X 0510:2018 (ISO/IEC 18004:2015)
(1)
目 次
ページ
序文 ··································································································································· 1
1 適用範囲························································································································· 1
2 適合条件························································································································· 1
3 引用規格························································································································· 2
4 用語及び定義··················································································································· 2
5 数学記号及び論理記号,略語並びに記法 ··············································································· 4
5.1 数学記号及び論理記号 ···································································································· 4
5.2 略語 ···························································································································· 4
5.3 記法 ···························································································································· 4
6 QRコードの仕様 ············································································································· 5
6.1 基本的特性 ··················································································································· 5
6.2 追加機能のまとめ ·········································································································· 6
6.3 シンボルの構造 ············································································································· 7
7 要求事項························································································································ 15
7.1 符号化手順の概要 ········································································································· 15
7.2 データ分析 ·················································································································· 18
7.3 モード ························································································································ 18
7.4 データの符号化 ············································································································ 20
7.5 誤り訂正 ····················································································································· 34
7.6 最終的なメッセージコード語列の構成 ·············································································· 44
7.7 マトリックスにおけるコード語の配置 ·············································································· 45
7.8 マスク処理 ·················································································································· 49
7.9 形式情報 ····················································································································· 54
7.10 マイクロQRコードの形式情報ビット配置 ······································································· 56
8 構造的連接····················································································································· 57
8.1 基本原理 ····················································································································· 57
8.2 シンボル列指示子 ········································································································· 58
8.3 パリティデータ ············································································································ 58
9 シンボルの印刷及びマーキング ·························································································· 59
9.1 寸法 ··························································································································· 59
9.2 文字による表記 ············································································································ 59
9.3 マーキングの手引 ········································································································· 59
10 シンボルの品質 ············································································································· 59
10.1 方法論 ······················································································································· 59
10.2 シンボルの品質パラメタ ······························································································· 60
X 0510:2018 (ISO/IEC 18004:2015) 目次
(2)
ページ
10.3 プロセス制御の測定 ····································································································· 60
11 復号手順の概要 ············································································································· 60
12 QRコードの参照復号アルゴリズム ··················································································· 61
13 自動識別能力 ················································································································ 67
14 送信データ ··················································································································· 67
14.1 一般原理 ···················································································································· 67
14.2 シンボル体系識別子 ····································································································· 68
14.3 拡張チャネル解釈 ········································································································ 68
14.4 FNC1 ························································································································ 69
附属書A(規定)誤り検出及び訂正の生成多項式 ······································································ 70
附属書B(規定)誤り訂正復号手順 ························································································ 74
附属書C(規定)形式情報 ···································································································· 75
附属書D(規定)型番情報 ···································································································· 77
附属書E(規定)位置合せパターンの位置 ··············································································· 79
附属書F(規定)シンボル体系識別子······················································································ 81
附属書G(規定)QRコードの印刷品質−シンボル体系に固有の特徴 ············································ 82
附属書H(参考)JIS X 0201の8ビットの情報交換用符号化文字集合及び
JIS X 0208のシフト符号化表現 ························································································ 88
附属書I(参考)シンボルの符号化例 ······················································································ 90
附属書J(参考)ビット列の長さの最適化 ················································································ 94
附属書K(参考)QRコードシンボルの印刷及び読取りのための利用者手引 ·································· 103
附属書L(参考)自動識別能力 ····························································································· 105
附属書M(参考)プロセス制御技術······················································································· 106
附属書N(参考)QRコードモデル1シンボルの特性 ································································ 108
参考文献 ··························································································································· 111
X 0510:2018 (ISO/IEC 18004:2015)
(3)
まえがき
この規格は,工業標準化法第14条によって準用する第12条第1項の規定に基づき,一般社団法人電子
情報技術産業協会(JEITA)及び一般財団法人日本規格協会(JSA)から,工業標準原案を具して日本工業
規格を改正すべきとの申出があり,日本工業標準調査会の審議を経て,経済産業大臣が改正した日本工業
規格である。
これによって,JIS X 0510:2004は改正され,この規格に置き換えられた。
この規格は,著作権法で保護対象となっている著作物である。
この規格の一部が,特許権,出願公開後の特許出願又は実用新案権に抵触する可能性があることに注意
を喚起する。経済産業大臣及び日本工業標準調査会は,このような特許権,出願公開後の特許出願及び実
用新案権に関わる確認について,責任はもたない。
日本工業規格 JIS
X 0510:2018
(ISO/IEC 18004:2015)
情報技術−自動認識及びデータ取得技術−
QRコード バーコードシンボル体系仕様
Information technology-Automatic identification and data capture
techniques-QR Code bar code symbology specification
序文
この規格は,2015年に第3版として発行されたISO/IEC 18004を基に,技術的内容及び構成を変更する
ことなく作成した日本工業規格である。
なお,この規格で点線の下線を施してある参考事項は,対応国際規格にはない事項である。
1
適用範囲
この規格は,QRコードとして知られるシンボル体系の要件を定める。QRコードのシンボル体系の特徴,
データキャラクタの符号化,シンボルの形式,寸法特性,誤り訂正規則,参照復号アルゴリズム,印刷品
質の要件及び利用者が選択可能なアプリケーションパラメタを規定する。
注記 この規格の対応国際規格及びその対応の程度を表す記号を,次に示す。
ISO/IEC 18004:2015,Information technology−Automatic identification and data capture techniques
−QR Code bar code symbology specification(IDT)
なお,対応の程度を表す記号“IDT”は,ISO/IEC Guide 21-1に基づき,“一致している”こ
とを示す。
2
適合条件
この規格に規定する機能を備える又は提供するQRコードシンボル(及びQRコードの生成又は読取り
用に設計された機器)は,この規格に適合しているものとみなす。
JIS X 0510:2004に規定されているQRコードシンボルのモデル1の要件に適合するシンボルは,この規
格に適合する機器で読めなくてもよい。
JIS X 0510:2004に規定されているQRコードシンボルのモデル2の要件に適合するシンボルは,この規
格に適合する機器で読める。
JIS X 0510:1999に適合する読取機器は,この規格に適合するシンボルの全てを読めなくてもよい。追加
の特徴を用いたQRコードシンボルは,そのような機器では読めないことがある。
JIS X 0510:1999に適合する印字機器は,この規格に適合するシンボルの全てを印字できなくてもよい。
追加の特徴を用いたQRコードシンボルは,そのような機器では印字できないことがある。
新規用途及びオープンシステム用途にあっては,QRコードモデル2シンボル及びマイクロQRコード
シンボルが推奨されるシンボル体系の形式であることに注意することが望ましい。
2
X 0510:2018 (ISO/IEC 18004:2015)
3
引用規格
次に掲げる規格は,この規格に引用されることによって,この規格の規定の一部を構成する。これらの
引用規格のうちで,西暦年を付記してあるものは,記載の年の版を適用し,その後の改正版(追補を含む。)
は適用しない。西暦年の付記がない引用規格は,その最新版(追補を含む。)を適用する。
JIS X 0201 7ビット及び8ビットの情報交換用符号化文字集合
JIS X 0500-1 自動認識及びデータ取得技術−用語−第1部:一般
注記 対応国際規格:ISO/IEC 19762-1,Information technology−Automatic identification and data
capture (AIDC) techniques−Harmonized vocabulary−Part 1: General terms relating to AIDC
JIS X 0500-2 自動認識及びデータ取得技術−用語−第2部:光学的読取媒体
注記 対応国際規格:ISO/IEC 19762-2,Information technology−Automatic identification and data
capture (AIDC) techniques−Harmonized vocabulary−Part 2: Optically readable media (ORM)
JIS X 0526 情報技術−自動認識及びデータ取得技術−バーコードシンボル印刷品質の評価仕様−二
次元シンボル
注記 対応国際規格:ISO/IEC 15415,Information technology−Automatic identification and data capture
techniques−Bar code symbol print quality test specification−Two-dimensional symbols
ISO/IEC 8859-1:1998,Information technology−8-bit single-byte coded graphic character sets−Part 1: Latin
alphabet No. 1
4
用語及び定義
この規格で用いる主な用語及び定義は,JIS X 0500-1及びJIS X 0500-2によるほか,次による。
4.1
文字数指示子(character count indicator)
モード内におけるデータ文字列の長さを定義するビット列。
4.2
マスク処理(data masking)
(対応国際規格では,この細分箇条において,4.10と重複する用語を定義しているため,削除した。)
4.3
マスクパターン参照子(mask pattern reference)
シンボルに適用するマスクパターンを示す,2ビット又は3ビットの識別子。
4.4
符号化領域(encoding region)
データ,誤り訂正コード語,型番情報及び形式情報の符号化に用いる機能パターン以外のシンボルの領
域。
4.5
排他的部分集合(exclusive subset)
あるモードの文字集合における部分文字集合であり,別のモードの文字集合と共用されない文字集合。
4.6
拡張パターン(extension pattern)
モデル1のQRコードシンボルの中でデータを符号化することのない機能パターン。
3
X 0510:2018 (ISO/IEC 18004:2015)
4.7
形式情報(format information)
シンボルに適用する誤り訂正レベル及び使用するマスク処理パターンに関する情報をもち,符号化領域
を復号するために必要な符号化パターン。
4.8
QRコード(QR Code)
QRコード1型〜40型として識別されるシンボル(マイクロQRコードとは明確に異なる。)。
4.9
機能パターン(function pattern)
復号を補助する,シンボル位置の検索又は特性の識別に必要な,シンボルのオーバヘッド部分(位置検
出パターン,タイミングパターン及び位置合せパターン)。
4.10
マスク処理(masking)
明及び暗のモジュール数を均一化し,画像の高速処理の障害となるパターン(例えば,位置検出パター
ンなど)の発生を抑えるために行う,符号化領域のビットパターンとマスク処理パターンとのXOR処理。
4.11
マイクロQRコード(micro QR Code)
マイクロQRコードM1型〜M4型として識別されるシンボル(QRコードとは明確に異なる。)。
4.12
モード(mode)
定義された文字集合をビット列として表示する方法。
4.13
モード指示子(mode indicator)
次のデータ列がどのモードで符号化されるかを示す4ビットの識別子。
4.14
埋め草ビット(padding bit)
データビット列の終端パターンの後にある最終コード語の空の位置を埋める目的で用いる,データを示
さないゼロのビット。
4.15
残余ビット(remainder bit)
符号化領域が8ビットのシンボル文字で割り切れない場合に,最終シンボル文字の後にあるシンボル符
号化領域の空の位置を埋める目的で用いる,データを示さない0(ゼロ)のビット。
4.16
残余コード語(remainder codeword)
データ及び誤り訂正コード語の総数が,基準のシンボル容量を満たさない場合に,シンボルを完成させ
るために,誤り訂正コード語の後にある空のコード語位置を埋めるために用いる埋め草コード語。
4.17
セグメント(segment)
一つのECIモード又は一つの符号化モードの規則に基づいて符号化されるデータ列。
4
X 0510:2018 (ISO/IEC 18004:2015)
4.18
分離パターン(separator)
位置検出パターンをシンボルの残りの部分から分離するために用いる,1モジュール幅の全てが明モジ
ュールの機能パターン。
4.19
シンボル番号(symbol number)
マイクロQRコードにおいて,形式情報の一部として用いられる,シンボルの型番及び誤り訂正レベル
を示す,3ビットの2進数で表される番号。
4.20
終端パターン(terminator)
データを示すビット列の終了に用いる,決められた数(シンボルによって決まる。)が全てゼロのビット
パターン。
4.21
タイミングパターン(timing pattern)
シンボル内のモジュール座標を決定する,明モジュールと暗モジュールとの交互列。
4.22
型番(version)
マイクロQRコードでは11×11モジュール(M1型)〜17×17(M4型)の間,又はQRコードでは21
×21モジュール(1型)〜177×177モジュール(40型)の間において番号で示されるシンボルの大きさ。
注記 例えば,型番4-L,M3-Qのように,シンボルに適用される誤り訂正レベルを型番指示子に添付
してもよい。
4.23
型番情報(version information)
あるQRコードにおけるシンボルの型番を表すデータ及びその誤り訂正ビットの情報をもつ符号化パタ
ーン。
5
数学記号及び論理記号,略語並びに記法
5.1
数学記号及び論理記号
公式及び数式で用いる記号は,それらを用いる公式又は数式の直後で定義する。
この規格では,次の演算記号を適用する。
div
整数の除算
mod 除算後の整数剰余
XOR 二つの入力が等しくない場合に,出力が“1”となる排他的論理和。記号⊕で表す。
5.2
略語
BCH ボーズ・チョードリ・オッケンジェム(Bose-Chaudhuri-Hocquenghem)
ECI
拡張チャネル解釈(Extended Channel Interpretation)
RS
リードソロモン(Reed-Solomon)
5.3
記法
5.3.1
モジュール位置
参照を容易にするため,モジュール位置は,シンボルの行及び列の座標(i,j)で定義する。ここに,i
5
X 0510:2018 (ISO/IEC 18004:2015)
及びjは,0から数え始め,モジュールの位置する行(上から下へ数える。)及び列(左から右へ数える。)
を示す。したがって,モジュール(0,0)は,シンボルの左上隅に位置する。
5.3.2
バイト表記
バイトの内容は,16進法で示す。
5.3.3
型番参照
QRコードのシンボルの型番は,V-Eの形式で参照される。ここに,Vは型番号(1〜40)を示し,Eは
誤り訂正レベル(L,M,Q及びH)を示す。
注記 L,M,Q及びHは,6.1 f)を参照。
マイクロQRコードのシンボルの型番は,MV-Eの形式で参照される。ここに,Mは,マイクロQRコ
ードの形式を示し,V(1〜4)及びE(L,M,及びQ)は,上記と同じ意味をもつ。
6
QRコードの仕様
6.1
基本的特性
QRコードは,次の特性をもつマトリックス式シンボル体系である。
a) 形式
1) 全ての機能及び最大のデータ容量をもつQRコード
2) QRコードと比較して,少ないオーバーヘッド,幾つかの機能制限及び少ないデータ容量をもつマ
イクロQRコード
b) 符号化文字集合
1) 数字データ(数字0〜9)
2) 英数字データ[数字0〜9,大文字A〜Z及び9個のその他の文字(スペース,$,%,*,+,−,.,
/及び:)]
3) 8ビットバイトデータ[ISO/IEC 8859-1の文字を既定値とするが,別に規定する場合はその既定の
文字(7.3.5参照)]
4) 漢字データ(JIS X 0208の附属書1のシフト符号化表現で規定された文字。QRコードで符号化す
る漢字データは,8140HEX〜9FFCHEX及びE040HEX〜EBBFHEXとしてあるので,13ビットに圧縮する
ことが可能となっている。)
c) データ表示 暗のモジュールは,2進法の1,明のモジュールは,2進法の0を意味する。明暗反転の
詳細は,6.2を参照。
d) シンボルサイズ(クワイエットゾーンを除く。)
1) マイクロQRコード:11×11モジュール〜17×17モジュール(M1型〜M4型,型番が一つ上がる
ごとに一辺につき2モジュールずつ増加)
2) QRコード:21×21モジュール〜177×177モジュール(1型〜40型,型番が一つ上がるごとに一辺
につき4モジュールずつ増加)
e) シンボル当たりの文字数
1) マイクロQRコードの最大シンボルサイズ,M4-L型は,次のとおり。
− 数字データ
35文字
− 英数字データ
21文字
− 8ビットバイトデータ
15文字
− 漢字データ
9文字
6
X 0510:2018 (ISO/IEC 18004:2015)
2) QRコードの最大シンボルサイズ,40-L型は,次のとおり。
− 数字データ
7 089文字
− 英数字データ
4 296文字
− 8ビットバイトデータ
2 953文字
− 漢字データ
1 817文字
f)
選択可能な誤り訂正 QRコードでは,次の4段階のRS誤り訂正(能力を昇順にL,M,Q及びHで
表す。)を用いて,シンボルの中のコード語を,それぞれ示してある割合まで復元することができる。
− L
7 %
− M 15 %
− Q
25 %
− H
30 %
マイクロQRコードでは,誤り訂正Hは利用できない。マイクロQRコードM1型では,RS誤り訂
正は,誤り検出だけに制限される。
g) コード形式 マトリックス
h) 方向の独立性 独立している(表裏反転及び明暗反転の両方)。
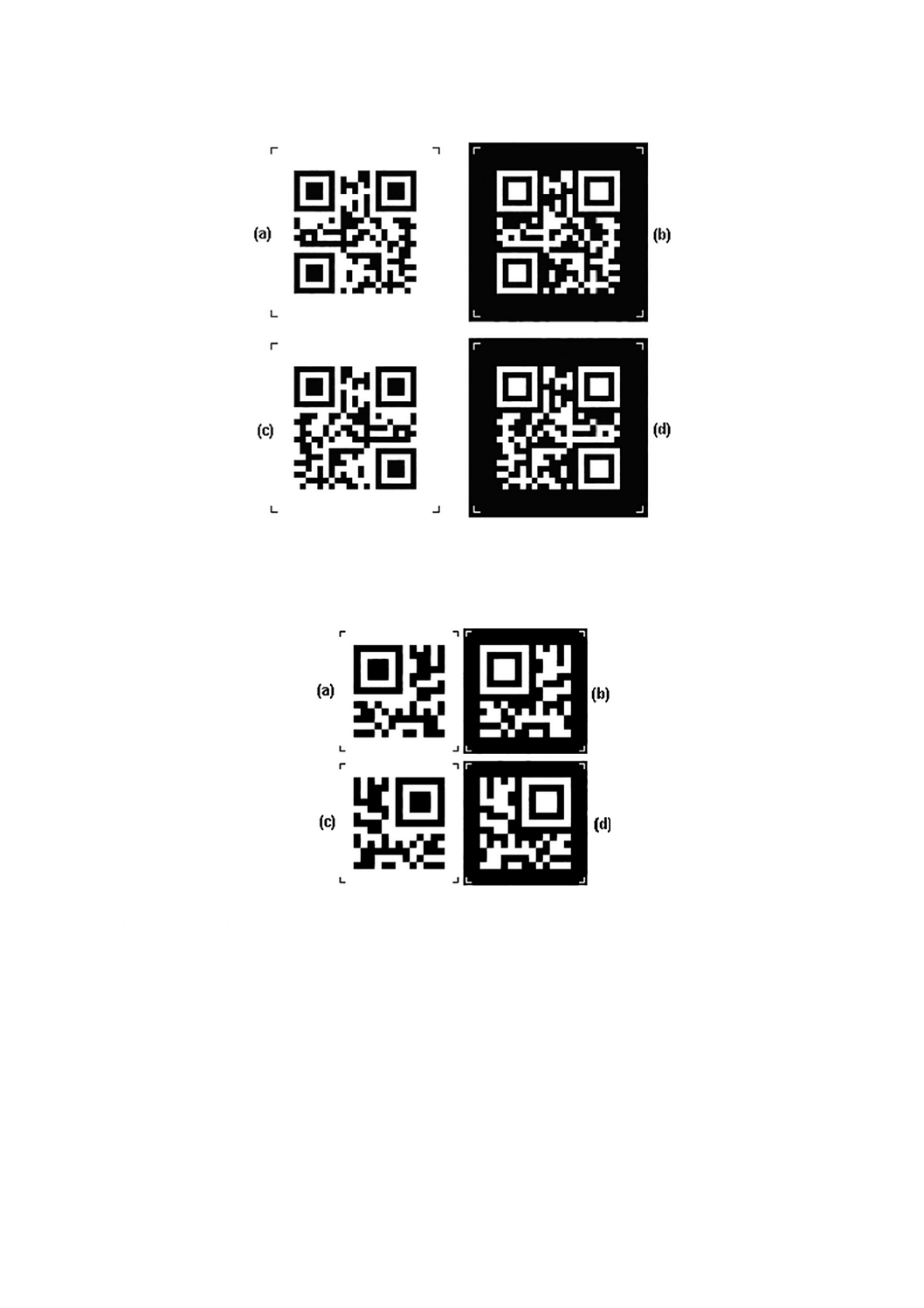
図1に明色の地に暗色の印字及び明暗反転(6.2参照)の1型QRコードシンボルを,非反転及び表裏反
転の両方で示す。
図2に明色の地に暗色の印字及び明暗反転(6.2参照)のM2型マイクロQRコードシンボルを,非反転
及び表裏反転の両方で示す。
6.2
追加機能のまとめ
QRコードで,次の追加機能の使用は,任意とする。
a) 構造的連接
この機能によって,データを,論理的に連続する最大16個までのQRコードシンボルで表現することが
できる。それらは,任意の順序で読み取っても元のデータを正しく再構成することができる。マイクロQR
コードでは,構造的連接を用いることはできない。
b) 拡張チャネル解釈
この機能によって,既定の符号化文字集合でない文字集合(例えば,アラビア文字,キリル文字,ギリ
シャ文字など)を用いて,別のデータ解釈(例えば,定義された圧縮方式を用いた圧縮済みデータ)を用
いたデータ,又は他の業界専用の要件を用いたデータの符号化を行うことができる。マイクロQRコード
では,既定の解釈でない拡張チャネル解釈を用いることはできない。
c) 明暗(白黒)反転
シンボルは,明の上に暗又は暗の上に明(図1及び図2参照)で印字した画像を読むことを意図してい
る。この規格において,明の背景に暗の画像を印字することが基本仕様のため,明暗(白黒)反転で生成
したシンボルの場合,暗モジュール又は明モジュールは,それぞれ明モジュール又は暗モジュールとして
解釈することが望ましい。
d) 表裏反転
この規格で規定するモジュールの配置は,シンボルの“標準”方向を表す。しかし,モジュールの配置
を横方向に置き換えたシンボルも,有効な復号が可能である。位置検出パターンを,シンボルの左上,右
上及び左下の隅に見て,表裏反転による影響は,モジュールの行及び列の位置を置き換えなければならな
い(図1及び図2参照)。
7
X 0510:2018 (ISO/IEC 18004:2015)
図1−文字列“QR Code Symbol”を符号化したQRコードの例
(a) 標準方向及び標準反射率配置,(b) 標準方向及び明暗反転配置,(c) 表裏反転及び標準反射率配置
及び(d) 表裏反転及び明暗反転配置
図2−文字列“01234567”を符号化したマイクロQRコードの例
(a) 標準方向及び標準反射率配置,(b) 標準方向及び明暗反転配置,(c) 表裏反転及び標準反射率配置
及び(d) 表裏反転及び明暗反転配置
注記 図1及び図2のコーナーマークは,クワイエットゾーンの範囲を示す。
6.3
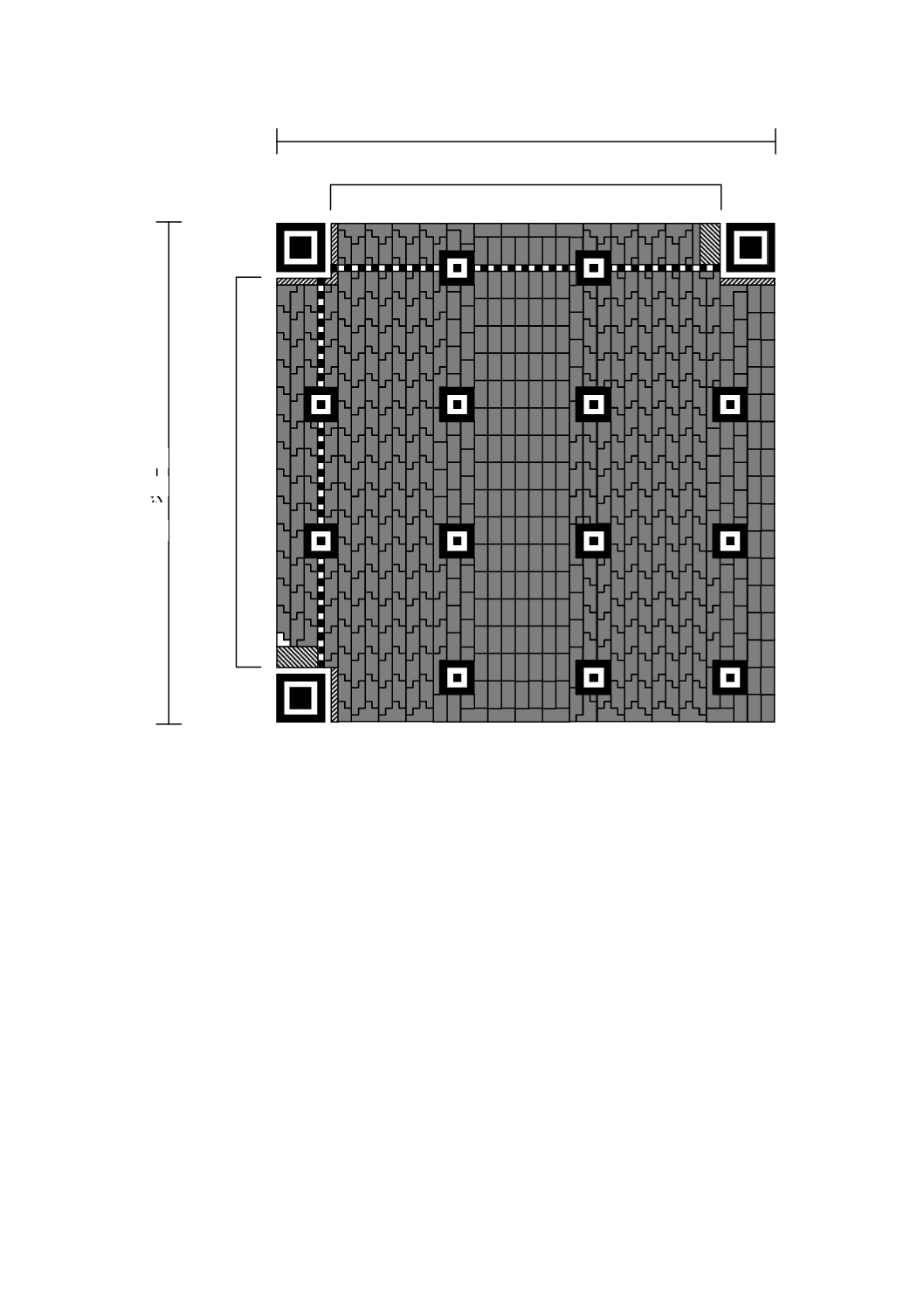
シンボルの構造
6.3.1
一般
各QRコードシンボルは,正方形様のモジュールを正方形配列に並べ,符号化領域及び機能パターン,
すなわち,位置検出パターン,分離パターン,タイミングパターン及び位置合せパターンの組合せとして
構成しなければならない。機能パターンは,データを符号化しない。シンボルは,その4辺の周囲にクワ
イエットゾーンをもたなければならない。図3は,7型のシンボルの構造を示す。図4は,M3型のシンボ
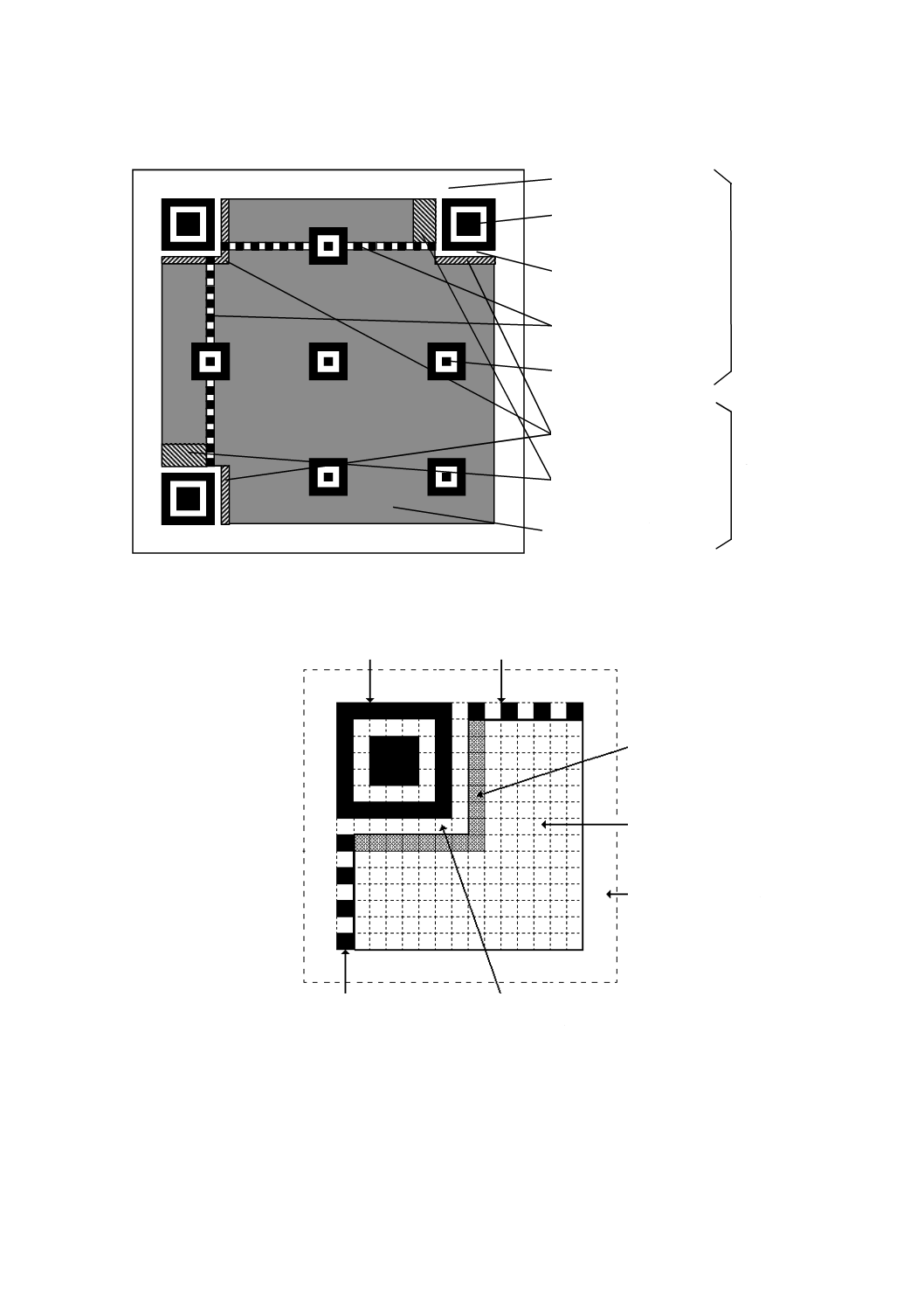
8
X 0510:2018 (ISO/IEC 18004:2015)
ルの構造を示す。
クワイエットゾーン
位置検出パターン
タイミングパターン
分離パターン
位置合せパターン
機能
パターン
データ及び
誤り訂正コード語
形式情報
型番情報
符号化
領域
図3−QRコードシンボルの構造
位置検出パターン タイミングパターン
タイミングパターン
分離パターン
図4−M3型マイクロQRコードシンボルの構造
6.3.2
シンボルの型番及び大きさ
6.3.2.1
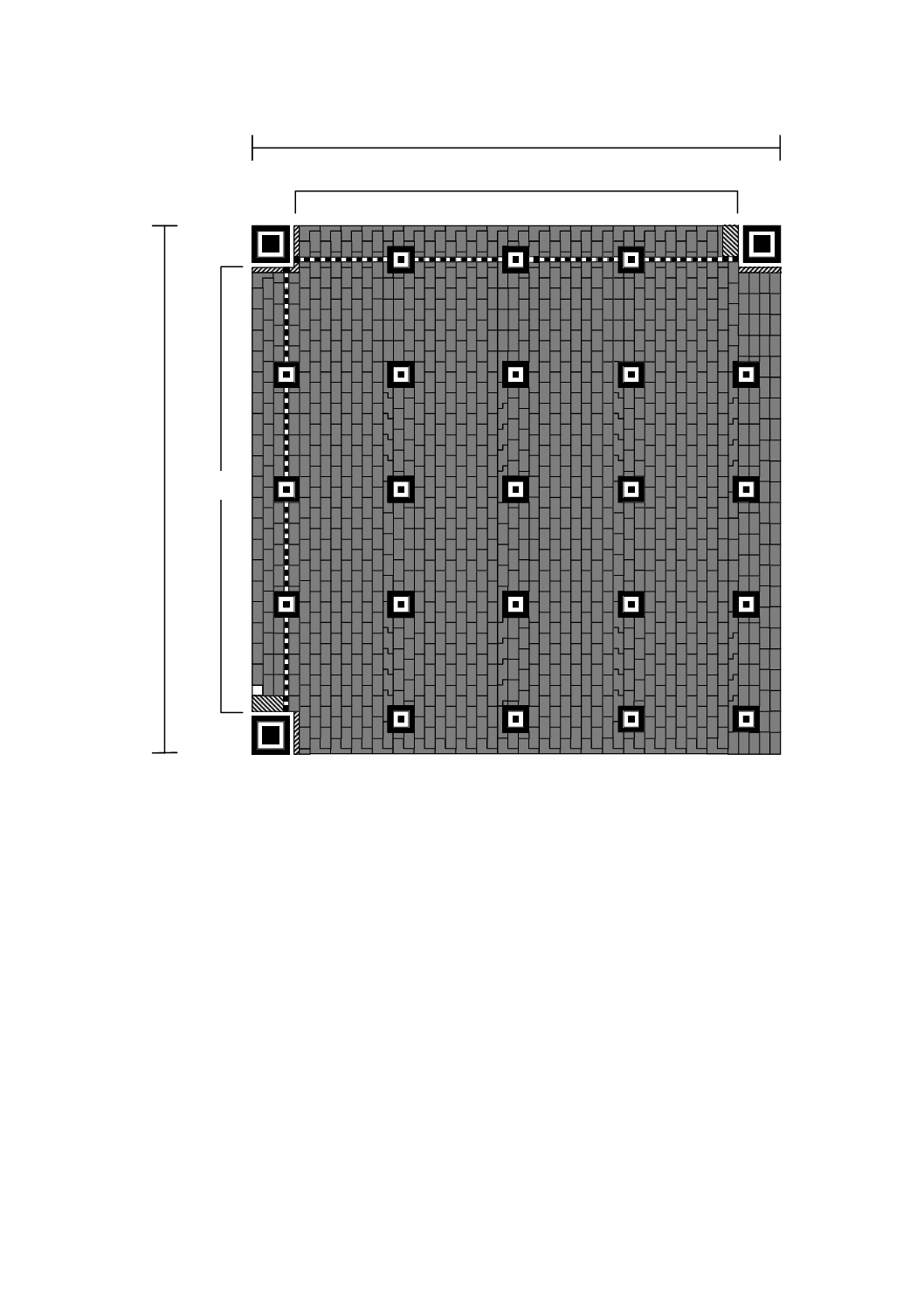
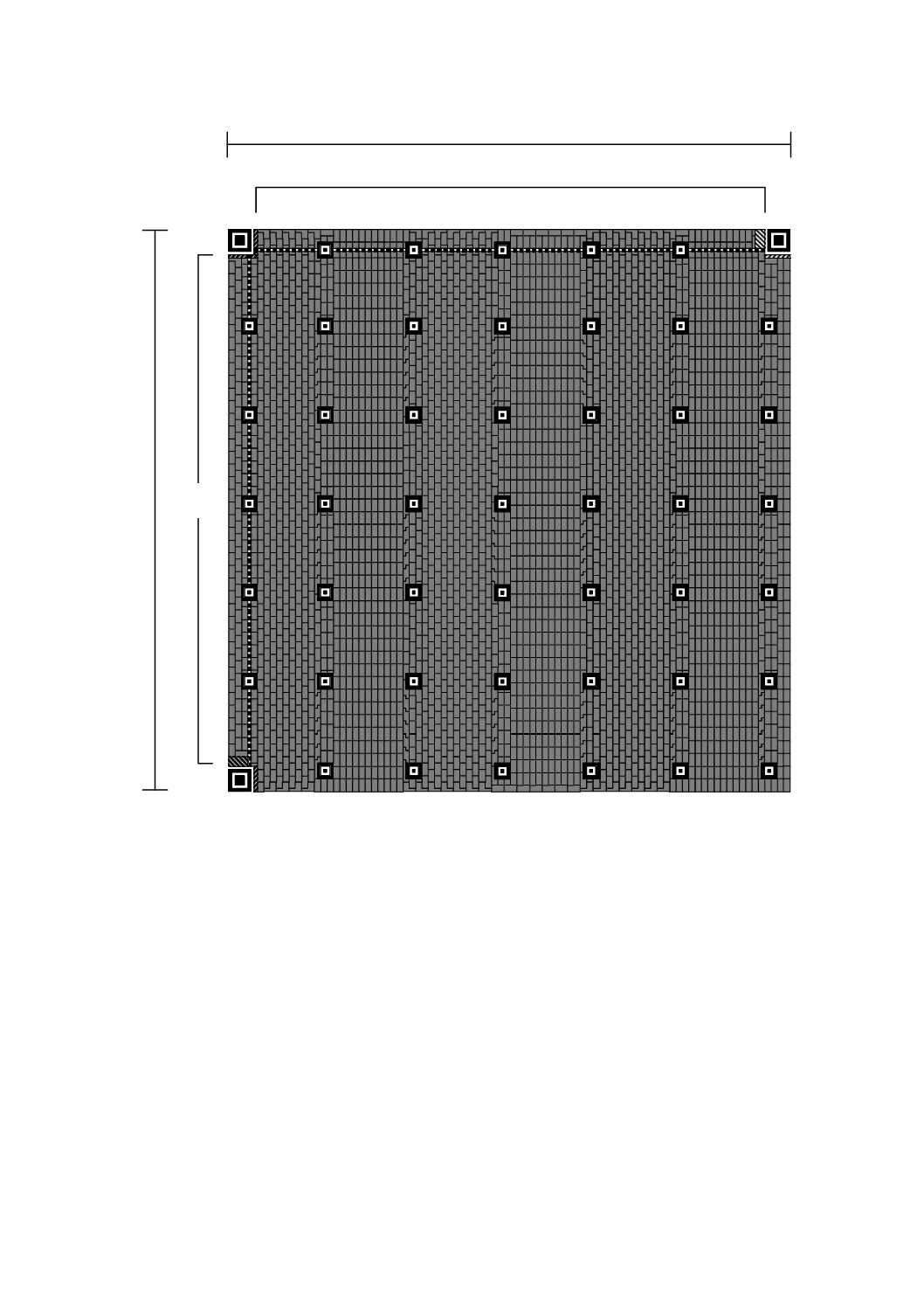
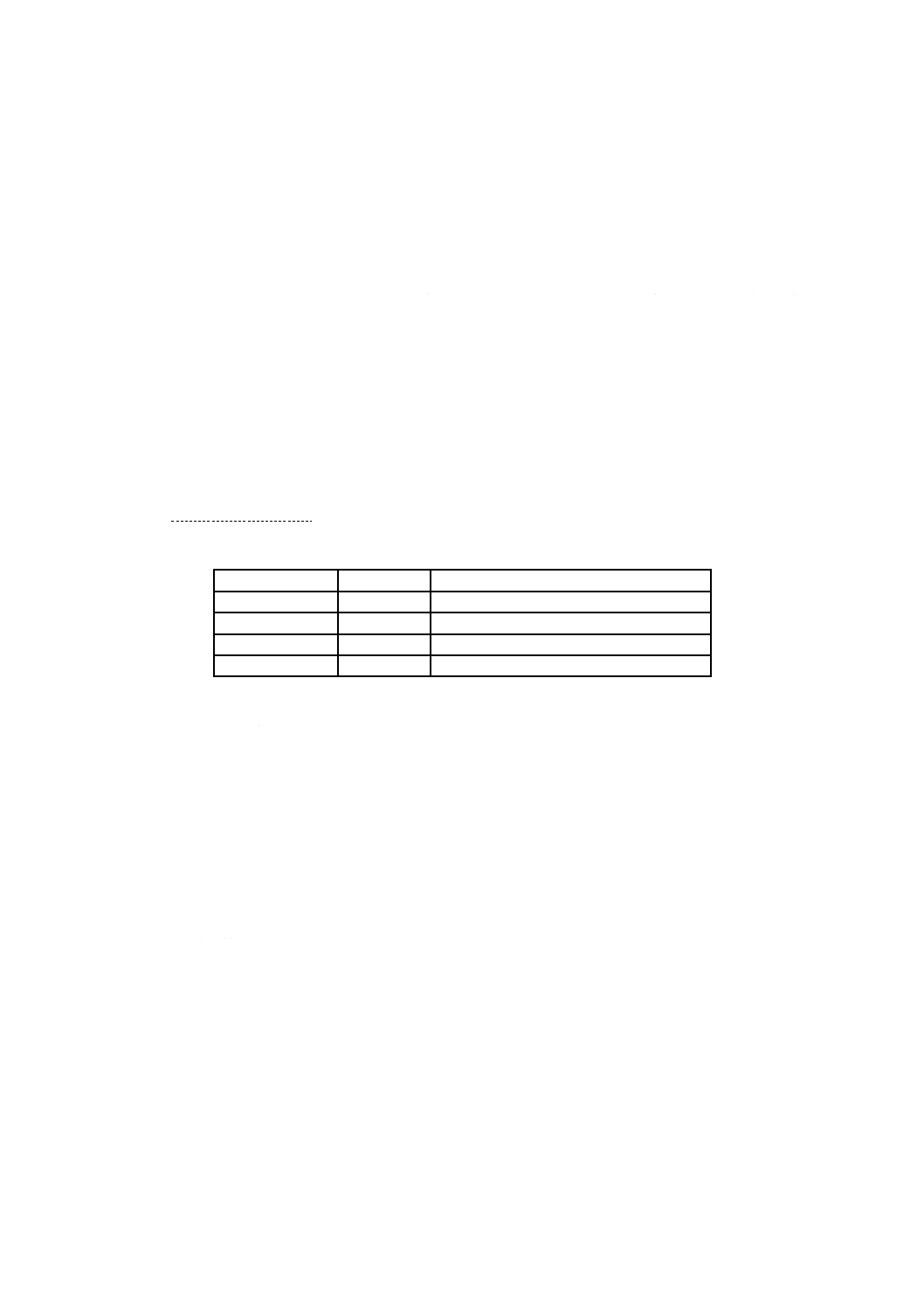
QRコードシンボル
QRコードシンボルには,1型〜40型として参照される,40種類の大きさがある。1型は,21×21モジ
ュール,2型は,25×25モジュールというように,型番が一つ上がるごとに一辺につき4モジュールずつ
クワイエットゾーン
符号化領域
型番情報
9
X 0510:2018 (ISO/IEC 18004:2015)
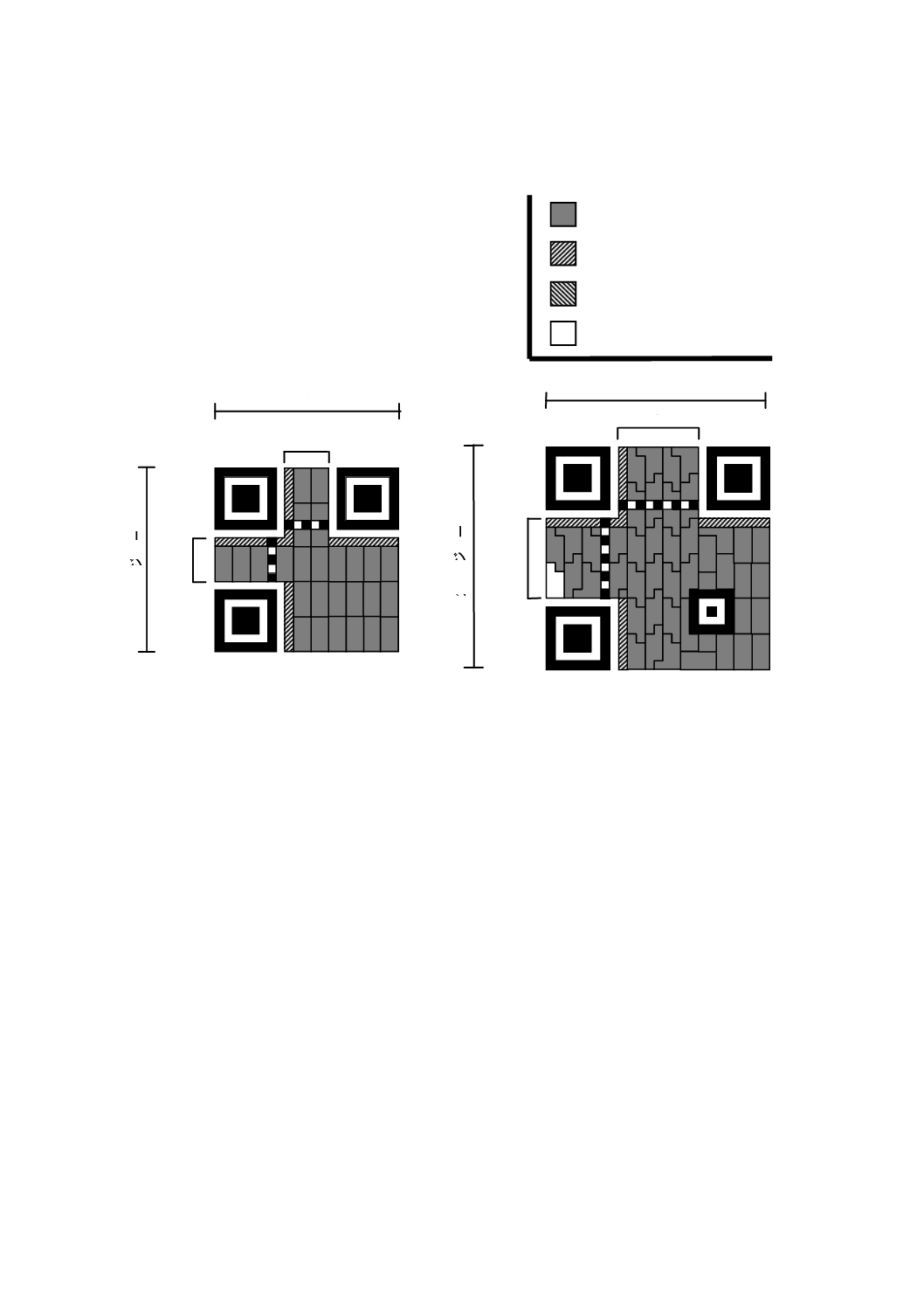
増加し,40型は,177×177モジュールとなる。図5〜図10は,1型,2型,6型,7型,14型,21型及び
40型の構造を示す。
5
2型
25 モジュール
9
9
データ及び誤り訂正コード語
形式情報及びその誤り訂正符号
型番情報及びその誤り訂正符号
残余ビット
21 モジュール
1型
5
2
5
モジ
ュー
ル
2
1
モジ
ュー
ル
図5−1型及び2型のシンボル
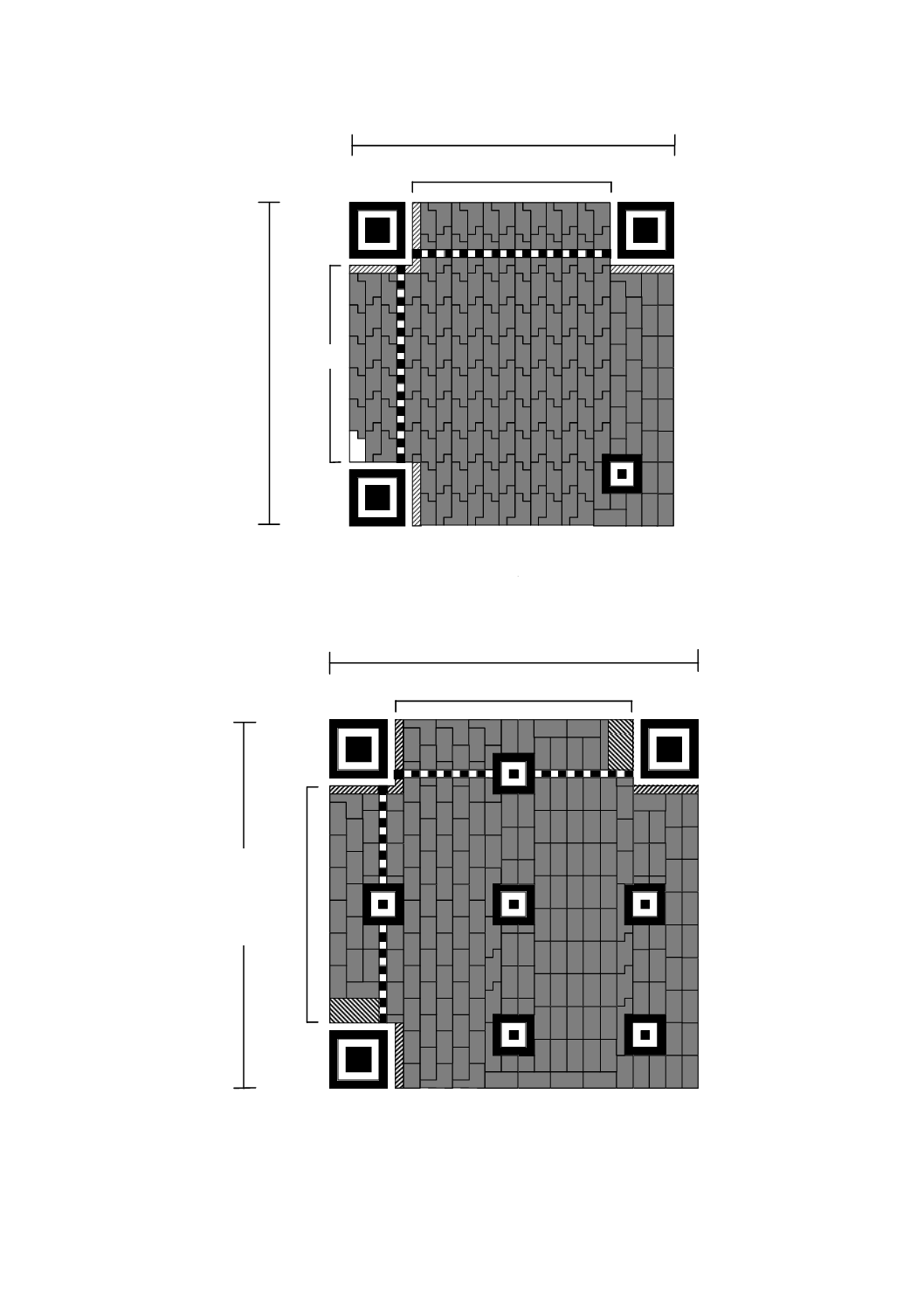
10
X 0510:2018 (ISO/IEC 18004:2015)
6型
25
41モジュール
4
1
モ
ジ
ュ
ー
ル
2
5
図6−6型のシンボル
29
45モジュール
4
5
モ
ジ
ュ
ー
ル
29
7型
図7−7型のシンボル
11
X 0510:2018 (ISO/IEC 18004:2015)
14型
57
73モジュール
7
3
モジ
ュー
ル
5
7
図8−14型のシンボル
12
X 0510:2018 (ISO/IEC 18004:2015)
21型
85
101モジュール
1
0
1
モ
ジ
ュ
ー
ル
8
5
図9−21型のシンボル
13
X 0510:2018 (ISO/IEC 18004:2015)
40型
161
177モジュール
1
7
7
モ
ジ
ュ
ー
ル
1
6
1
図10−40型のシンボル
6.3.2.2
マイクロQRコードシンボル
マイクロQRコードシンボルには,M1型〜M4型として参照される,4種類の大きさがある。M1型は,
11×11モジュール,M2型は,13×13モジュール,M3型は,15×15モジュール及びM4型は,17×17モ
ジュールというように,型番が一つ上がるごとに一辺につき2モジュールずつ増加する。図11は,M1型
〜M4型のマイクロQRコードの構造を示す。
注記 M3型シンボルの二つの構造は,誤り訂正レベルによってコード語の配置だけが異なる。

