X 0611:2018
(1)
目 次
ページ
1 一般······························································································································· 1
1.0A 適用範囲 ···················································································································· 1
1.1 構成 ···························································································································· 1
1.2 適合性 ························································································································· 2
1.3 参照 ···························································································································· 3
2 基本制約及び基本要件 ······································································································· 8
2.0A 要約 ·························································································································· 8
2.1 第1部 一般 ················································································································ 9
2.2 第3部 ボリューム構造 ································································································ 16
2.3 第4部 ファイルシステム ····························································································· 29
2.4 第5部 レコード構造 ··································································································· 40
3 システム依存要件 ············································································································ 40
3.1 第1部 一般 ··············································································································· 40
3.2 第3部 ボリューム構造 ································································································ 41
3.3 第4部 ファイルシステム ····························································································· 42
4 利用者インタフェース要件 ································································································ 64
4.1 第3部 ボリューム構造 ································································································ 64
4.2 第4部 ファイルシステム ····························································································· 65
5 参考情報························································································································ 71
5.1 記述子長 ····················································································································· 71
5.2 処理システム用領域の使用 ····························································································· 72
5.3 起動記述子(Boot Descriptor) ························································································ 72
5.4 未記録セクタの明確化(Clarification of Unrecorded Sectors) ················································ 72
5.5 技術的問合せ ··············································································································· 73
6 関連する規定 ·················································································································· 73
6.1 UDF実体識別記述子······································································································ 73
6.2 UDF実体識別値 ··········································································································· 74
6.3 オペレーティングシステム識別子(OS識別子) ································································· 74
6.4 OSTA圧縮Unicodeの圧縮アルゴリズム ············································································ 75
6.5 CRC計算 ···················································································································· 77
6.6 方策種別4 096のアルゴリズム ························································································ 80
6.7 識別子翻訳アルゴリズム ································································································ 80
6.8 拡張属性チェックサムアルゴリズム(Extended Attribute Checksum Algorithm) ······················· 95
6.9 DVD-ROMに対する要件(Requirements for DVD-ROM) ···················································· 96
6.10 CD媒体に関する勧告 ··································································································· 99
X 0611:2018 目次
(2)
ページ
6.11 Real-Timeファイル(Real-Time Files) ··········································································· 104
6.12 DVDの交換のための要件 ····························································································· 104
6.13 UDF媒体フォーマット改正履歴 ···················································································· 106
附属書JA(参考)商標又は登録商標 ······················································································ 108
X 0611:2018
(3)
まえがき
この規格は,工業標準化法第14条によって準用する第12条第1項の規定に基づき,一般財団法人光産
業技術振興協会(OITDA)及び一般財団法人日本規格協会(JSA)から,OSTA(Optical Storage Technology
Association)による団体規格Universal Disk Format Specification Revision 2.01:2000を基に作成した工業標準
原案を具して日本工業規格を改正すべきとの申出があり,日本工業標準調査会の審議を経て,経済産業大
臣が改正した日本工業規格である。これによって,JIS X 0611:2012は改正され,この規格に置き換えられ
た。
この規格は,著作権法で保護対象となっている著作物である。
この規格の一部が,特許権,出願公開後の特許出願又は実用新案権に抵触する可能性があることに注意
を喚起する。経済産業大臣及び日本工業標準調査会は,このような特許権,出願公開後の特許出願及び実
用新案権に関わる確認について,責任はもたない。
日本工業規格 JIS
X 0611:2018
ユニバーサルディスクフォーマット(UDF)2.01
Universal Disk Format (UDF) 2.01
1
一般
1.0A 適用範囲
この規格は,JIS X 0607規格類(JIS X 0607:2001,ISO/IEC 13346-2,ISO/IEC 13346-3,ISO/IEC 13346-4
及びISO/IEC 13346-5)の部分集合として,UDF 2.01を規定する。データ交換を最大限にすること,並び
にJIS X 0607規格類を実施するためのコスト及び複雑さを最小限にすることを,その主な目的とする。
注記1 この規格で点線の下線を施してある参考事項は,対応団体規格にはない事項である。
注記2 この規格では,JIS X 0607規格類に含まれるJIS X 0607:2001を第1部,ISO/IEC 13346-2を
第2部,ISO/IEC 13346-3を第3部,ISO/IEC 13346-4を第4部,ISO/IEC 13346-5を第5部
と呼ぶ。
この目的を達成するために,範囲を定義する。範囲は,JIS X 0607規格類の使用上の規則及び制約を定
義する。ここで定義する範囲を,UDFの適合範囲(UDF Compliant domain)とする。
この規格は,JIS X 0607規格類の構造Xが与えられたとき,その構造Xの各欄について,指定されたオ
ペレーティングシステム(OS)に関する次の課題を解決する。
a) その欄を読み出すOSが,その欄中のデータを利用可能である場合,そのOSの何に対して,その欄
は対応しなければならないか。
b) その欄を読み出すOSが,その欄中のデータを制限付きで利用可能である場合,そのOSにおいて,
その欄をどのように解釈しなければならないか。
c) その欄を読み出すOSが,その欄中のデータを利用可能でない場合,そのOSにおいて,その欄をど
のように解釈しなければならないか。
d) その欄を書き込むOSが,その欄中のデータを利用可能である場合,そのOSにおける何を,その欄
へ対応させなければならないか。
e) その欄を書き込むOSが,その欄中のデータを利用可能でない場合,そのOSにおいて,その欄をど
のように解釈しなければならないか。
JIS X 0607規格類の構造の幾つかに関しては,これらの課題への回答は自明なため,その構造は,ここ
には含めない。
JIS X 0607規格類を明確にするための補足として,各構造に関する付加情報を提供することがある。
この規格は,JIS X 0607規格類を実装する作業をより容易にする。
注記3 この規格では,附属書JAに示す商標又は登録商標を使用しているが,商標を示す記号™又
は登録商標を示す記号®は表記していない。
1.1
構成
この規格は,JIS X 0607規格類が規定する構造の扱いについての情報を与える。
2
X 0611:2018
この規格は,次に示す四つの基本的な箇条から成る。
箇条2 基本制約及び基本要件:OSに依存しない制約及び要件を定義。
箇条3 システム依存要件:OSに依存する制約及び要件を定義。
箇条4 利用者インタフェース要件:利用者インタフェースに関連する制約及び要件を定義。
箇条6 関連する規定:追加の有用な情報。
注記 箇条2〜箇条4内の細分箇条の題名(例 “2.1 第1部 一般”)に含まれる“第n部”(n = 1
〜5)の表記は,それぞれJIS X 0607規格類の第n部の規定内容への対応を示す。
この規格は,JIS X 0607規格類で定義する構造の扱いに関する情報を提供し,次に示す分野を網羅して
いる。
a) 媒体から読み出す場合の構造及び欄の解釈:これを“意味”として示す。
b) 媒体に書き込む場合の構造及び欄の内容:これを“設定値”として示す。特記しない限り,書込みは,
媒体中に新しい構造を作成することだけを意味する。媒体中に存在する構造の更新に適用する場合は,
その旨を特記する。
各構造の欄がまず示され,次いで前述の分類に関して各欄の記述がある。各欄の記述情報で補足する。
欄に関する意味が明白な場合には,構造の1個以上の欄を,記述しない場合がある。
用語遣い:この規格では,“(し)なければならない(shall)”は必須の行為又は要件を示し,“してもよい
(may)”は任意機能の行為又は要件を示し,“であることが望ましい(should)”は推奨するが任意機能で
ある行為又は要件を示す。
欄及び/又は構造に関連する特別な注釈には,“特記事項”を前置きし,一般的な注釈には,“注記”を
前置きして示す。
1.2
適合性
この規格に適合するためには,JIS X 0607規格類の第1部,第2部,第3部及び第4部への適合性が必
要である。この規格は,JIS X 0607規格類の第5部への適合性については規定しない。
ある処理システムがこの規格への適合性を主張するためには,その処理システムは,この規格で規定す
る全ての必須の要件を満たさなければならない。
適合性に関して幾つかの要点を,次に確認する。
a) 複数ボリュームの利用の任意選択性:処理システムは,単一ボリュームだけを利用可能にして,適合
性を主張できる。
b) 複数区画の利用の任意選択性:処理システムは,この規格で定義する単一ボリューム中の特別な複数
区画を利用可能にすることなく,適合性を主張できる。
c) 利用可能な媒体:処理システムは,一つの種別の媒体についての適合性を主張できるし,二つ以上の
種別の媒体の組合せに対しても適合性を主張できる。
d) 複セションを利用可能にする:CD-Rの読出しができる処理システムでは,6.10.3に規定するとおり,
複セションで記録したCD-Rの読出しができなければならない。
e) ファイル名の翻訳:処理システムは,OSの制約に適合するために,ファイル名を翻訳する必要があ
る場合,必ずこの規格で定義するアルゴリズムを使用しなければならない。
f)
拡張属性:全ての適合処理システムでは,媒体中に存在する既存の拡張属性を保存しなければならな
い。処理システムは,利用可能なOSに関する拡張属性の作成及び保守をしなければならない。参考
として,例えば,Macintoshの処理システムは,媒体中に存在するOS/2の拡張属性を保存しなければ
ならない。Macintoshの処理システムは,この規格が規定する全てのMacintosh拡張属性の作成及び保
3
X 0611:2018
守をもしなければならない。
g) 読出しの下位互換性:この規格(UDF 2.01規定)に適合する処理システムは,UDF 2.01規定より若い
UDF版数の規定に従って書き込まれた全ての媒体の読出しができなければならない。
h) 書込みの下位互換性:UDF 2.00及びUDF 2.01の構造を,UDF 1.50及びUDF 1.02構造を含む媒体に書
き込んではならない。UDF 1.50及びUDF 1.02の構造を,UDF 2.00及びUDF 2.01の構造を含む媒体に
書き込んではならない。これら二つの要件は,媒体が,異なる版のUDF構造を含むことを防止する。
1.3
参照
1.3.1
引用規格
次に掲げる規格は,この規格に引用されることによって,この規格の規定の一部を構成する。これらの
引用規格は,記載の年の版を適用し,その後の改正版(追補を含む。)は適用しない。
JIS X 0221:2007 国際符号化文字集合(UCS)
注記 JIS X 0221:2007は,ISO/IEC 10646:2003,Information technology−Universal Multiple-Octet
Coded Character Set (UCS) に一致している。
JIS X 0606:1998 情報交換用CD-ROMのボリューム構造及びファイル構造
注記 JIS X 0606:1998は,ISO 9660:1988,Information processing−Volume and file structure of
CD-ROM for information interchange及びAmendment 1:2013に一致している。
JIS X 6281:2012 120 mm再生専用形光ディスク(CD-ROM)
注記1 JIS X 6281:2012は,ISO/IEC 10149:1995,Information technology−Data interchange on
read-only 120 mm optical data disks (CD-ROM)に一致している。
注記2 Yellow Book:Compact Disc Read Only Memory System Descriptionが,JIS X 6281:2006に対応
している。
JIS X 6282:2012 情報交換用120 mm追記形光ディスク(CD-R)
注記 Orange Book, Recordable Compact Disc System, part-IIが,JIS X 6282:2009に一致している。
JIS X 6283:2012 情報交換用120 mmリライタブル光ディスク(CD-RW)
注記 Orange Book, Recordable Compact Disc System, part-IIIが,JIS X 6283:2009に一致している。
IEC 908:1987,Compact disc digital audio system
注記 IEC 908:1987は,既に改正されて,IEC 60908:1999として発行されている。
ISO/IEC 13346-1:1995,ISO/IEC 13346-2:1999,ISO/IEC 13346-3:1999,ISO/IEC 13346-4:1999及び
ISO/IEC 13346-5:1995,Information technology−Volume and file structure of write-once and rewritable
media using non-sequential recording for information interchange−Part 1-5
注記1 ECMA 167 3rd Edition, Volume and file structure of write-once and rewritable media using
non-sequential recording for information interchangeは,ISO/IEC 13346-1〜ISO/IEC 13346-5に
一致している。
注記2 対応日本工業規格:JIS X 0607:2001 非逐次記録を用いる追記形及び書換形の情報交換用
媒体のボリューム及びファイルの構造
注記3 この規格(JIS X 0611)において,[ ]でくくられた参照は,JIS X 0607規格類を[x/a.b.c]の
様式で参照し,ここで,xは部番号,a.b.cは細分箇条番号又は図番号とする。
1.3.2
用語及び定義
この規格で用いる主な用語及び定義は,次による。
4
X 0611:2018
1.3.2.1
オーディオセション(Audio session)
一つ以上のオーディオトラックを含み,データトラックを含まないセション。
1.3.2.2
オーディオトラック(Audio track)
IEC 908が規定するオーディオセクタを含むように設計されたトラック。
1.3.2.3
CD-R(CD-Recordable)
追記形CD。JIS X 6282が規定する追記形コンパクトディスク。
1.3.2.4
CD-RW(CD-Rewritable)
書換形CD。JIS X 6283が規定するリライタブルコンパクトディスク。
1.3.2.5
クリーンファイルシステム(Clean File System)
この規格に適合する媒体のファイルシステム。
1.3.2.6
データトラック(Data track)
JIS X 6281が規定するデータセクタを含む設計がなされたトラック。
1.3.2.7
ダーティファイルシステム(Dirty File System)
クリーンファイルシステムではないファイルシステム。
1.3.2.8
固定パケット(Fixed Packet)
与えられたトラックに含まれるパケット全てが,トラック記述子ブロックに指定された長さをもつ,イ
ンクリメンタル記録方式。CDドライブに提示される番地は,JIS X 6282及びJIS X 6283が規定する,番
地付け方式の方式2に従って翻訳される。
1.3.2.9
ICB(Information Control Block)
JIS X 0607規格類における制御ノード。
1.3.2.10
論理ブロック番地(Logical Block Address)
論理ブロック番号[3/8.8.1]。
特記事項1 これを,[4/7.1]で規定する論理ブロック番地と混同してはならない。[4/7.1]で規定する論
理ブロック番地は,論理ブロック番号[3/8.8.1]と,区画参照番号[3/8.8]とを含むlb̲addr
構造で示され,区画参照番号は,指し示された論理ブロック[3/8.8.1]を含む区画[3/8.7]を
識別する。
特記事項2 [3/8.8.1]で定義する論理ブロック番号は,指し示す論理ブロック[3/8.8.1]を含む区画
[3/8.7]の,区画マップ[3/10.7]が示す方法に従って,論理セクタ番号[3/8.1.2]に変換される。
1.3.2.11
媒体ブロック番地(Media Block Address)
5
X 0611:2018
記録のための関連規格[1/5.10]で示される,一意のセクタ番地から派生するセクタ番号[3/8.1.1]。この規
格では,セクタ番号[3/8.1.1]は論理セクタ番号[3/8.1.2]に等しい。
1.3.2.12
パケット(Packet)
連続する整数個のセクタ[1/5.9]からなる記録可能単位。利用者データセクタから構成される。パケット
ライト動作のオーバヘッドとして記録される追加セクタ[1/5.9]を含むことがあり,記録のための関連規格
[1/5.10]に従って指し示すことができる。
1.3.2.13
物理番地(Physical Address)
記録のための関連規格[1/5.10]で示される,特有のセクタ番地によって定まるセクタ番号[3/8.1.1]。この
規格では,セクタ番号[3/8.1.1]は,論理セクタ番号[3/8.1.2]に等しい。
1.3.2.14
物理ブロック番地(Physical Block Address)
物理番地。
1.3.2.15
物理セクタ(Physical Sector)
記録のための関連規格[1/5.10]で示されるセクタ[1/5.9]。この規格では,セクタ[1/5.9]は,論理セクタ
[3/8.1.2]に等しい。
1.3.2.16
ランダムアクセスファイルシステム(Random Access File System)
任意の位置に書込みができる媒体のためのファイルシステム。追記形又は書換形のいずれか。
1.3.2.17
逐次ファイルシステム(Sequential File System)
逐次に書き込まれる媒体(例えば,CD-R)のためのファイルシステム。
1.3.2.18
セション(Session)
トラックの列(トラックは1個でもよい。)であって,各トラック番号が連続した昇順を形成しているも
の。ボリューム中のトラックは,JIS X 6282の規定どおりに,一つ以上のセションに編成しなければなら
ない。
1.3.2.19
トラック(Track)
セクタの列であって,各セクタ番号が連続した昇順を形成しているもの。ボリューム中のセクタは,一
つ以上のトラックに編成されなければならない。一つのセクタが複数のトラックに属してはならない。
特記事項 トラック間に間隙がある場合もある。すなわち,トラックの最後のセクタが,次のトラッ
クの最初のセクタと隣接している必要はない。
1.3.2.20
UDF(Universal Disk Format)
ユニバーサルディスクフォーマット。
1.3.2.21
利用者データブロック(user data blocks)
6
X 0611:2018
パケットのセクタ[1/5.9](この規格では論理セクタ[3/8.1.2]と同じ。)に記録された論理ブロック[3/8.8.1]。
ドライブの利用者が意図的に記録したデータが含まれる。記録のための関連規格[1/5.10]に従って番地付
け可能なセクタが存在したときでも,そのセクタがパケット記録のオーバヘッドに使用された論理ブロッ
ク[3/8.8.1]は,特にこれには含まれない。利用者データブロックは,論理ブロック[3/8.8.1]と同様に,論理
ブロック番号[3/8.8.1]で識別される。
1.3.2.22
利用者データセクタ(user data sectors)
ドライブの利用者が意図的に記録したデータを含む,パケットのセクタ[1/5.9]。パケットを記録するオ
ーバヘッドに使用されるセクタ[1/5.9]は,記録のための関連規格[1/5.10]に従って番地付けできても,利用
者データセクタには含まれない。いずれのセクタ[1/5.9]とも同じく,利用者データセクタはセクタ番号
[3/8.1.1]で識別される。この規格では,セクタ番号[3/8.1.1]は,論理セクタ番号[3/8.1.2]に等しい。
1.3.2.23
可変パケット(Variable Packet)
与えられたトラックにおける各パケットが,ホストが決定した長さをもつインクリメンタル記録方式。
CDドライブに提示される番地は,JIS X 6282及びJIS X 6283における,方式1の番地付けで規定すると
おりとする。
1.3.2.24
仮想番地(Virtual Address)
仮想区画における論理ブロック[3/8.8.1]の論理ブロック番号[3/8.8.1]。このような論理ブロック[3/8.8.1]
は,対応する非仮想区画の論理ブロック[3/8.8.1]の空間を使って記録される。VATのN番目のUint32は,
対応する仮想区画の論理ブロック番号Nを記録するために使われる,非仮想区画の論理ブロック番号
[3/8.8.1]を表す。最初の仮想番地は,0である。
1.3.2.25
仮想区画(virtual partition)
この規格の2.2.8に従って記録される種別2の区画マップ[3/10.7.3]によって,論理ボリューム記述子
[3/10.6]で識別される論理ボリューム[3/8.8]の区画。仮想区画マップには,区画番号が含まれるが,これは,
同一の論理ボリューム記述子[3/10.6]における種別1の区画マップ[3/10.7.2]の区画番号[3/10.7.2.4]と同じで
ある。仮想区画の各論理ブロック[3/8.8.1]は,その対応する非仮想区画の論理ブロック[3/8.8.1]の空間を使
って記録される。VATには,その対応する仮想区画の論理ブロック[3/8.8.1]を記録するために使われてい
る,非仮想区画の論理ブロック[3/8.8.1]が列挙される。
1.3.2.26
仮想セクタ(virtual sector)
仮想区画の論理ブロック[3/8.8.1]。このような論理ブロック[3/8.8.1]は,対応する非仮想区画の論理ブロ
ック[3/8.8.1]の空間を使って記録される。仮想セクタを,セクタ[1/5.9]又は論理セクタ[3/8.1.2]と混同しな
いほうがよい。
1.3.2.27
仮想割付け表,VAT(Virtual Allocation Table, VAT)
非仮想区画の空間に記録されるファイル[4/8.8]。対応する仮想区画をもち,そのデータ空間[4/8.8.2]は
2.2.10に従って構成される。このファイルでは複数のUint32の配列リストを備えているが,N番目のUint32
は,対応する仮想区画の論理ブロック番号Nを記録するのに使う,非仮想区画の論理ブロック番号[3/8.8.1]
7
X 0611:2018
を表す。このファイル[4/8.8]は,論理ボリューム[3/8.8]のファイル集合[4/8.5]におけるディレクトリ[4/8.6]
のファイル識別記述子[4/14.4]で,必ずしも参照されるわけではない。
1.3.2.28
VAT ICB(Virtual Allocation Table ICB)
VATを含むファイルを記述する,ファイルエントリICB。
1.3.3
用語遣い
1.3.3.1
してもよい(May)
任意選択の行為又は機能を示す。
1.3.3.2
任意選択の(Optional)
実装しても,しなくてもよい機能を示す。実装する場合,その機能は規定どおりに実装しなければなら
ない。
1.3.3.3
(し)なければならない(Shall)
必須であって,この規格に適合していることを主張するために実装しなければならない行為又は機能を
示す。
1.3.3.4
望ましい(Should)
任意ではあるが,その実装が強く推奨される行為又は機能を示す。
1.3.3.5
予約(Reserved)
将来の使用のために確保されている。予約欄は,将来の使用のために確保された欄であり,0に設定し
なければならない。予約値は,将来の使用のために確保された値であり,使用してはならない。
注記1 JIS X 0607,JIS X 0609,JIS X 0610では予備と訳している。
注記2 Reserve Volume Descriptor Sequenceの訳語は,予備ボリューム記述子列とする(JIS X 0607の
8.4.2.2を参照)。
1.3.4
略語
この規格で用いる主な略語は,次による。
略語
意味
AD
割付け記述子(Allocation Descriptor)
AVDP
開始ボリューム記述子ポインタ(Anchor Volume Descriptor Pointer)
EA
拡張属性(Extended Attribute)
EFE
拡張ファイルエントリ(Extended File Entry)
FE
ファイルエントリ(File Entry)
FID
ファイル識別記述子(File Identifier Descriptor)
FSD
ファイル集合記述子(File Set Descriptor)
ICB
JIS X 0607規格類における制御ノード(Information Control Block)
IUVD
処理システム用ボリューム記述子(Implementation Use Volume Descriptor)
LV
論理ボリューム(Logical Volume)
LVD
論理ボリューム記述子(Logical Volume Descriptor)
8
X 0611:2018
略語
意味
LVID
論理ボリューム保全記述子(Logical Volume Integrity Descriptor)
PD
区画記述子(Partition Descriptor)
PVD
基本ボリューム記述子(Primary Volume Descriptor)
USD
未割付け空間記述子(Unallocated Space Descriptor)
VAT
仮想割付け表(Virtual Allocation Table)
VDS
ボリューム記述子列(Volume Descriptor Sequence)
VRS
ボリューム認識列(Volume Recognition Sequence)
2
基本制約及び基本要件
2.0A 要約
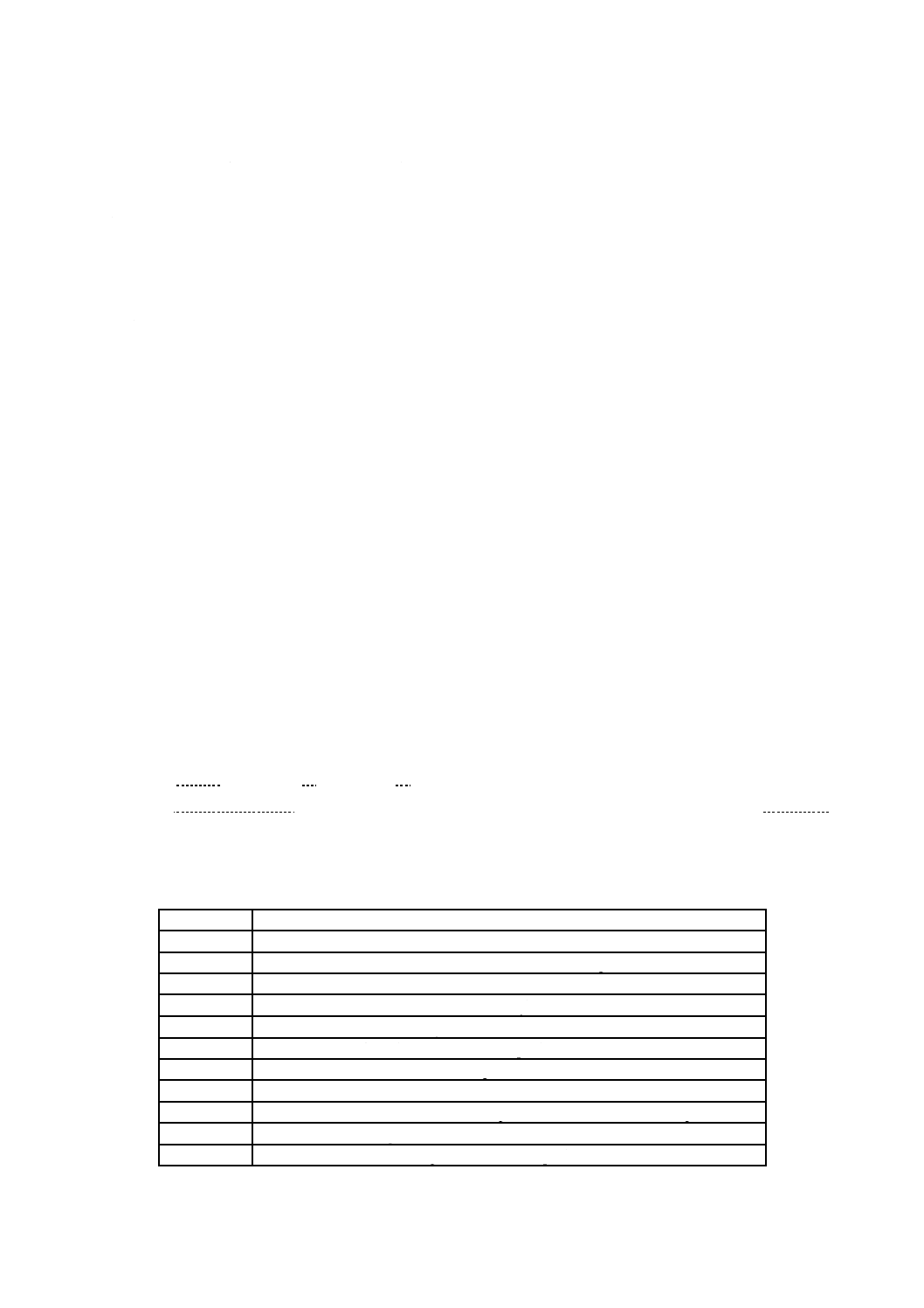
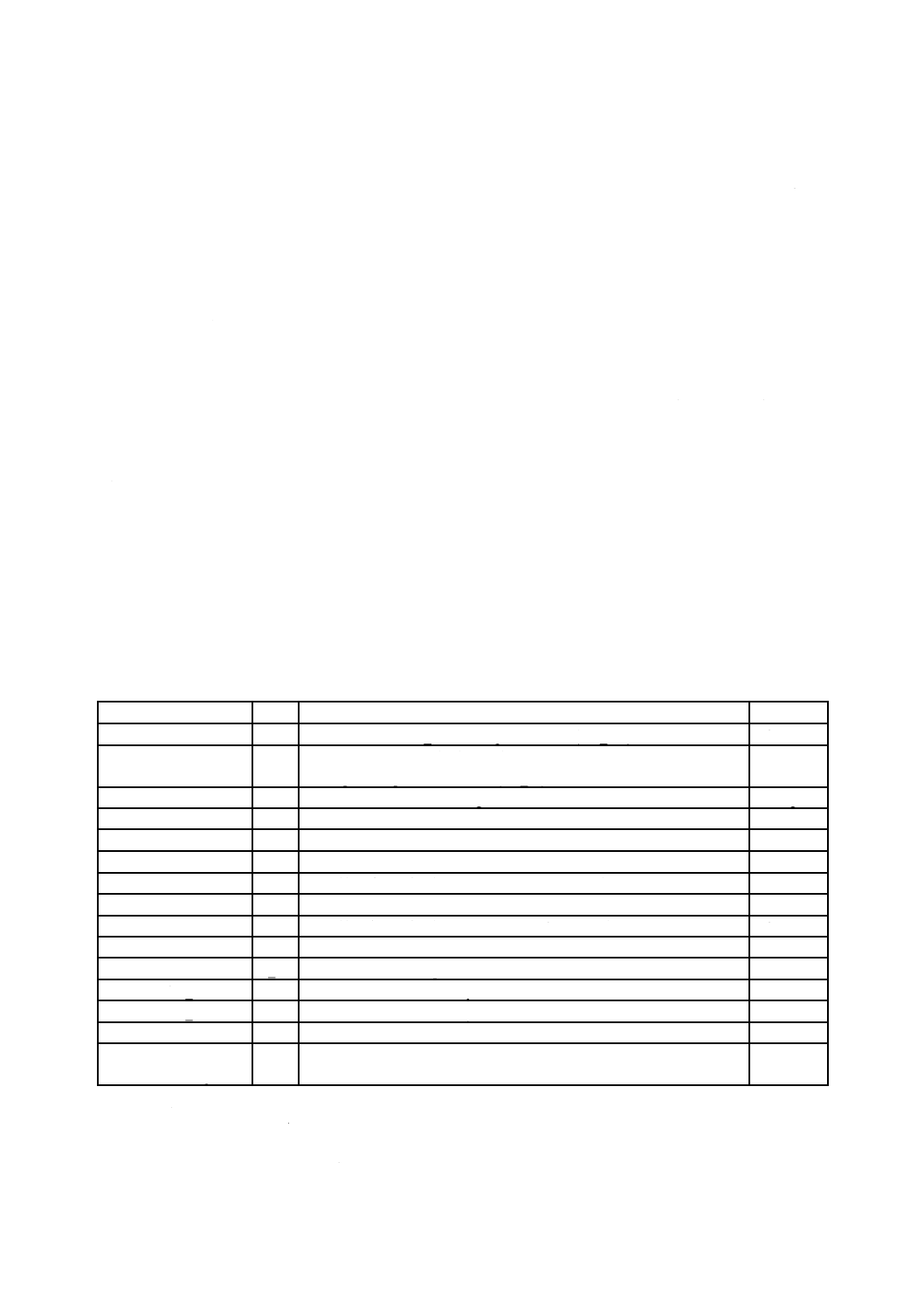
表1は,この規格が定義する基本制約及び基本要件の幾つかを要約している。これらの制約及び要件は,
追加の制約及び要件とともに,この規格の2.1以降で詳細に規定する。
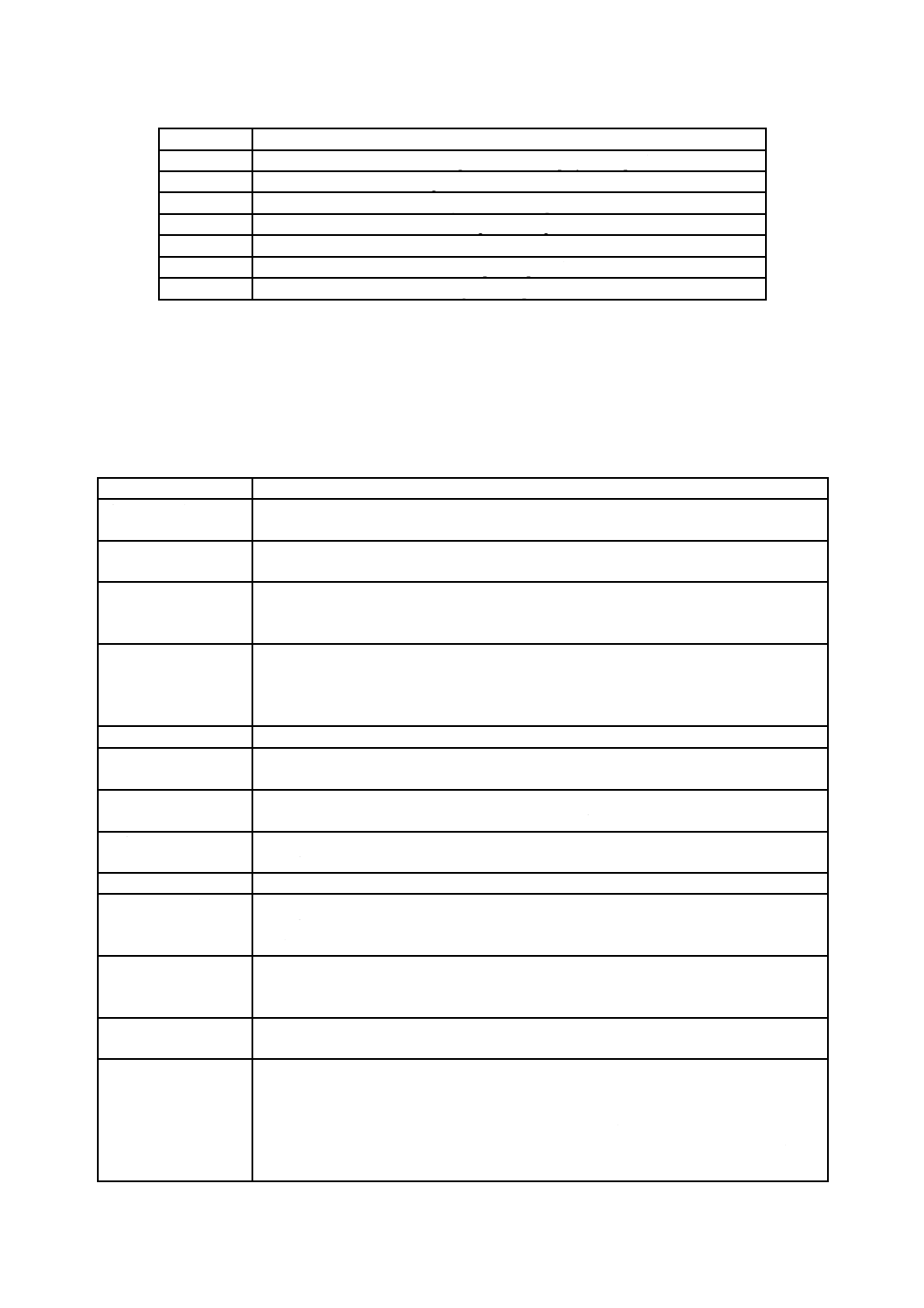
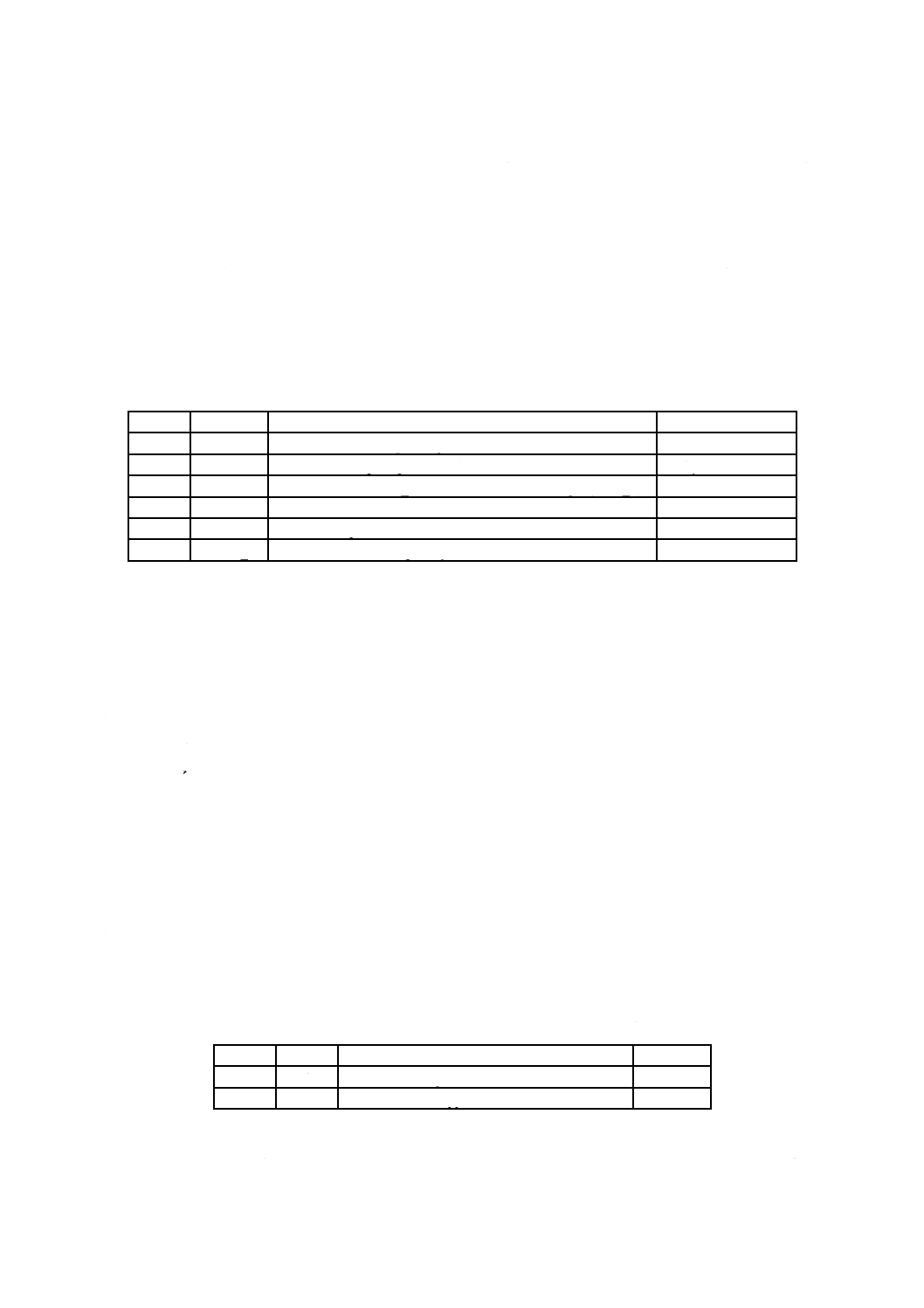
表1−基本制約及び基本要件
項目
制約及び要件
論理セクタ長
特定のボリュームに関する論理セクタ長は,この特定のボリュームの物理セクタ長と同じ
としなければならない。
論理ブロック長
論理ボリュームに関する論理ブロック長は,この特定の論理ボリュームが存在するボリュ
ーム又はボリューム集合の論理セクタ長に設定しなければならない。
ボリューム集合
同一ボリューム集合中の全ての媒体は,同じ物理セクタ長をもたなければならない。書換
形又は上書き可能形の媒体,及び追記形の媒体は,同一ボリューム集合に混在してはなら
ない。
ボリューム空間の最初
の32Kバイト
ボリューム空間の最初の32 768バイトは,JIS X 0607規格類の構造の記録に使用してはな
らない。この領域は,未割付け空間記述子又は他のいかなるJIS X 0607規格類の記述子も
参照してはならない。この領域は,元のオペレーティングシステム(OS)での自由使用に
任されている。
ボリューム認識列
JIS X 0607規格類の第2部の規定に従ってボリューム認識列を記録しなければならない。
日時表示
全ての日時表示は,現地時で記録しなければならない。時間帯は,時間帯の概念をサポー
トするOSに従って記録しなければならない。
実体識別子
実体識別子は,この規格に従って記録しなければならない。この規格で特記しない限り,
実体識別子は,処理システムを一意に識別する値を含まなければならない。
記述子CRC
CRCは,空間ビットマップ記述子を除く全ての記述子に関して,利用可能で,計算されな
ければならない。
ファイル名の長さ
最大255バイトとする。
エクステント長
最大エクステント長は,230−1を,論理ブロックサイズの最も近い整数倍の値に端数を切
り下げた値(バイト)でなければならない。仮想区画における最大エクステント長は,論
理ブロックサイズでなければならない。
基本ボリューム記述子 ボリュームごとにただ一つの最新の基本ボリューム記述子を記録しなければならない。こ
の記述子のボリューム順序番号欄が1である媒体は,最新の論理ボリューム記述子で定義
された論理ボリュームの一部でなければならない。
開始ボリューム記述子
ポインタ
ボリュームの最大セクタ番号をNとするとき,256,N−256,及びNの三つの位置のうち,
最低2か所に記録しなければならない(2.2.3参照)。
区画記述子
再生専用形,書換形又は上書き可能形,及び追記形の区画アクセス種別を利用可能としな
ければならない。次に示す一つの例外を除き,ボリュームごとにただ一つの最新の区画記
述子を記録しなければならない。単一ボリュームで構成するボリューム集合において,一
つの区画が再生専用のアクセス種別をもち,他区画が書換形・上書き可能形のアクセス種
別をもつ場合だけ,ボリュームは二つの最新の区画記述子とともに,二つの区画を含んで
もよい。このボリュームの論理ボリュームは,両方の区画の内容で構成する。

9
X 0611:2018
表1−基本制約及び基本要件(続き)
項目
制約及び要件
論理ボリューム記述子 ボリューム集合ごとにただ一つの最新のボリューム記述子を記録する。
論理ボリューム識別子欄は,空にしてはならず,論理ボリュームの識別のための識別子を
含むことが望ましい。特に,この規格に適合するボリュームを作成するソフトウェアは,
この欄に固定の値又は無意味な値を設定してはならない。同一であることを意図する重複
ディスクは,この欄が同一の値でもよい。この欄は,ジュークボックス中に複数の媒体が
存在するときの,論理ボリュームの識別のために,特に重要となる。この名前は,一般的
には,利用者に表示されているものである。
基本ボリューム記述子のボリューム順序番号欄が1であるボリュームに記録された論理ボ
リューム記述子は,論理ボリュームの全体を示す区画マップの個数欄の値と区画マップ欄
の内容とをもたなければならない。例えば,ボリューム集合が区画を追加することによっ
て拡張された場合は,更新された論理ボリューム記述子が集合の最後のボリュームに書き
込まれ,集合の最初のボリュームにも書き込まれ(又は再度書き込まれ)なければならな
い。
論理ボリューム保全記
述子
記録しなければならない。LVIDのエクステントは,エクステント長で終了してもよい。
未割付け空間記述子
ボリュームごとに一つだけの最新の未割付け空間記述子を記録する。
ファイル集合記述子
書換形又は上書き可能形の媒体中の論理ボリュームごとに,一つだけのファイル集合記述
子を記録する。追記形の媒体においては,この規格で定義する制約に従って複数のファイ
ル集合記述子を記録してもよい。FSDエクステントは,エクステント長で終了してもよい。
ICBタグ
方策種別4又は方策種別4 096だけを記録しなければならない。
ファイル識別記述子
一つのファイル識別記述子の全長は,一つの論理ブロックの長さを超えてはならない。
ファイルエントリ
一つのファイルエントリの全長は,一つの論理ブロックの長さを超えてはならない。
割付け記述子
短割付け記述子及び長割付け記述子だけを記録できる。
割付けエクステント記
述子
割付け記述子からなる一つのエクステントの長さは,一つの論理ブロックの長さを超えて
はならない。
未割付け空間エントリ 一つの未割付け空間エントリの全長は,一つの論理ブロックの長さを超えてはならない。
空間ビットマップ記述
子
CRCは必要でない。
区画保全エントリ
記録してはならない。
ボリューム記述列エク
ステント
主ボリューム記述子列エクステント及び予備ボリューム記述子列エクステントの両方と
も,最小長16個の論理セクタで構成しなければならない。VDSエクステントはエクステ
ント長で終了してもよい。
レコード構造
JIS X 0607規格類の第5部で定義するレコード構造ファイルは,作成してはならない。
2.1
第1部 一般
2.1.1
文字集合
この規格で定義する構造に関して,UDFで使用する文字集合は,CS0文字集合である。OSTA CS0文字
集合は,ここで定義する。
OSTA CS0は,JIS X 0221に規定されるUCS-2から#FEFF及び#FFFEを除いたd文字から成り,表2に
定義するOSTA圧縮Unicodeフォーマットで記録される。
注記 表2などに記載されているRBPとは,Relative Byte Position(相対バイト位置)の略である。
10
X 0611:2018
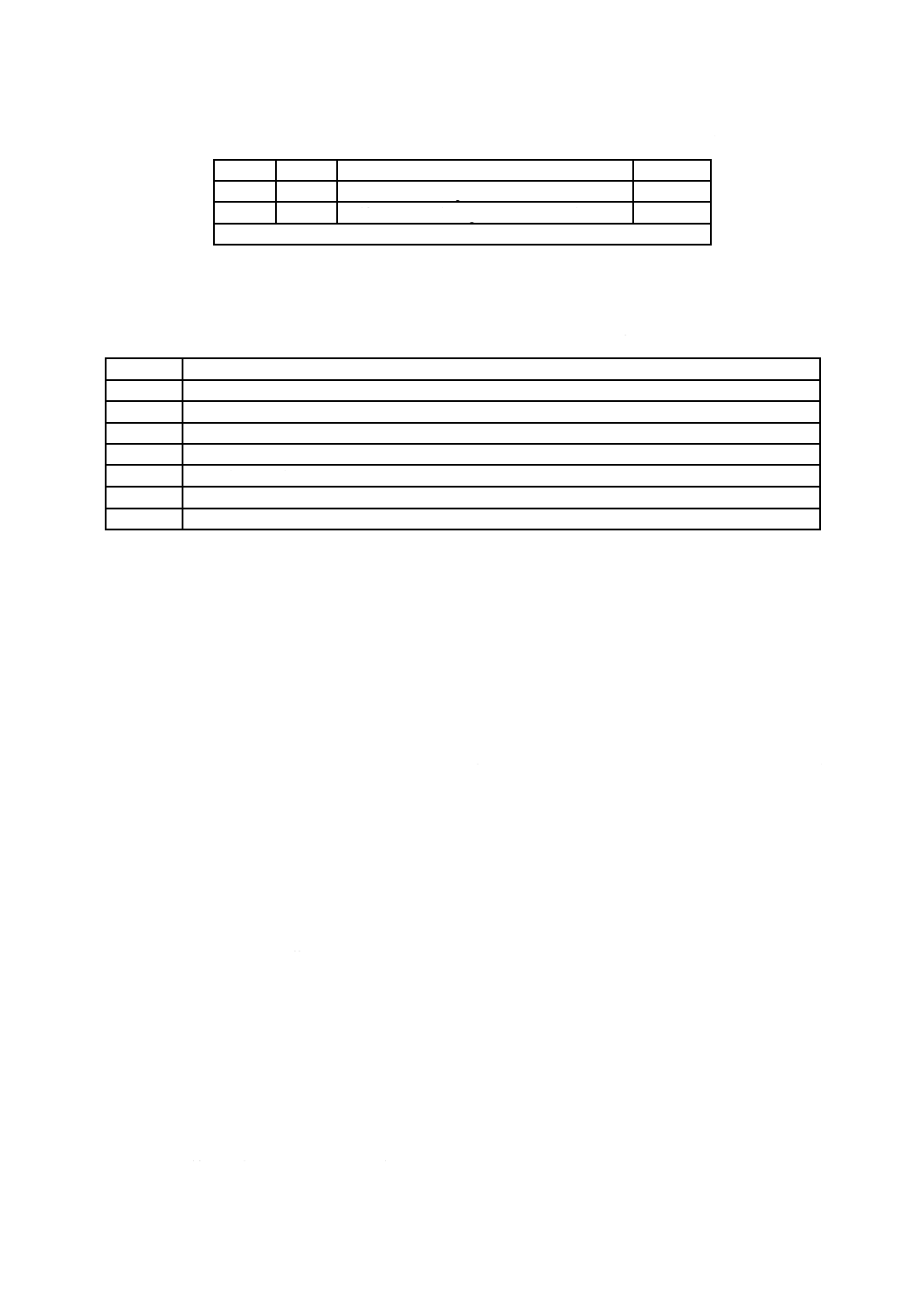
表2−OSTA圧縮Unicodeフォーマット(OSTA Compressed Unicode format)
RBP
長さ
名前
内容
0
1
圧縮識別子(Compression ID)
Uint8
1
??
