X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
(1)
目 次
ページ
序文 ··································································································································· 1
1 適用範囲························································································································· 1
2 引用規格························································································································· 2
3 用語及び定義 ··················································································································· 2
4 適合性···························································································································· 9
4.1 概要 ···························································································································· 9
4.2 情報交換の適合性 ·········································································································· 9
4.3 装置の適合性 ··············································································································· 10
5 国際符号化文字集号の全体構造 ·························································································· 10
6 基本構造及び名称 ············································································································ 11
6.1 構造 ··························································································································· 11
6.2 文字の符号化 ··············································································································· 11
6.3 符号位置の種類 ············································································································ 12
6.4 文字の名前 ·················································································································· 13
6.5 符号位置の短い識別子(UID) ························································································ 13
6.6 UCS列識別子 ··············································································································· 14
6.7 オクテット列識別子 ······································································································ 14
7 UCSの維持・改正 ··········································································································· 14
8 部分集合························································································································ 15
8.1 概要 ··························································································································· 15
8.2 制限部分集合 ··············································································································· 15
8.3 選択部分集合 ··············································································································· 15
9 UCSの符号化形式 ··········································································································· 15
9.1 概要 ··························································································································· 15
9.2 UTF-8 ························································································································· 15
9.3 UTF-16 ······················································································································· 16
9.4 UTF-32(UCS-4) ········································································································· 17
10 UCSの符号化方式 ········································································································· 17
10.1 概要 ·························································································································· 17
10.2 UTF-8 ······················································································································· 17
10.3 UTF-16BE ·················································································································· 17
10.4 UTF-16LE ·················································································································· 17
10.5 UTF-16 ······················································································································ 17
10.6 UTF-32BE ·················································································································· 18
10.7 UTF-32LE ·················································································································· 18
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019) 目次
(2)
ページ
10.8 UTF-32 ······················································································································ 18
11 UCSでの制御機能の使用 ································································································· 18
12 機能識別の宣言 ············································································································· 20
12.1 識別の目的及び構文 ····································································································· 20
12.2 UCSの符号化方式の識別 ······························································································ 21
12.3 図形文字部分集合の識別 ······························································································· 21
12.4 制御機能集合の識別 ····································································································· 22
12.5 JIS X 0202の符号化方式の識別 ······················································································ 22
13 符号表及び一覧表の構造 ································································································· 22
14 ブロック及び組の名前 ···································································································· 23
14.1 ブロックの名前 ··········································································································· 23
14.2 組の名前 ···················································································································· 23
15 双方向文脈での鏡像文字 ································································································· 23
15.1 鏡像文字 ···················································································································· 23
15.2 双方向テキストの方向性 ······························································································· 24
16 特殊文字 ······················································································································ 24
16.1 概要 ·························································································································· 24
16.2 空白の文字 ················································································································· 24
16.3 通貨記号 ···················································································································· 25
16.4 書式文字 ···················································································································· 25
16.5 漢字構成記述文字 ········································································································ 26
16.6 字形選択子及び字形指示列 ···························································································· 27
17 文字の表示形 ················································································································ 29
18 互換用文字 ··················································································································· 29
19 文字の順序 ··················································································································· 29
20 結合文字 ······················································································································ 30
20.1 結合文字の順序 ··········································································································· 30
20.2 結合クラス及び基準順序 ······························································································· 30
20.3 符号表上での形 ··········································································································· 30
20.4 符号化表現のばらつき ·································································································· 30
20.5 結合文字の重複 ··········································································································· 31
20.6 結合文字を含む組 ········································································································ 31
20.7 図形素結合子(合成可能) ···························································································· 32
21 正規形 ························································································································· 32
22 個々の用字及び記号の特性 ······························································································ 33
22.1 ハングル音節の合成方法 ······························································································· 33
22.2 インド及び他の南アジアで使う用字の特性 ······································································· 33
22.3 ビザンチン音楽記号 ····································································································· 34
22.4 絵文字記号の原典情報 ·································································································· 34
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019) 目次
(3)
ページ
23 漢字の原典参照 ············································································································· 34
23.1 原典参照一覧 ·············································································································· 34
23.2 CJK統合漢字の原典参照ファイル ·················································································· 37
23.3 CJK統合漢字の原典参照の表示 ····················································································· 40
23.4 CJK互換漢字の原典参照の表示 ····················································································· 42
24 西夏文字の原典参照 ······································································································· 43
24.1 原典参照一覧 ·············································································································· 43
24.2 西夏文字の原典参照ファイル ························································································· 43
24.3 西夏文字の原典参照の表示 ···························································································· 44
25 女書文字の原典参照 ······································································································· 45
25.1 原典参照一覧 ·············································································································· 45
25.2 女書文字の原典参照ファイル ························································································· 45
26 文字の名前及び注記 ······································································································· 46
26.1 名前 ·························································································································· 46
26.2 名前の形式 ················································································································· 46
26.3 名前の単一性 ·············································································································· 47
26.4 名前の不変性 ·············································································································· 47
26.5 名前の一意性 ·············································································································· 47
26.6 漢字の名前 ················································································································· 48
26.7 西夏文字の名前 ··········································································································· 48
26.8 女書文字の名前 ··········································································································· 48
26.9 ハングル音節文字の名前 ······························································································· 48
27 名前付きUCS列識別子 ··································································································· 50
28 基本多言語面の構造 ······································································································· 51
29 用字及び記号群に用いる追加多言語面の構造 ······································································ 54
30 追加漢字面の構造 ·········································································································· 56
31 第三漢字面の構造 ·········································································································· 57
32 追加特殊用途面の構造 ···································································································· 57
33 符号表及び文字の名前一覧表 ··························································································· 58
33.1 概要 ·························································································································· 58
33.2 符号表 ······················································································································· 58
33.3 文字の名前の一覧表 ····································································································· 58
33.4 既定の字形指示列の概要 ······························································································· 60
33.5 符号表及び文字の名前一覧 ···························································································· 60
附属書A(規定)部分集合用図形文字の組 ··············································································· 61
附属書B(規定)結合文字一覧 ····························································································· 102
附属書C(規定)面01〜面10のUCS変換形式(UTF-16) ························································ 103
附属書D(規定)UCS変換形式8(UTF-8) ············································································ 104
附属書E(規定)双方向文脈での鏡像文字··············································································· 105
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019) 目次
(4)
ページ
附属書F(参考)書式文字 ···································································································· 106
附属書G(参考)文字の名前のアルファベット順一覧 ······························································· 114
附属書H(参考)UCSを識別するための“印”(しるし)の使用 ················································· 115
附属書I(参考)漢字構成記述文字 ························································································ 116
附属書J(参考)内部記憶機能をもつ送受信兼用装置に対する推奨 ·············································· 119
附属書K(参考)オクテット値表現の記法 ·············································································· 120
附属書L(参考)文字の名前付け指針····················································································· 121
附属書M(参考)文字の出所 ································································································ 124
附属書N(参考)文字レパートリに対する外部参照 ·································································· 147
附属書P(参考)CJK統合漢字に関する追加情報 ····································································· 149
附属書Q(参考)ハングル音節文字の符号対応表 ····································································· 152
附属書R(参考)ハングル音節文字の名前 ·············································································· 153
附属書S(参考)漢字の統合及び配列の手順 ············································································ 154
附属書T(参考)タグ文字による言語のタグ付け ······································································ 165
附属書U(参考)識別子用の文字 ·························································································· 166
附属書JA(参考)日本文字関連部分集合用図形文字の組 ··························································· 167
附属書JB(参考)元号“令和”の合字 ··················································································· 169
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019) 目次
(5)
まえがき
この規格は,産業標準化法第16条において準用する同法第12条第1項の規定に基づき,一般社団法人
情報処理学会(IPSJ)及び一般財団法人日本規格協会(JSA)から,産業標準原案を添えて日本産業規格
を改正すべきとの申出があり,日本産業標準調査会の審議を経て,経済産業大臣が改正した日本産業規格
である。これによって,JIS X 0221:2014は改正され,この規格に置き換えられた。
この規格は,著作権法で保護対象となっている著作物である。
この規格の一部が,特許権,出願公開後の特許出願又は実用新案権に抵触する可能性があることに注意
を喚起する。経済産業大臣及び日本産業標準調査会は,このような特許権,出願公開後の特許出願及び実
用新案権に関わる確認について,責任はもたない。
この規格には,次の添付ファイル(CD-ROM:別添)がある(それぞれのファイルを参照する箇所を括
弧内に示す。)。
− UCSVariants.txt(16.6)
− EmojiSrc.txt(22.4)
− CJKSrc.txt(23.2)
− TangutSrc.txt(24.2)
− NushuSrc.txt(25.2)
− NUSI.txt(箇条27)
− ISO 10646-2017-1-0000-4DFF.pdf(33.5)
− ISO 10646-2017-2-4E00-9FFF.pdf(33.5)
− ISO 10646-2017-3-A000-1FFFF.pdf(33.5)
− ISO 10646-2017-4-20000-25333.pdf(33.5)
− ISO 10646-2017-5-25334-2A6FF.pdf(33.5)
− ISO 10646-2017-6-2A700-10FFFF.pdf(33.5)
− IICORE.txt(附属書A)
− JIS-X-0213-FromPrevious.txt(附属書A)
− JapaneseCoreKanji.txt(附属書A)
− JMJKI-2016.txt(附属書A)
− Allnames.txt(附属書G)
− HangulSy.txt(附属書R)
− BasicJ.txt(附属書JA)
− JIExt.txt(附属書JA)
− JISup.txt(附属書JA)
− MJSrc.txt(附属書JA)
− JNIExt.txt(附属書JA)
− CommonJ.txt(附属書JA)
− JNIExt2.txt(附属書JA)
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
日本産業規格 JIS
X 0221:2020
(ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
国際符号化文字集合(UCS)
Information technology-Universal Coded Character Set (UCS)
序文
この規格は,2017年に第5版として発行されたISO/IEC 10646,2019年に発行されたAmendment 1及び
Amendment 2を基に,技術的内容を変更することなく作成した日本産業規格である。ただし,追補
(amendment)については,編集し,一体とした。
なお,この規格で点線の下線を施してある参考事項,附属書JA及び附属書JBは,対応国際規格にはな
い事項である。
1
適用範囲
この規格は,国際符号化文字集合について規定する。この規格は,世界の言語(用字)を書き表した形
(表記形)並びに記号の表現,伝送,交換,処理,蓄積,入力及び表示に適用できる。
この規格は,国際符号化文字集合(以下,“この符号化文字集合”又は“UCS”という。)について,次
の事項を規定する。
− この符号化文字集合の全体的な体系
− この規格で使用する用語の定義
− UCS符号空間の構造
− UCSの基本多言語面(BMP)の定義
− UCSの追加多言語面(SMP),追加漢字面(SIP),第三漢字面(TIP)及び追加特殊用途面(SSP)の
定義
− 世界の言語の用字及び表記形で使用する図形文字の集合の定義
− BMP,SMP,SIP,TIP及びSSP上の図形文字及び書式文字の名前並びにこれらのUCS符号空間にお
ける符号化表現
− 制御機能及び私用文字の符号化表現
− UCSの三つの符号化形式:UTF-8,UTF-16及びUTF-32
− UCSの七つの符号化方式:UTF-8,UTF-16,UTF-16BE,UTF-16LE,UTF-32,UTF-32BE及びUTF-32LE
− この符号化文字集合への将来の追加方法
UCSは,JIS X 0202で規定されたものとは異なる方式による符号系である。JIS X 0202からUCSを指示
する方法は,12.2による。
この規格では,一つの図形文字に対して,BMP又は他の追加面の中から,ただ一つの符号位置を割り当
てる。
注記 この規格の対応国際規格及びその対応の程度を表す記号を,次に示す。
ISO/IEC 10646:2017,Information technology−Universal Coded Character Set (UCS),Amendment
2
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1:2019及びAmendment 2:2019(IDT)
なお,対応の程度を表す記号“IDT”は,ISO/IEC Guide 21-1に基づき,“一致している”こ
とを示す。
2
引用規格
次に掲げる規格は,この規格に引用されることによって,この規格の規定の一部を構成する。これらの
引用規格のうちで,西暦年を付記してあるものは,記載の年の版を適用し,その後の改正版(追補を含む。)
は適用しない。西暦年の付記がない引用規格は,その最新版(追補を含む。)を適用する。
JIS X 0202:1998 情報技術−文字符号の構造及び拡張法
注記 対応国際規格:ISO/IEC 2022:1994,Information technology−Character code structure and
extension techniques
JIS X 0211:1994 符号化文字集合用制御機能
注記 対応国際規格:ISO/IEC 6429:1992,Information technology−Control functions for coded character
sets
ユニコード附属書, UAX #9 Unicode Bidirectional Algorithm
<http://www.unicode.org/reports/tr9/tr9-35.html>
ユニコード附属書, UAX #15 Unicode Normalization Forms
<http://www.unicode.org/reports/tr15/tr15-44.html>
ユニコード技術標準, UTS #37 Ideographic Variation Database
<http://www.unicode.org/reports/tr37/tr37-8.html>
ユニコード標準第9.0版, Chapter 4 Character Properties
<http://www.unicode.org/versions/Unicode9.0.0/ch04.pdf>
Section 4.3, Combining Classes−規定
Section 4.5, General Category−規定
Section 4.7, Bidi Mirrored−規定
ユニコード標準第9.0版, Age Property
<http://www.unicode.org/Public/9.0.0/ucd/DerivedAge.txt>
3
用語及び定義
この規格で用いる主な用語及び定義は,次による。
ISO及びIECは,標準化で使用する次の用語データベースを整備している。
− IEC Electropedia: available at http://www.electropedia.org/
− ISO Online browsing platform: available at https://www.iso.org/obp/ui
3.1
基底文字(base character)
結合文字でない図形文字。
注記1 図形文字の多くは,基底文字である。基底文字を表示するときに,文脈に依存した様々な形
を用いたり,合字(ligature)の一部にしたりすることを,結合文字でないということが排除
するものではない。
注記2 基底文字は,先行する文字と図形的に結合しないことが普通だが,幾つかの複雑な書記系で
3
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
は例外がある。
3.2
基本多言語面,BMP(basic multilingual plane, BMP)
UCS符号空間の面00。
3.3
ブロック(block)
共通の特性をもつ文字の集合(例えば,用字)が割り当てられた符号位置の連続する範囲。ブロック同
士は,重なり合わない。ブロック中には,文字が割り当てられていない符号位置が一つ以上あってもよい。
3.4
基準形式(canonical form)
この符号化文字集合の文字を,UCS符号空間中の一つの符号位置を用いて表現する形式。
注記 基準形式を,UCS符号位置と一つ以上の符号単位との関係を意味する符号化形式と混同しては
ならない(3.23参照)。
3.5
文字(character)
データの構成,制御又は表現に用いる要素の集合の構成単位。
注記 図形記号は,一つ以上の符号化文字の列によって表現されることもある。
3.6
文字境界(character boundary)
符号化文字の最後の符号単位と次に続く符号化文字の最初の符号単位との間の(符号単位列の)境目。
3.7
符号表(code chart, code table)
UCS符号空間のある範囲に割り当てた符号化文字群の表現を,長方形に配置して示したもの。
3.8
符号化文字(coded character)
文字と符号位置とを結び付けたもの。
3.9
符号化文字集合(coded character set)
符号化文字の集合。
3.10
符号位置(code point, code position)
UCS符号空間中の値。
3.11
符号単位(code unit)
処理又は交換用の符号化テキストの単位を表現できる,最小のビット組合せ。
注記 符号単位の例として,UTF-8符号形式で用いるオクテット(8ビットの符号単位),UTF-16符
号形式で用いる16ビットの符号単位及びUTF-32符号形式で用いる32ビットの符号単位があ
る。
3.12
符号単位列,CCデータ要素,符号化文字データ要素(code unit sequence, CC-data-element,
4
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
coded-character-data-element)
符号化文字集合に関する特定された一つ以上の規格に適合して,符号単位の並びを構成するように仕様
決めされた,情報交換の単位。
注記1 この列は,どのような種類の符号位置に対応付けられる符号単位をも含むことができる。
注記2 この規格は,旧規格(JIS X 0221:2014)から実装水準を用いていない。この規格の符号単位
列の定義は,以前の実装水準3(制限のない水準)に対応する。従来,水準1又は水準2と
して知られていた符号単位列の定義は,廃止された。これらの従来の版との互換性を維持す
るために,ISO/IEC 8824規格群及びISO/IEC 8825規格群のような規格の中の符号化表現を
識別する文脈においては,その実装の方針は,“実装水準3”として参照できる。附属書N参
照。
3.13
組(collection)
番号及び名前が付けられたものの集合。
注記1 拡張組(3.25参照)でない組は,符号位置が一つ以上の識別された範囲に含まれるような符
号化文字だけからなる集合である。
注記2 識別された範囲のいずれかに文字の割り当てられていない符号位置があり,将来この規格の
改正によってそのどこかの符号位置に追加文字が割り当てられたときには,組のレパートリ
が変わる。しかし,組の番号及び名前は,この規格の将来の版においても変えないことを意
図している。
3.14
結合文字(combining character)
一般分類の値が,Spacing Combining Mark(Mc),Non Spacing Mark(Mn)又はEnclosing Mark(Me)の
いずれかである文字。
注記 結合文字は,先行する,結合文字でない図形文字と組み合わせるか,又は結合文字ではない文
字の後に結合文字の列が続いた形のものと組み合わせることを意図している(3.17参照)。
3.15
結合クラス(combining class)
結合文字の図形文字に対する作用及び結合文字の並びの中での基準順序を決定するために,個々の結合
文字に対応付けた値。
3.16
互換用文字(compatibility character)
主として既存の符号化文字集合との互換性のため,この規格に符号化文字として含めた図形文字。
3.17
合成列(composite sequence)
基底文字とそれに続く一つ以上の結合文字,ZERO WIDTH JOINER又はZERO WIDTH NON-JOINER
とからなる図形文字の列(3.14参照)。
注記1 合成列からなる図形記号は,通常,その合成列を構成する各文字の図形記号の組合せからな
る。
注記2 合成列は,この規格のレパートリとして符号化されていない文字を表現するために用いるこ
とができる。
5
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
3.18
制御文字(control character)
その符号化表現が一つの符号位置からなる制御機能。
注記 制御文字は,DELETE,FORM FEED,ESCなどの名前のようなものを用いて呼ぶことがあるが,
これらの呼び名は,正式な文字の名前ではない。JIS X 0211が制御文字に対応させている長い
名前の一覧は,箇条11を参照。
3.19
制御機能(control function)
符号単位列によって表現され,データの記録,処理,伝送又は解釈に影響を及ぼす動作。
3.20
分解写像(decomposition mapping)
一つの文字を,基準等価又は互換等価な一つ以上の文字の一つの列に写す写像。
3.21
既定状態(default state)
状態が明示的に指定されていないときに,想定する状態(F.2.1〜F.2.3参照)。
3.22
装置(device)
符号単位列内の符号化情報を送信及び/又は受信できる情報処理機器の一部分。
注記 装置は,通常の入出力機器であってもよく,応用プログラム又はゲートウェイ機能のような処
理であってもよい。
3.23
符号化形式(encoding form)
UCSの文字を表す個々のUCS符号位置を,その符号化形式が用いる一つ以上の符号単位によって表す
方法を決定するもの。
注記 この規格は,符号化形式としてUTF-8,UTF-16及びUTF-32を規定している。
3.24
符号化方式(encoding scheme)
符号化形式を構成する符号単位をオクテットの並びに直列化する方法の規定。
注記 UCSの符号化方式には,符号化形式と同じ呼び名をもつものがある。しかし,符号化方式の呼
び名と符号化形式の呼び名とは,異なる文脈で用いる。UCSの符号化形式は,メモリ上及び応
用インタフェースでのテキストデータの表現に言及する。UCSの符号化方式は,オクテットの
並びに直列化されたテキストデータに言及する。
3.25
拡張組(extended collection)
正規形C(NFC)である符号位置の列を含んでもよい組。
注記1 3 LATIN EXTENDED-A,4 LATIN EXTENDED-B,15 ARABIC EXTENDEDなどのように
“extended”(拡張)という語を名前に含む組が多数あるが,組の名前に“extended”という
語が含まれていることとその組が拡張組であることとの間には,関係がない。
注記2 正規形Cについては,箇条21参照。
注記3 符号位置の列は,一般的に,名前付きUCS列識別子(箇条27参照)によって参照される。
6
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
3.26
確定組(fixed collection)
識別された範囲に含まれる全ての符号位置に文字が割り当てられている組であって,この規格の将来の
版においても(その組に含まれるレパートリが)変わらないことを意図しているもの。
3.27
書式文字(format character)
周囲の文字の配置又は処理に作用することを主な機能とする文字。
注記 書式文字は,通常,それ自身の可視化表現をもたない。
3.28
一般分類,GC(General Category, GC)
字,句読点,記号類などの文字の重要な分類を決定するために,個々のUCS符号位置に割り当てた値。
注記1 実際の値は,ユニコード標準の2文字省略形を用いた一般分類属性として定める(箇条2に
示す最新のユニコード標準の一般分類を参照)。
注記2 最初の文字が同一であるような全ての一般分類をまとめて扱うときには,一般分類の値の最
初の文字だけを用いて表すことがある。例えば,“L”は,“Lu”,“Ll”,“Lt”,“Lm”及び“Lo”
という字に関する一般分類の全体を表す。
3.29
図形文字(graphic character)
制御機能でも書式文字でもない文字であって,通常は,手書き,印字又は表示の可視化表現をもつもの。
3.30
図形記号(graphic symbol)
図形文字又は合成列の可視化表現。
3.31
上位サロゲート符号位置(high-surrogate code point)
UTF-16で用いるために保留されているD800〜DBFFの範囲の符号位置。
3.32
上位サロゲート符号単位(high-surrogate code unit)
UTF-16でサロゲートペアの先頭の符号単位として用いるD800〜DBFFの範囲の16ビットの符号単位
(9.3参照)。
3.33
誤った形式の符号単位列(ill-formed code unit sequence)
UCSのある符号化形式に従うと称するUCS符号単位列であって,その符号化形式の規定に適合しない
もの。
例 対をなさないサロゲート符号単位は,誤った形式の符号単位列の例である。
3.34
誤った形式の符号単位列部分集合(ill-formed code unit sequence subset)
ある符号単位列の空でない部分集合であって,その符号単位列の,正しい形式の符号単位の最小列であ
るようなサブセットに属する符号単位を含まないもの。
注記 誤った形式の符号単位列部分集合は,正しい形式の符号単位の最小列と重ならない。
7
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
3.35
交換(interchange)
通信手段又は交換可能な媒体によって,ある利用者から他の利用者に文字の符号化データを転送するこ
と。
注記 交換は,データを直列化し,UCSの符号化方式を用いる。
3.36
相互動作(interworking)
それぞれ異なる符号化文字集合を採用している二つ以上のシステム間で,意味のある文字の符号化デー
タの交換ができるようにすること。
注記 二つの符号の間での変換を含むこともある。
3.37
ISO/IEC 10646-1
この規格の対応国際規格が以前に部編成であったときに,体系及び基本多言語面(BMP)を規定してい
た部。
注記1 ISO/IEC 10646の第1部とも呼ぶ。
注記2 ISO/IEC 10646-1には,第1版と第2版とがあった。
3.38
ISO/IEC 10646-2
この規格の対応国際規格が以前に部編成であったときに,追加多言語面(SMP),追加漢字面(SIP)及
び追加特殊用途面(SSP)を規定していた部。
注記1 ISO/IEC 10646の第2部とも呼ぶ。
注記2 ISO/IEC 10646-2には,第1版だけがあった。
3.39
下位サロゲート符号位置(low-surrogate code point)
UTF-16で用いるために保留されているDC00〜DFFFの範囲の符号位置。
3.40
下位サロゲート符号単位(low-surrogate code unit)
UTF-16でサロゲートペアの末尾の符号単位として用いるDC00〜DFFFの範囲の16ビットの符号単位
(9.3参照)。
3.41
正しい形式の符号単位の最小列(minimal well-formed code unit sequence)
正しい形式の符号単位列であって,一つのUCSスカラ値に写像されるもの。
3.42
鏡像文字(mirrored character)
右から左に配置するテキストにおいて,その像が水平に反転される文字。
3.43
オクテット(octet)
8ビットの符号単位。
注記 この規格では,オクテットの値は,16進数を用いて00〜FFとして表記する(附属書K参照)。
8
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
3.44
面(plane)
UCS符号空間の一部分であって,65 536の倍数の符号位置から始まり65 536個の連続する符号位置から
なる,00〜10の数値によって識別されるもの。
注記 UCS符号空間は,17の面からなる。
3.45
表示(presentation)
図形記号を書いたり,印字したり,画面表示したりする処理。
3.46
表示形(presentation form)
(一部の言語の用字を表示する際に,)他の文字との相対的な位置に依存して文字を表現する図形記号の
形。
3.47
私用面(private use plane)
この符号化文字集合中の面であって,この規格で文字を規定しない面。
注記 面0F及び面10が私用面である。
3.48
レパートリ(repertoire)
符号化文字集合で表現する文字の指定された集合。
3.49
区(row)
面の一部であって,256の倍数の符号位置から始まり256個の連続する符号位置からなる,00〜FFの数
値によって識別されるもの。
3.50
用字(script)
一つ以上の言語の表記形で使用する図形文字の集合。
3.51
追加面(supplementary plane)
UCS符号空間の面00以外の面。
注記 追加面は,基本多言語面に割り当てていない文字を収容する。
3.52
用字及び記号のための追加多言語面,SMP(Supplementary Multilingual Plane for scripts and symbols, SMP)
UCS符号空間の面01。
3.53
追加漢字面,SIP(Supplementary Ideographic Plane, SIP)
UCS符号空間の面02。
3.54
追加特殊用途面,SSP(Supplementary Special-purpose Plane, SSP)
UCS符号空間の面0E。
9
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
3.55
サロゲートペア(surrogate pair)
二つの16ビット符号単位からなる一文字の表現であって,ペアの最初の値が上位サロゲート符号単位で
あり,2番目の値が下位サロゲート符号単位であるもの。
3.56
第三漢字面,TIP(Tertiary Ideographic Plane, TIP)
UCS符号空間の面03。
3.57
UCS符号空間(UCS codespace)
UCSの文字のレパートリを割り当てるために用いる,0〜10FFFF(16進数)の整数からなる符号空間。
3.58
UCSスカラ値(UCS scalar value)
上位サロゲート符号位置及び下位サロゲート符号位置を除く任意のUCS符号位置。
3.59
対をなさないサロゲート符号単位(unpaired surrogate code unit)
符号単位列の中の符号単位であって,次のいずれかであるもの。
− 上位サロゲート符号単位であって,下位サロゲート符号単位が直後にないもの。
− 下位サロゲート符号単位であって,上位サロゲート符号単位が直前にないもの。
3.60
利用者(user)
装置が提供するサービスを使う人又はそれに代わるもの。
注記 “装置”が符号変換機又はゲートウェイ機能の場合,これは,応用プログラムのような処理で
あってもよい。
3.61
正しい形式の符号単位列(well-formed code unit sequence)
UCSのある符号化形式に従うと称するUCS符号単位列であって,その符号化形式の規定に適合し,誤
った形式の符号単位列部分集合を含まないもの。
4
適合性
4.1
概要
私用文字をこの規格の規定に従って使用する場合,その文字自身は,この適合性要件の適用外とする。
注記 私用文字については,6.3.5を参照。
4.2
情報交換の適合性
情報交換のために符号化された情報における符号単位列(CCデータ要素)は,次の条件を全て満たし
ている場合に,この規格に適合する。
a) 符号単位列中の図形文字の符号化表現は,全て箇条6に適合し,箇条9に示すうちから選択した一つ
の識別された符号化形式に適合し,かつ,箇条10に示すうちから選択した一つの識別された符号化方
式に適合する。
b) 符号単位列中で表現されている図形文字は,全て識別された部分集合(箇条8参照)の図形文字から
なる。
10
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
c) 符号単位列中の制御機能の符号化表現は,全て箇条11に適合する。
適合性を主張する場合,採用した符号化形式及び符号化方式を明示するとともに,採用した部分集合を
組及び/又は文字の一覧で明示しなければならない。
4.3
装置の適合性
装置は,次のa)の要件に適合し,かつ,b)及び/又はc)に適合する場合,この規格に適合する。
適合性を主張する場合,次のa)に規定する記述を含む文書を明示しなければならず,採用した符号化形
式,符号化方式,部分集合及び箇条11に従って採用した制御機能の種類を明示しなければならない(部分
集合は,組及び/又は文字の一覧によって示す。)。
a) 装置についての記述 この規格に適合させる装置には,それぞれ次のb)及びc)に規定するとおり,利
用者が装置に文字を送出できる方法及び/又は文字が利用者に提示されたときに利用者がそれを認識
できる方法を明示した記述を備えなければならない。
b) 送信装置 送信装置は,採用した部分集合から利用者が任意の文字を送出できるようにしなければな
らない。さらに,送信装置は,符号単位列中にあるそれらの文字の符号化表現を,採用した符号化形
式及び符号化方式に従って送信する能力をもたなければならない。したがって,送信装置は,誤った
形式の符号単位列を送出してはならない。
c) 受信装置 受信装置は,符号単位列中にある任意の文字の符号化表現を,採用した符号化形式及び符
号化方式に従って受信し解釈する能力をもたなければならない。さらに,受信装置は,符号化表現に
対応する文字が採用した部分集合にある場合,その全てを,利用者が識別できる方法で,利用者に渡
さなければならない。受信装置は,誤った形式の符号単位列を誤った状態として処理しなければなら
ず,そのようなデータを文字列として解釈してはならない。
対応する文字が採用した部分集合にない場合,それらの文字を利用者に示さなければならない。それら
を示す方法は,文字を互いに区別する必要はない。
注記1 この規格では,誤り条件についても,採用した部分集合にない文字を利用者に示す方法につ
いても,規定していない。
注記2 再送能力をもつ受信装置については,附属書Jを参照。
5
国際符号化文字集号の全体構造
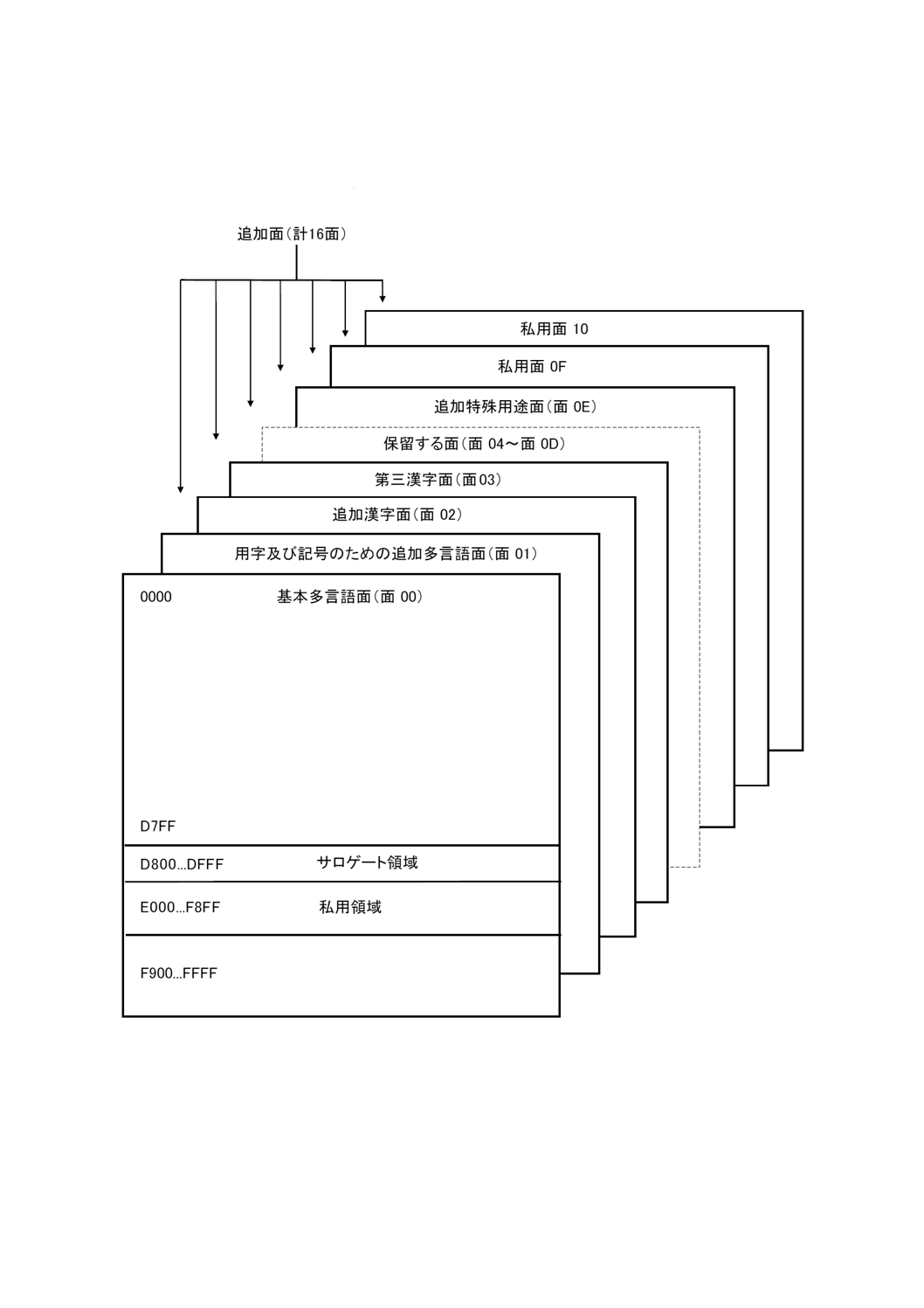
ここでは,国際符号化文字集合(以下,“この符号化文字集合”という。)の大まかな構造について示し,
図1に図示する。構造の規定は,箇条6及び箇条8による。
この符号化文字集合の基準形式(規格を理解するための形式)は,0〜10FFFFの整数からなるUCS符号
空間を用いる。
この規格は,次の面の符号化文字を定義する。
− 基本多言語面(BMP,すなわち,面00)。
− 用字及び記号のための追加多言語面(SMP,すなわち,面01)。
− 追加漢字面(SIP,すなわち,面02)。
− 追加特殊用途面(SSP,すなわち,面0E)。
第三漢字面(TIP,面03)を漢字のために保留する。TIPは,現在空である。面04〜面0Dは,将来の標
準化のために保留する。
面0F及び面10は,私用のために保留する。
符号空間の部分集合を,図形文字の部分レパートリを定めるために使ってもよい。
11
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
6
基本構造及び名称
6.1
構造
この規格が規定する国際符号化文字集合は,17の面からなる一つのものとみなさなければならない。
図1−国際符号化文字集合の面
6.2
文字の符号化
UCS符号空間の中で符号化される個々の文字は,0〜10FFFFの範囲の一つの整数によって表現され,符
号位置として識別される。
一つの文字を符号位置によって識別するときには,整数の6桁形式によって次のように表現する。
12
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
000030は,DIGIT ZEROを表現する。
000041は,LATIN CAPITAL LETTER Aを表現する。
010000は,LINEAR B SYLLABLE B008 Aを表現する。
面00の中の文字を引用するときは,先頭の2桁の数字を省略してもよい。面01〜面0Fの中の文字を引
用するときは,頭の1桁の数字を省略してもよい。例えば,次のように表現してもよい。
0030によって,DIGIT ZEROを表現する。
0041によって,LATIN CAPITAL LETTER Aを表現する。
10000によって,LINEAR B SYLLABLE B008 Aを表現する。
6.3
符号位置の種類
6.3.1
分類
UCS符号位置は,一般分類の値に基づいて基本の種類に分類される。一般分類の値は,ユニコード標準
の一般分類属性に従って決定する(箇条2参照)。符号位置の種類を,表1に示す。
表1−符号位置の種類
基本の種類
概要
一般分類
文字の状態
符号位置の状態
図形
字,マーク,数,句読点,記号及び空白 L,M,N,P,
S及びZs
文字として
割当て済み
割当て済みの
符号位置
書式
可視化されずに周囲の文字に影響する
Cf,Zl及びZp
制御
一つの符号位置からなる制御機能
Cc
私用
この規格の外側での私的な合意に基づ
き定義する用途
Co
サロゲート
UTF-16のために永久に保留
Cs
文字として
割り当てていない
非文字
内部利用のために永久に保留
Cn
保留
将来の割当てのために保留
割り当てていない
符号位置
サロゲート,非文字(noncharacter)及び保留の符号位置は,文字として割り当てていないので交換には
制約がある。例えば,サロゲート符号位置は,どのUCS符号化形式にも正しい形式の表現がない。
6.3.2
図形文字
同一の図形文字を複数の符号位置に割り当てることはない。この符号化文字集合には,似た形の図形文
字が複数存在するが,それらは,異なる目的で使用する異なる文字であって,異なる名前をもつ。
6.3.3
書式文字
書式文字は,可視化されずに周囲の文字に影響を与えるような文字の分類である。
6.3.4
制御文字
BMPの符号位置0000〜001F及び007F〜009Fは,制御文字のために保留する(箇条11参照)。
6.3.5
私用文字
BMPの符号位置E000〜F8FFは,私用のために保留する。面0F及び面10の,FFFFE,FFFFF,10FFFE
及び10FFFFを除く全ての符号位置は,私用のために保留する。
この規格では,私用文字にはいかなる制限も加えない。私用文字は,利用者定義の文字を備えるために
使用可能である。例えば,これは,漢字の用字の利用者には一般的な要件となる。
注記 私用文字の意味のある交換のためには,この規格とは別に,送信者と受信者との間の合意が必
要となる。
13
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
6.3.6
サロゲート符号位置
符号位置D800〜DFFFは,UTF-16の符号化形式で使用するために保留する(9.3参照)。前半(D800〜
DBFF)を上位サロゲート符号位置とし,後半(DC00〜DFFF)を下位サロゲート符号位置とする。
6.3.7
非文字符号位置
非文字である符号位置の状態を将来の規格の改正によって変更することはない。非文字は,FDD0〜FDEF
及び下位4桁がFFFE又はFFFFであるような全ての符号位置とする。
注記 符号位置FFFEは,“印”(しるし)用に保留する。符号位置FDD0〜FDEF及びFFFFは,符号
化文字ではないことが保証された数値を必要とする内部処理に使用できる(例えば,表を終了
させる,テキストの終わりを通知するなど。)。さらに,FFFFは,BMPの最大値であるから,
UTF-16の文脈においては,2進探索又は順次探索の索引最終値として使用することもできる。
6.3.8
保留符号位置
保留符号位置は,将来の標準化のために保留する。保留符号位置を他の目的に用いてはならない。この
規格の将来の版は,保留符号位置の一部に文字を割り当てることがある。
6.4
文字の名前
この規格は,全ての図形文字及び書式文字に一意的な名前を付ける。命名の基準は,次のいずれかとす
る。
a) 文字の慣例的な意味を示す。
b) 対応する図形記号の形を表す。
c) 中国,日本及び韓国の漢字(CJK漢字)については,26.6に示す規則に従う。
d) 西夏文字については,26.7に示す規則に従う。
e) 女書文字については,26.8に示す規則に従う。
f)
ハングル音節文字については,26.9に示す規則に従う。
文字によっては,文字の別名と呼ぶ代替の名前を一つ以上もつことがある。これは,元の名前を補正す
るものである。文字の名前を構成するためのその他の規則は,箇条26に示す。
CJK漢字,西夏文字及びハングル音節文字以外の文字の名前の一覧を箇条33に示す。
注記 文字の名前の一覧は,ユニコードの文字データベースにも含まれている。これは,
<http://www.unicode.org/Public/UNIDATA/NamesList.txt>にあり,構文は,
<http://www.unicode.org/Public/UNIDATA/NamesList.html>に記載されている。
6.5
符号位置の短い識別子(UID)
この規格は,保留されている(未割当ての)符号位置を含む各符号位置の短い識別子(short identifier)
を定義する。いずれの符号位置の短い識別子も,他のいずれの符号位置の短い識別子とは異なる。ある文
字がある符号位置に配置されているとき,その符号位置の短い識別子は,その符号位置に配置される文字
を引用するために使用できる。
注記1 例えば,U+DC00は,サロゲートの符号位置を識別し,U+FFFFは,非文字の符号位置を識
別する。U+0025は,図形文字が配置されている符号位置を識別する。同時に,U+0025は,
そこに配置される文字(すなわち,PERCENT SIGN)をも識別する。
注記2 この短い識別子は,規格の記述に使用される言語とは独立である。規格の文章を翻訳する場
合でも,そのままにする。
ここでは,短い識別子を次のいずれかとして定義する。
a) 短い識別子の6桁形式は,文字の符号位置を示す六つの16進数字の列とする(6.2参照)。
14
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
b) 短い識別子の4〜5桁形式は,6桁形式の最後の四つ又は五つの数字とする。4桁を超える部分の頭の
0は,省略する。
c) 短い識別子の4〜5桁形式又は6桁形式の前に,文字“+”(PLUS SIGN)を付けてもよい。
d) 上のa)〜c)で定義した三つの短い識別子の形式の前に,前置文字(prefix letter)“U”(LATIN CAPITAL
LETTER U)を付けてもよい。
短い識別子の中に現れる大文字のA〜F及びUは,対応する小文字に置き換えてもよい。
バッカス・ナウア記法(Backus-Naur form)による,短い識別子の完全な構文は,次による。
{ U | u }{+}(xxxx | xxxxx | xxxxxx)
ここに,“x”は,一つの16進数字(0〜9,A〜F又はa〜f)を表す。
例 LATIN SMALL LETTER LONG Sは,次のいずれの形式によって表記してもよい。
017F
+017F
U017F
U+017F
任意の大文字を対応する小文字に置き換えてもよい。
6.6
UCS列識別子
この規格は,この規格中の任意の符号位置の列に対して識別子を定義する。このような識別子を,UCS
列識別子(以下,USIという。)という。n個の符号位置からなる列のUCS識別子は,次の形式とする。
<UID1, UID2, ..., UIDn>
ここに,UID1,UID2などは,対応する符号位置の短い識別子であって,列における符号位置の出現順
序と同じ順に表記する。このような列におけるそれぞれの符号位置に文字が割り当てられている場合,そ
れらの符号位置に割り当てられた文字の列を識別するためにUSIを用いることができる。UID1,UID2な
どの構文は,6.5で規定する。UIDの間は,COMMA(コンマ)で区切る。COMMAの後ろに一つのSPACE(ス
ペース)を付加してもよい。UCS列識別子は,少なくとも二つのUIDを含み,LESS-THAN SIGN[不等
号(より小)]で始まり,GREATER-THAN SIGN[不等号(より大)]で終わる。
バッカス・ナウア記法による,UCS列識別子の完全な構文は,次による。
“<”(xxxx | xxxxx | xxxxxx) ((“,”space?) (xxxx | xxxxx | xxxxxx))+“>”
ここに,“x”は,一つの16進数字(0〜9,A〜F又はa〜f)を表す。
UCS列識別子は,部分集合の内容の指定に用いることはできない。UCS列識別子は,この規格の外で,
対応付けを示す合成列,フォントでのレパートリなどの指定に用いてもよい。
注記 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記の
記載内容を本文に移動した。
6.7
オクテット列識別子
符号化方式の定義(箇条10参照)の文脈において,直列化されたオクテットを表現するために,この規
格は,直列化したオクテット列の識別子を定義する。n個のオクテットからなる列は,次による。
<xx1 xx2 … xxn>
ここに,xx1,xx2及びxxnは,二つの16進数字からなる最初,2番目及びn番目のオクテットを表す。
7
UCSの維持・改正
この符号化文字集合は,ISO/IEC JTC 1(情報技術)のSC 2(符号化文字集合)によって,維持・改正
される。
この符号化文字集合における全ての文字の名前及び符号位置割当ては,この規格の将来の版及び改正に
よって変更されない。これは文字の別名も含まれる。
15
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 規格の公示後に文字の名前を変更できないので,文字の名前が不適切であった場合は,文字の
別名を作成する。文字の別名は,ユニコードの文字データベースの“NameAliases.txt”ファイ
ルに記述される(http://www.unicode.org/Public/UCD/latest/ucd/NameAliases.txt)。
8
部分集合
8.1
概要
この規格は,情報交換,送信装置及び受信装置で使用するための,符号化図形文字の部分集合の仕様を
規定する。
部分集合の仕様として,制限部分集合及び選択部分集合の二つを規定する。採用される部分集合は,こ
の二つのいずれか又は両者の組合せで構成してもよい。
8.2
制限部分集合
制限部分集合は,指定する部分集合が含む図形文字の一覧によって示す。この仕様は,他の符号系を使
う適用業務群及び装置群が,この符号化文字集合との間で相互動作することを可能とする。
制限部分集合への適合性を主張する場合,この規格で定義された図形文字の名前又は符号位置を用いて,
部分集合中の図形文字の一覧を示さなければならない。
8.3
選択部分集合
選択部分集合は,この規格で定義された図形文字の組の一覧によって示す。選択の対象となる組の一覧
を附属書Aに示す。選択部分集合では,符号位置0020〜007Eが,いつでも自動的に含まれる。
選択部分集合への適合性を主張する場合,選択された,この規格で定義されている組の一覧を,示さな
ければならない。
9
UCSの符号化形式
9.1
概要
この規格は,個々のUCSスカラ値を一つ以上の符号単位の一意の列で表現する符号化形式を三つ規定す
る。これらを,UTF-8,UTF-16及びUTF-32という。
9.2
UTF-8
UTF-8は,表2で指定されるように各UCSスカラ値を一つ〜四つのオクテットのオクテット列に割り当
てるUCSの符号化形式である。
− 組BASIC LATINのUCS文字は,UTF-8では,ISO/IEC 4873に従って表現される。すなわち,20〜
7Eの値をもつ単一オクテットである。
− 符号位置0000〜001Fの制御機能及び符号位置007FのDELETEは,箇条11で規定する詰込みオクテ
ットなしで表現される。すなわち,ISO/IEC 4873及びJIS X 0202の8ビット構造に従った,それぞれ
00〜1F及び7Fの値の単一オクテットである。
− そのほかには,00〜7Fの値のオクテットは,いかなる文字のUTF-8符号化表現においても使われな
い。これによって,UTF-8符号化表現と,これらのオクテット値を手掛かりにして符号単位列を解析
するような既存のファイル操作システム及び通信サブシステムとの互換性が保たれる。
− 任意の位置から始めて符号単位列を1オクテットずつ調べるとき,いかなる文字も,そのUTF-8符号
化表現の最初のオクテットを直ちに識別できる。そのオクテットは,その文字の符号化表現を構成す
る複数オクテットの列に含まれる継続オクテット(もしあれば)の数を示す。
UTF-8符号化形式におけるビット割当てを指定し,UCSスカラ値の範囲と一つ〜四つのオクテット列と
16
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
の対応を表2に示す。
表2−UTF-8ビット割当て
スカラ値
第1オクテット
第2オクテット
第3オクテット
第4オクテット
000000000xxxxxxx
0xxxxxxx
00000yyyyyxxxxxx
110yyyyy
10xxxxxx
zzzzyyyyyyxxxxxx
1110zzzz
10yyyyyy
10xxxxxx
000uuuuuzzzzyyyyyyxxxxxx
11110uuu
10uuzzzz
10yyyyyy
10xxxxxx
サロゲート符号位置は,UCSスカラ値ではないため,符号位置D800〜DFFFに対応するUTF-8のいか
なる列も,誤った形式である。
全ての正しい形式のUTF-8のオクテット列の範囲を表3に示す。表3に示すパターンに一致しない任意
のUTF-8列は,誤った形式である。
表3−正しい形式のUTF-8オクテット列
符号位置
第1オクテット
第2オクテット
第3オクテット
第4オクテット
0000〜007F
00〜7F
0080〜07FF
C2〜DF
80〜BF
0800〜0FFF
E0
A0〜BF
80〜BF
1000〜CFFF
E1〜EC
80〜BF
80〜BF
D000〜D7FF
ED
80〜9F
80〜BF
E000〜FFFF
EE〜EF
80〜BF
80〜BF
10000〜3FFFF
F0
90〜BF
80〜BF
80〜BF
40000〜FFFFF
F1〜F3
80〜BF
80〜BF
80〜BF
100000〜10FFFF
F4
80〜8F
80〜BF
80〜BF
表3で示す形式の正しさの条件を理由として,C0〜C1及びF5〜FEのオクテット値は,UTF-8では許さ
れない。
9.3
UTF-16
UTF-16は,表4で指定されるように各UCSスカラ値を一つ〜二つの符号なし16ビット符号単位列に割
り当てるUCSの符号化形式である。
UTF-16符号化形式では,0000〜D7FF及びE000〜FFFFの範囲の符号位置は,単一の16ビット符号単位
で表現される。10000〜10FFFFの範囲にある符号位置は,二つの16ビット符号単位で表現される。この特
別な符号単位の対を,サロゲートペアという。
サロゲートペアに用いる符号単位は,単一符号単位の表現で使用する符号単位と重複しないので,
UTF-16における全ての符号位置の表現は,他の表現と重なることがない。
UTF-16は,一般的に使用される文字の大多数を含むBMPの文字の表現に最適化されている。
サロゲート符号位置は,UCSスカラ値ではないため,単独のサロゲート符号単位は,誤った形式である。
表4は,UTF-16符号化形式のビット割当てを指定する。サロゲートペアの計算において,スカラ値のオ
フセット開始の計算に当たり16進数の10000の減算が行われる(表中において“wwww = uuuuu−1”で表
現される。)。