14
X 0510:2018 (ISO/IEC 18004:2015)
図11−マイクロQRコードの型番
6.3.3
位置検出パターン
6.3.3.1
QRコードシンボル
図3に示すように,シンボルの左上,右上及び左下に3個の同一形状の位置検出パターンが配置される。
各位置検出パターンは,3個の同心正方形が重なった形状で,暗の7×7モジュール,明の5×5モジュー
ル及び暗の3×3モジュールから構成される。各位置検出パターンにおけるモジュール幅の比率は,図12
に示すように1:1:3:1:1とする。これに類似するパターンがシンボルの任意の位置に出現する可能性
を抑え,視野内でQRコードシンボルを素早く認識できるようにシンボルを符号化する。位置検出機能を
実現する3個の位置検出パターンを識別することによって,視野内でのシンボルの大きさ,位置及び回転
方向を明確に認識できる。
6.3.3.2
マイクロQRコードシンボル
単一の位置検出パターン(6.3.3.1で規定)を,図4に示すようにシンボルの左上に配置する。位置検出
パターンをタイミングパターンとともに識別することによって,視野内でのシンボルの大きさ,位置及び
回転方向を明確に認識できる。

15
X 0510:2018 (ISO/IEC 18004:2015)
A: 3モジュール
B: 5モジュール
C: 7モジュール
1 : 1 : 3 : 1 : 1
A B
C
図12−位置検出パターンの構造
6.3.4
分離パターン
図3及び図4に示すように,全て明のモジュールで構成する1モジュール幅の分離パターンは,位置検
出パターンと符号化領域との間に配置する。
6.3.5
タイミングパターン
水平及び垂直タイミングパターンは,それぞれ1モジュール幅で暗と明とが交互になっているモジュー
ルの行又は列によって構成され,暗のモジュールで始まり,暗のモジュールで終了する。それらによって,
モジュール間隔及び型番を決めることができ,モジュール座標を決めるデータ位置が得られる。
QRコードシンボルでは,水平タイミングパターンは,シンボルの6行目,上部位置検出パターンに対
する分離パターンと分離パターンとの間にわたっている。垂直タイミングパターンは,同様にシンボルの
6列目,左側の位置検出パターンに対する分離パターンと分離パターンとの間にわたっている(図3参照)。
マイクロQRコードでは,水平タイミングパターンは,シンボルの0行目,位置検出パターンの右側に
対する分離パターンとシンボルの右端との間にわたっている。垂直タイミングパターンは,同様にシンボ
ルの0列目,位置検出パターンに対する分離パターンとシンボルの下端との間にわたっている(図4参照)。
6.3.6
位置合せパターン
位置合せパターンは,2型以上のQRコードだけに存在する。各位置合せパターンは,3個の同心正方形
が重なった形状で,暗の5×5モジュール,明の3×3モジュール及び中心となる暗の1モジュールで構成
してもよい。位置合せパターンの数は,シンボルの型番によって決まり,2型以上の全てのシンボルの附
属書Eに規定する位置に配置しなければならない。
6.3.7
符号化領域
この領域には,データを示すシンボルキャラクタ,それらに対する誤り訂正コード語,形式情報及び型
番情報(存在する場合)を含まなければならない。シンボルキャラクタの詳細は,7.7.1を参照。形式情報
の詳細は,7.9を参照。型番情報の詳細は,7.10を参照。
6.3.8
クワイエットゾーン
クワイエットゾーンは,シンボルの4辺の周囲を囲む,何も表示されない領域で,その公称反射率値は,
明モジュールの値と等しくなければならない。
QRコードのクワイエットゾーンの幅は,4Xとしなければならない。
マイクロQRコードのクワイエットゾーンの幅は,2Xとしなければならない。
7
要求事項
7.1
符号化手順の概要
ここでは,入力データをQRコードシンボルに変換する際に要求する手順の概要を規定する(符号化例
16
X 0510:2018 (ISO/IEC 18004:2015)
は,附属書I参照)。
手順1 データ分析
符号化する種々の異なる文字を識別するため,入力データ列を分析する。QRコードは,拡張チャネル
解釈機能に対応しており,既定の文字集合とは異なるデータを符号化することができる(ただし,マイク
ロQRコードでは対応していない。)。QRコードには,異なる文字集合を効果的にシンボルキャラクタに
変換するための幾つかのモード(7.3参照)がある。最も効果的にデータを2進文字列へ変換するため,
必要に応じてモードを切り替える。必要な誤り検出及び誤り訂正レベルを選択する。利用者が使用するシ
ンボル型番を指定していない場合は,データが収容できる最小型番を選択する。シンボル型番及びそのデ
ータ容量の一覧を,表1に示す。
手順2 データの符号化
7.4.2〜7.4.6で定義するとおり,適用中のモードの規則に従ってデータ文字をビット列に変換する。新し
いモードセグメントの開始時にモード変更に必要なモード指示子を挿入し,データ列の最後に終端パター
ンを挿入する。得られたビット列を8ビットコード語に分割する。その型番が要求するデータコード語数
を満たすために必要に応じて埋め草キャラクタを付加する。
手順3 誤り訂正符号
誤り訂正アルゴリズムを実行するため,コード語列を要求するブロック数(表9で定義)に分割する。
各ブロックに対して誤り訂正コード語を生成し,データコード語列の後に付加する。
手順4 最終的なメッセージの構築
7.6(手順3)で規定するとおり,各ブロックのデータコード語及び誤り訂正コード語のそれぞれを交互
配置し,必要に応じて残余ビットを付加する。
手順5 マトリックスにおけるモジュールの配置
マトリックスに位置検出パターン,分離パターン,タイミングパターン及び位置合せパターン(必要で
あれば)とともにコード語モジュールを配置する。
手順6 マスク処理
シンボルの符号化領域にマスク処理パターンを適用する。明及び暗のモジュールバランスを最適にし,
また,望ましくないパターンの出現を最小限に抑えるパターンを評価し,選択する。
手順7 形式情報及び型番情報
形式情報及び型番情報(適用する場合)を生成し,シンボルを完成する。

17
X 0510:2018 (ISO/IEC 18004:2015)
表1−QRコードの全型番のデータ容量
型番
モジュール数/
辺(A)
機能パターン
モジュール(B)
形式情報及び
型番情報
モジュール(C)
(C)以外のデー
タモジュール
(D=A2−B−C)
データ容量
[コード語]a)(E)
残余
ビット
M1
11
70
15
36
5
0
M2
13
74
15
80
10
0
M3
15
78
15
132
17
0
M4
17
82
15
192
24
0
1
21
202
31
208
26
0
2
25
235
31
359
44
7
3
29
243
31
567
70
7
4
33
251
31
807
100
7
5
37
259
31
1079
134
7
6
41
267
31
1383
172
7
7
45
390
67
1568
196
0
8
49
398
67
1936
242
0
9
53
406
67
2336
292
0
10
57
414
67
2768
346
0
11
61
422
67
3232
404
0
12
65
430
67
3728
466
0
13
69
438
67
4256
532
0
14
73
611
67
4651
581
3
15
77
619
67
5243
655
3
16
81
627
67
5867
733
3
17
85
635
67
6523
815
3
18
89
643
67
7211
901
3
19
93
651
67
7931
991
3
20
97
659
67
8683
1085
3
21
101
882
67
9252
1156
4
22
105
890
67
10068
1258
4
23
109
898
67
10916
1364
4
24
113
906
67
11796
1474
4
25
117
914
67
12708
1588
4
26
121
922
67
13652
1706
4
27
125
930
67
14628
1828
4
28
129
1203
67
15371
1921
3
29
133
1211
67
16411
2051
3
30
137
1219
67
17483
2185
3
31
141
1227
67
18587
2323
3
32
145
1235
67
19723
2465
3
33
149
1243
67
20891
2611
3
34
153
1251
67
22091
2761
3
35
157
1574
67
23008
2876
0
36
161
1582
67
24272
3034
0
37
165
1590
67
25568
3196
0
38
169
1598
67
26896
3362
0
39
173
1606
67
28256
3532
0
40
177
1614
67
29648
3706
0
注a) 全てのコード語は,8ビット長とする。
18
X 0510:2018 (ISO/IEC 18004:2015)
7.2
データ分析
内容を決定するために入力データ文字列を分析し,7.4に従って各文字列を符号化するために既定又は他
の適切なECI及び適切なモードを選択する。数字モードから漢字モードに進むにつれ,文字当たりに要求
されるビット数が増加する。モードが混在する場合には,データのビット列の長さを最小にするため,シ
ンボル内でモードを切り替えることができ,部分的には,一つのモードで,他の部分よりも効率的に符号
化できる(例えば,数字列の後に英数字列が続く場合)。一般的には,文字当たりの最少ビットを要求する
モードでデータを符号化することが最も効率的であるが,モード変更に伴ってモード指示子及び文字数指
示子のオーバーヘッドがあるため,文字数の少ない場合にモードを変更することで,常に全体のビット列
が最短となるわけではない。また,シンボルの容量は,ある型番から次の型番へと段階的に増加するため,
全ての事例で最大の変換効率を達成することを,常に必要としなくてもよい。ビット列の長さを最短にす
るための手引を,附属書Jに示す。マイクロQRコードでは,小さな型番において用いることができるモ
ードに制約がある。J.3 1) に,様々な二つのモードの組合せに対する適切なマイクロQRコードの型番を示
す。
注1) 対応国際規格ではJ.2となっていたが,明らかに誤記のためJ.3とした。
7.3
モード
7.3.1
一般
次に定義するモードは,文字値及び既定のECI値を伴う割当てに基づいている。他のECIを適用する場
合(マイクロQRコードを除く。)には,最適なデータ圧縮モードを選択するのに特定の文字割当ての代わ
りにバイト値を用いる。例えば,データのバイト値が30HEX〜39HEXの範囲にある文字列の場合には,数字
モードが適切である。この場合,既定の数字又は英字相当のバイト値を用いて圧縮する。
7.3.2
拡張チャネル解釈モード
AIM Inc.の“International Technical Specification Extended Channel Interpretations:−Part 1, Identification
Schemes and Protocols”で定義された拡張チャネル解釈(ECI)プロトコルによって,出力データ列は,既
定の文字集合とは異なる解釈を得ることができる。ECIプロトコルは,多くのシンボル体系にわたり,一
貫して適用できるように定義されている。ECIプロトコルは,印字前及び復号後のバイト値の特定の解釈
に関する一貫した規定方法を提供する。マイクロQRコードには,ECIプロトコルは,用いることができ
ない。
QRコードの既定の解釈は,ISO/IEC 8859-1の文字集合を表すECI 000003である。
他の文字集合を用いる国際的な用途では,ECIプロトコルを用いることが望ましい。例えば,JIS X 0201
及びJIS X 0208の文字集合を表現するQRコードのECI値は,ECI 000020である。
ECIモードの効果は,データの中のECIエスケープシーケンスを挿入した位置で生じる。直後に別のモ
ード指示子(例えば,効果的なデータ符号化のための)が続き,メッセージの最後まで又は次のECIモー
ド指示子まで効果は継続する。
7.3.3
数字モード
数字モードは,10進数集合(0〜9)(バイト値30HEX〜39HEX)のデータを符号化する。通常,3文字を
10ビットで表す。
7.3.4
英数字モード
英数字モードは,45文字のデータ,すなわち,10個の数字(0〜9)(バイト値30HEX〜39HEX),26個の
アルファベット文字(A〜Z)(バイト値41HEX〜5AHEX),及び9個の記号(スペース,$,%,*,+,−,.,
/ 及び:)(それぞれ,バイト値20 HEX,24 HEX,25 HEX,2A HEX,2B HEX,2D HEX〜2F HEX及び3AHEX)を符
19
X 0510:2018 (ISO/IEC 18004:2015)
号化する。通常,2文字を11ビットで表す。
英数字モードは,マイクロQRコードの型番M1では用いることができない。
7.3.5
8ビットバイトモード
このモードにおいて,データは,1文字を8ビットで符号化する。
特定の国内クローズドシステム又は特定用途においてQRコードを用いる場合には,例えば,ISO/IEC
8859の適切なパートに規定された,別の8ビット文字集合をバイトモードに指定してもよい。しかし,別
の文字集合を指定する場合には,そのQRコードを読もうとする関係者は,適用可能な文字集合をアプリ
ケーション仕様書又は双方の合意によって通知されることが必要である。
8ビットバイトモードは,マイクロQRコードの型番M1又は型番M2では用いることができない。
注記 このモードで用いる符号化文字集合は,QRコードを用いるアプリケーションで指定する符号
化文字集合である。ただし,アプリケーションごとに用いる符号化文字集合が異なると,複数
のアプリケーションを扱うシステムでは符号化文字集合の切替えが必要となり,システムが複
雑になる。このため,国際的なアプリケーションにおいては,JIS X 0201,JIS X 0221及び
ISO/IEC 8859-15の使用を推奨する。各国国内に限られたアプリケーションでは,ISO/IEC 8859
規格群の各パートの使用を推奨する。日本では,JIS X 0201の使用を推奨する。UTF-8は,UCS-2
(Universal Multiple-Octet Coded Character Set-2)で定義される文字集合を用いて記述された文字
列をバイト列に変換する方式の一つで,1文字を1〜6バイトの可変長マルチバイトに変換する。
7.3.6
漢字モード
漢字モードは,JIS X 0208に基づくシフトJISの方法(シフト符号化表現)に従って,漢字を効率よく
符号化する。シフトJISの漢字符号の値は,JIS X 0208の値からシフトされている。JIS X 0208(の附属
書1)が,シフト符号化表現の詳細を規定している。それぞれの2バイト文字の値は13ビットの2進コー
ド語に圧縮する。
8ビットバイトモード用に規定した文字集合が,81HEX〜9FHEX及び/又はE0HEX〜EBHEXの範囲にあるバ
イト値を用いる場合には,読取システムは,送られたデータのバイト値が2バイト文字の先頭バイトかど
うかを判断することができないため,曖昧さを残さずに,漢字モードを用いることができなくてもよい。
データが適切なバイト値の並びになった場合[すなわち,81HEX〜9FHEX及び/又はE0HEX〜EAHEX 2) の範囲
にある先頭バイトに,7FHEXを除く40HEX〜FCHEXの範囲にあるバイトが続く場合又はEBHEXに7FHEXを除
く 3) 40HEX〜BFHEXが続く場合]には,漢字モードの圧縮規則を用いることによって,より短いビット列を
得てもよい。図H.1にバイトの組合せを図示する。
漢字モードは,マイクロQRコードの型番M1又は型番M2では用いることができない。
注2) 対応国際規格に記載の“EBHEX”は,明らかに“EAHEX”の誤記のため修正した。
3) 対応国際規格は,明らかに“7FHEXを除く”が記載漏れのため追記した。
7.3.7
モード混在
QRコードは,7.3.2〜7.3.9に規定する任意のモードの組合せによるデータ列を扱ってもよい。マイクロ
QRコードにおいては,表7に示す,適用可能な型番に応じて,7.3.3〜7.3.7に規定する任意のモードの組
合せによるデータ列を扱ってもよい。
QRコードでモードが混在する場合の入力データ文字列の最も効率的な表現方法の選択については,附
属書Jを参照。また,マイクロQRコードの利用可能な二つのモードの組合せにおける効率的な表現方法
の選択については,J.3を参照。
20
X 0510:2018 (ISO/IEC 18004:2015)
7.3.8
構造的連接モード
構造的連接モードは,データの符号化を幾つかのQRコードシンボル上に分割するために使用する。全
てのシンボルを読み出すことを要求し,データメッセージを,正しい順序で再構成する。データメッセー
ジの長さ及びシンボルの位置を識別するために,各シンボルの構造的連接ヘッダを符号化し,全てのシン
ボルが同じメッセージに属することを検証する。構造的連接モードの符号化の詳細については,箇条8を
参照。
構造的連接モードは,マイクロQRコードでは用いることができない。
7.3.9
FNC1モード
FNC1モードは,特定のデータ形式を含むメッセージに用いる。“1番目の位置”にあるとは,GS1総合
仕様書のデータ形式に従っていることを示す。“2番目の位置”にあるとは,AIM Inc.と既に合意した特定
産業アプリケーションのデータ形式に従っていることを示す。FNC1モードは,シンボル全体に適用し,
次のモード指示子に影響されない。
注記 “1番目の位置”及び“2番目の位置”は,実際の場所を参照しないが,コード128における
FNC1キャラクタの位置に基づいて,同等の方法で用いる。
FNC1モードは,マイクロQRコードでは用いることができない。
7.4
データの符号化
7.4.1
データの順序
入力データは,それぞれ別のモードの1個以上のセグメントから構成するビット列に変換する。既定の
ECI値では,ビット列は,最初のモード指示子で開始する。最初のECIが既定のECI値以外の場合は,ビ
ット列は,最初のセグメントが後続するECIヘッダで開始する。
ECIヘッダ(存在する場合)は,次をもつ。
− ECIモード指示子(4ビット)
− ECI指定(8ビット,16ビット又は24ビット)
ECIヘッダは,ECIモード指示子の最初(最上位桁)のビットで開始し,ECI指定の最後(最下位桁)
のビットで終了しなければならない。
残りのビット列は,次をもつセグメントで構成する。
− モード指示子
− 文字数指示子
− データビット列
各モードセグメントは,モード指示子の最初(最上位桁)のビットで開始し,データビット列の最後(最
下位桁)のビットで終了しなければならない。セグメントの長さは,適用中のモードの規則及び入力デー
タの文字数によって明確に定義されるので,セグメントとセグメントとの間には,明確な区切りは存在し
てはならない。
既定のモードで入力データ列を符号化するには,7.4.2〜7.4.7に定義する手順に従わなければならない。
表2に,各モードのモード指示子を示す。表3に,適用するモード及びシンボル型番によって変化する,
文字数指示子の長さを定義する。

21
X 0510:2018 (ISO/IEC 18004:2015)
表2−QRコードのモード指示子
モード
QRコード
マイクロQRコード
型番
全て
M1
M2
M3
M4
長さ(ビット)
4
0
1
2
3
ECI
0111
−
−
−
−
数字
0001
−
0
00
000
英数字
0010
−
1
01
001
8ビットバイト
0100
−
−
10
010
漢字
1000
−
−
11
011
構造的連接
0011
−
−
−
−
FNC1 a)
0101(1番目の位置)
1001(2番目の位置)
−
−
−
−
終端パターン
(メッセージの終了)b)
0000
000
00000
0000000
000000000
注a) 7.4.8.2及び7.4.8.3参照。
b) 終端パターンそれ自体は,モード指示子ではない。
表3−QRコードの文字数指示子のビット数
型番
数字
モード
英数字
モード
8ビットバイト
モード
漢字
モード
M1
3
−
−
−
M2
4
3
−
−
M3
5
4
4
3
M4
6
5
5
4
1〜9
10
9
8
8
10〜26
12
11
16
10
27〜40
14
13
16
12
完全なシンボルにおけるデータの最後は,3〜9ビットのゼロからなる終端パターンで示し(表2参照),
データビット列の後ろの残りのシンボル容量が,必要なビット長未満の場合,終端パターンは,省略又は
短縮する。終端パターンそれ自体は,モード指示子ではない。
7.4.2
拡張チャネル解釈(ECI)モード
7.4.2.1
一般
このモードは,この形式のデータを前処理する方法を規定するAIM Inc.のECI仕様に従って,バイト値
を別の解釈(例えば,別の文字集合)に従うデータを符号化するために用いられ,モード指示子0111によ
って機能を呼び出す。QRコードの既定のECI値(000020)は,JIS X 0208のシフト符号化表現の文字集
合に対応しており,任意のシンボルの開始時に特にこれを指定する必要はない。
ECIは,シンボル体系識別子を送信できる読取装置によってだけ使用できる。シンボル体系識別子を送
信できない読取装置は,ECIを含むどのシンボルからのデータも送信できない。
入力したECIデータは,一連の8ビットバイト値として符号化システムで処理しなければならない。
ECI手順におけるデータは,その意味に関係なく,どのモード又は最も効率的な符号化を行うモードに
よって符号化してもよい。例えば,30HEX〜39HEXの範囲にあるバイト列は,実際には数字を意味しない場
合でも,0〜9の数字列のように,数字モード(7.4.3参照)で符号化できる。文字数指示子の値を決定す
るために,バイト数(漢字モードではバイトの組の数)を用いなければならない。
22
X 0510:2018 (ISO/IEC 18004:2015)
7.4.2.2
ECI指定
ECIは,6桁の割当て番号で指定する。この番号は,ECIモード指示子に続く最初の1個〜3個のコード
語としてQRコードシンボルに符号化する。符号化規則は,表4で定義する。ECI指定は,5CHEX(ISO/IEC
8859-1では“\”,すなわち,逆斜線,JIS X 0201では“¥”,すなわち,円記号)に続く6桁の割当て番
号が符号化されたデータとして出現する。実データとして5CHEXが出現する場合には,シンボルに符号化
する前の,ECIプロトコルを適用するデータ列の中では5CHEXを二重にしなければならない。
復号器に,ただ一つの5CHEXが入力された場合には,ECIモード指示子(ECI割当てが続く。)を挿入す
る。二重の5CHEXが入力された場合には,二つの5CHEXバイトとして復号4) する。
復号の際,最初のECI割当てコード語(すなわち,ECIモードでのモード指示子に続くコード語)の2
進パターンによってECI指定を示すコード語の長さが決まる。最初の0ビットの前の1ビットの数によっ
て,ECI割当て番号を示すために用いた第1コード語の後の追加コード語数が決まる。最初の0ビット後
のビット列は,ECI割当て番号を示す2進値とする。ECIの割当て番号が小さいときは,複数の方法で符
号化してもよいが,短い方法がよい。
注4) 対応国際規格では“encoded”となっているが,復号器の機能の説明であり,“復号”が正しい
ことから訂正した。
表4−ECI割当て番号の符号化
ECI指定
コード語数
コード語値
000000〜000127
1
0bbbbbbb
000000〜016383
2
10bbbbbb bbbbbbbb
000000〜999999
3
110bbbbb bbbbbbbb bbbbbbbb
ここに,b…b=ECI割当て番号の2進値
例 1-H型シンボルでISO/IEC 8859-7(ECI 000009)の文字集合を用いて,データをギリシャ文字で
符号化する場合は,次のようになる。
符号化するデータ:
ABΓ∆E(文字値A1HEX,A2HEX,A3HEX,A4HEX,A5HEX)
シンボルのビット列
ECIモード指示子:
0111
ECI割当て番号(000009):
00001001
モード指示子(8ビットバイト): 0100
文字数指示子(5桁):
00000101
データ:
10100001 10100010 10100011 10100100 10100101
最終的なビット列:
0111 00001001 0100 00000101 10100001 10100010 10100011
10100100 10100101
復号したデータの送信例については,14.3参照。
7.4.2.3
複数のECI
ECIデータセグメントにおける連続するECI指定の効果を指定する規則については,AIM Inc.のECI仕
様を参照する。例えば,文字集合ECIが適用されたデータは,最初のECIと共存できる変換ECIを用いて,
暗号化又は圧縮することがある。また,2番目の文字集合ECIが最初のECIを無効にし,新たなECIセグ
メントを開始する効果をもつことがある。データ中に,ECI指定が出現するところでは,いずれのECI指
定も7.4.2.2に従ってQRコードシンボルに符号化し,新たなモードセグメントを開始しなければならばい。
23
X 0510:2018 (ISO/IEC 18004:2015)
7.4.2.4
ECI及び構造的連接
適用する任意のECIは,7.4.2.3の規則及びAIM Inc.のECI仕様に従って,符号化するデータの終了又は
ECIの変更(モード指示子0111による。)が発生するまで適用しなければならない。ECIにおいて符号化
したデータが構造的連接モードで2個以上のシンボルにわたる場合,ECIを適用し続けている後続シンボ
ルでは,構造的連接ヘッダの直後に,ECIモード指示子及び適用する各ECIに対するECI指定番号から構
成するECIヘッダが必要となる。
7.4.3
数字モード
入力データ文字列を3桁のグループに分割し,各グループを10ビットの2進値に変換する。入力桁数が
3の倍数でない場合,最終の一桁又は二桁は,それぞれ4ビット又は7ビットに変換する。次に2進デー
タを連結し,モード指示子及び文字数指示子を最初の部分に付加する。数字モードにおけるモード指示子
の長さは,QRコードでは,4ビット,マイクロQRコードでは,表2で定義するビット長で,文字数指示
子は,表3で定義するビット長とする。入力データ文字数を,等価の2進値に変換し,文字数指示子とし
てモード指示子の後で2進データ列の前に付加する。
例1 1-H型シンボル
入力データ
01234567
a) 三桁のグループに分割:
012 345 67
b) 各グループを2進値に変換: 012=0000001100
345=0101011001
67 =1000011
c) 2進データを順に接続:
0000001100 0101011001 1000011
d) 文字数指示子を2進値(1-H型は,10ビット)に変換:
入力データ文字数
8=0000001000
e) モード指示子0001及び文字数指示子を2進データに付加:
0001 0000001000 0000001100 0101011001 1000011
例2 マイクロQRコード M3-M型シンボル
入力データ
0123456789012345
a) 三桁のグループに分割:
012 345 678 901 234 5
b) 各グループを2進値に変換: 012=0000001100
345=0101011001
678=1010100110
901=1110000101
234=0011101010
5 =0101
c) 2進データを順に接続:
0000001100 0101011001 1010100110 1110000101 0011101010 0101
d) 文字数指示子を2進値(M3-M型は,5ビット)に変換:
入力データ文字数
16=10000
e) モード指示子(M3-M型では00)及び文字数指示子を2進データに付加:
00 10000 0000001100 0101011001 1010100110 1110000101 0011101010 0101
数字モードにおいて,任意の数のデータ文字数に対するビット列の長さは,次の式によって得られる。
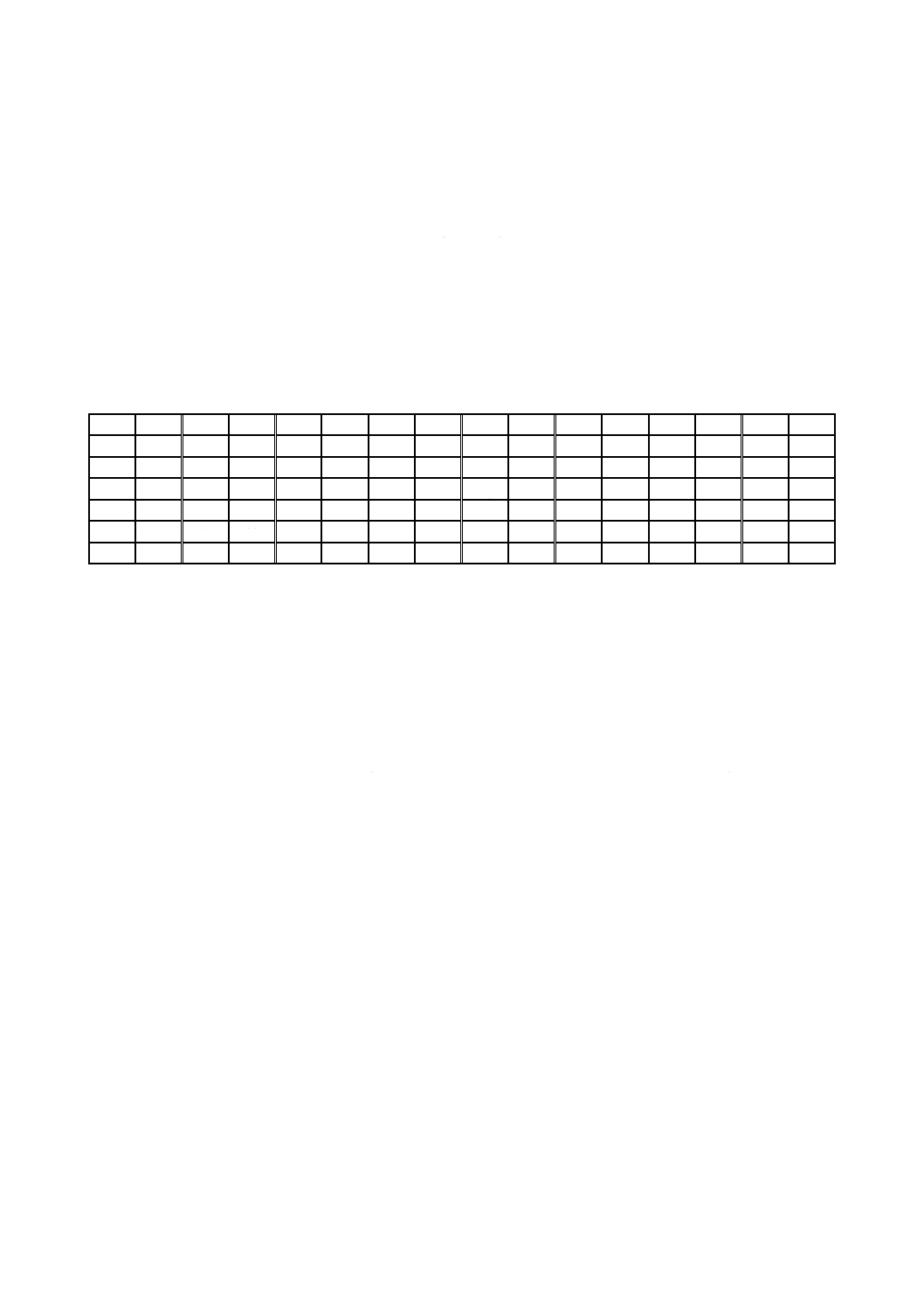
24
X 0510:2018 (ISO/IEC 18004:2015)
B=M+C+10(D DIV 3)+R
ここに,
B: ビット列のビット数
M: モード指示子のビット数(QRコードでは,4ビット,マイク
ロQRコードでは,表2で定義するビット長)
C: 文字数指示子のビット数(表3による。)
D: 入力データ文字数
R: (D MOD 3)=0ならば0
(D MOD 3)=1ならば4
(D MOD 3)=2ならば7
7.4.4
英数字モード
各入力文字に,表5に基づいて0〜44の文字値を割り当てる。
表5−英数字モードの符号化・復号表
文字
値
文字
値
文字
値
文字
値
文字
値
文字
値
文字
値
文字
値
0
0
6
6
C
12
I
18
O
24
U
30
SP
36
.
42
1
1
7
7
D
13
J
19
P
25
V
31
$
37
/
43
2
2
8
8
E
14
K
20
Q
26
W
32
%
38
:
44
3
3
9
9
F
15
L
21
R
27
X
33
*
39
4
4
A
10
G
16
M
22
S
28
Y
34
+
40
5
5
B
11
H
17
N
23
T
29
Z
35
−
41
入力文字を,二桁のグループに分け,11ビットの2進コードに符号化する。最初の文字の文字値は,45
で乗算し,2番目の文字値を乗算結果に加算する。合計値を11ビットの2進値に変換する。入力データ文
字数が2の倍数でない場合,最終文字の文字値は,6ビットの2進値に変換する。これらの2進データを
連結し,モード指示子及び文字数指示子を前に付加する。英数モードにおけるモード指示子の長さは,QR
コードでは,4ビット,マイクロQRコードでは,表2で定義するビット長で,文字数指示子は,表3で
定義するビット長とする。入力データ文字数を,等価の2進値に変換し,文字数指示子としてモード指示
子の後で2進データ列の前に付加する。
FNC1モードのシンボルにおいて,データの中にFNC1が現れてもよい。これは,英数字モードでは%
で表現する。FNC1及び%の符号化及びデータ転送の詳細は,7.4.8.2,7.4.8.3及び14.4参照。
例 1-H型シンボル
入力データ AC-42
a) 表5に従って文字値を割当て:
AC-42
(10,12,41,4,2)
b) 結果を二桁の10進数のグループに分割: (10,12) (41,4) (2)
c) 各グループを11ビットの2進値に変換: (10,12) 10×45+12=462
00111001110
(41,4)
41×45+4=1 849 11100111001
(2)
2
000010
d) 2進データを順に接続:
00111001110 11100111001 000010
e) 文字数指示子を2進値(1-H型は,9ビット)に変換:
入力データ文字数
5=000000101
f)
モード指示子0010及び文字数指示子を2進データに付加:
0010 000000101 00111001110 11100111001 000010
英数字モードにおいて,任意の数のデータ文字数に対するビット列の長さは,次の式で得られる。
25
X 0510:2018 (ISO/IEC 18004:2015)
B=M+C+11(D DIV 2)+6(D MOD 2)
ここに,
B: ビット列のビット数
M: モード指示子のビット数(QRコードでは,4ビット,マイク
ロQRコードでは,表2で定義するビット長)
C: 文字数指示子のビット数(表3による。)
D: 入力データ文字数
7.4.5
8ビットバイトモード
このモードでは,1個の8ビットコード語は,表6に示す入力データ文字に対する文字値を直接割り当
てる(密度は,1文字当たり8ビット)。
26
X 0510:2018 (ISO/IEC 18004:2015)
表6−ISO/IEC 8859-1文字集合の符号化・復号表
バイト 文字 バイト 文字 バイト 文字 バイト 文字 バイト 文字 バイト 文字 バイト 文字 バイト 文字
0
NUL
32
space
64
@
96
̀
128
160
NBSP
192
À
224
à
1
SOH
33
!
65
A
97
a
129
161
¡
193
Á
225
á
2
STX
34
"
66
B
98
b
130
162
¢
194
Â
226
â
3
ETX
35
#
67
C
99
c
131
163
£
195
Ã
227
ã
4
EOT
36
$
68
D
100
d
132
164
¤
196
Ä
228
ä
5
ENQ
37
%
69
E
101
e
133
165
¥
197
Å
229
å
6
ACK
38
&
70
F
102
f
134
166
¦
198
Æ
230
æ
7
BEL
39
'
71
G
103
g
135
167
§
199
Ç
231
ç
8
BS
40
(
72
H
104
h
136
168
¨
200
È
232
è
9
HT
41
)
73
I
105
I
137
169
©
201
É
233
é
10
LF
42
*
74
J
106
j
138
170
ª
202
Ê
234
ê
11
VT
43
+
75
K
107
k
139
171
«
203
Ë
235
ë
12
FF
44
,
76
L
108
l
140
172
¬
204
Ì
236
ì
13
CR
45
-
77
M
109
m
141
173
SHY
205
Í
237
í
14
SO
46
.
78
N
110
n
142
174
®
206
Î
238
î
15
SI
47
/
79
O
111
o
143
175
¯
207
Ï
239
ï
16
DLE
48
0
80
P
112
p
144
176
°
208
Ð
240
ð
17
DC1
49
1
81
Q
113
q
145
177
±
209
Ñ
241
ñ
18
DC2
50
2
82
R
114
r
146
178
²
210
Ò
242
ò
19
DC3
51
3
83
S
115
s
147
179
³
211
Ó
243
ó
20
DC4
52
4
84
T
116
t
148
180
´
212
Ô
244
ô
21
NAK
53
5
85
U
117
u
149
181
µ
213
Õ
245
õ
22
SYN
54
6
86
V
118
v
150
182
¶
214
Ö
246
ö
23
ETB
55
7
87
W
119
w
151
183
·
215
×
247
÷
24
CAN
56
8
88
X
120
x
152
184
¸
216
Ø
248
ø
25
EM
57
9
89
Y
121
y
153
185
¹
217
Ù
249
ù
26
SUB
58
:
90
Z
122
z
154
186
º
218
Ú
250
ú
27
ESC
59
;
91
[
123
{
155
187
»
219
Û
251
û
28
FS
60
<
92
\
124
|
156
188
¼
220
Ü
252
ü
29
GS
61
=
93
]
125
}
157
189
½
221
Ý
253
ý
30
RS
62
>
94
^
126
~
158
190
¾
222
Þ
254
þ
31
US
63
?
95
̲
127
DEL
159
191
¿
223
ß
255
ÿ
注記1 JIS X 0201の8ビット符号(表H.1参照)のバイト値80HEX〜9FHEX及びE0HEX〜FFHEXまでは未定義で,保留
とする。これらの幾つかは,シフト符号化表現(図H.1参照)では第1バイトとして用い,8ビット符号とシ
フト符号化表現との区別又は漢字モードの圧縮に適用できる。シフト符号化表現の詳細については,JIS X
0208を参照する。
注記2 JIS X 0201の8ビット符号のバイト値00HEX〜7FHEXは,5CHEX及び7EHEXを除いて,ISO/IEC 8859-1及び
ISO/IEC 646の国際基準版に対応している。
次に2進データを接続し,モード指示子及び文字数指示子を前に付加する。8ビットバイトモードにお
けるモード指示子の長さは,QRコードでは,4ビット,マイクロQRコードでは,表2で定義するビット
長で,文字数指示子は,表3で定義するビット長とする。入力データ文字数を,等価の2進値に変換し,
文字数指示子としてモード指示子の後で2進データ列の前に付加する。
8ビットバイトモードにおいて,任意の数のデータ文字数に対するビット列の長さは,次の式によって
得られる。
27
X 0510:2018 (ISO/IEC 18004:2015)
B=M+C+8D
ここに,
B: ビット列のビット数
M: モード指示子のビット数(QRコードでは,4ビット,マイク
ロQRコードでは,表2で定義するビット長)
C: 文字数指示子のビット数(表3による。)
D: 入力データ文字数
7.4.6
漢字モード
JIS X 0208のシフト符号化表現では,漢字は,2バイトの組合せによって表現する。シフト符号化表現
におけるバイト値は,JIS X 0208の値からシフトされている。シフト符号化表現の詳細は,JIS X 0208 附
属書1参照。漢字モードの入力データ文字は,次に示すように,13ビット2進コード語に圧縮する。次に
2進データを連結し,モード指示子及び文字数指示子を前に付ける。漢字モードのモード指示子の長さは,
QRコードでは,4ビット,マイクロQRコードでは,表2で定義するビット長で,文字数指示子は,表3
で定義するビット長とする。入力データ文字数を,等価の2進値に変換し,文字数指示子としてモード指
示子の後で2進データ列の前に付加する。
a) 8140HEX〜9FFCHEXまでのシフト符号化表現値の文字
1) シフト符号化表現値から8140HEXを減算する。
2) 得られた値の上位バイトにC0HEXを乗じる。
3) 2)の結果に下位バイトを加算する。
4) 結果を13ビット2進文字列に変換する。
注記 JIS X 0208のシフト符号化表現では,下位バイトは,40HEX〜FCHEX(7Fを除く。)の範囲の
ため,下位バイトがこの範囲以外の場合には,8ビットバイトモードで符号化する。
b) E040HEX〜EBBFHEXまでのシフト符号化表現値の文字
1) シフト符号化表現値からC140HEXを減算する。
2) 得られた値の上位バイトにC0HEXを乗じる。
3) 2)の結果に下位バイトを加算する。
4) 結果を13ビット2進文字列に変換する。
注記 JIS X 0208のシフト符号化表現では,下位バイトは,40HEX〜FCHEX(7Fを除く。)の範囲の
ため,下位バイトがこの範囲以外の場合には,8ビットバイトモードで符号化する。
例 入力文字
“点”
“茗”
(シフト符号化表現値)
935F
E4AA
1. 8140又はC140を引く。
935F−8140=121F
E4AA−C140=236A
2. 上位バイトにC0を乗じる。
12×C0=D80
23×C0=1A40
3. 下位バイトを足す。
D80+1F=D9F
1A40+6A=1AAA
4. 13ビット2進に変換する。
0D9F=
1AAA=
0 1101 1001 1111
1 1010 1010 1010
c) 8140HEX〜9FFCHEXまでのシフト符号化表現値の文字及びE040HEX〜EBBFHEXまでのシフト符号化表現
値の全ての文字に対し,入力文字の2進列の前にモード指示子(表2による。)及び文字数指示子2
進値(表3で定義するビット長)を付加する。
漢字モードにおいて,任意の数のデータ文字数に対するビット列の長さは,次の式によって得られる。
B=M+C+13D