圧縮ビット列(Compressed Bit Stream)
バイト
注記 ??は可変長欄を示す。
圧縮識別子(CompressionID)は,圧縮ビット列(CompressedBitStream)欄の圧縮に使用する圧縮アルゴ
リズムを識別する。表3に示すアルゴリズムが,現在利用できる。
表3−圧縮アルゴリズム(Compressed Algorithm)
値
意味
0〜7
予約(Reserved)
8
圧縮ビット列(CompressedBitStream)中の1文字が,8ビットであることを示す。
9〜15
予約(Reserved)
16
圧縮ビット列中の1文字が,16ビットであることを示す。
17〜253
予約(Reserved)
254
CS0伸張は,空である一意な状態であることを示す。圧縮アルゴリズム値8が圧縮に使われる。
255
CS0伸張が,空である一意な状態であることを示す。圧縮アルゴリズム値16が圧縮に使われる。
圧縮識別子の値が8又は16のとき,その値は,圧縮ビット列欄で定義するd文字のビット数を規定する。
圧縮識別子が指定するビット数で圧縮ビット列を区切ったときの各ビット列は,OSTA圧縮Unicodeのd
文字を表す。符号化される文字のビットは,最上位ビットから最下位ビットまで,圧縮ビット列に加えな
ければならない。符号化される文字のビットは,符号化先の着目しているバイトの最上位ビットの位置か
ら圧縮ビット列に加えていかなければならない。
特記事項 この符号化によって,圧縮識別子16のアルゴリズムで書き込まれた文字は,ビッグエン
ディアンフォーマットで書き込まれる。
Uint16として解釈されるOSTA圧縮Unicodeのd文字の値は,Unicode 2.0の規定の対応するd文字の値
を定義する。OSTA圧縮Unicodeについては,6.4に掲げるOSTA圧縮UnicodeとUnicode 2.0との間の変換
Cのソースコードの例を参照。
Unicodeのバイト順マーク#FEFF及び#FFFEは,使用してはならない。254又は255の圧縮識別子は,削
除ビットが1に設定されたファイル識別子だけに使わなければならない。254又は255の圧縮識別子をも
つファイル識別子を非圧縮にすると,結果の識別子は空である一意な状態であるとして取り扱わなければ
ならない。
2.1.2
OSTA CS0 Charspec
struct charspec{
/* JIS X 0607 1/7.2.1 */
Uint8
CharacterSetType;
byte
CharacterSetInfo[63];
}
文字集合の種別(CharacterSetType)欄は,CS0符号化文字集合を示す値0を指定する。
文字集合情報(CharacterSetInfo)欄は,次に示すバイト値を設定し,欄の残りバイトは0に設定する。
#4F, #53, #54, #41, #20, #43, #6F, #6D, #70, #72, #65, #73, #73, #65,
#64, #20, #55, #6E, #69, #63, #6F, #64, #65
このバイト値は,次に示すASCII列を表す。
11
X 0611:2018
“OSTA Compressed Unicode”
2.1.3
dstring
この規格と同様に,JIS X 0607規格類は,通常は相対バイト位置を0から定義している。これに反し,
[1/7.2.12]では,相対位置が1からのものとして,dstringを定義している。これは混乱を招くことがあるの
で,[1/7.2.12]の規定を相対位置が0からのものとして変更したものを次に示す。
“7.2.12 固定長文字欄
長さnのdstringは,d文字[1/7.2]を記録するnバイトの欄である。文字の記録に使用するバイト
の数は,バイトn−1にUint8[1/7.1.1]で記録する。ここで,nはこの欄の長さである。文字は欄の先
頭バイトから記録し,記録した文字の後からバイトn−2までのバイト位置に,全て#00を設定する
([1/7.2.12]参照)。”
符号化するd文字の数が0の場合,dstringの長さは0としなければならない。
注記 長さ0の列の場合を除いて,dstringの長さは圧縮識別子(2.1.1)を含む。長さ0の列は,dstring
欄に全て0を設定することによって記録されることが望ましい。
2.1.4
日時表示(Timestamp)
struct timestamp{
/* JIS X 0607 1/7.3 */
Uint16
TypeAndTimezone;
Uint16
Year;
Uint8
Month;
Uint8
Day;
Uint8
Hour;
Uint8
Minute;
Uint8
Second;
Uint8
Centiseconds;
Uint8
HundredsofMicroseconds;
Uint8
Microseconds;
}
2.1.4.1
種別及び時間帯(Uint16 TypeAndTimezone)
次の記載において,種別(Type)は,この欄の最上位4ビットを示し,時間帯(TimeZone)欄は,この
欄の最下位12ビットを示し,その値は2の補数形式の符号付き12ビット数と解釈する。
a) 種別(Type)
1) 意味:この構造の時刻は,現地時として解釈しなければならない。OSTA UDF適合媒体では,種別
は1でなければならない。
2) 設定値:種別は,現地時を示す1を設定しなければならない。
b) 時間帯(TimeZone)
1) 意味:時間帯欄はこの欄を最後に更新したときの現地の時間帯を指定していると解釈しなければな
らない。この欄が値(−2 047)の場合には,時間帯を指定していない。
2) 設定値:時間帯の概念が利用可能なOSは,協定世界時からの時間帯の差(1分ごと)を時間帯欄に
指定しなければならない。それ以外は,時間帯欄には,値(−2 047)を設定しなければならない。
注記1 協定世界時より西の時間帯は,負の時間差をもつ。例えば,米国東部標準時は−300分であ
り,米国東部夏時間は−240分である。

12
X 0611:2018
注記2 時間帯を利用可能としているシステム上の実装は,時間帯が指定されていない場合は協定世
界時と解釈することが望ましい。また,必須ではないが,この解釈では時間帯を利用可能と
していないシステムで作成されたファイルが,読出しシステムの現地時間帯と関係なく,常
に同じ日時表示で表示されるという利点をもつ。
2.1.5
実体識別子(Entity Identifier)
struct EntityID {
/* JIS X 0607 1/7.4 */
Uint8
Flags;
char
Identifier[23];
char
IdentifierSuffix[8];
}
UDFは,実体識別子を次に示す四つの種別に分類する。
a) 範囲実体識別子(Domain Entity Identifiers)
b) UDF実体識別子(UDF Entity Identifiers)
c) 処理システム実体識別子(Implementation Entity Identifiers)
d) アプリケーション実体識別子(Application Entity Identifiers)
これらの異なる種別に基づいて実体識別子のフォーマット及び使用方法を次に示す。
2.1.5.1
フラグ(Uint8 Flags)
a) 意味:自明。
b) 設定値:0を設定しなければならない。
2.1.5.2
識別子(char Identifier)
この規格では,特記しない限り,この欄には,処理システムを一意に識別する識別子を設定しなければ
ならない。この方法は,異なる処理システム間で交換する媒体中に記録した構造が,どの処理システムに
よるものかの識別を可能にする。
処理システムが,他の処理システムで書き込んだ媒体中に存在する構造を更新する場合,現状の処理シ
ステムは,現状の処理システムを一意に識別する値を識別子欄に設定しなければならない。
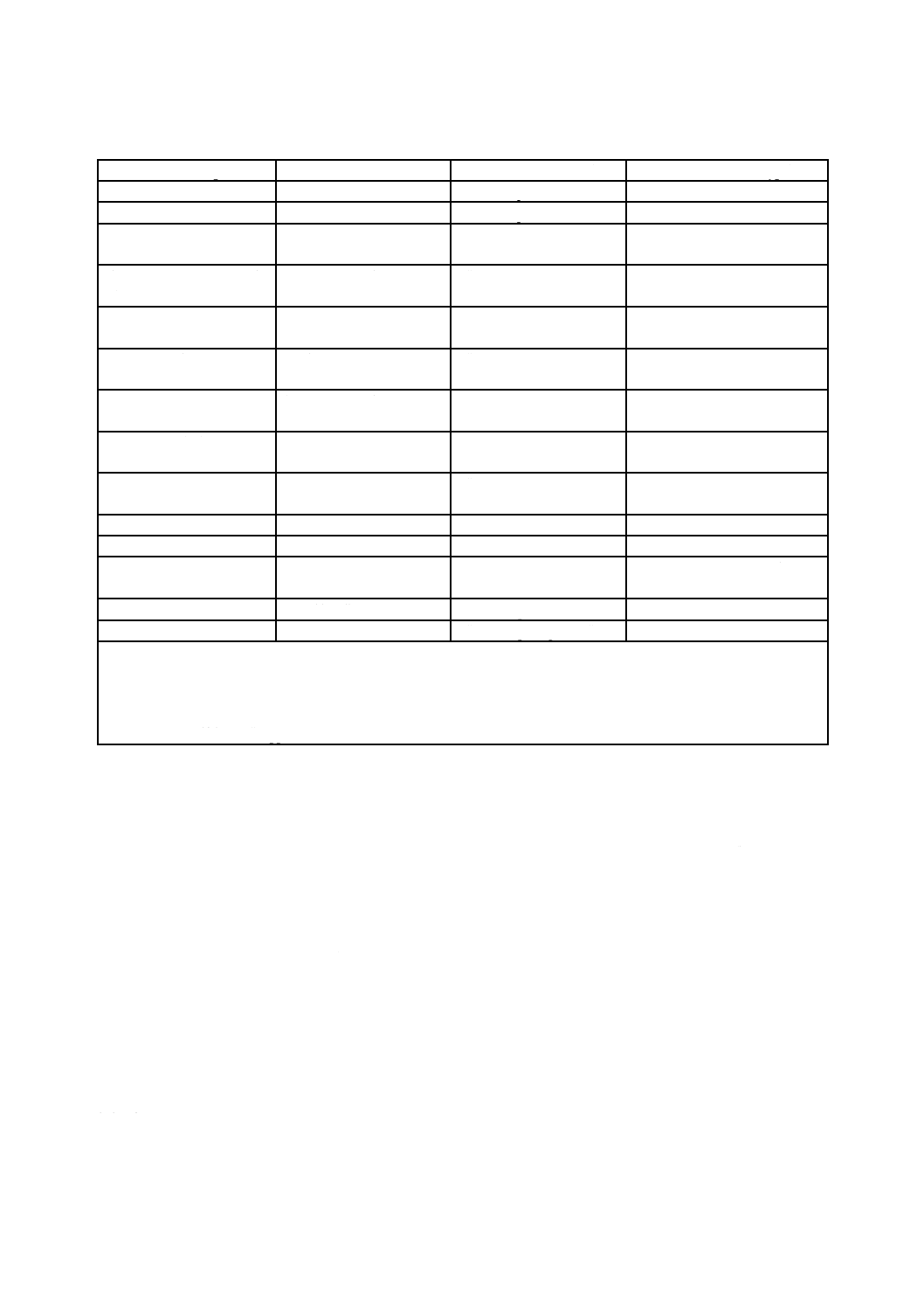
表4は,JIS X 0607規格類及びこの規格で定義する実体識別子欄を要約したものであり,設定しなけれ
ばならない値を示す。
表4−実体識別子(Entity Identifiers)
記述子(Descriptor)
欄(Field)
識別子値(ID Value)
添字種別(Suffix Type)
基本ボリューム記述子
処理システム識別子
“*Developer ID”
処理システム識別子添字
基本ボリューム記述子
アプリケーション識別子
“*Application ID”
アプリケーション識別子添字
処理システム用
ボリューム記述子
処理システム識別子
“*UDF LV Info”
UDF識別子添字
処理システム用
ボリューム記述子
処理システム識別子
(処理システム用欄内)
“*Developer ID”
処理システム識別子添字
区画記述子
処理システム識別子
“*Developer ID”
処理システム識別子添字
区画記述子
区画内容
“+NSR03”
アプリケーション識別子添字
論理ボリューム記述子
処理システム識別子
“*Developer ID”
処理システム識別子添字
論理ボリューム記述子
範囲識別子
“*OSTA UDF Compliant” 範囲識別子添字
ファイル集合記述子
範囲識別子
“*OSTA UDF Compliant” 範囲識別子添字
ファイル識別記述子
処理システム用
“*Developer ID”
処理システム識別子添字
(任意機能)
13
X 0611:2018
表4−実体識別子(Entity Identifiers)(続き)
記述子(Descriptor)
欄(Field)
識別子値(ID Value)
添字種別(Suffix Type)
ファイルエントリ
処理システム識別子
“*Developer ID”
処理システム識別子添字
装置仕様拡張属性
処理システム識別子
“*Developer ID”
処理システム識別子添字
UDF処理システム用拡張
属性
処理システム識別子
3.3.4.5参照
UDF識別子添字
非UDF処理システム用拡
張属性
処理システム識別子
“*Developer ID”
処理システム識別子添字
UDFアプリケーション用
拡張属性
アプリケーション識別子
3.3.4.6参照
UDF識別子添字
非UDFアプリケーション
用拡張属性
アプリケーション識別子
“*Application ID”
アプリケーション識別子添字
UDF一意IDマッピングデ
ータ
処理システム識別子
“*Developer ID”
処理システム識別子添字
パワーこう(較)正表スト
リーム
処理システム識別子
“*Developer ID”
処理システム識別子添字
論理ボリューム保全記述
子
処理システム識別子
(処理システム用欄内)
“*Developer ID”
処理システム識別子添字
区画保全エントリ
処理システム識別子
N/A
N/A
仮想区画マップ
区画種別識別子
“*UDF Virtual Partition” UDF識別子添字
仮想割付け表
処理システム用
“*Developer ID”
処理システム識別子添字
(任意機能)
予備区画マップ
区画種別識別子
“*UDF Sparable Partition”UDF識別子添字
予備表
予備識別子
“*UDF Sparing Table”
UDF識別子添字
注記1 N/Aは,“規定しない”ことを示す。
注記2 実体識別子欄の値は,バイトの列として解釈し,CS0で規定するdstringとしては解釈しない。UDFで容易
に使用するために,この欄で使用する値は,ASCII文字列で指定する。UDFで定義する実体識別子で使用
するバイト列は,6.2で規定する。
注記3 識別子値欄の“*Application ID”は,書込みを行ったアプリケーションを一意に識別する識別子を示す。
表4の識別子値欄の“*Developer ID”は,現状の処理システムを一意に識別する実体識別子を示す。指
定した値は,新しい記述子を作成するときに使用することが望ましい。規定した値は,指定した実体識別
子欄の有効範囲内で何かを更新する場合には,存在する記述子にも使用することが望ましい。
特記事項 “*Developer ID”のために選択された値は,処理システムに関する社名及び製品名を識別
できるだけの情報を含むことが望ましい。例えば,DataOneというUDF製品をもつXYZ
という会社は,Developer IDとして“*XYZ DataOne”を選択してもよい。Developer IDの
添字においても,DataOne製品の現在の版数を記録することを選択してもよい。この情報
は,異なる会社の複数の製品が媒体に記録されていた場合,どの処理システムが媒体の一
部に不適切な構造を書き込んだのかを決定するとき,非常に助けになる。
表4の添字種別欄は,相当する実体識別子で使用する添字のフォーマットを定義する。これらの異なる
添字種別は,以降で定義する。
特記事項 この規格で定義する全ての識別子(6.1)は,UDF識別子としてOSTAによって登録され
ていなければならない。
2.1.5.3
識別子添字(Identifier Suffix)
識別子添字(IdentifierSuffix)欄のフォーマットは,識別子の種別に依存する。
この規格で規定するOSTA範囲実体識別子(6.1)に関しては,識別子添字欄を表5に示す構成でなけれ
14
X 0611:2018
ばならない。
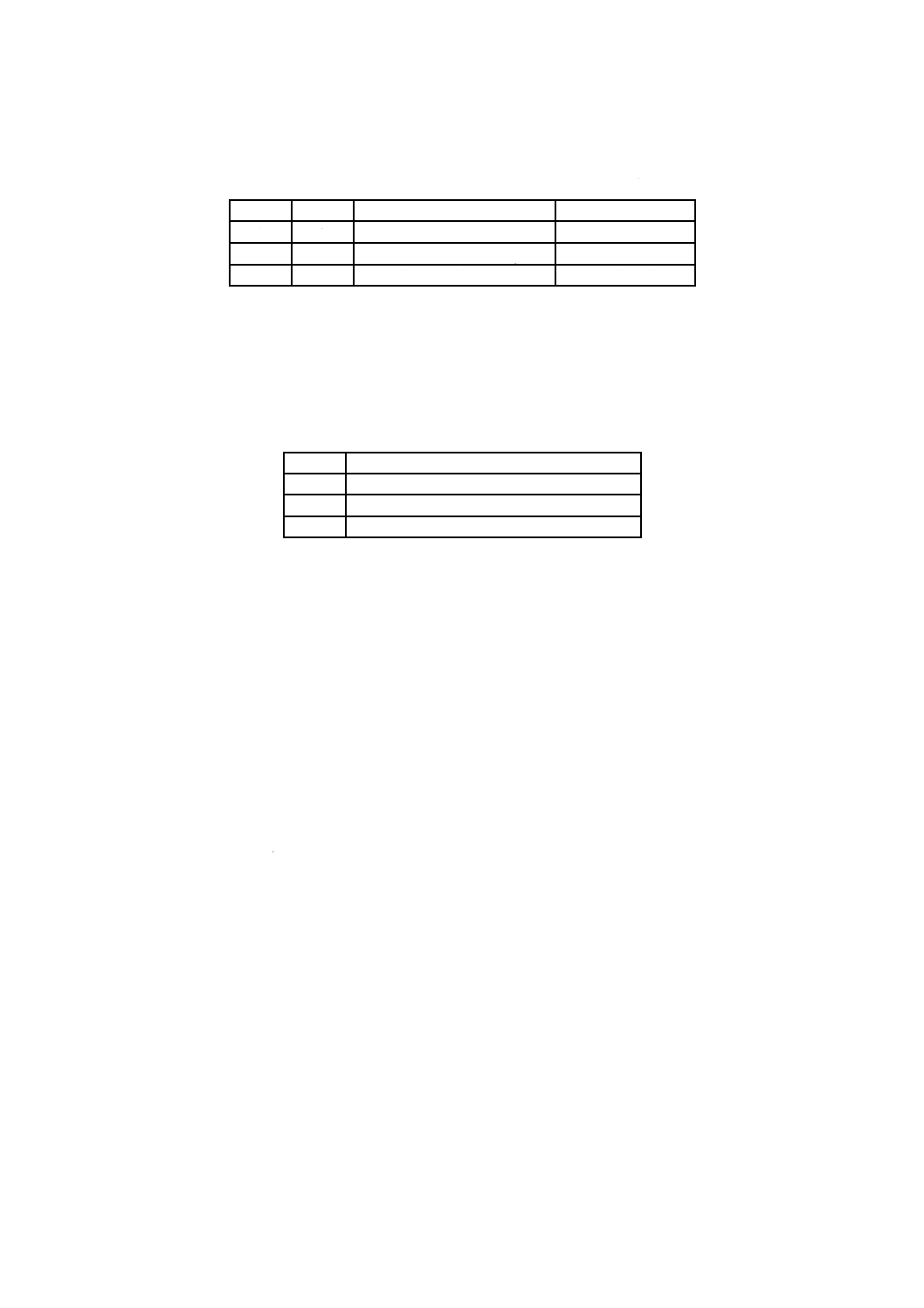
表5−範囲識別子添字欄フォーマット(Domain IdentifierSuffix field format)
RBP
長さ
名前
内容
0
2
UDF版数(UDF Revision)
Uint16(= #0201)
2
1
範囲フラグ(Domain Flags)
Uint8
3
5
予約(Reserved)
バイト(= #00)
UDF版数(UDFRevision)欄は,この規格の対応団体規格の規定の版数2.01を示す値#0201を設定する。
この欄は,この規格の対応団体規格の規定の改正版に加えられた変更を,処理システムが検出することを
可能にする。OSTA範囲識別子は,論理ボリューム記述子及びファイル集合記述子だけに使用する。範囲
フラグ(Domain Flags)欄は,表6に示すビットフラグを定義する。
表6−範囲フラグ(Domain Flags)
Bit
意味
0
ハード書込み保護(Hard Write-Protect)
1
ソフト書込み保護(Soft Write-Protect)
2〜7
予約(Reserved)
ソフト書込み保護(SoftWriteProtect)フラグは,利用者が設定可能なフラグであり,このフラグが存在
する記述子の有効範囲で,ボリューム構造又はファイルシステム構造が書込み保護されていることを示す。
ソフト書込み保護フラグの値が1の場合,利用者の書込み保護を示さなければならない。このフラグは,
利用者が設定及び解除してもよい。ハード書込み保護(HardWriteProtect)フラグは,処理システムが設定
可能なフラグであり,このフラグが存在する記述子の有効範囲で永久的な書込み保護を示さなければなら
ない。ハード書込み保護フラグの値が1の場合,永久的な書込み保護を示さなければならない。このフラ
グは,一度設定した場合解除してはならない。ハード書込み保護フラグは,ソフト書込み保護フラグに優
先する。
書込み保護フラグは,論理ボリューム記述子及びファイル集合記述子の中に現れる。それらは次のとお
りに解釈しなければならない。
is̲fileset̲write̲protected = LVD.HardWriteProtect || LVD.SoftWriteProtect ||
FSD.HardWriteProtect || FSD.SoftWriteProtect
is̲fileset̲hard̲protected = LVD.HardWriteProtect || FSD.HardWriteProtect
is̲fileset̲soft̲protected = (LVD.SoftWriteProtect || FSD.SoftWriteProtect) &&
(! is̲vol̲hard̲protected)
is̲vol̲write̲protected = LVD.HardWriteProtect || LVD.SoftWriteProtect
is̲vol̲hard̲protected = LVD.HardWriteProtect
is̲vol̲soft̲protected = LVD.SoftWriteProtect && !LVD.HardWriteProtect
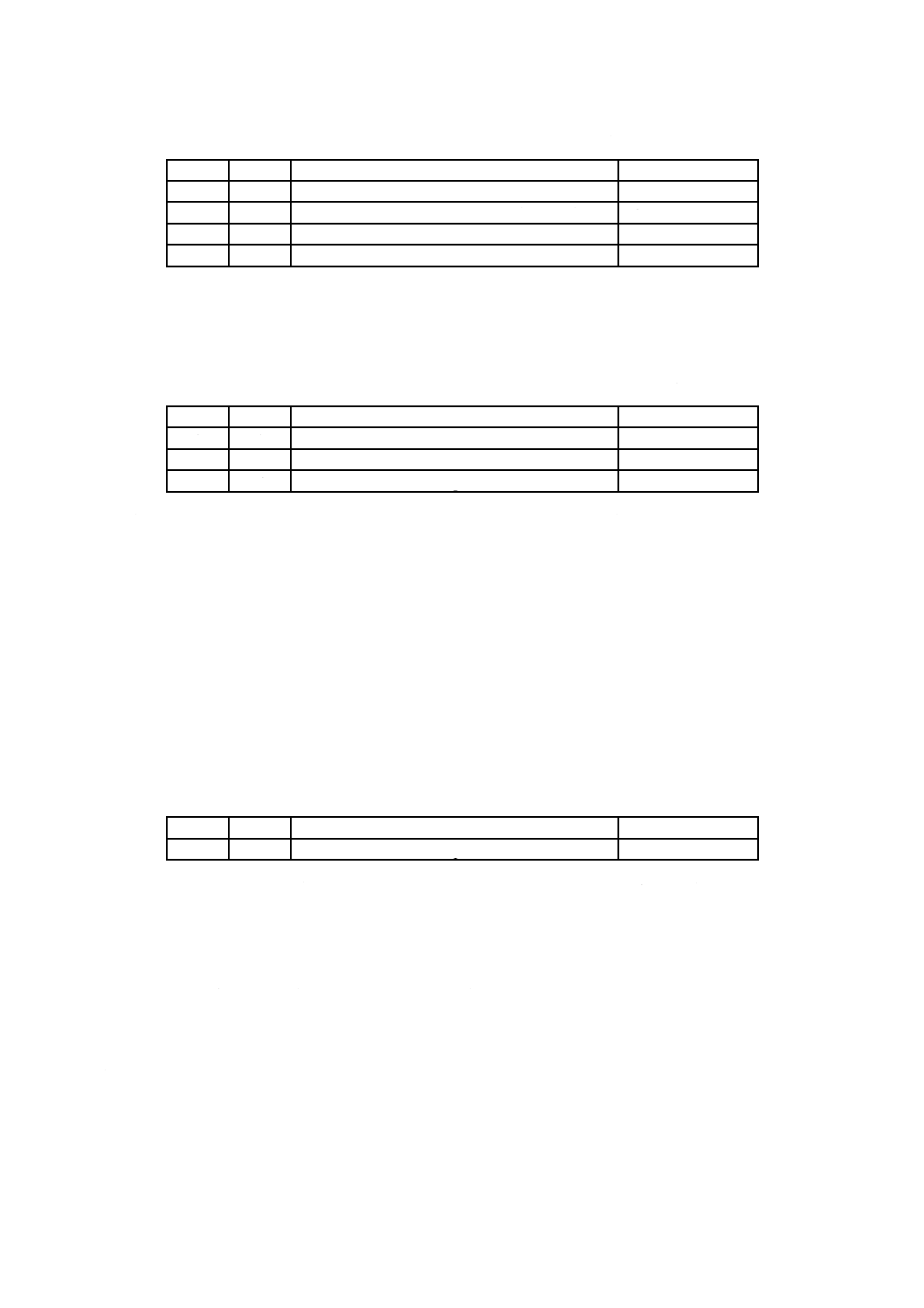
UDFで定義する実体識別子(6.1)に対しては,識別子添字欄は,表7に示す構成でなければならない。
15
X 0611:2018
表7−UDF識別子添字(UDF IdentifierSuffix)
RBP
長さ
名前
内容
0
2
UDF版数(UDF Revision)
Uint16(= #0201)
2
1
オペレーティングシステムクラス(OS Class)
Uint8
3
1
オペレーティングシステム識別子(OS Identifier) Uint8
4
4
予約(Reserved)
バイト(= #00)
オペレーティングシステムクラス(OS Class)及びオペレーティングシステム識別子(OS Identifier)欄
の内容は,6.3に規定する。
UDFで定義しない実体識別子に対しては,識別子添字欄は,表8に示す構成でなければならない。
表8−処理システム識別子添字(Implementation IdentifierSuffix)
RBP
長さ
名前
内容
0
1
オペレーティングシステムクラス(OS Class)
Uint8
1
1
オペレーティングシステム識別子(OS Identifier) Uint8
2
6
処理システム用領域(Implementation Use Area)
バイト
注記 OSクラス欄及びOS識別子欄の,意図した使用及び重要性を理解することが重要になる。これ
らの欄の主な目的は,UDFボリューム中で問題を検出したときに,誤りを取り除く支援をする
ことである。この欄は,利用者に提供可能な有効な情報も提供する。これらの二つの欄を正し
く設定した場合,処理システムに次の情報を提供する。
− 最後に特定の構造を更新したOSを識別する。
− 最後に特定のファイル又はディレクトリを更新したOSを識別する。
− 開発者が処理システムとともに複数OSを提供する場合,問題が発生したOSを決定する支
援をする。
UDFで定義しないアプリケーション実体識別子に対しては,識別子添字(IdentifierSuffix)欄は,特記し
ない限り,表9に示す構成としなければならない。
表9−アプリケーション識別子添字(Application IdentifierSuffix)
RBP
長さ
名前
内容
0
8
処理システム用領域(Implementation USE Areas)
バイト
2.1.6
初期化時の記述子タグ通し番号(Descriptor Tag Serial Number at Formatting Time)
障害回復に対応するため,全てのUDF記述子のタグ通し番号(TagSerialNumber)は初期化時に記録さ
れ,ボリュームの再初期化時には,以前に記録した値と異なる値を設定しなければならない。
障害回復が対応されない場合は,全てのUDF記述子のタグ通し番号欄には,初期化時に値0(#0000)
を記録しなければならない([3/7.2.5]及び[4/7.2.5]参照)。
障害回復が対応される場合は,使用すべき値はボリュームが初期化される前の状態に依存する。将来に
おいて障害回復可能なボリュームの取り得る状態は,次の二つしかない。
a) 完全に消去されたボリューム:これが行われた後,障害回復が対応される場合にだけ,タグ通し番号
の値に1(#0001)が使われなければならない。
b) タグ通し番号によって障害回復に対応しているクリーンなUDFボリュームであって,少なくとも二つ
の開始ボリューム記述子ポインタのタグ通し番号の値がいずれもXと等しく,Xが0と等しくない場
16
X 0611:2018
合。障害回復が対応される場合は,値X+1がタグ通し番号の値として用いられなければならない。X
+1が0に戻ってしまう場合は,それを0のままにして障害回復が対応されていないことを示す。
注記 この理由は,もし,X+1が0に戻ってしまうのであれば,値が0でないいずれかのタグ通し
番号の一意性がそのボリューム上では保証できなくなってしまうからである。
特記事項 この2.1.6では,消去という用語を,例えば,セクタを0で埋めることによって,UDFと
しては無効なセクタにするという意味で使用している。
2.1.7
ボリューム認識列(Volume Recognition Sequence)
次の規則は,ボリューム認識列を書き込むときに守られなければならない。
a) 設定値:JIS X 0607規格類の第2部及び第3部で定義されているボリューム認識列を記録しなければ
ならない。ボリューム認識列内には,一つだけのNSR記述子がなければならない。NSR及びBOOT2
記述子は拡張領域になければならない。一つのBEA01及び一つのTEA01をもつ一つだけの拡張領域
がなければならない。その他のボリューム構造記述子は,拡張領域よりも前だけに置いてもよい。ボ
リューム認識列の直後のブロックは未記録であるか全て#00で埋まっていなければならない。
b) 意味:処理システムの作成者はUDF 2.00以前の版数で記録された媒体は2.1.7の規則に従っていない
ことを予期することが望ましく,それらの場合をそれに応じて扱うことが望ましい。
2.2
第3部 ボリューム構造
2.2.1
記述子タグ(Descriptor Tag)
struct tag{
/* JIS X 0607 3/7.2 */
Uint16
TagIdentifier;
Uint16
DescriptorVersion;
Uint8
TagChecksum;
byte
Reserved;
Uint16
TagSerialNumber;
Uint16
DescriptorCRC;
Uint16
DescriptorCRCLength;
Uint32
TagLocation;
}
2.2.1.1
タグ通し番号(Uint16 TagSerialNumber)
a) 意味:無視する。障害回復を意図する。
b) 設定値:このボリュームの開始ボリューム記述子ポインタのタグ通し番号(TagSerialNumber)の値に
設定しなければならない。
障害回復に対応するため,タグ通し番号はボリュームの再初期化時には,以前に記録した値と異なる値
を設定しなければならない。この値はボリュームの初期化時に決定され,初期化される前の状態に依存す
る。詳細については2.1.6を参照。
2.2.1.2
記述子CRC長(Uint16 DescriptorCRCLength)
CRCは,各記述子で利用可能であり,計算されなければならない。この欄の値は,(記述子の大きさ)
−(記述子タグの長さ)を設定しなければならない。記述子を読み出すときは,CRCを検証することが望
ましい。
注記 記述子CRC長(DescriptorCRCLength)欄は記述子の実際の長さ又は読み込むバイト長を決定
するのに使用しないことを推奨する。これらの長さは,全ての場合では一致せず,規格中には,
17
X 0611:2018
記述子CRC長が記述子の長さと一致しない例外が存在する。
2.2.2
基本ボリューム記述子(Primary Volume Descriptor)
struct PrimaryVolumeDescriptor{ /* JIS X 0607 3/10.1 */
struct tag
DescriptorTag;
Uint32
VolumeDescriptorSequenceNumber;
Uint32
PrimaryVolumeDescriptorNumber;
dstring
VolumeIdentfier[32];
Uint16
VolumeSequenceNumber;
Uint16
MaximumVolumeSequenceNumber;
Uint16
InterchangeLevel;
Uint16
MaximumInterchangeLevel;
Uint32
CharacterSetList;
Uint32
MaximumCharacterSetList;
dstring
VolumeSetIdentifier[128];
struct charspec
DescriptorCharacterSet;
struct charspec
ExplanatoryCharacterSet;
struct extent̲ad
VolumeAbstract;
struct extent̲ad
VolumeCopyrightNotice;
struct EntityID
ApplicationIdentifier;
struct timestamp
RecordingDateandTime;
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[64];
Uint32
PredecessorVolumeDescriptorSequenceLocation;
Uint16
Flags;
byte
Reserved[22];
}
2.2.2.1
交換水準(Uint16 InterchangeLevel)
a) 意味:関連するボリュームの内容の現状の交換水準([3/11]で規定)及び規定水準が意味する制約につ
いての指定と解釈する。
b) 設定値:このボリュームが,複数ボリュームからなるボリューム集合に属する場合,この水準は値3
を設定し,それ以外の場合は,値2を設定しなければならない。
JIS X 0607規格類は,規定する現状の交換水準に関連する制約の実施を処理システムに要求する。処理
システムは,最大交換水準(Maximum Interchange Level)欄の値を超えない限り,この欄の値を変更しても
よい。
2.2.2.2
最大交換水準(Uint16 MaximumInterchangeLevel)
a) 意味:関連するボリュームの内容についての最大交換水準([3/11]で規定)の指定と解釈する。
b) 設定値:利用者が特別に異なる値を与えない限り,この欄は水準3(制限なし)を設定しなければな
らない。
特記事項 この欄は,ボリューム作成者の意図の指定に使用する。この欄が値2の場合,作成者は,
このボリュームが複数ボリュームからなるボリューム集合(交換水準3)に属さないこ
18
X 0611:2018
とを意図する。受領者は,この欄を無視して値3を設定してもよいが,その場合には,
処理システムは,ボリューム作成者の意図を示す警告を受領者に与えることが望ましい。
2.2.2.3
文字集合リスト(Uint32 CharacterSetList)
a) 意味:[3/10.1.9]で定義する構造で使用する文字集合の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.2.2.4
文字最大集合リスト(Uint32 MaximumCharacterSetList)
a) 意味:文字集合リスト(CharacterSetList)欄で指定してもよい利用可能な文字集合(JIS X 0607規格
類で規定)の最大値の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.2.2.5
ボリューム集合識別子(dstring VolumeSetIdentifier)
a) 意味:ボリューム集合の識別子の指定と解釈する。
b) 設定値:この欄の最初の16文字は,一意の値に設定することが望ましい。この欄の残りは,使用可能
な任意の値を設定してもよい。特に,この規格に従ってボリューム構造を生成するソフトウェアは,
この欄に,固定値又は無意味な値を設定してはならない。同一であることを意図された複製ディスク
は,この欄に同じ値を入れてもよい。
注記 ここで意図する目的は,一意の識別子をもつボリューム集合の保証にある。この欄の最初の
16文字において,最初の8文字は,32ビットの日時の値のCS0による16進表示とすること
が望ましく,残りの8文字は,処理システム用に任されている。
2.2.2.6
記述子文字集合(struct charspec DescriptorCharacterSet)
a) 意味:ボリューム識別子(Volume Identifier)欄及びボリューム集合識別子(Volume Set Identifier)欄で
使用可能な文字集合の指定と解釈する。
b) 設定値:2.1.2で定義するCS0を利用可能とする設定をしなければならない。
2.2.2.7
説明用文字集合(struct charspec ExplantoryCharacterSet)
a) 意味:ボリューム抄録(VolumeAbstract)及びボリューム著作権通知(VolumeCopyrightNotice)エクス
テントの内容の解釈に使用する文字集合の指定と解釈する。
b) 設定値:2.1.2で定義するCS0を利用可能とする設定をしなければならない。
2.2.2.8
処理システム識別子(struct EntityID ImplementationIdentifier)
この欄の適切な扱いに関する詳細情報は,2.1.5を参照。
2.2.2.9
アプリケーション識別子(struct EntityID ApplicationIdentifier)
a) 意味:この欄の有効な実体識別子(2.1.5)は,この欄を最後に書いたアプリケーションを識別し,又
はこの欄が全て#00バイトで埋められている場合は,アプリケーションが識別されないと解釈する。
b) 設定値:この欄は全て#00バイトとするか,有効な実体識別子(2.1.5)を設定しなければならない。
2.2.3
開始ボリューム記述子ポインタ(Anchor Volume Descriptor Pointer)
struct AnchorVolumeDescriptorPointer{ /* JIS X 0607 3/10.2 */
struct tag
DescriptorTag;
struct extent̲ad
MainVolumeDescriptorSequenceExtent;
struct extent̲ad
ReserveVolumeDescriptorSequenceExtent;
byte
Reserved[480];
}
特記事項 開始ボリューム記述子ポインタ構造は,媒体中の次に示す三つの位置のうち,最低2か所
19
X 0611:2018
に記録する。
− 論理セクタ 256
− 論理セクタ(N−256)
− 論理セクタ N
注記 6.10で規定されているように,閉じていないCD-R媒体では,セクタ256又は512のいずれか
に一つだけの開始ボリューム記述子ポインタが記録されてもよい。閉じていない媒体でセクタ
256に一つだけの開始ボリューム記述子ポインタがある場合は,セクタ512に記録された開始
ボリューム記述子ポインタは,無視されることを推奨する。閉じられたCD-R媒体は,これら
の規則に従うことを推奨する。
2.2.3.1
主ボリューム記述子列エクステント(struct MainVolumeDescriptorSequenceExtent)
主ボリューム記述子列エクステントは,最小長16論理セクタでなければならない。
2.2.3.2
予備ボリューム記述子列エクステント(struct ReserveVolumeDescriptorSequenceExtent)
予備ボリューム記述子列エクステントは,最小長16論理セクタでなければならない。
2.2.4
論理ボリューム記述子(Logical Volume Descriptor)
struct LogicalVolumeDescriptor{ /* JIS X 0607 3/10.6 */
struct tag
DescriptorTag;
Uint32
VolumeDescriptorSequenceNumber;
struct charspec
DescriptorCharacterSet;
dstring
LogicalVolumeIdentifier[128];
Uint32
LogicalBlockSize;
struct EntityID
DomainIdentifier;
byte
LogicalVolumeContentsUse[16];
Uint32
MapTableLength;
Uint32
NumberofPartitionMaps;
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[128];
extent̲ad
IntegritySequenceExtent;
byte
PartitionMaps[];
}
2.2.4.1
記述子用文字集合(struct charspec DescriptorCharacterSet)
a) 意味:論理ボリューム識別子(LogicalVolumeIdentifier)欄で使用可能な文字集合の指定と解釈する。
b) 設定値:2.1.2で定義するCS0を利用可能とする設定をしなければならない。
2.2.4.2
論理ブロック長(Uint32 LogicalBlockSize)
a) 意味:この論理ボリューム記述子(LogicalVolumeDescriptor)で識別する論理ボリュームの論理ブロッ
ク長の指定と解釈する。
b) 設定値:この欄は,論理ボリューム記述子で識別する論理ボリュームを構成する媒体中の全ての区画
のうち,最大の論理セクタ長を設定しなければならない。UDFでは,ボリューム集合中の全てのボリ
ュームが同一論理セクタ長であることを要求するため,論理ブロック長(LogicalBlockSize)は,ボリ
ュームの論理セクタ長に等しい。
2.2.4.3
範囲識別子(struct EntityID DomainIdentifier)
20
X 0611:2018
a) 意味:記述子中の欄の使用規則及び制限を規定する範囲の指定と解釈する。この欄の全てが0の場合,
無視する。それ以外の場合は,実体識別子規則に従う。
特記事項 この欄の内容が“*OSTA UDF Compliant”でない場合,処理システムは論理ボリューム
に対する利用者からのアクセスを拒否してもよい。
b) 設定値:この欄は,この規格で定義する範囲に適合する論理ボリュームの内容であることを示す。し
たがって,この範囲識別子(DomainIdentifier)は,
“*OSTA UDF Compliant”
に指定しなければならない。
2.1.5で記載したとおり,実体識別子の識別子添字(IdentifierSuffix)欄には,論理ボリュームの内容が互
換性をもつこの規格の対応団体規格の規定の版数を含む。この欄の適切な扱いに関する詳細情報は,2.1.5
を参照。
特記事項 実体識別子の識別子添字欄は,ソフト書込み保護(SoftWriteProtect)フラグ及びハード書
込み保護(HardWriteProtect)フラグを含む(2.1.5.3参照)。
2.2.4.4
論理ボリューム内容用[16](byte LogicalVolumeContentUse[16])
この欄には,ファイル集合記述子のエクステント位置が含まれる。これは,[4/3.1]に次のとおりに規定
される。
“3.1 入力
ボリュームが第3部に従って記録される場合,論理ボリュームの最初のファイル集合記述子列が
記録されるエクステントは,long̲ad[4/14.14.2]で識別される。このlong̲adは,ファイル集合記述子
を記録する論理ボリュームを記載する論理ボリューム記述子の論理ボリューム内容用欄[3/10.6.7]に
記録されている([4/3.1]参照)。”
この欄は,ファイル集合記述子を見つけるのに使用でき,ファイル集合記述子からルートボリュームを
見つけることができる。
2.2.4.5
処理システム識別子(struct EntityID ImplementationIdentifier)
この欄の適切な扱いに関する詳細情報は,2.1.5を参照。
2.2.4.6
保全列エクステント(struct extent̲ad IntegritySequenceExtent)
この欄の値は,論理ボリューム保全記述子のために必要となる。書換形媒体又は上書き可能形媒体に関
しては,最小値8Kバイトを設定しなければならない。
警告 追記形媒体に対しては,この欄は,十分な長さのエクステントを設定することが望ましい。論
理ボリューム保全記述子は,最新論理ボリューム記述子と同一のボリュームに存在しなければ
ならないため,論理ボリューム保全記述子が存在する追記形媒体が一杯になった場合は,ボリ
ューム集合に新しいボリュームを追加しなければならない。
2.2.4.7
区画マップ(byte PartitionMaps)
交換の目的として,区画マップは,2.2.8及び2.2.9に記載されているとおり,種別2を除き,区画マッ
プ種別1に限定しなければならない。
2.2.5
未割付け空間記述子(Unallocated Space Descriptor)
struct UnallocatedSpaceDesc{ /* JIS X 0607 3/10.8 */
struct tag
DescriptorTag;
Uint32
VolumeDescriptorSequenceNumber;
Uint32
NumberofAllocationDescriptors;
21
X 0611:2018
exted̲ad
AllocationDescriptors[];
}
使用可能なボリューム空間がない場合でも,この記述子を記録しなければならない。ボリューム空間の
始めの32 768バイトはJIS X 0607規格類の構造を記録するのに使用してはならない。この領域は未割付け
空間記述子又は他のどのJIS X 0607規格類の記述子によっても参照されてはならない。
2.2.6
論理ボリューム保全記述子(Logical Volume Integrity Descriptor)
struct LogicalVolumeIntegrityDesc{ /* JIS X 0607 3/10.10 */
struct tag
DescriptorTag;
Timestamp
RecordingDateAndTime;
Uint32
IntegrityType;
struct extend̲ad
NextIntegrityExtent;
byte
LogicalVolumeContentsUse[32];
Uint32
NumberOfPartitions;
Uint32
LengthOfImplementationUse;
Uint32
FreeSpaceTable[];
Uint32
SizeTable[];
byte
ImplementationUse[];
}
論理ボリューム保全記述子は,関連する論理ボリュームの内容を更新したときに書き込まれなければな
らない構造である。論理ボリューム保全記述子の内容によって,処理システムは,次に示す有用な問いに
対し容易に回答できる。
a) 論理ボリュームの内容は,一貫性のある状態か否か
b) 論理ボリュームを更新した最終日時
c) 論理ボリューム中の使用可能空間の論理ブロック総数
d) 論理ボリューム中の論理ブロック総数
e) 論理ボリューム中で次に使用可能な一意ID
f)
論理ボリュームを作成した処理システムが最後にアクセスした日時以降に論理ボリューム中の内容を
更新した他の処理システムの有無
2.2.6.1
論理ボリューム内容用(byte LogicalVolumeContensUse)
この欄の内容の情報に関しては,3.2.1を参照。
2.2.6.2
使用可能空間表(Uint32 FreeSpaceTable)
ほとんどのOSは,媒体のマウント時に,処理システムが論理ボリューム中の使用可能空間の大きさを
提供することを要求するため,これらの値を全ての非仮想区画のために保守することは重要となる。有効
な使用可能空間の量が不明なことを示す#FFFFFFFFの任意値は,非仮想区画に使用してはならない。仮想
区画については,使用可能空間表を#FFFFFFFFに設定しなければならない。
注記 論理ボリューム保全記述子をクローズ状態にしたときだけ,正しい使用可能空間表を保証する。
2.2.6.3
サイズ表(Uint32 SizeTable)
ほとんどのOSは,媒体のマウント時に,処理システムが論理ボリュームの大きさを提供することを要
求するため,これらの値を全ての非仮想区画に保守することは重要となる。区画長が不明なことを示す
#FFFFFFFFの任意値は仮想区画に使用してはならない。仮想区画については,サイズ表を#FFFFFFFFに設

22
X 0611:2018
定しなければならない。
2.2.6.4
処理システム用(byte ImplementationUse)
論理ボリューム保全記述子(Logical Volume Integrity Descriptor)の処理システム用(ImplementationUse)
領域は,表10に示す構成でなければならない。
表10−処理システム用フォーマット(ImplementationUse format)
RBP
長さ
名前
内容
0
32
処理システム識別子(ImplementationID)
EntityID
32
4
ファイル数(Number of Files)
Uint32
36
4
ディレクトリ数(Number of Directories)
Uint32
40
2
UDF読出し最小版数(Minimum UDF Read Revision)
Uint16
42
2
UDF書込み最小版数(Minimum UDF Write Revision)
Uint16
44
2
UDF書込み最大版数(Maximum UDF Write Revision)
Uint16
46
??
