も大きい記録番号が44であ
れば,ファイルの終りは記録番号45の記録領域となる。ファイル中に記録が一つもなければ,ファ
イルの終りは記録番号1の記録領域となる。
相対編成ファイル中の記録は,読み書きできるばかりでなく,rewrite操作によって変更でき,
delete文によって削除できる。更に記録は,ファイルの終りばかりでなく,ファイルの終りを越え
た位置も含めて,任意の空の記録領域に追加することができる。1回の記録操作では,たかだか1
個の記録を操作する。
(4.5) 索引編成ファイルは,記録の列とする。個々の記録は,キー (key) と呼ばれる文字列で識別する。
記録の論理的な順序は,それらのキーの大小順序によって定まる[(7)参照]。したがって,順編成
ファイルに与えられている手段のほかに,キーを使用することによってもファイル指示子を操作す
ることができる。順編成ファイルと同様に,ファイルの始めは記録の列(もしあれば)の先頭の記
録とし,ファイルの終りは最後の記録の直後の位置とする。
記録は,列の中の任意の位置に追加できる。ただし,記録を生成するときには,正確なキーを必
ず指定しなければならず,キーの値の重複は許されない。記録はまた入力,変更及び削除すること
ができる。1回の記録操作では,たかだか1個の記録を操作する。
(4.6) open文にorganization句を書かなかったときのファイル編成属性は,そのファイルに関して利用可
能なシステム情報によって決められる。そのような情報が不十分であれば,処理系は,SEQUENTIAL
を与えてそのファイルを開こうとする。ゼロ番の経路は,SEQUENTIALを与えて開かれたかのよう
に動作する。
(5) rectype句 rectype句 (record-type) は,記録中のデータ又は個々のファイル要素としてのデータの論
理表現を指定する記録形式 (record type) 属性を与える。記録形式属性は,データがプログラムとファ
イルの間を転送されるときのデータの解釈及び変換の方法に影響を与える。この属性は,rectype句の
もつ機能語DISPLAY(表示形式),INTERNAL(内部形式),NATIVE(固有形式)のいずれか又は値
がこれらの機能語のいずれかになる文字列式によって指定する。
(5.1) 記録形式属性がDISPLAYであれば,記録が文字の列であることを示す。文字の列は,出力ではprint
操作,入力ではinput操作の意味の規定に従って処理される(10.参照)。表示形式記録は,read操
87
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
作及びwrite操作で入出力することもできる。このときは,それぞれinput操作及びprint操作に対
する規定に従う。
(5.2) 記録形式属性がINTERNALであれば,記録が型をもつ値の列である(又は一つのファイル要素が一
つの値である)ことを示す。これは,プログラム中の変数が値を含むのと同じとする。内部形式の
機能の目的は,(狭義ファイルに対して)値を保存したり取り出したりすることである。すなわち,
数値又は文字列値をプログラム中のある変数から出力し,後で他の変数に入力したとき,初めの変
数の値が変更されていなければ,二つの変数の値は正確に等しい。input操作及びprint操作は,本
質的に文字の列に対するものであるので,内部形式として開いたファイルに対して使用すると例外
状態になる。
(5.3) 記録形式属性がNATIVEであれば,記録が,プログラムに指定した枠 (template) によって記述され
ている欄 (field) の列であることを示す。この枠は,関連する記録操作の作用対象の並びと関連付け
られて,その記録中の欄の大きさ,型,個数及び順序を指定する。これによって,ファイル中のデ
ータを,同じような記録記述能力をもつ他の言語処理系との交換に適するような形に整えることが
できる。値は,記録中の欄の大きさに関する制限に従って保存される。内部形式の場合と同様に,
input操作及びprint操作は,固有形式として開いたファイルに対して使用すると例外状態になる。
(5.4) open文にrectype句を書かなかったときの記録形式属性は,そのファイルに関して利用可能なシス
テム情報によって決められる。そのような情報が不十分であれば,処理系は,DISPLAYを与えてそ
のファイルを開こうとする。ゼロ番の経路は,DISPLAYを与えて開かれたかのように動作する。
(6) recsize句 recsize句 (record-size) は,ファイル中の記録の最大長を指定する記録長 (record size) 属性
を与える。この属性は,length句によって明示的に指定できる。
(6.1) recsize句のもつ機能語VARIABLE(可変長)及び値がこの機能語になる文字列式は,可変長属性を
指定する。将来の拡充規格が固定長 (fixed-length) 記録を提供しない限り,すべてのファイルは,
可変長 (variable-length) 記録すなわち記録の長さが互いに独立な記録で構成される。表示形式記録
の長さは,その記録中の文字数とする。内部形式又は固有形式の記録の長さは,処理系定義とする。
明示的指定又は省略時想定によってopen文で決められた最大長より長い記録に対して,記録操作
を実行しようとすると,例外状態になる。length句に書く記録長の指標の値は,1以上でなければ
ならない。
(6.2) open文にrecsize句を書かなかったときの記録長属性は,そのファイルに関して利用可能なシステ
ム情報によって決められる。そのような情報が不十分であれば,処理系は,VARIABLEを与え,length
句を省略したとみなしてそのファイルを開こうとする。length句を省略したときの記録の最大長は,
処理系定義とする。ゼロ番の経路は,VARIABLEを与え,length句を省略して開かれたかのように
動作する。
(6.3) 処理系は,狭義ファイルに対して,最低限132の記録長を保証しなければならない。
(7) collate句 collate句 (collate-sequence) は,索引編成ファイルに対して記録のキーの大小順序を指定す
る大小順序 (collate sequence) 属性を与える。この属性は,collate句のもつ機能語STANDARD(標準
の大小順序),NATIVE(固有の大小順序)のいずれか又は値がこれらの機能語のいずれかになる文字
列式によって指定する。
(7.1) 大小順序属性は,索引編成ファイルに対してだけ意味をもち,他のファイル編成属性をもつファイ
ルに対しては何の効果ももたない。
(7.2) collate句によって与えられるファイルの大小順序属性は,そのファイルに対するすべての記録操作
88
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
及びファイル操作であるerase文を制御する。すなわち,read操作,write操作,rewrite操作,delete
文,指示子制御を指定したset文,erase文及びask文によってファイルを操作するとき,ファイル
の論理的な見え方は,collate句によって指定される大小順序に適合したものとなる[(4)及び11.2参
照]。大小順序属性としてファイルに与えられる標準及び固有の大小順序は,option文(6.6参照)
の場合と正確に同じ順序付けを意味する。したがって,ファイルのcollate句に関連する大小順序と
プログラム単位のcollate選択子に関連する大小順序とが一致すれば,常にファイル中のより前のキ
ーがより後のキーより小さいとして比較される。両者が一致していなければ,この関係は成り立た
ない。それでも,ファイルのcollate句に関連する大小順序とは異なったcollate選択子に関連する
大小順序をもつプログラム単位が,索引編成ファイルに入出力することはできる。すなわち,collate
句に関連する大小順序は,記録の論理的順序にだけ影響を与え,その内容には影響を与えない。
(7.3) 索引編成ファイルの機能をもつ処理系は,標準及び固有の両方の大小順序属性を支援しなければな
らない。
(7.4) open文にcollate句を書かなかったときの大小順序属性は,そのファイルに関して利用可能なシス
テム情報によって決められる。そのような情報が不十分であれば,処理系は,そのopen文を含む
プログラム単位で有効なcollate選択子に関連する大小順序と同じ順序付けを意味する大小順序属性
を与えてそのファイルを開こうとする。ゼロ番の経路は,ファイル編成属性がSEQUENTIALであ
る(索引編成ではない。)ので、大小順序属性は無関係である。
(8) close文 close文 (close-statement) を実行すると,指定された経路に割り当てられているファイルが閉
じられ,その経路は不活性状態 (inactive) になる。その経路にファイルが割り当てられていなければ,
何も起こらない。外部副プログラム定義,外部関数定義又は外部絵定義から出る時及び並行単位の終
了時には,その手続きによって開かれたすべてのファイルが,その経路が参照仮引き数でない限り自
動的に閉じられる。プログラムの終了時には,開いているすべてのファイルが自動的に閉じられる。
(9) erase文 erase文 (erase-statement) は,指定された経路に割り当てられている狭義ファイルの一部又
は全部のデータを削除する。そのファイルに関連したファイル属性は,変更されない。
(9.1) rest指定を書かないと,すべてのファイル要素を削除する。ただし,相対編成ファイルでは,すべ
ての記録領域から記録を削除する。そのファイルは空になり,ファイル指示子はファイルの終りを
指す。このときのファイルの終りは,ファイルの始めと同じとする。
(9.2) rest指定を書くと,ファイル指示子が現在指している位置以後(その位置を含む。)のすべてのデー
タを削除する。それより前のすべてのデータは,変更されずに残る。ファイル指示子は,ファイル
の終りを指すように設定される。
(9.3) 装置に対するerase文は,必ずしも有効でない。装置がこの機能を支援するか否かは,ask文によっ
て知ることができる。
(9.4) ゼロ番の経路に対してerase文を実行すると,例外状態になる。そのほかに何の効果も及ぼさない。
(9.5) erase文は,入出力方向属性としてOUTINを与えて開かれたファイルに対してだけ許される。他の
入出力方向属性のときには,例外状態になる。そのとき,ファイルには何の効果も及ぼさない。
(10) ask文 ask文 (ask-statement) を実行すると,指定された経路に現在割り当てられているファイルの
属性に対応する値が,質問項目並び中の変数に代入される。
(10.1) 質問項目と値の対応を表11.5に示す。経路が不活性状態にある場合には,文字列変数には空文字列,
数値変数にはゼロが代入される。
表11.5 質問項目

89
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
この表は,ファイルに関連してask文に書く質問項目と,その中の変数に与えられる値を示す。
a$:文字列変数,n:数値変数
質問項目
値
ACCESS a$
ファイルの入出力方向属性。すなわち,“INPUT”,“OUTPUT”又は“OUTIN”。
COLLATH a$
索引編成ファイルに関連付けられた大小順序属性。すなわち,“STANDARD”又は
“NATIVE”。索引編成以外のファイルに対しては,空文字列。
DATUM a$
ファイル指示子の現在の位置の次にあるデータ要素の型。すなわち,“NUMERIC”,
“STRING”,“NONE”(次のデータ要素がないとき)又は“UNKNOWN”(次のデータ要素
の型又は存在が決定できないとき)。DATUMは,流れ編成の内部形式ファイルに対して
だけ規定する。その他のファイル編成に対しては,処理系定義とする。
ERASABLE a$
そのファイルが消去可能(erase文によってファイル要素が削除できること)であれば
“YES”,消去可能でなければ“NO”。
FILETYPE a$
そのファイルがデータを保存できる狭義ファイルならば“FILE”,装置ならば“DEVICE”。
KEY a$
索引編成ファイルのファイル指示子によって識別される記録に関連付けられたキーの
値。ファイル指示子がファイルの終りを指しているか又はファイルが索引編成でない場
合には,空文字列。
MARGIN n
表示形式ファイルにおける現在の行幅(記録が任意に長くてよいときには,MAXNUM)。
表示形式以外のファイルに対しては,ゼロ。
NAME a$
その経路に割り当てられているファイルの名前。
ORGANIZATION a$
そのファイルのファイル編成属性。すなわち,“SEQUENTIAL”,“STREAM”,“RELATIVE”
又は“KEYED”。
POINTER a$
そのファイルのファイル指示子の現在の位置。すなわち,“BEGIN”,“MIDDLE”又は
“END”。ここで,“MIDDLE”は,始めでも終りでもないことを示す。空ファイルにおける
ファイル指示子の位置及び相対編成ファイルにおけるファイルの終り以降の位置は,
“END”になる。どの値が正しいかを処理系が決定できない装置の場合には,“UNKNOWN”
が返される。
RECORD n
ファイル指示子によって識別される記録領域の番号。相対編成以外のファイルに対して
は,ゼロ。
RECSIZE a$ n
そのファイルの記録長属性。すなわち,“VARIABLE”と記録の最大長(記録長の制限が
意味をもたないとき,例えば通信回線では,MAXNUM)。
RECTYPE a$
そのファイルの記録形式属性。すなわち,“DISPLAY”,“INTERNAL”又は“NATIVE”。
SETTER a$
そのファイルが記録設定の能力をもっていれば“YES”,もっていなければ“NO”。
ZONEWIDTH n
表示形式ファイルにおける現在の印字欄幅。表示形式以外のファイルに対しては,ゼロ。
(10.2) ゼロ番の経路に対するask文の実行の効果は,表11.6による。

90
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表11.6 ゼロ番の経路の属性
質問属性
値
ACCESS
“OUTIN”
COLLATE
空文字列
DATUM
“UNKNOWN”
ERASABLE
“NO”
FILETYPE
“DEVICE”
KEY
空文字列
MARGIN
現在の行幅
NAME
処理系定義
ORGANIZATION
“SEQUENTIAL”
POINTER
“UNKNOWN”
RECORD
ゼロ
RECSIZE
“VARIABLE”, “MAXNUM”
RECTYPE
“DISPLAY”
SETTER
“NO”
ZONEWIDTH
現在の印字欄幅
11.1.5 例外状態 例外状態は,次による。
(1) 経路式の値が,ゼロ以上処理系定義の最大値以下の範囲にない。(7001,続行不能。)
(2) open文,close文又はerase文で,ゼロ番の経路を指定している。(7002,続行可能。何もしないで処
理を続ける。)
(3) open文で指定したゼロ番以外の経路が,既に活性状態にある。(7003,続行不能。)
(4) ファイル属性を指定するための文字列式が許される値をもっていない。(7100,続行不能。)
(5) open文での明示的な指定又は省略時想定のファイル属性によるファイル参照が,可能でない。(71xx,
続行不能。xxの値と意味は,処理系定義とする。)
(6) 索引編成ファイルを,以前に開いたときの大小順序属性とは異なる大小順序属性で,再び開こうとす
る。(7050,続行不能。)
(7) length句の指標の値が,1以上でない。(7051,続行不能。)
(8) 装置を,相対編成又は索引編成として開こうとする。(7052,続行不能。)
(9) erase文で指定したゼロ番以外の経路が,不活性状態にある。(7004,続行不能。)
(10) 入出力両用として開いたのでないファイルに対して,erase文を使用する。(7301,続行不能。)
(11) 入出力両用として開いた,消去の能力のない装置に対して,erase文を使用する。(7311,続行可能。
何もしないで処理を続ける。)
11.1.6 注意 注意は,次による。
(1) 処理系が,ファイル名として,少なくとも英大文字の後に0〜3文字の英大文字又は数字が続いた文字
の列を許すことを推奨する。更に,ファイルの安全を保護する目的でオペレーティングシステムが必
要とする情報を,ファイル名の一部とみなして受け渡しをすることを推奨する。
(2) 狭義ファイルを開くのか,通信回線又は行印字装置のような,狭義ファイルでない装置を開くのかを,
処理系が,ファイル名によって区別することを推奨する。
(3) 同時に活性状態になりうる経路の個数は,ゼロ番の経路以外に4個以上とすることを推奨する。
(4) ファイル中の記録の省略時想定の最大長は特に制限をせず,どのような長さの記録も許すことを推奨
する。
(5) 処理系が,内部形式及び固有形式の記録長属性の意味を,表示形式の場合に準じて定めることを推奨
91
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する。すなわち,記録長属性で記録中の文字(バイト)の最大数を指定するようにすることを推奨す
る。
(6) この規格で定める以外に追加の入出力方向属性,ファイル編成属性,記録形式属性,記録長属性又は
大小順序属性を支援する処理系は,ask文によって追加の値を返してもよい。
(7) 処理系が,種々のファイル操作に伴う状態符号 (status code) を返すのであれば,一つの文字列値を返
す属性名IOSTATを追加して行うことを推奨する。
例 ASK IOSTAT S$は,最後に行った操作に伴うファイルの状態を表す値をS$に返す。
(8) キーの最大長は,処理系定義とする。
11.2 ファイル指示子の操作
11.2.1 概要 開いているファイルに対する指示子 (file pointer) は,データ転送を伴わずに,幾つかの方法
によって変更することができる。指示子制御 (pointer-items) を,set文 (set-statement) に指定したときのフ
ァイル指示子操作の規則は,他の記録操作と組み合わせて使用するときにも適用する。
11.2.2 構文 構文は,次による。ここで,(1)〜(7)は中核の生成規則,(8)〜(12)は拡充ファイルの生成規
則とする。
中核の生成規則
(1) 設定対象⊃経路指定 指示子制御
(2) 指示子制御=指示子制御項目|データ存否|指示子制御項目 コンマ データ存否
(3) 指示子制御項目⊃POINTER 中核記録設定
(4) 記録設定⊃中核記録設定
(5) 中核記録設定=BEGIN|END|NEXT|SAME
(6) データ存否=if-missing句|if-there句
(7) if-there句=IF THERE THEN データ存否動作
拡充ファイルの生成規則
(8) 指示子制御項目⊃拡充記録設定
(9) 記録設定⊃拡充記録設定
(10) 拡充記録設定=RECORD 指標|KEY {等値探索|大号探索} 文字列式
(11) 等値探索=等号?
(12) 大号探索=大号|非小
11.2.3 例 構文の例を次に示す。
#N:POINTER BEGIN
(1)
#3:RECORD N+1, IF MISSING THEN 1200
(1)
#4:KEY ”Jones”, IF THERE THEN EXIT DO
(1)
11.2.4 意味 意味は,次による。
(1) 指示子制御を指定したset文
(1.1) 指示子制御を指定したset文を実行すると,その経路に割り当てられたファイルに対する指示子の
設定が行われる。データ存否 (io-recovery) が指定されていれば,それは指示子の位置付けが行われ
た後に実行される。
備考 記録設定 (record-setter) に関する意味及びデータ存否の実行される時点は,すべての記録操作
を通じて同じとする(11.3,11.4及び11.5参照)。
(1.2) 11.2.5に示す例外状態のいずれかが起こると,ファイル指示子は,そのset文が実行される前の状態
92
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
のままで変更されない。装置は,記録設定の能力をもつとは限らない。ある装置が記録設定の能力
をもつか否かは,ask文によって知ることができる。
(2) 記録設定
(2.1) 記録設定を書かないと,ファイル指示子は,以前の状態のままで変更されない。その場合でも,デ
ータ存否[(3)参照]があれば,それはそのまま有効とする。
(2.2) 記録設定NEXTは,指示子を,現在の位置又はそれ以後にある,次の存在する記録(流れ編成以外
のとき)又は値(流れ編成のとき)に位置付ける。したがって,相対編成ファイルでは,指示子は,
NEXTによって次の存在する記録までにある空の記録領域をすべて飛び越す。指示子がファイルの
終り以後又は存在する記録に既に位置付けられていれば,指示子は,NEXTによって変更されない。
この機能によって,相対編成ファイルを順編成ファイルであるかのようにみなして処理することが
できる。
流れ編成ファイル及び索引編成ファイルでは,指示子は,存在するファイル要素又はファイルの
終りに常に位置付けられているので,変更されない。
順編成ファイルでは,NEXTが何らかの効果をもつのは,部分記録が保留されている場合だけと
する(11.3参照)。この場合には,記録末 (end-of-record) が作られ,指示子はファイルの終りに位
置付けられたままとする。
(2.3) 記録設定BEGINは,指示子をファイルの始め,すなわち,先頭のファイル要素に位置付ける。フ
ァイルが空であるときには,この位置はファイルの終りでもある。
(2.4) 記録設定ENDは,指示子をファイルの終りに位置付ける。ファイルの終りは,順編成ファイル,
流れ編成ファイル及び索引編成ファイルの場合には,(もしあれば)末尾のファイル要素の直後の位
置とし,相対編成ファイルの場合には,存在する最後の記録の直後の位置(記録が全く存在しなけ
れば,記録番号1の記録領域)とする。
(2.5) 記録設定SAMEによって,その経路に割り当てられたファイルを開いて以来,いちばん最近に処理
したのと同じファイル要素(複数個のこともある。)を参照することができる。その経路を通してい
ちばん最近に実行した記録操作が,次の二つの条件を満たす場合だけ,SAMEの実行は正しい。
(a) その記録操作がdelete文でない。
(b) その記録操作の実行中,少なくともファイル指示子の位置付けが完了するまでは,どのような例外
状態にもならなかった。
これらの条件を満たしていない場合,指示子操作は行われず,例外状態になる。
これらの条件を満たしている場合,その最近の記録操作がread操作,input操作,指示子制御を
指定したset文又はrewrite操作であれば,SAMEは,指示子をその操作の記録設定が位置付けたの
と同じファイル要素に再び位置付ける。その操作に記録設定の指定がなかったときは,SAMEは,
指示子をその操作の開始時にあったのと同じ位置に再び位置付ける。最近の記録操作がwrite操作
又はprint操作であれば,SAMEは,指示子をその操作によって生成された最初のファイル要素に
位置付ける。
(2.6) 記録設定RECORDは,相対編成ファイルに対して使用する場合にだけ正しい。相対編成ファイル
として開いたのでないファイルに対してこの記録設定を使用すると,指示子は変更されず,例外状
態になる。
指標は整数値に丸めて評価され,指示子は対応する記録領域に,記録のあるなしにかかわらず位
置付けられる。指標を評価した結果がゼロ以下である場合には,指示子は変更されず,例外状態に
93
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
なる。
(2.7) 記録設定KEYは,索引編成ファイルに対して使用する場合にだけ正しい。索引編成ファイルとし
て開いたのでないファイルに対してこの記録設定を使用すると,指示子は変更されず,例外状態に
なる。
等値探索 (exact-search) では,指示子は文字列式の値に等しいキーをもつ記録に位置付けられる。
該当する記録がなければ,指示子は,文字列式の値より大きいキーをもつ最初の記録に位置付けら
れる。そのような記録もなければ,指示子はファイルの終りに位置付けられる。
非小を指定した大号探索 (inexact-search) では,データ存在状態[(3)参照]の設定を除けば,等
値探索と全く同じに指示子が位置付けられる。大号を指定した大号探索では,指示子は文字列式の
値より大きいキーをもつ最初の記録に位置付けられる。該当する記録がなければ,指示子はファイ
ルの終りに位置付けられる。
(3) データ存否
(3.1) 指示子操作が完了すると,データ存在 (data-found) と呼ばれる状態が設定される。この状態は,真
又は偽の値をもつ。データ存在状態が真でかりif-there句が指定されている場合,及びデータ存在
状態が偽でかつif-missing句が指定されている場合には,データ存否動作 (io-recovery-action) が実
行される。この二つの場合以外は,データ存否動作は無視される。
(3.2) 次のいずれかの場合に,データ存在状態は偽となる。これら以外の場合には,データ存在状態は真
となる。
(a) 等値探索が指定されたが,文字列式の値に等しいキーをもつ記録が存在しない。
(b) 位置付け後,その指示子がファイルの終りを指している。
(c) 位置付け後,その指示子が空の記録領域を指している。
(d) 装置の場合に,入力に使用できるデータが存在しないことを意味する処理系定義の条件が発生して
いる。
(3.3) データ存否動作がexit-do文又はexit-for文であれば,その文は通常と同じ効果をもつ(8.3参照)。
データ存否動作が行番号であれば,指定した行から実行を続ける。
11.2.5 例外状態 例外状態は,次による。
(1) 不活性状態にある経路に対して指示子制御を指定したset文を実行する。(7004,続行不能。)
(2) ゼロ番の経路に対して記録設定を使用する。(7002,続行可能。何もしないで処理を続ける。)
(3) 記録設定の能力をもたない装置に対して,記録設定を使用する。(7205,続行可能。何もしないで処理
を続ける。)
(4) 指定した経路に対していちばん最近に実行した記録操作がdelete文であるにもかかわらず,記録設定
SAMEを使用する。(7204,続行不能。)
(5) 指定した経路に対していちばん最近に実行した記録操作が,指示子操作がなされる前に例外状態を引
き起こしたにもかかわらず,記録設定SAMEを使用する。(7204,続行不能。)
(6) 指定した経路に対して,開いて以来全く記録操作を実行していないにもかかわらず,記録設定SAME
を使用する。(7204,続行不能。)
(7) 相対編成以外のファイル編成属性で開いたファイルに,記録設定RECORDを使用する。(7202,続行
不能。)
(8) 索引編成以外のファイル編成属性で開いたファイルに,記録設定KEYを使用する。(7203,続行不能。)
(9) 記録設定RECORDの指標の値がゼロ以下である。(7206,続行不能。)
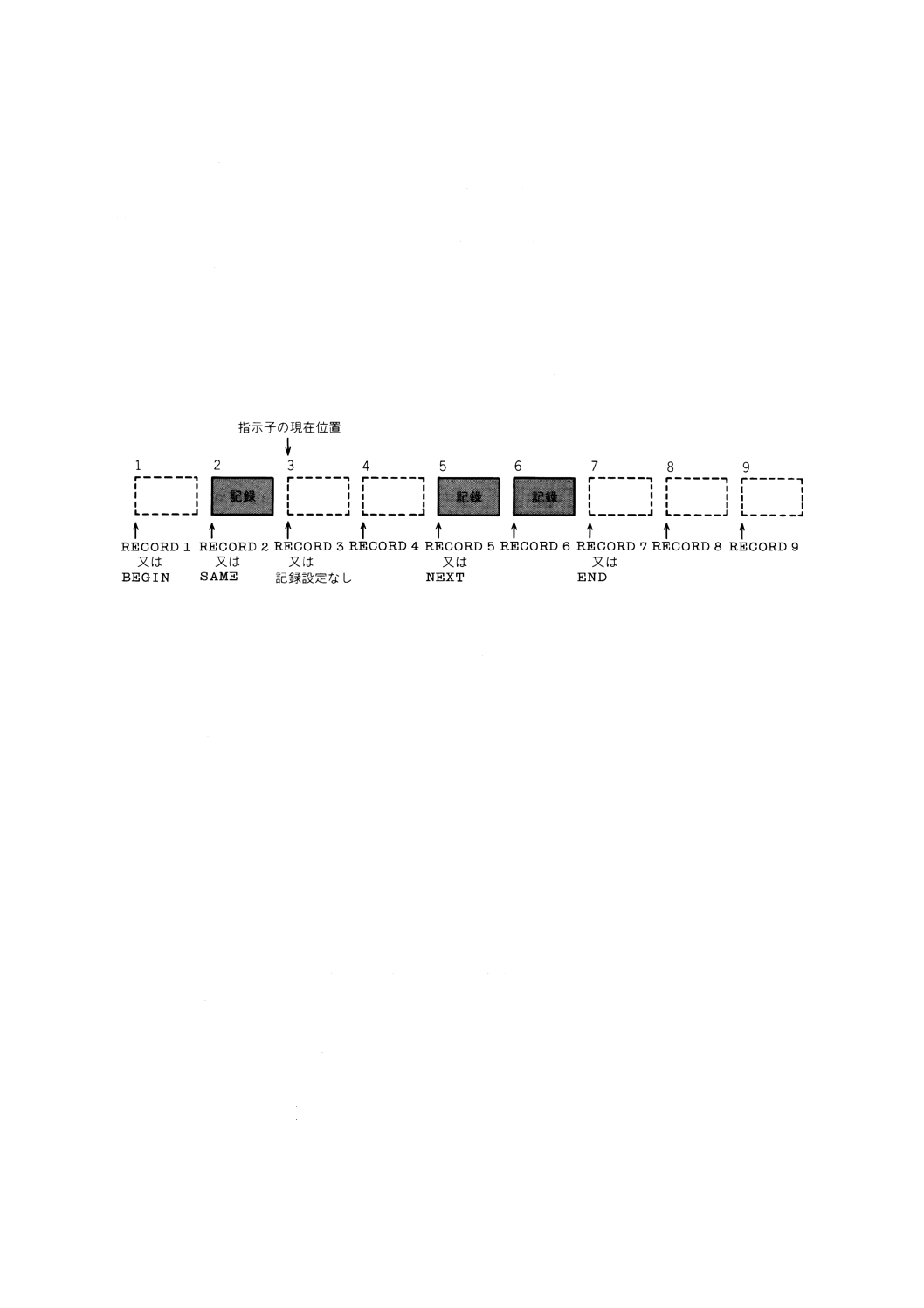
94
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(10) 記録設定KEYにおいて,空文字列による等値探索を指定している。(7207,続行不能。)
11.2.6 注意 注意は,次による。
(1) 装置の場合,例えば次のような条件によって,データ存在状態が偽となることがある。
(a) カード読取り装置に読み込むカードが尽きた。
(b) 端末から位置1/10の制御文字 (control-Z) が送られた。(これは,ある種のシステムではファイルの
終りを意味する。)
(c) 装置が,行印字装置のような出力専用装置である。
(2) 相対編成ファイルに対する記録設定の効果を,図11.1に例示する。
図11.1 相対編成ファイルに対する記録設定の効果の例示
相対編成ファイル中に,記録番号2,5,6の三つの記録だけが存在するとする。記録設定RECORD 2を
指定したread文を実行した直後の各記録設定は,ファイル指示子を次のように位置付ける。
11.3 ファイルへのデータ生成
11.3.1 概要 利用者は,プログラムによって作成されたデータを外部に出力することができる。狭義ファ
イル (true file) の場合,後のプログラムによってそのデータを入力したり変更したりすることができる。
この機能は,10.の出力機能をファイル向きに拡充したものとする。更に,さまざまな記録形式 (record-type)
向きの出力を行う新しい機能も定める。set文のmargin句及びzonewidth句は,データ生成文 (data creation
statement) には含まれないが,表示形式記録と関連するので,ここで規定する。
11.3.2 構文 構文は,次による。ここで,(1)〜(11)は中核の生成規則,(12)〜(27)は拡充ファイルの生成
規則,(28)〜(35)は両方の機能単位に適用する構文,“固”は固有形式拡充ファイルの生成規則とする。
中核の生成規則
(1) print文⊃PRINT 経路式 印字制御 {コロン {印字項目並び|書式印字式並び}}?
(2) mat-print文⊃MAT PRINT 経路式 印字制御 コロン {印字配列名並び|書式印字配列名並び}
(3) 印字制御={コンマ 印字制御項目}*
(4) 印字制御項目=中核記録設定|if-there句|USING 書式引用
(5) 設定対象⊃経路指定 {MARGIN|ZONEWIDTH} 指標
(6) write文=WRITE 経路式 書出し制御 コロン 式並び
(7) mat-write文=MAT WRITE 経路式 書出し制御 コロン 配列名並び
(8) 書出し制御={コンマ 書出し制御項目}*
(9) 書出し制御項目⊃記録設定|if-there句
(10) 式並び=式 {コンマ 式}*
(11) 配列名並び=配列名 {コンマ 配列名}*
拡充ファイルの生成規則
固(12) 書出し制御項目⊃枠引用
95
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
固(13) 枠引用=WITH {行番号|文字列式}
固(14) 宣言文⊃template文
固(15) template文=TEMPLATE コロン 枠要素並び
固(16) 枠要素並び=枠要素 {コンマ 枠要素}*
固(17) 枠要素=欄数固定 {欄指定子|左括弧 枠要素並び 右括弧}|欄数不定 欄指定子
固(18) 欄数固定=SKIP? {符号なし整数 OF}?
固(19) 欄数不定=疑問符 OF
固(20) 欄指定子=数値欄指定子|文字列欄指定子
固(21) 数値欄指定子=NUMERIC 星印 数値欄幅
固(22) 数値欄幅=小数点指定|E
固(23) 小数点指定=整数幅 小数点?|整数幅? 小数点 小数幅
固(24) 整数幅=符号なし整数
固(25) 小数幅=符号なし整数
固(26) 文字列欄指定子=STRING 星印 文字列欄幅
固(27) 文字列欄幅=符号なし整数
(28) print文又はmat-print文において,書式引用と印字項目並び又は印字配列名並びとを併用することは
できない。すなわち,印字制御として書式引用を書いたときにこれらの文に使用できるのは,書式印
字式並び又は書式印字配列名並びだけとする。
(29) 枠引用の行番号は,同じプログラム単位中のtemplate文を参照するものでなければならない。
(30) 欄数固定における符号なし整数の値は,1以上とする。
(31) 小数点指定において,整数幅又は小数幅の少なくとも一方は,1以上とする。
(32) 文字列欄幅は,1以上とする。
(33) 書出し制御中の記録設定には,大号探索を指定してはならない。
(34) 一つの印字制御項目は,一つの印字制御中では,たかだか1回だけ書くことができる。
(35) 一つの書出し制御項目は,一つの書出し制御中では,たかだか1回だけ書くことができる。
11.3.3 例 構文の例を次に示す。
PRINT #3:A, B, C
(1)
PRINT #3, END, USING 123:A$, B+C;
(1)
MAT PRINT #N, SAME, IF THERE THEN EXIT FOR:A$;B$, C
(2)
#3:MARGIN N+1
(5)
WRITE #3, RECORD 47, IF THERE THEN 666:A+B, C$ & D$
(6)
WRITE #X+Y, WITH TEMPLATE3$:X, Y, Z+W
(6)
MAT WRITE #3, KEY ”Whoever”, IF THERE THEN 666, WITH 111:A, B$
(7)
TEMPLATE:STRING*5, 2 OF NUMERIC*3.4
(15)
TEMPLATE:?OF NUMERIC*5.2,? OF STRING*5
(15)
5 OF STRING*22, 3 OF NUMERTC*E,? OF NUMERIC*.6
(16)
11.3.4 意味 意味は,次による。ここで,(1)は,すべてのデータ生成文に対する一般的な規則を定める。
すべての場合において,データ生成文は,ファイルに対して一つ以上の新しいファイル要素 (file element)
を追加するが,既存のファイル要素には影響を与えない。(2)〜(13)は,個々の文の構文形式に特有の規則
を文の形式ごとに定める。
96
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(1) データ生成処理
(1.1) 最初に,経路式によって,データを出力する経路 (channel) が定められ,意図した操作にファイル
属性が適合するか否かが調べられる。データ生成文においては,入出力方向属性が出力専用又は入
出力両用でなければならない。経路が活性状態にあり,ファイル属性がデータ生成文に適合するな
らば,次の段階に進む。そうでなければ,ファイル,ファイル指示子及びすべてのプログラム変数
は変更されず,例外状態になる。
(1.2) 段階2の処理では,記録設定 (record-setter) に基づいて(記録設定がない場合にも),11.2.4(2)の規
定どおりにファイル指示子 (file pointer) の位置付けが行われ,11.2.4(3)の規定どおりにデータ存在
状態 (data-found) が設定される。データ存在状態が真である場合,if-there句を指定してあるときは
データ存否動作が実行され,指定してないときは例外状態になる。いずれのときにも,指示子の位
置及びファイルは変更されたままとする。
(1.3) データ存在状態が偽である場合には,段階3に進み,指示子によって指された位置にデータが出力
される。並びの作用対象が左から右に順番に評価され,データがちょうどファイル要素を満たすま
でになると,ファイル要素がファイルに追加され,指示子は生成されたファイル要素の直後の位置
を指す。特に,データ転送の途中で例外状態になったときに,ファイル要素の一部分だけがファイ
ルに追加されることはない。しかし,一つの文が複数個のファイル要素を生成しているときには,
例外状態になるまでに生成されたファイル要素は,ファイル中に残る。
データ転送が終わった時に,ファイル指示子は,最後に生成されたファイル要素の次のファイル
要素(次のファイル要素がないときはファイルの終り)を指している。例外状態になり,ファイル
要素が生成されなかった場合には,指示子は,段階2で設定された位置にとどまる。
(2) print文
(2.1) print文によるデータ転送は,10.3及び10.4による。ただし,生成される一連の文字の列が現在行
ではなく表示形式ファイルの1記録を構成し,そこで行末ではなく記録末が生成される。文字の列
をもたない記録を生成することもできる。
記録末は,ファイル中の一つのファイル要素の生成が完了したことを示す手段とし,処理系定義
とする。すなわち,記録末が生成されると,データ生成文を用いて,この記録を変更したりこの記
録にデータを追加したりすることはできなくなる。(2.2)に定める特別な場合を除いて,有効な記録
末が生成されるまでファイルにデータが実際に追加されることはない。すなわち,その場合を除い
て,部分記録がファイルに追加されることはない。
記録末の生成位置を制御する実効行幅は,そのファイルを開く時にrecsize句の値として与えるか,
又は開いた後でこの経路に対してmargin句のあるset文を実行して与える[(4)参照]。
(2.2) ここに定める特別な場合に限って,部分記録 (partial record) がファイルに追加される。すなわち、
印字項目並び又は書式印字式並びの末尾に印字区切りがある場合,部分記録がファイルの終りに生
成され,指示子が部分記録の直後のファイルの終りを指して,文の実行が完了する。文の実行が完
了する前に例外状態になると,(1.3)と同様に,部分記録はファイルに追加されない。
この経路に対する次の操作が記録設定なしのprint文である場合にだけ,そこで生成される一連
の文字の列が,行幅に関する通常の規則に従ってこの部分記録の後ろに追加される。その経路に対
する次の操作がそのようなprint文でない場合には,他のあらゆる処理に先立って,部分記録は後
ろに記録末を付けられて完成し,指示子はファイルの終りを指す。
(3) mat-print文
97
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3.1) mat-print文 (array-print-statement) によるデータ転送は,10.5による。ただし,生成される一連の文
字の列が現在行ではなく表示形式ファイルの1記録を構成し,そこで行末ではなく記録末が生成さ
れる。
(3.2) mat-print文では,10.5の規定どおり,部分記録が,印字配列名並びを指定したときは生成されず,
末尾にセミコロンのある書式印字配列名並びを指定したときは生成される。mat-print文は常に新た
な行を開始するので,部分記録を完成するために用いることはできない。実効行幅の制御は,(2)及
び(4)による。
(4) 行幅の設定
(4.1) 行幅 (margin) は,開いている表示形式ファイルの一つごとに定められ,一つの記録が含むことので
きる文字の最大個数とする。行幅は,print文及びmat-print文において,記録末を生成する位置を
定める。ファイルを開いた時点では,実効行幅は,recsize句に書いたlength句の指標の値,又はlength
句を省略したときは処理系定義の値とする。この処理系定義の値は,印字欄幅の省略時想定値以上
とする。
(4.2) margin句のあるset文は,活性状態にある経路の行幅を,指定した指標の値に変更する。margin句
の影響を受けるファイル中に部分記録が存在する場合には,次にその部分記録にデータを追加する
時に新しい行幅が採用される。行幅としてMAXNUMを設定すると,記録は任意の長さにできる。
ファイルを閉じると,margin句の効果はなくなる。
(4.3) 可能な行幅の最大値は,処理系定義とする。
(5) 印字欄幅の設定
(5.1) 印字欄幅 (zone width) は,開いている表示形式ファイルの一つごとに定められ,print操作の効果を
10.3で規定したとおりに制御する。ファイルを開いた時点では,印字欄幅は処理系定義の省略時想
定値に設定される。その値は,d+e+6以上とする[10.3.4(3)参照]。
(5.2) zonewidth句のあるset文は,活性状態にある経路の印字欄幅を,指定した指標の値に変更する。右
端以外の印字欄の幅は,すべて同じとする。端数があるとき,右端の印字欄が短くなる。zonewidth
句の影響を受けるファイル中に部分記録が存在する場合には,次にその部分記録にデータを追加す
る時に新しい印字欄幅が採用される。set文のzonewidth句の指標の値は,1以上でなければならな
い。ファイルを閉じると,zonewidth句の効果はなくなる。
(5.3) 可能な印字欄幅の最大値は,処理系定義とする。
(6) 表示形式記録とprint操作 表示形式記録は,文字の列とし,10.に規定したとおりprint操作によっ
て生成される。数値の精度は,処理系定義の有効数字部の幅又は書式項目(10.4.2参照)の長さ,及
び有効なarithmetic選択子によってだけ制限を受ける。
(7) ゼロ番の経路とprint操作 ゼロ番の経路に対するprint操作は,記録設定及び消去の能力をもたない
装置の定義に従って処理される。出力データの出力先は,経路指定を省略した場合と同じとする。例
外状態に対して,10.と11.とで異なった回復手続きが規定されている場合には,10.の手続きを適用す
る。margin句又はzonewidth句のあるset文にゼロ番の経路を指定したときの効果は,経路指定を省
略したときと同じとする。
(8) write操作 write文 (write-statement) 及びmat-write文 (array-write-statement) は,どの記録形式の記
録をも生成する。式の値は,その順序に従って,値,欄又は文字の列に配置され,ファイルに書き出
される。部分記録が生成されることはない。
(9) ファイル編成とwrite操作
98
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(9.1) 流れ編成 (stream) ファイルに対しては,一つの文で複数個のファイル要素を生成できる。具体的に
は,一つの式又は一つの配列要素を評価するたびに一つのファイル要素が生成される。内部的な評
価の間に例外状態になると,既に生成されている値はファイル中に残り,ファイル指示子はファイ
ルの終りを指し,残りの値は無視される。
(9.2) 流れ編成でなく,表示形式でないファイルに対しては,式又は配列によって生成された一つ以上の
値又は欄が一つの記録を形成する。したがって,文の実行の完了前に例外状態になると,記録はフ
ァイルに書き出されず,ファイル指示子は段階2で設定された位置にとどまる。
(9.3) 索引編成 (keyed) の記録は,キーによって識別されるので,新しい記録の生成時に,明示的にキー
を指定する必要がある。すなわち,索引編成ファイルに書出しを実行するときには,記録設定に等
値探索 (exact-search) を指定しなければならない。データ存在状態が偽ならば,等値探索の文字列
式に等しい値のキーの位置に新しい記録が挿入される。
(10) 表示形式記録とwrite操作
(10.1) 表示形式 (display) 記録に対してwrite操作を実行すると,同じ式並び又は配列名並びでprint操作
を実行したときと全く同じ記録の列及び文字の列を生成する。ただし,write操作は記録向きである
ので,行向きであるprint操作のすべての機能を含んでいるわけではない。
(10.2) 表示形式ファイルに対しては,行幅を越える出力の場合に,一つの文が複数個のファイル要素を生
成することがある。一つのファイル要素の生成途中で続行不能な例外状態になると,その文によっ
て既に生成されているファイル要素はファイル中に残り,ファイル指示子はファイルの終りを指し,
残りの式は無視される。
(11) 内部形式記録とwrite操作
(11.1) 内部形式 (internal) 記録及び流れ編成ファイルは,値の列とする。この値には,数値型と文字列型
の2種類の型がある。
(11.2) 値の列とそれらの型は,値を生成するときの式又は配列要素によって定められる。ファイルに記録
された値を後で読み込むことは,その値を生成した式又は配列要素をlet文によってその入力変数
に代入するのと同じ効果をもつ。文字列値の長さと内容は,保持される。数値は,有効なarithmetic
選択子で指定された精度の通常の制限に従って保持される。
(12) 固有形式記録とwrite操作
(12.1) 枠 (template) は,記録中の欄 (field) の位置,幅及び型を記述する。固有形式 (native) ファイルに
書き出すときには,必ず枠を使用しなければならない。枠は,他の記録形式に使用してはならない。
一つのデータ生成文は,文中の枠引用 (template-identifier) によって一つの枠を引用する。
(12.2) 枠引用は,template文 (template-statement) 又は文字列式を指定する。文字列式の場合,その値は,
構文的に正しい枠要素並びでなければならない。write文及びmat-write文においては,枠引用の文
字列式を評価してから出力される式並び又は配列名並びを評価する。同じtemplate文を二つ以上の
文で引用してもよい。
(12.3) 固有形式記録にデータを生成するときには,式並び中の一つの式ごとに,枠中の一つの欄指定子
(field-specifier) が関連付けられる。次いでその欄指定子を用いて,その式の値が記録中の一つの欄
に変換される。この関連付けは,式並び中の一つの式に枠要素並び中の次に使用可能な一つの欄指
定子を用いて,左から右に順番に行われる。
(12.4) 式の型(数値又は文字列)が欄指定子の型と一致しない場合は,例外状態になる。式の個数は,欄
指定子の個数より多くてはならない。最後の式の後の余分な欄指定子は,無視される。欄の内容は,
99
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
式の値と欄指定子の幅の指定によって定められる。
(12.5) 文字列値の場合に,文字列欄幅 (string-field-size) とは,その欄の文字数とする。文字列値は,その
欄の中で左寄せされる。文字列長が欄幅より長い場合は,例外状態になる。短い場合は,欄の右側
に空白が埋められる。
(12.6) 数値欄は,数値として符号と絶対値の両方を保持する。符号は常に欄中に保持されるが,数値欄幅
(numeric-field-size) は,数値の絶対値の幅だけを明示的に指定する。数値欄幅Eに対しては,有効
なarithmetic選択子に関する処理系定義のけた数の有効数字が保持される。小数点指定
(fixed-point-size) に対しては,整数幅 (integer-size) が小数点以上のけた数を定め,小数幅
(fraction-size) が小数点以下のけた数を定める。整数幅又は小数幅を省略すると,それぞれゼロとみ
なされる。数値は,これらの幅に従って記録される。欄で使用可能なけた位置の右端を越えて有効
数字がある場合には,その値は丸められて記録される。欄は,この結果,値ゼロをもつこともあり
うる。欄で使用可能なけた位置の左端を越えて有効数字がある場合には,例外状態になる。
(12.7) 枠中の欄数固定 (fixed-field-count) は,単独又は一連の欄指定子の飛越し又は反復を示す。欄数固定
の符号なし整数は反復の回数を示し,skip指定は飛越しする欄を生成することを示す。欄数は,そ
の枠要素中の対象(欄指定子又は括弧でくくられた枠要素並び)に適用する。
欄数に符号なし整数を書くと,その欄数によって制御される対象をその回数だけ明示的に書いた
のと同じ効果をもつ。
欄数にskip指定を書くと,それによって制御される欄指定子が,式並び又は配列名並びの値と関
連付けられないことを示す。記録を生成するとき,記録中のその欄は,その欄指定子の通常の幅と
型に従って,数値ならゼロの値,文字列なら空白の値になる。ある欄指定子が(入れ子になった)
複数個のskip指定によって制御されているときは,その効果は一つのときと同じとする。
例 次の式並び及び枠要素並びを考える。
(a) A,B,C及びNUMERIC*4,NUMERIC*5,NUMERIC*6
(b) D,E及びNUMERIC*4,SKIP NUMEIRIC*5,NUMERIC*6
このとき,AとD,CとEは,それぞれ同じ欄位置を占める。2番目の記録の2番目の欄は,1
番目の記録のBによって占められた欄と幅が同じで,値はゼロである。
(12.8) (12.7)の規定によって等価となる枠要素並びの対を例示する。
例1.
(a) STRING*4, STRING*4, STRING*4
(b) 3 OF STRING*4
例2.
(a) STRING*5, STRING*4, NUMERIC*2, NUMERIC*2, NUMERIC*2, STRING*4,
NUMERIC*2, NUMERIC*2, NUMERIC*2
(b) STRING*5, 2 OF (STRING*4, 3 OF NUMERIC*2)
例3.