28
X 0510:2018 (ISO/IEC 18004:2015)
ここに,
B: ビット列のビット数
M: モード指示子のビット数(QRコードでは,4ビット,マイク
ロQRコードでは,表2で定義するビット長)
C: 文字数指示子のビット数(表3による。)
D: 入力データ文字数
7.4.7
モード混在
データの内容によって,あるモードにおけるデータ列を別のモードへ変更する場合又は符号化密度を高
める場合,この任意機能を用いる。手引に関しては,附属書Jによる。データの各セグメントは,モード
指示子,文字数指示子,データ及び次のセグメントを開始するモード指示子によって続く基本構造で,7.4.2
〜7.4.6に示す適切なモードで符号化する。図13に,n個のセグメントを含むデータの構造を図示する。
セグメント1
セグメント2
・・・
セグメントn
終端
パターン
モード
指示子1
文字数
指示子
データ
モード
指示子2
文字数
指示子
データ
・・・
モード
指示子n
文字数
指示子
データ
図13−モードが混在する場合の形式
7.4.8
FNC1モード
7.4.8.1
一般
QRコードシンボルでは,特定のあらかじめ定義された業界仕様又はアプリケーション仕様に従うメッ
セージ形式を符号化するシンボルを識別するために,7.3.2〜7.3.9及び7.4.2〜7.4.7で定義するモードとと
もに重複して使われる二つのモード指示子を用いる。この二つのモード指示子(任意のパラメタデータを
伴う。)は,データを効率よく符号化するために,用いるモード指示子の前に置く。これらのモード指示子
を用いる場合,復号器は,14.2及び附属書Fで定義するシンボル体系識別子を送信する必要がある。
7.4.8.2
FNC1(1番目の位置)
注記 “1番目の位置”は,文字どおりの意味ではなく,コード128(JIS X 0504)でのFNC1キャラ
クタの位置に対する歴史的な参照として用いている。
このモード指示子は,GS1アプリケーション識別子規格に従うデータ形式を符号化するシンボルを認識
する。このために,シンボル内で1回だけ用い,効率的なデータ符号化(数字データ,英数字データ,8
ビットバイトデータ又は漢字データ)のために用いる最初のモード指示子の前で,かつ,任意のECIヘッ
ダ又は構造的連接ヘッダの後に置く。GS1仕様が,データのフィールド分離パターン(すなわち,可変長
データの最後で)として用いるFNC1(他のシンボルではこの特殊文字を用いる。)を要求する場合,QR
コードシンボルは,この機能を実行するために,英数字モードにおける%又は8ビットバイトモードにお
けるIS3(1DHEX)を用いる。
%がデータの一部として現れる場合は,%%として符号化しなければならない。復号器は,シンボル内で%
に出会うと1DHEXとして送信しなければならない。%%の場合は,1個の%として送信しなければならない。
例1
入力データ
0104912345123459(アプリケーション識別子01=商品識別コード,固定長データ
04912345123459)
15970331(アプリケーション識別子15=品質保持期限日YYMMDD,固定長データ97年3
月31日)
30128(アプリケーション識別子30=数量,可変長データ128)(分離パターン文字が必要)
29
X 0510:2018 (ISO/IEC 18004:2015)
10ABC123(アプリケーション識別子10=バッチ番号又はロット番号,可変長データABC123)
符号化するデータ
01049123451234591597033130128%10ABC123
シンボルのビット列
0101[モード指示子 FNC1(1番目の位置)]
0001(モード指示子 数字モード)
0000011101(文字数カウント指示子 29桁)
<01049123451234591597033130128に対するデータビット>
0010(モード指示子 英数字モード)
000001001(文字数カウント指示子 9桁)
<%10ABC123に対するデータビット>
送信データ(14.2及び附属書F参照)
]Q301049123451234591597033130128<1DHEX>10ABC123
例2 データにおける%の符号化及び送信
入力データ 123%
符号化
123%%
送信
123%
7.4.8.3
FNC1(2番目の位置)
注記 “2番目の位置”は,文字どおりの意味ではなく,コード128でのFNC1キャラクタの位置に
対する歴史的な参照として用いている。
このモード指示子は,AIM Inc.が認めた特定の業界仕様又はアプリケーション仕様に従って形式付けす
るシンボルを認識する。AIM Inc.によって関係付けされた仕様を識別するアプリケーション指示子の値と
する1バイトのコード語が後続する。このために,シンボル内で1回だけ用い,効率的なデータ符号化(数
字データ,英数字データ,8ビットバイトデータ又は漢字データ)のために用いる最初のモード指示子の
前で,かつ,任意のECIヘッダ又は構造的連接ヘッダの後に置かなければならない。アプリケーション指
示子は,a〜z及びA〜Zの任意のラテンアルファベット文字(文字の8ビット符号値に100を加えた。)又
は二桁の数字(直接数値で表示)の形式としてもよく,復号器によって,データの直前に最初の1個又は
2個の文字として送信されなければならない。この業界仕様又はアプリケーション仕様が,データのフィ
ールド分離パターンとして用いるFNC1(他のシンボルではこの特殊文字を用いる。)を要求する場合,QR
コードシンボルは,この機能を実行するために,英数字モードにおける%又は8ビットバイトモードにお
けるIS3(1DHEX)を用いなければならない。%がデータの一部として現れる場合は,%%として符号化し
なければならない。復号器は,シンボル内で%に出会うと1DHEXとして送信し,%%の場合は,1個の%と
して送信しなければならない。
例
注記 アプリケーション指示子37は,この規格の対応国際規格の発行時には割当機関による割当
てをしておらず,例のデータ内容は,全くの架空である。
アプリケーション指示子 37
入力データ
AA1234BBB112text text text text<CR>
シンボルのビット列
1001[モード指示子 FNC1(2番目の位置)]
30
X 0510:2018 (ISO/IEC 18004:2015)
00100101(アプリケーション指示子 37)
0010(モード指示子 英数字モード)
000001100(文字数カウント指示子 12桁)
<AA1234BBB112に対するデータビット>
0100(モード指示子 8ビットバイトモード)
00010100(文字数カウント指示子 20桁)
<text text text text<CR>に対するデータビット>
送信データ
]Q537AA1234BBB112text text text text<CR>
7.4.9
終端パターン
シンボルのデータの最後は,表2で定義する0のビット列の終端パターンで示し,最終のモードセグメ
ントに続いてデータビット列に付加する。データビット列がシンボル容量を完全に満たしている場合は,
終端パターンを省略し,シンボルの残りの容量が必要な終端パターンのビット長未満の場合は短縮する。
7.4.10 コード語変換に対するビット列
各モードセグメントに対応するビット列を順番に接続しなければならない。7.4.9で定義するように,完
全なビット列に,終端パターンを付加しなければならない。次に,得られたメッセージのビット列を,コ
ード語に分割しなければならない。全てのコード語は,マイクロQRコードのM1型及びM3型の最終シ
ンボルキャラクタ(4ビット長)を除いて8ビット長である。ビット列が,コード語の境界の最後で終了
しない長さの場合には,コード語の境界まで延長するために,2進値0の埋め草ビットをデータ列の最終
ビット(最下位桁)の後に付加しなければならない。メッセージビット列は,埋め草コード語11101100及
び00010001を交互に付加することによって,表7で定義する,型番及び誤り訂正レベルに対応するシン
ボルのデータ容量を満たす長さにしなければならない。マイクロQRコードのM1型及びM3型シンボル
では,最終のコード語は,4ビット長である。マイクロQRコードのM1型及びM3型シンボルの最後のデ
ータシンボルキャラクタの位置で用いる埋め草コード語は,0000としなければならない。得られた一連の
コード語,すなわち,データコード語列は,7.5で規定するとおり処理し,誤り訂正コード語をメッセー
ジに付加する。シンボルのある型番においては,シンボル容量を完全に満たすためにメッセージの最後,
すなわち,最後の誤り訂正コード語の後に,3個,4個又は7個の残余ビット(全て値0)を付加してもよ
い(表1参照)。
31
X 0510:2018 (ISO/IEC 18004:2015)
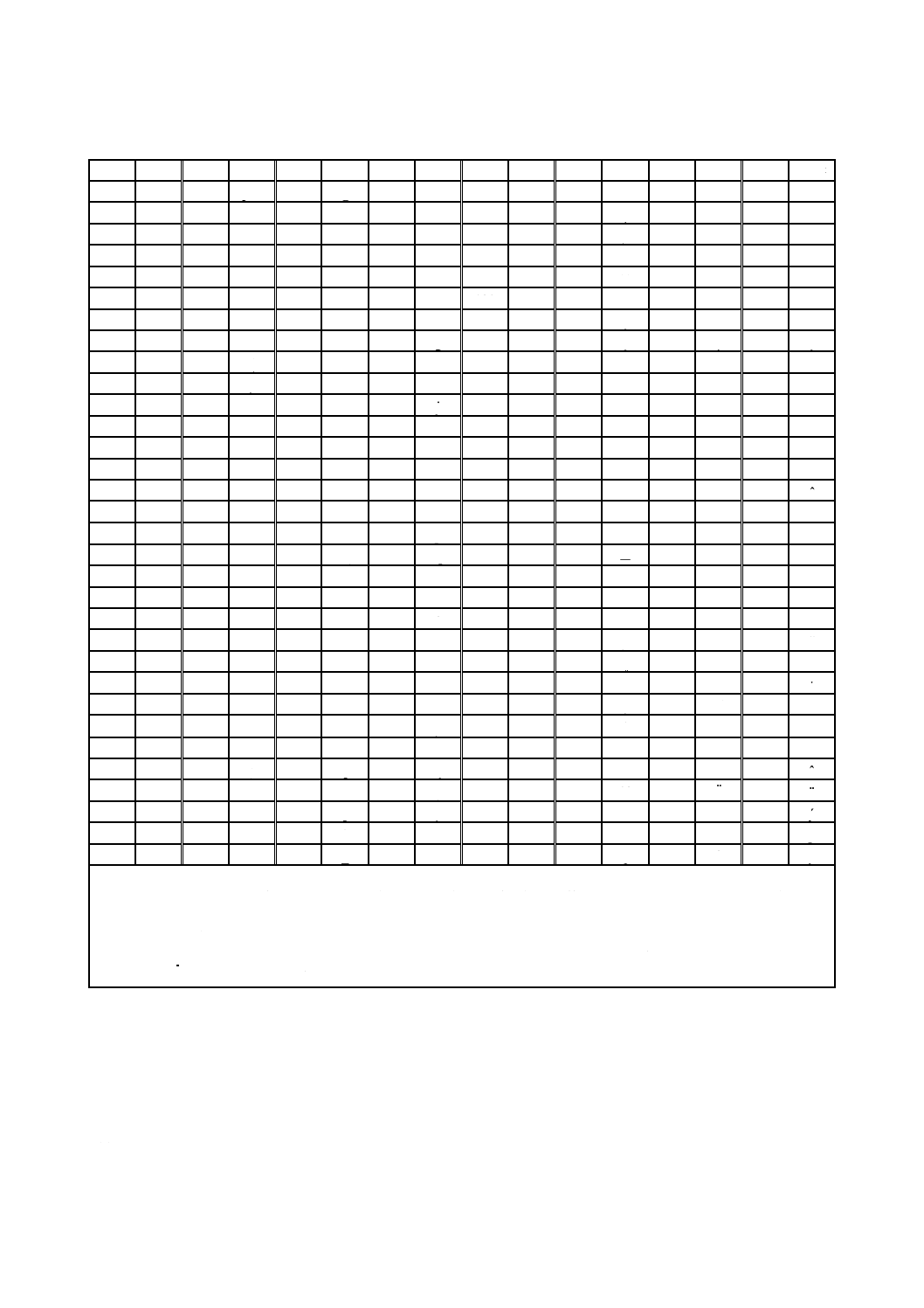
表7−QRコードのデータコード語数及び入力データ容量
型番
誤り訂正
レベル
データ
コード語数
データ
ビット数
データ容量
数字
英数字
8ビットバイト
漢字
M1
誤り検出だけ
3
20
5
−
−
−
M2
L
M
5
4
40
32
10
8
6
5
−
−
−
−
M3
L
M
11
9
84
68
23
18
14
11
9
7
6
4
M4
L
M
Q
16
14
10
128
112
80
35
30
21
21
18
13
15
13
9
9
8
5
1
L
M
Q
H
19
16
13
9
152
128
104
72
41
34
27
17
25
20
16
10
17
14
11
7
10
8
7
4
2
L
M
Q
H
34
28
22
16
272
224
176
128
77
63
48
34
47
38
29
20
32
26
20
14
20
16
12
8
3
L
M
Q
H
55
44
34
26
440
352
272
208
127
101
77
58
77
61
47
35
53
42
32
24
32
26
20
15
4
L
M
Q
H
80
64
48
36
640
512
384
288
187
149
111
82
114
90
67
50
78
62
46
34
48
38
28
21
5
L
M
Q
H
108
86
62
46
864
688
496
368
255
202
144
106
154
122
87
64
106
84
60
44
65
52
37
27
6
L
M
Q
H
136
108
76
60
1088
864
608
480
322
255
178
139
195
154
108
84
134
106
74
58
82
65
45
36
7
L
M
Q
H
156
124
88
66
1248
992
704
528
370
293
207
154
224
178
125
93
154
122
86
64
95
75
53
39
8
L
M
Q
H
194
154
110
86
1552
1232
880
688
461
365
259
202
279
221
157
122
192
152
108
84
118
93
66
52
9
L
M
Q
H
232
182
132
100
1856
1456
1056
800
552
432
312
235
335
262
189
143
230
180
130
98
141
111
80
60
32
X 0510:2018 (ISO/IEC 18004:2015)
表7−QRコードのデータコード語数及び入力データ容量(続き)
型番
誤り訂正
レベル
データ
コード語数
データ
ビット数
データ容量
数字
英数字
8ビットバイト
漢字
10
L
M
Q
H
274
216
154
122
2192
1728
1232
976
652
513
364
288
395
311
221
174
271
213
151
119
167
131
93
74
11
L
M
Q
H
324
254
180
140
2592
2032
1440
1120
772
604
427
331
468
366
259
200
321
251
177
137
198
155
109
85
12
L
M
Q
H
370
290
206
158
2960
2320
1648
1264
883
691
489
374
535
419
296
227
367
287
203
155
226
177
125
96
13
L
M
Q
H
428
334
244
180
3424
2672
1952
1440
1022
796
580
427
619
483
352
259
425
331
241
177
262
204
149
109
14
L
M
Q
H
461
365
261
197
3688
2920
2088
1576
1101
871
621
468
667
528
376
283
458
362
258
194
282
223
159
120
15
L
M
Q
H
523
415
295
223
4184
3320
2360
1784
1250
991
703
530
758
600
426
321
520
412
292
220
320
254
180
136
16
L
M
Q
H
589
453
325
253
4712
3624
2600
2024
1408
1082
775
602
854
656
470
365
586
450
322
250
361
277
198
154
17
L
M
Q
H
647
507
367
283
5176
4056
2936
2264
1548
1212
876
674
938
734
531
408
644
504
364
280
397
310
224
173
18
L
M
Q
H
721
563
397
313
5768
4504
3176
2504
1725
1346
948
746
1046
816
574
452
718
560
394
310
442
345
243
191
19
L
M
Q
H
795
627
445
341
6360
5016
3560
2728
1903
1500
1063
813
1153
909
644
493
792
624
442
338
488
384
272
208
20
L
M
Q
H
861
669
485
385
6888
5352
3880
3080
2061
1600
1159
919
1249
970
702
557
858
666
482
382
528
410
297
235
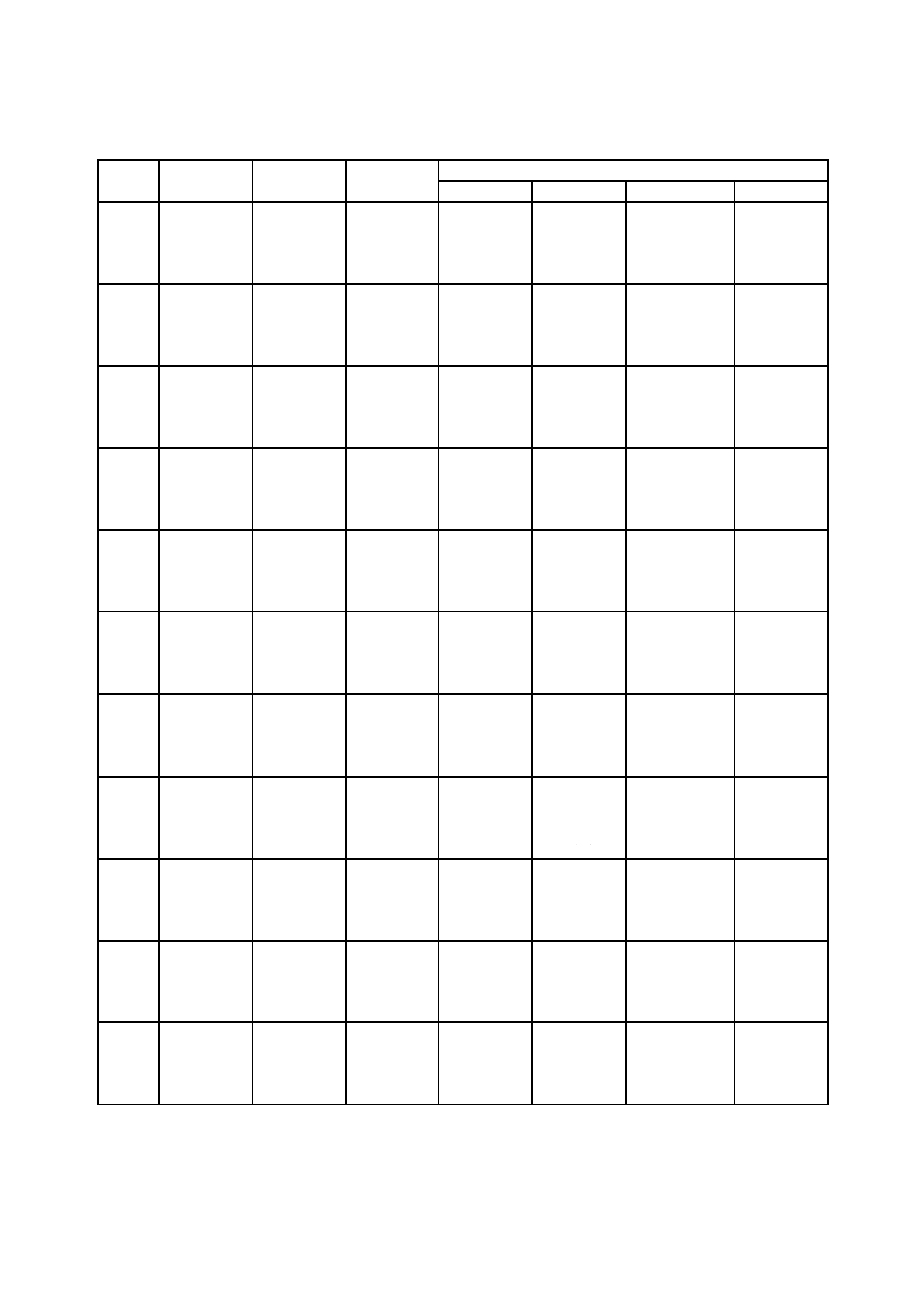
33
X 0510:2018 (ISO/IEC 18004:2015)
表7−QRコードのデータコード語数及び入力データ容量(続き)
型番
誤り訂正
レベル
データ
コード語数
データ
ビット数
データ容量
数字
英数字
8ビットバイト
漢字
21
L
M
Q
H
932
714
512
406
7456
5712
4096
3248
2232
1708
1224
969
1352
1035
742
587
929
711
509
403
572
438
314
248
22
L
M
Q
H
1006
782
568
442
8048
6256
4544
3536
2409
1872
1358
1056
1460
1134
823
640
1003
779
565
439
618
480
348
270
23
L
M
Q
H
1094
860
614
464
8752
6880
4912
3712
2620
2059
1468
1108
1588
1248
890
672
1091
857
611
461
672
528
376
284
24
L
M
Q
H
1174
914
664
514
9392
7312
5312
4112
2812
2188
1588
1228
1704
1326
963
744
1171
911
661
511
721
561
407
315
25
L
M
Q
H
1276
1000
718
538
10208
8000
5744
4304
3057
2395
1718
1286
1853
1451
1041
779
1273
997
715
535
784
614
440
330
26
L
M
Q
H
1370
1062
754
596
10960
8496
6032
4768
3283
2544
1804
1425
1990
1542
1094
864
1367
1059
751
593
842
652
462
365
27
L
M
Q
H
1468
1128
808
628
11744
9024
6464
5024
3517
2701
1933
1501
2132
1637
1172
910
1465
1125
805
625
902
692
496
385
28
L
M
Q
H
1531
1193
871
661
12248
9544
6968
5288
3669
2857
2085
1581
2223
1732
1263
958
1528
1190
868
658
940
732
534
405
29
L
M
Q
H
1631
1267
911
701
13048
10136
7288
5608
3909
3035
2181
1677
2369
1839
1322
1016
1628
1264
908
698
1002
778
559
430
30
L
M
Q
H
1735
1373
985
745
13880
10984
7880
5960
4158
3289
2358
1782
2520
1994
1429
1080
1732
1370
982
742
1066
843
604
457
31
L
M
Q
H
1843
1455
1033
793
14744
11640
8264
6344
4417
3486
2473
1897
2677
2113
1499
1150
1840
1452
1030
790
1132
894
634
486
34
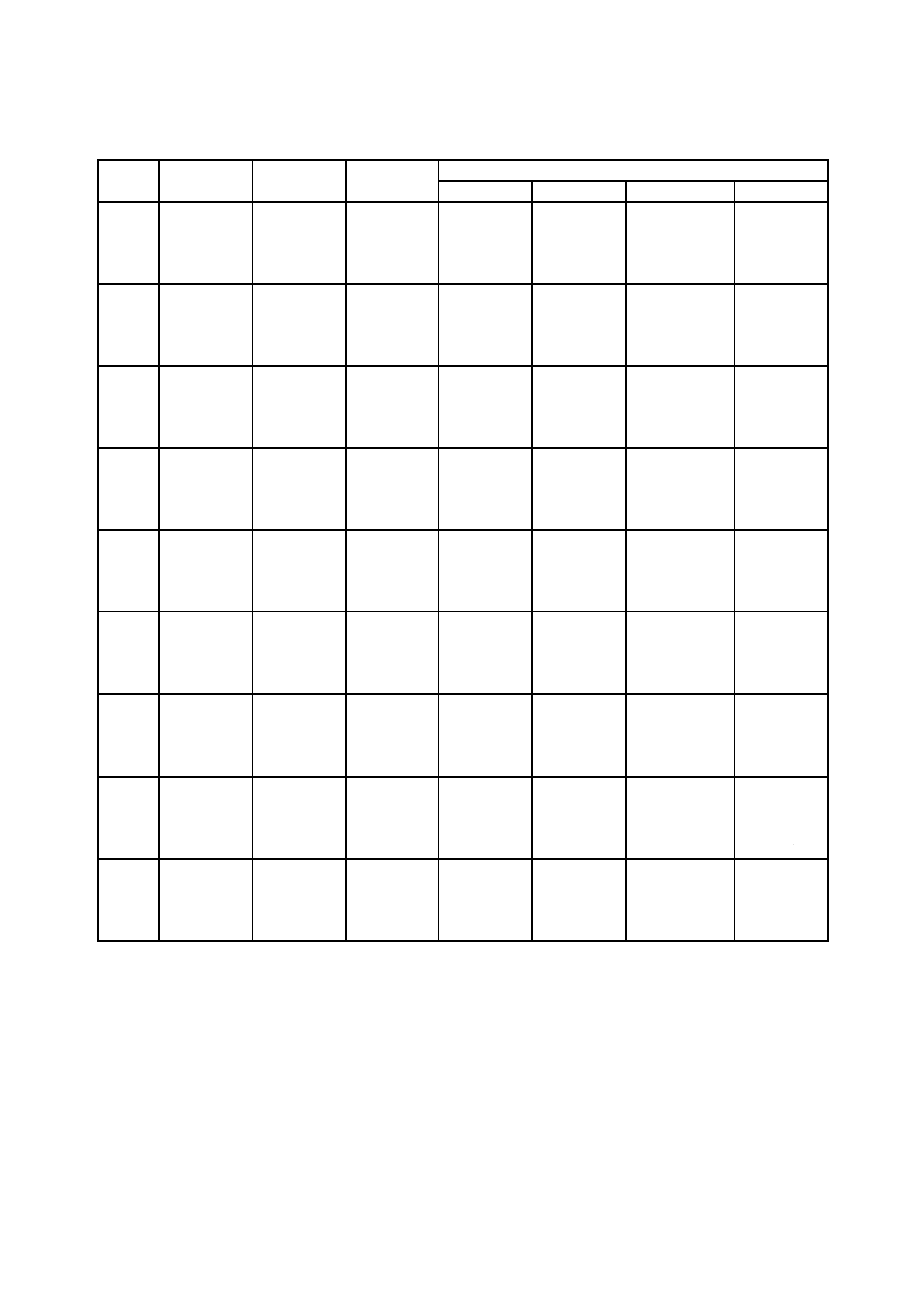
X 0510:2018 (ISO/IEC 18004:2015)
表7−QRコードのデータコード語数及び入力データ容量(続き)
型番
誤り訂正
レベル
データ
コード語数
データ
ビット数
データ容量
数字
英数字
8ビットバイト
漢字
32
L
M
Q
H
1955
1541
1115
845
15640
12328
8920
6760
4686
3693
2670
2022
2840
2238
1618
1226
1952
1538
1112
842
1201
947
684
518
33
L
M
Q
H
2071
1631
1171
901
16568
13048
9368
7208
4965
3909
2805
2157
3009
2369
1700
1307
2068
1628
1168
898
1273
1002
719
553
34
L
M
Q
H
2191
1725
1231
961
17528
13800
9848
7688
5253
4134
2949
2301
3183
2506
1787
1394
2188
1722
1228
958
1347
1060
756
590
35
L
M
Q
H
2306
1812
1286
986
18448
14496
10288
7888
5529
4343
3081
2361
3351
2632
1867
1431
2303
1809
1283
983
1417
1113
790
605
36
L
M
Q
H
2434
1914
1354
1054
19472
15312
10832
8432
5836
4588
3244
2524
3537
2780
1966
1530
2431
1911
1351
1051
1496
1176
832
647
37
L
M
Q
H
2566
1992
1426
1096
20528
15936
11408
8768
6153
4775
3417
2625
3729
2894
2071
1591
2563
1989
1423
1093
1577
1224
876
673
38
L
M
Q
H
2702
2102
1502
1142
21616
16816
12016
9136
6479
5039
3599
2735
3927
3054
2181
1658
2699
2099
1499
1139
1661
1292
923
701
39
L
M
Q
H
2812
2216
1582
1222
22496
17728
12656
9776
6743
5313
3791
2927
4087
3220
2298
1774
2809
2213
1579
1219
1729
1362
972
750
40
L
M
Q
H
2956
2334
1666
1276
23648
18672
13328
10208
7089
5596
3993
3057
4296
3391
2420
1852
2953
2331
1663
1273
1817
1435
1024
784
注記1 全てのコード語は,M1型及びM3型の最終データコード語の4ビット長を除き,8ビット長
である。
注記2 データビット数には,モード指示子及び文字数指示子も含んでいる。
7.5
誤り訂正
7.5.1
誤り訂正能力
QRコードは,誤りを検出して訂正する,RS誤り訂正符号を使用する。データを損失することなく,シ
ンボルが損傷に耐えることができるよう,データコード語列に付加する一連の誤り訂正コード語を生成す
る。誤り訂正には,表8に示すように利用者が選択できる4段階のレベルがあり,次のように損傷の度合