処理システム用(Implementation Use)
バイト
注記 ??は可変長欄を示す。
a) 処理システム識別子(ImplementationID):処理システム識別子は,実体識別子の有効範囲内のどれか
を最後に更新した処理システムの実体識別子。実体識別子の有効範囲は,論理ボリューム識別子及び
関連する論理ボリュームの内容である。この欄は,論理ボリュームの内容を最後に更新した処理シス
テムを識別することを可能とする。
b) ファイル数(Number of Files):関連する論理ボリューム中の現状のファイルの個数。この情報は,
Macintosh OSで必要となる。全ての処理システムは,この情報を保守しなければならない。
注記 この値は,拡張属性又はファイルのストリーム部の数を含まない。
c) ディレクトリ数(Number of Directories):関連する論理ボリューム中の現状のディレクトリの個数。
この情報は,Macintosh OSで必要となる。全ての処理システムは,この情報を保守しなければならな
い。
特記事項 ルートディレクトリは,ディレクトリ数に含まれなければならない。ディレクトリ数に
は,ストリームディレクトリが含まれない。
d) UDF読出し最小版数(Minimum UDF Read Revision):この媒体中の全ての構造を読み出すために,処
理システムが利用可能とする必要があるUDF版数の最小値でなければならない。この番号は,10進
数の2進表示で記録しなければならない。例えば,#0150はUDF 1.50を示す。
e) UDF書込み最小版数(Minimum UDF Write Revision):この媒体中の全ての構造を更新するために,処
理システムが利用可能とする必要があるUDF版数の最小値でなければならない。この番号は,2進化
10進法表示で記録しなければならない。例えば,#0150はUDF 1.50を示す。
f)
UDF書込み最大版数(Maximum UDF Write Revision):媒体中を更新した処理システムが利用可能とす
るUDF版数の最大値でなければならない。処理システムは,媒体の更新によって,媒体がこの欄の現
状の値より大きいUDF版数を必要とするようになった場合だけ,この欄を更新しなければならない。
この番号は,2進化10進法表示で記録しなければならない。例えば,#0150は,UDF 1.50を示す。
g) 処理システム用(Implementation Use):処理システム識別子で識別する処理システムだけの固有情報
を含む。
23
X 0611:2018
2.2.7
処理システム用ボリューム記述子(Implementation Use Volume Descriptor)
struct ImpUseVolumeDescriptor{ /* JIS X 0607 3/10.4 */
struct tag
DescriptorTag;
Uint32
VolumeDescriptorSequenceNumber;
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[460];
}
この2.2.7は,UDF処理システム用ボリューム記述子を定義する。この記述子はボリューム集合の全て
のボリュームに記録しなければならない。ボリュームは,処理システム固有の追加の処理システム用ボリ
ューム記述子を含んでもよい。この記述子の意図する目的は,特定の論理ボリュームに属するボリューム
集合中のボリュームの識別を支援することである。
特記事項 処理システムは,媒体中にそれ自体のフォーマットにおける追加の処理システム用ボリュ
ーム記述子を記録してもよい。UDF処理システム用ボリューム記述子は,追加の記述子を
除外しない。
2.2.7.1
処理システム識別子(EntityID ImplementationIdentifier)
この欄は“*UDF LV Info”を指定しなければならない。実体識別子については2.1.5を参照。
2.2.7.2
処理システム用(byte ImplementationUse)
処理システム用領域は,次に示す構造でなければならない。
struct LVInformation{
struct charspec
LVICharset;
dstring
LogicalVolumeIdentifier[128];
dstring
LVInfo1[36];
dstring
LVInfo2[36];
dstring
LVInfo3[36];
struct EntityID
ImplementationID;
byte
ImplementationUse[128];
}
2.2.7.2.1
論理ボリューム情報用文字集合(charspec LVICharset)
a) 意味:論理ボリューム識別子(LogicalVolumeIdentifier)欄及び論理ボリューム情報(LVInfo)欄で使用
可能な文字集合の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.2.7.2.2
論理ボリューム識別子(dstring LogicalVolumeIdentifier)
この記述子で参照する論理ボリュームの識別子。
2.2.7.2.3
論理ボリューム情報(dstring LVInfo1, LVInfo2, LVInfo3)
論理ボリューム情報欄(LVInfo1,LVInfo2及びLVInfo3)は,媒体の識別を支援する追加情報を含むこ
とが望ましい。例えば,論理ボリューム情報欄は,所有者名,組織名及び連絡先の情報を含むことができ
る。
2.2.7.2.4
処理システム識別子(struct EntityID ImplementionID)
実体識別子に関する2.1.5を参照。
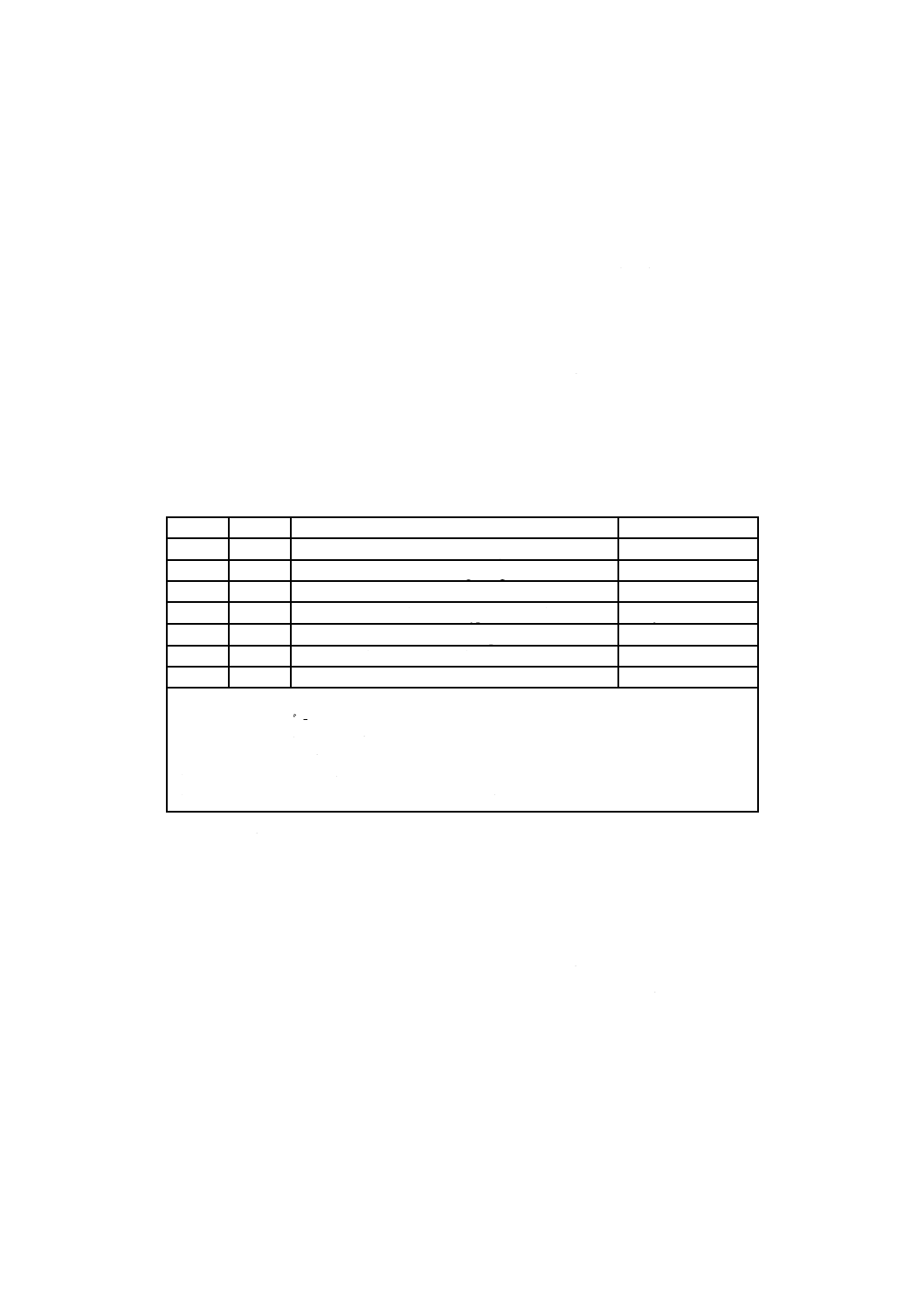
24
X 0611:2018
2.2.7.2.5
処理システム用(byte ImplementationUse[128])
この領域は,追加の処理システム固有の情報を記録するために処理システムで使用してもよい。
2.2.8
仮想区画マップ
これは,JIS X 0607規格類の範囲を拡大し,連続書込み媒体(例えば,CD-R)を含んだものである。こ
れを拡大したのは,区画マップエントリが仮想空間を記載するためである。
論理ボリューム記述子には,与えられたボリュームを構成する区画の一覧が含まれる。仮想区画は,物
理区画と同じ方法で記載することはできないので,次に指定する種別2区画マップを使わなければならな
い。
仮想区画マップが記録されると,論理ボリューム記述子は,最低二つの区画マップを含まなければなら
ない。一つの区画マップは種別1の区画マップとして記録しなければならない。もう一つの区画マップは
種別2区画マップとして記録しなければならない。この種別2の区画マップのフォーマットは,表11に指
定されたとおりでなければならない。
表11−仮想区画に関する種別2区画マップの配置
(Layout of Type 2 partition map for virtual partitions)
RBP
長さ
名前
内容
0
1
区画マップ種別(Partition Map Type)
Uint8=2
1
1
区画マップ長(Partition Map Length)
Uint8=64
2
2
予約(Reserved)
#00バイト
4
32
区画種別識別子(Partition Type Identifier)
EntityID
36
2
ボリューム列番号(Volume Sequence Number)
Uint16
38
2
区画番号(Partition Number)
Uint16
40
24
予約(Reserved)
#00バイト
注記1 区画種別識別子:
− フラグ = 0
− 識別子 = *UDF Virtual Partition
− 識別子添字は,2.1.5.3のとおりに記録する。
注記2 ボリューム列番号 = VAT及び区画を記録するボリューム
注記3 区画番号 = 同じ論理ボリューム記述子に含まれる種別1区画マップ内の区画番号
2.2.9
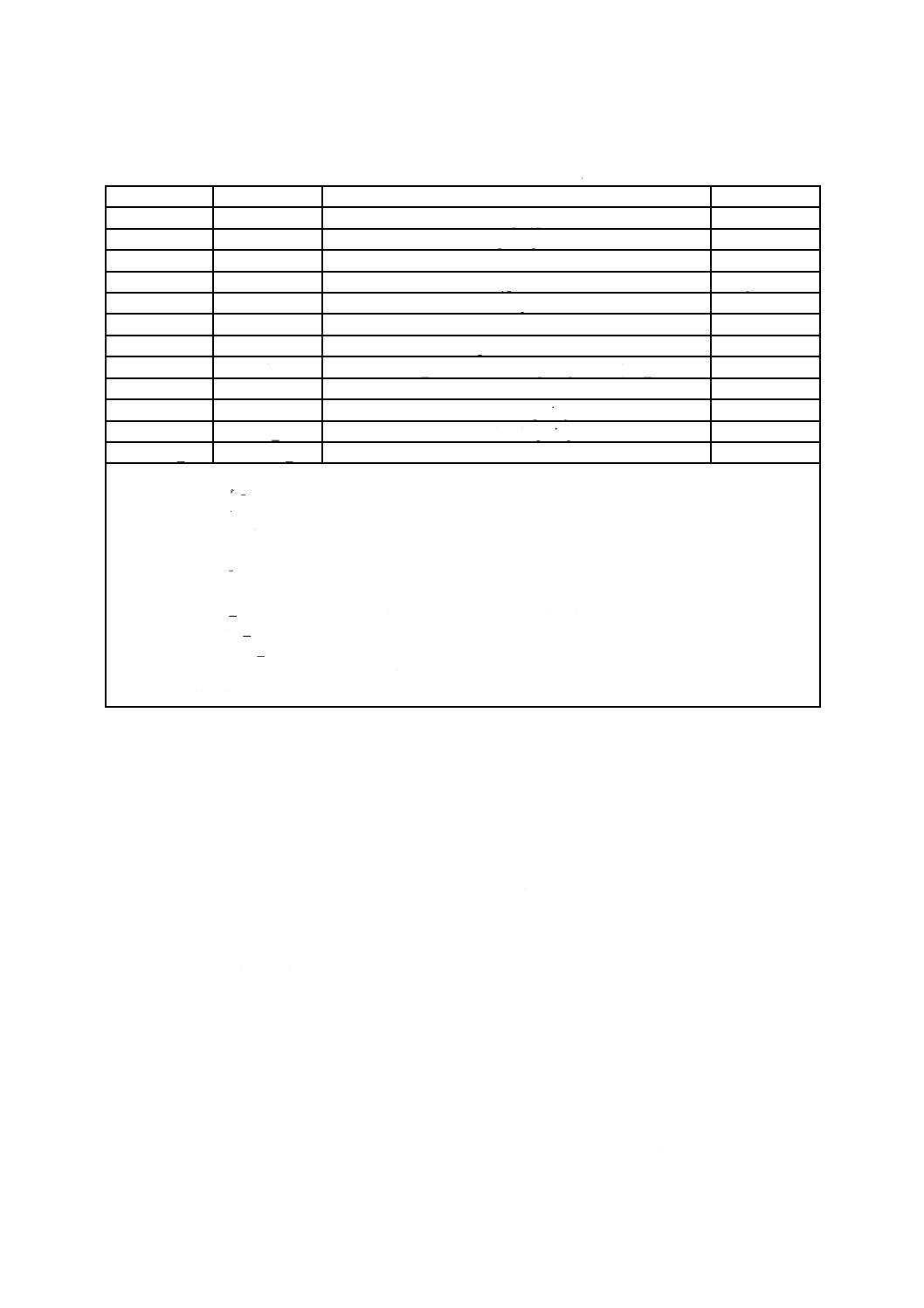
予備区画マップ
ディスクドライブシステムの中には,欠陥管理を行わないものもある(例えば,CD-RW)。これらのシ
ステムに明らかに欠陥のない空間を与えるために,種別2の区画が使われる。区画マップは,区画番号,
パケットサイズ(1.3.2参照),並びに予備表の大きさ及び位置を定義する。この種別2のマップは,通常
の媒体にある種別1のマップと置き換えることを意図している。予備区画マップが記録された場合は種別
1のマップを記録してはならない。予備区画マップは,区画番号とボリューム列番号とを識別するだけで
なく,パケット長及び予備表を識別する。予備区画マップは,欠陥管理を行うディスクドライブシステム
に記録してはならない(表12参照)。
25
X 0611:2018
表12−予備区画に関する種別2区画マップの配置
(Layout of Type 2 partition map for sparable partitions)
RBP
長さ
名前
内容
0
1
区画マップ種別(Partition Map Type)
Uint8=2
1
1
区画マップ長(Partition Map Length)
Uint8=64
2
2
予約(Reserved)
#00バイト
4
32
区画種別識別子(Partition Type Identifier)
EntityID
36
2
ボリューム列番号(Volume Sequence Number)
Uint16
38
2
区画番号(Partition Number)
Uint16
40
2
パケット長(Packet Length)
Uint16
42
1
予備表数(= N̲ST)[Number of Sparing Tables (= N̲ST)]
Uint8
43
1
予約(Reserved)
#00バイト
44
4
各予備表の大きさ(Size of each sparing tables)
Uint32
48
4×N̲ST
予備表の位置(Locations of each sparing tables)
Uint32
48+4×N̲ST
16−4×N̲ST
パッド(Pad)
#00バイト
注記1 区画種別識別子:
− フラグ = 0
− 識別子 = *UDF Sparable Partition
− 識別子添字は,2.1.5.3のとおりに記録する。
注記2 区画番号 = この区画の番号。この区画に関連する区画記述子を識別することが望ましい。
注記3 パケット長 = 固定パケットごとの利用者データブロック数。この値は箇条6の媒体固有の規定において
示す。
注記4 予備表数 = 記録された冗長な表の数。これは1〜4の範囲の値が望ましい。
注記5 各予備表数 = 各予備表に割り付けられるバイト数。
注記6 予備表の位置 = 媒体ブロック番地として指定される各予備表のスタート位置。処理システムでは,各予
備表のスタートをパケットの始めに合わせることが望ましい。処理システムでは,最小二つの予備表を
物理的に離れている位置に記録することが望ましい。
2.2.10 仮想割付け表
仮想割付け表(VAT)(表13参照)は,連続書込み媒体(例えば,CD-R)に使われ,ランダムに書込み
可能な媒体のようにシステムに見せかけるために用いられる。VATは連続書込み媒体(例えば,CD-R)に
だけ記録しなければならない。
VATは仮想番地を論理番地に変換するマップである。これは,ファイルエントリICB(VAT ICB)で識
別されるファイルとして記録しなければならないが,表を構築する際,大幅な柔軟性を認める。VAT ICB
はいかなる処理でも,最後に記録されるセクタである。VAT自体は,どの位置に記録してもよい。
VATは,ファイル種別248のファイルエントリICBによって識別しなければならない。このICBは,記
録された最後の有効データセクタでなければならない。エラー修復計画は,ファイル種別248をもつICB
を見つけることで,最後の有効なVATを見つけることができる。
このファイルは,小さいときは,記載するICBに埋め込むことができる。大きくなると,ICBに先行す
るセクタに記録できる。セクタは,隣接する必要はないが,必要に応じて表の新しい部分にだけ書込みが
できる。これによって,多くのディレクトリをもつディスクでも,僅かな増加分の更新が可能になる。
VATが小さいとき(ディスク上の少数ディレクトリ),VATは,埋込みVATで新しいファイルICBを書
き込むことによって更新される。VATが大きくなりすぎてICBに合わなくなると,VATで一つのセクタを
書き込み,ICBで他のセクタを書き込むことが必要になる。この点を超えると,VATのために複数のセク
タが必要になる。しかし,複数のエクステントが利用可能になるため,VATの更新は,全てのVATを示す
26
X 0611:2018
ポインタでICBを更新し書き込む必要のあるセクタだけを,書き込むだけでよい。
VATは,ある種の情報を求める要求を,適切な論理位置に転送するために使う。この表を用いた間接的
アクセス方法で,直接的な上書き能力があるかのように見せかけることができる。例えば,ルートディレ
クトリを記載するICBは仮想セクタ1として参照できる。仮想セクタは,仮想区画マップエントリによっ
て識別する区画に含まれる。ディスクを更新する過程でルートディレクトリが変わるかもしれない。変わ
る場合,ルートディレクトリを記載する新しいセクタが書き込まれ,論理ブロック番地は,仮想セクタ1
に対応する論理ブロック番地として記録される。仮想セクタ1を参照するものは,たとえ,新しい論理ブ
ロック番地に存在していても,既存の最新の仮想セクタ1を示すため,変わる必要はない。
仮想番地付けの使用によって,要求された構造の実効上の上書きが可能になる。この構造は,参照する
全てのポインタが,仮想番地だけでできるとき,書換え可能になる。書換え構造が書き込まれると,仮想
の参照は変わる必要がなくなる。VATへの適切なエントリは,対応する仮想番地の新しい論理ブロック番
地を反映するように変えられ,その後あらゆる仮想の参照は間接的に新しい構造を示す。ディレクトリICB
のとおりに,更新が必要な全ての構造は,仮想番地で参照しなければならない。各構造が更新されると,
VAT ICB内の対応するエントリが更新されなければならない。
VATは,Uint32エントリの連続としてファイルに記録されなければならない。各エントリは,VATが位
置する物理区画へのセクタ数でのオフセットでなければならない。最初のエントリは,仮想区画セクタ0
でなければならず,2番目のエントリは仮想区画セクタ1でなければならず,以降同様でなければならな
い。Uint32エントリはVATヘッダに続かなければならない。事前のVAT ICBの入力によって,前の状態
のようなファイルシステムを一覧できる。この欄が#FFFFFFFFである場合,そうしたICBは,指定されな
い。
表13−仮想割付け表構造(Virtual Allocation Table structures)
オフセット
長さ
名前
内容
0
2
ヘッダの長さ(= L̲HD)[Length of Header (= L̲HD)]
Uint16
2
2
処理システム用の長さ(= L̲IU)
[Length of Implementation Use (= L̲IU)]
Uint16
4
128
論理ボリューム識別子(Logical Volume Identifier)
dstring
132
4
VAT ICB前位置(Previous VAT ICB location)
Uint32
136
4
ファイル数(Number of Files)
Uint32
140
4
ディレクトリ数(Number of Directories)
Uint32
144
2
UDF最小読取り版(Minimum UDF Read Version)
Uint16
146
2
UDF最小書込み版(Minimum UDF Write Version)
Uint16
148
2
UDF最大書込み版(Maximum UDF Write Version)
Uint16
150
2
予約(Reserved)
#00バイト
152
L̲IU 処理システム用(Implementation Use)
バイト
152+L̲IU
4
VATエントリ0(VAT entry 0)
Uint32
156+L̲IU
4
VATエントリ1(VAT entry 1)
Uint32
…
…
…
…
情報の長さ−4
(Information Length−4)
4
VATエントリn(VAT entry n)
Uint32
a) ヘッダの長さ(Length of Header):VATエントリに先行するデータの量を識別する。この値は,152+
L̲IUでなければならない。
b) 処理システム用の長さ(Length of Implementation Use):処理システム用欄のバイト数を指定しなけれ
27
X 0611:2018
ばならない。この欄が0でない場合,この値は,最低32で4の整数倍でなければならない。
c) 論理ボリューム識別子(Logical Volume Identifier):論理ボリュームを識別しなければならない。この
欄は,論理ボリューム識別子で対応する欄の代わりに,処理システムで使用しなければならない。こ
の欄の値は,利用者が変更するまで,LVDの欄と同じであることが望ましい。
d) VAT ICB前位置(Previous VAT ICB location):区画マップエントリで識別される区画において,前の
VAT ICBの論理ブロック番号を指定しなければならない。この欄が#FFFFFFFFのとき,ICBは指定さ
れない。
e) ファイル数(Number of Files):対応する論理ボリューム中の現在のファイル数。この情報はMachintosh
OSで必要とされる。全ての処理システムはこの情報を維持しなければならない。この欄の内容は,
LVIDにおいて対応する欄に代わって,処理システムで使用しなければならない。
特記事項 この値は拡張属性又はファイルのストリーム部の数は含まない。
f)
ディレクトリ数(Number of Directories):対応する論理ボリューム中の現在のディレクトリの数。こ
の情報はMachintosh OSで必要とされる。全ての処理システムは,この情報を維持しなければならな
い。この欄の内容は,LVIDで対応する欄の代わりに処理システムで使用しなければならない。
特記事項 ルートディレクトリは,ディレクトリの数に含まれなければならない。ディレクトリの
数にストリームディレクトリの数は含まれない。
g) UDF最小読取り版(Minimum UDF Read Version):2.2.6に定義されている。この欄の内容は,論理ボ
リューム保全記述子(LVID)で対応する欄の代わりに,処理システムで使用しなければならない。
h) UDF最小書込み版(Minimum UDF Write Version):2.2.6に定義されている。この欄の内容は,LVIDに
おいて対応する欄の代わりに処理システムで使用しなければならない。
i)
UDF最大書込み版(Maximum UDF Write Version):2.2.6に定義されている。この欄の内容は,LVIDに
おいて対応する欄の代わりに処理システムで使用しなければならない。
j)
処理システム用(Implementation Use):長さが0でない場合,処理システム用領域の残りの使用を識
別する実体識別子から始める。
k) VATエントリ(VAT entry):VATエントリnは,仮想ブロックnの論理ブロック番号を識別しなけれ
ばならない。#FFFFFFFFのエントリは,仮想セクタが現在使用されていないことを示している。LBN
指定は,区画マップエントリで識別される区画に位置する。表のエントリの数は,ICBのVATファイ
ルサイズから決定できる。
エントリ数(N)=(情報の長さ−L̲HD)/4
2.2.11 予備表
ディスクドライブシステムの中には,欠陥管理を行わないものもある(例えば,CD-RW)。予備表は,
これらのシステムに見かけ上欠陥のない空間を作るために用いられる。特定の媒体では,セクタのまとま
り(パケット)にだけ書込みができ,再配置を更に複雑にする。これは,セクタだけが書き込まれるので
はなく,パケット全体を再配置しなければならないことによる。この問題に取り組むため,区画マップが
予備区画を識別し,予備表の位置を更に識別する。予備表は,媒体上で再配置された領域を識別する。予
備表は,予備表区画マップで識別される。予備表は,欠陥管理を行うディスクシステム・ドライブシステム
に記録してはならない。
予備表は,予備用に割り付けられた空間を示し,取替え部分に対する欠陥セクタの配置リストを含む。
予備表の分離コピーは,分離パケットに記録しなければならない。予備表は,最新のものを維持しなけれ
ばならない。
28
X 0611:2018
区画マップの論理空間を物理空間へ配置する。通常,これは,オフセットと長さとが指定される直線配
置である。予備区画では,この配置に基づくが,物理空間内の区画のオフセットと長さとは,区画記述子
(2.2.12参照)で指定される。予備区画は一つのパケットの境界で始まり,かつ,一つのパケットの境界
で終わらなければならない。予備表は,更に論理配置から物理配置への例外リストを指定する。あらゆる
配置の長さは,パケット一つ分である。パケットサイズは,予備区画マップで指定される。
予備領域は,媒体のどの部分でも,つまり区画の内外いずれでもよい。区画の内側の場合,予備空間は
割り付けられたとして表示されなければならず,割付け禁止空間ストリームに含まれなければならない。
マップされた位置は,フォーマット時に埋めることが望ましい。元の位置は,エラーが起こると,動的に
割り当てられる。各予備表は,表14のような構造でなければならない。
表14−予備表配置(Sparing Table Layout)
BP
長さ
名前
内容
0
16
記述子タグ(Descriptor Tag)
タグ=0
16
32
予備識別子(Sparing Identifier)
EntityID
48
2
再割付け表長(= RT̲L)[Reallocation Table Length (= RT̲L)] Uint16
50
2
予約(Reserved)
#00バイト
52
4
列番号(Sequence Number)
Uint32
56
8×RT̲L
マップエントリ(Map Entry)
マップエントリ
この構造は,必要ならば一つのセクタより大きくてもよい。
a) 記述子タグ
タグ識別子0を含むが,これは,記述子タグのフォーマットが,JIS X 0607規格類で指定されてい
ないことを示す。記述子タグの他の欄は,全てタグ識別子は,JIS X 0607規格類で定義された値であ
るかのように,有効でなければならない。
b) 予備識別子
1) フラグ = 0
2) 識別子 = *UDF Sparing Table
3) 識別子添字は,2.1.5.3のとおりに記録される。
c) 再割付け表長
マップエントリ表のエントリの数を示す。
d) 列番号
予備表更新の都度,増加する数を含む。
e) マップエントリ
マップエントリは,表15に記述される。マップは元の位置の欄によって昇順に分類しなければなら
ない。
表15−マップエントリ記述(Map Entry description)
RBP
長さ
名前
内容
0
4
元の位置(Original Location)
Uint32
4
4
マップ位置(Mapped Location)
Uint32
f)
元の位置
パケットの論理ブロック番地を予備とする。パケットの番地は,パケットの,最初の利用者データ
29
X 0611:2018
ブロックの番地とする。この欄が#FFFFFFFFのとき,このエントリは,予備のために可能となる。こ
の欄が#FFFFFFF0のとき,対応するマップ位置は欠陥と表示され,マッピングには使わないことが望
ましい。#FFFFFFFF〜#FFFFFFF1の元の位置は,予約しておく。
g) マップ位置
動作中のデータの物理ブロック番地。元のパケット位置への要求は,ここで識別されるパケット位
置に転送される。マップ位置のエントリは全て有効で,元の位置が#FFFFFFF0,#FFFFFFFF,又は予
約であるエントリを含む。マップ位置が区画と重なる場合,その区画は,割付け済みと表示された空
間をもち,その空間は,割付け禁止空間ストリームの一部に入れなければならない。
2.2.12 区画記述子(Partition Descriptor)
struct PartitionDescriptor { /* JIS X 0607 3/10.5 */
struct tag
DescriptorTag;
Uint32
VolumeDescriptorSequenceNumber;
Uint16
PartitionFlags;
Uint16
PartitionNumber;
struct EntityID
PartitionContents;
byte
PartitionContentsUse[128];
Uint32
AccessType;
Uint32
PartitionStartingLocation;
Uint32
PartitionLength;
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[128];
byte
Reserved[156];
}
2.2.12.1 区画内容(Struct EntityID PartitionContents)
この欄の適切な扱いに関する詳細情報は,実体識別子に関する2.1.5を参照。
2.2.12.2 区画開始位置(Uint32 PartitionStartingLocation)
予備区画においてはこの欄の値は,パケット長の整数倍でなければならない。パケット長は,予備区画
マップで定義される。
2.2.12.3 区画長(Uint32 PartitionLength)
予備区画においてはこの欄の値は,パケット長の整数倍でなければならない。パケット長は,予備区画
マップで定義される。
2.2.12.4 処理システム識別子(Struct EntityID ImplementationIdentifier)
この欄の適切な扱いに関する詳細情報は,実体識別子に関する2.1.5を参照。
2.3
第4部 ファイルシステム
2.3.1
記述子タグ(Descriptor Tag)
struct tag{
/* JIS X 0607 4/7.2 */
Uint16
TagIdentifier;
Uint16
DescriptorVersion;
Uint8
TagChecksum;
byte
Reserved;
30
X 0611:2018
Uint16
TagSerialNumber;
Uint16
DescriptorCRC;
Uint16
DescriptorCRCLength;
Uint32
TagLocation;
}
2.3.1.1
タグ通し番号(Uint16 TagSerialNumber)
a) 意味:無視する。障害回復のためにある。
b) 設定値:このボリュームの開始ボリューム記述子ポインタのタグ通し番号(TagSerialNumber)と同じ
値を設定しなければならない。
ボリューム構造のタグ通し番号と同じ制約が適用される(2.2.1.1及び2.1.6参照)。
2.3.1.2
記述子CRC長(Uint16 DescriptorCRCLength)
特記しない限り,CRCは,各記述子で利用可能であり,計算されなければならない。この欄の値は,(記
述子の大きさ)−(記述子タグの長さ)に設定しなければならない。記述子を読み出すときは,CRCを検
証することが望ましい。
注記 記述子CRC長(DescriptorCRCLength)欄は記述子の実際の長さ又は読み込むバイト長を決定
するのに使用しないことが望ましい。これらの長さは,全ての場合では一致せず,規格中には,
記述子CRC長が記述子の長さと一致しない例外が存在する。
2.3.1.3
タグ位置(Uint32 TagLocation)
仮想番地(例えば,VATを通した参照)を通して参照される構造のために,この値は物理番地又は論理
番地ではなく,仮想番地でなければならない。
2.3.2
ファイル集合記述子(File Set Descriptor)
struct FileSetDescriptor{
/* JIS X 0607 4/14.1 */
struct tag
DescriptorTag;
struct timestamp
RecordingDateandTime;
Uint16
InterchangeLevel;
Uint16
MaximumInterchangeLevel;
Uint32
CharacterSetList;
Uint32
MaximumCharacterSetList;
Uint32
FileSetNumber;
Uint32
FileSetDescriptorNumber;
struct charspec
LogicalVolumeIdentifierCharacterSet;
dstring
LogicalVolumeIdentifier[128];
struct charspec
FileSetCharacterSet;
dstring
FileSetIdentifier[32];
dstring
CopyrightFileIdentifier[32];
dstring
AbstractFileIdentifier[32];
struct long̲ad
RootDirectoryICB;
struct EntityID
DomainIdentifier;
struct long̲ad
NextExtent;
struct long̲ad
StreamDirectoryICB
31
X 0611:2018
byte
Reserved[32];
}
書換形及び上書き可能形媒体中には,一つだけファイル集合記述子を記録しなければならない。追記形
媒体中には,複数のファイル集合記述子を記録してもよい。
複数のファイル集合に関するUDF規定を,次に示す。
a) 複数のファイル集合は,追記形媒体中だけに許可する。
b) デフォルトのファイル集合は,最大のファイル集合番号をもつものと定義する。
c) デフォルトのファイル集合だけを,書込み可能としてもよい。その列における他の全てのファイル集
合は,ハード書込み保護(2.1.5.3参照)を設定しなければならない。
d) 書込み不可のファイル集合は,その他のファイル集合で参照(直接又は間接的に)するメタデータ構
造を参照しなければならない。書込み可能のファイル集合は,実ファイルデータエクステントを参照
してもよい。
追記形媒体のファイル集合中では,全てのファイル及びディレクトリをICB方策種別4で記録する場合,
そのファイル集合記述子の範囲識別子には,ハード書込み保護を設定しなければならない。
追記形媒体中の複数のファイル集合の意図する目的は,媒体中に複数のアーカイブをもつ機能を利用可
能にすることである。例えば,一つのファイル集合は,特定の時点で作成した情報集合のバックアップを
表現する。
後続のファイル集合は,その後作成した同一情報集合の他のバックアップとして表現する。
2.3.2.1
交換水準(Uint16 InterchangeLevel)
a) 意味:関連するファイル集合の内容の現状の交換水準([4/15]で規定)及び規定水準が意味する制約の
指定と解釈する。
b) 設定値:水準3を設定しなければならない。
処理システムは,指定された現状の交換水準に関連する制約を実施しなければならない。
2.3.2.2
最大交換水準(Uint16 MaximumInterchangeLevel)
a) 意味:関連するファイル集合の内容についての最大交換水準の指定と解釈する。この値は,現状の交
換水準欄で設定してもよい値を制限する。
b) 設定値:水準3を設定しなければならない。
2.3.2.3
文字集合リスト(Uint32 CharacterSetList)
a) 意味:JIS X 0607規格類の第4部において定義され,この欄を含む記述子によって記述するファイル
集合に記録される全ての記述子において,内容をcharspecと規定する全ての欄で指定される文字集合
の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.3.2.4
文字最大集合リスト(Uint32 MaximumCharacterSetList)
a) 意味:関連するファイル集合で利用可能な文字集合の最大値及び規定水準が意味する制限の指定と解
釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.3.2.5
論理ボリューム識別子用文字集合(struct charspec LogicalVolumeIdentifierCharacterSet)
a) 意味:論理ボリューム識別子欄で使用可能なd文字の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
32
X 0611:2018
2.3.2.6
ファイル集合用文字集合(struct charspec FileSetCharacterSet)
a) 意味:JIS X 0607規格類の第4部で定義された,ファイル集合記述子の有効範囲内の内容がdstringで
ある欄で使用可能なd文字の指定と解釈する。
b) 設定値:2.1.2で定義するCS0だけを利用可能とする設定をしなければならない。
2.3.2.7
範囲識別子(struct EntityID DomainIdentifier)
a) 意味:記述子中の欄の使用規則及び制約を規定する範囲の指定と解釈する。この欄がNULLの場合,
無視する。それ以外の場合は,実体識別子の規則に従う。
b) 設定値:この欄は,この規格で定義する範囲に適合するファイル集合記述子の有効範囲を示すもので
なければならない。したがって,範囲識別子は,
“*OSTA UDF Compliant”
に設定しなければならない。
2.1.5で記載したとおり,実体識別子の識別子添字(IdentifierSuffix)欄には,論理ボリュームの内容が互
換性をもつこの規格の対応団体規格の規定の版数を含む。この欄の適切な扱いに関する詳細情報は,2.1.5.3
を参照。
特記事項 実体識別子の識別子添字欄は,ソフト書込み保護フラグ及びハード書込み保護フラグを含
む。
2.3.3
区画ヘッダ記述子(Partition Header Descriptor)
struct PartitionHeaderDescriptor{ /* JIS X 0607 4/14.3 */
struct short̲ad
UnallocatedSpaceTable;
struct short̲ad
UnallocatedSpaceBitmap;
struct short̲ad
PartitionIntegrityTable;
struct short̲ad
FreedSpaceTable;
struct short̲ad
FreedSpaceBitmap;
byte
Reserved[88];
}
すなわち,未割付け空間とした論理ブロックは,前処理なしに書込み可能なブロックである。書換形媒
体の場合,消去処理なしに書き込める。空き空間とした論理ブロックは,書込み準備が必要なブロックで
あり,何らかの前処理をする必要がある。書換形媒体の場合,消去処理後に書き込む。
特記事項 空間表又は空間ビットマップの使用は,論理ボリューム中で一貫していなければならな
い。空間表及び空間ビットマップの両方を一つの論理ボリューム中で同時に使用してはな
らない。
2.3.3.1
区画保全表(struct short̲ad PartitionIntegrityTable)
区画保全エントリは使用しないため,全て0を指定しなければならない。
2.3.4
ファイル識別記述子(File Identifier Descriptor)
struct FileIdentifierDescriptor{ /* JIS X 0607 4/14.4 */
struct tag
DescriptorTag;
Uint16
FileVersionNumber;
Uint8
FileCharacteristics;
Uint8
LengthofFileIdentifier;
struct long̲ad
ICB;
33
X 0611:2018
Uint16
LengthofImplementationUse;
byte
ImplementationUse[];
char
FileIdentifier[];
byte
Padding[];
}
ファイル識別記述子は,一つの論理ブロックの長さに制限しなければならない。
特記事項 UDFの全てのディレクトリは,親ディレクトリの位置を示すファイル識別記述子を一つも
たなければならない。親ディレクトリを記述するファイル識別記述子は,ディレクトリの
最初のファイル識別記述子にしなければならない。ルートディレクトリの親ディレクトリ
は,[4/8.6]に示されているのと同様に,ルートディレクトリにしなければならない。
2.3.4.1
ファイル版数(Uint16 FileVersionNumber)
a) 意味:ファイルの版数は一つだけとする。
b) 設定値:値1を設定しなければならない。
2.3.4.2
ファイル特性(Uint8 FileCharacteristics)
削除ビットは,ディレクトリからFIDを除去せずに,ファイル又はディレクトリが削除されていること
を表示するために使用してもよい。この場合,その地点から最後まで,ディレクトリを書き換えることが
必要になる。ファイル又はディレクトリの空間の割付けが解除されているとき,処理システムでは,ICB
欄を0に設定しなければならない。これは,削除ビットが設定されても,FIDの欄が全て有効でなければ
ならないことによる([4/14.4.3],注記21,及び[4/14.4.5]を参照)。
[4/8.6]は,あるディレクトリの全てのFIDのファイル識別子(及び常に1でなければならないファイル
版数)が一意であることを要求する。JIS X 0607規格類の第4部は削除ビットを設定されたFIDにもこの
要求が及ぶか否か記載がないが,意図は否である。削除ビットを設定されたFIDは,一意であることの要
求を受けないと解釈される。
この解釈をしないで,JIS X 0607規格類の第4部を誤解して作られた可能性があるUDF処理システムを
補助するために,処理システムはFIDの削除ビットが設定されるとき,これらの規則に従わなければなら
ない。
もし,ファイル識別子の圧縮識別子が8ならば,圧縮識別子は254に書き換える。もし,ファイル識別
子の圧縮識別子が16ならば,圧縮識別子は255に書き換える。ファイル識別子の残りのバイトは変えない
ままにする。
このように,ファイル又はディレクトリを削除しないことを望むユーティリティは,圧縮IDの書換え
を逆にすることによって元の名前を回復できる。
注記 処理システムでは,ディレクトリが大きくなるのを避けるため,削除ビットが1に設定され,
ICB欄が0に設定されたFIDを再使用することが望ましい。
2.3.4.3
ICB(struct long̲ad ICB)
あらゆるファイル識別記述子のlong̲adの処理システム用バイトは,ファイル及びディレクトリ名前空
間のUDF一意IDを記録するために使用しなければならない(表16参照)。
long̲adの処理システム用バイトは,2.3.10.1で規定されている割付け記述子の処理システム用の構造を
保持する。この構造の四つの処理用バイトは,UDF一意IDを保持するUnit32として解釈される。

34
X 0611:2018
表16−UDF一意ID(ADImpUse structure holding UDF Unique ID)
RBP
長さ
名前
内容
0
2
フラグ(2.3.10.1参照)[Flags (see 2.3.10.1)] Uint16
2
4
UDF一意ID(UDF Unique ID)
Uint32
3.2.1の論理ボリュームヘッダ記述子は,ファイル識別記述子のlong̲adの処理システム用バイトにおけ
るUDF一意ID(UDF Unique ID)欄,並びにファイルエントリ及び拡張ファイルエントリの一意ID(Unique
ID)欄の設定方法を記述している。
2.3.4.4
処理システム用の長さ(Uint16 LengthofImplementationUse)
a) 意味:処理システム用(ImplementationUse)欄の長さを指定しなければならない。
b) 設定値:この欄には,処理システム用欄の長さを指定しなければならないが,処理システム用欄が未
使用であることを示す0を設定してもよい。
ファイル識別記述子を追記形媒体に書き込むとき,次のFIDの記述子タグ欄がブロック境界に及ばない
ことを保証するため,FIDの後の現在のブロックに16未満のバイトが残っていれば,FIDの長さは,これ
を避けるのに十分なだけ増加させる(この場合,処理システム用欄を使用する。)。後者の場合,処理シス
テム用欄は少なくとも32バイトでなければならない。
2.3.4.5
処理システム用(byte ImplementationUse)
a) 意味:処理システム用の長さ(LengthofImplementationUse)欄が0でない場合,この欄の最初の32バ
イトは,ファイル識別記述子を最後に更新した処理システムの処理システム実体識別子の指定と解釈
する。
b) 設定値:処理システム用の長さ欄が0でない場合,この欄の最初の32バイトに,現状の処理システム
の処理システム実体識別子を指定しなければならない。
特記事項 この欄の適切な扱いに関する詳細情報は,実体識別子に関する2.1.5を参照。
この欄は,特定のファイル識別記述子を最後に作成又は更新した処理システムを識別することを可能と
する。
2.3.5
ICBタグ(ICB Tag)
struct icbtag{
/* JIS X 0607 4/14.6 */
Uint32
PriorRecordedNumberofDirectEntries;
Uint16
StrategyType;
byte
StrategyParameter[2];
Uint16
NumberofEntries;
byte
Reserved;
Uint8
FileType;
Lb̲addr
ParentICBLocation;
Uint16
Flags;
}
2.3.5.1
方策種別(Uint16 StrategyType)
a) 意味:この欄の内容には,使用するICB方策種別を指定する。読出しアクセスの目的の処理システム
は,方策種別4及び4 096を利用可能としなければならない。
b) 設定値:値4又は4 096を設定しなければならない。
35
X 0611:2018
特記事項 6.6で定義する方策種別4 096は,追記形媒体中で主に使用することを意図しているが,
書換形及び上書き形媒体で使用してもよい。
2.3.5.2
ファイル種別(Uint8 FileType)
標準のバイトで番地付け可能なファイルのために値5を使用しなければならず,0を使用してはならな
い。VAT(2.2.10参照)のために値248を使用しなければならない。Real-Timeファイル(6.11参照)を示
すために値249を使用しなければならない。値250〜255は使用してはならない。
2.3.5.2.1
ファイル種別249(File Type 249)
ファイル種別249のファイルはこのファイルのデータ領域にアクセスするための特別なコマンドを要求
する。起こり得るダメージを避けるために,これらのコマンドが利用可能でない処理システムの場合,こ
のファイルのデータ領域にアクセスするか又は変更するコマンドを全く出さない。これは,読出し,書込
み及び削除を含むが限定されるものではない。
2.3.5.3
親ICB位置(ParentICBLocation)
この欄の使用は,任意とする。
特記事項 [4/14.6.7]では,この欄が0の場合,そのようなICBを指定していないことを意味すると規
定している。これは,処理システムがICBを論理ブロック番地0に記録できることから,
規定の誤りである。したがって,この欄を使用する場合,ICBを論理ブロック0に記録し
てはならない。
2.3.5.4
フラグ(Uint16 Flags)
a) ビット0〜2
これらのビットは,使用する割付け記述子の種別を指定する。使用する割付け記述子種別の選択の
ガイドラインについては,2.3.10を参照。
b) ビット3[分類(Sorted)]
1) 意味:OSTA UDF適合媒体に関して,このビットは,ディレクトリが未分類でもよい(0)ことを示
さなければならない。
2) 設定値:0を設定しなければならない。
c) ビット4[再配置不可(Non-relocatable)]
1) 意味:OSTA UDF適合媒体に関して,このビットは,もし,ファイルが再配置不可であるならば,
(1)を示さなければならない。もし,[4/14.6.8]でのこのビットの定義に反するならば,処理システ
ムはこのビットを0に設定しなければならない。
2) 設定値:0を設定することが望ましい。
特記事項 このフラグはファイルをロックするものではない。それは,処理システムが特定の応
用プログラムの要求を満たすためにファイルの割付けをアレンジしたことを示すの
に使用される。これらの場合では,記録済みのブロック(UDF予備区画に関する2.2.9
を参照)の再割当て,又はファイルの断片解消処理(defragmentation)は望まれない
かもしれない。1に設定されたフラグをもつファイルが複写される場合,ファイルの
新しいコピーは,このビットを0に設定することが望ましい。
d) ビット9[連続性(Contiguous)]
1) 意味:OSTA UDF適合媒体に関して,このビットは,ファイルが連続である(1)ことを示してもよ
い。ファイルが連続であることを処理システムが保証できない場合に,ファイルが不連続でもよい
ことを示すために,処理システムはこのビットを0に設定してもよい。
36
X 0611:2018
2) 設定値:0を設定することが望ましい。
e) ビット11[変換(Transformed)]
1) 意味:OSTA UDF適合媒体に関して,このビットは,変換がない(0)ことを示さなければならない。
2) 設定値:0を設定しなければならない。
データ圧縮法及びその他のデータ変換形式は,将来のOSTAの規定で示す。
f)