17
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表4−UTF-16ビット割当て
スカラ値
UTF-16
xxxxxxxxxxxxxxxx
xxxxxxxxxxxxxxxx
000uuuuuxxxxxxxxxxxxxxxx
110110wwwwxxxxxx 110111xxxxxxxxxx
注記 この規格の以前の版には,UCS-2という2オクテットBMP形式が含まれていた。これは,UTF-16
符号化形式のサブセットであって,UCSスカラ値をBMPの範囲に制限したものとみなすこと
ができた。UCS-2符号化形式は,廃止された。
9.4
UTF-32(UCS-4)
UTF-32(UCS-4も同じ。)は,各UCSスカラ値を単一の符号なし32ビット符号単位に割り当てるUCS
符号化形式である。用語UTF-32とUCS-4とは,この符号化形式を指定するために互いに取り替えて用い
てもよい。
サロゲート符号位置は,UCSスカラ値ではないため,0000D800〜0000DFFFの範囲のUTF-32符号単位
は,誤った形式である。
10 UCSの符号化方式
10.1 概要
符号化方式とは,それぞれのUCS符号化形式に特有のオクテット直列化の方式であって,印(しるし)
の仕様もその一部である。印は,対応する符号化形式における,符号位置FEFFのZERO WIDTH NO-BREAK
SPACEに対応する符号単位列とする。印が使われる場合,印は,直列化オクテット列の先頭において,文
字の表現に使われる符号化形式におけるオクテットの順序を示す。
この規格では,UTF-8,UTF-16BE,UTF-16LE,UTF-16,UTF-32BE,UTF-32LE及びUTF-32の七つの
符号化方式を規定する。
10.2 UTF-8
UTF-8符号化方式では,UTF-8の符号単位列を,その符号単位列の順序そのままに直列化する。
UTF-8で表現するとき,印は,オクテット列<EF BB BF>になる。UTF-8データ列の先頭におけるその利
用は必要でなく,また,推奨もされないが,適合性に影響しない。
10.3 UTF-16BE
UTF-16BE符号化方式は,UTF-16の符号単位列を,上位オクテットを下位オクテットより前置するオク
テットの並べ方によって直列化する(この並べ方は,ビッグエンディアンとしても知られている。)。
UTF-16BEでは,先頭のオクテット列<FE FF>は,FEFF ZERO WIDTH NO-BREAK SPACEとして解釈さ
れ,印としての意味は,もたない。
10.4 UTF-16LE
UTF-16LE符号化方式は,UTF-16の符号単位列を,下位オクテットを上位オクテットより前置するオク
テットの並べ方によって直列化する(この並べ方は,リトルエンディアンとしても知られている。)。
UTF-16LEでは,先頭のオクテット列<FF FE>は,FEFF ZERO WIDTH NO-BREAK SPACEとして解釈さ
れ,印としての意味は,もたない。
10.5 UTF-16
UTF-16符号化方式は,UTF-16の符号単位列を,上位オクテットを下位オクテットより前置又は後置す
るオクテットの並べ方によって直列化する。
18
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
UTF-16符号化方式では,<FE FF>として読み込まれる最初の印は,上位オクテットを下位オクテットよ
り前置することを示し,<FF FE>は,その逆を示す。印は,テキストデータの一部には,含まれない。
印がない場合は,UTF-16符号化方式のオクテット順序は,上位オクテットを下位オクテットより前置す
る。
10.6 UTF-32BE
UTF-32BE符号化方式は,UTF-32の符号単位列を,上位オクテットを下位オクテットより前置するオク
テットの並べ方によって直列化する(この並べ方は,ビッグエンディアンとしても知られている。)。
UTF-32BEでは,先頭のオクテット列<00 00 FE FF>は,FEFF ZERO WIDTH NO-BREAK SPACEとして
解釈され,印としての意味は,もたない。
10.7 UTF-32LE
UTF-32LE符号化方式は,UTF-32の符号単位列を,下位オクテットを上位オクテットより前置するオク
テットの並べ方によって直列化する(この並べ方は,リトルエンディアンとしても知られている。)。
UTF-32LEでは,先頭のオクテット列<FF FE 00 00>は,FEFF ZERO WIDTH NO-BREAK SPACEとして
解釈され,印としての意味は,もたない。
10.8 UTF-32
UTF-32符号化方式は,UTF-32の符号単位列を,下位のオクテットを上位のオクテットより前置又は後
置するオクテットの並べ方によって直列化する。
UTF-32符号化方式では,先頭にある印が<00 00 FE FF>として読み込まれる場合は,上位オクテットが
下位オクテットより前置されることを示し,<FF FE 00 00>であれば,その逆である。印は,テキストデー
タの一部には,含まれない。
印がない場合は,UTF-32符号化方式のオクテット順序は,上位のオクテットを下位のオクテットより前
置する。
11 UCSでの制御機能の使用
この符号化文字集合は,JIS X 0211又はこれと同様な構造の制御機能の規格,及びこれらから導出され
た規格に従って符号化された制御機能を使用できるようにする。これらの符号化制御機能の集合又は部分
集合は,この符号化文字集合とともに使ってもよい。これらの規格は,制御機能を1オクテット以上の列
で符号化している。
JIS X 0211の制御文字をこの符号化文字集合とともに使うときは,その制御文字の符号化表現は,採用
した符号化形式の符号単位でのオクテット数(箇条9参照)と一致するように詰め込まなければならない。
この場合,最下位オクテットは,JIS X 0211で規定されたビット組合せとし,上位のオクテットは,全て
00とする。
例えば,制御文字FORM FEEDは,UTF-16符号化形式では“000C”で,UTF-32符号化形式では“0000
000C”で表現する。
符号化制御文字の後に20〜7Fの範囲にあるビット組合せが続く形のエスケープシーケンス,制御シー
ケンス及び制御列(JIS X 0211参照)については,それぞれのビット組合せは,00の値をもつオクテット
を詰め込まなければならない。
例えば,エスケープシーケンスの“ESC 02/00 04/00”は,UTF-8符号化形式では“1B 20 40”で,UTF-16
符号化形式では“001B 0020 0040”で,UTF-32符号化形式では“0000001B 00000020 00000040”で表現す
る。
19
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記1 JIS X 0211で規定される制御機能の多くのものの定義では,その制御機能が動作する要素を
識別するために,“文字”という語が現れる。そのような制御機能をこの規格の符号化文字に
適用する場合,制御機能の動作は,制御機能が作用する要素(又は文字)として応用が選択
した,この規格の要素の種類による。これらの要素としては,文字(基底文字及び/又は結
合文字)が選ばれてもよいし,適切であれば他のもの(例えば,合成列など)が選ばれても
よい。
JIS X 0202の符号拡張制御機能(指示用エスケープシーケンス,シングルシフト及びロッキングシフト)
は,この符号化文字集合と一緒に使ってはならない。
注記2 JIS X 0211が制御文字に関連付けて用いている長い名前の一覧を次に示す。
0000
NULL
0001
START OF HEADING
0002
START OF TEXT
0003
END OF TEXT
0004
END OF TRANSMISSION
0005
ENQUIRY
0006
ACKNOWLEDGE
0007
BELL
0008
BACKSPACE
0009
CHARACTER TABULATION
000A
LINE FEED
000B
LINE TABULATION
000C
FORM FEED
000D
CARRIAGE RETURN
000E
SHIFT-OUT
000F
SHIFT-IN
0010
DATA LINK ESCAPE
0011
DEVICE CONTROL ONE
0012
DEVICE CONTROL TWO
0013
DEVICE CONTROL THREE
0014
DEVICE CONTROL FOUR
0015
NEGATIVE ACKNOWLEDGE
0016
SYNCHRONOUS IDLE
0017
END OF TRANSMISSION BLOCK
0018
CANCEL
0019
END OF MEDIUM
001A
SUBSTITUTE
001B
ESCAPE
001C
INFORMATION SEPARATOR FOUR
001D
INFORMATION SEPARATOR THREE
001E
INFORMATION SEPARATOR TWO
20
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
001F
INFORMATION SEPARATOR ONE
007F
DELETE
0082
BREAK PERMITTED HERE
0083
NO BREAK HERE
0084
INDEX
0085
NEXT LINE
0086
START OF SELECTED AREA
0087
END OF SELECTED AREA
0088
CHARACTER TABULATION SET
0089
CHARACTER TABULATION WITH JUSTIFICATION
008A
LINE TABULATION SET
008B
PARTIAL LINE FORWARD
008C
PARTIAL LINE BACKWARD
008D
REVERSE LINE FEED
008E
SINGLE-SHIFT TWO
008F
SINGLE-SHIFT THREE
0090
DEVICE CONTROL STRING
0091
PRIVATE USE ONE
0092
PRIVATE USE TWO
0093
SET TRANSMIT STATE
0094
CANCEL CHARACTER
0095
MESSAGE WAITING
0096
START OF GUARDED AREA
0097
END OF GUARDED AREA
0098
START OF STRING
009A
SINGLE CHARACTER INTRODUCER
009B
CONTROL SEQUENCE INTRODUCER
009C
STRING TERMINATOR
009D
OPERATING SYSTEM COMMAND
009E
PRIVACY MESSAGE
009F
APPLICATION PROGRAM COMMAND
制御文字0084 INDEXは,JIS X 0211:1994以降削除されている。加えて,制御文字000E
及び000Fは,7ビット環境では,それぞれSHIFT-OUT及びSHIFT-INと呼ばれ,8ビット
環境では,LOCKING-SHIFT ONE及びLOCKING-SHIFT ZEROと呼ばれる。
12 機能識別の宣言
12.1 識別の目的及び構文
この規格に適合する符号単位列は,送信者と受信者との間で交換される符号化情報の構成要素の全て又
は一部となることを意図している。送信者がこの規格(符号化形式及び符号化方式も含む。)を採用してい
るという識別情報及び符号化空間の部分集合の識別情報は,受信者にも届くことが望ましい。これらの識
21
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
別情報を受信者に伝える経路は,この規格の適用範囲外とする。
しかし,幾つかの符号化情報の交換のための規格は,符号単位列に適用される識別情報を交換情報の一
部に含めることを,許してもよいし,要求してもよい。この箇条は,部分集合をもつUCSを識別するため
の符号化表現,並びにこの規格と一緒に使うJIS X 0211の制御機能のC0集合及びC1集合を識別するため
の符号化表現を規定する。このような符号化表現は,識別データ要素の全て又は一部となり,関係する規
格に従って,情報交換で用いてもよい。
これらの識別情報の目的においては,直列化に当たって上位オクテットを下位オクテットより前置する
ので,UTF-8,UTF-16及びUTF-32の各符号化形式において選択できる符号化方式は,それぞれUTF-8,
UTF-16BE及びUTF-32BEだけである。
識別情報が二つ以上ある場合は,この識別の順序は,この箇条12に規定する順序による。
注記1 別の識別法を附属書Nに示す。
注記2 箇条10に規定する印も,識別法の一種である。
12.2 UCSの符号化方式の識別
JIS X 0202のエスケープシーケンスを使う場合,この規格で規定するUCSの符号化方式(箇条10参照)
の識別は,次に示す指示シーケンスによる。
ESC 02/05 02/15 04/09 UTF-8符号化形式によるUTF-8符号化方式
ESC 02/05 02/15 04/12 UTF-16符号化形式によるUTF-16BE符号化方式
ESC 02/05 02/15 04/06 UTF-32符号化形式によるUTF-32BE符号化方式
注記 この規格の以前の版で使われていた,実装水準1及び実装水準2を識別する指示シーケンスESC
02/05 02/15 04/00,ESC 02/05 02/15 04/01,ESC 02/05 02/15 04/03,ESC 02/05 02/15 04/04,ESC 02/05
02/15 04/07,ESC 02/05 02/15 04/08,ESC 02/05 02/15 04/10及びESC 02/05 02/15 04/11は,廃止
した。残っているエスケープシーケンスは,この規格の以前の版の実装水準3に対応するもの
であるが,この実装水準が現在有効な唯一の符号単位列の内容定義に相当する。
ESC 02/05 04/07 UTF-8符号化形式によるUTF-8符号化方式
このようなエスケープシーケンスがJIS X 0202に適合した符号単位列に現れる場合,ここに示す一連の
ビット組合せのとおりでなければならない。
このようなエスケープシーケンスが,この規格に適合した符号単位列に現れる場合,符号化形式が
UTF-16又はUTF-32のいずれかであると識別されるときには,箇条11の規定に従って詰め込まなければ
ならない。UTF-8と識別されるときには,詰込みは不要である。12.5参照。
12.3 図形文字部分集合の識別
JIS X 0211の制御シーケンスを使うときは,この規格で規定する部分集合(箇条8参照)を制御シーケ
ンスIDENTIFY UNIVERSAL CHARACTER SUBSET(IUCS,国際符号化文字部分集合識別)で,次に示
すとおりに識別しなければならない。
CSI Ps... 02/00 06/13
Ps... は,選択パラメタが複数個あってもよいことを示す。パラメタは,附属書Aに規定する部分集合の
組番号からなる。パラメタが二つ以上ある場合,それぞれのパラメタ値は,03/11の値をもつオクテットで
区切る。
パラメタ値は,数字0〜9にそれぞれ対応するオクテット値03/00〜03/09の数字で表現する。
このエスケープシーケンスは,JIS X 0202に適合した符号単位列中に現れる場合,ここに示す一連のビ
ット組合せのとおりでなければならない。
22
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
この制御シーケンスは,この規格に適合した符号単位列中に現れる場合,箇条11の規定に従って詰め込
まなければならない。
12.4 制御機能集合の識別
JIS X 0202のエスケープシーケンスを使う場合,この規格と一緒に使用するJIS X 0211の制御機能の集
合(箇条11参照)は,次に示す形の識別シーケンスで識別する。
ESC 02/01 04/00 JIS X 0211の全C0集合を識別する。
ESC 02/02 04/03 JIS X 0211の全C1集合を識別する。
これら以外のC0集合又はC1集合については,終端オクテットFは,符号化文字集合の国際登録簿から
得る。これらの集合の識別シーケンスを,次に示す。
ESC 02/01 F C0集合を識別する。
ESC 02/02 F C1集合を識別する。
このエスケープシーケンスは,JIS X 0202に適合した符号単位列中に現れる場合,ここに示す一連のビ
ット組合せのとおりでなければならない。
このエスケープシーケンスは,この規格に適合した符号単位列中に現れる場合,箇条11の規定に従って
詰め込まなければならない。
12.5 JIS X 0202の符号化方式の識別
JIS X 0202のエスケープシーケンスを使う場合,UCSからJIS X 0202の符号化方式への復帰又は遷移は,
エスケープシーケンスESC 02/05 04/00による。このエスケープシーケンスは,この規格に適合した符号単
位列中に現れる場合,箇条11の規定に従って詰め込まなければならない。
このエスケープシーケンスは,JIS X 0202に適合した符号単位列中に現れる場合,ここに示す一連のビ
ット組合せのとおりでなければならない。
注記 ESC 02/05 04/00のエスケープシーケンスは,通常,JIS X 0202から移ったときに保持されたJIS
X 0202の状態に復帰するために使われる。ここで規定するESC 02/05 04/00のエスケープシー
ケンスは,詰込みオクテットがあるために,JIS X 0202に規定されたものと同一ではないこと
がある。このため,UCSを識別するために12.2で使われるエスケープシーケンス(ESC 02/05
04/07を除く。)は,復帰が必ずしもJIS X 0202に適合しないことを示すために02/15オクテッ
トを含んでいる。
13 符号表及び一覧表の構造
箇条33に図形文字の詳細符号表及び文字の名前の一覧表を示す。これによって,それぞれの文字に対す
る,図形記号,符号化表現及び文字の名前を規定する。
注記 箇条33は,名付け若しくは用法又は付随する図形記号のような,文字の幾つかの特徴を明らか
にするための,文字についての追加情報も含む。
図形記号は,文字の代表的な可視化表現とする。この規格は,各文字の正確な形又は色を規定しようと
するものではない。文字の形は,採用するフォント又はその他の表示手段のデザインに左右されるもので
あり,この規格の適用範囲外とする。この規格における代表字形は,一貫して白黒で表示されているが,
この規格は,特定の一色若しくは複数の色をもつ図形記号,一部若しくは全部をアニメーション化した図
形,又はその両方を組み合わせて実装することを妨げるものではない。文字が特定の色と関連付けられて
いる場合には,符号表では,ヨーロッパの紋章で使用される慣習を用いて,単色の線画として表示してい
る。さらに,文字名に現れるBLACK(“黒”)又はWHITE(“白”)の語は,特定の色を指定するものでは
23
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
なく,単にいわゆるベタ文字といわゆる袋文字とを識別するためのものである。
この規格で規定する図形文字は,その名前で一意に識別される。名前が異なっていても,図形文字を可
視化した図形記号が常に異なるわけではない。類似の図形記号をもつ図形文字の例としては,LATIN
CAPITAL LETTER A(ラテン大文字A),GREEK CAPITAL LETTER ALPHA(ギリシア大文字A)及び
CYRILLIC CAPITAL LETTER A(キリル大文字A)がある。
文字のもつ意味は,この規格では規定しない。これは,国によって異なったり,適用業務によって異な
ったりする。
アルファベット類の用字については,文字をほぼアルファベット順に区の中に配列することを基本原則
とする。用字に大文字と小文字とがある場合には,対にして配列する。しかし,例えば,用字を配列した
規格が存在する場合には,基本原則よりもその規格に従うことを優先して文字を割り当てる。このように
文字を符号表中に配列することによって,既存の規格とこの符号化文字集合との間の変換が容易になる。
しかし,一般的には,この符号化文字集合と他の符号化文字集合との間の変換には,変換表を使うことに
なると考えられる。
この規格では,利用者が必要とする文字が,符号表のどこかの部分にまとまって見つかることを意図し
ていないし,実際に分散していることが多い。
さらに,利用者は,どの用字を使うにせよ,必要とする文字の幾つかが,この符号化文字集合の別の所
で定義されているのに気付くことが多いであろう。これは,特に,数字,記号及び複数の用字を使う場合
のラテン文字などについていえることである。
したがって,この符号化文字集合の利用者は,最初にA.2のブロック名の一覧表又は図8〜図13の面の
概観を調べ,その後に関連する用字,記号及び数字の符号表を調べることが望ましい。附属書Gにアルフ
ァベット順に分類した文字の名前の一覧を示す。
14 ブロック及び組の名前
14.1 ブロックの名前
連続した符号位置からなる名前の付いたブロックを,共通の特性(例えば,用字)をもった文字を割り
当てる目的で,面の中に定める。BMP,SMP,SIP及びSSPの中に定義されたブロックをA.2に示し,図
8〜図13に図示する。
ブロックの名前を構成するための規則は,26.5.1で規定する。
14.2 組の名前
組は,附属書Aで定義する。
組の名前を構成するための規則は,26.5.2で規定する。
15 双方向文脈での鏡像文字
15.1 鏡像文字
ある種の文字は,双方向テキストの文脈で,特別な意味をもつ。これらの文字の解釈及び表示は,符号
単位列中にその文字の符号化表現が現れた時点での文字の進行方向に関係する。これらの文字の一覧は,
ユニコード標準の“Bidi̲Mirrored”属性が“Y”に設定されているものからなる。これらの値は,ユニコ
ード標準の双方向鏡像属性(箇条2参照)で決定される。
注記1 一般的には,鏡像文字は,右から左に並べられたときに用いる水平方向に裏返した画像をも
つ。しかし,幾つかの数学記号においては,“鏡像”は,単純な裏返しにはならない。詳細は,
24
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
ユニコード技術報告書 UTR #25“Unicode Support for Mathematics”(ユニコードの数学向け機
能)を参照。
このような文字の裏返しは,対になった文字に限定されるものでなく,同種の文字全てに適用しなけれ
ばならない。
例 右から左のテキスト断片では,GREATER-THAN SIGN(左から右のテキストでは“>”と表示さ
れる。)は,“<”という図形記号で表示されることがある。
注記2 多くの古代文字及び幾つかの現在の用字では,右から左及び左から右の両方で書くことがで
きる。これらの用字の中には,しばしば慣習的に,垂直軸の周りで対称でない図形記号の任
意の文字表現に,適切な鏡像図形記号を用いるものがある。この場合,図形画像を運用上の
書記方向に合わせて適切に表示するのは,表示システムの責任となる。文字符号表の代表図
形記号の方向は,用字の既定の書記方向と対応する。これらの用字に属する文字は,ユニコ
ード標準の“Bidi̲Mirrored”属性が“N”に設定されている(箇条2のユニコード標準第9.0
版,Chapter 4 Section 4.7,Bidi Mirroredを参照)。
このような用字には,既定の書記方向が左から右である古代用字である古代イタリア文字,及び既定の
用字方向が右から左である古代用字であるキプロス文字が含まれる。
15.2 双方向テキストの方向性
The Unicode Bidirectional Algorithm(ユニコード双方向アルゴリズム)(箇条2参照)は,双方向テキス
トの方向性を決定するアルゴリズムについて記載している。この規格でもそれを用いる。
16 特殊文字
16.1 概要
印字できる図形記号がないか,又は他の何らかの点で特別な文字がある。
16.2 空白の文字
次の文字は,空白の文字とする。これらは,一般分類の値が“Zs”である全ての文字の一覧である。
符号位置 文字の名前
0020
SPACE
00A0
NO-BREAK SPACE
1680
OGHAM SPACE MARK
2000
EN QUAD
2001
EM QUAD
2002
EN SPACE
2003
EM SPACE
2004
THREE-PER-EM SPACE
2005
FOUR-PER-EM SPACE
2006
SIX-PER-EM SPACE
2007
FIGURE SPACE
2008
PUNCTUATION SPACE
2009
THIN SPACE
200A
HAIR SPACE
202F
NARROW NO-BREAK SPACE
25
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
205F
MEDIUM MATHEMATICAL SPACE
3000
IDEOGRAPHIC SPACE
注記1 文字1680 OGHAM SPACE MARKは,中心ステム線を示す見えるグリフによって表現されるこ
とも多いが,ステムなし書体のフォントでは空白のグリフによって表現される。
注記2 202F NARROW NO-BREAK-SPACEは,改行しないスペース文字(non-breaking space)である。
00A0 NO-BREAK SPACE(ノーブレークスペース)と同様であるが,これより表示幅が狭い。
モンゴルの用字とともに使われるとき,通常,この文字は,普通のスペースの3分の1の幅
で表示され,モンゴル語の語幹から接尾辞を分離する。これによって,その位置に語の境界
がないことを示しながら,モンゴル文字の字形選択の通常の規則が適用できる。
16.3 通貨記号
この規格の通貨記号は,必ずしもある国の通貨を特定するものではない。例えば,YEN SIGN(円記号)
は,日本の円に使うこともできるが,中国の元に使うこともできる。さらに,DOLLAR SIGN(ドル記号)
は,米国も含め,多くの国で使用できる。
16.4 書式文字
次の文字は,書式文字とする(6.3.3参照)。これらは,一般分類の値が“Cf”,“Zl”及び“Zp”である
全ての文字の一覧である。附属書Fを参照。
符号位置 文字の名前
00AD
SOFT HYPHEN
0600
ARABIC NUMBER SIGN
0601
ARABIC SIGN SANAH
0602
ARABIC FOOTNOTE MARKER
0603
ARABIC SIGN SAFHA
0604
ARABIC SIGN SAMVAT
0605
ARABIC NUMBER MARK ABOVE
061C
ARABIC LETTER MARK
06DD
ARABIC END OF AYAH
070F
SYRIAC ABBREVIATION MARK
180E
MONGOLIAN VOWEL SEPARATOR
200B
ZERO WIDTH SPACE
200C
ZERO WIDTH NON-JOINER
200D
ZERO WIDTH JOINER
200E
LEFT-TO-RIGHT MARK
200F
RIGHT-TO-LEFT MARK
2028
LINE SEPARATOR
2029
PARAGRAPH SEPARATOR
202A
LEFT-TO-RIGHT EMBEDDING
202B
RIGHT-TO-LEFT EMBEDDING
202C
POP DIRECTIONAL FORMATTING
202D
LEFT-TO-RIGHT OVERRIDE
202E
RIGHT-TO-LEFT OVERRIDE
26
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2060
WORD JOINER
2061
FUNCTION APPLICATION
2062
INVISIBLE TIMES
2063
INVISIBLE SEPARATOR
2064
INVISIBLE PLUS
2066
LEFT-TO-RIGHT ISOLATE
2067
RIGHT-TO-LEFT ISOLATE
2068
FIRST STRONG ISOLATE
2069
POP DIRECTIONAL ISOLATE
206A
INHIBIT SYMMETRIC SWAPPING
206B
ACTIVATE SYMMETRIC SWAPPING
206C
INHIBIT ARABIC FORM SHAPING
206D
ACTIVATE ARABIC FORM SHAPING
206E
NATIONAL DIGIT SHAPES
206F
NOMINAL DIGIT SHAPES
FEFF
ZERO WIDTH NO-BREAK SPACE
FFF9
INTERLINEAR ANNOTATION ANCHOR
FFFA
INTERLINEAR ANNOTATION SEPARATOR
FFFB
INTERLINEAR ANNOTATION TERMINATOR
110BD
KAITHI NUMBER SIGN
1BCA0
SHORTHAND FORMAT LETTER OVERLAP
1BCA1
SHORTHAND FORMAT CONTINUING OVERLAP
1BCA2
SHORTHAND FORMAT DOWN STEP
1BCA3
SHORTHAND FORMAT UP STEP
1D173
MUSICAL SYMBOL BEGIN BEAM
1D174
MUSICAL SYMBOL END BEAM
1D175
MUSICAL SYMBOL BEGIN TIE
1D176
MUSICAL SYMBOL END TIE
1D177
MUSICAL SYMBOL BEGIN SLUR
1D178
MUSICAL SYMBOL END SLUR
1D179
MUSICAL SYMBOL BEGIN PHRASE
1D17A
MUSICAL SYMBOL END PHRASE
E0001
LANGUAGE TAG
E0020〜E007F
TAG SPACE 〜 CANCEL TAG
16.5 漢字構成記述文字
漢字構成記述文字(Ideographic Description Character,以下,IDCという。)は,漢字構成記述文字列
(Ideographic Description Sequence,以下,IDSという。)を作り出すため,他の図形文字の列とともに使わ
れる図形文字である。この種の文字列は,この規格で規定されていない漢字のような文字(ideographic
character)を記述する目的で使ってもよい。附属書Iに詳細な説明を示す。IDCは,次による。
27
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
符号位置 文字の名前
2FF0
IDEOGRAPHIC DESCRIPTION CHARACTER LEFT TO RIGHT
2FF1
IDEOGRAPHIC DESCRIPTION CHARACTER ABOVE TO BELOW
2FF2
IDEOGRAPHIC DESCRIPTION CHARACTER LEFT TO MIDDLE AND RIGHT
2FF3
IDEOGRAPHIC DESCRIPTION CHARACTER ABOVE TO MIDDLE AND BELOW
2FF4
IDEOGRAPHIC DESCRIPTION CHARACTER FULL SURROUND
2FF5
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM ABOVE
2FF6
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM BELOW
2FF7
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM LEFT
2FF8
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM UPPER LEFT
2FF9
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM UPPER RIGHT
2FFA
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM LOWER LEFT
2FFB
IDEOGRAPHIC DESCRIPTION CHARACTER OVERLAID
16.6 字形選択子及び字形指示列
16.6.1 概要
字形選択子は,特別な種類の結合文字であって,基準写像も等価な合成列もない基底文字又は結合文字
の直後に置かれる。字形選択子及び字形指示列の目的は,基底文字又は結合文字に対する図形文字の特定
の形状を示すことにある。基底文字又は結合文字とそれに続く字形選択子を含む文字列とは,字形指示列
と呼ばれる。
注記 字形選択子は,既存の符号化文字に対して,許容できる形のうちから特定のものを選ぶだけで
ある。字形選択子は,一般的な符号拡張方式として意図されたものではない。
字形選択子は,字形選択子ブロックに含まれる16符号位置,字形選択子補助に含まれる240符号位置,
及び3個のモンゴル自由字形選択子(FVS1〜VSF3)から構成される。
基底文字がCJK統合漢字であり,かつ,その字形選択子が字形選択子補助にある字形指示列は,漢字字
形指示列と呼ばれる。他の全ての字形指示列は,既定の字形指示列と呼ばれる。既定の字形指示列で特定
される図形記号のそれぞれの形状は,既定形と呼ばれる。
16.6で定義又は参照される字形指示列だけが,図形記号の特定の形状を規定する。他の全ての字形指示
列は,許容しない。さらに,他の基底文字及び結合文字の次にくる字形選択子は,符号化文字に対応する
図形記号の選択に何の効果ももたない。
16.6.2 既定の字形指示列
既定の字形指示列は,機械可読形式の添付ファイル“UCSVariants.txt”によって定義される。
添付ファイルは,既定の字形指示列を示すテキストファイルであり,ISO/IEC 646のIRVの文字及び行
末を表すCARRIAGE RETURN/LINE FEEDを使用する。各行は,次に示すような2個又は3個の項目から
構成される。
− 項目1は,UCS識別子(コンマ及び山括弧を省略した変形USI構文を用いている。)として表現され
た字形指示列
− 項目2は,字形指示列の記述
− 項目3(任意)は,字形指示列が適用される描画環境。可能な値:isolate,initial,medial,final。
項目は,SEMICOLON(“;”)とそれに続く0個又は複数個(任意)のSPACEとによって区切られる。最
後の項目の後には,NUMBER SIGN(“#”)に始まり基底文字の名称を記述するコメントが続く場合がある。
28
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
NUMBER SIGN(“#”)で始まる注釈行は,単なる参考情報である。テキストファイルの注釈行及び空白行
は,このファイルを自動的に処理して,規定項目である既定形のリストを抽出する際には無視するのがよ
い。
既定の字形指示列は,次の分類で許される基底文字に字形選択子を後置した文字列からなる。
− 数学記号
注記1 VARIATION SELECTOR-1(字形選択子1, FE00)は,数学記号とともに使用する唯一の字
形選択子である。
− モンゴル文字。モンゴル自由字形選択子とともに用いるモンゴル文字の基底文字の幾つかの表示形だ
けが変形を生成する。
注記2 モンゴル文字は,符号単位列中の位置に依存して,各種の異なる表示形をもつ。これらの
表示形は,語頭形(initial),語中形(medial),語末形(final)又は独立形(isolate)のいず
れかに分類される。
− マニ文字
注記3 これらはモンゴル文字の字形選択子と同様に,符号単位列中の位置に依存する。ただし,
独立形(isolate)及び語末形(final)の表示形に用いられる。
− ミャンマー文字。これらの字形選択子は,カムティ文字(Khamti),アイトン文字(Aiton),及びパケ
ー文字(Phake)での子音字及び母音記号で用いられ,点が付加された表示形が可能となる。
− パスパ文字。これらの字形選択子の列は,特定の可視化表示を選択するのではなく,字形選択子の直
前の文字から予測される通常の形とは左右反転した表示を選択する。
− 絵記号。表示形の範囲は,VARIATION SELECTOR-15(字形選択子15, FE0E)を用いる従来の白黒
のテキスト風表現,又はVARIATION SELECTOR-16(字形選択子16, FE0F)を用いる絵文字風表現
(その表示形は,しばしば多色,グレイスケール及び/又はアニメーション効果を含む。)からなる。
注記4 0023 NUMBER SIGN,及び0030〜0039[DIGIT ZERO (0) 〜 DIGIT NINE(9)]を含む既
定の字形指示列は,20E3 COMBINING ENCLOSING KEYCAPとともに用いることを意図し
ている。例えば,<0023, FE0E, 20E3>はテキスト書体のNUMBER SIGNがCOMBINING
ENCLOSING KEYCAPの内部に表示されることを意図している。
− CJK統合漢字。これらの字形指示列は,CJK互換漢字に対応する。指示列に対して規定された表示形
は,対応するCJK互換漢字の表示形である。
注記5 全ての正規形は,CJK互換漢字を対応するCJK統合漢字に置き換える。しかし,字形指示
列は変更されない(箇条21参照)。正規形を用いるものの,同時にCJK互換漢字とCJK
統合漢字とを区別することが望まれる場合,字形指示列の利用がこの区別を維持する仕組
みとなる。これらの字形指示列と対応する互換漢字の間には等価関係は定義されない。こ
の規格では,字形指示列と互換漢字との変換に関しても規定しない。
16.6.3 漢字字形指示列
基底文字として統合漢字を用い,追加特殊用途面(SSP)のVARIATION SELECTOR-17(字形選択子
17)〜VARIATION SELECTOR-256(字形選択子256)の文字とともに構成される字形指示列は,ユニコ
ード技術標準 UTS #37によって規定される漢字字形データベース(Ideographic Variation Database,IVD)
に登録される。この規格では,箇条2に示す版を用いる。漢字字形データベースへの登録は,統合可能(附
属書S参照)でありCJK統合漢字で符号化すべきではない漢字の表示形を表現する技術的な解決方法を提
供するためのものである。
29
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 この規格は,2014-05-16版の漢字字形データベースの字形指示列の一覧を参照し,取り込んで
いる。これは,次にある。<http://www.unicode.org/ivd/data/2014-05-16/>
17 文字の表示形
文字の表示形は,特定の文脈で使用するために,他の図形文字領域にある文字又はそれらの文字列がも
つ通常の形に対する代替の形を与える。通常の形から表示形への変換は,置換,重ね合せ又は組合せによ
ってもよい。
重ね合せ,形の異なる文字なのか若しくは合字(ligature)への組合せなのかの選択,又は連結(これは,
極度に複雑になることが多い。)のための規則は,この規格では規定しない。
表示形は,一般に,この符号化文字集合で規定する図形文字の通常の形の代替として使用することを意
図していない。しかし,特定の適用業務では,既存の装置との互換性などの特殊事情のために,通常の形
の代わりに表示形を用いてもよい。表示形の探索・分類及び表示形に対するその他の処理操作の規則は,
この規格の適用範囲外とする。
BMPでは,これらの文字のほとんどは,区FB〜区FF内の符号位置に割り当ててある。
18 互換用文字
この規格には互換用文字が含まれているが,これは,既存の符号化文字集合との互換性を保ち,情報を
失うことなく双方向の符号変換を可能にすることを目的としている。
BMPでは,これらの文字の多くは,区F9,区FA,区FE及び区FF内並びに区31及び区33内の符号位
置に割り当てている。互換用文字の幾つかは,他の区の中にも割り当てている。
注記1 BMPの区FAの中には,CJK統合漢字として割り当てた符号位置が12か所ある。
追加漢字面(SIP)では,これらの文字は,区F8〜区FAの中の符号位置に割り当てている。
CJK互換漢字とは,附属書Sに示す統合の規則によってCJK統合漢字の一つに統合される漢字である。
それにもかかわらずCJK互換漢字がこの規格に含まれているのは,特定の国及び地域に特有の様々な国家
的,文化的又は歴史的な理由に基づいて,それらの文字がある国家又は地域の規格で異なる符号位置に割
り当てられているからである。
このため,互換漢字は,特定の国家,地域又はその他の規格との間の往復の変換を維持及び担保するた
めにだけ用いることが望ましい。他の用途には用いないことを強く推奨する。
互換漢字はいかなる正規形を通しても維持されないため,統合漢字に対する既定の字形指示列の使用
(16.6参照)は,正規形が使われていて,互換漢字とそれに対応する統合漢字の区別が維持される状況に
おいてより好ましい。互換漢字が維持されるべき状況においては,正規形は使われないことが望ましい。
注記2 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記
2及び注記3の記載内容を本文に移動した。
19 文字の順序
通常,符号化文字は,論理的な順序で符号単位列として現れる(論理的な順序又は記憶順序とは,おお
よそ,キーボードから文字が入力され,挿入,削除及び重ね打ちをした後の順序に対応する。)。これは,
進行方向が異なる文字が混在する場合にも適用する。例えば,左から右への用字(ギリシア文字,ラテン
文字,タイ文字など)と,右から左への用字(アラビア文字,ヘブライ文字など)又は縦への用字(モン
ゴル文字など)とが混在する場合にも,適用する。
30
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
幾つかの文字は,最終の出力テキスト中に同じ順序で現れない場合がある。例えば,DEVANAGARI VOWEL
SIGN I(デーヴァナーガリー母音記号I)の中間形は,符号単位列で論理的にある文字の後にそのデーヴ
ァナーガリー母音記号Iが続くとき,その文字の前にそのデーヴァナーガリー母音記号Iを表示する。
20 結合文字
20.1 結合文字の順序
結合文字の符号化表現は,それが結合される基底文字の符号化表現の後に置かなければならない。例え
ば,LATIN SMALL LETTER A(ラテン小文字A)の後にCOMBINING TILDE[チルド(合成可能)]が
続く符号化表現は,ラテンの合成列“ã”を表現する。
一つの結合文字自身を合成列とみなさなければならない場合,その結合文字は,文字00A0 NO-BREAK
SPACE(ノーブレークスペース)と結合した合成列として符号化しなければならない。例えば,グレーブ
アクセントは,00A0のNO-BREAK SPACEの後に0300のCOMBINING GRAVE ACCENT[グレーブアクセ
ント(合成可能)]を置いて合成できる。
インド系の用字で母音を意味する結合文字は,特殊な部類の結合文字である。理由は,その表示が周囲
の二つ以上の文字に依存できるからである。したがって,インド系の用字の結合文字をNO-BREAK SPACE
と結合させるのは,望ましくない。
注記 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記の
記載内容を本文に移動した。
20.2 結合クラス及び基準順序
それぞれの結合文字は,ユニコード標準によって定められた結合クラスの値をもつ。これらの値は,ユ
ニコード標準の結合クラス属性に従って定める(箇条2のユニコード標準第9.0版,Chapter 4 Section 4.3,
Combining Classesを参照)。結合クラスは,正規化手続(normalization process)の一部である規範順序を定
めるために用いる(箇条21参照)。基準順序では,結合文字を結合クラスの昇順に並べ替える。結合クラ
スの値がゼロである文字と組み合わせた結合文字は,他の文字との相対位置に並べ直すことはない。
20.3 符号表上での形
基底文字に相対的に位置決めしようとする結合文字は,文字符号表上では,基底文字との相対的位置を
示すための破線の円の上,下,右,左,中,周り又は貫通位置に示す。結合文字は,表示のときに,先立
つ基底文字に相対的に位置決めされることを意図したものであって,それ自身では,基底文字として独立
して存在したり,基底文字の機能を果たしたりしない。そのため,結合文字と名付けられている。
注記 ダイアクリティカルマーク(diacritics)は,ヨーロッパのアルファベットで用いられる結合文
字の主要種類となっている。インド及び東南アジアで使われる他の多くの用字では,結合文字
は,母音の字を符号化したものである。そのため,通常,“ダイアクリティカルマーク”とは呼
ばない。
20.4 符号化表現のばらつき
複数の結合文字を異なった順序で使用したり,文字と合成列との等価な組合せを混用したりすることに
よって,テキストの符号化表現にばらつきが生じる。ばらつきのある符号化表現の結果として,一つのテ
キストが複数の表現をもつことになる。ばらつきのある符号化表現を正規化(箇条21参照)することによ
って,完全に排除できないまでも,符号化表現のばらつきが大幅に減る。
注記 例えば,フランス語の“là”は,LATIN SMALL LETTER L(ラテン小文字L)の次にLATIN SMALL
LETTER A WITH GRAVE(グレーブアクセント付きA小文字)が続くと表現できるし,LATIN
31
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
SMALL LETTER L(ラテン小文字L),次にLATIN SMALL LETTER A(ラテン小文字A),そ
の次にCOMBINING GRAVE ACCENT[グレーブアクセント(合成可能)]が続くと表現できる。
これらの符号化表現のばらつきに正規化を適用することによって,ただ一つの符号化表現が残
る。残る符号化表現の形式は,どの正規形を用いるかによって異なる。
20.5 結合文字の重複
二つ以上の結合文字が一つの基底文字に結合されることもある。この規格では,一つの基底文字に結合
される結合文字の個数は,制限しない。結合文字の重複の規則は,次のとおりとする。
a) 結合文字同士が(例えば,COMBINING MACRON[マクロン(合成可能)]とCOMBINING DIAERESIS
[ダイエレシス(合成可能)]とが)表示に影響し合う場合,結果の図形表示中での結合文字の位置は,
結合文字の符号化表現の順序による。結合文字の表示は,基底文字から外に向かって位置決めする。
例えば,基底文字の上に置く結合文字は,符号化表現の列で最初に出てきたものから始め,基底文字
に続く符号化された結合文字のある限り,順次,上に積み重ねる。基底文字の下に置く結合文字の場
合,積重ねの状態は,逆になり,基底文字から始め,結合文字を順次,下に重ねる。
基底文字の上に複数の結合文字を置く例がタイ文字にある。タイ文字では,子音字の上に0E34〜
0E37の母音記号の一つを置くことができ,更にその上に0E48〜0E4Bの四つの声調記号(tone mark)
の一つを置くことができる。この符号化表現の順序は,子音字の基底文字,次に母音記号,その次に
声調記号となる。
b) ある特別の結合文字は,既定の積重ね動作に従わず,縦ではなく横に並べたり,隣り合った結合文字
と合字(ligature)を作ったりする。横に並べるときは,符号化表現の順序は,結合文字を使用する用
字の主要な進行方向中での位置によって決まる。例えば,左から右への用字では,横に並べて置かれ
るアクセントは,左から右へ符号化する。
既定の積重ね動作をしない,このような特別な文字は,特定の用字又はアルファベットで使われる。
例えば,COMBINING GREEK KORONIS(0343)と,それに続くアキュートアクセント記号又はグレ
ーブアクセント記号とを一緒に用いる場合,COMBINING GREEK KORONISの上にアクセント記号を
積み重ねず,一つの文字の上でそれらを横に並べなければならない。符号化表現の順序は,文字自身,
次に気息記号(breathing mark),その次にアクセント記号の順とする。ラテンのアキュートアクセン
ト記号及びグレーブアクセント記号と同じ外観をもつベトナム語の二つの声調記号は,サーカムフレ
クスダイアクリティカルマーク(circumflex diacritic)を既に含んでいる三つの母音文字(â,ê及びô)
の上には重ねずに,母音文字のサーカムフレクスダイアクリティカルマークと合字を作る。
c) 結合文字同士が表示上で互いに影響を与えない場合(例えば,一つの結合文字が図形文字の上に置か
れ,他の結合文字が下に置かれる。),基底文字と,順序が異なる複数の結合文字とからできる結果の
図形記号は,同じに見えてもよい。例えば,LATIN SMALL LETTER A,次にCOMBINING CARON,
その次にCOMBINING OGONEKと続く符号化表現からできる図形記号と,LATIN SMALL LETTER A,
次にCOMBINING OGONEK,その次にCOMBINING CARONと続く符号化表現からできる図形記号とは,
結果的に同じになってもよい。
ヘブライ又はアラビアの用字の結合文字は,通常,互いに影響を与えない。したがって,合成列を
なすそれらの符号化表現の順序は,図形記号に影響を与えない。図形記号の結合を作る規則は,この
規格の適用範囲外とする。
20.6 結合文字を含む組
附属書Aに規定する文字の組の幾つかには,例えば,組14[BASIC ARABIC(基本アラビア文字)]又

32
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
は組25[THAI(タイ文字)]には,結合文字と基底文字との両方が含まれている。
附属書Aに規定する他の幾つかの文字の組は,結合文字だけからなっている[例えば,組7(COMBINING
DIACRITICAL MARKS)]。
20.7 図形素結合子(合成可能)
文字034F COMBINING GRAPHEME JOINER[図形素結合子(合成可能)]は,言語に依存する照合及び
検索の目的のために前後の文字を一まとまりとして扱うことを示すために用いる。言語に依存する照合及
び検索において,その目的のために特別に調整した照合要素表の場合以外は,図形素結合子を無視しなけ
ればならない。
COMBINING GRAPHEME JOINERは,ある結合文字の二つの用法のうちの一つを他の用法と区別するた
めに用いてもよい。例えば,ウムラウトとトレマとを区別する必要がある場合,COMBINING GRAPHEME
JOINER(034F)の後にCOMBINING DIAERESIS(0308)が続くものをトレマとし,COMBINING DIAERESIS
(0308)だけのものをウムラウトとしてもよい。
注記 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記の
記載内容を本文に移動した。
21 正規形
正規形(normalization form)は,同一のテキストの幾つかの符号化表現のばらつきのうちで,ただ一つ
の符号化表現を選択するための機構である。この規格で用いる正規形は,ユニコード附属書,UAX #15(箇
条2参照)に規定されており,この規格でも用いる。正規形には,次の四つがある。
a) 正規形D(NFD)
b) 正規形C(NFC)
c) 正規形KD(NFKD)
d) 正規形KC(NFKC)
注記1 これらの正規形のいずれかを符号単位列に適用した結果は,将来にわたって安定しているこ
とを意図している。すなわち,この規格で割当てが行われている文字を含む符号単位列の正
規化表現は,この規格が改正されても,正規化された状態である。
注記2 幾つかの正規形は,テキストの短い表現よりもある種の合成列を優先し,他の幾つかの正規
形は,テキストの短い表現を優先する。テキストの短い表現を定義するに当たってISO/IEC
10646-1:2000(第2版)及びISO/IEC 10646-2:2001(第1版)を参照用の版として確定するこ
とで,後方互換の要求が満たされる。両規格のレパートリの和集合は,確定組UNICODE 3.2
(A.6参照)と同一である。
注記3 正規形の幾つかの目的の中で特に重要なものは,任意に与えられた符号単位列に対する正規
形をただ一つ定めることによって,同一性の一致判定(identity matching)を容易にすること
である。正規形は,言語学的な観点では必ずしも適切な並びとは限らない。
注記4 四つの全ての正規形において,互換漢字は対応する統合漢字に置き換えられる。しかしなが
ら,正規化は字形選択子を変更せず,字形指示列は維持される。このため,互換漢字に対し
て対応する統合漢字からなる既定の字形指示列を使用することは正規化の観点で好ましい
(16.6参照)。
33
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
22 個々の用字及び記号の特性
22.1 ハングル音節の合成方法
描字では,ハングル字母(HANGUL JAMOブロック,1100〜11FF)の列は,一連の音節ブロックとして
表示される。字母は,初声(音節頭子音字,choseong),中声(音節核をなす母音字,jungseong)及び終声
(音節末子音字,jongseong)の三つに分類される。完全な音節ブロックは,初声,中声及び付加的な終声
から構成される。
完全な音節を構成していない一つ以上の文字の列(例えば,初声だけ,中声だけ,終声だけ,又は中声
の後ろに終声が続いたもの。)を不完全な音節(incomplete syllable)という。中声で始まる不完全な音節は,
その前に必ずCHOSEONG FILLER(初声埋め文字,115F)がなければならない。終声だけからなる不完全
な音節は,その前に必ずCHOSEONG FILLER(115F)及びJUNGSEONG FILLER(中声埋め文字,1160)
がなければならない。初声だけからなる不完全な音節は,その後に必ずJUNGSEONG FILLER(1160)が
なければならない。
注記1 ハングル字母は,結合文字ではない。
注記2 この規格では,ハングルのテキストは,複数の異なる方法で表現できる。韓国の規格KS X
1026-1: Information Technology−Universal Multiple-Octet Coded Character set (UCS)−Hangul−
Part 1, Hangul processing guide for information interchangeは,情報交換において相互運用性を確
実にするためのガイドラインを提供している。
HANGUL SINGLE DOT TONE MARK(ハングル単点声調記号,302E)のような結合文字をハングル字母
の列に適用することを意図するときには,その列の末尾で,完全な音節ブロックの最後に位置するハング
ル字母の次にその結合文字を付加することが望ましい。
注記3 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記
の記載内容を本文に移動した。
22.2 インド及び他の南アジアで使う用字の特性
BMPの,区09〜0D及び区0Fの符号表,並びに区10のMYANMAR(ミャンマー文字)ブロック(箇条
33参照)の符号表では,幾つかの文字に対する図形記号は,同じ表にある他の二つの文字の図形記号の合
成によって形作られたように示してある。
例1 0906 DEVANAGARI LETTER AAの図形記号は,0905 DEVANAGARI LETTER A及び093E
DEVANAGARI VOWLEL SIGN AAの図形記号から構成されたように示してある。
例2 0D08 MALAYALAM LETTER IIの図形記号は,0D07 MALAYALAM LETTER I及び0D57
MALAYALAM AU LENGTH MARKの図形記号から構成されたように示してある。
そのような場合,合成列(3.17参照)と同様に,単独の符号化文字が,結合されると,その単独の符号
化文字の図形記号と視覚的に似るような図形記号をもつ二つの符号化文字の列と同等であるとして,利用
者に対して現れてもよい。
この規格では,次のような独自のつづり規則(unique-spelling rule)を規定する。この規則では,区09
〜0D若しくは0Fの符号表又は区10のMYANMARブロックの符号表においては,次に示す例外を除いて,
いかなる符号化文字も,同じ符号表の他の符号化文字の長さ2以上の列と同等であるとは,みなさない。
− 2部分からなる母音記号(two-part dependent vowel sign)
− 独立母音字である1026 MYANMAR LETTER UU
− ヌクタ記号の付いた子音字
注記 これらの全ての文字は,2文字からなる列への基準写像をもつ。
34
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
22.3 ビザンチン音楽記号
ビザンチン音楽の記譜法は,3段の帯状の表現を利用する。記号は,上段,中段又は下段の帯の中に書
く。これとは別に,楽譜の歌詞の部分に,音楽文字と呼ぶ記号を書く。複数の記号は,適切な帯の中で積
み重ねて表記することができる。
22.4 絵文字記号の原典情報
幾つかの記号は,複数の原典との対応関係をもつ。CJK統合漢字とは異なり,これらの参照は,文字を
特定するものではない。これらの原典における一つの文字は,単一の符号位置又は符号位置の列に対応す
る。
記号の原典は,次のとおりである。
− DoCoMoのシフトJIS符号
− KDDIのシフトJIS符号
− SoftBankのシフトJIS符号
原典参照は機械可読形式の添付ファイル“EmojiSrc.txt”によって定義される。添付ファイルは,テキス
トファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE RETURN/LINE FEEDを使用す
る。ファイルの先頭の7行は,ヘッダであり,その後の“#”で始まる行は,注釈である。その後に,原典
参照の行が続く。各行は,次の項目からなる。項目は,“;”で区切る。
− 項目1は,UCS 符号位置又は符号位置の列を (hhhh | hhhhh) (<space> (hhhh | hhhhh))* の形式で示す。
− 項目2は,DoCoMoのシフトJIS符号を (hhhh) の形式で示す。
− 項目3は,KDDIのシフトJIS符号を (hhhh) の形式で示す。
− 項目4は,SoftBankのシフトJIS符号を (hhhh) の形式で示す。
ここに,“h”は,16進数を表し,<space>は,SPACE文字を表す。アスタリスク(“*”)は0個,1個又
はそれ以上の前のパターンの繰返しを表す。
注記1 (対応国際規格の注記1は,この規格では該当しないため不採用とした。)
注記2 ファイルの内容は,一方をUCSの符号位置又は符号位置の列とし,他方を携帯電話通信事業
者の絵文字を示すシフトJISの符号とする写像を与える。個々の対応は,同等な,UCSと携
帯電話通信事業者の記号とに関して,単独でも列としてでも,対称である(いわゆる“往復
の保全性”をもつ。)。このファイルは,いずれの写像方向においても,似ているが同じでは
ない記号に対応させるような最善の(best-fit)写像[代用(fallback)写像ともいう。]を含
まない。
23 漢字の原典参照
23.1 原典参照一覧
漢字のそれぞれの文字には,少なくとも一つの原典参照がある。原典参照は,機械可読形式の添付ファ
イルで示す。原典参照は,この規格の規定の一部である。
原典参照情報は,漢字の文字を識別する。原典参照は,漢字の符号位置を,この箇条において次に示す
原典の中の値に関連付ける。これらの原典を次のとおり分類する。
− 原典G
− 原典H
− 原典M
− 原典T

35
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− 原典J
− 原典K
− 原典KP
− 原典V
− 原典U
ある符号位置には,原典の分類(すなわち,G,H,M,T,J,K,KP,V及びU)ごとにただ一つの原
典参照だけを作成する。広範な原典の分類に対応できるように,原典参照は,原典と漢字との一意的な関
係を全て示す。
BMP及びSIPの漢字が参照する原典の一覧を次に示す。
原典Gは,次のとおりに識別する。

36
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記1 康熙字典(GKX)として参照されている文字に対する符号表上での図形記号は,現在中国で
使用されているものであり,康熙字典に示されている図形記号とは僅かに異なる場合がある。
原典Hは,次のとおりに識別する。
H
Hong Kong Supplementary Character Set−2008
HB0
HB1 Big-5, Level 1
HB2 Big-5, Level 2
HD
Hong Kong Supplementary Character Set−2016
原典Mは,次のとおりに識別する。
MAC Macao Information System Character Set
原典Tは,次のとおりに識別する。
T1
TCA-CNS 11643-1992 第1面
T2
TCA-CNS 11643-1992 第2面
T3
TCA-CNS 11643-1992 第3面及び幾つかの追加文字
T4
TCA-CNS 11643-1992 第4面
T5
TCA-CNS 11643-1992 第5面
T6
TCA-CNS 11643-1992 第6面
T7
TCA-CNS 11643-1992 第7面
TB
TCA-CNS 11643-2007 第11面
TC
TCA-CNS 11643-2007 第12面
TD
TCA-CNS 11643-2007 第13面
TE
TCA-CNS 11643-2007 第14面
TF
TCA-CNS 11643-2007 第15面
原典Jは,次のとおりに識別する。
J0
JIS X 0208-1990
J1
JIS X 0212-1990
J3
JIS X 0213:2004 第3水準
J3A
JIS X 0213:2004 第3水準
J13A J1をJIS X 0213:2000 第3水準に追加したJIS X 0213:2004 第3水準で置き換えたもの
J13
J1をJIS X 0213:2004 第3水準で置き換えたもの
JA3
JAをJIS X 0213:2004 第3水準で置き換えたもの