(a) SKIP NUMERIC*3, SKIP NUMERIC*3, NUMERIC*4, SKIP STRING*5,
SKIP STRING*6
(b) SKIP 2 OF NUMERIC*3, NUMERIC*4, SKIP (STRING*5,
SKIP STRING*6)
ここで,例3の(b)のSTRING * 6の直前のskip指定は,冗長である。
100
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(12.9) 欄数不定 (variable-field-count) は,配列に関連してだけ用いることができる[(13)参照]。
(12.10) プログラムの実行がtemplate文の行に到達すると,何もしないで次の行に進む。
(13) mat-write文
(13.1) 内部形式記録及び固有形式記録に対するmat-write文 (array-write-statement) の効果は,その配列の
配列要素を行方向の順番(最後の添字が最も早く変わる順番)で明示的に指定したwrite文と同じ
とする。
例 DIM A(3),B(2, 2)とOPTION BASE 1が有効である場合には,次の二つの文は等価である。
(a) MAT WRITE #3:A, B
(b) WRITE #3:A(1),A(2),A(3),B(1,1),B(1,2),B(2,1),B(2,2)
(13.2) 固有形式記録の書出しには,配列名並び中の配列は欄数不定を用いることができる。欄数固定の場
合には,write文と同様に,欄指定子の個数及び型がその配列要素のものと一致しなければならない。
一方,ある配列の最初の要素に欄指定子を関連付ける時に,前の枠要素がちょうど完了したところ
であって(又は,この配列が並び中の最初のものであって),かつ次の枠要素が欄数不定であれば,
その欄指定子がその配列のすべての要素に使用される。その配列が評価された後,次の配列があれ
ば,それは次の枠要素を使用する。これは,欄数不定であってもなくてもよい。一つの配列の出力
に,欄数不定と欄数固定を併用してはならない。どちらか一方だけを指定する。
(14) 一般に,入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及び
その入出力装置の状態は,処理系定義とする。この規定は,10.及び11.の入出力全般に適用する。
参考 ANSI X3.113にはこの(14)項がないが,TIBによって補った。
11.3.5 例外状態 set文に関する例外状態は,(1)〜(5)による。データ生成文に関する(6)〜(20)の例外状態
は,それが検出される処理段階に従って分類する。段階1の例外状態では,ファイル及びファイル指示子
は変更されない。段階2の例外状態では,ファイルは変更されない。段階3の例外状態では,その時点で
幾つかのファイル要素が生成されていることがありうる。
(1) set文のmargin句の指標の値が,そのファイルの現在の印字欄幅の値より小さい。(4006,続行不能。)
(2) set文のzonewidth句の指標の値が,1より小さい又はそのファイルの現在の行幅の値より大きい。
(4007,続行不能。)
(3) margin句又はzonewidth句のあるset文が,不活性状態にある経路を指定している。(7004,続行不能。)
(4) margin句又はzonewidth句のあるset文が,表示形式として開いたのでないファイルを指定している。
(7312,続行不能。)
(5) margin句又はzonewidth句のあるset文が,入力専用として開いたファイルを指定している。(7313,
続行不能。)
段階1の例外状態
(6) データ生成文が,不活性状態にある経路を参照している。(7004,続行不能。)
(7) print文又はmat-print文が,内部形式又は固有形式として開いたファイルを参照している。(7317,
続行不能。)
(8) 記録設定を正しく処理できない。(11.2.5に規定する例外状態7002及び7202〜7207による。)
(9) データ生成文が,入力専用として開いたファイルを参照している。(7302,続行不能。)
(10) write文又はmat-write文が索引編成ファイルを参照しているが,記録設定の中に等値探索を指定して
いない。(7314,続行不能。)
(11) 枠引用の文字列式が構文的に正しい枠要素並びでない。(8251,続行不能。)
101
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(12) 枠引用を,表示形式又は内部形式として開いたファイルに対して使用する。(7315,続行不能。)
(13) 枠引用を指定してないwrite文又はmat-write文が,固有形式として開いたファイルを参照している。
(7316,続行不能。)
段階2の例外状態
(14) データ生成文に対して,データ存在状態が真であって,かつif-there句の指定がない。(7308,続行不
能。)
段階3の例外状態
(15) 表示形式でなく,recsize句で指定した値より長い記録を生成しようとする。(8301,続行不能。)
(16) 式又は配列要素の型が,関連する欄指定子の型(数値又は文字列)と一致しない。(8252,続行不能。)
(17) 欄数不定を指定した枠要素が配列の最初の要素に対応しない。(8253,続行不能。)
(18) 式及び配列要素に対して十分な個数の欄指定子が枠中にない。(8254,続行不能。)
(19) 数値が,枠中の欄で使用可能なけた位置の左端を越えて有効数字をもつ。(8255,続行不能。)
(20) 文字列値が,枠中の欄の幅より長い。(8256,続行不能。)
11.3.6 注意 注意は,次による。
(1) 処理系は,枠要素並びに対して,例えば,新しくデータの型を追加するような構文上の拡張をしても
よい。そのとき,構文的に正しくないことを示す例外状態は,拡張した枠要素並びの定義に従う。
(2) 欄数不定の指定は,プログラム中で大きさの変わりうる配列を書くときに特に有効である。欄数固定
を指定するには,事前に正確な大きさを知らなければならない。
11.4 ファイルからのデータ入力
11.4.1 概要 プログラムは,ファイル用のデータ入力文 (data retrieval statement) を用いて装置又は以前に
データ生成したファイルからデータを入力する。この機能は,10.の入力機能をファイル向きに拡充したも
のとする。更に,さまざまな記録形式向きの入力を行う新しい機能も定める。
11.4.2 構文 構文は,次による。ここで,(1)〜(10)は中核の生成規則,(11)は拡充ファイルの生成規則,
(12)〜(15)は両方の機能単位に適用する構文,“固”は固有形式拡充ファイルの生成規則とする。
中核の生成規則
(1) input文⊃INPUT 経路式 入力制御 コロン 変数名並び {コンマ SKIP REST}?
(2) mat-input文⊃MAT INPUT 経路式 入力制御 コロン {再定義配列並び|不定長ベクトル}
(3) line-input文⊃LINE INPUT 経路式 入力制御 コロン 文字列変数名並び
(4) mat-line-input文⊃MAT LINE INPUT 経路式 入力制御 コロン 再定義文字列配列並び
(5) 入力制御={コンマ 入力制御項目}*
(6) 入力制御項目=中核記録設定|if-missing句|prompt句|timeout句|elapsed句
(7) read文⊃READ 経路式 読込み制御 コロン 変数名並び {コンマ SKIP REST}?
(8) mat-read文⊃MAT READ 経路式 読込み制御 コロン 再定義配列並び
(9) 読込み制御={コンマ 読込み制御項目}*
(10) 読込み制御項目⊃記録設定|if-missing句
拡充ファイルの生成規則
固(11) 読込み制御項目⊃枠引用
(12) 枠引用の行番号は,同じプログラム単位中のtemplate文を参照するものでなければならない。
(13) 一つの入力制御項目は,一つの入力制御中では,たかだか1回だけ書くことができる。
(14) 一つの読込み制御項目は,一つの読込み制御中では,たかだか1回だけ書くことができる。
102
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(15) 不定長ベクトルの配列は,1次元でなければならない。
11.4.3 例 構文の例を次に示す。
INPUT #3:A,B,C,A$
(1)
MAT INPUT #W, BEGIN, IF MISSING THEN EXIT DO:A,B$
(2)
LINE INPUT #Q, NEXT:A$, B$, C$
(3)
MAT LINE INPUT #4, IF MISSING THEN 1234:A$, B$(N), C$(8)
(4)
READ #3, SAME, WITH 333:W$, SKIP REST
(7)
MAT READ #N, RECORD P+2, IF MISSING THEN 111, WITH 222:V, W(Q)
(8)
11.4.4 意味 意味は,次による。ここで,(1)は,すべてのデータ入力文に対する一般的な規則を定める。
(2)〜(13)は,個々の文の構文形式に特有の規則を文の形式ごとに定める。
(1) データ入力処理
(1.1) 最初に,経路式によって,データを入力する経路 (channel) が定められ,意図した操作にファイル
属性が適合するか否かが調べられる。データ入力文においては,入出力方向属性が入力専用又は入
出力両用でなければならない。経路が活性状態にあり,ファイル属性がデータ入力文に適合するな
らば,次の段階に進む。そうでなければ,ファイル指示子及びすべてのプログラム変数は変更され
ず,例外状態になる。
(1.2) 段階2の処理では,記録設定 (record-setter) に基づいて(記録設定がない場合にも),11.2.4(2)の規
定どおりにファイル指示子 (file pointer) の位置付けが行われ,11.2.4(3)の規定どおりにデータ存在
状態 (data-found) が設定される。データ存在状態が偽である場合,if-missing句を指定してあるとき
はデータ存否動作が実行され,指定してないときは例外状態になる。いずれのときにも,指示子の
位置は変更されたままとする。
(1.3) データ存在状態が真である場合には,段階3に進み,指示子によって指されたファイル要素から実
際のデータ入力が行われる。データは,一つ以上のファイル要素から各作用対象(変数又は配列)
に,左から右に順番に転送され,そのファイルの一連のデータ要素,値又は欄が,一連の変数又は
配列に代入される。
このとき,添字,部分文字列指定又は再定義上下限指定部があれば,それらは,先行する(すな
わち左側の)作用対象にデータが代入されてから評価され,続いてそれらを含む作用対象にデータ
が代入される。部分文字列指定のある文字列変数への文字列値の代入は,6.5で規定した文字列代入
の通常の意味に従って行われる。
データ転送中に例外状態になると,正当な代入が行われた変数及び配列要素は新しい値をもつが,
後続のすべての変数及び配列要素はもとの値のままとする。データ入力操作が完了すると,指示子
は,次のファイル要素,すなわちファイルの次の記録,記録領域又は値を指すように進められる。
(1.4) 1回のデータ入力操作は,通常,一つのファイル要素にだけ影響を及ぼす。ただし,次の三つの場
合には,複数個のファイル要素が処理されることがある。
(a) line-input文及びmat-line-input文
(b) 流れ編成ファイルに対するread操作
(c) 末尾に(データの継続を示す)コンマのある記録をもつ表示形式ファイルに対するinput操作又は
read操作
(1.5) skip-rest指定は,流れ編成以外のファイルに対してだけ指定できる。指定すると,最後のデータ要
素,値又は欄を得た記録の残りの部分は無視される。枠を指定した場合には,残りの欄指定子も無

103
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
視される。skip-rest指定があっても,記録中には,並びの中の変数又は配列を満たすのに十分な個
数のデータがなければならない。
(1.6) この段階3の処理の間に,さまざまな例外状態になることがある。各例外状態は,特定のファイル
要素に関連している。どの場合にも,指示子は例外状態に関連したファイル要素の直後の要素を指
すように進められる。これらの例外状態に関連するファイル要素を,表11.7に要約する。
表11.7 例外状態に関連するファイル要素
例外状態
関連するファイル要素
recsize句の指定より長いファイル要素
そのファイル要素
不正な再定義上下限指定部,不正な添字,不正な
部分文字列指定,大きすぎる再定義上下限指定
データを得ようとしたファイル要素
不適切な枠。すなわち,型の不一致,配列の最初
の要素以外に対する欄数不定の指定“?”,欄指定
子の個数の不足
データを得ようとしたファイル要素
不適切なデータ。すなわち,型の不一致,不正な
構文,あふれ
そのデータを含むファイル要素
ファイル要素中のデータの個数の不足
データの個数の不足したファイル要素
ファイル中のデータの個数の不足
ファイルの終り(すなわち,関連するファイル要
素はない。)
ファイル要素中のデータの個数の余分
余分なデータをもつファイル要素
(2) input文
(2.1) prompt句,timeout句及びelapsed句の効果は,10.2による。これらの入力制御項目は,対話方式
の端末装置にだけ有効とする。その他の装置及び狭義ファイル (true file) に対するこれらの句の効
果は,処理系定義とする。
(2.2) input文 (input-statement) によるデータ転送は,10.2による。ただし,記録が入力応答のように,記
録末が行末のように取り扱われる。各データ要素(10.1参照)は,変数名並び中の変数に順番に代
入される。input操作は,(read操作と違い,)表示形式として開いたファイルにだけ有効とする。
その他の記録形式の場合には,例外状態になる。
(2.3) input文は,記録中の空白でない最後の文字がコンマである場合には,複数個の記録を処理すること
ができる。そのような末尾にコンマのある記録に続いて,すべての変数に値が代入される前にファ
イルの終りに達した場合には,残りの変数はもとの値のままで,ファイル指示子はファイルの終り
を指し,例外状態になる。
(2.4) ある装置に対してinput操作を実行して段階3の例外状態になる場合に,処理系は,11.で狭義ファ
イルに対して規定する回復手続きを用いてもよいし,同じ例外状態が10.で規定されていれば,代わ
りにその回復手続きを用いてもよい。これによって,処理系は,対話方式の二つ以上の装置からの
入力において,続行可能な回復手続きを採用することができる。
(3) mat-input文
(3.1) mat-input文 (array-input-statement) の効果は,その配列の配列要素を行方向の順番(最後の添字が
最も早く変わる順番)で明示的に指定したinput文と同じとする。ただし,追加の機能として,上
下限の再定義をも許す。再定義上下限指定部は,経路式のないmat-input文に対して10.5で規定し
たとおりに,配列の寸法を変える。
例1. DIM A(3)とOPTION BASE1が有効である場合には,次の二つの文は等価である。
(a) MAT INPUT #N:A
104
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) INPUT #N:A(1), A(2), A(3)
例2. 次の二つの文も等価である。
(a) MAT INPUT #N:A$(2,2), C(2)
(b) INPUT #N:A$(1,1), A$(1,2), A$(2,1), A$(2,2), C(1), C(2)
例3. 次の文の場合には,最初のデータ要素が配列Bの実際の寸法を決定するので,そのデータ要素
によって効果が変わる。
MAT INPUT #N:A(1), B(A(1))
それでも,このmat-input文は,配列Bの代わりに必要な個数の配列要素を指定したinput
文と全く同じ効果をもつ。
(3.2) 上下限が再定義される時に,配列のいずれかの次元の寸法が1より小さくなる場合には,その配列
及び後続のすべての配列はもとの値のままで,例外状態になる。
(4) 不定長ベクトル 不定長ベクトル (variable-length-vector) のデータ転送及びそれに伴う配列の上下限
の再定義は,10.5による。
(5) line-input文 line-input文 (line-imput-statement) の効果は,10.2による。ただし,記録が行入力応答
のように,記録末が行末のように取り扱われる。一連の記録の内容が先行及び後続の空白列をも含め
て,一連の文字列変数の値として代入される。記録は,空文字列であってもよい。その場合にもそれ
は,通常のやり方で代入される。すべての変数に値が代入される前にファイルの終りに達した場合に
は,残りの変数はもとの値のままで,ファイル指示子はファイルの終りを指し,例外状態になる。
(6) mat-line-input文 mat-line-input文 (array-line-input-statement) の効果は,mat-input文の場合と同様に,
その配列の配列要素を明示的に指定したline-input文と同じとする[(3)参照]。ここでも,配列の寸法
は,それより前の配列に代入される値によって変わりうる。
例 MAT LINE INPUT #N:A$(1), B$(VAL(A$(1)))
最初の記録が文字列“12”である場合には,後続の12個の記録が配列B$に読み込まれる。
上下限が再定義される時に,配列のいずれかの次元の寸法が1より小さくなる場合には,その配列
及び後続のすべての配列はもとの値のままで,例外状態になる。
(7) ゼロ番の経路とinput操作 ゼロ番の経路からの入力は,狭義ファイルでない装置からの入力の規定
に従う。例外状態に対して,10.と11.とで異なった回復手続きが規定されている場合には,10.の手続
きを適用する。
(8) read文 read文 (read-statement) 及びmat-read文 (array-read-statement) は,どの記録形式のファイル
からのデータ入力にも用いることができる。一連のデータ要素,値又は欄が並び中の一連の作用対象
(変数又は配列)に代入される。read文は,順編成又は流れ編成のファイルでは複数個のファイル要
素を参照することができるが,相対編成又は索引編成のファイルではただ一つのファイル要素しか参
照できない。
(9) ファイル編成とread操作
(9.1) 流れ編成以外のファイルでは,変数は記録中の一連のデータ要素,値又は欄から値を受け取る。そ
の記録(末尾にコンマのある表示形式記録の場合は複数個の記録)の中には,[(1.5)のskip-rest指
定がある場合を除いて,]変数名並びをちょうど満たすだけの個数のデータがなければならない。
(9.2) 流れ編成ファイルでは,各変数は指示子で指されたファイル要素から始めて,ファイルを構成する
列から直接に値を受け取るので,ファイル要素の境界は意味をもたない。すべての変数に値が代入
される前にファイルの終りに達した場合には,残りの変数はもとの値のままで,ファイル指示子は
105
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ファイルの終りを指し,例外状態になる。
(10) 表示形式記録とデータ入力文
(10.1) 表示形式 (display) ファイル中の記録は,文字の列とする。ファイルからの文字列データの入力は,
10.2による。print操作によって生成された記録から入力したデータは,生成時と同じ値になるとは
限らない。例えば,単純文字列としての入力では,先行及び後続の空白列は保存されない。数値デ
ータの精度は,数値定数を数値変数に代入するときの通常の意味と一貫した扱いとする。すなわち,
有効数字は,arithmetic選択子でNATIVEを指定した場合は少なくとも6けたとし,DECIMALを
指定した場合は少なくとも10けたとする。DECIMALを指定した場合,処理系定義のけた数以下の
有効数字の数値定数は,厳密に正確な値が代入される。
(10.2) 表示形式記録に対してread操作を実行すると,同じ変数名並び又は再定義配列並びでinput操作を
実行したときと全く同じやり方で値を代入する。ただし,read操作は記録向きであり,input操作
のすべての機能を含んでいるわけではない。
(11) 内部形式記録とread操作
(11.1) 内部形式 (internal) 記録及び流れ編成ファイルは,値の列とする。この値には,数値型と文字列型
の2種類の型がある。
内部形式のファイル要素においては,値は必ずそれと同じ型の変数に入力しなければならない。
そうしなければ,例外状態になる。すなわち,内部形式ファイル要素の内容は,それ自身で型をも
っている。
(11.2) 値の列とそれらの型は,ファイル要素を生成又は変更した記録操作によって定められる。値の入力
は,その値を生成した式又は配列要素をlet文によってその入力変数に代入するのと同じ効果をも
つ。文字列値の長さと内容は,保持される。数値は,有効なarithmetic選択子で指定された精度の
通常の制限に従って保持される。
(12) 固有形式記録とread操作
(12.1) 枠 (template) は,記録中の欄 (field) の位置,幅及び型を記述する。固有形式 (native) 記録から読
み込むときには,必ず枠を使用しなければならない。枠は,他の記録形式に使用してはならない。
一つのデータ入力文は,文中の枠引用 (template-identifier) によって一つの枠を引用する。
(12.2) 枠引用は,template文 (template-statement) 又は文字列式を指定する。文字列式の場合,その値は,
構文的に正しい枠要素並びでなければならない。この文字列式を評価してから,入力を開始し,再
定義上下限指定,部分文字列指定及び添字を評価する。同じtemplate文を二つ以上の文で引用して
もよい。
(12.3) 固有形式記録からデータを入力するときには,変数名並び中の一つの変数ごとに,枠中の一つの欄
指定子 (field-specifier) が関連付けられる。次いでその欄指定子を用いて,記録中の一つの欄からデ
ータが入力される。この関連付けは,変数名並び中の一つの変数名に枠要素並び中の次に使用可能
な一つの欄指定子を用いて,左から右に順番に行われる。
(12.4) 変数は,先行する(すなわち左側の)変数に値が代入された後,その変数に対する添字,部分文字
列指定及び再定義上下限指定部が評価されてから,欄指定子に関連付けられる。変数の型(数値又
は文字列)が欄指定子の型と一致しない場合は,例外状態になる。欄指定子の個数は,変数の個数
より少なくてはならない。変数に対して余分な欄指定子は,無視される。記録中の次の欄の内容が
欄指定子によって解釈され,その結果の値が変数に代入される。
(12.5) データを入力するときに,記録中のすべての欄の欄指定子は,生成時の欄指定子と適合していなけ
106
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ればならない。適合していないときの結果は,処理系定義とする。適合している (compatible) とは,
生成時と入力時の欄指定子が双方とも,同じ文字列欄幅をもつ文字列型であるか,同じEの数値欄
幅をもつ数値型であるか又は同じ整数幅と小数幅をもつ数値型であることとする。整数幅又は小数
幅を省略すると,それぞれゼロとみなされる。
(12.6) 欄指定子がその記録に適合すると,欄幅に従って値が入力される。
文字列型の場合,その記録中に生成されたときの内容の値が,文字列欄幅に等しい長さで代入さ
れる。これは,欄の右側に埋められた空白を含む。
数値型の場合,数値欄幅とarithmetic選択子によってだけ制限された精度で値が代入される。
arithmetic選択子でDECIMALを指定したときは,Eの数値欄幅を用いて記録された数値,及び小
数点指定を用いて記録された,処理系定義のけた数以下の有効数字をもつ数値は,厳密に正確な値
が保持される。それ以外のときは,arithmetic選択子の指定に従って数値が丸められ,変数に代入
される。
(12.7) 固有形式記録の欄に対する値の記録と欄数の効果は,11.3.4による。ただし,skip指定が,出力に
おいてはゼロ又は空白の欄を生成するのに対し,入力においては単に欄を読み飛ばすということだ
けが異なる。11.3.4に規定したとおり,そのような欄指定子は,変数に関連付けられない。
(13) mat-read文
(13.1) 一般にmat-read文 (array-read-statement) の効果は,その配列の配列要素を明示的に指定したread
文と同じとする。
(13.2) input操作の場合と同様に,再定義上下限指定が後に評価されることがあるので,固有形式記録の読
込みには,欄数不定 (variable-field-count) を用いることができる。
欄数固定の場合には,read文と同様に,欄指定子の個数及び型がその配列要素のものと一致しな
ければならない。
一方,ある配列の最初の要素に欄指定子を関連付ける時に,前の枠要素がちょうど完了したとこ
ろであって(又は,この配列が並び中の最初のものであって),かつ次の枠要素が欄数不定であれば,
その欄指定子がその配列のすべての要素に使用される。その配列が満たされた後,次の配列があれ
ば,それは次の枠要素を使用する。これは,欄数不定であってもなくてもよい。一つの配列の入力
に,欄数不定と欄数固定を併用してはならない。どちらか一方だけを指定する。
(14) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(14)項がないが,TIBによって補った。
11.4.5 例外状態 データ入力文に関する例外状態は,それが検出される処理段階に従って分類する。段階
1の例外状態では,ファイル指示子及び変数は変更されない。段階2の例外状態では,変数は変更されな
い。段階3の例外状態では,その時点で幾つかの変数がファイルから値を受け取っていることがありうる。
段階1の例外状態
(1) データ入力文が,不活性状態にある経路を参照している。(7004,続行不能。)
(2) input文,mat-input文,line-input文又はmat-line-input文が,内部形式又は固有形式として開いたフ
ァイルを参照している。(7318,続行不能。)
(3) 記録設定を正しく処理できない。(11.2.5に規定する例外状態7002及び7202〜7207による。)
(4) データ入力文が,出力専用として開いたファイルを参照している。(7303,続行不能。)
(5) 枠引用の文字列式が,構文的に正しい枠要素並びでない。(8251,続行不能。)
107
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(6) 枠引用を,表示形式又は内部形式として開いたファイルに対して使用する。(7315,続行不能。)
(7) 枠引用を指定してないread文又はmat-read文が,固有形式として開いたファイルを参照している。
(7316,続行不能。)
(8) skip-rest指定を,流れ編成として開いたファイルに対して使用する。(7321,続行不能。)
段階2の例外状態
(9) データ入力文に対して,データ存在状態が偽であって,かつif-missing句の指定がない。(7305,続行
不能。)
段階3の例外状態
(10) recsize句で指定した値より長い記録を参照しようとする。(8302,続行不能。)
(11) 再定義上下限指定の1番目の指標の値が,2番目の指標の値より大きい。(6005,続行不能。)
(12) 再定義上下限指定に指標が一つだけ書いてあって,その値が,そのプログラム単位で有効な暗黙の下
限の値未満である。(6005,続行不能。)
(13) 上下限の再定義後の配列で必要な要素の総数が,もとの配列宣言で確保された要素数を超える。(5001,
続行不能。)
(14) 変数又は配列要素の型が,関連する欄指定子の型(数値又は文字列)と一致しない。(8252,続行不能。)
(15) 欄数不定を指定した枠要素が配列の最初の要素に対応しない。(8253,続行不能。)
(16) 変数及び配列要素に対して十分な個数の欄指定子が枠中にない。(8254,続行不能。)
(17) line-input文及びmat-line-input文を除くデータ入力文において,参照しようとする表示形式記録が,
構文的に正しい入力応答でない。(8105,続行不能。)
(18) 数値変数に代入しようとする表示形式記録中のデータ要素が,数値定数でない。(8101,続行不能。)
(19) 内部形式記録中の値の型が,代入しようとする変数の型(数値又は文字列)と一致しない。(8120,続
行不能。)
(20) ファイル中のデータ要素,値又は欄から変数への代入が,数値あふれを起こす。(1008,続行不能。)
(21) ファイル中のデータ要素,値又は欄から変数への代入が,文字列あふれを起こす。(1105,続行不能。)
(22) 流れ編成以外のファイルにおいて,記録中のデータ要素,値又は欄の個数がデータ入力文の作用対象
の個数よりも不足しており,かつその記録が末尾にコンマのある表示形式記録でない。(8012,続行不
能。)
(23) データ入力文の作用対象に対するデータを得ようとして,ファイルの終りに達した。(8011,続行不
能。)
(24) 記録中のデータの個数がデータ入力文の作用対象の個数より多く,かつskip-rest指定がない。(8013,
続行不能。)
(25) 表示形式記録において,入力の要求をちょうど満たすだけの個数のデータ要素の後ろにコンマが続い
ており,かつskip-rest指定がない。(8013,続行不能。)
11.4.6 注意 処理系は,下位けたあふれを例外状態(1508,続行可能。ゼロで置き換えて処理を続行する。)
としてもよい。この場合,下位けたあふれを例外処理区で処理することができる(12.1参照)。
11.5 ファイルにおけるデータ変更
11.5.1 概要 利用者は,データ変更文 (data modification statement) によって,以前にファイルに保存した
データを書換え又は削除することができる。変更は,常に記録単位に行われる。
11.5.2 構文 構文は,次による。ここで,(1)〜(9)は拡充ファイルの生成規則,(10)〜(12)は拡充ファイル
機能単位に適用する構文,“個”は固有形式拡充ファイルの生成規則とする。
108
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
中核の生成規則 なし
拡充ファイルの生成規則
(1) 単純実行文⊃rewrite文|mat-rewrite文|delete文
(2) rewrite文=REWRITE 経路式 書換え制御 コロン 式並び
(3) mat-rewrite文=MAT REWRITE 経路式 書換え制御 コロン 配列名並び
(4) 書換え制御={コンマ 書換え制御項目}*
(5) 書換え制御項目⊃if-missing句|記録設定
(6) delete文=DELETE 経路式 削除制御
(7) 削除制御={コンマ 削除制御項目}*
(8) 削除制御項目=if-missing句|記録設定
固(9) 書換え制御項目⊃枠引用
(10) 枠引用の行番号は,同じプログラム単位中のtemplate文を参照するものでなければならない。
(11) 一つの書換え制御項目は,一つの書換え制御中では,ただ1回だけ書くことができる。
(12) 一つの削除制御項目は,一つの削除制御中では,ただ1回だけ書くことができる。
11.5.3 例 構文の例を次に示す。
REWRITE #N, KEY=B$, IF MISSING THEN 666:A,B,C$
(2)
MAT REWRITE #3, RECORD N-1, WITH 111:X,Y,Z
(3)
DELETE #3, KEY ”JONES”
(6)
11.5.4 意味 意味は,次による。ここで,(1)は,すべてのデータ変更文に対する一般的な規則を定める。
データ変更文は,多くの点でデータ入力文とデータ生成文の様式に密接に合わせてある。データ変更文は,
データ入力文と同様に既存の記録を操作し,データ生成文と同様にファイルの状態を変えることができる。
(1) データ変更処理
(1.1) データ変更文は,相対編成 (relative) ファイル及び索引編成 (keyed) ファイルに対してだけ指定で
きる。それ以外のファイル編成のファイルに対する効果は,処理系定義とする。
(1.2) データ変更文においては,入出力方向属性が入出力両用でなければならない。入出力方向属性以外
の点では,データ変更文の段階1及び段階2の処理(すなわち,ファイル属性の検査及びファイル
指示子の設定)は,既存の記録を操作するものであるから,データ入力文(11.4.4参照)と全く同
じとする。段階3の処理は,操作がファイル属性に適合し,ファイル指示子が正しく位置付けられ,
データ存在状態 (data-found) が真になったときだけ実行される。(2)〜(4)は,段階3の処理を,個々
の文の形式ごとに定める。
(2) rewrite文
(2.1) rewrite文 (rewrite-statement) は,ちょうど一つの記録を生成する。この記録は,同じ式並び又は配
列名並び(及びもしあれば同じ枠引用)をもつwrite文によって生成される記録と同じとする(11.3.4
参照)。ただし,固有形式記録においては,skip指定によって制御される欄は,ゼロ又は空白が埋め
られるのではなく,もとの欄の内容が変更されずに残る。skip指定がこの効果をもつのは,rewrite
文の使用する枠が,その記録を生成するのに最後に使用された枠に適合している (compatible) とき
だけとする[適合の定義は11.4.4(12)参照]。skip指定を含む適合しない枠を使用した結果は,処理
系定義とする。skip指定を含まない適合しない枠を使用すると,11.3.4(12)に従って記録全体が置き
換えられる。
(2.2) データ生成時に例外状態にならなければ,ファイル指示子の指している記録が,いま生成された記
109
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
録によって置き換えられる。ファイル指示子は,次のファイル要素を指すように進められる。この
結果,相対編成ファイルの記録番号又は索引編成ファイルのキーは,変更されない。例外状態にな
ると,ファイル指示子は段階2の処理(11.3.4及び11.4.4参照)で設定された位置にとどまり,フ
ァイルのデータは変更されない。
(3) mat-rewrite文 mat-rewrite文 (array-rewrite-statement) の効果は,その配列の配列要素を明示的に指
定したrewrite文と同じとする。配列と枠中の欄指定子との対応の規則は,mat-write文の場合と全く
同じとする[11.3.4(13)参照]。
(4) delete文 delete文 (delete-statement) は,ファイル指示子で指されている記録を削除する。ファイル
指示子は,次のファイル要素を指すように進められる。この結果,相対編成ファイルでは操作された
記録領域が記録を含まなくなり,索引編成ファイルでは操作された記録が,ファイルを構成する記録
の列から除去される。
(5) 入出力の途中で入出力以外の例外状態が起こったとき,その部分的な入出力動作の効果及びその入出
力装置の状態は,処理系定義とする。
参考 ANSI X3.113にはこの(5)項がないが,TIBによって補った。
11.5.5 例外状態 データ変更文に関する例外状態は,それが検出される処理段階に従って分類する。段階
1の例外状態では,ファイル及びファイル指示子は変更されない。段階2の例外状態では,ファイルは変
更されない。段階3の例外状態でも,ファイルは変更されない。
段階1の例外状態
(1) データ変更文が不活性状態にある経路を参照している。(7004,続行不能。)
(2) データ変更文がゼロ番の経路を参照している。(7320,続行不能。)
(3) 記録設定を正しく処理できない。(11.2.5に規定する例外状態7002及び7202〜7207による。)
(4) データ変更文が,入力専用又は出力専用として開いたファイルを参照している。(7322,続行不能。)
(5) 枠引用の文字列式が,構文的に正しい枠要素並びでない。(8251,続行不能。)
(6) 枠引用を,表示形式又は内部形式として開いたファイルに対して使用する。(7315,続行不能。)
(7) 枠引用を指定してないrewrite文又はmat-rewrite文が,固有形式として開いたファイルを参照してい
る。(7316,続行不能。)
段階2の例外状態
(8) データ変更文に対して,データ存在状態が偽であって,かつif-missing句の指定がない。(7305,続行
不能。)
段階3の例外状態
(9) recsize句で指定した値より長い記録を書き換えようとする。(8301,続行不能。)
(10) 式又は配列要素の型が,関連する欄指定子の型(数値又は文字列)と一致しない。(8252,続行不能。)
(11) 欄数不定を指定した枠要素が配列の最初の要素に対応しない。(8253,続行不能。)
(12) 式及び配列要素に対して十分な個数の欄指定子が枠中にない。(8254,続行不能。)
(13) 数値が,枠中の欄で使用可能なけた位置の左端を越えて有効数字をもつ。(8255,続行不能。)
(14) 文字列値が,枠中の欄の幅より長い。(8256,続行不能。)
11.5.6 注意 delete文及びrewrite操作は,ファイル指示子がNEXTによって位置付けられる場合及び記
録設定を省略したので前回の操作時のままの位置を指している場合にも,指示子の指している記録に作用
する。
110
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
12. 例外状態処理及びデバッグ
12.1 例外状態処理
12.1.1 概要 例外状態処理 (exception handling) 機能によって,例外状態 (exception) の起こった後にプロ
グラムの制御を取り戻すことができる。
12.1.2 構文 構文は,次による。
(1) 保護区=when-in区|when-use区
(2) when-in区=when-in行 when本体 use行 例外処理区 end-when行
(3) when-in行=行番号 WHEN EXCEPTION IN 行末部
(4) when本体=区*
(5) use行=行番号 USE 行末部
(6) 例外処理区=区*
(7) end-when行=行番号 END WHEN 行末部
(8) when-use区=when-use行 when本体 end-when行
(9) when-use行=行番号 WHEN EXCEPTION USE 例外処理区名 行末部
(10) 例外処理区名=ルーチン識別名
(11) 例外処理区戻り文=RETRY|CONTINUE
(12) exit-handler文=EXIT HANDLER
(13) cause-exception文=CAUSE EXCEPTION 例外状態種別
(14) 例外状態種別=指標
(15) handler区=handler行 例外処理区 end-handler行
(16) handler行=行番号 HANDLER 例外処理区名 行末部
(17) end-handler行=行番号 END HANDLER 行末部
(18) 数値組込み関数名⊃EXLINE|EXTYPE
(19) 文字列組込み関数名⊃EXTEXT ドル記号
(20) 例外処理区戻り文及びexit-handler文は,例外処理区の中にだけ書くことができる。引き数のない数
値組込み関数EXLINE及びEXTYPEは,例外処理区の中からだけ呼ぶことができる。関数EXTEXT$の
実引き数は,一つの数値式とする。これは,指標として評価される。
(21) ある保護区の外部の行番号分岐中の行番号が,その保護区の内部にある行を参照してはならない。そ
のwhen-in行及びwhen-use行は,参照してもよい。例外処理区の内部の行番号分岐中の行番号が,そ
の例外処理区の外部にある行を参照してはならない。それ自身のend-handler行及びend-when行は,
参照してもよい。ある例外処理区の外部の行番号分岐中の行番号が,その例外処理区の内部にある行,
end-handler行及びend-when行を参照してはならない。
(22) ある内部手続き定義の内部のwhen-use行が参照するhandler区は,同じプログラム単位の内部で定義
しなければならない。
参考 ANSI X3.113の文章はやや異なるが,TIBによって訂正した。
一つのプログラム単位の中の二つのhandler行に,同じ例外処理区名を書いてはならない。保護区
の内部にhandler区を書いてはならない[(4),(6)参照]。
(23) 例外処理区の内部に保護区を書いてはならない。
12.1.3 例 構文の例を次に示す。
(1) 入力応答の誤りに対し,適切な通知を発行して,入力応答の再供給を可能にする[構文(2)]。
111
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
100 WHEIN EXCEPTION IN
110 PRINT ”Enter your age and weight”
120 INPUT a, w
130 IF a>10 THEN
140 PRINT ”What is your height”
150 INPUT h
160 END IF
170 USE
180 PRINT ”Please enter numbers only”
190 RETRY
200 END WHEN
(2) 動的にファイルを開く[構文(15),(8)など]
100 HANDLER file̲trouble
110 LET file̲ok$z =”false”6
120 IF EXTYPE=7107 THEN
130 LET message$=”doesn't exist”
140 ELSEIF EXTYPE=7102 THEN
150 LET message$=”is thewrong type"
160 ELSE
170 LET message$=”couldn't be used"
180 END IF
190 PRINT”file”;filename$;message$;”try again"
200 END HANDLER
500 DO
510 INPUT filename$
520 LET file ok$=”true”
530 WHEN EXCEPTION USE file̲trouble
540 OPEN #n:NAME filename$ ! other parameters omitted
550 END WHEN
560 LOOP UNTIL file̲ok$=”true”
(3) 例外処理区の入れ子[構文(2)]。
100 WHEN EXCEPTION IN
110 DO
120 READ#1, IF MISSING THEN EXIT DO:A
130 LET I = I+1 ! I initialized outside loop
140 WHEN EXCEPTION IN
150 LET B(I)=1000*A*A
160 USE
170 ! Assume it is numeric overflow
180 LET B(I)=MAXNUM
112
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
190 CONTINUE
200 END WHEN
210 LOOP
220 USE
230 IF EXTYPE=8101 THEN !non-numeric data
240 RETRY !get next data item
250 ELSE !give up
260 PRINT ”Unable to process file”
270 STOP
280 END IF
290 END WHEN
(4) 例外状態を引き起こす[構文(13)]。
CAUSE EXCEPTION I
12.1.4 意味 意味は,次による。
(1) プログラム単位の実行中に例外状態が起こったとき,とられる動作は,その例外状態がwhen本体の
内部で起こったか否かに依存する。例外状態がwhen本体の外部で起こった場合には,この規格で定
める省略時想定の例外状態処理手続き (dfault exception handling procedure) が適用される(2.4参照)。
この例外状態が続行可能なものであるならば,続行可能な例外状態に対する省略時想定の回復手続き
がとられる。
参考 ANSI X3.113ではこの最後の1文がないが,誤りであるので,TIBによって訂正した。
例外状態がwhen本体の内部で起こった場合には,例外状態を報告する省略時想定の例外状態処理
手続きは適用されず,代わりにその例外状態を起こした保護区 (protection-block) のうちで最も内側の
ものに対応する例外処理区 (exception-handler) に制御が移る。
(2) 保護区がwhen-in区であるとき,対応する例外処理区は,その保護区のuse行に続く部分とする。保
護区がwhen-use区であるとき,対応する例外処理区は,その保護区のwhen-use行で指名されたhandler
区 (detached-handler) とする。handler区の動作は,意味的にはwhen-in区における例外処理区の動作
と全く同じとする。
(3) 例外処理区の内部では,その例外処理区の実行を引き起こした例外状態の種別を,引き数なしの関数
EXTYPEの値によって知ることができる。この規格で規定されるすべての例外状態に対し,EXTYPE
の値が決められている。この値を,例外状態の説明とともに表12.1(166ページ)に示す。例外状態
を引き起こした行の行番号は,引き数なしの関数EXLINEの値によって知ることができる。
(4) 例外処理区から出るには,次の4通りの方法がある。
(a) 例外処理区戻り文 (handler-return-statement) CONTINUEを実行すると,例外状態を引き起こした文
に構文上続く文に制御が移る。do行,loop行,for行,if-then行,elseif-then行,select-case行又は
case行のように,構造を開始し,又は構造の一部となる行で例外状態が起こった場合は,その構造
全体に構文上続く文に制御が移る。
(b) 例外処理区戻り文RETRYを実行すると,例外状態を引き起こした文又は行に制御が移り,その文
又は行が再実行される。その文がデータ入力を実行していた場合には,以前の入力応答又は行入力
応答は無視されて,再度応答が要求される。
(c) 制御がend-handler行又は例外処理区を区切るend-when行に到達すると,制御はその例外状態を引
113
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
き起こした保護区のend-when行に続く行に移る[(5)参照]。
(d) exit-handler文 (exit-handler-statement) を実行すると,その例外状態は,その例外状態の行を含む最
も内側の保護区を構文的に取り囲む環境に伝達される。[これを“構文的”な伝達という。call文や
関数引用などの“呼出し”の伝達については,(9)による。]すなわち,その例外処理区は,(そこで
既に実行されてしまっている文の効果はそのままとして,)あたかも存在しなかったかのように無視
される。この例外状態の処理の規則は,外側をwhen本体が囲んでいるか否かに依存する。
(5) 制御がwhen-in区のuse行又はwhen-use区のend-when行に到達すると,制御はその保護区に続く行
に移る。制御がhandler区のend-handler行に到達すると,制御はその例外状態を引き起こした
when-use区のend-when行に続く行に移る[(4)(c)参照]。例外状態の発生によらないで制御がhandler
区のhandler行に到達すると,制御はそのend-handler行に続く行に移る。
制御がwhen-in行又はwhen-use行に到達すると,何もしないで次の行に進む。
(6) gosub用の行番号の棚は,各例外処理区ごとに独立して一つずつある[8.2.4(3)参照]。したがって,
retune文の実行によって,制御が例外処理区の内外をまたいで移行することはない。
(7) cause-exception文 (cause-statement) を実行すると,続行不能 (fatal) な例外状態になる。その例外状態
種別の値が最も近い整数値に丸められて,関数EXTYPEの値になる。
(8) 例外処理区の内部で重ねて起きた例外状態は,続行不能なものとして扱われる。このことは,
exit-handler文の実行,任意の例外状態種別をもつcause-exception文の実行及びその他の続行可能又
は続行不能なあらゆる例外状態を含む。
参考 ANSI X3.113の文章はやや異なるが,TIBによって訂正した。
(9) 手続きの外部への例外状態の伝達は,次による。
(9.1) ある外部手続き単位の内部又は内部手続き定義の内部で続行不能な例外状態になり,しかも次のい
ずれかの場合には,その外部手続き単位又は内部手続き定義を呼び出した行に,その例外状態が戻
され,伝達される。(“呼出し”の伝達。)
(a) その例外状態を引き起こした行はwhen本体中にないので,例外処理区に移ることがない。
(b) 例外処理区に移り,そこでexit-handler文を実行してその例外状態を構文的に外側に伝達するが,
それを受け止めるべきwhen本体が構文的に外側を囲んでいない。
(9.2) この伝達 (propagation) は,次のいずれかになるまで継続する。
(a) 利用者定義の例外処理区に入り,例外処理区戻り文を実行するか又はその例外処理区を区切る
end-handler行若しくはend-when行に制御を移すかして,その例外状態が解消される。
(b) 主プログラム又は並行単位に到達し,省略時想定の例外状態処理手続きが適用される。
(10) この伝達の結果,例外処理区が呼ばれた場合,関数EXTYPEの返す値は,(当初の例外状態が起こっ
た外部手続単位の内部又は内部手続定義の内部で関数EXTYPEが返すべき)通常の値に,100000を
加えた値とする。関数EXLINEの値は,例外状態が伝達された最後の行の行番号とする。(すなわち,
その例外処理区を指定するwhen本体中の行の行番号であり,例外状態の起こった当初の行の行番号
ではない。)
(11) 省略時想定の例外状態処理手続きが報告する関数EXTYPH及びEXLINEの値は,常に例外状態の起
こった当初の行に対するものとする。
(12) この規格に対して処理系が例外状態を追加した場合には,そのEXTYPEの値は負の数にしなければな
らない。EXTYPEの値が負である例外状態が伝達された場合,EXTYPEの返す値は,当初の例外状態
に対する通常の負の値から100000を引いた値とする。
114
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(13) 関数EXTYPEの値1〜999は,この規格の将来の拡張でも使用しない。処理系による拡張の場合にも,
使用してはならない。
(14) 関数EXTEXT$を引用すると,その実引き数の数値式の値が指標として評価され,最も近い整数値に
丸められる。その整数値を例外状態種別とする例外状態に対して,システムが用意する誤り通知 (error
message) の文章部分を,この関数の値とする。その整数値がシステムの標準例外状態の例外状態種別
と一致しないときには,関数EXTEXT$の値は,空文字列とする。
(15) 例外状態が伝達された結果,主プログラムに到達し,しかもそこで例外処理区が呼ばれない場合,そ
の例外状態は,この規格で定める省略時想定の例外状態処理手続きによって処理される。
12.1.5 例外状態 例外状態は,次による。
(1) cause-exception文が実行された。(例外状態種別,続行不能。)
12.1.6 注意 注意は,次による。
(1) この規格が規定する例外状態の伝達 (propagation) には,2種類ある。
(a) 一つは,“構文的”な外側への伝達であって,外部手続単位の内部又は内部手続定義の内部において,
例外状態の起こった行を取り囲む何重かの保護区に向かって,外側に進む。
(b) この伝達の結果,例外状態がそのような保護区の外部に出てしまうと,“呼出し”の伝達に移り,呼
び出した文に例外状態が伝達される。
(2) 関数EXLINEを利用するときは,注意が必要である。例えば,プログラムの行番号を付け直す再番号
付けの編集用機能(16.2参照)を用いると,EXLINEを含む計算の部分が無効になることがありうる。
例 次のようなプログラム部分は,行番号100から800までのプログラム部分に対して行番号の再番
号付けを行うと,異なった動作をする。
1000 SELECT CASE INT (EXLINE/100)
1010 CASE 1, 2
…
1100 CASE 3 TO 7
…
(3) 続行不能な例外状態が呼出し側の文に伝達されて,その結果,省略時想定の例外状態処理手続きで処
理されるとき,処理系は,当初の例外状態のEXTYPEとEXLINEだけは必ず報告する。処理系は,更
に,例外状態が伝達されてきた経路の行の行番号又は有用であると考えるあらゆる情報を報告しても
よい。
(4) 続行可能 (nonfatal) な例外状態は,呼び出されたルーチンの例外処理区又はシステムの省略時想定の
例外状態処理手続きで処理されるので,呼出し側のルーチンにそのまま伝達することはできない。し
かし,例外処理区の中でcause-exception文を実行して,続行不能な例外状態を引き起こすことはでき
る。
(5) cause-exception文は,実用上,規定されている例外状態を模擬することを意図したものではない。む
しろ,ある特定のEXTYPEの値をもった続行不能な例外状態を引き起こすために用いる。特に,
cause-exception文で指定されたEXTYPEの値が続行可能な例外状態を示すものである場合に,その続
行可能な例外状態があたかも実際に起こったかのように,処理系がその回復手続きを適用する必要は
ない。処理系は,通常,その例外状態を受け止めて処理する例外処理区が,利用者のプログラム中に
あると想定する。
(6) 正のEXTYPEの値は,すべてこの規格の将来の拡張に備えて予約されている。この規格に対して処理
115
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
系が拡張し定義する例外状態は,表12.1(166ページ)で定めた分類に従った値を負にしたEXTYPE
の値をもたなければならない。処理系の定めた例外状態が外部手続単位の内部又は内部手続定義の内
部で起きたとき,EXTYPEの値は,その例外状態を識別する負の値から100000を引いた値とする。
例えば,新しい組込み関数に誤った引き数を使った場合に対して,−4029というEXTYPEの値を処
理系で定めたとする。副プログラムの内部でこの例外状態になったときに例外処理区がそこになけれ
ば,呼出し側のプログラムの例外処理区中で,EXTYPEの値が−104029となる。
(7) 処理系作成上は,“これこれの分類におけるその他の例外状態”を表すのに,EXTYPEの値のその分
類中で第0番目の値を用いることを推奨する。例えば,EXTYPEの値1000は,規格の定めるあふれ
以外のあらゆるあふれを表すことに約束できる。
(8) EXTYPEの値1〜999は,応用プログラムの中でcause-exception文を用いてだけ起こすことができる。
これらの値に対しては,この規格の将来の拡張においても標準的な意味を与えない予定であるので,
応用プログラムはこの値を用いるよう推奨する。
(9) 例外処理区戻り文CONTINUEを用いるときには,注意がいる。例えば,def文,on-gosub文,on-goto
文,if文などの中で例外状態が起こったときに文CONTINUEを実行すると,制御はその行の構文的に
次の行に移る。この動作は,正常な制御の流れを回復することと等価であるとは限らない。
(10) 制御構造があるときの文CONTINUEの効果を次に例示する。
100 WHEN EXCEPTION IN
120 INPUT PROMPT ”Enter your age and weight”:a, w
130 DO WHILE a>1
140 IF a<9999999999 THEN
150 INPUT PROMPT ”What is your height”:h
160 PRINT ”Check the following:”
170 PRINT ”Age:”;a, ”Weight:”;w, ”Height:”;h
200 INPUT PROMPT ”Enter your age”:a
210 END IF
220 PRINT ”Lexically following IF”
230 LOOP
240 PRINT ”Lexically following DO WHILE”
……
例外状態の起こった行
CONTINUEによって制御の移る行
120 INPUT
130 DO WHILE (構文上の次の行)
130 DO WHILE
240 PRINT
(対応するLOOPの次の行)
140 IF … THEN
220 PRINT
(対応するEND IFの次の行)
150 INPUT
160 PRINT
(構文上の次の行)
(11) 関数EXTEXT$の値の正確な形は,処理系定義とする。例えば,例外状態の個々の発生に特有の誤り
通知中の欄に対して,特別のやり方で印を付けたり,欄を省いたりすることにしてもよい。欄の例と
しては,例外状態を起こした行の行番号や範囲外になった添字の値などがある。
12.2 デバッグ
116
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
12.2.1 概要 デバッグ (debugging) 機能は,BASIC言語の文によってプログラム中に検査点を設定できる
ようにする。これらの文によって利用者は,中断点 (break point) を設定したり,プログラムの動作を追跡
(trace) したり,デバッグシステム (debugging system) をそれぞれのプログラム単位ごとに活性化したり,
不活性化したりすることができる。
12.2.2 構文 構文は,次による。
(1) debug文=DEBUG {ON|OFF}
(2) break文=BREAK
(3) trace文=TRACE ON {TO 経路式}?|TRACE OFF
12.2.3 例 構文の例を次に示す。
TRACE ON
(3)
TRACE ON TO #3
(3)
12.2.4 意味 意味は,次による。
(1) 個々のプログラム単位は,一つごとにデバッグ状態 (debugging status) をもつ。これは,ある一時点で
は活性状態 (active) 又は不活性状態 (inactive) とする。主プログラム以外のプログラム単位における
デバッグ状態は,そのプログラム単位の次回の呼出しまで保持される。あるプログラム単位における
デバッグ状態の変更が,他のプログラム単位のデバッグ状態に影響を与えることはない。プログラム
の実行を開始する時点では,すべてのプログラム単位のデバッグ状態は,不活性状態とする。
(2) debug文 (debug-statement) DEBUG ONを実行すると,そのdebug文を含むプログラム単位においてデ
バッグが活性状態となる。このプログラム単位中でdebug文DHBUG OFFを実行するまでは,このプ
ログラム単位のこの回の実行の残り及びこのプログラム単位の以降の回の呼出しにおいて,デバッグ
は活性状態とする。プログラム単位中でdebug文DHBUG OFFを実行すると,そのdebug文を含むプ
ログラム単位においてデバッグが不活性状態となる。このプログラム単位中でdebug文DEBUG ON
を実行するまでは,このプログラム単位のこの回の実行の残り及びこのプログラム単位の以降の回の
呼出しにおいて,デバッグは不活性状態とする。
(3) デバッグが活性状態である時に,break文 (break-statement) を実行すると,例外状態になる。この例
外状態からの標準の回復手続は,break文の行番号を報告し,利用者にデバッグシステムとの対話が
可能であることを通知することとする。デバッグシステムが許す動作及びプログラムの実行を継続又
は終了させる方法は,処理系定義とする。デバッグが不活性状態である時にbreak文を実行すると,
次の行に進むこと以外に何の効果ももたない。
(4) デバッグが活性状態である時にtrace文 (trace-statement) を実行すると,ONであればそのtrace文を
含むプログラム単位において追跡を有効にし,OFFであれば無効にする。プログラム単位の各Eの呼
出しごとに,trace文を実行するまでは,追跡は無効とする。デバッグが不活性状態である時にtrace
文を実行すると,次の行に進むこと以外に何の効果ももたない。
(5) trace文の実行は,デバッグ状態に影響を及ぼさない。debug文の実行は,追跡状態の有効・無効に影
響を及ぼさない。
(6) プログラム単位において,デバッグが活性状態であり追跡が有効である時には,次の種類の行が実行
されるたびに,それぞれの動作がなされる。
(a) プログラム中の行の順次実行を中断する行の場合には,その行の行番号と次に実行されるべき行の
行番号の両方が報告される。
(b) 単純変数又は配列要素に値を代入する行の場合には,その行の行番号とその行の実行によって代入
117
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
される値の両方が報告される。
(7) 経路式を指定したtrace文によって追跡が有効になった場合,追跡報告は,その経路に割り当てられ
た表示形式のファイルに出力される。経路式を指定しなかった場合には,追跡報告は,ゼロ番の経路
の装置に出力される。
(8) 追跡報告の内容は,処理系定義とする。ただし,少なくとも追跡される変数の,追跡報告を引き起こ
した文に書かれた形での変数名,その値及び変数が配列要素である場合には添字の値を含む。
12.2.5 例外状態 例外状態は,次による。
(1) デバッグが活性状態である時に,break文を実行する。(10007,続行可能。回復手続きは,その文の
行番号を報告しデバッグシステムとの対話を可能にすることとする。)
(2) 不活性状態の経路に追跡報告を出力しようとする。(7401,続行不能。)
(3) 入出力指定属性OUTPUT又はOUTINで開かれた表示形式のファイルでないファイルに,追跡報告を
出力しようとする。(7402,続行不能。)
12.2.6 注意 注意は,次による。
(1) mat文によって配列要素に値を代入すると,mat文の追跡はすべての配列要素の新しい値を報告する。
(2) 追跡報告の形式は,処理系定義とする。
(3) 処理系は,これらの文のほかに指令によるデバッグ機能を提供してもよい。その指令には,これらの
文と同じ機能語を用いることを推奨する。
13. 図形
13.0 機能単位 ここでは,簡易図形出力機能単位 (mini graphics module) 【及び図形機能単位 (graphics
module) 】を規定する。
13.1〜13.3の括弧【 】で囲まれていない部分は,簡易図形出力機能単位を規定する。【13.1〜13.5は,
図形機能単位を規定する。括弧で囲まれた部分は,簡易図形出力機能単位には含まれない。】
13.1〜13.3【及び13.4】は,ISO 7942に規定されたGraphical Kernel System (GKS) の水準0bの機能の部
分集合とする。GKSと共通の例外状態に対する関数EXTYPEの値は,GKSの誤り番号の値に11000を加
えたものとする。
【図形機能単位をGKSの水準0bの全体まで拡張したいときに,処理系が採用できる構文を,附属書F(参
考)に示す。13.5は,GKSの規格の拡張である。】
GKSの立場からみれば,この規格の13.に規定する文を含むBASICのプログラムは,図形を処理するす
べての文の実行に先立って,GKSの機能OPEN GKS,OPEN WORKSTATION (#0, ”Maindev”, 1) 及び
ACTIVATE WORKSTATION #0を暗黙的に呼び出す。そして,プログラムの終了に当たって,DEACTIVATE
WORKSTATION #0,CLOSE WORKSTATION #0及びCLOSE GKSを呼び出す。
参考 簡易図形出力機能単位は,図形機能単位の13.1〜13.3の規定に対して,次の削除・制限を加え
たものであると考えることができる。
(1) 13.1については,削除はない。
(2) 13.2については,文章の形,大きさ,方向などは,ただ一つだけを許し,それ以外の規定及
び生成規則を削除する。COLOR MIX(色混合率)の規定を削除する。線の形の利用可能な
個数の最小値は,四つではなく三つとする。点の形の利用可能な個数の最小値は,五つでは
なく三つとする。これらに関連する例外状態11073,4102及び11088を削除する。
(3) 13.3については,着色胞の配列を出力する機能を削除する。幾何図形mat文の規定を削除す
118
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
る。13.3.4(1.2),すなわち,通常の文による出力と図形出力との相互関係の規定を削除する。
文章の高さ,そろえ,方向などの規定を削除する。配列による出力に関連する例外状態6401,
6402及び11085を削除する。
13.1 座標系
13.1.1 概要 図形出力を生成するのに用いる座標系は,応用分野に合わせて選ぶことができる。“問題座
標 (problem coordinate)”[論理座標 (world coordinate) ともいう。]系の範囲は,機能語WINDOW(窓)を
もつset文によって定める。この範囲を機能語VIEWPORT(視野面)をもつset文で指定された抽象視野
面 (abstract viewing surface) 中の長方形の中に写像する。抽象視野面中のどの部分を利用者が表示画面
(display surface) 中に表示するかを,機能語DEVICE WINDOW(装置窓)をもつset文によって指定する。
更に,この長方形を機能語DEVICE VIEWPORT(装置視野面)をもつset文によって表示画面上に位置付
ける。
出力が装置視野面の外に出たときには,何も生成されない。切取り (clipping) を有効にすれば,視野面
の外に写像された図形の出力が無視される。
ask文は,set文のどれかの実行(又は省略時想定)によって設定された係数の現在値を問い合わせる。
13.1.2 構文 構文は,次による。
(1) 設定対象⊃ WINDOW 境界四辺|VIEWPORT 境界四辺|DEVICE WINDOW 境界四辺|
DEVICE VIEWPORT 境界四辺|CLIP 文字列式
(2) 境界四辺=境界 コンマ 境界 コンマ 境界 コンマ 境界
(3) 境界=数値式
(4) ask文⊃ASK 質問対象 status句?