ビット12[複数版数(Multi-versions)]
1) 意味:OSTA UDF適合媒体に関して,このビットは,複数版数ファイルが存在しない(0)ことを示
さなければならない。
2) 設定値:0を設定しなければならない。
2.3.6
ファイルエントリ(File Entry)
struct FileEntry{
/* JIS X 0607 4/14.9 */
struct tag
DescriptorTag;
struct icbtag
ICBTag;
Uint32
Uid;
Uint32
Gid;
Uint32
Permissions;
Uint16
FileLinkCount;
Uint8
RecordFormat;
Uint8
RecordDisplayAttributes;
Uint32
RecordLength;
Uint64
InformationLength;
Uint64
LogicalBlocksRecorded;
struct timestamp
AccessTime;
struct timestamp
ModificationTime;
struct timestamp
AttributeTime;
Uint32
Checkpoint;
struct long̲ad
ExtendedAttributeICB;
struct EntityID
ImplementationIdentifier;
Uint64
UniqueID;
Uint32
LengthofExtendedAttributors;
Uint32
LengthofAllocationDescriptes;
byte
ExtendedAttributes[];
byte
AllocationDescriptors[];
}
特記事項 一つのファイルエントリ(FileEntry)の全長は,一つの論理ブロックの長さを超えてはな
らない。
2.3.6.1
レコードフォーマット(Uint8 RecordFormat)
a) 意味:OSTA UDF適合媒体に関して,ファイルに記録する情報の構造は,この欄で規定しない(0)こ
とを示さなければならない。
b) 設定値:0を設定しなければならない。
37
X 0611:2018
2.3.6.2
レコード表示属性(Uint8 RecordDisplayAttributes)
a) 意味:OSTA UDF適合媒体に関して,ファイルに記録する情報の構造は,この欄で規定しない(0)こ
とを示さなければならない。
b) 設定値:0を設定しなければならない。
2.3.6.3
レコード長(Uint32 RecordLength)
a) 意味:OSTA UDF適合媒体に関して,ファイルに記録する情報の構造は,この欄で規定しない(0)こ
とを示さなければならない。
b) 設定値:0を設定しなければならない。
2.3.6.4
情報長(Uint64 InformationLength)
大抵の場合,情報長は,各割付け記述子の合計の長さを見つけることによって,回復操作中に再構築で
きる。しかし,空間はファイルの最後尾(“ファイル後尾”として識別される。)の後に割り付けてもよい。
“割り付けられているが未記録”の空間は,ファイル本体の一部分なので,次の場合,割付け記述子を
使って情報長を確定することができる。
a) エクステント長がブロックサイズの整数倍でない割付け記述子が存在する場合
b) このようなエクステントが存在せず,エクステント長が0に等しくない最後の割付け記述子のエクス
テント種別が,“割り付けられているが未記録”に等しくない場合
最後の割付け記述子だけがブロックサイズの倍数でないエクステント長をもつ場合は,[4/12.1]及び
[4/14.14.1.1]を参照。
2.3.6.5
記録済み論理ブロック(Uint64 LogicalBlocksRecorded)
データを埋め込んだファイル又はディレクトリについて,この欄の値は0を設定しなければならない。
2.3.6.6
処理システム識別子(struct EntityID ImplementationIdentifier)
実体識別子に関する2.1.5を参照。
2.3.6.7
一意ID(Uint64 UniqueID)
ファイル集合のルートディレクトリに関して,この値は0を設定しなければならない。
3.2.1の論理ボリュームヘッダ記述子は,ファイル識別記述子におけるlong̲adの処理システム用バイト
のUDF一意ID欄,並びにファイルエントリ及び拡張ファイルエントリの一意ID欄の設定方法を記述し
ている。
2.3.7
未割付け空間エントリ(Unallocated Space Entry)
struct UnallocatedSpaceEntry{ /* JIS X 0607 4/14.11 */
struct tag
DescriptorTag;
struct icbtag
ICBTag;
Uint32
LengthofAllocationDescriptors;
byte
AllocationDescriptors[];
}
特記事項 未割付け空間エントリの最大長は,一つの論理ブロック長でなければならない。
2.3.7.1
割付け記述子(byte AllocationDescriptors)
短割付け記述子だけを使用する。
特記事項 割付け記述子中のエクステント長欄の上位2ビットは,エクステント種別[4/14.14.1.1]を指
定する。未割付け空間エントリで規定する割付け記述子に関して,この種別は,割り付け
てはいるが未記録であるエクステントを示す値1に設定するか,又はエクステントが割付
38
X 0611:2018
け記述子の後続エクステントであることを示す値3に指定するかしなければならない。割
付け記述子の後続エクステントは,一つの論理ブロックの長さに制限しなければならない。
割付け記述子は,位置の昇順に連続的に並べなければならない。表中の割付け記述子は重複してはなら
ない。例えば,位置 = 2,長さ = 2 048(論理ブロック長 = 1 024)の割付け記述子の次が,位置 = 3の割
付け記述子であることは許されない。隣接する割付け記述子が続いてはならない。例えば,位置 = 2,長
さ = 1 024(論理ブロック長 = 1 024)の割付け記述子の次が,位置 = 3の割付け記述子であってはならず,
位置 = 2,長さ = 2 048の一つの割付け記述子でなければならない。隣接する割付け記述子が続いてもよ
い唯一の場合は,いずれか一方の隣接する割付け記述子の長さが,割付け記述子で記述可能な最大値のと
きである。
2.3.8
空間ビットマップ記述子(Space Bitmap Descriptor)
struct SpaceBitmap{
/* JIS X 0607 4/14.12 */
struct Tag
DescriptorTag;
Uint32
NumberOfBits;
Uint32
NumberOfBytes;
byte
Bitmap[];
}
2.3.8.1
記述子タグ(struct Tag DescriptorTag)
空間ビットマップ(SpaceBitmap)記述子に関する記述子タグの記述子CRC(DescriptorCRC)欄の計算
及び保守は,任意機能である。CRCを保守できない場合,記述子CRC欄及び記述子CRC長
(DescriptorCRCLength)欄の両方を0に設定する。
2.3.9
区画保全エントリ(Partition Integrity Entry)
struct PartitionIntegrityEntry{ /* JIS X 0607 4/14.12 */
struct tag
DescriptorTag;
struct icbtag
ICBTag;
struct timestamp
RecordingTime;
Uint8
IntegrityType;
byte
Reserved[175];
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[256];
}
論理ボリューム保全記述子の機能によって,この記述子は必要でないため,この記述子は記録してはな
らない。
2.3.10 割付け記述子(Allocation Descriptor)
ファイルのデータ領域を構成するとき,処理システムは,選択対象の幾つかの種別の割付け記述子をも
つ。次に示すガイドラインは,使用する適切な割付け記述子の選択時に従わなければならない。
a) 短割付け記述子:単一ボリューム中に存在する論理ボリューム(例えば,独立した装置で作成した論
理ボリューム)で,他のボリュームを拡張する予定のない論理ボリュームに関して,短割付け記述子
を使用することが望ましい。
特記事項 最大交換水準については,2.2.2.2を参照。
b) 長割付け記述子:複数ボリュームに存在する論理ボリューム,又は現在は単一ボリューム内に存在す
39
X 0611:2018
るが,後で複数ボリュームにまたがる予定の論理ボリュームに関して,長割付け記述子を使用するこ
とが望ましい。
特記事項 単一ボリューム中でも長割付け記述子を使用する利点はある。この利点は,書換形媒体
中の消去したエクステントの追跡を利用可能とすることである。付加情報については,
2.3.10.1を参照。
短割付け記述子及び長割付け記述子の両方に関して,エクステント長(ExtentLength)欄の下位30ビッ
トが0の場合,上位2ビットは0でなければならない。
仮想空間を識別する割付け記述子は,ブロック長以下の長さのエクステント長をもたなければならない。
ファイルデータ,ディレクトリ,又はストリームデータを識別する割付け記述子は物理空間を識別しなけ
ればならない。仮想空間に記録されたICBは,物理空間を識別するために,long̲ad割付け記述子を使用
しなければならない。short̲ad割付け記述子を使用することによって,もし,ICBが仮想空間にあるなら
ば,仮想空間のファイルデータを識別することになる。
仮想空間に記録された記述子は,タグ位置欄に記録された仮想論理ブロック番号をもたなければならな
い。
2.3.10.1 長割付け記述子(Long Allocation Descriptor)
struct long̲ad{
/* JIS X 0607 4/14.14.2 */
Uint32
ExtentLength;
Lb̲addr
ExtentLocation;
byte
ImplementationUse[6];
}
UDF及び処理システムの両方に処理システム用(ImplementationUse)欄の使用を許可するために,6バ
イトの処理システム用欄の中に次の構造を記録しなければならない。
struct ADImpUse
{
Uint16 flags;
byte impUse[4];
}
/*
*ADImpUse Flags (NOTE:bits 1-15 reserved for future use by UDF)
*/
#define EXTENTErased (0x01)
前処理の利点である書換形媒体の効率のために,このエクステント消去(EXTENTErasd)フラグは,消
去したエクステントを示す1を設定しなければならない。これは,割り付けたが未記録であるエクステン
トだけに使用する。
2.3.11 割付けエクステント記述子(Allocation Extent Descriptor)
struct AllocationExtentDescriptor{ /* JIS X 0607 4/14.5 */
struct tag
DescriptorTag;
Uint32
PreviousAllocationExtentLocation;
Uint32
LengthOfAllocationDescriptors;
}
40
X 0611:2018
割付けエクステント記述子は,割付け記述子それ自体を含まない。UDFは,[4/14.5]を割付け記述子が割
付けエクステント記述子の割付け記述子長(LengthOfAllocationDescriptors)欄に続く最初のバイトから始
まる方法として解釈する。割付けエクステント記述子はその割付け記述子とともに割付け記述子のエクス
テントを構成する。割付け記述子のエクステントの長さは,論理ブロック長を超えてはならない。割付け
記述子の次から論理ブロックの最後まで続く不使用のバイトは,値#00をもつ。
2.3.11.1 記述子タグ(Struct tag DescriptorTag)
記述子タグの記述子CRC長は,割付け記述子エクステントに続く割付け記述子を含む。記述子CRC長
は,8又は8+割付け記述子長でなければならない。
2.3.11.2 先行割付けエクステント位置(Units32 PreviousAllocationExtentLocation)
a) 意味:この欄は使用してはならない。
b) 設定値:0を設定しなければならない。
2.3.12 パス名(Pathname)
2.3.12.1 パス要素(Path Component)
struct PathComponent{
/* JIS X 0607 4/14.16.1 */
Uint8
ComponentType;
Uint8
LengthofComponentIdentifier;
Uint16
ComponentFileVersionNumber;
char
ComponentIdentifier[];
}
2.3.12.1.1 要素ファイル版数(Uint16 ComponentFileVersionNumber)
a) 意味:ファイルの版数は一つだけとする。
b) 設定値:値0を設定しなければならない。
2.4
第5部 レコード構造
レコード構造ファイルは,作成してはならない。これらが媒体中に存在し,処理システムが利用可能で
ない場合は,内容を解釈しないバイト列として扱わなければならない。
3
システム依存要件
3.1
第1部 一般
3.1.1 日時表示(Timestamp)
struct timestamp{
/* JIS X 0607 1/7.3 */
Uint16
TypeAndTimezone;
Uint16
Year;
Uint8
Month;
Uint8
Day;
Uint8
Hour;
Uint8
Minute;
Uint8
Second;
Uint8
Centiseconds;
Uint8
HundredsofMicroseconds;
Uint8
Microsecond;
41
X 0611:2018
}
3.1.1.1 1/100秒(Uint8 Centisecond)
a) 意味:1/100秒の概念が利用可能でないオペレーティングシステム(OS)では,処理システムはこの
欄を無視しなければならない。
b) 設定値:1/100秒の概念が利用可能でないOSでは,処理システムはこの欄に0を設定しなければなら
ない。
3.1.1.2
100マイクロ秒(Uint8 HundredsofMicrosecond)
a) 意味:100マイクロ秒の概念が利用可能でないOSでは,処理システムはこの欄を無視しなければな
らない。
b) 設定値:100マイクロ秒の概念が利用可能でないOSでは,処理システムはこの欄に0を設定しなけ
ればならない。
3.1.1.3 マイクロ秒(Uint8 Microsecond)
a) 意味:マイクロ秒の概念が利用可能でないOSでは,処理システムはこの欄を無視しなければならな
い。
b) 設定値:マイクロ秒の概念が利用可能でないOSでは,処理システムはこの欄に0を設定しなければ
ならない。
3.2
第3部 ボリューム構造
3.2.1
論理ボリュームヘッダ記述子(Logical Volume Header Descriptor)
struct LogicalVolumeHeaderDesc{ /* JIS X 0607 4/14.15 */
Uint64
UniqeID,
bytes
reserved[24]
}
3.2.1.1
一意ID(Uint64 UniqueID)
この欄は,次の段階で使用することが望ましい,一意IDの値を含む。この欄は16に初期設定し,次に
記載する各割付けとともに単調に増加する。この値の下位32ビットが#FFFFFFFFに達すると,上位32ビ
ットは,64ビット値に期待されるとおり,1ずつ増加するが,下位32ビットは,16(初期設定値)に折り
返す。この動作は,包括的に16から231−1を含むID数の空間を使用しているMacintosh OSで可能であり,
他のプラットフォームには問題を生じない。
一意IDは,新しいファイル又はディレクトリが生成されるか,他の名前を既存のファイル又はディレ
クトリにリンクするときに使用する。ファイル識別記述子,及びファイルエントリ又は拡張ファイルエン
トリは,ファイル又はディレクトリに関連する,ストリームディレクトリ又は名前付きストリームに使わ
れるが,一意IDは使用しない。むしろ,これらの構造の一意ID欄は,ストリームが関連するファイル及
びディレクトリの,ファイルエントリ・拡張ファイルエントリの一意IDから,そうした値をとる。
ファイル又はディレクトリが生成されると,この一意IDは,ファイルエントリ・拡張ファイルエント
リの一意ID欄に割り付けられ,一意IDの下位32ビットは,ファイル識別記述子(2.3.4.3参照)のlong̲ad
の処理システム用バイトのUDF一意記述子に割り付けられ,一意IDは,前に記載された方法で増加する。
名前が現存のファイル又はディレクトリにリンクすると,次の一意IDの下位32ビットが,ファイル識
別記述子(2.3.4.3参照)のlong̲adの処理システム用バイトのUDF一意IDに割り付けられ,一意IDは先
に記載された方法で増加する。
下位32ビットは,ファイルエントリ・拡張ファイルエントリ及び最初のファイル識別記述子において同
42
X 0611:2018
じでなければならないが,後続のFIDでは異ならなければならない。
UDF処理システムは全て,この3.2.1.1に記載されているとおりに,FIDでUDF一意IDを維持するもの
とし,ファイルエントリ及び拡張ファイルエントリでは一意IDを維持しなければならない。閉じた論理
ボリュームヘッダ記述子の論理ボリュームヘッダ記述子は有効な一意IDをもたなければならない。
3.3
第4部 ファイルシステム
3.3.1
ファイル識別記述子(File Identifier Descriptor)
struct FileIdentifierDescriptor{ /* JIS X 0607 4/14.4 */
struct tag
DescriptorTag;
Uint16
FileVersionNumber;
Uint8
FileCharacteristics;
Uint8
LengthofFileIdentifier;
struct long̲ad
ICB;
Uint16
LengthofImplementationUse;
byte
ImplementationUse[];
char
FileIdentifier[];
byte
Padding[];
}
3.3.1.1 ファイル特性(Uint8 FileChacteristics)
いろいろなOSでのファイル特性の使用法を以降の細分箇条に記載する。
3.3.1.1.1
MS-DOS,OS/2,Windows 95,Windows NT及びMacintosh
a) 意味:
1) ビット0が1の場合,隠しファイルと解釈しなければならない。
2) ビット1が1の場合,ディレクトリファイルと解釈しなければならない。
3) ビット2が1の場合,削除ファイルと解釈しなければならない。
4) ビット3が1の場合,関連するファイル識別子構造中のICB欄は,この記述子に記録するディレク
トリの親ディレクトリを識別していると解釈しなければならない。
b) 設定値:
1) 隠しファイルを示す場合,ビット0に1を指定しなければならない。
2) ディレクトリファイルを示す場合,ビット1に1を指定しなければならない。
3) 削除ファイルを示す場合,ビット2に1を指定しなければならない。
3.3.1.1.2
UNIX及びOS/400
UNIX及びOS/400で,隠しファイルを隠しファイルでない普通のファイルとして処理することを除けば,
これらのビットは3.3.1.1.1の規定と同様に処理しなければならない。
3.3.2
ICBタグ
struct icbtag{
/* JIS X 0607 4/14.6 */
Uint32
PriorRecordedNumberofDirectEntries;
Uiny16
StrategyType;
byte
StrateryParameter[2];
Uint16
NumberofEntries;
byte
Reserved;
43
X 0611:2018
Uint8
FileType;
Lb̲addr
ParentICBLocation;
Uint16
Flags;
}
3.3.2.1 フラグ(Uint16 Flags)
3.3.2.1.1
MS-DOS,OS/2,Windows 95及びWindows NT
a) ビット6及び7(Setuid & Setgid)
1) 意味:無視する。
2) 設定値:これらのビットを利用可能とする環境の下でのセキュリティ情報のメンテナンスのために,
次に示す状態のいずれかの一つが真の場合,ビット6及び7を0に設定しなければならない。
− 一つのファイルを作成する。
− ファイルに関連付けた属性及び許可条件を修正する。
− ファイルを書き込む(ファイルに関係するデータの内容を更新して)。
− ファイルに関連する拡張属性を修正する。
− ファイルに関連するストリームを修正する。
b) ビット8(Sticky)
1) 意味:無視する。
2) 設定値:0を設定しなければならない。
c) ビット10(System)
1) 意味:MS-DOS及びOS/2システムビットに配置する。
2) 設定値:MS-DOS及びOS/2システムビットに配置する。
3.3.2.1.2
Macintosh
a) ビット6及び7(Setuid & Setgid)
1) 意味:無視する。
2) 設定値:これらのビットを利用可能とする環境の下でのセキュリティ情報のメンテナンスのために,
次に示す状態のいずれかの一つが真の場合,ビット6及び7を0に設定しなければならない。
− 一つのファイルを作成する。
− ファイルに関連付けた属性及び許可条件を修正する。
− ファイルを書き込む(ファイルに関係するデータの内容を更新して)。
− ファイルに関連する拡張属性を修正する。
− ファイルに関連するストリームを修正する。
b) ビット8(Sticky)
1) 意味:無視する。
2) 設定値:0を設定しなければならない。
c) ビット10(System)
1) 意味:無視する。
2) 設定値:ファイル作成時だけ0を設定し,それ以外では保守しなければならない。
3.3.2.1.3
UNIX
a) ビット6,7及び8(Setuid, Setgid, Sticky)
これらのビットは,対応する標準UNIXファイルシステムのビットに配置される。
44
X 0611:2018
b) ビット10(System)
1) 意味:無視する。
2) 設定値:ファイル作成時だけ0を設定し,それ以外では保守しなければならない。
3.3.2.1.4
OS/400
a) ビット6及び7(Setuid & Setgid)
1) 意味:無視する。
2) 設定値:これらのビットを利用可能とする環境の下でのセキュリティ情報のメンテナンスのために,
次に示す状態のいずれかの一つが真の場合,ビット6及び7を0に設定しなければならない。
− 一つのファイルを作成する。
− ファイルに関連付けた属性及び許可条件を修正する。
− ファイルを書き込む(ファイルに関係するデータの内容を更新して)。
− ファイルに関連する拡張属性を修正する。
− ファイルに関連するストリームを修正する。
b) ビット8(Sticky)
1) 意味:無視する。
2) 設定値:0を設定しなければならない。
c) ビット10(System)
1) 意味:無視する。
2) 設定値:ファイル作成時だけ0を設定し,それ以外では保守しなければならない。
3.3.3
ファイルエントリ(File Entry)
struct FileEntry{
/* JIS X 0607 4/14.9 */
struct tag
DescriptorTag;
struct icbtag
ICBTag;
Uint32
Uid;
Uint32
Gid;
Uint32
Permissions;
Uint16
FileLinkCount;
Uint8
RecordFormat;
Uint8
RecordDisplayAttributes;
Uint32
RecordLength;
Uint64
InformationLength;
Uint64
LogicalBlocksRecorded;
struct timestamp
AccessTime;
struct timestamp
ModificationTime;
struct timestamp
AttributeTime;
Uint32
checkpoint;
struct long̲ad
ExtendedAttributeICB;
struct EntityID
ImplementationIdentifier;
Uint64
UniqueID;
Uint32
LengthofExtendedAttributors;
45
X 0611:2018
Uint32
LengthofAllocationDescriptors;
byte
ExtendedAtrributes[];
byte
AllocationDescriptors[];
}
特記事項 ファイルエントリ(FileEntry)の全長は,一つの論理ブロック長を超えてはならない。
3.3.3.1 利用者ID(Uint32 Uid)
a) 意味:利用者識別子の概念を利用可能としないOSでは,処理システムは,この欄を無視しなければ
ならない。この欄を利用可能とするOSでは,(232−1)の値は無効な利用者IDと解釈し,他の場合,
この欄は有効な利用者IDを含まなければならない。
b) 設定値:利用者が指定しない限り,利用者IDの概念を利用可能としないOSでは,処理システムは,
無効な利用者IDと解釈するための値(232−1)をこの欄に設定しなければならない。
3.3.3.2 グループID(Uint32 Gid)
a) 意味:グループIDの概念を利用可能としないOSでは,処理システムは,この欄を無視しなければな
らない。この欄を利用可能とするOSでは,(232−1)の値は無効なグループIDと解釈し,他の場合,
この欄は有効なグループIDを含まなければならない。
b) 設定値:利用者が指定しない限り,グループIDの概念を利用可能としないOSでは,処理システムは,
無効なグループIDと解釈するための値(232−1)をこの欄に設定しなければならない。
3.3.3.3
許可条件(Uint32 Permissions)
/* Definition: */
/* Bit for a file
for a Directory
*/
/* - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - */
/* Execute May excute file
May search directory
*/
/* write May change file contents
May create and delete files
*/
/* Read May examine fil contents
May list files in directory
*/
/* ChAttr May change file attributes
May change dir attributes
*/
/* Delete May delete file
May delete directory
*/
#define OTHER̲Execute 0x00000001
#define OTHER̲Write
0x00000002
#define OTHER̲Read
0x00000004
#define OTHER̲ChAttr
0x00000008
#define OTHER̲Delete
0x00000010
#define GROUP̲Execute 0x00000020
#define GROUP̲Write
0x00000040
#define GROUP̲Read
0x00000080
#define GROUP̲ChAttr
0x00000100
#define GROUP̲Delete
0x00000200
#define OWNER̲Execute 0x00000400
#define OWNER̲Write
0x00000800
#define OWNER̲Read
0x00001000
#define OWNER̲ChAttr 0x00002000
#define OWNER̲Delete
0x00004000
セキュリティ情報を扱う許可条件の概念は,OS間で完全には移植可能でない。この規格では,次に示
す基本的な課題に言及することによって,許可条件ビットを処理する処理システム間で一貫性を保持する。
a) OSが,利用者ID及びグループIDの概念をもたない場合,所有者,グループ及びその他の許可条件
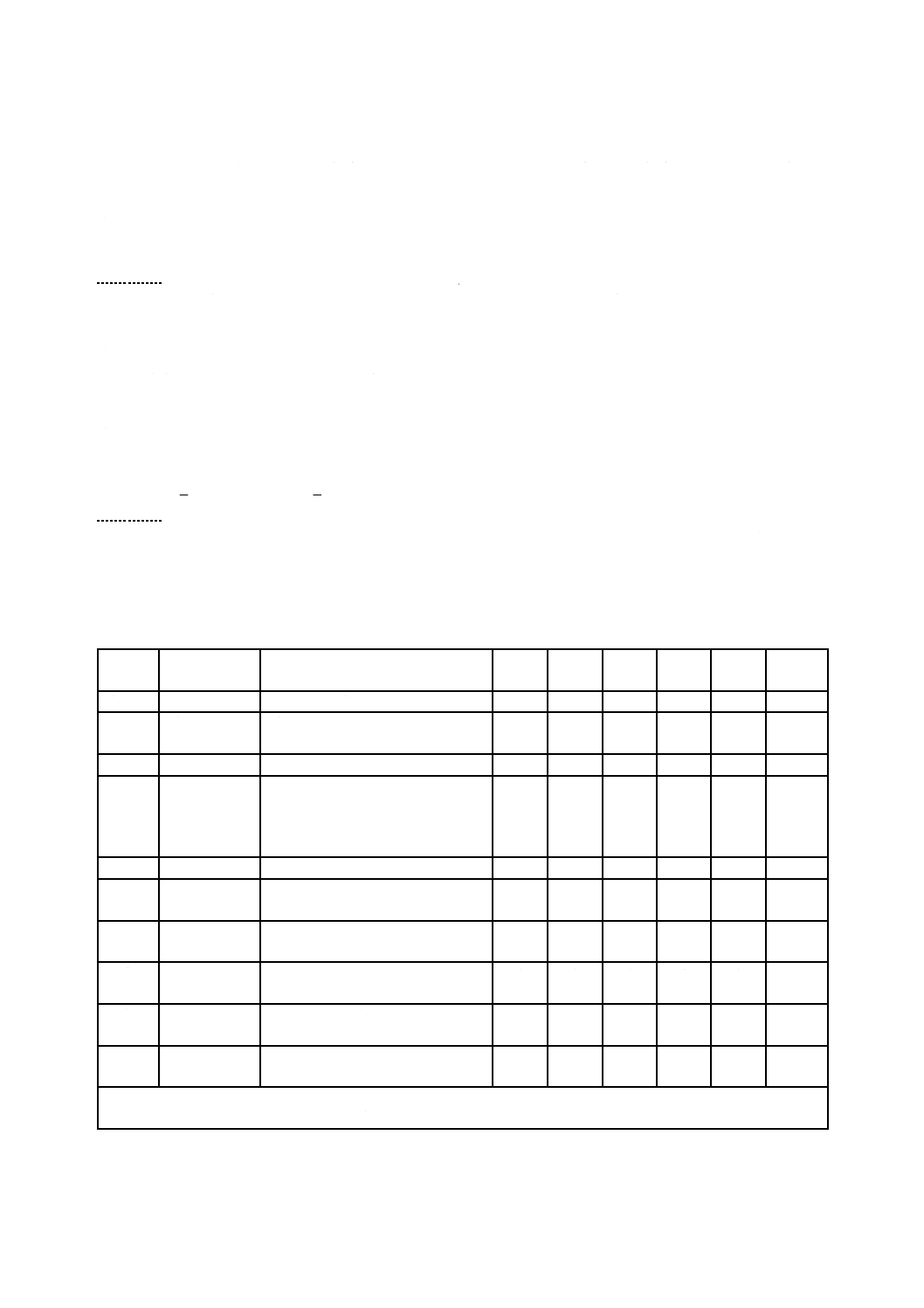
46
X 0611:2018
をどのように処理システムが扱うことが望ましいのか。
b) OSが,利用可能にする許可条件ビットに直接配置していない特定の許可条件ビットがある場合,処
理システムは,どのように許可条件ビットを処理することが望ましいのか。
c) 新しいファイルを作成するときに,OSが利用可能にする許可条件ビットに直接配置していない許可
条件に関しては,どのようなデフォルト値を用いることが望ましいのか。
3.3.3.3.1A 利用者,グループ,その他(Owner, Group and Other)
一般に,利用者ID及びグループIDを利用可能にしないOSでは,許可条件ビットを処理するとき,次
に示すアルゴリズムを使用する。
a) 特定の許可条件を読み出す場合,全ての三つ(所有者,グループ,その他)の許可条件の論理和で値
を検査することが望ましい。例えば,OWNER̲Write,GROUP̲Write及びOTHER̲Writeの論理和が1
に等しかった場合,ファイルは書込み可能を示す。
b) 特定の許可条件を設定する場合,処理システムは許可条件ビットの三つ(所有者,グループ,その他)
の集合を設定することが望ましい。例えば,書込み可能なファイルを示す場合,OWNER̲Write,
GROUP̲Write及びOTHER̲Writeを全て値1に設定することが望ましい。
3.3.3.3.2A デフォルト許可値(Default Permission Values)
表17では,この規格で扱う各OSに関して,そのOSで利用可能な許可条件ビットに直接変換されない
許可条件ビットについて,新しいファイルを作成するときにどのようなデフォルト値を使用することが望
ましいかを記載している。
表17−許可条件
許可
ファイル又は
ディレクトリ
記載
DOS
OS/2
Win
95
Win
NT
Mac
OS
UNIX &
OS/400
読出し
ファイル
ファイルを読み出してもよい。
1
1
1
1
1
U
読出し
ディレクトリ ディレクトリが実行の表示がある
場合だけ,読み出してもよい。
1
1
1
1
1
U
書込み
ファイル
ファイルの内容を修正してもよい。
U
U
U
U
U
U
書込み
ディレクトリ ディレクトリが実行の表示がある
場合だけ,ファイル,又はサブディ
レクトリは,名前を変更したり,加
えたり,削除してもよい。
U
U
U
U
U
U
実行
ファイル
ファイルは実行してもよい。
0
0
0
0
0
U
実行
ディレクトリ ディレクトリの許可条件は,変更し
てもよい。
1
1
1
1
1
U
属性
ファイル
ファイルの許可条件は変更しても
よい。
1
1
1
1
1
特記
事項1
属性
ディレクトリ ディレクトリの許可条件は変更し
てもよい。
1
1
1
1
1
特記
事項1
削除
ファイル
ファイルは削除してもよい。
特記
事項2
特記
事項2
特記
事項2
特記
事項2
特記
事項2
特記
事項2
削除
ディレクトリ ディレクトリは削除してもよい。
特記
事項2
特記
事項2
特記
事項2
特記
事項2
特記
事項2
特記
事項2
U:利用者指定 1:設定 0:除去
特記事項1 UNIXでは,ファイル及びディレクトリの所有者だけが,その属性を変更してもよい。
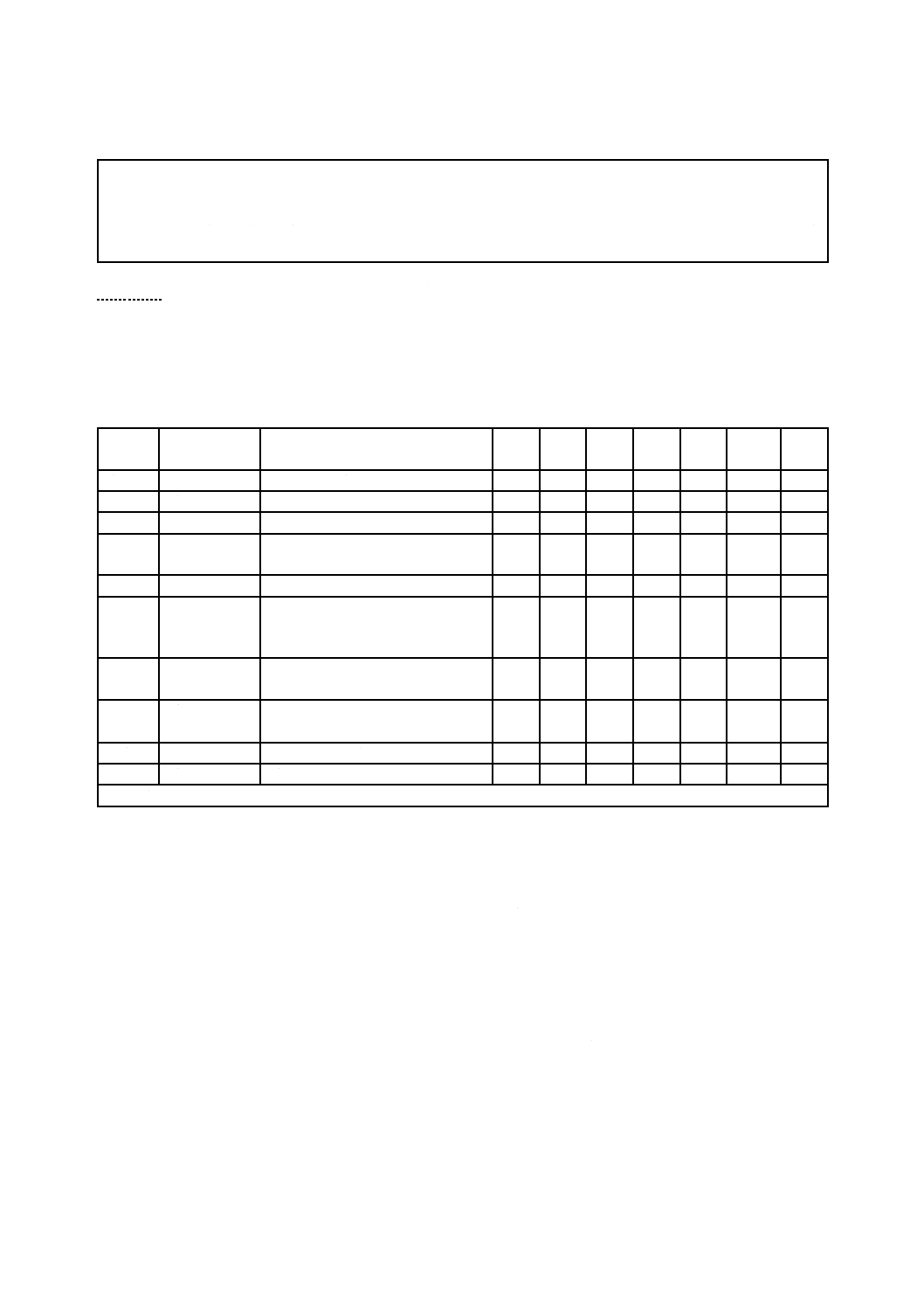
47
X 0611:2018
表17−許可条件(続き)
特記事項2 削除許可条件ビットは,書込み許可条件ビットの状態を基に設定することが望ましい。DOS,OS/2及
びMacintoshでは,ファイル又はディレクトリに書込みの表示が出たら(書込み許可条件設定),ファ
イルは削除可能と考えられ,削除許可条件ビットを設定することが望ましい。ファイルが再生専用の
場合,削除許可条件ビットを設定するのは望ましくない。これは,ファイル作成とファイルの属性変
更とにも適用する。
3.3.3.3.3A 許可条件処理(Processing Permissions)
この規格で扱うOSにおいて,許可条件ビットの処理法を記載する表18に従って,処理システムは許可
条件ビットを処理する。表18は,OSが利用可能な許可条件ビットに直接配置していない許可条件ビット
に関連する項目を示す。
表18−各OSの許可条件ビット処理
許可
ファイル又は
ディレクトリ
記載
DOS OS/2
Win
95
Win
NT
Mac
OS
UNIX
OS/
400
読出し
ファイル
ファイルを読み出してもよい。
E
E
E
E
E
E
E
読出し
ディレクトリ ディレクトリを読み出してもよい。
E
E
E
E
I
E
E
書込み
ファイル
ファイルの内容を更新してもよい。
E
E
E
E
E
E
E
書込み
ディレクトリ ファイル又はディレクトリを作成,
削除又は名前変更してもよい。
E
E
E
E
E
E
E
実行
ファイル
ファイルは実行してもよい。
I
I
I
I
I
E
I
実行
ディレクトリ ファイル又はサブディレクトリを
規定するために,ディレクトリを検
索してもよい。
E
E
E
E
E
E
E
属性
ファイル
ファイルの許可条件を変更しても
よい。
E
E
E
E
E
I
I
属性
ディレクトリ ディレクトリの許可条件を変更し
てもよい。
E
E
E
E
E
I
I
削除
ファイル
ファイルを削除してもよい。
E
E
E
E
E
I
I
削除
ディレクトリ ディレクトリを削除してもよい。
E
E
E
E
E
I
I
E:実施する I:無視する
検索ビットとしてときどき参照するディレクトリの実行ビットは,特別な意味をもつ。このビットは,
ディレクトリの検索を可能にするが,その内容を一覧表示できるわけではない。例えば,実行許可条件だ
けを設定し,さらに,読出し許可条件ビットを設定しないPRIVATEと呼ぶディレクトリがある場合,ディ
レクトリPRIVATEの内容は,一覧表示できない。PRIVATEディレクトリ中にREADMEと呼ぶ一つのファ
イルがあると仮定する。利用者は,PRIVATEディレクトリが検索可能であるため,READMEファイルに
アクセスできる。
ディレクトリの内容を一覧表示するためには,読出し許可条件ビット及び実行許可条件ビットの両方を
ディレクトリに設定しなければならない。ファイル又はサブディレクトリの作成,削除及び名前変更をす
るためには,書込み許可条件ビット及び実行許可条件ビットの両方をディレクトリに設定しなければなら
ない。ディレクトリに対する実行ビットをもっとよく理解するためには,ファイル及びディレクトリの許
可条件を扱うUNIXの文献を参照する。ディレクトリの実行ビットに定義する規則は,全ての処理システ
ムで実施しなければならない。この規則はMacintoshの処理システムには該当しない。Macintoshの処理シ
ステムでは,ディレクトリのアクセス可能性を決定する際,読出しビットの状態を無視してもよい。
48
X 0611:2018
特記事項 ファイル又はサブディレクトリを削除するには,ファイル又はサブディレクトリの削除許
可条件ビットが設定されており,ファイル又はサブディレクトリを含むディレクトリには,
書込み許可条件ビット及び実行許可条件ビットの両方が設定されていなければならない。
3.3.3.4
一意ID(Uint64 UniqueID)
特記事項 幾つかのOS(例えば,Macintosh)に関しては,この値はInt32の最大値(231−1)より小
さくする必要がある。Macintosh OSでは,この値はMacintoshのディレクトリID又はファ
イルIDを表すために使用する。そのために,処理システムはInt32の最大値(231−1)よ
り小さい値であることが望ましい。値1〜15は,Macintosh用に確保しなければならない。
3.3.3.5
バイト拡張属性(byte Extended Attributes)
ある種の拡張属性は,実行処理のためにファイルエントリ(FileEntry)のこの欄に記録することが望ま
しい。その他の拡張属性は,拡張属性ICB(ExtendedAttributeICB)欄で指示するICBに記録することが望
ましい。3.3.4では,この欄に記録することが望ましい拡張属性について規定する。
3.3.4
拡張属性(Extended Attributes)
長さの変更が起こり得る,より長い拡張属性(EA)を扱うために,次に示す規則をEA空間に適用する。
a) 一つの論理ブロック以上の属性長をもつ全てのEAは,論理ブロック境界で開始し,論理ブロック境
界で終了するブロック列でなければならない。
b) より短いEAは,4バイト単位の属性長でなければならない。
c) 各拡張属性空間は,次に示す構成のうち,一つの連続論理空間を表さなければならない。
1) JIS X 0607規格類の拡張属性
2) ブロック境界でない処理システム用拡張属性
3) ブロック境界の処理システム用拡張属性
4) 応用プログラム用拡張属性
特記事項 ファイルごとに,二つの拡張属性空間が存在してもよい。一方はファイルエントリ又は
拡張ファイルエントリに埋め込まれ,他方は,ファイルエントリ又は拡張ファイルエン
トリ内の拡張属性ICB番地によってアクセスされる分離された空間とする。各拡張属性
空間が存在する場合は,独自の拡張属性ヘッダ記述子をもたなければならない(3.3.4.1
参照)。
3.3.4.1
拡張属性ヘッダ記述子(Extended Attribute Header Descriptor)
struct ExtendedAttributedHeaderDescriptor{ /* JIS X 0607 4/14.10.1 */
struct tag
DescriptorTag;
Uint32
ImplementationAttributesLocation;
Uint32
ApplicationAttributesLocation;
}
a) 意味:前述の処理システム拡張位置欄の一つの値が,拡張属性空間の長さと同等であるか,それより
大きいものは,対応する属性が存在しないと解釈しなければならない。
b) 設定値:前述の処理システム拡張位置欄の一つに関係している属性が存在しない場合,対応する位置
欄の値は#FFFFFFFFに設定しなければならない。
3.3.4.2
代替許可条件(Alternate Permissions)
struct AltematePermissionsExtendedAttribute{ /* JIS X 0607 4/14.10.4 */
Uint32
AttributeType;
49
X 0611:2018
Uint8
AttributeSubtype;
byte
Reserved[3];
Uint32
AttributeLength;
Uint16
OwnerIdentification;
Uint16
GroupIdentification;
Uint16
Permission;
}
この構造は,記録してはならない。
3.3.4.3
ファイル日時拡張属性(File Times Extended Attribute)
struct FileTimesExtendedAttribute{ /* JIS X 0607 4/14.10.5 */
Uint32
AttributeType;
Uint8
AttributeSubtype;
byte
Reserved[3];
Uint32
AttributeLength;
Uint32
DataLength;
Uint32
FileTimeExistence;
byte
FileTimes;
}
3.3.4.3.1
ファイル日時(byte FileTimes)
a) 意味:この欄にファイル作成日時が含まれている場合,関連ファイルの作成日時と解釈しなければな
らない。主ファイルエントリが拡張ファイルエントリである場合,この構造のファイル作成日時は無
視し,主ファイルエントリのファイル作成日時を使用しなければならない。
b) 設定値:主ファイルエントリが拡張ファイルエントリである場合,この構造は,ファイル作成日時を
記録してはならない。
主ファイルエントリが拡張ファイルエントリではなく,ファイル日時拡張属性が存在しない場合,又は
ファイル作成日時を含まない場合,処理システムでは,ファイル作成日時を表すために,ファイルエント
リの訂正日時欄を使用しなければならない。
3.3.4.4
装置仕様の拡張属性(Device Specification Extended Attribute)
struct DeviceSpecificationExtendedAttribute{ /* JIS X 0607 4/14.10.7 */
Uint32
AttributeType;
Uint8
AttributeSubtype;
byte
Reserved[3];
Uint32
AttributeLength;
Uint32
ImplementationUseeLength; /* (= IU̲L) */
Uint32
MajorDeviceIdentification;
Uint32
MinorDeviceIdentification;
byte
ImplementationUse[IU̲L];
}
次に示す規範は,ファイルに関連する装置仕様拡張属性を作成する処理システムに従わなければならな
い。
50
X 0611:2018
a) ファイルが関連する装置仕様拡張属性をもつ場合,icbtag構造中のファイル種別欄の内容は,値6(ブ
ロック特殊装置ファイルを示す。)又は値7(文字特殊装置ファイルを示す。)を指定する。
b) icbtag構造中のファイル種別欄の内容が値6又は値7でない場合,ファイルに関連する装置仕様拡張
属性は無視する。
c) icbtag構造中のファイル種別欄内容が値6又は値7に等しく,ファイルに関連する装置仕様拡張属性
がない場合,ファイルへのアクセスは拒否しなければならない。
d) ブロック特殊装置ファイルに関連する解釈方法を提供しないOS環境において,関連する装置仕様拡
張属性をもつファイルへのopen, read, write及びclose要求は拒否しなければならない。
e) 全ての処理システムは,現状の処理システムを識別するdeveloperIDを処理システム用
(ImplementationUse)欄に記録しなければならない。
3.3.4.5
処理システム用拡張属性(Implementation Use Extended Attribute)
struct ImplementationUseExtendedAttribute{ /* JIS X 0607 4/14.10.8 */
Uint32
AttributeType;
Uint8
AttributeSubtype;
byte
Reserved[3];
Uint32
AttributeLength;
Uint32
ImplementationUseLength; /* (= IU̲L) */
struct EntityID
ImplementationIdentifier;
byte
ImplementationUse[IU̲L];
}
属性長(AttributeLength)欄は,全体の拡張属性の長さを指定する。処理システム用拡張属性の使用を定
義する可変長の拡張属性に関して,属性長欄には,処理システム用(Implementation Use)欄の最後と処理
システム用拡張属性(Implementation Use Extended Attribute)の最後との間に埋込み空間を残すのに,十分
な大きさを指定することが望ましい。
3.3.4.5.1〜3.3.4.5.6では,オペレーティングシステム(OS)固有の拡張属性を記録するために,いろい
ろなOSで処理システム用拡張属性を使用する方法を記述する。
3.3.4.5.1〜3.3.4.5.6に定義する構造は,ヘッダチェックサム(header checksum)欄を含む。この欄は,処
理システム用拡張属性ヘッダの16ビットチェックサムを表す。属性種別(AttributeType)から処理システ
ム識別子(ImplementationIdentifier)までの欄を,チェックサムで保護するデータとして表す。ヘッダチェ
ックサム欄は,拡張属性空間の障害回復の支援として使う。ヘッダチェックサムのためのCのソースコー
ドを6.8に示す。
特記事項 全ての適合する処理システムでは,媒体中の既存の拡張属性を保存することを推奨する。
処理システムは,動作中のOSに関する拡張属性を作成し,利用可能にすることが望まし
い。例えば,Macintoshの処理システムでは,媒体中に存在するOS/2拡張属性を保存する
ことを推奨する。また,この規格に規定する全てのMacintosh拡張属性を作成し,利用可
能にすることが望ましい。
3.3.4.5.1
全てのオペレーティングシステム(All Operating System)
3.3.4.5.1.1
空きEA空間(FreeEASpace)
この拡張属性は,拡張属性空間で未使用な空間を示すために使用しなければならない。この拡張属性は,
処理システム用拡張属性として記録しなければならない。その処理システム用拡張属性の処理システム識
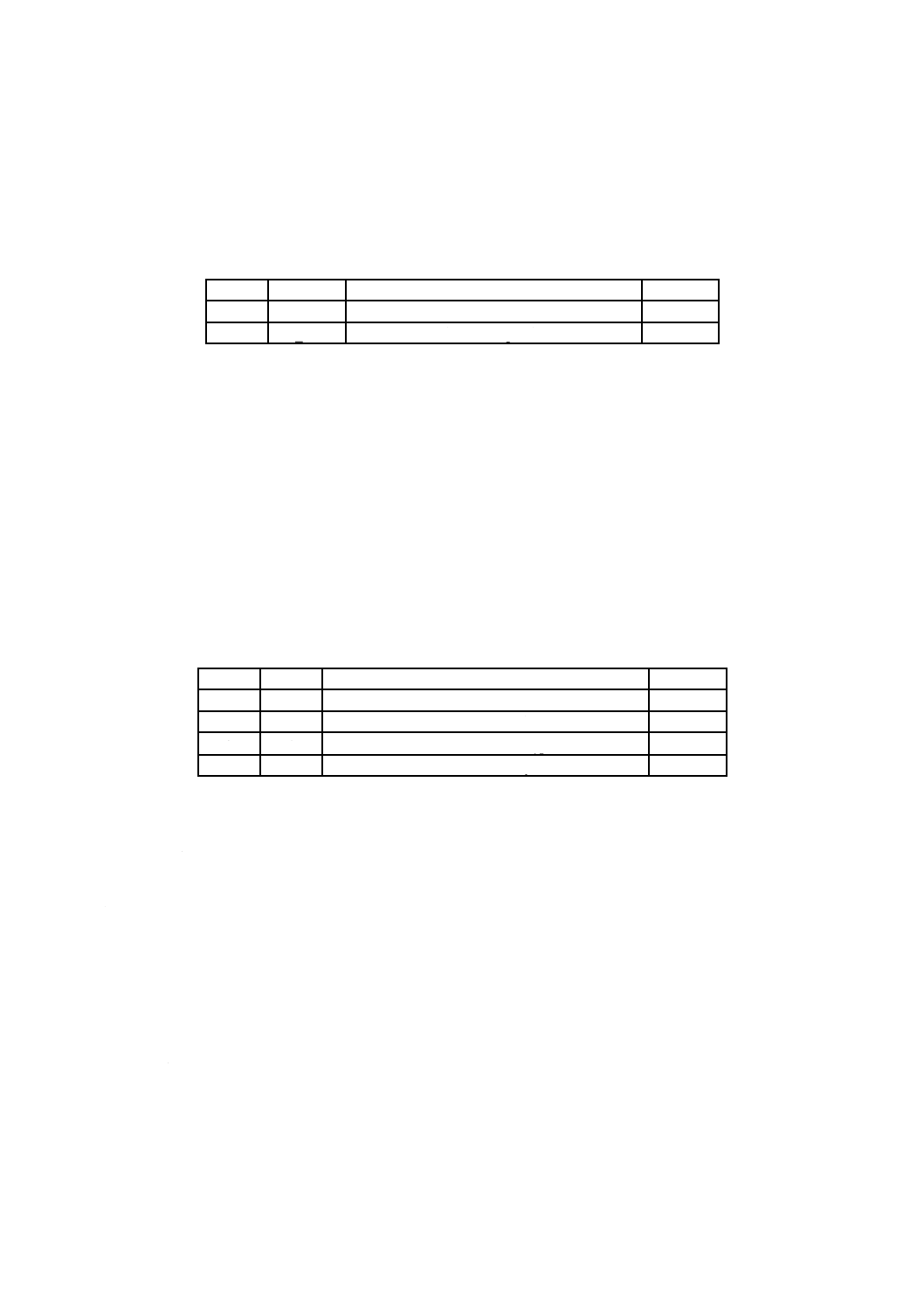
51
X 0611:2018
別子(ImplementationIdentifier)は,
“*UDF FreeEASpace”
に設定しなければならない。
この拡張属性の処理システム用(ImplementationUse)領域は,表19に示す構成でなければならない。