37
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
J4
JIS X 0213:2004 第4水準
J14
J1をJIS X 0213:2004 第4水準で置き換えたもの
JA4
JAをJIS X 0213:2004 第4水準で置き換えたもの
JA
国内5社漢字統合表,1993
JARIB 一般社団法人電波産業会 ARIB STD-B24 第5.1版,2007年3月14日
JH
汎用電子情報交換環境整備プログラム 2002〜2009
JMJ
文字情報基盤整備事業 2010〜
JK
日本国字集
注記2 JIS X 0213:2004などの原典が既により古い参照された原典に含まれていた符号化文字を含
むとき,現在行われている用法を反映するために,一般に,より最近の原典参照が使われる。
これは,また,これらのより最近の参照の幾つかが関連した文字の図形表現のための小さな
調整に付随して起きたという事実を反映している。
注記3 一部は別の原典参照に代わっているJ1及びJAの文字については,附属書Aに記載している
(A.4.3及びA.4.4参照)。それらは,Unihanデータベースの暫定的な原典一覧でも確認でき
る。J1及びJAの全ての文字は,http://www.unicode.org/reports/tr38/ の原典J1: JIS X 0212-1990
を表すkJis1及び原典JAを表すkJAで示されている。
原典Kは,次のとおりに識別する。
K0
KS X 1001:2004(以前は,KS C 5601-1987であった。)
K1
KS X 1002:2001(以前は,KS C 5657-1991であった。)
K2
KS X 1027-1:2011(以前は,PKS C 5700-1 1994であった。)
K3
KS X 1027-2:2011(以前は,PKS C 5700-2 1994であった。)
K4
KS X 1027-3:2011(以前は,PKS 5700-3:1998であった。)
K5
KS X 1027-4:2011(以前は,Korean IRG Hanja Character Set 5th Edition: 2001であった。)
KC
Korean History On-Line (
岭洀
椀
原典KPは,次のとおりに識別する。
KP0 KPS 9566-97
KP1 KPS 10721:2000及びKPS 10721:2003
原典Vは,次のとおりに識別する。
V0
TCVN 5773:1993
V1
TCVN 6056:1995
V2
VHN 01:1998
V3
VHN 02:1998
V4
Dictionary on Nom 2006, Dictionary on Nom of Tay ethnic 2006, Lookup Table for Nom in the South
1994
VU
原典Uは,次のとおりに識別する。
UTC ユニコード技術報告書 UTR #45, U-source Ideographs, September 2012
USAT Taishō Shinshū Daizōkyō (大正新脩大藏經), 1924-1934
23.2 CJK統合漢字の原典参照ファイル
CJK統合漢字の原典参照は,機械可読形式の添付ファイル“CJKSrc.txt”によって定義される。添付ファ
38
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
イルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE RETURN/LINE
FEEDを使用する。ファイルは,全てのCJK統合漢字の原典参照を規定している。また,同ファイルには,
部首画数索引,CJK互換漢字に対応するCJK統合漢字の符号位置の値,及びIICOREコレクション(A.4.1
参照)に属する文字に関するIICOREの情報が併せて記載されている。テキストファイルの各行は,次に
示すような三つの項目から構成される。
− 項目1は,UCS符号位置を(U+hhhh)又は(U+hhhhh)の形式で示す。
− 項目2は,項目3に示した情報の種別を示すタグ値,(kIRG̲GSource, kIRG̲HSource,kIRG̲MSource,
kIRG̲TSource, kIRG̲JSource, kIRG̲KSource, kIRG̲KPSource,kIRG̲VSource, kIRG̲USource, kIICore,
kCompatibilityVariant, kRSUnicode)を示す。
− 項目3は,項目2に示されたタグ値に対応する情報を示す。表5に詳細様式を示す。
項目1の“h”は,16進法による数値の1桁を表している。三つの項目は制御文字CHARACTER TABULATION
(0009)で区切られている。NUMBER SIGN (“#”)で始まる注釈行は,単なる参考情報である。テキストフ
ァイルの注釈行及び空白行は,このファイルを自動的に処理して原典参照情報を抽出する際には無視する
のがよい。
表5−CJK統合漢字の原典参照ファイルで用いられるタグの詳細
タグの値
タグの意味
項目3の形式
kIRG̲GSource
原典G
(G0-hhhh),(G1-hhhh),(G3-hhhh),(G5-hhhh),(G7-hhhh),(GS-hhhh),(G8-hhhh),
(G9-hhhh),(GE-hhhh),(GH-hhhh),(GK-hhhh),(G4K),(GBK),(GBK-dddd.dd),
(GCE-ddd),(GCH),(GCH-dddd.dd),(GCY),(GCY-dddd.dd),(GCYY-ddddd),
(GDZ-dddd.dd),(GFC-ddd),(GFZ),(GFZ-ddddd),(GGFZ-dddddd),
(GGH-ddddd.dd),(GHC),(GHC-dddd.dd),(GHZ-ddddd.dd),(GIDC-ddd),
(GJZ-ddddd),(GKX-dddd.dd),(GLGYJ-dddd),(GOCD-ddd),(GPGLG-dddd),
(GRM-dddd.dd),(GXC-dddd.dd),(GXH-dddd.dd),(GXHZ-ddd),(GWZ-dddd.dd),
(GZ-ddddddd),(GZFY-ddddd),(GZH-dddd.dd),(GZYS-ddddd)又は(GZJW-ddddd)
kIRG̲HSource
原典H
(H-hhhh),(HB0-hhhh),(HB1-hhhh),(HB2-hhhh)又は(HD-hhhh)
kIRG̲MSource
原典M
(MAC-ddddd)
kIRG̲TSource
原典T
(T1-hhhh),(T2-hhhh),(T3-hhhh),(T4-hhhh),(T5-hhhh),(T6-hhhh),(T7-hhhh),
(TB-hhhh),(TC-hhhh),(TD-hhhh),(TE-hhhh)又は(TF-hhhh)
kIRG̲JSource
原典J
(J0-hhhh),(J1-hhhh),(J3-hhhh),(J3A-hhhh),(J13-hhhh),(J13A-hhhh),(J4-hhhh),
(J14-hhhh),(JA-hhhh),(JA3-hhhh),(JA4-hhhh),(JARIB-hhhh),(JH-xxxxxx),
(JH-xxxxxxS),(JMJ-dddddd)又は(JK-ddddd)
kIRG̲KSource
原典K
(K0-hhhh),(K1-hhhh),(K2-hhhh),(K3-hhhh),(K4-hhhh),(K5-hhhh)又は
(KC-ddddd)
kIRG̲KPSource
原典KP
(KP0-hhhh)又は(KP1-hhhh)
kIRG̲VSource
原典V
(V0-hhhh),(V1-hhhh),(V2-hhhh),(V3-hhhh),(V4-hhhh)又は(VU-hhhhh)
kIRG̲USource
原典U
(USAT-ddddd),(UTC-ddddd)又は(UCI-ddddd)
kIICore
IICOREの情報
([ABC]{1}[GTJHKMP]{1,7})
kCompatibility
Variant
互換漢字情報
(U+hhhh)又は(U+hhhhh)
kRSUnicode
部首画数索引
((d{1,3}'.d{1,2})) (<space> (d{1,3}'.d{1,2}))*
形式の説明において,“d”は十進数の1桁を,“h”は16進数の1桁を,“x”は英数字(0〜9及びA〜Z),<space>
はSPACEを表す。括弧に囲まれた英大文字,数字及び記号はここに示されたとおりに現れる。アスタリスク(“*”)
は,その前に記されたパターンの0回以上の繰返しを示す。

39
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表5−CJK統合漢字の原典参照ファイルで用いられるタグの詳細(続き)
IICOREの値([ABC]{1}[GTJHKMP])の項目は,降順の優先度を示すA,B又はCの一文字で始まり,(G,T,J,H,K,M,P)
の1文字以上の文字によって,それぞれ原典G,原典T,原典J,原典H,原典K,原典M及び原典KPで用いられ
ることを表す。IICOREタグが記載されていることは,当該のCJK統合漢字がIICOREコレクションに属している
ことを示す。
CJK互換漢字の全てに付された互換漢字情報の項目には,当該CJK互換漢字に対応するCJK統合漢字の符号位置
の値が示される。
部首画数索引((d{1,3}'.d{1,2})) (space (d{1,3}'.d{1,2}))*の項目には,部首索引(1桁〜3桁の数字)[ただし,アポス
トロフィー(“ʼ”)が付加されているものは簡体字の部首である。]に続くFULL STOP(ピリオド)(“.”)と1桁又
は2桁の画数の組とが,一つ以上空白で区切って記載される。
注記1 JIS X 0213:2000及びJIS X 0213:2004については,第4水準は,漢字集合2面に,他の水準は,漢字集合1
面に,それぞれ対応する。注記2 K4(PKS 5700-3:1998)及びK5(Korean IRG Hanja Character Set 5th
Edition:2001)に含まれる原典参照は,漢字符号を区点番号ではなく単純な10進数で表記している。他の規
格との整合性を考慮して,参照ファイルでは,K4の値を16進数に変換している。他のK0〜K3の索引値
と異なり,K4及びK5の値は,区点番号に分解できない。
注記3 形式UCI-ddddd(原典U)である文字は,識別可能な原典参照がない。UCI値は,単純に場所を確保する。
注記4 原典参照ファイル中“U+”で始まるUCS符号位置は,ユニコード規格に含まれる類似ファイルと同値であ
る。
次の例は,CJK統合漢字3687,4E00,4E07,及びF928の情報を示す。最初の三つの定義はCJK統合漢
字に対応し,4E00及び4E07は,IICOREコレクションの一部である。4番目の定義はCJK互換漢字に対
応する。
例
U+3687
kIRG̲GSource
G3-3A36
U+3687
kIRG̲KPSource
KP1-3C87
U+3687
kIRG̲KSource
K3-2339
U+3687
kIRG̲TSource
T4-2861
U+3687
kRSUnicode
35.6 66.6
U+4E00
kIRG̲GSource
G0-523B
U+4E00
kIRG̲HSource
HB1-A440
U+4E00
kIRG̲JSource
J0-306C
U+4E00
kIRG̲KPSource
KP0-FCD6
U+4E00
kIRG̲KSource
K0-6C69
U+4E00
kIRG̲TSource
T1-4421
U+4E00
kIRG̲VSource
V1-4A21
U+4E00
kRSUnicode
1.0
U+4E00
kIICore
AGTJHKMP
U+4E07
kIRG̲GSource
G0-4D72
U+4E07
kIRG̲HSource
HB2-C945
U+4E07
kIRG̲JSource
J0-4B7C
U+4E07
kIRG̲KPSource
KP0-DAB9
U+4E07
kIRG̲KSource
K0-5832
U+4E07
kIRG̲TSource
T2-2126
U+4E07
kIRG̲VSource
V1-4A24
40
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
U+4E07
kRSUnicode
1.2
U+4E07
kIICore
AGJKP
U+F928
kIRG̲JSource
J3-742E
U+F928
kIRG̲KSource
K0-5227
U+F928
kRSUnicode
53.9
U+F928
kCompatibilityVariant U+5ECA
23.3 CJK統合漢字の原典参照の表示
23.3.1 概要
一つの文字に対して一つの図形記号しか示さない他の多くの文字レパートリと異なり,CJK統合漢字の
文字は,原典参照ごとに部首,画数及び様々な原典の数値とともに図形記号を示す。
注記 CJK COMPATIBILITY(CJK互換漢字)ブロックに含まれる12文字の表示は,23.4とは異な
る形式で記載されている。
符号位置の直後に,部首の図形表現を部首番号及び画数とともに示す。画数には,部首そのものの画数
を含まない。
CJK UNIFIED IDEOGRAPHS(CJK統合漢字)ブロック(4E00〜9FFF)の符号表は,固定カラム形式を
用いる。すなわち,ある原典からの原典情報は,常に同じカラムに示される。一方,他のCJK統合漢字ブ
ロックの符号表では,G,T,J,K,KP,V,H,M及びUの出現順に存在するものだけが示される。
23.3.2 CJK統合漢字ブロックの原典参照の表示
CJK UNIFIED IDEOGRAPHS(CJK統合漢字)ブロックの表示のために,漢字の原典G,原典H,原典
T,原典J,原典K及び原典Vが存在する場合は,この順番に表記する。原典Uは,原典Hの代わりに第
2カラムに表記する。このブロックには,原典H及び原典Uを共にもつ文字は存在しない。
図2には,4E00〜4E09及び4E14〜4E1Dの文字の例を示す。

41
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
図2−CJK統合漢字の符号表表示
23.3.3 CJK統合漢字拡張Aの原典参照の表示
CJK UNIFIED IDEOGRAPHS EXTENSION A(CJK統合漢字拡張A)ブロックの表示のために,1文字
ごとに1行に最大3個の原典参照を示す。4個以上の原典がある場合は,更に1行を用いて示す。
図3には,41C9〜41CC,41DB〜41DD及び41EE〜41F0の文字の例を示す。
図3−CJK統合漢字拡張Aの符号表表示
23.3.4 CJK統合漢字拡張Bの原典参照の表示
CJK UNIFIED IDEOGRAPHS EXTENSION B(CJK統合漢字拡張B)ブロックの表示のために,最初の
図形記号は,この規格の対応国際規格の第1版及び第2版(順に2003年版及び2011年版)での字形を
“UCS2003”という記述とともに示す。1文字ごとに1行に最大3個の原典参照を示す。4個以上の原典参

42
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
照がある場合は,更に1行を用いて示す。
図4には,200E8〜200EB,200FC〜200FF及び2010E〜20110の文字の例を示す。
図4−CJK統合漢字拡張Bの符号表表示
23.3.5 CJK統合漢字拡張C,拡張D,拡張E及び拡張Fの原典参照の表示
図5にCJK UNIFIED IDEOGRAPHS EXTENSION C(CJK統合漢字拡張C)及びCJK UNIFIED IDEOGRAPHS
EXTENSION D(CJK統合漢字拡張D)ブロックの表示を示す。CJK UNIFIED IDEOGRAPHS EXTENSION
C(CJK統合漢字拡張C),CJK UNIFIED IDEOGRAPHS EXTENSION D(CJK統合漢字拡張D),CJK UNIFIED
IDEOGRAPHS EXTENSION E(CJK統合漢字拡張E)及びCJK UNIFIED IDEOGRAPHS EXTENSION F
(CJK統合漢字拡張F)ブロックの表示のために,1文字ごとに1行に最大2個の原典参照を示す。3個以
上の原典が存在する場合は,更に1行を用いて示す。
図5には,2A7A0〜2A7A2,2A7B4〜2A7B6,2A7C8〜2A7CA及び2A7DC〜2A7DEの文字の例を示す。
図5−CJK統合漢字拡張C及び拡張Dの符号表表示
23.4 CJK互換漢字の原典参照の表示
CJK統合漢字と同様に,CJK互換漢字の符号表は,原典参照ごとに一つの図形記号を,部首,画数及び
様々な原典参照の数値のような文字の特定に関する追加情報とともに示す。
部首の図形表現についても符号位置のすぐ下に,部首番号及び画数とともに示す。画数には,部首その
ものの画数を含まない。
追加情報として,33.3に記載した参考情報の項目(例えば,分解写像及び既定の字形指示列)も,表記
中に表示する。
注記1 CJK互換漢字ブロックに含まれる12個のCJK統合漢字の表示も,この形式に従う。この12
個のCJK統合漢字の表示は,分解写像を含まない。
注記2 他のブロックに適用される慣習とは異なり,CJK統合漢字のための既定の字形指示列は,基
底文字が記述されるブロックには示さず,それらが対応付けられるCJK互換漢字のブロック
に示す。

43
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
図6には,F9F9〜F9FD,FA05〜FA09及びFA10〜FA14の各文字に対する例を示す。
図6−CJK互換漢字の符号表表示
24 西夏文字の原典参照
24.1 原典参照一覧
西夏文字のそれぞれの文字には,一つの原典参照がある。原典参照は,機械可読形式の添付ファイルで
示す。原典参照は,この規格の規定の一部である。
原典参照情報は,西夏文字を識別する。原典参照は,西夏文字の符号位置を,次に示す原典の中の値に
関連付ける。西夏文字は,次のとおりに識別する。
H2004-A Hán Xiǎománg 2004 (PhD dissertation on the correct form of Tangut ideographs), H1 subdivision
H2004-B
Hán Xiǎománg 2004 (PhD dissertation on the correct form of Tangut ideographs), H2 subdivision
L1986
Lǐ Fànwén 1986 (Study of the Homophones)
L1997
Lǐ Fànwén 1997 (Tangut-Chinese Dictionary, 1st edition)
L2006
Lǐ Fànwén 2006 (Comparative Study of Wuyin Qieyun and Wenhai Baoyun)
L2008
Lǐ Fànwén 2008 (Tangut- Chinese Dictionary, 2nd edition)
L2012
Lǐ Fànwén 2012 (Tangut- Chinese Dictionary, 3rd edition)
N1966
Nishida 1966 (Little Dictionary of Tangut)
S1968
Sofronov 1968 (Grammar of the Tangut Language)
UTN42
Unicode Technical Note #42: Tangut Character Additions and Glyphs Corrections
24.2 西夏文字の原典参照ファイル
西夏文字の原典参照は,機械可読形式の添付ファイル“TangutSrc.txt”で定義される。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルは,全ての西夏文字の原典参照を規定している。ファイルは
部首画数索引についての情報も示す。テキストファイルの各行は,次に示すような三つの項目から構成さ
れる。
44
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− 項目1は,UCS符合位置をU+hhhhhの形式で示す。
− 項目2は,情報の種類を示すタグを3番目の項目kTGT̲MergedSrc, kRSTUnicodeで示す。
− 項目3は項目2で規定されるタグの値に対応する情報を示す。表6は書式の詳細を示す。
ここに,項目1の“h”は,16進数の1桁を示す。三つの項目は,制御文字CHARACTER TABULATION (0009)
で区切られる。NUMBER SIGN (“#”)で始まる注釈行は,単なる参考情報である。テキストファイルの注
釈行及び空白行はこのファイルを自動的に処理して原典参照情報を抽出する際には無視するのがよい。
表6−西夏文字の原典参照ファイルで用いられるタグの詳細
タグの値
タグの意味
項目3の形式
kTGT̲MergedSrc 西夏文字の原典
(H2004-A-dddd),(H2004-B-dddd),(L1986-dddd),(L1997-dddd),(l2006-dddd),
(L2008-dddd),(L2008-dddd-dddd),(L2012-dddd),(N1966-ddd-ddx),
(N1966-ddd-ddxx),(S1968-dddd)又は(UT42-ddd)
kRSTUnicode
部首画数索引
(d{1,3}.d{1,2})
ここに,“d”は,10進数の1桁を,“x”は,英数字1文字(0〜9及びA〜Z)を表す。括弧に囲まれた英大文字,
数字及び記号は,ここに示したとおりに現れる。部首画数索引(d{1,3}.d{1,2})は,1桁〜3桁の部首索引及びFULL
STOP(ピリオド)に続く,1桁又は2桁の部首内画数をもつ構成要素を含む項目である。画数は,部首を含む文字
の全ての画数を含む。部首索引は,符号位置18800で表される索引“1”をもつ18800-18AFFの西夏文字構成要素
ブロックの項目である。
注記 Lǐ Fànwén 2008 entriesに関しては,(L2008-dddd-dddd)という表記が,二つの項目へマップされる文字を示すの
に対して,(L2008-dddd)は,単一の項目へマップされる文字を示す。
次の例は,西夏文字17000,17001,17A7A及び17E91の情報を示す。
例
U+17000
kTGT̲MergedSrc
L2008-0008
U+17000
kRSTUnicode
1.6
U+17001
kTGT̲MergedSrc
L2008-0030
U+17001
kRSTUnicode
1.7
U+17A7A
kTGT̲MergedSrc
N1966-204-10GG
U+17A7A
kRSTUnicode
141.14
U+17E91
kTGT̲MergedSrc
L2008-2027-2350
U+17E91
kRSTUnicode
259.10
24.3 西夏文字の原典参照の表示
西夏文字の符号表は,文字ごとに一つの図形記号を,部首,画数及び様々な原典参照の数値のような文
字の特定に関する追加情報とともに示す。
部首の図形表現についても符号位置のすぐ下に,部首番号及び画数とともに示す。画数には,部首その
ものの画数が含まれる。
注記 この表現で示される部首は,18800〜18AFFの西夏文字構成要素に含まれる。
図7には,177D0〜177D2,177E4〜177E6,177F8〜177FA,1780C〜1780E及び17820〜17822の各文字
に対する例を示す。

45
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
図7−西夏文字の符号表表示
25 女書文字の原典参照
25.1 原典参照一覧
女書文字は,常に一つ以上の原典によって参照される。原典参照は,機械可読形式の添付ファイルで示
す。原典参照はこの規格の規定の一部である。
原典参照情報は,女書の文字を識別する。原典参照は女書の符号位置を,この箇条において次に示す原
典の中の値に関連付ける。女書の原典は,次のとおりに識別する。
NushuDuben
Nüshu duben 女
本 (2008)
NushuYongziBijiao
Nüshu yongzi bijiao 女
用字比
注記 この規格ではNushuDubenだけが参照されている。NushuYongziBijiao及びそれ以外の原典は将
来追加される。
25.2 女書文字の原典参照ファイル
女書文字の原典参照は,機械可読形式の添付ファイル“NushuSrc.txt”によって定義される。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルは,全ての女書文字の原典参照を規定している。テキストフ
ァイルの各行は,次に示すような三つの項目から構成されている。
− 項目1は,UCS 符号位置を (U+hhhhh)の形式で示す。
− 項目2は,項目3 (kSrc̲NushuDuben, kReading)の情報の形式を示すタグである。
− 項目3は,項目2で指定されたタグの値に対応する情報である。表7に形式の詳細を示す。
ここに,項目1に使われている“h”は,16進数の1桁を表す。三つの項目は制御文字CHARACTER
TABULATION(0009)によって区切られている。NUMBER SIGN(“#”)で始まる注釈行は,単なる参考情報で
ある。テキストファイルの注釈行及び空白行はこのファイルを自動的に処理して原典参照情報を抽出する
際には無視するのがよい。
表7−女書文字の原典参照に用いられるタグの形式詳細
タグの値
タグの意味
項目3の形式
kSrc̲NushuDuben 女書文字の原典
(dd.dd)
kReading
一般的な読み
a(1,6)d(1,2)
ここに,“d”は,10進数の1桁を,“a”は,英字1文字(a〜z)を表す。括弧に囲まれた英大文字,数字及び記
号は,ここに示したとおりに現れる。
女書文字の原典において,FULL STOP(ピリオド)の前の数字はページ番号であり,FULL STOP(ピリオド)
の後の数字はそのページの中でのその文字の位置を0を詰め込んで示すものである。
一般的な読みは韻母,声母及び声調の組合せである。
次の例は,女書文字1B180及び1B181の記載項目を示したものである。
46
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
例
U+1B180
kSrc̲NushuDuben
37.01
U+1B180
kReading
thu35
U+1B181
kSrc̲NushuDuben
37.02
U+1B181
kReading
njyu13
26 文字の名前及び注記
26.1 名前
この規格は,次に示すものの名前を規定する。
− 文字(文字の名前及び文字の別名)
− 名前付きUCS列識別子(箇条27参照)
− ブロック(箇条14及びA.2参照)
− 組(A.1参照)
この規格がこれらのものに付与する名前は,この箇条が規定する名前の形式及び名前の一意性に関する
規則に従わなければならない。この規則は,この規格の英語版に対して適用する。
注記1 英語以外の規格では,次のとおりである。
a) その言語に適切と考えられる言葉及び構文を用いて文字の名前を付けられるように,規
則を修正してもよい。
b) この規格が規定する名前を,上のa)によって修正した規則に従って構成した同等で一意
な名前によって,置き換えてもよい。
注記2 この規格では,英語の対応国際規格の規則を修正しないし,名前を置き換えることもしない。
名前は,英語の対応国際規格のものと同一とする。ただし,理解のために必要な場合は,日
本語による通用名称を参考として併記する。日本語による通用名称は,名前又はその一部で
はなく,必ずしもこの箇条の規定に従わない。
注記3 この規格では,日本語による通用名称を併記する場合,通用名称を括弧で囲み点線の下線を
施した。
注記4 名前付けに関する追加の指針を,附属書Lに示す。
26.2 名前の形式
名前は,次の文字だけを含んでよい。
− LATIN CAPITAL LETTER A(ラテン大文字A)〜LATIN CAPITAL LETTER Z(ラテン大文字Z)
− DIGIT ZERO(0)〜DIGIT NINE(9)
− SPACE(スペース)
− HYPHEN-MINUS(ハイフン,負符号)
− FULL STOP(ピリオド)(組の名前に限る。)
名前の最初の文字は,ラテンの大文字とする。名前の最後の文字は,ラテンの大文字又は数字とする。
名前は,連続する2個以上のSPACE又は連続する2個以上のHYPHEN-MINUSを含んではならない。さ
らに,組以外のものの名前は,SPACEに続く数字(DIGIT ZERO〜DIGIT NINE)を含んではならない。
組の名前は,連続する2個以上のFULL STOPを含んではならない。
SPACEにHYPHEN-MINUSが続く列,又はHYPHEN-MINUSにSPACEが続く列は,文字の名前又は名前
付きUCS列識別子の名前にだけ現れてもよい。
47
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
例1 次に示す二つの文字の名前は,SPACEとHYPHEN-MINUSとの並びを含んでいる。
TIBETAN LETTER -A
TIBETAN MARK BKA- SHOG YIG MGO
FULL STOPは,組の名前の中で,二つの英数字(LATIN CAPITAL LETTER A〜LATIN CAPTITAL LETTER
Z又はDIGIT ZERO〜DIGIT NINE)の間にだけ現れてもよい。
例2 次に示す組の名前は,2個の数字DIGIT FOUR(4)とDIGIT ONE(1)との間にFULL STOP
を含む。
UNICODE 4.1
例3 次に示す組の名前は,1個のラテン文字LATIN CAPITAL LETTER D(ラテン大文字D)と1
個の数字DIGIT SEVEN(7)との間にFULL STOPを含む。
BMP-AMD.7
26.3 名前の単一性
この規格の中で名前付けられる全てのものは,それぞれ名前を一つだけ付与する。ただし,文字に対し
て一つ以上の文字の別名が関連付けられてもよい。
この規定は,明確化を目的とし,参考のために使用する別名又は省略形の使用を妨げるものではない。
しかし,規定としての名前は,一つだけである。こうした,参考としての別名は,文字の名前として同じ
名前空間を共有し,規定事項である文字の別名と混同しない方がよい。
注記 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記の
記載内容を本文に移動した。
26.4 名前の不変性
ある種の名前は,この規格の将来の版においても変更されない。この性質は,文字の名前及び文字の別
名に適用される。箇条7参照。
26.5 名前の一意性
名前は,この箇条で示すように,対応する名前空間内で一意でなければならない。
26.5.1 ブロックの名前
ブロックの名前の集合は,一つの名前空間を構成する。一つ一つのブロックの名前は,一意であって,
この規格が規定する他の全てのブロックの名前と区別できなければならない。
26.5.2 組の名前
組の名前の集合は,一つの名前空間を構成する。一つ一つの組の名前は,一意であって,この規格が規
定する他の全ての組の名前と区別できなければならない。
26.5.3 文字の名前,文字の別名及び名前付きUCS列識別子
文字の名前,文字の別名及び名前付きUCS列識別子は,それらを共に含む集合が一つの名前空間を構成
する。一つ一つの文字の名前,文字の別名又は名前付きUCS列識別子は,一意であって,この規格が規定
する他の全ての文字の名前,文字の別名及び名前付きUCS列識別子と区別できなければならない。
26.5.4 一意性の判定
ブロックの名前及び組の名前は,二つの名前をSPACE及び中間のHYPHEN-MINUSを無視して比較を行
っても異なる場合に,一意であって区別できるものとみなす。中間のHYPHEN-MINUSとは,SPACE以外
の文字に挟まれた1個のHYPHEN-MINUSである。
例1 次に示す架空のブロックの名前は,一意であって区別できる。
LATIN-A
48
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
LATIN-B
例2 次に示す架空のブロックの名前は,一意ではなく区別できない。
LATIN-A
LATIN A
LATINA
文字の名前及び名前付きUCS列識別子の名前は,二つの名前をSPACE及び中間のHYPHEN-MINUSを
無視し,更に,“LETTER”,“CHARACTER”及び“DIGIT”の語を無視して比較を行っても異なる場合に,
一意であって区別できるものとみなす。
例3 次に示す二つの架空の文字の名前は,一意ではなく区別できない。
MANICHAEAN CHARACTER A
MANICHAEAN LETTER A
例4 次に示す二つの実在の文字の名前は,中間のHYPHEN-MINUSでない一つのHYPHEN-MINUSに
よって異なるので,一意であって区別できる。
TIBETAN LETTER A
TIBETAN LETTER -A
ただし,次に示す二つの文字の名前は,一意であって区別できるものとみなす。
HANGUL JUNGSEONG OE
HANGUL JUNGSEONG O-E
注記 これら二つの文字の名前だけは,特別に例外として取り扱う。なぜならば,これらは,この規
格の以前の版で規定されたものであって,その版ではまだ名前の一意性に関する要求事項が規
定されていなかったからである。これら二つの文字は,この規格での一意性に関する規則にお
ける唯一の例外であって,今後ともこれ以外の例外を設けることはない。
26.6 漢字の名前
CJK統合漢字の名前は,“CJK UNIFIED IDEOGRAPH-”(CJK統合漢字)の後に,CJK互換漢字の名前
は,“CJK COMPATIBILITY IDEOGRAPH-”(CJK互換漢字)の後に,それぞれ16進表記の符号化表現を
付けることによって,アルゴリズム的に構成する。
BMPの漢字では,符号化表現は,4桁の16進数で表現された2オクテットの値で示す。例えば,BMP
中の最初のCJK統合漢字は,“CJK UNIFIED IDEOGRAPH-3400”という名前をもつ。
SIPの漢字では,符号化表現は,5桁の16進数の値である。例えば,SIP中の最初のCJK統合漢字は,
“CJK UNIFIED IDEOGRAPH-20000”という名前をもつ。
26.7 西夏文字の名前
西夏文字の名前は,“TANGUT IDEOGRAPH-”の後に,5桁の16進表記の符号化表現を付けることによ
って,アルゴリズム的に構成する。例えば,最初の西夏文字は,“TANGUT IDEOGRAPH-17000”という
名前をもつ。
26.8 女書文字の名前
女書文字の名前は,“NUSHU CHARACTER-”の後に,5桁の16進表記の符号化表現を付けることによっ
て,アルゴリズム的に構成する。例えば,最初の女書文字は,“NUSHU IDEOGRAPH-1B100”という名前
をもつ。
26.9 ハングル音節文字の名前
符号位置AC00〜D7A3のハングル音節文字の名前は,その符号位置の値から,次の計算手順によって導
49
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
出する。これらの文字の名前の一覧は,符号表に示さない。
a) ハングル音節文字の符号位置の数を得る。これは,h1h2h3h4の形式である。ここで,数h1h2h3h4は,AC00
〜D7A3の範囲にある。
b) それぞれ,16進数h1,h2,h3及びh4と値が等しい10進数d1,d2,d3及びd4を導出する。
c) 文字の指標Cを,次の式によって計算する。
C=4 096×(d1−10)+256×(d2−12)+16×d3+d4
d) 音節要素(syllablecomponent)の指標I,P及びFを次の式によって計算する。
I=C/588
(0≦I≦18)
P=(C%588)/28
(0≦P≦20)
F=C%28
(0≦F≦27)
ここに,“/”は,整数除算(すなわち,x/yは,商の整数部分とする。)を示し,“%”は,剰余演算
(すなわち,x%yは,整数除算x/yの剰余とする。)を示す。
e) 三つの指標I,P及びFに対応するラテンの文字列を,それぞれ表8の欄2,欄3及び欄4から得る(I
=11及びF=0に対応する文字列は,空である。)。この三つの文字列を左から右の順に連結し,音節
名(syllable-name)の文字列を得る。
f)
このとき,符号位置h1h2h3h4の文字の名前は,次のとおりとする。
HANGUL SYLLABLE s-n
ここに,“s-n”は,e)で得られた音節名を示す。
例1 符号位置D4DEの文字では,次のようになる。
d1=13,d2=4,d3=13,d4=14
C=10462
I=17,P=16,F=18
対応するラテンの文字列は,P,WI及びBSである。音節名は,PWIBSであり,文字の名前
は,HANGUL SYLLABLE PWIBSである。
それぞれのハングル音節文字に対して,短い注記も規定する。この注記は,そのハングル音節文字
のラテン文字への,代替の翻字からなる。これらも,また,その符号位置の数値から,次の同様の計
算手順によって導き出される。
g) 上のa)〜d)の段階を実行する。
h) 表8の欄5,欄6及び欄7から,I,P及びFの三つの指標に相当するラテンの文字列を得る(I=11
とF=0とに対応する文字列は,空である。)。この三つの文字列を左から右の順に連結し,一つの文
字列を得る。
例2 符号位置D4DEの文字では,次のようになる。
d1=13,d2=4,d3=13,d4=14
C=10 462
I=17,P=16,F=18
対応するラテンの文字列は,ph,wi及びpsである。追加情報は,phwipsとなる。
附属書Rにハングル音節の名前と注記を添付ファイルで参照できるようにしてある。
50
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表8−ハングル音節文字の名前及び注記の要素
指標の数値
音節名の要素
注記の要素
Iの文字列
Pの文字列
Fの文字列
Iの文字列
Pの文字列
Fの文字列
0
G
A
k
a
1
GG
AE
G
kk
ae
k
2
N
YA
GG
n
ya
kk
3
D
YAE
GS
t
yae
ks
4
DD
EO
N
tt
eo
n
5
R
E
NJ
r
e
nc
6
M
YEO
NH
m
yeo
nh
7
B
YE
D
p
ye
t
8
BB
O
L
pp
o
l
9
S
WA
LG
s
wa
lk
10
SS
WAE
LM
ss
wae
lm
11
OE
LB
oe
lp
12
J
YO
LS
c
yo
ls
13
JJ
U
LT
cc
u
lth
14
C
WEO
LP
ch
weo
lph
15
K
WE
LH
kh
we
lh
16
T
WI
M
th
wi
m
17
P
YU
B
ph
yu
p
18
H
EU
BS
h
eu
ps
19
YI
S
yi
s
20
I
SS
i
ss
21
NG
ng
22
J
c
23
C
ch
24
K
kh
25
T
th
26
P
ph
27
H
h
注記1 表8に示す音節名の要素のI及びFの文字列は,符号表の1100〜1112(110Bを除く。)及び11A8
〜11C2の範囲のハングル字母の名前の後に注記として示されているハングル字母の短い名前
に対応する。短い名前は,これらのハングルの音訳である。
注記2 音節名の要素のI及びFの文字列は,ISO/TR 11941:1996,Information and documentation−
Transliteration of Korean script into Latin charactersの方法Iに基づく。同じ表の注記の要素のI及
びFは,ISO/TR 11941の方法IIに基づく。音節名の要素及び注記の要素のPの文字列は,
ISO/TR 11941に基づく。ISO/TR 11941は,2000年7月4日に大韓民国文化観光部が発行した
Revised Romanization of Korean script(改訂版韓国語用字のローマ字表記)とは異なる。
27 名前付きUCS列識別子
名前付きUCS列識別子(以下,“名前付きUSI”又は“NUSI”という。)は,文字の名前と同じ規則に
従った名前を伴うUSIとする。名前付きUCS列識別子の名前付けの規則は,箇条26に従う。
注記1 UCS列識別子に名前を付ける目的は,一まとまりとして扱う文字の列を特定することである。
例えば,フォント又はキーボードの,特定の種類の処理,規格による参照又はレパートリの
列挙である。
各NUSIに対応するUCS列識別子の値は,正規形NFC(箇条21参照)によって決定される符号化表現
51
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
を使って記述される。それぞれの名前付きUCS列識別子は,一意の符号化表現をもつ。この規格に含まれ
る全ての名前付きUCS列識別子は,添付ファイルで参照できる。他の全ての名前付き列は,定義されてい
ない。
名前付きUCS列識別子は,機械可読形式の添付ファイル“NUSI.txt”によって定義される。添付ファイ
ルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE RETURN/LINE FEED
を使用する。各行は,次に示すような二つの項目から構成される。
− 項目1は,NUSI名である(箇条26の規則に従う。)。
− 項目2は,名前に属するUSIである(USIには修正された文法を用い,コンマ及び山括弧を省略する。)。
以上の2項目は,セミコロン(“;”)及び0又はそれ以上のSPACEで区切られる。NUMBER SIGN (“#”)
で始まる注釈行は,単なる参考情報である。テキストファイルの注釈行及び空白行はこのファイルを自動
的に処理して規定項目であるNUSIのリストを抽出する際には無視するのがよい。
注記2 この規格によって許容される全ての名前付きUCS列識別子は,ユニコード文字データベース
http://www.unicode.org/Public/UNIDATA/NamedSequences.txtでも示される。
28 基本多言語面の構造
基本多言語面の概観を図8に示し,区00〜区33のそれより詳細な概観を図9に示す。
基本多言語面には,表音文字,音節文字及び漢字の用字で一般的に用いる文字並びに様々な記号及び数
字が含まれる。

52
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。図中のブロック名称は紙面の都合に
よって省略される場合がある。省略されていない名称については,A.2を参照。
図8−基本多言語面の概観

53
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注a) 新タイ゠ロ文字は,シーソンパンナータイ文字とも呼ぶ。
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。図中のブロック名称は紙面の都合に
より省略される場合がある。省略されていない名称については,A.2を参照。
図9−基本多言語面区00〜33の概観
a)
54
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
29 用字及び記号群に用いる追加多言語面の構造
漢字の追加のために別の追加面を用意したので,現時点では,SMP(面01)を漢字の符号化に用いない。
SMPは,世界の他の用字で用いる図形文字のうちBMPで符号化されない文字の符号化に用いる。現時点
では,SMPで符号化する用字の大半は,現存の用字として現代の利用者集団が用いるものではない。
注記 SMPを次のように分割することが提案されている。
− アルファベットの用字
− 象形文字,表意文字及び音節文字
− 漢字以外の表意文字
− 新規に発明された用字
− 記号の集合
SMPの概観を図10に,区00〜6Fのそれより詳細な概観を図11に示す。

55
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。図中のブロック名称は紙面の都合に
よって省略される場合がある。省略されていない名称については,A.2を参照。
図10−用字及び記号群に用いる追加多言語面の概観

56
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。図中のブロック名称は紙面の都合に
よって省略される場合がある。省略されていない名称については,A.2を参照。
図11−用字及び記号群に用いる追加多言語面の区00〜6Fの概観
30 追加漢字面の構造
SIP(面02)は,CJK統合漢字(東アジアの漢字を統合したもの。)のうち,BMPで符号化されないも
のに用いる。統合の手順及び配列の規則を,附属書Sに示す。
SIPは,CJK互換漢字にも用いる。CJK互換漢字は,箇条18で規定する互換用文字である。
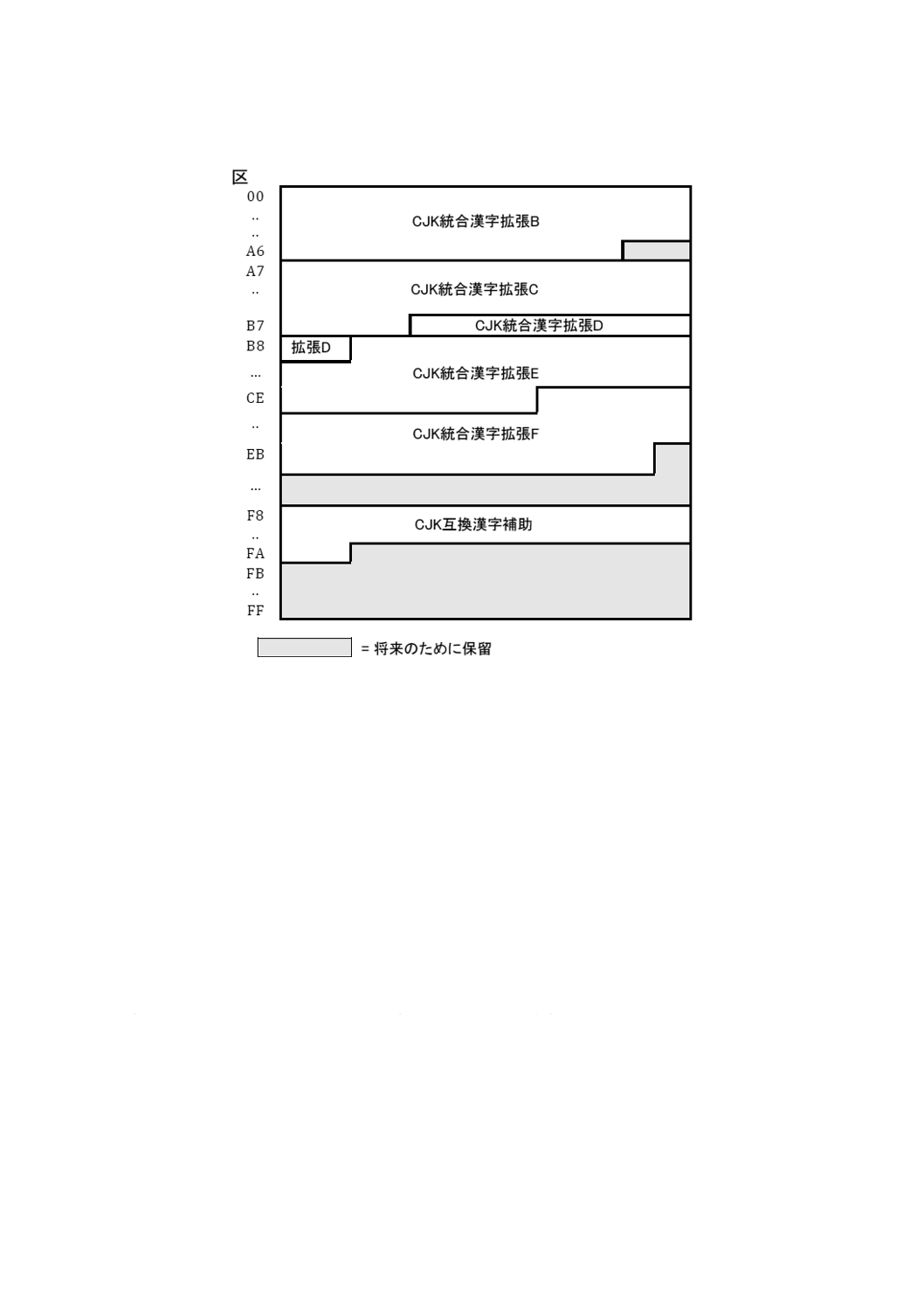
57
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
SIPの概観を図12に示す。
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。図中のブロック名称は
紙面の都合によって省略される場合がある。省略されていない名称については,A.2を参照。
図12−追加漢字面の概観
31 第三漢字面の構造
TIP(面03)は,BMP又はSIPに符号化されていないCJK統合漢字(東アジアの統合漢字)を符号化す
る予定である。古代の漢字のような用字であって,CJK統合漢字と関連するがCJK統合漢字には分類され
ない用字にも用いてよい。現在のところTIPに符号化されている文字はない。
注記 この規格の将来の版ではTIPに甲骨文字又は小篆を含めることもある。
32 追加特殊用途面の構造
SSP(面0E)は,特殊な用途の図形文字及び書式文字に用いる。
SSPの概観を図13に示す。
通常の処理又は表示では,この範囲の未定義の符号位置は,無視することが望ましい。
注記 注記には,要求事項,推奨事項及び許容事項を含めてはならないため,対応国際規格の注記の
記載内容を本文に移動した。

58
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 区の中の縦の区切りは,おおよその位置の目安を示しているだけである。
図13−追加特殊用途面の概観
33 符号表及び文字の名前一覧表
33.1 概要
基本多言語面(BMP),追加多言語面(SMP),追加漢字面(SIP)及び追加特殊用途面(SSP)に対する
詳細符号表及び文字の名前の一覧を添付ファイルによって示す。符号表は,ブロックごとに整理されてお
り,複数ページにまたがるブロックもある。
それぞれの符号表の後には,対応する文字の名前一覧を示す(ただし,漢字,西夏文字及びハングル音
節のブロックを除く。)。
注記1 場所が許せば,一つのブロックの符号表と文字の名前一覧とを一つのページにまとめること
もある。
注記2 漢字の符号表は,形式が異なる(23.3及び23.4参照)。
33.2 符号表
符号表は,文字を表す図形記号を,それぞれが16個の記号を含む1列〜16列に編成した配列として表
示される。符号化表現の下位1桁を左側の余白に表示し,残りの上位桁を上側の余白に表示する。さらに,
符号化表現の全体をそれぞれの図形記号の下に表示する。ただし,漢字及び西夏文字の符号表の形式は異
なる。23.3及び24.3参照。
注記1 図形文字の表示に対応する図形記号は,参考である。箇条13参照。
注記2 標準化された字形指示列が定義されている文字は,対応する符号表の枠の右上に三角の印が
示されている。
33.3 文字の名前の一覧表
文字の名前の一覧表は,規定事項と参考情報との両方を含む。次の項目は,規定事項とする。
− 文字の符号位置
− 付随する文字の名前
− 文字の別名(“※”に引き続いて記載する。)
他の全ての情報は,参考情報であり,次のようなものがある。
− 文字に関連付いた図形記号
− あるブロックの様々な部分に対する見出し。例えば,LATIN-1 SUPPLEMENTブロックには,“Latin-1
punctuation and symbols”,“Letters”及び“Mathematical operator”の見出しがある。
− 見出し又はブロック全体に関して補足する説明の文章
− “=”に引き続いて記載する,参考の別名。これは,文字の代替の名前を示す。
− “→”に引き続いて記載する,相互参照。これは,関連する文字を示す。