35
X 0510:2018 (ISO/IEC 18004:2015)
いに応じた復元能力が得られる。
表8−誤り訂正レベル
誤り訂正レベル
復元能力%(概数)
L
7
M
15
Q
25
H
30
K.2に,シンボルに適用する誤り訂正の適正レベルに関する手引を示す。
誤り訂正レベルHは,マイクロQRコードでは用いることができない。
誤り訂正コード語は,2種類の誤りコード語,すなわち,消失誤り(位置が分かっている誤りコード語)
及び代入誤り(位置が分からない誤りコード語)を訂正することができる。消失誤りは,未走査又は復号
不能のシンボルキャラクタとする。代入誤りは,間違って復号したシンボルキャラクタとする。QRコー
ドは,マトリックス式シンボル体系のため,暗から明へ又は明から暗へのモジュール変換での不具合は,
シンボルキャラクタとしては有効であるが,異なるコード語に復号する結果になる。データ内におけるそ
のような代入誤りを訂正するには,2個の誤り訂正コード語が必要となる。
訂正可能な消失誤り及び代入誤りの数は,次の式で得られる。
e+2t≦d−p
ここに,
e: 消失誤りの数
t: 代入誤りの数
d: 誤り訂正コード語の数
p: 誤り検出用に予約されたコード語の数
一般的な場合,p=0である。しかし,誤り訂正能力のほとんどが消失誤りの訂正に用いられた場合には,
代入誤りが検出されない可能性が増加する。消失誤りの数が,誤り訂正コード語数の半分よりも多い場合
には,いつでもp=3とする。誤り訂正コード語数が8個よりも少ない小さなシンボルに対して,消失誤り
の訂正を用いないのが望ましい(e=0かつp>0)。
例えば,6-H型には,全部で172のコード語があり,そのうちの112が誤り訂正コード語である(残り
の60は,データコード語である。)。112個の誤り訂正コード語は,56の復号誤り又は代入誤りを訂正する
ことができる(すなわち,56/172又はシンボル容量の32.6 %)。
上の式において,次の値をpに代入するのがよい。
− p=3 1-L型及びM2-L型シンボルの場合。
− p=2 1-M型,2-L型,M1型,M2-M型,M3-L型及びM4-L型シンボルの場合。
− p=1 1-Q型,1-H型及び3-L型シンボルの場合。
− p=0 その他全ての場合。
p>0の場合,誤り検出コード語として機能し,誤り数が誤り訂正能力を超える場合に,シンボルからの
データ送信を防止するコード語がp(すなわち1,2又は3)個となり,eは,d/2未満となる。例えば,2-L
型において,コード語の合計が44の場合,そのうち34は,データコード語で,10が誤り訂正コード語と
なる。表9から,e=0とした場合,誤り訂正能力は,4であることが分かる。上の式に代入すると,次の
とおりになる。
0+(2×4)=10−2
36
X 0510:2018 (ISO/IEC 18004:2015)
この式は,4個の誤り訂正には8個の誤り訂正コード語が必要で,残りの2個の誤り訂正コード語はそ
れに加えて他の誤りを検出(訂正ではない。)することができ,誤りが4個を超える場合,復号できないこ
とを示す。
型番及び誤り訂正レベルによっては,データコード語列を一つ以上のブロックに分けなければならない。
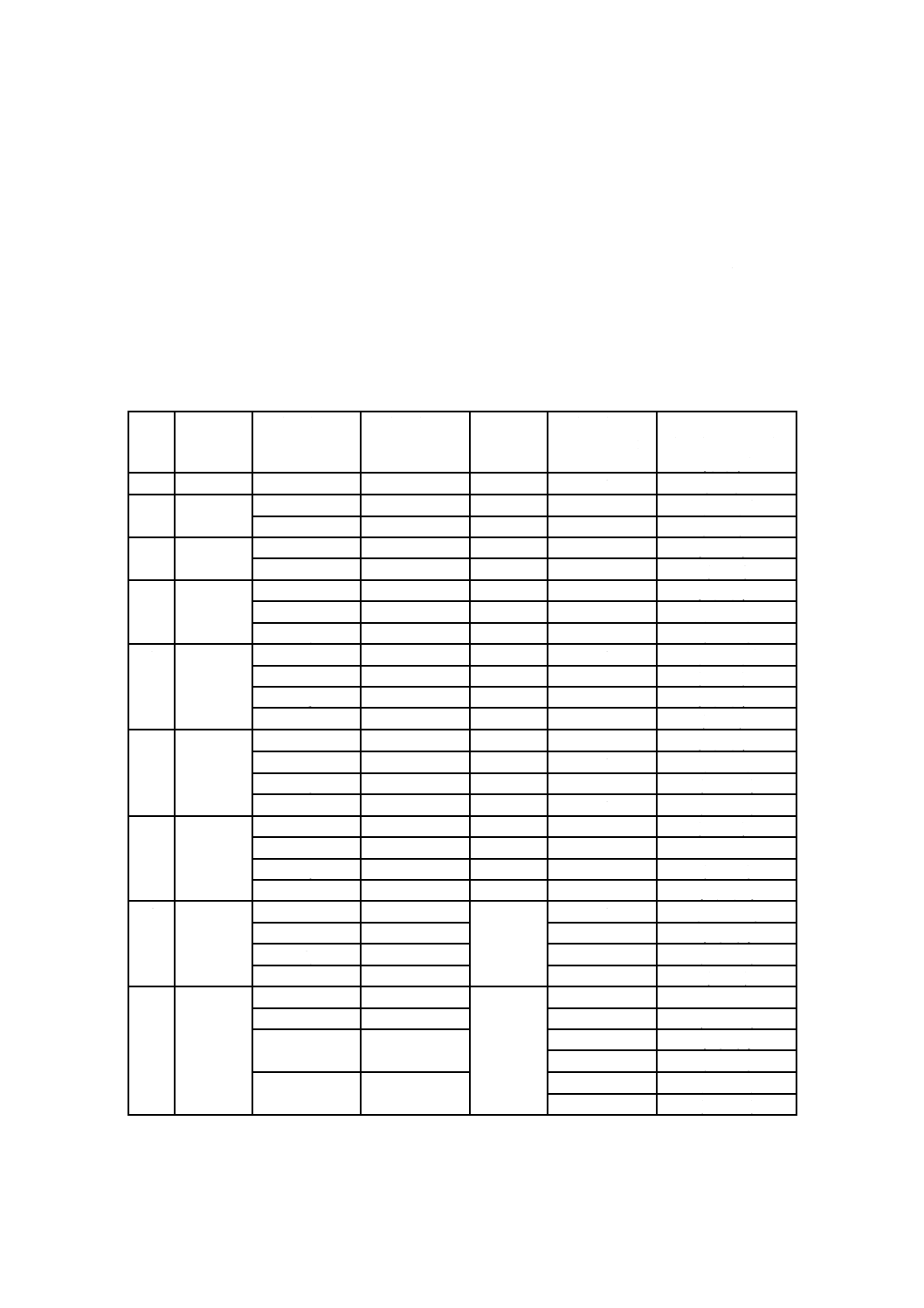
それぞれのブロックに対し,誤り訂正アルゴリズムを別々に適用しなければならない。表9に,各型番及
び誤り訂正レベルについて,コード語の総数,誤り訂正コード語の総数,並びに誤り訂正ブロックの構造
及び数を示す。
シンボル容量の残りを満たすために残余ビットが必要な型番に対しては,それらのビットは,4.15に定
義するとおり,全て0としなければならない。
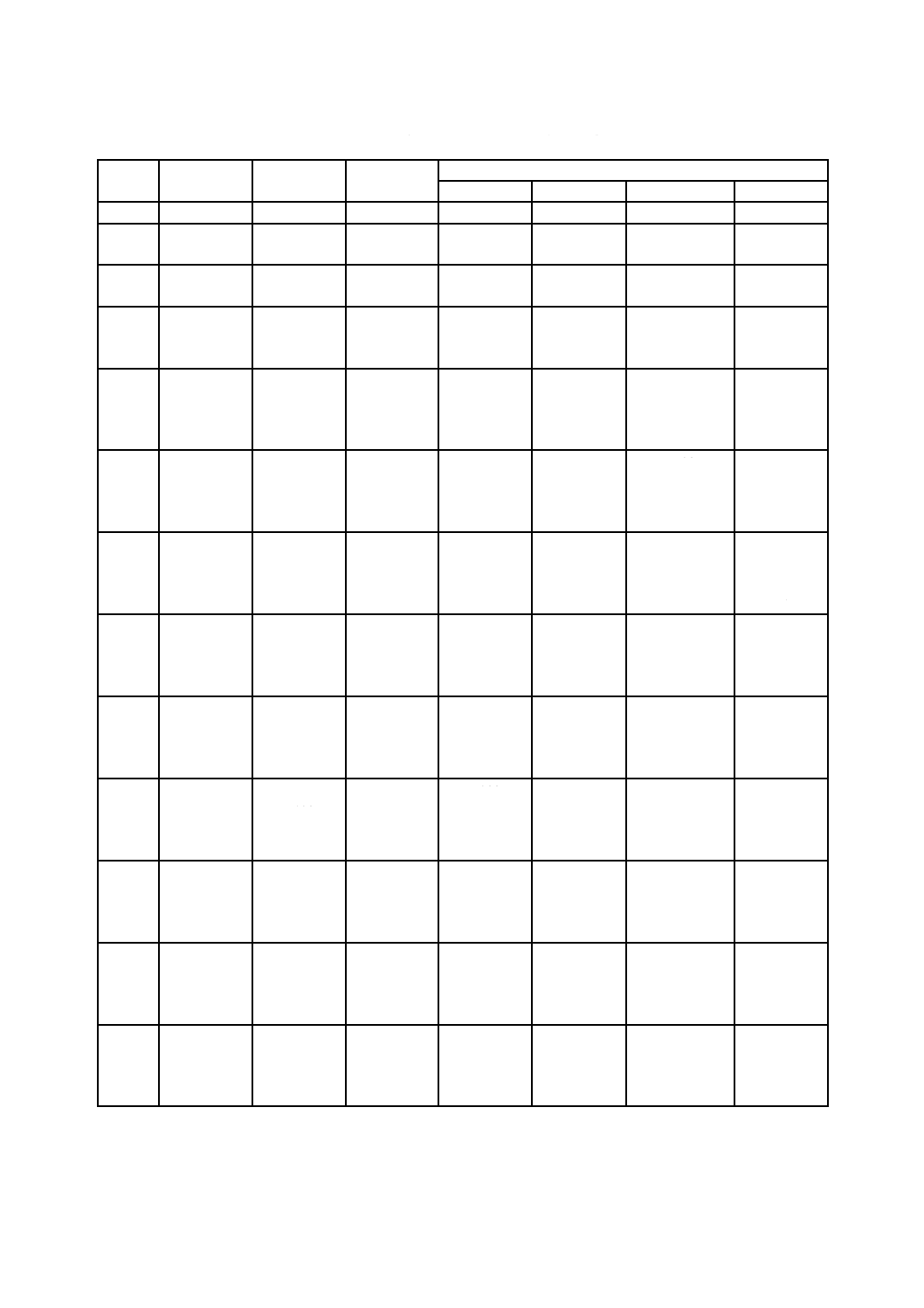
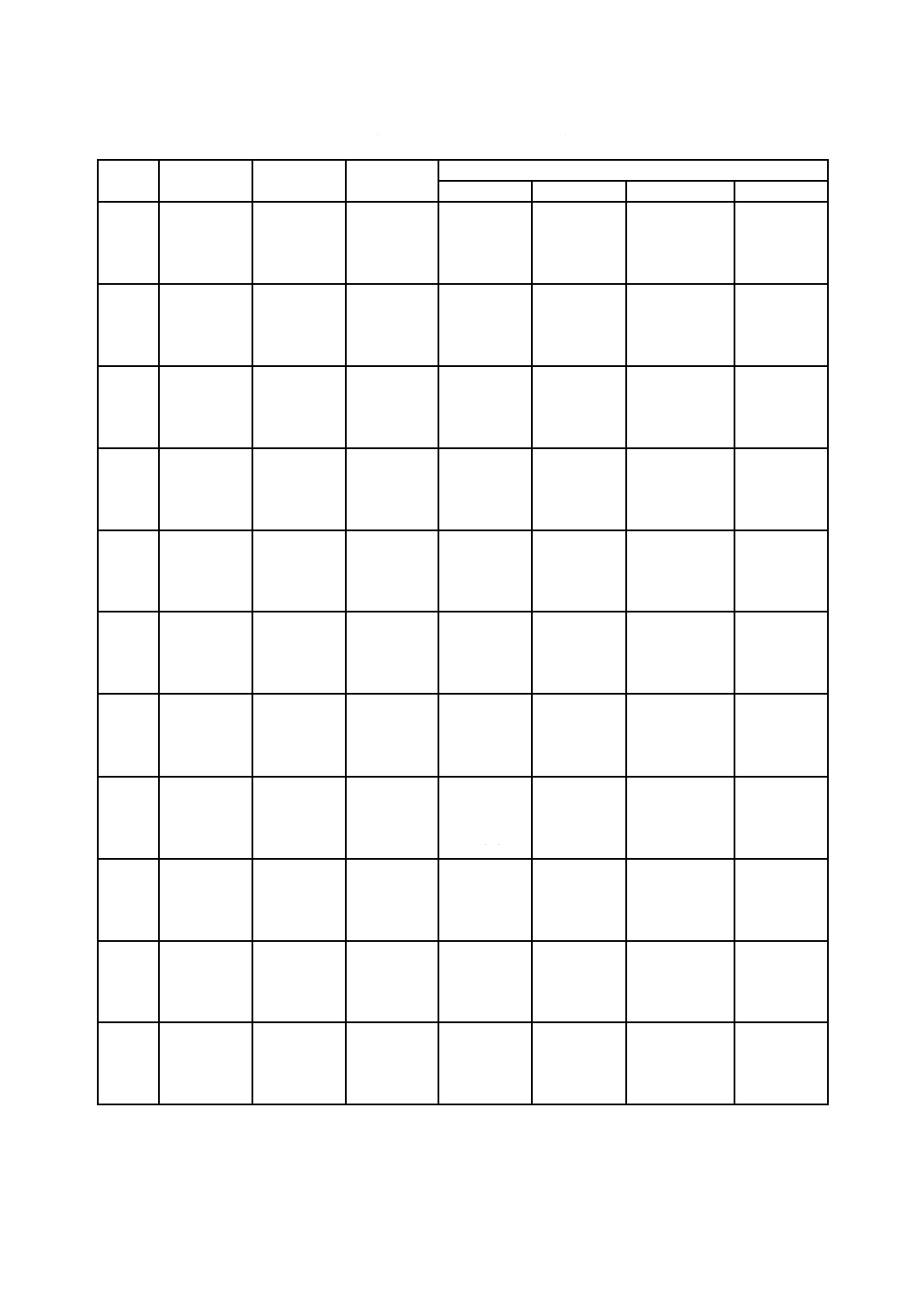
表9−マイクロQRコード及びQRコードの誤り訂正特性
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
M1
5
誤り検出だけ
2
2
1
(5,3,0) b)
M2
10
L
5
3
1
(10,5,1) b)
M
6
2
1
(10,4,2) b)
M3
17
L
6
2
1
(17,11,2) b)
M
8
2
1
(17,9,4)
M4
24
L
8
2
1
(24,16,3) b)
M
10
0
1
(24,14,5)
Q
14
0
1
(24,10,7)
1
26
L
7
3
1
(26,19,2) b)
M
10
2
1
(26,16,4) b)
Q
13
1
1
(26,13,6) b)
H
17
1
1
(26,9,8) b)
2
44
L
10
2
1
(44,34,4) b)
M
16
0
1
(44,28,8)
Q
22
0
1
(44,22,11)
H
28
0
1
(44,16,14)
3
70
L
15
1
1
(70,55,7) b)
M
26
0
1
(70,44,13)
Q
36
0
2
(35,17,9)
H
44
0
2
(35,13,11)
4
100
L
20
0
1
(100,80,10)
M
36
2
(50,32,9)
Q
52
2
(50,24,13)
H
64
4
(25,9,8)
5
134
L
26
0
1
(134,108,13)
M
48
2
(67,43,12)
Q
72
2
(33,15,9)
2
(34,16,9)
H
88
2
(33,11,11)
2
(34,12,11)
37
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
6
172
L
36
0
2
(86,68,9)
M
64
4
(43,27,8)
Q
96
4
(43,19,12)
H
112
4
(43,15,14)
7
196
L
40
0
2
(98,78,10)
M
72
4
(49,31,9)
Q
108
2
(32,14,9)
4
(33,15,9)
H
130
4
(39,13,13)
1
(40,14,13)
8
242
L
48
0
2
(121,97,12)
M
88
2
(60,38,11)
2
(61,39,11)
Q
132
4
(40,18,11)
2
(41,19,11)
H
156
4
(40,14,13)
2
(41,15,13)
9
292
L
60
0
2
(146,116,15)
M
110
3
(58,36,11)
2
(59,37,11)
Q
160
4
(36,16,10)
4
(37,17,10)
H
192
4
(36,12,12)
4
(37,13,12)
10
346
L
72
0
2
(86,68,9)
2
(87,69,9)
M
130
4
(69,43,13)
1
(70,44,13)
Q
192
6
(43,19,12)
2
(44,20,12)
H
224
6
(43,15,14)
2
(44,16,14)
11
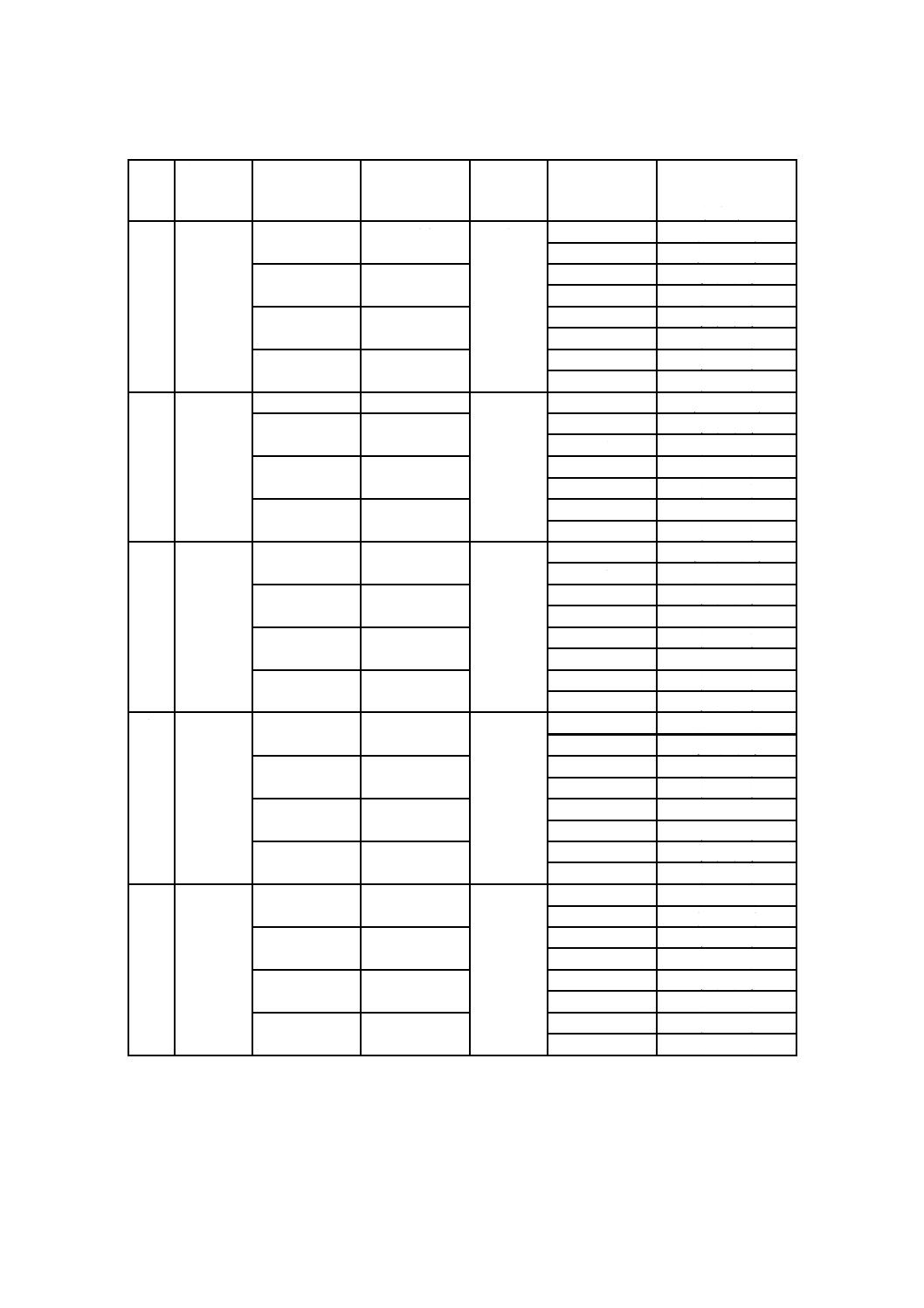
404
L
80
0
4
(101,81,10)
M
150
1
(80,50,15)
4
(81,51,15)
Q
224
4
(50,22,14)
4
(51,23,14)
H
264
3
(36,12,12)
8
(37,13,12
38
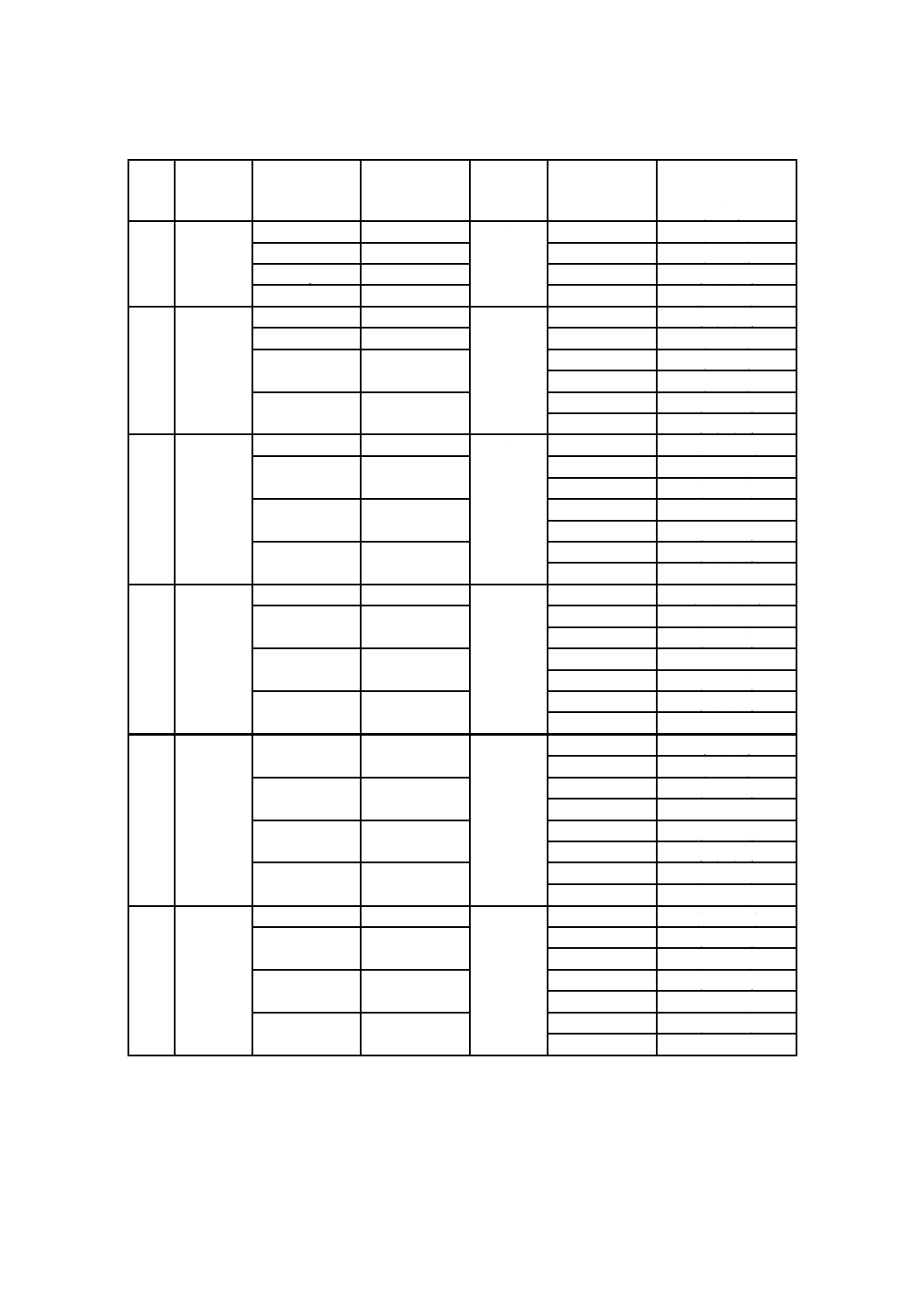
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
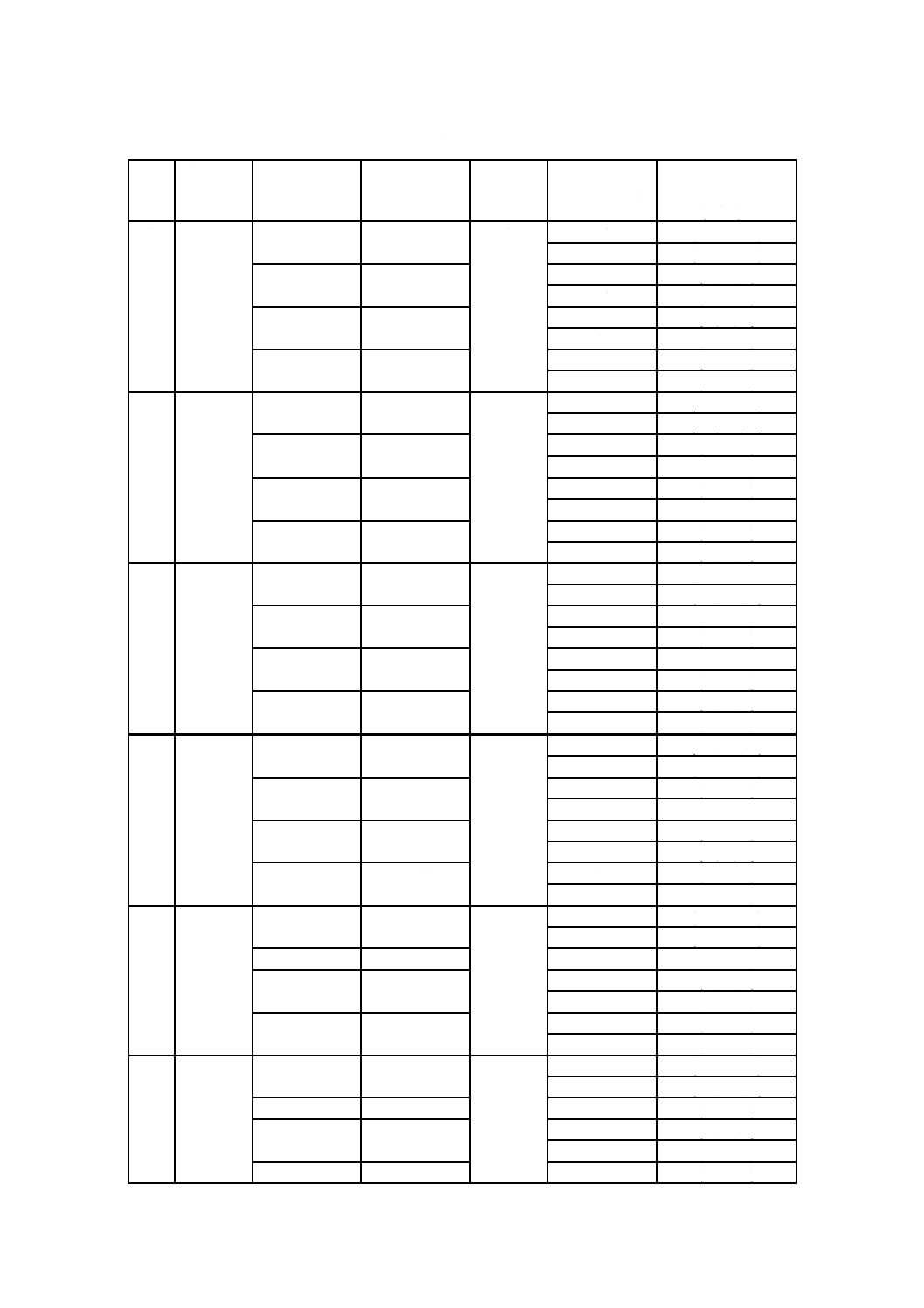
12
466
L
96
0
2
(116,92,12)
2
(117,93,12)
M
176
6
(58,36,11)
2
(59,37,11)
Q
260
4
(46,20,13)
6
(47,21,13)
H
308
7
(42,14,14)
4
(43,15,14)
13
532
L
104
0
4
(133,107,13)
M
198
8
(59,37,11)
1
(60,38,11)
Q
288
8
(44,20,12)
4
(45,21,12)
H
352
12
(33,11,11)
4
(34,12,11)
14
581
L
120
0
3
(145,115,15)
1
(146,116,15)
M
216
4
(64,40,12)
5
(65,41,12)
Q
320
11
(36,16,10)
5
(37,17,10)
H
384
11
(36,12,12)
5
(37,13,12)
15
655
L
132
0
5
(109,87,11)
1
(110,88,11)
M
240
5
(65,41,12)
5
(66,42,12)
Q
360
5
(54,24,15)
7
(55,25,15)
H
432
11
(36,12,12)
7
(37,13,12)
16
733
L
144
0
5
(122,98,12)
1
(123,99,12)
M
280
7
(73,45,14)
3
(74,46,14)
Q
408
15
(43,19,12)
2
(44,20,12)
H
480
3
(45,15,15)
13
(46,16,15)
39
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
17
815
L
168
0
1
(135,107,14)
5
(136,108,14)
M
308
10
(74,46,14)
1
(75,47,14)
Q
448
1
(50,22,14)
15
(51,23,14)
H
532
2
(42,14,14)
17
(43,15,14)
18
901
L
180
0
5
(150,120,15)
1
(151,121,15)
M
338
9
(69,43,13)
4
(70,44,13)
Q
504
17
(50,22,14)
1
(51,23,14)
H
588
2
(42,14,14)
19
(43,15,14)
19
991
L
196
0
3
(141,113,14)
4
(142,114,14)
M
364
3
(70,44,13)
11
(71,45,13)
Q
546
17
(47,21,13)
4
(48,22,13)
H
650
9
(39,13,13)
16
(40,14,13)
20
1085
L
224
0
3
(135,107,14)
5
(136,108,14)
M
416
3
(67,41,13)
13
(68,42,13)
Q
600
15
(54,24,15)
5
(55,25,15)
H
700
15
(43,15,14)
10
(44,16,14)
21
1156
L
224
0
4
(144,116,14)
4
(145,117,14)
M
442
17
(68,42,13)
Q
644
17
(50,22,14)
6
(51,23,14)
H
750
19
(46,16,15)
6
(47,17,15)
22
1258
L
252
0
2
(139,111,14)
7
(140,112,14)
M
476
17
(74,46,14)
Q
690
7
(54,24,15)
16
(55,25,15)
H
816
34
(37,13,12)
40
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
23
1364
L
270
0
4
(151,121,15)
5
(152,122,15)
M
504
4
(75,47,14)
14
(76,48,14)
Q
750
11
(54,24,15)
14
(55,25,15)
H
900
16
(45,15,15)
14
(46,16,15)
24
1474
L
300
0
6
(147,117,15)
4
(148,118,15)
M
560
6
(73,45,14)
14
(74,46,14)
Q
810
11
(54,24,15)
16
(55,25,15)
H
960
30
(46,16,15)
2
(47,17,15)
25
1588
L
312
0
8
(132,106,13)
4
(133,107,13)
M
588
8
(75,47,14)
13
(76,48,14)
Q
870
7
(54,24,15)
22
(55,25,15)
H
1050
22
(45,15,15)
13
(46,16,15)
26
1706
L
336
0
10
(142,114,14)
2
(143,115,14)
M
644
19
(74,46,14)
4
(75,47,14)
Q
952
28
(50,22,14)
6
(51,23,14)
H
1110
33
(46,16,15)
4
(47,17,15)
27
1828
L
360
0
8
(152,122,15)
4
(153,123,15)
M
700
22
(73,45,14)
3
(74,46,14)
Q
1020
8
(53,23,15)
26
(54,24,15)
H
1200
12
(45,15,15)
28
(46,16,15)
41
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
28
1921
L
390
0
3
(147,117,15)
10
(148,118,15)
M
728
3
(73,45,14)
23
(74,46,14)
Q
1050
4
(54,24,15)
31
(55,25,15)
H
1260
11
(45,15,15)
31
(46,16,15)
29
2051
L
420
0
7
(146,116,15)
7
(147,117,15)
M
784
21
(73,45,14)
7
(74,46,14)
Q
1140
1
(53,23,15)
37
(54,24,15)
H
1350
19
(45,15,15)
26
(46,16,15)
30
2185
L
450
0
5
(145,115,15)
10
(146,116,15)
M
812
19
(75,47,14)
10
(76,48,14)
Q
1200
15
(54,24,15)
25
(55,25,15)
H
1440
23
(45,15,15)
25
(46,16,15)
31
2323
L
480
0
13
(145,115,15)
3
(146,116,15)
M
868
2
(74,46,14)
29
(75,47,14)
Q
1290
42
(54,24,15)
1
(55,25,15)
H
1530
23
(45,15,15)
28
(46,16,15)
32
2465
L
510
0
17
(145,115,15)
M
924
10
(74,46,14)
23
(75,47,14)
Q
1350
10
(54,24,15)
35
(55,25,15)
H
1620
19
(45,15,15)
35
(46,16,15)
42
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
33
2611
L
540
0
17
(145,115,15)
1
(146,116,15)
M
980
14
(74,46,14)
21
(75,47,14)
Q
1440
29
(54,24,15)
19
(55,25,15)
H
1710
11
(45,15,15)
46
(46,16,15)
34
2761
L
570
0
13
(145,115,15)
6
(146,116,15)
M
1036
14
(74,46,14)
23
(75,47,14)
Q
1530
44
(54,24,15)
7
(55,25,15)
H
1800
59
(46,16,15)
1
(47,17,15)
35
2876
L
570
0
12
(151,121,15)
7
(152,122,15)
M
1064
12
(75,47,14)
26
(76,48,14)
Q
1590
39
(54,24,15)
14
(55,25,15)
H
1890
22
(45,15,15)
41
(46,16,15)
36
3034
L
600
0
6
(151,121,15)
14
(152,122,15)
M
1120
6
(75,47,14)
34
(76,48,14)
Q
1680
46
(54,24,15)
10
(55,25,15)
H
1980
2
(45,15,15)
64
(46,16,15)
37
3196
L
630
0
17
(152,122,15)
4
(153,123,15)
M
1204
29
(74,46,14)
14
(75,47,14)
Q
1770
49
(54,24,15)
10
(55,25,15)
H
2100
24
(45,15,15)
46
(46,16,15)
43
X 0510:2018 (ISO/IEC 18004:2015)
表9−マイクロQRコード及びQRコードの誤り訂正特性(続き)
型番
総コード
語数
誤り訂正
レベル
誤り訂正
コード語数
pの値
誤り訂正
ブロック数
ブロック当たりの
誤り訂正コード語
(c, k, r) a)
38
3362
L
660
0
4
(152,122,15)
18
(153,123,15)
M
1260
13
(74,46,14)
32
(75,47,14)
Q
1860
48
(54,24,15)
14
(55,25,15)
H
2220
42
(45,15,15)
32
(46,16,15)
39
3532
L
720
0
20
(147,117,15)
4
(148,118,15)
M
1316
40
(75,47,14)
7
(76,48,14)
Q
1950
43
(54,24,15)
22
(55,25,15)
H
2310
10
(45,15,15)
67
(46,16,15)
40
3706
L
750
0
19
(148,118,15)
6
(149,119,15)
M
1372
18
(75,47,14)
31
(76,48,14)
Q
2040
34
(54,24,15)
34
(55,25,15)
H
2430
20
(45,15,15)
61
(46,16,15)
注a) c=総コード語数,k=データコード語数及びr=誤り訂正能力を示す。
b) 誤り訂正能力は,復号誤りの可能性を低減するため,誤り訂正コード語の半分未満となっている。
7.5.2
訂正コード語の生成
データコード語(必要に応じ,埋め草コード語を含む。)は,表9で示すブロック数に分割しなければな
らない。誤り訂正コード語は,各ブロックに対して計算し,データコード語に付加しなければならない。
注記1 マイクロQRコードは単一のブロックからなる。
QRコードの多項式は,ビットごとのモジュロ2演算及びバイトごとのモジュロ100011101演算を用い
て計算しなければならない。これは,体を表す原始多項式x8+x4+x3+x2+1の係数を示す100011101をも
つ28のガロア体である。
データコード語は,最初の誤り訂正コード語の前にある多項式の項の係数で,最高次項を最初のデータ
コード語,最低次項を最終データコード語とする。
誤り訂正コード語は,誤り訂正コード(附属書A参照)で用いる多項式g(x)によってデータコード語を
除算して得られた剰余とする。この剰余の最上位係数が最初の誤り訂正コード語となり,ゼロ乗の係数が
最終誤り訂正コード語で,ブロックにおける最終コード語となる。
注記2 “長除法”によってこの計算を実行する場合,シンボルデータ多項式は,最初にxkを乗算す
る必要がある。
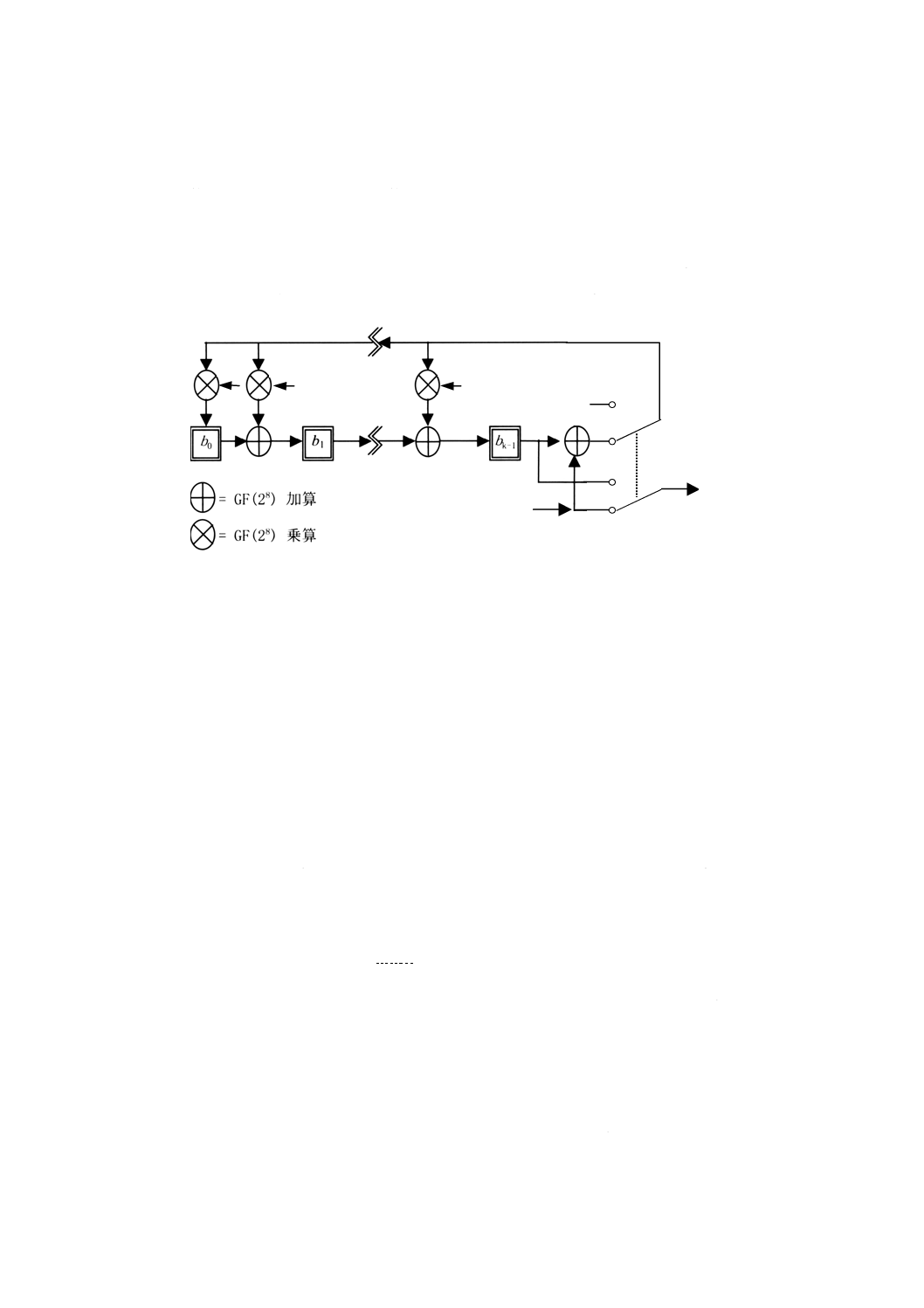
44
X 0510:2018 (ISO/IEC 18004:2015)
QRコード及びマイクロQRコードの誤り訂正コード語の生成には,36の異なる生成多項式を用いる。
附属書Aにこれらの式を示す。
これらの演算は,図14に示すような除算回路を用いて実施することができる。レジスタb0〜bk-1は,0
で初期化する。符号化には2段階がある。第1段階では,データコード語は,スイッチが下向きの状態で
出力及び回路の両方を通過することになる。第1段階は,n個のクロックパルスの後に終了する。第2段
階(n+1,…,n+k回のクロックパルス)では,スイッチを上向きの状態にして,データ入力を0で保持
している間レジスタを順送りにし,誤り訂正コード語εk-1,…,ε0を生成する。
入力
0
出力
gk-1
g1
g0
スイッチ
図14−誤り訂正コード語の符号化回路
7.6
最終的なメッセージコード語列の構成
メッセージのコード語の総数は,表7及び表9で示すように,シンボル表示が可能なコード語の総数と
常に等しくなければならない。
コード語の最終列(データ,誤り訂正コード語及び必要であれば,残余コード語を付加する。)を構成す
るには,次の手順に従わなければならない。
a) 表9で定義する型番及び誤り訂正レベルに基づき,データコード語列をn個のブロック(又はマイク
ロQRコードでは,一つのブロック)に分割する。
b) 各データブロックに対して,7.5.2及び附属書Aで定義するように,対応するデータブロックの誤り訂
正コード語を計算する。
c) 各ブロックからデータコード語と誤り訂正コード語とを順次取り出し,最終列を構成する。例えば,
図15のように,四つのデータブロックがある場合の順番は,次のとおりである。データブロック1〜
データブロック4の最初のコード語(D1),データブロック1〜データブロック4の2番目のコード語
(D12),…データブロック1〜データブロック4の最終コード語(D46),次に誤り訂正ブロック1〜誤
り訂正ブロック4の最初のコード語(E1),誤り訂正ブロック1〜誤り訂正ブロック4の2番目のコー
ド語(E23),…誤り訂正ブロック1〜誤り訂正ブロック4の最終コード語(E88)を並べて,QRコード
シンボルとする。QRコードシンボルは,シンボルのコード語サイズを常に満たすデータ及び誤り訂
正ブロックで構成する。しかし,ある型番(データコード語及び誤り訂正コード語に利用できるモジ
ュール数が正確に8の倍数でない。)においては,符号化領域のモジュール数を完全に満たすため,最
終メッセージのビット列に付加する3個,4個又は7個の残余ビットを必要とする。
一番短いデータブロックをデータ列の最初に配置し,全てのデータコード語は,最初の誤り訂正コード
語の前に配置しなければならない。例えば,5-H型シンボルは,4個のデータブロック及び誤り訂正ブロ
ックで構成するが,最初の2ブロックは,それぞれ11個のデータコード語及び22個の誤り訂正コード語
45
X 0510:2018 (ISO/IEC 18004:2015)
を含み,一方,3番目及び4番目のブロックは,それぞれ12個のデータコード語及び22個の誤り訂正コ
ード語を含む。このシンボルにおけるキャラクタ配列は,図15のように表現できる。図の各行は,一つ
のデータコード語(Dnで示す。)のブロック及び後に続く関連する誤り訂正コード語(Enで示す。)のブロ
ックに対応する。シンボルにおけるキャラクタ配置の列は,表の各列を順次,下にとっていくことで得ら
れる。
データコード語
誤り訂正コード語
ブロック1
Dl
D2
…
D11
E1
E2
…
E22
ブロック2
D12
D13
…
D22
E23
E24
…
E44
ブロック3
D23
D24
…
D33
D34
E45
E46
…
E66
ブロック4
D35
D36
…
D45
D46
E67
E68
…
E88
図15−最終的なメッセージコード語列の構成
したがって,5-H型シンボルにおける最終的なメッセージコード語列は,次のようになる。すなわち,
D1,D12,D23,D35,D2,D13,D24,D36,…D11,D22,D33,D45,D34,D46,E1,E23,E45,E67,E2,E24,
E46,E68,…E22,E44,E66,E88となる。最終コード語の後に必要な7ビットの残余ビット“0”を付加する
ことでシンボルのモジュール容量を満たす。
7.7
マトリックスにおけるコード語の配置
7.7.1
シンボルキャラクタの表示
QRコードシンボルには,規則的及び不規則的な2種類のシンボルキャラクタがある。これらの使用は,
シンボルの中での位置に依存し,他のシンボルキャラクタ及び機能パターンに関係する。
シンボルにおいて多くのコード語は,規則的な2×4モジュールブロックとして表示しなければならない。
これらのブロックの配置は,2種類とし,垂直配列(幅が2モジュール,高さが4モジュール)と,必要
に応じて配列方向を変更する場合の水平配列(幅が4モジュール,高さが2モジュール)とになる。不規
則的なシンボルキャラクタは,配列方向が変わる場合又は位置合せパターン若しくは他の機能パターン付
近で用いる。
7.7.2
機能パターンの配置
用いる型番に対応した数の水平及び垂直に配置するモジュールで正方形の空マトリックスを構成しなけ
ればならない。位置検出パターン,分離パターン,タイミングパターン及び位置合せパターンに対応する
位置は,特定の暗モジュール又は明モジュールで占めなければならない。形式情報及び型番情報のモジュ
ール位置は,一時的に空としなければならない。これらの位置は,全ての型番(型番1〜型番6には型番
情報は,存在しないが)に共通し,図19及び図20に示す。位置合せパターンの位置については,附属書
Eに規定する。
7.7.3
シンボルキャラクタの配置
QRコードシンボルの符号化領域において,シンボルキャラクタは,2モジュール幅の縦列で,シンボル
の右下隅から開始し,上方向及び下方向を交互に走査し,右から左へ配置する。主なキャラクタ及びキャ
ラクタ内のビット配置方法については,次による。これらの規則を適用した2型及び7型のシンボルを図
19及び図20に示す。
a) 列におけるビット配列方向は,右から左とし,シンボルキャラクタの配置方向によって上向き又は下
向きのいずれかとする(図16参照)。
b) 各コード語の最上位ビット(ビット7で示す。)は,最初に利用できるモジュール位置に配置する。後

46
X 0510:2018 (ISO/IEC 18004:2015)
続するビットは,次のモジュール位置に配置する(図16参照)。したがって,最上位ビットは,配置
方向が上向きの場合は,規則的なシンボルキャラクタの右下モジュールに,配置方向が下向きの場合
は,右上モジュールに置く。しかし,直前のキャラクタが右側のモジュール列で終了する場合などは,
不規則的なシンボルキャラクタの左下に置いてもよい(図18参照)。
図16−規則的なシンボルキャラクタにおける上方向及び下方向のビット配置
c) シンボルキャラクタが両モジュール列で位置合せパターン又はタイミングパターンの水平境界に達す
る場合,符号化領域が連続しているとし,それらのパターンの上又は下に連続しなければならない(図
17参照)。
d) シンボルキャラクタ領域の上側又は下側の境界に到達した場合(すなわち,シンボルの端,形式情報,
型番情報又は分離パターン),コード語の残りのビットは,左側の次の列に配置しなければならない。
配置方向は,反転する(図17参照)。
図17−(i)規則的,及び(ii)不規則的なシンボルキャラクタにおけるビット配置の方向転換の例
e) シンボルキャラクタ列の右側のモジュール列が,位置合せパターン又は型番情報で占められている領
域に到達した場合,ビットは,位置合せパターン又は型番情報に隣接する1列のモジュールに沿って
延長する不規則的なシンボルキャラクタを形成するように配置する。2列が次のシンボルキャラクタ
で利用できる前にキャラクタが終了する場合は,次のキャラクタの最上位ビットは1列で配置しなけ
ればならない(図18参照)。
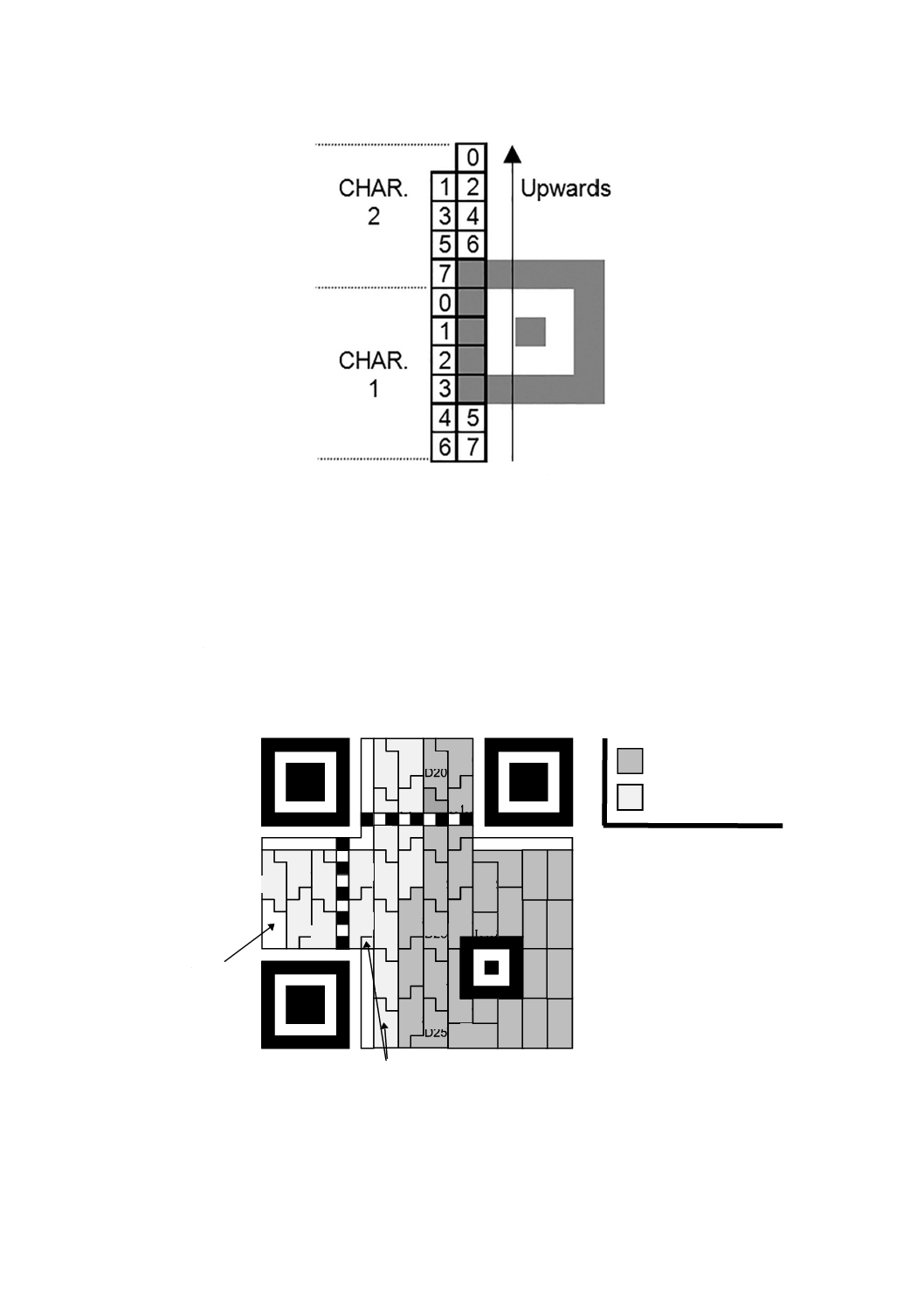
47
X 0510:2018 (ISO/IEC 18004:2015)
図18−位置合せパターンに隣接するビットの配置例
シンボルにおける配置の別法(結果的に同じ。)は,単一ビット列として2モジュール幅の左右交互配置
コード語列とみなし,シンボルの右から左へ,上方向及び下方向を交互に2モジュール幅の列で配置(最
上位ビットで開始)する。各列において,ビットは,右及び左のモジュールを交互に,配置方向によって
上向き又は下向きに,機能モジュールで占められている領域を飛ばし,列の一番上又は一番下で方向を変
えながら配置する。各ビットは,常に最初に利用できるモジュールから配置しなければならない。
シンボルのデータ容量が8ビットのシンボルキャラクタで割り切れない場合,シンボル容量を満たすた
めに適切な個数の残余ビット(表1に示すとおり3,4又は7)を使用しなければならない。これらの残余
ビットは,7.8によるマスク処理の前では,常に値0としなければならない。
データコード語
誤り訂正コード語
E9
D10
D7
D8
D13
D9
D15
D12
D14
D11
D6
D16
D17
D22
D23
D21
D20 D19
D3
D1
D2
D4
D5
D18
E5
E6
E4
D24
D26 D25
D23
E3
E1
E2
D28
D27
E15
E16
E14
E7
E10
E8
E12
E13
E11
残余ビット
図19−2-M型シンボルにおけるシンボルキャラクタ配列
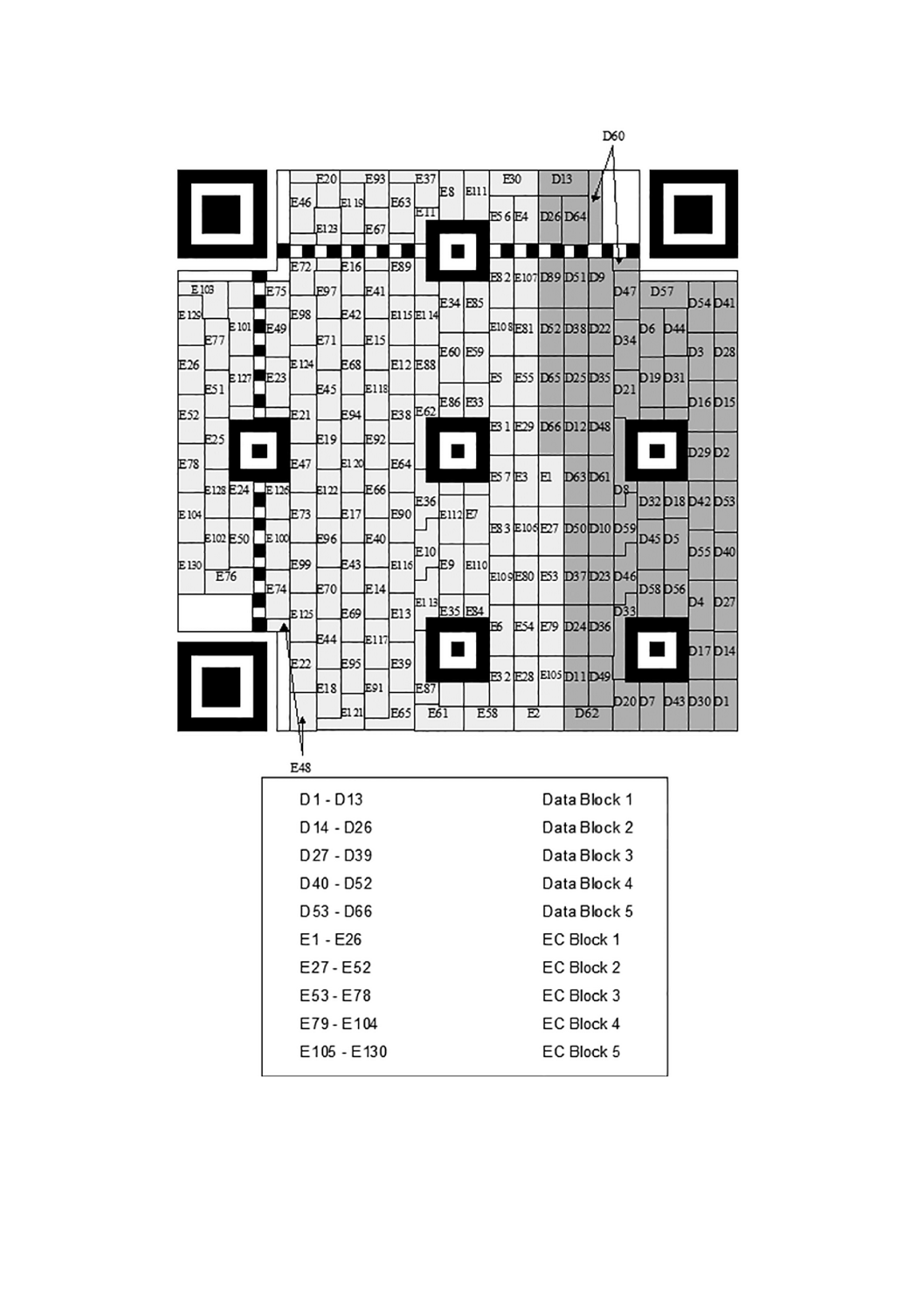
48
X 0510:2018 (ISO/IEC 18004:2015)
図20−7-H型シンボルにおけるシンボルキャラクタ配列
マイクロQRコードにも全く同じ規則を適用する。マイクロQRコードには不規則的なシンボルキャラ
クタは,M1型シンボルにおけるD3,M3-L型シンボルにおけるD11,及びM3-M型シンボルにおけるD9

49
X 0510:2018 (ISO/IEC 18004:2015)
が2×2の4モジュールの正方形ブロックであるという例外を除いて存在しない(図11参照)。
7.8
マスク処理
7.8.1
一般
QRコードの読出しを確実にするためには,明及び暗のモジュールをバランスよくシンボル内に配列す
ることが望ましい。位置検出パターンに特徴的に見られる1011101のモジュールパターンが,シンボルの
別の領域にできるだけ存在しないようにすることが望ましい。上の条件を満たすため,次の手順に従って
マスク処理を適用するのがよい。
a) マスク処理は,機能パターンには適用しない。
b) 符号化領域(形式情報及び型番情報を除く。)で与えられたモジュールパターンと複数のマスク処理マ
トリックスパターンとで順にXOR演算による変換をする。XOR演算とは,各マスク処理マトリック
スパターン上にモジュールパターンを重ね合わせ,マスク処理パターンの暗モジュールに対応するモ
ジュールを反転(明から暗へ又は暗から明へ)することとする。
c) それぞれの変換結果において,望ましくない項目に失点を課すことで全ての変換結果を評価する。
d) 失点の合計が一番低いパターンを選択する。
7.8.2
マスクパターン
表10は,マスクパターン参照子(形式情報で用いられる2進値)及びマスクパターン生成条件を示す。
マスクパターンは,符号化領域(形式情報及び型番情報のために予約した領域を除く。)において条件が真
であるモジュールを暗と定義することで,マスクパターンを生成する。条件において,iはモジュールの
行位置を示し,jは列位置を示す。(i,j)=(0,0)は,シンボルの左上モジュールを示す。
表10−マスクパターン生成条件
QRコードの
マスクパターン参照子
マイクロQRコードの
マスクパターン参照子
条件
000
−
(i+j) mod 2=0
001
00
i mod 2=0
010
−
j mod 3=0
011
−
(i+j) mod 3=0
100
01
((i div 2)+(j div 3)) mod 2=0
101
−
(i j) mod 2+(i j) mod 3=0
110
10
((i j) mod 2+(i j) mod 3) mod 2=0
111
11
((i+j) mod 2+(i j) mod 3) mod 2=0
図21は,1型シンボルに対する全てのマスクパターンを示す。図23は,マスクパターン参照子000〜111
によるマスク処理効果のシミュレーションを示す。

50
X 0510:2018 (ISO/IEC 18004:2015)
図21−1型シンボルに対するマスクパターン
注記1 各パターン下の3ビットがマスクパターン参照子となる。
注記2 3ビットの下の式は,マスクパターン生成条件を示し,式を満たすモジュールが暗モジュー
ルに対応する。
図22に,M-4型のマイクロQRコードに適用する4種類のマスクパターンを示す。
((i+j) mod 2+(i j) mod 3) mod 2=0