表19−空きEA空間のフォーマット(FreeEASpace format)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
IU̲L−2
空きEA空間(Free EA Space)
バイト
この拡張属性は,拡張属性空間の全てを再度書き込むことなく,処理システムが他の拡張属性の全長を
縮小又は拡大することを可能にする。空きEA空間(FreeEASpace)の拡張属性は上書きしてもよく,上書
きを必要とする処理システムがその空間を再利用してもよい。
3.3.4.5.1.2
DVD著作権管理情報(DVD Copyright Management Information)
この拡張属性は,DVD著作権管理情報を示すために使用しなければならない。この拡張属性は,処理シ
ステム用拡張属性として記録しなければならない。その処理システム用拡張属性の処理システム識別子
(ImplementationIdentifier)は,
“*UDF DVD CGMS Info”
に設定しなければならない。
この拡張属性の処理システム用(ImplementationUse)領域は,表20に示す構成でなければならない。
表20−DVD CGMS Infoのフォーマット
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
1
CGMS情報(CGMS Information)
バイト
3
1
データ構造種別(Data Structure Type)
Uint8
4
4
保護システム情報(Protection System Information) バイト
この拡張属性は,DVD著作権管理情報の記録を可能にする。このフォーマットの解釈は,DVDコンソ
ーシアム(6.9.3参照)が出版するDVD規定で定義しなければならない。この拡張属性を利用可能にする
ことは,任意選択とする。
3.3.4.5.2
MS-DOS,Windows95及びWindowsNT
a) 意味:無視する。
b) 設定値:この拡張属性は,利用できない。媒体中の既存ファイルの拡張属性は保存しなければならな
い。
3.3.4.5.3
OS/2
OS/2は,制限のない個数の拡張属性を利用可能にする。これらの拡張属性は,3.3.8.2に定義するとおり,
名前付きストリームとして記録しなければならない。性能を高めるために,次に示す処理システム用拡張
属性を作成する。
3.3.4.5.3.1
OS/2拡張属性長(OS2EALength)
この拡張属性は,OS/2拡張属性ストリーム(3.3.8.2)情報の長さを規定する。この値は,ディレクトリ
操作でOS/2に通知する必要があるため,効率上の理由から,ファイルエントリ(FileEntry)の拡張属性
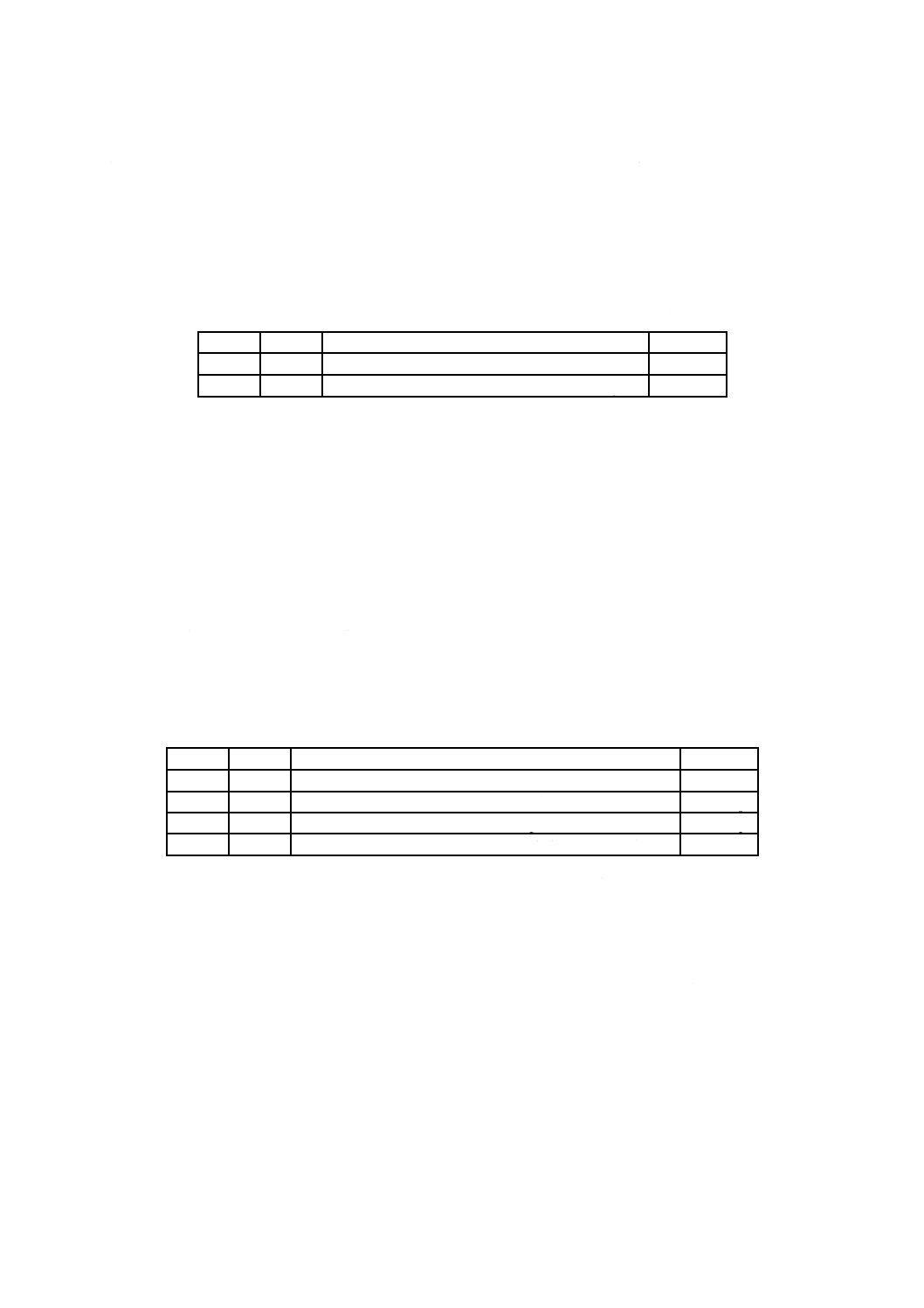
52
X 0611:2018
(ExtendedAttributes)欄に記録することが望ましい。この拡張属性は,処理システム識別子
(ImplementationIdentifier)に,処理システム用拡張属性として記録しなければならない。その処理システ
ム用拡張属性の処理システム識別子(ImplementationIdentifier)は,
“*UDF OS/2 EALength”
に設定しなければならない。
この拡張属性の処理システム用(ImplementationUse)領域は,表21に示す構成でなければならない。
表21−OS/2拡張属性長フォーマット(OS/2 EALength format)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
4
OS/2拡張属性長(OS/2 Extended Attribute Length) Uint32
OS/2拡張属性長欄に記録する値は,OS/2EAストリームのファイルエントリの情報長(OS/2Extended
AttributedLength)欄に一致しなければならない。
3.3.4.5.4
Macintosh OS
Macintosh OSは,次の3.3.4.5.4.1及び3.3.4.5.4.2に示す拡張属性の利用を要求する。
3.3.4.5.4.1
Macintoshボリューム情報(MacVolumeInfo)
この拡張属性は,Machintoshボリューム情報を含み,処理システム用識別子(ImplementationIdentifier)
に処理システム用拡張属性として記録しなければならない。その処理システム用拡張属性の処理システム
識別子(ImplementationIdentifier)は,
“*UDF Mac VolumeInfo”
に設定しなければならない。
この拡張属性の処理システム用(ImplementationUse)領域は,表22に示す構成でなければならない。
表22−Macintoshボリューム情報フォーマット(MacVolumeInfo format)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
12
最後の更新日時(Last Modification Date)
timestamp
14
12
最後のバックアップ日時(Last Backup Date)
timestamp
26
32
ボリュームファインダ情報(Volume Finder Information)
Uint32
Macintoshボリューム情報(MacVolumeInfo)の拡張属性は,ルートディレクトリのファイルエントリ
(FileEntry)の拡張属性として記録しなければならない。
3.3.4.5.4.2
Macintoshファインダ情報(MacFinderInfo)
この拡張属性は,関連ファイル又はディレクトリのMacintoshファインダ情報を含む。この情報は頻繁
にアクセスするため,効率上の理由からファイルエントリ(FileEntry)の拡張属性(ExtendedAttributes)
欄に記録することが望ましい。
Macintoshファインダ情報の拡張属性は,処理システム用識別子(ImplementationIdentifier)に処理システ
ム用拡張属性として記録しなければならない。その処理システム用拡張属性の処理システム識別子
(ImplementationIdentifier)は,
“*UDF Mac FinderInfo”
に設定しなければならない。
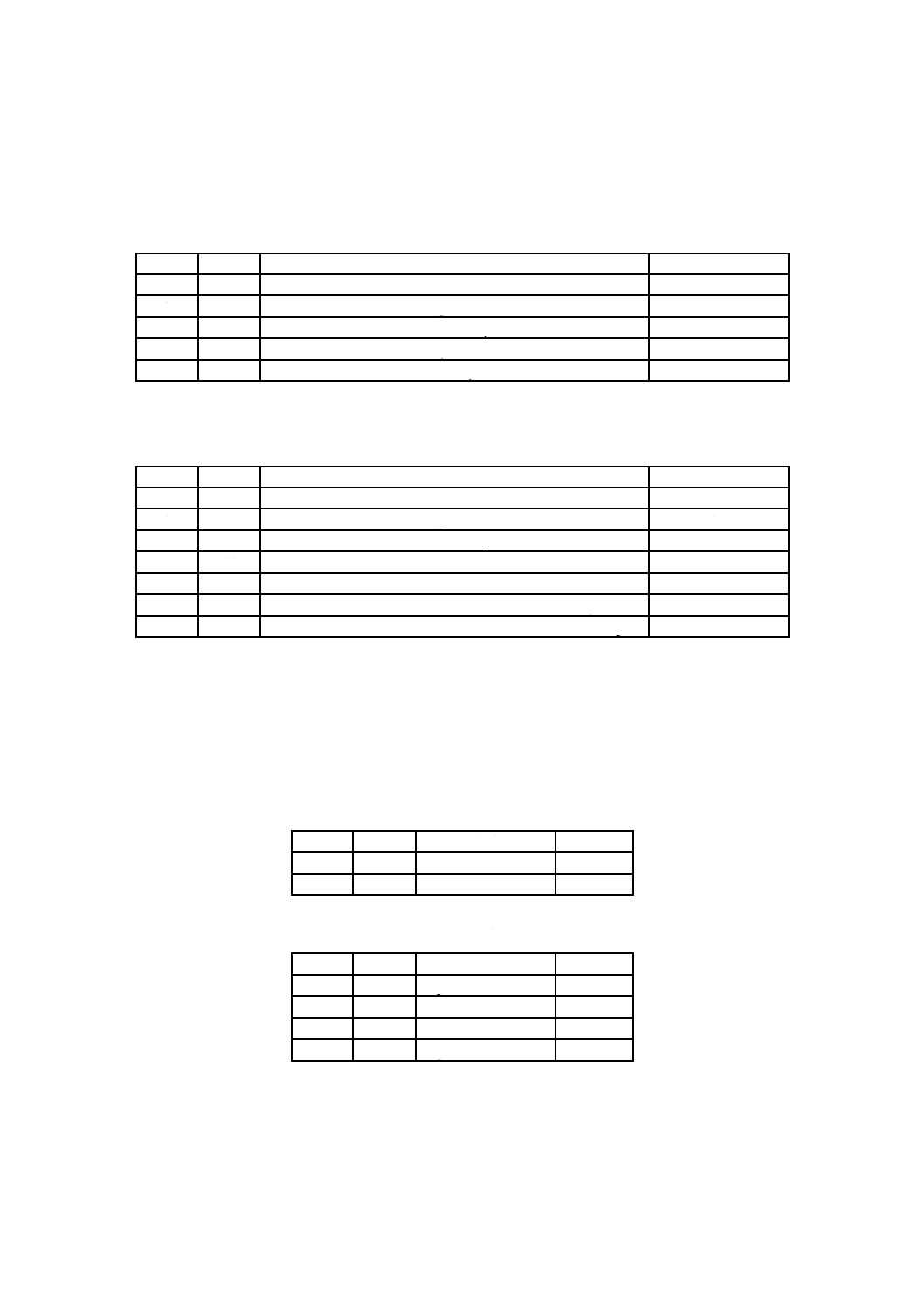
53
X 0611:2018
この拡張属性の処理システム用(ImplementationUse)領域は,表23及び表24に示す構成でなければな
らない。
表23−ディレクトリに対するMacintoshファインダ情報フォーマット
(MacFinderInfo format for a directory)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
2
埋込み(Reserved for Padding)
Uint16 = 0
4
4
親ディレクトリID(Parent Directory ID)
Uint32
8
16
ディレクトリ情報(Directory Information)
UDFDInfo
24
16
ディレクトリ拡張情報(Directory Extended Information)
UDFDXInfo
表24−ファイルに対するMacintoshファインダ情報フォーマット
(MacFinderInfo format for a file)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
2
埋込み(Reserved for Padding)
Uint16 = 0
4
4
親ディレクトリID(Parent Directory ID)
Uint32
8
16
ファイル情報(File Information)
UDFFInfo
24
16
ファイルの拡張情報(File Extended Information)
UDFFXInfo
40
4
リソースフォークデータ長(Resource Fork Data Length)
Uint32
44
4
リソースフォーク割付け長(Resource Fork Allocated Length) Uint32
Macintoshファインダ情報(MacFinderInfo)の拡張属性は,論理ボリューム中の全てのファイル及びデ
ィレクトリの拡張属性として記録しなければならない。
Macintoshファインダ情報中で使用する構造は,明確化のために表25〜表30で示す。これらの構造の完
全な情報については,“Inside Macintosh”と呼ぶMacintoshの文献を参照する。各構造のボリューム及びペ
ージ番号は,“Inside Macintosh”固有のボリューム及びページに対応する。
表25−UDFPointフォーマット(ボリュームI,139ページ)
RBP
長さ
名前
内容
0
2
V
Int16
2
2
H
Int16
表26−UDFRectフォーマット(ボリュームI,141ページ)
RBP
長さ
名前
内容
0
2
Top
Int16
2
2
Left
Int16
4
2
Bottom
Int16
6
2
Right
Int16
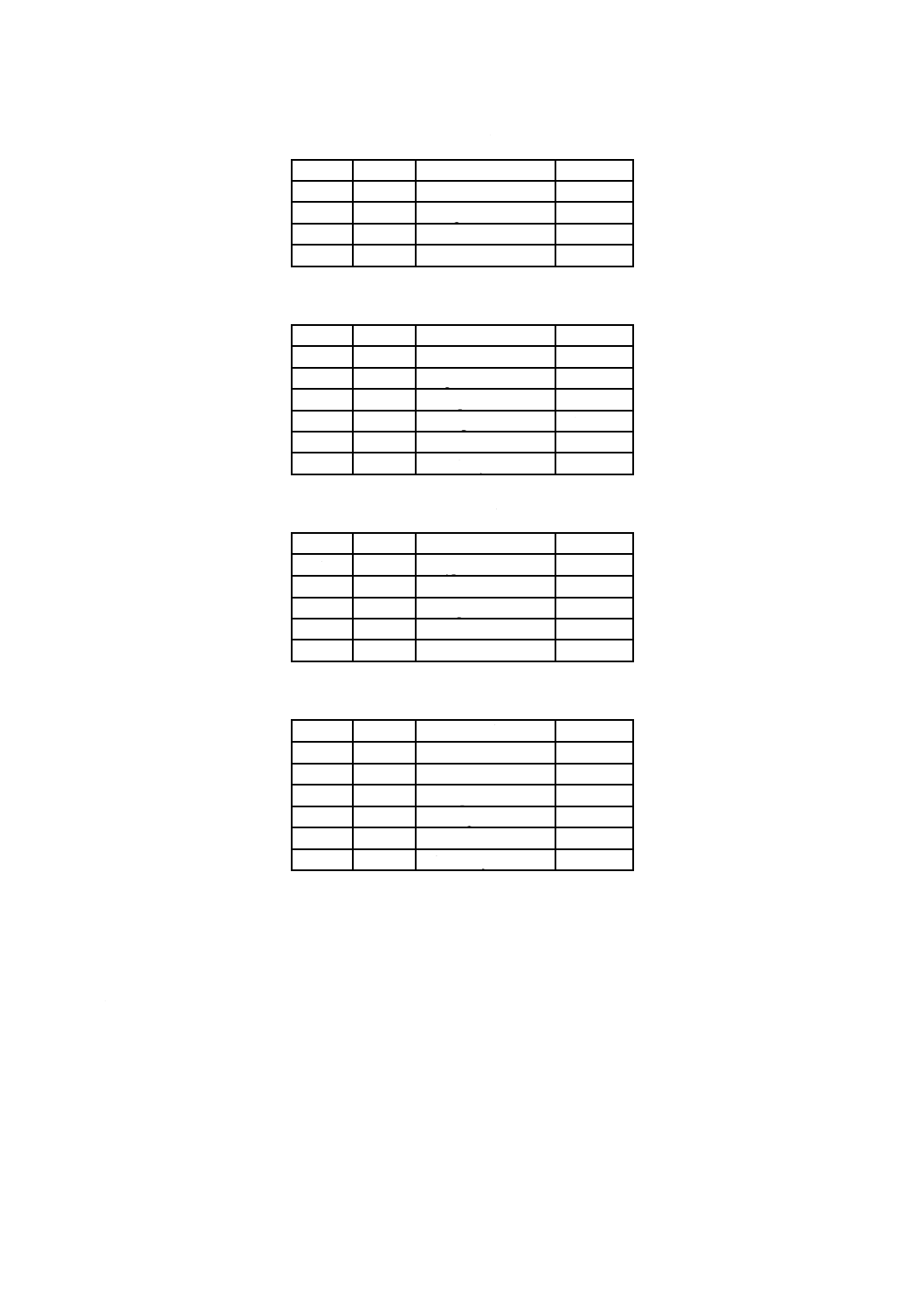
54
X 0611:2018
表27−UDFDInfoフォーマット(ボリュームIV,105ページ)
RBP
長さ
名前
内容
0
8
FrRect
UDFRect
8
2
FrFlags
Int16
10
4
FrLocation
UDFPoint
14
2
FrView
Int16
表28−UDFDXInfoフォーマット(ボリュームIV,106ページ)
RBP
長さ
名前
内容
0
4
FrScroll
UDFPoint
4
4
FrOpenChain
Int32
8
1
FrScript
Uint8
9
1
FrXflags
Uint8
10
2
FrComment
Int16
12
4
FrPutAway
Int32
表29−UDFFInfoフォーマット(ボリュームII,84ページ)
RBP
長さ
名前
内容
0
4
FdType
Uint32
4
4
FdCreator
Uint32
8
2
FdFlags
Uint16
10
4
FdLocation
UDFPoint
14
2
FdFldr
Int16
表30−UDFFXInfoフォーマット(ボリュームIV,105ページ)
RBP
長さ
名前
内容
0
2
FdIconID
Int16
2
6
FdUnused
バイト
8
1
FdScript
Int8
9
1
FdXFlags
Int8
10
2
FdComment
Int16
12
4
FdPutAway
Int32
特記事項 前述した構造は,元のMacintosh構造と実際に異なることを示すために,“UDF”が先行す
る元のMacintosh名をもつ。媒体中では,ビッグエンディアン形式の元のMacintosh構造に
対して,UDF構造では,リトルエンディアンで記録する。
3.3.4.5.5
UNIX
a) 意味:無視する。
b) 設定値:この拡張属性は,利用できない。媒体上の既存ファイルの拡張属性は,保存しなければなら
ない。
3.3.4.5.6
OS/400
OS/400は,次の3.3.4.5.6.1に示す拡張属性の利用を要求する。
3.3.4.5.6.1
OS400DirInfoフォーマット
この属性は,OS/400拡張ディレクトリ情報を規定する。この値は,ディレクトリ操作でOS/400に通知
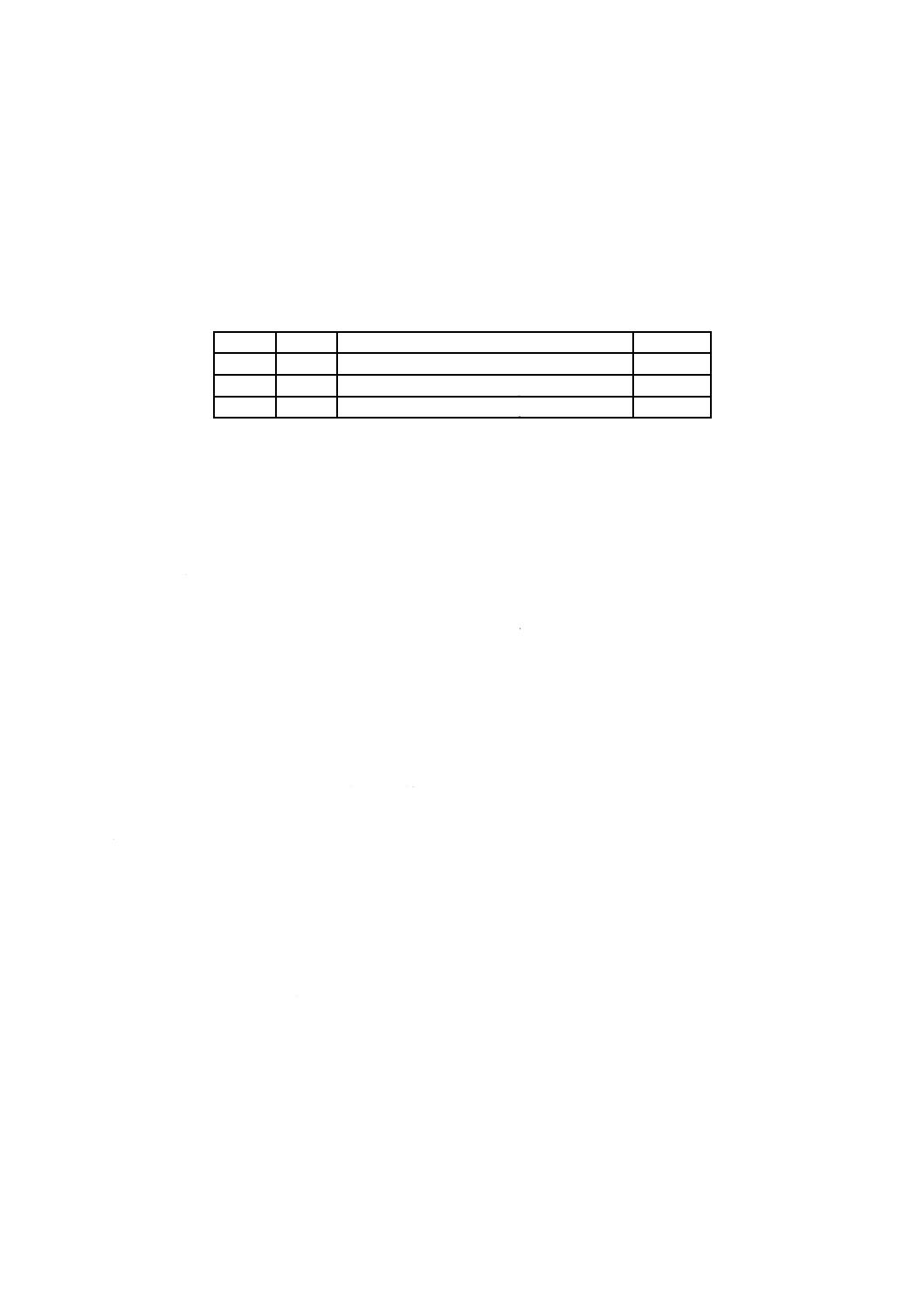
55
X 0611:2018
する必要があるため,効率上の理由から,ファイルエントリの拡張属性欄に記録することが望ましい。こ
の拡張属性は,処理システム用拡張属性として記録しなければならない。その処理システム用拡張属性の
処理システム識別子は,
“*UDF OS/400 DirInfo”
に設定しなければならない。
この拡張属性の処理システム用(ImplementationUse)領域は,表31に示す構成でなければならない。
表31−OS400DirInfoフォーマット(OS400DirInfo format)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Int16
2
2
埋込み(Reserved for Padding)
Int16 = 0
4
44
ディレクトリ情報(DirectoryInfo)
Int16
OS400DirInfoフォーマットに記録するディレクトリ情報の構造の全ての情報は,IBMの次の規定を参照
する。
IBM OS/400 UDF Implementation
Optical Storage Solutions, Department HTT
IBM
Rochester, Minnesota
3.3.4.6
アプリケーション用拡張属性(Application Use Extended Attribute)
struct ApplicationUseExtendedAttribute{ /* JIS X 0607 4/14.10.9 */
Uint32
AttributeType; /*= 65536 */
Uint8
AttributeSubtype;
byte
Reserved[3];
Uint32
AttributeLength;
Uint32
ApplicationUseLength; /* (= AU̲L) */
struct EntityID
ApplicationIdentifier;
byte
ApplicationUse[AU̲L];
}
属性長(AttributeLength)欄は,全体の拡張属性の長さを指定する。アプリケーション用拡張属性の使用
を定義する可変長の拡張属性に対して,属性長欄には,アプリケーション用(Application Use)欄の最後と
アプリケーション用拡張属性(Application Use Extended Attribute)の最後との間に埋込み空間を残すのに,
十分な大きさを指定することが望ましい。
次の3.3.4.6.1に定義する構造は,ヘッダチェックサム(header checksum)欄を含む。この欄は,アプリ
ケーション用拡張属性ヘッダの16ビットチェックサムを表す。属性種別(AttributeType)からアプリケー
ション識別子(ApplicationIdentifier)までの欄を,チェックサムで保護するデータとして表す。ヘッダチェ
ックサム欄は,拡張属性空間の障害回復の支援として使う。ヘッダチェックサムのためのプログラミング
言語Cのソースコードを6.8に例示する。
注記 全ての適合する処理システムでは,媒体中の既存の拡張属性を保存することを推奨する。処理
システムは,動作中のOSに対する拡張属性を作成し,利用可能にすることが望ましい。例え
ば,Macintoshの処理システムでは,媒体中に存在するOS/2拡張属性を保存することを推奨す
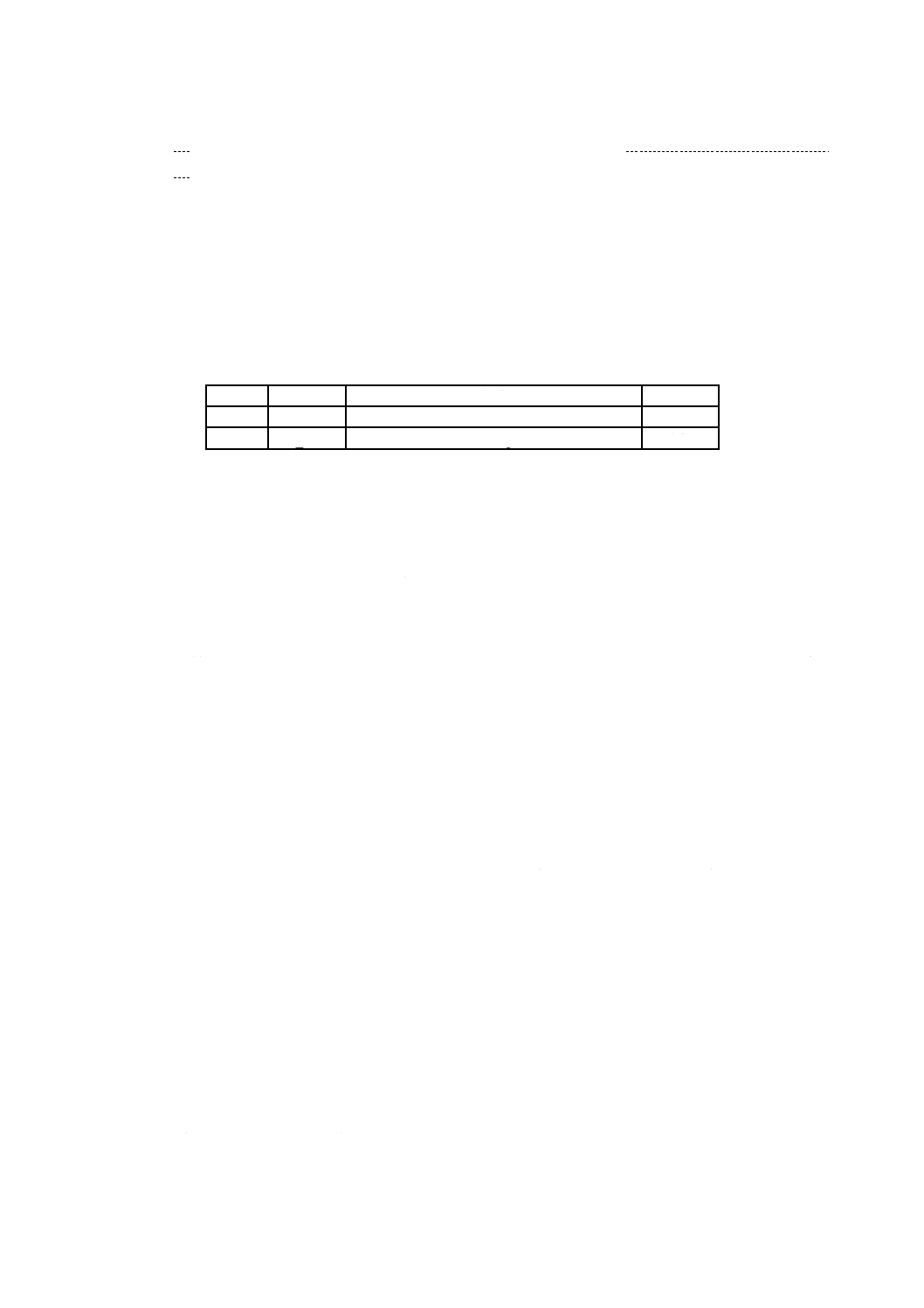
56
X 0611:2018
る。この規格に規定する全てのMacintosh拡張属性をも作成し,利用可能にすることが望まし
い。
3.3.4.6.1
全てのオペレーティングシステム(All Operating System)
この拡張属性は,拡張属性空間でアプリケーション用拡張属性に確保された未使用な空間を示すために
使用しなければならない。この拡張属性は,アプリケーション識別子(ApplicationIdentifier)に
“*UDF FreeAppEASpace”
を設定するアプリケーション用拡張属性として記録しなければならない。
この拡張属性のアプリケーション用(ApplicationUse)領域は,表32に示す構成でなければならない。
表32−FreeAppEASpaceのフォーマット(FreeAppEASpace format)
RBP
長さ
名前
内容
0
2
ヘッダチェックサム(Header Checksum)
Uint16
2
IU̲L−1
空きEA空間(Free EA Space)
バイト
この拡張属性は,拡張属性空間の全てを再度書き込むことなく,処理システムが他の拡張属性の全長を
縮小又は拡大することを可能にする。FreeAppEASpaceの拡張属性は,上書きしてもよく,上書きを必要と
する処理システムがその空間を再利用してもよい。
3.3.5
名前付きストリーム(Named Stream)
名前付きストリームは,ファイルの関連データを関連付ける機構を提供する。この機構は,概念的に拡
張属性に類似している。しかし,名前付きストリームは,拡張属性よりもはるかに優れている。名前付き
ストリームには,長さの制限がない。各ストリームは独自の空間をもつため,拡張属性の共通空間よりも
はるかに空間管理を行いやすい。特定のストリームを見つけるのに,拡張属性の場合に必要であったデー
タ空間全体の検索は行わない。
名前付きストリームは,主に利用者データを対象にする。例えば,データベースアプリケーションは,
レコードをデフォルトストリーム又は主ストリームに記録してもよく,索引を名前付きストリームに記録
してもよい。そこで利用者は,多くのファイルではなくデータベース用の一つのファイルだけを見ること
になり,アプリケーションは,多様なストリームをあたかも独立したファイルとして使用できる。
名前付きストリームは,拡張ファイルエントリによって識別する。拡張ファイルエントリは,関連付け
られた名前付きストリームをもつファイルに必要となる。名前付きストリームをもたないファイルは,拡
張ファイルエントリを使用することが望ましい。ファイルは通常のファイルエントリを含んでもよい。通
常のファイルエントリは,DVD-Videoディスクの書込みなどの下位互換性が必要な場合に使われる。
ファイル集合記述子によって識別されるストリームディレクトリであるシステムストリームディレクト
リがある。これらのストリームは,ファイルに関連するデータではなく,媒体全体に関連するデータを記
載するために使用する。UDFは,システムストリームディレクトリによって識別される幾つかのシステム
ストリームを定義する。
唯一の例外は,システムストリームディレクトリの親は,システムストリームディレクトリでなければ
ならないことである。
名前付きストリームは,新しい処理システムにおいて,拡張属性ではなく,メタデータ及びアプリケー
ションデータを記録するのに使うことを推奨する。
3.3.5.1
名前付きストリームの制約(Named Stream Restrictions)
JIS X 0607規格類はその追補1とともに,ストリームディレクトリを識別する欄を含む,新しいファイ
57
X 0611:2018
ルエントリを定義している。新しいファイルエントリは,古いファイルエントリの代わりに用い,ストリ
ーム自体を記述するのに用いることが望ましい。新旧のファイルエントリは,自由に混合してもよい。特
に,古い再生用の処理システムとの互換性は,特定のファイルのために保守され得る。
制約:
a) ストリームディレクトリ又は名前付きストリームを記述するICBの,ストリームディレクトリICB欄
は,0に設定しなければならない(階層的なストリームではない。)。
b) 各名前付きストリームは,厳密に一つのストリームディレクトリにおける,厳密に一つのFIDによっ
て識別されなければならない[名前付きストリーム又はファイルとのハードリンク(hard link)では
ない。]。
c) 各ストリームディレクトリICBは,厳密に一つのストリームディレクトリICB欄によって識別されな
ければならない(ストリームディレクトリへのハードリンクではない。)。
d) 名前付きストリームをもつファイルへのハードリンクは,許容される。
e) 名前付きストリーム及びストリームディレクトリは,拡張属性をもってはならない。
f)
名前付きストリーム及びストリームディレクトリの一意ID欄は,主データストリームの一意IDと同
等だと考えなければならない。
g) 主ファイルエントリのUID,GID及び許可条件の欄は,主ストリームに関連付けられた全ての名前付
きストリームに適用する。名前付きストリームの作成時に,主ファイルエントリのUID,GID及び許
可条件の欄の値は,名前付きストリームの対応する欄のデフォルト値として使用することが望ましい。
処理システムは,名前付きストリームのこれらの欄を保守又は検査する必要はない。
h) 処理システムは,FIDの中で設定されたメタデータビットでマーク付けされたストリームを利用者に
示さないことが望ましい。メタデータビットでマーク付けされたストリームは,ファイルシステムの
実装での使用だけを目的とする。
i)
ストリームディレクトリにおける親エントリFIDは,主拡張ファイルエントリを指示し,したがって,
その参照は,拡張ファイルエントリのLink Count欄で数えなければならない。
唯一の例外は,システムストリームディレクトリの親は,システムストリームディレクトリでなけ
ればならないことである。
注記 ファイル又はディレクトリを削除する場合,次の危険があり得る。FIDが削除されるときに,
リンクカウントが1になると,処理システムでは,ストリームディレクトリの存在を検査す
ることが望ましい。ストリームディレクトリが存在すると,このファイルエントリを示すFID
はもはやない。したがって,それと関連する構造は,全て削除されることが望ましい。
j)
主拡張ファイルエントリの訂正日時欄は,関連する名前付きストリームの訂正時には必ず更新するこ
とが望ましい。主拡張ファイルエントリのアクセス日時欄は,関連する名前付きストリームへのアク
セス時には必ず更新することが望ましい。主拡張ファイルエントリにおけるICBタグフラグ欄の
SETUIDビット及びSETGIDビットは,関連する名前付きストリームの訂正時には,必ずクリアする
ことが望ましい。
k) 名前付きストリームディレクトリのICBは,ファイル種別13をもたなければならない。全ての名前
付きストリームは,ファイル種別5をもたなければならない。
l)
全てのシステムは,名前付きストリームを実装していない実装システムにおいても,主データストリ
ームを利用可能にしなければならない。
3.3.5.2
システム名前付きストリーム(メタデータ)[System Named Stream(Metadata)]

58
X 0611:2018
名前付きストリームの集合は,ファイルシステム用にUDFによって規定する。UDF名前付きストリー
ムの中には,ファイル集合記述子によって識別され,ファイル集合全体[システムストリームディレクト
リ(System Stream Directory)]に適用されるものもある。他のUDF名前付きストリームは,個々のファイ
ル又はディレクトリに属し,ストリームディレクトリによって識別される。
全てのUDF名前付きストリームは,この規格で特記しない限り,ストリームディレクトリのファイル識
別記述子においてセットされたメタデータビットをもたなければならない。ファイルシステムの実装によ
って生成されないストリームは,全てこのビットを0に設定しなければならない。
全てのUDF名前付きストリームは,ストリームを識別するICBにファイル種別5をもたなければなら
ない。
4文字の*UDFは,この規格におけるUDF定義の全ての名前付きストリームの最初の4文字である。処
理システムは,この規格で規定していない名前付きストリームに,*UDFで始まる識別子を使用してはな
らない。*UDFで始まる名前付きストリームのための全ての識別子は,OSTAによる将来の定義のために
確保される。
3.3.6
名前付きストリームとしての拡張属性(Extended Attributes as named stream)
名前付きストリームの代わりに拡張属性を記録してもよい。拡張属性は,次の規則に従って変換される。
a) ストリームは,メタデータストリームとしてマーク付けされる。
b) 拡張属性のヘッダ及びヘッダチェックサムは,記録されない。拡張属性が,ヘッダチェックサムと残
りのデータとの間にパッドバイトを含んでいたら,これらも記録されない。ファイル又はディレクト
リの拡張属性は,次のアルゴリズムによって,同じファイル又はディレクトリのストリームに変換で
きる。
1) 拡張属性を含むファイル又はディレクトリのためのストリームを作成する。実体識別子に指定され
る識別子が,ストリーム名になる。
2) 拡張属性のデータをストリームにコピーする。
3) 拡張属性を消去する。
3.3.7
UDF定義のシステムストリーム(UDF Defined System Streams)
この細分箇条は,UDF定義のシステムストリームの規定を含む(表33参照)。
表33−UDF定義のシステムストリーム
ストリーム名
ストリーム位置
メタデータフラグ
“*UDF Unique ID Mapping Data”
システムストリームディレクトリ(ファイル集合記述子)
1
“*UDF Non-Allocatable Space”
システムストリームディレクトリ(ファイル集合記述子)
1
“*UDF Power Cal Table”
システムストリームディレクトリ(ファイル集合記述子)
1
“*UDF Backup”
システムストリームディレクトリ(ファイル集合記述子)
1
表33に列挙されたストリームは,メタデータフラグ集合を備えているので,処理システムは,プラット
フォームのプラグインファイルシステムインタフェースを介してストリームの名前を通してはならない。
3.3.7.1
一意IDマッピングデータストリーム(Unique ID Mapping Data Stream)
一意IDマッピングデータは,処理システムが,UDF一意IDに関連付けられたファイル及びディレクト
リに対するICB階層に直接進むことを可能にするか,又はUDF一意IDに関連付けられたファイル及びデ
ィレクトリを含むディレクトリに対するICB階層に進むことを可能にする。一意IDマッピングデータは,
(ファイル集合記述子に関連付けられた)システムストリームディレクトリの名前付きストリームとして
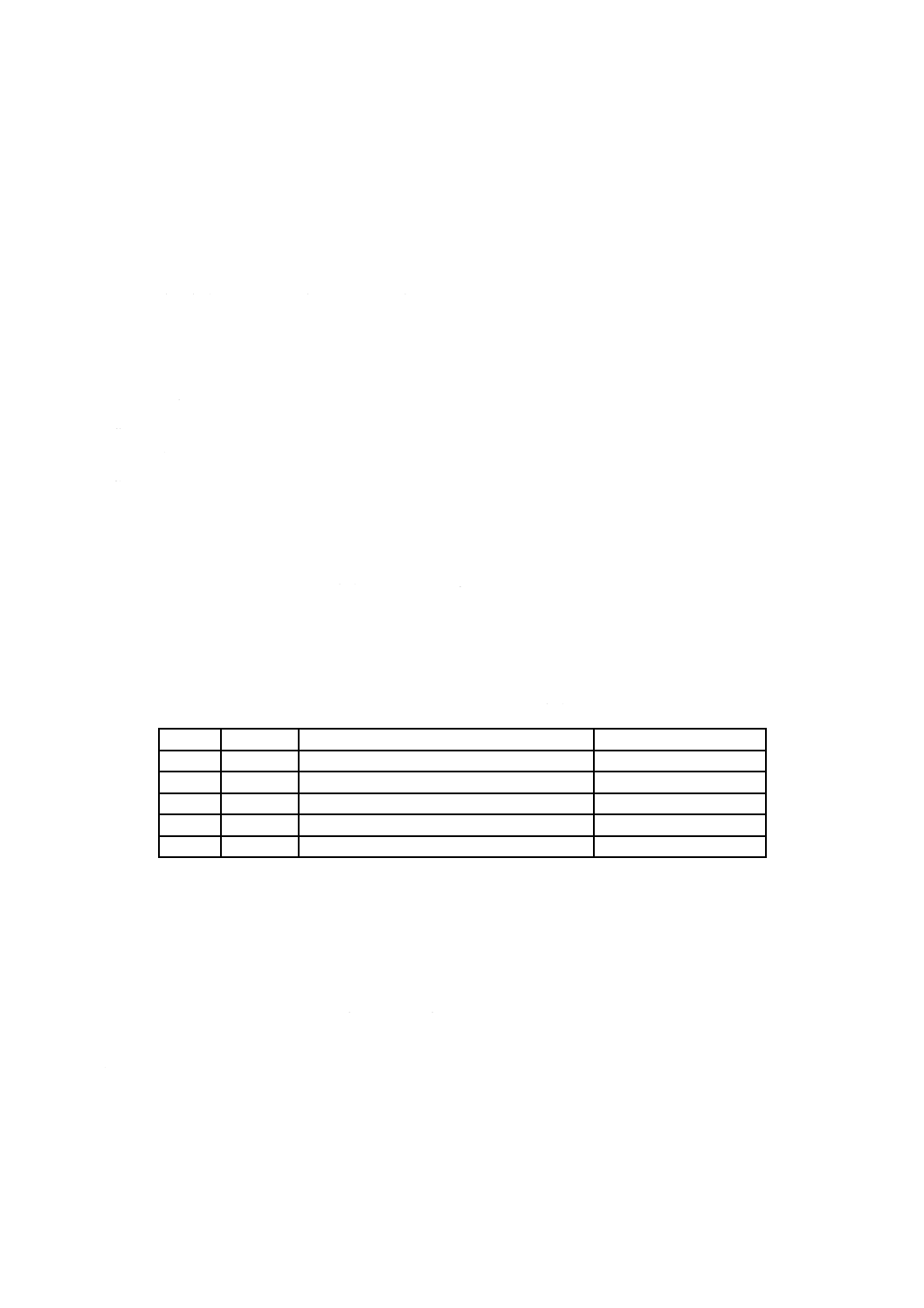
59
X 0611:2018
記録される。このストリームの名前は
“*UDF Unique ID Mapping Data”
に設定しなければならない。
ファイル識別記述子のファイル特性欄の中のメタデータビットは,プラットフォームのファイルシステ
ムインタフェースのクライアントに,このファイルの存在を知らせないことが望ましいことを示すため,1
に設定しなければならない。
a) 再生専用媒体のために作成されなければならない。
b) 追記形及び書換可能形媒体にボリュームをバッチ書込みする処理システム(例えば,プリマスタリン
グツール)によって作成されなければならない。
c) 追記形又は書換可能形媒体(例えば,オンラインファイルシステム)にボリュームのインクリメンタ
ルな更新をする処理システムには,次の規則を適用する。
1) 存在しない場合は,作成し,保守してもよい。
2) 存在しており,ボリュームがクリーンな場合,保守しなければならない。
3) 存在しているが,ボリュームがダーティな場合,修復し保守することが望ましいが,消去してもよ
い。
これらの規則に関して,有効な閉じた論理ボリューム保全記述子,又は有効な仮想番地表のいずれかが
記録されれば,ボリュームはクリーンである。
3.3.7.1.1
UDF一意IDマッピングデータ(UDF Unique ID Mapping Data)
一意IDマッピングのストリームの内容は,“UDF一意IDマッピングエントリ”の配列の前にヘッダ欄
を含む“UDF一意IDマッピングデータ”表によって示される。構造の欄は,表34の対応表によって示さ
れる。
表34−UDF一意IDマッピングデータ
RBP
長さ
名前
内容
0
32
処理システム識別子
実体ID
32
4
フラグ
Uint32
36
4
マッピングエントリカウント(= MEC)
Uint32
40
8
予約(Reserved)
バイト(= #00)
48
16×MEC マッピングエントリ
IDマッピングエントリ
処理システム識別子は,2.1.5に記載されている。
フラグは,次のとおりに規定される。
a) ビット0は,1に設定するとき,UDF一意IDを意味するものとし,16(次の一意IDが初期設定され
る値)ずつ減らす場合,配列マッピングエントリの項目として使用できる。空白のエントリは,もし
それがあると,UDF一意IDをもつ最後の配列要素を超えることはない。
b) 予約のビット1〜31は,0に設定しなければならない。
c) マッピングエントリカウントは,配列マッピングエントリの,エントリにおける大きさである。
d) マッピングエントリは,UDF一意IDマッピングエントリ(表35参照)構造の配列である。非ストリ
ームの親でないファイル識別記述子ごとに,一つのマッピングエントリがある。
ボリュームが一致していれば,常に配列は,UDF一意IDの昇順にソートされる。フラグで制限される
場合を除いて,空白エントリは,配列のどの位置でも可能であり,エントリは,直前のエントリより一つ

60
X 0611:2018
大きいUDF一意IDの値をもつ必要はない。空白エントリは,全ての欄で0の値をもつ。
3.3.7.1.2
UDF一意IDマッピングエントリ(UDF Unique ID Mapping Entry)
表35−UDF一意IDマッピングエントリ
RBP
長さ
名前
内容
0
4
UDF一意ID
Uint32
4
4
親論理ブロック番号
Uint32
8
4
対象論理ブロック番号
Uint32
12
2
親区画参照数
Uint16
14
2
対象区画参照数
Uint16
a) UDF一意IDは,ファイル又はディレクトリに関するFIDの値である。
b) 親論理ブロック番号は,対象を識別するFIDを含むディレクトリを識別するICBの論理ブロック番号
である。
c) 対象論理ブロック番号は,この対象を識別するICBの論理ブロック番号である。
d) 親区画参照番号は,このファイル又はディレクトリ用のFIDを含む,同一のディレクトリの親におけ
るICB欄のlong̲adからの区画参照番号である。
e) 対象区画参照番号は,このUDF一意IDをもつFIDのICB欄のlong̲adからの区画参照番号である。
3.3.7.2
割付け禁止空間ストリーム(Non-Allocatable Space Stream)
JIS X 0607規格類は,媒体の欠陥領域を記載したり,ファイルシステム以外の割付けのために使用でき
ない領域を記載する機構を規定しない。割付け禁止空間ストリームは,ファイルシステムが使用できない
空間を記載するための方法を提供する。割付け禁止空間ストリームは,欠陥管理をしない媒体システム(例
えば,CD-RW)だけに記録されなければならない。
割付け禁止空間ストリームは,初期化時に生成されなければならない。割付け禁止空間ストリームが示
す空間も,全て使用可能空間マップで割付けられたとしてマーク付けされなければならない。割付け禁止
空間ストリームは,ファイル集合記述子のシステムストリームディレクトリで名前付きストリームとして
記録されなければならない。ストリーム名は,次のとおりでなければならない。
“*UDF Non-Allocatable Space”
ストリームは,属性メタデータ(1に設定されたファイル特性集合の4ビット)及びシステム(1に設定
されたICBフラグ欄の10ビット)でマーク付けされなければならない。このストリームは,割付けエク
ステントが識別する全ての割付け禁止セクタをもたなければならない。割付けエクステントは,各エクス
テントが割り付けられるが記録されないことを示さなければならない。このリストには,初期化時の欠陥
セクタと初期化時に予備のため割り付けられる空間との両方が含まれなければならない。
注記 パケット化された媒体では,欠陥を含むパケットの全ては,割付け禁止空間ストリームに割り
付けられることが望ましい。
3.3.7.3
パワーこう(較)正ストリーム(Power Calibration Stream)
CD-Rドライブのパケットライト機能を効果的に利用するときにあり得る制限の一つに,現CD-R媒体
で利用可能な,パワーこう(較)正領域の限られた数(100)がある。これらのパワーこう(較)正領域は,
ドライブに現在入っているCD-Rディスクに,データを確実にうまく書き込める適切なパワーこう(較)
正設定を確立するのに使われる。特定のドライブのための適切な設定値は,同一の製造及び型をもつ二つ
の異なるドライブ間で異なり,同一のディスク,ドライブ及びシステム構成を使っても,環境条件が異な

61
X 0611:2018
れば,ディスク間で大きく異なる。
このため,ほとんどの現在のCD-Rドライブは,媒体変更が起きた後の最初の書込みが行われようとす
るときに,こう(較)正し直す。ディスクアトワンス又はトラックアトワンスのモードを使って記録する
場合には,これが制約を課すことはない。それは,これらの各モードでは,100回に満たない各書込みで
ディスクが(利用可能なデータ容量を全て使い,又は記録可能なトラック数を全て使って)一杯になるこ
とによる。しかし,パケットライトを使うと,ディスクはディスクが一杯になるまで,長期間にわたって,
何千回も書き込むことができる。
例えば,仮に,各作業日の最後に新規ファイル・訂正ファイルを増加的にバックアップしたいとする(ド
ライブは同じ日に他の仕事で断続的に使われるかもしれないが)。これらのバックアップには,1日に1 MB
(又はそれ以下)程度の書込みが必要かもしれない。毎日ディスクに書込みする前に,パワーこう(較)
正領域の一つがドライブのこう(較)正に使われれば,5か月以内にパワーこう(較)正領域は全て使用
されることになるが,消費されるのは,ディスクの全容量の一部分だけとなる。その結果は,それらの製
品の利用者が予期しないことであり,受け入れられそうもない。
業界では,CD-Rディスクのパワーこう(較)正領域を使わなければならない頻度を減らす方法を提供
しようと試みている。少なくとも,現在のCD-Rドライブのあるモデルは,最近使用した少数のディスク
それぞれにデータを記録するのに使われた最後のパワーこう(較)正値を記憶しようとする。ほとんどの
CD-Rドライブは,ホストソフトウェアが,現ディスクにデータを記録するために,ドライブで使われた
最新のパワーこう(較)正設定をドライブから検索し,将来それらを回復して使用する機構を備えている。
ここに示されるパワーこう(較)正表は,互換性のある処理システムで将来使用するため,こうして得
られたパワーこう(較)正情報をディスクに記録するのに使われる。表はヘッダで構成されており,この
ヘッダの後には,このディスクにデータを記録するため,異なる条件の下で多様なドライブ・ホストが使
用してきたパワーこう(較)正設定を含むレコードのリストが続く。記録済みこう(較)正設定のいずれ
が将来の状況で使用するのに適しているかを決定するのに使用できる,他の関連情報も続く。記録済みパ
ワーこう(較)正情報を効果的に使用するため,あらゆる必要な情報を予想し,含めるための努力が払わ
れてきたが,それらの情報が実際に使われるのか,使われる場合はいつどのような形でかを決定するには,
個々の処理システムに依存している。
パワーこう(較)正表は,3.3.5の規則に従って,ファイル集合記述子のシステムストリームとして記録
されなければならない。ストリーム名は,次のとおりでなければならない。
“*UDF Power Cal Table”
パワーこう(較)正表を利用できない処理システムは,このストリームを消去してはならない。パワー
こう(較)正表を利用可能な処理システムは,その処理システムがその使用によって,明らかにかつ特別
に時代遅れにしたことも更新したこともなかった表からのレコードを消去したり修正してはならない。
ストリームは次のとおりに初期化しなければならない。
3.3.7.3.1
パワーこう(較)正表ストリーム(Power Calibration Table Stream)
表36−パワーこう(較)正表ストリーム
RBP
長さ
名前
内容
0
32
処理システム識別子(Implementation Identifier)
実体ID(2.1.5)
32
4
レコード数(Number of Records)
Uint32 [1/7.1.5]
56
*
パワーこう(較)正表レコード(Power Calibration Table Records) バイト
62
X 0611:2018
処理システム識別子については,2.1.5を参照。
レコード数は,パワーこう(較)正表に含まれるレコード数を指定しなければならない。
パワーこう(較)正表レコードは,このディスクに書き込んだドライブのための一連のパワーこう(較)
正表レコードとする。この表の長さは可変であるが,4バイトの倍数とする。未構造化欄のデータの記録
は左そろ(揃)えにしなければならず,右側は,#20バイトで埋めなければならない(表36参照)。
表37−パワーこう(較)正表レコードレイアウト
RBP
長さ
名前
内容
0
2
レコード長(Record Length)
Uint16 [1/7.1.3]
2
2
ドライブ一意領域長[DUA̲L](Drive Unique Area Length [DUA̲L])
Uint16 [1/7.1.3]
4
32
ベンダID(Vendor ID)
バイト
36
16
製品ID(Product ID)
バイト
52
4
ファームウェア改正レベル(Firmware Revision Level)
バイト
56
16
連続番号又は装置一意ID(Serial Number/Device Unique ID)
バイト
72
8
ホストID(Host ID)
バイト
80
12
生成日時スタンプ(Originating Time Stamp)
日時スタンプ[1/7.3]
92
12
更新日時スタンプ(Updated Time Stamp)
日時スタンプ[1/7.3]
104
2
速度(Speed)
Uint16 [1/7.1.3]
106
6
パワーこう(較)正値(Power Calibration Values)
バイト
112
[DUA̲L]
ドライブ一意領域(Drive Unique Area)
バイト
a) レコード長:このパワーこう(較)正表レコード(表37参照)のバイトの長さで,任意機能の可変長
ドライブ一意領域を含む。4バイトの倍数でなければならない。
b) ドライブ一意領域長:このレコードの最後のバイトに記録される任意機能のドライブ一意領域の長さ。
4バイトの倍数でなければならない。
c) ベンダID:ドライブによって報告されるベンダID。
d) 製品ID:ドライブによって報告される製品ID。
e) ファームウェア改正レベル:ドライブによって報告されるファームウェア改正レベル。
f)
連続番号又は装置一意ID:ベンダによって指定されるモデルの,特定ドライブに関する連続番号又は
その他の一意識別子,及びこのディスクにデータを記録するために報告されたパワーこう(較)正値
をうまく使用した,与えられた製品ID。
g) ホストID:ホスト連続番号,イーサネットID又はその他の値(又は値の組合せ)。これは,このディ
スクにデータを記録するために報告されるパワーこう(較)正値をうまく使用したときに,ドライブ
が接続されている特定のホストコンピュータを識別する処理システムによって使用される。処理シス
テムでは,各ホストに対して一意の値を提供しようとしなければならないが,値の一意性を保証する
必要はない。
h) 生成日時スタンプ:パワーこう(較)正値が記録された日時で,適切に使用されたことを最初に証明
している。
i)
更新日時スタンプ:パワーこう(較)正値が記録された日時で,適切に使用されたことを最近証明し
ている。
j)
速度:ドライブで報告される記録速度で,ここに記録されたパワーこう(較)正値が適切に使用され
た記録速度。この値は,データがドライブによってディスクに書き込まれた,毎秒のキロバイト(バ
イト/1 000分の1)数である(端数は切り捨てる。)。例えば,176という速度は,データがディスク

63
X 0611:2018
に毎秒176キロバイトで書き込まれたことを意味する。これは,基本的なCD-DA(ディジタルオーデ
ィオ)のデータ速度(CD-DAで別名“1X”)である。353の速度は,データがディスクに毎秒353キ
ロバイト,つまり,CD-DAの基本速度の2倍の速度(CD-DAで別名“2X”)で書き込まれたことを
意味する。CD-ROMの記録速度は,正しい速度値(例えば,“1X”のCD-ROMデータ速度は,176の
速度である“1X”CD-DAとして記録することが望ましい。)を決定するために,対応するCD-DA速
度に対して高めに(約15 %)調整することが望ましい。注意することは,これらは未処理のデータで
あり,(追加の)ヘッダ,エラー訂正データなどに起因するオーバヘッドを全て反映しているわけでは
ない。
k) パワーこう(較)正値:ドライブによって報告されるベンダ固有のパワーこう(較)正値である。
l)
ドライブ一意領域:ドライブに対して一意の,非制限情報を記録するための任意機能領域で,ある処
理システムは,記録済みパワーこう(較)正情報の使用,又は関連付けられたドライブの操作を拡張
するために,この領域を使用してもよい。この欄のデータの記録は,ドライブ製造業者が定義しなけ
ればならない。この領域は,4バイト長の整数倍でなければならない。
3.3.7.4
UDFバックアップ日時(UDF Backup Time)
このストリームの名前は
“*UDF Backup”
に設定しなければならない。
このストリームは,表38の内容をもつものとし,ICBに埋め込まなければならない。
表38−UDFバックアップ日時
RBP
長さ
名前
内容
0
12
バックアップ日時(Backup Time)
日時スタンプ
バックアップ日時は,このボリュームのバックアップが実行された最新の時間である。
3.3.8
UDF定義の非システムストリーム(UDF Defined Non-System Streams)
この細分箇条では,表39の非システムストリームを定義している。
表39−UDF定義の非システムストリーム
ストリーム名
ストリーム位置
メタデータフラグ
*UDF Macintosh Resource Fork
ファイル(Any File)
0
*UDF OS/2 EA
ファイル又はディレクトリ(Any File or directory)
0
*UDF NT ACL
ファイル又はディレクトリ(Any File or directory)
0
*UDF UNIX ACL
ファイル又はディレクトリ(Any File or directory)
0
3.3.8.1
Macintosh資源フォークストリーム(Macintosh Resource Fork Stream)
資源フォークは明瞭なインタフェースで参照するため,UDF処理システムでは,このストリームに正式
な名前を与えていない。交換のためには,名前は,次のとおりに設定しなければならない。
“*UDF Macintosh Resource Fork”
ファイル識別記述子のファイル特性(File Characteristics)欄のメタデータビットは,プラットフォーム
ファイルシステムインタフェースのクライアントに,このファイルの存在を知らせることが望ましいこと
を示すため,0に設定しなければならない。
3.3.8.2
OS/2 EAストリーム(OS/2 EA Stream)

64
X 0611:2018
OS/2で規定できる拡張属性は,全て名前付きストリームとして記録するものとし,その名前は,次のと
おりに設定しなければならない。
“*UDF OS/2 EA”
OS/2 EAストリーム(OS2EA Stream)は,表40に示すとおり,OS/2完全EA(FEA)の表を含む。
表40−FEAフォーマット
RBP
長さ
名前
内容
0
1
Flags
Uint8
1
1
Length of Name (= L̲N)
Uint8
2
2
Length of Value (= L̲V)
Uint16
4
L̲N
Name
バイト
4+L̲N
L̲V
Value
バイト
完全EA(FEA)の完全な記述のためには,IBMの次の規定を参照。
“Installable File System for OS/2 Version 2.0”
OS/2 File Systems Department
PSPC Boca Raton, Florida
February 17, 1992
3.3.8.3
アクセス管理リスト(Access Control List)
ある種のオペレーティングシステム(OS)では,ファイルへのアクセスの制約を強化するためアクセス
管理リスト(ACL)の概念を利用可能としている。ACLの利用を促進するため,UDF 2.00では,システム
レベルの名前付きストリームの集合を規定している。このストリームの目的は,与えられたファイル対象
に関連するACLを記録することである。
UDFのACLは,3.3.5の規則に従って,名前付きストリームとして記録される。名前付きストリームACL
の内容は不明瞭であり,この規格では規定しない。名前付きストリームACLの内容の解釈は,ACLが意
図しているOSに任されなければならない。次の名前は,ACLを識別するのに使われ,予約されなければ
ならない。これらの名前はアプリケーション名前付きストリームに使用してはならない。
“*UDF NT ACL”
この名前は,Windows NT OSで,名前付きストリームACLを識別しなければならない。
“*UDF UNIX ACL”
この名前は,UNIX OSで,名前付きストリームACLを識別しなければならない。
4
利用者インタフェース要件
4.1
第3部 ボリューム構造
JIS X 0607規格類の第3部には,処理システムに依存して,利用者に提示しなければならないいろいろ
な識別子を含む。
a) ボリューム識別子(VolumeIdentifier)
b) ボリューム集合識別子(VolumeSetIdentifier)
c) 論理ボリューム識別子(LogicalVolumeIdentifier)
これらの識別子は,CS0で記録され,利用者に表示可能にするために,ある翻訳方式を採らなければな
らないことがある。そのため,処理システムが前記の識別子について,オペレーションシステム(OS)固
65
X 0611:2018