59
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− “・”に引き続いて記載する,言語に関する情報。これは,その文字を使用する言語を非網羅的に示
す。大文字と小文字とをもつ用字の場合,この情報は,小文字に対してだけ示す。
− “・”に引き続いて記載する,大文字と小文字との対応情報。これは,名前から単純に類推すること
ができない場合にだけ示す。
− “・”に引き続いて記載する,その他の情報。これは,奇妙な名前,歴史的配慮事項などの,文字に
関して記録すべき特徴を示す。
− 分解写像。“≡”に引き続いて基準写像を,“≈”に引き続いて互換写像を,それぞれ記載する。
注記 分解写像の文法は,ユニコード標準第9.0版の24.1に詳しい記載がある。
− “〜”に引き続いて記載する,既定の字形指示列。これは,示されたような字形指示列の基底文字と
してこの文字が使用されることを示す。
次の例は,ここに示した参考項目を含む,文字名一覧の様々な部分を用いて説明している。
例
60
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
33.4 既定の字形指示列の概要
既定の字形指示列(16.6.2参照)の概要は,次の分類の後に示される。
− 数学記号
− モンゴル文字
− パスパ文字
− マニ文字
注記 絵文字に対応する,既定の字形指示列が,将来この規格に登録されることもある。
33.5 符号表及び文字の名前一覧
基本多言語面(BMP),追加多言語面(SMP),追加漢字面(SIP)及び追加特殊用途面(SSP)に対する
詳細符号表及び文字の名前の一覧を添付ファイルによって示す。これらの符号表及び名前の一覧は,次の
とおりとする。
− BASIC LATIN〜YIJING HEXAGRAM SYMBOLS(0000〜4DFF)は,添付ファイル“ISO
10646-2017-1-0000-4DFF.pdf”とする。
− CJK UNIFIED IDEOGRAPHS(4E00〜9FFF)は,添付ファイル“ISO 10646-2017-2-4E00-9FFF.pdf”と
する。
− YI SYLLABLES〜CHESS SYMBOLS(A000〜1FFFF)は,添付ファイル“ISO
10646-2017-3-A000-1FFFF.pdf”とする。
− CJK UNIFIED IDEOGRAPHS EXTENSION Bの前半(20000〜25333)は,添付ファイル“ISO
10646-2017-4-20000-25333.pdf”とする。
− CJK UNIFIED IDEOGRAPHS EXTENSION Bの後半(25334〜2A6FF)は,添付ファイル“ISO
10646-2017-5-25334-2A6FF.pdf”とする。
− CJK UNIFIED IDEOGRAPHS EXTENSION C〜VARIATION SELECTORS SUPPLEMENT(2A700〜10FFFF)
は,添付ファイル“ISO 10646-2017-6-2A700-10FFFF.pdf”とする。
61
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書A
(規定)
部分集合用図形文字の組
A.1 符号化図形文字の組
次に示す組は,組番号の順に並べている。“符号位置”の“*”は,その組が確定組であることを示す。
組番号 名前
符号位置
1
BASIC LATIN
0020〜007E *
2
LATIN-1 SUPPLEMENT
00A0〜00FF *
3
LATIN EXTENDED-A
0100〜017F *
4
LATIN EXTENDED-B
0180〜024F *
5
IPA EXTENSIONS
0250〜02AF *
6
SPACING MODIFIER LETTERS
02B0〜02FF *
7
COMBINING DIACRITICAL MARKS
0300〜036F *
8
BASIC GREEK
0370〜03CF
9
GREEK SYMBOLS AND COPTIC
03D0〜03FF
10
CYRILLIC
0400〜04FF *
11
ARMENIAN
0530〜058F
12
BASIC HEBREW
05D0〜05EA *
13
HEBREW EXTENDED
0590〜05CF
05EB〜05FF
14
BASIC ARABIC
0600〜065F
15
ARABIC EXTENDED
0660〜06FF *
16
DEVANAGARI
0900〜097F *
200C,200D
17
BENGALI
0980〜09FF
200C,200D
18
GURMUKHI
0A00〜0A7F
200C,200D
19
GUJARATI
0A80〜0AFF
200C,200D
20
ORIYA
0B00〜0B7F
200C,200D
21
TAMIL
0B80〜0BFF
200C,200D
22
TELUGU
0C00〜0C7F
200C,200D
23
KANNADA
0C80〜0CFF
200C,200D
62
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
24
MALAYALAM
0D00〜0D7F
200C,200D
25
THAI
0E00〜0E7F
26
LAO
0E80〜0EFF
27
BASIC GEORGIAN
10D0〜10FF
28
GEORGIAN EXTENDED
10A0〜10CF
29
HANGUL JAMO
1100〜11FF *
30
LATIN EXTENDED ADDITIONAL
1E00〜1EFF *
31
GREEK EXTENDED
1F00〜1FFF
32
GENERAL PUNCTUATION
2000〜206F
33
SUPERSCRIPTS AND SUBSCRIPTS
2070〜209F
34
CURRENCY SYMBOLS
20A0〜20CF
35
COMBINING DIACRITICAL MARKS FOR SYMBOLS
20D0〜20FF
36
LETTERLIKE SYMBOLS
2100〜214F *
37
NUMBER FORMS
2150〜218F
38
ARROWS
2190〜21FF *
39
MATHEMATICAL OPERATORS
2200〜22FF *
40
MISCELLANEOUS TECHNICAL
2300〜23FF *
41
CONTROL PICTURES
2400〜243F
42
OPTICAL CHARACTER RECOGNITION
2440〜245F
43
ENCLOSED ALPHANUMERICS
2460〜24FF *
44
BOX DRAWING
2500〜257F *
45
BLOCK ELEMENTS
2580〜259F *
46
GEOMETRIC SHAPES
25A0〜25FF *
47
MISCELLANEOUS SYMBOLS
2600〜26FF *
48
DINGBATS
2700〜27BF *
49
CJK SYMBOLS AND PUNCTUATION
3000〜303F *
50
HIRAGANA
3040〜309F
51
KATAKANA
30A0〜30FF *
52
BOPOMOFO
3100〜312F
31A0〜31BF
53
HANGUL COMPATIBILITY JAMO
3130〜318F
54
CJK MISCELLANEOUS
3190〜319F
55
ENCLOSED CJK LETTERS AND MONTHS
3200〜32FF
56
CJK COMPATIBILITY
3300〜33FF *
57〜59 [これらの組番号は,使用しない(注記2参照)。]
60
CJK UNIFIED IDEOGRAPHS
4E00〜9FFF
61
PRIVATE USE AREA
E000〜F8FF
62
CJK COMPATIBILITY IDEOGRAPHS
F900〜FAFF
63
(組63は,他の組の組合せによって定義する。)
63
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
64
ARABIC PRESENTATION FORMS-A
FB50〜FDCF
FDF0〜FDFF
65
COMBINING HALF MARKS
FE20〜FE2F *
66
CJK COMPATIBILITY FORMS
FE30〜FE4F *
67
SMALL FORM VARIANTS
FE50〜FE6F
68
ARABIC PRESENTATION FORMS-B
FE70〜FEFE
69
HALFWIDTH AND FULLWIDTH FORMS
FF00〜FFEF
70
SPECIALS
FFF0〜FFFD
71
HANGUL SYLLABLES
AC00〜D7A3 *
72
BASIC TIBETAN
0F00〜0FBF
73
ETHIOPIC
1200〜137F
74
UNIFIED CANADIAN ABORIGINAL SYLLABICS
1400〜167F *
75
CHEROKEE
13A0〜13FF
76
YI SYLLABLES
A000〜A48F
77
YI RADICALS
A490〜A4CF
78
KANGXI RADICALS
2F00〜2FDF
79
CJK RADICALS SUPPLEMENT
2E80〜2EFF
80
BRAILLE PATTERNS
2800〜28FF
81
CJK UNIFIED IDEOGRAPHS EXTENSION A
3400〜4DBF
FA1F,FA23
82
OGHAM
1680〜169F
83
RUNIC
16A0〜16FF
84
SINHALA
0D80〜0DFF
85
SYRIAC
0700〜074F
86
THAANA
0780〜07BF
87
BASIC MYANMAR
1000〜104F *
200C,200D
88
KHMER
1780〜17FF
200C,200D
89
MONGOLIAN
1800〜18AF
90
EXTENDED MYANMAR
1050〜109F *
91
TIBETAN
0F00〜0FFF
92
CYRILLIC SUPPLEMENT
0500〜052F
93
TAGALOG
1700〜171F
94
HANUNOO
1720〜173F
95
BUHID
1740〜175F
96
TAGBANWA
1760〜177F
97
MISCELLANEOUS MATHEMATICAL SYMBOLS-A
27C0〜27EF *
98
SUPPLEMENTAL ARROWS-A
27F0〜27FF *
99
SUPPLEMENTAL ARROWS-B
2900〜297F *
64
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
100
MISCELLANEOUS MATHEMATICAL SYMBOLS-B
2980〜29FF *
101
SUPPLEMENTAL MATHEMATICAL OPERATORS
2A00〜2AFF *
102
KATAKANA PHONETIC EXTENSIONS
31F0〜31FF *
103
VARIATION SELECTORS
FE00〜FE0F *
104
LTR ALPHABETIC PRESENTATION FORMS
FB00〜FB1C
105
RTL ALPHABETIC PRESENTATION FORMS
FB1D〜FB4F
106
LIMBU
1900〜194F
107
TAI LE
1950〜197F
108
KHMER SYMBOLS
19E0〜19FF *
109
PHONETIC EXTENSIONS
1D00〜1D7F *
110
MISCELLANEOUS SYMBOLS AND ARROWS
2B00〜2BFF
111
YIJING HEXAGRAM SYMBOLS
4DC0〜4DFF *
112
ARABIC SUPPLEMENT
0750〜077F *
113
ETHIOPIC SUPPLEMENT
1380〜139F
114
NEW TAI LUE
1980〜19DF
115
BUGINESE
1A00〜1A1F
116
PHONETIC EXTENSIONS SUPPLEMENT
1D80〜1DBF *
117
COMBINING DIACRITICAL MARKS SUPPLEMENT
1DC0〜1DFF
118
GLAGOLITIC
2C00〜2C5F
119
COPTIC
03E2〜03EF
2C80〜2CFF
120
GEORGIAN SUPPLEMENT
2D00〜2D2F
121
TIFINAGH
2D30〜2D7F
122
ETHIOPIC EXTENDED
2D80〜2DDF
123
SUPPLEMENTAL PUNCTUATION
2E00〜2E7F
124
CJK STROKES
31C0〜31EF
125
MODIFIER TONE LETTERS
A700〜A71F *
126
SYLOTI NAGRI
A800〜A82F
127
VERTICAL FORMS
FE10〜FE1F
128
NKO
07C0〜07FF
129
BALINESE
1B00〜1B7F
130
LATIN EXTENDED-C
2C60〜2C7F *
131
LATIN EXTENDED-D
A720〜A7FF
132
PHAGS-PA
A840〜A87F
133
SUNDANESE
1B80〜1BBF *
134
LEPCHA
1C00〜1C4F
135
OL CHIKI
1C50〜1C7F *
136
VAI
A500〜A63F
137
SAURASHTRA
A880〜A8DF
138
KAYAH LI
A900〜A92F *
65
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
139
REJANG
A930〜A95F
140
CYRILLIC EXTENDED-A
2DE0〜2DFF *
141
CYRILLIC EXTENDED-B
A640〜A69F
142
CHAM
AA00〜AA5F
143
TAI THAM
1A20〜1AAF
144
HANGUL JAMO EXTENDED-A
A960〜A97F
145
TAI VIET
AA80〜AADF
146
HANGUL JAMO EXTENDED-B
D7B0〜D7FF
147
SAMARITAN
0800〜083F
148
UNIFIED CANADIAN ABORIGINAL SYLLABICS EXTENDED
18B0〜18FF
149
VEDIC EXTENSIONS
1CD0〜1CFF
150
LISU
A4D0〜A4FF *
151
BAMUM
A6A0〜A6FF
152
COMMON INDIC NUMBER FORMS
A830〜A83F
153
DEVANAGARI EXTENDED
A8E0〜A8FF *
154
JAVANESE
A980〜A9DF
155
MYANMAR EXTENDED-A
AA60〜AA7F *
156
MEETEI MAYEK
ABC0〜ABFF
157
MANDAIC
0840〜085F
158
BATAK
1BC0〜1BFF
159
ETHIOPIC EXTENDED-A
AB00〜AB2F
160
ARABIC EXTENDED-A
08A0〜08FF
161
SUNDANESE SUPPLEMENT
1CC0〜1CCF
162
MEETEI MAYEK EXTENSIONS
AAE0〜AAFF
163
COMBINING DIACRITICAL MARKS EXTENDED
1AB0〜1AFF
164
MYANMAR EXTENDED-B
A9E0〜A9FF
165
LATIN EXTENDED-E
AB30〜AB6F
166
CHEROKEE SUPPLEMENT
AB70〜ABBF *
167
CYRILLIC EXTENDED-C
1C80〜1C8F
168
SYRIAC SUPPLEMENT
0860〜086F
169
GEORGIAN EXTENDED
1C90〜1CBF
1001
OLD ITALIC
10300〜1032F
1002
GOTHIC
10330〜1034F
1003
DESERET
10400〜1044F *
1004
BYZANTINE MUSICAL SYMBOLS
1D000〜1D0FF
1005
MUSICAL SYMBOLS
1D100〜1D1FF
1006
MATHEMATICAL ALPHANUMERIC SYMBOLS
1D400〜1D7FF
1007
LINEAR B SYLLABARY
10000〜1007F
1008
LINEAR B IDEOGRAMS
10080〜100FF
1009
AEGEAN NUMBERS
10100〜1013F
66
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1010
UGARITIC
10380〜1039F
1011
SHAVIAN
10450〜1047F *
1012
OSMANYA
10480〜104AF
1013
CYPRIOT SYLLABARY
10800〜1083F
1014
TAI XUAN JING SYMBOLS
1D300〜1D35F
1015
ANCIENT GREEK NUMBERS
10140〜1018F
1016
OLD PERSIAN
103A0〜103DF
1017
KHAROSHTHI
10A00〜10A5F
1018
ANCIENT GREEK MUSICAL NOTATION
1D200〜1D24F
1019
PHOENICIAN
10900〜1091F
1020
CUNEIFORM
12000〜123FF
1021
CUNEIFORM NUMBERS AND PUNCTUATION
12400〜1247F
1022
COUNTING ROD NUMERALS
1D360〜1D37F
1023
PHAISTOS DISC
101D0〜101FF
1024
LYCIAN
10280〜1029F
1025
CARIAN
102A0〜102DF
1026
LYDIAN
10920〜1093F
1027
ANCIENT SYMBOLS
10190〜101CF
1028
MAHJONG TILES
1F000〜1F02F
1029
DOMINO TILES
1F030〜1F09F
1030
AVESTAN
10B00〜10B3F
1031
EGYPTIAN HIEROGLYPHS
13000〜1342F
1032
IMPERIAL ARAMAIC
10840〜1085F
1033
OLD SOUTH ARABIAN
10A60〜10A7F
1034
INSCRIPTIONAL PARTHIAN
10B40〜10B5F
1035
INSCRIPTIONAL PAHLAVI
10B60〜10B7F
1036
OLD TURKIC
10C00〜10C4F
1037
RUMI NUMERAL SYMBOLS
10E60〜10E7F
1038
KAITHI
11080〜110CF
1039
ENCLOSED ALPHANUMERIC SUPPLEMENT
1F100〜1F1FF
1040
ENCLOSED IDEOGRAPHIC SUPPLEMENT
1F200〜1F2FF
1041
BRAHMI
11000〜1107F
1042
KANA SUPPLEMENT
1B000〜1B0FF
1043
BAMUM SUPPLEMENT
16800〜16A3F
1044
PLAYING CARDS
1F0A0〜1F0FF
1045
MISCELLANEOUS SYMBOLS AND PICTOGRAPHS
1F300〜1F5FF *
1046
EMOTICONS
1F600〜1F64F *
1047
TRANSPORT AND MAP SYMBOLS
1F680〜1F6FF
1048
ALCHEMICAL SYMBOLS
1F700〜1F77F
1049
MEROITIC HIEROGLYPHS
10980〜1099F *
67
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1050
MEROITIC CURSIVE
109A0〜109FF
1051
SORA SOMPENG
110D0〜110FF
1052
CHAKMA
11100〜1114F
1053
SHARADA
11180〜111DF
1054
TAKRI
11680〜116CF
1055
MIAO
16F00〜16F9F
1056
ARABIC MATHEMATICAL ALPHABETIC SYMBOLS
1EE00〜1EEFF
1057
COPTIC EPACT NUMBERS
102E0〜102FF
1058
ELBASAN
10500〜1052F
1059
LINEAR A
10600〜1077F
1060
PALMYRENE
10860〜1087F *
1061
NABATAEAN
10880〜108AF
1062
OLD NORTH ARABIAN
10A80〜10A9F *
1063
MANICHAEAN
10AC0〜10AFF
1064
SINHALA ARCHAIC NUMBERS
111E0〜111FF
1065
KHOJKI
11200〜1124F
1066
KHUDAWADI
112B0〜112FF
1067
TIRHUTA
11480〜114DF
1068
PAU CIN HAU
11AC0〜11AFF
1069
MRO
16A40〜16A 6F
1070
BASSA VAH
16AD0〜16AFF
1071
DUPLOYAN
1BC00〜1BC9F
1072
SHORTHAND FORMAT CONTROLS
1BCA0〜1BCAF
1073
ORNAMENTAL DINGBATS
1F650〜1F67F *
1074
GEOMETRIC SHAPES EXTENDED
1F780〜1F7FF
1075
SUPPLEMENTAL ARROWS-C
1F800〜1F8FF
1076
OLD PERMIC
10350〜1037F
1077
CAUCASIAN ALBANIAN
10530〜1056F
1078
PSALTER PAHLAVI
10B80〜10BAF
1079
MAHAJANI
11150〜1117F
1080
GRANTHA
11300〜1137F
1081
SIDDHAM
11580〜115FF
1082
MODI
11600〜1165F
1083
WARANG CITI
118A0〜118FF
1084
PAHAWH HMONG
16B00〜16B8F
1085
MENDE KIKAKUI
1E800〜1E8DF
1086
HATRAN
108E0〜108FF
1087
OLD HUNGARIAN
10C80〜10CFF
1088
MULTANI
11280〜112AF
1089
AHOM
11700〜1173F
68
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1090
EARLY DYNASTIC CUNEIFORM
12480〜1254F
1091
ANATOLIAN HIEROGLYPHS
14400〜1467F
1092
SUTTON SIGNWRITING
1D800〜1DAAF
1093
OSAGE
104B0〜104FF
1094
MONGOLIAN SUPPLEMENT
11660〜1167F
1095
BHAIKSUKI
11C00〜11C6F
1096
MARCHEN
11C70〜11CBF
1097
IDEOGRAPHIC SYMBOLS AND PUNCTUATION
16FE0〜16FFF
1098
TANGUT
17000〜187F7
1099
TANGUT COMPONENTS
18800〜18AFF
1100
GLAGOLITIC SUPPLEMENT
1E000〜1E02F
1101
SUPPLEMENTAL SYMBOLS AND PICTOGRAPHS
1F900〜1F9FF
1102
HANIFI ROHINGYA
10D00〜10D3F
1103
NEWA
11400〜1147F
1104
ZANABAZAR SQUARE
11A00〜11A4F
1105
SOYOMBO
11A50〜11AAF
1106
MASARAM GONDI
11D00〜11D5F
1107
NUSHU
1B170〜1B2FF
1108
ADLAM
1E900〜1E95F
1109
OLD SOGDIAN
10F00〜10F2F
1110
SOGDIAN
10F30〜10F6F
1111
DOGRA
11800〜1184F
1112
GUNJALA GONDI
11D60〜11DAF
1113
MAKASAR
11EE0〜11EFF
1114
MEDEFAIDRIN
16E40〜16E9F
1115
KANA EXTENDED-A
1B100〜1B12F
1116
MAYAN NUMERALS
1D2E0〜1D2FF
1117
INDIC SIYAQ NUMBERS
1EC70〜1ECBF
1118
CHESS SYMBOLS
1FA00〜1FA6F
1120
ELYMAIC
10FE0〜10FFF
1121
NANDINAGARI
119A0〜119FF
1122
TAMIL SUPPLEMENT
11FC0〜11FFF
1123
EGYPTIAN HIEROGLYPHS FORMAT CONTROLS
13430〜1343F
1124
SMALL KANA EXTENSION
1B130〜1B16F
1125
NYIAKENG PUACHUE HMONG
1E100〜1E14F
1126
WANCHO
1E2C0〜1E2FF
1127
OTTOMAN SIYAQ NUMBERS
1ED00〜1ED4F
2001
CJK UNIFIED IDEOGRAPHS EXTENSION B
20000〜2A6DF
2002
CJK COMPATIBILITY IDEOGRAPHS SUPPLEMENT
2F800〜2FA1F
2003
CJK UNIFIED IDEOGRAPHS EXTENSION C
2A700〜2B73F
69
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2004
CJK UNIFIED IDEOGRAPHS EXTENSION D
2B740〜2B81F
2005
CJK UNIFIED IDEOGRAPHS EXTENSION E
2B820〜2CEAF
2006
CJK UNIFIED IDEOGRAPHS EXTENSION F
2CEB0〜2EBEF
3001
TAGS
E0000〜E007F
3003
VARIATION SELECTORS SUPPLEMENT
E0100〜E01EF *
次の組は,代替書式及び用字に特有の書式で使用する文字を規定する(附属書F参照)。
200
ZERO-WIDTH BOUNDARY INDICATORS
200B〜200D
FEFF
201
FORMAT SEPARATORS
2028〜2029
202
BI-DIRECTIONAL FORMAT MARKS
200E〜200F
203
BI-DIRECTIONAL FORMAT EMBEDDINGS
202A〜202E
204
HANGUL FILL CHARACTERS
115F〜1160
3164,FFA0
205
CHARACTER SHAPING SELECTORS
206A〜206D
206
NUMERIC SHAPE SELECTORS
206E〜206F
207
IDEOGRAPHIC DESCRIPTION CHARACTERS
2FF0〜2FFF
208
CONTROL CHARACTERS
0000〜001F
007F〜009F
3002
ALTERNATE FORMAT CHARACTERS
E0000〜E0FFF
次の組は,この規格の対応国際規格の以前の版が発行された時点でのUCS全体を表す組である。
299
(この組番号は,使用しない。A.3.3を参照)*
301
BMP-AMD.7
A.3.2を参照。*
302
BMP SECOND EDITION
A.3.4を参照。*
303
UNICODE 3.1
A.6を参照。*
304
UNICODE 3.2
A.6を参照。*
305
UNICODE 4.0
A.6を参照。*
306
UNICODE 4.1
A.6を参照。*
307
UNICODE 5.0
A.6を参照。*
308
UNICODE 5.1
A.6を参照。*
309
UNICODE 5.2
A.6を参照。*
310
UNICODE 6.0
A.6を参照。*
311
UNICODE 6.1
A.6を参照。*
312
UNICODE 6.2
A.6を参照。*
313
UNICODE 6.3
A.6を参照。*
314
UNICODE 7.0
A.6を参照。*
315
UNICODE 8.0
A.6を参照。*
316
UNICODE 9.0
A.6を参照。*
317
UNICODE 10.0
A.6を参照。*
318
UNICODE 11.0
A.6を参照。*
340
COMBINED FIRST EDITION
A.3.5を参照。*
70
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
10646
UNICODE
0000〜FDCF
FDF0〜FFFD
10000〜1FFFD
20000〜2FFFD
30000〜3FFFD
40000〜4FFFD
50000〜5FFFD
60000〜6FFFD
70000〜7FFFD
80000〜8FFFD
90000〜9FFFD
A0000〜AFFFD
B0000〜BFFFD
C0000〜CFFFD
D0000〜DFFFD
E0000〜EFFFD
F0000〜FFFFD
100000〜10FFFD
注記1 組UNICODEは,この規格が現在符号化している全ての文字を包含する。
次の組は,漢字だけを含む。
370
IICORE
A.4.1を参照。*
371
JIS2004 IDEOGRAPHICS EXTENSION
A.4.2を参照。*
372
JAPANESE IDEOGRAPHICS SUPPLEMENT
A.4.3を参照。*
373
JAPANESE IT VENDORS CONTEMPORARY IDEOGRAPHS-1993
A.4.4を参照。*
374
JIS X 0213:2004 IDEOGRAPHS FROM PREVIOUS JIS STANDARDS
A.4.5を参照。*
375
JAPANESE CORE KANJI
A.4.6を参照。*
380
CJK UNIFIED IDEOGRAPHS-2001
3400〜4DB5
4E00〜9FA5
FA0E〜FA0F
FA11
FA13〜FA14
FA1F,FA21
FA23〜FA24
FA27〜FA29
20000〜2A6D6 *
381
CJK COMPATIBILITY IDEOGRAPHS-2001
F900〜FA0D
FA10,FA12
FA15〜FA1E
71
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
FA20,FA22
FA25〜FA26
FA2A〜FA6A
2F800〜2FA1D *
382
CJK UNIFIED IDEOGRAPHS-2005
組380
9FA6〜9FBB *
383
CJK COMPATIBILITY IDEOGRAPHS-2005
組381
FA70〜FAD9 *
384
CJK UNIFIED IDEOGRAPHS-2007
組382
9FBC〜9FC3 *
385
CJK UNIFIED IDEOGRAPHS-2008
組384
9FC4〜9FC6
2A700〜2B734 *
386
CJK COMPATIBILITY IDEOGRAPHS-2008
組383
FA6B〜FA6D *
387
CJK UNIFIED IDEOGRAPHS-2009
組385
9FC7〜9FCB
2B740〜2B81D *
388
CJK UNIFIED IDEOGRAPHS-2014
組387 *
2B820〜2CEA1
389
CJK UNIFIED IDEOGRAPHS-2016
組388 *
9FCC〜9FE9
2CEB0〜2EBE0
390
MOJI-JOHO-KIBAN IDEOGRAPHS-2016
A.5.10を参照。*
その他の組(拡張組を含む。)を,次に規定する。
270
COMBINING CHARACTERS
BMPにある結合文字
(3.14参照)。
271
(この組番号は,使用しない。注記2を参照)
281
MES-1
A.5.2を参照。*
282
MES-2
A.5.3を参照。*
283
MODERN EUROPEAN SCRIPTS
A.5.4を参照。*
284
CONTEMPORARY LITHUANIAN LETTERS
A.5.5を参照。*
285
BASIC JAPANESE
A.5.6を参照。*
286
JAPANESE NON IDEOGRAPHICS EXTENSION
A.5.7を参照。*
287
COMMON JAPANESE
A.5.8を参照。*
288
MULTILINGUAL LATIN SUBSET
A.5.9を参照。*
300
BMP
0000〜D7FF
E000〜FFFD
400
[この組番号は,使用しない(注記2参照)。]
401
PRIVATE USE PLANES-0F-10
面0F〜10
72
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
500
[この組番号は,使用しない(注記2参照)。]
1000
SMP
10000〜1FFFD
1900
SMP COMBINING CHARACTERS
SMPにある結合文字
(3.14参照)。
2000
SIP
20000〜2FFFD
3000
SSP
E0000〜EFFFD
上に定義した特定の組を組み合わせた組を,次に規定する。
63
ALPHABETIC PRESENTATION FORMS
組104〜105
250
GENERAL FORMAT CHARACTERS
組200〜203
251
SCRIPT-SPECIFIC FORMAT CHARACTERS
組204〜206
4000
UCS PART-2
組1000,2000,3000
注記2 番号57〜59の組は,ISO/IEC 10646-1の最初の版で規定されていたが,その後,削除された。
番号400及び500の組は,ISO/IEC 10646-1の最初の版及び第2版で規定されていたが,そ
の後,削除された。番号271の組は,この規格の最初の版で規定されていたが,その後,削
除された。
注記3 上に示した組の名前で使われる主要な語(キーワード)を,アルファベット順に,次に列挙
する。各語の行には,組の名前がその語を含む組番号を全て示す。ただし,これらの語は,
用字の名前など,特定の属性をもつ文字を見つけ出すことができるような組全てへの完全な
相互参照となるものではない。これらの語の多くは,組の中の文字の属性を識別するが,そ
の属性をもつ文字の中には,他の,その語の行に番号が現れない組に入れたものもある。
Adlam
1107
Aegean numbers
1009
Ahom
1089
Alphabetic
63
Alphanumeric
43
Anatolian Hieroglyphs
1091
Ancient Greek
1015,1018
Arabic
14,15,64,68,112,160,1056
Armenian
11
Arrows
38,98,99,110,1075
Avestan
1030
Balinese
129
Bamum
151,1043
Bassa Vah
1070
Batak
158
Bengali
17
Bhaiksuki
1095
Bidirectional
202,203
Block elements
45
BMP
300〜302 (299)
73
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Box drawing
44
Bopomofo
52
Brahmi
1041
Braille patterns
80
Buginese
115
Buhid
95
Byzantine musical symbols
1004
Canadian Aboriginal
74,148
Carian
1025
Caucasian Albanian
1077
Chakma
1052
Cham
142
Cherokee
75,166
CJK
49,54〜56,60,62,66,78,81,124,2001〜2005
Combining
7,35,65,117,270,271
Compatibility
53,56,62,66
Control pictures
41
Coptic
9,119,1057
Counting Rod numerals
1022
Cuneiform
1020,1021,1090
Currency
34
Cypriot syllabary
1013
Cyrillic
10,92,140,141,167
Deseret
1003
Devanagari
16,153
Diacritical marks
7,35,117,163
Dingbats
48,1073
Dogra
1111
Duployan
1071
Elbasan
1058
Enclosed
43,55
Egyptian hieroglyphs
1031,1123
Elymaic
1120
Ethiopic
73,113,122,159
Format
201〜203,250,251,1072
Fullwidth
69
Game tiles
1028,1029
Geometric shapes
46,1074
Georgian
27,28,120,169
Glagolitic
118,1100
74
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Gondi
1106
Gothic
1002
Grantha
1080
Greek
8,9,31
Gujarati
19
Gunjala Gondi
1112
Gurmukhi
18
Half (marks, width)
65,69
Hangul
29,53,71,144,146,204
Hanifi Rohingya
1102
Hanunoo
94
Hatran
1086
Hebrew
12,13
Hiragana
50,1042,1115,1124
Ideographs
60,62,81,207,380〜388
Imperial Aramaic
1032
Indic Siyaq Numbers
1117
Inscriptional Pahlavi
1035
Inscriptional Parthian
1034
IPA extensions
5
Jamo
29,53,144,146
Javanese
154
Kaithi
1038
Kangxi
78
Kannada
23
Katakana
51,102,1042,1115,1124
Kayah Li
138
Kharoshthi
1017
Khmer
88,108
Khojki
1065
Khudawadi
1066
Lao
26
Latin
1〜4,30,130,131,165
Lepcha
134
Letter
36,55,1039,1040
Limbu
106
Linear A
1059
Linear B ideograms
1008
Linear B syllabary
1007
Lisu
150
75
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Lycian
1024
Lydian
1026
Mahajani
1079
Makasar
1113
Malayalam
24
Mandaic
157
Manichaean
1063
Marchen
1096
Mathematical alphanumeric symbols 1006,1056
Mathematical operators
39,101
Mathematical symbols
97,100
Mayan
1116
Medefaidrin
1114
Meetei Mayek
156,162
Mende Kikakui
1085
Meroitic
1049,1050
MES
281,282
Miao
1055
Modi
1082
Mongolian
89,1094
Months
55
Mro
1069
Multani
1088
Musical notation
1018
Musical symbols
1004,1005
Myanmar
87,90,155,164
Nabataean
1061
Nandinagari
1121
New Tai Lue
114
Newa
1103
NKo
128
Number
37,152,1009,1015
Nüshu
1108
Nyiakeng Puachue Hmong
1125
Ogham
82
Ol Chiki
135
Old Hungarian
1087
Old Italic
1001
Old North Arabian
1062
Old Permic
1076
76
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Old Persian
1016
Old Sogdian
1109
Old South Arabian
1033
Old Turkic
1036
Optical character recognition
42
Oriya
20
Osage
1093
Osmanya
1012
Ottoman Siyaq Numbers
1127
Pahawh Hmong
1084
Palmyrene
1060
Pau Cin Hau
1068
Phags-pa
132
Phaistos Disc
1023
Phoenician
1019
Phonetic extensions
109,116
Presentation forms
63,64,68,104,105
Private use
61,401
Psalter Pahlavi
1078
Punctuation
32,49,123,1098
Radicals
77〜79
Rejang
139
Rumi numeral symbols
1037
Runic
83
Samaritan
147
Saurashtra
137
Shape, shaping
205,206
Sharada
1053
Shavian
1011
Siddham
1081
Sinhala
84,1064
Small form
67
Sogdian
1110
Sora Sompeng
1051
Soyombo
1105
Spacing modifier
6,125
Specials
70
Strokes
124
Subscripts, superscripts
33
Sundanese
133,161
77
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Sutton SignWriting
1092
Syllables, syllabics
71,74,76
Syloti Nagri
126
Symbols
9,34〜36,47,49,97,100,1027,1044〜1048,
1097,1101,1118
Syriac
85,168
Tagalog
93
Tagbanwa
96
Tags
3001
Tai Tham
143
Tai Viet
145
Tai Xuan Jing symbols
1014
Tail Le
107
Takri
1054
Tamil
21,1122
Tangut
1098,1099
Technical
40
Telugu
22
Thaana
86
Thai
25
Tibetan
72,91
Tifinagh
121
Tirhuta
1067
Ugaritic
1010
Unicode
303〜318,10646
Vai
136
Variation selectors
103,3003
Vedic
149
Vertical form
127
Wancho
1126
Warang Citi
1083
Yi
76,77
Yijing hexagram symbols
111
Zanabazar Square
1104
Zero-width
200
A.2 ブロックの一覧
A.2.1 BMPのブロック
次のブロックは,BMPで規定される。次は,符号位置の順に並べている。
78
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
ブロックの名前
から まで
[日本語による通用名称(参考)]
BASIC LATIN
0020〜007E
(基本ラテン文字)
LATIN-1 SUPPLEMENT
00A0〜00FF
(ラテン1補助)
LATIN EXTENDED-A
0100〜017F
(ラテン文字拡張A)
LATIN EXTENDED-B
0180〜024F
(ラテン文字拡張B)
IPA (INTERNATIONAL PHONETIC ALPHABET) EXTENSIONS
0250〜02AF
(IPA拡張)
SPACING MODIFIER LETTERS
02B0〜02FF
(前進を伴う修飾文字)
COMBINING DIACRITICAL MARKS
0300〜036F
[ダイアクリティカルマーク(合成
可能)]
GREEK AND COPTIC
0370〜03FF
(ギリシア文字及びコプト文字)
CYRILLIC
0400〜04FF
(キリル文字)
CYRILLIC SUPPLEMENT
0500〜052F
(キリル文字補助)
ARMENIAN
0530〜058F
(アルメニア文字)
HEBREW
0590〜05FF
(ヘブライ文字)
ARABIC
0600〜06FF
(アラビア文字)
SYRIAC
0700〜074F
(シリア文字)
ARABIC SUPPLEMENT
0750〜077F
(アラビア文字補助)
THAANA
0780〜07BF
(ターナ文字)
NKO
07C0〜07FF
(ンコ文字)
SAMARITAN
0800〜083F
(サマリア文字)
MANDAIC
0840〜085F
(マンダ文字)
SYRIAC SUPPLEMENT
0860〜086F
(シリア文字補助)
ARABIC EXTENDED-A
08A0〜08FF
(アラビア文字拡張A)
DEVANAGARI
0900〜097F
(デーヴァナーガリー文字)
BENGALI
0980〜09FF
(ベンガル文字)
GURMUKHI
0A00〜0A7F
(グルムキー文字)
GUJARATI
0A80〜0AFF
(グジャラート文字)
ORIYA
0B00〜0B7F
(オリヤー文字)
TAMIL
0B80〜0BFF
(タミル文字)
TELUGU
0C00〜0C7F
(テルグ文字)
KANNADA
0C80〜0CFF
(カンナダ文字)
MALAYALAM
0D00〜0D7F
(マラヤーラム文字)
SINHALA
0D80〜0DFF
(シンハラ文字)
THAI
0E00〜0E7F
(タイ文字)
LAO
0E80〜0EFF
(ラオス文字)
TIBETAN
0F00〜0FFF
(チベット文字)
MYANMAR
1000〜109F
(ミャンマー文字)
GEORGIAN
10A0〜10FF
(ジョージア文字)
HANGUL JAMO
1100〜11FF
(ハングル字母)
79
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
ETHIOPIC
1200〜137F
(エチオピア文字)
ETHIOPIC SUPPLEMENT
1380〜139F
(エチオピア文字補助)
CHEROKEE
13A0〜13FF
(チェロキー文字)
UNIFIED CANADIAN ABORIGINAL SYLLABICS
1400〜167F
(統合カナダ先住民音節)
OGHAM
1680〜169F
(オガム文字)
RUNIC
16A0〜16FF
(ルーン文字)
TAGALOG
1700〜171F
(タガログ文字)
HANUNOO
1720〜173F
(ハヌノオ文字)
BUHID
1740〜175F
(ブヒッド文字)
TAGBANWA
1760〜177F
(タグバヌア文字)
KHMER
1780〜17FF
(クメール文字)
MONGOLIAN
1800〜18AF
(モンゴル文字)
UNIFIED CANADIAN ABORIGINAL SYLLABICS EXTENDED
18B0〜18FF
(統合カナダ先住民音節拡張)
LIMBU
1900〜194F
(リンブ文字)
TAI LE
1950〜197F
(タイ゠ロ文字)
NEW TAI LUE
1980〜19DF
(新タイ゠ロ文字)
KHMER SYMBOLS
19E0〜19FF
(クメール文字用記号)
BUGINESE
1A00〜1A1F
(ブギス文字)
TAI THAM
1A20〜1AAF
(タイ゠タム文字)
COMBINING DIACRITICAL MARKS EXTENDED
1AB0〜1AFF
[ダイアクリティカルマーク(合成
可能)補助]
BALINESE
1B00〜1B7F
(バリ文字)
SUNDANESE
1B80〜1BBF
(スンダ文字)
BATAK
1BC0〜1BFF
(バタク文字)
LEPCHA
1C00〜1C4F
(レプチャ文字)
OL CHIKI
1C50〜1C7F
(オル゠チキ文字)
CYRILLIC EXTENDED
1C80〜1C8F
(キリル文字拡張)
GEORGIAN EXTENDED
1C90〜1CBF
(ジョージア文字拡張)
SUNDANESE SUPPLEMENT
1CC0〜1CCF
(スンダ文字補助)
VEDIC EXTENSIONS
1CD0〜1CFF
(ヴェーダ用拡張)
PHONETIC EXTENSIONS
1D00〜1D7F
(音声記号拡張)
PHONETIC EXTENSIONS SUPPLEMENT
1D80〜1DBF
(音声記号拡張補助)
COMBINING DIACRITICAL MARKS SUPPLEMENT
1DC0〜1DFF
[ダイアクリティカルマーク(合成
可能)補助]
LATIN EXTENDED ADDITIONAL
1E00〜1EFF
(ラテン文字拡張追加)
GREEK EXTENDED
1F00〜1FFF
(ギリシア文字拡張)
80
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
GENERAL PUNCTUATION
2000〜206F
(一般句読点)
SUPERSCRIPTS AND SUBSCRIPTS
2070〜209F
(上付き・下付き)
CURRENCY SYMBOLS
20A0〜20CF
(通貨記号)
COMBINING DIACRITICAL MARKS FOR SYMBOLS
20D0〜20FF
[記号用ダイアクリティカルマーク
(合成可能)]
LETTERLIKE SYMBOLS
2100〜214F
(文字様記号)
NUMBER FORMS
2150〜218F
(数字に準じるもの)
ARROWS
2190〜21FF
(矢印)
MATHEMATICAL OPERATORS
2200〜22FF
(数学記号)
MISCELLANEOUS TECHNICAL
2300〜23FF
(その他の技術用記号)
CONTROL PICTURES
2400〜243F
(制御機能用記号)
OPTICAL CHARACTER RECOGNITION
2440〜245F
(光学的文字認識,OCR)
ENCLOSED ALPHANUMERICS
2460〜24FF
(囲み英数字)
BOX DRAWING
2500〜257F
(けい線素辺)
BLOCK ELEMENTS
2580〜259F
(ブロック要素)
GEOMETRIC SHAPES
25A0〜25FF
(幾何学模様)
MISCELLANEOUS SYMBOLS
2600〜26FF
(その他の記号)
DINGBATS
2700〜27BF
(装飾記号)
MISCELLANEOUS MATHEMATICAL SYMBOLS-A
27C0〜27EF
(その他の数学記号A)
SUPPLEMENTAL ARROWS-A
27F0〜27FF
(補助矢印A)
BRAILLE PATTERNS
2800〜28FF
(点字図形)
SUPPLEMENTAL ARROWS-B
2900〜297F
(補助矢印B)
MISCELLANEOUS MATHEMATICAL SYMBOLS-B
2980〜29FF
(その他の数学記号B)
SUPPLEMENTAL MATHEMATICAL OPERATORS
2A00〜2AFF
(補助数学記号)
MISCELLANEOUS SYMBOLS AND ARROWS
2B00〜2BFF
(その他の記号及び矢印)
GLAGOLITIC
2C00〜2C5F
(グラゴル文字)
LATIN EXTENDED-C
2C60〜2C7F
(ラテン文字拡張C)
COPTIC
2C80〜2CFF
(コプト文字)
GEORGIAN SUPPLEMENT
2D00〜2D2F
(ジョージア文字補助)
TIFINAGH
2D30〜2D7F
(ティフナグ文字)
ETHIOPIC EXTENDED
2D80〜2DDF
(エチオピア文字拡張)
CYRILLIC EXTENDED-A
2DE0〜2DFF
(キリル文字拡張A)
SUPPLEMENTAL PUNCTUATION
2E00〜2E7F
(補助句読点)
CJK RADICALS SUPPLEMENT
2E80〜2EFF
(CJK部首補助)
KANGXI RADICALS
2F00〜2FDF
(康熙部首)
IDEOGRAPHIC DESCRIPTION CHARACTERS
81
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2FF0〜2FFF
(漢字構成記述文字,IDC)
CJK SYMBOLS AND PUNCTUATION
3000〜303F
(CJKの記号及び句読点)
HIRAGANA
3040〜309F
(平仮名)
KATAKANA
30A0〜30FF
(片仮名)
BOPOMOFO
3100〜312F
(注音字母)
HANGUL COMPATIBILITY JAMO
3130〜318F
(ハングル互換字母)
KANBUN (CJK miscellaneous)
3190〜319F
[漢文用記号(その他のCJK文字)]
BOPOMOFO EXTENDED
31A0〜31BF
(注音字母拡張)
CJK STROKES
31C0〜31EF
(CJKの筆画)
KATAKANA PHONETIC EXTENSIONS
31F0〜31FF
(片仮名拡張)
ENCLOSED CJK LETTERS AND MONTHS
3200〜32FF
(囲みCJK文字・月)
CJK COMPATIBILITY
3300〜33FF
(CJK互換用文字)
CJK UNIFIED IDEOGRAPHS EXTENSION A
3400〜4DBF
(CJK統合漢字拡張A)
YIJING HEXAGRAM SYMBOLS
4DC0〜4DFF
(易経記号)
CJK UNIFIED IDEOGRAPHS
4E00〜9FFF
(CJK統合漢字)
YI SYLLABLES
A000〜A48F
(イ文字)
YI RADICALS
A490〜A4CF
(イ文字部首)
LISU
A4D0〜A4FF
(リス文字)
VAI
A500〜A63F
(ヴァイ文字)
CYRILLIC EXTENDED-B
A640〜A69F
(キリル文字拡張B)
BAMUM
A6A0〜A6FF
(バムン文字)
MODIFIER TONE LETTERS
A700〜A71F
(声調修飾文字)
LATIN EXTENDED-D
A720〜A7FF
(ラテン文字拡張D)
SYLOTI NAGRI
A800〜A82F
(シロティナーガリー文字)
COMMON INDIC NUMBER FORMS
A830〜A83F
(インド慣用数量記号)
PHAGS-PA
A840〜A87F
(パスパ文字)
SAURASHTRA
A880〜A8DF
(サウラーシュトラ文字)
DEVANAGARI EXTENDED
A8E0〜A8FF
(デーヴァナーガリー文字拡張)
KAYAH LI
A900〜A92F
(カヤー文字)
REJANG
A930〜A95F
(レジャン文字)
HANGUL JAMO EXTENDED-A
A960〜A97F
(ハングル字母拡張A)
JAVANESE
A980〜A9DF
(ジャワ文字)
MYANMAR EXTENDED-B
A9E0〜A9FF
(ミャンマー文字拡張B)
CHAM
AA00〜AA5F
(チャム文字)
MYANMAR EXTENDED-A
AA60〜AA7F
(ミャンマー文字拡張A)
TAI VIET
AA80〜AADF
(タイ゠ヴィエト文字)
MEETEI MAYEK EXTENSIONS
AAE0〜AAFF
(メイテイ文字拡張)
ETHIOPIC EXTENDED-A
AB00〜AB2F
(エチオピア文字拡張A)
LATIN EXTENDED-E
AB30〜AB6F
(ラテン文字拡張E)
82
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
CHEROKEE SUPPLEMENT
AB70〜ABBF
(チェロキー文字補助)
MEETEI MAYEK
ABC0〜ABFF
(メイテイ文字)
HANGUL SYLLABLES
AC00〜D7A3
(ハングル音節文字)
HANGUL JAMO EXTENDED-B
D7B0〜D7FF
(ハングル字母拡張B)
PRIVATE USE AREA
E000〜F8FF
(私用領域)
CJK COMPATIBILITY IDEOGRAPHS
F900〜FAFF
(CJK互換漢字)
ALPHABETIC PRESENTATION FORMS
FB00〜FB4F
(アルファベット表示形)
ARABIC PRESENTATION FORMS-A
FB50〜FDFF
(アラビア表示形A)
VARIATION SELECTORS
FE00〜FE0F
(字形選択子)
VERTICAL FORMS
FE10〜FE1F
(縦書き形)
COMBINING HALF MARKS
FE20〜FE2F
[半記号(合成可能)]
CJK COMPATIBILITY FORMS
FE30〜FE4F
(CJK互換形)
SMALL FORM VARIANTS
FE50〜FE6F
(小字形)
ARABIC PRESENTATION FORMS-B
FE70〜FEFE
(アラビア表示形B)
HALFWIDTH AND FULLWIDTH FORMS
FF00〜FFEF
(半角・全角形)
SPECIALS
FFF0〜FFFD
(特殊用途文字)
A.2.2 SMPのブロック
次のブロックは,SMPで規定される。次は,符号位置の順に並べている。
ブロックの名前
から まで
[日本語による通用名称(参考)]
LINEAR B SYLLABARY
10000〜1007F
(線文字B音節文字)
LINEAR B IDEOGRAMS
10080〜100FF
(線文字B表意文字)
AEGEAN NUMBERS
10100〜1013F
(エーゲ数字)
ANCIENT GREEK NUMBERS
10140〜1018F
(古代ギリシア数字)
ANCIENT SYMBOLS
10190〜101CF
(古代記号)
PHAISTOS DISC
101D0〜101FF
(ファイストスの円盤文字)
LYCIAN
10280〜1029F
(リュキア文字)
CARIAN
102A0〜102DF
(カリア文字)
COPTIC EPACT NUMBERS
102E0〜102FF
(コプト゠エパクト数字)
OLD ITALIC
10300〜1032F
(古代イタリア文字)
GOTHIC
10330〜1034F
(ゴート文字)
OLD PERMIC
10350〜1037F
(古ペルム文字)
UGARITIC
10380〜1039F
(ウガリト文字)
OLD PERSIAN
103A0〜103DF
(古代ペルシャ文字)
DESERET
10400〜1044F
(デザレット文字)
SHAVIAN
10450〜1047F
(ショー文字)
OSMANYA
10480〜104AF
(オスマニア文字)
OSAGE
104B0〜104FF
(オセージ文字)
ELBASAN
10500〜1052F
(エルバサン文字)
CAUCASIAN ALBANIAN
10530〜1056F
(カフカース゠アルバニア文字)
LINEAR A
10600〜1077F
(線文字A)
83
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
CYPRIOT SYLLABARY
10800〜1083F
(キプロス音節文字)
IMPERIAL ARAMAIC
10840〜1085F
(帝国アラム文字)
PALMYRENE
10860〜1087F
(パルミラ文字)
NABATAEAN
10880〜108AF
(ナバテア文字)
HATRAN
108E0〜108FF
(ハトラ文字)
PHOENICIAN
10900〜1091F
(フェニキア文字)
LYDIAN
10920〜1093F
(リュディア文字)
MEROITIC HIEROGLYPHS
10980〜1099F
(メロエ文字楷書体)
MEROITIC CURSIVE
109A0〜109FF
(メロエ文字草書体)
KHAROSHTHI
10A00〜10A5F
(カローシュティー文字)
OLD SOUTH ARABIAN
10A60〜10A7F
(古代南アラビア文字)
OLD NORTH ARABIAN
10A80〜10A9F
(古代北アラビア文字)
MANICHAEAN
10AC0〜10AFF
(マニ文字)
AVESTAN
10B00〜10B3F
(アヴェスタ文字)
INSCRIPTIONAL PARTHIAN
10B40〜10B5F
(碑文パルティア文字)
INSCRIPTIONAL PAHLAVI
10B60〜10B7F
(碑文パフラヴィ文字)
PSALTER PAHLAVI
10B80〜10BAF
(詩篇パフラヴィ文字)
OLD TURKIC
10C00〜10C4F
(突厥文字)
OLD HUNGARIAN
10C80〜10CFF
(古代ハンガリー文字)
HANIFI ROHINGYA
10D00〜10D3F
(ハニーフィー゠ロヒンギャ文字)
RUMI NUMERAL SYMBOLS
10E60〜10E7F
(ルミ数字記号)
OLD SOGDIAN
10F00〜10F2F
(古代ソグド文字)
SOGDIAN
10F30〜10F6F
(ソグド文字)
ELYMAIC
10FE0〜10FFF
(エリマイス文字)
BRAHMI
11000〜1107F
(ブラーフミー文字)
KAITHI
11080〜110CF
(カイティー文字)
SORA SOMPENG
110D0〜110FF
(ソラングソンペング文字)
CHAKMA
11100〜1114F
(チャクマ文字)
MAHAJANI
11150〜1117F
(マハージャニー文字)
SHARADA
11180〜111DF
(シャーラダー文字)
SINHALA ARCHAIC NUMBERS
111E0〜111FF
(シンハラ旧数字)
KHOJKI
11200〜1124F
(ホジャ文字)
MULTANI
11280〜112AF
(ムルターニー文字)
KHUDAWADI
112B0〜112FF
(クダワーディー文字)
GRANTHA
11300〜1137F
(グランタ文字)
NEWA
11400〜1147F
(ネワール文字)
TIRHUTA
11480〜114DF
(ティルフティー文字)
SIDDHAM
11580〜115FF
(悉曇文字)
MODI
11600〜1165F
(モーディー文字)
MONGOLIAN SUPPLEMENT
11660〜1167F
(モンゴル文字補助)
84
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
TAKRI
11680〜116CF
(タークリー文字)
AHOM
11700〜1173F
(アーホム文字)
DOGRA
11800〜1184F
(ドーグリー文字)
WARANG CITI
118A0〜118FF
(ワラング゠クシティ文字)
NANDINAGARI
119A0〜119FF
(ナンディナーガリー文字)
ZANABAZAR SQUARE
11A00〜11A4F
(ザナバザル方形文字)
SOYOMBO
11A50〜11AAF
(ソヨンボ文字)
PAU CIN HAU
11AC0〜11AFF
(パウ゠チン゠ハウ文字)
BHAIKSUKI
11C00〜11C6F
(バイクシュキー文字)
MARCHEN
11C70〜11CBF
(マーチェン文字)
MASARAM GONDI
11D00〜11D5F
(マサラム゠ゴーンディー文字)
GUNJALA GONDI
11D60〜11DAF
(グンジャラ゠ゴーンディー文字)
MAKASAR
11EE0〜11EFF
(マカッサル文字)
TAMIL SUPPLEMENT
11FC0〜11FFF
(タミル文字補助)
CUNEIFORM
12000〜123FF
(くさび形文字)
CUNEIFORM NUMBERS AND PUNCTUATION
12400〜1247F
(くさび形文字の数字及び句読点)
EARLY DYNASTIC CUNEIFORM
12480〜1254F
(初期王朝くさび形文字)
EGYPTIAN HIEROGLYPHS
13000〜1342F
(エジプト聖刻文字)
EGYPTIAN HIEROGLYPHS FORMAT CONTROLS
13430〜1343F
(エジプト聖刻文字制御記号)
ANATOLIAN HIEROGLYPHS
14400〜1467F
(アナトリア象形文字)
BAMUM SUPPLEMENT
16800〜16A3F
(バムン文字補助)
MRO
16A40〜16A6F
(ムロ文字)
BASSA VAH
16AD0〜16AFF (バサ文字)
PAHAWH HMONG
16B00〜16B8F
(パハウ゠フモン文字)
MEDEFAIDRIN
16E40〜16E9F
(メデファイドリン文字)
MIAO
16F00〜16F9F
(ミャオ文字)
IDEOGRAPHIC SYMBOLS AND PUNCTUATION
16FE0〜16FFF
(漢字の記号及び句読点)
TANGUT
17000〜187EF
(西夏文字)
TANGUT COMPONENTS
18800〜18AFF
(西夏文字要素)
KANA SUPPLEMENT
1B000〜1B0FF
(仮名補助)
KANA EXTENDED-A
1B100〜1B12F
(仮名拡張A)
SMALL KANA EXTENSION
1B130〜1B16F
(小仮名拡張)
NUSHU
1B170〜1B2FF
(女書)
DUPLOYAN
1BC00〜1BC9F
(デュプロワイエ式速記文字)
SHORTHAND FORMAT CONTROL
1BCA0〜1BCAF (速記書式制御記号)
BYZANTINE MUSICAL SYMBOLS
1D000〜1D0FF
(ビザンチン音楽記号)
MUSICAL SYMBOLS
1D100〜1D1FF
(音楽記号)
85
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
ANCIENT GREEK MUSICAL NOTATION
1D200〜1D24F
(古代ギリシア音符記号)
MAYAN NUMERALS
1D2E0〜1D2FF
(マヤ数字)
TAI XUAN JING SYMBOLS
1D300〜1D35F
(太玄経記号)
COUNTING ROD NUMERALS
1D360〜1D37F
(算木用数字)
MATHEMATICAL ALPHANUMERIC SYMBOLS
1D400〜1D7FF
(数学用英数字記号)
SUTTON SIGNWRITING
1D800〜1DAAF (サットン手話文字)
GLAGOLITIC SUPPLEMENT
1E000〜1E02F
(グラゴル文字補助)
NYIAKENG PUACHUE HMONG
1E100〜1E14F
(ニヤケン゠プアチュ゠フモン文字)
WANCHO
1E2C0〜1E2FF
(ワンチョ文字)
MENDE KIKAKUI
1E800〜1E8DF
(メンデ文字)
ADLAM
1E900〜1E95F
(アドラム文字)
INDIC SIYAQ NUMBERS
1EC70〜1ECBF (インド゠シヤク数字)
OTTOMAN SYAQ NUMBERS
1ED00〜1ED4F
(オスマン゠シヤク数字)
ARABIC MATHEMATICAL ALPHABETICAL SYMBOLS
1EE00〜1EEFF
(アラビア数学記号)
MAHJONG TILES
1F000〜1F02F
(マージャン記号)
DOMINO TILES
1F030〜1F09F
(ドミノ記号)
PLAYING CARDS
1F0A0〜1F0FF
(トランプ記号)
ENCLOSED ALPHANUMERIC SUPPLEMENT
1F100〜1F1FF
(囲み英数字補助)
ENCLOSED IDEOGRAPHIC SUPPLEMENT
1F200〜1F2FF
(囲み漢字補助)
MISCELLANEOUS SYMBOLS AND PICTOGRAPHS
1F300〜1F5FF
(その他の記号及び絵記号)
EMOTICONS
1F600〜1F64F
(顔文字)
ORNAMENTAL DINGBATS
1F650〜1F67F
(装飾用絵記号)
TRANSPORT AND MAP SYMBOLS
1F680〜1F6FF
(交通及び地図記号)
ALCHEMICAL SYMBOLS
1F700〜1F77F
(錬金術記号)
GEOMETRIC SHAPES EXTENDED
1F780〜1F7FF
(幾何学模様拡張)
SUPPLEMENTAL ARROWS-C
1F800〜1F8FF
(補助矢印C)
SUPPLEMENTAL SYMBOLS AND PICTOGRAPHS
1F900〜1F9FF
(補助記号及び絵記号)
CHESS SYMBOLS
1FA00〜1FA6F
(チェス記号)
A.2.3 SIPのブロック
次のブロックは,SIPで規定される。次は,符号位置の順に並べている。
ブロックの名前
から まで
[日本語による通用名称(参考)]
CJK UNIFIED IDEOGRAPHS EXTENSION B
20000〜2A6DF
(CJK統合漢字拡張B)
CJK UNIFIED IDEOGRAPHS EXTENSION C
2A700〜2B73F
(CJK統合漢字拡張C)
CJK UNIFIED IDEOGRAPHS EXTENSION D
86
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2B740〜2B81F
(CJK統合漢字拡張D)
CJK UNIFIED IDEOGRAPHS EXTENSION E
2B820〜2CEAF
(CJK統合漢字拡張E)
CJK UNIFIED IDEOGRAPHS EXTENSION F
2CEB0〜2EBEF (CJK統合漢字拡張F)
CJK COMPATIBILITY IDEOGRAPHS SUPPLEMENT
2F800〜2FA1F
(CJK互換漢字補助)
A.2.4 SSPのブロック
次のブロックは,SSPで規定される。次は,符号位置の順に並べている。
ブロックの名前
から まで
[日本語による通用名称(参考)]
TAGS
E0000〜E007F
(タグ)
VARIATION SELECTORS SUPPLEMENT
E0100〜E01EF
(字形選択子補助)
A.3 BMP全体の確定組(ユニコードの組を除く。)
A.3.1 概要
次に示す確定組(3.26参照)は,この規格の以前の版が発行された時点でのUCSの割当て済み文字全て
を含む。ユニコードの組は,A.6に示す。
A.3.2 301 BMP-AMD.7
組番号301の確定組BMP-AMD.7は,次のとおり規定する。これは,ISO/IEC 10646-1の最初の版に,
国際規格の追補7までの変更だけを適用した結果のBMPに含まれていた符号化文字だけからなる。した
がって,この組のレパートリは,それ以降の変更によって新しい文字がBMPに加えられても,変更の対
象にならない。
組301 BMP-AMD.7は,次のそれぞれの区又は隣接した区の列で示す符号位置の範囲によって規定する。
面00
区
区の中の値
00
20〜7E,A0〜FF
01
00〜F5,FA〜FF
02
00〜17,50〜A8,B0〜DE,E0〜E9
03
00〜45,60〜61,74〜75,7A,7E,84〜8A,8C,8E〜A1,A3〜CE,D0〜D6,DA,DC,
DE,E0,E2〜F3
04
01〜0C,0E〜4F,51〜5C,5E〜86,90〜C4,C7〜C8,CB〜CC,D0〜EB,EE〜F5,
F8〜F9
05
31〜56,59〜5F,61〜87,89,91〜A1,A3〜B9,BB〜C4,D0〜EA,F0〜F4
06
0C,1B,1F,21〜3A,40〜52,60〜6D,70〜B7,BA〜BE,C0〜CE,D0〜ED,F0〜F9
09
01〜03,05〜39,3C〜4D,50〜54,58〜70,81〜83,85〜8C,8F〜90,93〜A8,AA,B0,
B2,B6〜B9,BC,BE〜C4,C7〜C8,CB〜CD,D7,DC〜DD,DF〜E3,E6〜FA
0A
02,05〜0A,0F〜10,13〜28,2A〜30,32〜33,35〜36,38〜39,3C,3E〜42,47〜48,
4B〜4D,59〜5C,5E,66〜74,81〜83,85〜8B,8D,8F〜91,93〜A8,AA〜B0,
B2〜B3,B5〜B9,BC〜C5,C7〜C9,CB〜CD,D0,E0,E6〜EF
0B
01〜03,05〜0C,0F〜10,13〜28,2A〜30,32〜33,36〜39,3C〜43,47〜48,4B〜4D,
87
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
56〜57,5C〜5D,5F〜61,66〜70,82〜83,85〜8A,8E〜90,92〜95,99〜9A,9C,
9E〜9F,A3〜A4,A8〜AA,AE〜B5,B7〜B9,BE〜C2,C6〜C8,CA〜CD,D7,E7〜F2
0C
01〜03,05〜0C,0E〜10,12〜28,2A〜33,35〜39,3E〜44,46〜48,4A〜4D,55〜56,
60〜61,66〜6F,82〜83,85〜8C,8E〜90,92〜A8,AA〜B3,B5〜B9,BE〜C4,
C6〜C8,CA〜CD,D5〜D6,DE,E0〜E1,E6〜EF
0D
02〜03,05〜0C,0E〜10,12〜28,2A〜39,3E〜43,46〜48,4A〜4D,57,60〜61,
66〜6F
0E
01〜3A,3F〜5B,81〜82,84,87〜88,8A,8D,94〜97,99〜9F,A1〜A3,A5,A7,
AA〜AB,AD〜B9,BB〜BD,C0〜C4,C6,C8〜CD,D0〜D9,DC〜DD
0F
00〜47,49〜69,71〜8B,90〜95,97,99〜AD,B1〜B7,B9
10
A0〜C5,D0〜F6,FB
11
00〜59,5F〜A2,A8〜F9
1E
00〜9B,A0〜F9
1F
00〜15,18〜1D,20〜45,48〜4D,50〜57,59,5B,5D,5F〜7D,80〜B4,B6〜C4,
C6〜D3,D6〜DB,DD〜EF,F2〜F4,F6〜FE
20
00〜2E,30〜46,6A〜70,74〜8E,A0〜AB,D0〜E1
21
00〜38,53〜82,90〜EA
22
00〜F1
23
00,02〜7A
24
00〜24,40〜4A,60〜EA
25
00〜95,A0〜EF
26
00〜13,1A〜6F
27
01〜04,06〜09,0C〜27,29〜4B,4D,4F〜52,56,58〜5E,61〜67,76〜94,98〜AF,
B1〜BE
30
00〜37,3F,41〜94,99〜9E,A1〜FE
31
05〜2C,31〜8E,90〜9F
32
00〜1C,20〜43,60〜7B,7F〜B0,C0〜CB,D0〜FE
33
00〜76,7B〜DD,E0〜FE
4E〜9F
4E00〜9FA5
AC〜D7 AC00〜D7A3
E0〜F8
E000〜F8FF
F9〜FA F900〜FA2D
FB
00〜06,13〜17,1E〜36,38〜3C,3E,40〜41,43〜44,46〜B1,D3〜FF
FC
00〜FF
FD
00〜3F,50〜8F,92〜C7,F0〜FB
FE
20〜23,30〜44,49〜52,54〜66,68〜6B,70〜72,74,76〜FC,FF
FF
01〜5E,61〜BE,C2〜C7,CA〜CF,D2〜D7,DA〜DC,E0〜E6,E8〜EE,FD
A.3.3 299 BMP FIRST EDITION
組番号299の確定組BMP FIRST EDITIONは,ISO/IEC 10646-1の最初の版のBMPに含まれていた符
号化文字の全てを識別するために保留されている。この組は,今では,この規格に適合するものではない。
88
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記 組299 BMP FIRST EDITIONの定義は,次に示す二つの変更を除いて,組301 BMP-AMD.7の
規定と同じであった。
次のとおり,対応する区の内容を置き換える。
区
区の中の値
05
31〜56,59〜5F,61〜87,89,B0〜B9,BB〜C3,D0〜EA,F0〜F4
0F
(該当する位置なし)
1E
00〜9A,A0〜F9
20
00〜2E,30〜46,6A〜70,74〜8E,A0〜AA,D0〜E1
AC〜D7 (該当する位置なし)
ISO/IEC 10646-1の最初の版以降にこの規格から削除した符号化文字が含まれていた三つの
組(57〜59)に対応する符号の範囲に関連して次の区の範囲を含める。
区
区の中の値
34〜4D
3400〜4DFF
A.3.4 302 BMP SECOND EDITION
組番号302の確定組BMP SECOND EDITIONは,ISO/IEC 10646-1の第2版のBMPに含まれる符号化
文字だけからなる。この組のレパートリは,それ以降の変更によって新しい文字がBMPに追加されても,
変更の対象にならない。
組302 BMP SECOND EDITIONは,次の,それぞれの区又は隣接した区の列によって示す符号位置の範
囲によって規定する。
面00
区
区の中の値
00
20〜7E,A0〜FF
01
00〜FF
02
00〜1F,22〜33,50〜AD,B0〜EE
03
00〜4E,60〜62,74〜75,7A,7E,84〜8A,8C,8E〜A1,A3〜CE,D0〜D7,DA〜F3
04
00〜86,88〜89,8C〜C4,C7〜C8,CB〜CC,D0〜F5,F8〜F9
05
31〜56,59〜5F,61〜87,89〜8A,91〜A1,A3〜B9,BB〜C4,D0〜EA,F0〜F4
06
0C,1B,1F,21〜3A,40〜55,60〜6D,70〜ED,F0〜FE
07
00〜0D,0F〜2C,30〜4A,80〜B0
09
01〜03,05〜39,3C〜4D,50〜54,58〜70,81〜83,85〜8C,8F〜90,93〜A8,AA〜B0,
B2,B6〜B9,BC,BE〜C4,C7〜C8,CB〜CD,D7,DC〜DD,DF〜E3,E6〜FA
0A
02,05〜0A,0F〜10,13〜28,2A〜30,32〜33,35〜36,38〜39,3C,3E〜42,47〜48,
4B〜4D,59〜5C,5E,66〜74,81〜83,85〜8B,8D,8F〜91,93〜A8,AA〜B0,
B2〜B3,B5〜B9,BC〜C5,C7〜C9,CB〜CD,D0,E0,E6〜EF
0B
01〜03,05〜0C,0F〜10,13〜28,2A〜30,32〜33,36〜39,3C〜43,47〜48,4B〜4D,
56〜57,5C〜5D,5F〜61,66〜70,82〜83,85〜8A,8E〜90,92〜25,99〜9A,9C,
9E〜9F,A3〜A4,A8〜AA,AE〜B5,B7〜B9,BE〜C2,C6〜C8,CA〜CD,D7,E7〜F2
0C
01〜03,05〜0C,0E〜10,12〜28,2A〜33,35〜39,3E〜44,46〜48,4A〜4D,55〜56,
60〜61,66〜6F,82〜83,85〜8C,8E〜90,92〜A8,AA〜B3,B5〜B9,BE〜C4,
C6〜C8,CA〜CD,D5〜D6,DE,E0〜E1,E6〜EF
89
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
0D
02〜03,05〜0C,0E〜10,12〜28,2A〜39,3E〜43,46〜48,4A〜4D,57,60〜61,
66〜6F,82〜83,85〜96,9A〜B1,B3〜BB,BD,C0〜C6,CA,CF〜D4,D6,D8〜DF,
F2〜F4
0E
01〜3A,3F〜5B,81〜82,84,87〜88,8A,8D,94〜97,99〜9F,A1〜A3,A5,A7,
AA〜AB,AD〜B9,BB〜BD,C0〜C4,C6,C8〜CD,D0〜D9,DC〜DD
0F
00〜47,49〜6A,71〜8B,90〜97,99〜BC,BE〜CC,CF
10
00〜21,23〜27,29〜2A,2C〜32,36〜39,40〜59,A0〜C5,D0〜F6,FB
11
00〜59,5F〜A2,A8〜F9
12
20〜26,28〜46,48,4A〜4D,50〜56,58,5A〜5D,60〜86,88,8A〜8D,90〜AE,B0,
B2〜B5,B8〜BE,C0,C2〜C5,C8〜CE,D0〜D6,D8〜EE,F0〜FF
13
00〜0E,10,12〜15,18〜1E,20〜46,48〜5A,61〜7C,A0〜F4
14〜15
1401〜15FF
16
00〜76,80〜9C,A0〜F0
17
80〜DC,E0〜E9
18
00〜0E,10〜19,20〜77,80〜A9
1E
00〜9B,A0〜F9
1F
00〜15,18〜1D,20〜45,48〜4D,50〜57,59,5B,5D,5F〜7D,80〜B4,B6〜C4,
C6〜D3,D6〜DB,DD〜EF,F2〜F4,F6〜FE
20
00〜46,48〜4D,6A〜70,74〜8E,A0〜AF,D0〜E3
21
00〜3A,53〜83,90〜F3
22
00〜F1
23
00〜7B,7D〜9A
24
00〜26,40〜4A,60〜EA
25
00〜95,A0〜F7
26
00〜13,19〜71
27
01〜04,06〜09,0C〜27,29〜4B,4D,4F〜52,56,58〜5E,61〜67,76〜94,98〜AF,
B1〜BE
28
00〜FF
2E
80〜99,9B〜F3
2F
00〜D5,F0〜FB
30
00〜3A,3E〜3F,41〜94,99〜9E,A1〜FE
31
05〜2C,31〜8E,90〜B7
32
00〜1C,20〜43,60〜7B,7F〜B0,C0〜CB,D0〜FE
33
00〜76,7B〜DD,E0〜FE
34〜4D
3400〜4DB5
4E〜9F
4E00〜9FA5
A0〜A3 A000〜A3FF
A4
00〜8C,90〜A1,A4〜B3,B5〜C0,C2〜C4,C6
AC〜D7 AC00〜D7A3
E0〜F8
E000〜F8FF
90
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
F9〜FA F900〜FA2D
FB
00〜06,13〜17,1D〜36,38〜3C,3E,40〜41,43〜44,46〜B1,D3〜FF
FC
00〜FF
FD
00〜3F,50〜8F,92〜C7,F0〜FB
FE
20〜23,30〜44,49〜52,54〜66,68〜6B,70〜72,74,76〜FC,FF
FF
01〜5E,61〜BE,C2〜C7,CA〜CF,D2〜D7,DA〜DC,E0〜E6,E8〜EE,F9〜FD
A.3.5 340 COMBINED FIRST EDITION
組番号340の確定組COMBINED FIRST EDITIONは,次のとおり規定する。組340は,この規格の対
応国際規格の最初の版であるISO/IEC 10646:2003に含まれていた符号化文字だけを含み,A.1及びA.3に
示す幾つかの組と幾つかの符号位置の範囲とからなる。この組を,面ごとに次に示す。
面00
組番号
名前
302
BMP SECOND EDITION
98
SUPPLEMENTAL ARROWS-A
99
SUPPLEMENTAL ARROWS-B
100
MISCELLANEOUS MATHEMATICAL SYMBOLS-B
101
SUPPLEMENTAL MATHEMATICAL OPERATORS
102
KATAKANA PHONETIC EXTENSIONS
103
VARIATION SELECTORS
108
KHMER SYMBOLS
111
YIJING HEXAGRAM SYMBOLS
区
区の中の値
02
20〜21,34〜36,AE〜AF,EF〜FF
03
4F〜57,5D〜5F,63〜6F,D8〜D9,F4〜FB
04
8A〜8B,C5〜C6,C9〜CA,CD〜CE
05
00〜0F
06
00〜03,0D〜15,56〜58,6E〜6F,EE〜EF,FF
07
2D〜2F,4D〜4F,B1
09
04,BD
0A
01,03,8C,E1〜E3,F1
0B
35,71,F3〜FA
0C
BC〜BD
10
F7〜F8
17
00〜0C,0E〜14,20〜36,40〜53,60〜6C,6E〜70,72〜73,DD,F0〜F9
19
00〜1C,20〜2B,30〜3B,40,44〜4F,50〜6D,70〜74
1D
00〜6B
20
47,4E〜54,57,5F〜63,71,B0〜B1,E4〜EA
21
3B,3D〜4B,F4〜FF
22
F2〜FF
23
7C,9B〜D0
91
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
24
EB〜FF
25
96〜9F,F8〜FF
26
14〜17,72〜7D,80〜91,A0〜A1
27
68〜75,D0〜EB
2B
00〜0D
30
3B〜3D,95〜96,9F〜A0,FF
32
1D〜1E,50〜5F,7C〜7D,B1〜BF,CC〜CF
33
77〜7A,DE〜DF,FF
A4
A2〜A3,B4,C1,C5
FA
30〜6A
FD
FC〜FD
FE
45〜48,73
FF
5F〜60
面01
組番号
名前
1003
DESERET
1011
SHAVIAN
区
区の中の値
00
00〜0B,0D〜26,28〜3A,3C〜3D,3F〜4D,50〜5D,80〜FA
01
00〜02,07〜33,37〜3F
03
80〜9D,9F
04
80〜9D,A0〜A9
08
00〜05,08,0A〜35,37〜38,3C,3F
D0
00〜F5
D1
00〜26,2A〜DD
D3
00〜56
D4
00〜54,56〜9C,9E〜9F,A2,A5〜A6,A9〜AC,AE〜B9,BB,BD〜C3,C5〜FF
D5
00〜05,07〜0A,0D〜14,16〜1C,1E〜39,3B〜3E,40〜44,46,4A〜50,52〜FF
D6
00〜A3,A8〜FF
D7
00〜C9,CE〜FF
面02
区
区の中の値
00〜A6
0000〜A6D6
F8〜FA F800〜FA1D
面0E
組番号
名前
3003
VARIATION SELECTORS SUPPLEMENT
区
区の中の値
00
01,20〜7F
92
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
面0F
区
区の中の値
00〜FF
0000〜FFFD
面10
区
区の中の値
00〜FF
0000〜FFFD
A.4 CJKの組
A.4.1 370 IICORE
組番号370の確定組IICOREは,組CJK UNIFIED IDEOGRAPHS-2001の,中核となる国際的な部分
集合である。
注記1 文字数(9 810字)が多く符号位置の範囲が不連続なので,この組は,符号位置の一覧を文章
中に列挙するのではなく添付ファイルによって規定している。
注記2 IICOREについては,UTCから改正案が提出され,SC2において審議が進行している。
添付ファイル“IICORE.txt”は,CJK漢字の原典参照として用いられたものと同じものである。IICORE
タグ(kIICORE)が記載されていることで,その漢字が組IICOREに含まれることを示している(23.2を
参照)。
A.4.2 371 JIS2004 IDEOGRAPHICS EXTENSION
組番号371の確定組JIS2004 IDEOGRAPHICS EXTENSION(JIS2004拡張漢字集合)は,JIS X 0213:2004
の第3水準及び第4水準漢字からなる。組371は3 695文字を含む。
注記 文字数(3 695字)が多く符号位置の範囲が不連続なので,この組は,符号位置の一覧を文章中
に列挙するのではなく添付ファイルによって規定する。
この組の符号位置は,CJK統合漢字の原典参照ファイル(CJKSrc.txt)における原典J3の漢字(J3,J3A,
J13,J13A及びJA3),並びに原典J4の漢字(J4,J14及びJA4)と一致する(23.1及び23.2参照)。
A.4.3 372 JAPANESE IDEOGRAPHICS SUPPLEMENT
組番号372の確定組JAPANESE IDEOGRAPHICS SUPPLEMENT(補助漢字集合)は,JIS X 0212:1990
の全ての漢字からなる。組372は,5 801文字を含む。
注記 組371と組372とは,2 742文字を共有している。
この組の符号位置は,CJK統合漢字の原典参照ファイル(CJKSrc.txt)においてJ1,J13,J13A及びJ14
で識別される原典Jの漢字全てとする(23.1参照)。
A.4.4 373 JAPANESE IT VENDORS CONTEMPORARY IDEOGRAPHS-1993(国内5社漢字統合表,
1993)
組番号373の確定組JAPANESE IT VENDORS CONTEMPORARY IDEOGRAPHS-1993は,国内5社漢字
統合表,1993に規定されている全ての漢字から構成されている。組373は660文字を含む。
この組の符号位置は,CJK統合漢字の原典参照ファイル(CJKSrc.txt)においてJA,JA3及びJ14で識
別される原典Jの漢字全てとする(23.1参照)。
A.4.5 374 JAPANESE JIS X 0213:2004 IDEOGRAPHS FROM PREVIOUS JIS STANDARDS
組番号374の確定組JAPANESE JIS X 0213:2004 IDEOGRAPHS FROM PREVIOUS JIS STANDARDS
(日本語JIS X 0213:2004のうち,既存のJISに含まれている漢字)は,2 828文字を含んでいる。そのう
ち,2 743文字はJIS X 0212-1990(対応国際規格の前の版でJ1として参照されていたもの)であり,85
93
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
文字は,国内5社漢字統合表,1993(対応国際規格の前の版でJAとして参照されていたもの)の一部で
ある。2 828文字のうち,205文字はその例示字形が若干変更されている。これら2 828文字は,23.1で記
載した原典を指示する接頭辞としては,J13,J13A,J14及びJA4が用いられている。
注記 文字数が多く符号位置の範囲が不連続なので,この組は,符号位置の一覧を文章中に列挙する
のではなく添付ファイルによって規定している。
確定組274は,機械可読形式の添付ファイル“JIS-X-0213-FromPrevious.txt”によって定義される。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルの先頭の7行はヘッダであり,その後に組に含まれる文字と
同じ数の行が続く。各行は,固定長フィールドで次の情報を含む。
− 項目1は,UCSの基本多言語面の符号位置(hhhh)を示す。項目1は,必須とする。
− 項目2は,この規格の前の版における日本の原典参照を示す。
− 項目3は,この規格における日本の原典参照を示す。
各フィールドはSPACEで区切られている。符号位置の“h”は,16進数の1桁を示す。日本の原典参照
は23.3に記載した様式で記述してある。
A.4.6 375 JAPANESE CORE KANJI
組番号375の確定組JAPANESE CORE KANJI(日本語中核漢字集合)は,2 136文字のCJK漢字からな
る。これらのうち4文字を除く全ての文字はJ0で識別される。4文字はU+525D (原典J3A),U+5861 (原
典J13),U+9830 (原典J13)及びU+20B9F (原典J3A)である。
注記 文字数が多く符号位置の範囲が不連続なので,この組は,符号位置の一覧を文章中に列挙する
のではなく添付ファイルによって規定している。
確定組375は,機械可読書式の添付ファイル“JapaneseCoreKanji.txt”によって定義される。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルの先頭の5行はヘッダであり,その後に組に含まれる文字と
同じ数の行が続く。各行は,固定長フィールドで次の情報を含む。
− UCSの符号位置(hhhh)。この項目は,必須とする。
符号位置の“h”は,16進数の1桁を示す。
A.5 その他の組
A.5.1 概要
A.5では,利用者コミュニティの参照の用を満たすための組を規定する。文字は,異なる書記系から選
ばれていたり,異なる面に符号化されていたりする。リトアニア,日本,及び欧州全体の利用者コミュニ
ティの組を含む。
注記 略語MESは,多言語欧州部分集合(Multilingual European Subset)を意味する。
A.5.2 281 MES-1
組番号281の確定組MES-1は,それぞれの区に対する符号位置の範囲によって次のとおり規定する。
区
区の中の値
00
20〜7E,A0〜FF
01
00〜13,16〜2B,2E〜4D,50〜7E
02
C7,D8〜DB,DD
20
15,18〜19,1C〜1D,AC
94
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
21
22,26,5B〜5E,90〜93
26
6A
A.5.3 282 MES-2
組番号282の確定組MES-2は,それぞれの区に対する符号位置の範囲によって次のとおり規定する。
区
区の中の値
00
20〜7E,A0〜FF
01
00〜7F,8F,92,B7,DE〜EF,FA〜FF
02
18〜1B,1E〜1F,59,7C,92,BB〜BD,C6〜C7,C9,D8〜DD,EE
03
74〜75,7A,7E,84〜8A,8C,8E〜A1,A3〜CE,D7,DA〜E1
04
00〜5F,90〜C4,C7〜C8,CB〜CC,D0〜EB,EE〜F5,F8〜F9
1E
02〜03,0A〜0B,1E〜1F,40〜41,56〜57,60〜61,6A〜6B,80〜85,9B,F2〜F3
1F
00〜15,18〜1D,20〜45,48〜4D,50〜57,59,5B,5D,5F〜7D,80〜B4,B6〜C4,
C6〜D3,D6〜DB,DD〜EF,F2〜F4,F6〜FE
20
13〜15,17〜1E,20〜22,26,30,32〜33,39〜3A,3C,3E,44,4A,7F,82,A3〜A4,
A7,AC,AF
21
05,16,22,26,5B〜5E,90〜95,A8
22
00,02〜03,06,08〜09,0F,11〜12,19〜1A,1E〜1F,27〜2B,48,59,60〜61,
64〜65,82〜83,95,97
23
02,10,20〜21,29〜2A
25
00,02,0C,10,14,18,1C,24,2C,34,3C,50〜6C,80,84,88,8C,90〜93,A0,
AC,B2,BA,BC,C4,CA〜CB,D8〜D9
26
3A〜3C,40,42,60,63,65〜66,6A〜6B
FB
01〜02
FF
FD
A.5.4 283 MODERN EUROPEAN SCRIPTS
組番号283の組MODERN EUROPEAN SCRIPTS(現代ヨーロッパの用字)は,次に示す組の全体とする。
組番号
名前
1
BASIC LATIN
2
LATIN-1 SUPPLEMENT
3
LATIN EXTENDED-A
4
LATIN EXTENDED-B
5
IPA EXTENSIONS
6
SPACING MODIFIER LETTERS
7
COMBINING DIACRITICAL MARKS
8
BASIC GREEK
9
GREEK SYMBOLS AND COPTIC
10
CYRILLIC
11
ARMENIAN
27
BASIC GEORGIAN
30
LATIN EXTENDED ADDITIONAL
95
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
31
GREEK EXTENDED
32
GENERAL PUNCTUATION
33
SUPERSCRIPTS AND SUBSCRIPTS
34
CURRENCY SYMBOLS
35
COMBINING DIACRITICAL MARKS FOR SYMBOLS
36
LETTERLIKE SYMBOLS
37
NUMBER FORMS
38
ARROWS
39
MATHEMATICAL OPERATORS
40
MISCELLANEOUS TECHNICAL
42
OPTICAL CHARACTER RECOGNITION
44
BOX DRAWING
45
BLOCK ELEMENTS
46
GEOMETRIC SHAPES
47
MISCELLANEOUS SYMBOLS
65
COMBINING HALF MARKS
70
SPECIALS
92
CYRILLIC SUPPLEMENT
104
LTR ALPHABETIC PRESENTATION FORMS
A.5.5 284 CONTEMPORARY LITHUANIAN LETTERS
組番号284の確定組である拡張組CONTEMPORARY LITHUANIAN LETTERS(現代リトアニア文字)を,
次のように定める。
面00
区
区の中の値
00
41〜50,52〜56,59〜5A,61〜70,72〜76,79〜7A,C0〜C1,C3,C8〜C9,CC〜CD,
D1〜D3,D5,D9〜DA,DD,E0〜E1,E3,E8〜E9,F1〜F3,F5,F9〜FA,FD
01
04〜05,0C〜0D,16〜19,28,2E〜2F,60〜61,68〜6B,72〜73,7D〜7E
1E
BC〜BD,F8〜F9
UCS列識別子
<0104, 0301>,<0105, 0301>,<0104, 0303>,<0105, 0303>,<0118, 0301>,<0119, 0301>,<0118,
0303>,<0119, 0303>,<0116, 0301>,<0117, 0301>,<0116, 0303>,<0117, 0303>,<0069, 0307,
0300>,<0069, 0307, 0301>,<0069, 0307, 0303>,<012E, 0301>,<012F, 0307, 0301>,<012E,
0303>,<012F, 0307, 0303>,<004A, 0303>,<006A, 0307, 0303>,<004C, 0303>,<006C, 0303>,
<004D, 0303>,<006D, 0303>,<0052, 0303>,<0072, 0303>,<0172, 0301>,<0173, 0301>,
<0172, 0303>,<0173, 0303>,<016A, 0301>,<016B, 0301>,<016A, 0303>,<016B, 0303>
A.5.6 285 BASIC JAPANESE
組番号285の確定組BASIC JAPANESE(基本日本文字集合)は,日本の文字の基本的な部分集合であ
る。これに含まれる6 884文字は,次のとおりである。
− CJK統合漢字の原典参照ファイル(CJKSrc.txt)において,J0で識別される原典Jの漢字全て(23.1
参照)。
96
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− 次に示す符号位置の範囲。
面00
区
区の中の値
00
20〜7E,A2,A3,A5,A7〜A8,AC,B0〜B1,B4,B6,D7,F7
03
91〜A1,A3〜A9,B1〜C1,C3〜C9
04
01,10〜4F,51
20
10,14,16,18〜19,1C〜1D,20〜21,25〜26,30,32〜33,3B,3E
21
03,2B,90〜93,D2,D4
22
00,02〜03,07〜08,0B,12,1A,1D〜1E,20,27〜2C,34〜35,3D,52,60〜61,
66〜67,6A〜6B,82〜83,86〜87,A5
23
12
25
00〜03,0C,0F〜10,13〜14,17〜18,1B〜1D,20,23〜25,28,2B〜2C,2F〜30,
33〜34,37〜38,3B〜3C,3F,42,4B,A0〜A1,B2〜B3,BC〜BD,C6〜C7,CB,
CE〜CF,EF
26
05〜06,40,42,6A,6D,6F
30
00〜03,05〜15,1C,41〜93,9B〜9E,A1〜F6,FB〜FE
A.5.7 286 JAPANESE NON IDEOGRAPHICS EXTENSION
組番号286の確定組JAPANESE NON IDEOGRAPHICS EXTENSION(拡張非漢字集合)は,日本の文字
の部分集合である。これは,組285 BASIC JAPANESE又は組287 COMMON JAPANESEのいずれかと組み
合わせて,JIS X 0213の非漢字のレパートリを補完する。組286は,631文字を含み,次に示す符号位置
の範囲からなる。
面00
区
区の中の値
00
A0〜A1,A4,A6,A9〜AB,AD〜AF,B2〜B3,B7〜D6,D8〜F6,F8〜FF
01
00〜09,0C〜0F,11〜13,18〜1D,24〜25,27,2A〜2B,34〜35,39〜3A,3D〜3E,41
〜44,47〜48,4B〜4D,50〜55,58〜65,6A〜71,79〜7E,93,C2,CD〜CE,D0〜D2,
D4,D6,D8,DA,DC,F8〜F9,FD
02
50〜5A,5C,5E〜61,64〜68,6C〜73,75,79〜7B,7D〜7E,81〜84,88〜8E,90〜92,
94〜95,98,9D,A1〜A2,C7〜C8,CC,D0〜D1,D8〜D9,DB,DD〜DE,E5〜E9
03
00〜04,06,08,0B〜0C,0F,18〜1A,1C〜20,24〜25,29〜2A,2C,2F〜30,34,39
〜3D,61,C2
1E
3E〜3F
1F
70〜73
20
13,22,3C,3F,42,47〜49,51,AC
21
0F,13,16,21,27,35,53〜55,60〜6B,70〜7B,94,96〜99,C4,E6〜E9
22
05,09,13,1F,25〜26,2E,43,45,48,62,76〜77,84〜85,8A〜8B,95〜97,BF,
DA〜DB
23
05〜06,18,BE〜CC,CE
24
23,60〜73,D0〜E9,EB〜FE
25
B1,B6〜B7,C0〜C1,C9,D0〜D3,E6
97
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
26
00〜03,0E,16〜17,1E,60〜69,6B〜6C,6E
27
13,56,76〜7F
29
34〜35,BF,FA〜FB
30
16〜19,1D,1F〜20,33〜35,3B〜3D,94〜96,9A,9F〜A0,F7〜FA,FF
31
F0〜FF
32
31〜32,39,51〜5F,A4〜A8,B1〜BF,D0〜E3,E5,E9,EC〜ED,FA
33
03,0D,14,18,22〜23,26〜27,2B,36,3B,49〜4A,4D,51,57,7B〜7E,8E〜8F,
9C〜9E,A1,C4,CB,CD
FE
45〜46
FF
5F〜60
A.5.8 287 COMMON JAPANESE
組番号287の確定組COMMON JAPANESE(通用日本文字集合)は,日本の文字の基本的な部分集合であ
って,7 493文字を含む。A.5に規定する一つの確定組と符号位置の範囲とからなる。
面00
組番号
名前
285
BASIC JAPANESE
面00
区
区の中の値
20
15
21
16,21,60〜69,70〜79
22
11,1F,25,2E,BF
24
60〜73
30
1D,1F
32
31〜32,39,A4〜A8
33
03,0D,14,18,22〜23,26〜27,2B,36,3B,49〜4A,4D,51,57,7B〜7E,8E〜8F,
9C〜9E,A1,C4,CD
4E
28,E1,FC
4F
00,03,39,56,8A,92,94,9A,C9,CD,FF
50
1E,22,40,42,46,70,94,D8,F4
51
4A,64,9D,BE,EC
52
15,9C,A6,AF,C0,DB
53
00,07,24,72,93,B2,DD
54
8A,9C,A9,FF
55
86
57
59,65,AC,C7〜C8
58
9E,B2
59
0B,53,5B,5D,63,A4,BA
5B
56,C0,D8,EC
5C
1E,A6,BA,F5
5D
27,42,53,6D,B8〜B9,D0
98
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
5F
21,34,45,67,B7,DE
60
5D,85,8A,D5,DE,F2
61
11,20,30,37,98
62
13,A6
63
F5
64
60,9D,CE
65
4E
66
00,09,15,1E,24,2E,31,3B,57,59,65,73,99,A0,B2,BF,FA〜FB
67
0E,66,BB,C0
68
01,44,52,C8,CF
69
68,98,E2
6A
30,46,6B,73,7E,E2,E4
6B
D6
6C
3F,5C,6F,86,DA
6D
04,6F,87,96,AC,CF,F2,F8,FC
6E
27,39,3C,5C,BF
6F
88,B5,F5
70
05,07,28,85,AB,BB
71
04,0F,46〜47,5C,C1,FE
72
B1,BE
73
24,77,BD,C9,D2,D6,E3,F5
74
07,26,29〜2A,2E,62,89,9F
75
01,2F,6F
76
82,9B〜9C,9E,A6
77
46
78
21,4E,64,7A