51
X 0510:2018 (ISO/IEC 18004:2015)
マスクパターン00
マスクパターン01
マスクパターン00
マスクパターン01
マスクパターン00
マスクパターン01
マスクパターン00
マスクパターン01
マスクパターン10
マスクパターン11
図22−M-4型マイクロQRコードに適用するマスクパターン
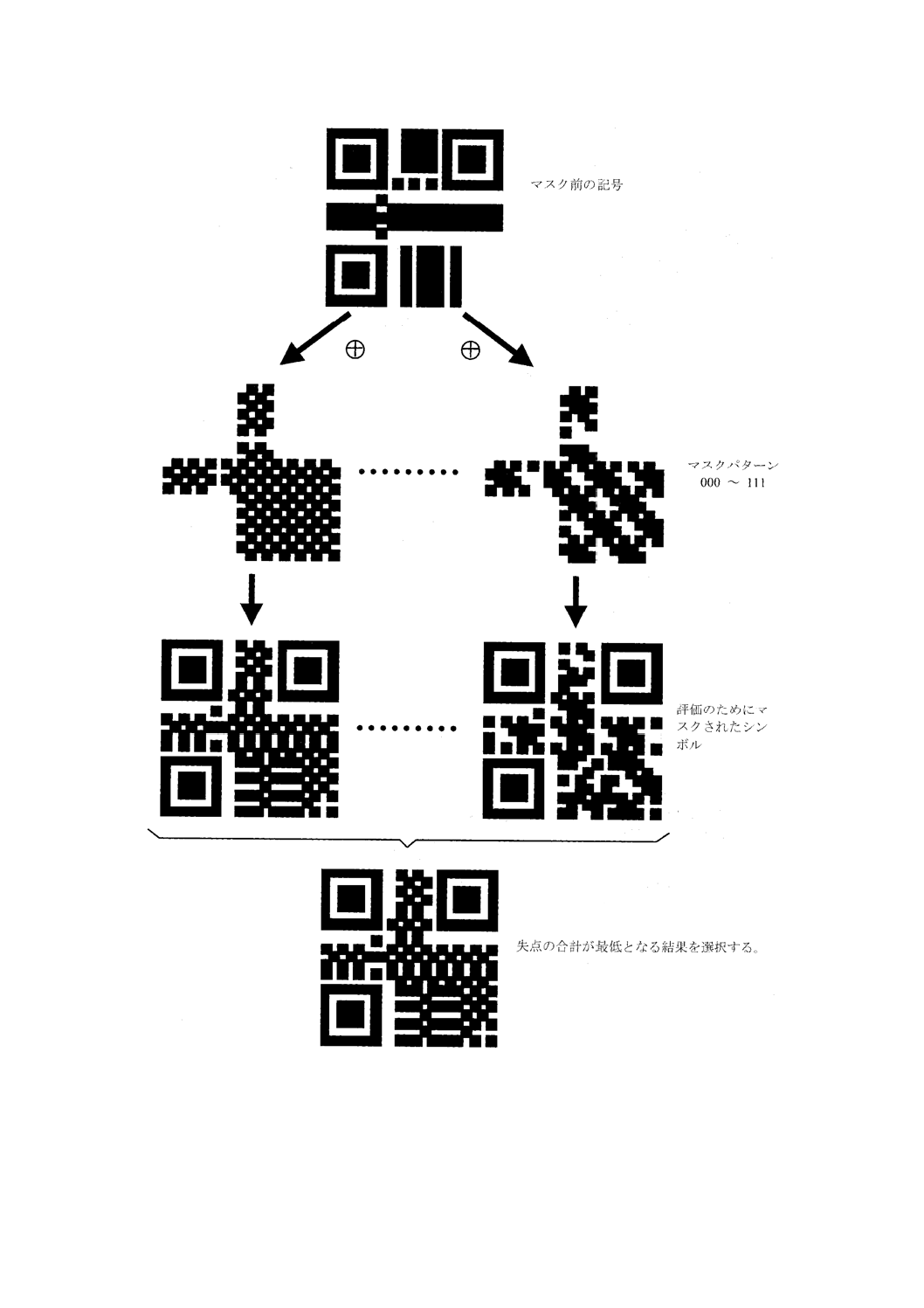
52
X 0510:2018 (ISO/IEC 18004:2015)
図23−QRコードでのマスク処理のシミュレーション
7.8.3
マスク処理結果の評価
7.8.3.1
QRコードの評価
各マスクパターンで順次マスク処理を実行した後,次の特徴の発生に失点を課すことで結果を評価しな
53
X 0510:2018 (ISO/IEC 18004:2015)
ければならない。失点が高いほど,結果が受け入れにくい。表11で,変数N1〜N4は,望ましくない特徴
(N1=3,N2=3,N3=40,N4=10)に対する重み付けされた失点を示す。iは,同色の隣接モジュール数が
5個を超える分で,kは,シンボル内の暗モジュール比率で,50 %から5 %ごとの偏差の度合いとする。マ
スク処理は,シンボルの符号化領域[形式情報及び(存在する場合)型番情報を除く。]について行われる
が,評価する領域は,シンボル全体とする(図3参照)。
表11−マスク処理結果の失点
特徴
評価条件
失点
同色の行又は列の隣接モジュール
モジュール数=(5+i)
N1+i
同色のモジュールブロック
ブロックサイズ=2×2
N2
行・列における1:1:3:1:1比率の
(暗:明:暗:明:暗)のパターンの前又は後ろ
に比率4の幅以上の明パターンが存在する。
1:1:3:1:1比率のパターンの前又は後ろの,
比率4の幅以上の明パターンの存在
N3
全体に対する暗モジュールの占める割合
50±(5×k) %〜50±(5×(k+1)) %
N4×k
注記1 同色の行又は列の隣接モジュール
マスク処理結果の評価のため,横及び縦の両方向について,明(白)モジュール又は暗(黒)モジュー
ルが5個以上連続するブロックを確認する。
なお,失点は,5個連続のブロック1個につき3点,6個連続のブロック1個につき4点とし,ブロック
数が増加する度に1点ずつ増加する。例えば,“暗暗暗暗暗暗暗”のブロックがあった場合には,7個連続
するモジュールが1ブロックとみなし,失点は5点とする。ただし,3点(暗の5個連続が1個)+4点(暗
の6個連続が1個)+5点(暗の7個連続が1個)=12点と重複して数えない。
注記2 同色のモジュールブロック
暗又は明の2×2のブロックの個数を数え,その個数を失点とする。例えば,暗の3×3ブロックには,
暗の2×2ブロックが4個あるので,4個×3点=12点を失点とする。
注記3 行又は列における1:1:3:1:1比率のパターン
1:1:3:1:1の比率の暗:明:暗:明:暗のパターンに続いて比率4の幅以上の明パターンが存在する
場合,失点は40点とする。
注記4 全体に占める暗モジュールの割合
50 %(0点)から5 %増減するたびに10点を加算する。例えば,暗のモジュールの比率が45 %以上55 %
以下の場合,失点は0点,40 %以上45 %未満又は55 %超60 %以下の場合,失点は10点とする。
失点の合計が最小となるマスクパターンをシンボルに適用しなければならない。
7.8.3.2
マイクロQRコードの評価
各マスクパターンで符号化領域に順次マスク処理を実行した後,タイミングパターンでない2辺のそれ
ぞれの暗モジュールの数に対する評価点で結果を評価しなければならない。評価点が低いほど,結果が受
け入れ難い。マイクロQRコードにおいては,クワイエットゾーンと符号化領域とを,より効果的に区別
するために,タイミングパターンではない辺に暗モジュールが多いことが望ましい。
各マスクパターンに対し,順次シンボルの右辺及び下辺の暗モジュールの数(タイミングパターンの最
後のモジュールを除く。)を数え,次の評価式で評価点を求める(図24参照)。
・ SUM1≦SUM2の場合。
評価点=SUM1×16+SUM2
・ SUM1>SUM2の場合。
評価点=SUM2×16+SUM1
ここに, SUM1: 右辺の暗モジュールの数
SUM2: 下辺の暗モジュールの数
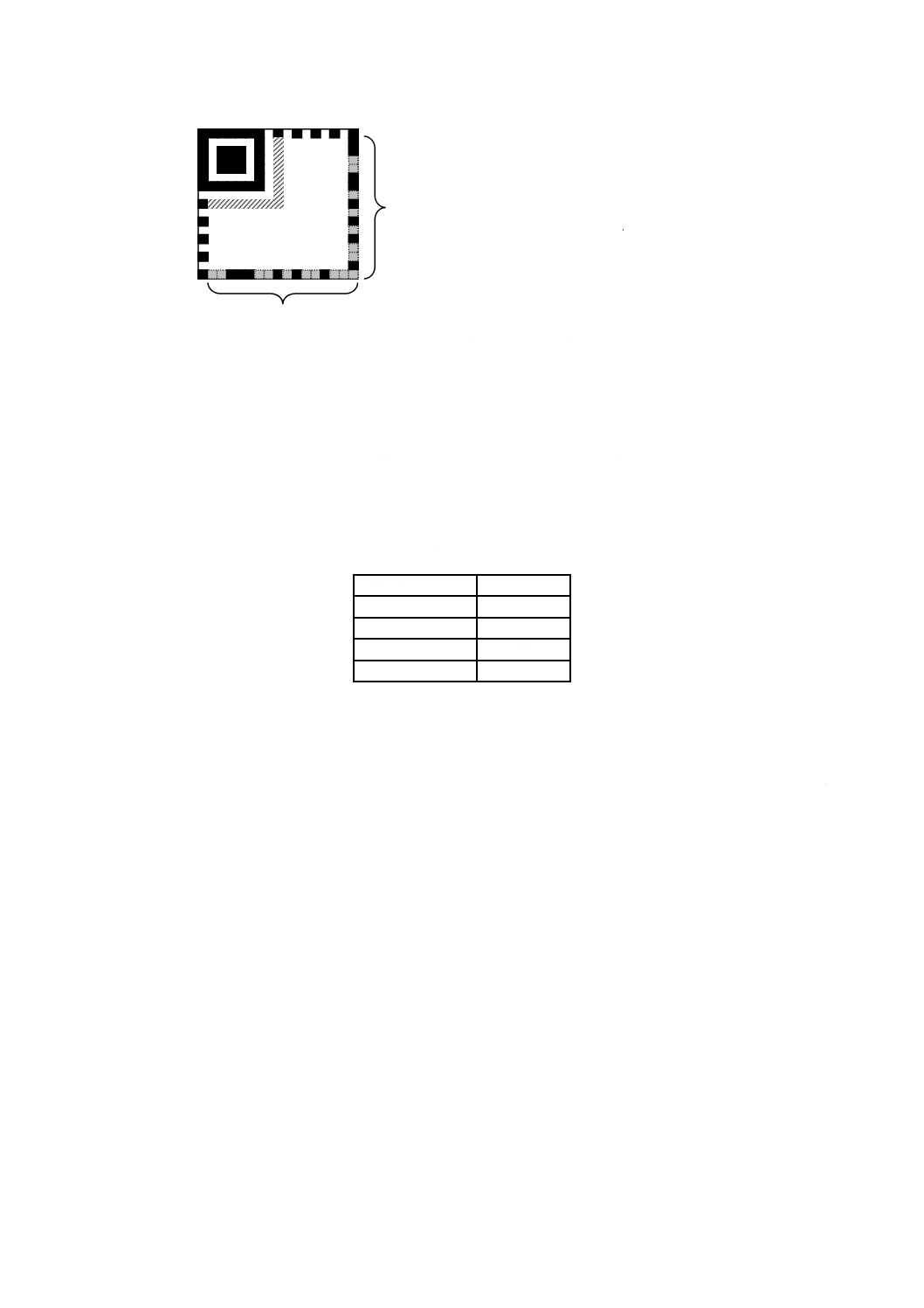
54
X 0510:2018 (ISO/IEC 18004:2015)
SUM2=6(暗モジュール数)
図24−マイクロQRコードのマスク処理結果の評価
評価点が一番高いマスクパターンを選択しなければならない。
7.9
形式情報
7.9.1
QRコードの形式情報
形式情報は,(15,5)BCHコードで計算する10誤り訂正ビット及び5データビットをもつ15ビット列
とする。形式情報の誤り訂正計算に関する詳細は,附属書Cによる。最初の2データビットは,表12に
示すシンボルの誤り訂正レベルを表す。
表12−QRコードの誤り訂正レベル指示子
誤り訂正レベル
2進指示子
L
01
M
00
Q
11
H
10
形式情報の3番目〜5番目のデータビットは,7.8.3に基づき選択されるパターンに対するマスクパター
ン参照子(表10参照)とする。
10誤り訂正ビットは,附属書Cのとおり計算し,5データビットに付加しなければならない。
次に,15ビットの誤り訂正化した形式情報は,誤り訂正レベル及びマスクパターンの組合せによってデ
ータ文字列が全てゼロにならないよう,ビットパターン101010000010010とでXOR演算しなければなら
ない。
得られたマスク形式情報は,図25に示すようにシンボルの予約領域に割り当てなければならない。形式
情報の正確な復号は,完全なシンボルの復号に必須であるので,その冗長性を与えるため,形式情報はシ
ンボルに2か所存在する。形式情報の最下位ビットは,図25のモジュール番号0に位置し,最上位ビッ
トは,モジュール番号14に位置する。位置(4V+9,8)のモジュールは,常に暗としなければならず,
また,形式情報の一部ではない(ここに,Vは型番番号)。
SUM1=8
(暗モジュール数)
SUM1>SUM2によって
評価点=SUM2×16+SUM1
=6×16+8
=104
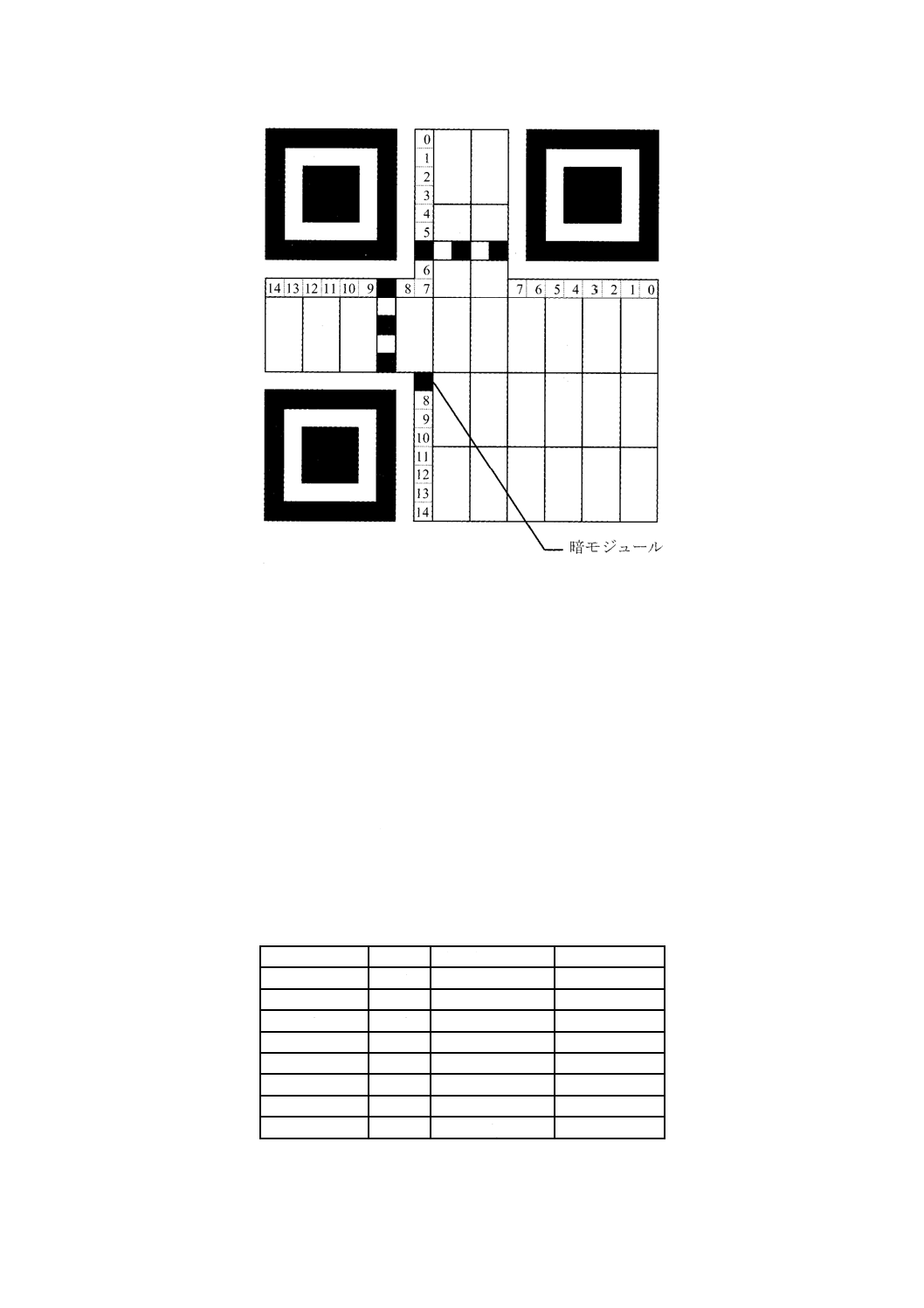
55
X 0510:2018 (ISO/IEC 18004:2015)
例 誤り訂正レベルM:
00
マスクパターン参照子:
101
データ:
00101
BCHビット:
0011011100
マスク前のビット列:
001010011011100
XOR演算用マスクパターン:
101010000010010
形式情報モジュールパターン: 100000011001110
|
|
bit 14
bit 0
図25−QRコードの形式情報ビット配置
7.9.2
マイクロQRコードの形式情報
形式情報は,(15,5)BCHコードで計算する10誤り訂正ビット及び5データビットをもつ15ビット列
とする。形式情報の誤り訂正計算に関する詳細は,附属書Cによる。表13に示すように,最初の3デー
タビットは,型番及び誤り訂正レベルを識別するための2進値のシンボル番号を含む。
表13−マイクロQRコードのシンボル番号
シンボル番号
型番
誤り訂正レベル
2進指示子
0
M1
誤り検出だけ
000
1
M2
L
001
2
M2
M
010
3
M3
L
011
4
M3
M
100
5
M4
L
101
6
M4
M
110
7
M4
Q
111
形式情報の4番目及び5番目のデータビットは,7.8.3に基づき選択されるパターンに対するマスクパタ

56
X 0510:2018 (ISO/IEC 18004:2015)
ーン参照子(表10参照)とする。
10誤り訂正ビットは,附属書Cのとおり計算し,5データビットに付加しなければならない。
次に,15ビットの誤り訂正化した形式情報は,シンボル番号及びマスクパターンの組合せによってデー
タ文字列が全てゼロにならないよう,ビットパターン100010001000101とでXOR演算しなければならな
い。
得られたマスク形式情報は,図26 5) に示すようにシンボルの予約領域に割り当てなければならない。形
式情報の最下位ビットは図26 5) のモジュール番号0に位置し,最上位ビットはモジュール番号14に位置
する。
注5) 対応国際規格の参照先番号は,明らかに図26の誤りのため修正して記載した。
例
シンボル番号0:
00
マスクパターン参照子:
11
データビット(シンボル番号,
マスクパターン参照子):
00011
BCHビット:
1101011001
マスク前のビット列:
000111101011001
XOR演算用マスクパターン:
100010001000101
形式情報モジュールパターン:
100101100011100
|
|
bit 14
bit 0
図26−マイクロQRコードの形式情報ビット配置
7.10 マイクロQRコードの形式情報ビット配置
型番情報は,7型以上のQRコードがもつ。型番情報は,(18,6)Golayコード(拡張BCHコード)で
計算される12誤り訂正ビット及び6データビットをもつ18ビット列とする。型番情報の誤り訂正計算に
関する詳細は,附属書Dによる。6データビットは,型番情報であり,最上位ビットを先頭とする。
12誤り訂正ビットは,附属書Dのとおり計算し,6データビットに付加しなければならない。
7型〜40型のシンボルだけが型番情報を含むために,全てが0のデータ列となる型番情報は,存在しな
い。したがって,型番情報に,マスク処理は適用しない。
得られた型番情報は,図27に示すようにシンボルの予約領域に割り当てなければならない。型番情報の
正確な復号は,完全なシンボルの復号に必須であるので,その冗長性を与えるため,型番情報はシンボル
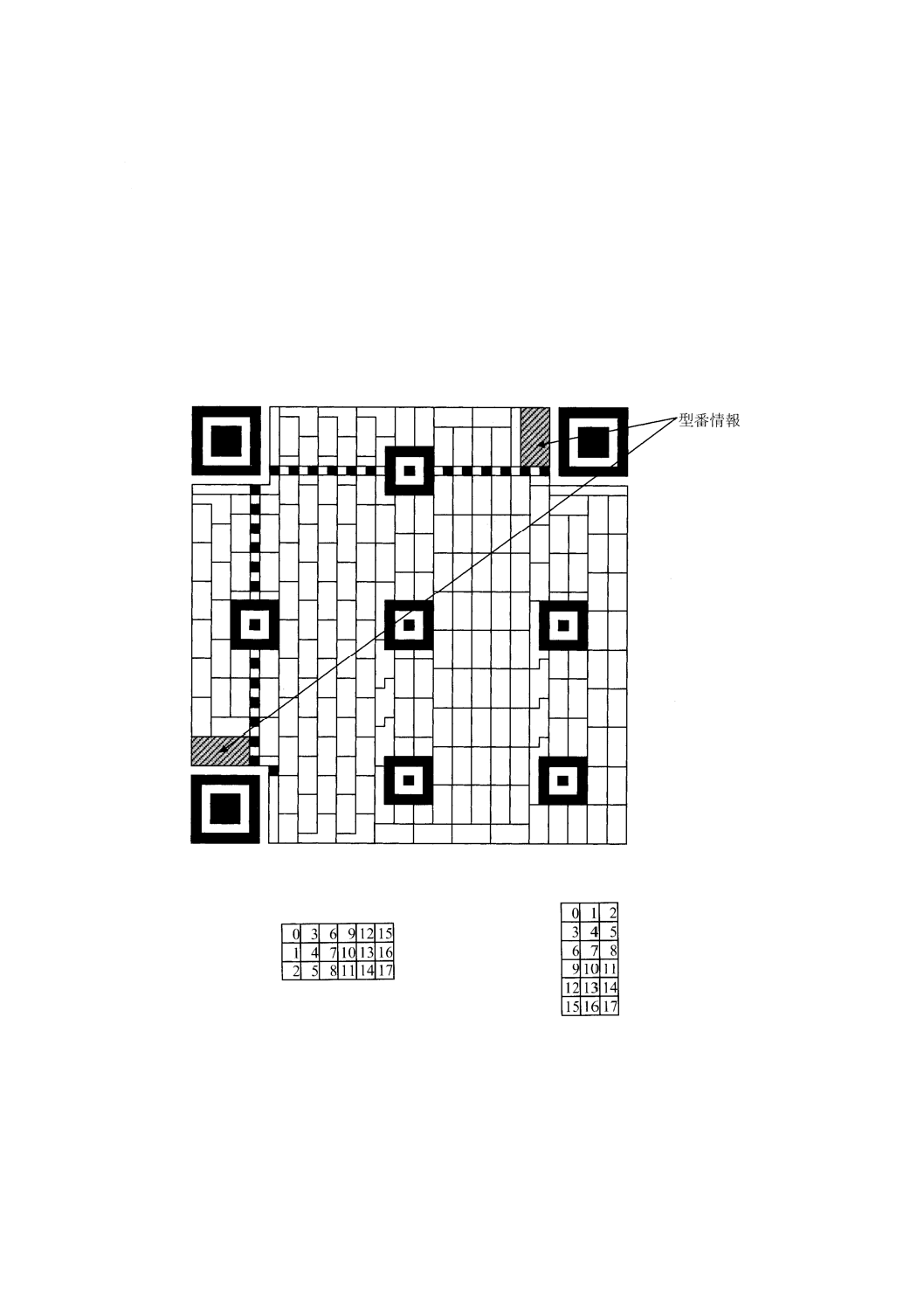
57
X 0510:2018 (ISO/IEC 18004:2015)
に2か所存在する。型番情報の最下位ビットは,図28のモジュール番号0に位置し,最上位ビットは,
モジュール番号17に位置する。
例 型番番号:
7
データ:
000111
BCHビット:
110010010100
型番情報モジュールパターン: 000111110010010100
型番情報の領域は,タイミングパターンの上側で,右上位置検出パターンのセパレータのすぐ左の6×3
モジュールブロック及びタイミングパターンの左側で,左下位置検出パターンのすぐ上の3×6モジュール
ブロックとする。
図27−型番情報の配置
左下の型番情報
右上の型番情報
図28−型番情報のモジュール配列
8
構造的連接
8.1
基本原理
構造的連接は,マイクロQRコードでは利用できない。

58
X 0510:2018 (ISO/IEC 18004:2015)
最大16個までのQRコードシンボルを構造的連接の形で連結してもよい。シンボルが構造的連接メッセ
ージの一部の場合には,最初の2個半のシンボルキャラクタ位置にあるヘッダブロックに構造的に連接さ
れていることを示す。
構造的連接モード指示子0011を最初のシンボルキャラクタの上位4ビットに置く。
次に,2個の構造的連接コード語が後続する。最初のシンボルキャラクタの下位4ビット,2番目のシン
ボルキャラクタ及び3番目のシンボルキャラクタの上位4ビットにわたる。最初のコード語は,シンボル
列指示子(8.2参照)6) とする。2番目のコード語は,パリティデータ(8.3参照)6) で,メッセージの全シ
ンボルで等しく,全てのシンボルが同じ構造的連接メッセージから読み出されたことが確認できる。この
ヘッダのすぐ後に,最初のモード指示子で始まるシンボルのデータコード語が続く。既定のECI以外の一
つ以上のECIを適用する場合,各ECIに対するECIヘッダ(ECIモード指示子及びECI指定で構成する。)
は,構造的連接ヘッダの後に続けなければならない。
注6) 対応国際規格の参照先番号は,明らかに誤りのため修正して記載した。
図29の下側に,上側のシンボルと同じデータをもつ,四つの構造的連接シンボルの例を示す。
図29−“ABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ”
を符号化した,単一のシンボル(上)及び構造的連接シンボル(下)
8.2
シンボル列指示子
このコード語は,連接構造におけるQRコードシンボルのセット(最大16個まで)の中でのシンボル位
置を示す(nシンボル中のm番目の形式で)。このコード語の最初の4ビットは,そのシンボルの位置を示
す。最後の4ビットは,構造的連接の形で連結されるシンボルの合計数を示す。4ビットパターンは,そ
れぞれ(m−1)及び(n−1)の2進値としなければならない。
例 合計7シンボル中の第3シンボルを示す場合は,次のように符号化しなければならない。
第3位置
0010
全7シンボル
0110
ビットパターン 00100110
8.3
パリティデータ
パリティデータは,シンボル列指示子に続く8ビットバイトとしなければならない。パリティデータは,
シンボルブロックへの分割前の全入力データをバイトごとにXOR演算して得られる値である。モード指
59
X 0510:2018 (ISO/IEC 18004:2015)
示子,文字数指示子,埋め草ビット,終端パターン及び埋め草キャラクタは,この計算から除かなければ
ならない。入力データは,漢字の場合には2バイトのシフト符号化表現で規定された文字(各バイトはXOR
計算において,最上位バイトから別個に処理する。),他の文字は,表6に示す8ビット符号で表示する。
ECIモードでは,データの暗号化又は圧縮後に得られる8ビットバイト値を計算に用いなければならない。
例えば,“0123456789日本”を次のように“0123”,“4567”及び“89日本”に分割した場合,次のとお
りとなる。
第1シンボルブロック(“0123”)− 30HEX,31 HEX,32 HEX,33 HEX
第2シンボルブロック(“4567”)− 34 HEX,35 HEX,36 HEX,37 HEX
第3シンボルブロック(“89日本”)− 38 HEX,39 HEX,93FA HEX,967B HEX
バイトごとに,順次,データをXOR演算することで“0123456789日本”のパリティデータを得る。
30⊕31⊕32⊕33⊕34⊕35⊕36⊕37⊕38⊕39⊕93⊕FA⊕96⊕7B=85
パリティデータの計算は,印字装置の能力に応じて,データを印字装置へ転送する前又は印字装置内で
実行してもよいことに注意がいる。
9
シンボルの印刷及びマーキング
9.1
寸法
QRコードシンボルは,次の寸法に従わなければならない。
X寸法: モジュール幅は,用いる読取技術及びシンボル生成技術を考慮した上でアプリケーションによ
って指定する。
Y寸法: モジュールの高さはX寸法と同じとする。
最小クワイエットゾーン:
4辺全てにおいて,マイクロQRコードでは2X,QRコードでは,4Xと同値とする。
9.2
文字による表記
QRコードシンボルは,何千もの文字を符号化することができるので,データ文字を人が読取可能な文
字で表記することは余り実際的ではない。その代わりとして,テキストそのものを示すのでなく,そのシ
ンボルの内容を記述するものをシンボルに併記してもよい。
文字の大きさ及びフォントについて特に指定はなく,また,メッセージは,シンボルの周辺のどこか適
切なところに印刷してもよい。人が読取可能な記述は,シンボル及びクワイエットゾーンを妨害しないほ
うがよい。
9.3
マーキングの手引
QRコードシンボルは,多くの異なる技術を用いて印刷及びマーキングすることができる。附属書Kに
利用者のための手引を示す。
10 シンボルの品質
10.1 方法論
QRコードは,JIS X 0526に示す二次元マトリックスシンボルの印刷品質に関する指針を次のように補
足及び修正した方法を用いて評価しなければならない。
幾つかのマーキング技術では,特別な予防措置をとらなければ,この規格に適合するシンボルを生成で
きないことがある。附属書Mに,有効なQRコードを印字するための追加の指針を示す。
ダイレクトパーツマーキング(DPM)及び/又はつながっていないドット(隙間があるドット)で印字
60
X 0510:2018 (ISO/IEC 18004:2015)
したシンボルは,この方法論に合格せず,QRコードリーダで読めなくてもよい。このようなシンボルを
必要とするアプリケーションは,JIS X 0526の品質拡張版であるISO/IEC/TR 29158を用いて,品質評価
方法を明記することが望ましく,専用のDPM読取装置を要求するのがよい。
10.2 シンボルの品質パラメタ
10.2.1 固定パターン損傷
附属書Gに,固定パターン損傷の測定及びグレード付けの基準を規定する。
10.2.2 走査グレード及び総合シンボルグレード
走査グレードは,シンボルの個々の画像における,シンボルコントラスト,モジュレーション,固定パ
ターン損傷,復号,軸の非均一性,グリッドの非均一性及び未使用誤り訂正の各パラメタの最低グレード
値としなければならない。総合シンボルグレードは,全試験画像(JIS X 0526参照)における個々の走査
グレードの算術平均値である。
10.2.3 グリッドの非均一性
参照復号アルゴリズム(箇条12参照)を用いて位置を決めるように,位置検出パターン及び位置合せパ
ターンを基準点として用いて,理想的なグリッドを計算する。
10.3 プロセス制御の測定
QRコードシンボルの作成プロセスの監視及び制御に有用な測定をするため,様々なツール及び方法が
利用できる。これらのツール及び方法を,附属書Mに示す。これらの手法は,生成されたシンボル(この
箇条及び附属書Gで規定した方法は,シンボルの印刷品質評価のために必要な方法である。)の印刷品質
検査を構成するものではないが,個別に,かつ,総合的に,シンボルの生成過程が,使用可能なシンボル
を作成しているかどうかを判定する,よい指針となる。
11 復号手順の概要
QRコードシンボルの読取りからデータ文字出力に至る復号手順は,符号化手順の逆手順である。図30
にこの過程の概要を示す。
a) シンボルの位置を検出し,画像を取得する。“0”及び“1”のビット列として明及び暗のモジュールを
認識する。位置検出パターンモジュールの色から反射極性(明暗反転か否か)を特定する。
b) 形式情報を読み出す。マスク処理を解除し,必要に応じて形式情報モジュールに誤り訂正を実行する。
成功すればシンボルは“標準”方向であり,そうでなければ表裏反転として形式情報の復号を試みる。
誤り訂正レベル(QRコードでは直接,又はマイクロQRコードのシンボル番号から)及びマスクパ
ターン参照を特定する。
c) 型番情報(存在する場合)を読み,シンボルの型番(マイクロQRコードの場合は,シンボル番号か
ら)を決定する。
d) 形式情報から得られたマスクパターンを用いて符号化領域のビットパターンをXOR演算し,マスク
処理を解除する。
e) 配置規則に従い,シンボルキャラクタを読み取り,メッセージのデータ及び誤り訂正コード語を復元
する。
f)
レベル情報に対応する誤り訂正コード語を用いて,誤りの検出をする。誤りが検出された場合,これ
を訂正する。
g) モード指示子及び文字数指示子に基づいて,データコード語をセグメントに分割する。
h) 最後に,使用モードに基づいてデータ文字を復号し,結果を出力する。
61
X 0510:2018 (ISO/IEC 18004:2015)
・
図30−QRコードの復号手順
12 QRコードの参照復号アルゴリズム
この参照復号アルゴリズムは,画像内のシンボルを検出し,復号する。この復号アルゴリズムは,画像
内の明暗状態を参照する。
a) 画像内における最大反射値及び最小反射値の間の中間反射値を全域的しきい値とする。この全域的し
きい値を用いて,画像を暗及び明のピクセル集合に変換する。
b) 位置検出パターンの位置を求める。QRコードの位置検出パターンは,シンボルの4隅のうちの3隅
に配置される同一のパターンで構成する。マイクロQRコードの位置検出パターンは,一つである。
6.3.3で示すように,各位置検出パターンの相対的なモジュール幅が,1:1:3:1:1の比率をもつ暗
−明−暗−明−暗の列で構成する。このアルゴリズムにおいて,これらの幅の許容値は,0.5とする(つ
まり,1個のモジュールに対しては0.5〜1.5の範囲,3個のモジュールに対しては2.5〜3.5の範囲とな
る。)。
1) 領域の候補が検出されたときに,画像内のピクセル線が位置検出パターンの外縁に接する最初の点
A及び最後の点Bの位置を記憶する(図31参照)。画像内のx軸方向に対して位置検出パターンの
内側の暗の正方形を横切る全ての線が認識されるまで,画像内の隣接するピクセル線についてこれ
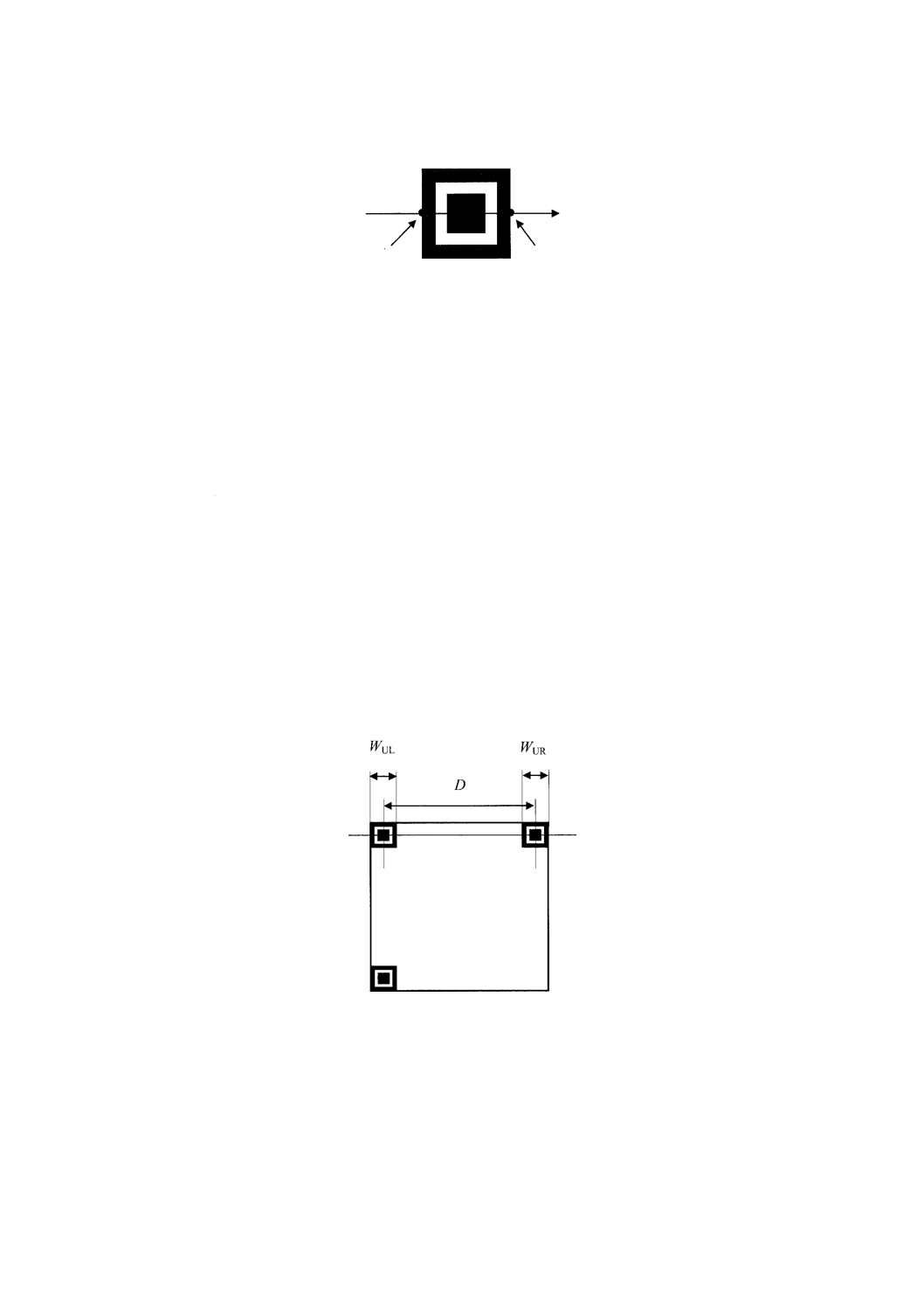
62
X 0510:2018 (ISO/IEC 18004:2015)
を繰り返す。
図31−位置検出パターンの走査線
2) 画像内のy軸方向に対して,位置検出パターンの内側の暗の正方形を横切るピクセル列について手
順1)を繰り返す。
3) パターンの中心位置を求める。x軸方向に対して位置検出パターンの内側の暗の正方形を横切る一
番外側のピクセル線上の点A及び点Bの中央を通る線を求める。同様に,y軸方向に対して位置検
出パターンの内側の暗の正方形を横切る一番外側のピクセル列上の点A及び点Bの中央を通る線を
求める。パターンの中心は,この2本の線の交点として求める。
4) 1)〜3)の手順を繰り返し,他の2個の位置検出パターンの中心位置を求める。
5) 領域の候補が検出されなかった場合,明ピクセル及び暗ピクセルの明色及び暗色を反転させた明暗
(白黒)反転シンボルとして,手順b)の最初から復号を再開する。
6) 一つの位置検出パターンが検出されたが,更に二つの位置検出パターンが見つけられなかった場合
には,マイクロQRコードの参照復号手順[手順m)から]に飛んで,マイクロQRコードとして復
号を試みる。
c) 三つの位置検出パターンの中心座標を分析することによって,どのパターンがシンボルの左上のパタ
ーンか及びシンボルの回転角を認識し,シンボルの回転方向を決定する。
d) シンボルの全幅を横切る,左上の位置検出パターン及び右上の位置検出パターンの中心間の距離D及
び二つのパターンの幅(WUL及びWUR)を求める(図32参照)。
図32−上側の位置検出パターン
e) シンボルの公称X寸法を計算する。
X=(WUL+WUR)/14
f)
シンボルの型番Vを仮に求める。
V=[(D/X)−10]/4
g) 仮のシンボル型番が6以下の場合,この値を型番として使用する。仮のシンボル型番が7以上の場合
A
B
63
X 0510:2018 (ISO/IEC 18004:2015)
は,次のように型番情報を復号する。
1) 右上の位置検出パターンの幅WURを7で除し,モジュールサイズCPURを求める。
CPUR=WUR/7
2) 図33に示す3個の位置検出パターンの中心位置A,B及びCを通る補助線AC及びABを求める。
この補助線の平行線,位置検出パターンの中心座標及びモジュールサイズCPURに基づき,型番情
報1領域の各モジュールの中心に対するサンプリンググリッドを設定する。サンプリンググリッド
上の明又は暗の状態から2進値0及び1を決定する。
図33−位置検出パターン及び型番情報
3) 型番情報1領域の情報を用い,附属書Dに基づいて型番を決定する。誤りがあれば附属書Dに基づ
いて訂正し,型番を決定する。
注記 対応国際規格では,“D.2の表に基づき,誤りがあれば,それを検出訂正し,型番を決定す
る。”とあるが,手順をより明確にするため上記とした。
4) 誤り訂正能力を超える誤りを検出した場合,左下の位置検出パターンのパターン幅WDLを計算し,
同様の方法で上の手順1),2)及び3)を実施し,型番情報2を復号する。
h) 1型シンボルについては,上側タイミングパターンにおける暗及び明のモジュールの中心点の平均間
隔でXを再定義する。同様に左側のタイミングパターンにおける暗及び明のモジュールの中心点の平
均間隔でYを再定義する。次のi)及びii)に基づいて,サンプリンググリッドを設定する。i) 上側のタ
イミングパターンを通り,そのタイミングパターンと平行な水平線,その水平基準線からY間隔で上
に6本の線,及びその下にシンボルの型番に必要とされる数の線。ii) 左側のタイミングパターンを通
り,そのタイミングパターンと平行な垂直線,その垂直基準線からX間隔で左に6本の線,及びその
右にシンボルの型番に必要とされる数の線。2型以上のシンボルについては,6.3.6及び附属書Eに示
す座標で定義する各位置合せパターンの中心座標を求め,これらの点と等間隔にサンプリンググリッ
ドを設定する(図34参照)。
64
X 0510:2018 (ISO/IEC 18004:2015)
図34−位置検出パターン及び位置合せパターン
1) 左上の位置検出パターンPULの幅WULを7で除し,モジュールの大きさCPULを求める。
CPUL=WUL/7
2) 左上の位置検出パターンPULの中心座標A,g)の2)で求めた補助線AC及びABの平行線,並びに
モジュールの大きさCPULに基づいて,位置合せパターンP1及びP2(図34参照)7) の仮の中心座
標を求める。
注7) 対応国際規格の参照先番号は,明らかに誤りのため修正して記載した。
3) 仮の中心座標のピクセルから,それぞれ,位置合せパターンP1及びP2の白い正方形の外形を走査
し,実際の中心座標Xi及びYjを求める(図35参照)。
図35−位置合せパターンの中心座標
4) 左上の位置検出パターンPULの中心座標及び3)で求めた位置合せパターンP1及びP2の実際の中心
座標から,位置合せパターンP3の仮の中心座標を推定する。
5) 3)と同様の手順で,位置合せパターンP3の実際の中心座標を求める。
6) 位置合せパターンP2とP3との中心距離Lx,及び位置合せパターンP1とP3との中心距離Lyを求
める。Lx及びLyを定義されている位置合せパターン間隔で除し,シンボルの左上領域(図36参照)
の下辺及び右辺におけるモジュールピッチCPx及びCPyを求める。
CPx=Lx/AP
CPy=Ly/AP
ここに,
AP: 位置合せパターンの中心モジュール間隔(表E.1参照)
同様に,左上の位置検出パターンPULの中心座標と位置合せパターンP1の中心座標との間の水平
距離Lx',及び左上の位置検出パターンの中心座標と位置合せパターンP2の中心座標との間の垂直
65
X 0510:2018 (ISO/IEC 18004:2015)
距離Ly'を求める。Lx'及びLy'を次の式の間隔で除し,シンボルの左上領域の上辺及び左辺における
モジュールピッチCPx'及びCPy'を求める。
CPx'=Lx'/(位置合せパターンP1の中心の列座標−左上の位置検出パターンPULの中心の列座標)
CPy'=Ly'/(位置合せパターンP2の中心の行座標−左上の位置検出パターンPULの中心の行座標)
図36−シンボルの左上領域
7) シンボルの左上領域の各辺のモジュールピッチCPx,CPx',CPy及びCPy' に基づき,左上の領域を
覆うサンプリンググリッドを設定する。
8) 同様にして,シンボルの右上領域(右上の位置検出パターンPUR,位置合せパターンP1,P3及び
P4で囲まれる。)及び左下領域(左下の位置検出パターンPDL,位置合せパターンP2,P3及びP5
で囲まれる。)のサンプリンググリッドを設定する。
9) 位置合せパターンP6(図37参照)については,位置合せパターンP3,P4及びP5の間隔から求め
たモジュールピッチCPx'及びCPy',位置合せパターンP3及びP4の中心を通る補助線,P3及びP5
の中心を通る補助線,並びにそれらの位置合せパターンの中心座標から仮の中心座標を推定する。
図37−シンボルの右下領域
10) 手順5)〜8)を繰り返して,シンボルの右下領域のサンプリンググリッドを設定する。
11) 同様の手法で未処理の領域のサンプリンググリッドを設定する。
i)
グリッド線の各交点上の3×3の画像ピクセルをサンプリングし,全域的しきい値に基づき,それらが
明暗のいずれかを決める。暗のピクセルを2進1とし,明のピクセルを2進0とするビットマトリッ
クスを構築する。
j)
左上の位置検出パターンに隣接する形式情報を復号し,シンボルに適用された誤り訂正レベル及びマ
スクパターンを得る(C.3参照)。形式情報の誤り訂正能力を超える誤りが検出された場合は,右上及