(5) status句=STATUS 数値変数名
(6) 質問対象⊃ WINDOW 境界四辺変数|VIEWPORT 境界四辺変数|DEVICE WINDOW
境界四辺変数|DEVICE VIEWPORT 境界四辺変数|DEVICE SIZE 数値変数名
コンマ 数値変数名 コンマ 文字列変数名|CLIP 文字列変数名
(7) 境界四辺変数=数値変数名 コンマ 数値変数名 コンマ 数値変数名 コンマ 数値変数名
13.1.3 例 構文の例を次に示す。
WINDOW 0, PI*2, −1, 1
(1)
Viewport .5*width, width, .5*height, height
(1)
DEVICE WINDOW 0, .8, 0, 1
(1)
DEVICE VIEWPORT .3, .5, .1, 1
(1)
CLIP ”Off”
(1)
ASK WINDOW X1, X2, Y1, Y2
(4)
ASK VIEWPORT L, R, B, T
(4)
ASK DEVICE WINDOW XMIN, XMAX, YMIN, YMAX
(4)
ASK DEVICE VIEWPORT LEFT, RIGHT, BOTTOM, TOP
(4)
Ask device size Width, Height, Units$
(4)
ASK CLIP CLIP̲STATE$
(4)
13.1.4 意味 意味は,次による。
(1) 図形出力は,問題座標上で指定する。基準化変形は,問題座標系から基準装置座標 (normalized device
coordinate, NDC) 空間への写像を定義する。この基準装置座標空間を抽象視野面とする。
119
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) 基準化変形は,窓 (window) と呼ばれる長方形の限界を問題座標中に定義することで指定する。その
窓が,基準装置座標中の視野面 (viewport) と呼ばれる指定された長方形の領域に,線形写像される(図
13.1参照)。
(3) 機能語WINDOWをもつset文を実行すると,窓の境界四辺 (boundaries) が定められる。係数は,問
題座標中の窓の長方形のそれぞれ左辺,右辺,下辺及び上辺を表す。プログラムの実行を開始する時
の窓のこれらの値は, (0, 1, 0, 1) とする。
(4) 機能語VIEWPORTをもつset文を実行すると,視野面の境界四辺が定められる。係数は,基準装置座
標中の視野面の長方形のそれぞれ左辺,右辺,下辺及び上辺を表す。これらの値は,ゼロ以上1以下
でなければならない。左辺の座標値は右辺より小さく,下辺の座標値は上辺より小さくなければなら
ない。プログラムの実行を開始する時の視野面のこれらの値は, (0, 1, 0, 1) とする。
(5) この視野面は,切取りをする長方形をも定める。機能語CLIPをもつset文を実行すると,視野面境界
における切取りが,文字列式の値の“ON”又は“OFF”に従って,有効又は無効になる。文字列式の
値の中の文字は,英大文字と英小文字を混ぜて指定してもよい。プログラムの実行を開始する時には,
切取りは有効になっている。
(6) 装置変形 (device transformation) は,装置窓 (device window) と呼ばれる基準装置座標空間中の長方形
を装置視野面 (device viewport) と呼ばれる物理画面上の長方形に一様に写像する。この変形は,両軸
に対して等しい正の比率をもった拡大縮小 (scaling) を行う。すなわち,装置窓と同じ縦横比 (aspect
ratio) をもつ最大の長方形を装置視野面中に左下端を合わせて設定し,装置窓をこの長方形に写像す
る(図13.1参照)。
(7) 機能語DEVICE WINDOWをもつset文を実行すると,装置窓の境界四辺が定められる。係数は,基準
装置座標中の装置窓の長方形のそれぞれ左辺,右辺,下辺及び上辺を表す。これらの値は,ゼロ以上
1以下でなければならない。左辺の座標値は右辺より小さく,下辺の座標値は上辺より小さくなけれ
ばならない。プログラムの実行を開始する時の装置窓のこれらの値は, (0, 1, 0, 1) とする。装置窓の
外への出力をしないように,切取りが装置窓の境界で行われる。この切取りを無効にすることはでき
ない。機能語DEVICE WINDOWをもつset文を実行すると,表示画面が(まだ消去されていないなら)
消去される。
(8) 機能語DEVICE VIEWPORTをもつset文を実行すると,装置視野面が定められる。係数は,装置視野
面の長方形のそれぞれ左辺,右辺,下辺及び上辺の座標を表す。装置視野面の単位は,正確に拡大縮
小された像を生成することのできる装置上ではメートルとし,さもなければ装置に依存した適当な座
標とする。表示画面の左辺及び下辺の座標値は,ゼロとする。プログラムの実行を開始する時の装置
視野面は,画面全体とする。機能語DEVICE VIEWPORTをもつset文を実行すると,表示画面が(ま
だ消去されていないなら)消去される。
(9) 図13.1は,窓,視野面,装置窓,装置視野面の関係を示す。ここで,切取りは有効になっているもの
とする。
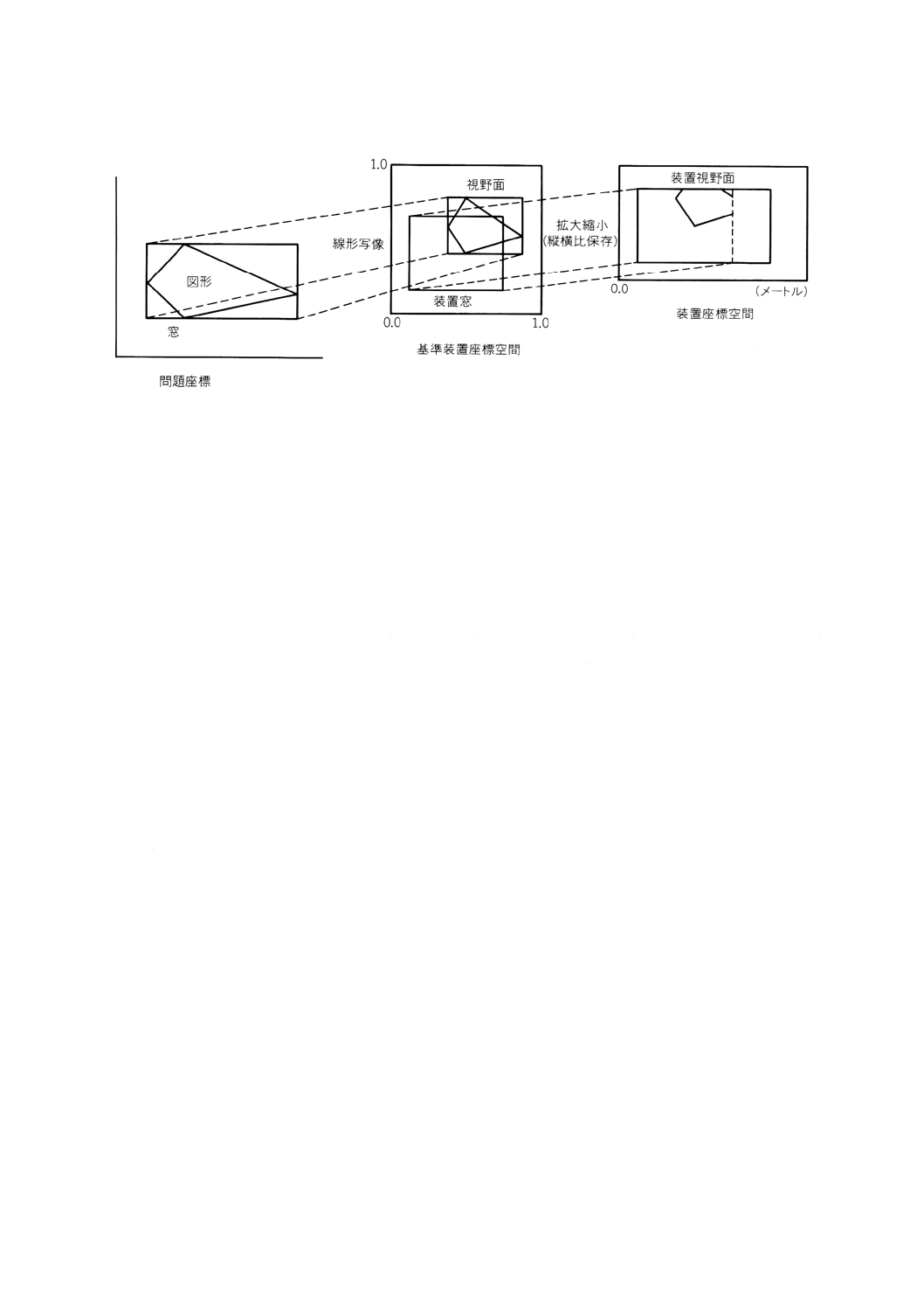
120
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
図13.1 窓と視野面との関係
(10) ask文に書いたstatus句は,そのask文の実行に関する状態を数値変数に返す。ask文が質問対象につ
いて意味のある値を返したときには,status句は値ゼロを返す。ask文が質問対象について意味のある
値を返せなかったときには,status句はそれぞれの質問対象に関する意味の項で規定されているゼロ
でない値を返す。ある特定の質問対象に対するask文が,必ず意味のある値を返すとわかっていると
きには,その質問対象に関する意味の項は代わりの値を規定せず,必ず値ゼロが返される。
(11) 機能語WINDOW,VIEWPORT,DEVICE WINDOW又はDEVICE VIEWPORTをもつask文を実行す
ると,指定された長方形の現在値が返される。実行された最後のset文によって設定された左辺,右
辺,下辺及び上辺の値をそれぞれの境界四辺変数 (boundary variables) に代入する。関連するset文が
まだ実行されていないときには,省略時想定の値を代入する。
(12) 機能語DEVICE SIZEをもつask文を実行すると,有効な表示画面の水平方向の寸法が1番目の数値変
数に代入され,垂直方向の寸法が2番目の変数に代入される。文字列変数は,寸法がメートル単位で
あれば値“METERS”が代入される。そうでなくて,寸法の単位が装置座標系によるその他の単位で
あれば,値“OTHER”が代入される。値“METERS”及び“OTHER”は,英大文字とする。
(13) 機能語CLIPをもつask文を実行すると,切取りが有効であれば文字列変数に値“ON”が代入され,
無効であれば値“OFF”が代入される。返される値は,英大文字とする。
13.1.5 例外状態 例外状態は,次による。
(1) set文の境界四辺が,ゼロの幅又はゼロの高さの長方形を指定する。(11051,続行可能。今までの値を
維持して処理を続ける。)
(2) 機能語VIEWPORT,DEVICE WINDOW又はDEVICE VIEWPORTをもつset文の境界四辺が,負の幅
又は負の高さを指定する。(11051,続行可能。今までの値を維持して処理を続ける。)
(3) 視野面の境界が閉区間 [0, 1] の範囲にない。(11052,続行可能。今までの値を維持して処理を続け
る。)
(4) 装置窓の境界が閉区間 [0, 1] の範囲にない。(11053,続行可能。今までの値を維持して処理を続け
る。)
(5) 装置視野面の境界が,表示画面の範囲にない。(11054,続行可能。今までの値を維持して処理を続け
る。)
(6) 機能語CLIPをもつset文の文字列式の値が,英大文字に変換した後に“ON”でも“OFF”でもない。
(4101,続行可能。今までの値を維持して処理を続ける。)
13.1.6 注意 注意は,次による。
(1) 特定の図形表示装置をプログラムによって選択する方法は,処理系定義とする。
121
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) 左辺の値が右辺より大きい又は下辺の値が上辺より大きい窓の意味は,処理系定義とする。可能な場
合には,処理系は,適切に逆転した像とすることを推奨する。すべての図形出力【及び図形入力】の
効果は,抽象問題空間を用いて定義される。抽象問題空間は,左及び下が小さい値そして右及び上が
大きい値とする。この問題空間を基準装置座標に写像するとき,その窓の境界四辺の値の大小関係に
よっては,像が逆転することがありる。このことは,逆転している窓座標は誤りとなるというGKS
の規則を緩和する。
(3) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語WINDOW,VIEWPORT,DEVICE WINDOW又はDEVICE VIEWPORTをもつset
文
GKS : 機能SET WINDOW,SET VIEWPORT,SET WORKSTATION WINDOW又はSET
WORKSTATION VIEWPORT;これらの文に対して,GKSの変形番号は1,GKSの図形処
理装置 (workstation) 番号は#0とする。
(4) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語CLIPをもつset文
GKS : 機能SET CLIPPING INDICATOR
(5) 次のBABASICの文は,次のGKSの機能に対応する。
BASIC : 機能語WINDOW又はVIEWPORTをもつask文
GKS : 基準化変形1に対する機能INQUIRE NORMALIZATION TRANSFORMATION
(6) 次のBABASICの文は,次のGKSの機能に対応する。
BASIC : 機能語CLIPをもつask文
GKS
: 機能INQUIRE CLIPPING INDICATOR
(7) 次のBABASICの文は,次のGKSの機能に対応する。
BASIC : 機能語DEVICE WINDOW又はDEVICE VIEWPORTをもつask文
GKS : 図形処理装置識別子#0に対する機能INQUIRE WORKSTATION TRANSFORMATIONの現
在の図形処理装置窓 (workstation window) 又は現在の図形処理装置視野面 (workstation
viewport) の係数
参考 ANSI X3.113では,ここの“#0”が“one”となっているが,誤りであるので,TIBによって訂
正した。
(8) DEVICE VIEWPORTをもつset文を実行する前に,DEVICE VIEWPORTをもつask文を実行して,有
効な装置画面全体の装置座標を知ることができる。
(9) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語DEVICE SIZEをもつask文
GKS : 機能INQUIRE MAXIMUM DISPLAY SURFACE SIZEの装置座標単位及びそれによる
最大表示画面寸法の係数
(10) 【附属書F(参考)に示す質問対象の多くには,意味のある値を返せない場合がある。その場合,status
句の返す値は,GKSの誤り指示子係数値に11000を加えた値とする。】
13.2 属性及び画面制御
13.2.1 概要 図形の表示は,次による。
(1) 図形表示装置は,さまざまの太さや形をもつ複数種類の線や点を描くことができる。図形の出力に当
たって,特定の形を選択できる。更に,図形表示装置は,さまざまの色を用いて線を描いたり,領域
122
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
を塗りつぶしたりできる。描線及び画面背景に,特定の色を選択できる。
(2) 幾何対象の現在の形及び色は,ask文によって問い合わせることができる。利用可能な色の個数,線
の形の個数及び点の形の個数も,ask文によって問い合わせることができる。
(3) 【図形表示装置は,さまざまの高さや方向をもつ多様な文章 (text) を表示することができる。文章の
出力に当たって,一つの組合せを選択できる。】
(4) clear文は,全画面を消去して背景色 (background color) に戻す。消去不能な表示装置に対するclear
文は,用紙を進める,ペンをわきに寄せるなどの動作をする。
(5) 簡易図形出力では,ある1種類の形及び大きさをもち,開始点から水平右方向に進む文章を出力でき
る。[13.3.4(3)参照。]
13.2.2 構文 構文は,次による。
(1) 単純実行文⊃clear文
(2) clear文=CLEAR
(3) 設定対象⊃ 線点指定 STYLE 指標|面指定 COLOR 指標
【|TEXT 文章特性 数値式|TEXT JUSTIFY 文字列式 コンマ 文字列式|
COLOR MIX 左括弧 指標 右括弧 三原色指定】
(4) 面指定=線点指定|TEXT|AREA
(5) 線点指定=POINT|LINE
(6) 【三原色指定=数値式 コンマ 数値式 コンマ 数値式】
(7) 質問対象⊃ 線点指定 STYLE 数値変数名|面指定 COLOR 数値変数名|
【TEXT 文章特性 数値変数名|TEXT JUSTIFY 文字列変数名 コンマ 文字列変
数名|】
MAX 線点指定 STYLE 数値変数名|MAX COLOR 数値変数名
【|COLOR MIX 左括弧 指標 右括弧 三原色取得】
(8) 【三原色取得=数値変数名 コンマ 数値変数名 コンマ 数値変数名】
(9) 【文章特性=HEIGHT|ANGLE】
13.2.3 例 構文の例を次に示す。
LINE STYLE 2
(3)
TEXT COLOR 5
(3)
【AREA COLOR RED
(3)】
【TEXT HEIGHT (N+3)/42
(3)】
【Text justify ”Center”, ”Half”
(3)】
【color mix (4) .5, R*.5, .3
(3)】
【Point style P̲style
(7)】
Max color color̲max
(7)
Max point style PtStyles
(7)
13.2.4 意味 意味は,次による。
(1) clear文を実行すると,図形表示が(まだ消去されていないなら)消去される。消去可能な表示装置に
対しては,画面を消去する。消去不能な表示装置に対しては,その媒体を進めたり,利用者に媒体を
交換させたりする。
(2) 機能語LINE STYLE又はPOINT STYLEをもつset文を実行すると,指標が最も近い整数値nに丸め
123
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
られて評価され,それ以後の線の形又は点の形は,利用できる線の形又は点の形の集合のn番目のも
のに設定される。利用できる線の形の個数は,処理系定義とするが,簡易図形出力では少なくとも三
つ【,図形機能単位では少なくとも四つ】はなければならない。1,2,3【及び4】の線の形は,それ
ぞれ実線,破線,点線【及び一点鎖線】とする。その他の線の形の値は,処理系定義とする。プログ
ラムの実行を開始する時の線の形は,1(実線)とする。
(3) 点の形は,中心付けられた記号を示す。点の形の個数は,処理系定義とするが,簡易図形出力では少
なくとも三つ【,図形機能単位では少なくとも五つ】はなければならない。1, 2, 3【,4及び5】の点
の形は,それぞれ黒点 (・),十字 (+),星印 (*) 【,白丸 (○) 及びばつ印 (×)】とする。その他の
点の形の値は,処理系定義とする。プログラムの実行を開始する時の点の形は,3(星印)とする。
(4) 機能語LINE STYLE又はPOINT STYLEをもつask文を実行すると,その時の実際の線の形又は点の
形の現在値が,その数値変数に代入される。
(5) 機能語MAX LINE STYLE又はMAX POINT STYLEをもつask文を実行すると,LINE STYLE又は
POINT STYLEのそれぞれの利用可能な最大値がその数値変数に代入される。
値1からこの最大値までのすべての整数値が,点の形又は線の形として利用可能とする。
(6) 機能語POINT COLOR,LINE COLOR,TEXT COLOR又はAREA COLORをもつset文を実行すると,
指標が最も近い整数値nに丸められて評価され,それ以後の点,線,文章又は塗りつぶし領域 (filled
area) の色指標 (color index) が,その時の図形表示装置で利用できる色の集合のn番目のものに設定
される。この色を前景色 (foreground color) と呼ぶ。プログラムの実行を開始する時に,それぞれの指
標に対応する色は,処理系定義とし,前景色の指標は,すべて値1とする。利用できる色の個数は,
処理系定義とする。
(7) 機能語POINT COLOR,LINE COLOR,TEXT COLOR又はAREA COLORをもつask文を実行すると,
その時の点,線,文章又は塗りつぶし領域に対する色指標の現在値が,その数値変数に代入される。
(8) 【機能語COLOR MIXをもつset文を実行すると,指標が最も近い整数値に丸められて評価され,そ
の色指標に対応する色を変更する。三つの数値式は,それぞれ赤,緑及び青の強度 (intensity) を定め,
これをその色指標に設定する。赤,緑及び青に対する値は,ゼロ以上1以下でなければならない。
背景色が意味をもつ装置では,色指標ゼロは背景色を表現する。機能語COLOR MIXをもつset文
の効果が,それ以後表示する色を変更するだけか,又は既に表示されている色も変更するかは,処理
系定義とする。】
(9) 【機能語COLOR MIXをもつask文を実行すると,指標が最も近い整数値に丸められる。指定された
色指標に対応する赤,緑及び青の強度が,この順でそれぞれの数値変数に代入される。返される値は,
機能語COLOR MIX及びその指標の値をもって実行された最後のset文によって設定された値とする。
色混合率を正確に設定できなかった場合には,実際に有効な値が返される。プログラムの実行を開始
する時の色混合率の値は,処理系定義とする。
機能語COLOR MIX及びstatus句をもち,色指標がゼロより小さい又は利用可能な最大色指標より
大きいask文を実行すると,status句は,値11086を返す。その色指標に対して色混合率が設定され
ていないと,値11087を返す。これらの場合,赤,緑及び青に対して,値ゼロが返される。】
(10) 機能語MAX COLORをもつask文を実行すると,機能語【COLOR MIX,】POINT COLOR,LINE COLOR,
TEXT COLOR又はAREA COLORをもつset文における色指標として利用可能な最大値が,その数値
変数に代入される。処理系が,値1からこの最大値までのすべての整数値を色指標として利用可能に
することが望ましい。
124
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(11) 【文章属性は,(11)〜(16)による。
機能語TEXT HEIGHTをもつset文を実行すると,それ以後の図形text文によって印字される文字
の問題座標における近似の高さが設定される。設定された文字寸法が現在の視野変形によって基準装
置座標に写像され,その要求された高さを超えない最大寸法の機械文字集合が選択される。すべての
利用可能な寸法が要求された高さを超える場合,最小寸法の機械文字集合が採用される。そもそも機
械文字集合が存在しない場合には,この規則に従ってソフトウェア的に生成された文字が使用される。
文字の高さの省略時想、定値は,0.01とする。文字の高さとは,英大文字の高さとする(図13.2参照)。】
(12) 【機能語TEXT HEIGHTをもつask文を実行すると,文字の高さの現在値がその数値変数に代入され
る。実際の文字の高さが,機能語TEXT HEIGHTをもって実行された最後のset文による設定と異な
る場合,実際の文字の高さが返される。】
(13) 【機能語TEXT ANGLEをもつset文は,それ以後に表示される文章の問題座標における角度を設定す
る。TEXT ANGLEがゼロであれば,先頭の文字を左端にして,通常の水平方向で画面上に名札を描く。
TEXT ANGLEがゼロでなければ,JUSTIFYで設定された点を中心として,通常の水平方向から逆時計
回りの方向に,指定された角度だけ名札が回転される。
角度は,angle選択子の指定による度又はラジアンで表す。180度の整数倍の角度では水平に,90
度の奇数倍の角度では垂直に文字の列を表示する。45度の奇数倍の角度では,その角度に対応して,
水平でも垂直でもない,中間の対応する斜め方向に文字の列を表示する。その他の方向の利用可能性
は,処理系定義とする。名札中での個々の文字の方向は,処理系定義とする。
プログラムの実行を開始する時の文章の角度は,ゼロ(水平右方向)とする。】
(14) 【機能語TEXT ANGLEをもつask文を実行すると,文章の角度の現在値がその数値変数に代入され
る。実際の角度が,機能語TEXT ANGLEをもって実行された最後のset文による設定と異なる場合,
実際の角度が返される。】
(15) 【機能語TEXT JUSTIFYをもつset文を実行すると,文字列式を評価して,以後の図形text文によっ
て印字される文章出力の位置が定められる。図形text文に指定した開始点を,文章位置とする。文章
出力を囲む長方形が,この開始点に対して相対的に指定される。
1番目の文字列式の有効な値は,“LEFT”,“CENTER”又は“RIGHT”とし,文章そろえの水平相
対位置を指定する。2番目の文字列式の有効な値は,“TOP”,“CAP”,“HALF”,“BASE”又は
“BOTTOM”とし,文章そろえの垂直相対位置を指定する。これらの値は,英大文字と英小文字を混
ぜて指定してもよい。
値“LEFT”を指定すると,文章長方形の左端を文章位置に位置付ける。値“CENTER”を指定する
と,文章長方形の左端と右端の中点を文章位置に位置付ける。値“RIGHT”を指定すると,文章長方
形の右端を文章位置に位置付ける。
垂直位置は,フォントに固有の,字形を定める基準線によって指定する(図13.2参照)。値“TOP”
を指定すると,文章長方形の頂線を文章位置にそろえる。値“CAP”を指定すると,文字列の全高線
をそろえる。値“HALF”を指定すると,文字列の半高線をそろえる。値“BASE”を指定すると,文
字列の並び線をそろえる。値“BOTTOM”を指定すると,文章長方形の底線をそろえる。
プログラムの実行を開始する時の文章そろえの値は,“LEFT”及び“BOTTOM”とする。】
(16) 【機能語TEXT JUSTIFYをもつask文を実行すると,現在の文章そろえの水平位置及び垂直位置の値
がそれぞれ1番目及び2番目の文字列変数に代入される。返される値は,すべて英大文字とする。】
(17) 字形の基準線を図13.2に示す。

125
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
図13.2 字形の基準線
13.2.5 例外状態 例外状態は,次による。
(1) 機能語【COLOR MIX,】POINT COLOR,LINE COLOR,TEXT COLOR又はAREA COLORをもつset
文の色指標が,ゼロより小さい又は処理系定義の最大色指標より大きい。(11085,続行可能。処理系
定義の省略時想、定値を用いる。)
(2) 機能語LINE STYLEをもつset文の指標の値が,ゼロ以下である又は利用可能な形の最大値より大き
い。(11062,続行可能。値1を用いる。)
参考 ANSI X3.113では,(2)及び(3)の“指標”が数値式となっているが,誤りであるので,TIBによ
って訂正した。
(3) 機能語POINT STYLEをもつset文の指標の値が,ゼロ以下である又は利用可能な形の最大値より大き
い。(11056,続行可能。値3を用いる。)
(4) 【機能語TEXT HEIGHTをもつset文の数値式の値がゼロ以下である。(11073,続行可能。今までの
値を維持して処理を続ける。)】
(5) 機能語TEXT JUSTIFYをもつset文の文字列式の値が,13.2.4(15)に規定された値でない。(4102,続行
可能。今までの値を維持して処理を続ける。)】
(6) 【機能語COLOR MIXをもつset文の三原色指定の数値式の値が,ゼロより小さい又は1より大きい。
(11088,続行可能。今までの値を維持して処理を続ける。)】
13.2.6 注意 注意は,次による。
(1) 機能語MAX COLORをもつask文に対して処理系が返す色の個数は,同時に表示することのできる色
(背景色は除く。)の個数とすることが望ましい。一つの装置において利用可能な色の総数ではない。
(2) 【処理系は,色指標の値の一部又は全部に対して,色混合率をあらかじめ定義しておいてもよい。】
(3) 【処理系は,可能ならば,問題座標における文字の幅を,機能語TEXT HEIGHTによって定められる
文字の高さに比例させることが望ましい。】
(4) 【処理系は,単色の表示装置に対する強度を,0.30×赤+0.59×緑+0.11×青とすることが望ましい。】
(5) 次のBASICの文は,次のGKSの機能に対応する。
BASIC :clear文
126
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
GKS
:機能CLEAR WORKSTATION (#0, CONDITIONALLY)
BASIC :機能語LINE STYLE又はPOINT STYLEをもつset文
GKS
:機能SET LINETYPE又はSET MARKER TYPE
BASIC :機能語LINE COLOR,POINT COLOR,TEXT COLOR又はAREA COLORをもつset文
GKS
:機能SET POLYLINE COLOUR INDEX,SET POLYMARKER COLOUR INDEX,SET TEXT
COLOUR INDEX又はSET FILL AREA COLOUR INDEX
【BASIC :機能語TEXT HEIGHTをもつset文
GKS
:機能SET CHARACTER HEIGHT
BASIC :SET TEXT ANGLE Xというset文
GKS
:機能SET CHARACTER UP VECTOR (Cos(X+PI/2), Sin (X+PI/2))
BASIC :機能語JUSTIFYをもつset文
GKS
:機能SET TEXT ALIGNMENT
BASIC :機能語COLOR MIXをもつset文
GKS
:機能SET COLOUR REPRESENTATION】
(6) 次のBASICの質問対象は,GKSの機能INQUIRE CURRENT INDIVIDUAL ATTRIBUTE VALUESの,
次の係数に対応する。
BASIC
GKS
LINE STYLE
線の種類 (linetype)
POINT STYLE
マーカの種類 (marker type)
LINE COLOR
線の色指標 (polyline colour index)
POINT COLOR
マーカの色指標 (polymarker colour index)
TEXT COLOR
文章の色指標 (text colour index)
AREA COLOR
塗りつぶし領域の色指標 (fill area colour index)
(7) 【次のBASICの質問対象は,GKSの機能INQUIRE CURRENT PRIMITIVE ATTRIBUTE VALUESの係
数から,次のようにして導くことができる。ここでDXとDYは,文字の上げ下げ (character up) の値
から求める。
BASIC
GKS
TEXT HEIGHT
文字の高さ (character height)
TEXT ANGLE
ANGLE面(DX, DY)−PI/2
TEXT JUSTIFY
文字のそろえ (text alignment)】
(8) 【次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語COLOR MIXをもったask文
GKS : 機能INQUIRE COLOUR REPRESENTATIONにおいて図形処理装置を#0とし,返る値を
REALIZEDとしたときの指標及び色係数
127
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
BASIC : 機能語MAX LINE STYLEをもつask文
GKS : 機能INQUIRE POLYLINE FACILITIESにおける利用可能な線の種類の係数の個数
BASIC : 機能語MAX POINT STYLEをもつask文
GKS : 機能INQUIRE POLYMARKER FACILITIESにおける利用可能なマーカの種類の係数の個
数】
(9) 【同時に表示することのできる色の個数を,“色彩表の項目数”の係数によって示すGKS処理系にお
いては,GKSの機能INQUIRE LIST OF COLOUR INDICESによってこれを知ることができる。機能語
MAX COLORをもつask文は,この値より1小さい値を返す。】
13.3 図形出力
13.3.1 概要 ここでは,各種の図形出力の生成に使う文を規定する。利用者は,図形出力文によって,画
面上に点,線分又は塗りつぶし領域を描くことができる。図形出力文には,そのほかに文章を描画中に含
める機能【や着色胞 (colored cell) の配列を出力する機能】がある。図形出力文の効果は,13.1及び13.2
に規定したさまざまな設定対象の現在値によって制御される。【図形出力の追加の機能が,13.5に規定して
ある。】
13.3.2 構文 構文は,次による。
(1) 単純実行文⊃図形出力文
(2) 図形出力文=幾何図形文|【機何図形mat文|】図形text文【|mat-cells文】
(3) 幾何図形文⊃図形動詞 幾何対象 コロン 点並び
(4) 図形動詞⊃GRAPH
(5) 幾何対象=POINTS|LINES|AREA
(6) 点並び=座標対 {セミコロン 座標対}*
(7) 座標対=数値式 コンマ 数値式
(8) 【幾何図形mat文=MAT 図形動詞 幾何対象 {コンマ limit句}? コロン 配列点並び】
(9) 【limit句=LIMIT 指標】
(10) 【配列点並び=数値配列名 {コンマ 数値配列名}?】
(11) 図形text文= 図形動詞 TEXT 開始点 {コンマ USING 書式引用 コロン 式並び|コロン
文字列式}
(12) 開始点=コンマ AT 座標対
(13) 【mat-cells文=MAT 図形動詞 CELLS コンマ IN 点対 コロン 数値配列名】
(14) 【点対=座標対 セミコロン 座標対】
(15) 【配列点並び (array-point-list) に数値配列を二つ指定するときには,それらは両方とも1次元でなけ
ればならない。一つのときには,2次元でなければならない。】
(16) 幾何対象LINESをもつ図形出力文では,その点並び (point-list) の中に少なくとも二つの座標対
(coordinate-pair) をもたなければならず,幾何対象AREAをもつ図形出力文では,少なくとも三つの座
標対をもたなければならない。
13.3.3 例 構文の例を次に示す。
GRAPH LINES:3,4;5,6;66.66,77.77
(3)
MAT GRAPH POINTS:XY̲PTS
(8)
128
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
MAT GRAPH AREA, LIMIT 7:X,Y
(8)
【GRAPH TEXT, AT XP,YP:”here is the label:”& TEXT$
(11)】
【GRAPH TEXT, AT 0,Y̲VALUE, USING ”##. ##^^^^” : , Y̲VALUE
(11)】
【MAT GRAPH CELLS, IN p̲i̲x, p̲l̲y;p̲2̲x, p̲2̲y:color̲array
(13)】
13.3.4 意味 意味は,次による。
(1) 図形出力文
(1.1) 利用者による図形出力の生成は,すべて図形出力文によって行われる。幾何図形文【及び幾何図形
mat文】は,形及び色を与えられた描点列,接続した線分の集まり又は多角形の塗りつぶし領域を
描く。図形text文は,英数字で構成される名札を作り出す。【mat-cells文は,長方形で閉じられた
領域中に長方形の着色胞の集合を生成する。】
(1.2) 【print文,input文及びtrace文によって生成される出力は,図形出力文によって生成される出力
に影響を与えない。】
(2) 幾何図形文【及び幾何図形mat文】
(2.1) 幾何図形文【及び幾何図形mat文】は,問題座標中で指定された点の列を与える。幾何図形文では,
点並び中の最初の座標対が最初の点を示し,以下順次に点並びの終りまでの座標対が点の列を定め
る。
【幾何図形mat文では,limit句と配列点並びとが点の列を次のとおりに定める。limit句を書く
と,指標が最も近い整数値に丸められて評価され,その値が点の個数になる。limit句を書かないと,
配列点並びに書いたベクトルの長さ又は配列の第1次元の要素数が,点の個数になる。配列点並び
が二つのベクトルで構成されている場合には,点のx座標は1番目のベクトルからとられ,y座標
は2番目のベクトルからとられる。配列点並びが2次元の配列であり,その配列の第2次元の寸法
が2であれば,x座標は第1列からとられ,y座標は第2列からとられる。点の列は,いつも配列の
第1行又はベクトルの第1要素から始まり,順次にとられる。点の列は,limit句のない場合には配
列又はベクトルの終りで終了し,limit句のある場合にはそこで指定された点の個数に達したときに
終了する。】
(2.2) 幾何対象がPOINTSである場合,POINT STYLE及びPOINT COLORの現在値に応じた形及び色の
点が描かれる。
幾何対象がLINESである場合,隣接した各2点を結んで,1番目の点から2番目の点,2番目の
点から3番目の点へというように線分が描かれる。したがって線分の本数は,点の個数より1だけ
少なくなる。線分の形及び色は,LINE STYLE及びLINE COLORの現在値によって定められる。
幾何対象がAREAである場合,このLINESの規定と同じ線分の連なりを辺とする多角形が,内
部を塗りつぶされて描かれる。点の連なりの最初と最後の点が同一点でないときには,その2点を
つなぐ線分が追加されて外周が完成される。AREA COLORの現在値が,多角形の辺及び内部の色
を定める。ある点を起点とする半直線が多角形の辺と奇数回交差するとき,そのようなすべての点
(画素)の集合をその多角形の内部と定義する。それが可能な装置では,多角形の内部は,すきま
なく塗りつぶされる。
(2.3) 【第2次元の寸法が3以上である配列をもつ配列点並びの効果は,処理系定義とする。】
(3) 図形text文
(3.1) 図形text文は,その文字列式又は書式文字列と式並びとによって生成される文字の列からなる名札
を描く。【書式文字列によって生成される文字の列は,10.4による。】名札として使われる文字は,
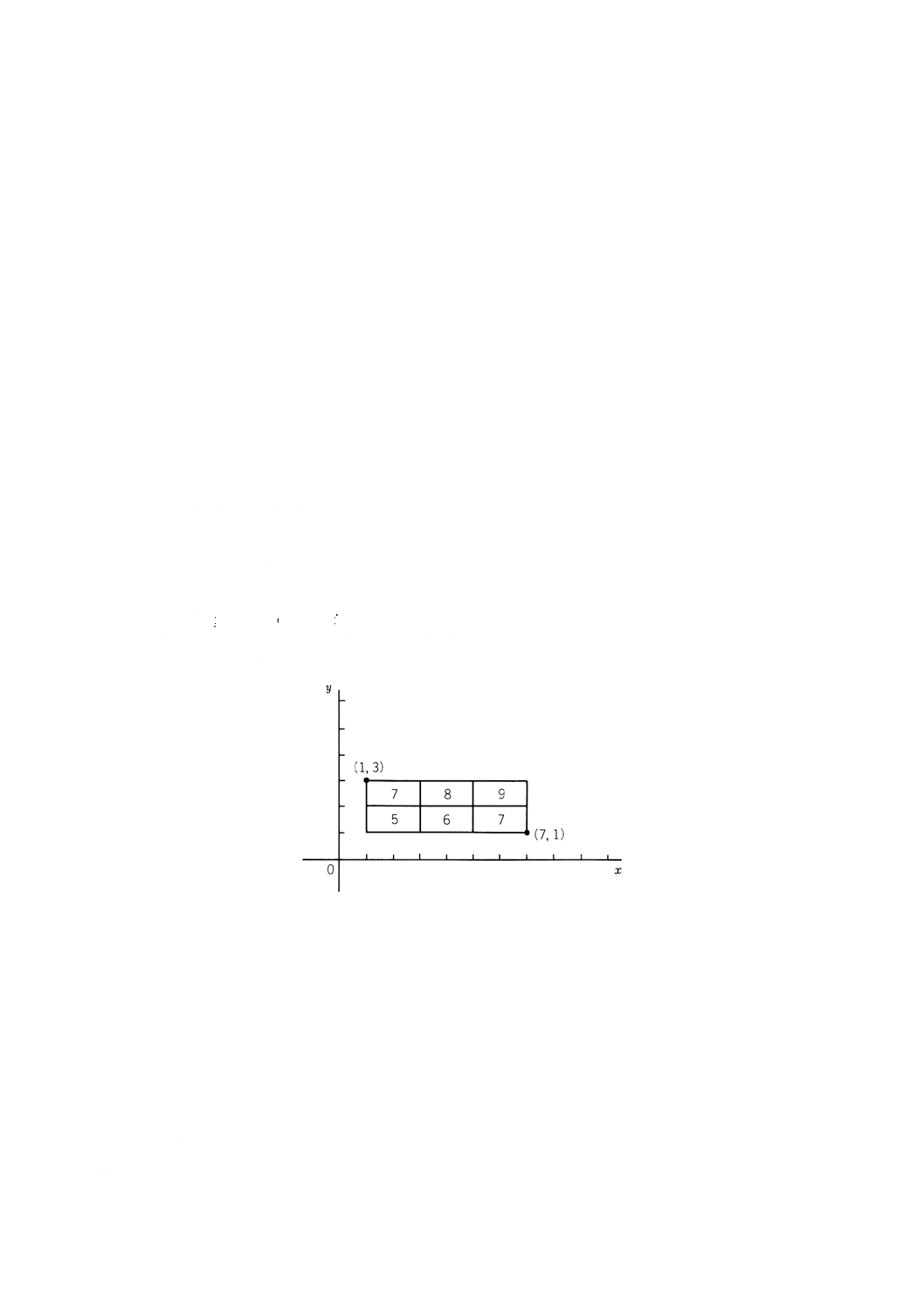
129
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
処理系定義の寸法,形【及び方向】をもつ。画面上の視野面の内と外にまたがって置かれる文字の
切取り方は,処理系定義とする。
(3.2) 簡易図形出力における名札の表示のされ方は,13.2.1(5)による。【図形機能単位における名札の表示
のされ方は,TEXT HEIGHT,TEXT JUSTIFY及びTEXT ANGLEの現在値によって制御される。】
(4) 【mat-cells文
(4.1) mat-cells文は,長方形の領域を塗りつぶす。長方形の対角位置にある二つの頂点の問題座標を,点
対によって与える。数値配列の現在の寸法が,胞数を定める。第1次元の寸法が水平方向の列数,
第2次元の寸法が垂直方向の行数になる。各胞は同一の大きさとし,
(ABS(1番目のx座標−2番目のx座標)/第1次元の寸法)の幅,
(ABS(1番目のy座標−2番目のy座標)/第2次元の寸法)の高さ
をもつ。各胞は,その数値配列中の対応する要素の値を丸めた指標で示される色で塗りつぶされ
る。点対の第1点のほうの位置にある胞が,配列の第1行,第1列の要素に対応する。点対の第2
点のほうの位置にある胞が,配列の最後の行,最後の列の要素に対応する。
例 配列Aが次の値をもっているとする。
A (1, 1) =7, A (1, 2) =5,
A (2, 1) =8, A (2, 2) =6,
A (3, 1) =9, A (3, 2) =7
ここで次の文を実行する。
mat graph cells, in 1,3;7,1:A
点対は,1, 3; 7, 1すなわち (1, 3) 及び (7, 1) の2点である。その結果,長方形は次のようになる。
指標はその胞の色を表す。
(4.2) 出力装置が画素出力の能力をもたないとき,処理系は,胞出力を模擬しなければならない。模擬の
最低条件は,変形された結果の胞長方形の外縁を描くこととする。】
13.3.5 例外状態 例外状態は,次による。
(1) 【limit句の指定がなく,配列点並び中の二つのベクトル中の要素の個数が等しくない。(6401,続行
不能)】
(2) 【配列点並び中に,ただ一つの数値配列だけが指定されており,その第2次元の寸法が1である。(6401,
続行不能。)】
(3) 【limit句の指標の値がゼロ以下である,又は配列点並びで利用可能な点の個数より大きい。(6402,
続行不能。)】
(4) 幾何対象LINESをもつ図形出力文が,1点以下の点を指定している。(11100,続行不能。)
(5) 幾何対象AREAをもつ図形出力文が,2点以下の点を指定している。(11100,続行不能。)
130
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(6) 【mat-cells文中の数値配列によって指定されている色指標が,利用可能でない。(11085,続行可能。
処理系定義の省略時想、定値を用いる。)】
13.3.6 注意 注意は,次による。
(1) 図形text文は,装置のハードウェアによって生成される文字集合を容易に参照できるように設計され
ている。【だから例えば,個々の文字の向きや一般の向きの文章の方向などは,規定しない。】
(2) 文章は,問題座標を用いて指定される。したがって,窓と視野面の縦横比が異なる場合には,文章が
歪むことがある。
(3) ある装置で多角形の塗りつぶしが不可能である場合には,処理系が,多角形の外周を描き,その内側
に現在の色指標に応じた色の斜線列,線影などを描くことを推奨する。
(4) 同一直線上にある点だけからなる塗りつぶし領域は,処理系が,その点を通る一つの線分として描く
ことを推奨する。同一の点だけからなる塗りつぶし領域及び線は,処理系が,一つの点として描くこ
とを推奨する。【mat-cells文の点対が,幅がゼロ又は高さがゼロの長方形領域を指定する場合には,
処理系が,一列に並んだ胞として描くことを推奨する。】
(5) 次のBASICの文は,次のGKSの機能に対応する。
BASIC
: 機能語POINTSをもつgraph文【及び機能語GRAPH POINTSをもつmat文】
GKS
: 機能POLYMARKER
BASIC
: 機能語LINESをもつgraph文【及び機能語GRAPH LINESをもつmat文】
GKS
: 機能POLYLINE
BASIC
: 機能語AREAをもつgraph文【及び機能語GRAPH AREAをもつmat文】
GKS
: 機能FILL AREA
BASIC
: 機能語TEXTをもつgraph文
GKS
: GKSの機能TEXTをUSINGの書式を許すように拡張したもの
【BASIC : 機能語GRAPH CELLSをもつmat文
GKS
: 機能CELL ARRAY】
(6) 【配列点並びの2次元数値配列において,第2次元の寸法が3以上であるときの効果は,処理系定義
であり [13.3.4(2.3)],例外状態を引き起こすように規定はされていない。これは,将来,3次元図形出
力を規定するようにこの規格を拡張することを許すためである。この規格に定めるとおりの図形機能
だけを支援する場合,処理系が,これに対して例外状態6401を与えることを推奨する。】
(7) 【ゼロ番の経路に結び付けられている非図形装置に対して,print文,input文,続行可能な例外状態
又はtrace文が出力を行うと,GKSの機能UPDATE WORKSTATION #0 : “SUPPRESS” が暗黙的に呼
ばれる。】
【
13.4 図形入力
備考 13.4は,簡易図形出力機能単位には含まれない。
131
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
13.4.1 概要 プログラムは,1台の図形処理装置 (workstation) に接続する一つ以上の入力機構からデー
タを入力することができる。例えば,表示画面上の十字カーソルやマウスを用いて,一つの点又は点の配
列を入力できる。ボタン又はメニュー項目で選択をし,それを整数値として入力することもできる。ダイ
ヤル又はそれに類似した機構によって,連続量を入力することもできる。一つ一つの種類について,何台
もの入力機構を図形処理装置に接続することもできる。
更に,ラスタ(走査線,raster)方式の表示装置の場合には,指定した長方形の中の最小表示単位である
画素 (pixel) の個数を問い合わせたり,これらの画素の色を問い合わせたりすることもできる。
13.4.2 構文 構文は,次による。
(1) 単純実行文⊃図形入力文
(2) 図形入力文⊃locate文|mat-locate文
(3) locate文=LOCATE {point句 コロン 座標変数対|値選択 コロン 数値変数名}
(4) mat-locate文=MAT LOCATE point句 コロン 配列位置対象
(5) point句=POINT 機構選択? 開始点?