79
30,94,9B
7A
D1,E7,EB
7B
9E
7D
48,5C,A0,B7,D6
7E
52,8A
7F
47,A1
83
01,62,7F,C7,F6
84
48,B4,DC
85
53,59,6B,B0
88
07,F5
89
1C
8A
12,37,79,A7,BE,DF,F6
8B
53,7F
8C
F0,F4
99
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
8D
12,76
8E
CF
90
67,DE
91
15,27,D7,DA,DE,E4〜E5,ED〜EE
92
06,0A,10,39〜3A,3C,40,4E,51,59,67,77〜78,88,A7,D0,D3,D5,D7,
D9,E0,E7,F9,FB,FF
93
02,1D〜1E,21,25,48,57,70,A4,C6,DE,F8
94
31,45,48
95
92
96
9D,AF
97
33,3B,43,4D,4F,51,55
98
57,65
99
27,9E
9A
4E,D9,DC
9B
72,75,8F,B1,BB
9C
00
9D
6B,70
9E
19,D1
F9
29,DC
FA
0E〜2D
FF
01〜5E,61〜9F,E0〜E5
A.5.9 288 MULTILINGUAL LATIN SUBSET
組番号288の確定組MULTILINGUAL LATIN SUBSET(多言語ラテン文字部分集合)は,国際的に利用
するラテン文字の部分集合である。これは,それぞれの区に対する符号位置の範囲によって次のとおり規
定する。
注記 組番号288 MULTILINGUAL LATIN SUBSETはラテン文字での正書法を用いる全ての言語を網
羅できているわけではない。また,この組はISO/IEC 9995-3:2010,Information technology−
Keyboard layouts for text and office systems−Part 3: Complementary layouts of the alphanumeric zone
of the alphanumeric sectionに参照されている。
面00
区
区の中の値
00
20〜7E,A0〜FF
01
00〜80,8F,97,9A〜9B,9D〜A1,AF〜B0,B5〜B7,CD〜DC,DE〜F0,F4〜F5,
F8〜FF
02
00〜1B,1E〜20,22〜23,26〜33,3A〜3E,41〜44,46〜49,4C〜4F,59,68,72,75,
7C,89,92,94,B7,B9〜BC,BE〜C1,C7〜C8,CC〜CD,D8〜DB,DD
03
00〜04,06〜11,13,15,1B,23〜29,2D〜2E,31〜32,35,38,44,47〜48,5C〜61
1D
7D,CD
1E
00〜19,1C〜2B,2E〜73,76〜99,9B,9E,A0〜F9
20
0C,11,13〜15,18〜1A,1C〜1E,26,2F,32〜33,39〜3A,4A,A5,AC
100
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
21
22,26,4D,5B〜5E,90〜93,9A〜9B
22
12,15,60,64〜65,6E〜71
23
00
26
6A
2C
63,65〜66
A7
88,8B〜8C
A.5.10 390 MOJI-JOHO-KIBAN IDEOGRAPHS-2016
組番号390の確定拡張組MOJI-JOHO-KIBAN IDEOGRAPHS-2016(文字情報基盤漢字集合2016)は,
漢字,漢字字形指示列及び既定の字形指示列からなる。この組を構成する文字は,日本の行政で用いられ
る人名漢字をこの規格で表現するための文字情報基盤セットに対応付けている。
注記 この組は非常に大きく,また多くの不連続な範囲が含まれるため,符号位置の範囲と字形指示
列とを規格本文に列挙するのではなく,参照ファイルによって示す。
確定拡張組390は,機械可読書式の添付ファイル“JMJKI-2016.txt”によって定義される。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルの先頭の7行はヘッダであり,その後に組に含まれる符号位
置の数と同じ数の行が続く。各行は,次の情報を含む。
− (CP)(,<CP,SV>)*(,<CP,IV>)* ここで,CPは,対応するCJK統合漢字の符号位置を表し,その形式は
h{4,5}である。SVは,既定の字形選択子である(範囲はFE00〜FE0Fであり,その形式はh{4}である。)。
IVは,漢字字形選択子である(範囲はE0100〜E01EFであり,その形式はh{5}である。)。全て規定の
一部である。
例 7E04〜7E0Eの範囲の例を次に示す。
7E04
7E05
7E08
7E09,<7E09,FE00>
7E0A,<7E0A,E0101>,<7E0A,E0102>,<7E0A,E0103>
7E0B,<7E0B,E0101>,<7E0B,E0102>
7E0C,<7E0C,E0100>,<7E0C,E0101>
7E0D
7E0E
A.6 ユニコードの組
これらの確定組は,ユニコード標準の様々な版に相当する。ユニコードの組は,BMPの文字と追加面の
文字とを含む。ユニコード標準は“Age”特性を定めている。これは,様々な符号位置について,連続し
たユニコード標準の版の中で,いつ,意味付け及び割当てされたかを定めるものである(箇条2を参照)。
ある符号位置が特定の版のユニコード標準に属するかは,その符号位置の“Age”特性の値が,その版と
同じか,又は小さいことによって判断することができる。次にユニコード標準の組を列挙する。
303
UNICODE 3.1
Age特性の値が3.1以下
304
UNICODE 3.2
Age特性の値が3.2以下
101
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
305
UNICODE 4.0
Age特性の値が4.0以下
306
UNICODE 4.1
Age特性の値が4.1以下
307
UNICODE 5.0
Age特性の値が5.0以下
308
UNICODE 5.1
Age特性の値が5.1以下
309
UNICODE 5.2
Age特性の値が5.2以下
310
UNICODE 6.0
Age特性の値が6.0以下
311
UNICODE 6.1
Age特性の値が6.1以下
312
UNICODE 6.2
Age特性の値が6.2以下
313
UNICODE 6.3
Age特性の値が6.3以下
314
UNICODE 7.0
Age特性の値が7.0以下
315
UNICODE 8.0
Age特性の値が8.0以下
316
UNICODE 9.0
Age特性の値が9.0以下
317
UNICODE 10.0
Age特性の値が10.0以下
318
UNICODE 11.0
Age特性の値が11.0以下
注記 ユニコード標準の第2.0版は,組301に相当する。ユニコード標準の第2.1版では,組301に
20AC EURO SIGN及びFFFC OBJECT REPLACEMENT CHARACTERの符号位置が加わる。ユニ
コード標準の第3.0版は,組302に相当する。
102
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書B
(規定)
結合文字一覧
注記 この規格の以前の版でこの附属書に規定していた内容は,文字の種類による形式的な定義に変
更した(3.14参照)。
103
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書C
(規定)
面01〜面10のUCS変換形式(UTF-16)
注記 この規格の以前の版でこの附属書に規定していた内容は,本体に記載した。UTF-16の符号化形
式については,箇条9を参照。UTF-16の符号化方式については,箇条10を参照。
104
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書D
(規定)
UCS変換形式8(UTF-8)
注記 この規格の以前の版でこの附属書に規定していた内容は,本体に記載した。UTF-8の符号化形
式については,箇条9を参照。UTF-8の符号化方式については,箇条10を参照。
105
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書E
(規定)
双方向文脈での鏡像文字
注記 この規格の以前の版でこの附属書に規定していた内容は,文字の種類による形式的な鏡像文字
の定義に変更した(15.1参照)。
106
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書F
(参考)
書式文字
書式文字と呼ぶ特別な種類の文字がある。その主要な用途は,周囲の文字の配置又は処理に影響を与え
ることである。少数の例外を除いて,書式文字は,印字可能な図形文字をもたない。符号表中では,空白
の文字と同様の点線の長方形で囲って示している。
多くの書式文字の機能は,符号単位列の正しい表示を示すことにある。表示以外のテキストの処理(例
えば,分類及び探索)では,F.1.3で説明するZWJ及びZWNJを除く書式文字は,それを除いてしまうこと
によって,無視できる。書式文字は,JIS X 0211の双方向性制御機能とともに使うことを意図していない。
F.1
一般書式文字
F.1.1
ハイフン境界表示子
SOFT HYPHEN(00AD):SOFT HYPHEN(SHY)は,語の途中で改行するのにふさわしい候補を示す書
式文字である。行をSOFT HYPHENによって示される位置で改行する場合,辞書の参照などのような他の
仕組みによって語の途中で改行したかのように改行するとよい。言語及びその語に応じて,語の途中の改
行の可視的な結果は,異なってもよい。例えば,次のような結果としてもよい。
− 語が分割されたことを表す図形記号を挿入し,その図形記号の直後で改行を行う。
− 語が分割されたことを表す図形記号を挿入し,その図形記号の直後で改行し,分割された語の一部の
つづりを変更する。
− 視覚上の変更を行わず,単にSOFT HYPHENの位置で改行する。
何かの図形記号を挿入する場合,状況に応じて最適な様々な形,例えば,HYPHEN(2010)(ハイフン),
ARMENIAN HYPHEN(058A)(アルメニア文字用ハイフン),MONGOLIAN TODO SOFT HYPHEN(1806)
(モンゴルトド文字用ハイフン)の形としてもよい。
明示的な改行の位置の指定を含むテキストを語の途中での改行を含めて符号化する場合,言語に応じて,
HYPHEN,ARMENIAN HYPHEN及びMONGOLIAN TODO SOFT HYPHENのような文字を用いてもよい。
語の途中の改行が可能な位置を符号化する目的で(例えば,“tug{00AD}gumi”のように)符号単位列に
SOFT HYPHENを挿入しても,文字の表示は変わらない。語の途中の改行を含む強制的な改行を符号化す
る文字を含む符号単位列を符号化する場合,テキストの列の文字による表現は,(例えば,“/”が改行を意
味するものとして,“tugg{2010}”/“gumi”とするような)語の途中の改行による一切の変更を反映する
ことが望ましい。
注記 ここに,{00AD}及び{2010}という表記法は,符号位置00AD及び2010を符号単位列中に含め
ることを示す。ただし,“{”及び“}”は,符号単位列の一部ではない。
F.1.2
単語及び行の境界表示子
ZERO WIDTH SPACE(200B):この文字は,SPACE(スペース)と同様に語の境界を示すが,SPACE
と異なり表示幅をもたない。例えば,この文字は,語を区切るのに可視的な間隔を使用しないタイ語の語
の境界を示すのに使える。
WORD JOINER(2060)及びZERO WIDTH NO-BREAK SPACE(FEFF):これらの文字は,NO-BREAK
SPACE(ノーブレークスペース)と同様に行の境界がないことを示すが,NO-BREAK SPACEと異なり表
107
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
示幅をもたない。例えば,これらの文字は,テキスト“base+delta”の4番目の文字の後に挿入し,“e”と
“+”との間に行の区切りがあってはならないことを示す。
注記 ZERO WIDTH NO-BREAK SPACEを“印”(しるし)に使う方法は,箇条10参照。
F.1.3
続け書き分離子
この細分箇条で説明する文字は,表示するときに,隣接する文字と接合するかどうかを示すのに使う[続
け書き接合子(cursive joiner)という。]。
ZERO WIDTH NON-JOINER(200C):この文字は,通常,続け書き文字形として続ける隣接する文字
を,続け書き接合で続けないことを示す。例えば,ARABIC LETTER NOON(アラビア文字ヌーン)とARABIC
LETTER MEEM(アラビア文字ミーム)との間のZERO WIDTH NON-JOINERは,この二つの文字を通常
の続け書き接合で表示しないことを示す。
注記1 ZERO WIDTH NON-JOINERの略号としてZWNJを用いることがある。
MONGOLIAN VOWEL SEPARATOR(180E):この文字はZERO WIDTH NONJOINERと同様に,モン
ゴル母音の文脈であっても隣接する文字同士が続け書き接合することを抑制する。
ZERO WIDTH JOINER(200D):この文字は,通常,続け書き文字形として続けない隣接する文字を,
続け書き接合で続けた形で表現することを示す。例えば,SPACEの後にARABIC LETTER BEH(アラビ
ア文字ベー)が続き,その後にSPACEが続く文では,ZERO WIDTH JOINERは,ARABIC LETTER BEH
の最終形を表示するために,最初の文字と2番目の文字との間に挿入できる。
注記2 ZERO WIDTH JOINERの略号としてZWJを用いることがある。
F.1.4
書式分離子
次の2文字は,行間又は段落間の書式上の境界を示すのに使う。
LINE SEPARATOR(2028):この文字は,どこから新しい行を始めるかを示すのに使う。すなわち,テ
キストは次の行に続くが,新しい段落は始めないときに使う。例えば,段落間の行あけ又は段落の字下げ
は,適用されないと考えられる。
PARAGRAPH SEPARATOR(2029):この文字は,どこから新しい段落を始めるかを示す。例えば,テ
キストは,次の行に続き,段落間の行あけ又は段落の字下げを適用すると考えられる。
F.1.5
双方向テキストの書式付け
ここで示す文字は,双方向テキストの書式付けに使う。部分集合の仕様にこれらの文字が入っている場
合には,右から左へ書く文字を含むテキストは,暗黙的な双方向性アルゴリズムで表示される。
暗黙的なアルゴリズムでは,テキストの水平行に文字を正しい順序で表示するために,文字の方向性の
特性を使う。
次の3文字は,文字の順序付けに影響を及ぼすという意味で,右から左へ書く文字又は左から右へ書く
文字と全く同じように働く書式文字とする[双方向性書式マーク(bi-directional format mark)という。]。
これらの文字は,可視的な表現をもたず,文脈にも影響しない。
これらの文字は,その作用範囲がより局所的であり,明示的な埋込み文字又は上書き文字の利用よりも
便利なことがある。
LEFT-TO-RIGHT MARK(200E):双方向性の書式付けにおいて,この文字は,左から右へ書く文字(例
えば,LATIN SMALL LETTER A)のように働く。
ARABIC LETTER MARK(061C):双方向性の書式付けにおいて,この文字は,右から左へ書くアラビ
ア文字(例えば,ARABIC LETTER NOON)のように働く。
RIGHT-TO-LEFT MARK(200F):双方向性の書式付けにおいて,この文字は,一般的な右から左へ書
108
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
く文字(例えば,NKO LETTER A)のように働く。
次の5文字は,テキストの一部を挿入部分として扱い,かつ,その部分に特定の順序付けがなければな
らないことを示す[双方向性書式挿入子(bi-directional format embedding)という。]。例えば,アラビア語
の文章の途中にある英語の引用には,挿入された左から右へ書く文字列としてマークを付けることができ
る。これらの書式文字は,ブロックの入れ子を作る。ブロックの開始(プッシュ)は,“埋込み文字(embedding
character)”及び“上書き文字(override character)”が示す。ブロックの終了(ポップ)は,“挿入終了文字
(pop character)”が示す。
埋込み文字と上書き文字との機能は,非常に似ている。主な違いは,埋込み文字がテキストの暗黙的な
方向性を指定するのに対して,上書き文字は,テキストの明示的な方向性を指定することにある。テキス
トが明示的な方向をもつ場合,通常の文字の方向性の特性が無視され,テキスト全体が上書き文字で定ま
る方向をもつとみなす。
LEFT-TO-RIGHT EMBEDDING(202A):この文字は,左から右への暗黙的な方向性をもつ挿入の開始
を示すのに使う。
RIGHT-TO-LEFT EMBEDDING(202B):この文字は,右から左への暗黙的な方向性をもつ挿入の開始
を示すのに使う。
LEFT-TO-RIGHT OVERRIDE(202D):この文字は,左から右への明示的な方向性をもつ挿入の開始を
示すのに使う。
RIGHT-TO-LEFT OVERRIDE(202E):この文字は,右から左への明示的な方向性をもつ挿入の開始を
示すのに使う。
POP DIRECTIONAL FORMATTING(202C):この文字は,上の四つの文字で開始された暗黙的又は明
示的な方向性をもつ挿入の終了を示すのに使う。
次の4文字は一般的に独立形文字と呼ばれていて,中立的な文字に対する双方向性の順序付けの効果を
減らすためにテキスト断片に適用できる。これは強い機能をもつ既存の埋込み書式文字(LEFT-TO-RIGHT
EMBEDDING, RIGHT-TO-LEFT EMBEDDING, POP DIRECTIONAL FORMATTING)と対照的である。一
方,独立形文字は埋込み文字に似ている。それらはテキストの内部にあって書字方向を宣言する。そして
ほかの独立形文字又は埋込み文字と入れ子になり,逆もまた同様である。
LEFT-TO-RIGHT ISOLATE(2066):この文字は,左から右への独立形の開始を示すのに使う。
RIGHT-TO-LEFT ISOLATE(2067):この文字は,右から左への独立形の開始を示すのに使う。
FIRST STRONG ISOLATE(2068):この文字は,最初の強い独立系の開始を示すのに使う。例えば,明
示的にUnicode Bidirectional Algorithm(ユニコード双方向アルゴリズム)(箇条2参照)のパラグラフのレ
ベルの規則を,それが別個のパラグラフであるかのように独立した内容に適用することによって,書字方
向を決定する。
POP DIRECTIONAL ISOLATE(2069):この文字は,独立形の終了を示すのに使う。
F.2
用字特有の書式文字
F.2.1
対称入替え様式文字
次の2文字は,箇条15に示す左向き用及び右向き用と対をなす鏡像文字の種類と一緒に使う。次の書式
文字は,文字の名前中にあるLEFT(左)又はRIGHT(右)という語をそれぞれ“開き”又は“閉じ”と
解釈するかどうかを示すのに使う。これらの文字は,入れ子とはならない。
実装上の既定状態は,上位のプロトコル又はJIS X 0211のような規格で設定してもよい。このようなプ
109
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
ロトコルがない場合,既定状態は,ACTIVATE SYMMETRIC SWAPPINGによって設定される状態とする。
INHIBIT SYMMETRIC SWAPPING(206A):この文字と(存在するならば)後続のACTIVATE
SYMMETRIC SWAPPING書式文字との間では,箇条15に示す鏡像文字は,“左”及び“右”として解釈さ
れ,表される。箇条15で示された処理は,行わない。
ACTIVATE SYMMETRIC SWAPPING(206B):この文字と(存在するならば)後続のINHIBIT
SYMMETRIC SWAPPING書式文字との間では,箇条15に示す鏡像文字は,箇条15で示されたとおり“開
き”及び“閉じ”の文字として解釈され,表される。
F.2.2
アラビア文字の字形選択子
次の2文字,すなわち,アラビア文字の字形選択子は,アラビア文字の表示形と一緒に使う。表示処理
の間,ある文字は,続け書き接合又は合字で互いに続けてもよい。字形選択子は,この表示の効果を出す
ために使用する字形決定処理を活性化するか又は抑制するかを示すのに使う。これらの文字は,入れ子と
はならない。
INHIBIT ARABIC FORM SHAPING(206C):この字形選択子と(存在するならば)後続のACTIVATE
ARABIC FORM SHAPING書式文字との間では,字形決定処理は,抑制される。アラビア文字の表示形は,
字形を変更することなく表示される。これを既定状態とする。
ACTIVATE ARABIC FORM SHAPING(206D):この字形選択子と(存在するならば)後続のINHIBIT
ARABIC FORM SHAPING書式文字との間では,アラビア文字の表示形は,字形決定処理で字形を変更し
て表示される。
注記 これらの字形選択子は,表示形ではない文字には影響を与えない。特に,0600〜06FFにある通
常の形のアラビア文字は,常に字形変更の対象となっており,これらの書式文字の影響を受け
ない。
F.2.3
数字の字形選択子
次の2文字は,0030〜0039にある数字を表すときの形を選択できるようにする。これらの文字は,入れ
子とはならない。
NATIONAL DIGIT SHAPES(206E):この文字と(存在するならば)後続のNOMINAL DIGIT SHAPES
書式文字との間では,0030〜0039にある数字は,合意によって定められたとおりに,国で使う数字(national
digit)の形で表される。例えば,これらを0660〜0669にあるアラビア語の数字の形で表示できる。
NOMINAL DIGIT SHAPES(206F):この文字と(存在するならば)後続のNATIONAL DIGIT SHAPES
書式文字との間では,0030〜0039にある数字は,符号表に示されたとおりの形で表される。これを既定状
態とする。
F.3
行間注釈文字(Interlinear annotation character)
次の3文字は,ある識別された文字列[注釈文字列(annotation string)という。]が,他の識別された文
字列[基底文字列(base string)という。]の注釈を提供すると考えられることを示すために使う。
INTERLINEAR ANNOTATION ANCHOR(FFF9):この文字は,基底文字列の開始位置を示す。
INTERLINEAR ANNOTATION SEPARATOR(FFFA):この文字は,基底文字列の終了位置及び注釈文
字列の開始位置を示す。
INTERLINEAR ANNOTATION TERMINATOR(FFFB):この文字は,注釈文字列の終了位置を示す。
注釈文字列と基底文字列との関係は,送信装置の利用者と受信装置の利用者との合意によって,定義さ
れる。例えば,基底文字列が可視的に表示される場合,注釈文字列は,基底文字列と異なる行の基底文字
110
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
列に近い位置に表示してもよい。
処理によって行間注釈文字を除いてしまう場合は,INTERLINEAR ANNOTATION SEPARATORと
INTERLINEAR ANNOTATION TERMINATORとの間の全ての文字も,一緒に除去することが望ましい。
F.4
限定性書式文字
次の9文字は,続く文字の並びを限定する。
0600
ARABIC NUMBER SIGN
0601
ARABIC SIGN SANAH
0602
ARABIC FOOTNOTE MARKER
0603
ARABIC SIGN SAFHA
0604
ARABIC SIGN SAMVAT
0605
ARABIC NUMBER MARK ABOVE
06DD
ARABIC END OF AYAH
070F
SYRIAC ABBREVIATION MARK
110BD
KAITHI NUMBER SIGN
これらの文字の目的及びその使い方の詳細は,ユニコード標準(附属書M参照)に記載している。
F.5
速記用書式文字
多くの速記方式で,略語及び頭文字語を示すために文字を重ねることが行われている。次の2文字は,
このような文字の重なりを制御するために用いられる。
SHORTHAND FORMAT LETTER OVERLAP(1BCA0):この文字は,一文字の重ねを指示し,文字列
の流れは,重ねられた文字があたかも存在しなかったかのように続けられる。
SHORTHAND FORMAT CONTINUING OVERLAP(1BCA1):この文字は,連続する重ねを指示し,
文字列の流れは,重ねられた文字から続けられる。
幾つかの速記方式では,特定の単語の末尾が,テキストの流れがデフォルトの方向(右向き)ではなく,
単語の上又は下に続くことによって示される。次の2文字はそのような振る舞いを制御するために使用さ
れる。
SHORTHAND FORMAT DOWN STEP(1BCA2):この文字は,後続の文字が前の文字の下方に引き下
げられて描画され,後続の結合された文字は,引き下げられたグリフを基準にして処理されることが望ま
しいことを示す。これによって,単語の境界では,次の単語(又は速記単位)が低い位置になる。
SHORTHAND FORMAT UP STEP(1BCA3):この文字は,続く単語(又は速記単位)の位置をもち上
げることを示す。
F.6
表示されない数学用演算子
数式の記述では,表示されない演算子及び区切り記号が暗黙に用いられることがある。表示されない演
算子(Invisible operators)として知られる特殊な書式制御文字は,そのような目に見えない演算子などを記
載し,数学的な記述を機械的に解釈できるようにするために用いることができる。
FUNCTION APPLICATION(2061):この文字は,関数の適用を示す。
INVISIBLE TIMES(2062):この文字は,乗算を示す。
INVISIBLE SEPARATOR(2063):この文字は,隣接する数学記号がリストを形成することを示す。例
111
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
えば,複数の添え字の間に目に見えるCOMMAを置かないときに用いる。
INVISIBLE PLUS(2064):この文字は,加算を示す。
F.7
西洋音楽記号
この規格は,音楽の楽譜又は音程の符号化の完全な手段を規定しない。その種の要件を満たすためには,
この規格が規定する文字の符号化の規則に加えて,他の事柄を記述する追加の階層が必要である。しかし,
追加の階層を用いなくても,この規格が規定する文字は,一般的な音楽に関するテキスト記述において簡
単に音楽に言及するための記号として用いることができる。
音楽の記法では,音価の短い音符をまとめる連こう(桁)が多用される。書式文字1D173 MUSICAL
SYMBOL BEGIN BEAM[音楽記号連こう(桁)開始]及び1D174 MUSICAL SYMBOL END BEAM[音楽記
号連こう(桁)終了]を用いて,連こう(桁)によるまとまりの範囲を示すことができる。特別な場合,
連こう(桁)の端が閉じないことがある。連こう(桁)の端に符幹が付かないことを示すために,いわゆ
る“透明音符”[すなわち,MUSICAL SYMBOL NULL NOTEHEAD(音楽記号空白符頭)]を用いることが
できる。
これと同様に,他の接続構造を表現するための別の書式文字を用意してある。次の文字は,この種の働
きをもつ。
− 1D175 MUSICAL SYMBOL BEGIN TIE(音楽記号タイ開始)
− 1D176 MUSICAL SYMBOL END TIE(音楽記号タイ終了)
− 1D177 MUSICAL SYMBOL BEGIN SLUR(音楽記号スラー開始)
− 1D178 MUSICAL SYMBOL END SLUR(音楽記号スラー終了)
− 1D179 MUSICAL SYMBOL BEGIN PHRASE(音楽記号楽句開始)
− 1D17A MUSICAL SYMBOL END PHRASE(音楽記号楽句終了)
これらの対になる文字は,完全な音楽の記法において,音符及び楽句のまとまり又は配置を変更する。
音楽の一部分がプレーンテキストの一部に書かれたり描かれたりする場合,特別なソフトウェアが利用で
きないときには,開始及び終了を示す書式文字の対を括弧のように描いたり無視したりしてもよい。洗練
された組込み手続は,対になる書式文字を可能な限界まで解釈し,実際に備える制御能力を用いて,タイ,
スラー,連こう(桁)及び楽句を適切に描いてもよい。
最大の柔軟性のために,音楽記号の文字集合は,特定の音価の音符として前もって合成された図形記号
をもつ文字と,完全な音符を組み立てる場合の基本要素としての図形記号をもつ文字との双方を含む。音
楽記号は,至る所で使われるので,主として利用者の便宜のために,前もって合成された図形記号をもつ
文字を用意してある。
符号化の点では,便利ではないが,様々な符頭,符幹及び符尾並びに演奏指示の記号を組み合わせて音
符を構成する手段が,複雑な楽譜を扱う完全な実装に必要となる。この用法の例として,アメリカ式の特
別な形の音符及び現代打楽器曲の表記法がある。例えば,次のような用法がある。
MUSICAL SYMBOL SQUARE NOTEHEAD BLACKとMUSICAL SYMBOL COMBINING STEMとの組合せ。
MUSICAL SYMBOL X NOTEHEADとMUSICAL SYMBOL COMBINING STEMとの組合せ。
付点及び演奏指示記号は,前もって合成された図形記号をもつ文字と組み合わせることもできるし,基
本要素から組み立てた音符と組み合わせることもできる。
さらに,付点及び演奏指示記号は,一つの完全な音符の形を表すために必要に応じて繰り返してもよい。
例えば,次のような用法がある。
112
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
MUSICAL SYMBOL EIGHTH NOTEとMUSICAL SYMBOL COMBINING AUGMENTATION DOTとMUSICAL
SYMBOL COMBINING AUGMENTATION DOTとMUSICAL SYMBOL COMBINING ACCENTとの組合せ。
F.8
タグ文字による言語のタグ付け
F.8.1
概要
タグ文字は,テキストの属性を,テキストの文字列の一つの位置又は範囲に関連付けることを目的とす
る。特定のタグの値は,通常は,テキストの内容の一部とはみなさない。例えば,テキストの一部分に適
用される言語又はフォントの標識として用いることができる。その用途以外では,タグ文字は,無視して
もよい。
タグ文字は,プレーンテキストに埋め込まなければならない何らかのASCII(ISO/IEC 646のIRVのこ
とをいう。)に基づくタグ付けの体系において文字列を書き下すために用いることができる。タグ文字は,
符号の値が工夫されているので容易に識別でき,タグ文字の利用には,負担がかからない。タグ文字は,
タグの値を表現することだけが可能であって,テキストの内容自体を表すことはできない。
文字を,タグ文字と同様の関連付け機能を備える明示的なマーク付けを含んだプロトコル又は構文の文
脈で使う場合は,これらのプロトコルに従ってタグ文字を取り除き無視してもよい。
例えば,SGML又はXMLでは,明示的な言語のマーク付けが規定されている。そこで,LANGUAGE TAG
(E0001)(言語タグ)及び他のタグ文字は,SGML又はXMLでは,言語の標識として使わない方がよい。
ユニコードのウェブサイト(http://www.unicode.org/reports/)から入手できる“Unicode in XML and other
Markup Languages”(ユニコード技術報告書 UTR #20)という技術報告書をユニコードコンソーシアム及び
W3Cが共同で執筆したが,この技術報告書には,SGML又はXMLでは,タグ文字を使用しない方がよい
ことが詳細に書かれている。
TAGS(タグ)ブロックは,97個のタグ専用の文字を含み,BASIC LATIN(基本ラテン文字)ブロック
に含まれる図形文字の複製[これは,BASIC LATINブロックの文字の名前に語“TAG”(タグ)を前置し
た名前の文字であり,符号位置E0020〜E007Eにある。]と,言語のタグを識別する文字であるLANGUAGE
TAG(言語タグ)及びタグを取り消す文字であるCANCEL TAG(取消しタグ)とからなる。
タグ識別文字は,異なる種類のタグを識別するための仕組みとして用いる。タグ識別文字によって,二
つ以上の種類のタグをプレーンテキストに埋め込んで共存させることが可能になり,かつ,あるタグが別
のタグと直接連続した場合のタグの切れ目の問題も解決する。現時点では,言語のタグという一つのタグ
の種類だけを規定しているが,将来異なるタグ識別文字を符号化することになれば,異なる種類のタグを
用いることもできるようになる。
F.8.2
タグ文字を埋め込む構文
プレーンテキストにASCIIから導出された任意のタグを埋め込むためには,適切なタグ識別文字を前置
し,埋め込むタグをタグ文字によって単純に書き下す。その文字列を直接テキストに埋め込む。
タグには,終わりを表す文字が必要ない。一つのタグは,特殊用途面の文字でない最初の文字に出会う
か又は次のタグ識別文字に出会うかのいずれかによって終わる。
タグの引数は,タグ文字によってだけ符号化できる。その他の文字は,タグの引数を表現するためには
適切ではない。
F.8.3
タグの範囲及び入れ子
タグの値は,テキストにタグが埋め込まれた位置から次のいずれかの位置まで続く。
− 符号単位列の終わりの位置
113
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− タグがCANCEL TAG文字によって明示的に取り消された位置
同じ種類のタグは,入れ子にならない。例えば,既に言語のタグ付けが行われているテキストに続けて,
新しく埋め込まれた言語のタグが現れたならば,続くテキストに対するタグの値が新しいタグによって指
定されたタグの値に単純に変わる。
F.8.4
タグの値の取消し
CANCEL TAG(取消しタグ)文字は,特にタグの値を取り消すために用意されている。例えば,言語タ
グを取り消すには,LANGUAGE TAG(言語タグ)文字がCANCEL TAG文字の前になければならない。
直前にタグ識別文字がないCANCEL TAG文字は,定義されているかもしれない任意のタグの値を取り消
すために用いる。
CANCEL TAG文字の主な機能は,文字列の境目を越えて不適切なタグの値を広げてしまうことなく,複
数の文字列を,タグの内容を気にせずに連結するような操作を可能にすることである。
F.8.5
言語のタグ
言語のタグは,誰でも関心があり,言語のタグのプロトコルとしての利用は,高度の相互運用性がある。
例えば,日本語を表す言語のタグを埋め込むためには,タグ文字を次のように用いることができる。
E0001 E006A E0061
ここで,第1の値は,LANGUAGE TAG(言語タグ)文字の符号の値であり,第2の値は,TAG LATIN SMALL
LETTER Jに対応する値であり,かつ,第3の値は,TAG LATIN SMALL LETTER Aに対応する値であ
る。“ja”という列は,JIS X 0412規格群(対応国際規格:ISO 639規格群)において,日本語を表す2文
字コードである。
114
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書G
(参考)
文字の名前のアルファベット順一覧
文字の名前のアルファベット順一覧を,機械可読形式の添付ファイル“Allnames.txt”によって示す。添
付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルの先頭の5行は,ヘッダであり,その後にハングル音節文字,
漢字,女書及び西夏文字(すなわち,HANGUL SYLLABLES,CJK UNIFIED IDEOGRAPHS,CJK UNIFIED
IDEOGRAPHS EXTENSION A,CJK UNIFIED IDEOGRAPHS EXTENSION B,CJK UNIFIED IDEOGRAPHS
EXTENSION C,CJK UNIFIED IDEOGRAPHS EXTENSION D,CJK UNIFIED IDEOGRAPHS EXTENSION
E,CJK UNIFIED IDEOGRAPHS EXTENSION F,CJK COMPATIBILITY IDEOGRAPHS,CJK COMPATIBILITY
IDEOGRAPHS SUPPLEMENT,NUSHU及びTANGUTのブロックの文字)を除く全てのこの規格の文字の名
前を連ねる。
各行は,次の情報がTAB文字で区切られた項目で構成されている。
− 項目1は,UCS 符号位置をhhhh 又はhhhhhの形式で示す(ただし,hは16進数の1桁とする。)。
− 項目2は,文字名を形式で示す。
115
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書H
(参考)
UCSを識別するための“印”(しるし)の使用
注記 この規格の以前の版でこの附属書に記載していた内容は,本体に記載した(箇条10参照)。
116
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書I
(参考)
漢字構成記述文字
I.1
概要
漢字構成記述文字(Ideographic Description Character,以下,IDCという。)は,漢字構成記述文字列
(Ideographic Description Sequence,以下,IDSという。)を作り出すため,他の図形文字の列とともに使わ
れる図形文字である。この種の文字列は,この規格で規定されていない漢字のような文字(ideographic
character)を記述する目的で使ってもよい。
IDSは,一つの漢字を抽象字形で記述する。合成された一つの文字と解釈するものではなく,何らかの
特定の表示方法を意図するものでもない。
注記 IDSは,文字ではなく,この規格のレパートリの構成単位ではない。
I.2
漢字構成記述文字列の構文
IDSは,一つのIDCから始まり,CJK漢字又は西夏文字のような用字分類ごとに対応する下位集合の中
に編成される一定の数の記述構成要素(description component,以下,DCという。)が後に続く。IDSは,
それが属する用字を明らかにするために,一つの下位集合に帰属する項目だけを用いるのがよい。DCは,
次のいずれかであってよい。下位集合及びその内容は,次のとおりである。
− CJK IDS 下位集合は,次のうちのどれかのDCを含むことができる。
− 一つの符号化CJK漢字で,CJK UNIFIED IDEOGRAPHS又はCJK COMPATIBILITY IDEOGRAPHS
ブロックの文字で構成されるもの
− 一つの符号化部首で,CJK RADICALSブロック又はKANGXI RADICALSブロックの符号化文字で
構成されるもの
− 一つの符号化画線で,CJK STROKESブロックの符号化文字で構成されるもの
− FF1FのFULLWIDTH QUESTION MARKの文字で,これ以外によっては未記述となるDCを表現す
る。
− 私用文字(ただし,情報交換を行う当事者同士が特定の私用文字が特定のCJK漢字又はCJK漢字
の部分字形を表現することに同意した場合に限る。)
− 別のCJK IDS
− 西夏文字IDS下位集合は,次のうちのどれかのDCを含むことができる。
− 一つの西夏文字で,TANGUTブロックの文字で構成されるもの
− 一つの西夏文字部分字形で,TANGUT COMPONENTSブロックの符号化文字で構成されるもの
− 一つの符号化画線で,CJK STROKESブロックの符号化文字で構成されるもの
− FF1FのFULLWIDTH QUESTION MARKの文字で,これ以外によっては未記述となるDCを表現す
る。
− 別の西夏文字IDS
注記 これは,あるIDSが,他のIDSに入れ子として含まれてもよいことを示す。
各IDCは,次に示す四つの特性をもつ。これを表I.1にまとめて示す。
− そのIDCで始まるIDSで使われるDCの数
117
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
− その略号の定義
− 対応するIDSの構文
− 抽象字形として記述された漢字を可視化で表現したときの,各DCの相対位置
それぞれのIDCから始まるIDSの構文は,表I.1の“IDSの略号及び構文”の欄で,そのIDCの略号(例
えば,IDC-LTR)と,それに続く規定の数のDC,すなわち,(D1 D2)又は(D1 D2 D3)とによって示す。
I.3
個々の漢字構成記述文字の定義
IDEOGRAPHIC DESCRIPTION CHARACTER LEFT TO RIGHT(2FF0)
この文字によって記述されるIDSは,D1が左に,D2が右に位置する,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER ABOVE TO BELOW(2FF1)
この文字によって記述されるIDSは,D1がD2の上に位置する,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER LEFT TO MIDDLE AND RIGHT(2FF2)
この文字によって記述されるIDSは,D1がD2の左に,さらに,そのD2がD3の左に位置する,漢字の
抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER ABOVE TO MIDDLE AND BELOW(2FF3)
この文字によって記述されるIDSは,D1がD2の上に,さらに,そのD2がD3の上に位置する,漢字の
抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER FULL SURROUND(2FF4)
この文字によって記述されるIDSは,D1がD2を囲む,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM ABOVE(2FF5)
この文字によって記述されるIDSは,D1がD2を上及び両側から囲む,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM BELOW(2FF6)
この文字によって記述されるIDSは,D1がD2を下及び両側から囲む,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM LEFT(2FF7)
この文字によって記述されるIDSは,D1がD2を左及び上下から囲む,漢字の抽象字形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM UPPER LEFT(2FF8)
この文字によって記述されるIDSは,D1がD2の左上に位置し,左及び上の一部を囲む,漢字の抽象字
形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM UPPER RIGHT(2FF9)
この文字によって記述されるIDSは,D1がD2の右上に位置し,右及び上の一部を囲む,漢字の抽象字
形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER SURROUND FROM LOWER LEFT(2FFA)
この文字によって記述されるIDSは,D1がD2の左下に位置し,左及び下の一部を囲む,漢字の抽象字
形を記述する。
IDEOGRAPHIC DESCRIPTION CHARACTER OVERLAID(2FFB)
この文字によって記述されるIDSは,D1とD2とが互いに重なり合う,漢字の抽象字形を記述する。
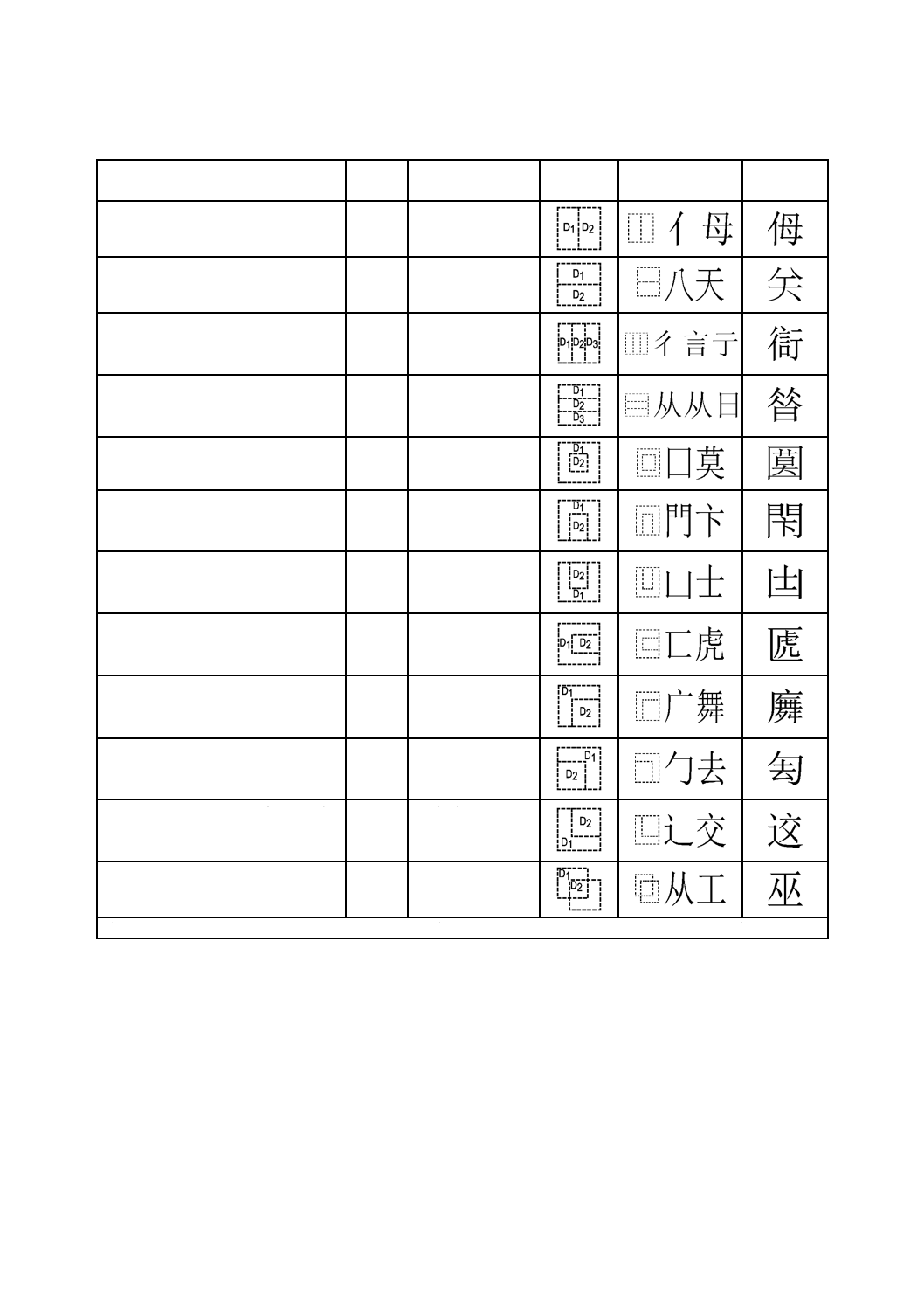
118
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表I.1−漢字構成記述文字の属性
文字の名前
DC数
IDSの略号
及び構文
DCの
相対位置
IDSの例
IDSが表す
ものの例
IDEOGRAPHIC
DESCRIPTION
CHARACTER LEFT TO RIGHT
2
IDC-LTR D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER ABOVE TO BELOW
2
IDC-ATB D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER LEFT TO MIDDLE AND
RIGHT
3
IDC-LMR D1 D2
D3
IDEOGRAPHIC
DESCRIPTION
CHARACTER ABOVE TO MIDDLE
AND BELOW
3
IDC-AMB D1 D2
D3
IDEOGRAPHIC
DESCRIPTION
CHARACTER FULL SURROUND
2
IDC-FSD D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
ABOVE
2
IDC-SAV D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
BELOW
2
IDC-SBL D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
LEFT
2
IDC-SLT D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
UPPER LEFT
2
IDC-SUL D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
UPPER RIGHT
2
IDC-SUR D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER SURROUND FROM
LOWER LEFT
2
IDC-SLL D1 D2
IDEOGRAPHIC
DESCRIPTION
CHARACTER OVERLAID
2
IDC-OVL D1 D2
注記 IDC-OVLでは,D1とD2とは,互いに重なり合う。この図は,D1が左上,D2が右下という意味ではない。
119
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書J
(参考)
内部記憶機能をもつ送受信兼用装置に対する推奨
附属書Jは,受信した符号単位列を後続の再転送のために記憶しておける装置で,広く使われているク
ラスのものに適用できる。
この附属書は,受信した符号単位列とその再転送との間で,情報の損失が最少になるように意図して推
奨するものである。
このクラスの装置は,4.3に示した受信装置部分と送信装置部分との両方をもち,受信した符号単位列を,
その中に表現されている対応する文字を利用者が修正し又は修正せずに,再転送のために記憶できる。こ
のクラスの装置について,ここでは,2種類の異なる方法を推奨する。
a) 完全な再転送機能をもつ受信装置 送信装置部分は,受信装置部分が識別できる部分集合外の符号化
表現も含め,受信した文字の符号化表現を,利用者が修正しない限りそのまま再転送する。
b) 部分集合の再転送機能をもつ受信装置 送信装置部分は,その受信装置部分に採用された部分集合の
文字の符号化表現だけを再転送できる。
120
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書K
(参考)
オクテット値表現の記法
この規格のオクテット値の表現は,箇条12を除き,JIS X 0202,JIS X 0211及びISO/IEC 8859(Information
technology−8-bit single-byte coded graphic character sets)規格群のような他の符号化文字集合の規格と異な
る。附属書Kは,両者の記法間の関係を明確にする。
この規格では,オクテット値を表す記法は,zとしている。ここに,zは,00〜FFの範囲にある16進数
である。例えば,JIS X 0202の文字ESCAPE(ESC)は,この規格では1Bで表現される。
他の符号化文字集合の規格では,オクテット値を表す記法は,x/yとしている。ここに,x及びyは,00
〜15の範囲にある二つの10進数である。x/y形式の記法とオクテット値との間の対応は,次のとおりであ
る。
− xは,ビット8,ビット7,ビット6及びビット5で表現される数であって,これらのビットには,そ
れぞれ8,4,2及び1の重みを与える。
− yは,ビット4,ビット3,ビット2及びビット1で表現される数であって,これらのビットには,そ
れぞれ8,4,2及び1の重みを与える。
例えば,JIS X 0202の文字ESCは,01/11で表現される。
このように,JIS X 0202(及び他の符号化文字集合の規格)のオクテット値の記法は,x及びyの値を
16進表記に変換することによって,この規格のオクテット値の記法に変換できる。例えば,04/15は,4F
と同値である。
121
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書L
(参考)
文字の名前付け指針
この規格の箇条26では,名前の編成及び名前の一意性についての規則を規定している。箇条26の規則
は,ISO/IEC 646,ISO/IEC 6937,ISO/IEC 8859,ISO/IEC 10367などの他の情報技術の符号化文字集合規
格でも用いる。
注記 JIS X 0201,JIS X 0208,JIS X 0213などの規格でも用いる。
附属書Lでは,名前を作り出す場合の追加の指針を示す。
この附属書で示す指針は,CJK統合漢字,西夏文字,女書文字及びハングル音節文字の名前には適用し
ない。CJK統合漢字,西夏文字,女書文字及びハングル音節文字の名前は,それぞれ,26.6,26.7,26.8
及び26.9で規定する規則を用いて編成する。
指針1
名前は,できる限り通常的に使われる意味を表す(例えば,文字の名前としてPLUS SIGN又はブロッ
ク名BENGALI。)。
幾つかの文字の名前など,ある種の名前は,使用法ではなく形によってもよい(例えば,文字の名前と
してUPWARDS ARROW。)。
名前は,指針4の場合を除いて,ものの特質若しくは属性を識別すること,又は言語的特徴についての
情報を提供することを意図しない。
指針2
略号は,ラテン大文字のA〜Z及び数字からなり,名前と関連させる。
略号は,既に使用が定着していて,かつ,明確化のために必要なものの名前に用いる。例えば,制御機
能の名前は,略号と結び付いている。
例
名前
略号
LOCKING-SHIFT TWO RIGHT
LS2R
SOFT HYPHEN
SHY
INTERNATIONAL PHONETIC ALPHABET
IPA
注記 JIS X 0211では,モードの名前にも略号を適用している。
指針3
文字の名前及び名前付きUSI(NUSI)の名前は,数字を英単語として書き下すことが適切でないときに
限って,数字の文字0〜9を含んでよい。
注記 例えば,位置201Aの文字の名前は,SINGLE LOW-9 QUOTATION MARK(下9形引用符)で
ある。文字の形状を明らかにするために,数字9の記号がこの名前に含まれているが,数値に
意味は,ない。
指針4
文字の名前及びNUSIの名前は,次に示す区分に属する語のうちで適用可能なものの集合から構成し,
次に示す順序で並べる。例外は,指針9〜11による。必要ならば,一層の明確化のために,語WITH及び
ANDを含めてもよい。
122
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1
用字
2
大文字・小文字
3
種類
4
言語
5
属性
6
意味
7
マーク(複数でもよい。)
8
修飾子
この語の例を次に示す。
用字
Latin,Cyrillic,Arabic
大文字・小文字
capital,small
種類
letter,ligature,digit
言語
Ukrainian
属性
final,sharp,subscript,vulgar
意味
通常の名前,アルファベットの名前
マーク
acute,ogonek,ring above,diaeresis
修飾子
sign,symbol
名前の例を次に示す。
1
LATIN
2
CAPITAL
3
LETTER6
A
WITH
7
ACUTE
3
DIGIT
6
FIVE
5
LEFT
5
CURLY
6
BRACKET
注記 合字(ligature)は,二つ以上の異なる図形記号が単一の図形記号として可視化された図形記号
である。
一つの文字が一つの基底文字部と複数個のマークとから構成される文字の名前に関しては,名前中のこ
れらの順序は,マークが基底文字部に対して相対的に位置決めされる順序とする。すなわち,昇順にとら
れる文字の上に置くマークから始まり,その後に降順にとられる文字の下に置くマークが続くか,又はそ
の逆(文字の下に置くマークから始まり,その後に文字の上に置くマークが続く。)とする。
一つの基底文字部と複数個のマークとから構成されるNUSIに関しては,個々の名前をそれらが符号化
される順に記述する。
例
LATIN CAPITAL LETTER O WITH CIRCUMFLEX AND DOT BELOW
LATIN CAPITAL LETTER C WITH CEDILLA AND ACUTE
LATIN CAPITAL LETTER U WITH OGONEK AND ACUTE
指針5
ラテンの用字の文字は,名前の中では,基本図形記号(A,B,Cなど)によって表現する。他の用字の
文字は,最初に刊行された国際規格の言語からの転写で表現する。
例 K
LATIN CAPITAL LETTER K
Ю
CYRILLIC CAPITAL LETTER YU
123
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
指針6
与えられた用字の文字が複数の言語で使われている場合,言語名は,使わない。しかし,曖昧さが生じ
る場合は,この限りではない。
例 И
CYRILLIC CAPITAL LETTER I
I
CYRILLIC CAPITAL LETTER BYELORUSSIAN-UKRAINIAN I
指針7
複数個の用字の構成要素となっている文字は,形が同じでも異なるものとみなし,異なる名前をもつ。
例 A
LATIN CAPITAL LETTER A
A
GREEK CAPITAL LETTER ALPHA
A
CYRILLIC CAPITAL LETTER A
指針8
可能ならば,NUSIの名前は,その構成要素の名前の要素を,重複を無視して連結することによって構
成する。この手順によって既に存在する名前が得られたならば,その名前は,文字の名前及びNUSIの名
前の中での一意性を保証するために適切に修正する。一層の明確化のために,語WITH及びANDを含めて
もよい。
指針9
例えば,物理量の単位に関連する図形記号のように,他の用字の中で独立して使われる一つの用字の文
字は,それ本来の用字の文字と異なる文字とみなす。
例 μ
MICRO SIGN
指針10
幾つかの文字は,1語又は2語からなる伝統的な名前をもっている。これを変えることは,意図しない。
例 ʼ
APOSTROPHE
:
COLON
@
COMMERCIAL AT
_
LOW LINE
〜
TILDE
指針11
与えられた用字の文字(句読点のことが多い。)が他の用字で異なる用法で使われる場合がある。この場
合,最も一般的に使われる慣習的な名前を,その文字に与える。その用字名の後に慣習名をその用字で書
き直したものを続けて注釈として文字一覧表に付けてもよい。
例
124
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書M
(参考)
文字の出所
この符号化文字集合を作成するに当たって,幾つかの原典及び寄書を使用した。それらは分野ごとに分
類される。次に,分野ごとに,最初に国家規格及び国際規格を示し,その後に関連する参考文献を示す。
General
ISO international register of character sets to be used with escape sequences. (registration procedure ISO
2375:1985).
ISO 8879:1986,Information processing−Text and office systems−Standard Generalized Markup Language
(SGML)
ISO/IEC TR 15285:1998,Information technology−An operational model for characters and glyphs
JIS X 0201:1976 情報交換用符号 (Code for Information Interchange)
Allworth, Edward. Nationalities of the Soviet East: Publications and Writing Systems. New York, London,
Columbia University Press, 1971. ISBN 0-231-03274-9.
Barry, Randall K. 1997. ALA-LC romanization tables: transliteration schemes for non-Roman scripts. Washington,
DC: Library of Congress Cataloging Distribution Service. ISBN 0-8444-0940-5
Daniels, Peter T., and William Bright, eds. 1996. The world's writing systems. New York; Oxford: Oxford
University Press. ISBN 0-19-507993-0
Diringer, David. 1996. The alphabet: a key to the history of mankind. New Delhi: Munshiram Manoharlal. ISBN
81-215-0780-0
Faulmann, Carl. 1990 (1880). Das Buch der Schrift. Frankfurt am Main: Eichborn. ISBN 3-8218-1720-8
Haarmann, Harald. 1990. Universalgeschichte der Schrift. Frankfurt/Main; New York: Campus. ISBN
3-593-34346-0
Imprimerie Nationale. 1990. Les caractères de l'Imprimerie nationale. Paris: Imprimerie nationale Éditions. ISBN
2-11-081085-8
Jensen, Hans. 1969. Die Schrift in Vergangenheit und Gegenwart. 3., neubearbeitete und erweiterte Auflage.
Berlin: VEB Deutscher Verlag der Wissenschaften.
Knuth, Donald E. The TeXbook. ‒ 19th. printing, rev, ‒ Reading, MA: Addison-Wesley, 1990.
Nakanishi, Akira. 1990. Writing systems of the world: alphabets, syllabaries, pictograms. Rutland, VT: Charles E.
Tuttle. ISBN 0-8048-1654-9
Shepherd, Walter. Shepherd's glossary of graphic signs and symbols. Compiled and classified for ready reference.
‒ New York: Dover Publications, [1971].
The Unicode Consortium The Unicode Standard. Worldwide Character Encoding Version 1.0, Volume One. ‒
Reading, MA: Addison-Wesley, 1991.
The Unicode Consortium The Unicode Standard, Version 2.0. Reading, MA: Addison-Wesley, 1996. ISBN
0-201-48345-9
The Unicode Consortium The Unicode Standard, Version 3.0. Reading, MA: Addison-Wesley Developer's Press,
125
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2000. ISBN 0-201-61633-5
The Unicode Consortium The Unicode standard, Version 4.0. Reading, MA: Addison-Wesley Developer's Press,
2003. ISBN 0-321-18578-1
The Unicode Consortium The Unicode Standard, Version 5.0. Reading, MA: Addison-Wesley Developerʼs Press,
2007. ISBN 0-321-48091-0
The Unicode Consortium The Unicode Standard, Version 6.3. Mountain View, CA: The Unicode Consortium,
2013. ISBN 978-1-936213-08-5 http://www.unicode.org/versions/Unicode6.3.0/
The Unicode Consortium The Unicode Standard, Version 7.0.0, Mountain View, CA: The Unicode Consortium,
2014. ISBN 978-1-936213-09-2 http://www.unicode.org/versions/Unicode7.0.0/
The Unicode Consortium The Unicode Standard, Version 8.0.0, Mountain View, CA: The Unicode Consortium,
2015. ISBN 978-1-936213-10-8 http://www.unicode.org/versions/Unicode8.0.0/
The Unicode Consortium The Unicode Standard, Version 9.0.0, (Mountain View, CA: The Unicode Consortium,
2016. ISBN 978-1-936213-13-9 http://www.unicode.org/versions/Unicode9.0.0/
Ahom
Barua, Bimala Kanta, and N.N. Deodhari Phukan. Ahom Lexicons, Based on Original Tai Manuscripts. Guwahati:
Department of Historical and Antiquarian Studies, 1964.
Hazarika, Nagen, ed. Lik Tai Khwam Tai (Tai letters and Tai words). Souvenir of the 8th Annual conference of
Ban Ok Pup Lik Mioung Tai. Eastern Tai Literary Association, 1990.
Kar, Babul. Tai Ahom Alphabet Book. Sepon, Assam: Tai Literature Associate, 2005..
Alchemical Symbols
Berthelot, Marcelin. Collection des anciens alchimistes grecs. 3 vols. Paris: G. Steinheil, 1888.
Berthelot, Marcelin. La chimie au moyen âge. 3 vols. Osnabrück: O. Zeller, 1967.
Lüdy-Tenger, Fritz. Alchemistische und chemische Zeichen. Würzburg: JAL-reprint, 1973.
Schneider, Wolfgang. Lexicon alchemistisch-pharmazeutischer Symbole. Weinheim/Bergstr.: Verlag Chemie,
1962.
Anatolian Hieroglyphs
Hawkins, John David, and Halet Çambel. Corpus of Hieroglyphic Luwian Inscriptions. Berlin and New York:
Walter de Gruyter, 2000. ISBN 3-11-010864-X.
Herbordt, Suzanne. Die Prinzen- und Beamtensiegel der hethitischen Grossreichszeit auf Tonbullen aus dem
Nişantepe-Archiv in Hattusa. Mit Kommentaren zu den Siegelinschriften und Hieroglyphen von J. David Hawkins.
Mainz am Rhein: Verlag Philipp von Zabern, 2005. ISBN: 3-8053-3311-0.
Laroche, Emmanuel. Les hiéroglyphes hittites. Première partie: Lʼécriture. Paris : Éditions du Centre National de
la Recherche Scientifique, 1960.
Marazzi, Massimiliano, Natalia Bolatti-Guzzo, and Paola Dardano. 1998. Il geroglifico Anatolico: sviluppi della
ricerca a venti anni dalla sua “ridecifrazione” . Atti del Colloquio e della tavola rotonda Napoli-Procida, 5-9 giugno
1995. Istituto Universitario Orientale, Dipartimento di Studi Asiatici, Series Minor; 57. Napoli: Istituto Universitario
Orientale, 1998.
Arabic
ISO 233:1984,Documentation−Transliteration of Arabic characters into Latin characters
ISO/IEC 8859-6:1999,Information technology−8-bit single-byte coded graphic character sets Part 6:
126
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Latin/Arabic alphabet
ISO 9036:1987,Information processing−Arabic 7-bit coded character set for information interchange
ASMO 449-1982,Arab Organization for Standardization and Metrology. Data processing−7-bit coded character
set for information interchange
Avestan
Geldner, Karl F. Avesta: The Sacred Books of the Parsis. Stuttgart: W. Kohlhammerm, 1880. Reprinted, with an
introduction in Persian by Dr. Jaleh Amouzgar. Tehran: Asatir, 2003. ISBN 964-331-126-0.
Hoffmann, Karl, and B. Forssman. Avestische Laut- und Flexionslehre. Innsbruck: Innsbrucker Beiträge zur
Sprachwissenschaft, 1996. ISBN 3851246527.
Oryan, Said. Pahlavi-Pazand Glossary: Farhang \ Pahlavi. Tehran: Research Institute for Islamic Culture and Art,
1999 (1377 AP). (Language and Literature, 4). ISBN 964-471-414-8.
Reichelt, Hans. Avesta Reader: An Approach to the Zoroasterʼs Gathas and New Avestan Texts. Translated and
annotated with Persian translation of hymns and texts by Jalil Doostkhah. Tehran: Qoqnoos Publishing, 2004 (1383
AP). ISBN 964-311-473-2.
Balinese
Medra, Nengah. Pedoman Pasang Aksara Bali. Denpasar: Dinas Kebudayaan Propinsi Bali, 2003.
Menaka, Made. Kamus Kawi Bali / olih, made Menaka. Singaraja: Yayasan Kawi Sastra Mandala, 1990.
Simpen, I Wayan. Pasang Aksara Bali. Denpasar: Upada Sastra, 1992.
Bamum
Dugast, J., and M. D. W. Jeffreys. Lʼécriture des bamum: sa naissance, son évolution, sa valeur phonétique, son
utilisation. Mémoires de lʼInstitut Français dʼAfrique Noire, Centre du Cameroun, 1950.
Nchare, Oumarou. The Writing of King Njoya: Genesis, Evolution, Use. Foumban: Palais des Rois Bamoun,
Maison de la Culture, [s.d.].
Schmitt, Alfred. Die Bamum-Schrift. Band I: Text. Wiesbaden: Harrassowitz, 1963.
Batak
Kozok, Uli. Warisan leluhur: sastra lama dan aksara Batak. Jakarta: École française dʼExtrême Orient, 1999. ISBN
979-9023-33-5.
Meerwaldt, J H. Handleiding tot de beoefening der Bataksche taal. Leiden: E.J. Brill, 1904.
Tuuk, Herman Neubronner van der. A Grammar of Toba Batak. Translated by Jeune Scott-Kemball, edited by
Andries Teeuw and R. Roolvink. The Hague: Nijhoff, 1971.
Brahmi
Baums, Stefan. “Towards a Computer Encoding for Brāhmī.” In Script and Image: Papers on Art and Epigraphy,
edited by Adalbert J. Gail, Gerd J. R. Mevissen and Richard Salomon, vol. 11.1, 111‒143. Delhi: Motilal Banarsidass
Publishers, 2006.
Bühler, G. “The Bhattiprolu Inscriptions.” In Epigraphia Indica: A Collection of Inscriptions Supplementary to the
Corpus Inscriptionum Indicarum of the Archaeological Survey, vol. 2, 323‒329. Calcutta: Epigraphia Indica, 1894.
Dani, Ahmad Hasan. Indian Palaeography. 2nd edition. New Delhi: Munshiram Manoharlal Publishers, 1986.
Mahadevan, Iravatham. Early Tamil Epigraphy: From the Earliest Times to the Sixth Century A.D. Chennai, India:
Cre-A, 2003. (Harvard Oriental Series, vol. 62.)
127
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Braille
ISO/TR 11548-1:2001,Communication aids for blind persons−Identifiers, names and assignation to coded
character sets for 8-dot Braille characters−Part 1: General guidelines for Braille identifiers and shift marks
Canadian Aboriginal Syllabics
Canadian Aboriginal Syllabic Encoding Committee. Repertoire of Unified Canadian Aboriginal Syllabics
Proposed for Inclusion into ISO/IEC 10646: International Standard Universal Multi-Octet Coded Character Set.
[Canada]: CASEC [1994]
Carian
Adiego, Ignacio-Javier. The Carian Language. Leiden; Boston: Brill, 2007.
Melchert, H. Craig. “Carian”. In The Cambridge Encyclopedia of the Worldʼs Ancient Languages, edited by Roger
Woodard, 609-613. Cambridge: Cambridge University Press, 2004. ISBN-13: 978-0521562560.
Caucasian Albanian
Gippert, Jost, Wolfgang Schulze, Zaza Aleksidzé, and J.-P. Mahé. The Caucasian Albanian Palimpsests of Mount
Sinai. 3 vols. Turnhout: Brepols, 2009-2010.
Chakma
Cā mā, Cirajyoti and Ma gal Cā gmā. Cā mār āgpudhi = Chakma primer. Rā amā i: Cā mābhā ā Prakāśanā
Pari ad. 1982.
Khisa, Bhagadatta. Cā mā pattham pāt = Chakma primer. Rā amā i: Tribal Cultural Institute, 2001.
Cham
Aymonier, Étienne, and Antoine Cabaton. Dictionnaire Čam-Français. Paris, 1906.
Bùi Khánh Th . T diên Chǎm-Vi t: Inālang cam-biet đam. [H Chí Minh]: Nhà xu t ban Khoa H c Xã H i,
1995.
Kōno Rokurō, Chino Eiichi, and Nishida Tatsuo. The Sanseido Encyclopaedia of Linguistics. Volume 7: Scripts
and Writing Systems of the World [Gengogaku dai ziten (bekkan) sekai mozi ziten]. Tokyo: Sanseido Press, 2001.
ISBN 4-385-15177-6.
注記 これは,次の文献である。河野六郎・千野栄一・西田龍雄 世界文字辞典 東京 三省堂出版
2001 言語学大辞典別巻 ISBN 4-385-15177-6。
Cherokee
Alexander, J. T. A Dictionary of the Cherokee Indian Language. [Sperry, Oklahoma?]: Published by the author,
1971.
Holmes, Ruth Bradley. Beginning Cherokee, by Ruth Bradley Holmes and Betty Sharp Smith. 2nd ed. Norman:
University of Oklahoma Press, 1977. ISBN 0-8061-1464-9.
New Echota Letters: Contributions of Samuel A. Worcester to the Cherokee Phoenix, edited by Jack Frederick
Kilpatrick and Anna Gritts Kilpatrick. Dallas: Southern Methodist University Press, [s.d.]. Includes reprint of an
article by S. A. Worcester, which appeared in the Cherokee Phoenix, Feb. 21, 1828.
CJK Ideographs
GB 2312-80,Code of Chinese Graphic Character Set for Information Interchange: Jishu Biaozhun Chubanshe
(Technical Standards Publishing)
GBK (Guo Biao Kuo) Han character internal code extension specification: Jishu Biaozhun Chubanshe (Technical
Standards Publishing, Beijing)
128
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
JIS X 0208:1990 情報交換用漢字符号 (Code of the Japanese Graphic Character Set for Information
Interchange)
JIS X 0212:1990 情報交換用漢字符号−補助漢字 (Code of the supplementary Japanese graphic character set
for information interchange)
JIS X 0213:2000 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合 (7-bit and 8-bit double
byte coded extended KANJI sets for information interchange), 2000-01-20
JIS X 0213:2004 7ビット及び8ビットの2バイト情報交換用符号化拡張漢字集合
KS X 1001:2004 (formerly KS C 5601-1992),Korean Industrial Standards Association. Code for Information
Interchange (Hangeul and Hanja) (Jeongbo gyohwanyong buhogye)
ANSI Z39.64-1989,American National Standards Institute. East Asian character code for bibliographic use
Mandarin Promotion Council, Ministry of Education, Taiwan. Shiangtu yuyan biauyin fuhau shoutse (The
Handbook of Taiwan Languages Phonetic Alphabet). 1999.
Shinmura, Izuru. Kojien ‒ Dai 4-han. ‒ Tokyo : Iwanami Shoten, Heisei 3[1991]
注記1 これは,次の文献である。新村出 広辞苑 第4版 東京 岩波書店 1991。
注記2 CJK統合漢字の原典については,箇条23を参照。
Coptic
Browne, Gerald M. Old Nubian Grammar. München: Lincom Europa, 2002. (Languages of the world: Materials,
330). ISBN 3-89586-893-0 (pbk.).
Kasser, Rodolphe. “La ʻGenève 1986ʼ: une nouvelle série de caractères typographiques coptes, protocoptes et
vieux-coptes créée à Genève.” Bulletin de la Société dʼégyptologie de Genève, 12 (1988): 59-60. ISSN 0255-6286.
Kasser, Rodolphe. “A standard system of Sigla for referring to the dialects of Coptic.” Journal of Coptic Studies, 1
(1990): 141-151. ISSN 1016-5584.
Cypriot
“Linear B and Cypriot”を参照。
Cyrillic
ISO/IEC 8859-5:1999,Information technology−8-bit single-byte coded graphic character sets−Part 5:
Latin/Cyrillic alphabet
ISO 5427:1984,Extension of the Cyrillic alphabet coded character set for bibliographic information interchange
ISO 10754:1996,Information and documentation−Extension of the Cyrillic alphabet coded character set for
non-Slavic languages for bibliographic information interchange
Deseret
Encyclopedia of Mormonism, entry for “Deseret Alphabet.” New York: Macmillan, 1992. ISBN 0-02-904040-X.
Ivins, Stanley S. “The Deseret Alphabet” Utah Humanities Review 1 (1947): 223-39.
Monson, Samuel C. Representative American Phonetic Alphabets. New York: 1954. Ph.D. dissertation-Columbia
University.
Duployan
Hautefeuille, Arthur, and C. Ramaude. Cours de Sténographie Duployé Fondamentale. Paris: Bertrand-Lacoste,
1983.
Le Jeune, Jean Marie Raphael. Chinook and Shorthand Rudiments, with which the Chinook Jargon and the Wawa
Shorthand can be measured without a Teacher in a Few Hours. Kamloops, B.C.: [s.n.], 1898.
129
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
http://eco.canadiana.ca/view/oocihm.15465/4?r=0&s=1
Sloan, John Matthew, and Émile Duployé. Modern Shorthand: the Sloan-Duployan Phonographic Instructor: the
most legible, briefest, and simplest Shorthand Method in the World. 11th ed. London: Head Offices of
Sloan-Duployan Phonography, Ramsgate, 1884. First edition 1882.
Egyptian Hieroglyphic
Allen, James P. Middle Egyptian: An Introduction to the Language and Culture of Hieroglyphs. Cambridge:
Cambridge University Press, 1999. ISBN 0-521-77483-7.
Gardiner, Alan H. Catalogue of the Egyptian Hieroglyphic Printing Type, from Matrices Owned and Controlled by
Dr. Alan H. Gardiner, in Two Sizes, 18 Point, 12 Point with Intermediate Forms. Oxford: Oxford University Press,
1928.
Gardiner, Alan H. “Additions to the New Hieroglyphic Fount (1928).” The Journal of Egyptian Archaeology, 15
(1929): 95. ISSN 0307 5133.
Gardiner, Alan H. “Additions to the New Hieroglyphic Fount (1931).” The Journal of Egyptian Archaeology, 17
(1931): 245‒247. ISSN 0307 5133.
Gardiner, Alan H. Supplement to the Catalogue of the Egyptian Hieroglyphic Printing Type, Showing Acquisitions
to December 1953. Oxford: Oxford University Press, 1953.
Gardiner, Alan H. Egyptian Grammar: Being an Introduction to the Study of Hieroglyphs. 3rd edition. London:
Oxford University Press, 1957. ISBN 0-900416-35-1.
Elbasan
Elsie, Robert. “The Elbasan Gospel Manuscript (Anonimi i Elbasanit), 1761, and the Struggle for an Original
Albanian Alphabet.” Südost-Forschungen 54 (1995): 105-159. Online version:
http://www.elsie.de/pdf/articles/A1995ElbasanMs̲Fig.pdf
Ethiopic
Armbruster, Carl Hubert. Initia Amharica: an Introduction to Spoken Amharic. Cambridge, Cambridge University
Press, 1908-20.
Launhardt, Johannes. Guide to Learning the Oromo (Galla) Language. Addis Ababa, Launhardt [1973?]
Leslau, Wolf. Amharic Textbook. Weisbaden, Harrassowitz; Berkeley, University of California Press, 1968.
Glagolitic
ISO 6861,Information and documentation−Glagolitic alphabet coded character set for bibliographic information
interchange.
Glagolitica: zum Ursprung der slavischen Schriftkultur, herausgegeben von Heinz Miklas, unter der Mitarbeit von
Sylvia Richter und Velizar Sadovski. Wien: Verlag der Österreichischen Akademie der Wissenschaften, 2000.
(Schriften der Balkan-Kommission, Philologische Abteilung, 41). ISBN 3-7001-2895-9.
Khaburgaev, Georgii Aleksandrovich. Staroslavianskii iazyk. Izd. 2-e, perer. i dop. Moskva: Prosveshchenie, 1986.
Žubrinic, Darko. Hrvatska glagoljica: biti pismen-biti svoj. Zagreb: Hrvatsko književno društvo sv. Jeronima (sv.
Cirila i Metoda): Element, 1996. ISBN 953-6111-35-7.
Gothic
Ebbinghaus, Ernst. “The Gothic Alphabet.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and
William Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Fairbanks, Sydney, and F. P. Magoun Jr. 1940. ʻOn writing and printing Gothicʼ, in Speculum 15:313-16.
130
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Grantha
Grünendahl, Reinhold. South Indian Scripts in Sanskrit Manuscripts and Prints: Grantha Tamil ‒ Malayalam ‒
Telugu ‒ Kannada ‒ Nandinagari. Wiesbaden: O. Harrassowitz, 2001. ISBN: 3-447-04504-3.
Venugopalan, K. A Primer in Grantha Characters. St. Peter, MN: James H. Nye, 1983.
http://dsal.uchicago.edu/digbooks/dig̲toc.html?BOOKID=PK419.V468̲1983
Visalakshy, P. The Grantha Script. St. Xavierʼs College, University of Kerala, Trivandrum, India: Dravidian
Linguistics Association, 2003.
Greek
ISO 5428:1984,Greek alphabet coded character set for bibliographic information interchange
ISO/IEC 8859-7:2003,Information technology−8-bit single-byte coded graphic character sets Part 7:
Latin/Greek alphabet
Greek Editorial Marks
Austin, Colin. Comicorum Graecorum Fragmenta in Papyris Reperta, ed. Colinus Austin. Berolini [Berlin], Novi
Eboraci [New York]: de Gruyter, 1973, p. 29. ISBN 3110024012.
Homer. Iliad. Homeri Ilias, edidit Thomas W. Allen. 3 vols. Oxonii [Oxford]: e typographeo Clarendoniano
[Clarendon Press], 1931, vol. 2: pp. 39, 234.
The Oxyrhynchus Papyri, Part XV, edited with translations and notes by Bernard P. Grenfell and Arthur S. Hunt.
London: Egypt Exploration Society, 1921, p. 56. (Egypt Exploration Society, Graeco-Roman Memoirs, 18).
Hatran
Aggoula, Basile. Inventaire des inscriptions hatréennes. Paris: Librairie orientaliste Paul Geuthner, 1991.
Bertolino, Roberto. Manuel dʼépigraphie hatréenne. Paris: Geuthner Manuels, 2008.
Beyer, Klaus. 1998. Die aramäischen Inschriften aus Assur, Hatra und dem übrigen Ostmesopotamien. Göttingen:
Vandenhoeck & Ruprecht, 1998. ISBN 3-525-53645-3
Hebrew
ISO/IEC 8859-8:1999,Information technology−8-bit single-byte coded graphic character sets Part 8:
Latin/Hebrew alphabet
ISO 8957:1996,Information and documentation−Hebrew alphabet coded character sets for bibliographic
information interchange
SI 1311.1-1996,Standards Institution of Israel. Information technology. ISO 8 bit coded character set with
Hebrew points
SI 1311.2-1996,The Standards Institution of Israel. Information Technology. ISO 8-bit coded character set for
information interchange with Hebrew points and cantillation marks
Imperial Aramaic
Driver, G. R. Semitic Writing from Pictograph to Alphabet. 3rd ed. by S. A. Hopkins. London: Oxford University
Press for the British Academy, 1976. ISBN 9780197259177.
Lidzbarski, Mark. Handbuch der nordsemitischen Epigraphik nebst ausgewählten Inschriften. Hildesheim: Georg
Olms Verlagsbuchhandlung, 1962. Reprint of 1898 edition.
Naveh, Joseph. Early History of the Alphabet: An Introduction to West Semitic Epigraphy and Palaeography.
Jerusalem: Magnes Press, the Hebrew University, 1987. ISBN 965-223-436-2.
Porten, Bezalel, and Ada Yardeni. Textbook of Aramaic Documents from Ancient Egypt. 4 vols. Jerusalem:
131
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Hebrew University, 1986‒1999. ISBN 9652220752 (v. 1), 9653500031 (v. 2), 9653500147 (v. 3), 9653500899 (v. 4).
Rosenthal, Franz. A Grammar of Biblical Aramaic. 7th rev. ed. Wiesbaden: Harrassowitz, 2006. ISBN
3-447-05251-1.
Inscriptional Parthian and Inscriptional Pahlavi
Akbarzādeh, Dāriyūš. Katibe-hā-ye Pahlavi-ye Aškāni (Pārti) = Parthian Inscriptions. Vol. 2. Tehran: Pazineh
Press, 2002 (1381 AP). ISBN 964-5722-74-8.
Akbarzādeh, Dāriyūš. Katibe-hā-ye Pahlavi: sang-negāre, sekke, mohr, asar-e mohr, zarfnebešte = Pahlavi
Inscriptions: Inscriptions, Coins, Seals, Sealing Impression. Vol. I. Tehran: Pazineh Press, 2003 (1382 AP). ISBN
964-5722-44-6.
Nyberg, Henrik Samuel. A Manual of Pahlavi. 2 vols. Wiesbaden: Harrassowitz, 1964-1974. ISBN
9783447015806 (vol. 2). Reprinted: Tehran: Asatir, 2003. ISBN 964-331-132-5, 964-331-131-7.
Oryan, Saeed. Rahnmā-ye katibe-hā-ye Irāni-ye miyāne Pahlavi-Pārti = Manual of Middle Iranian Inscriptions
(Parthian-Pahlavi). Tehran: Iranian Cultural Heritage Organization, 2003 (1382 AP). ISBN 964-7483-71-6.
Rezai Baghbidi, Hassan. Dastur-e Zabān-e Pārti (Pahlavi-e Aškāni) = A Grammar of Parthian (Arsacid Pahlavi).
Iranian Academy of Persian Language and Literature, 2002 (1381 AP). ISBN 964-7531-05-2.
Indian scripts
IS 13194:1991,Bureau of Indian Standards Indian script code for information interchange−ISCII
LTD 37(1610)-1988,Indian standard code for information interchange
International Phonetic Alphabet
Esling, John. Computer coding of the IPA: supplementary report. Journal of the International Phonetic Association,
20:1 (1990), p. 22-26.
International Phonetic Association. The IPA 1989 Kiel Convention Workgroup 9 report: Computer Coding of IPA
Symbols and Computer Representation of Individual Languages. Journal of the International Phon. Assoc., 19:2
(1989), p. 81-82.
International Phonetic Association. Handbook of the International Phonetic Association: A Guide to the Use of the
International Phonetic Alphabet. Cambridge: Cambridge University Press, 1999. ISBN 0-521-65236-7;
0-521-63751-1 (pbk.).
International Phonetic Association. http://www2.arts.gla.ac.uk/IPA/ipa.html.
Journal of the International Phonetic Association, 24:2 (1994), 95‒98, and 25:1 (1995), 21.
Pullum, Geoffrey K. Remarks on the 1989 revision of the International Phonetic Alphabet. Journal of the