有の解釈を実行しなければならないとき,処理システムは4.2.2.1に記載するアルゴリズムを使用しなけれ
ばならない。
翻訳アルゴリズムのためのプログラミング言語Cのソースコードは,6.7に示す。
4.2
第4部 ファイルシステム
4.2.1
ICBタグ(ICB Tag)
Struct icbtag {
/* JIS X 0607 4/14.6 */
Uint32
PriorRecordedNumberofDirectEntries;
Uint16
StrategyType;
byte
StrategyParameter[2];
Uint16
NumberofEntries;
byte
Reserved;
/* == #00 */
Uint8
FileType;
Lb̲addr
ParentICBLocation;
Uint16
Flags;
}
4.2.1.1
ファイル種別(FileType)
UNIXでないOS環境では,次に示す値のいずれかをこの欄の中にもつファイルに関するopen,close,
read及びwrite要求は,アクセス拒否エラーの状態でなければならない。
ファイル種別値−0(Unknown),6(ブロック装置),7(文字装置),9(FIFO)
及び10(C̲ISSOCK)
種別12[シンボリックリンク(SymbolicLink)]のファイルに関するopen,close,read及びwrite要求は,
このシンボリックリンクが指し示しているファイル又はディレクトリにアクセスしなければならない。
4.2.2
ファイル識別記述子(File Identifier Descriptor)
Struct FileIdentifierDescriptor{
/* JIS X 0607 4/14.4 */
struct tag
DescriptorTag;
Uint16
FileVersionNumber;
Uint8
FileCharacteristics;
Uint8
LengthofFileIdentifier;
struct long̲ad ICB;
Uint16
LengthofImplementationUse;
byte
ImplementationUse[];
char
FileIdentifier[];
byte
Padding[];
}
4.2.2.1
ファイル識別子(char FileIdentifier)
ほとんどのOSには,正当なファイル識別子(FileIdentifier)の特性に関するそれ自体の規定があるので,
ファイル識別子が交換に際して問題となる。そのため,全ての処理システムが,ファイル識別子翻訳の何
らかの方式を実行しなければならないので,全ての処理システムが同一アルゴリズムを使用すれば,それ
は利用者にとって有益となる。
ファイル識別子翻訳の問題は,次に示すa)〜e) のうちの一つ以上に分類される。
66
X 0611:2018
a) 名前長(Name Length):ほとんどのOSは,ファイル識別子の長さに,ある決まった制限がある。
b) 無効文字(Invalid Characters):ほとんどのOSは,ファイル識別子名中に不当と考えられる文字があ
る。
c) 表示可能文字(Displayable Characters):UDFがUnicode文字集合を利用可能にするので,ファイル識
別子中の文字が,受領システムで表示可能でないものを含むことがある。
d) 大文字と小文字との区別(Case Insensitive):幾つかのOSは,ファイル識別子に関して大文字と小文
字との区別を行わない。例えば,OS/2はファイルを作成するとき,ファイル識別子の元の状態を記録
するが,ファイル識別子にアクセスしているとき,大文字と小文字との区別をしない操作を使用する。
OS/2では,“Abc”及び“ABC”は同一ファイル名とする。
e) 予約名(Reserved Names):幾つかのOSには,ファイル識別子名に使用できない名前がある。
4.2.2.1.1〜4.2.2.1.6は,この規格で扱う各特定OSに対するファイル識別子の翻訳アルゴリズムを概説す
る。OSTA UDFに適合する全ての処理システムは,このアルゴリズムを使用しなければならない。このア
ルゴリズムは,不当なファイル識別子を読み出した場合だけに適用する。媒体中の元のファイル識別子名
は,変更してはならない。このアルゴリズムは,OSのファイル識別子の制約に合致させるために,ファ
イル識別子の翻訳方式を実行する処理システムに適用しなければならない。
OSTA UDFに適合する全ての処理システムは,UDFの翻訳アルゴリズムを利用可能としなければならな
いが,追加のアルゴリズムを利用可能にしてもよい。複数のアルゴリズムを利用可能にする場合,処理シ
ステムの利用者に,UDF翻訳アルゴリズムの選択方法を提供しなければならない。デフォルトの表示可能
アルゴリズムは,UDFが定義するアルゴリズムであることを推奨する。
これらのアルゴリズムの主目的は,ファイルが属するディレクトリの全てを調べずに,固有のOSの制
約に適合する一意のファイル名を作成することである。
次に示すアルゴリズムのためのプログラミング言語Cのソースコードは,6.7に示す。
特記事項 次のアルゴリズムの定義では,常に,d文字は引用符中に指定され,Unicodeの16進の数
値が指定される。さらに,このアルゴリズムは,CS0の16進表示を参照する。これは,16
進数で値を表すのにUnicodeの値#0030〜#0039及び#0041〜#0046を使用することに相当す
る。さらに,次のアルゴリズムは,CS0のBase41表示を参照する。これは,16〜40数字
を表すのにUnicodeの値#0047〜#005A, #0023, #005F, #007E, #002D及び#0040を使用する
CS0の16進表示を増大させることに相当する。
次のアルゴリズムは,処理システムの利用者に名前の重複を報告する結果となることもある。その理由
としては,(可能ならば,ファイル名の変更によって)ディレクトリ中のどんなファイルも利用者がアクセ
スできるときに,ディレクトリの内容への効率的なアクセスが必要なこと,並びに複数の論理ボリューム
マウント間及び複数のファイルシステムドライバの処理システム間の名前の翻訳の一貫性が必要なことが
含まれる。
この細分箇条での幾つかの名前の変換は,与えられたディレクトリですぐに認識できる二つの名前空間
をもたらす。与えられたディレクトリとは,物理的にディレクトリに記録される基本の名前の空間,及び
基本の名前から得られる生成された名前の空間のことである。この変換は,システム上のディレクトリの
名前空間の一部とは考えられない不法な名前(変換しなければ不法な名前になる名前)を合法なフォーム
にする変換とは異なる。このような変換を使用するUDF処理システムでは,当該処理システムは,二つの
処理でディレクトリを探すことが望ましい。処理1は基本名前空間に一致することが望ましく,処理2は
生成された名前空間に一致することが望ましい。基本名前空間での一致は,生成された名前空間に対する
67
X 0611:2018
一致よりも望ましい。
定義:ファイル識別子は,ファイル名及びファイル拡張子の二つの部分で構成しなければならない。
文字“.”(#002E)は,ファイルのファイル識別子に関する分離子としなければならない。最後の“.”
(#002E)に続く文字が5文字以下の場合,それはファイル拡張子を構成しなければならない。5文字を超
える場合,ファイル拡張子は存在してはならない。ファイル拡張子に先行して現れ,最後の“.”(#002E)
を除いた文字は,ファイル名を構成しなければならない。
特記事項 たとえ,OS/2,Macintosh及びUNIXが,ファイル拡張子の概念を形式的にもたないとし
ても,1〜5文字の拡張子がその後に続く“.”でもってファイルを終えることが,共通の
ファイル命名規則である。そのため,次のアルゴリズムでは,ファイル拡張子は最大5文
字までとしている。
4.2.2.1.1
MS-DOS
MS-DOS OS環境が,ファイルに関連するファイル識別子に制約を強いるため,上に挙げたOS環境でフ
ァイル識別子を扱うために,次に示す方法を使用しなければならない。
例外:通常,この変換を使用することで二元的な名前空間(8.3形式及び非8.3形式)を提供するかもしれ
ない非MS-DOSシステムの実現は,その使用を無効にするためのメカニズムを省略してもよいし,
提供してもよい。
制約:ファイル識別子のファイル名要素は,8文字を超えてはならない。ファイル識別子のファイル拡張
子要素は,3文字を超えてはならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をしない比較を実行しなければならない。
b) ファイル識別子の有効性確認:ファイル識別子が有効なMS-DOSファイル識別子である場合,次の段
階は適用しない。
c) スペースの除去:識別子中の全ての埋込みスペースは,削除されなければならない。
d) 無効文字:(先に定義した)ファイル名中の無効文字,ファイル拡張子中の無効文字,又は現状の環境
で表示不可能な文字を含むファイル識別子は,これらを“̲”(#005F)に翻訳しなければならない(媒
体中のファイル識別子は,変更しない。)。複数の連続する無効文字,又は表示不可能な文字は,1文
字の“̲”(#005F)に翻訳しなければならない。無効文字は6.7に示すプログラミング言語Cのソース
コードを参照。
e) 先行終止符:最初の“.”(#002E)文字の前に文字が存在しない場合,このヒューリスティックなアプ
リケーションでは,先行する“.”(#002E)を,最初の“.”(#002E)でない文字まで無視しなければ
ならない。
f)
複数終止符:複数の“.”(#002E)文字を含むファイル識別子の場合,最後の“.”(#002E)に続く全
ての文字が5文字以下の場合,ファイル拡張子を構成しなければならない。ファイル拡張子の前の最
後の“.”(#002E)を除く文字はファイル名を構成しなければならない。ファイル名中の“.”(#002E)
文字は,削除しなければならない。
g) 長拡張子:この処理のこの段階で,ファイル拡張子を構成する文字数が3を超える場合,このファイ
ル拡張子は,この処理のこの段階でのファイル拡張子を構成している文字の中の先頭の3文字で構成
するとみなさなければならない。
h) 長ファイル名:この処理のこの段階で,ファイル名を構成する文字数が8を超える場合,ファイル名
は4文字に切り縮めなければならない。
68
X 0611:2018
i)
ファイル識別子CRC:前述の処理によって,元のファイル識別子の文字情報が失われているので,同
一ディレクトリ中で重複ファイル識別子を作成する機会が増す。重複ファイル識別子をもつ機会を大
きく減らすために,ファイル名を元ファイル識別子のCRCを含むように変更しなければならない。フ
ァイル名は,この処理のこの段階でファイル名を構成する4文字を先頭として,これに分離子“#”
(#0023)を続け,元のファイル名のUNICODE伸張の16ビットCRCをCS0 のBase41表示した3
数字を続けて構成しなければならない。
j)
新しいファイル識別子は,全て大文字に翻訳しなければならない。
4.2.2.1.2
OS/2
OS/2 OS環境が,ファイルに関連するファイル識別子に制約を強いるため,前述のOS環境でファイル
識別子を扱うために,次に示す方法を使用しなければならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をする比較を実行してもよい。大文字と小文字との区別をする比較が行われない又は失敗し
た場合,大文字と小文字との区別をしない比較を実行しなければならない。
b) ファイル識別子の有効性確認:ファイル識別子が有効なOS/2ファイル識別子である場合,次の段階
は適用しない。
c) 無効文字:OS/2のファイル名として無効な文字,又は現状の環境で表示不可能な文字を含むファイル
識別子は,これらを“̲”(#005F)に翻訳しなければならない。複数の連続する無効文字又は表示不
可能な文字は,1文字の“̲”(#005F)に翻訳しなければならない。無効文字は6.7に示すCソースコ
ードを参照。
d) 末尾の終止符及びスペース:全ての末尾の“.”(#002E)及び“ ”(#0020)は削除しなければならな
い。
e) ファイル識別子CRC:前述の処理によって,元のファイル識別子の文字情報が失われるので,同一デ
ィレクトリ中で重複ファイル識別子を作成する機会が増す。重複ファイル識別子をもつ機会を大きく
減らすために,ファイル名を元のファイル識別子のCRCを含むように変更しなければならない。
ファイル拡張子がある場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の文字数から成らなければならず,その個数は次による。
254−(新ファイル拡張子の長さ+1)−5
ここに,
1: “.”用
5: #CRC用
これに分離子“#”(#0023)が続き,元のCS0ファイル識別子の16ビットCRCをCS0の16進表示した
4数字を続けて,更に“.”(#002E)及びこの処理のこの段階でのファイル拡張子を続けて構成しなければ
ならない。
ファイル拡張子がない場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の[254−(#CRC用の)5]個の文字から成る。これに分離子“#”(#0023)を続け,元のCS0ファイル
識別子の16ビットCRCをCS0の16進表示した4数字を続けて構成する。
4.2.2.1.3
Macintosh
Macintosh OS環境が,ファイルに関連するファイル識別子に制約を強いているため,前述のOS環境で
ファイル識別子を扱うために,次に示す方法を使用しなければならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をする比較を実行してもよい。大文字と小文字との区別をする比較が行われない又は失敗し
69
X 0611:2018
た場合,大文字と小文字との区別をしない比較を実行しなければならない。
b) ファイル識別子の有効性確認:ファイル識別子が有効なMacintoshファイル識別子である場合,次の
段階を適用しない。
c) 無効文字:Macintoshファイル名として無効な文字,又は現状の環境で表示不可能な文字を含むファイ
ル識別子は,これらを“̲”(#005F)に翻訳しなければならない。複数の連続する無効文字又は表示
不可能文字は,1文字の“̲”(#005F)に翻訳しなければならない。無効文字は6.7に示すプログラミ
ング言語Cのソースコードを参照。
d) 長ファイル識別子:この処理のこの段階で,ファイル識別子を構成する文字数が31個(Macintosh OS
での名前の最大長)より大きい場合,この処理のこの段階で,新しいファイル識別子はファイル識別
子の先頭26文字で構成する。
e) ファイル識別子CRC:前述の処理によって,元のファイル識別子の文字情報が失われているので,同
一ディレクトリ中で重複ファイル識別子を作成する機会が増す。重複ファイル識別子をもつ機会を大
きく減らすために,ファイル名を元のファイル識別子のCRCを含むように変更しなければならない。
ファイル拡張子がある場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の文字数から成らなければならず,その個数は次による。
31−(新ファイル拡張子の長さ+1)−5
ここに,
1: “.”用
5: #CRC用
これに分離子“#”(#0023)が続き,元のCS0ファイル識別子の16ビットCRCをCS0の16進表示した
4数字を続けて,更に“.”(#002E)及びこの処理のこの段階でのファイル拡張子を続けて構成しなければ
ならない。
ファイル拡張子がない場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の[31−5(#CRC用)]個の文字から成る。これに分離子“#”(#0023)を続け,元のCS0ファイル識別
子の16ビットCRCをCS0の16進表示した4数字を続けて構成しなければならない。
4.2.2.1.4
Windows 95及びWindows NT
Windows 95及びWindows NT OS環境が,ファイルに関連するファイル識別子に制約を強いるため,前
述のOS環境でファイル識別子を扱うために,次に示す方法を使用しなければならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をする比較を実行してもよい。大文字と小文字との区別をする比較が行われない又は失敗し
た場合,大文字と小文字との区別をしない比較を実行しなければならない。
b) ファイル識別子の有効性確認:ファイル識別子が有効なWindows 95又はWindows NTファイル識別子
である場合,下の段階を適用しない。
c) 無効文字:Windows 95又はWindows NTのファイル名として無効な文字,又は現状の環境で表示可能
でない文字を含むファイル識別子は,これらを“̲”(#005F)に翻訳しなければならない。複数の連
続する無効文字又は表示不可能な文字は,1文字の“̲”(#005F)に翻訳しなければならない。無効文
字は6.7に示すプログラミング言語Cのソースコードを参照。
d) 末尾の終止符及びスペース:全ての末尾の“.”(#002E)及び“ ”(#0020)は削除しなければならな
い。
e) ファイル識別子CRC:前述の処理によって,元のファイル識別子の文字情報が失われているので,同
一ディレクトリ中で重複ファイル識別子を作成する機会が増す。重複ファイル識別子をもつ機会を大
70
X 0611:2018
きく減らすために,ファイル名を元のファイル識別子のCRCを含むように変更しなければならない。
ファイル拡張子がある場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の文字数から成らなければならず,その個数は次による。
255−(新ファイル拡張子の長さ+1)−5
ここに,
1: “.”用
5: #CRC用
これに分離子“#”(#0023)が続き,元のCS0ファイル識別子の16ビットCRCのCS0の16進表示した
4数字を続けて,更に“.”(#002E)及びこの処理のこの段階でのファイル拡張子を続けて構成しなければ
ならない。
ファイル拡張子がない場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する最
初の[255−5(#CRC用)]個の文字から成らなければならない。これに分離子“#”(#0023)を続け,元
のCS0ファイル識別子の16ビットCRCをCS0の16進表示した4数字を続けて構成する。
4.2.2.1.5
UNIX
UNIX OS環境による制約のため,ファイルに関連するファイル識別子に関して,前述のOS環境でファ
イル識別子を扱うために,次の方法を採用しなければならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をする比較を実行しなければならない。
b) 有効ファイル識別子:ファイル識別子が,現在のシステム環境に有効なUNIXファイル識別子である
場合,次の段階には適用しない。
c) 無効ファイル識別子:現在のシステム環境に関して,UNIXファイル名内で無効と考えられる文字,
又は,現在の環境で表示できないと考えられる文字を含むファイル識別子は,それらを“̲”(#005F)
に変換しなければならない。複数の連続無効文字又は表示不能文字は,1文字の“̲”(#005F)に変換
しなければならない。無効文字の完全リストについては6.7に示すプログラミング言語Cのソースコ
ードを参照。
d) 長ファイル識別子:この処理のこの段階でファイル識別子を構成する文字数が最大名前長(特定の
UNIX OSの最大名前長)より大きい場合,新しいファイル識別子は,この処理のこの段階のファイル
識別子の,最初の5文字の最大名前長から成る。
e) ファイル識別子CRC:前述の手順によって,元のファイル識別子の文字情報が失われるので,同一の
ディレクトリに,重複ファイル識別子を作成する機会が増える。重複ファイル識別子を作成する機会
を大幅に減らすためには,元のファイル識別子のCRCを含むように,ファイル名を変更しなければな
らない。
ファイル拡張子がある場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の文字数から成らなければならず,その個数は次による。
最大名前長−(新ファイル拡張子の長さ+1)−5
ここに,
1: “.”用
5: #CRC用
これに分離子“#”(#0023)を続け,元のCS0ファイル識別子の16ビットCRCのCS0の16進表示した
4数字を続け,更に“.”及びこの処理のこの段階でのファイル拡張子を続けて構成しなければならない。
ファイル拡張子がない場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する,
先頭[最大名前長−5(#CRC用)]の数文字で構成しなければならない。これに,分離子“#”(#0023)が
71
X 0611:2018
続き,元のCS0ファイル識別子の16ビットのCRCをCS0の16進表示した4数字が続く。
4.2.2.1.6
OS/400
OS/400 OS環境が,ファイルに関連するファイル識別子に制約を強いているため,前述のOS環境でフ
ァイル識別子を扱うために,次に示す方法を使用しなければならない。
a) ファイル識別子(FileIdentifier)の照合:ファイル識別子の“照合”に対する要求に,大文字と小文字
との区別をする比較を実行してもよい。大文字と小文字との区別をする比較が行われない又は失敗し
た場合,大文字と小文字との区別をしない比較を実行しなければならない。
b) ファイル識別子の有効性確認:ファイル識別子が有効なOS/400ファイル識別子である場合,次の段
階を適用しない。
c) 無効文字:OS/400ファイル名として無効な文字,又は現状の環境で表示不可能な文字を含むファイル
識別子は,これらを“̲”(#005F)に翻訳しなければならない。複数の連続する無効文字又は表示不
可能文字は,1文字の“̲”(#005F)に翻訳しなければならない。
d) 末尾のスペース:全ての末尾の“.”(#002E)は削除しなければならない。
e) ファイル識別子CRC:前述の処理によって,元のファイル識別子の文字情報が失われるので,同一デ
ィレクトリ中で重複ファイル識別子を作成する機会が増す。重複ファイル識別子をもつ機会を大きく
減らすために,ファイル名を元のファイル識別子のCRCを含むように変更しなければならない。
ファイル拡張子がある場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の文字数から成らなければならず,その個数は次による。
255−(新ファイル拡張子の長さ+1)−5
ここに,
1: “.”用
5: #CRC用
これに分離子“#”(#0023)が続き,元のCS0ファイル識別子の16ビットCRCをCS0の16進表示した
4数字を続けて,更に“.”(#002E)及びこの処理のこの段階でのファイル拡張子を続けて構成しなければ
ならない。
ファイル拡張子がない場合,新しいファイル識別子は,この処理のこの段階でファイル名を構成する先
頭の[255−(#CRC用の)5]個の文字から成る。これに分離子“#”(#0023)を続け,元のCS0ファイル
識別子の16ビットCRCをCS0の16進表示した4数字を続けて構成する。
注記 OS/400の無効文字は,“/”(#002F)だけである。OS/400の表示不可能な文字は,EBCDIC
Multilingualの500ページのコードに翻訳しない文字である。
5
参考情報
5.1
記述子長
表41は,JIS X 0607規格類に規定する記述子の長さに対するUDF制限を要約する。
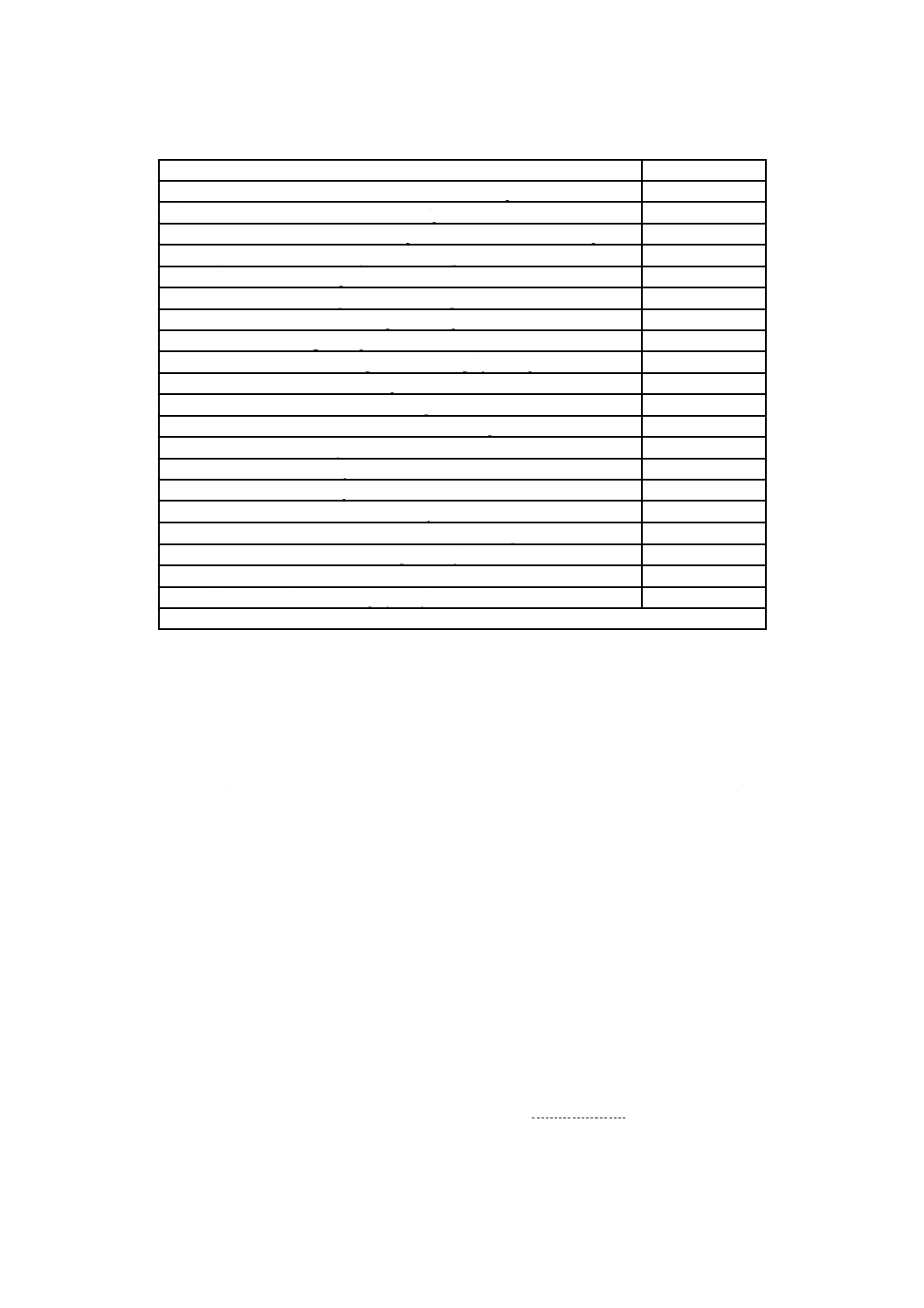
72
X 0611:2018
表41−JIS X 0607規格類に規定する記述子の長さに対するUDF制限
記述子
長さ
開始ボリューム記述子ポインタ(Anchor Volume Descriptor Pointer)
512
ボリューム記述子ポインタ(Volume Descriptor Pointer)
512
処理システム用ボリューム記述子(Implementation Use Volume Descriptor)
512
基本ボリューム記述子(Primary Volume Descriptor)
512
区画記述子(Partition Descriptor)
512
論理ボリューム記述子(Logical Volume Descriptor)
最大値なし
未割付け空間記述子(Unallocated Space Descriptor)
最大値なし
終端記述子(Terminating Descriptor)
512
論理ボリューム保全記述子(Logical Volume Intrgrity Descriptor)
最大値なし
ファイル集合記述子(File Set Descriptor)
512
ファイル識別記述子(File Identifier Descriptor)
論理ブロック長
割付けエクステント記述子(Allocation Extent Descriptor)
24
間接エントリ(Indirect Entry)
52
終端エントリ(Terminal Entry)
36
ファイルエントリ(File Entry)
論理ブロック長
拡張ファイルエントリ(Extended File Entry)
論理ブロック長
拡張属性ヘッダ記述子(Extended Attribute Header Descriptor)
24
未割付け空間エントリ(Unallocated Space Entry)
論理ブロック長
空間ビットマップ記述子(Space Bit Map Descriptor)
最大値なし
区画保全エントリ(Partition Integrity Entry)
N/A
N/A:規定しない
5.2
処理システム用領域の使用
5.2.1
実体識別子(Entity Identifiers)
実体識別子は,この規格のはじめに定義する実体識別子に関する2.1.5を参照。
5.2.2
孤立空間(Orphan Space)
孤立空間が論理ボリューム中に存在してもよいが推奨はしない。それは,幾つかの論理ボリュームの修
理機能によって再割付けされる可能性があるためである。孤立空間は,JIS X 0607規格類で定義する処理
システム用記述子以外のいずれかの記述子で,直接又は間接に参照しない空間として定義する。
特記事項 処理システム用欄中だけに参照が存在する割付け済みのエクステントを孤立空間とみな
す。
5.3
起動記述子(Boot Descriptor)
将来,決定する。
5.4
未記録セクタの明確化(Clarification of Unrecorded Sectors)
[3/8.1.2.2]には,次のように記載されている。
“論理セクタを構成するどのような未記録構成セクタであっても全て#00バイトを含むものとして解
釈されなければならない。論理セクタの最後のバイトを含むセクタの中では,その最後のバイトの後の
どのようなバイトの解釈も,この第3部によって規定されない。
記録の規格がセクタが未記録かどうかの検出方法を規定しており,論理セクタを構成するセクタの全
てが未記録の場合,論理セクタは未記録である。論理セクタの構成セクタは,全て記録されているか,
又は全て記録されていないことが望ましい([3/8.1.2.2]参照)。”
交換の目的のために,UDFはこのセクションの正しい解釈を明確にしなければならない。
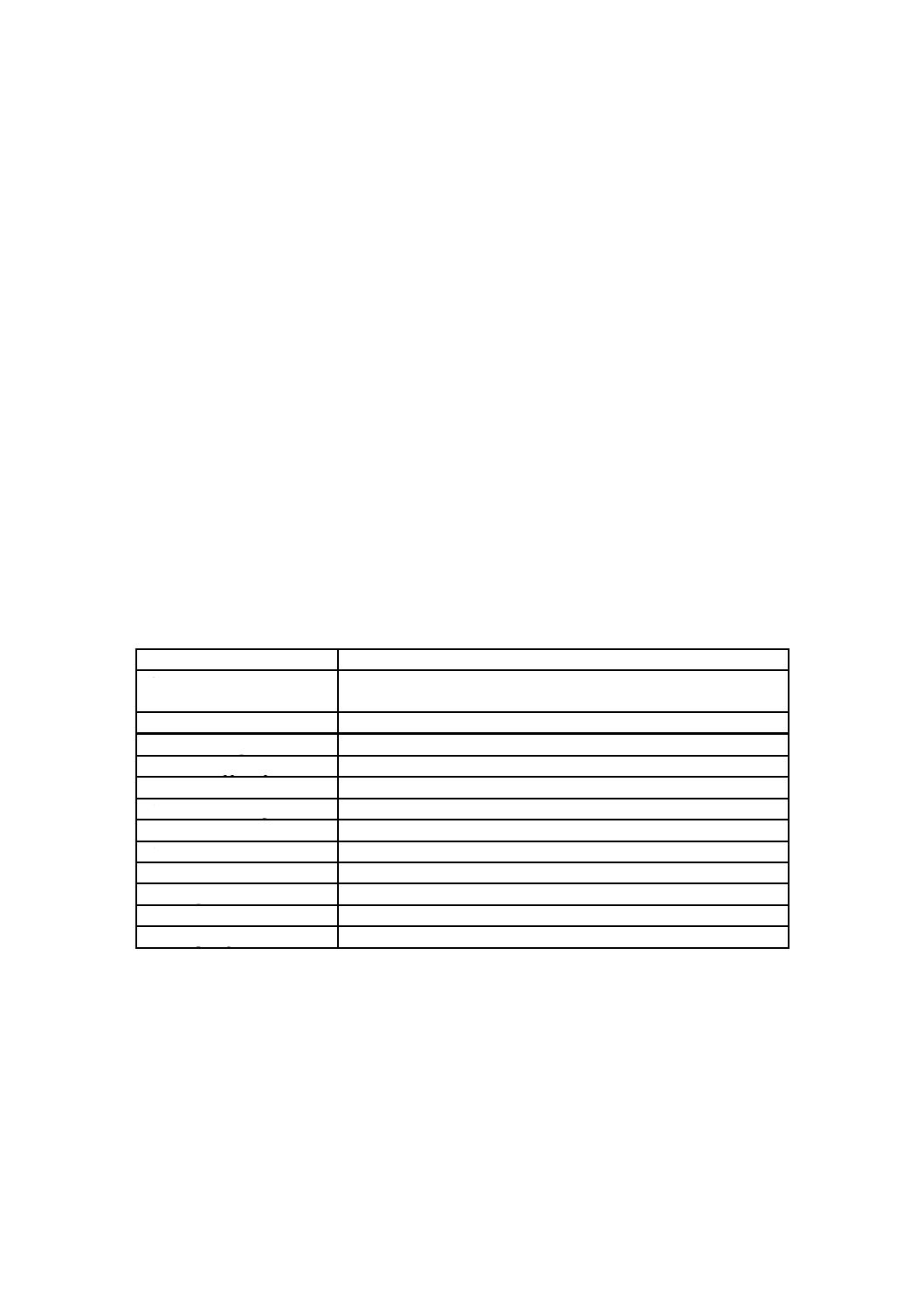
73
X 0611:2018
上記の部分は,未記録セクタは論理的に#00バイトを含むことを規定している。しかし,#00バイトだけ
を含むセクタが未記録であるという逆の主張は成立せず,そのようなセクタはJIS X 0607規格類において
は,“未記録”ではない。媒体におけるセクタの記録を支配する規格だけが,セクタが未記録であるか否か
を決定するための規則を提供できる。例えば,ブランクチェック状態は,追記形ディスクのための正しい
決定を提供できる。
JIS X 0607規格類の[3/8.4.2],[3/8.8.2],[4/3.1],[4/8.3.1]及び[4/8.10]は,[3/8.1.2.2]に定義された規則を参
照している。これによって,この規格の6.6も影響を受ける。未記録のセクタ又はブロックは,記述子の
列の終了条件である。したがって,処理システムは,使用されている記録媒体が未記録セクタの検知可能
性をもっていることを確認しなければならず,セクタに書き込まれていないことが検出可能であることを
前提としてはならない。そうでない場合は,正しくない上記の逆の主張を,結果として信用してしまうこ
とがあり得る。適切な未記録セクタが検出されないような場合には,明白な終端記述子が使われなければ
ならない。
5.5
技術的問合せ
(対応団体規格では,この箇条において技術的問合せ先を記載しているが,記載された連絡先は現在で
は有効でないため,不採用とした。)
6
関連する規定
6.1
UDF実体識別記述子(表42参照)
表42−UDF実体識別記述子
実体識別子
記述
“*OSTA UDF Compliant”
指定した論理ボリューム,又はファイル集合の内容が,この規格で定
義する適合範囲であることを示す。
“*UDF LV Info”
付加的な論理ボリューム識別情報を含む。
“*UDF FreeEASpace”
処理システム用拡張属性空間中の未使用の空き空間を含む。
“*UDF FreeAppEASpace”
アプリケーション用拡張属性空間中に未使用の空き空間を含む。
“*UDF DVD CGMS Info”
DVD著作権管理情報を含む。
“*UDF OS/2 EALength”
OS/2拡張属性長を含む。
“*UDF Mac Volume Info”
Macintoshボリューム情報を含む。
“*UDF Mac FinderInfo”
Macintoshファインダ情報を含む。
“*UDF Virtual Partition”
UDF仮想区画を記載する。
“*UDF Sparable Partition”
UDF予備区画を記載する。
“*UDF OS/400 DirInfo”
OS/400拡張ディレクトリ情報
“*UDF Sparing Table”
媒体で欠陥領域を扱う情報を含む。
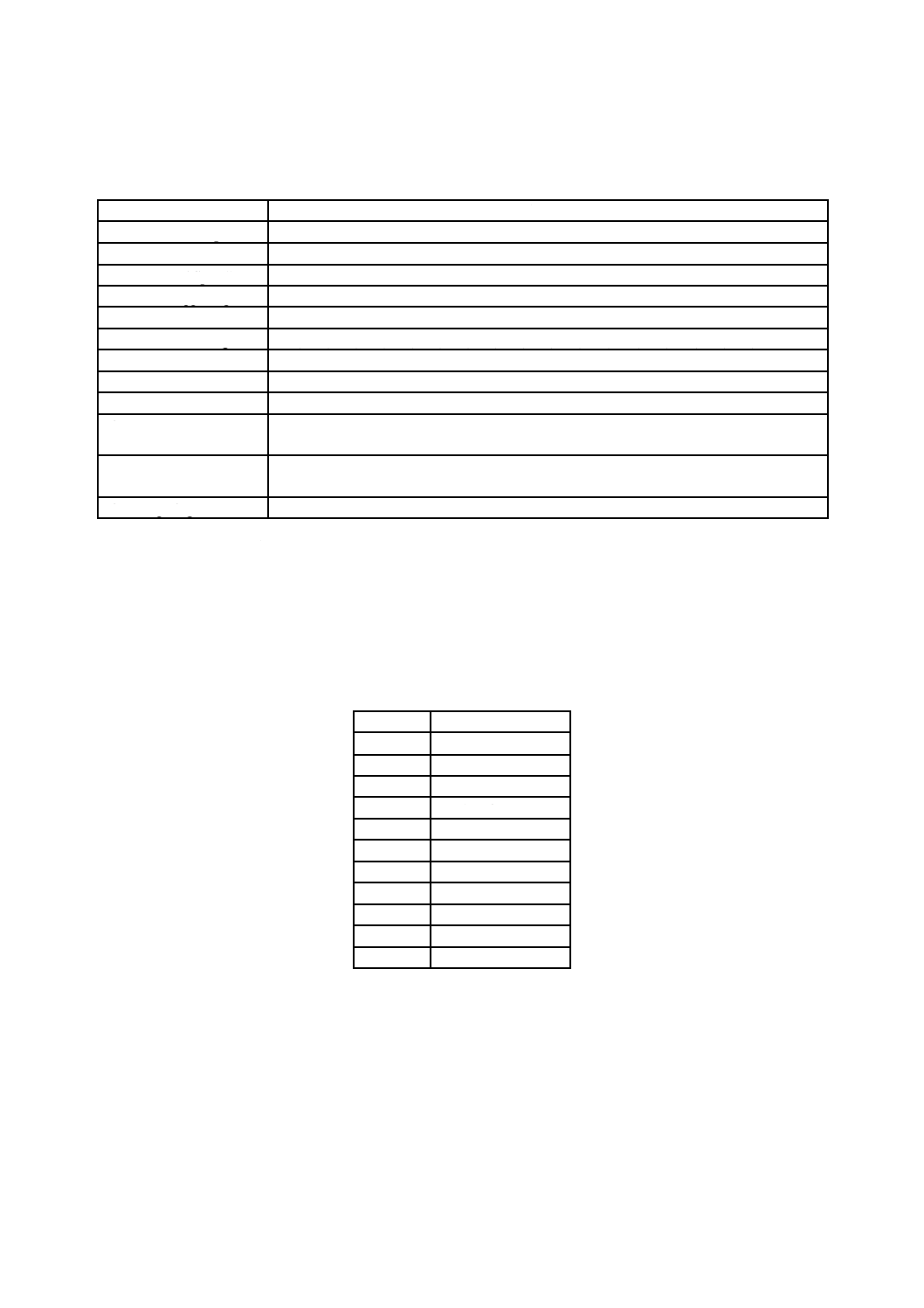
74
X 0611:2018
6.2
UDF実体識別値(表43参照)
表43−UDF実体識別子値
実体識別子
バイト値
“*OSTA UDF Compliant”
#2A, #4F, #53, #54, #41, #20, #55, #44, #46, #20, #43, #6F, #6D, #70, #6C, #69, #61, #6E, #74
“*UDF LV Info”
#2A, #55, #44, #46, #20, #4C, #56, #20, #49, #6E, #66, #6F
“*UDF FreeEASpace”
#2A, #55, #44, #46, #20, #46, #72, #65, #65, #45, #41, #53, #70, #61, #63, #65
“*UDF FreeAppEASpace”
#2A, #55, #44, #46, #20, #46, #72, #65, #65, #41, #70, #70, #45, #41, #53, #70, #61, #63, #65
“*UDF DVD CGMS Info”
#2A, #55, #44, #46, #20, #44, #56, #44, #20, #43, #47, #4D, #53, #20, #49, #6E, #66, #6F
“*UDF OS/2 EALength”
#2A, #55, #44, #46, #20, #4F, #53, #2F, #32, #20, #45, #41, #4C, #65, #6E, #67, #74, #68
“*UDF OS/400 DirInfo”
#2A, #55, #44, #46, #20, #4F, #53, #2F, #34, #30, #30, #20, #44, #69, #72, #49, #6E, #66, #6F
“*UDF Mac VolumeInfo”
#2A, #55, #44, #46, #20, #4D, #61, #63, #20, #56, #6F, #6C, #75, #6D, #65, #49, #6E, #66, #6F
“*UDF Mac FinderInfo”
#2A, #55, #44, #46, #20, #4D, #61, #63, #20, #49, #69, #6E, #64, #65, #72, #49, #6E, #66, #6F
“*UDF Virtual Partition”
#2A, #55, #44, #46, #20, #56, #69, #72, #74, #75, #61, #6C, #20, #50, #61, #72, #74, #69, #74,
#69, #6F, #6E
“*UDF Sparable Partition"
#2A, #55, #44, #46, #20, #53, #70, #61, #72, #61, #62, #6C, #65, #20, #50, #61, #72, #74, #69,
#74, #69, #6F, #6E
“*UDF Sparing Table”
#2A, #55, #44, #46, #20, #53, #70, #61, #72, #69, #6E, #67, #20, #54, #61, #62, #6C, #65
6.3
オペレーティングシステム識別子(OS識別子)
表44及び表45は,実体識別子の識別子添字中のOSクラス欄及びOS識別子欄に対して現状許可する
値を定義する。
OSクラス(OS Class)欄は,記述子を記録したOSのクラスを識別する。この欄の有効な値を表44に示
す。
表44−OSクラス欄の値
値
OSクラス
0
未定義(Undefined)
1
DOS
2
OS/2
3
Macintosh OS
4
UNIX
5
Windows 9x
6
Windows NT
7
OS/400
8
BeOS
9
Windows CE
10〜255
予約(Reserved)
OS識別子(OS Identifier)欄は,記述子を記録したOSを識別する。この欄の有効な値を表45に示す。

75
X 0611:2018
表45−OS識別子欄の値
OSクラス
OS識別子
識別されるOS
0
任意の値
未定義(Undefined)
1
0
DOS/Windows 3.x
2
0
OS/2
3
0
Macintosh OS
4
0
UNIX-Generic
4
1
UNIX-IBM AIX
4
2
UNIX-SUN OS/Solaris
4
3
UNIX-HP/UX
4
4
UNIX-Silicon Graphics Irix
4
5
UNIX-Linux
4
6
UNIX-MKLinux
4
7
UNIX-FreeBSD
5
0
Windows 9x−generic(Windows 98を含む。)
6
0
Windows NT−generic(Windows 2000を含む。)
7
0
OS/400
8
0
BeOS-generic
9
0
WindowsCE-generic
OSクラス及びOS識別子に関する値の最新の表については,OSTAに連絡し,UDF実体識別子のディレ
クトリのコピーを要求する。このディレクトリには,必須情報をOSTAへ提供した独立系ソフトウェアベ
ンダ(ISV)の処理システム識別子も含まれる。
特記事項 この表への追加を希望する場合,OSTA Technical Committee Chairmanに連絡する。
注記 表45は,この規格が制定された時点で,対応団体規格に記載されていたものである。
6.4
OSTA圧縮Unicodeの圧縮アルゴリズム
/*****************************************************************************
* OSTA compliant unicode compression, uncompression routines.
* Copyright 1995 Micro Design International, Inc,
* Written by Jason M. Rinn.
* Micro Design International gives permission for the free use of the
* following source code.
*/
#include <stddef.h>
/******************************************************************************
* The follwing two typedef's are to remove compiler dependancies.
* byte needs to be unsigned 8-bit, and unicode̲t needs to be
* unsigned 16-bits.
*/
typedef unsigned short unicode̲t;
typedef unsigned char byte;
/***********************************************************************************
* Takes an OSTA CS0 compressed unicode name, and converts
* it to unicode.
* The unicode output will be in the byte order
* that the local compiler uses for 16-bit values.
* NOTE: This routine only performs error checking on the compID.
* It is up to the user to ensure that the unicode buffer is large
* enough, and that the compressed unicode name is correct.
76
X 0611:2018
*
* RETURN VALUE
*
* The number of unicode characters which were uncompressed.
* A -1 is returned if the compression ID is invalid.
*/
int UncompressUnicode(
int numberOfBytes, /* (Input) number of bytes read from media. */
byte *UDFCompressed, /* (Input) bytes read from media. */
unicode̲t *unicode) /* (Output) uncompressed unicode characters. */
{
unsigned int compID;
int returnValue, unicodeIndex, byteIndex;
/* Use UDFCompressed to store courrent byte being read. */
compID=UDFCompressed[0];
/* First check for valid compID. */
if (compID !=8 && compID !=16)
{
returnValue =-1;
}
else
{
unicodeIndex =0;
byteIndex =1;
/* Loop through all the bytes. */
while (byteIndex < numberOfBytes)
{
if (compID ==16)
{
/*Move the first byte to the high bits the unicode char. */
unicode[unicodeIndex] = UDFCompressed[byteIndex++] <<8;
}
else
{
unicode[unicodeIndex]=0;
}
if (byteIndex < numberOfBytes)
{
/*Then the next byte to the low bits. */
unicode[unicodeIndex] |= UDFCompressed[byteIndex++];
}
unicodeIndex++;
}
returnValue = unicodeIndex;
}
return(returnValue);
}
/***************************************************************************
* DESCRIPTION:
* Takes a string of unicode wide characters and returns an OSTA CS0
* compressed unicode string. The unicode MUST be in the byte order of
* the compiler in order to obtain correct results. Returns an error
77
X 0611:2018
* if the commpression ID is invalid.
*
* NOTE: This routine assumes the implementation already knows, by
* the local environment, how many bits are appropriate and
* therefore does no checking to test if the input characters fit
* into that number of bits or not.
*
* RETURN VALUE
*
* The total number of bytes in the compressed OSTA CS0 string,
* including the compression ID.
* A -1 is returned if the compression ID is invarild.
*/
int CompressUnicode(
int numberOfChars, /* (Input) number of unicode characters. */
int compID, /* (Input) compression ID to be used. */
unicode̲t *unicode, /* (Input) unicode characters to compress. */
byte *UDFCompressed) /* (Output) compressed string, as bytes. */
{
int byteIndex, unicodeIndex;
if (compID != 8 && compID != 16)
{
byteIndex = -1; /* Unsupported compression ID ! */
}
else
{
/* place compression code in first byte. */
UDFCompressed[0] = compID;
byteIndex = 1;
unicodeIndex = 0;
while (unicodeIndex < numberOfChars)
{
if (compID == 16)
{
/* First, place the high bits of the char
* into the byte stream.
*/
UDFCompressed[byteIndex++] =
(unicode[unicodeIndex] & 0xFF00) >> 8;
}
/* Then place the low bits into the stream. */
UDFCompressed[byteIndex++] = unicode[unicodeIndex] & 0x00FF;
unicodeIndex++;
}
}
return(byteIndex);
}
6.5
CRC計算
次に示すプログラミング言語Cのソースコードは,JIS X 0607規格類のタグ記述子に使用する
CRC-CCITTチェックサムを計算するために利用する。
なお,次に示すソースコードは,アルゴリズムを表現するものであって,標準のプログラミング言語C
78
X 0611:2018
の規格に規定される仕様のC(以下,標準のCという。)でそのままコンパイルできないことがある。
/*
* CRC 010041
*/
static unsigned short crc̲table[256] = {
0x0000,
0x1021, 0x2042,
0x3063,
0x4084,
0x50A5, 0x60C6, 0x70E7,
0x8108,
0x9129, 0xA14A,
0xB16B,
0xC18C,
0xD1AD, 0xE1CE, 0xF1EF,
0x1231,
0x0210, 0x3273,
0x2252,
0x52B5,
0x4294, 0x72F7, 0x62D6,
0x9339,
0x8318, 0xB37B,
0xA35A,
0xD3BD, 0xC39C, 0xF3FF, 0xE3DE,
0x2462,
0x3443, 0x0420,
0x1401,
0x64E6, 0x74C7, 0x44A4, 0x5485,
0xA56A,
0xB54B, 0x8528,
0x9509,
0xE5EE, 0xF5CF, 0xC5AC, 0xD58D,
0x3653,
0x2672, 0x1611,
0x0630,
0x76D7, 0x66F6, 0x5695, 0x46B4,
0xB75B,
0xA77A, 0x9719,
0x8738,
0xF7DF, 0xE7FE, 0xD79D, 0xC7BC,
0x48C4,
0x58E5, 0x6886,