(6) 座標変数対=数値変数名 コンマ 数値変数名
(7) 値選択=CHOICE 機構選択? 開始値?|VALUE 機構選択? range句 開始値?
(8) 配列位置対象= 再定義数値配列 {コンマ 再定義数値配列}?|数値不定長ベクトル コンマ
数値不定長ベクトル|数値不定長行列
(9) 再定義数値配列=数値配列名 再定義上下限指定部?
(10) 数値不定長ベクトル=数値配列名 左括弧 疑問符 右括弧
(11) 数値不定長行列=数値配列名 左括弧 疑問符 コンマ 右括弧
(12) range句=コンマ RANGE 数値式 TO 数値式
(13) 機構選択=左括弧 指標 右括弧
(14) 開始値=コンマ AT 数値式
(15) 質問対象⊃ MAX 機構種別 DEVICE 数値変数名|PIXEL SIZE 左括弧 点対 右括弧
数値変数名 コンマ 数値変数名|PIXEL ARRAY 点位置 数値配列名
{コンマ 文字列変数名}?|PIXEL VALUE 点位置 数値変数名
(16) 点位置=左括弧 座標対 右括弧
(17) 機構種別=POINT|MULTIPOINT|CHOICE|VALUE
(18) 機能語CHOICEをもつlocate文の開始値は,その使用に先立って,最も近い整数に丸められる。
参考 ANSI X3.113にはこの(18)項はないが,TIBによって補った。
(19) 配列位置対象に再定義数値配列を一つ指定するときには,それは2次元でなければならない。二つの
ときには,両方とも1次元でなければならない。
(20) 質問対象に機能語PIXEL ARRAYを書くときには,その数値配列は2次元でなければならない。
(21) 数値不定長ベクトルの数値配列は,1次元でなければならない。数値不定長行列の数値配列は,2次元
でなければならない。
13.4.3 例 構文の例を次に示す。
LOCATE POINT:X̲IN, Y̲IN
(3)
LOCATE POINT, AT 4.7,5.2:wide, long
(3)
LOCATE VALUE(3), range −7 to 7:Amps
(3)
Locate choice:button
(3)
132
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
MAT LOCATE POINT:XVALS(?), YVALS(?)
(4)
Mat locate point(indev), at 0,0:Points(2,10)
(4)
MAT LOCATE POINT:SKETCH(?,)
(4)
mat locate point:times, temps
(4)
MAX CHOICE DEVICE Last̲button̲set
(15)
MAX MULTIPOINT DEVICE NSTROKES
(15)
PIXEL SIZE (.5,2.5;0,0) xvals, yvals
(15)
Pixel array (.5,2.5) Pix̲vals
(15)
pixel value (time1,weight) curpoint
(15)
原点右上の単位長方形中にある画素の色を問い合わせる例を示す。
! Find the colors of pixels in unit square at (0,0)
Option Base 1
Dim pix (30,30) ! expected maximum of 30x30 pixels
|900画素以内
Ask pixel size (0,0;1,1) one, two
|単位長方形の辺の画素数
If one*two <=900 AND one> 0 and two> 0 then
Mat pix=zer(one,two) ! redim to right size
|画素行列
Ask pixel array (0,1) pix
|左上を指定して色指標を
End if
問い合わせる
13.4.4 意味 意味は,次による。
(1) locate文とmat-locate文は,それぞれinput文とmat-input文に似ている。文字で表現された値を与え
る代わりに,利用者はカーソルを1個又は複数個の点に位置付けたり,ボタンを押したり,ダイヤル
を回したり,又はそれらと類似の操作を行ったりすることによって,入力を与える。利用者に図形入
力要求を知らせる手段は,処理系定義とする。その図形処理装置において,ある機構種別 (device-type)
中に1台も入力機構が付いていないときには,処理系は,けん(鍵)盤その他の適切な手段によって,
その種別中の1番の機構を代行する。
(2) 開始点 (initial-point) を指定して図形入力文を実行すると,利用者の入力に先立って,指示子(例えば,
カーソルや追跡十字)が問題座標上のその点に位置付けられる。開始点を指定しない場合の指示子の
位置は,処理系定義とする。
(3) point句をもつlocate文を実行すると,一つの点の問題座標が座標変数 (coordinate-variables) に代入さ
れる。x座標が1番目の変数に,y座標が2番目の変数に,それぞれ代入される。現在の窓の内側にあ
る点の位置だけを返すことができる。この窓は,機能語WINDOWをもって実行された最後のset文
の問題座標又はset文が実行されていない場合には省略時想定の問題座標によって設定されている。
現在の窓,装置窓又は装置視野面の外側にある点の位置を入力しようとしたときの効果は,処理系定
義とする[13.4.6(2)参照]。
(4) mat-locate文を実行すると,一つ以上の点の問題座標が配列位置対象 (array-locate-object) に代入され
る。配列位置対象が二つの1次元配列である場合には,水平方向の座標値xが1番目の配列の要素に,
垂直方向の座標値yが2番目の配列の要素に代入される。配列位置対象が一つの2次元配列である場
合には,水平方向の座標値xが第1列の要素に,垂直方向の座標値yが第2列の要素に代入される。
再定義数値配列 (redim-numeric-array) の上下限の動的な再定義が,10.5.4の配列入力での動的な再
定義の規則に従って,入力に先立って行われる。
133
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
配列位置対象が二つの1次元配列である場合には,再定義の指定があれば再定義をした後で,それ
らの寸法が同じでなければならない。それらのベクトルの寸法と同じ個数の点が入力される。配列位
置対象が一つの再定義数値配列である場合には,再定義をした後で,第2次元の寸法が2でなければ
ならない。配列の第1次元の寸法の個数の点が入力される。
配列位置対象が一つの数値不定長行列であるか又は二つの数値不定長ベクトルである場合は,可変
の個数の点が入力される。入力機構に依存した信号を利用者が送って,点の入力が終わったことを示
すまでの,すべての点が入力される。二つのベクトルへの代入は,おのおののベクトルの現在の下限
値のところがら始まる。すべての点の入力後に,数値不定長ベクトルは,最後の点を受け取った要素
のもつ添字をおのおのの上限値として,動的に再定義される。
数値不定長行列への代入も同様に,次によって行われる。代入は,第2次元の添字の現在め下限値
のところから始まる。x座標は第1列に代入され,y座標は第2列に代入される。すべての点の入力後
に,数値不定長行列は,最後の点を受け取った要素のもつ先頭の添字を第1次元の上限値とし,第2
次元の添字の現在の下限値に1を加えた値を第2次元の上限値として(すなわち寸法を2として),動
的に再定義される。現在の窓,装置窓又は装置視野面の外側にある点の位置を入力しようとしたとき
の効果は,処理系定義とする[13.4.6(2)参照]。
(5) 機能語CHOICEをもつlocate文を実行すると,正の整数値が数値変数に代入される。代入される値は,
選択機構 (choice device) からの応答に対応する。その最大値は,利用者の選択可能な項目数に対応す
る。機構が利用者に選択しないことを許し,利用者が選択しなかった場合には,値ゼロが代入される。
開始値 (start-value) の意味は,機構に依存し,すべての機構で処理可能とは限らない。処理可能な場
合には,入力機構がその指示子を開始値の位置にする。
(6) 機能語VALUEをもつlocate文を実行すると,実数値が数値変数に代入される。代入される値は,利
用者が設定し終わったことを指示した時の連続量入力機構 (valuator device) 上の量を基準化したもの
とする。基準化は,機構上の最小物理量をrange句の1番目の数値式の値に写像し,機構上の最大物
理量をrange句の2番目の数値式の値に写像して行われる。中間の量は,二つの数値式の間で比例配
分した値とする。
range句の指定を省略すると,同じ機構で機能語VALUEをもって実行された最後のlocate文のrange
句の値が使われる。そのような値が設定されていないときには,閉区間 [0, 1] が想定される。開始値
の意味は,機構に依存し,幾つかの機構では処理可能ではないかもしれない。処理可能な場合には,
入力機構がその指示子を開始値の値にする。
(7) locate文又はmat-locate文に機構選択 (device-select) を指定すると,その指標は整数値nに丸められ,
その図形処理装置に接続しているその種別の機構のn番目のものを選択する。機構選択の指定を省略
すると,値1が使われる。図形入力機構のそれぞれの種別 (POINT, MULTIPOINT, VALUE, CHOICE) は,
機構選択の値の組をもつ。それぞれの組は,その種別の最初の機構を選択する値1から始まる。選択
された機構が存在しないと,例外状態になる。
(8) 機能語MAX POINT DEVICEをもつask文を実行すると,point句をもつlocate文で使用できる機構の
個数が返される。
(9) 機能語MAX MULTIPOINT DEVICEをもつask文を実行すると,mat-locate文で使用できる機構の個
数が返される。
(10) 機能語MAX CHOICE DEVICEをもつask文を実行すると,機能語CHOICEをもつlocate文で使用で
きる機構の個数が返される。
134
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(11) 機能語MAX VALUE DEVICEをもつask文を実行すると,機能語VALUEをもつlocate文で使用でき
る機構の個数が返される。
(12) 点対は,長方形の対角位置にある二つの頂点を,問題座標中で指定する。その順序は任意とする。機
能語PIXEL SIZEをもつask文を実行すると,その長方形の中に位置付けられる画素の水平方向及び
垂直方向の個数が,その順序で数値変数に代入される。画素の個数が決定できないとき(例えば,ラ
スタ方式でない装置のとき)は,値ゼロがそれらの変数に代入される。機能語PIXEL SIZEをもつask
文に書いたstatus句は,常に値ゼロを返す。
(13) 機能語PIXEL ARRAYをもつask文を実行すると,点位置によって問題座標中の一つの点が定められ
る。その点を左上の頂点とする長方形の領域中の画素の色指標が,数値配列に代入される。長方形中
の画素の水平方向の列数は,数値配列の第1次元の要素の個数とする。長方形中の画素の垂直方向の
行数は,数値配列の第2次元の要素の個数とする。画素の色指標が決定できないときは,その要素に
対して−1の値が返される。表示画面の外側の点及びラスタ方式でない装置でのすべての点に対して
も−1の値とする。文字列変数がある場合は,決定できない点が1個でもあれば英大文字の“PRESENT”
の値が代入され,そうでなければ英大文字の“ABSENT”の値が代入される。
(14) 機能語PIXEL VALUEをもつask文を実行すると,点位置によって問題座標中の一つの点が定められ
る。その位置の画素の色指標が,数値変数に代入される。その色指標が決定できないときは,−1の
値が代入される。
(15) 画素の読取り機能がない場合,status句及び機能語PIXEL ARRAY又はPIXEL VALUEをもつask文を
実行すると,status句は11040の値を数値変数に返す。
13.4.5 例外状態 例外状態は,次による。
(1) 再定義後の配列で必要な要素の総数が,もとの配列宣言で確保された要素の総数を超える。(5001,続
行不能。)
(2) 配列位置対象が二つの1次元の再定義数値配列であって,その寸法が異なる。(6401,続行不能。)
参考 ANSI X3.113の文章はやや異なるが,誤りであるので,TIBによって訂正した。
(3) 機構選択で指定された図形入力機構が,図形処理装置に存在しない。(11140,続行不能。)
(4) 配列位置対象に数値配列を一つだけ書いて,しかもその第2次元の寸法が1以下である。(6401,続行
不能。)
(5) 機能語CHOICEをもつlocate文の開始値を丸めた整数値が,負である又はその機構の最大選択番号よ
り大きい。(11152,続行不能。)
参考 ANSI X3.113には“を丸めた整数値”という言葉がないが,TIBによって訂正した[13.4.2(18)
参照]。
(6) 機能語VALUEをもつlocate文の開始値が,その機構に対して現在定義されている範囲の外にある。
(11152,続行不能。)
(7) 開始点の位置が,基準化と装置変形とを適用した後の装置視野面の外側になる。(11152,続行不能。)
13.4.6 注意 注意は,次による。
(1) 配列位置対象において,第2次元の寸法が3以上である数値配列の意味は,処理系定義とする。
(2) point句が現在の窓,装置窓又は装置視野面の外側にある点を指す図形入力文を実行しようとした場合,
処理系がそれを例外状態(8106,続行可能。図形入力要求を再発行する。)として報告し,例外処理区
で処理できるようにすることを推奨する。
(3) 次のBASICの文は,次のGKSの機能に対応する。装置座標空間中の点を問題座標に変形するときに,
135
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
GKSの変形番号1が想定される。
BASIC : point句をもつlocate文
GKS
: 機能REQUEST LOCATORの部分集合
BASIC : locate文のpoint句に指定する開始点
GKS
: 機能INITIALISE LOCATORの部分集合
BASIC : point句をもつmat-locate文
GKS
: 機能REQUEST STROKEの部分集合
BASIC : mat-locate文のpoint句に指定する開始点
GKS
: 機能INITIALISE STROKEの部分集合
(4) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語VALUEをもつlocate文
GKS
: 機能REQUEST VALUATORの部分集合
BASIC : locate文の機能語VALUEの後ろに指定するrange句及び開始値
GKS
: 機能INITIALISE VALUATORの部分集合
(5) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語CHOICEをもつlocate文
GKS
: 機能REQUEST CHOICEの部分集合
BASIC : locate文の機能語CHOICEの後ろに指定する開始値
GKS
: 機能INITIALISEl CHOICE
(6) GKSの機能SET LOCATOR MODE,SET STROKE MODE, SET VALUATOR MODE及びSET CHOICE
MODEは,暗黙的に“REQUEST”に設定される。
(7) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語MAX POINT DEVICE,MAX MULTIPOINT DEVICE,MAX CHOICE DEVICE又は
MAX VALUE DEVICEをもつask文
GKS
: 機能INQUIRE NUMBER OF AVAILABLE LOGICAL INPUT DEVICESのlocator(位置),
stroke(一連の位置),choice(選択)又はvaluator(連続量入力)の各係数
(8) 次のBASICの文は,次のGKSの機能に対応する。
BASIC : 機能語PIXEL SIZE,PIXEL ARRAY又はPIXEL VALUEをもつask文
GKS
: 機能INQUIRE PIXEL ARRAY DIMENSIONS,INQUIRE PIXEL ARRAY又はINQUIRE
PIXEL
】
【
13.5 絵及び描点出力
備考 13.5は,簡易図形出力機能単位には含まれない。
13.5.1 概要 13.5は,GKSの拡張であって,GKSの規格に含まれない機能を規定する。
136
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
絵を描く図形手続きを,副プログラムにおける手続きと類似の方法で定義することができる。そのよう
な絵定義は,呼び出すことができ,その手続き中での図形入力及び図形出力に対して,拡大縮小,平行移
動又は回転のような平面図形の変形指示を与えることができる。
二つ以上の実行文に分けて指定された点を結んで,線分を引く機能も定める。現在の変形指示の逆行列
を,入力に対して適用することができる。
13.5.2 構文 構文は,次による。
(1) 単純実行文⊃draw文|exit-picture文|変形指示mat文
(2) draw文=DRAW 絵呼出し {WITH 変形}?
(3) 絵呼出し=絵名 参照実引き数部?
(4) 絵名=ルーチン識別名
(5) 変形=変形項 {星印 変形項}*
(6) 変形項=変形関数名 値実引き数部|数値配列名|現在変形
(7) 変形関数名=ROTATE|SHEAR|SHIFT|SCALE
(8) exit-picture文=EXIT PICTURE
(9) 変形指示mat文=MAT 数値配列名 等号 変形
(10) 図形動詞⊃PLOT
(11) 幾何図形文⊃PLOT LINES|PLOT LINES コロン 点並び セミコロン?
参考 ANSI X3.113では,ここの“セミコロン”の次の疑問符がないが,誤りであるので,TIBによ
って訂正した。
(12) 絵定義=内部絵定義|外部絵定義
(13) 外部手続き定義⊃外部絵定義
(14) 内部手続き定義⊃内部絵定義
(15) 内部絵定義=内部picture行 区* end-picture行
(16) 内部picture行=行番号 内部picture文 行末部
(17) 内部picture文=PICTURE 絵名 参照仮引き数部?
(18) end-picture行=行番号 END PICTURE 行末部
(19) 外部絵定義=external-picture行 手続き区* end-picture行
(20) external-picture行=行番号 EXTERNAL 内部picture文 行末部
(21) 宣言指定⊃内部picture宣言|external-picture宣言
(22) 内部picture宣言=PICTURE 絵名並び
(23) 絵名並び=絵名 {コンマ 絵名}*
(24) external-picture宣言=EXTERNAL PICTURE 絵名並び
(25) 行⊃end-picture行|external-picture行|内部picture行
(26) 現在変形=TRANSFORM
(27) 図形入力文⊃GET point句 コロン 座標変数対|MAT GET point句 コロン 配列位置対象
(28) 数値配列値⊃TRANSFORM
(29) 内部絵定義の外部の行番号分岐中の行番号は,内部絵定義の内部にある行を参照してはならない。た
だし,内部picture行は,参照してもよい。内部絵定義の内部の行番号分岐中の行番号は,その内部
絵定義の外部にある行及びその内部picture行を参照してはならない。
(30) 外部絵定義の内部の行番号分岐中の行番号は,そのexternal-picture行を参照してはならない。
137
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(31) 一つのプログラム中で,同じ名前の外部絵定義を2回以上定義してはならない。一つのプログラム単
位中で,同じ名前の内部絵定義を2回以上定義してはならない。
(32) 一つのプログラム単位中で,同じ名前の(内部又は外部)絵を2回以上宣言したり定義したりしては
ならない。
(33) 絵名が外部絵定義によって定義されている場合,そのプログラム単位中でその絵名を参照するどの
draw文よりも早い位置に,その絵名を含むexternal-picture宣言のdeclare文を書かなければならない。
(34) 絵名が内部絵定義によって定義されている場合,そのプログラム単位中でその絵名を参照するどの
draw文よりも早い位置に,その内部絵定義,又はその絵名を含む内部picture宣言のdeclare文のど
ちらかを書かなければならない。
(35) 自己再帰的な絵は,自分自身を宣言する必要はない。すなわち,内部絵定義又は外部絵定義が自分自
身を参照するdraw文を含むときに,その参照は,より早い位置でその絵名を宣言しておくことを必
要としない。
(36) exit-picture文は,絵定義の中にだけ書くことができる。
(37) draw文の参照実引き数の個数及び型は,対応する絵定義の参照仮引き数の個数及び型と一致しなけれ
ばならない。これは,副プログラムにおける規定 [9.2.2(29)] と同じとする。
(38) 参照実引き数の実配列の次元数は,対応する仮配列の次元数と同じでなければならない。仮配列の次
元数は,その仮配列宣言中のコンマの個数に1を加えたものとする。
(39) 数値型の参照実引き数を,別のプログラム単位中の対応する数値型の参照仮引き数に渡す場合,有効
なarithmetic選択子がプログラム単位間で一致していなければならない。
(40) 一つの参照仮引き数部に,同じ参照仮引き数の名前を2回以上書いてはならない。
参照仮引き数を,その内部絵定義又は外部絵定義の内部で,declare文又はdim文に書いてはならな
い。
(41) 参照仮引き数として,経路番号ゼロを書いてはならない。
(42) 内部picture宣言中に書いた絵名には,そのプログラム単位中のどこかで,内部絵定義を与えなけれ
ばならない。
(43) external-picture宣言中に書いた絵名には,そのプログラム中のどこかで,外部絵定義を与えなければ
ならない。
(44) 変形項及び変形指示mat文の中のすべての数値配列は,2次元でなければならない。
(45) 変形関数の値実引き数の個数及び型は,13.5.4の規定に合致しなければならない。
13.5.3 例 構文の例を次に示す。
DRAW CIRCLE
(2)
DRAW CIRCLE WITH SHIFT (2,0)*SCALE(.4)
(2)
DRAW HOUSE (”SPLIT̲LEVEL”, 80000) WITH SHEAR(.1)
(2)
EXIT PICTURE
(8)
MAT SPIN̲SHRINK=ROTATE (180)*SCALE(.1)
(9)
MAT Where̲am̲I=Transform
(9)
Plot lines : x, sin(x);
(11)
138
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
100 EXTERNAL PICTURE CIRCLE
150 LET P=2*3.14159265/50
200 FOR I=0 TO 50
250 LET IP=I*P
(19)
300 PLOT LINES:COS(IP),SIN(IP);
400 NEXT I
500 END PICTURE
13.5.4 意味 意味は,次による。
(1) 絵定義及び変形
(1.1) draw文を実行すると,その絵名をもつ絵定義が実行される。絵は,副プログラムと同様の方法で呼
び出す。参照実引き数は,副プログラムの場合と同じ規則に従って受け渡す。絵と副プログラムは,
どちらも再帰的に呼び出すことができる。ルーチン識別名及び絵定義中の変数名の有効範囲の規則
は,副プログラムの場合と同じとし,絵定義が内部絵定義であるか,外部絵定義であるかによる。
副プログラムにおける経路番号に対する規則も,絵定義に対して同様に適用する。ただし,次の二
つの点で重要な相違がある。
第一に,座標系を再定義するset文(すなわち,機能語WINDOW,VIEWPORT,DEVICE WINDOW
若しくはDEVICE VIEWPORTをもつset文),又は切取りに影響するset文(すなわち,機能語CLIP
をもつset文)を,絵定義の実行中に,実行してはならない。
第二に,図形動詞PLOTをもつ図形出力文によって生成される図形出力は,図形動詞GRAPHを
もつ図形出力文によって生成される図形出力と同じとする。ただし,その座標は,絵定義を呼び出
すdraw文で指定された変形指示に従って,(1.2)のとおりに変形される。図形動詞PLOTをもつ図
形出力文を実行するときに,絵定義の実行中でなければ,図形出力は13.3の規定に従う。図形動詞
GRAPHをもつ図形出力文によって生成される図形出力は,その絵に対して現在有効な変形指示に
は影響されない。
(1.2) 変形を行うために,2次元平面上の点の問題座標 (x, y) を,同次座標 (homogeneous coordinates) (cx,
cy, 0, c) で表現する。ここで,cはゼロでない数値とする。この行ベクトルに,draw文における変
形項の値である4行4列の行列を右から乗ずると,座標が変形され,同次座標の新しい行ベクトル
が得られる。
一つ又は二つの数値式の実引き数をもち,4行4列の行列の値を生成する変形関数を用いて,変
形を指示することができる。これらの変形関数の値実引き数の個数,その効果及び値は,表13.1に
よる。
関数ROTATE及び関数SHEARの値実引き数は,そのプログラム単位におけるangle選択子の指
定に従って,度単位又はラジアン単位とする(5.6参照)。

139
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表13.1 図形変形関数
関数
変形
SHIFT (a, b)
(x, y) を (x+a, y+b) に平行移動する。
値:
1
0
0
0
0
1
0
0
0
0
1
0
a
b
0
1
SCALE (a, b)
(x, y) を (ax, by) に拡大縮小する。
値:
a
0
0
0
0
b
0
0
0
0
1
0
0
0
0
1
SCALE (a)
(x, y) を (ax, ay) に拡大縮小する。
値:
a
0
0
0
0
a
0
0
0
0
a
0
0
0
0
1
ROTATE (a)
(x, y) を,問題座標系の原点について,逆時計回りにa度又は
aラジアン回転する。
値:
cos (a)
sin (a)
0
0
−sin (a)
cos (a)
0
0
0
0
1
0
0
0
0
1
SHEAR (a)
(x, y) を (x+ytan (a), y) に写像して, (x, y) 平面上の垂直線を
a度又はaラジアン傾ける。
値:
1
0
0
0
tan (a)
1
0
0
0
0
1
0
0
0
0
1
(1.3) 引き数のない関数TRANSFORMは,現在有効なすべての変形を重ねた結果の現在変形を,4行4列
の行列として返す。直接的にも間接的にもdraw文によって呼ばれていないプログラム単位の中で
は,この関数は,単位行列を返す。
(1.4) 変形項として用いる数値配列は,すべて4行4列の行列でなければならない。そのような変形指示
による変形の結果は,各変形項に従う変形を左から右に適用することによって得られる。
(1.5) 絵定義は,他の手続きを呼び出すことができる。更に,直接的に又は他の手続きを通して間接的に,
自分自身を呼び出すこともできる。
(1.6) ある絵定義の実行中に,次の絵定義を変形を伴って呼び出すと,2番目の絵定義によって生成され
る点に対して,二重の(更には多重の)変形が適用される。まず2番目の絵定義を呼び出すdraw
文で指定された変形が行われ,次にもとの絵定義に対する変形が行われる。
(1.7) end-picture行は,絵定義の構文上の終りを示すとともに,それを実行すると絵定義の実行が終了す
る。exit-picture文を実行すると,その絵定義の実行が終了する。絵定義の実行が終了すると,絵定
義の実行を開始させたdraw文の次の行から実行が続く。
(1.8) 絵定義中でstop文を実行すると,プログラム全体の実行が終了する。
(1.9) 変形指示mat文を実行すると,変形の値である4行4列の行列が等号の左辺の数値配列に代入され
る。必要であれば,その数値配列は,7.2の規定に従って,動的に上下限が再定義される。
(2) 変形入力 機能語GET POINT又はMAT GET POINTをもつ図形入力文の実行は,機能語LOCATE
140
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
POINT又はMAT LOCATE POINTをもつ図形入力文と同様とする。ただし,GETによって入力される
点の座標は,基準化,装置変形及び現在変形の逆行列によって変形される。現在変形の逆行列を求め
られないとき(すなわち,現在変形が特異行列であるとき),この文の効果は,処理系定義とする。
(3) 描点出力
(3.1) 機能語PLOT LINESをもつ幾何図形文の実行は,機能語GRAPH LINESをもつ幾何図形文と同様と
する。ただし,次の三つの点で相違がある。
第一に,点の座標は,絵呼出しによって(1)に定めたとおりに変形される。
第二に,点並び中の点の個数が,1個以下であっても例外状態にならない。
第三に,実際に描かれる線は,それより前に実行された,機能語PLOT LINESをもつ幾何図形文
に依存することがある。
(3.2) 点並び中の点の座標は,13.3による。出力は,画面上の描点 (beam) の移動の概念によって規定す
る。描点と画面とは,実際には,プロッタのペンと紙又はその他の物理的な装置の組合せでありう
る。
(3.3) 描点の状態は,オン又はオフとする。オンの状態で移動すると,その始点と終点を結ぶ線分が画面
上に描かれる。オフの状態で移動すると,画面上には何も効果がない。
(3.4) 機能語PLOT LINESをもつ幾何図形文を実行すると,描点が,現在の位置から点並びの最初の点に
移動してオンになり,以後各点を順次にたどる。各回の移動の終点で,描点がオンになる。点並び
の後ろにセミコロンがある場合,そしてその場合に限り,文の実行が終わった時,描点はオンのま
まとする。
(3.5) 次の場合,描点はオフになる。その座標位置は,不定とする。
(a) 機能語PLOT LINESをもち,点並び又はセミコロンのない幾何図形文の実行後
(b) 機能語PLOT LINESをもたない図形出力文の実行前
(c) プログラムの実行開始時
(d) 図形入力文の実行前
(e) 基準装置座標空間の変形に効果を与える文(すなわち,機能語WINDOW,VIEWPORT,DEVICE
WINDOW又はDEVICE VIEWPORTをもつset文)の実行前
(f) 絵定義に入る時及びそこから出る時
(3.6) 次の絵定義の例は,円を近似的に描く。適切な座標が与えられているとする。
110 External picture circle
120 Let P = 2*PI/100
130 For I = 0 to 100
140 Plot lines : cos (I*P), sin (I*P) ;
150 Next I
160 End picture
参考 ANSI X3.113では,上の例のコロンがないが,誤りであるので,TIBによって訂正した。
13.5.5 例外状態 例外状態は,次による。
(1) 座標を再定義したり切取りに影響したりするset文を,絵定義の実行中に実行する。(11004,続行不
能。)
(2) draw文の変形項が,4行4列の行列でない。(6201,続行不能。)
(3) 変形指示mat文によって値が代入される数値配列のもとの寸法が,4行4列の行列に再定義できない
141
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
寸法である。(5002,続行不能。)
13.5.6 注意 注意は,次による。
(1) 変形の行列が4行4列であるのは,3次元への拡張を許すためである。
(2) 13.3.5に規定するすべての例外状態は,13.5に規定する図形出力文にも適用する。ただし,図形対象
LINESの点並び中に点が1個以下しかないときの例外状態 [13.3.5(4)] は,適用しない。
(3) 13.4.5に規定するすべての例外状態は,13.5に規定する図形入力文にも適用する。
(4) 点並びのない文PLOT LINESのただ一つの効果は,描点をオフにすることである。
参考 ANSI X3.113では,“点並びもセミコロンもない文”となっているが,誤りであるので,TIBに
よって訂正した。
(5) 次の事項に関する9.1.6の注意は,絵に対しても同様に適用する。
(a) 異なるcollate選択子をもつプログラム単位は,誤りとはしない[9.1.6(1)参照]。
(b) 定義又は宣言されていながら引用されない関数名は,誤りとはしない[9.1.6(2)参照]。
(c) 定義が宣言に先行する関数名は,内部関数定義では誤りとはしない[9.1.6(3)参照]。
(d) プログラム単位中で引用する外部関数名は,そのプログラム単位中で必ず宣言しなければならない。
内部関数名は,必ずしも宣言しなくてもよい[9.1.6(4)参照]。
(e) 外部関数と同じ名前の内部関数を使ってもよい[9.1.6(5)参照]。
参考 ANSI X3.113では,ここが“異なったプログラム単位においては”となっているが,誤りであ
るので,TIBによって訂正した。
(6) 別名 (alias) に関する9.2.6の注意は,絵定義に対しても同様に適用する。
】
14. 実時間
14.0 概要 この規格の実時間 (real-time) 機能単位は,制御,オートメーション,監視などを含む適用業
務に使用することを意図する。これによって,プログラムを,幾つかの並行動作する単一系列の活動に分
割できるようになる。これらの活動は,適用業務の目標を全体として達成するように協同する。
内部的又は外部的に発生する事象 (event) に応ずるために,並行活動 (concurrent activity) の実行をスケ
ジュールする機能を提供する。共用データを使用したり,通報 (message) を送受したりして,並行活動間
で交信できる。
処理対象 (process object) は,実時間プログラムの外部環境の一部とする。代表的な処理対象としては,
設備のインタフェースにおける測定点及び制御点がある。並行活動と処理対象間の通信は,処理域 (process
port) を通して処理対象を参照する入出力操作によって行う。
14.1 実時間プログラム
14.1.1 概要 実時間プログラム (real-time-program) は,処理環境を記述する実時間宣言単位
(real-time-declarations,14.2参照),一つ以上の並行単位 (parallel-section) の一つの列,及びこれらの並行
単位から呼び出すことができる幾つかの手続きで構成する。それぞれの並行単位は,名前を付け,機能語
PARACT (PARallel ACTivity) とEND PARACTで区切る。複数個の並行単位は,それぞれ別のプログラム単
位を構成し,並行活動を定義する。
並行動作制御文(scheduling-statement,14.3参照)が,並行単位を実行可能にする。実行は,並行単位の
先頭の行から始まる。
14.1.2 構文 構文は,次による。
142
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(1) プログラム⊃program行? 実時間プログラム
(2) 実時間プログラム=実時間宣言単位 並行単位 並行単位* 外部手続き単位*
(3) プログラム単位⊃並行単位
(4) 並行単位=注釈行* paract行 区* end-paract行
(5) 行⊃paract行|end-paract行
(6) paract行=行番号 paract文 行末部
(7) paract文=PARACT ルーチン識別名 {URGENCY 優先度}?
(8) 優先度=符号なし整数
(9) end-paract行=行番号 end-paract文 行末部
(10) end-paract文=END PARACT
(11) 単純文⊃実時間文
(12) 実時間文= parstop文|並行動作制御文|処理域入出力文|共用域入出力文|通報域入出力文|
exit-seize文
(13) parstop文=PARSTOP
(14) 区⊃実時間区
(15) 実時間区=select-on-port区|seize区
(16) 一つの実時間プログラム中の二つ以上のparact文に,同じルーチン識別名を書いてはならない。
(17) 一つの実時間プログラム中のすべてのプログラム単位は,同じarithmetic選択子を指定しなければな
らない。
(18) 実時間文及び実時間区は,並行単位の中にだけ書くことができる。
14.1.3 例 構文の例を次に示す。
320PARACT Rigl
330WAIT TIME 17*60*60
(4)
340PRINT ”Time to go home”
350END PARACT
14.1.4 意味 意味は,次による。
(1) 実時間プログラム中で並行単位を実行すると,一つの並行活動が作られる。実時間プログラムの実行
中の任意の時点において,並行活動は,次のいずれかの状態にある。
(a) 進行状態 (in progress)。先頭に書いてある並行単位で定義された並行活動の初期状態,及びstart文
の実行後のそのstart文で指名された並行活動の状態。
(b) 停止状態 (stopped)。まだ進行状態でないか,又は以前に進行状態にあったがその後parstop文の実
行,end-paract文の実行若しくは例外処理区によって受け止められない続行不能な例外状態を発生
させた文の実行によって停止した状態。
(c) 待ち状態 (waiting)。以前に進行状態にあったが,wait文又は通報域入出力文の実行によって,指定
した事象が発生するか,指定した時間が経過するか,指定した時刻になるか,又は通報が交換され
るかまで一時休止した状態。
(2) 任意の時点で幾つかの並行活動が進行状態にありうる。最初は,実時間プログラム中の先頭に書いて
ある並行単位で定義された並行活動だけが進行状態になる。他の並行活動は,start文(start-statement,
14.3参照)の実行によってだけ進行状態にされる。実時間プログラムのprogram行に値仮引き数部が
あるとき,その値仮引き数の有効範囲は,先頭に書いてある並行単位だけとする。
143
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3) 並行単位の優先度は,その並行活動の相対的な重要度をスケジューラに対して示す。小さい値ほど大
きな重要度を示す。優先度の詳細な意味付けは,処理系定義とする。
(4) start文によって並行単位が進行状態になる時,すべての変数の初期値は,変数の初期化についての処
理系定義の通常の方針に従う[9.1.4(3)参照]。
(5) 並行単位中の各行は,並行単位の先頭の行から始めて,次のいずれかになるまで,順番に実行される。
(a) 行の実行によって,他の動作が指示される。
(b) 例外状態になる。
(c) stop文,chain文,parstop文又はend-paract文が実行される。
(6) parstop文 (parstop-statement) 又はend-paract文 (end-paract-statement) を実行すると,その並行単位
に局所的なファイルがすべて閉じられ,その並行活動の実行が停止状態になる。start文の再度の実行
によって,再び進行状態にすることができる。stop文 (stop-statement) 又はchain文 (chain-statement) を
実行すると,実時間プログラム全体の実行が終了される。例外処理区で処理されない続行不能な例外
状態が発生すると,それを引き起こした並行活動が停止状態になる。実行が実時間宣言単位に到達す
ると例外状態になる処理系では,その例外状態がその実時間プログラム全体の実行を終了させる。
(7) 各並行単位はそれぞれ別の構成要素とし,その中の変数,配列,内部関数及び例外処理区を命名する
識別名は,その並行単位に局所的とする。すなわち,それらの識別名は,別の並行単位では異なる対
象を指名する。組込み関数,並行単位,プログラム単位として定義された手続き,処理域,処理域配
列,事象,構造,通報域及び共用域を命名する識別名は,実時間プログラム全体に広域的とする。す
なわち,それらの識別名は,どこに書いても同じ対象を指名する。
14.1.5 例外状態 なし。
14.1.6 注意 注意は,次による。
(1) 処理系は,進行状態にある一つの並行活動を実行するために,他の並行活動の実行を処理系定義の時
点で中断してもよい。
(2) 並行単位の優先度の解釈は,その並行単位の実行を開始する優先順位としてもよく,またその並行単
位を実行するための最終期限としてもよい。
14.2 実時間宣言
14.2.1 概要 実時間宣言単位 (real-time-declarations) は,実時間プログラムの処理環境を記述する。
(1) 並行活動は,処理域 (process port) を通して外部環境と通信する。process宣言 (process-port-dec) は,
処理域の名前,及びこれらの域に結び付けられた実時間システム中の処理対象 (process object) の属性
を定義する。処理対象は,能動的か受動的かのいずれかとする。受動的 (passive) な処理対象の代表
的なものとして,設備のインタフェースにおける温度検出子やステップモータ制御機構のような測定
点及び制御点がある(14.4参照)。能動的 (active) な処理対象すなわち処理事象 (process event) の代
表的なものとして,時計機構やアラームのようなプログラム割込みの発生源となるものがある(14.3
参照)。
(2) 共用域 (data port) は,個々の並行活動よりも広い有効範囲をもつデータを参照する手段を提供する。
shared宣言 (data-port-dec) は,共用域の名前及びそれを通して参照できるデータの構造を定義する
(14.5参照)。
(3) 通報域 (message port) は,二つの並行活動の間でデータを転送する手段を提供する。転送されるデー
タは,それら二つの活動の外に存在するものではない。message宣言 (message-port-dec) は,通報域の
名前及びそれを通して転送されるデータの構造を定義する。二つの並行活動の間で,一方ではsend-to
144
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
文 (send-statement),他方ではreceive-from文 (receive-statement) で同じ通報域名を指名して,通報の
送信を行う(14.6参照)。
(4) structure宣言 (data-structure-dec) は,処理域,共用域及び通報域を通して転送されるデータの構造を
指定する。それは,域を通してデータを送受信する文の正しさを言語処理系が検査できるようにし,
また共用データ (shared data) の分割できない単位を指定する。
14.2.2 構文 構文は,次による。
(1) 実時間宣言単位={注釈行|実時間宣言行|処理域配列宣言}*
(2) 行⊃実時間宣言行|declare-process行|処理要素行|end-process行
(3) 実時間宣言行=行番号 実時間宣言文 行末部
(4) 実時間宣言文=DECLARE {structure宣言|process宣言|shared宣言|message宣言
(5) structure宣言= STRUCTURE 構造名 コロン 反復回数? 型指示 {コンマ 反復回数?
型指示}*
(6) 構造名=英字 識別名文字*
(7) 反復回数=符号なし整数 OF
(8) 型指示={NUMERIC 精度指定?|STRING} 上下限指定部?
(9) process宣言=PROCESS {処理指定|event句} 参照情報?