International Phonetic Association, 20:1 (1990), p. 33-40.
Pullum, Geoffrey K., and William A. Ladusaw. Phonetic Symbol Guide. 2nd ed. Chicago: University of Chicago
Press, 1996. ISBN 0-226-68535-7; 0-226-68536-5 (pbk.).
Wells, John Christopher. Accents of English. Cambridge, New York: Cambridge University Press, 1982. Vol. 1:
Introduction. ISBN 0-521-22919-7; ISBN 0-521-29719-2 (pbk.); vol. 2: The British Isles. ISBN 0-521-24224-X,
ISBN 0-521-28540-2 (pbk.); vol. 3: Beyond the British Isles. ISBN 0-521- 24225-8, ISBN 0-521-28541-0 (pbk.).
Javanese
Bohatta, Hanns. Praktische Grammatik der javanischen Sprache, mit Lesestücken, einem javanisch-deutschen und
deutsch-javanischen Wörterbuch. Wien, Pest, Leipzig: Hartleben, [1892]. (Kunst der Polyglottie, 39).
Rochadi GK, R. H., and R. L. Sadeli Erawan BK. Cacarakan aksara Sunda. Bandung: Harisma, 1984.
132
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Roorda, T. Javaansche grammatica, benevens een leesboek tot oefening in de javaansche taal. Amsterdam:
Johannes Müller, 1855.
Walbeehm, A. H. J. G. Javaansche spraakkunst: schrift, uitspraak, taalsoorten en woordafleiding. Leiden: E. J. Brill,
1905.
Kaithi
Bihar High Court of Judicature. Selection of Hindusthani Documents from the Courts of Bihar, compiled by S. K.
Das. Patna, Bihar: Superintendent, Government Printing, 1939.
Grierson, George A. A Handbook to the Kaithi Character. 2nd rev. ed. Calcutta: Thacker, Spink & Co., 1899.
Revised edition of A Kaithi Handbook, 1881.
King, Christopher R. One Language, Two Scripts: The Hindi Movement in Nineteenth Century North India.
Bombay: Oxford University Press, 1994.
Kayah Li
Bennett, J. Fraser. Kayah Li Script: A Brief Description. Urbana-Champaign: University of Illinois, 1993.
Karenni Literature Department. Ka1ya3lhi1-Ku3la3 Nghôchozha3: The Modern Western Kayah Li-English Lexicon.
[Chiang Mai]: Payap University, 1994. [without tones = Kayalhi-Kula Nghôchozha]
Solnit, David B. Eastern Kayah Li: Grammar, Texts, Glossary. Honolulu: University of Hawaiʻi Press, 1997. ISBN
0-8248-1743-5.
Kharoshthi
Glass, Andrew. A Preliminary Study of Kharosthi Manuscript Paleography. 2000. Thesis (M.A.), University of
Washington, 2000.
Glass, Andrew. “KharoDEhG Manuscripts: A Window on GandhFran Buddhism.” Nagoya Studies in Indian
Culture and Buddhism, 24 (2004): 129-152. ISSN 0285-7154.
Salomon, Richard. Ancient Buddhist Scrolls from GandhZra: The British Library Kharosthi Fragments. Seattle:
University of Washington Press; London: British Library, 1999. ISBN 029597768X; 0295977698 (pbk).
Khojki
Asani, Ali S. “The KhojkS Script: A Legacy of Ismaili Islam in the Indo-Pakistan Subcontinent.” Journal of the
American Oriental Society 107.3 (Jul.−Sep. 1987): 439‒449.
Asani, Ali S. “The KhojkS Script and its Manuscript Tradition.” Ecstasy and Enlightenment: The Ismaili
Devotional Literature of South Asia, by Ali Asani, 124‒152. London: I. B. Tauris & Co. in association with The
Institute of Islamic Studies, 2002.
Daftary, Farhad. “Ismaili History and Literary Traditions” . An Anthology of Ismaili Literature: A Shiʻi Vision of
Islam, edited by Hermann Landolt, Samira Sheikh, and Kutub Kassam, 1‒29. London; New York: I.B. Tauris in
Association with the Institute of Ismaili Studies, 2008.
Shackle, Christopher and Zawahir Moir. Ismaili Hymns from South Asia: An Introduction to the Ginans. London:
School of Oriental and African Studies, University of London, 1992.
Khudawadi
Grierson, George A. The Linguistic Survey of India. Vol. 8: Indo-Aryan Family. North-Western Group. Part 3:
Sindh¥ and LahndZ. Calcutta: Office of the Superintendent of Government Printing, India, 1919.
Jetley, Murlidhar Kishinchand. Boliya jo sirishto ain likhawata: sindhi boliya jawan lipiyon. [Structure of
Language and Writing System: A Brief History of Sindhi Script]. Delhi: Akhil Bharatiya Sindhi Sahitya Vidvat
133
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Parishad, 1999. In Sindhi language in Arabic script.
Latin
ISO/IEC 646:1991,Information technology−ISO 7-bit coded character set for information interchange
ISO 5426:1983,Extension of the Latin alphabet coded character set for bibliographic information interchange
ISO 6438:1983,Documentation−African coded character set for bibliographic information interchange
ISO 6937:1994,Information technology−Coded graphic character set for text communication−Latin alphabet
ISO/IEC 8859,Information technology−8-bit single-byte coded graphic character sets
Part 1: Latin alphabet No. 1 (1998).
Part 2: Latin alphabet No. 2 (1999).
Part 3: Latin alphabet No. 3 (1999).
Part 4: Latin alphabet No. 4 (1998).
Part 9: Latin alphabet No. 5 (1999)
Part 10: Latin alphabet No. 6 (1998).
ISO/IEC 10367:1991,Information technology−Standardized coded graphic character sets for use in 8-bit codes
ANSI X3.4-1986,American National Standards Institute. Coded character set−7-bit American national standard
code
ANSI Z39.47-1985,American National Standards Institute. Extended Latin alphabet coded character set for
bibliographic use
LVS 18-92,Latvian National Centre for Standardization and Metrology Libiesu kodu tabula ar 191 simbolu
Kuruch, Rimma Dmitrievna. Saamsko-russkiy slovar'. Moskva: Russkiy iazyk. 1985
Lepcha
Mainwaring, G. B. A Grammar of the Rong (Lepcha) Language as it Exists in the Dorjeling and Sikim Hills.
Delhi: Daya Publishing House, 1985 (1876).
Plaisier, H. “A Brief Introduction to Lepcha Orthography and Literature.” Bulletin of Tibetology 41:1 (2005),
7‒24.
Plaisier H. A Grammar of Lepcha. Leiden: Brill, 2007. (Brillʼs Tibetan Studies Library, Languages of the Greater
Himalayan Region 5).
Limbu
Bairagi Kaila, ed. Limbu-Nepali-Angreji śabdakoś. [Limbu-Nepali-English Dictionary.] Kathmandu: Royal Nepal
Academy, [in press.]
Cemjonga, Imana Simha. Yakthun-Pene-Mikphula Pancheka. = Limbu-Nepali-Angareji śabdakoś. =
Limbu-Nepali-English Dictionary. [Lekhaka] Imanasimha Cemajon. [Kathamandu]: Nepala Ekedemi [2018 vi., i.e.,
1962]
Driem, George van. A Grammar of Limbu. Berlin, New York: Mouton de Gruyter, 1987. (Mouton grammar library,
4.) ISBN 0-89925-345-8. Appendix: Anthology of Kiranti scripts, pp. 550‒558.
Shafer, Robert. Introduction to Sino-Tibetan. Wiesbaden: Harrassowitz, 1966‒1974.
Sprigg, R. K. “Limbu Books in the Kiranti Script.” In International Congress of Orientalists (24th: 1957: Munich).
Akten des Vierundzwanzigsten Internationalen Orientalisten-Kongresses München 28. August bis 4. September 1957,
hrsg. von Herbert Franke. Wiesbaden: Deutsche Morgenländische Gesellschaft, in Kommission bei Franz Steiner
Verlag, 1959.
134
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Sprigg, R. K. [Review of van Driem (1987)]. Bulletin of the School of Oriental and African Studies, University of
London, 52 (1989):1.163‒165.
Subba, B. B. Limbu, Nepali, English Dictionary. Gangtok: Text Book Unit, Directorate of Education, Govt. of
Sikkim, 1979 [i.e. 1980]. Cover title: Yakthun-Pene-Mikphula-panchekva.
Subba, B. B. Yakthuŋ hu
siŋlam (“Limbu self-teaching method”) = Limbu ak
ar gāi
(“Limbu letter guide”).
Gangtok: Kwality Stores, 1991?
Yo hā , Khel Rāj. Limbū Nepālī śabdakoś. [Lalitpur]: 2052 B.S. [i.e. 1995].
Linear A
Bennett, Emmett L. “Aegean Scripts.” The Worldʼs Writing Systems, edited by Peter T. Daniels and William
Bright, 125-133. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Chadwick, John. Linear B and Related Scripts. Berkeley: University of California Press; [London]: British
Museum, 1987. (Reading the Past, v. 1). ISBN: 0-520-06019-9.
Godart, Louis, and Jean-Pierre Olivier. Recueil des inscriptions en Linéaire A. Vols. 1-5. Paris : Librairie
Orientaliste Paul Geuthner, 1976‒1985. (Études Crétoises, 21). (GORILA).
Younger, John G. Linear A Texts in Phonetic Transcription. 2000‒present.
http://people.ku.edu/~jyounger/LinearA/
Linear B and Cypriot
Bennett, Emmett L. “Aegean Scripts.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and William
Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Chadwick, John. The Decipherment of Linear B. 2nd ed. London: Cambridge University Press., 1967 [i.e. 1968].
Chadwick, John. Linear B and Related Scripts. Berkeley: University of California Press; [London]: British
Museum, 1987. (Reading the Past, v. 1.) ISBN 0-520-06019-9.
Hooker, J. T. Linear B: An Introduction. Bristol: Bristol Classical Press, 1980. ISBN 0-906515-69-6. Cor-rected
printing published 1983. ISBN 0-906515-69-6; 0-906515-62-9 (pbk.).
International Colloquium on Mycenaean Studies (3rd: 1961: Racine, WI). Mycenaean Studies: Proceedings of the
Third International Colloquium for Mycenaean Studies held at “Wingspread,” 4-8 September 1961, edited by
Emmett L. Bennett, Jr. Madison: University of Wisconsin Press, 1964.
Masson, Olivier. Les Inscriptions chypriotes syllabiques: recueil critique et commenté. Réimpr. augm. Paris: E. de
Boccard, 1983.
Sampson, Geoffrey. Writing Systems: A Linguistic Introduction. Stanford, CA: Stanford University Press, 1985.
ISBN 0-8047-1254-9. Also published: London, Hutchinson. ISBN 0-09-156980-X; 0-09-173051-1 (pbk.).
Ventris, Michael. Documents in Mycenaean Greek. 1st ed. by Michael Ventris and John Chadwick with a foreword
by Alan J. B. Wace. 2nd ed. by John Chadwick. Cambridge: Cambridge University Press, 1973. ISBN
0-521-08558-6.
Lisu
Bya, Yuliya. Li-su Tho Uh Ba Pa Pha Tso So Du (Lisu Alphabet Primer). Chiang Mai: Christian Literature
Fellowship, 2000.
Xu, Lin, Yuzhang Mu, and Xingzhi Gai, eds. Lisuyu Jianzhi (A Sketch of the Lisu Language). Beijing: The Ethnic
Publishing House, 1986. (Chinese Minority Language Sketch Series.)
Yunnan Minority Language Commission, and Weixi Culture and Education Bureau, eds. Li-su Tho Uh Tso So Du
135
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
(Lisu Primer). Kunming: Yunnan Nationality Publishing House, 1981.
Zhu, Faqing. Li-su Be Xuh Ngo Bae Khuh Tae Du Ra (Small Lisu-Chinese Dictionary). Dehong: Dehong
Nationality Publishing House, 1984.
Lycian
Carruba, O. “La scrittura licia.” Annali della scuola normale superiore di Pisa, classe di letter e filosofia. 3rd series.
8 (1978):849‒867.
Melchert, H. Craig. “Lycian.” In The Cambridge Encyclopedia of the Worldʼs Ancient Languages, edited by Roger
Woodard, 591‒600. Cambridge: Cambridge University Press, 2004. ISBN-13: 978-0521562560.
Lydian
Gérard, Raphaël. Phonétique et morphologie de la langue lydienne. Louvain-la-Neuve: Peeters, 2005.
Gusmani, Roberto. Lydisches Wörterbuch mit grammatischer Skizze und Inschriftensammlung. Heidelberg: Carl
Winter, 1964.
Melchert, H. Craig. “Lydian.” In The Cambridge Encyclopedia of the Worldʼs Ancient Languages, edited by Roger
Woodard, 601‒608. Cambridge: Cambridge University Press, 2004. ISBN-13: 978-0521562560.
Mahajani
Lālā Ga gādāsa (Mu śī Lāla). Mahājanī-sāra-hissā-avvala-va-doyama = Mahajani primer, parts one and two.
Dehalī, 18-?.
Leitner, Gottlieb William. “A Collection of Specimens of Commercial and Other Alphabets and Handwritings as
also of Multiplication Tables Current in Various Parts of the Panjab, Sind and the North West Provinces” . Appendix
V of History of Indigenous Education in the Punjab. Lahore: Anjuman-i-Punjab Press, 1882.
Mandaic
Daniels, “Aramaic Scripts for Aramaic Languages,” in Daniels & Bright, eds., The Worldʼs Writing Systems,
Oxford University Press, 1996, pp. 511-513 “Mandaic.”
Häberl, “Iranian Scripts for Aramaic Languages: The Origin of the Mandaic Script,” Bulletin of the American
Schools of Oriental Research, No. 341 (Feb., 2006), pp. 53-62.
Coulmas, The Blackwell Encyclopedia of Writing Systems, Blackwell 1999, p. 320 “Mandean script.”
Manichaean
Skjærvø, P. Oktor. “Aramaic scripts for Iranian Languages.” The Worldʼs Writing Systems, edited by Peter T.
Daniels and William Bright, 515-535. New York: Oxford University Press, 1996. ISBN 0-19-507993-0
Mathematical Symbols
ISO 6862,Information and documentation−Mathematical coded character set for bibliographic information
interchange
ANSI Y10.20-1988,American National Standards Institute. Mathematic signs and symbols for use in physical
sciences and technology
Mathematical Markup Language (MathML) Version 2.0. (W3C Recommendation 21 February 2001). Editors:
David Carlisle, Patrick Ion, Robert Miner, [and] Nico Poppolier. Latest version: http://www.w3.org/TR/MathML2/
Selby, Samuel M. Standard mathematical tables. ‒ 16th ed. ‒ Cleveland, OH : Chemical Rubber Co., 1968.
Shepherd, Walter.
STIPub Consortium. STIX (Scientific and Technical Information Exchange) Project. http://www.ams.org/STIX/
Swanson, Ellen. Mathematics into Type. Updated ed. by Arlene OʼSean and Antoinette Schleyer. Providence, RI:
136
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
American Mathematical Society, 1999. ISBN 0-8218-1961-5.
Meetei Mayek
Chelliah, Shobhana L. A Grammar of Meithei. Berlin and New York: Mouton de Gruyter, 1997. ISBN
978-3-11-014321-8.
Debendra Singh, N. Evolution of Manipuri Script. [Imphal]: Manipur University, Centre for Manipuri Studies,
1990. (Research Report, 5).
Mende Kikakui
Dalby, David. “A Survey of the Indigenous Scripts of Liberia and Sierra Leone: Vai, Mende, Loma, Kpelle and
Bassa.” African Language Studies 8 (1967): 1-51.
Tuchscherer, Konrad. The Kikakui (Mende) Syllabary and Number Writing System: Descriptive, Historical and
Ethnographic Accounts of a West African Tradition of Writing. London: 1996. Ph.D. dissertation-The School of
Oriental and African Studies, University of London.
Tuchscherer, Konrad. 2007. “Recording, Communicating and Making Visible: A History of Writing and Systems
of Graphic Symbolism in Africa.” Inscribing Meaning: Writing and Graphic Systems in African Art, edited by
Christine Mullen Kreamer et al., 37-53. [Washington D.C.]: Smithsonian, National Museum of African Art. ISBN:
97888-7439-377-0.
Meroitic
Griffith, F. Ll. Karanòg: The Meroitic inscriptions of Shablûl and Karanòg. Philadelphia: University Museum,
1911.
Millet, N. B. “The Meroitic script.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and William
Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Rilly, Claude. La langue du royaume de Méroé: un panorama de la plus ancienne culture écrite dʼAfrique
subsaharienne. Paris: Librairie Honoré Champion, 2007.
Miao
Enwall, Joakim. A Myth Become Reality: History and development of the Miao written language. 2 vols.
Stockholm: Institute of Oriental Languages, Stockholm University, 1994‒1995. (Stockholm East Asian monographs
no. 5-6.)
Xiong Yuyou. Miao zu wen hua shi = A Cultural History of the Miao Nationality. Kunming Shi: Yunnan min zu
chu ban she, 2003.
Modi
Dīksit, Moreśvar G. and V. G. Khobarekar. Marāthekālīna prasiddha vyaktī cī hastāksarayukta patra. Mumbaī,
Śāsakīya Madhyavartī Mudra ālaya, 1969. In Marathi language in Devanagari script.
Kunte, B. G. [ed.]. Illustrative Modi Documents. Maharashtra State Archives, Government of Maharashtra.
Bombay: Government Central Press, 1987.
Strandberg, Elisabeth [ed]. The Modī Documents from Tanjore in Danish Collections. Wiesbaden: Franz Steiner
Verlag, 1983. (Beiträge zur Südasienforschung, Südasien-Institut, Universität Heidelberg, Band 81).
Mro
Angkea Ngiycea Wean Shang Beaik. [Get Language Class: Childʼs Class]. Dhaka, Bangladesh: Gonoshasthaya
Kendra, 2004. In Mro script.
Caa Yang Beaik: Prei Taing. [Get Language Class: Second Book]. Dhaka, Bangladesh: Gonoshasthaya Kendra,
137
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
2002. In Mro script.
Multani
Leitner, Gottlieb William. “A Collection of Specimens of Commercial and Other Alphabets and Handwritings as
also of Multiplication Tables Current in Various Parts of the Panjab, Sind and the North West Provinces.” In History
of Indigenous Education in the Punjab. Lahore: Anjuman-i-Punjab Press, 1882.
Shackle, Christopher. From Wuch to Southern Lahnda: A Century of Siraiki Studies in English. Multani:
Bazm-eSaqafat, 1983.
Musical Symbols
ELOT 1373. The Greek Byzantine Musical Notation System. Athens, 1997 (ΣΕΠ ΕΛΟΤ 1373: 1997).
Catholic Church. Graduale Sacrosanctae Romanae Ecclesiae de Tempore et de Sanctis SS. D. N. Pii X. Pontificis
Maximi. Parisiis: Desclée, 1961. (Graduale Romanum, no. 696.)
Gazimihal, Mahmut R. Anadolu türküleri ve mûsikî istikbâlimiz [by] Mahmut Ragip. [Istanbul]: Mârifet Matbaasi,
1928.
Heussenstamm, George. Norton Manual of Music Notation. New York: W.W. Norton, 1987. ISBN 0-393-95526-5
(pbk.).
Kennedy, Michael. Oxford Dictionary of Music. Oxford, New York: Oxford University Press, 1985. ISBN
0-19-311333-3. Second ed. published 1994. ISBN 0-19-869162-9.
New Encyclopedia Britannica. 15th ed. Entry for “Music.”
The New Harvard Dictionary of Music, edited by Don Michael Randel. Cambridge, MA: Belknap Press of
Harvard University Press, 1986. ISBN 0-674-61525-5.
Ottman, Robert W. Elementary Harmony: Theory and Practice. 2nd ed. Englewood Cliffs, NJ: Prentice-Hall, 1970.
ISBN 0-13-257451-9. Fifth ed. published 1998. ISBN 0-13-281610-5.
Rastall, Richard. The Notation of Western Music: An Introduction. London: Dent, 1983. ISBN 0-460-04205-X.
Also published: New York: St. Martinʼs Press, 1982. ISBN 0-312-57963-2.
Read, Gardner. Music Notation: A Manual of Modern Practice. Boston: Allyn and Bacon, 1964.
Stone, Kurt. Music Notation in the Twentieth Century: A Practical Guidebook. New York: W.W. Norton, 1980.
ISBN 0-393-95053-0.
Understanding Music with AI: Perspectives on Music Cognition, edited by Mira Balaban, Kemal Ebcioglu, and
Otto Laske. Cambridge, MA: MIT Press; Menlo Park, CA: AAAI Press, 1992. ISBN 0-262-52170-9.
Myanmar
Mranmā‒A
glip abhidhān = Myanmar‒English Dictionary. Rankun: Dept. of Myanmar Language Commission,
Ministry of Education, Union of Myanmar, 1993. Compiled and edited by the Myanmar Language Commission.
Mranmā cālui:po
g:satpui kyam: nha
. khwaithā:. [Rankun]: 1996. Translated title: Myanmar orthography
treatise.
Okell, John. 1971. A guide to the romanization of Burmese. (James G. Forlang Fund; 27) London: Royal Asiatic
Society of Great Britain and Ireland.
Roop, D. Haigh. An Introduction to the Burmese Writing System. [Honolulu]: Center for Southeast Asian Studies,
University of Hawaii at Manoa, 1997. (Southeast Asia Paper, 11). Originally published: New Haven: Yale University
Press, 1972. (Yale linguistic series). ISBN 0-300-01528-3.
138
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Nabataean
Christian, Arthur. Débuts de lʼimprimerie en France : LʼImprimerie Nationale : LʼHôtel de Rohan. Paris :
Imprimerie Nationale, 1905.
Fossey, Charles. Notices sur les caractères étrangers anciens et modernes rédigées par un groupe de savants.
Nouvelle édition mise à jour à lʼoccasion du 21e Congrès des Orientalistes. Paris : Imprimerie Nationale de France,
1948.
Yardeni, Ada. Textbook of Aramaic, Hebrew, and Nabataean Documentary Texts from the Judaean Desert and
Related Material. Jerusalem: The Ben-Zion Dinur Center for Research in Jewish History, The Hebrew University,
2000. ISBN 965-350-083-X.
N'Ko
Kanté, Souleymane. Méthode pratique dʼécriture nʼko, 1961. Kankan, Guinea: Association de traditherapeutes et
pharmacologues, 1995.
NʼKo: The Common Language of Mandens. www.nkoinstitute.com
NʼKo: The Mandingo Language Site. www.kanjamadi.com
Ogham
I. S. 434:1999, Information Technology−8-bit single-byte graphic coded character set for Ogham =
Teicneolaíocht Eolais−Tacar carachtar grafach Oghaim códaithe go haonbheartach le 8 ngiotán. National Standards
Authority of Ireland.
McManus, Damian. A Guide to Ogam. Maynooth: An Sagart, 1991. (Maynooth monographs, 4). ISBN
1-87068-417-6.
Ol Chiki
Hembram, S. M., et al. Adibasi Ol script = atʼipʼasi al ciki. Calcutta: Adibasi Socio-Educational & Cultural
Association, 1972.
Murmu, Raghunath. Rana
: A Santali Grammar in Santali. Singhbhum, Bihar: Adibasi Socio-Educational &
Cultural Association, 1972.
Zide, Norman. “Scripts for Munda languages.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and
William Bright. New York; Oxford: Oxford University Press, 1996. ISBN 0-19-507993-0.
Old Italic
Bonfante, Larissa. “The Scripts of Italy.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and William
Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Cristofani, Mauro. “Lʼalfabeto etrusco.” In Lingue e dialetti dellʼItalia antica, a cura di Aldo Larosdocimi. Roma:
Biblioteca di storia patria, a cura dellʼ Ente per la diffusione e lʼeducazione storia, 1978. (Popoli e civiltà dellʼItalia
antica, VI.)
Gordon, Arthur E. Illustrated Introduction to Latin Epigraphy. Berkeley: University of California Press, 1983.
ISBN 0-520-03898-3.
Marinetti, Anna. Le iscrizione sudpicene. I. Testi. Firenze: Olschki, 1985. ISBN 88-222-3331-X (v. 1).
Parlangèli, Oronzo. Studi Messapici. Milano: Istituto lombardo di scienze e lettere, 1960.
Old North Arabian
Macdonald, Michael C. A. “Ancient North Arabian.” The Cambridge Encyclopedia of the Worldʼs Ancient
Languages, edited by Roger D. Woodard, 488-533. Cambridge: Cambridge University Press, 2004. ISBN
139
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
0-521-56256-2.
Macdonald, Michael C. A. Literacy and Identity in Pre-Islamic Arabia. Farnham: Ashgate, 2009.
Macdonald, Michael C. A. Forthcoming. “Towards a re-assessment of the Ancient North Arabian alphabets used in
the oasis of al-ʻUlā.”.
Old Permic
Lytkin V. I. Drevnepermskij jazyk: chtenie tekstov, grammatika, slovarʼ. Moskva, 1952. In Russian.
Stipa, Günter Johannes. Finnisch-ugrische Sprachforschung von der Renaissance bis zum Neupositivismus.
Helsinki: Suomalais-ugrilainen Seura, 1990. (Mémoires de la Société Finno-ougrienne, 206). ISBN 951-9403-35-3.
Old Persian
Schmitt, Rüdiger. The Bisitun Inscriptions of Darius the Great, Old Persian Text. London, School of Oriental and
African Studies, 1991 (Corpus Inscriptionum Iranicarum, Part I: Inscriptions of ancient Iran, v.1, Text 1). ISBN
0-7286-0181-8.
Schweiger, Günter. Kritische Neuedition der achaemenidischen Keilinschriften. Taimering: Schweiger
VWT-Verlag, 1998. (Studien zur Iranistik). ISBN 3-934548-00-8.
Old South Arabian
Nebes, Norbert, and Peter Stein. “Ancient South Arabian.” In The Cambridge Encyclopedia of the Worldʼs
Ancient Languages, edited by Roger D. Woodard. 454-487. Cambridge University Press, 2004. ISBN-13:
978-0521562560.
Ryckmans, J. “Origin and Evolution of South Arabian Minuscule Writing on Wood (1).” Arabian Archaeology and
Epigraphy 12 (2001): 223‒235. ISSN 0905-7196.
Smithsonian Institution. “Written in Stone: Inscriptions from the National Museum of Saudi Arabic.”
http://www.mnh.si.edu/epigraphy/figs-stones/x-large/color̲xl̲jpeg/fig02.jpg
Stein, Peter. “The Ancient South Arabian Minuscule Inscriptions on Wood: A New Genre of Pre-Islamic
Epigraphy.” Jaarbericht van het Vooraziatisch-Egyptisch Genootschap “Ex Oriente Lux”, 39 (2005): 181-199. ISSN
0075-2118.
Old Turkic
Erdal, Marcel. A Grammar of Old Turkic. Leiden & Boston: Brill, 2004. ISBN 9004102949.
Scharlipp, Wolfgang Ekkehard. Eski Türk run yazitlarina giri!: ders kitabi = An Introduction to the Old Turkish
Runic Inscriptions: A Textbook in English and Turkish. Engelschoff: Auf dem Ruffel, 2000. ISBN 3-933847-00-X.
von Gabain, A. Alttürkische Grammatik mit Bibliographie, Lesestücken und Wörterverzeichnis, auch Neutürkisch.
Leipzig: Harrassowitz, 1941. (Porta Linguarum Orientalium, 23).
Osmanya
Afkeenna iyo fartiisa: buug koowaad. Xamar: Goosanka afka iyo suugaanta Soomaalida, 1971. Translated title:
Our language and its handwriting: book one.
Cerulli, Enrico. “Tentativo indigeno di formare un alfabeta somalo.” Oriente moderno, 12 (1932): 212‒213. ISSN
0030-5472.
Gaur, Albertine. A History of Writing. London: British Library, 1992. ISBN 0-7123-0270-0. Also published: Rev.
ed. New York: Cross River Press, 1992. ISBN 1-558-59358-6.
Gregersen, Edgar A. Language in Africa: An Introductory Survey. New York: Gordon and Breach, 1977. (Library
of Anthropology). ISBN: 0-677-04380-5; 0-677-04385-6 (pbk.).
140
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Maino, Mario. “Lʼalfabeta ʻOsmaniaʼ in Somalia.” Rassegna di studi etiopici, 10 (1951): 108‒121. ISSN
0390-3699.
Nakanishi, Akira. Writing Systems of the World: Alphabets, Syllabaries, Pictograms. Rutland, VT: Tuttle, 1980.
ISBN 0-8048-1293-4; 0-8048-1654-9 (pbk.). Revised translation of Sekai no moji.
Pahawh Hmong
Chia Koua Vang. Moj Kuab Hmoob: Lawj 2 [Hmong Language: Second Grade]. St. Paul: Hmong National
Organization, 2002.
Lee Nao Long, Yang Lee Hue, Yang Nao Shoua, and Christina Eira. Keeb Hmoob Phau Kuab Meej Sim [The
Hmong Bilingual Dictionary]. [s.l., Australia]: Yang Shong Lueʼs Millennium Academy for the Hmong Language
and Writing System, 2001.
Smalley, William A., Chia Koua Vang, and Gnia Yee Yang. Mother of Writing: the Origin and Development of a
Hmong Messianic Script. Chicago and London: University of Chicago Press, 1990. ISBN 0-226-76287-4.
Palmyrene
Fossey, Charles. Notices sur les caractères étrangers anciens et modernes rédigées par un groupe de savants.
Nouvelle édition mise à jour à lʼoccasion du 21e Congrès des Orientalistes. Paris: Imprimerie Nationale de France,
1948.
Lidzbarski, Mark. Handbuch der nordsemitischen Epigraphik nebst ausgewählten Inschriften. Hildesheim: Georg
Olms Verlagsbuchhandlung, 1962. Reprint of 1898 edition.
Naveh, Joseph. Early History of the Alphabet: An Introduction to West Semitic Epigraphy and Palaeography.
Jerusalem: Magnes Press, the Hebrew University, 1987. ISBN 965-223-436-2.
Pau Cin Hau
British and Foreign Bible Society. 1931. [The Sermon on the Mount (Kamhow-Sokte)]. Rangoon, 1931. In Pau
Cin Hau script.
Banks, E. Pendleton. “Pau Cin Hau: A Case of Religious Innovation among the Northern Chin.” American
Historical Anthropology: Essays in Honor of Leslie Spier, edited by Carroll Riley, and Walter Taylor. Carbondale:
Southern Illinois University Press, 1967.
Pau Chin Hau and Tham Chin Kham. [Spelling Book in Kamhow-Sokte]. Toungoo: P. R. G. Press, 1932. In Pau
Cin Hau script.
Phags-pa
Luo, Changpei. Basibazi yu Yuandai Hanyu [ziliao huibian] / Luo Changpei, Cai Meibiao bian zhu. Beijing:
Kexue chubanshe, 1959.
Poppe, Nikolai Nikolaevich. The Mongolian Monuments in hPʼags-pa Script. Translated and edited by John R.
Krueger. 2nd ed. Wiesbaden: Harrassowitz, 1957. (Göttinger asiatische Forschungen, 8).
Zhaonasitu. Menggu ziyun jiaoben / Zhaonasitu, Yang Naisi bian zhu. [Beijing]: Min zu chu ban she, 1987. Author
Zhaonasitu also known as Jagunasutu or Junast.
Philippines Scripts
Doctrina Christiana: The First Book Printed in the Philippines, Manila 1593. A facsimile of the copy in the
Lessing J. Rosenwald Collection, with an introductory essay by Edwin Wolf II. Washington, DC: Library of
Congress, 1947.
Kuipers, Joel C., and Ray McDermott. “Insular Southeast Asian Scripts.” In The Worldʼs Writing Systems. Edited
141
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
by Peter T. Daniels and William Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Santos, Hector. The Living Scripts. Los Angeles: Sushi Dog Graphics, 1995. (Ancient Philippine scripts series, 2).
Userʼs guide accompanying Computer Fonts, Living Scripts software.
Santos, Hector. Our Living Scripts. January 31, 1997. http://www.bibingka.com/dahon/living/living.htm Part of
his A Philippine Leaf.
Santos, Hector. The Tagalog Script. Los Angeles: Sushi Dog Graphics, 1994. (Ancient Philippine scripts series, 1).
Userʼs guide accompanying Tagalog Script Fonts software.
Santos, Hector. The Tagalog Script. October 26, 1996. http://www.bibingka.com/dahon/tagalog/tagalog.htm Part
of his A Philippine Leaf.
Phoenician
Branden, Albertus van den. Grammaire phénicienne. Beyrouth: Librairie du Liban, 1969. (Bibliothèque de
lʼUniversité Saint-Esprit, 2).
McCarter, P. Kyle. The Antiquity of the Greek Alphabet and the Early Phoenician Scripts. Missoula, MT:
Published by Scholars Press for Harvard Semitic Museum, 1975. (Harvard Semitic Monographs; 9.) ISBN
0-89130-066-X.
Noldeke, Theodor. Beiträge zur semitischen Sprachwissenschaft. Strassburg: Karl J. Trübner, 1904. Reprinted as:
vol. 1 of Beiträge und Neue Beiträge zur semitischen Sprachwissenschaft: achtzehn Aufsätze und Studien.
Amsterdam: APA-Philo Press, [1982]. Also published on microfiche by the American Theological Library
Association.
Powell, Barry B. Homer and the Origin of the Greek Alphabet. Cambridge, New York: Cambridge University
Press, 1991. ISBN 0-521-37157-0. Reprinted, 1996. ISBN 0-521-58907-X (pbk).
Psalter Pahlavi
Nyberg, Henrik Samuel. A Manual of Pahlavi. 2 vols. Wiesbaden: Harrassowitz, 1964-1974. ISBN
9783447015806 (vol. 2). Reprinted: Tehran: Asatir, 2003. ISBN 964-331-132-5, 964-331-131-7.
Oryan, Said. Zabur-e Pahlavi: matn-e Pahlavi, harf-nevisi, āvā-nevisi, tarojme-ye Fārsi va yaddašt-hā = Pahlavi
Translation of the Psalms: Text, Transliteration, Transcription, Persian Translation, and Notes. Tehran: Iranian
Cultural Heritage Organization, 2003 (1382 AP). ISBN 964-7483-75-9.
Skjærvø, P. Oktor. “Aramaic Scripts for Iranian Languages.” The Worldʼs Writing Systems, edited by Peter T.
Daniels and William Bright, 515-535. New York: Oxford University Press, 1996. ISBN 0-19-507993-0
Rejang
Jaspan, M. A. Folk Literature of South Sumatra: Redjang Ka-Ga-Nga Texts. Canberra: Australian National
University, 1964.
Runic
Benneth, Solbritt, Jonas Ferenius, Helmer Gustavson, & Marit Åhlén. 1994. Runmärkt: från brev till klotter.
Runorna under medeltiden. [Stockholm]: Carlsson Bokförlag. ISBN 91-7798-877-9
Derolez, René. 1954. Runica manuscripta: the English tradition. (Rijksuniversiteit te Gent: Werken uitgegeven
door de Faculteit van de Wijsbegeerte en Letteren; 118e aflevering) Brugge: De Tempel.
Friesen, Otto von. Runorna. Stockholm, A. Bonnier [1933]. (Nordisk kultur, 6).
Haugen, Einar Ingvald. The Scandinavian Languages: An Introduction to Their History. London: Faber, 1976.
ISBN 0-571-10423-1. Also published: Cambridge, MA: Harvard University Press, 1976. ISBN 0-674-79002-2.
142
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Musset, Lucien. Introduction à la runologie. Paris: Aubier-Montaigne, 1965.
Page, Raymond Ian. Runes. Berkeley: University of California Press; [London]: British Museum, 1987. (Reading
the Past). ISBN 0-520-06114-4. British Museum Publications edition has ISBN 0-7141-8065-3.
Samaritan
Ben-Hayyam, Zeʼev. A Grammar of Samaritan Hebrew, Based on the Recitation of the Law in Comparison with
the Tiberian and other Jewish Traditions. Jerusalem: Hebrew University Magnes Press, 2000. ISBN 1-57506-047-7.
Macuch, Rudolf. Grammatik des samaritanischan Hebräisch. Berlin: Walter de Gruyter, 1969. ISBN
9783110083767.
Murtonen, A. Materials for a Non-Masoretic Hebrew Grammar III: A Grammar of the Samaritan Dialect of
Hebrew. Helsinki: Societas Orientalis Fennica, 1964. (Studia Orientalia, 29).
Saurashtra
Norihiko Učida. Language of the Saurashtrans in Tirupati. 2nd revised ed. Bangalore: Mahalaxmi Enterprises,
1991. (In Latin script.)
Norihiko Učida. Saurashtra-English Dictionary. Wiesbaden: Harrassowitz, 1990. ISBN 3447030550. (In Latin
script.)
Sharada
Deambi, Kaul and Bushan Kumar. Śāradā and
ākarī Alphabets: Origin and Development. New Delhi: Indira
Gandhi National Centre for the Arts, 2008.
Grierson, George A. “On the Sharada Alphabet.” The Journal of the Asiatic Society of Great Britain and Ireland,
(1916): 677‒708.
Shavian
ConScript Unicode Registry [by] John Cowan and Michael Everson. “E700‒E72F Shavian.” Included in the
ConScript Registry (http://www.evertype.com/standards/csur/index.html) in 1997. Shavian was withdrawn from the
ConScript Registry in 2001, because of its addition to the Unicode Standard and ISO/IEC 10646.
Crystal, David. The Cambridge Encyclopedia of Language. Cambridge, New York: Cambridge University Press,
1987. ISBN 0-521-26438-3. 2nd ed. Cambridge, New York: Cambridge University Press, 1997. ISBN
0-521-55050-5; 0-521-55967-7.
DeMeyere, Ross. About Shavian. 1997. http://www.demeyere.com/Shavian/info.html.
Shaw, George Bernard. Androcles and the Lion: An Old Fable Renovated, by Bernard Shaw, with a Parallel Text
in Shawʼs Alphabet to Be Read in Conjunction Showing Its Economies in Writing and Reading. Harmondsworth:
Penguin Books, 1962.
Siddham
Bühler, Georg. “Palaeographical Remarks on the Horiuzi Palm-Leaf MSS.” The Ancient Palm-Leaves, edited by
Friedrich Max Müller and Bunyiu Nanjio, 61‒95. Oxford: Clarendon Press, 1884. (Anecdota Oxoniensia, Aryan
Series, Vol. 1, Pt. 3).
Chaudhuri, Saroj Kumar. Siddham in China and Japan. Philadelphia: Department of Asian and Middle Eastern
Studies, University of Pennsylvania, 1998. (Sino-Platonic Papers, 88).
淨嚴 (Jōgon). Shittan Sanmitsushō. In Taishō Shinshū Daizōkyō (大正新脩大藏經),vol. 84, no. 2710, 715-810.
[Japan: s.n.]: Nishiura ShirobR, Tenna 2, 1682. Accessed electronically at the SAT Daizōkyō Text Database:
http://21dzk.l.u-tokyo.ac.jp/SAT/ddb-sat3.php?s=&mode=detail&useid=2710̲,84
143
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
van Gulik, Robert Hans. Siddham: An Essay on the History of Sanskrit Studies in China and Japan. Reprint. New
Delhi: Sharada Rani, 1980. (Śata-PiPaka series, Indo-Asian literatures, 247). Originally published: Nagpur:
International Academy of Indian Culture, 1956. (Sarasvati Vihara Series, 36).
Sinhala
SLS 1134:1996,Sri Lanka Standards Institution Sinhala character code for information interchange.
Gunasekara, Abraham Mendis. A comprehensive grammar of the Sinhalese language. New Delhi: Asian
Educational Services, 1986 (Reprint of 1891 edition).
Sora Sompeng
Mahapatra, Khageshwar. “ʻSoraŋ Sompeŋʼ: A Sora Script.” Unpublished conference paper. Delhi, Mysore, 1978‒
1979.
Zide, Norman. “Scripts for Munda languages.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and
William Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Zide, Norman. “Three Munda scripts.” In Linguistics of the Tibeto-Burman Area. Vol. 22.2−Fall 1999
Sumero-Akkadian Cuneiform
Bauer, Josef, Robert K. Englund, and Manfred Krebernick. Mesopotamien: Späturuk-Zeit und frühdynastische
Zeit. (= Orbis Biblicus et Orientalis 160.1.) Freiburg: Universitätsverlag Freiburg Schweiz; Göttingen, Vandenhoeck
& Ruprecht, 1998.
Biggs. Robert D. Inscriptions from Tell Abu Salabikh. Oriental Institute Publications, vol. 99. Chicago: University
of Chicago Press, 1974. ISBN 0-226-62202-9.
Borger, Rykle. Mesopotamisches Zeichenlexikon. 2nd revised ed. Alter Orient und Altes Testament, vol. 305.
Münster: Ugarit-Verlag, 2010. ISBN 3-86835-043-8
Deimel, Anton. Liste der archaischen Keilschriftzeichen [LAK]. Inschriften von Fara, vol. 1. Wissenschaftliche
Veröffentlichung der Deutschen Orientgesellschaft, vol. 40. Leipzig: J.C. Hinrichsʼsche Buchhandlung, 1922. Online
version: http://www.cdli.ucla.edu/tools/SignLists/LAK/index.html
Labat, René. Manuel d'épigraphie akkadienne. Extended by Florence Malbran-Labat. 5th ed. Paris: P. Geuthner,
1976.
Mittermayer, Catherine. Altbabylonische Zeichenliste der sumerisch-literarischen Texte. Unter Mitarbeit von
Pascal Attinger. Fribourg: Academic Press; Göttingen: Vandenhoeck & Ruprecht, 2006.
Schneider, Nikolaus. Die Keilschriftzeichen der Wirtschaftsurkunden von Ur III nebst ihren charakteristischsten
Schreibvarianten, systematisch zusammengestellt. Rom: Päpstliches Bibelinstitut, 1935.
Sundanese
Baidillah, Idin, Cucu Komara, and Deuis Fitni. Ngalagena: Panglengkep Pangajaran Aksara Sunda pikeun Murid
Sakola Dasar/Dikdas 9 Taun. [Bandung]: CV Walatra, [2002].
Hardjasaputra, A. Sobana, Tedi Permadi, Undang A. Darsa, and Edi S. Ekadjati. Rancangan Pembakuan Aksara
Sunda. Bandung, 1998.
Sutton SignWriting
次のSutton SignWriting関連の文献は,http://www.signwriting.orgから入手できる。
Sutton, Valerie. SignWriting: Sign Languages are Written Languages. Part 1: SignWriting Basics by Valerie Sutton.
La Jolla, CA: SignWriting Press, 2009. ISBN 978-0-914336-49-5.
Sutton, Valerie, and Adam Frost. SignWriting: Sign Languages are Written Languages. Part 2: SignWriting Hand
144
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Symbols by Valerie Sutton and Adam Frost. La Jolla, CA: SignWriting Press, 2010 and 2011. ISBN:
978-0-91433686-0.
Sutton, Valerie. The SignWriting Alphabet. The International SignWriting Alphabet 2010 (ISWA 2010). La Jolla,
CA: SignWriting Press, 2008-2011. ISBN: 978-0-914336-84-6.
Symbols (Miscellaneous)
ISO 2033:1983,Information processing−Coding of machine readable characters (MICR and OCR)
ISO 2047:1975,Information processing−Graphical representations for the control characters of the 7-bit coded
character set
ISO/IEC 9995-7:1994,Information technology ‒ Keyboard layouts for text and office systems ‒ Part 7: Symbols
used to represent functions
ANSI X3.32-1973,American National Standards Institute. American national standard graphic representation of
the control characters of American national standard code for information interchange
ANSI Y14.5M-1982,American National Standard. Engineering drawings and related document practices,
dimensioning and tolerances
Syriac
Kefarnissy, Paul. Grammaire de la langue araméenne syriaque. Beyrouth, 1962.
Nöldeke, Theodor. Compendious Syriac Grammar. With a table of characters by Julius Euting. Translated from the
2nd and improved German ed., by James A. Crichton. London: Williams & Norgate, 1904. Reprinted: Tel Aviv: Zion
Pub. Co. [1970].
Robinson, Theodore Henry. Paradigms and Exercises in Syriac Grammar. 4th ed. Rev. by L. H. Brockington.
Oxford: Clarendon Press; New York: Oxford University Press, 1962. ISBN 0-19-815416-X, 0-19-815458-5 (pbk.).
Tai Le
Coulmas, Florian. The Blackwell Encyclopedia of Writing Systems. Oxford, Cambridge: Blackwell, 1996. ISBN
0-631-19446-0. Dehong writing, pp. 118‒119.
Lá ai2 maɯ3 lá ai2 ka va3 mi2 tse2 laɯ ya pa me na4 ka na: tá va ʔá na kó ma6 sá na2 teh ma6. Yina5lána5 mina5su4
su4pána2se3 (Yunnan minzu chubanshe). 1988. ISBN 7-5367-1100-4.
Tsa va4 má3 hó va3: la ta6 mé2 sá ai3 seh va2 xo ŋa3. Yina5lána5 mina5su4 su4pána2se3 (Yunnan minzu chubanshe).
1997. ISBN 7-5367-1455-6.
Tai Tham
Peltier, Anatole-Roger. 1996. Lanna Reader. Chiang Mai: Wat Tha Kradas.
Kasēm Siriratphiriya, and Mahāwitthayālai Sukhōthaithammāthirāt. Tūa Mueang: kānrīan phāsā Lānnā phān
khrōngsāng kham. Nonthaburī: Rōngphim Mahāwitthayālai Sukhōthaithammāthirāt, 2548 [2005]. ISBN
974-9942-00-0.
Rungrueangsri, Udom. 2004. Pacanānukrom Lānnā-Thai: Chabaph maefāhluang. ISBN 974-685-175-9.
Baephryar phāsā Lānnā. ISBN 974-386-044-4.
Takri
Deambi, Kaul and Bushan Kumar. Śāradā and
ākarī Alphabets: Origin and Development. New Delhi: Indira
Gandhi National Centre for the Arts, 2008.
Tangut
Grinstead, Eric, Analysis of the Tangut Script (Scandanavian Institute of Asian Studies Monograph Series No.10).
145
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
1972.
Hán Xiǎománg (韓小忙), 西夏文正字研究 (Xīxiàwén Zhèngzì Yánjiū) [Research into the Correct Forms of
Tangut Characters].2004.
Kepping, K. B. (К. Б. Кепинг) et al., Море письмен (More pis men) [The Sea of Characters]. Moscow, 1969
Kolokolov, V. S. (В. С. Колоколов) and E. I. Kyčanov (Е. И. Кычанов), Китайская классика в тангутском
переводе (Kitajskaja klassika v tangutskom perevode) [Chinese Classics in Tangut Translation]. Moscow, 1966.
Kyčanov, E.I. (Е.И. Кычанов) and Arakawa Shintaro 荒川慎太郎, Словарь тангутского (Си Ся) языка (Slovar
tangutskogo (Si Sja) jazyka) [Tangut-Russian-English-Chinese Dictionary]. St. Petersburg and Kyoto, 2006.
Lǐ Fànwén (李範文), 同音研究 (Tóngyīn Yánjiū) [Study of the Homophones]. Yinchuan. 1986.
Lǐ Fànwén (李範文), 夏漢字典 (Xià-Hàn Zìdiàn) [Tangut-Chinese Dictionary]. Beijing. 1997.
Lǐ Fànwén (李範文), 《五音切韵》与《文海宝韵》比 研究 (Wǔyīn Qiēyùn yǔ Wénhǎi Bǎoyùn bǐjiào yánjiū);
in 西夏研究 (Xīxià Yánjiū) [Western Xia Studies] no.2. Beijing. 2006.
Lǐ Fànwén (李範文). 夏漢字典 (Xià-Hàn Zìdiàn) [Tangut-Chinese Dictionary]. Beijing, 2008.
Nakajima Motoki (中嶋幹起) et al., 電脳処理 西夏文字字素分析 (Dennō shori Seika moji jiso bunseki)
[Computer Processing: Analysis of Tangut Character Elements]. Tokyo, 2000.
Nevskij, N.A. (Н. А. Невский), Тангутская филология: Исследования и словарь (Tangutskaja filologija:
Issledovanija i slovar ) [Tangut Philology: Researches and Dictionary]. Moscow, 1960.
Nishida Tatsuo (西田龍雄), 西夏文小字典 (Seikabun Shōjiten) [Little Dictionary of Tangut]. In 西夏語の研究
(Seikago nokenkyū) [A Study of the Hsi-Hsia Language] (1964-1966) vol. 2. Tokyo, 1966.
Shǐ Jīnbō (史金波) et al., 文海研究 (Wénhǎi Yánjiū) [Study of the Sea of Characters].Beijing,1983.
Sofronov M. V. (М. В. Софронов), Грамматика тангутского языка (Grammatika tangutskogo jazyka) [Grammar
of the Tangut Language]. Moscow, 1968.
Thaana
Geiger, Wilhelm. Maldivian Linguistic Studies. New Delhi: Asian Educational Services, 1996. ISBN
81-206-1201-9. Originally published: Colombo: H. C. Cottle, Govt. Printer, 1919.
Maniku, Hassan Ahmed. Say It in Maldivian (Dhivehi), [by] H. A. Maniku [and] J. B. Disanayaka. Colombo:
Lake House Investments, 1990.
Tibetan
Beyer, Stephen V. The classical Tibetan language. State University of New York. ISBN 0-7914-1099-4
Tirhuta
Grierson, George A. An Introduction to the Maithilí language of North Bihár, Containing a Grammar,
Chrestomathy and Vocabulary. Calcutta: J.N. Banerjee and Son, 1882.
Jhā, Subhadra. The Formation of the Maithilī Language. London: Luzac, 1958.
Mishra, Jayakanta. 1973. B
hat Maithilī Śabdakośa [The Great Maithili Dictionary]. Fascicule 1. 1st ed. Simla:
Indian Institute of Advanced Study, 1973. In Maithili script.
Raya, Jivanatha. 2003. Maithilī Prathama Pustaka [Maithili Primer]. Reprint of edition published by Pustaka
Bhaņd. In Maithili script.
Ugaritic
OʼConnor, M. “Epigraphic Semitic Scripts.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and
William Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
146
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
Walker, C. B. F. Cuneiform. London: British Museum Press, 1987. (Reading the Past, v. 3.) ISBN 0-7141-8059-9.
University of California Press edition has ISBN 0-520-06115-2 (pbk.).
Thai
TIS 620-2533,Thai Industrial Standard for Thai Character Code for Computer. (1990)
Vai
Dalby, David. “A Survey of the Indigenous Scripts of Liberia and Sierra Leone: Vai, Mende, Loma, Kpelle and
Bassa.” African Language Studies 8 (1967):1-51.
Kandakai, Zuke, et al. Vai kpolo saikilamaa mɛ = The Standard Vai Script. Monrovia: University of Liberia
African Studies Program, 1962.
Massaquoi, Momolu. “The Vai People and Their Syllabic Writing.” Journal of the Royal African Society 10.40,
July (1911), 459-466.
Singler, John. “Scripts of West Africa.” In The Worldʼs Writing Systems, edited by Peter T. Daniels and William
Bright. New York: Oxford University Press, 1996. ISBN 0-19-507993-0.
Stewart, Gail, and P. E. H. Hair. “A Bibliography of the Vai Language and Script.” Journal of West African
Languages 6.2 (1969), 124.
Warang Citi
Pinnow, Heinz-Jürgen. “Schrift und Sprache in den Werken Lako Bodras im Gebiet der Ho von Singbhum
(Bihar).” Anthropos 67 (1972): 822-857.
Zide, Norman. “Scripts for Munda languages.” The Worldʼs Writing Systems, edited by Peter T. Daniels and
William Bright, 612-618. New York: Oxford University Press, 1996. ISBN 0-19-507993-0..
Yi
GB13134: Xinxi jiaohuanyong yiwen bianma zifuji (Yi coded character set for information interchange),
[prepared by] Sichuansheng minzushiwu weiyuanhui. Beijing, Jishu Biaozhun Chubanshe (Technical Standards
Press), 1991. (GB 13134-1991).
Nuo-su bbur-ma shep jie zzit. = Yi wen jian zi ben. Chengdu: Sichuan minzu chubanshe, 1984.
Nip huo bbur-ma ssix jie. = Yi Han zidian. Chengdu: Sichuan minzu chubanshe, 1990. ISBN 7-5409-0128-4.
147
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書N
(参考)
文字レパートリに対する外部参照
N.1 文字レパートリ及びその符号化の参照方法
プログラム言語及びそれ以外のデータオブジェクトの構文を定義する方法では,通常,この規格で規定
するものの中から特定の文字レパートリを宣言することが必要になる。さらに,このレパートリに適用可
能な符号化表現のうち対応する符号化表現を宣言する必要がある場合もある。
この規格に従った文字レパートリに対しては,そのレパートリの厳密な宣言の中に次のパラメタを含め
るのがよい。
− この規格の識別
− レパートリの採用した部分集合,一つ以上の組番号で識別されるもの
− 符号単位列の内容の定義
− 採用した符号化形式(UTF-8,UTF-16又はUTF-32)
データオブジェクトの構文定義に現在一般的に使われている方法の一つが,ISO/IEC 8824規格群に規定
された抽象構文記法1(ASN.1)である。これに対応する符号化表現は,ISO/IEC 8825規格群に規定され
ている。この方法を使う場合の文字レパートリ及び符号化を参照する形式を,N.2及びN.3に示す。
N.2 ASN.1文字抽象構文の識別
この規格に従って識別されたレパートリの文字で構成される全ての文字列の集合は,ISO/IEC 8824規格
群の用語では,“文字抽象構文”として定義される。個々の文字抽象構文に対して,ASN.1を使ったときに
その構文を参照できるように,対応するオブジェクト識別子の値が定義される。
ISO/IEC 8824-1の附属書D(オブジェクト識別子構成要素値のISOによる割当て)に,ISOの規格で規
定されたオブジェクトに対するオブジェクト識別子値の形式が規定されている。この識別子では,この規
格の機能及び任意選択機能を識別するために,弧“10646”及び弧“0”に数字(弧)を続ける方法を用い
る。
注記1 弧“0”は,ISO/IEC 10646-1及びISO/IEC 10646-2を識別するために過去に使われた弧“1”
及び弧“2”を埋め合わせるために用いる。弧“1”及び弧“2”を用いない。
この“0”に続く最初の弧は,符号単位列の内容の定義を識別し,level-3 (3)(実装水準3)として参照さ
れる。
注記2 この規格では,符号単位列の内容に対してただ一つの定義を与える。その定義は,この規格
の以前の版で実装水準3と呼ばれていたものである。
その次に続く弧は,次のレパートリの部分集合のいずれかを識別する。
− all (0)
全ての組
− collections (1) 指定した組
弧 (0) は,この規格で規定した文字の全てからなる組を識別する。この弧に続く弧は,ない。
注記3 この組は,私用群及び私用面も含む。したがって,完全には定義できない。その使用につい
ては,事前の合意が必要である。
弧 (1) には一つの弧又は弧の列が続く。それぞれの弧は,附属書Aの組番号とし,昇順に並べる。この
148
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
列は,その列に現れる組番号の複数の組からなる部分集合を識別する。
注記4 例として,組BASIC LATIN,組LATIN-1 SUPPLEMENT及び組MATHEMATICAL OPERATORS
からなる部分集合のオブジェクト識別子を,次に示す。
{iso standard 10646 (0) level-3 (3) collections (1) 1 2 39}
さらに,ISO/IEC 8824-1は,オブジェクト識別子値に対応するオブジェクト記述子を規定している。制
約されないレパートリに対して,対応するオブジェクト記述子は,次のとおりとする。
3 0 : "ISO 10646 level-3 unrestricted"
組の名前“xxx”をもつ単一の組に対しては,次のとおりとする。
3 1 : "ISO 10646 level-3 xxx"
m1,m2,…の組番号をもつ一つ以上の組からなるレパートリに対しては,次のとおりとする。
3 1 : "ISO 10646 level-3 collections m1, m2, m3, .."
注記5 スペースは,全て1個のスペース(single space)である。
N.3 ASN.1文字転送構文の識別
この規格に従った文字からなる文字列の符号化方法は,ISO/IEC 8824規格群の用語では,“文字転送構
文”として定義される。個々の文字転送構文に対して,ASN.1を使ったときにその構文を参照できるよう
に,対応するオブジェクト識別子の値が定義される。
ISO/IEC 8824-1の附属書D(オブジェクト識別子構成要素値のISOによる割当て)に従ったオブジェク
ト識別子では,この国際規格で規定する符号化表現を識別するために,弧“10646”及び弧“0”に数字(弧)
を続ける方法を用いる。
この“0”に続く最初の弧は,次のとおりとする。
− transfer-syntaxes (0)
転送構文
その次に続く弧は,符号化形式を識別し,次のいずれかとする。
− four-octet-form (4)
UTF-32符号化形式
− utf16-form (5)
UTF-16符号化形式
− utf8-form (8)
UTF-8符号化形式
注記1 UTF-32符号化形式のオブジェクト識別子の例を,次に示す。
{iso standard 10646 (0) transfer-syntaxes (0) four-octet-form (4)}
次のオブジェクト識別子は,有効な形式であるが,現在は,使用を禁止する。
{iso standard 10646 (1) transfer-syntaxes (0) four-octet-form (4)}
注記2 この規格の以前の版ではtwo-octet-BMP-form (2)を規定していたが,現在は,使用を禁止して
いる。
対応するオブジェクト記述子は,次のとおりとする。
− "ISO 10646 form 4"
− "ISO 10646 utf-16"
− "ISO 10646 utf-8"
注記3 この規格の以前の版ではオブジェクト識別子"ISO 10646 form 2"を規定していたが,現在は,
使用を禁止している。
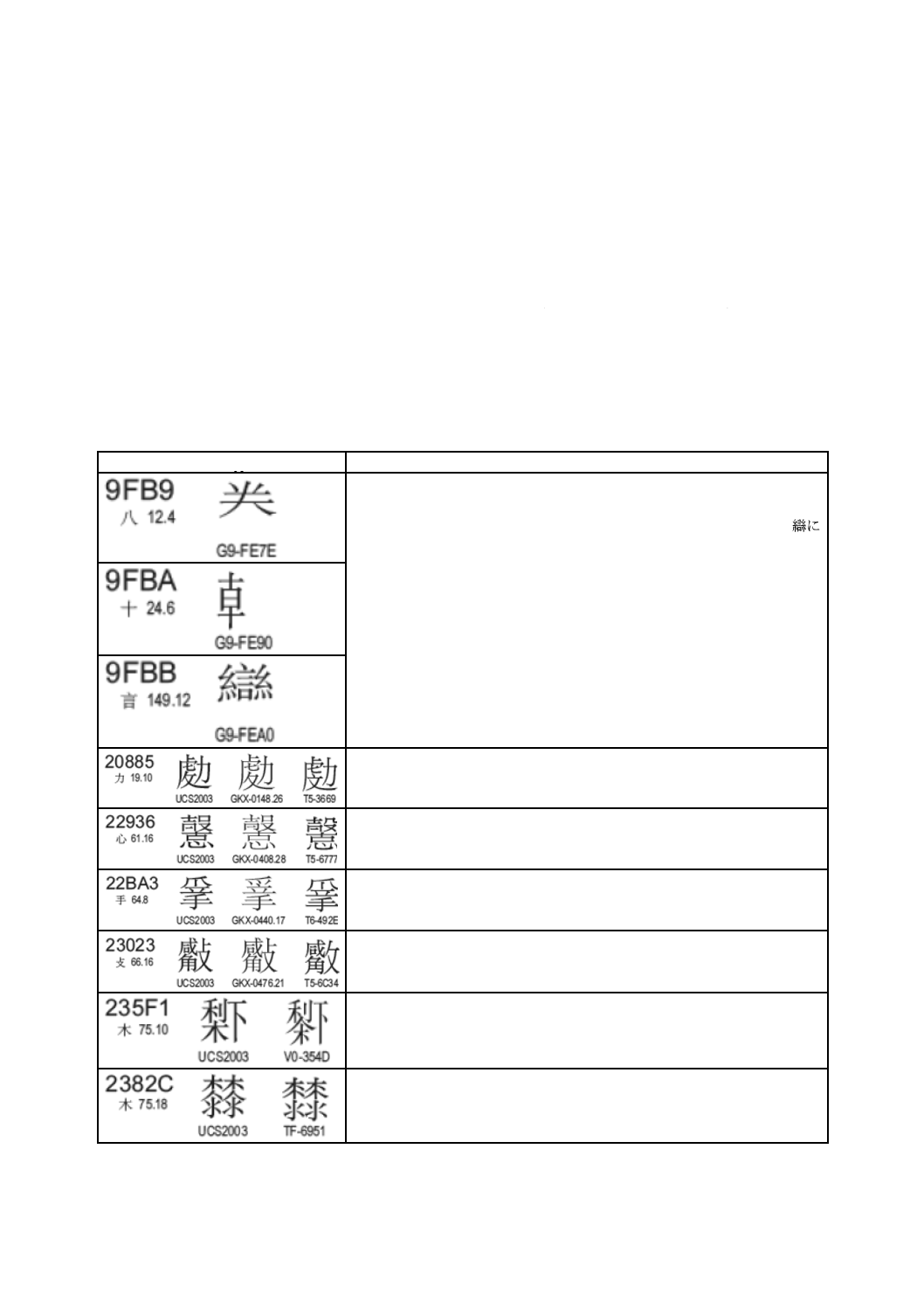
149
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書P
(参考)
CJK統合漢字に関する追加情報
附属書Pは,CJK統合漢字に関する追加情報を示す。
注記 この規格の以前の版では,この附属書に全ての文字に対する追加情報を記述していた。この規
格においては,そうした情報のほとんどは,符号表に含まれている。CJK統合漢字の符号表は,
名前の一覧を含まないため,それらの文字の情報は,この附属書に残してある。
表P.1の各項目は,符号表におけるCJK統合漢字の符号位置を抜き出し,次の列に関連する追加情報を
並べる。項目は,符号位置の昇順に並べている。
表P.1−CJK統合漢字に関する追加情報
UCS/Glyph
追加情報
これらの三つの文字は,漢字の特定の位置の構成要素を表すために用い
ることを意図している。これらの文字と同じ構造の漢字だが特定の位置に
用いる意図ではないものを,それぞれ20509 𠔉,2099D𠦝及び470C 䜌に
符号化している。
T5-3669の原典字形は,誤ってこの符号位置に統合された。
T5-6777の原典字形は,誤ってこの符号位置に統合された。
GKX-0440.17の原典字形は,誤ってこの符号位置に統合された。
T5-6C34の原典字形は,誤ってこの符号位置に統合された。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。