66
X 0510:2018 (ISO/IEC 18004:2015)
び左下の位置検出パターンに隣接する形式情報を復号し,同様の手順を実施する。
k) 有効な形式情報ビット列が得られない場合には,表裏反転で読めば正しいかどうかを確認し,それが
正しい場合には,画像の行及び列の座標を変換し,表裏を反転したシンボルに対して復号処理を継続
する。
l)
手順y)に進む。
m) マイクロQRコードでは,b)の3)で得た線の角度を解析することによって,シンボルとイメージセン
サの座標軸との相対角度を,ϑ(図38参照),ϑ+90°,ϑ+180°及びϑ+270°のように回転角で決定
する。
図38−イメージセンサの座標軸に対する相対角度
n) 位置検出パターンのそれぞれの軸に平行で等間隔の3本の線を作図し,それぞれの線の点Aから点B
までの距離を測定する(図31参照)。間隔の制約はないが,3本の線は,位置検出パターン内にある
こと。
o) n)における,三つのAB間距離の平均値を7で除し,シンボルの仮のモジュール寸法Xを求める。
p) 位置検出パターンの外側の辺それぞれに対し,端から0.5X内側を通り,それらの辺に平行な線を位置
検出パターンから外側に向かって両方向に延長する。
q) タイミングパターンの探索
1) 名目上は,互いに直角をなす位置検出パターンの二つの辺を確認する。各辺は次の両方をもつ。
1.1) 少なくとも一方向の1.5Xの空白の領域
1.2) 位置検出パターンの辺から反対方向に,中心の間隔が等しく1Xの明及び暗の交互のパターン(タ
イミングパターンの候補)
2) それぞれのタイミングパターン候補に,同じ数でその数が2〜5の明及び暗のモジュールがあること
を確認する。
r) タイミングパターンの暗モジュールの数から,シンボルの仮の型番を決定する。
− 暗モジュールが二つであれば型番は,M1
− 暗モジュールが三つであれば型番は,M2
− 暗モジュールが四つであれば型番は,M3
− 暗モジュールが五つであれば型番は,M4
s)
それぞれのタイミングパターンの最初の暗モジュールの中心から,互いの線の交点まで,隣接する位
置検出パターンに平行な線を延長する。形式情報のそれぞれのモジュールの明暗を判定するために,
67
X 0510:2018 (ISO/IEC 18004:2015)
その線に沿って,1X間隔で3×3の領域のピクセルをサンプリングする。暗のピクセルを2進1とし,
明のピクセルを2進0とする形式情報ビット列を決定する。
t)
形式情報を7.9.2に示すビット列でXOR演算してマスク処理を解除し,形式情報を復号(必要であれ
ば附属書Bに示す誤り訂正手順を適用する。)し,シンボル番号(したがって,シンボルの型番及び
誤り訂正レベル)及びシンボルに適用したマスクパターンを得る。
u) 有効な形式情報ビット列が得られない場合には,表裏反転で読めば正しいかどうかを確認し,それが
正しい場合には,画像の行及び列の座標を変換して,表裏を反転したシンボルに対して復号処理を継
続する。附属書Cの有効なビット列と2ビットまでの違いであれば,このビット列と置き換えて形式
情報を復号し,シンボル番号及びマスクパターンを得る。
v) クワイエットゾーンに隣接する位置検出パターンの外側の端点から,タイミングパターンの最後の暗
モジュールの外側の端点までの全幅をシンボルの型番に対応するモジュール数で除し,それぞれの軸
のモジュールピッチXを決定する。
w) タイミングパターンモジュールの中心から及び位置検出パターンの同様な位置から,互いに平行で,
位置検出パターンの辺にも平行な,シンボルの型番に対応する数のサンプリンググリッドを,1X間隔
でそれぞれの軸方向に設定する。
x) グリッド線の各交点上の3×3の画像ピクセルをサンプリングし,全域的しきい値に基づき,それらの
明暗を決定する。暗のピクセルを2進1とし,明のピクセルを2進0とするビットマトリックスを構
築する。
y) シンボルの符号化領域でマスクパターンとXOR演算することによって,マスク処理を解除し,デー
タコード語及び誤り訂正コード語を示すシンボルキャラクタを復元する。この手順は,符号化の過程
で適用したマスク処理の効果を解除する。
z) 7.7.3の配置規則に従い,シンボルのコード語を求める。
aa) 7.6の手順c)に示す交互配置処理を逆に実行し,コード語列を,シンボルの型番及び誤り訂正レベル
で決められたブロックに並び替える。
ab) 附属書Bの誤り検出及び誤り訂正復号手順に従い,シンボル型番及び誤り訂正レベルに対する最大の
誤り訂正能力までの代入誤り及び消失誤りを訂正する。
ac) データブロックを順番に結合することによって,元のメッセージのビット列を復元する。
ad) データビット列を,モード指示子で始まるセグメントに,更に分割する。その長さは,モード指示子
に続く文字数指示子によって決まる。
ae) 適用中のモードの規則に従い,各セグメントを復号する。
13 自動識別能力
QRコードは,他の多くのシンボル体系とともに自動識別環境で用いることができる(附属書L参照)。
モデル1(附属書N参照)及びQRコードは,形式情報のマスクパターンを分析することによって自動識
別が可能となるが,モデル1シンボルは,QRコードと同じ環境で用いないほうがよい。
14 送信データ
14.1 一般原理
全ての符号化データは,データ送信に含めなければならない。機能パターン,形式情報,型番情報,誤
り訂正キャラクタ,埋め草キャラクタ及び残余キャラクタは,送信してはならない。全てのデータに対す
68
X 0510:2018 (ISO/IEC 18004:2015)
る既定の送信モードは,バイト(8ビット符号値又は16ビットシフト符号値)としなければならない。送
信の前に全メッセージを再構築するバッファモードで運用している場合,復号器によって構造的連接ヘッ
ダブロックを,送信してはならない。非バッファモードで運用している場合,それぞれのシンボルの最初
の2バイトである構造的連接ヘッダブロックを,送信しなければならない。拡張チャネル解釈におけるデ
ータ送信を含む,より複雑なものは,14.3による。
14.2 シンボル体系識別子
JIS X 0530は,復号器に設定される任意機能及びシンボルに見られる特別な特徴とともに読み取ったシ
ンボルの送信に関する標準手順を規定している。
データ(任意のECIの使用を含む。)の構造を識別すると,復号器は,適切なシンボル体系識別子を送
信データの前に付加する。ECIが使用されている場合,シンボル体系識別子を必要とする。シンボル体系
識別子及びQRコードに適用する任意機能値に関しては,附属書Fによる。
14.3 拡張チャネル解釈
ECIプロトコルを使用できるシステムでは,送信ごとにシンボル体系識別子の送信を必要とする。ECI
モード指示子がある場合,それはエスケープ文字5CHEXとして送信しなければならない。5CHEXは,ISO/IEC
8859-1及びAIM Inc.のECI仕様における逆斜線“\”,並びにJIS X 0201における“¥”に対応する。ECI
指定を示すコード語は,表4に定義されている規則で6桁の数字に変換する。この6桁の数字は,エスケ
ープ文字に続いて30HEX〜39HEXの範囲で対応する8ビット値として送信しなければならない。
\nnnnnnを認識するアプリケーションソフトウェアは,それに続く全てのキャラクタを6桁の指定によ
って定義するECIからのものとして解釈することが望ましい。この解釈は,次のことが発生するまで有効
とする。
− 符号化データの最後
− モード指示子0111による別のECIへの変更(AIM Inc.のECI仕様に従う。)
既定の解釈へ復帰する場合,復号器は,データの前に適切なエスケープ列を付加し,出力しなければな
らない。
符号化データとして5CHEXを用いる必要がある場合,5CHEXを2個送信しなければならない。5CHEXの1
回の出現は,常にエスケープ文字であり,2回の出現は,実データを意味する。
例1 a) 符号化データ(16進値) 41 42 43 5C 31 32 33 34
送信データ(16進値)
41 42 43 5C 5C 31 32 33 34
b) 符号化データ(16進値) ABCに続くECI 123456の規則による“あるデータ”の符号化
送信データ(16進値)
41 42 43 5C 31 32 33 34 35 36“あるデータ”
例2 (7.4.2.2のデータを使用)
メッセージは,ECIモード指示子,ECI指定,モード指示子,文字数指示子及びデータで次
のとおり構成する。
0111 00001001 0100 00000101 10100001 10100010 10100011 10100100 10100101
シンボル体系識別子]Q2(附属書F参照)を,送信データに付加する。
送信データ(16進値)
5D 51 32 5C 30 30 30 30 30 39 A1 A2 A3 A4 A5
ECI000009における符号化データ ABΓΔE
構造的連接モードで,ECIモード指示子のいずれかがシンボルの先頭に出現した場合,後続するデータ
文字は,前のシンボルの最後で適用されていたECIからのものとして解釈しなければならない。
注記 5CHEXは,ISO/IEC 8859-1における逆斜線“\”及びJIS X 0201における“¥”と等価とする。
69
X 0510:2018 (ISO/IEC 18004:2015)
14.4 FNC1
FNC1が1番目又は2番目の位置に適用されているモードにおいて,FNC1に対応するバイト値が存在し
ないので,これらのモードを意味する文字を直接,送信することはできない。したがって,適切なシンボ
ル識別子(附属書Fで定義する,]Q3,]Q4,]Q5又は]Q6を用いる。)の送信によって,1番目又は2番目
の位置におけるFNC1の存在を示す必要がある。これらのシンボルにおける他の位置において,FNC1は,
適切なアプリケーション仕様に従うデータのフィールド分離子として使用される場合がある。それは,英
数字モードでは%で,8ビットバイトモードではIS3として表現する。両方の場合において,復号器は,1DHEX
を送信しなければならない。
FNC1モードのシンボルにおいて,英数字モードで%を符号化データの一部として用いている場合,シ
ンボル内でその文字は%%として表現しなければならない。%%が出現すると,復号器は,1個の%を送信
しなければならない。
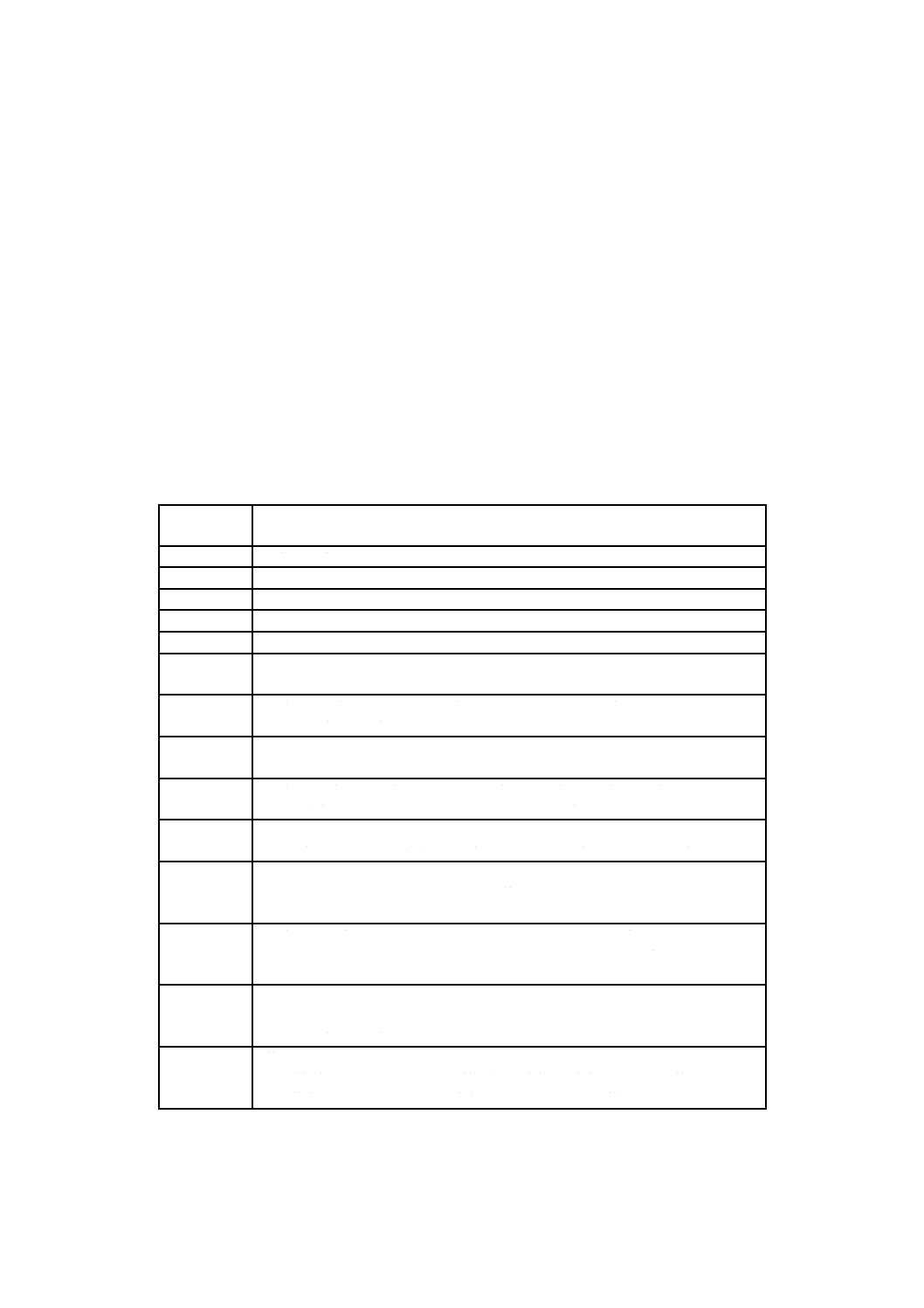
70
X 0510:2018 (ISO/IEC 18004:2015)
附属書A
(規定)
誤り検出及び訂正の生成多項式
誤り訂正の生成多項式は,データコード語の多項式の除算に用いる。ここで各コード語は,累乗の降順
に除算される多項式の係数となる。この除算の剰余の係数は,誤り訂正コード語の値となる。
表A.1は,全てのQRコードにおける,各型番及びレベルで用いる誤り訂正コードに対する生成多項式
を示す。ある特定の型番及び誤り訂正レベルに必要な誤り訂正コード語の数は,表9で得られる。表A.1
において,αは,GF(28)上の原始要素2の根とする。各生成多項式は,一次多項式x−α0,x−α1,…,x−
αn-1から生成される。ここに,nは,生成多項式の次数とする。
注記 対応国際規格では,一次多項式を“x−20,x−21,…,x−2n-1”としていた。誤りではないが,
より一般的な表記とした。
表A.1−RS誤り訂正コード語の生成多項式
誤り訂正
コード語数
生成多項式
2
x2 + α25x + α
5
x5 + α113x4 + α164x3 + α166x2 + α119x + α10
6
x6 + α166x5 + x4 + α134x3 + α5x2 + α176x + α15
7
x7 + α87x6 + α229x5 + α146x4 + α149x3 + α238x2 + α102x + α21
8
x8 + α175x7 + α238x6 + α208x5 + α249x4 + α215x3 + α252x2 + α196x + α28
10
x10 + α251x9 + α67x8 + α46x7 + α61x6 + α118x5 + α70x4 + α64x3 + α94x2
+ α32x + α45
13
x13 + α74x12 + α152x11 + α176x10 + α100x9 + α86x8 + α100x7 + α106x6 + α104x5
+ α130x4 + α218x3 + α206x2 + α140x + α78
14
x14 + α199x13 + α249x12 + α155x11 + α48x10 + α190x9 + α124x8 + α218x7
+ α137x6 + α216x5 + α87x4 + α207x3 + α59x2 + α22x + α91
15
x15 + α8x14 + α183x13 + α61x12 + α91x11 + α202x10 + α37x9 + α51x8 + α58x7
+ α58x6 + α237x5 + α140x4 + α124x3 + α5x2 + α99x + α105
16
x16 + α120x15 + α104x14 + α107x13 + α109x12 + α102x11 + α161x10 + α76x9
+ α3x8 + α91x7 + α191x6 + α147x5 + α169x4 + α182x3 + α194x2 + α225x + α120
17
x17 + α43x16 + α139x15 + α206x14 + α78x13 + α43x12 + α239x11 + α123x10
+ α206x9 + α214x8 + α147x7 + α24x6 + α99x5 + α150x4 + α39x3 + α243x2
+ α163x + α136
18
x18 + α215x17 + α234x16 + α158x15 + α94x14 + α184x13 + α97x12 + α118x11
+ α170x10 + α79x9 + α187x8 + α152x7 + α148x6 + α252x5 + α179x4 + α5x3
+ α98x2 + α96x + α153
20
x20 + α17x19 + α60x18 + α79x17 + α50x16 + α61x15 + α163x14 + α26x13 + α187x12
+ α202x11 + α180x10 + α221x9 + α225x8 + α83x7 + α239x6 + α156x5 + α164x4
+ α212x3 + α212x2 + α188x + α190
22
x22 + α210x21 + α171x20 + α247x19 + α242x18 + α93x17 + α230x16 + α14x15
+ α109x14 + α221x13 + α53x12 + α200x11 + α74x10 + α8x9 + α172x8 + α98x7
+ α80x6 + α219x5 + α134x4 + α160x3 + α105x2 + α165x + α231
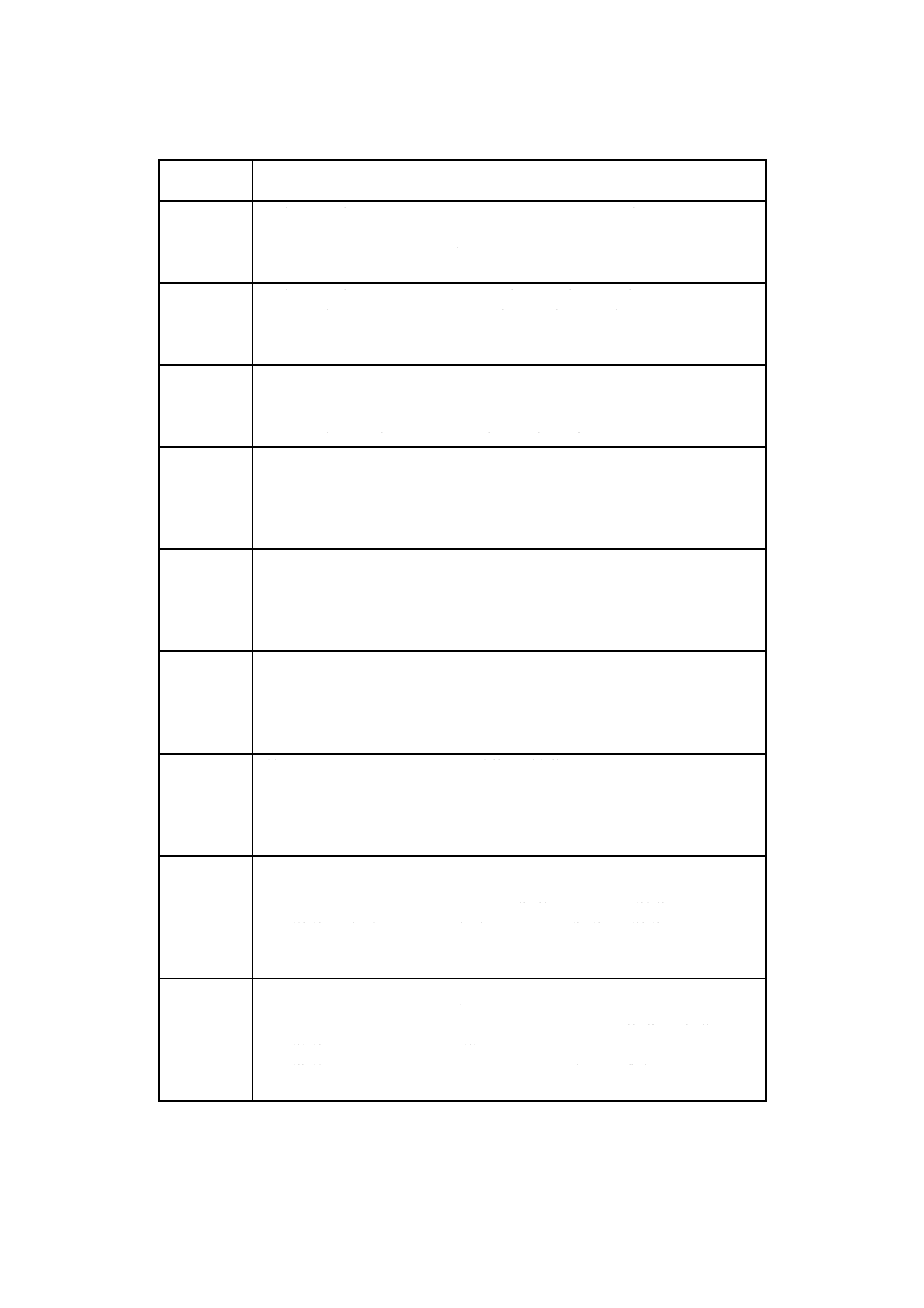
71
X 0510:2018 (ISO/IEC 18004:2015)
表A.1−RS誤り訂正コード語の生成多項式(続き)
誤り訂正
コード語数
生成多項式
24
x24 + α229x23 + α121x22 + α135x21 + α48x20 + α211x19 + α117x18 + α251x17
+ α126x16 + α159x15 + α180x14 + α169x13 + α152x12 + α192x11 + α226x10
+ α228x9 + α218x8 + α111x7 + x6 + α117x5 + α232x4 + α87x3 + α96x2 + α227x
+ α21
26
x26 + α173x25 + α125x24 + α158x23 + α2x22 + α103x21 + α182x20 + α118x19
+ α17x18 + α145x17 + α201x16 + α111x15 + α28x14 + α165x13 + α53x12
+ α161x11 + α21x10 + α245x9 + α142x8 + α13x7 + α102x6 + α48x5 + α227x4
+ α153x3 + α145x2 + α218x + α70
28
x28 + α168x27 + α223x26 + α200x25 + α104x24 + α224x23 + α234x22 + α108x21
+ α180x20 + α110x19 + α190x18 + α195x17 + α147x16 + α205x15 + α27x14
+ α232x13 + α201x12 + α21x11 + α43x10 + α245x9 + α87x8 + α42x7
+ α195x6 + α212x5 + α119x4 + α242x3 + α37x2 + α9x + α123
30
x30 + α41x29 + α173x28 + α145x27 + α152x26 + α216x25 + α31x24 + α179x23
+ α182x22 + α50x21 + α48x20 + α110x19 + α86x18 + α239x17 + α96x16
+ α222x15 + α125x14 + α42x13 + α173x12 + α226x11 + α193x10 + α224x9
+ α130x8 + α156x7 + α37x6 + α251x5 + α216x4 + α238x3 + α40x2 + α192x
+ α180
32
x32 + α10x31 + α6x30 + α106x29 + α190x28 + α249x27 + α167x26 + α4x25 + α67x24
+ α209x23 + α138x22 + α138x21 + α32x20 + α242x19 + α123x18 + α89x17
+ α27x16 + α120x15 + α185x14 + α80x13 + α156x12 + α38x11 + α69x10
+α171x9 + α60x8 + α28x7 + α222x6 + α80x5 + α52x4 + α254x3 + α185x2
+ α220x + α241
34
x34 + α111x33 + α77x32 + α146x31 + α94x30 + α26x29 + α21x28 + α108x27
+ α19x26 + α105x25 + α94x24 + α113x23 + α193x22 + α86x21 + α140x20
+ α163x19 + α125x18 + α58x17 + α158x16 + α229x15 + α239x14 + α218x13
+ α103x12 + α56x11 + α70x10 + α114x9 + α61x8 + α183x7 + α129x6
+ α167x5 + α13x4 + α98x3 + α62x2 + α129x + α51
36
x36 + α200x35 + α183x34 + α98x33 + α16x32 + α172x31 + α31x30 + α246x29
+ α234x28 + α60x27 + α152x26 + α115x25 + x24 + α167x23 + α152x22
+ α113x21 + α248x20 + α238x19 + α107x18 + α18x17 + α63x16 + α218x15
+ α37x14 + α87x13 + α210x12 + α105x11 + α177x10 + α120x9 + α74x8
+ α121x7 + α196x6 + α117x5 + α251x4 + α113x3 + α233x2 + α30x + α120
40
x40 + α59x39 + α116x38 + α79x37 + α161x36 + α252x35 + α98x34 + α128x33
+ α205x32 + α128x31 + α161x30 + α247x29 + α57x28 + α163x27 + α56x26
+ α235x25 + α106x24 + α53x23 + α26x22 + α187x21 + α174x20 + α226x19
+ α104x18 + α170x17 + α7x16 + α175x15 + α35x14 + α181x13 + α114x12
+ α88x11 + α41x10 + α47x9 + α163x8 + α125x7 + α134x6 + α72x5 + α20x4
+ α232x3 + α53x2 + α35x + α15
42
x42 + α250x41 + α103x40 + α221x39 + α230x38 + α25x37 + α18x36 + α137x35
+ α231x34 + x33 + α3x32 + α58x31 + α242x30 + α221x29 + α191x28 + α110x27
+ α84x26 + α230x25 + α8x24 + α188x23 + α106x22 + α96x21 + α147x20 + α15x19
+ α131x18 + α139x17 + α34x16 + α101x15 + α223x14 + α39x13 + α101x12 + α213x11
+ α199x10 + α237x9 + α254x8 + α201x7 + α123x6 + α171x5 + α162x4 + α194x3
+ α117x2 + α50x + α96