(10) 処理指定=入出力指示 処理域名 OF 構造名
(11) 入出力指示=INPUT|OUTPUT|OUTIN
(12) 処理域名=英字 識別名文字*
(13) 処理域配列宣言=declare-process行 処理要素行* end-process行
(14) declare-process行=行番号 declare-process文 行末部
(15) declare-process文= DECLARE PROCESS 入出力指示 処理域配列名 上下限指定部 OF 構造
名
(16) 処理域配列名=英字 識別名文字*
(17) 処理要素行=行番号 処理要素文 行末部
(18) 処理要素文=処理域配列名 左括弧 整数 {コンマ 整数}? 右括弧 コロン 参照情報
(19) end-process行=行番号 END PROCESS 行末部
(20) event句=EVENT 事象名
(21) 事象名=英字 識別名文字*
(22) 参照情報=文字列定数
(23) shared宣言=SHARED 共用域名 上下限指定部? OF 構造名
(24) 共用域名=英字 識別名文字*
(25) message宣言=MESSAGE 通報域名 OF 構造名
(26) 通報域名=英字 識別名文字*
(27) 識別名⊃実時間識別名
(28) 実時間識別名=構造名|事象名|処理域名|処理域配列名|共用域名|通報域名
(29) 処理指定,declare-process文,shared宣言又はmessage宣言に書くすべての構造名は,より早い位置
に,structure宣言で定義しておかなければならない。
(30) 同じ実時間識別名を,二つ以上の構造,事象,処理域,処理域配列,共用域又は通報域を命名するの
に書いてはならない。
145
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(31) 反復回数における符号なし整数の値は,1以上とする。
(32) 処理域配列宣言においては,その先頭にあるdeclare-process文中の上下限指定部で定められた配列の
すべての要素に対し,ちょうど一つずつの処理要素文を書かなければならない。処理要素は,行別の
昇順で記述する。
(33) 処理域配列の名前及び次元数は,declare-process文と処理要素文とで一致しなければならない。
14.2.3 例 構文の例を次に示す。
STRUCTURE OPR:STRING, 2 OF NUMERIC, NUMERIC(10)
(5)
STRUCTURE A1:2 OF NUMERIC
(5)
STRUCTURE B1:NUMERIC
(5)
PROCESS INPUT WEIGHT OF A1 ”ADCCHAN 3”
(9)
PROCESS OUTIN PANEL OF OPR ”Q, 177640”
(9)
PROCESS INPUT A OF B1 ”BCD 4”
(9)
PROCESS OUTPUT Z1 OF B1
(9)
PROCESS EVENT FULL ”INT 36”
(9)
参考 ANSI X3.113では,6行目のOF B1がないが,誤りであるので訂正した。
100 DECLARE PROCESS INPUT xyz(2, −1 TO 1) OF A1
110 xyz (1, −1):“wb slot 10”
120 xyz (1, 0):“wb slot 11”
130 xyz (1, 1):“wb slot 12”
(13)
140 xyz (2, −1):“wb slot 20”
150 xyz (2, 0):“wb slot 21”
160 xyz (2, 1):“wb slot 22”
170 END PROCESS
SHARED FLIGHT(10) OF OPR
(23)
SHARED D OF B1
(23)
MESSAGE LINK OF OPR
(25)
14.2.4 意味 意味は,次による。
(1) 構造名,処理域名,処理域配列名,共用域名,通報域名及び事象名の有効範囲は,一つの実時間プロ
グラム中のすべての並行単位とする。
(2) process宣言,処理域配列宣言,shared宣言及びmessage宣言に書くデータ構造 (data structure) の名
前は,structure宣言で宣言しなければならない。データ構造は,抽象的な構造(すなわち,それに対
して記憶場所が割り振られない構造)であって,数値又は文字列かつスカラ又は配列のいずれである
かを指定する型指示の順序付けられた並びとする。反復回数は,それに続く型指示の出現回数を指定
する。省略すると,1が想定される。
(3) process宣言は,処理域の名前及び実時間システム中でその域に結び付けられる処理対象の属性を定義
する。おのおのの処理域配列宣言 (process-array-dec) は,処理域からなる一つの配列を宣言する。配
列の次元数,添字の最大値及び添字の最小値は,上下限指定部によって通常の方法で指定する(7.1
参照)。処理要素文 (process-element-statement) は,配列の各要素に特有の参照情報を宣言する。
(4) process宣言中に処理指定 (process-clause) を書くと,その処理域に結び付けられた処理対象が受動的
146
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
であることを示す。処理域配列宣言で宣言される処理対象は,常に受動的である。入出力指示は,域
を通過するデータ転送の許容される方向を指示する。INPUTは,処理対象が入力だけをもたらし,
OUTPUTは処理対象が出力だけを受け付け,そしてOUTINは入力と出力の両方を支援することを示
す。
(5) 処理指定又は処理域配列宣言に構造名を書いて,その処理域又は処理域配列の各要素の構造を定める。
参考 ANSI X3.113では,ここに“構造名を省略すると,暗黙のデータ構造は単一の数値になる”と
いう文章があるが,誤りであるので,TIBによって削除した。
(6) process宣言中にevent句 (event-clause) を書くと,指定した処理対象が能動的である,すなわち,処
理事象であることを宣言する。この処理事象は,connect-event文によって接続されると,事象を発生
することができるようになる。この事象は,それを待っていた並行活動を進行状態に戻す(14.3参照)。
(7) 処理域に対する参照情報は,処理域に結び付けられる特定の処理対象及びそのデータの形式を指定す
る。能動的な処理対象に対する参照情報の代表的なものは,ハードウェア割込みの発生源の情報に,
その割込みをどのように制御するかの情報を添えたものである。このハードウェア割込みは,その対
象に関連する事象の発生を知らせるものである。参照情報の解釈及び参照情報の省略の解釈は,処理
系定義とする。
(8) shared宣言は,共用域の名前及びそれを通して参照できるデータの構造を定義する。shared宣言中で
上下限指定部を指定すると,それは,指名された構造をもつ要素の配列を定義する。このようにして
定義した配列は,上下限指定部に書く上下限指定の個数1〜3に従って,1〜3次元とする。上下限指
定部を省略すると,与えられた構造をもつ単一の要素が定義される。共用データは,すべての並行活
動から参照できる(14.5参照)。
(9) message宣言は,通報域の名前及びそれを通して転送されるデータの構造を定義する。
14.2.5 例外状態 例外状態は,次による。
(1) 処理対象の属性が,その宣言と一致しない。(12201,続行不能。)
14.2.6 注意 注意は,次による。
(1) 受動的な処理対象だけを配列にできる。すなわち,処理事象は配列にはできない。
(2) 処理域に対する参照情報は,位取りや,処理対象中の数値の文字符号化外部表現と浮動小数点内部表
現との間の変換などのような自動データ変換を処理系が実行するための書式情報を含んでいてもよい。
処理系は,処理域が参照されたときに,特殊な装置を標準的な機構によって操作するために自動的に
呼び出すルーチンの名前を,この参照情報に含めることにしてもよい。これらのルーチンは,例えば,
切替え時間の長いマルチプレクサを通じた参照や,特殊なグレイコード (Gray code) 機構を取り扱う
のに用いることができる。
(3) 精度指定は,15.(固定小数点10進数機能単位)による。これは選択的な機能単位であるので,機能
単位の組合せによっては,指定できないこともある。
14.3 並行動作制御
14.3.1 概要 start文 (start-statement) 及びwait文 (wait-statement) を実行して,複数個の並行活動をスケ
ジュールする。start文は,一つの並行活動を進行状態にする。進行状態にある並行活動の実際の実行は,
これらの活動の優先度に従って,処理系が制御する。wait文は,指定した一定時間だけ,指定した時刻ま
で又は指定した事象 (event) が発生するまで,並行活動の実行を休止する。事象は,接続されている処理
対象 (process object) によって外部から発生することもあるし,signal文 (signal-statement) の実行によって
内部から発生することもある。
147
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
事象を参照するconnect-event文 (connect-statement) 及びdisconnect-event文 (disconnect-statement) は,
外部のハードウェアからの指定した事象信号 (event signal) の受付けを,それぞれ可能又は不能にする。
14.3.2 構文 構文は,次による。
(1) 並行動作制御文=start文|wait文|signal文|connect-event文|disconnect-event文
(2) start文=START ルーチン識別名
(3) wait文=WAIT {time句|delay句|event-timeout句}
(4) time句=TIME 時間式
(5) 時間式=数値時間式|文字列時間式
(6) 文字列時間式=文字列式
(7) delay句=DELAY 数値時間式
(8) event-timeout句=EVENT 事象名 timeout句?
(9) signal文=SIGNAL 事象名
(10) connect-event文=CONNECT EVENT 事象名並び
(11) 事象名並び=事象名 {コンマ 事象名}*
(12) disconnect-event文=DISCONNECT EVENT 事象名並び
(13) process宣言で宣言してない事象名を,connect-event文及びdisconnect-event文に書いてはならない。
(14) process宣言で宣言した事象名を,signal文に書いてはならない。
(15) start文中のルーチン識別名は,プログラム中のどれかのparact行に書いてなければならない。
(16) wait文中の事象名は,signal文に書いてあるか,又は処理事象としてprocess宣言中に宣言してあるか
でなければならない。
14.3.3 例 構文の例を次に示す。
START FILL
(2)
WAIT DELAY 1.5*60*60
(3)
WAIT TIME ”09:15:00”
(3)
WAIT EVENT READY TIMEOUT 4
(3)
WAIT TIME A$
(3)
SIGNAL READY
(9)
CONNECT EVENT FULL
(10)
DISCONNECT EVENT FULL, TOOFUL
(12)
14.3.4 意味 意味は,次による。
(1) start文を実行すると,指名された並行単位で定義される並行活動が進行状態になる。wait文を実行す
ると,指定した定時間だけ,指定した時刻まで又は指定した事象が発生するまで,そのwait文を実行
した並行活動が休止される。
(2) 数値時間式の値は,秒数を表す。式の値が整数でない場合,時間式の精度は,時計機構の分解能に依
存する。文字列時間式の値は,関数TIME$の形式,範囲及び意味による(6.4参照)。
(3) delay句のあるwait文の場合,並行活動は,指定された長さの時間だけ休止され,その時間が経過し
た後に再び進行状態になる。
数値時間式をもつtime句のあるwait文の場合,並行活動は,その日の午前0時からの経過時間が
指定された秒数になるまで休止され,その時刻に再び進行状態になる。午前0時からの経過時間が指
定された秒数を既に超えている場合,並行活動は,翌日のその時刻まで待たされる。
148
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
文字列時間式をもつtime句のあるwait文の場合,並行活動は,その日の指定された時刻まで休止
され,その時刻に再び進行状態になる。その日の指定された時刻が既に過ぎている場合,並行活動は,
翌日のその時刻まで待たされる。
(4) event-timeout句のあるwait文の場合,並行活動は,指定された事象が発生するまで休止され,その事
象が発生した時に再び進行状態になる(14.2及び14.4参照)。event-timeout句にtimeout句を書いた
場合,指定された時間内に事象が発生しないと例外状態になる。
(5) signal文を実行すると,指定された事象が発生する。signal文の実行後も,その並行活動は進行状態の
ままとする。
(6) connect-event文を実行すると,指定された処理事象 (process event) が接続される。接続された処理対
象は,事象を発生することができる。
(7) disconnect-event文を実行すると,指定された処理事象が切り離される。disconnect-event文を実行す
る以前に発生した事象で,まだwait文に対して効果を及ぼしていないものは,無効になる。接続され
ていない処理対象は,事象を発生することができない。
(8) 発生した事象は,その事象を待っている並行活動を再び進行状態にする。その事象を待っている並行
活動がない場合,事象の発生後最初にその事象に対するwait文を実行した並行活動が,休止されずに
そのまま進行状態を続ける。どちらの場合も,発生した事象は,これらの効果を及ぼした後無効にな
る。
(9) 同じ事象を待っている並行活動が複数個ある場合,その事象の発生によってどの並行活動が進行状態
になるかは,処理系定義とする。1回の事象の発生に対しては,一つの並行活動だけが進行状態にな
る。
(10) signal文によって発生した事象がwait文に対して効果を及ぼさないままに,再び同じ事象を発生する
signal文を実行すると,例外状態になる。それらの事象は,無効になる。
(11) 接続されている処理対象の発生した事象がwait文に対して効果を及ぼさないままに,同じ対象が再び
事象を発生し,かつその事象に対するwait文を実行すると,例外状態になる。それらの事象は,無効
になる。
(12) 実時間プログラムの実行の初めでは,どの事象も発生していないし,どの処理事象も接続されていな
い。
14.3.5 例外状態 例外状態は,次による。
(1) start文で指定された並行活動が,停止状態でない。(12001,続行不能。)
(2) ある事象が,既に発生されていて,その事象が待ち状態の並行活動を進行状態にすることにまだ使わ
れていないのに,signal文が同じ事象を再び発生しようとした。(12002,続行不能。)
(3) 時間式として使われている数値式の値が,1日の秒数86400を超える,又は負である。(12004,続行
不能。)
(4) 時間式として使われている文字列式の値が,関数TIME$の形式でない。(12005,続行不能。)
(5) wait文で指定された事象が,timeout句で指定された時間内に発生しない。(12101,続行不能。)
(6) 接続されている処理対象の発生した事象で,まだwait文に対して効果を及ぼしていないものが二つ以
上あるときに,wait文を実行する。(12003,続行不能。)
(7) 既に接続されている事象に対してconnect-event文を実行する。(12006,続行不能。)
(8) 既に切り離されている事象に対してdisconnect-event文を実行する。(12007,続行不能。)
149
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
14.3.6 注意 処理系の時計機構を,季節時間の変更,誤差などのために調整する必要があるとき,time
句のあるwait文に問題が生ずる。待ち時刻が来て,活動がいったん進行状態にされると,時計機構を戻し
たときに,戻される時間の間に待ち時刻があっても,その活動は,翌日まで再び進行状態にはされないよ
うにすることを推奨する。同様に,時計機構を進める場合,進められる時間の間に待ち時刻のある活動は,
待ち時刻が来たものとして進行状態にされるようにすることを推奨する。
14.4 処理入出力
14.4.1 概要 in-from文 (in-statement) 及びout-to文 (out-statement) は,受動的な処理対象 (process object)
と実時間プログラムとの間の通信路を通して,データの転送を行う。in-from文は,外部の値をプログラ
ム中の変数に転送する。out-to文は,値を外部の処理対象に転送する。
14.4.2 構文 構文は,次による。
(1) 処理域入出力文=in-from文|out-to文
(2) in-from文=IN FROM {処理域名|処理域配列名 添字部} TO 入力構造 timeout句?
(3) 入力構造=入力構造要素 {コンマ 入力構造要素}*
(4) 入力構造要素=変数名|配列名
(5) out-to文=OUT TO {処理域名|処理域配列名 添字部} FROM 出力構造 timeout句?
(6) 出力構造=出力構造要素 {コンマ 出力構造要素}*
(7) 出力構造要素=式|配列名
(8) in-from文及びout-to文中に書く処理域名及び処理域配列名は,すべてprocess宣言又は処理域配列宣
言で宣言しておかなければならない。
(9) in-from文及びout-to文の中の添字部の添字の個数は,対応する処理域配列宣言中の上下限指定の個
数と一致しなければならない。
(10) 入力構造及び出力構造の中の要素の個数及び型は,その処理域に対する宣言中で指名した構造名の
structure宣言による構造と,要素ごとに一致しなければならない。すなわち,
(a) 入力構造及び出力構造の中の要素の個数は,その処理域のstructure宣言中の(反復回数をも含めた)
型指示の個数と,一致しなければならない。
(b) 入力構造及び出力構造の中の要素を,その処理域のstructure宣言中の型指示に,一つずつ順番に対
応付けたとき,表のとおりに対応しなければならない。
structure宣言中の型指示
入力構造要素
出力構造要素
NUMERIC
数値単純変数名
数値式
STRING
文字列単純変数名
文字列式
NUMERIC 上下限指定部
数値配列名
数値配列名
STRING 上下限指定部
文字列配列名
文字列配列名
(11) 入力構造要素及び出力構造要素の中の配列の次元数は,その処理域の宣言中で指名されたstructure
宣言と一致しなければならない。structure宣言の型指示に精度指定があるときには,対応する入力構
造要素及び出力構造要素にも同じ型指示を書かなければならない(15.1参照)。
(12) OUTPUTと宣言された処理域名及び処理域配列名を,in-from文に書いてはならない。INPUTと宣言
された処理域名及び処理域配列名を,out-to文に書いてはならない。
14.4.3 例 構文の例を次に示す。
IN FROM WEIGHT TO X, Y
(2)
IN FROM PANEL TO A$, B, C, Fvect
(2)
IN FROM RIG1(NEXT) TO ALPHA TIMEOUT 2.5
(2)
150
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
OUT TO Z1 FROM B*C+X
(5)
OUT TO PANEL FROM A$&B$, JIM, FRED, Cvect
(5)
14.4.4 意味 意味は,次による。
(1) in-from文を実行すると,指定した処理域から値を得て,それを入力構造中の対応する変数及び配列に
代入する。変数への代入,添字の評価及び部分文字列指定の評価の順序は,input文の場合と同じと
する。
(2) 数値が下位けたあふれになると,その値はゼロで置き換えられる。
(3) in-from文の実行は,入力構造中のすべての変数及び配列に値が代入されたときか,又は続行不能な例
外状態になったときにだけ完了する。これらの例外状態としては,正しくないデータ又はハードウェ
アの誤動作によるもの,timeout句で指定した秒数が経過した場合などがある。
(4) out-to文を実行すると,出力構造中の式が評価され,その値及び指定した配列中のすべての要素の値
が,指定した処理域に送られる。
参考 ANSI X3.113では“仮配列”となっているが,誤りであるので,TIBによって訂正した。
(5) out-to文の実行は,出力構造からのすべての値が処理環境によって受け入れられたときか,又は続行
不能な例外状態になったときにだけ完了する。これらの例外状態としては,正しくないデータ又はハ
ードウェアの誤動作による場合,timeout句で指定した秒数が経過した場合などがある。
(6) 入力構造又は出力構造の中に配列名があると,その名前の配列全体の内容が,行別の昇順で入力又は
出力される。
14.4.5 例外状態 例外状態は,次による。
(1) 入力構造中の数値変数又は数値配列への値の代入が,数値あふれを起こす。(1201,続行不能。)
(2) 入力構造中の文字列変数又は文字列配列への値の代入が,文字列あふれを起こす。(1203,続行不能。)
(3) 入力構造又は出力構造の中で使われている配列名の各次元の現在の寸法が,指名された処理域の宣言
中で指定された構造のstructure宣言と一致しない。(6301,続行不能。)
(4) in-from文又はout-to文の実行が,timeout句で与えられた制限時間内に完了しない。(12102,続行不
能。)
(5) 処理域に対する添字が,処理域配列宣言で指定された範囲の中にない。(2001,続行不能。)
14.4.6 注意 処理系定義の例外状態があってもよい。これらは,主に特定の処理対象の特性に関するもの
である。
14.5 共用データ
14.5.1 概要 get-from文 (get-statement) 及びput-to文 (put-statement) は,並行活動と共用データ (shared
data) の集まりとの間のデータ転送を行う。データは,共用域を通して転送される。
14.5.2 構文 構文は,次による。
(1) 共用域入出力文=put-to文|get-from文
(2) put-to文=PUT TO 共用域名 添字部? FROM 出力構造 timeout句?
(3) get-from文=GET FROM 共用域名 添字部? TO 入力構造 timeout句?
(4) put-to文及びget-from文中に書く共用域名は,すべてshared宣言で宣言しておかなければならない。
(5) 共用域名に後続する添字部は,その共用域名に対するshared宣言中に上下限指定部があるときにだけ
書くことができるし,書かなければならない。この場合,添字部の添字の個数は,上下限指定部で指
定した次元数と一致しなければならない。
(6) 入力構造及び出力構造の中の要素の個数及び型は,その共用域に対するshared宣言で指名した構造名
151
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
のstructure宣言による構造に,14.4.2(10)の規定に従って一致しなければならない。
14.5.3 例 構文の例を次に示す。
PUT TO FLIGHT(N+1) FROM I$, N, 2, P
(2)
GET FROM D TO E
(3)
14.5.4 意味 意味は,次による。
(1) put-to文を実行すると,出力構造中の式が評価され,その値及び指定した配列中のすべての要素の値
が,対応する共用データの集まりに送られる。
(2) get-from文を実行すると,対応する共用データの集まりからの値が,入力構造中の変数及び配列に代
入される。入力構造中の添字及び部分文字列指定は,入力構造中の先行する(左側の)変数及び配列
がすべて値を代入されてから,評価される。
(3) get-from文が初期化されていないデータを引用した場合,その結果は,処理系定義とする。
(4) put-to文及びget-from文の実行は,すべての値が転送されたときか,又は続行不能な例外状態になっ
たときに完了する。一つのget-from文又はput-to文の実行が完了するまでは,他のどの並行活動も指
定されている共用データの集まりを参照することができない。
(5) 共用域入出力文とseize区(14.8参照)との関係は,次のとおりとする。
(5.1) 共用域入出力文がseize区の中にない場合,それはあたかも次の行からなるseize区の中にあるかの
ように実行される。
(a) その共用域入出力文と同じ共用域名及びtimeout句を指定するseize行。
(b) その共用域入出力文,ただし,timeout句は除く。
(c) end-seize行。
(5.2) 共用域入出力文がseize区の中にある場合,特別な制約はない。
14.5.5 例外状態 例外状態は,次による。
(1) 入力構造中の数値変数又は数値配列への値の代入が数値あふれを起こす。(1202,続行不能。)
(2) 入力構造中の文字列変数又は文字列配列への値の代入が文字列あふれを起こす。(1204,続行不能。)
(3) 入力構造又は出力構造の中で使われている配列の各次元の現在の寸法が,指名された共用域の宣言中
で指定された構造のstructure宣言と一致しない。(6301,続行不能。)
(4) 共用域に対する添字が,shared宣言で指定された範囲の中にない。(2001,続行不能。)
14.5.6 注意 なし。
14.6 通報の受け渡し
14.6.1 概要 send-to文 (send-statement) とreceive-from文 (receive-statement) は,並行活動間でデータを
送受する。データは,一方の並行活動に含まれるsend-to文の中の通報出力域 (message output port) と他方
の並行活動に含まれるreceive-from文の中の通報入力域 (message input port) とを結ぶ通報路 (message
path) を通して送受される。
通報路は,一方の並行活動に含まれるsend-to文の中と,他方の並行活動に含まれるreceive-from文の
中とで同じ通報域名を使用することによって,実行時に暗黙的に確立される。
14.6.2 構文 構文は,次による。
(1) 通報域入出力文=send-to文|receive-from文
(2) send-to文=SEND TO 通報域名 FROM 出力構造 timeout句
(3) receive-from文=RECEIVE FROM 通報域名 TO 入力構造 timeout句
(4) select-on-port区= select-on-port行 注釈行* 通報case区 通報case区* case-timeout区?
152
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
end-select行
(5) select-on-port行=行番号 select-on-port文 行末部
(6) select-on-port文=SELECT ON PORT
(7) 通報case区=通報case行 区*
(8) 通報case行=行番号 通報case文 行末部
(9) 通報case文=CASE {SEND|RECEIVE} MESSAGE 通報域名|CASE EVENT 事象名
(10) case-timeout区=case-timeout行 区*
(11) case-timeout行=行番号 case-timeout文 行末部
(12) case-timeout文=CASE TIMEOUT 数値時間式
(13) send-to文,receive-from文及びselect-on-port区に書く通報域名は,message宣言中で宣言しておかな
ければならない。
(14) send-to文及びreceive-from文に指定した出力構造及び入力構造の中の要素の個数及び型は,その通報
域名に対するmessage宣言で指名した構造名のstructure宣言による構造に,14.4.2(10)の規定に従っ
て一致しなければならない。
(15) 一つの並行単位中に,同じ通報域名を指名するsend-to文とreceive-from文の双方を書いてはならない。
(16) 機能語CASE SEND MESSAGEで始まる通報case区には,その通報域名を指名するsend-to文を書か
なければならない。機能語CASE RECEIVE MESSAGEで始まる通報case区には,その通報域名を指
名するreceive-from文を書かなければならない。
(17) 一つのselect-on-port区中の異なる通報case文は,おのおの別の通信域名又は事象名を指名しなけれ
ばならない。
(18) select-on-port区,通報case区及びcase-timeout区の外部の行番号分岐中の行番号は,そのselect-on-port
区,通報case区及びcase-timeout区のそれぞれ内部にある行を参照してはならない。
(19) 通報case文に書く事象名は,process宣言によって宣言しておかなければならない。
14.6.3 例 構文の例を次に示す。
SEND TO LINK FROM ”FIRST”, X/2, 17.35, RESULTS
(2)
RECEIVE FROM LINK TO A$, P(1), P(2), I TIMEOUT 30
(3)
153
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
100 SELECT ON PORT
110 CASE EVENT E
120 PRINT ”E occurred at”;time$
130 START E̲processor
140 CASE SEND MESSAGE X
150 SEND TO X FROM a, b, c
160 CASE SEND MESSAGE Y
(4)
170 SEND TO Y FROM d$, e$
180 CASE RECEIVE MESSAGE Z
190 PRINT ”Someone just sent me a Z”
200 RECEIVE FROM Z TO f, g$
210 CASE TIMEOUT 600
220 PRINT ”Ten-minute timeout.”
230 END SELECT
14.6.4 意味 意味は,次による。
(1) 一つの並行活動の中である通報域名をもつsend-to文又はreceive-from文を実行し,それに引き続いて
別の並行活動の中で同じ通報域名をもつreceive-from文又はsend-to文を実行すると,一方の並行活動
中の通報域が他方の並行活動中の通報域に結び付けられる。
(2) send-to文又はreceive-from文の実行は,相手方となる並行活動中にあるreceive-from文又はsend-to
文が実行されて,指定された通報域が結び付けられるか,又は例外状態になったときに完了する。そ
れまでは,その処理は14.1の規定に従って待ち状態になる。
(3) 通報域が結び付けられると,send-to文にある出力構造中の式が評価され,その値及び出力構造中のす
べての配列の値が,対応するreceive-from文にある入力構造中の対応する変数及び配列に代入される。
(4) 入力構造中の添字及び部分文字列指定は,入力構造中の先行する(左側の)変数及び配列がすべて値
を代入されてから,評価される。入力の代入が終わると,交信した二つの活動間の通報域が切り離さ
れ,処理が進行状態に戻る。
(5) send-to文又はreceive-from文にtimeout句を書いたとき,与えられた制限時間内に通報域が結び付け
られなければ,例外状態になる。
(6) send-to文で時間切れになると,その通報は,receive-from文によって受け取られることはない。
(7) send-to文を実行したときに,二つ以上の並行活動が同じ通報域名の通報域を通して通報を受け取ろう
として待っていた場合,どの並行活動がその通報を受け取るかは,処理系定義とする。それらの活動
のうち,ただ一つだけが通報を受け取る。そのほかの活動は,待ち状態を続ける。
(8) receive-from文を実行したときに,二つ以上の並行活動が同じ通報域名の通報域を通して通報を送ろ
うとして待っていた場合,どの並行活動が通報を送るかは,処理系定義とする。それらの活動のうち,
ただ一つだけが通報を送る。そのほかの活動は,待ち状態を続ける。
(9) select-on-port区を実行すると,次のいずれかになるまで並行活動が待ち状態になる。
(a) その通報case文で指名した通報域名を指名し,かつその通報case文で指定した通信方向に対応す
る通報域入出力文が,実行される,又は実行されたがその通報域が並行活動に結び付けられていな
かった。ここで,通信方向の対応とは,文CASE RECEIVE MESSAGEに対するsend-to文及び文CASE
SEND MESSAGEに対するreceive-from文をいう。
154
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) その通報case文で指名した事象名を指名するsignal文が,実行される,又は実行されたが並行活動
を進行状態にしていなかった。
(c) その通報case文で指名した事象名の一つが,発生する,又は発生したが並行活動を進行状態にして
いなかった。
(d) case-timeout文で指定した秒数が経過した。
(10) 通報域入出力文の実行によってselect-on-port区の待ち状態が解除されると,対応する通報域名と通信
方向とをもった通報case区が選択され実行される。その通報域入出力文の通報は,その通報case区
中で対応する通報域入出力文が実行される場合にだけ転送される。
(11) ある事象の発生によってselect-on-port区の待ち状態が解除されると,対応する事象名を指名した通報
case区が選択され実行される。通報case区が実行されると,その事象の発生は効果を失う。
(12) 二つ以上の通報case区が実行可能になった場合,どれが実行されるかは,処理系定義とする。
(13) case-timeout区を書いておくと,select-on-port区に入ってからcase-timeout文で指定した秒数以内に
待ち状態が解除されなかったときに,そのcase-timeout文に続く文が実行される。
(14) 制御が通報case区又はcase-timeout区の終りに到達すると,対応するend-select行に続く行に制御が
移る。
14.6.5 例外状態 例外状態は,次による。
(1) 入力構造中の数値変数又は数値配列への値の代入が数値あふれを起こす。(1202,続行不能。)
(2) 入力構造中の文字列変数又は文字列配列への値の代入が文字列あふれを起こす。(1204,続行不能。)
(3) receive-from文の入力構造又はsend-to文の出力構造の中で使われている配列の各次元の現在の寸法が,
指名された通報域の宣言中で指定された構造のstructure宣言と一致しない。(6301,続行不能。)
(4) send-to文又はreceive-from文の実行が,timeout句で与えられた制限時間内に完了しない。(12103,
続行不能。)
14.6.6 注意 親システムは,ある通報域又は事象に対して一つの通報case区を選択したことによって,
他の通報域又は事象への反応を抑制することのないようにしなければならない。
14.7 ビット列操作
14.7.1 概要 ビット列 (bit pattern) は,プロセス制御系において情報を符号化する一般的な手段とする。
プログラム中では,ビット列を文字列として表現する。ビット列に対する操作は,連結及び部分文字列抽
出の文字列操作によって行うことができる。
列と数値との間の変換を行う関数が用意されている。
14.7.2 構文 構文は,次による。
(1) 文字列組込み関数名⊃BSTR ドル記号
(2) 数値組込み関数名⊃BVAL
14.7.3 例 なし。
14.7.4 意味 意味は,次による。
(1) 組込み関数の値,値実引き数の個数及び値実引き数の型は,表14.1による。

155
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表14.1 ビット列関数
b$:文字列式; r,v:指標; rのとる値:2,8又は16だけ
関数
関数値
BVAL (b$, r)
b$で与えられた文字列表現を,基数をrとして解釈した非負整数。
例 BVAL (”101”, 2) =5
BVAL (”2F”, 16) =47
BSTR$ (v, r)
vの値を,基数をrとして表現した文字列。続行不能な例外状態とならない
限り,BSTR$は必ず少なくとも1文字は返す。特に,vがゼロのときの
BSTR$の値は,“0”とする。それ以外の先行するゼロは,返されない。
例 BSTR$ (3.14, 2) =“11”
BSTR$ (15, 8) =“17”
(2) 文字列b$中に許される文字は,rの値による。rが2であれば,正しい文字は,数字0及び1とする。
rが8であれば,正しい文字は,数字0〜7とする。rが16であれば,正しい文字は,数字0〜9及び
英大文字A〜Fとする。
14.7.5 例外状態 例外状態は,次による。
(1) 関数BVALの文字列の実引き数の値が,基数rに対する正しい数値表現でない。(4201,続行不能。)
(2) 関数BVALの文字列の実引き数を数値として解釈したときに,その値が数値変数の精度の制限の中で
正確に表現できない。(4202,続行不能。)
(3) 関数BVALの文字列の実引き数を数値として解釈したときに,その値が表現可能な最大の数値を超え
る。(1003,続行不能。)
(4) 関数BSTR$の第1引き数を丸めた値vが負である。(4203,続行不能。)
(5) 関数BVAL又はBSTR$の第2引き数を丸めた値rが,2でも8でも16でもない。(4204,続行不能。)
14.7.6 注意 ビット列の典型的な使用例としては,状態レジスタの操作及び個々のビットがスイッチや標
識のような特定の構成要素を表す処理対象からのデータの操作がある。
14.8 資源管理
14.8.1 概要 並行活動系においては,逐次再利用可能 (serially reusable) な資源の割付けを,応用プログ
ラムが管理しなければならないことがある。例えば,一つのプログラムが二つ以上の並行活動をもってい
るとする。これらの活動が同じ一つの表示面にそれぞれ複数行の通知を印字したい。通知の各行が交錯し
ないようにするには,活動が表示面を排他的に確保 (seize) して,行を全部印字しおわるまで他の活動を
排除する。この確保操作には,時間切れを指定して,対象の資源が空くのを無期限に待つことがないよう
にできる。
14.8.2 構文 構文は,次による。
(1) seize区=seize行 区* end-seize行
(2) seize行=行番号 seize文 行末部
(3) seize文=SEIZE 確保項目並び timeout句?
(4) 確保項目並び=確保項目 {コンマ 確保項目}*
(5) 確保項目=SHARED 共用域名|[処理系定義]
(6) end-seize行=行番号 END SEIZE 行末部
(7) exit-seize文=EXIT SEIZE
(8) 行⊃seize行|end-seize行
(9) 一つの確保項目並び中に,同じ確保項目を2回以上書いてはならない。
(10) seize区 (seize-block) の外部の行番号分岐中の行番号は,そのseize区の内部にある行を参照してはな
156
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
らない。
(11) seize区の内部の行番号分岐中の行番号は,そのseize区の外部にある行を参照してはならない。
(12) seize区は,入れ子にしてはならない。seize区中に,そのseize区の先頭を区切るseize行 (seize-line) 以
外のseize行を書いてはならない。seize区中に,そのseize区の末尾を区切るend-seize行 (end-seize-line)
以外のend-seize行を書いてはならない。
(13) exit-seize文 (exit-seize-statement) は,seize区の中にだけ書くことができる。
(14) seize区の内部から,そのseize区の外部で定義された定義関数又は手続を参照してはならない。
(15) seize区中に書く共用域入出力文の共用域名は,そのseize区中のseize文で確保項目として指定してお
かなければならない。
(16) seize区中に書く共用域入出力文には,timeout句を書いてはならない。
(17) seize区中に,gosub文又はon-gosub文を書いてはならない。
14.8.3 例 構文の例を次に示す。
SEIZE SHARED DPORT TIMEOUT 10
(3)
14.8.4 意味 意味は,次による。
(1) seize文の実行の結果は,成功又は不成功とする。seize文がその確保項目並び中の資源全部を確保でき
た場合,seize文の実行は成功したとされて完了する。そして,制御が次の行に進む。
利用可能でない資源が一つでもあると,不成功になる。この場合,確保項目並び中のどの資源も,
その活動によって排他的に確保されることはない。活動は,待ち状態になる。要求した資源全部が利
用可能になると,待ち状態が解除される。資源全部が同時的に確保され,制御が次の行に進む。timeout
句が書いてあって,その時間内にseize文の実行が完了できないときには,例外状態になる。
(2) 確保項目の機能語SHAREDの後に書いた共用域名は,共用データの名前を参照する。その他の処理系
定義の資源の名前を,確保項目並びに書くことができる。
(3) end-seize行を実行すると,この活動が排他的に確保した資源全部が解放される。
(4) exit-seize文を実行すると,制御がそのseize区のend-seize行に移る。
(5) ある一つの資源を待っているseize文が二つ以上あって,その資源が利用可能になったときに,どの
seize文が資源を確保し実行が成功するかは,処理系定義とする。
(6) seiz区の内部で続行不能な例外状態が発生し,しかもそのseize区の内部で処理されなかった場合には,
12.1及び14.1の規定に従って,外側の例外処理区に制御が移るか,又はその並行活動が停止状態にな
る。どちらの場合にも,そのseize区の資源は解放される。
seize区の外側にある例外処理区がRETRYを発行したときには,制御がそのseize区の先頭のseize
行に戻り,seize文が再び確保項目並び中の資源を待つ。CONTINUEを発行したときには,制御がそ
のseize区の末尾のend-seize行に構文上続く行に移る。
14.8.5 例外状態 例外状態は,次による。
(1) timeout句で指定された秒数以内に,seize文の実行が成功・完了できなかった。(12102,続行不能。)
14.8.6 注意 seize区を入れ子にできないという構文の規定及び資源全部が確保されるか又はどれも確保
されないという意味規定は,すくみ (deadlock) を防ぐ。
157
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
15. 固定小数点10進数
15.0 概要 固定小数点10進数機能単位 (fixed decimal numbers module) は,すべての数値変数の値が,プ
ログラムで定義する精度をもった固定小数点10進数として論理的に扱われる選択子を規定する。この選択
子を指定すると,数値定数及び数値式もまた,一般に固定小数点10進数 (fixed-point decimal mumber) と
して表現される。
このデータ型の主な目的は,BASIC以外の処理系とのインタフェースを提供することにある。したがっ
て,数値式の精度 (precision) と正確度(accuracy,15.1.6参照)に関する要求は,規定しない。
15.1 固定小数点10進数の精度
15.1.1 概要 プログラム単位中のすべての数値変数が,値として固定小数点10進数をもつように定義す
る選択子を定める。この選択子の指定によって,変数の値に対する省略時想定の精度が決まる。更に,個々
の変数に対して別の精度属性 (precision attribute) を指定することができる。
15.1.2 構文 構文は,次による。
(1) 選択子⊃ARITHMETIC FIXED 精度指定
(2) 精度指定=星印 小数点指定
(3) numeric宣言⊃NUMERIC 精度指定? 固定小数点宣言 {コンマ 固定小数点宣言}*
(4) 固定小数点宣言=数値単純変数名 精度指定?|数値配列宣言 精度指定?
(5) arithmetic選択子でFIXEDを指定したoption文を書く場合には,同じプログラム単位中の,どの数値
式及び数値変数名よりも早い位置,かつNUMERICを指定したどのdeclare文よりも早い位置に書か
なければならない。
(6) 固定小数点宣言は,その単純変数名及び配列名に対するどの参照よりも早い位置に書かなければなら
ない。
(7) FIXEDを指定したarithmetic選択子をプログラム単位に書いたときにだけ,精度指定 (fixed-point-type)
をdeclare文に書くことができる。
(8) ある一つの単純変数名及び配列名は,declare文,dim文,値仮引き数部及び参照仮引き数部の中には,
たかだか1回だけ書くことができる。
(9) 小数点指定 (fixed-point-size) は,11.3.2(23)の規定による。これは,選択的な機能単位である固有形式
拡充ファイル機能単位と固定小数点10進数機能単位との双方に適用する。
15.1.3 例 構文の例を次に示す。
ARITHMETIC FIXED*8.2
(1)
NUMERIC*5.2 A, B, C*5.5, D (1 TO 8)*6.6
(3)
NUMERIC E (1 TO 10, 1961 TO 1981)
(3)
15.1.4 意味 意味は,次による。
(1) arithmetic選択子でFIXEDを指定すると,数値定数,数値変数及び数値式の値は,論理的に固定小数
点10進数として扱われる。おのおのの変数がとることのできる値は,整数幅 (integer-size) のけた数
の10進数字を小数点の左側にもち,小数幅 (fraction-size) のけた数の10進数字を小数点の右側にも
つ,正負の数値によって表現できる値とする。正負の符号は,表現のけた数には数えない。数値の表
現に用いる10進数のけた数は,処理系定義の最大値pによって制御する。この値は,18以上とする。
(2) 数値定数の意味は,次の点以外は5.1の規定による。各数値定数は,次に定める固定小数点10進数と
しての有効数字 (significant digits) のけた数で定義される精度属性をもつ。最初の有効数字とは,最初
のゼロでない数字又は小数点のすぐ右側の数字の両者のうち,左側のものとする。最後の有効数字と
158
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,明示的に書かれた最後の数字又は小数点のすぐ左側の数字の両者のうち,右側のものとする。こ
の規定に従うと有効数字をもたないことになってしまうゼロの場合は,小数点のすぐ左側の1けたを
有効数字とする。指数あり形式 (scaled notation) で書かれた数値定数は,それと等価な指数なし形式
(unscaled notation) で書かれたように解釈する。
例
書かれた定数
有効数字
12.34
12.34
12.300
12.300
12.300E−4
.0012300
12.300E7
123000000.
00.00E−3
.00000
0.0E3
0.
有効数字のけた数がpを超える場合,処理系はpけた以上の精度で値を丸める。小数点の左側の有
効数字のけた数がpを超えると,あふれの例外状態になる。
(3) 数値単純変数及び数値配列は,整数部分と小数部分で保持される数字のけた数すなわち整数幅と小数
幅で定義される精度属性をもつ。おのおのの単純変数及び配列の表現は,次の優先順位で決められる。
(a) その単純変数名又は配列名の固定小数点宣言の中に書く精度指定
(b) その単純変数名又は配列名に対する固定小数点宣言を含むdeclare文のNUMERICに書く精度指定
(c) arithmetic選択子のFIXEDに指定されている省略時想定の精度指定
数値配列に対する精度属性は,その配列の各要素に対して適用する。数値変数の有効数字は,そ
の変数の値を数値定数として精度杯に書き表したものと同じとする。
(4) 数値式及び数値組込み関数の意味は,次の点以外は5.3及び5.4の規定による。数値組込み関数又は数
値式を評価して得られる結果の精度属性は,処理系定義とする。この評価における正確度も,処理系
定義とする。
(5) 数値変数への代入は,let文によるような内部での代入もinput文によるような外部からの代入も,と
もに次のとおり処理される。その値の整数部分と小数部分が,それぞれ変数の整数部分と小数部分に
小数点の位置を合わせて移される。ゼロでない数字が変数の整数部分より左側にあると,あふれの例
外状態になる。変数の小数部分より右側に数字があると,結果の値は変数のけた数に丸められる。必
要な場合には,受取り側の変数のすべての数字位置を埋めるために,整数部分の左側及び小数部分の
右側にゼロが詰められる。
(6) 入力及び出力における意味は,次の点以外は10.の規定による。print文中の印字項目に書いた数値式
の値は,小数点なし (implicit point) 又は小数点あり (explicit point) のいずれかの指数なし形式で印字
される。印字される数字は,(2)で規定した有効数字の部分だけとする。変数名でも定数でもない数値
式の有効数字は,処理系定義とする。小数点の右側に有効数字がなければ,小数点なし形式で印字さ
れ,あれば小数点あり形式で印字される。
(7) ファイルにおける意味は,次の追加以外は11.の規定による。
(7.1) 表示形式記録 (display record) については,入力,出力及び代入は(5)及び(6)の規定による。
(7.2) 内部形式記録 (intetnal record) については,値は自分で型をもっているので,入力及び出力は(5)及
び(6)の規定による。例えば,ファイル中の同じ値を参照するWRITE AとREAD Bの結果は,LET B
= Aと同じになる。あるarithmetic選択子を指定して出力された内部形式ファイルが,他の
arithmetic選択子を指定して入力できるか否かは,処理系定義とする。FIXEDを指定したarithmetic
159
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
選択子は,たとえ異なった省略時想定の精度指定をもっていても,ファイル参照に関して異なった
選択子の指定とはみなさない[15.2.4(2)参照]。
(7.3) 固有形式記録 (native record) については,小数点指定のある欄への記録及びその欄からの代入は,
通常の固定小数点数の代入の規則(5)に従う。数値欄幅の指定がE(浮動小数点)である欄(11.3参
照)への値は,有効数字の先頭pけた以上が正しく出力される。このような欄から値が変数に代入
されるときは,その欄は,(2)で定めた指数あり形式の数値定数として扱われる。この場合も,ある
arithmetic選択子を指定して出力された固有形式ファイルが,他のarithmetic選択子を指定して入
力できるか否かは,処理系定義とする。
(7.4) ask文の属性名 (ask-attribute-name) にDATUMを書いて,ファイル中の次のデータ要素の型を知る
ことができる[11.1.4(10)参照]。arithmetic選択子でFIXEDを指定して書き出した内部形式流れ編
成ファイル中の数値データに対しては,ask文のこのDATUM属性に返される型 (type) は,
“NUMERIC * ii.ff”とする。ここで,iiは整数幅を表す2けたの数字,ffは小数幅を表す2けたの
数字とする。
15.1.5 例外状態 例外状態は,次による。
(1) 数値定数の整数部分の有効数字のけた数がpを超える。(1001,続行不能。)
(2) option文又はdeclare文で,精度指定中の整数幅と小数幅の和がpを超える。(1010,続行不能。)
(3) 変数への数値の代入において,整数部分の有効数字のけた数がその変数の整数幅を超える。(1011,続
行不能。)
15.1.6 注意 LOG,COSH,ATN,SIN,EXPなどの超越関数の正確度は,arithmetic選択子でDECIMAL
を指定した場合の正確度以上とすることを推奨する。ABS,INT,MAXなど,超越関数でない関数,並び
に+,−,*,/及び^の演算では,中間結果の値をp+2けたの有効数字をもつ浮動小数点10進数で保持
することを推奨する。これは,数値式の中間結果の正確な値がすべて10進p+2けた以内であり,最終結
果の正確な値が10進pけた以内であれば,最終結果の値が厳密に正確であることを意味する。
15.2 固定小数点10進数のプログラム分割
15.2.1 概要 プログラム単位中に指定した固定小数点10進数の選択子は,そのプログラム単位の有効範
囲内にあるすべての数値に適用される。適用される数値には,値仮引き数,参照仮引き数及び(外部関数
定義の場合の)関数評価の結果も含まれる。
15.2.2 構文 構文は,次による。
(1) 値仮引き数⊃固定小数点仮引き数
(2) 参照仮引き数⊃固定小数点仮引き数
(3) 固定小数点仮引き数=数値単純変数名 精度指定|固定小数点仮配列宣言
(4) 固定小数点仮配列宣言=仮配列宣言 精度指定
(5) 内部function行⊃行番号 FUNCTION 固定小数点定義関数名 値仮引き数部? 行末部
(6) external-function行⊃ 行番号 EXTERNAL FUNCTION 固定小数点定義関数名 値仮引き数部?