0x78A7,
0x0840, 0x1861, 0x2802, 0x3823,
0xC9CC,
0xD9ED, 0xE98E,
0xF9AF,
0x8948, 0x9969, 0xA90A, 0xB92B,
0x5AF5,
0x4AD4, 0x7AB7,
0x6A96,
0x1A71, 0x0A50, 0x3A33, 0x2A12,
0xDBFD,
0xCBDC, 0xFBBF,
0xEB9E,
0x9B79, 0x8B58, 0xBB3B, 0xAB1A,
0x6CA6,
0x7C87, 0x4CE4,
0x5CC5,
0x2C22, 0x3C03, 0x0C60, 0x1C41,
0xEDAE,
0xFD8F, 0xCDEC,
0xDDCD,
0xAD2A, 0xBD0B, 0x8D68, 0x9D49,
0x7E97,
0x6EB6, 0x5ED5,
0x4EF4,
0x3E13, 0x2E32, 0x1E51, 0x0E70,
0xFF9F,
0xEFBE, 0xDFDD,
0xCFFC,
0xBF1B, 0xAF3A, 0x9F59, 0x8F78,
0x9188,
0x81A9, 0xB1CA,
0xA1EB,
0xD10C, 0xC12D, 0xF14E, 0xE16F,
0x1080,
0x00A1, 0x30C2,
0x20E3,
0x5004, 0x4025, 0x7046, 0x6067,
0x83B9,
0x9398, 0xA3FB,
0xB3DA,
0xC33D, 0xD31C, 0xE37F, 0xF35E,
0x02B1,
0x1290, 0x22F3,
0x32D2,
0x4235, 0x5214, 0x6277, 0x7256,
0xB5EA,
0xA5CB, 0x95A8,
0x8589,
0xF56E, 0xE54F, 0xD52C, 0xC50D,
0x34E2,
0x24C3, 0x14A0,
0x0481,
0x7466, 0x6447, 0x5424, 0x4405,
0xA7DB,
0xB7FA, 0x8799,
0x97B8,
0xE75F, 0xF77E, 0xC71D, 0xD73C,
0x26D3,
0x36F2, 0x0691,
0x16B0,
0x6657, 0x7676, 0x4615, 0x5634,
0xD94C,
0xC96D, 0xF90E,
0xE92F,
0x99C8, 0x89E9, 0xB98A, 0xA9AB,
0x5844,
0x4865, 0x7806,
0x6827,
0x18C0, 0x08E1, 0x3882, 0x28A3,
0xCB7D,
0xDB5C, 0xEB3F,
0xFB1E,
0x8BF9, 0x9BD8, 0xABBB, 0xBB9A,
0x4A75,
0x5A54, 0x6A37,
0x7A16,
0x0AF1, 0x1AD0, 0x2AB3, 0x3A92,
0xFD2E,
0xED0F, 0xDD6C,
0xCD4D,
0xBDAA, 0xAD8B, 0x9DE8, 0x8DC9,
0x7C26,
0x6C07, 0x5C64,
0x4C45,
0x3CA2, 0x2C83, 0x1CE0, 0x0CC1,
0xEF1F,
0xFF3E, 0xCF5D,
0xDF7C,
0xAF9B, 0xBFBA, 0x8FD9, 0x9FF8,
0x6E17,
0x7E36, 0x4E55,
0x5E74,
0x2E93, 0x3EB2, 0x0ED1, 0x1EF0
};
unsigned short
cksum(s, n)
register unsigned char *s;
register int n;
{
register unsigned short crc=0;
while (n-- > 0)
crc = crc̲table[(crc>>8 ^ *s++) & 0xff] ^ (crc<<8);
return crc;
}
/* UNICODE Checksum */
unsigned short
unicode̲cksum(s, n)
79
X 0611:2018
register unsigned short *s;
register int n;
{
register unsigned short crc=0;
while (n-- > 0) {
/* Take high order byte first-corresponds to a big endian byte stream.*/
crc = crc̲table [(crc >>8 ^ (*s>>8) & 0xff] ^ (crc <<8);
crc = crc̲table [(crc >>8 ^ (*s++ & 0xff)) & 0xff] ^ (crc <<8);
}
return crc;
}
#ifdef MAIN
unsigned char bytes[] = { 0x70, 0x6A, 0x77};
main()
{
usigned short x;
x = cksum(bytes, sizeof bytes);
printf("checksum: calculated=%4.4x, correct=%4.4x\en", x, 0x3299);
exit(0);
}
#endif
先に挙げたCRC表は,次のプログラムで生成した。
#include <stdio.h>
/*
* a.out 010041 for CRC-CCITT
*/
main(argc, argv)
int argc; char *argv[];
{
unsigned long crc, poly;
int n, i;
sscanf(argv[1], "%lo", &poly);
if(poly & 0xffff0000){
fprintf(stderr, "polynomial is too large\en");
exit(1);
}
printf("/*\en * CRC 0%o\en */\en", poly);
printf("static unsigned short crc̲table[256] = {\en");
for(n =0; n < 256; n++){
if(n % 8 ==0)
printf(" ");
crc = n <<8;
for(i = 0; i < 8; i++){
if(crc & 0x8000)
crc = (crc << 1) ^ poly;
else
crc <<= 1;
80
X 0611:2018
crc &= 0xFFFF;
}
if(n == 255)
printf("0x%04X ", crc);
else
printf("0x%04X, ", crc);
if(n % 8 == 7)
printf("\en");
}
printf("};\en");
exit(0);
}
これらの全てのCRC符号は,AT&T Bell研究所のDon P. Mitchell及びSoftware System GroupのNed W.
Rhodesが考案した。これは,既に文献“Design and Validation of Computer Protocols”(Prentice Hall, Englewood
Cliffs, NJ, 1991, Chapter 3, ISBN 0-13-539925-4)で公開されており,AT&Tが著作権をもっている。
AT&Tは,上記のソースコードの自由使用の許可を与えている。
6.6
方策種別4 096のアルゴリズム
この細分箇条は,ICB階層を構成するための方策を記載する。方策種別4 096のルートICB階層は,1
個の直接エントリ及び1個の間接エントリを含まなければならない。1個の直接エントリがあることを示
すために,ICBタグ欄の方策パラメタ欄中のUint16に値1を記録する。ICBタグ欄のエントリの最大個数
(MaximumNumberOfEntries)欄に値2を記録する。
間接エントリが,1個の直接エントリ及び1個の間接エントリをも含む他のICB番地を指定し,この間
接エントリは,同一種別の他のICB番地を指定しなければならない(図1を参照)。
図1−ICB番地の規定
特記事項 この方策は,直接エントリの簡単なリンクリストのICB階層を構成する。
6.7
識別子翻訳アルゴリズム
次に示すプログラミング言語Cのソースコードは,この規格に記載するファイル識別子翻訳アルゴリズ
ムを与えている。
次に示す基本アルゴリズムは,ボリューム識別子(VolumeIdentifier),ボリューム集合識別子
(VolumeSetIdentifier),論理ボリューム識別子(LogicalVolumeID)及びファイル集合識別子(FileSetID)の
OS固有の翻訳を扱うために利用してもよい。
6.7.1
DOSアルゴリズム(DOS Algorithm)
次に示すソースコードは,アルゴリズムを表現するものであって,標準のCでそのままコンパイルでき
DE
IE
DE :直接エントリ
IE :間接エントリ
DE
IE
DE
IE
81
X 0611:2018
ないことがある。
/* OSTA UDF compliant file name translation routine for DOS and */
/* Windows short namespaces */
/* Define constants for namespace translation */
#define DOS̲NAME̲LEN 8
#define DOS̲EXT̲LEN 3
#define DOS̲LABEL̲LEN 11
#define DOS̲CRC̲LEN 4
#define DOS̲CRC̲MODULUS 41
/* Define standard types used in example code. */
typedef BOOLEAN int;
typedef short INT16;
typedef unsigned short UINT16;
typedef UINT16 UNICODE̲CHAR;
#define FALSE 0
#define TRUE 1
static char crcChar[] =
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ#̲~-@";
/* FUNCTION PROTOTYPES */
UNICODE̲CHAR UnicodeToUpper(UNICODE̲CHAR value);
BOOLEAN IsFileNameCharLegal(UNICODE̲CHAR value);
BOOLEAN IsVolumeLabelCharLegal(UNICODE̲CHAR value);
INT16 NativeCharLength(UNICODE̲CHAR value);
BOOLEAN IsDeviceName(UNICODE̲CHAR* name, UINT16 nameLen);
/***********************************************************************/
/* UDFDOSName( ) */
/* Translate udfName to dosName using OSTA compliant algorithm. */
/* dosName must be a Unicode string buffer at least 12 characters */
/* in length. */
/***********************************************************************/
UINT16 UDFDOSName(UNICODE̲CHAR* dosName, UNICODE̲CHAR* udfName,
UINT16 udfNameLen)
{
INT16 index;
INT16 targetIndex;
INT16 crcIndex;
INT16 extLen;
INT16 nameLen;
INT16 charLen;
INT16 overlayBytes;
INT16 bytesLeft;
UNICODE̲CHAR current;
BOOLEAN needsCRC;
UNICODE̲CHAR ext[DOS̲EXT̲LEN];
needsCRC = FALSE;
/* Start at the end of the UDF file name and scan for a period */
/* ('.'). This will be where the DOS extension starts (if */
/* any). */
index = udfNameLen;
while (index-- > 0) {
if (udfName[index] == '.')
82
X 0611:2018
break;
}
if (index < 0) {
/* There name was scanned to the beginning of the buffer */
/* and no extension was found. */
extLen = 0;
nameLen = udfNameLen;
}
else {
/* A DOS extension was found, process it first. */
extLen = udfNameLen - index - 1;
nameLen = index;
targetIndex = 0;
bytesLeft = DOS̲EXT̲LEN;
while (++index < udfNameLen && bytesLeft > 0) {
/* Get the current character and convert it to upper */
/* case. */
current = UnicodeToUpper(udfName[index]);
if (current == ' ') {
/* If a space is found, a CRC must be appended to */
/* the mangled file name. */
needsCRC = TRUE;
}
else {
/* Determine if this is a valid file name char and */
/* calculate its corresponding BCS character byte */
/* length (zero if the char is not legal or */
/* undisplayable on this system). */
charLen = (IsFileNameCharLegal(current)) ?
NativeCharLength(current) : 0;
/* If the char is larger than the available space */
/* in the buffer, pretend it is undisplayable. */
if (charLen > bytesLeft)
charLen = 0;
if (charLen == 0) {
/* Undisplayable or illegal characters are */
/* substituted with an underscore ("̲"), and */
/* required a CRC code appended to the mangled */
/* file name. */
needsCRC = TRUE;
charLen = 1;
current = '̲';
/* Skip over any following undiplayable or */
/* illegal chars. */
while (index +1 <udfNameLen &&
(!IsFileNameCharLegal(udfName[index + 1]) ||
NativeCharLength(udfName[index + 1]) == 0))
index++;
}
/* Assign the resulting char to the next index in */
/* the extension buffer and determine how many BCS */
83
X 0611:2018
/* bytes are left. */
ext[targetIndex++] = current;
bytesLeft -= charLen;
}
}
/* Save the number of Unicode characters in the extension */
extLen = targetIndex;
/* If the extension was too large, or it was zero length */
/* (i.e. the name ended in a period), a CRC code must be */
/* appended to the mangled name. */
if (index < udfNameLen || extLen == 0)
needsCRC = TRUE;
}
/* Now process the actual file name. */
index = 0;
targetIndex = 0;
crcIndex = 0;
overlayBytes = -1;
bytesLeft = DOS̲NAME̲LEN;
while (index < nameLen && bytesLeft > 0) {
/* Get the current character and convert it to upper case. */
current = UnicodeToUpper(udfName[index]);
if (current ==' ' ||current == '.') {
/* Spaces and periods are just skipped, a CRC code */
/* must be added to the mangled file name. */
needsCRC = TRUE;
}
else {
/* Determine if this is a valid file name char and */
/* calculate its corresponding BCS character byte */
/* length (zero if the char is not legal or */
/* undisplayable on this system). */
charLen = (IsFileNameCharLegal(current)) ?
NativeCharLength(current) : 0;
/* If the char is larger than the available space in */
/* the buffer, pretend it is undisplayable. */
if (charLen > bytesLeft)
charLen = 0;
if (charLen == 0) {
/* Undisplayable or illegal characters are */
/* substituted with an underscore ("̲"), and */
/* required a CRC code appended to the mangled */
/* file name. */
needsCRC = TRUE;
charLen = 1;
current = '̲';
/* Skip over any following undiplayable or illegal */
/* chars. */
while (index +1 <nameLen &&
84
X 0611:2018
(!IsFileNameCharLegal(udfName[index + 1]) ||
NativeCharLength(udfName[index + 1]) == 0))
index++;
/* Terminate loop if at the end of the file name. */
if (index >= nameLen)
break;
}
/* Assign the resulting char to the next index in the */
/* file name buffer and determine how many BCS bytes */
/* are left. */
dosName[targetIndex++] = current;
bytesLeft -= charLen;
/* This figures out where the CRC code needs to start */
/* in the file name buffer. */
if (bytesLeft >= DOS̲CRC̲LEN) {
/* If there is enough space left, just tack it */
/* onto the end. */
crcIndex = targetIndex;
}
else {
/* If there is not enough space left, the CRC */
/* must overlay a character already in the file */
/* name buffer. Once this condition has been */
/* met, the value will not change. */
if (overlayBytes < 0) {
/* Determine the index and save the length of */
/* the BCS character that is overlayed. It */
/* is possible that the CRC might overlay */
/* half of a two-byte BCS character depending */
/* upon how the character boundaries line up. */
overlayBytes = (bytesLeft + charLen > DOS̲CRC̲LEN)?1 :0;
crcIndex = targetIndex - 1;
}
}
}
/* Advance to the next character. */
index++;
}
/* If the scan did not reach the end of the file name, or the */
/* length of the file name is zero, a CRC code is needed. */
if (index < nameLen || index == 0)
needsCRC = TRUE;
/* If the name has illegal characters or and extension, it */
/* is not a DOS device name. */
if (needsCRC == FALSE && extLen == 0) {
/* If this is the name of a DOS device, a CRC code should */
/* be appended to the file name. */
if (IsDeviceName(udfName, udfNameLen))
needsCRC = TRUE;
85
X 0611:2018
}
/* Append the CRC code to the file name, if needed. */
if (needsCRC) {
/* Get the CRC value for the original Unicode string */
UINT16 udfCRCValue = CalculateCRC(udfName, udfNameLen);
/* Determine the character index where the CRC should */
/* begin. */
targetIndex = crcIndex;
/* If the character being overlayed is a two-byte BCS */
/* character, replace the first byte with an underscore. */
if (overlayBytes > 0)
dosName[targetIndex++] = '̲';
/* Append the encoded CRC value with delimiter. */
dosName[targetIndex++] = '#';
dosName[targetIndex++] =
crcChar[udfCRCValue / (DOS̲CRC̲MODULUS * DOS̲CRC̲MODULUS)];
udfCRCValue %= DOS̲CRC̲MODULUS * DOS̲CRC̲MODULUS;
dosName[targetIndex++] =
crcChar[udfCRCValue / DOS̲CRC̲MODULUS];
udfCRCValue %= DOS̲CRC̲MODULUS;
dosName[targetIndex++] = crcChar[udfCRCValue];
}
/* Append the extension, if any. */
if (extLen > 0) {
/* Tack on a period and each successive byte in the */
/* extension buffer. */
dosName[targetIndex++] = '.';
for (index = 0; index < extLen; index++)
dosName[targetIndex++] = ext[index];
}
/* Return the length of the resulting Unicode string. */
return (UINT16)targetIndex;
}
/*******************************************************************/
/* UDFDOSVolumeLabel() */
/* Translate udfLabel to dosLabel using OSTA compliant algorithm. */
/* dosLabel must be a Unicode string buffer at least 11 characters */
/* in length. */
/*******************************************************************/ UINT16
UDFDOSVolumeLabel(UNICODE̲CHAR* dosLabel, UNICODE̲CHAR*
udfLabel, UINT16 udfLabelLen)
{
INT16 index;
INT16 targetIndex;
INT16 crcIndex;
INT16 charLen;
INT16 overlayBytes;
INT16 bytesLeft;
86
X 0611:2018
UNICODE̲CHAR current;
BOOLEAN needsCRC;
needsCRC = FALSE;
/* Scan end of label to see if there are any trailing spaces. */
index = udfLabelLen;
while (index-- > 0) {
if (udfLabel[index] != ' ')
break;
}
/* If there are trailing spaces, adjust the length of the */
/* string to exclude them and indicate that a CRC code is */
/* needed. */
if (index +1 !=udfLabelLen) {
udfLabelLen = index + 1;
needsCRC = TRUE;
}
index = 0;
targetIndex = 0;
crcIndex = 0;
overlayBytes = -1;
bytesLeft = DOS̲LABEL̲LEN;
while (index < udfLabelLen && bytesLeft > 0) {
/* Get the current character and convert it to upper case. */
current = UnicodeToUpper(udfLabel[index]);
if (current == '.') {
/* Periods are just skipped, a CRC code must be added */
/* to the mangled file name. */
needsCRC = TRUE;
}
else {
/* Determine if this is a valid file name char and */
/* calculate its corresponding BCS character byte */
/* length (zero if the char is not legal or */
/* undisplayable on this system). */
charLen = (IsVolumeLabelCharLegal(current)) ?
NativeCharLength(current) : 0;
/* If the char is larger than the available space in */
/* the buffer, pretend it is undisplayable. */
if (charLen > bytesLeft)
charLen = 0;
if (charLen == 0) {
/* Undisplayable or illegal characters are */
/* substituted with an underscore ("̲"), and */
/* required a CRC code appended to the mangled */
/* file name. */
needsCRC = TRUE;
charLen = 1;
current = '̲';
/* Skip over any following undiplayable or illegal */
/* chars. */
while (index +1 <udfLabelLen &&
87
X 0611:2018
(!IsVolumeLabelCharLegal(udfLabel[index + 1]) ||
NativeCharLength(udfLabel[index + 1]) == 0))
index++;
/* Terminate loop if at the end of the file name. */
if (index >= udfLabelLen)
break;
}
/* Assign the resulting char to the next index in the */
/* file name buffer and determine how many BCS bytes */
/* are left. */
dosLabel[targetIndex++] = current;
bytesLeft -= charLen;
/* This figures out where the CRC code needs to start */
/* in the file name buffer. */
if (bytesLeft >= DOS̲CRC̲LEN) {
/* If there is enough space left, just tack it */
/* onto the end. */
crcIndex = targetIndex;
}
else {
/* If there is not enough space left, the CRC */
/* must overlay a character already in the file */
/* name buffer. Once this condition has been */
/* met, the value will not change. */
if (overlayBytes < 0) {
/* Determine the index and save the length of */
/* the BCS character that is overlayed. It */
/* is possible that the CRC might overlay */
/* half of a two-byte BCS character depending */
/* upon how the character boundaries line up. */
overlayBytes = (bytesLeft + charLen >
DOS̲CRC̲LEN)
?1 :0;
crcIndex = targetIndex - 1;
}
}
}
/* Advance to the next character. */
index++;
}
/* If the scan did not reach the end of the file name, or the */
/* length of the file name is zero, a CRC code is needed. */
if (index < udfLabelLen || index == 0)
needsCRC = TRUE;
/* Append the CRC code to the file name, if needed. */
if (needsCRC) {
/* Get the CRC value for the original Unicode string */
UINT16 udfCRCValue = CalculateCRC(udfName, udfNameLen);
/* Determine the character index where the CRC should */
/* begin. */
88
X 0611:2018
targetIndex = crcIndex;
/* If the character being overlayed is a two-byte BCS */
/* character, replace the first byte with an underscore. */
if (overlayBytes > 0)
dosLabel[targetIndex++] = '̲';
/* Append the encoded CRC value with delimiter. */
dosLabel[targetIndex++] = '#';
dosLabel[targetIndex++] =
crcChar[udfCRCValue / (DOS̲CRC̲MODULUS * DOS̲CRC̲MODULUS)];
udfCRCValue %= DOS̲CRC̲MODULUS * DOS̲CRC̲MODULUS;
dosLabel[targetIndex++] =
crcChar[udfCRCValue / DOS̲CRC̲MODULUS];
udfCRCValue %= DOS̲CRC̲MODULUS;
dosLabel[targetIndex++] = crcChar[udfCRCValue];
}
/* Return the length of the resulting Unicode string. */
return (UINT16)targetIndex;
}
/*******************************************************************/
/* UnicodeToUpper() */
/* Convert the given character to upper-case Unicode. */
/*******************************************************************/
UNICODE̲CHAR UnicodeToUpper(UNICODE̲CHAR value)
{
/* Actual implementation will vary to accommodate the target */
/* operating system API services. */
/* Just handle the ASCII range for the time being. */
return (value >= 'a' && value <= 'z') ?
value - ('a' - 'A') : value;
}
/*******************************************************************/
/* IsFileNameCharLegal() */
/* Determine if this is a legal file name id character. */
/*******************************************************************/
BOOLEAN IsFileNameCharLegal(UNICODE̲CHAR value)
{
/* Control characters are illegal. */
if (value <' ')
return FALSE;
/* Test for illegal ASCII characters. */
switch (value) {
case '\\':
case '/':
case ':':
case '*':
case '?':
case '\"':
case '<':
89
X 0611:2018
case '>':
case '|':
case ';':
case '^':
case ',':
case '&':
case '+':
case '=':
case '[':
case ']':
return FALSE;
default:
return TRUE;
}
}
/*******************************************************************/
/* IsVolumeLabelCharLegal() */
/* Determine if this is a legal volume label character. */
/*******************************************************************/
BOOLEAN IsVolumeLabelCharLegal(UNICODE̲CHAR value)
{
/* Control characters are illegal. */
if (value <' ')
return FALSE;
/* Test for illegal ASCII characters. */
switch (value) {
case '\\':
case '/':
case ':':
case '*':
case '?':
case '\"':
case '<':
case '>':
case '|':
case '.':
case ';':
case '^':
case ',':
case '&':
case '+':
case '=':
case '[':
case ']':
return FALSE;
default:
return TRUE;
}
}
/*******************************************************************/
/* NativeCharLength() */
90
X 0611:2018
/* Determines the corresponding native length (in bytes) of the */
/* given Unicode character. Returns zero if the character is */
/* undisplayable on the current system. */
/*******************************************************************/
INT16 NativeCharLength(UNICODE̲CHAR value)
{
/* Actual implementation will vary to accommodate the target */
/* operating system API services. */
/* This is an example of a conservative test. A better test */
/* will utilize the platformʼs language/codeset support to */
/* determine how wide this character is when converted to the */
/* active variable width character set. */
return 1;
}
/*******************************************************************/
/* IsDeviceName() */
/* Determine if the given Unicode string corresponds to a DOS */
/* device name (e.g. "LPT1", "COM4", etc.). Since the set of */
/* valid device names with vary from system to system, and */
/* a means for determining them might not be readily available, */
/* this functionality is only suggested as an optional */
/* implementation enhancement. */
/*******************************************************************/
BOOLEAN IsDeviceName(UNICODE̲CHAR* name, UINT16 nameLen)
{
/* Actual implementation will vary to accommodate the target */
/* operating system API services. */
/* Just return FALSE for the time being. */
return FALSE;
}
6.7.2
OS/2, Macintosh,Windows 95,Windows NT及びUNIXアルゴリズム(OS/2,Macintosh,Windows
95,Windows NT and UNIX Algorithm)
次に示すソースコードは,アルゴリズムを表現するものであって,標準のCでそのままコンパイルでき
ないことがある。
/*************************************************************************
* OSTA UDF compliant file name translation routine for OS/2.
* Windows 95, Windows NT, Macintosh and UNIX.
* copyright 1995 Micro Design International, Inc
* Written by Jason M.Rinn.
* Micro Design International gives permission for the free use of the
* following source code.
*/
/*************************************************************************
* To use these routines with different operating systems.
*
* OS/2
* Define OS2
* Define MAXLEN = 254
*
* Windows 95
91
X 0611:2018
* Define WIN̲95
* Define MAXLEN = 255
*
*Windows NT
* Define WIN̲NT
* Define MAXLEN = 255
*
*Macintosh:
* Define MAC.
* Define MAXLEN = 31.
*
* UNIX
* Define UNIX.
* Define MAXLEN as specified by unix version.
*/
#define ILLEGAL̲CHAR̲MARK 0x005F
#define CRC̲MARK 0x0023
#define EXT̲SIZE
5
#define TRUE
1
#define FALSE
0
#define PERIOD 0x002E
#define SPACE 0x0020
/**************************************************************************
* The following two typedef's are to remove compiler dependancies.
* byte needs to be unsigned 8-bit, and unicode̲t needs to
* be unsigned 16-bit.