150
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表P.1−CJK統合漢字に関する追加情報(続き)
UCS/Glyph
追加情報
この符号位置のUCS2003字形は,誤って設計された。
T7-243Fの原典字形は,誤ってこの符号位置に統合された。
GKX-0672.02の原典字形は,誤ってこの符号位置に統合された。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。
T7-2F4Bの原典字形は,24381
と統合されるべきであったが,誤って
ここに配置された。この符号位置のUCS2003字形は,T7-2F4Bに基づくべ
きであったが誤って異なる字形が示されている。この規格において243BE
の原典参照は,TCA-CNS標準 との一貫性を保つためにT7-2F4Bのままと
している。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。
この符号位置のUCS2003字形は,誤って設計された。
GHZ-64018.09の原典字形は,誤ってこの符号位置に統合された。
この符号位置のUCS2003字形は,誤って設計された。

151
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
表P.1−CJK統合漢字に関する追加情報(続き)
UCS/Glyph
追加情報
T6-632Aの原典字形は,誤ってこの符号位置に統合された。
V4-5565の原典字形は,誤ってこの符号位置に統合された。
TCA-CNS標準のTF-686Dの字形は,ISO/IEC 10646のCJK統合漢字拡張
Bの元の版が出版された後に変更された。TF-686Dの字形は,通常,この
符号位置のUCS2003字形と統合されないものであるが,TCA-CNS標準と
の一貫性を保つためにそのままとしている。
TCA-CNS標準のT5-7C22の字形は,ISO/IEC 10646のCJK統合漢字拡張
Bの元の版が出版された後に変更された。T5-7C22の字形は,通常,この符
号位置のGHZ-74512.13の字形及び/又はUCS2003字形と統合されないも
のであるが,TCA-CNS標準との一貫性を保つためにそのままとしている。
この符号位置のGCH字形は,ISO/IEC 10646のCJK統合漢字拡張Bの最
初の出版の後,変更された。GCH字形は,対応国際規格の形のままである
べきであるが,通常は対応国際規格の2003年版のこの符号位置の字形とは
統合されない。
TCA-CNS規格のT7-5666の字形は,ISO/IEC 10646のCJK統合漢字拡張
Bの最初の出版の後,変更された。TCA CNS規格との一貫性を保つため,
T7-5666字形は,対応国際規格の形のままであるべきであるが,通常は対応
国際規格の2003年版のこの符号位置の字形とは統合されない。
TCA-CNS規格のT7-523Aの字形は,ISO/IEC 10646-2のCJK統合漢字拡
張Bの最初の出版の後,変更された。TCA CNS規格との一貫性を保つため,
T7-523A字形は,対応国際規格の形のままであるべきであるが,通常は
GKX-1494.15及び/又は対応国際規格の2003年版のこの符号位置の字形と
は統合されない。
GKX-1538.20 原典字形は,この符号位置に誤って統合された。
この規格で参照されるJIS X 0213:2004は,その前のJISに規定された文字の一部の集合を含む。この集
合は,JIS X 0212-1990(この規格の以前の版では,J1ソースとして参照されている。)の2 743文字,及び
1993年・国内5社漢字統合表(この規格の以前の版では,JAソースとして参照されている。)の85文字
からなる2 828文字からなる。これらの2 828文字のうち,205文字は代表字形が以前の版から微妙に変更
されている。これらの2 828文字は,23.1で示される原典を識別するための接頭語J13,J13A,J14,JA3
及びJA4表記を用いている。これらの字形の表現は,また,JIS X 0213:2004で示されたものを反映してい
る。さらに,これらの2 828文字は,固定組374として定義されている(A.4.5参照)。
152
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書Q
(参考)
ハングル音節文字の符号対応表
注記 この規格の以前の版では,この附属書は,JIS X 0221:1995が規定していたハングル音節文字(及
び符号位置)と,その後変更した符号位置(この規格が規定する符号位置と同一)との対応表
を示していた。
153
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書R
(参考)
ハングル音節文字の名前
附属書Rでは,ハングル音節文字の名前及び注釈を添付ファイル“HangulSy.txt”によって示す。
添付ファイルは,テキストファイルであり,ISO/IEC 646のIRVの文字及び行末を表すCARRIAGE
RETURN/LINE FEEDを使用する。ファイルの先頭の6行は,ヘッダであり,その後に全てのハングル音
節文字を続ける。行は,次に示す形式である。
− 第1〜4オクテットは,符号位置を16進数によって示す。
− 第5オクテットは,SPACE(スペース)とする。
− 第6オクテットから行の終わりまでは,ハングル音節文字の名前を括弧に囲んだ注釈とともに示す。
154
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書S
(参考)
漢字の統合及び配列の手順
この規格のCJK統合漢字の図形文字の組は,箇条33で規定する。これらは,広範な国家規格及び団体
規格の符号化文字集合(原典という。)に収容された多数の漢字を基にしている。
附属書Sは,この規格の漢字が,どのような統合手順を適用して,原典から引き出されたかを記載して
いる。また,この規格の漢字が,どのように一連の符号位置に配列されるかをも記載している。
CJK統合漢字の原典参照は,箇条23に示す。
この規格では,統合手順を,原典グループの符号から取り出した漢字に対して適用する。この手順では,
二つ以上の原典グループから取り出した単一の漢字を関連付け,この規格で単一の符号位置を割り当てる。
関連付けは,次の手順によって行う。ここでは,漢字をこのように関連付けることを,“統合(unified)”
という。
注記 この統合手順は,次の漢字のような文字の組には適用しない。
− CJK RADICALS SUPPLEMENT(2E80〜2EFF)
− KANGXI RADICALS(2F00〜2FDF)
− CJK COMPATIBILITY IDEOGRAPHS(F900〜FAFF。ただし,FA0E,FA0F,FA11,FA13,
FA14,FA1F,FA21,FA23,FA24及びFA27〜FA29を除く。)
− CJK COMPATIBILITY IDEOGRAPHS SUPPLEMENT(2F800〜2FA1F)
S.1
統合手順
S.1.1
統合の範囲
歴史的由来から関連しないとみなされる漢字[非同系文字(non-cognate character)]は,統合しない。
例
注記 上の例の二つの漢字の形の違いは,下部横線の長さである。これは,本来の字形の違いと考え
られる。さらに,これらの漢字は,異なる意味をもつ。最初の漢字の意味は,“兵士”であり,
2番目の漢字の意味は,“土又は土地”である。
異なる原典から取り出した漢字の関連付けは,次の分類システムに従って,字形が十分に似ているとき
に行う。
S.1.2
2階層分類
分類の2階層システムを用いて,抽象字形の相違と,特定の書体で定まる実字形の相違とを,区別する。
ある漢字の異体字のうち,統合できないものは,抽象字形の相違として識別する。
S.1.3
手順
二つの漢字が,同一の抽象字形をもつのか,異なる抽象字形をもつのかを決定するために,統合手順を
用いる。統合手順は,次の順序で示す二つの段階で適用する。
a) 部分字形(component)の構造の把握
b) 部分字形の特徴の抽出
155
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
S.1.3.1
部分字形の構造の把握
手順の第1段階では,各漢字の部分字形の構造を考察する。漢字の部分字形は,点画の幾何学的な組合
せである。同じ部分字形の集まりから,別の漢字が構成されることがある。複数の部分字形を組み合わせ
ることで,入り組んだ構造の新たな部分字形を作ることができる。このことから,一つの漢字は,部分字
形の木構造として捉えられる。ここで,最上位の節点は,その漢字そのものであり,最下位の節点は,点
画である。これを図S.1に示す。
図S.1−部分字形の構造
S.1.3.2
部分字形及び特徴抽出
手順の第2段階では,図S.2に示すように,二つの漢字の対応する節点に位置付けられた部分字形を最
上位から比較する。
図S.2−部分字形の最も顕著な節点
比較する漢字の,次の特徴を考察する。
a) 部分字形の数
b) 漢字の全体の中での,部分字形の配置位置
c) 対応する部分字形の構造
比較される漢字について,上記のa)〜c)のうち一つ以上の特徴が異なれば,それらの漢字は,抽象字形
の相違とみなし,統合しない。
漢字の,a)〜c)の全ての特徴が同じならば,それらの漢字は,同じ抽象字形をもつとみなし,統合する。
S.1.4
抽象字形相違の例
S.1.3.2のa)〜c)から導出される規則を説明するため,抽象字形の相違によって非統合となる漢字の代表
的な例をS.1.4.1〜S.1.4.3に示す。
S.1.4.1
部分字形の数の相違
次の例は,S.1.3.2のa)の規則を説明する。それぞれの対の二つの漢字は,異なる数の部分字形をもつ。
S.1.4.2
部分字形の配置位置の相違
次の例は,S.1.3.2のb)の規則を説明する。それぞれの対の二つの漢字は,同じ数の部分字形をもつが,
部分字形の配置位置が異なる。