行末部
(7) 数値def文⊃DEF 固定小数点定義関数名 値仮引き数部? 等号 数値式
(8) 定義関数名⊃固定小数点定義関数名
(9) 固定小数点定義関数名=数値定義関数名 精度指定
(10) call文中に書く数値変数名又は実配列の整数幅 (integer-size) 及び小数幅 (fraction-size) は,対応する
参照仮引き数と同じでなければならない。その他の数値型の値実引き数及び参照実引き数と,それら
160
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
に対応する値仮引き数及び参照仮引き数との間では,それぞれのプログラム単位のarithmetic選択子
が同じであればよい。すなわち,両方とも,DECIMALであるか,NATIVEであるか又はFIXEDであ
ればよい。
(11) arithmetic選択子でFIXEDを指定したoption文は,そのプログラム単位中で,数値定義関数名を宣言
する又は数値型の値仮引き数を指定するどの内部関数定義よりも早い位置に書かなければならない。
(12) 精度指定は,arithmetic選択子でFIXEDを指定したプログラム単位の中でだけ,内部function行又は
数値def文に書くことができる。
(13) 固定小数点仮引き数は,arithmetic選択子でFIXEDを指定したプログラム単位の中でだけ書くことが
できる。
(14) 内部function宣言又はexternal-function宣言の中で固定小数点定義関数名を宣言するとき,そこで明
示的に又は省略時想定によって指定される精度指定は,対応する関数定義のものと一致しなければな
らない。
15.2.3 例 構文の例を次に示す。
A( )*8.2
(3)
B(,)*4.4
(3)
123 FUNCTION SUMVECTOR*5.2 (V( )*5.2)
(5)
234 EXTERNAL FUNCTION ANSWER*1 (A$)
(6)
DEF AVERAGE*10.3 (X*10.3, Y*10.3)=(X+Y)/2
(7)
15.2.4 意味 意味は,次による。
(1) arithmetic選択子でFIXEDを指定したプログラム単位では,数値型の参照仮引き数,数値型の値仮引
き数及び数値定義関数の値は,固定小数点10進数として表現され,扱われる。これらに対する精度指
定が,それぞれの参照仮引き数,値仮引き数,def行,内部function行又はexternal-function行で明
示的に書いてない場合には,arithmetic選択子のFIXEDの後ろに書いた値が,省略時想定値としてと
られる。仮配列宣言の精度指定は,その配列の各要素に適用する。
(2) 関数引用中の値実引き数の評価及び関数定義中の値仮引き数への代入は,9.1で規定した手順で行われ
る。ただし,値実引き数の精度指定が対応する値仮引き数と異なるときは,15.1.4の規定に従って代
入される。
(3) call文中の参照実引き数と,対応するsub文中の参照仮引き数との結び付けば,9.2で規定した手順で
行われる。ただし,数値変数名以外の数値式である参照実引き数の精度指定が対応する参照仮引き数
と異なるときは,15.1.4の規定に従って代入される。
15.2.5 例外状態 例外状態は,次による。
(1) 固定小数点仮引き数又は固定小数点定義関数名で,精度指定中の整数幅と小数幅の和がpを超える。
(1010,続行不能。)
(2) 固定小数点仮引き数又は固定小数点定義関数名への数値の代入において,有効数字の整数部分のけた
数がその仮引き数又は関数名の整数幅を超える。(1011,続行不能。)
15.2.6 注意 なし。
161
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
16. 編集
16.0 概要 この規格の編集機能単位 (editing module) は,プログラムの作成及び修正を援助する機能を提
供する。編集機能単位は,BASICの環境を作り出すという特定の目的のためのものとする。この環境では,
利用者はBASICプログラムの,再番号付け (renumbering),表示 (listing) 及びdelete指令又はextract指令
による部分抽出 (subsetting) ができる。この機能単位は,BASICプログラムを編集している間だけ使用可
能とする。プログラムの編集から実行への移行は,処理系定義とする。
16.1 未整列プログラム
16.1.1 概要 編集機能によって,プログラムの行を任意の順で入力することができる。
16.1.2 構文 構文は,次による。
(1) 未整列プログラム=未整列行*
(2) 未整列行=行番号 {プログラム文字|行継続}* 行末
16.1.3 例 構文の例を次に示す。
20 PRINT TWO+TWO
30 END
(1)
20 PRINT 2+2
15 PRINT ”2+2 EQUALS”
10 SUB SORT (A(), & ! List to be sorted
(2)
& N) ! Length of list
16.1.4 意味 未整列プログラム (unsorted-program) 中の未整列行 (program-line) は,行番号が昇順になる
ように並べ換えられる。同じ行番号をもつ未整列行が複数個ある場合は,そのうちで文面上の最後の未整
列行だけが残る。
16.1.5 例外状態 なし。
16.1.6 注意 未整列行は,論理行[3.2(10)“行”参照]である。
16.2 編集用指令
16.2.1 概要 編集用指令 (editing command) によって利用者は,プログラム中の部分を選択して表示,削
除及び再番号付けの操作ができる。
16.2.2 構文 構文は,次による。
(1) 編集指令=delete指令|extract指令|list指令|renumber指令
(2) delete指令=DELETE 行範囲並び
(3) 行範囲並び=行範囲 {コンマ 行範囲}*
(4) 行範囲=行指定 {TO 行指定}?
(5) 行指定=行番号|FIRST|LAST
(6) extract指令=EXTRACT 行範囲並び
(7) list指令=LIST 行範囲並び?
(8) renumber指令=RENUMBER 行範囲? 番号指定?
(9) 番号指定=AT 開始番号 {STEP 刻み}?|STEP 刻み {AT 開始番号}?
(10) 開始番号=行番号
(11) 刻み=符号なし整数
(12) 行範囲並び中の行番号は,昇順でなければならない。機能語FIRSTを書くときには,行範囲並び中の
162
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
先頭でなければならない。機能語LASTは,最後でなければならない。
16.2.3 例 構文の例を次に示す。
DELETE 10
(2)
EXTRACT 100 TO 200, 300, 500 TO LAST
(6)
LIST
(7)
LIST 500 TO 999
(7)
RENUMBER
(8)
RENUMBER AT 1000
(8)
RENUMBER AT 1000 STEP 5
(8)
RENUMBER 100 TO 200 STEP 5 AT 100
(8)
16.2.4 意味 意味は,次による。
(1) 行範囲 (segment-specifier) は,プログラム中の論理行の集まりを指定する。行範囲が一つの行指定
(segment-item) だけからなるときは,そこで指示された行だけが指定される。(その行番号が存在しな
いときには,行の集まりは空とする。)行範囲が機能語TOによって二つの行指定からなるときは,1
番目の行指定以上で2番目の行指定以下の行番号をもつすべての行が指定される。行範囲並びは,そ
の中のすべての行範囲で指定された行からなる行の集まりを指定する。行指定のFIRSTは,そのプロ
グラム中の最も小さい行番号を表す。LASTは,最も大きい行番号を表す。
(2) delete指令 (delete-command) は,指定された行の集まりを,プログラムから削除する。
(3) extract指令 (extract-command) は,指定された行の集まり以外のすべての行を,プログラムから削除
する。
(4) list指令 (list-command) は,指定された行の集まりを表示する。list指令で行範囲並びを省略すると,
プログラム中のすべての行が表示される。
(5) renumber指令 (remumber-command) は,指定された行の集まり中のすべての行(行範囲並びを省略
したときは,プログラム中のすべての行)に対し,新しい行番号を割り当てる。その集まりの中の先
頭行の新しい行番号は,開始番号 (initial-number) になる。開始番号を省略すると,100になる。集ま
り中のそれ以降の行の行番号は,指定された刻み (step-size) を順々に加えて生成される。刻みを省略
すると,10が加えられる。プログラム全体を通して,再番号付けされた行の集まりに含まれる行番号
を参照している箇所は,すべて新しい行番号に変更される。
(8) 次のいずれかの場合,renumber指令は実行されず,プログラムも変更されない。この中止の理由を,
処理系は利用者に通知する。
(a) 指定された番号指定 (renumber-parameter) によると,再番号付けされる行が,再番号付けされない
行と重なるか又はそれらをまたぐ。
(b) 再番号付けによって,行の順序が変わる。
(c) 行番号分岐,書式付き印字指定,枠引用などの中で参照不能であった行番号の参照が,再番号付け
によって,参照可能になる。
(d) 再番号付けによって,処理系の許容範囲よりも大きい行番号が生成される。
16.2.5 例外状態 なし。
16.2.6 注意 注意は,次による。
(1) delete指令又はextract指令の行範囲が,存在しない行番号を指定するとき,処理系は警告を出しても
よい。
163
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(2) この規格で規定する指令は,論理行だけを操作する。処理系は,この機能を拡張して,論理行中の個々
の物理行を編集する機能を提供してもよい。
(3) list指令によってプログラムを表示するとき,行番号中の先行するゼロ列は,利用者が入力したとお
りに表示して,BASICプログラムの字並びを保つことを推奨する。
表4.1 標準文字集合
標準文字集合を示す(4.1及び6.4参照)。処理系は,標準文字集合の順序位置128以降に,非プログラム文字を追加
してもよい。追加する非プログラム文字の個数は,処理系定義とする。
関数ORD
の値(順序
位置)
符号の位置
文字図形 関数ORD
における呼
び名
名称
JIS X 0201-1976における名称が異
なるもの(参考)
0
0/0
NUL
空記号
空白
1
0/1
SOH
ヘッディング開始
2
0/2
STX
テキスト開始
3
0/3
ETX
テキスト終結
4
0/4
EOT
伝送終了
5
0/5
ENQ
問合せ
6
0/6
ACK
肯定応答
7
0/7
BEL
ベル
8
0/8
BS
後退
9
0/9
HT
水平タブ
10
0/10
LF
改行
11
0/11
VT
垂直タブ
12
0/12
FF
書式送り
13
0/13
CR
復帰
14
0/14
SO
シフトアウト
15
0/15
SI
シフトイン
16
1/0
DLE
伝送制御拡張
17
1/1
DC1
装置制御1
18
1/2
DC2
装置制御2
19
1/3
DC3
装置制御3
20
1/4
DC4
装置制御4
21
1/5
NAK
否定応答
22
1/6
SYN
同期信号
23
1/7
ETB
伝送ブロック終結
24
1/8
CAN
取消し
取消
25
1/9
EM
媒体終端
26
1/10
SUB
置換キャラクタ
27
1/11
ESC
拡張
28
1/12
FS
ファイル分離キャラクタ
29
1/13
GS
グループ分離キャラクタ
30
1/14
RS
レコード分離キャラクタ
31
1/15
US
ユニット分離キャラクタ
32
2/0
SP
空白
間隔
33
2/1
!
感嘆符
34
2/2
”
引用符
引用符,ウムラウト
35
2/3
#
番号記号
36
2/4
$
ドル記号
37
2/5
%
パーセント記号
パーセント
38
2/6
&
アンド記号
アンパサンド
39
2/7
ʼ
アポストロフィ
アポストロフィ,アクサンテギュ
164
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
関数ORD
の値(順序
位置)
符号の位置
文字図形 関数ORD
における呼
び名
名称
JIS X 0201-1976における名称が異
なるもの(参考)
40
2/8
(
左括弧
左小括弧
41
2/9
)
右括弧
右小括弧
42
2/10
*
星印
アステリスク
43
2/11
+
正号
正符号
44
2/12
,
コンマ
コンマ,セディユ
45
2/13
−
負号
ハイフン,負符号
46
2/14
.
小数点
ピリオド
47
2/15
/
斜線
48
3/0
0
数字0
49
3/1
1
数字1
50
3/2
2
数字2
51
3/3
3
数字3
52
3/4
4
数字4
53
3/5
5
数字5
54
3/6
6
数字6
55
3/7
7
数字7
56
3/8
8
数字8
57
3/9
9
数字9
58
3/10
:
コロン
59
3/11
;
セミコロン
60
3/12
<
小号
不等号(より小)
61
3/13
=
等号
62
3/14
>
大号
不等号(より大)
63
3/15
?
疑問符
64
4/0
@
単価記号
65
4/1
A
英大文字A
66
4/2
B
英大文字B
67
4/3
C
英大文字C
68
4/4
D
英大文字D
69
4/5
E
英大文字E
70
4/6
F
英大文字F
71
4/7
G
英大文字G
72
4/8
H
英大文字H
73
4/9
I
英大文字I
74
4/10
J
英大文字J
75
4/11
K
英大文字K
76
4/12
L
英大文字L
77
4/13
M
英大文字M
78
4/14
N
英大文字N
79
4/15
O
英大文字O
80
5/0
P
英大文字P
81
5/1
Q
英大文字Q
82
5/2
R
英大文字R
83
5/3
S
英大文字S
84
5/4
T
英大文字T
85
5/5
U
英大文字U
86
5/6
V
英大文字V
87
5/7
W
英大文字W
88
5/8
X
英大文字X
165
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
関数ORD
の値(順序
位置)
符号の位置
文字図形 関数ORD
における呼
び名
名称
JIS X 0201-1976における名称が異
なるもの(参考)
89
5/9
Y
英大文字Y
90
5/10
Z
英大文字Z
91
5/11
[
左角括弧
左大括弧
92
5/12
¥
円記号
93
5/13
]
右角括弧
右大括弧
94
5/14
^
山記号
アクサンシルコンフレックス
95
5/15
̲
UND
下線
アンダライン
96
6/0
̀
GRA
低アクセント記号
アクサングラーブ
97
6/1
a
LCA
英小文字a
98
6/2
b
LCB
英小文字b
99
6/3
c
LCC
英小文字c
100
6/4
d
LCD
英小文字d
101
6/5
e
LCE
英小文字e
102
6/6
f
LCF
英小文字f
103
6/7
g
LCG
英小文字g
104
6/8
h
LCH
英小文字h
105
6/9
i
LCI
英小文字i
106
6/10
j
LCJ
英小文字j
107
6/11
k
LCK
英小文字k
108
6/12
l
LCL
英小文字l
109
6/13
m
LCM
英小文字m
110
6/14
n
LCN
英小文字n
111
6/15
o
LCO
英小文字o
112
7/0
p
LCP
英小文字p
113
7/1
q
LCQ
英小文字q
114
7/2
r
LCR
英小文字r
115
7/3
s
LCS
英小文字s
116
7/4
t
LCT
英小文字t
117
7/5
u
LCU
英小文字u
118
7/6
v
LCV
英小文字v
119
7/7
w
LCW
英小文字w
120
7/8
x
LCX
英小文字x
121
7/9
y
LCY
英小文字y
122
7/10
z
LCZ
英小文字z
123
7/11
{
LBR
左波括弧
左中括弧
124
7/12
|
VLN
縦線
125
7/13
}
RBR
右波括弧
右中括弧
126
7/14
TIL
上線(ティルド)
オーバライン
127
7/15
DEL
抹消

166
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表12.1 例外状態種別
規格で定める例外状態に対する関数EXTYPEの値を示す。続行可能な例外状態は,感嘆符 (!) で示す。括弧の中の
数字は,その例外状態を規定する箇条の番号である。
あるプログラム単位の中で例外状態になり,それがそのプログラム単位の中の例外処理区で処理されないと,その
例外状態は,そのプログラム単位を呼び出した行に伝達される。そして,この行での例外状態は,当初の例外状態種
別の値に100000を加えた値で識別される。
あふれ (1000)
1001 数値定数を評価するときのあふれ (5.1, 15.1)
1002 数値式を評価するときのあふれ (5.3)
1003 数値組込み関数を評価するときのあふれ (5.4, 14.7)
1004 関数VALを評価するときのあふれ (6.4)
1005 数値配列式を評価するときのあふれ (7.2)
1006 data文から (mat-) read文への数値データ要素のあふれ (10.1, 10.5)
!1007 端末から (mat-) input文への数値データ要素のあふれ (10.2, 10.5)
1008 ファイルからの入力の数値データ要素のあふれ (11.4)
1009 関数DET又はDOTを評価している間のあふれ (7.2)
1010 固定小数点宣言に対する精度指定のけた数が,処理系定義の制限を超える (15.1, 15.2)
1011 固定小数点10進数における代入のあふれ (15.1, 15.2)
1051 文字列式を評価するときのあふれ (6.3)
1052 文字列配列式を評価するときのあふれ (7.3)
1053 data文から (mat-) read文への文字列データ要素のあふれ (10.1, 10.5)
!1054 端末から (mat-) input文への文字列データ要素のあふれ (10.2, 10.5)
1105 ファイルからの入力の文字列データ要素のあふれ (11.4)
1106 文字列代入のあふれ (6.5, 9.1, 7.3)
1201 処理入力における数値代入のあふれ (14.4)
1202 処理入力における共用データ又は通報の数値代入のあふれ (14.5, 14.6)
1203 処理入力における文字列代入のあふれ (14.4)
1204 処理入力における共用データ又は通報の文字列代入のあふれ (14.5, 14.6)
下位けたあふれの誤り (1500)
次の例外状態は,注意の項にある推奨規定である。要求規定ではない。
!1501 数値定数の下位けたあふれ (5.1)
!1502 数値式の下位けたあふれ (5.3)
!1503 関数値の下位けたあふれ (5.4)
!1504 関数VALの値の下位けたあふれ (6.4)
!1505 配列式の下位けたあふれ (7.2)
!1506 data文の数値データ要素の下位けたあふれ (10.1)
!1507 端末からの入力数値の下位けたあふれ (10.2, 10.5)
!1508 ファイルからの入力数値の下位けたあふれ (11.4)
添字の誤り (2000)
2001 添字の値が,上下限指定の範囲外である (5.2, 6.2, 14.4, 14.5)
算術計算の誤り (3000)
3001 ゼロによる除算 (5.3)
3002 負数の非整数乗 (5.3)
3003 ゼロの負数乗 (5.3)
3004 対数関数の実引き数が,ゼロ又は負である (5.4)
3005 関数SQRの実引き数が,負である (5.4)
3006 関数MOD又はREMAINDERの除数が,ゼロである (5.4)
167
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
3007 関数ACOS又はASINの実引き数が,−1≦x≦1の範囲にない (5.4)
3008 関数ANGLE (0, 0) を評価しようとした (5.4)
3009 関数INVの実引き数が特異行列である,又は有効数字がすべて失われた (7.2)
初期化されていない変数の誤り (3100)
次の例外状態は,注意の項にある推奨規定である。要求規定ではない。
!3101 初期化されていない数値変数 (5.2)
!3102 初期化されていない文字列変数 (6.2)
実引き数の誤り (4000)
4001 関数VALの実引き数が,正しい数値定数の形でない (6.4)
4002 関数CHR$の実引き数の値が,範囲外である (6.4)
4003 関数ORDの実引き数の値が,正しい1文字又は正しい呼び名でない (6.4))
4004 関数SIZEの指標の値が,範囲外である (7.1)
!4005 位置指定TABの指標の値が,ゼロ以下である (10.3)
4006 set文のmargin句による行幅の設定が,現在の印字欄幅より小さい (10.3, 11.3)
4007 set文のzonewidth句の指標の値が,範囲外である (10.3, 11.3)
4008 関数LBOUNDの指標の値が,範囲外である (7.1)
4009 関数UBOUNDの指標の値が,範囲外である (7.1)
4010 関数REPEAT$の第2実引き数の指標の値が,負である (6.4)
!4101 set文のCLIP(切取り)が,“ON”でも“OFF”でもない (13.1)
!4102 set文のTEXT JUSTIFY(文章出力位置)が,適切な値でない (13.2)
4201 関数BVALの実引き数の文字列が,正しい数値表現でない (14.7)
4202 関数BVALの値が,数値の精度の制限内で表現できない (14.7)
4203 関数BSTR$の第1実引き数の指標の値が,負である (14.7)
4204 関数BVAL又はBSTR$の第2実引き数の指標の値が,2,8又は16でない (14.7)
4301 chain文とprogram行との引き数の型又は個数が,一致しない (9.3)
4302 chain文とprogram行との引き数の配列の次元数が,同じでない (9.3)
4303 chain文とprogram行との数値引き数のarithmetic選択子が,同じでない (9.3)
配列の大きさ不足の誤り (5000)
5001 配列の上下限の再定義に必要な要素の総数が,配列の宣言より多い (7.2, 7.3, 10.5, 11.4, 13.4)
5002 変形指示mat文によって代入される左辺の配列の寸法が,小さすぎる (13.5)
配列の誤り (6000)
6001 数値配列の寸法が,行列代数の規則に合わない (7.2)
6002 関数DETの実引き数が,正方行列でない (7.2)
6003 関数INVの実引き数が,正方行列でない (7.2)
6004 配列値IDNが,正方行列を指定していない (7.2)
6005 再定義上下限指定の上限の指標の値が,下限より小さい (7.2, 7.3, 10.5, 11.4)
6101 文字列配列式において,配列の寸法が合わない (7.3)
6201 draw文の変形項が,4行4列の行列でない (13.5)
6301 実時間処理の入出力配列の寸法が,structure宣言と一致しない (14.4, 14.5, 14.6)
6401 配列点並び又は配列位置対象の寸法が正しくない (13.3, 13.4)
6402 limit句の指標の値が,範囲外である (13.3)
ファイル利用の誤り (7000)
7001 経路番号が,ゼロから処理系定義の最大値までの範囲内にない (11.1)
!7002 ゼロ番の経路に対するopen文,close文,erase文又は記録設定 (11.1, 11.2)
168
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
7003 既に活性状態にある経路に対するopen文 (11.1)
7004 不活性状態の経路を参照する,open文又はask文以外のファイル文 (11.1, 11.2, 11.3, 11.4, 11.5)
7050 索引編成ファイルに対する,大小順序属性の食い違ったopen文 (11.1)
7051 LENGTHの指標の値がゼロ以下であるopen文 (11.1)
7052 装置を相対編成又は索引編成で開く (11.1)
7100 open文のファイル属性が,認識できる値をもっていない (11.1)
71xx 明示的な又は省略時想定のファイル属性をもったopen文によるファイル参照が,不可能なときの処理
系定義の例外状態 (11.1)
7202 相対編成以外のファイルに対する記録設定RECORD (11.2)
7203 索引編成以外のファイルに対する記録設定KEY (11.2)
7204 delete文,open文又は例外状態の後の記録設定SAME (11.2)
!7205 記録設定の能力のない装置に対する記録設定 (11.2)
7206 指標の値がゼロ以下である記録設定RECORD (11.2)
7207 空文字列値による等値探索の記録設定KEY (11.2)
7301 入出力両用 (OUTIN) で開かれたのでないファイルに対するerase文 (11.1)
7302 入力専用 (INPUT) のファイルに対する出力 (11.3)
7303 出力専用 (OUTPUT) のファイルに対する入力 (11.4)
7305 存在しない記録に対する削除 (delete),書換え (rewrite) 又は入力 (input) (11.4, 11.5)
7308 既存の記録に対する書出し (write) (11.3)
!7311 消去の能力のない装置に対するerase文 (11.1)
7312 表示形式でないファイルに対する印字欄幅又は行幅の設定 (11.3)
7313 入力専用のファイルに対する印字欄幅又は行幅の設定 (11.3)
7314 索引編成ファイルに対する,等値探索でない (mat-) write文 (11.3)
7315 表示形式又は内部形式のファイルに対する枠 (11.3, 11.4, 11.5)
7316 固有形式のファイルのデータに対する,枠なしの参照 (11.3, 11.4, 11.5)
7317 内部形式又は固有形式のファイルに対する (mat-) print文 (11.3)
7318 内部形式又は固有形式のファイルに対する (mat-) (line-) input文 (11.4)
7320 ゼロ番の経路に対する (mat-) rewrite文又はdelete文 (11.5)
7321 流れ編成ファイルに対するskip-rest指定 (11.4)
7322 入力専用又は出力専用のファイルに対するrewrite文又はdelete文 (11.5)
7401 不活性状態にある経路に対するtrace文 (12.2)
7402 表示形式でないファイル又は入力専用のファイルに対するtrace文 (12.2)
入出力の誤り (8000)
8001 データの終りを越えた (mat-) read文 (10.1, 10.5)
!8002 入力応答中のデータの個数の不足 (10.2, 10.5)
!8003 入力応答中のデータの個数の余分 (10.2, 10.5)
8011 入力におけるファイルの終り (11.4)
8012 記録中のデータの個数の不足 (11.4)
8013 記録中のデータの個数の余分 (11.4)
8101 表示形式記録から (mat-) read文又は (mat-) input文の数値変数への,数値型でないデータ要素 (10.1,
10.5, 11.4)
!8102 端末からの,構文的に正しくない入力応答 (10.2, 10.5)
!8103 (mat-) input文の数値変数に対する,数値型でないデータ要素 (10.2, 10.5)
8105 ファイルからの,構文的に正しくない入力応答 (11.4)
8120 内部形式記録の入力における型の不一致 (11.4)
169
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
8201 正しくない書式文字列 (10.4, 10.5)
8202 書式印字式並びの式に対して,書式文字列中に,対応する書式項目がない (10.4, 10.5)
!8203 生成された出力文字列が,対応する書式項目より長い (10.4)
!8204 指数部の出力文字列が,対応する指数書式項目の指数部の幅より長い (10.4)
8251 構文的に正しくない枠 (11.3, 11.4, 11.5)
8252 枠と一致しない型 (11.3, 11.4, 11.5)
8253 欄数不定の枠要素が,配列の最初の要素に対応しない (11.3, 11.4, 11.5)
8254 枠中の欄指定子の個数の不足 (11.3, 11.4, 11.5)
8255 枠の欄の幅より大きい値の数値 (11.3, 11.5)
8256 枠の欄の幅より長い値の文字列 (11.3, 11.5)
8301 ファイルの記録の長さを越える出力 (11.3, 11.5)
8302 recsize句の指定より長い記録の入力 (11.4)
8401 (mat-) (line-) input文の入力における時間切れ (10.2, 10.5)
8402 timeout句の数値時間式の負の値 (10.2, 10.5)
次の例外状態は,注意の項にある推奨規定である。要求規定ではない。
!8106 現在の窓,装置窓又は装置視野面の外側にある点に対する図形入力文 (13.4)
装置の誤り (9000)
9xxx 装置における処理系定義の誤り
制御の誤り (10000)
10001 else句のないon-goto文又はon-gosub文の指標の値が範囲外である (8.2)
10002 gosub文又はon-gosub文が実行されていないreturn文 (8.2)
10004 case-else区のないselect-case区で一致するcase区がない (8.4)
10005 chain文の対象のプログラムが利用可能でない (9.3)
!10007 デバッグが活性状態にあるときのbreak文の実行 (12.2)
図形の誤り (11000)
11004 絵定義の実行中の座標の再定義又は切取りの変更 (13.5)
!11051 ゼロの幅又はゼロの高さの境界四辺をもつset文 (13.1)
!11052 視野面が範囲外である (13.1)
!11053 装置窓が範囲外である (13.1)
!11054 装置視野面が表示画面の範囲外である (13.1)
!11056 set文のPOINT STYLE(点の形)の指標の値が範囲外である (13.2)
!11062 set文のLINE STYLE(線の形)の指標の値が範囲外である (13.2)
!11073 set文のTEXT HEIGHT(文字の高さ)の数値式がゼロ以下である (13.2)
!11085 set文又はmat-cells文の色指標の値が範囲外である (13.2, 13.3)
!11088 set文のCOLOR MIX(色混合率)の値が範囲外である (13.2)
11100 図形出力文の幾何対象LINESの点が1点以下又はAREAの点が2点以下である (13.3)
11140 指定された図形入力機構が利用可能でない (13.4)
11152 locate文のCHOICE又はVALUEの開始値が範囲外である (13.4)
実時間の誤り (12000)
12001 停止状態にない並行活動に対するstart文 (14.3)
12002 既に発生されている事象が待ち状態の並行活動をまだ進行状態にしていないのに,同じ事象を重ねて発
生しようとするstart文 (14.3)

170
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
12003 2回以上発生している事象に対するwait文の実行 (14.3)
12004 数値時間式の値が範囲外である (14.3)
12005 文字列時間式の形式が正しくない (14.3)
12006 既に接続されている事象に対するconnect-event文 (14.3)
12007 既に切り離されている事象に対するdisconnect-event文 (14.3)
12101 wait文の時間切れ (14.3)
12102 in-from文,out-to文又はseize文の時間切れ (14.4, 14.8)
12103 send-to文又はreceive-from文の時間切れ (14.6)
12201 宣言と一致しない処理対象の属性 (14.2)
171
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書A(参考) 規格の構成
この規格は,章に分けて構成する。4.〜16.の各章は,それぞれBASICにおける関連ある一組の機能に対
応する。章は,BASICの個々の機能を扱う節 (x.x) に分け,各節は更に,次の項 (x.x.x) からなる。
第1項 概要 (general description) この項は,その節で規定する機能を簡潔に述べる。
第2項 構文 (syntax) BASICの構文は,文脈自由文法 (context-free grammar) すなわちBackus-Naur表
現を修正した生成規則 (production) で記述する。生成規則の詳細は,本体3.1で定める。
生成規則の記述を分かりやすく簡素にしたために,規格に合わない形が許されてしまうことがある。例
えば,生成規則だけに従うと,次のような誤った文が許されることになる。
LET X=A(1)+A(1,2)
この例では,Aが一方では1次元,他方では2次元の配列として参照されている。このような形を複雑
な生成規則によって除外することは避け,文章記述による制限を付けて除外する。
構文規則の主要な目標は,“プログラム”の概念とその構成要素を定義することであるが,“プログラム”
の定義には必要でない,次のような項目も含めて定義する。
(1) 入力を要求するための出力である“入力要求”
(2) 入力の要求に対する利用者の応答の文字列である“入力応答”及び“行入力応答”
(3) プログラムを修正するときに使用する“編集用指令”
第3項 例 (examples) 第2項の生成規則によって生成できる正しい形の幾つかの例を示す。例に付けた
番号は,生成規則の番号に対応する。例は,必ずしもすべての規則に対して与えないので,番号が連続し
ていないこともある。
第4項 意味 (semantics) 意味の規定は,構文によって生成される構造に対して意味を与える。
第5項 例外状態 (exceptions) この項は,規格合致処理系が認識しなければならない例外状態を示す。
また,例外状態種別(関数EXTYPEの値)をも示す。
第6項 注意 (remarks) この項は,処理系に対する要求,この規格中のある種の機能,及び操作環境に
おけるBASIC言語処理系の作成に関する推奨事項を述べる。
172
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書B(参考) 有効範囲
ある実体 (entity) の有効範囲 (scope) とは,その名前 (name) が(全く認識されなかったり,別の対象
への参照として認識されたりすることなく,)その対象への参照として認識されるプログラムの範囲のこと
とする。一般には,一つの実体は一つだけの名前によって認識されるので,その名前の認識される有効範
囲が,その対象自身を参照可能にする有効範囲でもある。参照によって渡される (pass by reference) 引き
数は特例であって,一つの対象が二つの別の名前によって認識され,その対象自身はその名前の有効範囲
の外部から参照されうる。
附属書B表1に示す対象の有効範囲は,その名前の有効範囲でもある。
附属書B表1 対象の有効範囲
番号
対象
有効範囲
(1)
仮引き数でない変数
プログラム単位
(2)
仮引き数でない配列
プログラム単位
(3)
プログラム単位の仮引き数
プログラム単位(1)
(4)
内部手続き定義の仮引き数
内部手続き定義(1)
(5)
内部手続き定義
プログラム単位
(6)
プログラム単位
プログラム
(7)
data文のデータ列
プログラム単位
(8)
ゼロ番以外の経路番号
プログラム単位
(9)
ゼロ番の経路番号
プログラム
(10)
書式(image行),枠(template文)
プログラム単位
(11)
行番号の棚(gosub文)
プログラム単位,内部手続き定義,when本体,
例外処理区のうちの最も狭い範囲
(12)
選択子(option文)
プログラム単位
(13)
ファイル名
プログラム
(14)
擬似乱数列(関数RND)
プログラム
(15)
共用域,通報域,処理域
プログラム
(16)
データ構造(structure宣言)
プログラム
(17)
図形及びprint文に関する設定対象
プログラム
(18)
行番号
プログラム単位
(19)
デバッグシステムの状態
(debug文とtrace文)
プログラム単位
注(1) 参照によって渡される仮引き数の名前は,そのプログラム単位又は内部手続き定義の側でだけ知ら
れているが,それが参照する対象は,呼び出した側と呼び出された側との双方で共用される。
173
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書C(参考) 処理系定義の機能
C1. 処置 この規格は,機能の幾つかを処理系定義 (implementation-defined) としている。しかし,このこ
とは,それぞれの節で推奨した制限が守られる限り,移植可能性 (portability) に影響を及ぼさない。これ
らの機能の処理方法は,処理系の取扱い説明書に定義しなければならない。
C2. 事項 処理系定義の事項を附属書C表1に示す。箇条番号は,規格の本体に対するものである。細別
符号(a), (b), …は,この表の中での番号である。
C3. 影響 同一プログラムであっても,異なった処理系で実行すると,次の理由又は他の理由によって,
処理系定義の機能が異なった結果を生じさせることがある。
(1) 擬似乱数列の生成算法は,プログラムの論理的な流れに影響を及ぼす。
(2) 機械最小値,関数MAXNUMの値,数値の精度及びこれらの組合せは,プログラムの論理的な流れに
影響を及ぼす。
(3) 変数の初期値は,論理的な誤りをもつプログラムの論理的な流れに影響を及ぼす。
(4) 数値式の評価の順序は,プログラムの論理的な流れに影響を及ぼす。
附属書C表1 処理系定義の事項
2.3 誤り
(a) 構文上誤っている部分の解釈
(b) 誤り通知 (error message) の形式
2.4 例外状態
(a) 例外状態通知 (exception message) の形式
(b) ハードウェア依存の例外状態
(c) 1行中の複数個の例外状態を検出する順序
3.2 用語の定義
(a) “固有” [3.2(13)] のデータについてのある種の意味規則
4.1 文字
(a) 非プログラム文字
(b) 文字の固有の大小順序(固有順序)
4.2 プログラム,行及び区
(a) 行末
(b) 物理行の長さの最大値
(c) chain文によらずに開始されるプログラムのprogram行の値仮引き数部の効果
(d) プログラム指示名とプログラム名の対応付け
4.4 識別名
(a) 主プログラムとは独立に翻訳される外部手続き定義のルーチン識別名に対する制限
5.1 数値定数
(a) 数値定数の精度及び範囲
5.2 数値変数
(a) 数値変数の初期値
5.3 数値式
(a) 数値式の評価の順序
5.4 数値組込み関数
(a) 数値関数の評価の正確度
174
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(b) 関数MAXNUM及びEPSの値
(c) 擬似乱数列
(d) 日付機能及び時計機能の有無
(e) 関数DATE及びTIMEに用いる基準時間帯
5.6 数値の扱い及び角度
(a) 数値の精度及び範囲
(b) 浮動小数点10進数演算の精度及び範囲
(c) 固有 (NATIVE) 数値演算の精度及び範囲
(d) 数値式の評価の正確度
6.2 文字列変数
(a) 宣言してない文字列変数の最大長
(b) 文字列変数の初期値
6.4 文字列組込み関数
(a) 固有文字集合における関数CHR$の値
(b) 固有文字集合における関数ORDの値
(c) 日付機能及び時計機能の有無
(d) 関数DATE及びTIMEに用いる基準時間帯
6.6 文字列宣言
(a) collate選択子でNATIVEを指定したときの文字の大小順序(固有順序)
(b) 最大長指定なしで宣言された文字列変数の最大長
7.1 配列宣言
(a) 最大長指定なしで宣言された文字列配列中の文字列の最大長
参考 ANSI X3.113では,“最大長指定あり”となっているが,誤りであるので,TIBによって訂正した。
7.2 数値配列
(a) 特異行列に対する関数INV(逆行列)の値
9.1 利用者定義関数
(a) 最大長指定のない文字列仮引き数の最大長
(b) 値が代入されなかったときの定義関数の値
(c) 外部関数中の局所変数の初期値
9.2 副プログラム
(a) 最大長指定のない文字列仮引き数の最大長
(b) ある配列とその要素の両方が引き数として渡されて,その配列を上下限再定義したときの効果
(c) 外部手続き定義中の参照仮引き数でない変数の初期値
9.3 プログラム連鎖
(a) chain文中のプログラム指示名の解釈
(b) プログラム指示名中の英大文字と英小文字の解釈
(c) chain文によって実行されるプログラム中の変数の初期値
10.2 入力
(a) 入力要求
(b) 一括方式において入力を要求する手段
(c) timeout句及びelapsed句の時間の最小値,最大値及び分解能
10.3 出力
(a) 印字を引き起こす関数が印字中に呼び出されるときの効果
(b) 印字する数値表現の有効数字部の幅
(c) 印字する数値表現の指数部の整数の幅
(d) 印字位置に対する非印字文字の効果
(e) 省略時想定の行幅
(f) 省略時想定の印字欄幅
(g) 印字行の右端における後続空白の処置
(h) 指数部のEの英大文字又は英小文字の使用
10.5 配列入出力
(a) 再定義配列への入力の再供給の取扱い
175
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
11.0 ファイル編成及び記録形式
(a) ファイル編成と記録形式とのある種の組合せの効果
11.1 ファイル操作
(a) 経路番号の最大値
(b) 英大文字と英小文字の別だけが異なるファイル名を,同じファイルを表すものとするか否か
(c) 既に開かれているファイルを開こうとしたときの効果
(d) 同時に活性状態でありうる経路の個数
(e) 生成したときと異なった属性でファイルを開けるか否か
(f) 生成したときと異なったarithmetic選択子でファイルを開けるか否か
(g) 二つのプログラム単位が,異なった属性又は選択子を指定して,一つのファイルを開こうとしたときの効果
(h) ある実行から次の実行までの間,ファイル内容が保存されることを保証する手段
(i) ファイル編成と記録形式とのある種の組合せの効果
(j) 内部形式及び固有形式のファイルの記録の長さ
(k) 指定がなく,利用可能な情報もないときの記録の最大長
(l) 流れ編成ファイルでないときの質問属性DATUMの値
(m) ゼロ番の経路に対する質問属性NAMEの値
(n) 例外状態種別7101〜7199の意味
(o) 索引ファイルのキーの最大長
11.2 ファイル指示子
(a) ファイルでない装置の経路の入力で,利用可能なデータが存在しないことを表す方法
11.3 ファイルへのデータ生成
(a) 記録末を示す手段
(b) 省略時想定の行幅及び印字欄幅
(c) 処理系の提供する行幅及び印字欄幅の最大値
(d) 表示形式のファイルに対してprint文で生成する印字数値の精度
11.4 ファイルからのデータ入力
(a) 固有形式のファイルの数値欄から入力される値の有効数字のけた数
(b) ファイル及び非端末形装置に対する入力制御項目の効果
(c) 表示形式のファイルから入力する数値定数の精度
(d) 固有形式のファイルから精度の損失なしに入力できる数値の精度
(e) 枠と適合しない内容をもつ記録の固有形式のファイルからの入力
(f) 間違った入力応答に対する続行不能又は続行可能な例外状態処理手続きの使用
11.5 ファイルにおけるデータ変更
(a) 相対編成,索引編成以外のファイルに対するデータ変更文の効果
(b) rewrite文でskip指定を含む適合しない枠を使用したときの効果
12.1 例外状態処理
(a) 処理系定義の固有の例外状態に対する関数EXTYPEの値
(b) 関数EXTEXT$の値の形
12.2 デバッグ
(a) デバッグシステムで許す機能
(b) 追跡の報告の形式
13.1 座標系
(a) 個々の図形表示装置を選択する方法
(b) “逆転”した窓の効果
13.2 属性及び画面制御
(a) 図形出力で利用できる線の形の個数
(b) 1,2,3,4以外の線の形の効果
(c) 図形出力で利用できる点の形の個数
(d) 1,2,3,4,5以外の点の形の効果
(e) 利用できる色の個数
(f) 色指標のそれぞれの値に対応する色
(g) 既に色が表示されている部分に対する文SET COLOR MIXの効果

176
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(h) 色混合率COLOR MIXの省略時想定値
(i) 文章を表示する方向における一般の角度の利用可能性
(j) 名札中の文字の方向
13.3 図形出力
(a) 第2次元の寸法が3以上である配列によって描いたり塗ったりすることの効果
(b) 名札の文字の大きさ,形及び方向
(c) 視野面の内と外にまたがった文字の切取り方
13.4 図形入力並びに13.5 絵及び描点出力
(a) 図形入力要求を利用者に知らせる手段
(b) 現在の窓,装置窓,装置視野面の外で図形入力を与えようとしたときの効果
(c) 現在変形が特異行列であるときの図形入力文GETの実行の効果
(d) 指示子の省略時想定の位置
(e) 第2次元の寸法が3以上である配列位置対象の配列の効果
14.1 実時間プログラム
(a) 並行単位のスケジューリング
(b) 並行単位の優先度の解釈
(c) 並行単位の実行の中断できる時点
(d) 並行単位中の変数の初期値
14.2 実時間宣言
(a) 処理対象に対する参照情報の解釈
14.3 並行動作制御
(a) 事象を待っている複数個の並行活動のうち,どれを再起動させるか
(b) 時計機能の正確度
14.4 処理入出力
(a) 処理対象に対する例外状態
14.5 共用データ
(a) 初期化されていないデータをget-from文で引用したときの効果
14.6 通報の受け渡し
(a) 複数個のreceive-from文のうち,どれが通報を受け取るか
(b) 複数個のsend-to文のうち,どれが通報を送るか
14.8 資源管理
(a) 確保項目の名前
15.1 固定小数点10進数
(a) 固定小数点10進数演算で可能な最大の精度
(b) 固定小数点10進数の式及び関数の評価の精度
(c) 固定小数点10進数の式及び関数の評価の正確度
(d) 印字される“有効数字”の定義
(e) 異なったarithmetic選択子をもつプログラム間で内部形式のファイルの参照が可能か否か
(f) 異なったarithmetic選択子をもつプログラム間で固有形式のファイルの参照が可能か否か
16. 編集
(a) プログラムの編集から実行への移行の方法
表4.1 標準文字集合
(a) 追加の非プログラム文字の個数
177
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書D(参考) 構文要素索引(索引参照)
[ANSI X3.113の附属書Dは,構文要素だけの索引として作成されている。この日本工業規格では,そ
の他の用語も含めて索引を作成した。それらは,索引【日本語】の部に示したので,ここでは省略する。]
178
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書E(参考) 生成規則一覧
本体中にあるすべての生成規則を,ABC順,あいうえお順にまとめて示す。各生成規則の左側に,その
生成規則が定義されている節番号を示す。生成規則は,示された各節の第2項構文に定義されている。
11.1
access句
= ACCESS {INPUT|OUTPUT|OUTIN|文字列式}
10.3, 11.1 ask文
= ASK 出力質問項目並び|ASK 経路指定 質問項目並び|
13.1
ASK 質問対象 status句?
12.2
break文
= BREAK
9.2
call文
= CALL 副プログラム名 参照実引き数部?
8.4
case行
= 行番号 case文 行末部
8.4
case区
= case行 区*
8.4
case文
= CASE 照合項目並び
8.4
case-else行
= 行番号 CASE ELSE 行末部
8.4
case-else区
= case-else行 区*
14.6
case-timeout行
= 行番号 case-timeout文 行末部
14.6
case-timeout区
= case-timeout行 区*
14.6
case-timeout文
= CASE TIMEOUT 数値時間式
12.1
cause-exception文
= CAUSE EXCEPTION 例外状態種別
9.3
chain文
= CHAIN プログラム指示名 {WITH 値実引き数部}?
13.2
clear文
= CLEAR
11.1
close文
= CLOSE 経路式
11.1
collate句
= COLLATE {STANDARD|NATIVE|文字列式}
14.3
connect-event文
= CONNECT EVENT 事象名並び
10.1
data文
= DATA データ要素並び
12.2
debug文
= DEBUG {ON|OFF}
5.6
declare文
= DECLARE 宣言指定
14.2
declare-process行
= 行番号 declare-process文 行末部
14.2
declare-process文
= DECLARE PROCESS 入出力指示 処理域配列名
上下限指定部 OF 構造名
9.1
def行
= 行番号 def文 行末部
9.1
def宣言
= DEF 定義関数名並び
9.1
def文
= 数値 def文|文字列 def文
14.3
delay句
= DELAY 数値時間式
16.2
delete指令
= DELETE 行範囲並び
11.5
delete文
= DELETE 経路式 削除制御
7.1
dim文
= DIM 配列宣言並び
14.3
disconnect-event文
= DISCONNECT EVENT 事象名並び
179
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
8.3
do行
= 行番号 do文 行末部
8.3
do区
= do行 do本体
8.3
do文
= DO 出口条件?
8.3
do本体
= 区* loop行
13.5
draw文
= DRAW 絵呼出し {WITH 変形}?
10.2
elapsed句
= ELAPSED 数値変数名
8.4
else行
= 行番号 ELSE 行末部
8.4
else区
= else行 区*
8.4
elseif行
= 行番号 ELSEIF 論理式 THEN 行末部
8.4
elseif区
= elseif行 区*
4.2
end行
= 行番号 end文 行末部
4.2
end文
= END
9.1
end-function行
= 行番号 END FUNCTION 行末部
12.1
end-handler行
= 行番号 END HANDLER 行末部
8.4
end-if行
= 行番号 END IF 行末部
14.1
end-paract行
= 行番号 end-paract文 行末部
14.1
end-paract文
= END PARACT
13.5
end-picture行
= 行番号 END PICTURE 行末部
14.2
end-process行
= 行番号 END PROCESS 行末部
14.8
end-seize行
= 行番号 END SEIZE 行末部
8.4
end-select行
= 行番号 END SELECT 行末部
9.2
end-sub行
= 行番号 end-sub文 行末部
9.2
end-sub文
= END SUB
12.1
end-when行
= 行番号 END WHEN 行末部
11.1
erase文
= ERASE REST? 経路式
14.2
event句
= EVENT 事象名
14.3
event-timeout句
= EVENT 事象名 timeout句?
8.3
exit-do文
= EXIT DO
8.3
exit-for文
= EXIT FOR
9.1
exit-function文
= EXIT FUNCTION
12.1
exit-handler文
= EXIT HANDLER
13.5
exit-picture文
= EXIT PICTURE
14.8
exit-seize文
= EXIT SEIZE
9.2
exit-sub文
= EXIT SUB
9.1, 15.2
external-function行
= 行番号 EXTERNAL FUNCTION {数値定義関数名|
文字列定義関数名 最大長指定?} 値仮引き数部?
行末部|行番号 EXTERNAL FUNCTION
固定小数点定義関数名 値仮引き数部? 行末部
9.1
external-function宣言
= EXTERNAL FUNCTION 定義関数名並び
13.5
external-picture行
= 行番号 EXTERNAL 内部picture文 行末部
180
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
13.5
external-picture宣言
= EXTERNAL PICTURE 絵名並び
9.2
external-sub行
= 行番号 EXTERNAL sub文 行末部
9.2
external-sub宣言
= EXTERNAL SUB 副プログラム名並び
16.2
extract指令
= EXTRACT 行範囲並び
8.3
for行
= 行番号 for文 行末部
8.3
for区
= for行 for本体
8.3
for文
= FOR 制御変数名 等号 始値 TO 限界 {STEP 増分}?
8.3
for本体
= 区* next行
14.5
get-from文
= GET FROM 共用域名 添字部? TO 入力構造 timeout句?
8.2
gosub文
= {GOSUB|GO SUB} 行番号
8.2
goto文
= {GOTO|GO TO} 行番号
12.1
handler行
= 行番号 HANDLER 例外処理区名 行末部
12.1
handler区
= handler行 例外処理区 end-handler行
8.4
if区
= if-then行 then本体 elseif区* else区? end-if行
8.4
if文
= IF 論理式 THEN 単純実行動作 {ELSE 単純実行動作}?
10.1
if-missing句
= IF MISSING THEN データ存否動作
8.4
if-then行
= 行番号 IF 論理式 THEN 行末部
11.2
if-there句
= IF THERE THEN データ存否動作
10.4
image行
= 行番号 IMAGE コロン 書式文字列 行末
14.4
in-from文
= IN FROM {処理域名|処理域配列名 添字部} TO 入力構
造 timeout句?
10.2, 11.4 input文
= INPUT 入力修飾? 変数名並び|INPUT 経路式 入力制御
コロン 変数名並び {コンマ SKIP REST}?
5.5, 6.5
let文
= 数値let文|文字列let文
13.3
limit句
= LIMIT 指標
10.2, 11.4 line-input文
= LINE INPUT 入力修飾? 文字列変数名並び|LINE INPUT
経路式 入力制御 コロン 文字列変数名並び
16.2
list指令
= LIST 行範囲並び?
13.4
locate文
= LOCATE {point句 コロン 座標変数対|値選択 コロン
数値変数名}
8.3
loop行
= 行番号 loop文 行末部
8.3
loop文
= LOOP 出口条件?