72
X 0510:2018 (ISO/IEC 18004:2015)
表A.1−RS誤り訂正コード語の生成多項式(続き)
誤り訂正
コード語数
生成多項式
44
x44 + α190x43 + α7x42 + α61x41 + α121x40 + α71x39 + α246x38 + α69x37 + α55x36
+ α168x35 + α188x34 + α89x33 + α243x32 + α191x31 + α25x30 + α72x29 + α123x28
+ α9x27 + α145x26 + α14x25 + α247x24 + αx23 + α238x22 + α44x21 + α78x20
+ α143x19 + α62x18 + α224x17 + α126x16 + α118x15 + α114x14 + α68x13 + α163x12
+ α52x11 + α194x10 + α217x9 + α147x8 + α204x7 + α169x6 + α37x5 + α130x4
+ α113x3 + α102x2 + α73x + α181
46
x46 + α112x45 + α94x44 + α88x43 + α112x42 + α253x41 + α224x40 + α202x39 + α115x38
+ α187x37 + α99x36 + α89x35 + α5x34 + α54x33 + α113x32 + α129x31 + α44x30
+ α58x29 + α16x28 + α135x27 + α216x26 + α169x25 + α211x24 + α36x23 + αx22
+ α4x21 + α96x20 + α60x19 + α241x18 + α73x17 + α104x16 + α234x15 + α8x14
+ α249x13 + α245x12 + α119x11 + α174x10 + α52x9 + α25x8 + α157x7 + α224x6
+ α43x5 + α202x4 + α223x3 + α19x2 + α82x + α15
48
x48 + α228x47 + α25x46 + α196x45 + α130x44 + α211x43 + α146x42 + α60x41 + α24x40
+ α251x39 + α90x38 + α39x37 + α102x36 + α240x35 + α61x34 + α178x33 + α63x32
+ α46x31 + α123x30 + α115x29 + α18x28 + α221x27 + α111x26 + α135x25 + α160x24
+ α182x23 + α205x22 + α107x21 + α206x20 + α95x19 + α150x18 + α120x17 + α184x16
+ α91x15 + α21x14 + α247x13 + α156x12 + α140x11 + α238x10 + α191x9 + α11x8
+ α94x7 + α227x6 + α84x5 + α50x4 + α163x3 + α39x2 + α34x + α108
50
x50 + α232x49 + α125x48 + α157x47 + α161x46 + α164x45 + α9x44 + α118x43 + α46x42
+ α209x41 + α99x40 + α203x39 + α193x38 + α35x37 + α3x36 + α209x35 + α111x34
+ α195x33 + α242x32 + α203x31 + α225x30 + α46x29 + α13x28 + α32x27 + α160x26
+ α126x25 + α209x24 + α130x23 + α160x22 + α242x21 + α215x20 + α242x19 + α75x18
+ α77x17 + α42x16 + α189x15 + α32x14 + α113x13 + α65x12 + α124x11 + α69x10
+ α228x9 + α114x8 + α235x7 + α175x6 + α124x5 + α170x4 + α215x3 + α232x2
+ α133x + α205
52
x52 + α116x51 + α50x50 + α86x49 + α186x48 + α50x47 + α220x46 + α251x45 + α89x44
+ α192x43 + α46x42 + α86x41 + α127x40 + α124x39 + α19x38 + α184x37 + α233x36
+ α151x35 + α215x34 + α22x33 + α14x32 + α59x31 + α145x30 + α37x29 + α242x28
+ α203x27 + α134x26 + α254x25 + α89x24 + α190x23 + α94x22 + α59x21 + α65x20
+ α124x19 + α113x18 + α100x17 + α233x16 + α235x15 + α121x14 + α22x13 + α76x12
+ α86x11 + α97x10 + α39x9 + α242x8 + α200x7 + α220x6 + α101x5 + α33x4
+ α239x3 + α254x2 + α116x + α51
54
x54 + α183x53 + α26x52 + α201x51 + α87x50 + α210x49 + α221x48 + α113x47 + α21x46
+ α46x45 + α65x44 + α45x43 + α50x42 + α238x41 + α184x40 + α249x39 + α225x38
+ α102x37 + α58x36 + α209x35 + α218x34 + α109x33 + α165x32 + α26x31 + α95x30
+ α184x29 + α192x28 + α52x27 + α245x26 + α35x25 + α254x24 + α238x23 + α175x22
+ α172x21 + α79x20 + α123x19 + α25x18 + α122x17 + α43x16 + α120x15 + α108x14
+ α215x13 + α80x12 + α128x11 + α201x10 + α235x9 + α8x8 + α153x7 + α59x6
+ α101x5 + α31x4 + α198x3 + α76x2 + α31x + α156
56
x56 + α106x55 + α120x54 + α107x53 + α157x52 + α164x51 + α216x50 + α112x49
+ α116x48 + α2x47 + α91x46 + α248x45 + α163x44 + α36x43 + α201x42 + α202x41
+ α229x40 + α6x39 + α144x38 + α254x37 + α155x36 + α135x35 + α208x34 + α170x33
+ α209x32 + α12x31 + α139x30 + α127x29 + α142x28 + α182x27 + α249x26 + α177x25
+ α174x24 + α190x23 + α28x22 + α10x21 + α85x20 + α239x19 + α184x18 + α101x17
+ α124x16 + α152x15 + α206x14 + α96x13 + α23x12 + α163x11 + α61x10 + α27x9
+ α196x8 + α247x7 + α151x6 + α154x5 + α202x4 + α207x3 + α20x2 + α61x + α10
73
X 0510:2018 (ISO/IEC 18004:2015)
表A.1−RS誤り訂正コード語の生成多項式(続き)
誤り訂正
コード語数
生成多項式
58
x58 + α82x57 + α116x56 + α26x55 + α247x54 + α66x53 + α27x52 + α62x51 + α107x50
+ α252x49 + α182x48 + α200x47 + α185x46 + α235x45 + α55x44 + α251x43 + α242x42
+ α210x41 + α144x40 + α154x39 + α237x38 + α176x37 + α141x36 + α192x35 + α248x34
+ α152x33 + α249x32 + α206x31 + α85x30 + α253x29 + α142x28 + α65x27 + α165x26
+ α125x25 + α23x24 + α24x23 + α30x22 + α122x21 + α240x20 + α214x19 + α6x18
+ α129x17 + α218x16 + α29x15 + α145x14 + α127x13 + α134x12 + α206x11 + α245x10
+ α117x9 + α29x8 + α41x7 + α63x6 + α159x5 + α142x4 + α233x3 + α125x2 + α148x
+ α123
60
x60 + α107x59 + α140x58 + α26x57 + α12x56 + α9x55 + α141x54 + α243x53 + α197x52
+ α226x51 + α197x50 + α219x49 + α45x48 + α211x47 + α101x46 + α219x45 + α120x44
+ α28x43 + α181x42 + α127x41 + α6x40 + α100x39 + α247x38 + α2x37 + α205x36
+ α198x35 + α57x34 + α115x33 + α219x32 + α101x31 + α109x30 + α160x29 + α82x28
+ α37x27 + α38x26 + α238x25 + α49x24 + α160x23 + α209x22 + α121x21 + α86x20
+ α11x19 + α124x18 + α30x17 + α181x16 + α84x15 + α25x14 + α194x13 + α87x12
+ α65x11 + α102x10 + α190x9 + α220x8 + α70x7 + α27x6 + α209x5 + α16x4 + α89x3
+ α7x2 + α33x + α240
62
x62 + α65x61 + α202x60 + α113x59 + α98x58 + α71x57 + α223x56 + α248x55 + α118x54
+ α214x53 + α94x52 + x51 + α122x50 + α37x49 + α23x48 + α2x47 + α228x46
+ α58x45 + α121x44 + α7x43 + α105x42 + α135x41 + α78x40 + α243x39 + α118x38
+ α70x37 + α76x36 + α223x35 + α89x34 + α72x33 + α50x32 + α70x31 + α111x30
+ α194x29 + α17x28 + α212x27 + α126x26 + α181x25 + α35x24 + α221x23 + α117x22
+ α235x21 + α11x20+ α229x19 + α149x18 + α147x17 + α123x16 + α213x15 + α40x14
+ α115x13 + α6x12 + α200x11 + α100x10 + α26x9 + α246x8 + α182x7 + α218x6
+ α127x5 + α215x4 + α36x3 + α186x2 + α110x + α106
64
x64 + α45x63 + α51x62 + α175x61 + α9x60 + α7x59 + α158x58 + α159x57 + α49x56
+ α68x55 + α119x54 + α92x53 + α123x52 + α177x51 + α204x50 + α187x49 + α254x48
+ α200x47 + α78x46 + α141x45 + α149x44 + α119x43 + α26x42 + α127x41 + α53x40
+ α160x39 + α93x38 + α199x37 + α212x36 + α29x35 + α24x34 + α145x33 + α156x32
+ α208x31 + α150x30 + α218x29 + α209x28 + α4x27 + α216x26 + α91x25 + α47x24
+ α184x23 + α146x22 + α47x21 + α140x20 + α195x19 + α195x18 + α125x17 + α242x16
+ α238x15 + α63x14 + α99x13 + α108x12 + α140x11 + α230x10 + α242x9 + α31x8
+ α204x7 + α11x6 + α178x5 + α243x4 + α217x3 + α156x2 + α213x + α231
66
x66 + α5x65 + α118x64 + α222x63 + α180x62 + α136x61 + α136x60 + α162x59 + α51x58
+ α46x57 + α117x56 + α13x55 + α215x54 + α81x53 + α17x52 + α139x51 + α247x50
+ α197x49 + α171x48 + α95x47 + α173x46 + α65x45 + α137x44 + α178x43 + α68x42
+ α111x41 + α95x40 + α101x39 + α41x38 + α72x37 + α214x36 + α169x35 + α197x34
+ α95x33 + α7x32 + α44x31 + α154x30 + α77x29 + α111x28 + α236x27 + α40x26
+ α121x25 + α143x24 + α63x23 + α87x22 + α80x21 + α253x20 + α240x19 + α126x18
+ α217x17 + α77x16 + α34x15 + α232x14 + α106x13 + α50x12 + α168x11 + α82x10
+ α76x9 + α146x8 + α67x7 + α106x6 + α171x5 + α25x4 + α132x3 + α93x2
+ α45x + α105
68
x68 + α247x67 + α159x66 + α223x65 + α33x64 + α224x63 + α93x62 + α77x61 + α70x60
+ α90x59 + α160x58 + α32x57 + α254x56 + α43x55 + α150x54 + α84x53 + α101x52
+ α190x51 + α205x50 + α133x49 + α52x48 + α60x47 + α202x46 + α165x45 + α220x44
+ α203x43 + α151x42 + α93x41 + α84x40 + α15x39 + α84x38 + α253x37 + α173x36
+ α160x35 + α89x34 + α227x33 + α52x32 + α199x31 + α97x30 + α95x29 + α231x28
+ α52x27 + α177x26 + α41x25 + α125x24 + α137x23 + α241x22 + α166x21 + α225x20
+ α118x19 + α2x18 + α54x17 + α32x16 + α82x15 + α215x14 + α175x13 + α198x12
+ α43x11 + α238x10 + α235x9 + α27x8 + α101x7 + α184x6 + α127x5 + α3x4
+ α5x3 + α8x2 + α163x + α238
74
X 0510:2018 (ISO/IEC 18004:2015)
附属書B
(規定)
誤り訂正復号手順
1-M型シンボルを例に規定する。このシンボルでは,GF(28)上の(26,16,4)RS符号を誤り訂正に用
いる。シンボルからマスク処理を解除した後のコード語が,
(
)
25
2
1
0
,...,
,
,
r
r
r
r
R=
すなわち,
()
25
25
2
2
1
0
...
x
r
x
r
x
r
r
x
R
+
+
+
+
=
であったとする。ここに,ri (i=0〜25)は,GF(28) の元とする。
a) n個のシンドローム[nは,表9に示す(c−k−p)で与えられる誤り訂正に利用可能なコード語の数に
等しい。]を計算する。
シンドロームSi [i=0〜(n−1)]を求める。
()
()
()
175
25
14
2
7
1
0
7
7
25
25
2
2
1
0
1
25
2
1
0
0
...
...
...
...
...
1
α
α
α
α
α
α
α
α
r
r
r
r
R
S
r
r
r
r
R
S
r
r
r
r
R
S
+
+
+
+
=
=
+
+
+
+
=
=
+
+
+
+
=
=
ここに, αは,GF(28) の原始元とする。
b) 誤り位置を求める。
0
0
0
0
7
1
6
2
5
3
4
4
3
6
1
5
2
4
3
3
4
2
5
1
4
2
3
3
2
4
1
4
1
3
2
2
3
1
4
0
=
+
−
+
−
=
+
−
+
−
=
+
−
+
−
=
+
−
+
−
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
S
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
σ
上の式を使ってそれぞれの誤り位置変数σi(i=1〜4)を求める。さらに,次の多項式にその変数を代入
し,GF(28)の元を順次代入する。
σ (x)=σ4+σ3x+σ2x2+σ1x3+x4
この結果,σ(αj)=0となる元αjに対し,j桁目(0桁目から数えて)に誤りがあることが分かる。
c) 誤りの大きさを求める。
b)においてj1,j2,j3,j4桁目に誤りがあるとし,次にその誤りの大きさを求める。
0
4
4
4
3
4
3
2
4
2
1
4
1
0
4
3
4
3
3
3
2
3
2
1
3
1
0
4
2
4
3
2
3
2
2
2
1
2
1
0
4
4
3
3
2
2
1
1
S
j
Y
j
Y
j
Y
j
Y
S
j
Y
j
Y
j
Y
j
Y
S
j
Y
j
Y
j
Y
j
Y
S
j
Y
j
Y
j
Y
j
Y
=
+
+
+
=
+
+
+
=
+
+
+
=
+
+
+
α
α
α
α
α
α
α
α
α
α
α
α
α
α
α
α
各誤りの大きさYi(i=1〜4)を求めるために上の式を解く。
d) 誤りを訂正
各誤り位置に誤りの大きさの値の補数を加算し,誤りを訂正する。
75
X 0510:2018 (ISO/IEC 18004:2015)
附属書C
(規定)
形式情報
C.1 一般
形式情報は,5ビットのデータ及び10ビットのBCH誤り訂正からなる15ビット列で構成する。この附
属書では,誤り訂正ビットの計算及び誤り訂正復号手順について規定する。
C.2 誤り訂正ビット計算
(15,5)BCH符号を誤り訂正に用いなければならない。データビット文字列を係数とする多項式を生
成多項式G (x)=x10+x8+x5+x4+x2+x+1で除算しなければならない。(15,5)BCH符号文字列を形成す
るために,剰余多項式の係数文字列をデータビット文字列に付加しなければならない。最後に,どのよう
なマスクパターン及び誤り訂正レベルの組合せでも形式情報のビットパターンが全てゼロにならないよう
に,ビット文字列を101010000010010(QRコードの場合)又は100010001000101(マイクロQRコードの
場合)とXOR演算し,マスク処理をしなければならない。
例 誤り訂正レベルM:マスクパターン 101
2進文字列:
00101
多項式:
x2+1
(15−5)乗する:
x12+x10
G(x)で除算する:
=(x10+x8+x5+x4+x2+x+1) x2+(x7+x6+x4+x3+x2)
上の多項式の係数文字列を形式情報のデータ文字列に付加する。
00101+0011011100
→
001010011011100
マスクとXOR演算
101010000010010
結果:
100000011001110
7.9に規定する方法で,これらのビットを形式情報領域に配置する。
C.3 誤り訂正復号手順
マスクパターン101010000010010(QRコードの場合)又は100010001000101(マイクロQRコードの場
合)でビット列をXOR演算し,形式情報のマスク処理を解除する。形式情報に用いる誤り訂正符号は,
ハミング距離が7であり,3ビットまでの訂正が可能である。形式情報に用いるビット列は,32種類しか
ないので,表C.1と比較して復号する方法が簡単で処理も速い。シンボルの形式情報領域から読み取った
ビット列を,表C.1の32種類の形式情報ビット列とビットごとに比較し,最も違いが少ないビット列を選
ぶ。その結果,3ビット以下の違いであれば,比較した表C.1の形式情報ビット列を採用する。
例 (QRコードの場合)
形式情報領域から読み取ったビット列
000011101001001
表から選んだ最も違いの少ないビット列
000111101011001
二つのビット列の違いは2ビットだけなので,比較は成功し,シンボルの形式は,誤り訂正レ
ベルがMでマスクパターンは011を用いたことが確認できる。
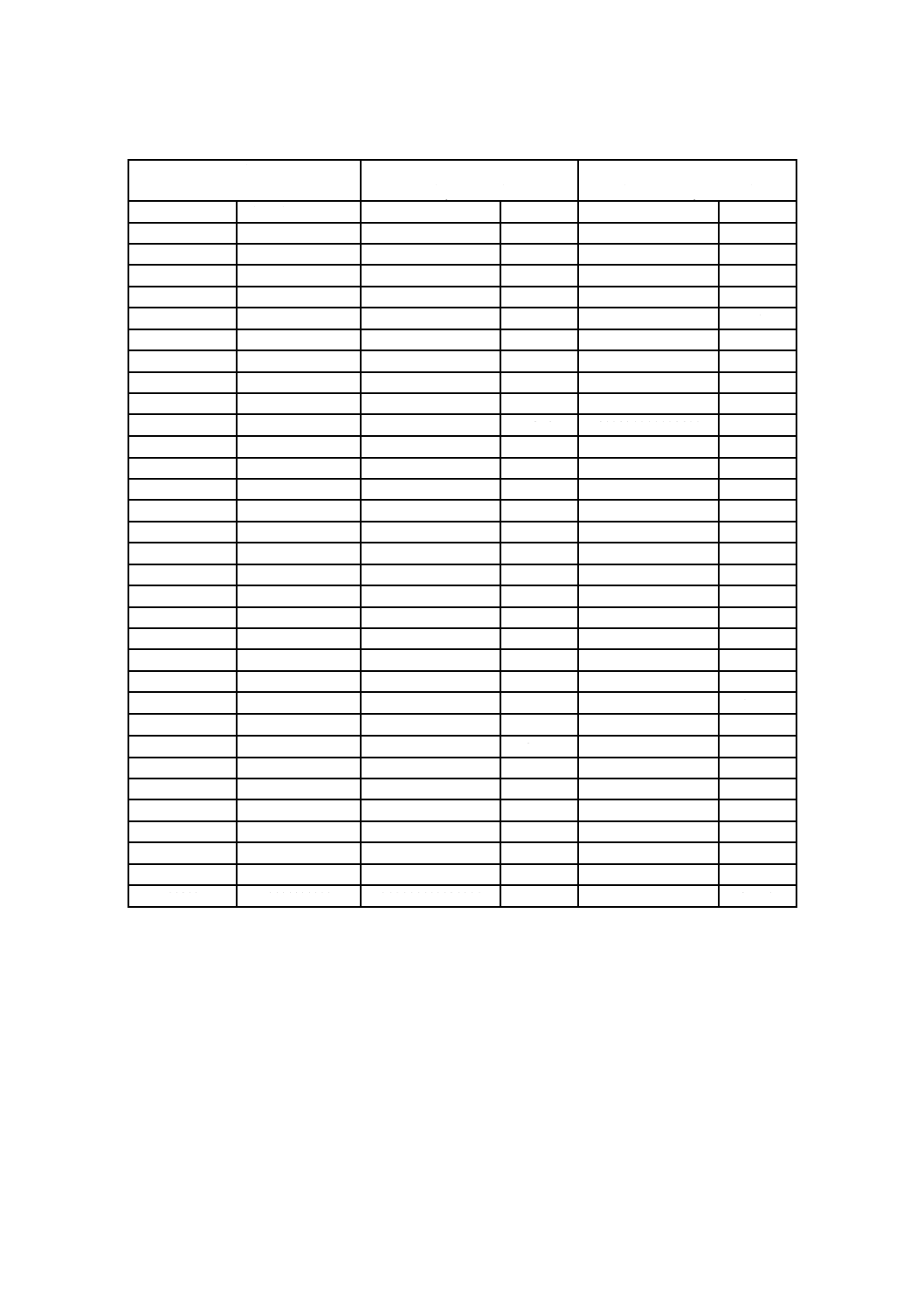
76
X 0510:2018 (ISO/IEC 18004:2015)
表C.1−有効な形式情報ビット列
マスク処理前のビット列
マスク処理後のビット列
(QRコード)
マスク処理後のビット列
(マイクロQRコード)
データビット
誤り訂正ビット
2進値
16進値
2進値
16進値
00000
0000000000
101010000010010
5412
100010001000101
4445
00001
0100110111
101000100100101
5125
100000101110010
4172
00010
1001101110
101111001111100
5E7C
100111000101011
4E2B
00011
1101011001
101101101001011
5B4B
100101100011100
4B1C
00100
0111101011
100010111111001
45F9
101010110101110
55AE
00101
0011011100
100000011001110
40CE
101000010011001
5099
00110
1110000101
100111110010111
4F97
101111111000000
5FC0
00111
1010110010
100101010100000
4AA0
101101011110111
5AF7
01000
1111010110
111011111000100
77C4
110011110010011
6793
01001
1011100001
111001011110011
72F3
110001010100100
62A4
01010
0110111000
111110110101010
7DAA
110110111111101
6DFD
01011
0010001111
111100010011101
789D
110100011001010
68CA
01100
1000111101
110011000101111
662F
111011001111000
7678
01101
1100001010
110001100011000
6318
111001101001111
734F
01110
0001010011
110110001000001
6C41
111110000010110
7C16
01111
0101100100
110100101110110
6976
111100100100001
7921
10000
1010011011
001011010001001
1689
000011011011110
06DE
10001
1110101100
001001110111110
13BE
000001111101001
03E9
10010
0011110101
001110011100111
1CE7
000110010110000
0CB0
10011
0111000010
001100111010000
19D0
000100110000111
0987
10100
1101110000
000011101100010
0762
001011100110101
1735
10101
1001000111
000001001010101
0255
001001000000010
1202
10110
0100011110
000110100001100
0D0C
001110101011011
1D5B
10111
0000101001
000100000111011
083B
001100001101100
186C
11000
0101001101
011010101011111
355F
010010100001000
2508
11001
0001111010
011000001101000
3068
010000000111111
203F
11010
1100100011
011111100110001
3F31
010111101100110
2F66
11011
1000010100
011101000000110
3A06
010101001010001
2A51
11100
0010100110
010010010110100
24B4
011010011100011
34E3
11101
0110010001
010000110000011
2183
011000111010100
31D4
11110
1011001000
010111011011010
2EDA
011111010001101
3E8D
11111
1111111111
010101111101101
2BED
011101110111010
3BBA
77
X 0510:2018 (ISO/IEC 18004:2015)
附属書D
(規定)
型番情報
D.1 一般
型番情報は,6ビットのデータ及び12ビットの拡張BCH誤り訂正からなる18ビット列で構成する。こ
の附属書では,誤り訂正ビットの計算及び誤り訂正復号手順について規定する。
D.2 誤り訂正ビット計算
(18,6)拡張BCH符号を誤り訂正として用いなければならない。データビット文字列を係数とする多
項式を,生成多項式G(x)=x12+x11+x10+x9+x8+x5+x2+1で除算しなければならない。(18,6)拡張BCH
符号文字列を形成するために,剰余多項式の係数文字列をデータビット文字列に付加しなければならない。
例 型番:
7
2進文字列:
000111
多項式:
x2+x+1
(18−6) 乗する:
x14+x13+x12
G(x) で除算する:
=(x12+x11+x10+x9+x8+x5+x2+1) x2+(x11+x10+x7+x4+x2)
上の多項式の係数文字列を,型番情報のデータ文字列に付加する。
000111+110010010100 → 000111110010010100
7.10で規定されているように,これらのビットを型番情報領域に配置する。
各型番に対する全型番情報のビット列を,表D.1に示す。
D.3 誤り訂正復号手順
型番情報に用いる誤り訂正符号は,ハミング距離が8であり,3ビットまでの訂正が可能である。型番
情報に用いるビット列は,34種類しかないので,表D.1と比較して復号する方法が簡単で処理も速い。シ
ンボルの型番情報領域から読み取ったビット列を,表D.1の34種類の型番情報ビット列とビットごとに比
較し,最も違いが少ないビット列を選ぶ。その結果,3ビット以下の違いであれば,比較した表D.1の型
番情報ビット列を採用する。
例 型番情報領域から読み取ったビット列
000111110110010100
表から選んだ最も違いの少ないビット列
000111110010010100
二つのビット列の違いは1ビットだけなので,比較は成功し,シンボルの型番は,7であるこ
とが確認できる。
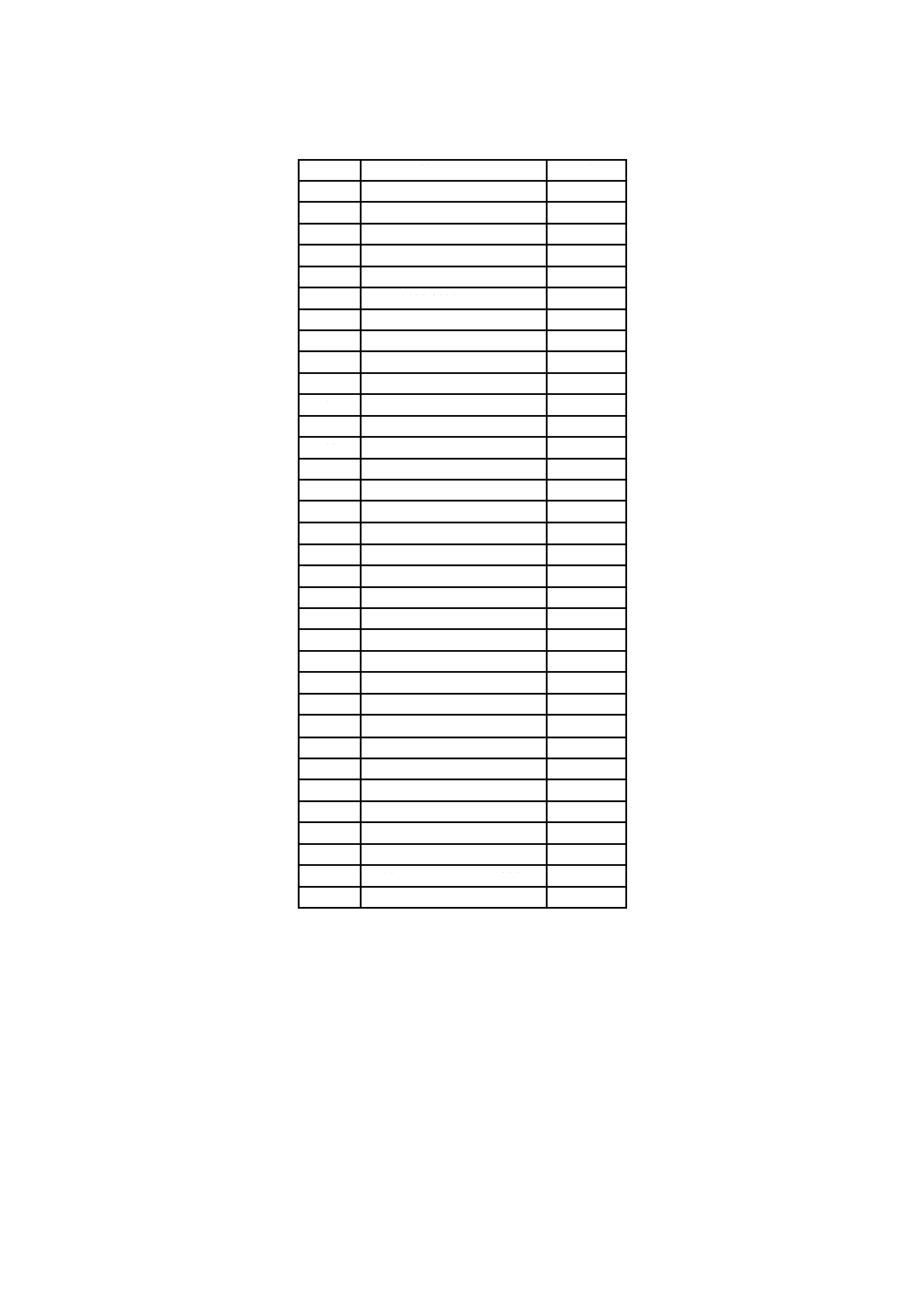
78
X 0510:2018 (ISO/IEC 18004:2015)
表D.1−各型番における型番情報のビット例
型番
型番情報のビット列
16進値
7
00 0111 1100 1001 0100
07C94
8
00 1000 0101 1011 1100
085BC
9
00 1001 1010 1001 1001
09A99
10
00 1010 0100 1101 0011
0A4D3
11
00 1011 1011 1111 0110
0BBF6
12
00 1100 0111 0110 0010
0C762
13
00 1101 1000 0100 0111
0D847
14
00 1110 0110 0000 1101
0E60D
15
00 1111 1001 0010 1000
0F928
16
01 0000 1011 0111 1000
10B78
17
01 0001 0100 0101 1101
1145D
18
01 0010 1010 0001 0111
12A17
19
01 0011 0101 0011 0010
13532
20
01 0100 1001 1010 0110
149A6
21
01 0101 0110 1000 0011
15683
22
01 0110 1000 1100 1001
168C9
23
01 0111 0111 1110 1100
177EC
24
01 1000 1110 1100 0100
18EC4
25
01 1001 0001 1110 0001
191E1
26
01 1010 1111 1010 1011
1AFAB
27
01 1011 0000 1000 1110
1B08E
28
01 1100 1100 0001 1010
1CC1A
29
01 1101 0011 0011 1111
1D33F
30
01 1110 1101 0111 0101
1ED75
31
01 1111 0010 0101 0000
1F250
32
10 0000 1001 1101 0101
209D5
33
10 0001 0110 1111 0000
216F0
34
10 0010 1000 1011 1010
228BA
35
10 0011 0111 1001 1111
2379F
36
10 0100 1011 0000 1011
24B0B
37
10 0101 0100 0010 1110
2542E
38
10 0110 1010 0110 0100
26A64
39
10 0111 0101 0100 0001
27541
40
10 1000 1100 0110 1001
28C69
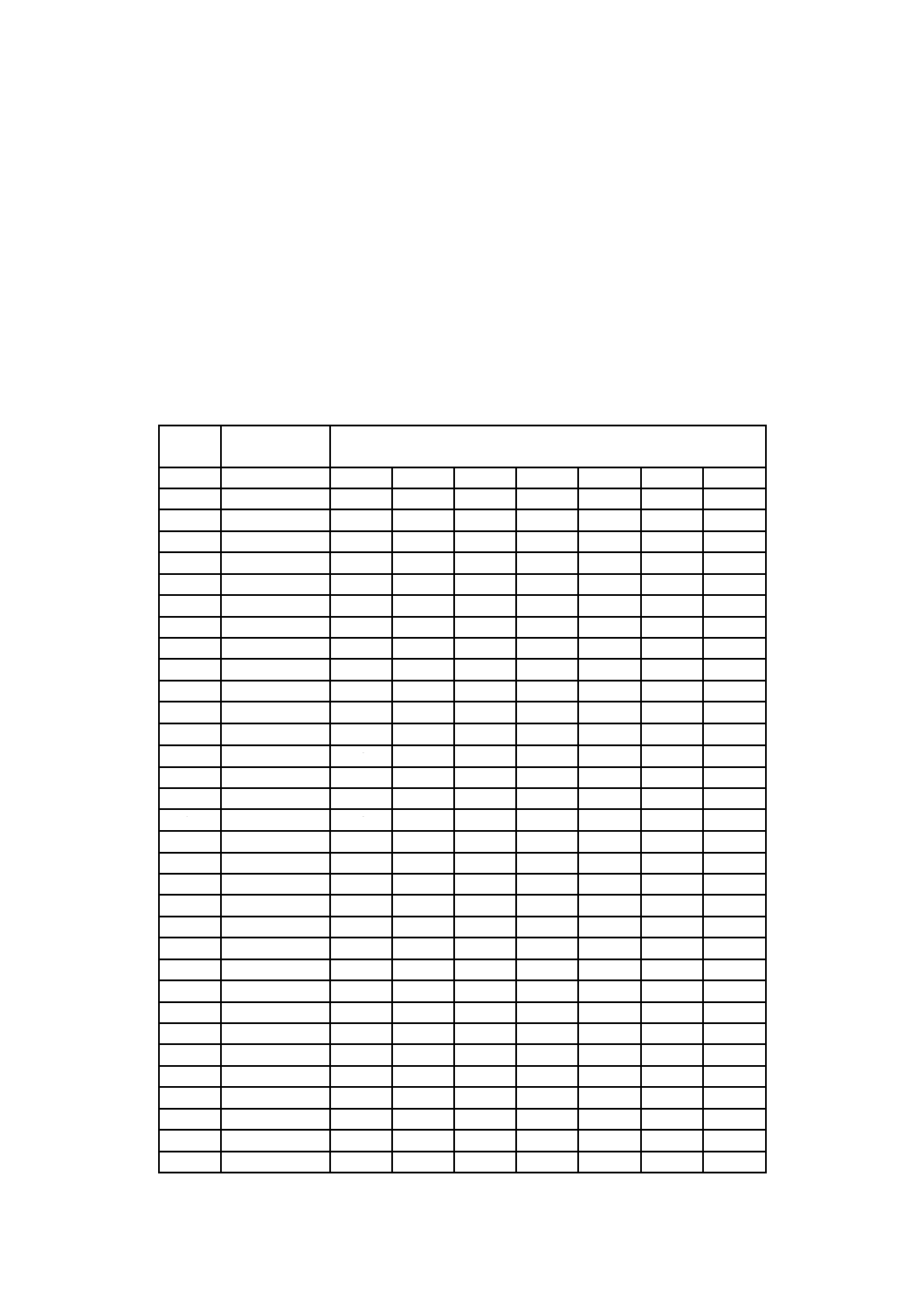
79
X 0510:2018 (ISO/IEC 18004:2015)
附属書E
(規定)
位置合せパターンの位置
位置合せパターンは,シンボルの左上隅から右下隅への対角線の両側で対称的に配置する。それらはタ
イミングパターンとその反対側との間でできるだけ均等間隔となる。不均等となる間隔は,タイミングパ
ターンと最初の位置合せパターンとの間で調整する。
各型番の位置合せパターンの数及び各位置合せパターンの中心モジュールの行座標又は列座標を,表
E.1に示す。
表E.1−位置合せパターンの中心モジュールの行座標又は列座標
型番
位置合せ
パターンの数
中心モジュールの行座標又は列座標
1
0
−
−
−
−
−
−
−
2
1
6
18
−
−
−
−
−
3
1
6
22
−
−
−
−
−
4
1
6
26
−
−
−
−
−
5
1
6
30
−
−
−
−
−
6
1
6
34
−
−
−
−
−
7
6
6
22
38
−
−
−
−
8
6
6
24
42
−
−
−
−
9
6
6
26
46
−
−
−
−
10
6
6
28
50
−
−
−
−
11
6
6
30
54
−
−
−
−
12
6
6
32
58
−
−
−
−
13
6
6
34
62
−
−
−
−
14
13
6
26
46
66
−
−
−
15
13
6
26
48
70
−
−
−
16
13
6
26
50
74
−
−
−
17
13
6
30
54
78
−
−
−
18
13
6
30
56
82
−
−
−
19
13
6
30
58
86
−
−
−
20
13
6
34
62
90
−
−
−
21
22
6
28
50
72
94
−
−
22
22
6
26
50
74
98
−
−
23
22
6
30
54
78
102
−
−
24
22
6
28
54
80
106
−
−
25
22
6
32
58
84
110
−
−
26
22
6
30
58
86
114
−
−
27
22
6
34
62
90
118
−
−
28
33
6
26
50
74
98
122
−
29
33
6
30
54
78
102
126
−
30
33
6
26
52
78
104
130
−
31
33
6
30
56
82
108
134
−
32
33
6
34
60
86
112
138
−
33
33
6
30
58
86
114
142
−
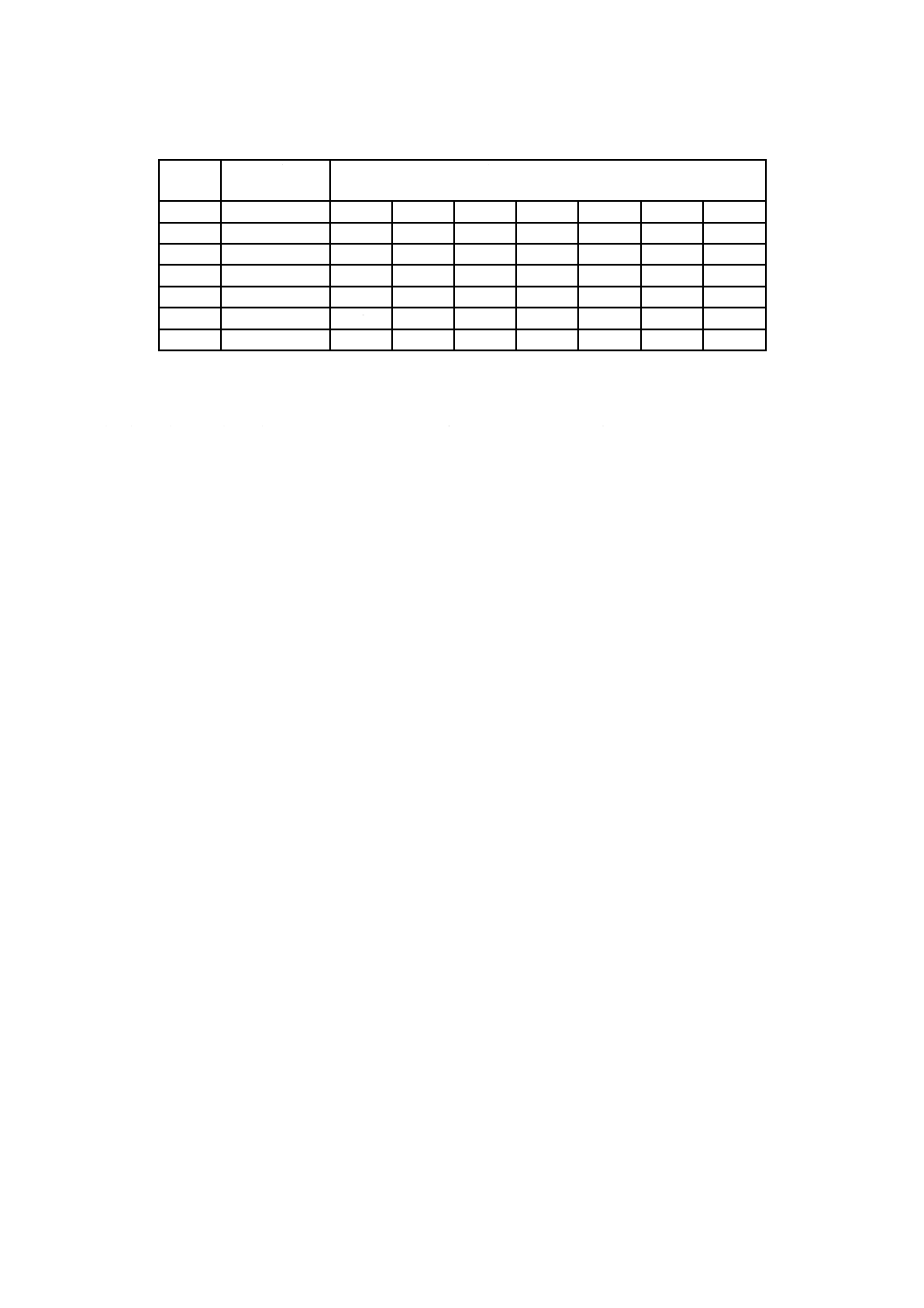
80
X 0510:2018 (ISO/IEC 18004:2015)
表E.1−位置合せパターンの中心モジュールの行座標又は列座標(続き)
型番
位置合せ
パターンの数
中心モジュールの行座標又は列座標
34
33
6
34
62
90
118
146
−
35
46
6
30
54
78
102
126
150
36
46
6
24
50
76
102
128
154
37
46
6
28
54
80
106
132
158
38
46
6
32
58
84
110
136
162
39
46
6
26
54
82
110
138
166
40
46
6
30
58
86
114
142
170
例えば,7型は,表で6,22,及び38という値である。したがって,位置合せパターンは,(行,列)す
なわち,座標(6,22),(22,6),(22,22),(22,38),(38,22)及び(38,38)を中心とする。座標(6,
6),(6,38)及び(38,6)は,位置検出パターンで占められるため,位置合せパターンとしては用いない。
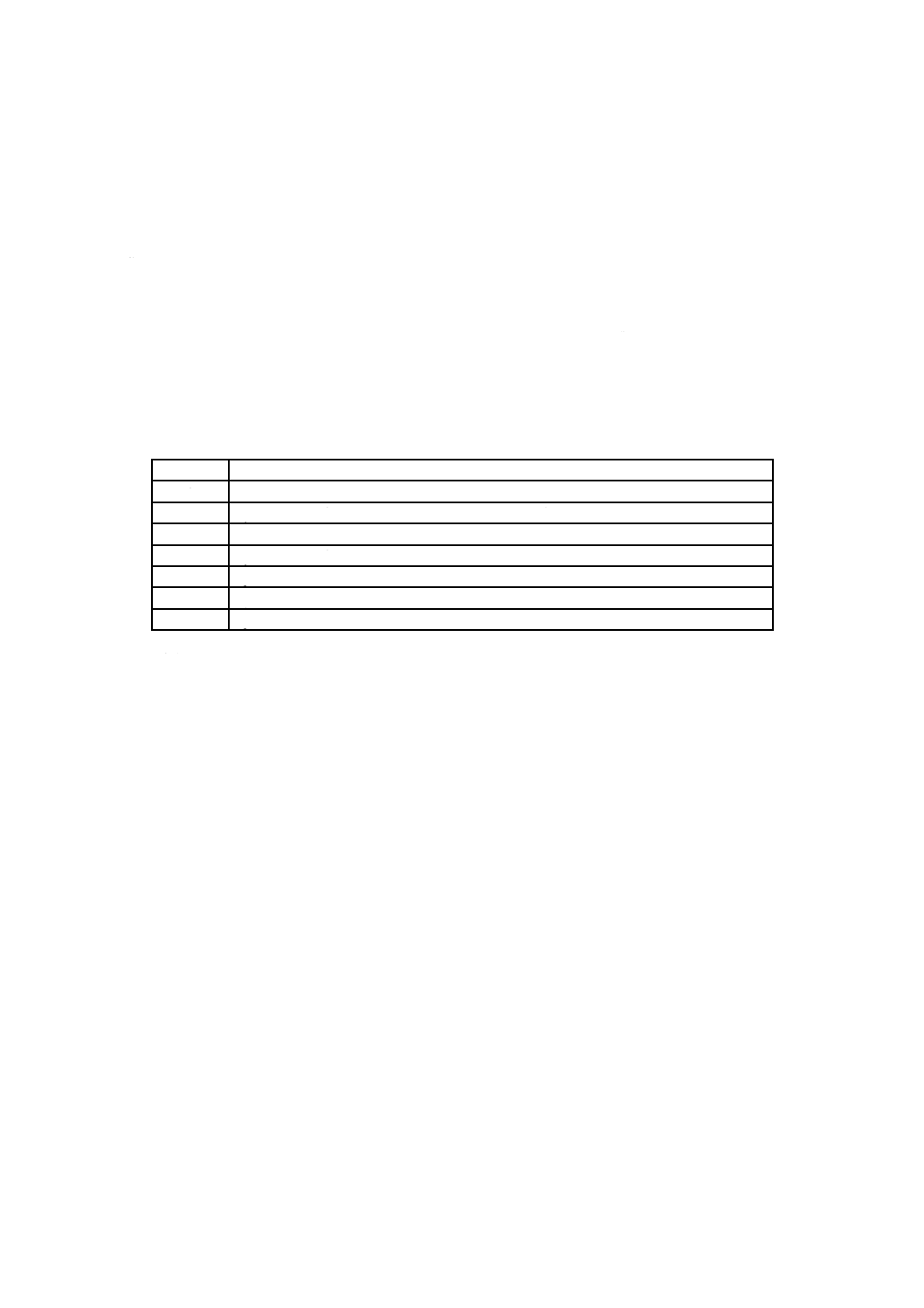
81
X 0510:2018 (ISO/IEC 18004:2015)
附属書F
(規定)
シンボル体系識別子
JIS X 0530でQRコードに割り当てているシンボル体系識別子(適切にプログラムされた復号器によっ
て,復号されたデータの先頭に付加することが望ましい。)は,次のとおりである。
]Qm
ここに,
]: シンボル体系識別子フラグ(JIS X 0201値93)
Q: QRコードシンボル体系のコードキャラクタ
m: 表F.1で規定するいずれかの値をもつ変更子
マイクロQRコードの場合,mの値は常に1とする。
表F.1−シンボル体系識別子の任意選択機能及び変更子値
変更子値
任意機能
0
QRコードモデル1シンボル
1
QRコードモデル2シンボル,ECIプロトコル未適用
2
QRコードモデル2シンボル,ECIプロトコル適用
3
QRコードモデル2シンボル,ECIプロトコル未適用, FNC1適用(1番目の位置)
4
QRコードモデル2シンボル,ECIプロトコル適用,
FNC1適用(1番目の位置)
5
QRコードモデル2シンボル,ECIプロトコル未適用, FNC1適用(2番目の位置)
6
QRコードモデル2シンボル,ECIプロトコル適用,
FNC1適用(2番目の位置)
mの許容値は,0,1,2,3,4,5及び6とする。
82
X 0510:2018 (ISO/IEC 18004:2015)
附属書G
(規定)
QRコードの印刷品質−シンボル体系に固有の特徴
G.1
一般
シンボル体系ごとに構造及び参照復号アルゴリズムが異なるため,あるパラメタがシンボルの読取性能
に与える影響度は異なることがある。JIS X 0526は,あるシンボル体系仕様に対する,そのシンボル体系
に固有の特徴をグレード付けする方法を規定している。この附属書は,固定パターン損傷のグレード付け
方法及びJIS X 0526をQRコードに適用する場合に用いる追加のパラメタ(形式情報及び型番情報)のグ
レード付け方法を規定する。
G.2
固定パターン損傷
G.2.1 評価する特徴
G.2.1.1 QRコード
評価する特徴は,次のとおりである。
− それぞれ次のパターンを含む3隅にある部分
− 7×7モジュールの位置検出パターン
− 位置検出パターンの内側の2辺を囲む,1X幅の分離パターン
− 最低4モジュール幅(又はアプリケーションで規定する場合は,より広い幅)のクワイエットゾー
ンの一部で,位置検出パターンの外側の2辺に沿って15モジュールの長さまで延長した領域
− 位置検出パターンの内側の角につながる,明及び暗を交互に繰り返す二つのタイミングパターン
− 5×5モジュールの位置合せパターン(2型以上のモデル2シンボルに存在する。)
上記の特徴を六つの特定部分(図G.1参照)として,次のとおり評価しなければならない。
− 三つの角の部分(関連する分離パターン及びクワイエットゾーンの一部を含む位置検出パターン)(そ
れぞれ部分A1,部分A2及び部分A3)
− 二つのタイミングパターン(それぞれ部分B1及び部分B2)
− 全ての位置合せパターンを含む単一部分(部分C)
タイミングパターンが位置合せパターンと交差する所では,一致する5モジュールをタイミングパター
ンの一部及び位置合せパターンの一部として評価する。
例えば,7型シンボル(45×45モジュール)では,部分Aは,それぞれ168モジュールを占め,部分B
は,29モジュール長,部分Cは,合計150モジュール(すなわち,6×25)を占める。
7型の場合の部分を図G.1に示す。A1,A2及びA3は3隅の部分を示し,B1及びB2は,二つのタイミ
ングパターン部分を示し,Cは,単一の部分C(六つの位置合せパターンからなる。)を示す。
注記 QRコードでは,クワイエットゾーンの幅は,4Xである。図G.1は,固定パターンの印刷品質
を評価する際に確認する部分を示す。クワイエットゾーンの残りの領域は,確認しない。
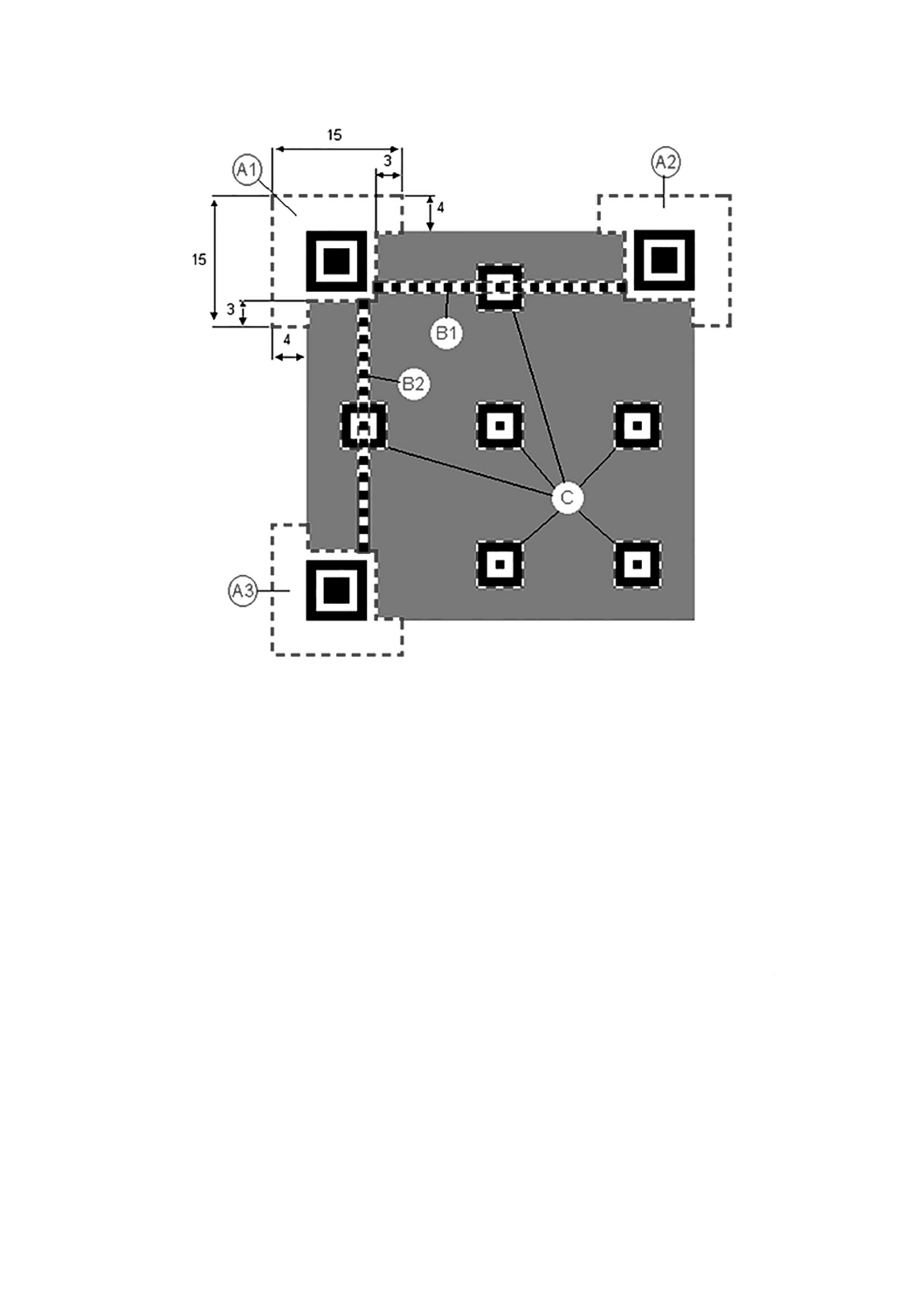
83
X 0510:2018 (ISO/IEC 18004:2015)
図G.1−QRコードの固定パターン部分
G.2.1.2 マイクロQRコード
評価する特徴は次のとおりである。
− 次のパターンを含む角の部分
− 位置検出パターン
− 位置検出パターンの内側の2辺に隣接する,1X幅の分離パターン
− 最低2モジュール幅(又はアプリケーションで規定する場合は,より広い幅)のクワイエットゾー
ンの一部で,位置検出パターンの外側の2辺に沿って11モジュールの長さまで延長した領域
− 位置検出パターンから,上辺及び左辺に沿って通る,明及び暗を交互に繰り返す二つのタイミングパ
ターン
上記の特徴を三つの特定部分(図G.2参照)として,次のとおり評価しなければならない。
− 104モジュールを占める角の部分(関連する分離パターン及びクワイエットゾーンの一部を含む位置
検出パターン)(部分A)
− 二つのタイミングパターン(それぞれ部分B1及び部分B2)
例えば,M4型シンボル(17×17モジュール)では,部分Bは,9モジュール長を占める。
M4型の場合の部分を図G.2に示す。Aは3隅の部分を示し,B1及びB2は,二つのタイミングパター
ン部分を示す。
注記 マイクロQRコードでは,クワイエットゾーンの幅は,2Xである。図G.2は,固定パターンの
印刷品質を評価する際に確認する部分を示す。クワイエットゾーンの残りの領域は,確認しな
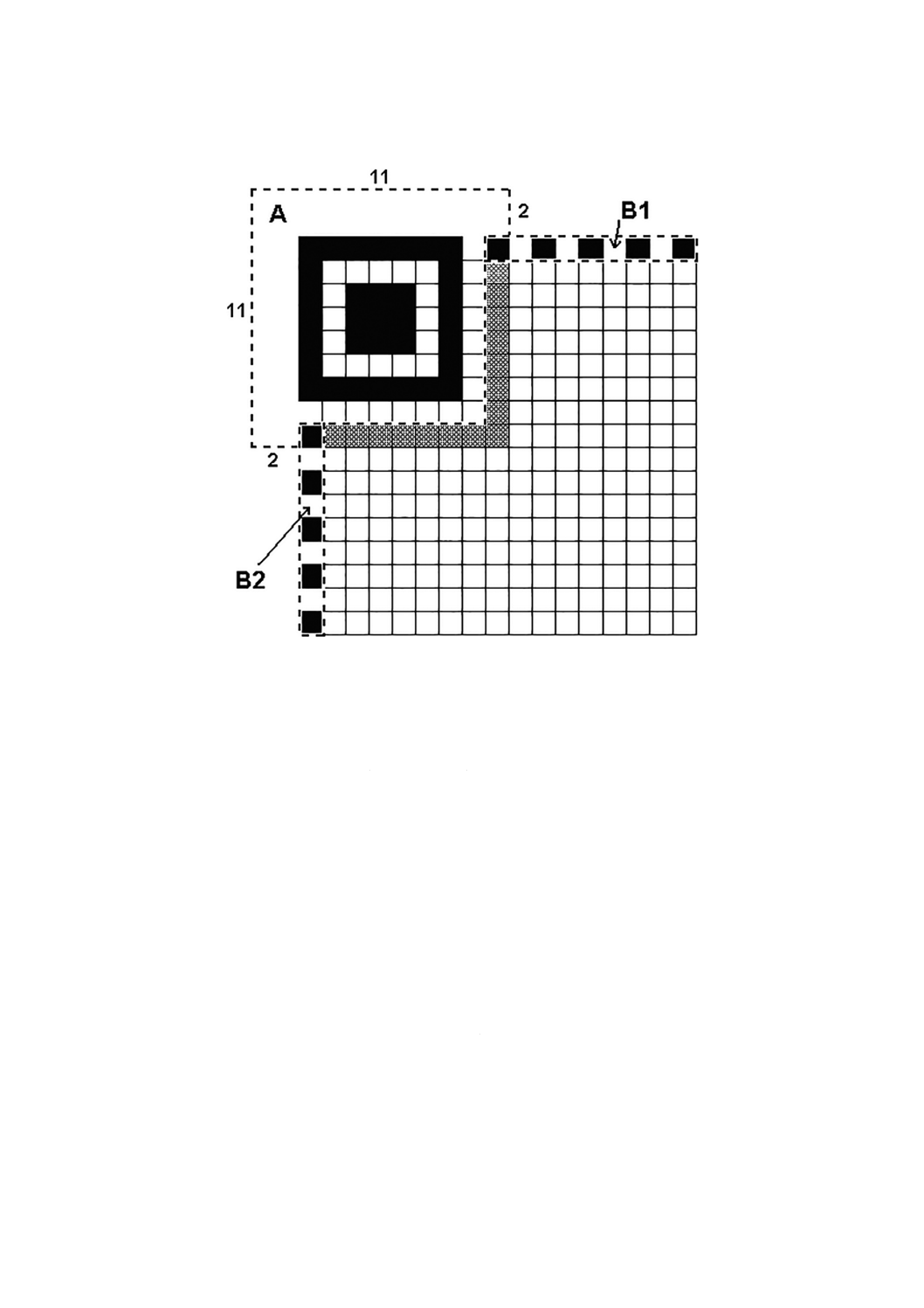
84
X 0510:2018 (ISO/IEC 18004:2015)
い。
図G.2−マイクロQRコードの固定パターン部分
G.2.2 固定パターン損傷のグレード付け
それぞれの部分への損傷を,構成する個々のモジュールのモジュレーションに基づいてグレード付けし
なければならない。
それぞれの部分に,次の手順を順次適用しなければならない。
a) JIS X 0526に示す値に基づいて,シンボルの参照グレースケール画像から,個々のモジュールに対す
るモジュレーショングレードを求める。本来あるべきモジュールの明暗は,分かっているため,暗で
あるべきモジュールで反射率値が全域的しきい値を超えるモジュール及び明であるべきモジュールで
反射率値が全域的しきい値未満のモジュールは,全てモジュレーショングレードを0としなければな
らない。
b) それぞれのモジュレーショングレードに対し,そのグレード又は高いグレードに達していないモジュ
ールは,全てモジュールエラーであると仮定し,表G.1に示すグレードしきい値に基づいて想定損傷
グレードを求める。モジュレーショングレード及び想定損傷グレードの低い方を取る。想定損傷グレ
ードは,次の手順で決定する。
1) 部分A1,A2及びA3(マイクロQRコードの場合は,部分A)それぞれに対して,モジュールエラ
ーの数を数える。
2) 部分B1及びB2に対して,モジュールエラーの数を数える。この数を,対象の部分の総モジュール
数のパーセントで表す。
3) 部分B1及びB2に対して,その部分に沿って1モジュール幅で,隣接する五つのモジュールを取り,
どの5モジュールのグループ内にも二つ以上の損傷がないことを確認する。このテストに失敗した
85
X 0510:2018 (ISO/IEC 18004:2015)
場合は,対象の部分のグレードを0としなければならない。このテストは,マイクロQRコードに
は適用しない。
4) 部分C(QRコードだけに存在する。)に対し,モジュールエラーを含む位置合せパターンの数を数
える。この数を,シンボルの位置合せシンボルの数のパーセントで表す。
5) 表G.1に示すグレードしきい値に基づいて,想定損傷グレードをそれぞれの部分に付与する。
c) 対象の部分に対する固定パターン損傷グレードは,全てのモジュレーショングレードレベルの最も高
い点数グレードとしなければならない。
シンボルの固定パターン損傷グレードは,セグメントグレードの最低のものとしなければならない。
表G.1−QRコードの固定パターン損傷に対するグレードしきい値
部分A1,A2及びA3
(QRコード);
部分A
(マイクロQRコード)
部分B1及びB2
(QRコード)
部分B1及びB2
(マイクロQRコード)
部分C
(QRコード)
グレード
モジュールエラー
の数
総モジュール数に
対するモジュール
エラーの割合
総モジュール数に
対するモジュール
エラーの割合
位置合せパターンに
対するモジュール
エラーの割合
−
0
0 %
0 %
0 %
4
1
≦7 %
−
≦10 %
3
2
≦11 %
≦30 %
≦20 %
2
3
≦14 %
−
≦30 %
1
≧4
>14 %
>30 %
>30 %
0
G.3
追加パラメタのグレード付け
G.3.1 一般
QRコードは,シンボルの形式を規定する情報を表すモジュール一式を二重にもつ。また,7型〜40型
のシンボルは,シンボルの大きさを規定する情報を表すモジュール一式を二重にもつ。マイクロQRコー
ドは,シンボルの形式を規定する情報を表すモジュール一式を一つもつ。このデータは,復号手順の初期
段階で確実に見つけることが必要で,見つけられなかった場合には,残りのシンボルを復号できない。こ
の理由で,形式情報及び型番情報のモジュールブロックは,別々にグレード付けし,最終的なシンボルグ
レードの判定にそれらのグレードを含める。
G.3.2 形式情報のグレード付け
形式情報のそれぞれのブロックに対し,次の方法に従って,そのブロックのグレードを決定する。
a) JIS X 0526に示す値に基づいて,シンボルの参照グレースケール画像から,個々のモジュールに対す
るモジュレーショングレードを求める。本来あるべきモジュールの明暗は,復号後には,分かってい
るため,暗であるべきモジュールで反射率値が全域的しきい値を超えるモジュール及び明であるべき
モジュールで反射率値が全域的しきい値未満のモジュールは,全てモジュレーショングレードを0と
しなければならない。もし形式情報が復号できなかった場合には,そのブロックのグレードを0とし
なければならない。
b) それぞれのモジュレーショングレードレベルに対し,次の手順を適用する。
1) そのグレード又は高いグレードに達していないモジュールは,全てモジュールエラーであると仮定
し,表G.2に示すグレードしきい値に基づいて想定グレードを求める。
86
X 0510:2018 (ISO/IEC 18004:2015)
表G.2−形式情報の想定グレード
モジュールエラーの数
グレード
0
4
1
3
2
2
3
1
≧4
0
2) 表G.3に示すとおり,それぞれのレベルで,モジュレーショングレード及び想定グレードの低い方
をそのレベルのグレードとして選ぶ。
3) 表G.3に示すとおり,結果として得られた最も高いグレードを,そのブロックのグレードとしなけ
ればならない。
表G.3−形式情報ブロックのグレード付けの例
モジュレーション
グレード
想定グレード
低い方のグレード
4
2
2
3
2
2
2
3
2
1
3
1
0
4
0
−
選択された(最も高い)
グレード→
2
c) 形式情報グレードを次のとおり求めなければならない。
1) QRコードの場合,二つの形式情報ブロックの平均値(必要であれば整数に四捨五入)とする。
2) マイクロQRコードの場合は,手順b) 3) 8) で決まる。
注8) 対応国際規格での記載が,明らかに誤りのため,訂正した。
G.3.3 型番情報のグレード付け(QRコード)
型番情報のそれぞれのブロックに対し,次の方法に従って,そのブロックのグレードを決定する。
a) JIS X 0526に示す値に基づいて,シンボルの参照グレースケール画像から,個々のモジュールに対す
るモジュレーショングレードを求める。本来あるべきモジュールの明暗は,復号後には,分かってい
るため,暗であるべきモジュールで反射率値が全域的しきい値を超えるモジュール及び明であるべき
モジュールで反射率値が全域的しきい値未満のモジュールは,全てモジュレーショングレードを0と
しなければならない。もし型番情報が復号できなかった場合には,そのブロックのグレードを0とし
なければならない。
b) それぞれのモジュレーショングレードレベルに対し,次の手順を適用する。
1) そのグレード又は高いグレードに達していないモジュールは,全てモジュールエラーであると仮定
し,表G.4に示すグレードしきい値に基づいて想定グレードを求める。
87
X 0510:2018 (ISO/IEC 18004:2015)
表G.4−型番情報の想定グレード
モジュールエラーの数
グレード
0
4
1
3
2
2
3
1
≧4
0
2) 表G.5に示すとおり,それぞれのレベルで,モジュレーショングレード及び理論上のグレードの低
い方をそのレベルのグレードとして選ぶ。
3) 表G.5に示すとおり,結果として得られた最も高いグレードを,そのブロックのグレードとしなけ
ればならない。
表G.5−型番情報ブロックのグレード付けの例
モジュレーション
グレード
想定グレード
低い方のグレード
4
2
2
3
2
2
2
3
2
1
3
1
0
4
0
−
選択された(最も高い)
グレード→
2
c) 型番情報グレードは,二つの型番情報ブロックの平均値(必要であれば整数に四捨五入)としなけれ
ばならない。
G.4
走査グレード
走査グレードは,JIS X 0526に従って評価した標準のパラメタのグレードに,この附属書に従って評価
した,固定パターン損傷,形式情報及び(適用可能なら)型番情報のグレードを加えた中で最も低いグレ
ードとしなければならない。
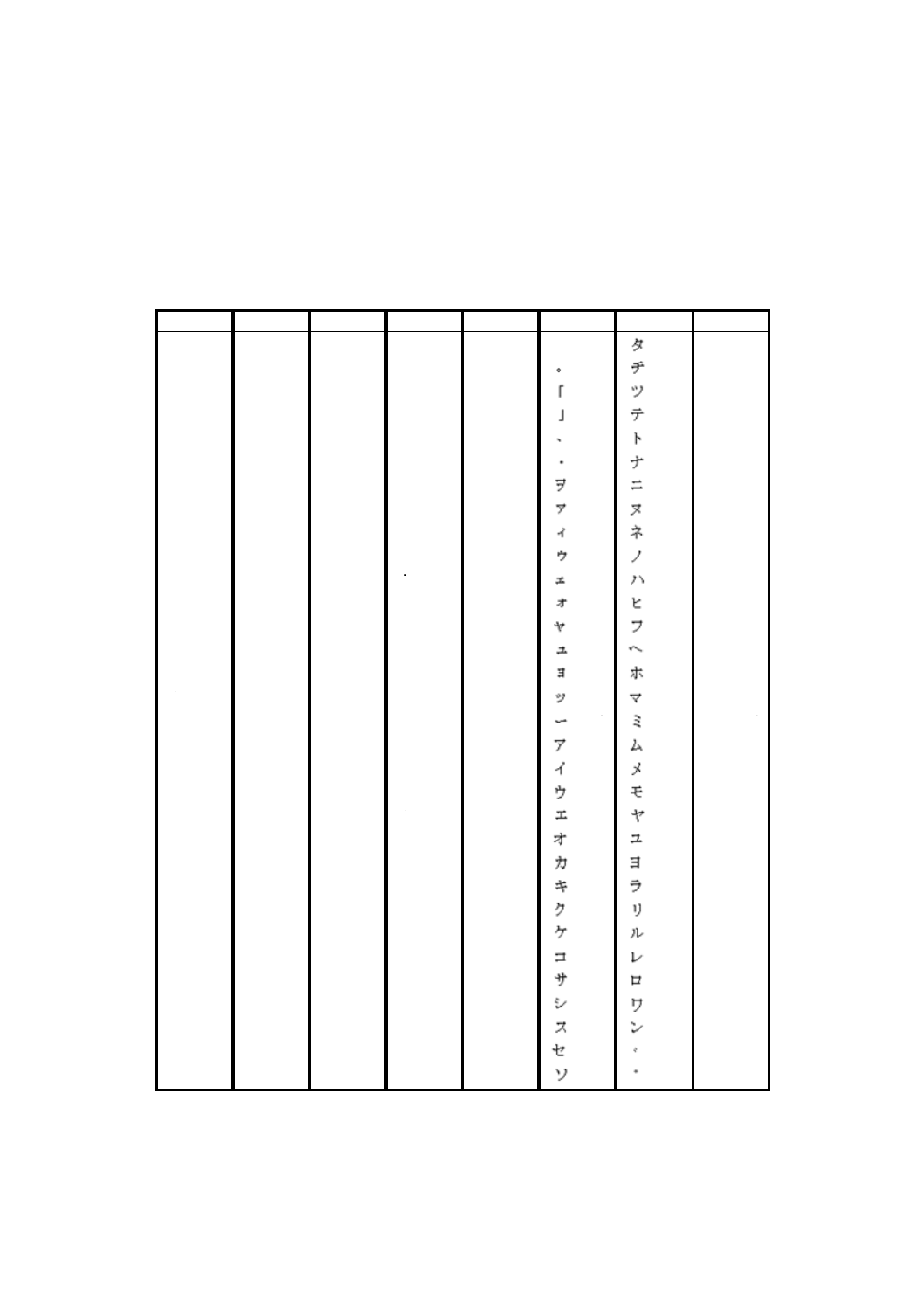
88
X 0510:2018 (ISO/IEC 18004:2015)
附属書H
(参考)
JIS X 0201の8ビットの情報交換用符号化文字集合及び
JIS X 0208のシフト符号化表現
表H.1−JIS X 0201の8ビット文字集合
Char. Hex Char. Hex Char. Hex Char. Hex Char. Hex Char. Hex Char. Hex Char. Hex
NUL 00
SP
20
@
40
̀
60
80
A0
C0
E0
SOH 01
!
21
A
41
a
61
81
A1
C1
E1
STX
02
"
22
B
42
b
62
82
A2
C2
E2
ETX
03
#
23
C
43
c
63
83
A3
C3
E3
EOT 04
$
24
D
44
d
64
84
A4
C4
E4
ENQ 05
%
25
E
45
e
65
85
A5
C5
E5
ACK 06
&
26
F
46
f
66
86
A6
C6
E6
BEL
07
'
27
G
47
g
67
87
A7
C7
E7
BS
08
(
28
H
48
h
68
88
A8
C8
E8
HT
09
)
29
I
49
I
69
89
A9
C9
E9
LF
0A
*
2A
J
4A
j
6A
8A
AA
CA
EA
VT
0B
+
2B
K
4B
k
6B
8B
AB
CB
EB
FF
0C
,
2C
L
4C
l
6C
8C
AC
CC
EC
CR
0D
-
2D
M
4D
m
6D
8D
AD
CD
ED
SO
0E
.
2E
N
4E
n
6E
8E
AE
CE
EE
SI
0F
/
2F
O
4F
o
6F
8F
AF
CF
EF
DLE
10
0
30
P
50
p
70
90
B0
D0
F0
DC1 11
1
31
Q
51
q
71
91
B1
D1
F1
DC2 12
2
32
R
52
r
72
92
B2
D2
F2
DC3 13
3
33
S
53
s
73
93
B3
D3
F3
DC4 14
4
34
T
54
t
74
94
B4
D4
F4
NAK 15
5
35
U
55
u
75
95
B5
D5
F5
SYN 16
6
36
V
56
v
76
96
B6
D6
F6
ETB
17
7
37
W
57
w
77
97
B7
D7
F7
CAN 18
8
38
X
58
x
78
98
B8
D8
F8
EM
19
9
39
Y
59
y
79
99
B9
D9
F9
SUB 1A
:
3A
Z
5A
z
7A
9A
BA
DA
FA
ESC 1B
;
3B
[
5B
{
7B
9B
BB
DB
FB
FS
1C
<
3C
¥
5C
|
7C
9C
BC
DC
FC
GS
1D
=
3D
]
5D
}
7D
9D
BD
DD
FD
RS
1E
>
3E
^
5E
¯
7E
9E
BE
DE
FE
US
1F
?
3F
̲
5F
DEL
7F
9F
BF
DF
FF
図H.1に,2バイト文字をJIS X 0208のシフト符号化表現した場合に占める,256×256の符号面の領域
を示す。
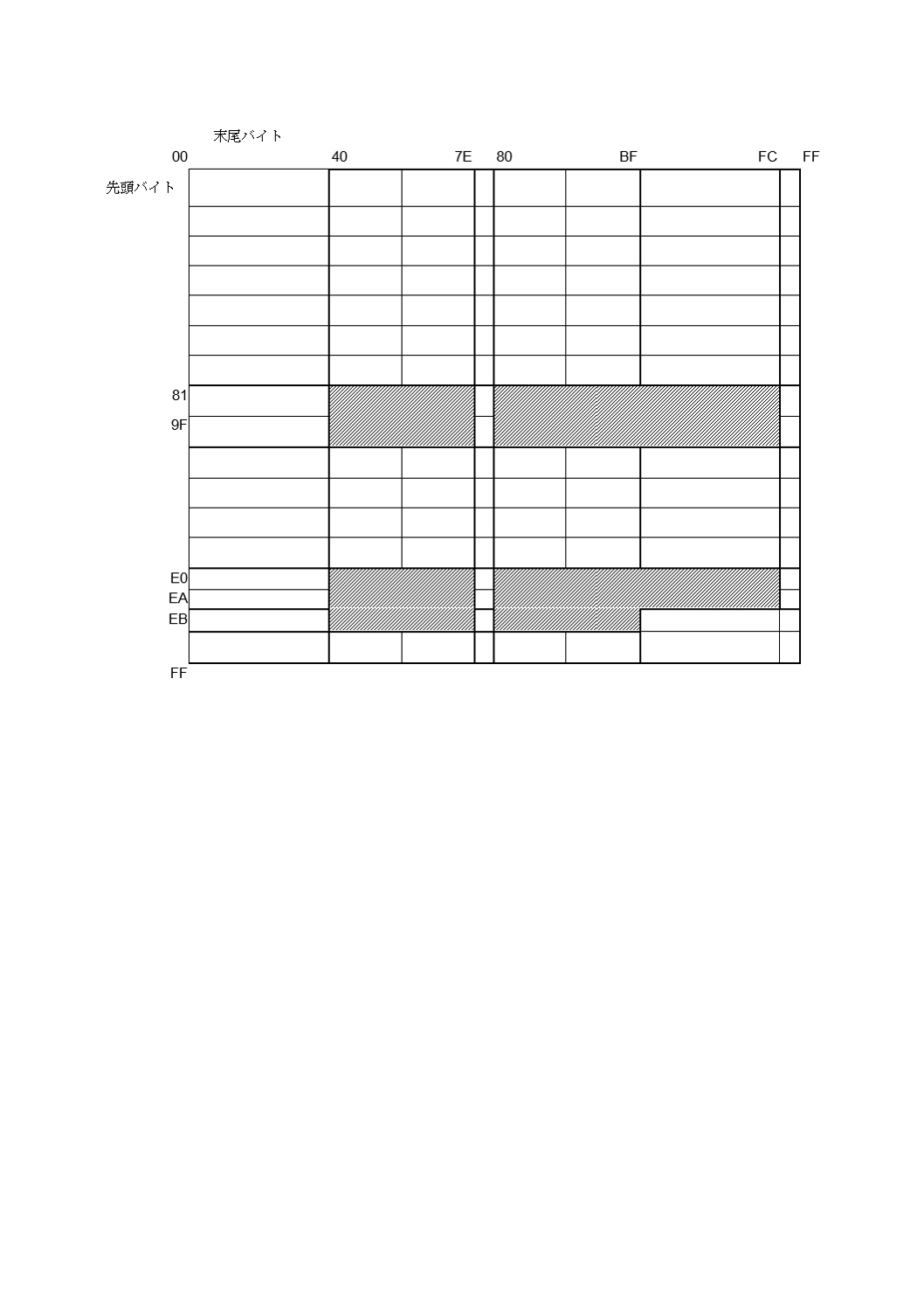
89
X 0510:2018 (ISO/IEC 18004:2015)
図H.1−JIS X 0208のシフト符号化表現の値
JIS X 0208:1997の附属書1に従って,網掛けで示した範囲にある先頭バイト及び末尾バイトは,JIS X
0208のシフト符号化表現をした漢字に割り当てる。これらの範囲にある,どのバイトペアも,漢字モード
の圧縮方法を用いて符号化してもよい。