*/
typedef unsigned int unicode̲t;
typedef unsigned char byte;
/*** PROTOTYPES ***/
int IsIllegal(unicode̲t ch);
unsigned short unicode̲cksum(register unsigned short *s, register int n);
/* Define a function or macros which determines if a Unicode character is
* printable under your implementation.
*/
int UnicodeIsPrint(unicode̲t);
/****************************************************************************
* Translates a long file name to one using a MAXLEN and an illegal
* char set in accord with the OSTA requirements. Assumes the name has
* already been translated to Unicode
*
* RETURN VALUE
*
* Number of unicode characters in translated name.
*/
int UDFTransName(
unicode̲t *newName, /* (Output)Translated name. Must be of length MAXLEN */
unicode̲t *udfName, /* (Input) Name from UDF volume. */
int udfLen, /* (Input) Length of UDF Name. */
{
int index, newIndex = 0, needsCRC = FALSE;
92
X 0611:2018
int extIndex, newExtIndex =0, hasExt = FALSE;
#ifdef (OS2 | WIN̲95 | WIN̲NT)
int trailIndex = 0;
#endif
unsigned short valueCRC;
unicode̲t current;
const char hexChar[] = "0123456789ABCDEF";
for (index = 0 ; index < udfLen ; index++)
{
current = udfName[index];
if (IsIllegal(current) || !UnicodeIsPrint(current))
{
needsCRC = TRUE;
/* Replace Illegal and non-displayable chars with underscore.*/
current = ILLEGAL̲CHAR̲MARK;
/* skip any other illegal or non-displayable characters. */
while(index+1 < udfLen && (IsIllegal(udfName[index+1])
|| !UnicodeIsPrint(udfName[index+1] )))
{
index++;
}
}
/*Record position of extension, if one is found. */
if (current == PERIOD && (udfLen - index -1) <= EXT̲SIZE)
{
if (udfLen == index +1)
{
/* A trailing period is NOT an extension. */
hasExt = FALSE;
}
else
{
hasExt = TRUE;
extIndex = index;
newExtIndex = newIndex;
}
}
#ifdef (OS2 | WIN̲95 | WIN̲NT)
/*Record position of last char which is NOT period or space. */
else if (current != PERIOD && current != SPACE)
{
trailIndex = newIndex;
}
#endif
if (newIndex < MAXLEN)
{
newName[newIndex++] = current;
}
else
{
needsCRC = TRUE;
93
X 0611:2018
}
}
#ifdef (OS2 | WIN̲95 | WIN̲NT)
/* For OS2, 95 & NT,truncate any trailing periods and\or spaces. */
if (trailIndex != newIndex -1)
{
newIndex = trailIndex +1;
needsCRC = TRUE;
hasExt = FALSE; /* Trailing period does not make an extension. */
}
#endif
if (needsCRC)
{
unicode̲t ext[EXT̲SIZE];
int localExtIndex = 0;
if (hasExt)
{
int maxFilenameLen;
/* Translate extension, and store it in ext. */
for(index = 0; index<EXT̲SIZE && extIndex + index +1 < udfLen;
index++ )
{
current = udfName[extIndex + index + 1];
if (IsIllegal(current) || !UnicodeIsPrint(current))
{
needsCRC = 1;
/* Replace Illegal and non-displayable chars
* with underscore.
*/
current = ILLEGAL̲CHAR̲MARK;
/* Skip any other illegal or non-displayable
* characters.
*/
while(index + 1 < EXT̲SIZE
&& (IsIllegal(udfName[extIndex + index + 2])
|| !isprint(udfName[extIndex + index + 2])))
{
index++;
}
}
ext[localExtIndex++] = current;
}
/* Truncate filename to leave room for extension and CRC. */
maxFilenameLen = ((MAXLEN - 5) - localExtIndex - 1);
if (newIndex > maxFilenameLen)
{
newIndex = maxFilenameLen;
}
else
{
newIndex = newExtIndex;
}
94
X 0611:2018
}
else if (newIndex > MAXLEN - 5)
{
/*If no extension, make sure to leave room for CRC. */
newIndex = MAXLEN - 5;
}
newName[newIndex++] = CRC̲MARK; /* Add mark for CRC. */
/*Calculate CRC from original filename from FileIdentifier. */
valueCRC = unicode̲cksum(udfName, udfLen);
/* Convert 16-bits of CRC to hex characters. */
newName[newIndex++] = hexChar[(valueCRC & 0xf000) >> 12];
newName[newIndex++] = hexChar[(valueCRC & 0x0f00) >> 8];
newName[newIndex++] = hexChar[(valueCRC & 0x00f0) >> 4];
newName[newIndex++] = hexChar[(valueCRC & 0x000f)];
/* Place a translated extension at end, if found. */
if (hasExt)
{
newName[newIndex++] = PERIOD;
for (index = 0;index < localExtIndex ;index++ )
{
newName[newIndex++] = ext[index];
}
}
}
return(newIndex);
}
#ifdef (OS2 | WIN̲95 | WIN̲NT)
/**********************************************************************
* Decides if a Unicode character matches one of a list
* of ASCII characters.
* Used by OS2 version of IsIllegal for readability, since all of the
* illegal characters above 0x0020 are in the ASCII subset of Unicode.
* Works very similarly to the standard C function strchr().
*
* RETURN VALUE
*
* Non-zero if the Unicode character is in the given ASCII string.
* /
int UnicodeInString(
unsigned char *string, /* (Input) String to search through. */
unicode̲t ch) /* (input) Unicode char to search for. */
{
int found = FALSE;
while (*string != '\0' && found == FALSE)
{
/* These types should compare, since both are unsigned numbers. */
if (*string == ch)
{
found = TRUE;
}
string++;
}
return(found);
95
X 0611:2018
}
#endif /* OS2 */
/*************************************************************************
* Decides whether the given character is illegal for a given OS.
*
* RETURN VALUE
*
* Non-zero if char is illegal.
*/
int IsIllegal(unicode̲t ch)
{
#ifdef MAC
/* Only illegal character on the MAC is the colon. */
if (ch == 0x003A)
{
return(1);
}
else
{
return(0);
}
#elif defined UNIX
/* Illegal UNIX characters are NULL and slash. */
if (ch == 0x0000 || ch == 0x002F)
{
return(1);
}
else
{
return(0);
}
#elif defined (OS2 | WIN̲95 | WIN̲NT)
/* Illegal char's for OS/2 according to WARP toolkit. */
if (ch < 0x0020 || UnicodeInString("\\ /:*?\"<>|", ch))
{
return(1);
}
else
{
return(0);
}
#endif
}
6.8
拡張属性チェックサムアルゴリズム(Extended Attribute Checksum Algorithm)
次に示すソースコードは,アルゴリズムを表現するものであって,標準のCでそのままコンパイルでき
ないことがある。
/*
* Calculates a 16-bit checksum of the Implementation Use
* Extended Attribute header or Application Use Extended Attribute
* header. The fields AttributeType through ImplementationIdentifier
96
X 0611:2018
* (or ApplicationIdentifier) inclusively represent the
* data covered by the checksum (48 bytes).
*
*/
Uint16 ComputeEAChecksum(byte *data)
{
Uint16 checksum = 0;
Uint count;
for(count =0; count < 48; count++)
{
checksum += *data++;
}
return(checksum);
}
6.9
DVD-ROMに対する要件(Requirements for DVD-ROM)
この細分箇条は,ユニバーサルディスクフォーマット(UDF)のDVD-ROMディスクに対する要件及び
制約を定義する。
a) DVD-ROMディスクは,UDFファイルシステムで作成しなければならない。
b) DVD-ROMディスクは,単一ボリューム及び単一区画から成らなければならない。
特記事項 ディスクは,JIS X 0606ファイルシステムも含んでよい。ディスクがUDFファイルシス
テム及びJIS X 0606ファイルシステムの両方を含むとき,UDFブリッジディスクとしな
ければならない。UDFブリッジディスクは,JIS X 0606だけを利用可能なコンピュータ
で直接DVD-ROM媒体を再生することを可能にする。UDF処理システムの提供によっ
て,JIS X 0606の必要性はなくなり,将来のディスクはUDFだけを含むことが望ましい。
6.9.1
DVD-Videoに関するUDFの制約(Constraints imposed by UDF for DVD-Video)
この細分箇条は,専用DVDプレーヤのためのUDFで初期化したDVD-Videoディスクに対する制限及
び要件を記載する。DVD-Videoは,家庭電気製品市場向けにUDFを使用するDVD-ROMの一つの専用ア
プリケーションである。DVDプレーヤ中では,処理機能が限られているのでDVDプレーヤがUDF定義
の全ての機能を利用可能にしなくてもよいように制限及び要件を作成した。
全てのDVD-Videoディスクは,JIS X 0607規格類(追補を含まない。)及びUDFの規定に従って,全て
の必要なデータを含むように作成しなければならない。これによって,DVD-Videoをコンピュータで再生
することが可能になる。そのデータの例は,日時及び許可条件のビット並びに使用可能空間マップ(使用
可能な空間がないことを示す。)を含む。DVDプレーヤの処理システムは,これらの欄を無視してもよい
が,コンピュータのUDF処理システムがこれらを無視することはしない。娯楽用の内容及びコンピュータ
用の内容が,同一のディスクに共存できる。
特記事項 この規格に従って作成されたDVD-VideoディスクはDVD-Videoプレーヤと互換性がない。
DVD-Videoプレーヤは,UDF 1.02フォーマットの媒体であることを前提にしている。
符号量の削減及び効率の向上を意図して,全ての除算は整数で記載し,全ての除数は2のn乗でなけれ
ばならない。その結果,全ての除算は論理シフト演算で行ってよい。
a) DVDプレーヤは,UDFだけを利用可能とし,JIS X 0606は利用可能としてはならない。
b) 作成システムは,各ファイルの長さを(230−論理ブロック長)バイト以下としなければならない。
c) 各ファイルのデータは,単一エクステントに記録する。各ファイルエントリは,ICB方策種別4を用
97
X 0611:2018
いて記録しなければならない。
d) ファイル名及びディレクトリ名は,OSTA圧縮Unicode形式で,1文字当たり8ビットに圧縮しなけれ
ばならない。
e) DVDプレーヤは,どんなファイルに対するシンボリックリンクにも従ってはならない。
f)
DVD-Videoファイルは,ルートディレクトリの下の“VIDEO̲TS”という名前のサブディレクトリに
記録しなければならない。ディレクトリ名は,文献“DVD Specifications for Read-Only Disc”において
標準化されている。
特記事項 DVD Specification for Read-Only Discは,DVDコンソーシアムが開発した規定であり,
媒体上に記録するDVD-Videoファイルの名前及びDVD-Videoディレクトリの名前を記
載している。さらに,DVD-Videoファイルの内容についても記載している。
g) VIDEO̲TSサブディレクトリにおいて“VIDEO̲TS.IFO”と名付けられたファイルを最初に読み出さ
なければならない。
これら全ての制約は,DVDプレーヤがアクセスする必要があるディレクトリ及びファイルだけに適用す
る。媒体中にはDVDプレーヤ向けではなく,これらの制約に適合しない,他のファイル及びディレクト
リが存在してもよい。これらの他のファイル及びディレクトリを,DVDプレーヤは無視する。これによっ
て,同一ディスク上に娯楽用の内容及びコンピュータ用の内容の両方をもつことができる。
6.9.2
UDFディスクの読出し法(How to read a UDF DVD-Video disc)
この細分箇条は,DVDプレーヤが,UDFで初期化したDVD-Videoディスクを読み出すために実行する
基本的な手続を記載する。
6.9.2.1
手順1 ボリューム認識列(Volume Recognition Sequence)
論理セクタ16から開始しなければならないボリューム認識列中のJIS X 0607記述子を見つける。
6.9.2.2
手順2 開始ボリューム記述子ポインタ(Anchor Volume Descriptor Pointer)
開始位置の開始ボリューム記述子ポインタを見つけなければならない。二つの開始位置は,論理セクタ
256及び論理セクタnに記録されなければならない。ここで,nはディスクの論理セクタに番号付けした最
大数とする。
DVDプレーヤは,論理セクタ256だけを見ればよい。論理セクタnのコピーは冗長であり,欠陥対応の
ためにだけ必要とする。開始ボリューム記述子ポインタは,次の3項目を含む。
a) ディスクの識別及び保全検証のために使用してもよい静的構造
b) 主ボリューム記述子列の位置(絶対論理セクタ番号)
c) 主ボリューム記述子列の長さ(バイト)
開始ボリューム記述子ポインタのバイト0〜3及び5にあるデータは,必要に応じて初期化検証に使用し
てもよい。バイト4のチェックサム及びバイト8〜11のCRCの検証は,実行すべき適切な追加検証である。
MVDS̲Location及びMVDS̲Lengthを,この構造から読み出す。
6.9.2.3
手順3 ボリューム記述子列(Volume Descriptor Sequence)
次の論理セクタを読み出す。
MVDS̲Location 〜 MVDS̲Location +(MVDS̲Length−1)/セクタ長
論理セクタ長は,DVD媒体では2048バイトでなければならない。この列が読み出せない場合,予備ボ
リューム記述子列を読み出すことが望ましい。
区画記述子は,値5のタグ識別子をもつ記述子でなければならない。区画番号及び論理セクタ番号によ
る区画位置が記録されなければならない。
98
X 0611:2018
この構造から,Partition̲Location及びPartition̲Lengthを得る。
論理ボリューム記述子は,値6のタグ識別子をもつ記述子でなければならない。ファイル集合記述子の
位置及び長さが論理ブロック番号で記録されなければならない。
この構造から,FSD̲Location及びFSD̲Lengthを得る。
6.9.2.4
手順4 ファイル集合記述子列(File Set Descriptor)
ファイル集合記述子は,次に示す論理セクタ番号の論理セクタに存在する。
Partition̲Location+FSD̲Location 〜
Partition̲Location+FSD̲Location +(FSD̲Length−1)/ブロック長
RootDir̲Location及びRootDir̲Lengthを,論理ブロック番号によってファイル集合記述子から読み出さ
なければならない。
6.9.2.5
手順5 ルートディレクトリのファイルエントリ(Root Directory File Entry)
RootDir̲Location及びRootDir̲Lengthは,ファイルエントリの位置を定義する。このファイルエントリ
は,ルートディレクトリのデータ空間及び許可条件を記載する。
ルートディレクトリの位置及び長さを得る。
6.9.2.6
手順6 ルートディレクトリ(Root Directory)
“VIDEO̲TS”サブディレクトリを見つけるために,ルートディレクトリエクステント中のデータを解
釈する。
VIDEO̲TSファイル識別子記述子を見つける。その名前は,8ビットの圧縮UDFフォーマットとしなけ
ればならない。VIDEO̲TSが,ディレクトリであることを検証する。
ファイル識別子記述子を読み出し,VIDEO̲TSディレクトリを記載するファイルエントリの位置及び長
さを得る。
6.9.2.7
手順7 VIDEO̲TSのファイルエントリ(File Entry of VIDEO̲TS)
前述の段階で見つけたファイルエントリは,VIDEO̲TSディレクトリのデータ空間及び許可条件を含む。
VIDEO̲TSディレクトリの位置及び長さを得る。
6.9.2.8
手順8 VIDEO̲TSディレクトリ(VIDEO̲TS Directory)
前述の段階で見つけたエクステントは,ファイル識別子記述子の集合を含む。このパスでは,エントリ
がファイルをポイントしており,かつ,VIDEO̲TS.IFOという名前をもつことを検証する。
6.9.2.9
手順9 VIDEO̲TS.IFOのファイルエントリ(File Entry of VIDEO̲TS.IFO)
前述の段階で見つけたファイルエントリは,VIDEO̲TS.IFOファイルのデータ空間及び許可条件を含む。
VIDEO̲TS.IFOファイルの位置及び長さを得る。
必要ならば,他のファイルは,VIDEO̲TS.IFOファイルと同じ方法で見つけることができる。
6.9.3
DVD関連文献の入手(Obtaining DVD Document)
文献“DVD Specifications for Read-Only Disc”及び他のDVD関連資料のコピーを入手するには,次に連
絡されたい。
DVD Format/Logo Licensing Corporation
Daimon Urbanist Bldg. 6F,
2-3-6 Shibadaimon, Minato-ku,
Tokyo, 105-0012 JAPAN
TEL: 03-5777-2883
FAX: 03-5777-2884
99
X 0611:2018
6.10 CD媒体に関する勧告
CD媒体(CD-R及びCD-RW)は,その特徴によって,特別な配慮を必要とする。CDは元々,再生専用
アプリケーションのために設計されており,そのことが書込み方法に影響する。次の指針は,交換を確実
に行うために作られた。
各ファイル及びディレクトリは,1個の直接ICBで記載しなければならない。そのICBは,書込み中の
データ不足を見込んで,ファイルデータの後で書き込まれることが望ましいが,これは,ファイルデータ
の論理ギャップを引き起こす。ICBは,後で書き込むことができるが,このことは,ファイルデータの全
てのエクステントを正しく識別する。ICBは,データトラック,ファイルシステムトラック(もし存在す
れば),又は両方に書き込まれなければならない。
6.10.1 CD-R媒体でのUDFの使用
JIS X 0607規格類では,セクタ256及び,N又は(N−256)のいずれかで(この場合,nは,媒体に最
後に記録された物理番地とする。),開始ボリューム記述子ポインタ(AVDP)を必要とする。UDFでは,
各セションが閉じると(2.2.3),セクタ256及びセクタ(N−256)の両方でAVDPを記録することを要求
する。ファイルシステムは,閉じる前は中間状態にあり,まだ交換可能状態であるが,JIS X 0607規格類
と厳密に互換性がなくてもよい。中間状態では,ただ一つのAVDPが存在する。セクタ256に存在するこ
とが望ましいが,トラック予約のためにそれが不可能な場合は,セクタ512に存在しなければならない。
処理システムでは,ファイルシステム管理構造を仮想空間に,ファイルデータは,現実の空間に置くこ
とが望ましい。読取装置の処理システムは,VAT全体をキャッシュメモリに入れてもよい。VATの大きさ
は,UDFに基づくソフトで検討することが望ましい。コンピュータを基本にした処理システムでは,最低
64Kバイトの大きさのVATを扱う。専用プレーヤの処理システムでは,より小さいサイズだけを扱っても
よい。
VATは,未完成媒体の場合にはREAD TRACK INFORMATIONを使用するか,又は完成媒体の場合には
READ TOC若しくはREAD CD RECORDED CAPACITYを使用して,位置を決めてもよい。X3T10-1048D
(SCSI-3 マルチメディアコマンド)を参照する。
6.10.1.1 要件
a) 書込みでは,モード1又はモード2フォーム1のセクタを使用しなければならない。1枚のディスク
で,モード1又はモード2フォーム1のいずれかを使用しなければならない。1枚のディスクでモー
ド1とモード2フォーム1とを混合して使用することはできない。
特記事項 JIS X 6282の箇条10(複セションディスク及び複合形ディスク)によると,ディスクの
データセションの全ては,同じ種別(モード1又はモード2フォーム1)でなければな
らない。
b) モード2フォーム1を使用する場合,利用者データファイル及びUDF構造で使用される全てのセクタ
のサブヘッダバイトは,次の値をもたなければならない。
ファイル数 = 0
チャネル数 = 0
サブモード = 08h
コード化情報 = 0
c) 中間状態は,ただ一つのADVPが記録されるCD-R媒体で可能とする。この一つのAVDPは,セクタ
256又はセクタ512にあるものとし,次の複セション規則に従う。
d) 逐次ファイルシステムの書込みは,可変パケットライトで行わなければならない。これは,更新の大

100
X 0611:2018
小によらず,最大の空間効率を可能にする。現在の様式では,固定パケットが要求する第2方式アド
レッシングが利用可能でないので,可変パケットライトは,CD-ROMドライブとより互換性がある。
e) 論理ボリューム保全記述子は,記録するものとし,ボリュームは開放と表示しなければならない。論
理ボリュームの保全性は,最後に記録された物理番地にVAT ICBを見つけることで証明できる。もし,
VAT ICBが存在すれば,ボリュームはクリーンであり,もし,存在していなければ,ダーティである。
f)
区画ヘッダ記述子は,記録される場合,未割付け空間表,未割付け空間ビットマップ,区画保全表,
空き空間表,及び空き空間ビットマップを指定してはならない。ドライブは,空き空間を直接報告す
ることができ,分離記述子の必要性を取り除く。
g) 各表面には,0個又は1個の読出し専用区画,0個又は1個の追記区画,及び0個又は1個の仮想区画
が含まれなければならない。CD媒体は,1個の追記区画,及び1個の仮想区画を含むことが望ましい。
6.10.1.2 UDF“ブリッジ”フォーマット
JIS X 0606では,セクタ16に基本ボリューム記述子(PVD)を要求する。JIS X 0606ファイルシステム
が要求すれば,JIS X 0607規格類構造でアクセスされる,同一ファイルへのアクセスを含んでもよい。ま
た,異なるファイル集合へのアクセス,又は両方の組合せを含んでもよい。
初期の処理システムでは,JIS X 0606構造を記録するが,UDFの処理システムが利用可能になると,JIS
X 0606構造の必要性は低下することが確実となる。
JIS X 0606ブリッジディスクにモード2フォーム1セクタが含まれる場合,JIS X 0606のCD-ROM XA
拡張を使用しなければならない。
6.10.1.3 セションデータの末端(表46参照)
CD-ROMドライブが読とりを行えるように,セションは閉じられる。ディスク上の最後の完全セション
は完全にJIS X 0607規格類に従い,2個のAVDPを記録しなければならない。これは,次のセションデー
タ表の末端に従って,データを書き込むことで完成しなければならない。次の例に示されてはいないが,
データは複数のパケットに書き込んでもよい。
表46−セションデータの末端
数
記述
1
開始ボリューム記述子ポインタ
255
処理システム仕様。利用者データ,ファイルシステム構造・リンク領域を含んでもよい。
1
VAT ICB
処理システム仕様データは,VAT及び,VAT ICBの反復コピーを含んでもよい。最後のセクタの位置を
正確に報告しないドライブとの互換性が高まる。処理システムでは,セションデータの最後尾を記録する
のに十分な空間が利用できることを確実にしなければならない。セションデータの最後尾を記録すること
によって,ボリュームはJIS X 0607規格類に適合する。
6.10.2 CD-RW媒体でのUDFの使用
CD-RW媒体は,任意の位置の読出し及びブロックの書込みができる。つまり,個々のセクタを読みと
るとき,複数セクタを含むブロックで書込みが行われなければならない。CD-RWシステムでは,不良領
域の予備は用意しない。書込み規則及び予備機構は定義されている。
6.10.2.1 要件
a) この規格のこの細分箇条に適合する書込みを行う場合,固定長パケットを使用しなければならない。
b) 書込みは,モード1又はモード2,フォーム1セクタを使用して行わなければならない。1枚のディス
101
X 0611:2018
クではモード1又はモード2フォーム1を使用しなければならない。
特記事項 JIS X 6282の箇条10によると,ディスクのデータセションの全ては,同じ種別(モード
1又はモード2のフォーム1)でなければならない。
c) モード2フォーム1を使用する場合,利用者データファイル及びUDF構造で使用する全てのセクタの
サブヘッダバイトは次の値をもたなければならない。
ファイル数 = 0
チャネル数 = 0
サブモード = 08h
コード化情報 = 0
d) ホストでは,2Kセクタの書込みを明確に行えるように,read,modify及びwriteを実行しなければな
らない。
e) パケット長は,ディスクの初期化時に設定しなければならない。パケット長は,32セクタ(64 KB)
でなければならない。
f)
ホストでは,割付け禁止空間リストを使用して,ディスクに欠陥リストを保守しなければならない
(3.3.7.2参照)。
g) 予備は,予備区画及び予備表を介してホストが管理しなければならない。
h) ディスクは,使用前に初期化しなければならない。
6.10.2.2 初期化
初期化は,リードイン,利用者データ領域及びリードアウトの書込みから成らならなければならない。
これらの領域は,任意の順序で書込みをしてもよい。この物理的フォーマットには,検証パスが続いても
よい。検証パスの間に見つかる欠陥は,割付け禁止空間リストに列挙しなければならない(3.3.7.2参照)。
最後にファイルシステムルート構造が記録されなければならない。これらの強制的なファイルシステム及
びルート構造にはボリューム認識列,開始ボリューム記述子ポインタ,ボリューム記述子列,ファイル集
合記述子,及びルートディレクトリが含まれる。
開始ボリューム記述子ポインタは,セクタ256及びN−256に記録しなければならないが,この場合,N
は,番地付け可能な最後のセクタの物理番地とする。
予備の割付けは,初期化プロセスの間に行わなければならない。予備割付けの長さは0でもよい。
未割当て空間記述子を,欠陥領域及びセクタ予備領域に割り付けられた空間を反映するように,記録し
なければならない。
フォーマットは,媒体で利用可能な全ての空間を含んでもよい。しかし,利用者が要求した場合,初期
化時間を節約するため,部分集合を初期化してもよい。その少量のフォーマットを,後に,完全に利用可
能な空間に“成長”させてもよい。
6.10.2.3 成長するフォーマット
媒体を部分的に初期化し,後に大きく成長させてもよい。この動作は次の要素から成る。
a) 最後のセションのリードインを任意機能として消去する。
b) 最後のセションのリードアウトを任意機能として消去する。
c) パケットの書込みを,事前に記録した最後のパケットのすぐ後から始める。
d) 予備表更新は,新しい空間領域を反映する。
e) 区画マップを適宜調節する。
f)
新しく利用可能な領域を示すために,使用可能空間マップを更新する。
102
X 0611:2018
g) 最後のAVDPを新しい(N−256)に移動する。
h) リードイン(新しいトラックサイズを反映する。)の書込みをする。
i)
リードアウトの書込みをする。
6.10.2.4 ホストベースの欠陥管理
ホストでは欠陥管理動作を行わなければならない。CDフォーマットは欠陥管理を含めないで定義され
たので,現存の技術及びコンポーネントと互換性をもたせるには,ホストで欠陥を管理しなければならな
い。欠陥管理には2段階がある。すなわち,初期化時に不良セクタをマーク付けすること,及びオンライ
ンで予備を割り当てることである。ホストは現在の媒体に表を保持しなければならない。
6.10.2.5 読み出し変更し書き込む動作
CD-RW媒体は大きな書込み可能単位を必要とする。これは,各装置が,14 KBオーバヘッドを受けるた
めである。ファイルシステムは2 KBの書込み可能単位を必要とする。書込みサイズの差は,ホストの読
み出し変更し書き込む動作で処理される。パケット全体が読みとられ,適切な部分が変更され,パケット
全体がCDに書き込まれる。
パケットは,32セクタ境界に整列しなくてもよい。
6.10.2.6 適合のレベル
6.10.2.6.1 レベル1
ディスクは,厳密に1個のリードイン,プログラム領域,及びリードアウトで初期化しなければならな
い。プログラム領域は,厳密に1個のトラックを含まなければならない。
6.10.2.6.2 レベル2
最後のセションはUDFファイルシステムを含まなければならない。その前のセションの全ては,一つの
読出し専用区画内に含まれなければならない。
6.10.2.6.3 レベル3
いかなる制約も適用してはならない。
6.10.3 複セション及び混合モード
ボリューム認識列及び開始ボリューム記述子ポインタの位置は,ディスクの始まりに関連する位置であ
ると,JIS X 0607規格類で規定されている。ディスクの始まりは,VRS及びAVDPを見つける目的で,基
本番地Sから決定しなければならない。
“S”は,ボリュームの最後の既存のセション内に記録された,最初のデータトラックの,最初のデー
タセクタの物理番地である。“S”は,複セションのJIS X 0606の記録で現在使われているものと同じ値と
する。このセションの最初のトラックはデータトラックでなければならない。
“N”はディスクに記録された最後のデータセクタの物理セクタ数である。任意書込みモードを使用す
る場合,媒体は0又は1のオーディオセションでフォーマットし,その後に,1個のトラックを含む,書
込み可能なデータセションを厳密に1個続けてもよい。他のセションの構成も可能だが,ここでは記載し
ていない。1回に1個だけ書込み可能区画又はセションがあるものとし,このセションはディスクでは最
後のセションでなければならない。
6.10.3.1 ボリューム認識列
複セションディスクを扱うために,次の記載をUDFに加える(JIS X 0607規格類の第2部参照)。
a) UDFブリッジフォーマットのボリューム認識領域は,セクタS+16で始まるボリューム空間の一部で
なければならない。
b) ボリューム認識空間の,始まりのトラックと終わりのトラックとは同じでなければならない。この定
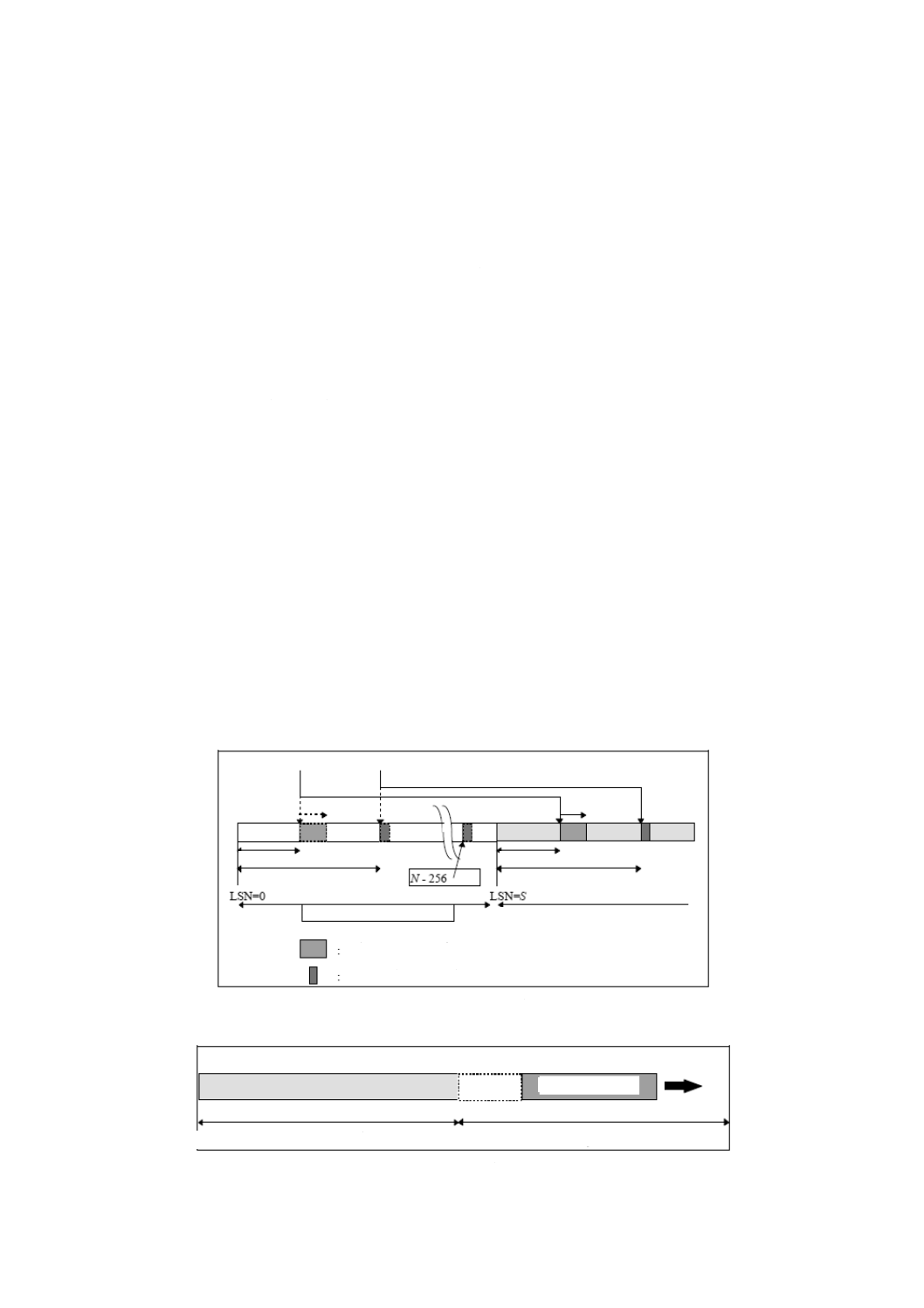
103
X 0611:2018
義の結果,ボリューム認識領域は常にディスクの最後のセションに存在する。
c) ランダムアクセスモードで記録するとき,重複ボリューム認識列は,セクタN−16から記録を始める
ことが望ましい。
6.10.3.2 開始ボリューム記述子ポインタ
開始ボリューム記述子ポインタ(AVDP)は,S+256及びN−256の論理セクタ数に記録しなければな
らない。セクタN−256のAVDPはセションを閉じる前に記録しなければならない。セションを開放して
いる間は,記録しなくてもよい。
6.10.3.3 UDFブリッジフォーマット
UDFブリッジフォーマットによって,UDFは,別のファイルシステムを含んでいるディスクに加えるこ
とができる。UDFブリッジディスクは,最後のセションにUDFファイルシステムを含まなければならな
い。最後のセションは,前述の“複セション及び混合モード”に記載された規則に従わなければならない。
このディスクは,JIS X 0606,CDオーディオ,若しくはベンダ独自のファイルシステム,又はそれらのフ
ァイルシステムの組合せに基づくセションを含んでもよい。UDFブリッジフォーマットによって,CD強
化ディスクが作成できる。
新しい主ボリューム記述子列及び予備ボリューム記述子列は,各追加セションに存在してもよく,前の
VDSと異なってもよい。
CDの最後のセションが,有効なUDFファイルシステムを含まない場合,そのディスクはUDFディス
クではない。最後のセションの中のUDF構造,並びにそのUDF構造を通じて参照される全てのUDF構造
及びデータだけが有効とする。
UDFセションは,他のセションのデータ若しくはメタデータを示すポインタ,UDFセション内だけにあ
るデータ若しくはメタデータを示すポインタ,又は両方のセションを組み合わせた場合のデータ若しくは
メタデータを示すポインタを,含んでいてもよい。UDFブリッジディスクの幾つかの例を図2〜図5に示
す。
図2−複セションUDFディスク
図3−CD強化ディスク
LSN=16+xへのアクセス
LSN=256へのアクセス
16セクタ
16セクタ
256セクタ
256セクタ
第1セション
最終セションで最初に記録されたトラック
ボリューム認識領域
開始点(Anchor point)
第1セション
第2セション
UDFセション
UDFに使用されている領域
従来のCDプレーヤにかかる演奏可能な領域
104
X 0611:2018
図4−JIS X 0606のUDFへの変換
図5−異種フォーマットのUDFへの変換
6.11 Real-Timeファイル(Real-Time Files)
Real-Timeファイルは,例えば,オーディオ・ビデオのデータを書き込むとき又は読み出すときに,最低
限のデータ転送レートの保証が必要なファイルである。これらのファイルは,特別な読出しコマンドと書
込みコマンドとを必要とする。例えば,CD及びDVDでは,これらの特別なコマンドは,Mount Fuji 4
specificationで見つけることができる。
Real-Timeファイルは,ファイルのICBタグのファイル種別欄のファイル種別249によって識別される。
6.12 DVDの交換のための要件
この規定は,コンピュータと家庭電気製品のユーザとの情報交換のために,DVD-RAMディスク(6.12.1
参照),DVD-RWディスク(6.12.2参照),DVD-Rディスク(6.12.3参照)を含むがそれに限らない,書込
み可能なDVD媒体に対するボリューム構造及びファイル構造の要件と制約とを規定する。これらの要件
はコンピュータのシステム環境だけで使われ,家庭電気製品との交換性のないディスクには適応されない。
これらのDVDディスクに対する共通の要件を,次に示す。
a) ボリューム及びファイル構造はUDF 2.00に従わなければならない。
b) UDF読出し最小版数及びUDF書込み最小版数は2.00でなければならない。
c) 論理セクタ長及び論理ブロック長は2 048バイトでなければならない。
d) 一つの主ボリューム記述子列及び一つの予備ボリューム記述子列が記録されなければならない。
6.12.1 DVD-RAMに対する要件
DVD-RAMディスクに対する要件はUDF 2.00によっている。ボリューム構造及びファイル構造は非逐
次記録を用いる上書き可能形のディスクとして単純化されている。
ボリューム構造に関する要件を,次に示す。
a) DVD-RAMディスクの区画は,アクセス種別4で指定される上書き可能区画でなければならない。
b) 仮想区画マップ及び仮想割付け表は記録してはならない。
c) 予備区画マップ及び予備表は記録してはならない。
ファイル構造に関する要件を,次に示す。
d) 未割付け空間表又は未割付け空間ビットマップを用いて空間を示さなければならない。空き空間表及
第1セション
第3セション
UDFセション
JIS X 0606セション
JIS X 0606セション
JIS X 0606フォーマッタで書かれた領域
UDFで管理されている領域
第2セション
第1セション
第3セション
データセション
データセション
UDFで管理されている領域
他のファイルシステムで書かれた領域
第2セション
UDFセション
105
X 0611:2018
び空き空間ビットマップは,記録してはならない。
e) 割付け禁止空間ストリームは,記録してはならない。
6.12.2 DVD-RWに対する要件
リストリクテッドオーバライトモードで記録されたDVD-RWディスクに対する要件は,UDF 2.00によ
っている。ボリューム構造及びファイル構造は,非逐次記録を用いる書換形のディスクとして単純化され
ている。
ボリューム構造に関する要件を,次に示す。
a) ディスクの各面は,一つの予備区画をもつ一つのボリュームで構成されなければならない。
b) 予備区画表及び予備表が記録されなければならない。
c) パケット長は16セクタ(32 KB)でなければならず,パケットの最初のセクタ番号は16の倍数でな
ければならない。
d) 仮想区画マップ及び仮想割付け表は,記録してはならない。
ファイル構造に関する要件を,次に示す。
e) 未割付け空間ビットマップを用いて空間を示さなければならない。未割付け空間表,空き空間表及び
空き空間ビットマップは記録してはならない。
f)
割付け禁止空間ストリームが記録されなければならない。
g) ICB方策種別4を用いなければならない。
h) ファイルエントリ又は拡張ファイルエントリの割付け記述子欄には,短割付け記述子又は埋込みデー
タが記録されなければならない。この欄には長割付け記述子を記録してはならない。
6.12.3 DVD-Rに対する要件
ディスクアトワンス記録モード及びインクリメンタル記録モードで記録されたDVD-Rディスクに対す
る要件は,UDF 2.00によっている。ボリューム構造及びファイル構造は逐次記録を用いる追記形のディス
クとして単純化されている。
ボリューム構造に関する要件を,次に示す。
a) パケット長は16セクタ(32 KB)でなければならず,パケットの最初のセクタ番号は16の倍数でな
ければならない。
b) 予備区画マップ及び予備表は記録してはならない。
c) インクリメンタル記録モードでは,論理ボリューム保全列には開いた保全記述子は一つだけしか記録
してはならない。
d) インクリメンタル記録モードでは,仮想区画マップが記録されなければならない。
ファイル構造に関する要件を,次に示す。
e) 未割付け空間表,未割付け空間ビットマップ,空き空間表及び空き空間ビットマップは記録してはな
らない。
f)
ファイル集合記述子は一つだけしか記録してはならない。
g) 割付け禁止空間ストリームは記録してはならない。
h) インクリメンタル記録モードでは,仮想割付け表及びVAT ICBが記録されなければならない。
i)
インクリメンタル記録モードでは,ICB方策種別4を用いなければならない。
j)
インクリメンタル記録モードでは,仮想割付け表のVATエントリは,次のように割り当てられなけれ
ばならない。
1) 仮想アドレス0は,ファイル集合記述子のために使わなければならない。
106
X 0611:2018
2) 仮想アドレス1は,ルートディレクトリのICBのために使わなければならない。
3) 仮想アドレス2〜255の範囲は,DVD̲RTAVディレクトリのファイルエントリ及びDVD̲RTAVディ
レクトリ下のファイルのファイルエントリのために使わなければならない。
6.12.4 DVDディスク上のReal-Timeファイルに対する要件
DVD-Videoの記録規定は,DVD固有のサブディレクトリ“DVD̲RTAV”及びDVD̲RTAVディレクトリ
下のDVD固有の全てのファイルを規定している。DVD固有のファイルは,ファイル種別249のReal-Time
ファイルと関連する情報ファイルとから構成されている。
ボリューム構造に関する要件を,次に示す。
a) DVD-RAMディスク及びDVD-RWディスクでは,ディスクの各面は,一つの区画をもつ一つのボリ
ュームで構成されなければならない。DVD-Rディスクでは,ディスクの各面は,一つの追記形区画と
一つの仮想区画とをもつ一つのボリュームで構成されなければならない。
b) DVD-RWディスクでは,第1予備表及び第2予備表が記録されなければならない。
ファイル構造に関する要件を,次に示す。
c) DVD-RAMディスク及びDVD-RWディスクでは,未割付け空間ビットマップだけを用いなければな
らない。
d) DVD-RWディスクでは,未割付け空間ビットマップのエクステントは,空間ビットマップ記述子の長
さを使用可能な記録領域を示すためにもつことが望ましい。
e) 家庭電気製品のUDFフォーマットに従って記録する記録機は,ルートディレクトリにある特別なサブ
ディレクトリであるDVD̲RTAVに全てのデータを記録する。DVD̲RTAVディレクトリ及びその内容
は,DVD FLLCの発行するDVD仕様に定められた特別なファイルシステム制約をもつ。実装又はア
プリケーションは,上記DVD仕様によって定められた制約に従えない場合は,このディレクトリ内
のファイルを作成又は変更することは望ましくない。
6.13 UDF媒体フォーマット改正履歴
表47は,媒体に記録できるUDFフォーマットに影響するUDF定義の変更がいつ行われたかを示す。各
変更を示す文書変更通知(DCN)が表中に記入してある。変更UDF版数の欄には,変更を含むUDF規定
の版数を示す。UDF読出し最小版数及びUDF書込み最小版数の欄は,2.2.6.4で記載する版数アクセス制
御欄に関連する。

107
X 0611:2018
表47−改正履歴
記述
DCN
変更UDF
版数
UDF読出し
最小版数
UDF書込み
最小版数
割付けエクステント記述子
2-002
1.02
1.02
1.02
パス要素ファイル版数
2-003
1.02
1.02
1.02
親ディレクトリエントリ
2-004
1.02
1.02
1.02
装置仕様拡張属性
2-005
1.02
1.01
1.02
最大論理エクステント長
2-006
1.02
1.02
1.02
未割付け空間エントリ
2-008
1.02
1.01
1.02
DVD著作権管理情報
2-009
1.02
1.02
1.02
論理ボリューム識別子
2-010
1.02
1.01
1.02
割付け記述子のエクステント長欄
2-012
1.02
1.01
1.02
再配置禁止フラグ及び連続フラグ
2-013
1.02
1.01
1.02
DVD-ROMに対する要件の改版
2-014
1.02
1.02
1.02
版数アクセス制御
2-015
1.02
1.01
1.02
ボリューム集合識別子
2-017
1.02
1.01
1.02
拡張IDの一意属性
2-018
1.02
1.02
1.02
Dstringの明確化
2-010
1.02
1.01
1.02
アプリケーションFreeEASpace拡張属性
2-020
1.02
1.02
1.02
識別子添字の1.02への変更
2-021
1.02
1.02
1.02
識別子添字の1.50への変更
2-025
1.50
1.50
1.50
仮想区画マップエントリ
2-026
1.50
1.50
1.50
予備区画マップの割付け
2-027
1.50
1.50
1.50
仮想割付け表の追加
2-028
1.50
1.50
1.50
予備表の追加
2-029
1.50
1.50
1.50
割付け禁止空間リストの追加
2-030
1.50
1.02
1.50
CD媒体の推薦
2-031
1.50
1.50
1.50
1.50から2.00への変更
2-033
2.00
1.02
2.00
明確化されたドメインフラグ
2-034
2.00
1.02
2.00
Unicode2.0の利用
2-035
2.00
1.02
2.00
名前付きストリーム
2-036
2.00
2.00
2.00
名前付きストリームとしての一意ID表
2-037
2.00
1.02
2.00
名前付きストリームとしてのMacリソースフォーク
2-038
2.00
2.00
2.00
拡張属性ヘッダの位置欄
2-043
2.00
1.02
2.00
アクセス管理リスト
2-044
2.00
2.00
2.00
ブロック境界にまたがる記述子タグ
2-047
2.00
1.02
2.00
パワーこう(較)正ストリーム
2-048
2.00
1.02
2.00
要求されるCD-R複セションの提供
2-050
2.00
1.50
2.00
CD-Rの仮想区画用LVIDの欄の値
2-051
2.00
1.50
2.00
ボリュームバックアップ日時を示すシステムストリーム
2-055
2.00
2.00
2.00
新VAT
2-056
2.00
2.00
2.00
制約的仮想番地
2-057
2.00
1.50
2.00
ファイル日時拡張属性
2-058
2.00
1.02
2.00
OS/2 EAストリーム
2-061
2.00
2.00
2.00
割付け禁止空間ストリーム
2-062
2.00
1.02
2.00
108
X 0611:2018
附属書JA
(参考)
商標又は登録商標
この附属書(参考)は,この規格にある商標又は登録商標について記載するものであって,規定の一部
ではない。
この規格における商標又は登録商標は,次による。
a) Universal Disk Format及びUDFは,OSTAの米国における登録商標である。
b) OS/2及びOS/400は,IBM Corp.の米国及び/又はその他の国における商標又は登録商標である。
c) Macintoshは,Apple Inc.の米国及び/又はその他の国における商標又は登録商標である。
d) UNIXは,The Open Groupの米国及び/又はその他の国における商標又は登録商標である。
e) Windows及びMS-DOSは,Microsoft Corp.の米国及び/又はその他の国における商標又は登録商標で
ある。
このほかにも商標又は登録商標があり得ることに注意を喚起する。