7.2, 7.3
mat文
= 数値mat文|文字列mat文
13.3
mat-cells文
= MAT 図形動詞 CELLS コンマ IN 点対 コロン
数値配列名
10.5, 11.4 mat-input文
= MAT INPUT 入力修飾? {再定義配列並び|
不定長ベクトル}|MAT INPUT 経路式 入力制御 コロン
{再定義配列並び|不定長ベクトル}
181
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
10.5, 11.4 mat-line-input文
= MAT LINE INPUT 入力修飾? 再定義文字列配列並び|
MAT LINE INPUT 経路式 入力制御 コロン
再定義文字列配列並び
13.4
mat-locate文
= MAT LOCATE point句 コロン 配列位置対象
10.5, 11.3 mat-print文
= MAT PRINT {印字配列名並び|USING 書式引用 コロン
書式印字配列名並び}|MAT PRINT 経路式 印字制御
コロン {印字配列名並び|書式印字配列名並び}
10.5, 11.4 mat-read文
= MAT READ {if-missing句 コロン}? 再定義配列並び|
MAT READ 経路式 読込み制御 コロン 再定義配列並び
11.5
mat-rewrite文
= MAT REWRITE 経路式 書換え制御 コロン 配列名並び
11.3
mat-write文
= MAT WRITE 経路式 書出し制御 コロン 配列名並び
14.2
message宣言
= MESSAGE 通報域名 OF 構造名
8.3
next行
= 行番号 next文 行末部
8.3
next文
= NEXT 制御変数名
5.6, 15.1
numeric宣言
= NUMERIC 数値宣言 {コンマ 数値宣言}*|NUMERIC
精度指定? 固定小数点宣言 {コンマ 固定小数点宣言}*
8.2
on-gosub文
= ON 指標 {GOSUB|GO SUB} 行番号 {コンマ
行番号}* {ELSE 単純実行文}?
8.2
on-goto文
= ON 指標 {GOTO|GO TO} 行番号 {コンマ 行番号}*
{ELSE 単純実行文}?
11.1
open文
= OPEN 経路指定 NAME ファイル名 ファイル属性並び
5.6
option文
= OPTION 選択子並び
11.1
organization句
= ORGANIZATION {ファイル編成値|文字列式}
14.4
out-to文
= OUT TO {処理域名|処理域配列名 添字部} FROM
出力構造 timeout句?
14.1
paract行
= 行番号 paract文 行末部
14.1
paract文
= PARACT ルーチン識別名 {URGENCY 優先度}?
14.1
parstop文
= PARSTOP
13.4
point句
= POINT 機構選択? 開始点?
10.3, 10.4, print文
= PRINT 印字項目並び|PRINT 書式付き印字指定|PRINT
11.3
経路式 印字制御 {コロン {印字項目並び|
書式印字式並び}}?
14.2
process宣言
= PROCESS {処理指定|event句} 参照情報?
4.2
program行
= 行番号 PROGRAM プログラム名 値仮引き数部? 行末部
10.2
prompt句
= PROMPT 文字列式
14.5
put-to文
= PUT TO 共用域名 添字部?FROM 出力構造 timeout句?
5.4
randomize文
= RANDOMIZE
13.4
range句
= コンマ RANGE 数値式 TO 数値式
182
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
10.1, 11.4 read文
= READ {if-missing句 コロン}? 変数名並び|READ
経路式 読込み制御 コロン 変数名並び
{コンマ SKIP REST}?
14.6
receive-from文
= RECEIVE FROM 通報域名 TO 入力構造 timeout句?
11.1
recsize句
= RECSIZE {VARIABLE|文字列式} {LENGTH 指標}?
11.1
rectype句
= RECTYPE {記録形式値|文字列式}
4.3
rem文
= REM 注釈文字列
16.2
renumber指令
= RENUMBER 行範囲? 番号指定?
10.1
restore文
= RESTORE 行番号?
8.2
return文
= RETURN
11.5
rewrite文
= REWRITE 経路式 書換え制御 コロン 式並び
14.8
seize行
= 行番号 seize文 行末部
14.8
seize区
= seize行 区* end-seize行
14.8
seize文
= SEIZE 確保項目並び timeout句?
8.4
select-case行
= 行番号 select-case文 行末部
8.4
select-case区
= select-case行 注釈行* case区 case区* case-else区?
end-select行
8.4
select-case文
= SELECT CASE 式
14.6
select-on-port行
= 行番号 select-on-port文 行末部
14.6
select-on-port区
= select-on-port行 注釈行* 通報case区 通報case区*
case-timeout区? end-select行
14.6
select-on-port文
= SELECT ON PORT
14.6
send-to文
= SEND TO 通報域名 FROM 出力構造 timeout句?
10.3
set文
= SET 設定対象
14.2
shared宣言
= SHARED 共用域名 上下限指定部? OF 構造名
14.3
signal文
= SIGNAL 事象名
14.3
start文
= START ルーチン識別名
13.1
status句
= STATUS 数値変数名
4.2
stop文
= STOP
6.6
string宣言
= STRING 最大長指定? 文字列宣言 {コンマ 文字列宣言}*
14.2
structure宣言
= STRUCTURE 構造名 コロン 反復回数? 型指示
{コンマ 反復回数? 型指示}*
9.2
sub文
= SUB 副プログラム名 参照仮引き数部?
11.3
template文
= TEMPLATE コロン 枠要素並び
8.4
then本体
= 区*
14.3
time句
= TIME 時間式
10.2
timeout句
= TIMEOUT 数値時間式
12.2
trace文
= TRACE ON {TO 経路式}?|TRACE OFF
12.1
use行
= 行番号 USE 行末部
14.3
wait文
= WAIT {time句|delay句|event-timeout句}
183
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
12.1
when本体
= 区*
12.1
when-in行
= 行番号 WHEN EXCEPTION IN 行末部
12.1
when-in区
= when-in行 when本体 use行 例外処理区 end-when行
12.1
when-use行
= 行番号 WHEN EXCEPTION USE 例外処理区名 行末部
12.1
when-use区
= when-use行 when本体 end-when行
11.3
write文
= WRITE 経路式 書出し制御 コロン 式並び
9.1, 15.2
値仮引き数
= 単純変数名|仮配列宣言|固定小数点仮引き数
9.1
値仮引き数部
= 左括弧 値仮引き数 {コンマ 値仮引き数}* 右括弧
5.3
値実引き数
= 式|実配列名
5.3
値実引き数部
= 左括弧 値実引き数 {コンマ 値実引き数}* 右括弧
13.4
値選択
= CHOICE 機構選択? 開始値?|VALUE 機構選択?
range句? 開始値?
10.3
位置指定
= TAB 左括弧 指標 右括弧
10.3
印字区切り
= コンマ|セミコロン
10.3
印字項目
= 式|位置指定
10.3
印字項目並び
= {印字項目? 印字区切り}* 印字項目?
11.3
印字制御
= {コンマ 印字制御項目}*
11.3
印字制御項目
= 中核記録設定|if-there句|USING 書式引用
10.5
印字配列名並び
= 配列名 {印字区切り 配列名}* 印字区切り?
4.1
引用文字
= 二連引用符|非引用符文字
6.1
引用文字列
= 引用符 引用文字* 引用符
4.1
英大文字
= A|B|C|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|
R|S|T|U|V|W|X|Y|Z
4.1
英小文字
= a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|
u|v|w|x|y|z
4.1
英字
= 英大文字|英小文字
13.5
絵定義
= 内部絵定義|外部絵定義
13.5
絵名
= ルーチン識別名
13.5
絵名並び
= 絵名 {コンマ 絵名}*
13.5
絵呼出し
= 絵名 参照実引き数部?
13.4
開始値
= コンマ AT 数値式
13.3
開始点
= コンマ AT 座標対
16.2
開始番号
= 行番号
13.5
外部絵定義
= external-picture行 手続き区* end-picture行
9.1
外部関数定義
= external-function行 手続き区* end-function行
4.2
外部手続き単位
= 注釈行* 外部手続き定義
4.2, 13.5
外部手続き定義
= 外部関数定義|外部副プログラム定義|外部絵定義
9.2
外部副プログラム定義
= external-sub行 手続き区* end-sub行
11.5
書換え制御
= {コンマ 書換え制御項目}*
11.5
書換え制御項目
= if-missing句|記録設定|枠引用
184
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
11.3
書出し制御
= {コンマ 書出し制御項目}*
11.3
書出し制御項目
= 記録設定|if-there句|枠引用
11.1
拡充記録形式値
= NATIVE
11.2
拡充記録設定
= RECORD 指標|KEY {等値探索|大号探索} 文字列式
11.1
拡充属性名
= RECORD|KEY|COLLATE
11.1
拡充ファイル属性
= collate句
11.1
拡充ファイル編成値
= RELATIVE|KEYED
14.8
確保項目
= SHARED 共用域名|[処理系定義]
14.8
確保項目並び
= 確保項目 {コンマ 確保項目}*
14.2
型指示
= {NUMERIC 精度指定?|STRING} 上下限指定部?
9.1
仮配列宣言
= 配列名 左括弧 コンマ* 右括弧
9.1
関数定義
= 内部関数定義|外部関数定義
13.3
幾何図形mat文
= MAT 図形動詞 幾何対象 コンマ limit句}? コロン
配列点並び
13.3, 13.5 幾何図形文
= 図形動詞 幾何対象 コロン 点並び|PLOT LINES|
PLOT LINES コロン 点並び セミコロン?
13.3
幾何対象
= POINTS|LINES|AREA
13.4
機構種別
= POINT|MULTIPOINT|CHOICE|VALUE
13.4
機構選択
= 左括弧 指標 右括弧
16.2
刻み
= 符号なし整数
4.2, 13.5,
14.1, 14.2,
14.8
行
= 単純行|case行|case-else行|declare-process行|def行|
do行|else行|elseif行|end行|end-function行|
end-handler行|end-if行|end-paract行|end-picture行|
end-process行|end-seize行|end-select行|end-sub行|
end-when行|external-function行|external-picture行|
external-sub行|for行|handler行|if-then行|image行|
loop行|next行|paract行|program行|seize行|
select-case行|use行|when-in行|when-use行|
実時間宣言行|処理要素行|注釈行|内部function行|
内部picture行|内部sub行
13.1
境界
= 数値式
13.1
境界四辺
= 境界 コンマ 境界 コンマ 境界 コンマ 境界
13.1
境界四辺変数
= 数値変数名 コンマ 数値変数名 コンマ 数値変数名 コンマ
数値変数名
4.2
行継続
= アンド記号 空白* 行末部 アンド記号
16.2
行指定
= 行番号|FIRST|LAST
10.2
行入力応答
= プログラム文字* 行末
16.2
行範囲
= 行指定 {TO 行指定}?
16.2
行範囲並び
= 行範囲 {コンマ 行範囲}*
4.2
行番号
= 数字 数字*
185
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
8.2
行番号分岐
= gosub文|goto文|if文|データ存否|on-gosub文|on-goto文
4.2
行末
= [処理系定義]
4.3
行末注釈
= 感嘆符 注釈文字列
4.2
行末部
= 行末注釈? 行末
14.5
共用域入出力文
= put-to文|get-from文
14.2
共用域名
= 英字 識別名文字*
11.1
記録形式値
= 中核記録形式値|拡充記録形式値
11.2
記録設定
= 中核記録設定|拡充記録設定
4.2, 14.1
区
= 単純行|繰返し区|if区|select-case区|image行|保護区|
実時間区
4.3
空文
= 行末注釈
8.3
繰返し区
= do区|for区
11.1
経路式
= 番号記号 指標
11.1
経路指定
= 経路式 コロン
9.2
経路番号
= 番号記号 符号なし整数
10.4
けた寄せ
= 大号|小号
8.3
限界
= 数値式
13.5
現在変形
= TRANSFORM
14.2
構造名
= 英字 識別名文字*
15.2
固定小数点仮配列宣言
= 仮配列宣言 精度指定
15.2
固定小数点仮引き数
= 数値単純変数名 精度指定|固定小数点仮配列宣言
15.1
固定小数点宣言
= 数値単純変数名 精度指定?|数値配列宣言 精度指定?
15.2
固定小数点定義関数名
= 数値定義関数名 精度指定
7.1
最大寸法実引き数部
= 左括弧 実配列名 右括弧
6.6
最大長指定
= 星印 符号なし整数
7.2
再定義上下限指定
= {指標 TO}? 指標
7.2
再定義上下限指定部
= 左括弧 再定義上下限指定 {コンマ 再定義上下限指定}*
右括弧
13.4
再定義数値配列
= 数値配列名 再定義上下限指定部?
10.5
再定義配列
= 配列名 再定義上下限指定部?
10.5
再定義配列並び
= 再定義配列 {コンマ 再定義配列}*
10.5
再定義文字列配列
= 文字列配列名 再定義上下限指定部?
10.5
再定義文字列配列並び
= 再定義文字列配列 {コンマ 再定義文字列配列}*
11.5
削除制御
= {コンマ 削除制御項目}*
11.5
削除制御項目
= if-missing句|記録設定
13.3
座標対
= 数値式 コンマ 数値式
13.4
座標変数対
= 数値変数名 コンマ 数値変数名
13.2
三原色指定
= 数値式 コンマ 数値式 コンマ 数値式
13.2
三原色取得
= 数値変数名 コンマ 数値変数名 コンマ 数値変数名
9.2, 15.2
参照仮引き数
= 単純変数名|仮配列宣言|経路番号|固定小数点仮引き数
186
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
9.2
参照仮引き数部
= 左括弧 参照仮引き数 {コンマ 参照仮引き数}* 右括弧
9.2
参照実引き数
= 式|実配列名|経路式
9.2
参照実引き数部
= 左括弧 参照実引き数 {コンマ 参照実引き数}* 右括弧
14.2
参照情報
= 文字列定数
14.3
時間式
= 数値時間式|文字列時間式
5.3, 6.3
式
= 数値式|文字列式
11.3
式並び
= 式 {コンマ 式}*
4.4, 14.2
識別名
= 数値識別名|文字列識別名|ルーチン識別名|実時間識別名
4.4
識別名文字
= 英字|数字|下線
11.2
指示子制御
= 指示子制御項目|データ存否|指示子制御項目 コンマ
データ存否
11.2
指示子制御項目
= POINTER 中核記録設定|拡充記録設定
14.2
事象名
= 英字 識別名文字*
14.3
事象名並び
= 事象名 {コンマ 事象名}*
10.4
指数書式項目
= {整数書式項目|小数書式項目} 山記号 山記号 山記号
山記号*
5.1
指数部
= E 符号? 符号なし整数
8.3
始値
= 数値式
14.1
実時間区
= select-on-port区|seize区
14.2
実時間識別名
= 構造名|事象名|処理域名|処理域配列名|共用域名|通報域名
14.2
実時間宣言行
= 行番号 実時間宣言文 行末部
14.2
実時間宣言単位
= {注釈行|実時間宣言行|処理域配列宣言}*
14.2
実時間宣言文
= DECLARE {structure宣言|process宣言|shared宣言|
message宣言}
14.1
実時間プログラム
= 実時間宣言単位 並行単位 並行単位* 外部手続き単位*
14.1
実時間文
= parstop文|並行動作制御文|処理域入出力文|
共用域入出力文|通報域入出力文|exit-seize文
5.3
実配列名
= 配列名
11.1
質問項目
= 属性名 変数名 変数名*
11.1
質問項目並び
= 質問項目 {コンマ 質問項目}*
187
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
13.1, 13.2,
13.4
質問対象
= WINDOW 境界四辺変数|VIEWPORT 境界四辺変数|
DEVICE
WINDOW 境界四辺変数|DEVICE VIEWPORT
境界四辺変数|DEVICE SIZE 数値変数名 コンマ
数値変数名 コンマ 文字列変数名|CLIP 文字列変数名|
線点指定 STYLE 数値変数名|面指定 COLOR
数値変数名|TEXT 文章特性 数値変数名|TEXT JUSTIFY
文字列変数名 コンマ 文字列変数名|MAX 線点指定
STYLE
数値変数名|MAX COLOR 数値変数名|COLOR MIX
左括弧 指標 右括弧 三原色取得|MAX 機構種別
DEVICE 数値変数名|PIXEL SIZE 左括弧 点対 右括弧
数値変数名 コンマ 数値変数名|PIXEL ARRAY 点位置
数値配列名 {コンマ 文字列変数名}?|PIXEL VALUE
点位置 数値変数名
5.2
指標
= 数値式
14.4
出力構造
= 出力構造要素 {コンマ 出力構造要素}*
14.41
出力構造要素
= 式|配列名
10.3
出力質問項目
= {MARGIN|ZONEWIDTH} 数値変数名
10.3
出力質問項目並び
= 出力質問項目 {コンマ 出力質問項目}*
4.2
主プログラム
= 手続き区* end行
7.1
上下限実引き数部
= 左括弧 実配列名 {コンマ 指標}? 右括弧
7.1
上下限指定
= 整数 TO 整数|整数
7.1
上下限指定部
= 左括弧 上下限指定 {コンマ 上下限指定} 右括弧
4.2
条件文
= if文|on-gosub文|on-goto文
8.4
照合項目
= 定数|範囲指定
8.4
照合項目並び
= 照合項目 {コンマ 照合項目}*
5.3
乗除算演算子
= 星印|斜線
10.4
小数書式項目
= 小数点 番号記号 番号記号*|整数書式項目 小数点
番号記号*
11.3
小数点指定
= 整数幅 小数点?|整数幅? 小数点 小数幅
11.3
小数幅
= 符号なし整数
5.1
小数部
= 小数点 符号なし整数
10.4
書式印字式並び
= 式 {コンマ 式}* セミコロン?
10.5
書式印字配列名並び
= 配列名 {コンマ 配列名}* セミコロン?
10.4
書式引用
= 行番号|文字列式
10.4
書式項目
= けた寄せ? 浮動文字列 {整数書式項目|小数書式項目|
指数書式項目}|けた寄せ
10.4
書式付き印字指定
= USING 書式引用 {コロン 書式印字式並び}?
10.4
書式文字列
= 即値文字列 {書式項目 即値文字列}*
188
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
14.4
処理域入出力文
= in-from文|out-to文
14.2
処理域配列宣言
= declare-process行 処理要素行* end-process行
14.2
処理域配列名
= 英字 識別名文字*
14.2
処理域名
= 英字 識別名文字*
14.2
処理指定
= 入出力指示 処理域名 OF 構造名
14.2
処理要素行
= 行番号 処理要素文 行末部
14.2
処理要素文
= 処理域配列名 左括弧 整数 {コンマ 整数}? 右括弧
コロン 参照情報
4.1
数字
= 0|1|2|3|4|5|6|7|8|9
10.4
数字位置
= 星印|番号記号|パーセント記号
9.1, 15.2
数値def文
= DEF 数値定義関数名 値仮引き数部? 等号 数値式|DEF
固定小数点定義関数名 値仮引き数部? 等号 数値式
5.5
数値let文
= LET 数値変数名並び 等号 数値式
7.2
数値mat文
= MAT 数値配列名 等号 数値配列式
5.3
数値一次子
= 符号なし数値定数|数値変数名|数値関数引用|左括弧 数値式
右括弧
5.3
数値因子
= 数値一次子 {山記号 数値一次子}*
5.3, 6.4
7.1, 7.2
数値関数引用
= 数値関数名 値実引き数部?|MAXLEN 左括弧
{文字列単純変数名|文字列配列名} 右括弧|MAXSIZE
最大寸法実引き数部|SIZE 上下限実引き数部|LBOUND
上下限実引き数部|UBOUND 上下限実引き数部|DET
左括弧 数値配列名 右括弧|DOT 左括弧 数値配列名
コンマ 数値配列名 右括弧
9.1
数値関数定義let文
= LET 数値定義関数名 等号 数値式
5.3
数値関数名
= 数値定義関数名|数値組込み関数名
5.4, 6.4,
12.1, 14.7
数値組込み関数名
= ABS|ACOS|ANGLE|ASIN|ATN|BVAL|CEIL|COS|
COSH|COT|CSC|DATE|DEG|EPS|EXLINE|EXP|
EXTYPE|FP|INT|IP|LEN|LOG|LOGIO|LOG2|MAX|
MAXNUM|MIN|MOD|ORD|PI|POS|RAD|
REMAINDER|RND|ROUND|SEC|SGN|SIN|SINH|
SQR|TAN|TANH|TIME|TRUNCATE|VAL
5.3
数値項
= 数値因子 {乗除算演算子 数値因子}*
10.2
数値時間式
= 数値式
5.3
数値式
= 符号? 数値項 {符号 数値項}*
4.4
数値識別名
= 英字 識別名文字*
5.6, 7.1
数値宣言
= 数値単純変数名|数値配列宣言
5.2
数値単純変数名
= 数値識別名
9.1
数値定義関数名
= 数値識別名
5.1
数値定数
= 符号? 符号なし数値定数
7.2
数値配列演算子
= 符号|星印
189
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
7.2
数値配列関数引用
= {TRN|INV} 左括弧 数値配列名 右括弧
7.2
数値配列式
= {数値配列名 数値配列演算子}? 数値配列名|スカラ乗数
数値配列名|数値配列値|数値配列関数引用
7.1
数値配列宣言
= 数値配列名 上下限指定部
7.2, 13.5
数値配列値
= スカラ乗数? {CON|IDN|ZER} 再定義上下限指定部?|
TRANSFORM
5.2
数値配列名
= 数値識別名
5.2
数値配列要素名
= 数値配列名 添字部
13.4
数値不定長行列
= 数値配列名 左括弧 疑問符 コンマ 右括弧
13.4
数値不定長ベクトル
= 数値配列名 左括弧 疑問符 右括弧
5.2
数値変数名
= 数値単純変数名|数値配列要素名
5.5
数値変数名並び
= 数値変数名 {コンマ 数値変数名}*
11.3
数値欄指定子
= NUMERIC 星印 数値欄幅
11.3
数値欄幅
= 小数点指定|E
7.2
スカラ乗数
= 数値一次子 星印
13.3
図形text文
= 図形動詞 TEXT 開始点 {コンマ USING 書式引用
コロン式並び|コロン 文字列式}
13.3
図形出力文
= 幾何図形文|幾何図形mat文|図形text文|mat-cells文
13.3, 13.5 図形動詞
= GRAPH|PLOT
13.4, 13.5 図形入力文
= locate文|mat-locate文|GET point句 コロン 座標変数対|
MAT GET point句 コロン 配列位置対象
8.3
制御変数名
= 数値単純変数名
7.1
整数
= 符号? 符号なし整数
10.4
整数書式項目
= 数字位置 数字位置* {コンマ 数字位置 数字位置*}*
11.3
整数幅
= 符号なし整数
15.1
精度指定
= 星印 小数点指定
10.3, 11.2,
11.3, 13.1,
13.2
設定対象
= {MARGIN|ZONEWIDTH} 指標|経路指定 指示子制御|
経路指定 {MARGIN|ZONEWIDTH} 指標|WINDOW
境界四辺|VIEWPORT 境界四辺|DEVICE WINDOW
境界四辺|DEVICE VIEWPORT 境界四辺|CLIP 文字列式|
線点指定 STYLE 指標|面指定 COLOR 指標|TEXT
文章特性 数値式|TEXT JUSTIFY 文字列式 コンマ
文字列式|COLOR MIX 左括弧 指標 右括弧 三原色指定
5.6, 6.6,
9.1, 9.2,
13.5
宣言指定
= numeric宣言|string宣言|def宣言|内部function宣言|
external-function宣言|内部sub宣言|external-sub宣言|
内部picture宣言|external-picture宣言
4.2, 11.3
宣言文
= 空文|data文|declare文|dim文|option文|rem文|
template文
190
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5.6, 6.6,
7.1, 15.1
選択子
= ARITHMETIC {DECIMAL|NATIVE} |ANGLE
{DEGREES|RADIANS} |COLLATE {NATVE|
STANDARD} |BASE {0|1} |ARITHMETIC FIXED
精度指定
5.6
選択子並び
= 選択子 {コンマ 選択子}*
13.2
線点指定
= POINT|LINE
8.3
増分
= 数値式
5.2
添字
= 指標
5.2
添字部
= 左括弧 添字 {コンマ 添字}* 右括弧
11.1
属性名
= 中核属性名|拡充属性名
10.4
即値文字
= 英字|数字|空白|感嘆符|アポストロフィ|左括弧|右括弧|
斜線|コロン|セミコロン|等号|疑問符|下線
10.4
即値文字列
= 即値文字*
11.2
大号探索
= 大号|非小
4.1
単語文字
= 数字|英字|小数点|正号|負号
4.2
単純行
= 行番号 単純文 行末部
8.4
単純実行動作
= 単純実行文|行番号
4.2, 11.5,
13.2, 13.3,
13.4, 13.5
単純実行文
= ask文|break文|call文|cause-exception文|chain文|
clear文|close文|debug文|delete文|draw文|erase文|
exit-do文|exit-for文|exit-function文|exit-handler文|
exit-picture文|exit-sub文|gosub文|goto文|input文|
let文|line-input文|mat文|mat-input文|mat-line-input文|
mat-print文|mat-read文|mat-rewrite文|mat-write文|
open文|print文|randomize文|read文|restore文|
return文|rewrite文|set文|stop文|trace文|write文|
数値関数定義let文|図形出力文|図形入力文|
変形指示mat文|文字列関数定義let文|例外処理区戻り文
4.2, 14.1
単純文
= 宣言文|単純実行文|条件文|実時間文
5.2, 6.2
単純変数名
= 数値単純変数名|文字列単純変数名
4.1
単純文字
= 空白|単語文字
10.1
単純文字列
= 単語文字|単語文字 単純文字* 単語文字
11.1
中核記録形式値
= DISPLAY|INTERNAL
11.2
中核記録設定
= BEGIN|END|NEXT|SAME
11.1
中核属性名
= ACCESS|DATUM|ERASABLE|FILETYPE|MARGIN|
NAME|ORGANIZATION|POINTER|RECSIZE|RECTYPE|
SETTER|ZONEWIDTH
11.1
中核ファイル属性
= access句|organization句|rectype句|recsize句
11.1
中核ファイル編成値
= SEQUENTIAL|STREAM
4.2
注釈行
= 行番号 {空文|rem文} 行末
4.3
注釈文字列
= プログラム文字*
191
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
14.6
通報case行
= 行番号 通報case文 行末部
14.6
通報case区
= 通報case行 区*
14.6
通報case文
= CASE {SEND|RECEIVE} MESSAGE 通報域名|CASE
EVENT 事象名
14.6
通報域入出力文
= send-to文|receive-from文
14.2
通報域名
= 英字 識別名文字*
9.1, 15.2
定義関数名
= 数値定義関数名|文字列定義関数名|固定小数点定義関数名
9.1
定義関数名並び
= 定義関数名 {コンマ 定義関数名}*
5.1, 6.1
定数
= 数値定数|文字列定数
11.2
データ存否
= if-missing句|if-there句
10.1
データ存否動作
= exit-do文|exit-for文|行番号
10.1
データ要素
= 定数|単純文字列
10.1
データ要素並び
= データ要素 {コンマ データ要素}*
8.3
出口条件
= {WHILE|UNTIL} 論理式
4.2
手続き区
= 内部手続き定義|区
13.4
点位置
= 左括弧 座標対 右括弧
13.3
点対
= 座標対 セミコロン 座標対
13.3
点並び
= 座標対 {セミコロン 座標対}*
11.2
等値探索
= 等号?
8.1
等値比較
= 等号|非等
9.1, 15.2
内部function行
= 行番号 FUNCTION {数値定義関数名|文字列定義関数名
最大長指定?} 値仮引き数部? 行末部|行番号 FUNCTION
固定小数点定義関数名 値仮引き数部? 行末部
9.1
内部function宣言
= FUNCTION 定義関数名並び
13.5
内部picture行
= 行番号 内部picture文 行末部
13.5
内部picture宣言
= PICTURE 絵名並び
13.5
内部picture文
= PICTURE 絵名 参照仮引き数部?
9.2
内部sub行
= 行番号 sub文 行末部
9.2
内部sub宣言
= SUB 副プログラム名並び
13.5
内部絵定義
= 内部picture行 区* end-picture行
9.1
内部関数定義
= def行|内部function行 区* end-function行
4.2, 13.5
内部手続き定義
= 内部関数定義|内部副プログラム定義|handler区|内部絵定義
9.2
内部副プログラム定義
= 内部sub行 区* end-sub行
14.2
入出力指示
= INPUT|OUTPUT|OUTIN
10.2
入力応答
= データ要素並び コンマ? 行末
14.4
入力構造
= 入力構造要素 {コンマ 入力構造要素}*
14.4
入力構造要素
= 変数名|配列名
10.2
入力修飾
= 入力修飾項目 {コンマ 入力修飾項目}* コロン
10.2
入力修飾項目
= prompt句|timeout句|elapsed句
11.4
入力制御
= {コンマ 入力制御項目}*
192
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
11.4
入力制御項目
= 中核記録設定|if-missing句|prompt句|timeout句|elapsed句
10.2
入力要求
= [処理系定義]
4.1
二連引用符
= 引用符 引用符
13.4
配列位置対象
= 再定義数値配列 {コンマ 再定義数値配列}?|
数値不定長ベクトル コンマ 数値不定長ベクトル|
数値不定長行列
7.1
配列宣言
= 数値配列宣言|文字列配列宣言
7.1
配列宣言並び
= 配列宣言 {コンマ 配列宣言}*
13.3
配列点並び
= 数値配列名 {コンマ 数値配列名}?
5.2, 6.2
配列名
= 数値配列名|文字列配列名
11.3
配列名並び
= 配列名 {コンマ 配列名}*
8.4
範囲指定
= {定数 TO|IS 比較演算子} 定数
16.2
番号指定
= AT 開始番号 {STEP 刻み}?|STEP 刻み
{AT 開始番号}?
14.2
反復回数
= 符号なし整数 OF
4.1
非引用符文字
= 感嘆符|番号記号|ドル記号|パーセント記号|アンド記号|
アポストロフィ|左括弧|右括弧|星印|コンマ|斜線|
コロン|セミコロン|小号|等号|大号|疑問符|山記号|
下線|単純文字
8.1
比較演算子
= 等値比較|大号|小号|非大|非小
8.1
比較式
= 数値式 比較演算子 数値式|文字列式 比較演算子 文字列式
8.1
非小
= 大号 等号|等号 大号
8.1
非大
= 小号 等号|等号 小号
8.1
非等
= 小号 大号|大号 小号
4.1
非プログラム文字
= [処理系定義]
11.1
ファイル属性
= 中核ファイル属性|拡充ファイル属性
11.1
ファイル属性並び
= {コンマ ファイル属性}*
11.1
ファイル編成値
= 中核ファイル編成値|拡充ファイル編成値
11.1
ファイル名
= 文字列式
9.2
副プログラム定義
= 内部副プログラム定義|外部副プログラム定義
9.2
副プログラム名
= ルーチン識別名
9.2
副プログラム名並び
= 副プログラム名 {コンマ 副プログラム名}*
5.1
符号
= 正号|負号
5.1
符号なし数値定数
= 有効数字部 指数部?
5.1
符号なし整数
= 数字 数字*
10.5
不定長ベクトル
= 配列名 左括弧 疑問符 右括弧
10.4
浮動文字列
= {正号*|負号*} ドル記号?|ドル記号* {正号|負号}?
6.2
部分文字列指定
= 左括弧 指標 コロン 指標 右括弧
4.2, 14.1
プログラム
= program行? 主プログラム 外部手続き単位*|program行?
実時間プログラム
193
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
9.3
プログラム指示名
= 文字列式
4.2, 14.1
プログラム単位
= 主プログラム|外部手続き定義|並行単位
4.2
プログラム名
= ルーチン識別名
4.1
プログラム文字
= 引用符|非引用符文字
13.2
文章特性
= HEIGHT|ANGLE
14.1
並行単位
= 注釈行* paract行 区* end-paract行
14.3
並行動作制御文
= start文|wait文|signal文|connect-event文|
disconnect-event文
13.5
変形
= 変形項 {星印 変形項}*
13.5
変形関数名
= ROTATE|SHEAR|SHIFT|SCALE
13.5
変形項
= 変形関数名 値実引き数部|数値配列名|現在変形
13.5
変形指示mat文
= MAT 数値配列名 等号 変形
16.2
編集指令
= delete指令|extract指令|list指令|renumber指令
5.2, 6.2
変数名
= 数値変数名|文字列変数名
10.1
変数名並び
= 変数名 {コンマ 変数名}*
12.1
保護区
= when-in区|when-use区
16.1
未整列行
= 行番号 {プログラム文字|行継続}* 行末
16.1
未整列プログラム
= 未整列行*
13.2
面指定
= 線点指定|TEXT|AREA
9.1
文字列def文
= DEF 文字列定義関数名 最大長指定? 値仮引き数部?
等号 文字列式
6.5
文字列let文
= LET 文字列変数名並び 等号 文字列式
7.3
文字列mat文
= MAT 文字列配列名 部分文字列指定? 等号 文字列配列式
6.3
文字列一次子
= 文字列定数|文字列変数名|文字列関数引用|左括弧 文字列式
右括弧
6.3
文字列関数引用
= 文字列関数名 値実引き数部?
9.1
文字列関数定義let文
= LET 文字列定義関数名 等号 文字列式
6.3
文字列関数名
= 文字列定義関数名|文字列組込み関数名
6.4, 12.1,
14.7
文字列組込み関数名
= {CHR|DATE|LCASE|LTRIM|REPEAT|RTRIM|STR|
TIME|UCASE|USING} ドル記号|EXTEXT ドル記号|
BSTR ドル記号
14.3
文字列時間式
= 文字列式
6.3
文字列式
= 文字列一次子 {連結演算子 文字列一次子}*
4.4
文字列識別名
= 英字 識別名文字* ドル記号
6.6, 7.1
文字列宣言
= 文字列単純宣言|文字列配列宣言 最大長指定?
6.6
文字列単純宣言
= 文字列単純変数名 最大長指定?
6.2
文字列単純変数名
= 文字列識別名
9.1
文字列定義関数名
= 文字列識別名
6.1
文字列定数
= 引用文字列
7.3
文字列配列一次子
= 文字列配列名 部分文字列指定?
194
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
7.3
文字列配列式
= 文字列配列一次子 {連結演算子 文字列配列一次子}?|
文字列一次子 連結演算子 文字列配列一次子|
文字列配列一次子 連結演算子 文字列一次子|文字列配列値
7.1
文字列配列宣言
= 文字列配列名 上下限指定部
7.3
文字列配列値
= {文字列一次子 連結演算子}? NUL ドル記号
再定義上下限指定部?
6.2
文字列配列名
= 文字列識別名
6.2
文字列配列要素名
= 文字列配列名 添字部
6.2
文字列変数名
= {文字列単純変数名|文字列配列要素名} 部分文字列指定?
6.5
文字列変数名並び
= 文字列変数名 {コンマ 文字列変数名}*
11.3
文字列欄指定子
= STRING 星印 文字列欄幅
11.3
文字列欄幅
= 符号なし整数
5.1
有効数字部
= 符号なし整数 小数点?|符号なし整数? 小数部
14.1
優先度
= 符号なし整数
11.4
読込み制御
= {コンマ 読込み制御項目}*
11.4
読込み制御項目
= 記録設定|if-missing句|枠引用
11.3
欄指定子
= 数値欄指定子|文字列欄指定子
11.3
欄数固定
= SKIP? {符号なし整数 OF}?
11.3
欄数不定
= 疑問符 OF
4.4
ルーチン識別名
= 英字 識別名文字*
12.1
例外状態種別
= 指標
12.1
例外処理区
= 区*
12.1
例外処理区名
= ルーチン識別名
12.1
例外処理区戻り文
= RETRY|CONTINUE
6.3
連結演算子
= アンド記号
8.1
論理一次子
= 比較式|左括弧 論理式 右括弧
8.1
論理項
= NOT? 論理一次子
8.1
論理式
= 論理和
8.1
論理積
= 論理項 {AND 論理項}*
8.1
論理和
= 論理積 {OR 論理積}*
11.3
枠引用
= WITH {行番号|文字列式}
11.3
枠要素
= 欄数固定 {欄指定子|左括弧 枠要素並び 右括弧}|
欄数不定 欄指定子
11.3
枠要素並び
= 枠要素 {コンマ 枠要素}*
195
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書F(参考) GKS水準0bのためのBASICの拡張
F1. 目的 この附属書は,Graphical Kernel System (GKS) の水準0bをBASIC言語から利用するときに,採
用するように推奨する構文を示す。意味の規定は,ANSI X3.124-1985又はISO 7942-1985による。ここに
示すGKSの機能の一部は,本体13.にある構文及び意味の規定を参照する。これらの言語要素は,自明な
やり方でANSI X3.124-1985又はISO 7942-1985の規定に対応付けることができる。附属書の目標は,本体
13.を上回る図形機能を要求する利用者に対して,可能な一つの手段を示すことにある。この構文は,ANSI
X3.124-1985又はISO 7942-1985と対応付けて読むことが望ましい。
F2. GKS制御機能
OPEN GKS
gks文⊃GRAPHICS START
CLOSE GKS
gks文⊃GRAPHICS STOP
OPEN WORKSTATION
gks文⊃GRAPHICS OPEN 処理装置指定 NAME ファイル名 コンマ 処理装置型式設定
処理装置指定=処理装置番号 コロン
処理装置番号=番号記号 指標
処理装置型式設定=TYPE 指標
CLOSE WORKSTATION
gks文⊃GRAPHICS CLOSE 処理装置番号
ACTIVATE WORKSTATION
gks文⊃GRAPHICS ACTIVATE 処理装置番号
DEACTIVATE WORKSTATION
gks文⊃GRAPHICS DEACTIVATE 処理装置番号
CLEAR WORKSTATION(本体13.参照)
gks文⊃CLEAR {処理装置指定 文字列式}?
文字列式の値は,英大文字に変換したときに“CONDITIONALLY”又は“ALWAYS”でなければならない。
波括弧の部分を省略すると,#0と“ALWAYS”が想定される。
EMERGENCY CLOSE GKS
gks文⊃GRAPHICS ABORT
196
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
UPDATE WORKSTATION
gks文⊃GRAPHICS UPDATE 処理装置指定? 文字列式
文字列式の値は,英大文字に変換したときに“PERFORM”又は“SUPPRESS”でなければならない。
ESCAPE
gks文⊃GRAPHICS ESCAPE 式並び
F3. 出力機能
POLYHNE(本体13.参照)
gks文⊃ GRAPH LINES コロン 点並び|MAT GRAPH LINES {コンマ limit句}?コロン
配列点並び
POLYMARKER(本体13.参照)
gks文⊃ GRAPH POINTS コロン 点並び|MAT GRAPH POINTS {コンマ limit句}?
コロン 配列点並び
TEXT(本体13.参照)
gks文⊃ GRAPH TEXT 開始点 {コンマ USING 書式引用 コロン 式並び|コロン 文字列式}
FILL AREA(本体13.参照)
gks文⊃ GRAPH AREA コロン 点並び|MAT GRAPH AREA {コンマ limit句}? コロン
配列点並び
CELL ARRAY(本体13.参照)
gks文⊃MAT GRAPH CELLS コンマ IN 点対 コロン 数値配列名
GENERALIZED DRAWING PRIMITIVE
gks文⊃ GRAPH GDP 指標 コロン 点並び FROM データ記録|MAT GRAPH GDP 指標
{コンマ limit句}? コロン 配列点並び FROM データ記録
データ記録=数値配列名 コンマ 文字列配列名
指標はGDPの識別子とし,データ記録はGDPの記録とする。
F4. 出力属性
SET POLYLINE INDEX
gks文⊃SET LINE INDEX 指標
SET LINETYPE(本体13.参照)
gks文⊃SET LINE STYLE 指標
197
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
SET LINE WIDTH SCALE FACTOR
gks文⊃SET LINE SIZE 数値式
SET POLYLINE COLOUR INDEX(本体13.参照)
gks文⊃SET LINE COLOR 指標
SET POLYMARKER INDEX
gks文⊃SET POINT INDEX 指標
SET MARKER TYPE(本体13.参照)
gks文⊃SET POINT STYLE 指標
SET MARKER SIZE SCALE FACTOR
gks文⊃SET POINT SIZE 数値式
SET POLYMARKER COLOUR INDEX(本体13.参照)
gks文⊃SET POINT COLOR 指標
SET TEXT INDEX
gks文⊃SET TEXT INDEX 指標
SET TEXT FONT AND PRECISION
gks文⊃SET FONT 指標 WITH 文字列式
指標は,字形番号とする。文字列式の値は,英大文字に変換したときに“STRING”,“CHAR”又は
“STROKE”でなければならない。
参考 ANSI X3.113では,この説明中の“指標”のところが“数値式”となっているが,誤りと考え
られるので訂正した。
SET TEXT COLOUR INDEX(本体13.参照)
gks文⊃SET TEXT COLOR 指標
SET CHARACTER EXPANSION FACTOR
gks文⊃SET TEXT EXPAND 数値式
SET CHARACTER SPACING
gks文⊃SET TEXT SPACE 数値式
SET CHARACTER HEIGHT(本体13.参照)
gks文⊃SET TEXT HEIGHT 数値式
198
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
SET CHARACTER UP VECTOR(本体13.参照)
gks文⊃SET TEXT ANGLE 数値式
SET TEXT PATH
gks文⊃SET TEXT PATH 文字列式
文字列式の値は,英大文字に変換したときに“RIGHT”,“LEFT”,“UP”又は“DOWN”でなければな
らない。
SET TEXT ALIGNMENT(本体13.参照)
gks文⊃SET TEXT JUSTIFY 文字列式 コンマ 文字列式
SET FILL AREA INDEX
gks文⊃SET AREA INDEX 指標
SET FILL AREA INTERIOR STYLE
gks文⊃SET AREA STYLE 文字列式
文字列式の値は,英大文字に変換したときに“HOLLOW”,“SOLID”,“PATTERN”又は“HATCH”で
ければならない。
SET FILL AREA STYLE INDEX
gks文⊃SET AREA STYLE INDEX 指標
SET FILL AREA COLOUR INDEX(本体13.参照)
gks文⊃SET AREA COLOR 指標
SET PATTERN SIZE
gks文⊃SET PATTERN SIZE 数値式 コンマ 数値式
SET PATTERN REFERENCE POINT
gks文⊃SET PATTERN REF 座標対
SET ASPECT SOURCE FLAGS
gks文⊃SET FLAGS フラグ種別 文字列式
フラグ種別= LINE STYLE|LINE SIZE|LINE COLOR|POINT STYLE|POINT SIZE|
POINT COLOR|TEXT FONT|TEXT EXPAND|TEXT SPACE|TEXT COLOR|
AREA STYLE|AREA STYLE INDEX|AREA COLOR
文字列式の値は,英大文字に変換したときに“BUNDLED”又は“INDIVIDUAL”でなければならない。
SET COLOUR REPRESENTATION(本体13.参照)
gks文⊃SET COLOR MIX 処理装置指定? 表指標 三原色指定
199
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表指標=左括弧 指標 右括弧
F5. 変形機能
SET WINDOW(本体13.参照)
gks文⊃SET WINDOW 変形番号指定? 境界四辺
変形番号指定=TRANSFORMATION 指標
変形番号指定を省略すると,1が想定される。
SET VIEWPORT(本体13.参照)
gks文⊃SET VIEWPORT 変形番号指定? 境界四辺
変形番号指定を省略すると,1が想定される。
SELECT NORMALISATION TRANSFORMATION
gks文⊃SET 変形番号指定
SET CLIPPING INDICATOR(本体13.参照)
gks文⊃SET CLIP 文字列式
SET WORKSTATION WINDOW(本体13.参照)
gks文⊃SET DEVICE WINDOW 処理装置指定? 境界四辺
SET WORKSTATION VIEWPORT(本体13.参照)
gks文⊃SET DEVICE VIEWPORT 処理装置指定? 境界四辺
F6. メタファイル機能
WRITE ITEM TO GKSM
gks文⊃GRAPHICS WRITE 処理装置番号 TYPE 指標 コロン 式並び
GET ITEM TYPE FROM GKSM
gks文⊃GRAPHICS READ TYPE 処理装置指定 数値変数名
数値変数は,項目の型を表す。
READ ITEM FROM GKSM
gks文⊃GRAPHICS READ ITEM 処理装置指定 文字列配列名
INTERPRET ITEM
gks文⊃GRAPHICS DO ITEM 文字列配列式
F7. 問合せ機能
ask文のstatus句は,GKSの誤り指示子を返す。
200
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
INQUIRE CLIPPING INDICATOR(本体13.参照)
gks文⊃ASK CLIP 文字列変数名
INQUIRE COLOUR FACILITIES(本体13.参照)
gks文⊃ ASK MAX COLOR 処理装置型式選択? 数値変数名 {コンマ 文字列変数名 コンマ
数値変数名}?
処理装置型式選択=左括弧 処理装置型式 右括弧
処理装置型式=指標
文字列変数には,“MONOCHROME”又は“COLOR”が代入される。
INQUIRE COLOUR REPRESENTATION(本体13.参照)
gks文⊃ASK COLOR MIX 処理装置指定? 表指標 三原色取得
INQUIRE CURRENT INDIVIDUAL ATTRIBUTE VALUES(本体13.参照)
gks文⊃ ASK 属性数値指定 数値変数名|ASK AREA STYLE 文字列変数名|ASK TEXT
FONT
数値変数名 コンマ 文字列変数名
属性数値指定= LINE STYLE|LINE SIZE|LINE COLOR|POINT STYLE|POINT SIZE|
POINT COLOR|TEXT EXPAND|TEXT SPACE|TEXT COLOR|
AREA STYLE INDEX|AREA COLOR
INQUIRE CURRENT NORMALISATION TRANSFORMATION NUMBER
gks文⊃ASK TRANSFORMATION 数値変数名
INQUIRE CURRENT PRIMITIVE ATTRIBUTE VALUES(本体13.参照)
gks文⊃ ASK 属性指標指定 数値変数名|ASK TEXT JUSTIFY 文字列変数名 コンマ
文字列変数名|ASK TEXT PATH 文字列変数名|ASK 属性数値対指定 数値変数名
コンマ 数値変数名
属性数値指定= LINE INDEX|POINT INDEX|TEXT INDEX|TEXT HEIGHT|
TEXT ANGLE|AREA INDEX
属性指標指定= PATTERN SIZE|PATTERN REF
INQUIRE FILL AREA FACILITIES
gks文⊃ ASK AREA TYPES 処理装置型式選択? 数値変数名 コンマ 文字列不定長ベクトル
コンマ 数値変数名 コンマ 数値不定長ベクトル コンマ 数値変数名
INQUIRE GENERALIZED DRAWING PRIMITIVE
gks文⊃ASK GDP 左括弧 処理装置型式 コンマ 指標 右括弧 文字列配列名
INQUIRE LEVEL OF GKS
201
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
gks文⊃ASK GRAPHICS LEVEL 文字列変数名
文字列変数には,“ma”,“mb”,“mc”,“0a”,“0b”,“0c”,“1a”,“1b”,“1c”,“2a”,
“2b”又は“2c”が代入される。
INQUIRE LIST OF AVAILABLE GDP
gks文⊃ASK GDP LIST 処理装置型式選択 数値不定長ベクトル
INQUIRE LIST OF AVAILABLE WORKSTATION TYPES
gks文⊃ASK DEVICE LIST 文字列不定長ベクトル
INQUIRE LIST OF COLOUR INDICES
gks文⊃ASK COLOR LIST 処理装置指定? 数値不定長ベクトル
INQUIRE LIST OF NORMALISATION TRANSFORMATION NUMBERS
gks文⊃ASK TRANSFORMATION LIST 数値不定長ベクトル
INQUIRE MAXIMUM DISPLAY SURFACE SIZE(本体13.参照)
gks文⊃ ASK DEVICE SIZE 処理装置型式選択? 数値変数名 コンマ 数値変数名 コンマ
文字列変数名
INQUIRE MAXIMUM NORMALISATION TRANSFORMATION NUMBER
gks文⊃ASK MAX TRANSFORMATION 数値変数名
INQUIRE NORMALISATION TRANSFORMATION(本体13.参照)
gks文⊃ASK {WINDOW|VIEWPORT} 変形番号指定? 境界四辺変数
INQUIRE OPERATING STATE VALUE
gks文⊃ASK GRAPHICS STATE 文字列変数名
INQUIRE PATTERN FACILITIES
gks文⊃ASK PATTERN TYPES 処理装置型式選択? 数値変数名
INQUIRE PIXEL(本体13.参照)
gks文⊃ASK PIXEL VALUE 処理装置指定? 点位置 数値変数名
INQUIRE PIXEL ARRAY(本体13.参照)
gks文⊃ASK PIXEL ARRAY 処理装置指定? 点位置 数値配列名 {コンマ 文字列変数名}?