90
X 0510:2018 (ISO/IEC 18004:2015)
附属書I
(参考)
シンボルの符号化例
I.1
一般
この附属書では,データ文字列01234567のQRコード及びマイクロQRコードへの符号化を記載する。
I.2
QRコードの符号化
データ文字列を,7.4.3に従って,数字モードを用いて1-M型シンボルに符号化する。
手順1 データの符号化
− 3桁のグループに分割し,各グループを10又は7ビットの2進値に変換する。
− 012 → 0000001100
− 345 → 0101011001
− 67 → 1000011
− 文字数指示子を2進(1-M型は,10ビット)に変換する。
文字数指示子(8)=0000001000
− 数字モードに対するモード指示子(0001),文字数指示子,2進データ及び終端パターン(0000)を接
続する。
0001 0000001000 0000001100 0101011001 1000011 0000
− 8ビットコード語に分割し,必要な埋め草ビット(下線で示す。)を付加する。
00010000 00100000 00001100 01010110 01100001 10000000
− シンボルのデータコード語容量(1-M型は,16データコード語であるので,10埋め草コード語が必要)
を満たすために埋め草コード語(下線で示す。)を付加する。結果は,次のとおりとなる。
00010000 00100000 00001100 01010110 01100001 10000000 11101100 00010001 11101100
00010001 11101100 00010001 11101100 00010001 11101100 00010001
手順2 誤り訂正コード語の生成
RS誤り訂正のアルゴリズムを用い,必要数の誤り訂正コード語(1-M型は,10個必要)を生成し,こ
れら(下線で示す。)を,ビット列に付加することが望ましい。結果は次のとおりとなる。
00010000 00100000 00001100 01010110 01100001 10000000 11101100 00010001 11101100
00010001 11101100 00010001 11101100 00010001 11101100 00010001 10100101 00100100
11010100 11000001 11101101 00110110 11000111 10000111 00101100 01010101
手順3 マトリックスにモジュールを配置
1-M型シンボルでは,一つのRSブロックしか存在しないので,この例ではインタリーブ配置は,必要
ではない。21×21の空マトリックス内に位置検出パターン及びタイミングパターンを配置し,形式情報の
モジュール位置は,一時的に空とする。手順2で得られたコード語を7.7.3に従ってマトリックス内に配
置すると,図I.1に示す配列となる。
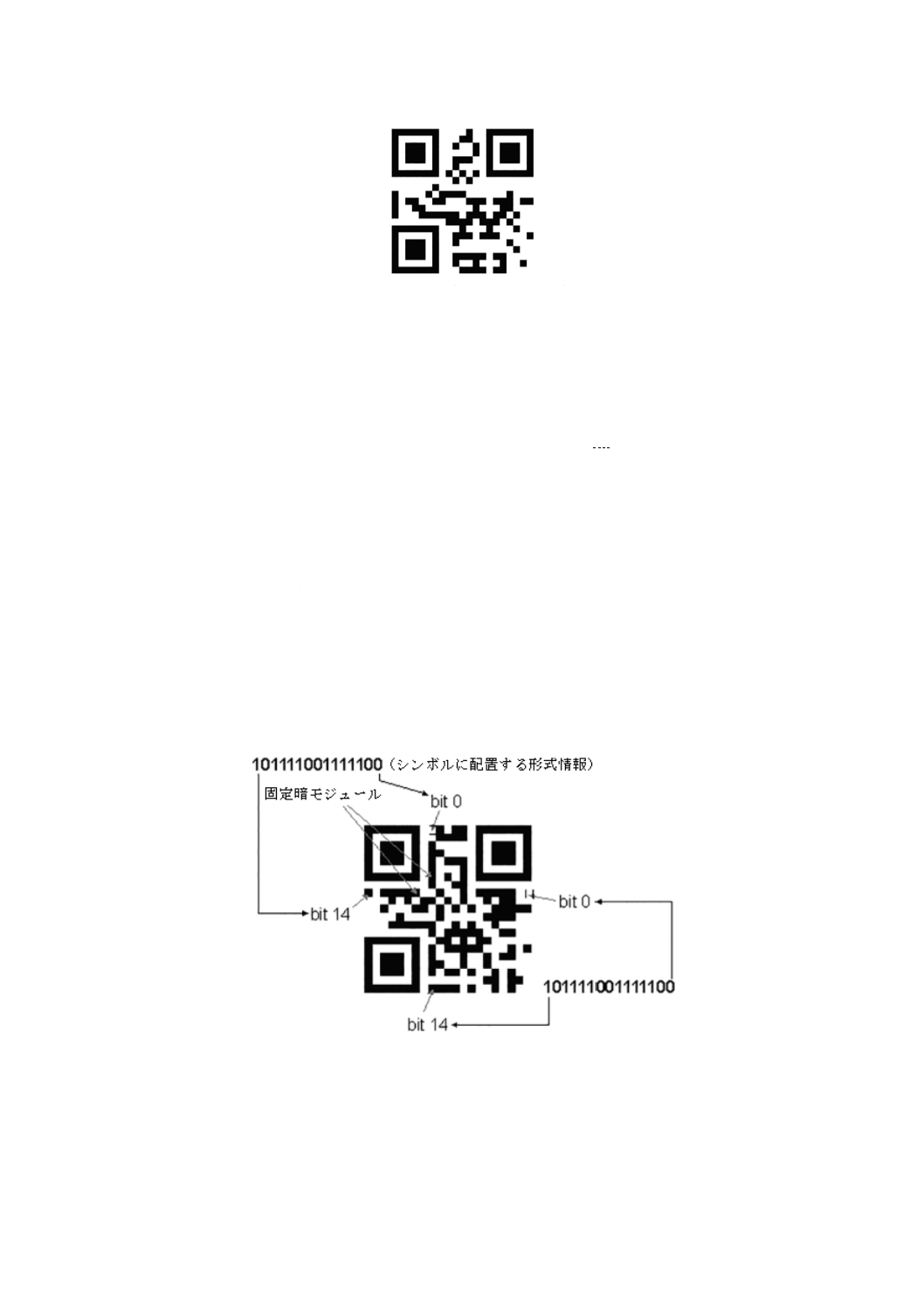
91
X 0510:2018 (ISO/IEC 18004:2015)
図I.1−マスク処理前にシンボルに配置したデータモジュール
手順4 マスク処理パターンの選択
7.8.2で定義しているマスク処理パターンを順次,適用し,7.8.3に従い,結果を評価する。選択したマス
ク処理パターンは,参照010となる。
手順5 形式情報
誤り訂正レベルはMであり,誤り訂正レベル指示子は,7.9.1から00 9) となる。したがって,形式情報
のデータビットは,00 010となる。
注9) 対応国際規格の明らかな誤りのため修正して記載した。
BCH誤り訂正の計算によって,データに付加するビット列として1001101110が生成され,マスク前の
形式情報として000101001101110を得る。
マスク101010000010010で上のビット列をXOR演算する。
000101001101110(マスク前のビット列)
101010000010010(マスク)
101111001111100(シンボルに配置される形式情報)
手順6 最終的なシンボル構築
7.8で規定しているように,シンボルの符号化領域に選択されたマスク処理パターンを適用し,手順3
で保留した位置に形式情報モジュールを付加する。最終的なシンボルを図I.2に示す。
図I.2−最終的なシンボル
I.3
マイクロQRコードの符号化
データ文字列01234567を,7.4.3に従って,数字モードを用いてM2-L型シンボルに符号化する。
手順1 データの符号化

92
X 0510:2018 (ISO/IEC 18004:2015)
− 3桁のグループに分割し,各グループを10又は7ビットの2進値に変換する。
− 012 → 0000001100
− 345 → 0101011001
− 67 → 1000011
− M2型の数字モードに対するモード指示子は,0である。
− 文字数8を2進(M2-L型は4ビット)に変換する。
文字数指示子(8)→ 1000
− M2型の終端パターンは,ゼロが5ビット(00000)
− 数字モードに対するモード指示子(0),文字数指示子(1000),2進データ及び終端パターン(00000)
を接続する。
0 1000 0000001100 0101011001 1000011 00000
− 8ビットコード語に分割し,最後のコード語は,5ビットのため,3ビットの埋め草ビット(下線で示
す。)を付加する。
01000000 00011000 10101100 11000011 00000000
− シンボルのデータコード語容量(M2-L型では5データコード語)を満たすための埋め草コード語は,
必要ない。
手順2 誤り訂正コード語の生成
RS誤り訂正のアルゴリズムを用い,必要数の誤り訂正コード語(M2-L型は,5個必要)を生成し,こ
れら(下線で示す。)を,ビット列に付加することが望ましい。結果は,次のとおりとなる。
01000000 00011000 10101100 11000011 00000000 10000110 00001101 00100010 10101110 00110000
手順3 マトリックスにモジュールを配置
13×13の空マトリックス内に位置検出パターン及びタイミングパターンを配置し,形式情報のモジュー
ル位置は,一時的に空とする。手順2で得られたコード語を7.7.3に従って,マトリックス内に配置する
と,図I.3に示すモジュール配列となる。
図I.3−マスク処理前にシンボルに配置したデータモジュール
手順4 マスク処理パターンの選択
7.8.2で定義しているマスク処理パターンを順次,適用し,7.8.3に従い,結果を評価する。選択したマス
ク処理パターンは参照01となる。選択したマスク処理パターンを,7.8に従い,符号化領域に適用する。
手順5 形式情報
M2-L型シンボルのシンボル番号は,1で,001と2進表記する。マスク処理パターンは,01である。し
たがって,形式情報のデータビットは,00101となる。
BCH誤り訂正の計算によって,データに付加されるビット列として0011011100が生成され,マスク前
の形式情報として001010011011100を得る。
マスク100010001000101で上のビット列をXOR演算する。

93
X 0510:2018 (ISO/IEC 18004:2015)
001010011011100(マスク前のビット列)
100010001000101(マスク)
101000010011001(シンボルに配置する形式情報)
手順6 最終的なシンボル構築
手順3で保留した位置に形式情報モジュールを付加する。最終的なシンボルを図I.4に示す。
図I.4−“01234567”を符号化した,最終的なM2-L型シンボル
94
X 0510:2018 (ISO/IEC 18004:2015)
附属書J
(参考)
ビット列の長さの最適化
J.1
一般
本体で規定するとおり,QRコードは様々な符号化モードがあり,その各モードは与えられたデータ列
を表すのに必要なビット数がそれぞれ異なる。各モードの文字集合間では重複があり,例えば,数字デー
タは,数字モード,英数字モード及び8ビットバイトモードで符号化してもよく,ラテン英数字データは
英数字モード及び8ビットバイトモードで符号化してもよい。したがって,シンボル生成ソフトウェアは,
複数のモードで表されるデータ文字を符号化する場合,最も適切なモードを選択してもよい。
QRコード又はマイクロQRコードのいずれかを選択することも可能である。
このモードの選択は最初に行わなければならないが,データ列の途中で変更してもよい。
ビット列長を最短にするために他の幾つかの手法を適用してもよい。アルゴリズムは,モード変更時に
要求される付加情報を考慮し,直後の文字列だけでなく,次のデータ列も考慮する必要がある。この附属
書において,“排他的部分集合”は,次の記載及び表J.1のとおり,あるモードの文字集合において,別の
モードのより限定された文字集合と共用されない文字集合とを参照する簡易的な方法として用いる。
数字の排他的部分集合は,16進数30〜39(数字の0〜9)の集合である。
英数字の排他的部分集合は,(スペース,$,%,*,+,-,.,/,: 及びA〜Z)に対応する16進数20,
24,25,2A,2B,2D〜2F,3A及び41〜5Aの集合である。
注記1 この集合には,数字を含んでいない。
8ビットバイトの排他的部分集合は,16進数20,24,25,2A,2B,2D〜3A及び41〜5Aを除く,16進
数00〜FFの集合である。
注記2 除外した値は,英数字及び数字の排他的部分集合に含まれている。
表J.1−QRコードのモードに対する排他的部分集合のバイト値
排他的部分集合
バイト値(16進)
数字
30〜39
英数字
20,24,25,2A,2B,2D〜2F,3A及び41〜5A
8ビットバイト
00〜1F,21〜23,26〜29,2C,3B〜40及び5B〜FF(予備の値80〜9F及びE0〜FFを除く。)
漢字
附属書Hに示す全ての2バイト
7.4.3〜7.4.6で与えられる圧縮効率を注意深く解釈する必要がある。与えられたデータ集合に対する最良
の方法は,データキャラクタごとに最小ビット数となる方法をとることではない。最高次の圧縮が要求さ
れる場合,モード変更に必要な追加ビット(追加のモード指示子及び文字数指示子)を考慮しなければな
らない。また,コード語数が最小でも,シンボルの容量を満たすために,コード語列を拡張してもよい場
合があることも考慮することが望ましい。この拡張には,埋め草キャラクタを用いる。
J.2
QRコードの最適化
QRコードに対し,次の指針は,与えられた任意の入力データに対する最小のビット列を決定する,あ
る一つのアルゴリズムの基本を形成する。
括弧で示される数字,例えば,[5,7,9]の場合,第1要素“5”は,1型〜9型,第2要素“7”は,10
95
X 0510:2018 (ISO/IEC 18004:2015)
型〜26型,第3要素“9”は,27型〜40型に適用する文字数を示す。
a) 初期モードの選択
1) 初期入力データが8ビットバイト文字の排他的部分集合の場合は,8ビットバイトモードを選択す
る。
2) 初期入力データが漢字の先頭バイトの排他的部分集合で,次のバイトが漢字の末尾バイトの排他的
部分集合で,かつ,次のデータが英数字又は数字の排他的部分集合の場合は,漢字モードを選択し,
次のデータが8ビットバイトの排他的部分集合で,かつ,それに続く[5,5,6]組のバイトペアが
漢字の排他的部分集合の場合は,8ビットバイトモードを選択する。
3) 初期入力データが英数字の排他的文字集合であり,それらが[6,7,8]より少ない文字数で,かつ,
8ビットバイト文字集合が後続する場合は,8ビットバイトモードを選択し,その他の場合は,英数
字モードを選択する。
4) 初期データが数字で,かつ,それらが[4,4,5]より少ない文字数で8ビットバイトの排他的文字
集合のデータが後続する場合は,8ビットバイトモードを選択し,[7,8,9]より少ない文字数で
英数字の排他的部分集合が後続する場合は,英数字モードを選択し,その他の場合は,数字モード
を選択する。
b) 8ビットバイトモード中において,
1) 8ビットバイト文字の排他的部分集合のデータの前に,少なくとも[9,12,13]組の漢字バイトペ
アが存在する場合は,漢字モードに変更する。
2) 8ビットバイト文字の排他的部分集合のデータの前に,少なくとも[11,15,16]個の英数字の排
他的部分集合の列が存在する場合は,英数字モードに変更する。
3) 8ビットバイト文字の排他的部分集合のデータの前に,少なくとも[6,8,9]個の数字の列が存在
する場合は,数字モードに変更する。
4) 英数字の排他的部分集合のデータの前に,少なくとも[6,7,8]個の数字の列が存在する場合は,
数字モードに変更する。
c) 英数字モード中において,
1) 一つ以上の漢字が存在する場合は,漢字モードに変更する。
2) 一つ以上の8ビットバイト文字の排他的部分集合が存在する場合は,8ビットバイトモードに変更
する。
3) 英数字の排他的部分集合のデータの前に,少なくとも[13,15,17]個の数字の列が存在する場合
は,数字モードに変更する。
d) 数字モード中において,
1) 一つ以上の漢字が存在する場合は,漢字モードに変更する。
2) 一つ以上の8ビットバイト文字の排他的部分集合が存在する場合は,8ビットバイトモードに変更
する。
3) 一つ以上の英数字の排他的部分集合が存在する場合は,英数字モードに変更する。
J.3
マイクロQRコードの最適化
J.3.1
最適化の原理
符号化するデータは,二つ以下の排他的部分集合に含まれ,それぞれの部分集合のデータは,全て一つ
にまとまっている(例えば,“123abcdef”)と仮定すると,マイクロQRコードの最短ビット列を決定する
96
X 0510:2018 (ISO/IEC 18004:2015)
アルゴリズムは,表J.2から得られる。これらの原理は,三つ以上のモードに拡張して適用できるが,得
られたビット列は,幾つかの表現可能なシンボルのうちの一つである。
低位モードで必要な文字当たりのビット数は,高位モードよりも少ないが,低位モードでのより高い符
号化密度では,モードを変更するために追加するモード指示子及び文字数指示子のオーバーヘッドが低位
モードの優位性を相殺する点が存在する。表J.2に,モードの変更で全体のビット列の長さを短くできる
低位モードでの最少の連続文字数を示す。これよりも少ない文字数であれば,全ての文字を高位モードで
符号化する方が短いビット列となる。
注記 モードの“低位”及び“高位”は,数字モードを最も低位とし,英数字モード,8ビットバイ
トモード,漢字モードの順番としている。
表J.2−モードを変更することでビット列の長さを最短にできる最小文字数
モードの組合せ
M2 シンボル
M3 シンボル
M4 シンボル
数字+英数字
数字3桁
数字4桁
数字5桁
数字+8ビットバイト
−
数字2桁
数字3桁
英数字+8ビットバイト
−
英数字3文字
英数字5文字
J.3.2
マイクロQRコードの容量
表J.2の原理及び様々な型番のシンボルのデータ容量に基づいて,それぞれのモードの組合せに対する,
特定のデータ量を符号化するために利用可能な選択肢を図J.1〜図J.6に示す。
列及び行の先頭にそれぞれのモードにおける文字数を示す。図は,シンボルの型番及び誤り訂正レベル
を最初のMを省略して示す。例えば,4Qは,誤り訂正レベルQのM4シンボルを表す。どの特定のモー
ドの組合せに対しても,利用可能なシンボルの型番は,対応する行及び列の交点とし,空欄の場合は,交
点の右又は下に示す。
例えば,6桁の数字と8英文字とで構成されたデータ列“123456ABCDEFGH”の場合,図J.1は,型番
M3-Lのシンボル(モード指示子及び文字数指示子を含む合計77ビット),M4-Mシンボル(81ビット)
又はM4-Lシンボル(81ビット)が適合することを示す。利用可能な表示領域又は必要な誤り訂正レベル
によっては,選択肢が狭くなってもよい。
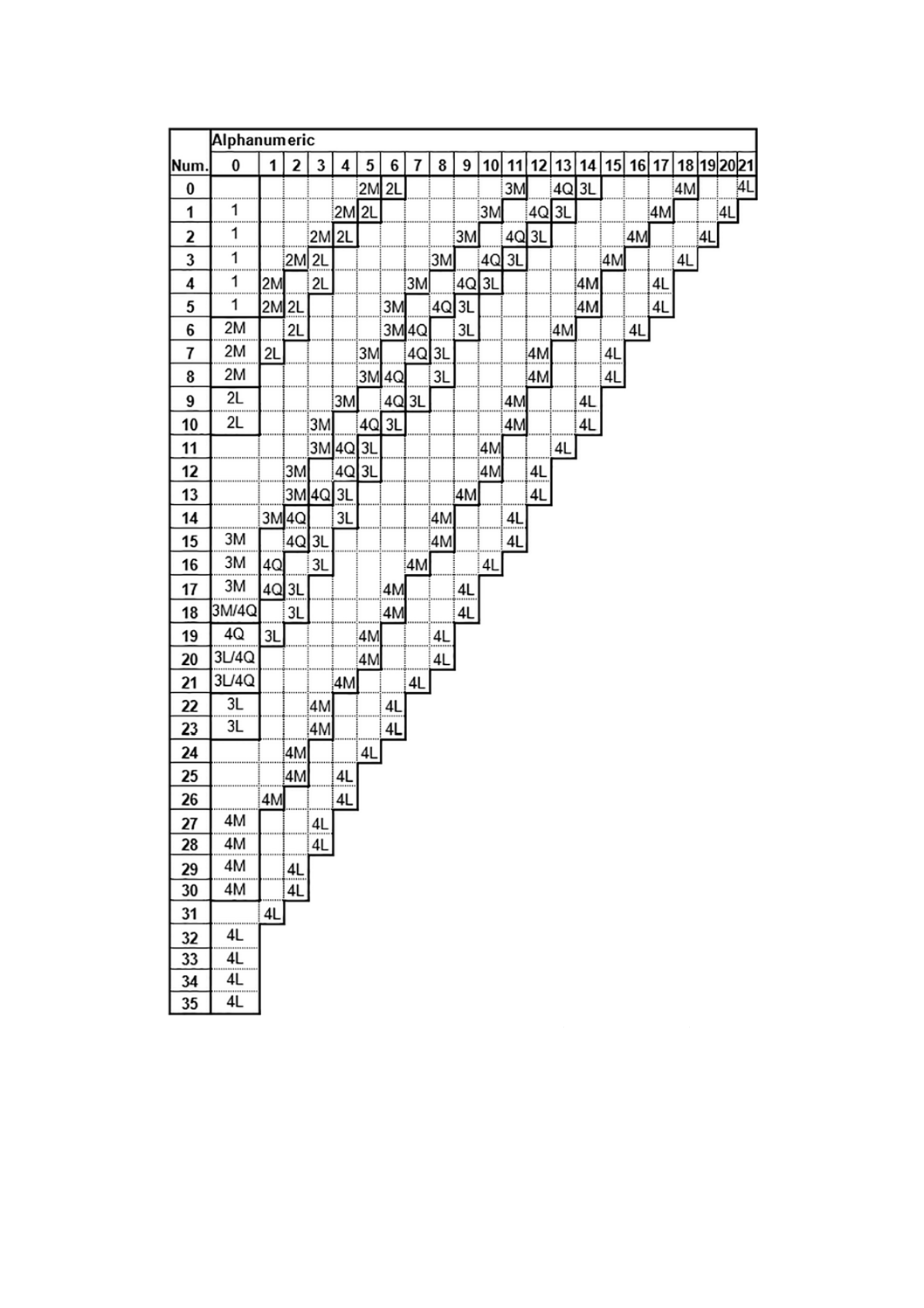
97
X 0510:2018 (ISO/IEC 18004:2015)
図J.1−マイクロQRコードのシンボル容量- 数字データ及び英数字データ
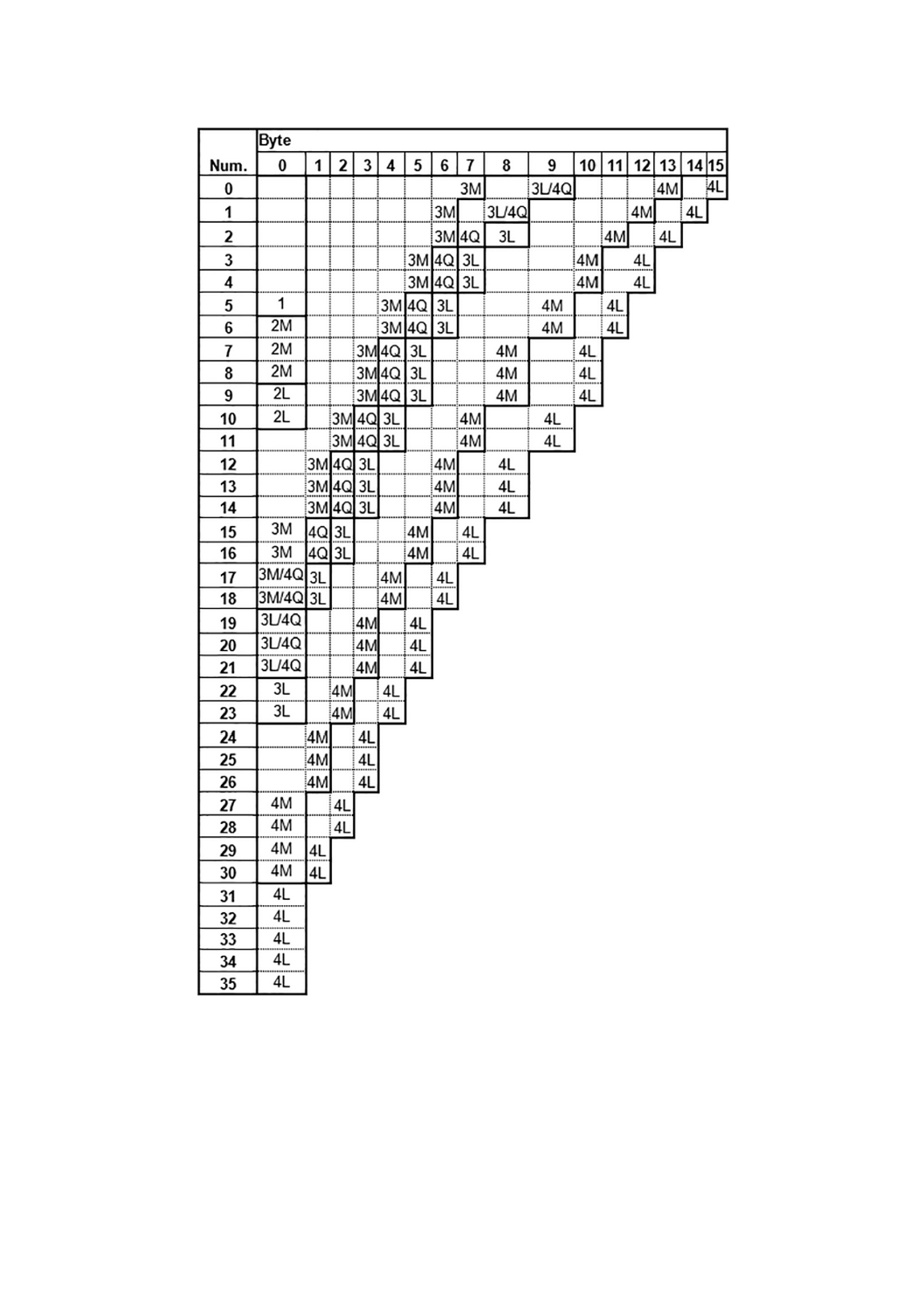
98
X 0510:2018 (ISO/IEC 18004:2015)
図J.2−マイクロQRコードのシンボル容量- 数字データ及び8ビットバイトデータ
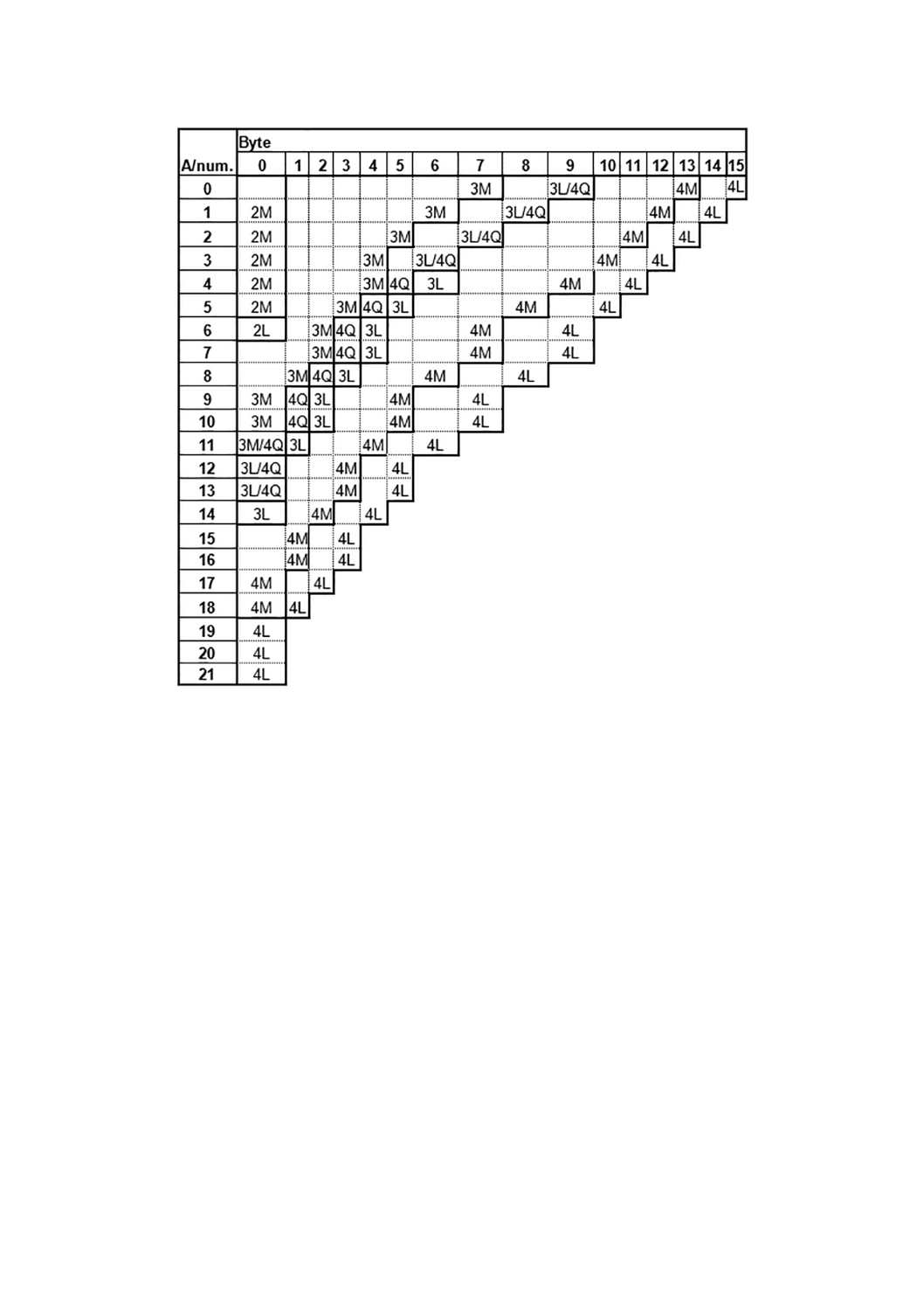
99
X 0510:2018 (ISO/IEC 18004:2015)
図J.3−マイクロQRコードのシンボル容量- 英数字データ及び8ビットバイトデータ
100
X 0510:2018 (ISO/IEC 18004:2015)
図J.4−マイクロQRコードのシンボル容量- 数字データ及び漢字データ
101
X 0510:2018 (ISO/IEC 18004:2015)
図J.5−マイクロQRコードのシンボル容量- 英数字データ及び漢字データ
102
X 0510:2018 (ISO/IEC 18004:2015)
図J.6−マイクロQRコードのシンボル容量- 8ビットバイトデータ及び漢字データ
103
X 0510:2018 (ISO/IEC 18004:2015)
附属書K
(参考)
QRコードシンボルの印刷及び読取りのための利用者手引
K.1 一般
いかなるQRコードのアプリケーションも総合的なシステムとして捉えなければならない。シンボル体
系の符号化及び復号の要素(マーカ又は印字装置,ラベル及び読取装置)が一つのシステムとして機能す
ることが重要である。いずれかの要素が動作不良を起こしたり,要素間の適合性が悪いと,システム全体
の性能低下を招くことになる。
仕様に従うことはシステム全体の成功を確実にする一つの鍵となるが,それ以外にも性能に影響する要
因が幾つか存在する。次の手引は,バーコードシステム又はマトリックスコードシステムの仕様を定めた
り,機器の選定をする際に考慮する点を示している。
a) 用いるマーキング技術又は印字技術で,許容範囲内の印字が可能な印字密度を選択する。モジュール
寸法が確実に印刷ヘッドピクセル寸法(印刷方向に対して水平方向及び垂直方向の両方)の整数倍と
なるようにする。個々の暗モジュール又は明モジュールの見掛け上のビットマップ表現を,適正な方
向に寸法を補正するが,モジュールの中心間隔が変わらないことを保証するために個々の暗モジュー
ル又は隣接する暗モジュール群の全ての暗から明への境界で,整数個のピクセルを暗から明(又は明
から暗)に変更することで,いかなる印刷による太り(又は細り)も確実に調整する。
b) マーキング技術又は印刷技術を用いて作成したシンボル密度及びシンボル品質に適した分解能をもつ
読取装置を選択する。
c) 印字されたシンボルの光学的な特性が,読取装置の光源又はセンサの波長に適合することを確認する。
d) 最終ラベル状態又は包装形態で,シンボルが仕様に合致していることを検証する。ラベルの被覆,透
過,湾曲又は凹凸は,いずれもシンボルの読みやすさに影響する。
光沢のあるシンボル面の場合には,鏡面反射の影響を考慮する必要がある。また,読取装置は,拡散反
射の明暗のばらつきも考慮しなければならない。読取角度によっては,反射光の鏡面反射成分が,望まし
い拡散反射成分を大幅に上回り,読取能力が変化する。材質又は部品の表面を変えることができる場合は,
つや消し又は無光沢面に変えることで鏡面反射の影響を最小限に抑えてもよい。これが不可能な場合には,
最適なコントラスト成分となるように,読み取るシンボルの照明に,特に注意を払う必要がある。
K.2 誤り訂正レベルの利用者選択
利用者は,アプリケーションの要件に合致する誤り訂正レベルを決めることが望ましい。表8に示すと
おり,順番に増加するL,M,Q及びHの4レベルで誤りを検出し訂正する能力があるが,レベルを上げ
ると与えられたメッセージの長さと引き替えに,シンボルの寸法が大きくなることがある。例えば,20-Q
型のシンボルの場合,485個のデータコード語をもつが,より低レベルの誤り訂正が許容できる場合は,
この同じデータを15-L型シンボルで表すこともできる(正確には523個のデータコード語容量)。
誤り訂正レベルは,次の関係を考慮して決定することが望ましい。
− 予測されるシンボルの品質(予測されるシンボル品質レベルが低ければ,より高いレベルを採用する。)
− 高い初回読取率の重要性
− 読取りができなかった場合に再読取りの機会の有無
104
X 0510:2018 (ISO/IEC 18004:2015)
− 高い誤り訂正レベルを用いることができないような,シンボル印刷領域の制約の有無
誤り訂正レベルLは,高いシンボル品質及び/又は与えられたデータに対してシンボルをできるだけ小
さくする必要がある場合に適している。レベルMは,“標準”レベルで,サイズの縮小化及び信頼性向上
の両方を実現する。レベルQは,“高い信頼性”をもつレベルで,より厳しいアプリケーション又は印刷
品質が低いアプリケーションに適している。レベルHは,実現し得る最高の信頼性を提供する。
105
X 0510:2018 (ISO/IEC 18004:2015)
附属書L
(参考)
自動識別能力
QRコードは,他のシンボル体系から自動識別するように設計された,適切にプログラムされた復号器
によって読み取ってもよい。適切にプログラムされたQRコード読取装置は,別のシンボル体系のシンボ
ルを,正当なQRコードとして復号することはない。しかし,QRコードを含む,どんなマトリックスシ
ンボルにおいても,短いバーコードシンボルの表現が見つかってもよい。
適切にプログラムされた復号器は,QRコードのモデル1シンボルとQRコードとを自動識別すること
ができるが,一つのアプリケーションで2種類のシンボルを混在させないほうがよいことを強く推奨する。
読取りの正確性を最大限にするために,復号器で読取りを有効にするシンボル体系を,利用するアプリ
ケーションで必要なシンボル体系に限定することが望ましい。
106
X 0510:2018 (ISO/IEC 18004:2015)
附属書M
(参考)
プロセス制御技術
M.1 一般
この附属書では,読取可能なQRコードシンボルの作成プロセスを監視及び制御するために有効なツー
ル及び手順を示す。これらの技術は,作成されるシンボルの印刷品質検査を規定するものではない(箇条
10及び附属書Gで規定する手法は,シンボルの品質評価に要求される手法)が,これらの技術は個別に,
かつ,総合的に,シンボル生成の過程で使用可能なシンボルが作成されるかどうかのよい指針となる。
M.2 シンボルコントラスト
大抵の一次元シンボル用検証器は,静的に反射率を計測するモード,又は走査反射率波形を描画するか
及び/又は復号不能な走査から(JIS X 0520で規定された)シンボルコントラストを出力するためのモー
ド,のいずれかを備えている。特殊な照明構成が要求されるシンボルを除き,波長が660 nmで0.150 mm
又は0.250 mmの測定口径で得られるシンボルコントラスト(最大走査反射率から最小走査反射率を通し
て得られるシンボルコントラスト値,又は反射率計測で得られる最大値と最小値との差,のいずれか。)は,
画像に起因するシンボルコントラスト値とよい相互関係があることが分かっている。特にこのような読取
りは,シンボルコントラストが,意図するシンボル品質グレードで許容される,最小値を十分に超えるも
のであることを検査するのに用いることができる。
M.3 軸の非均一性の評価
QRコードシンボルにおいて,左上の位置検出パターンの左端から右上の位置検出パターンの右端まで
の距離,及び左上の位置検出パターンの上端から左下の位置検出パターンの下端までの距離を測定する。
マイクロQRコードシンボルにおいて,左上の位置検出パターンの左端から上側タイミングパターンの最
右モジュールの右端までの距離及び左上の位置検出パターンの上端から左側タイミングパターンの最下モ
ジュールの下端までの距離を測定する。各距離をその型番の一辺のモジュール数で除す。例えば,2型の
シンボルは,除数が25となる。JIS X 0526に規定する方法を用いて10),軸の非均一性の評価に対する結
果をグレード化する。
注10) 対応国際規格で記載しているG.2.4は,附属書Gには記載がなく,対応国際規格の明らかな誤
りのため修正して記載した。
M.4 シンボルのひずみ及び欠陥の目視検査
サンプルシンボルの位置検出パターン及びタイミングパターンの目視検査中に,シンボル作成の過程の
重要な様相を監視することができる。
マトリックスコードシンボルは,マトリックスグリッドの部分的なひずみによるエラーを生じやすい。
そのようなひずみは,位置検出パターン上の湾曲した縁,又は位置検出パターンと位置検出パターン内部
境界線との間に並行するタイミングパターン内部の非均一な間隔,のいずれかとして視覚的に現れてもよ
い。
位置検出パターン及びそれに隣接するクワイエットゾーン領域は,常に一様に暗及び明であることが望
107
X 0510:2018 (ISO/IEC 18004:2015)
ましい。シンボルに明又は暗の線として欠陥を生じさせることがある印刷機構の不具合は,位置検出パタ
ーン又はクワイエットゾーンを横切る箇所で容易に視認できるのが望ましい。このような印刷の過程のシ
ステム的な不具合は,修正することが望ましい。
M.5 モジュール幅の太りの評価
バーパターン及びスペースパターンの直接測定値が出力可能な一次元シンボルの検証器を,水平方向及
び垂直方向の印刷の太り又は細りの評価に用いてもよい。評価は,位置検出パターンを通過し,3×3モジ
ュールのブロックの中央を横切る,2本の直交する走査線に沿って測定をすることで行う。出力を解析し
た結果が,明白な暗−明−暗−明−暗のパターンを示すことが望ましい。印刷の太り(又は細り)は,五
つのエレメント測定値と,理想的な1:1:3:1:1の幅の比率とを比較することで評価できる。
108
X 0510:2018 (ISO/IEC 18004:2015)
附属書N
(参考)
QRコードモデル1シンボルの特性
N.1 QRコードモデル1シンボル
AIM ITS 97-001で規定する,QRコードモデル1シンボルは,開発当初,幾つかの初期システム又はク
ローズドシステム用途で用いられたシンボル体系の形式であるが,新たな用途又はオープンシステム用途
での使用は,推奨しない。また,データ容量が多くなりそうな用途には適さない。ほとんどの事項でQR
コードと同じ仕様であるが,幾つかの重要な事項で異なるため,この附属書に要約する。
N.1.1 QRコードモデル1シンボルの特徴
a) シンボルサイズ(クワイエットゾーンを除く。)
21×21モジュール〜73×73モジュール(1型から14型,型番が一つ上がるごとに一辺につき4モ
ジュールずつ増加)
b) 最大データ容量[最も低い誤り訂正レベルをもつ最大シンボルサイズ(14-L型)に対する。]
− 数字データ:
1 167文字
− 英数字データ:
707文字
− 8ビットバイトデータ:
486文字
− 漢字データ:
299文字
c) QRコードと比較した,シンボルの構造
− 位置合せパターン:
モデル1シンボルは,位置合せパターンをもたない。
− 拡張パターン:
モデル1シンボルは,右側及び下側に拡張パターンをもつ。
− 型番情報:
モデル1シンボルは,型番情報をもたない。
− シンボルキャラクタの配置: 上記の結果,シンボルキャラクタの配置は,異なった規則に従う。
− モデル1シンボルは,ECIプロトコルを利用できない。
− モデル1シンボルは,表裏反転を利用できない。
− モデル1シンボルは,明暗(白黒)反転を利用できない。
d) 誤り訂正
誤り検出及び誤り訂正コード語は,QRコードと同様に計算するが,幾つかの型番に対する誤り訂
正ブロックの数及び大きさは異なる。データコード語ブロック及び誤り訂正コード語ブロックは,交
互配置には従わない。
図N.1にQRコードモデル1シンボルの7型の構造を示す。

109
X 0510:2018 (ISO/IEC 18004:2015)
図N.1−QRコードモデル1シンボルの構造
N.1.2 シンボルの型番及び大きさ
QRコードモデル1シンボルには,1型〜14型までの14種類の型番しかない。シンボルの大きさは,6.3.2
で規定のとおり,同じ型番であればモデル2シンボルの大きさと等しい。したがって,1型は,21×21モ
ジュール,14型は,73×73モジュールとなる。表N.1に,モデル1シンボルの全ての型番のデータ容量を
示す。
表N.1−QRコードモデル1の全型番のデータ容量
型番
モジュール数/
辺(A)
機能パターン
モジュール(B)
形式情報
モジュール(C)
(C)以外のデー
タモジュール
(D=A2−B−C)
データ容量
[コード語]a)(E)
1
21
206
31
204
26
2
25
230
31
364
46
3
29
238
31
572
72
4
33
262
31
796
100
5
37
270
31
1068
134
6
41
294
31
1356
170
7
45
302
31
1692
212
8
41
326
31
2044
256
9
53
334
31
2444
306
10
57
358
31
2860
358
11
61
366
31
3324
416
12
65
390
31
3804
476
13
69
398
31
4332
542
14
73
422
31
4876
610
注a) 最初のコード語は,4ビット長とする。それ以降の全てのコード語は,8ビット長とする。最初のデ
ータコード語(4ビット長)は,誤り訂正コード語生成時には0000を前に付け,8ビット長とする。
110
X 0510:2018 (ISO/IEC 18004:2015)
N.2 詳細仕様
QRコードモデル1シンボルの印刷及び読取りに関する全情報は,AIM ITS 97-001を参照。
111
X 0510:2018 (ISO/IEC 18004:2015)
参考文献
[1] ISO/IEC 646,Information technology−ISO 7-bit coded character set for information interchange
[2] ISO/IEC 8859-2:1999,Information technology−8-bit single-byte coded graphic character sets−Part 2: Latin
alphabet No. 2
[3] ISO/IEC 8859-3:1999,Information technology−8-bit single-byte coded graphic character sets−Part 3: Latin
alphabet No. 3
[4] ISO/IEC 8859-4:1998,Information technology−8-bit single-byte coded graphic character sets−Part 4: Latin
alphabet No. 4
[5] ISO/IEC 8859-5:1999,Information technology−8-bit single-byte coded graphic character sets−Part 5:
Latin/Cyrillic alphabet
[6] ISO/IEC 8859-6:1999,Information technology−8-bit single-byte coded graphic character sets−Part 6:
Latin/Arabic alphabet
[7] ISO/IEC 8859-7:2003,Information technology−8-bit single-byte coded graphic character sets−Part 7:
Latin/Greek alphabet
[8] ISO/IEC 8859-8:1999,Information technology−8-bit single-byte coded graphic character sets−Part 8:
Latin/Hebrew alphabet
[9] ISO/IEC 8859-9:1999,Information technology−8-bit single-byte coded graphic character sets−Part 9: Latin
alphabet No. 5
[10] ISO/IEC 8859-10:1998,Information technology−8-bit single-byte coded graphic character sets−Part 10:
Latin alphabet No. 6
[11] ISO/IEC 8859-11:2001,Information technology−8-bit single-byte coded graphic character sets−Part 11:
Latin/Thai alphabet
[12] ISO/IEC 8859-13:1998,Information technology−8-bit single-byte coded graphic character sets−Part 13:
Latin alphabet No. 7
[13] ISO/IEC 8859-14:1998,Information technology−8-bit single-byte coded graphic character sets−Part 14:
Latin alphabet No. 8 (Celtic)
[14] ISO/IEC 8859-15:1999,Information technology−8-bit single-byte coded graphic character sets−Part 15:
Latin alphabet No. 9
[15] ISO/IEC 8859-16:2001,Information technology−8-bit single-byte coded graphic character sets−Part 16:
Latin alphabet No. 10
(バーコード規格など)
[16] JIS X 0520:2014 自動認識及びデータ取得技術−バーコードシンボル印刷品質の評価仕様−一次元シ
ンボル
注記 原国際規格では,ISO/IEC 15416,Information technology−Automatic identification and data
capture techniques−Bar code print quality test specification−Linear symbolsを記載している。
[17] JIS X 0504:2014 自動認識及びデータ取得技術−バーコードシンボル体系仕様−コード128
注記 原国際規格では,ISO/IEC 15417,Information technology−Automatic identification and data
capture techniques−Code 128 bar code symbology specificationを記載している。
112
X 0510:2018 (ISO/IEC 18004:2015)
[18] JIS X 0530:2003 データキャリア識別子(シンボル体系識別子を含む)
注記 原国際規格では,ISO/IEC 15424,Information technology−Automatic identification and data
capture techniques−Data Carrier Identifiers (including Symbology Identifiers)を記載している。
[19] JIS X 0533:2003 情報技術−大容量自動認識情報媒体のための転送構文
注記 原国際規格では,ISO/IEC 15434,Information technology−Automatic identification and data
capture techniques−Syntax for high-capacity ADC mediaを記載している。
[20] ISO/IEC TR 29158,Information technology−Automatic identification and data capture techniques−Direct
Part Mark (DPM) Quality Guideline
[21] AIM ITS 97-001,International Symbology Specification−QR Code, AIM Inc.
[22] AIM International Technical Specification, Extended Channel Interpretations:−Part 1, Identification Schemes
and Protocols
[23] AIM International Technical Specification, Extended Channel Interpretations:−Part 2, Registration Procedure
for Coded Character Sets and Other Data Formats
[24] AIM International Technical Specification, Extended Channel Interpretations:−Character Set Register
[25] GS1 General Specifications, GS1
[26] JIS X 0208:2012 7ビット及び8ビットの2バイト情報交換用符号化漢字集合
[27] JIS X 0221 国際符号化文字集合(UCS)
注記 JISは,対応国際規格ISO/IEC 10646の2012年版対応が最新版だが,対応国際規格は2016
年版が最新である。