156
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
漢字が横に並ぶ部分字形をもつとき,左側部分字形の最後の画が右側部分字形の下部に及んでいるかど
うかの違いは,次のU+34F3の例に示すように分離符号化の根拠にはならない。
S.1.4.3
部分字形の種類の相違
次の例は,S.1.3.2のc)の規則を説明する。それぞれの対の二つの漢字は,一つ以上の部分字形が異なる。
S.1.5
実字形の相違
S.1.2で説明した分類を説明するため,統合する漢字の代表的な例を次に示す。次の各グループの二つ又
は三つの漢字又は部分字形は,実字形の相違をもつが,同じ抽象字形とみなし,その字形の文字又はその
字形を部分字形としてもつ漢字は,統合する。この相違は,次の例によって,分類される。
これらの相違は,次の例に示すように,更に分類される。
a) 点画の方向の相違
b) 点画が出る・出ない(抜ける・抜けない)
c) 部分字形・点画が付く・付かない
d) 画線の出方の相違
e) 画線の折れ曲がり方の相違
f)
ハネの有無
g) 起筆の相違
h) 屋根の相違

157
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
i)
重要でない点画の追加又は削除
j)
a)〜i)の組合せ
k) その他
注記 各グループに示された部分字形には,更に複雑な漢字の部分字形として使われたときには統合
されるが,単体の漢字としては,原規格分離漢字の取扱規則などの他の理由によって統合され
ないものがある。
統合した漢字の実字形の相違は,箇条33の符号表の各符号位置の,対応する原典の欄に示す。
S.1.6
原規格分離漢字の取扱規則(source separation rule)
複数の符号変換の段階を経たデータの完全性[“往復の保全性”(round-trip integrity)ともいう。]を確保
するため,次に示す各原典グループのいずれか一つの中で分離して符号化されている漢字は,統合しない。
注記1 これを原規格分離漢字の取扱規則という。
− 原典Gグループ GB 2312-80,GB 12345-90,GB 7589-87*,GB 7590-87*,GB 8565-88*,現代漢語通
用字表*
− 原典Tグループ TCA-CNS 11643-1986/第1面,TCA-CNS 11643-1986/第2面,TCA-CNS 11643-1986/
第14面*
− 原典Jグループ JIS X 0208:1990,JIS X 0212:1990
− 原典Kグループ KS X 1001:2004(KS C 5601-1989であったもの),KS X 1002:2001(KS C 5657-1991
であったもの)
注記2 この規格に符号化された原典JのJIS X 0212:1990に対応する文字は,組番号372のJAPANESE
IDEOGRAPHICS SUPPLEMENTに一覧によって示されている。
注記3 規格の参照番号の後の“*”は,その規格に含まれる漢字のうち幾つかが,統合漢字集合に含
まれていないことを示す。
しかしながら,一つの原典グループに属する二つの規格(例えば,GB 2312-80及びGB 12345-90)で符
号化されている幾つかの漢字は,原典グループから漢字を収集する手順において統合されている。
注記4 ここで“原典”としているものは,箇条23で“原典”としているものとは,一致しない。そ
れは,原規格分離漢字の取扱規則の適用の対象となる“原典”が,この規格の最初の版に含
まれていたものに限定されるのに対して,箇条23の“原典”は,その後追加されたものを含
むためである。
S.1.6で示した原規格分離漢字の取扱規則は,BMPのCJK UNIFIED IDEOGRAPHSブロックに対してだ
け適用する。

158
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
注記5 CJK互換漢字は,原規格分離漢字の取扱規則によく似た規則によって作成された。しかし,
CJK互換漢字では,似た漢字は,一つのCJK統合漢字と一つ以上のCJK互換漢字との組合
せとした。原規格分離漢字の取扱規則では,全ての似た漢字を異なるCJK統合漢字とみなす。
S.2
配列手順
S.2.1
配列の概要
この規格の箇条33の符号表で,CJK UNIFIED IDEOGRAPHSの配列は,次の辞書における漢字の並び
順を基にしている。
優先順位
辞書
版
1
康熙字典(Kangxi Dictionary) 北京第7版
2
大漢和辞典(Daikanwa Jiten) 第9版
3
漢語大字典(Hanyu Dazidian) 第1版
4
大字源(Daejaweon)
第1版
辞書は,上の表に示す優先順位で使用する。優先順位1が最優先である。漢字が,ある辞書で見つかっ
たならば,それよりも優先順位の低い辞書は,考察しない。
S.2.2
手順
S.2.2.1
辞書にある漢字
a) ある漢字が,康熙字典にある場合,康熙字典の順序に従って符号表に位置付ける。
b) ある漢字が,康熙字典になく大漢和辞典にある場合,大漢和辞典でその文字よりも前に記載された文
字で,康熙字典にも記載のある文字のうち,最も近くにある文字の属する部首画数グループの末尾に
位置付ける(康熙字典の部首画数グループの最後に位置付け,康熙字典及び大漢和辞典にある漢字に
続けて配列する。)。
c) ある漢字が,康熙字典及び大漢和辞典のいずれにもない場合,漢語大字典及び大字源を同様の手順で
参照する。
S.2.2.2
辞書にない漢字
ある漢字が,四つのどの辞書にもない場合,部首画数グループの末尾に(辞書にある漢字よりも後に)
位置付け,同じ部首画数の下に配列する。
S.3
原規格分離漢字の例
次に示す漢字の対(又は三つ組み)は,S.1に示した統合規則の例外である。これらは,S.1.6に示した
原規格分離漢字の取扱規則によって,統合しない。
注記1 原規格分離漢字の取扱規則の適用の対象となった,特定の原典グループについては,それぞ
れの漢字の対(又は三つ組み)の右側に,文字(G,J,K又はT)で示す。文字に対応する
原典グループは,S.1.6に示す。
注記2 次に示す七つの符号位置の対は,元々JIS X 0212:1990の第3水準の一部である原典Jの文字
を含み,原規格分離漢字の取扱規則が適用されている。加えて原典参照J13のJIS X 0213:2004
の一部でもある。それらの対(原典参照J13の符号位置を強調)は,U+5861-U+586B,
U+6483-U+64CA,U+75E9-U+7626,U+83D1-U+8458,U+848B-U+8523,U+91A4-U+91AC及
びU+985A-U+985Bである。

159
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
T
4E1F 4E22
GT
4E48 5E7A
GTJ
4E89 722D
J
4EDE4EED
T
4F75 5002
T
4FA3 4FB6
TJK
4FC1 4FE3
T
4FDE 516A
T
4FF1 5036
T
5024 503C
T
5077 5078
TJ
507D 50DE
T
514C 5151
TJ
514E 5154
T
5156 5157
TJ
518A 518C
G
51C0 51C8
T
51E2 51E3
TJ
5203 5204
TJ
520A 520B
T
5220 522A
T
5225 522B
TJ
5238 52B5
T
5239 524E
T
524F 5259
T
525D 5265
J
5292 5294
T
52FB 5300
T
5355 5358
TK
5373 537D
TJ
5377 5DFB
GT
53C1 53C2
T
53C3 53C4
T
5415 5442
T
541E 5451
TJ
5433 5434 5449
T
5436 5450
T
543F 544A
T
5527 559E
T
55A9 55BB
T
5618 5653
GTJ
568F 5694
T
56EF 56FD
TJ
5708 570F
T
570E 5713
T
5716 5717
T
5759 5DE0
J
57D2 57D3
T
5848 588D
TJ
5861 586B
T
5897 589E
GTJ
58EE 58EF
T
58FD 5900
T
5910 657B
GTJ
5932 672C
J
5965 5967
TJ
5968 596C 734E
GT
5986 599D
T
598D 59F8
T
59CD 59D7

160
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
GT
59EB 59EC
T
5A1B 5A2F 5A31
T
5A55 5AAB
T
5A7E 5AAE
TK
5AAA5ABC
T
5AAF 5B00
T
5B0E 5B14
GT
5B24 5B37
T
5B73 5B76
T
5BAB5BAE
T
5BDB5BEC
T
5BDC5BE7
GTJ
5BDD5BE2
J
5C02 5C08
GTJ
5C06 5C07
T
5C13 5C14
T
5C19 5C1A
T
5C2A 5C2B
T
5C36 5C37
T
5C4F 5C5B
GT
5CE5 5D22
T
5DD35DD4
T
5E21 5E32
TJ
5E2F 5E36
T
5E76 5E77
T
5EC4 5ECF
T
5F11 5F12
T
5F37 5F3A
T
5F39 5F3E
TJ
5F50 5F51
T
5F54 5F55
T
5F59 5F5A
J
5F5B 5F5C
T
5F5D 5F5E
T
5F65 5F66
T
5FB3 5FB7
T
5FB4 5FB5
TJ
6075 60E0
T
6085 60A6
T
609E 60AE
T
60B3 60EA
T
6120 614D
TJ
613C 614E
GT
6229 622C
T
622F 6231
T
6236 6237 6238
T
623B 623E
T
629B 62CB
TJ
629C 62D4
T
6329 635D
TJ
633F 63D2 63F7
TJ
634F 63D1
TJ
635C 641C
T
63B2 63ED
TJ
63FA 6416 6447
T
63FE 6435
TJ
6483 64CA
T
654E 6559
T
6553 655A
T
65E2 65E3
161
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
T
6602 663B
T
665A 6669
T
66A8 66C1
J
66FD 66FE
T
67B4 67FA
T
67E5 67FB
T
67F5 6805
T
68B2 68C1
T
6961 6986
T
6982 69EA
T
6985 69B2
T
699D 6A27
J
69C7 69D9
TJ
69D8 6A23
T
6A2A6A6B
T
6B65 6B69
T
6B72 6B73
T
6B7F 6B81
GTJ
6BBB6BBC
T
6BC0 6BC1
T
6BCE6BCF
T
6C32 6C33
T
6C5A 6C61
TJ
6C92 6CA1
TJ
6D44 6DE8
T
6D89 6E09
T
6D97 6D9A
T
6D99 6DDA
T
6DE5 6E0C
T
6DF8 6E05
T
6E07 6E34
T
6E29 6EAB
T
6E88 6F59
T
6E89 6F11
T
6EDA6EFE
GTJK
6F5B 6FF3
T
7028 702C
GTJ
70BA 7232
GTJK
712D 7162
J
7155 7199
T
7174 7185
GT
72B6 72C0
TJ
7464 7476
T
74F6 7501
T
7522 7523
J
75E9 7626
T
76A1 76A5
TJ
771E 771F
TJK
773E 8846
T
7814 784F
TJ
797F 7984
T
79BF 79C3
T
7A05 7A0E
TJ
7A42 7A57
GJ
7B5D 7B8F
T
7BB3 7C08
T
7BE1 7C12
T
7CA4 7CB5
T
7D55 7D76
T
7DA07DD1

162
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
T
7DD27DD6
T
7DE3 7E01
T
7DFC 7E15
T
7E48 7E66
TJ
7FAE 7FB9
T
7FF6 7FFA
T
80FC 8141
T
812B 8131
T
817D 8183
GT
8203 8204
TJ
820D 820E
J
8216 8217
TJ
8358 838A
TJ
83D1 8458
T
8480 8495
GJ
848B 8523
T
848D 853F
T
8570 8580
T
85AB 85B0
T
85F4 860A
T
865A 865B
T
86FB 8715
TJK
885B 885E
TK
886E 889E
GJK
88C5 88DD
T
8A2E 8A7D
T
8AAA8AAC
TJ
8ACC8AEB
J
8B20 8B21
T
8C5C 8C63
TJ
8D70 8D71
T
8EFF 8F27
J
8F1C 8F3A
T
8F3C 8F40
T
8FBE 8FD6
TJ
8FF8 902C
J
9059 9065
T
90A2 90C9
T
90CE 90DE
T
90F7 9109 9115
T
9196 919E
J
91A4 91AC
T
9203 9292
T
92B3 92ED
T
9304 9332
TK
932C 934A
TJ
93AD 93AE
T
95B1 95B2
G
9667 9689
T
9751 9752
GTJ
9759 975C
J
976D 9771
T
9839 983D
TJ
984F 9854
J
985A 985B
J
98EE 98F2
TJ
9905 9920
TJK
99B1 99C4
TK
99E2 9A08
T
9AA99AAB

163
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
T
9AD89AD9
TJ
9AEA9AEE
T
9B2C 9B2D
TJ
9C1B 9C2E
T
9CEF 9CF3
J
9D87 9DAB
J
9DC69DCF
T
9EAA9EAB
T
9EBC9EBD
T
9EC3 9EC4
T
9ED1 9ED2
S.4
非統合の例
S.1に記載した統合手順に従って,次に示す漢字の対(又は三つ組み)は,統合しない。非統合の理由
は,各対(又は三つ組み)の右側に示した参照によって示す。“非同系”は,S.1.1を参照。
注記 この例での非統合の理由は,S.1.6に記載した原規格分離漢字の取扱規則とは,異なるものであ
る。
非同系
5191 80C4
S.1.4.3
51B2 6C96
S.1.4.3
51B3 6C7A
S.1.4.3
51B5 6CC1
S.1.4.3
579B 579C
S.1.4.2
5B7C 5B7D
S.1.4.3
5BF3 5BF6
S.1.4.1
5EF0 5EF3
S.1.4.1
61D0 61F7
S.1.4.3
6560 656A
非同系
670C 80A6
非同系
670F 80D0
非同系
6710 80CA
非同系
6713 8101
非同系
6718 8127
非同系
6723 81A7
S.1.4.3
6735 6736
S.1.4.3
7054 7067
S.1.4.3
7A32 7A3B
S.1.4.3
7FF1 7FF6
S.1.4.3
8007 8008 8009
S.1.4.1
8074 807C 807D
S.1.4.2
8346 834A
S.1.4.3
8EB1 8EB2
165
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書T
(参考)
タグ文字による言語のタグ付け
注記 この規格の以前の版でこの附属書に記載していた内容は,F.8に記載した。
166
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書U
(参考)
識別子用の文字
UCSの実装者が判断する一般的な課題に,構文解析及び/又は字句解析での識別子の条件がある。それ
ぞれのプログラム言語の標準は,それ特有の識別子の構文を規定している。プログラム言語が異なれば,
ASCII(ISO/IEC 646のIRVのことをいう。)の範囲の幾つかの文字(例えば,“$”,“@”,“#”及び“̲”。)
の識別子での使用の扱いが異なる。どの文字を構文上の区切りとし,どの文字を識別子として許すか,大
文字と小文字とで対になっている文字を同一視するかどうか,正規化を行うかどうか,などの様々な要素
が,特定のプログラム言語における識別の目的にふさわしい文字の集合の規定に関与する。
ユニコードコンソーシアムは,ユニコード附属書 UAX #31“Identifier and Pattern Syntax”という文書を
出版することで,UCSの文字に基づく構文解析での扱いの標準化に寄与している。識別子での使用にふさ
わしいUCSの文字の一覧を決定するときには,このUAX #31の仕様を参考にするとよい。UAX #31は,
http://www.unicode.org/reports/tr31/ として参照できる。
167
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書JA
(参考)
日本文字関連部分集合用図形文字の組
この附属書は,附属書Aの部分集合用図形文字の組のうち,固有名詞を含む日本における一般の社会生
活に関わりのある7個の符号化図形文字の組,及び附属書Aには規定されていない1個の文字の組を参考
として示すものであって,規定の一部ではない。
JA.1 日本文字関連図形文字の組
7個の日本文字関連図形文字の組は,次のa)〜g)のとおりである。
a) BASIC JAPANESE BASIC JAPANESE(基本日本文字集合)は,組番号285の組である(A.5.6参照)。
これは,JIS X 0201,ISO/IEC 646のIRV及びJIS X 0208に相当する基本部分集合である。含まれる
文字の符号位置を,添付ファイル“BasicJ.txt”に参考として示す。
b) JIS2004 IDEOGRAPHICS EXTENSION JIS2004 IDEOGRAPHICS EXTENSION(JIS2004拡張漢字
集合)は,組番号371の組である(A.4.2参照)。これは,JIS X 0213の第3水準及び第4水準漢字部
分に相当する拡張用の部分集合である。含まれる文字の符号位置を,添付ファイル“JIExt.txt”に参考
として示す。
c) JAPANESE IDEOGRAPHICS SUPPLEMENT JAPANESE IDEOGRAPHICS SUPPLEMENT(補助漢字
集合)は,組番号372の組である(A.4.3参照)。これは,JIS X 0212の漢字部分に相当する拡張用の
部分集合である。含まれる文字の符号位置を,添付ファイル“JISup.txt”に参考として示す。
d) JAPANESE CORE KANJI JAPANESE CORE KANJI(日本語中核漢字集合)は,組番号375の組で
ある(A.4.6参照)。これは,2 136字のCJK統合漢字を含み,常用漢字表(平成22年内閣告示第2号)
に対応している。含まれる文字の符号位置を,添付ファイル“JapaneseCoreKanji.txt”に参考として示
す。
e) MOJI-JOHO-KIBAN IDEOGRAPHS-2016 MOJI-JOHO-KIBAN IDEOGRAPHS-2016(文字情報基盤
漢字集合2016)は,組番号390の組である(A.5.10参照)。これは,漢字,漢字字形指示列(IVS)及
び既定の字形指示列(SVS)からなる。この組に含まれる漢字,漢字指示列及び既定の字形指示列は
日本の行政で用いられる人名漢字をこの国際標準で表現するための文字情報基盤セットに対応してい
る。含まれる文字の符号位置,漢字字形指示列及び既定の字形指示列と,その典拠となった文字情報
基盤整備事業の漢字の識別情報との対応を,添付ファイル“MJSrc.txt”に参考として示す。
注記 文字情報基盤セットについては,対応国際規格の次の版で,より新しい文字の組の標準化作
業が進んでいる。この文字の組を指定する際には,注意が必要である。
f)
JAPANESE NON IDEOGRAPHICS EXTENSION JAPANESE NON IDEOGRAPHICS EXTENSION(拡
張非漢字集合)は,組番号286の組である(A.5.7参照)。これは,JIS X 0213の非漢字部分(ただし,
JIS X 0208にも含まれるものを除く。)に相当する拡張用の部分集合である。含まれる文字の符号位置
を,添付ファイル“JNIExt.txt”に参考として示す。
g) COMMON JAPANESE COMMON JAPANESE(通用日本文字集合)は,組番号287の組である(A.5.8
参照)。これは,a)に示したBASIC JAPANESEに,日本で広く用いられている拡張を加えた部分集合
である。含まれる文字の符号位置を,添付ファイル“CommonJ.txt”に参考として示す。
168
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
JA.2 附属書Aに含まれない日本文字関連図形文字の組
a) JAPANESE NON IDEOGRAPHICS SUPPLEMENT JAPANESE NON IDEOGRAPHICS SUPPLEMENT
(追加非漢字集合)は,JA.1のf)に示したJAPANESE NON IDEOGRAPHICS EXTENSIONを含み,
JIS X 0212で規定された漢字以外の文字(すなわち,“特殊文字”及び“アルファベット”)並びにJIS
X 0201,JIS X 0208及びJIS X 0212に含まれない文字のうち日本語文書で用いられる追加的な記号類
からなる。含まれる文字を,添付ファイル“JNIExt2.txt”に示す。
JA.3 部分レパートリの組合せ
日本文字部分レパートリのうち,BASIC JAPANESE及びCOMMON JAPANESEは,それぞれを単独で又
は他の日本文字部分レパートリと組み合わせて用いることを意図している。JIS2004 IDEOGRAPHICS
EXTENSION,JAPANESE IDEOGRAPHICS SUPPLEMENT,JAPANESE NON IDEOGRAPHICS EXTENSION
は,単独で用いることを意図していない。意図する組合せの例は,次のとおりである。
− BASIC JAPANESE及びJIS2004 IDEOGRAPHICS EXTENSIONの組合せ。
− BASIC JAPANESE,JIS2004 IDEOGRAPHICS EXTENSION及びJAPANESE NON IDEOGRAPHICS
EXTENSIONの組合せ。
− COMMON JAPANESE及びJIS2004 IDEOGRAPHICS EXTENSIONの組合せ。
− COMMON JAPANESE,JIS2004 IDEOGRAPHICS EXTENSION及びJAPANESE NON IDEOGRAPHICS
EXTENSIONの組合せ。
JA.4 適合性
この附属書に示す日本文字部分レパートリのうち,JAPANESE NON IDEOGRAPHICS SUPPLEMENTを
除く7個の文字の組は,この規格が規定する組である。これら7個の日本文字部分レパートリのいずれか
一つ以上の組合せを部分集合とする適合性の主張は,選択部分集合への適合性の主張の方法によるのがよ
い(8.3参照)。
JAPANESE NON IDEOGRAPHICS SUPPLEMENTは,この規格が規定する組ではない。JAPANESE NON
IDEOGRAPHICS SUPPLEMENTを含む部分集合への適合性の主張は,制限部分集合への適合性の主張の方
法による(8.2参照)。

169
X 0221:2020 (ISO/IEC 10646:2017,Amd.1:2019,Amd.2:2019)
附属書JB
(参考)
元号“令和”の合字
この附属書は,この規格に将来追加される文字を参考として示すものである。
JB.1 新たに追加される文字
次の文字をENCLOSED CJK LETTERS AND MONTHSブロックに追加する。この文字は対応国際規格の
次の版で追加するための作業が進められている。
32F
F
令和
32FF
32FF 令和 SQUARE ERA NAME REIWA
≈ <square> 4EE4 令 548C 和
参考文献 JIS X 0412規格群 言語名コード
対応国際規格:ISO 639 (all parts),Codes for the representation of names of languages
ISO/IEC 4873,Information technology−ISO 8-bit code for information interchange−Structure and
rules for implementation
ISO/IEC 8824 (all parts),Information technology−Abstract Syntax Notation One(ANS.1)
ISO/IEC 8825 (all parts),Information technology−ANS.1 encoding rules