INQUIRE PIXEL ARRAY DIMENSIONS(本体13.参照)
gks文⊃ ASK PIXEL SIZE 処理装置指定? 左括弧 点対 右括弧 数値変数名 コンマ
202
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
数値変数名
INQUIRE POLYLINE FACILITIES
gks文⊃ ASK LINE TYPES 処理装置型式選択? 数値不定長ベクトル コンマ 数値変数名
コンマ 数値変数名 コンマ 数値変数名 コンマ 数値変数名 コンマ 数値変数名
INQUIRE POLYMARKER FACILITIES
gks文⊃ ASK POINT TYPES 処理装置型式選択? 数値不定長ベクトル コンマ 数値変数名
コンマ 数値変数名 コンマ 数値変数名 コンマ 数値変数名 コンマ 数値変数名
INQUIRE PREDEFINED COLOUR REPRESENTATION
gks文⊃ASK PREDEFINED COLOR MIX 型式指標? 三原色取得
型式指標=左括弧 処理装置型式 コンマ 指標 右括弧
INQUIRE PREDEFINED FILL AREA REPRESENTATION
gks文⊃ ASK PREDEFINED AREA TYPES 型式指標? 文字列変数名 コンマ 数値変数名
コンマ 数値変数名
INQUIRE PREDEFINED PATTERN REPRESENTATION
gks文⊃ASK PREDEFINED PATTERN 型式指標? 数値不定長行列
INQUIRE PREDEFINED POLYLINE REPRESENTATION
gks文⊃ ASK PREDEFINED LINE TYPES 型式指標? 数値変数名 コンマ 数値変数名
コンマ 数値変数名
INQUIRE PREDEFINED POLYMARKER REPRESENTATION
gks文⊃ ASK PREDEFINED POINT TYPES 型式指標? 数値変数名 コンマ 数値変数名
コンマ 数値変数名
INQUIRE PREDEFINED TEXT REPRESENTATION
gks文⊃ ASK PREDEFINED TEXT 型式指標? 数値変数名 コンマ 文字列変数名 コンマ
数値変数名 コンマ 数値変数名 コンマ 数値変数名
INQUIRE SET OF OPEN WORKSTATIONS
gks文⊃ASK DEVICE OPEN LIST 数値不定長ベクトル
INQUIRE TEXT EXTENT
gks文⊃ ASK TEXT SIZE 処理装置指定? 左括弧 座標対 コンマ 文字列式 右括弧 点位置
コンマ 数値不定長行列
203
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
INQUIRE TEXT FACILITIES
gks文⊃ ASK TEXT TYPES 処理装置型式選択 数値不定長ベクトル コンマ
文字列不定長ベクトル|ASK TEXT HEIGHT RANGE 範囲指定|
ASK TEXT EXPAND RANGE 範囲指定
文字列不定長ベクトル=文字列配列名 左括弧 疑問符 右括弧
範囲指定=数値変数名 コンマ 数値変数名 コンマ 数値変数名
INQUIRE WORKSTATION CATEGORY
gks文⊃ASK DEVICE CATEGORY 処理装置型式選択? 文字列変数名
INQUIRE WORKSTATION CLASSIFICATION
gks文⊃ASK DEVICE CLASS 処理装置型式選択? 文字列変数名
INQUIRE WORKSTATION CONNECTION AND TYPE
gks文⊃ASK DEVICE CONNECTION 処理装置指定? 文字列変数名 コンマ 数値変数名
INQUIRE WORKSTATION DEFERRAL AND UPDATE STATES
gks文⊃ ASK DEVICE UPDATE 処理装置指定? 文字列変数名 コンマ 文字列変数名 コンマ
文字列変数名 コンマ 文字列変数名
INQUIRE WORKSTATION STATE
gks文⊃ASK DEVICE STATE 処理装置指定? 文字列変数名
INQUIRE WORKSTATION TRANSFORMATION(本体13.参照)
gks文⊃ ASK DEVICE {WINDOW|VIEWPORT} 処理装置指定? 境界四辺変数
F8. 初期設定入力機能
INITIALISE CHOICE(本体13.参照)
gks文⊃ SET CHOICE 処理装置指定? 機構選択 AT 数値式 PROMPT TYPE 数値式
ECHO AREA 境界四辺 RECORD データ記録
機構選択=左括弧 指標 右括弧
[本体13.4.2(13)参照]
INITIALISE LOCATOR(本体13.参照)
gks文⊃ SET POINT 処理装置指定? 機構選択 AT 座標対 TRAN 数値式 PROMPT TYPE
数値式 ECHO AREA 境界四辺 RECORD データ記録
INITIALISE STRING
gks文⊃ SET STRING 処理装置指定? 機構選択 AT 文字列式 PROMPT TYPE 数値式
ECHO AREA 境界四辺 RECORD データ記録
204
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
INITIALISE STROKE(本体13.参照)
gks文⊃ SET MULTIPOINT 処理装置指定? 機構選択 AT 配列点並び TRAN 数値式
PROMPT TYPE 数値式 ECHO AREA 境界四辺 RECORD データ記録
INITIALISE VALUATOR(本体13.参照)
gks文⊃ SET VALUE 処理装置指定? 機構選択 AT 数値式 PROMPT TYPE 数値式
ECHO AREA 境界四辺 RECORD データ記録
F9. 問合せ入力機能
INQUIRE CHOICE DEVICE STATE
gks文⊃ ASK CHOICE STATE 処理装置指定? 機構選択 選択状態取得
{コンマ 選択状態取得}*
選択状態取得= 基本機構状態取得|INITIAL 数値変数名
基本機構状態取得= MODE 文字列変数名|ECHO STATE 文字列変数名|PROMPT TYPE
数値変数名|ECHO AREA 数値変数名 コンマ 数値変数名 コンマ
数値変数名 コンマ 数値変数名|RECORD データ記録
INQUIRE DEFAULT CHOICE DEVICE DATA
gks文⊃ ASK CHOICE DEFAULTS 処理装置別機構選択 選択想定値取得 {コンマ
選択想定値取得}*
処理装置別機構選択= 左括弧 処理装置型式 コンマ 機構番号 右括弧
機構番号= 指標
選択想定値取得= 基本想定値取得|INITIAL 数値変数名
基本想定値取得= PROMPT TYPE 数値変数名|ECHO AREA 数値変数名 コンマ 数値変数名
コンマ 数値変数名 コンマ 数値変数名|RECORD データ記録
参考 ANSI X3.113では,PROMPT TYPEの“数値変数名”が“numeric-variable-array”となっている
が,誤りであるので,TIBによって訂正した。
INQUIRE DEFAULT LOCATOR DEVICE DATA
gks文⊃ ASK POINT DEFAULTS 処理装置別機構選択 点位置想定値取得 {コンマ
点位置想定値取得}*
点位置想定値取得=基本想定値取得|INITIAL 座標変数対
INQUIRE DEFAULT STRING DEVICE DATA
gks文⊃ ASK STRING DEFAULTS 処理装置別機構選択 文字列想定値取得 {コンマ
文字列想定値取得}*
文字列想定値取得=基本想定値取得|INITIAL 文字列変数名
205
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
INQUIRE DEFAULT STROKE DEVICE DATA
gks文⊃ ASK MULTIPOINT DEFAULTS 処理装置別機構選択 基本想定値取得 {コンマ 基本想
定値取得}*
INQUIRE DEFAULT VALUATOR DEVICE DATA
gks文⊃ ASK VALUE DEFAULTS 処理装置別機構選択 値想定値取得 {コンマ
値想定値取得}*
値想定値取得=基本想定値取得|INITIAL 数値変数名
INQUIRE LOCATOR DEVICE STATE
gks文⊃ ASK POINT STATE 処理装置指定? 機構選択 点状態取得 {コンマ 点状態取得}*
点状態取得=基本機構状態取得|INITIAL 座標変数対
INQUIRE NUMBER OF AVAILABLE LOGICAL INPUT DEVICES(本体13.参照)
gks文⊃ ASK MAX CHOICE DEVICE 処理装置型式選択? 数値変数名|
ASK MAX STRING DEVICE 処理装置型式選択? 数値変数名|
ASK MAX POINT DEVICE 処理装置型式選択? 数値変数名|
ASK MAX MULTIPOINT DEVICE 処理装置型式選択? 数値変数名|
ASK MAX VALUE DEVICE 処理装置型式選択? 数値変数名
INQUIRE STRING DEVICE STATE
gks文⊃ ASK STRING STATE 処理装置指定? 機構選択 文字列状態取得 {コンマ
文字列状態取得}*
文字列状態取得=基本機構状態取得|INITIAL 文字列変数名
INQUIRE STROKE DEVICE STATE
gks文⊃ ASK MULTIPOINT STATE 処理装置指定? 機構選択 多点状態取得 {コンマ
多点状態取得}*
多点状態取得=基本機構状態取得|INITIAL 数値不定長ベクトル コンマ 数値不定長ベクトル
INQUIRE VALUATOR DEVICE STATE
gks文⊃ ASK VALUE STATE 処理装置指定? 機構選択 評価状態取得 {コンマ
評価状態取得}*
評価状態取得=基本機構状態取得|INITIAL 数値変数名
F10. 要求状態入力機能
REQUEST CHOICE(本体13.参照)
gks文⊃ LOCATE CHOICE 処理装置指定? 機構選択? 開始値? コロン 数値変数名
206
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
REQUEST LOCATOR(本体13.参照)
gks文⊃ LOCATE POINT 処理装置指定? 機構選択? 開始点? コロン 座標変数対
{TRAN 数値変数名}?
REQUEST STRING
gks文⊃LOCATE STRING 処理装置指定? 機構選択? コロン 文字列変数名
REQUEST STROKE(本体13.参照)
gks文⊃ MAT LOCATE POINT 処理装置指定? 機構選択? 開始点? コロン 配列位置対象
{TRAN 数値変数名}?
REQUEST VALUATOR(本体13.参照)
gks文⊃ LOCATE VALUE 処理装置指定? 機構選択? range句? 開始値? コロン
数値変数名
F11. 設定状態入力機能
SET CHOICE MODE
gks文⊃SET CHOICE MODE 処理装置指定? 機構選択 文字列式 コンマ 文字列式
SET LOCATOR MODE
gks文⊃SET POINT MODE 処理装置指定? 機構選択 文字列式 コンマ 文字列式
SET STRING MODE
gks文⊃SET TEXT MODE 処理装置指定? 機構選択 文字列式 コンマ 文字列式
SET STROKE MODE
gks文⊃SET MULTIPOINT MODE 処理装置指定? 機構選択 文字列式 コンマ 文字列式
SET VALUATOR MODE
gks文⊃SET VALUE MODE 処理装置指定? 機構選択 文字列式 コンマ 文字列式
207
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書G(参考) 基本BASICとFull BASICとの相違点
基本BASICとFull BASICの中核機能単位との相違は,構文の非互換性と意味上(実行時)の相違に分類
できる。
G1. 構文の非互換性 次の点を除いて,中核機能単位は,JIS X 3003-1982(電子計算機プログラム言語基
本BASIC)に対し上位互換 (upward compatible) の拡充構文を形成する。
(1) 規格合致プログラムのすべての配列は,参照より前に明示的に配列宣言しなければならない。
このため,基本BASICで書かれたプログラムは,中核機能単位に規格合致する処理系で実行すると,
誤りを生ずることがある。そのようなプログラムを正しく実行するには,次のとおり変更すればよい。
基本BASICの配列名は英字1文字に制限されているから,変更が必要な配列は,26個以下である。
(a) 暗黙的に配列宣言されているすべての配列を識別する。
(b) それらの配列に対して,上限値が10であるdim文を挿入する。dim文は,その配列を参照する文
より前になければならない。かつ,dim文より前にbase選択子をもったoption文がなければなら
ない。
例 基本BASICのプログラムで使用されたベクトルAが明示的に配列宣言されていないとき,次の
文を挿入する。
DIM A(10)
これによってプログラムは,ベクトルAに関して正しく実行される。
G2. 意味上の相違 中核機能単位は,更に幾つかの点で基本BASICと異なる。これらは,“実行時”の相
違ということもできる。この結果,基本BASICのプログラムを中核機能単位に規格合致する処理系で実行
すると,幾らか異なった結果を生ずることがある。
(1) 配列の暗黙の下限が,基本BASICでは0であったのに,中核機能単位では1である。
すべてのdim文に先立って,次の文を挿入すれば,基本BASICのプログラムを正しく実行できる。
OPTION BASE 0
(2) 中核機能単位は,算術演算は浮動小数点10進数表現を用いて実行すると規定している。精度は,少な
くとも10進10けたである。一方,基本BASICの規定はよりゆるやかであって,他の表現(例えば浮
動小数点2進数)を使用した算術演算を許している。精度は少なくとも10進6けたである(本体5.6
参照)。これによる唯一の効果は,プログラムがより正確な結果を与えることであり,通常,利用者に
とって問題は生じないだろう。arithmetic選択子でNATIVEを指定して,処理系固有の算術演算を行
うようにすることもできる。この場合,個々の処理系は,基本BASICと同じになるように定義しても
よい。
(3) 文字列の省略時想定の最大長は,基本BASICでは少なくとも18文字であったのに,中核機能単位の
処理系は,少なくとも132文字を許容する。これによる唯一の相違は,基本BASICでは発生する可能
性のあった文字列あふれの例外状態が,発生しないことである。以前の動きは,文字列の最大長を以
前の値で宣言することによって再現できる。
(4) 処理系は,input文の変数への値の代入に先立って,入力応答の1行全体の正当性を調べる必要はな
い。一方,基本BASICではその必要があった。したがって,INPUT I, A (I), Jという文に対して“2, 4,
208
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
x”という間違った入力応答の行を与えたとき,中核機能単位ではA (2) の値が変更されうるが,これ
は基本BASICでは許されない。
(5) ある種の例外状態(例えば,あふれ,ゼロによる除算及びゼロの負数乗)は,基本BASICでは続行可
能であるが,Full BASICの中核機能単位では続行不能である。しかし,基本BASICの規格は,“続行
可能な例外状態をある環境のもとでは続行不能として処理系が取り扱うことができる”と規定してい
るので,基本BASICのプログラムは,これらの例外状態が続行可能であることに依存すべきでない。
209
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書H(参考) 将来の削除を考慮している言語要素
ANSI X3.113の原案作成委員会は,gosub文,on-gosub文及びreturn文を,将来,削除することを考慮
している。新しいプログラムを書いたり,既存のプログラムを改訂したりするときに,これらの文を使わ
ないようにして,この規格の将来の改訂版との互換性を高くしておくことを推奨する。
gosub機能の削除を考慮している理由は,次のとおりである。これは,多くの入口点をもつサブルーチ
ンを書くことを許す点で,わるいプログラミングの習慣を助ける。更に,この“サブルーチン”は,明確
な構文構造によって区切られていない。プログラムのどの文でも,サブルーチンの先頭の行になりうる。
サブルーチンが必要なときに,この規格に定める副プログラム機能(本体9.2参照)を利用することを推
奨する。
またgosub機能は,この言語の他の構文(例えば,内部手続き定義,例外処理区)と複雑な干渉を起こ
し,BASICプログラムの理解,規格合致処理系の作成,言語仕様の正確な記述を困難にする。したがって,
プログラマ,処理系作成者,教師,著述者のだれもが,BASICの仕事に当たって,能率がわるくなる。
210
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書I(参考) モジュール及び単文字入力
この附属書(参考)は,1989年7月26日に承認された次のアメリカ規格(ISOでもCD 10279 : 1991 Addendum
1からDISにすることに,1992年6月に承認された。)に基づいて,その技術的内容を変更することなく
作成した日本工業規格の参考である(解説1.3参照)。
ANSI X3.113A-1989 Supplement to ANSI X3.113-1987 American National Standard for Information Systems−
Programming Languages−Modules and Individual Character Input for Full BASIC, 14 pp., CD 10279 : 1991
Addendum 1
1. 序文 この附属書は,単文字入力機能及びモジュール機能を利用するさまざまな種類の自動データ処
理系の間での,BASICプログラムの移植可能性を高めるために規定する。この附属書は,本体を拡充する
ものであり,本体の規定と関連して適用する。この附属書の1.,2.及び3.は,この附属書にだけ適用する。
本体の1.,2.及び3.を置き換えるものではない。本体の4.〜16.の規定は,この附属書の規定によって影響
はされない。この附属書の17.及び本体の規定に合致したプログラムは,単文字入力機能をもつ規格Full
BASICで書かれているという。この附属書の18.及び本体の規定に合致したプログラムは,モジュール機
能をもつ規格Full BASICで書かれているという。
1.1
適用範囲 この附属書は,本体と関連して,次の事項を定める。
(1) 単文字入力やモジュールを用いて書かれたBASICプログラムの構文
(2) 単文字入力やモジュールを用いて書かれたBASICプログラムの意味を解釈する意味規則
(3) 検出されるべき誤り及び例外状態並びにそれらの誤り及び例外状態が処理される仕方
1.2
引用規格 本体1.3参照。
2. 規格への合致 規格への合致は,次による。
(1) 機能単位 この附属書は,本体の機能単位構成を拡充する。この規定への合致は,次の機能単位を本
体の15個の機能単位に追加した特定の組について定義する。
(p) 単文字入力機能単位 (individual character input module)。中核の規定及び17.の構文に従うすべてのプ
ログラムを範囲とする。
(q) モジュール機能単位 (modules module)。中核の規定及び18.の構文に従うすべてのプログラムを範囲
とする。
(2) 規格合致性 この附属書に定める機能単位の組に対する規格合致性の規定は,本体2.1〜2.4(規格合
致プログラム,規格合致処理系,誤り及び例外状態)による。
3. 構文の記述法及び用語の定義
3.1
構文の記述法 構文の記述法は,本体3.1による。
3.2
用語の定義 この附属書の用語の定義は,本体3.2によるほか,次による。
(1) 表示可能文字 (displayable character) 規定された図形表現をもつ文字。情報交換用符号においては,
位置2/0〜7/14の文字をいう。
(2) モジュール (module) 変数,配列及び経路を,引き数によらないで共用できる外部手続きの集まり。
これらの手続き,共用の変数,配列及び経路を,統制された仕方で“広域的 (public)”に参照できる。
211
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3) module-option文 (module option) モジュール本体及びそのモジュール中の外部手続きに適用される
option文。
(4) 広域 (public) モジュール中の手続き,変数,配列及び経路が,そのモジュールの外部から参照でき
ることを表す用語。
(5) 修飾識別名 (qualified-identifier) モジュール名,小数点及び識別名をつないだものであって,そのモ
ジュール中の広域的な手続き,変数又は配列を識別する。
(6) 共用 (share) モジュール中の変数,配列及び経路が,そのモジュール中の外部手続きから参照でき
ることを表す用語。
4. (本体参照)
5. (本体参照)
6. (本体参照)
7. (本体参照)
8. (本体参照)
9. (本体参照)
10. (本体参照)
11. (本体参照)
12. (本体参照)
13. (本体参照)
14. (本体参照)
15. (本体参照)
16. (本体参照)
17. 単文字入力
17.1 概要 character-input文 (char-input-statement) は,一時に1文字ずつをプログラムに入力する。こ
の機能は,本来,けん(鍵)盤上の打けん(鍵)を1文字単位で認識することを目的として設計してある。
しかし,ほかの目的で用いてもよい。
17.2 構文 構文は,次による。
212
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(1) 単純文⊃character-input文
(2) character-input文=CHARACTER INPUT 単文字入力修飾部? 文字列変数名
(3) 単文字入力修飾部=経路指定|単文字入力修飾|経路式 コンマ 単文字入力修飾
(4) 単文字入力修飾=単文字入力修飾項目 {コンマ 単文字入力修飾項目}* コロン
(5) 単文字入力修飾項目=CLEAR|NOWAIT|入力修飾項目
(6) 単文字入力応答=プログラム文字|行末
(7) 設定対象⊃経路指定? ECHO 文字列式
(8) ask文⊃ASK 経路指定? 単文字入力質問対象並び
(9) 単文字入力質問対象並び=単文字入力質問対象 {コンマ 単文字入力質問対象}*
(10) 単文字入力質問対象= CHARIN 文字列変数名|TYPEAHEAD 文字列変数名|ECHO CONTROL
文字列変数名|ECHO 文字列変数名|CHARACTER PENDING
数値変数名
17.3 例 構文の例を次に示す。
CHARACTER INPUT NEXT̲KEY$
(2)
Character input clear, prompt ”press anykey to continue”:trash$
(2)
Character Input #3, Timeout 15:select̲it$
(2)
Character input nowait:is̲any$
(2)
Ask #1 : charin yes no$
(8)
ASK CHARACTER PENDING HOW̲MANY
(8)
17.4 意味 意味は,次による。
(1) character-input文を実行すると,プログラムの実行は,ここに定める正しい単文字入力応答がなされ
るまで,又は入力バッファから1文字のプログラム文字若しくは行末が供給されるまで,待たされる。
character-input文は,一つの値を文字列変数に代入する。対話方式の場合,単文字入力修飾にprompt
句が書いてなければ,入力要求は出力されない。character-input文に経路指定を書かなかったとき及
びゼロ番の経路を指定したとき,単文字入力は,経路指定のないinput文及びline-input文と同じ装置
からとられる。一括方式におけるcharacter-input文及び対話方式でない装置に接続されている経路の
意味は,処理系定義とする。単文字入力バッファの容量は,処理系定義とする。
(2) 指定された経路からの単文字入力に対して,処理系が先行入力 (typeahead) の機能を支援している場
合,入力は,その経路における論理バッファの概念を用いて規定する。このことは,特定の実現手法
を要求するものではない。この論理バッファと処理系中の物理バッファとの関連は,定義しない。入
力装置が一つのプログラム文字又は行末を処理系に渡すと,処理系はそれを論理バッファ中のすべて
の既存のプログラム文字及び行末の次におく。単文字入力応答は,このバッファからとられる。バッ
ファ中の一番前の(最も古い)プログラム文字又は行末がバッファから論理的に取り除かれ,それが
単文字入力応答になる。単文字入力バッファの容量は,処理系定義とする。バッファの容量を超えた
ときの効果は,処理系定義とする。その経路に対する入力応答又は行入力応答を準備しているとき以
外のプログラム文字及び行末は,このバッファにおかれる。
(3) 単文字入力応答がプログラム文字であれば,その1文字が文字列変数に代入される。単文字入力応答
が処理系定義の行末であれば,“EOL”が文字列変数に代入される。timeout句の数値式の値がゼロよ
り小さいこと又は指定された時間が過ぎたことによって例外状態になると,文字列変数の値は,
character-input文を実行する前の値のまま変わらない。
213
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(4) 単文字入力修飾にprompt句を書くと,その文字列式の値が出力される。
(5) 単文字入力修飾にtimeout句を書くと,その数値時間式が評価され,秒数s(整数とは限らない。)が
定められる。s秒以内に正しい単文字入力応答が与えられなければ,例外状態になる。character-input
文を実行してから,単文字入力応答を受け取るまでに経過した秒数(整数とは限らない。)が,elapsed
句の数値変数に代入される。
処理系に時計機能がないとき,timeout句は,何も効果をもたない。elapsed句の結果は−1とする。
時計機能があるとき,elapsed句の結果は常に正又はゼロとする。timeout句及びelapsed句の値の範
囲(最小値及び最大値)及び分解能は,処理系定義とする。
(6) 単文字入力修飾にNOWAITを書くと,character-input文が単文字入力応答のくるまで,プログラムの
実行を待たせることがなくなる。入力バッファ中にプログラム文字又は行末があれば,その値が文字
列変数に代入される。バッファ中にプログラム文字又は行末がなければ,文字列変数の値は前のまま
変わらない。
(7) 単文字入力修飾にCLEARを書くと,バッファ中にあるプログラム文字及び行末がすべて取り除かれ
る。
参考 バッファの内容を消してから,単文字入力応答を待つのであろう。
(8) chain文を実行したときにバッファ中にあったプログラム文字及び行末の効果は,処理系定義とする。
(9) 機能語ECHOをもつset文を実行すると,画面における文字のエコー表示が,大文字に変換した文字
列式の値の“ON”又は“OFF”に従って,有効又は無効になる。
エコー表示を有効にすると,表示可能文字を打けんしたときに,その経路の出力媒体上に,可能な
らばその文字が表示される。エコー表示を無効にすると,そのような表示は,可能ならば抑制される。
ある経路上でエコー表示を有効又は無効にできるか否かは,処理系定義とする。
プログラムの実行を開始して,ファイルを開いたときには,どの経路に対してもエコー表示が有効
にされている。
(10) 機能語ECHOをもつask文を実行すると,指定された経路におけるエコー表示の現在の状態が,文字
列変数に代入される。エコ表示が有効であれば“ON”が,無効であれば“OFF”が,処理系がエコー
表示の状態を決定できないならば“UNKNOWN”が代入される。
(11) 機能語ECHO CONTROLをもつask文を実行すると,その経路がエコー表示を有効又は無効にできる
ならば“YES”が,できないならば“NO”が,処理系が決定できないならば“UNKNOWN”が文字
列変数に代入される。
(12) 機能語TYPEAHEADをもつask文を実行すると,その経路が先行入力の機能を支援しているならば
“YES”が,支援していないならば“NO”が,処理系がその状態を決定できないならば“UNKNOWN”
が文字列変数に代入される。
先行入力の機能が支援されていないならば,応用プログラムは,ある経路上でのプログラム文字及
び行末の入力が,バッファ中に保留されるとは期待しないほうがよい。
(13) 機能語CHARACTER PENDINGをもつask文を実行すると,数値変数に一つの値が代入される。その
経路の入力バッファ中にプログラム文字若しくは行末がない,又はその経路に先行入力バッファがな
い場合には,値はゼロとする。保留されているプログラム文字及び行末の個数を処理系が決定できな
い場合には,値は−1とする。値が正であれば,少なくともそれだけの個数のプログラム文字及び行
末が,入力バッファ中にある。
(14) 機能語CHARINをもつask文を実行すると,その経路のファイルで単文字入力機能が利用できるなら
214
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ば“YES”が,さもなければ“NO”が文字列変数に代入される。
17.5 例外状態 例外状態は,次による。
(1) 数値時間式の値がゼロより小さい。(8402,続行不能。)
(2) 単文字入力修飾のtimeout句で指定された秒数以内に,単文字入力応答がなかった。(8401,続行不
能。)
(3) 単文字入力機能をもたないファイルに対して,character-input文を実行しようとした。(7451,続行不
能。)
(4) character-input文が,不活性状態にある経路を参照しようとした。(7004,続行不能。)
(5) character-input文が,出力専用 (OUTPUT) として開かれたファイルを参照しようとした。(7303,続
行不能。)
(6) 機能語ECHOをもつset文の文字列式の値が,大文字に変換した後に“ON”でも“OFF”でもない。
(4103,続行不能。)
17.6 注意 注意は,次による。
(1) 単文字入力応答は,打けんされた後できるだけ早く“供給”される。処理系で可能ならば,input文
及びline-input文とは違って,行末が送られるのを待たない。
(2) 処理系が,入力バッファ中にあるプログラム文字及び行末の正確な個数を知ることができるのならば,
機能語CHARACTER PENDINGをもつask文に対して,その値を返すことが望ましい。しかし,プロ
グラムは,この数値が正確であると想定すべきではない。なぜならば,これを保証することは,時間
的に不可能だからである。
(3) 処理系がcharacter-input文に対して先行入力バッファを設ける場合には,それをinput文及び
line-input文に対するバッファと同じものにすることが望ましい。
(4) 処理系は,可能ならば,input文及びline-input文に対するエコー表示の制御にも,機能語ECHOをも
つset文を利用することが望ましい。
(5) 処理系は,非プログラム文字を定義し,これを単文字入力応答に用いてもよい(本体4.1参照)。非プ
ログラム文字の効果は,処理系定義とする。
(6) character-input文を実行してファイルの終り条件になったとき,処理系がそれを検出することが可能
ならば,それを関数EXTYPEの値が8011(続行不能)の例外状態(本体11.4参照)とすることが望
ましい。
18. モジュール
18.1 概要 モジュールは,外部手続きを内部に含むプログラム単位である。モジュールは,変数,配列,
手続き及び経路といった実体も含むことができる。これらの実体は,モジュール中の手続きが,統制され
た仕方で共用 (share) するが,このモジュールの外部のプログラムの部分が直接に参照することはできな
い。ある種の広域 (public) 手続きは,参照 (access) 手続きとも呼ばれ,サブルーチン呼出しや関数引用を
通じて,共用実体(変数,配列,手続き及び経路)を参照する。更に,広域の変数及び配列を,モジュー
ルの外部のプログラム単位から直接に参照可能にすることもできる。モジュール中の共用実体の値は,次
回の関数引用やサブルーチン呼出しまで保持される。共用実体を初期化する手段がある。
モジュールの利用方法は,幾種類もある。モジュールは,抽象データ型(データのカプセル化)の創成
を実現し,情報の封じ込めを許し,“対象指向 (object oriented)”プログラミング法の採用を可能にする。
モジュールは,処理系定義のライブラリを提供するのにも使える。例えば,新しい数学関数をモジュール
215
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
が用意し,そのうち必要なものだけをプログラムが参照して,残りは無視する。最後に,モジュールは,
BASICの機能を拡張するのにも使えよう。例えば,モジュールを利用して,GKSの完全水準をBASICに
結合できよう。
18.2 構文 構文は,次による。
(1) プログラム⊃program行? 主プログラム {外部手続き単位|モジュール単位}*
(2) モジュール単位=注釈行* モジュール定義
(3) モジュール定義=module行 モジュール本体 外部手続き単位* 注釈行* end-module行
(4) module行=行番号 module文 行末部
(5) module文=MODULE モジュール名
(6) モジュール名=ルーチン識別名
(7) モジュール本体={注釈行|public行}* {注釈行|share行}* モジュール本体区*
(8) モジュール本体区=注釈行|宣言行|dim行|module-option行|区
(9) public行=行番号 public文 行末部
(10) public文=PUBLIC 広域宣言
(11) 広域宣言= numeric宣言|string宣言|モジュールfunction宣言|モジュールsub宣言|
モジュールpicture宣言
(12) モジュールfunction宣言=FUNCTION 関数名並び
(13) モジュールsub宣言=SUB 副プログラム名並び
(14) モジュールpicture宣言=PICTURE 絵名並び
(15) share行=行番号 share文 行末部
(16) share文=SHARE {広域宣言|channel宣言}
(17) channel宣言=CHANNEL 経路番号並び
(18) 経路番号並び=経路番号 {コンマ 経路番号}*
(19) module-option行=行番号 module-option文 行末部
(20) module-option文=MODULE option文
(21) end-module行=行番号 end-module文 行末部
(22) end-module文=END MODULE
(23) 宣言指定⊃外部共用宣言
(24) 外部共用宣言= EXTERNAL {FUNCTION|SUB|PICTURE|NUMERIC|STRING}
修飾識別名並び
(25) 修飾識別名並び=修飾識別名 {コンマ 修飾識別名}*
(26) 修飾識別名= モジュール名 小数点 {定義関数名|ルーチン識別名|数値単純変数名|
文字列単純変数名|仮配列宣言}
(27) 数値識別名⊃モジュール名 小数点 英字 識別名文字*
(28) 文字列識別名⊃モジュール名 小数点 英字 識別名文字* ドル記号
(29) 副プログラム名⊃モジュール名 小数点 ルーチン識別名
(30) 絵名⊃モジュール名 小数点 ルーチン識別名
(31) 行⊃ public行|share行|module行|module-option行|モジュール本体区|end-module行|
dim行|宣言行
参考 ここで,モジュール本体区という構文単位名が行の定義中に入っていることは,あまり意味が
216
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ないように思われる。
(32) 宣言行=行番号 宣言文 行末部
参考 ANSI X3.113 Aでは,declaration-statementという構文単位名を使っているが,それは,定義さ
れていない。ここでは仮に,宣言文と訳しておく。
(33) dim行=行番号 dim文 行末部
(34) 一つの識別名は,ただ1回だけ数値型として宣言できる。すなわち,一つのモジュール定義中のモジ
ュール本体の中で,public文,share文若しくはdeclare文のnumeric宣言又はdim文に,1回だけ書
くことができる。
(35) 一つの識別名は,ただ1回だけ文字列型として宣言できる。すなわち,一つのモジュール定義中のモ
ジュール本体の中で,public文,share文若しくはdeclare文のstring宣言又はdim文に,1回だけ書
くことができる。
(36) 一つの識別名は,ただ1回だけ関数名として宣言できる。すなわち,一つのモジュール定義中のモジ
ュール本体の中で,public文,share文又はdeclare文のモジュールfunction宣言に,1回だけ書くこ
とができる。
(37) 一つの識別名は,ただ1回だけ副プログラム名として宣言できる。すなわち,一つのモジュール定義
中のモジュール本体の中で,public文,share文又はdeclare文のモジュールsub宣言に,1回だけ書
くことができる。
(38) 一つの識別名は,ただ1回だけ絵名として宣言できる。すなわち,一つのモジュール定義中のモジュ
ール本体の中で,public文,share文又はdeclare文のモジュールpicture宣言に,1回だけ書くことが
できる。
(39) 一つの経路番号は,ただ1回だけ経路番号として宣言できる。すなわち,一つのモジュール定義中の
モジュール本体の中で,share文のchannel宣言に,1回だけ書くことができる。
(40) あるモジュール定義中のpublic文に書いた識別名は,そのモジュール定義中の外部共用宣言に書いて
はならない。
(41) 識別名をpublic文に書いた変数,配列及びルーチンは,主プログラム,外部手続き単位又はそのプロ
グラム中の他のモジュール定義にその変数,配列又はルーチンを指名する外部共用宣言をもつdeclare
文を書けば,その主プログラム,外部手続き単位又はモジュール定義から参照することができる。
(42) 識別名をpublic文又はshare文に書いた変数,配列及びルーチンは,それ以上の宣言なしに,そのモ
ジュール定義中のモジュール本体及び外部手続き単位から参照できる。
(43) share文に書いた経路番号は,そのモジュール定義中のモジュール本体及び外部手続き単位から参照
できる。
(44) 識別名又は経路番号がpublic文又はshare文に指定されていない変数,配列及び経路は,そのモジュ
ール本体でだけ参照できる。
(45) angle選択子,arithmetic選択子,collate選択子及びbase選択子は,それぞれ,モジュール本体には,
たかだか1回だけ書くことができる。
(46) ある種類の選択子をモジュール本体のmodule-option文に書いたときには,同じ種類の選択子を,再
びそのモジュール定義中のモジュール本体及び外部手続き単位に書いてはならない。
(47)モジュール定義中の外部手続きがそのモジュール中の共用又は広域の数値識別名を参照する場合には,
その外部手続きとモジュール本体とのarithmetic選択子が同じでなければならない。
(48) モジュール定義中の外部手続きがそのモジュール中の共用又は広域の文字列識別名を参照する場合に
217
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
は,その外部手続きとモジュール本体とのcollate選択子が同じでなければならない。
参考 本体9.1.6(1)参照。
(49) 機能語EXTERNAL FUNCTIONの外部共用宣言に書いた修飾識別名は,その修飾識別名によって指名
されたモジュール定義中のpublic文に書いた定義関数名を指名しなければならない。
(50) 機能語EXTERNAL SUBの外部共用宣言に書いた修飾識別名は,その修飾識別名によって指名された
モジュール定義中のpublic文に書いた副プログラム名を参照するルーチン識別名を指名しなければな
らない。
(51) 機能語EXTERNAL PICTUREの外部共用宣言に書いた修飾識別名は,その修飾識別名によって指名さ
れたモジュール定義中のpublic文に書いた絵名を参照するルーチン識別名を指名しなければならない。
(52) 機能語EXTERNAL NUMERICの外部共用宣言に書いた修飾識別名は,その修飾識別名によって指名
されたモジュール定義中のpublic文に書いた数値単純変数名又は数値配列名を参照する数値単純変数
名又は数値仮配列宣言を指名しなければならない。
(53) 機能語EXTERNAL STRINGの外部共用宣言に書いた修飾識別名は,その修飾識別名によって指名さ
れたモジュール定義中のpublic文に書いた文字列単純変数名又は文字列配列名を参照する文字列単純
変数名又は文字列仮配列宣言を指名しなければならない。
(54) モジュール中の定義関数名,副プログラム名,絵名,数値識別名又は文字列識別名を参照するすべて
のプログラム単位は,対応する修飾識別名を,外部共用宣言に書かなければならない。この外部共用
宣言は,プログラム単位中でその識別名を参照するどの文よりも早い位置に,書かなければならない。
定義関数名,副プログラム名,絵名,数値識別名又は文字列識別名をプログラム単位中で参照する
ときに,あいまいでないならば,その外部共用宣言に書いた修飾識別名中のモジュール名と小数点は,
省略してもよい。
(55) 修飾識別名の仮配列宣言によって宣言した仮配列を参照するときには,その空の括弧を除いた配列名
を用いる。
18.3 例 構文の例を次に示す。
(1) モジュール定義[構文(2)]の例
1000 MODULE stack
1010 PUBLIC SUB push, pop
1020 PUBLIC FUNCTION isempty$, isfull$
1030 SHARE SUB inc, dec
1040 SHARE NUMERIC pointer, maxdepth, stack(1 to 100)
1050 LET maxdepth=100
1060 LET pointer=0
1070 ! Procedures of the module
1080 EXTERNAL SUB inc(x)
1090 LET x=x+1
1100 END SUB
1110 !
1120 EXTERNAL SUB dec(x)
1130 LET x=x−1
1140 END SUB
218
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1150 !
1160 EXTERNAL SUB push(item)
1170 IF pointer<maxdepth then
1180 CALL inc(pointer)
1190 LET stack(pointer)=item
1200 END IF
1210 END SUB
1220 !
1230 EXTERNAL SUB pop(item)
1240 IF pointer=0 then
1250 LET item=0 ! Signal for an empty stack
1260 ELSE
1270 LET item=stack (pointer)
1280 CALL dec (pointer)
1290 END IF
1300 END SUB
1310 !
1320 EXTERNAL FUNCTION isempty$
1330 IF pointer=0 then
1340 LET isempty$=”true”
1350 ELSE
1360 LET isempty$=”false”
1370 END IF
1380 END FUNCTION
1390 !
1400 EXTERNAL FUNCTION isfull$
1410 IF pointer>=maxdepth then
1420 LET isfull$=”true”
1430 ELSE
1440 LET isfull$=”false”
1450 END IF
1460 END FUNCTION
1470 END MODULE
(2) モジュール定義[構文(2)]の例
1000 MODULE Common
1010 PUBLIC NUMERIC x, y, z
1020 PUBLIC STRING a$
1030 LET x,y,z=0
1040 LET a$=””
1050 END MODULE
219
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(3) 外部共用宣言[構文(24)]の例
EXTERNAL NUMERIC common.x, common.y, common.z
EXTERNAL STRING common.a$
EXTERNAL SUB stack.push, stack.pop
EXTERNAL FUNCTION stack.isfull$, stack.isempty$
18.4 意味 意味は,次による。
(1) public文,share文,dim文又は外部共用宣言以外のdeclare文で宣言された変数及び配列並びにモジ
ュール本体の単純変数は,プログラムの実行を開始するときに,一貫した処理系定義の値を代入され
る。モジュール本体のpublic文で宣言された手続き,変数及び配列が最初に参照されるより前に,モ
ジュール本体中の区が実行される。これらの区は,プログラムの実行に当たって,たかだか1回だけ
実行される。
(2) call文や関数引用(例えば,RND)で起こりうるように,初期化における文の効果が,一つのプログ
ラム中の二つ以上のモジュールの初期化の順序に依存する場合,その効果は,処理系定義とする。
(3) モジュール本体中のshare文に書いた変数及び配列は,そのモジュール定義中に含まれる外部手続き
の次回の呼出しまで,その値を保持する。モジュール本体中のpublic文で宣言した変数及び配列は,
そのモジュール定義中に含まれる外部手続きの次回の呼出しまで,その存在を続ける。しかし,これ
らは,モジュール定義の外部からも参照できるので,その値は,変更されうる。
(4) モジュール本体中のshare文に経路番号を書いた経路は,そのモジュール定義中に含まれる外部手続
きの次回の呼出しまで,その状態を保持する。すなわち,ある経路が開いたファイルを参照している
ならば,そのモジュール定義中の外部手続きが特に閉じるまでは,その経路は開いたままである。
(5) モジュール定義中の外部手続きの内部にあって,仮引き数ではない変数,配列及び経路の有効範囲は,
通常の外部手続きの場合と同様に,局所的とする。
モジュール定義中のpublic文又はshare文に書いた変数,配列及び経路は,そのモジュール中の外
部手続きから参照できる。
(6) module-option文でないoption文を外部手続きに書いた場合には,その選択子の有効範囲は,その外
部手続きとする。モジュール本体に書いた場合には,その有効範囲はそのモジュール本体とする。
(7) module-option文の選択子の有効範囲は,そのモジュール本体と外部手続き全部を含むモジュール全体
とする。
(8) chain文によって実行されるプログラム中のモジュール定義は,処理系定義の仕方で初期化される。
18.5 例外状態 なし。
18.6 注意 注意は,次による。
(1) Full BASICにおけるモジュールの概念は,Modula-2のモジュール及びADAのパッケージの概念に似
ている。
(2) public文又はshare文に書いたスカラ及び配列の識別名は,直接に参照でき,参照手続きの利用を必
要としない。この概念は,実体の値を共用するための“外部 (external)”データ型又は“共通 (common)”
指定の方法に相当する手段を提供する。
(3) モジュール本体中にあって,かつpublic文にもshare文にも指定しなかった識別名は,モジュール定
義の初期化の間だけ利用できる。
(4) この附属書Iの18.は,二つ以上の並行単位(本体14.実時間参照)が,あるモジュール定義中の一つ
以上の外部手続きを参照するときに起こりうる相互作用については,規定しない。
220
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書Aの追加(参考) 規格の構成
附属書Iの17.及び18.は,Full BASICに対する独立した拡張を規定する。これらの章の節は,本体の項
の形式及び用法に従う。
221
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書Bの追加(参考) 有効範囲
18. (モジュール)について,次の有効範囲規則を追加する。附属書B表1参照。
番号
対象
有効範囲
(20)
module-option文の選択子
モジュール本体及びそのモジュール中の外部手続き
全部
(21)
public文で宣言された実体
プログラム全体(そのモジュール本体及びそのモジ
ュール中の外部手続き全部を含む。)
(22)
share文で宣言された実体
モジュール本体及びそのモジュール中の外部手続き
全部
(23)
モジュール中の外部手続き単位によって定義され,
かつその名前がモジュール本体中のpublic文で宣言
されていない外部手続き
モジュール本体及びそのモジュール全体

222
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書Cの追加(参考) 処理系定義の機能
C1. 処置 附属書Iは,機能の幾つかを処理系定義としている。本体で処理系定義とした機能の幾つかは,
ここでも参照する。これらは,それぞれの節で推奨した制限が守られる限り,移植可能性に影響を及ぼさ
ない。これらの機能の処理方法は,処理系の取扱い説明書に定義しなければならない。
C2. 事項 処理系定義の事項を表に示す。
17. 単文字入力
(a) 行末(本体4.2参照)
(b) 対話方式でないときのcharacter-input文の意味
(c) 単文字入力バッファの容量
(d) 単文字入力バッファの容量を超えたときの効果
(e) timeout句及びelapsed句の時間の最小値,最大値及び分解能
(f) 単文字入力応答における非プログラム文字の効果
(g) chain文を実行したときにバッファの内容が取り除かれるか否か
18. モジュール
(a) プログラム中に二つ以上のモジュールがあるときのモジュールの初期化の順序
(b) モジュール本体中の変数及び配列の初期値
223
X 3003-1993
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
解説表1 BASIC言語専門委員会 構成表(敬称略・順不同)
氏名
所属(当時)
82年度
83年度
(委員長)
西 村 恕 彦 東京農工大学
○
○
(委員)
高 田 正 之 東京農工大学
○
○
唐 木 幸比古 東京大学
○
○
中 西 正 和 慶応義塾大学
○
○
小 林 光 夫 電気通信大学
○
○
植 村 俊 亮 電子技術総合研究所
○
○
定 松 淳 一 三菱電機株式会社
○
○
細 谷 雅 寿 沖電気工業株式会社
○
○
田 中 吉 廣 株式会社日立製作所
○
石 田 悦 男 株式会社日立製作所
○
柴 田 勝 仁 富士通株式会社
○
中 村 修 一 富士通株式会社
○
福 岡 和 彦 日本電気株式会社
○
片 山 博 日本電気株式会社
○
西 山 茂 日本電信電話公社横須賀電気通信研究所
○
○
酒 井 俊 夫 株式会社管理工学研究所
○
○
軽 部 三 男 バロース株式会社
○
○
伊 野 誠 日本ユニバック株式会社
○
○
藤 脇 憲 文 日本アイ・ビー・エム株式会社
○
○
高 橋 一 成 シャープ株式会社
○
○
木 下 恂 電子協 言語標準化専門委貝会委員長
○
東京芝浦電気株式会社
○
森 俊 二 電子協 言語標準化専門委員会委員長
○
(沖電気工業株式会社)
楡 木 武 久 社団法人日本電子工業振興協会
○
○
*
張 愛 英 華北計算技術研究所(中華人民共和国)
○
(関係者)
坂 井 喜 毅 工業技術院
○
伊 東 厚 工業技術院
○
(事務局)
水 田 哲 郎 社団法人日本電子工業振興協会
○
○
備考 *印はオブザーバー