X 0180:2011
(1)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
目 次
ページ
序文 ··································································································································· 1
1 適用範囲························································································································· 2
2 引用規格························································································································· 2
3 用語及び定義 ··················································································································· 3
4 概要······························································································································· 3
4.1 この規格の取り扱う範囲の制限 ························································································ 3
4.2 規格の全体構成 ············································································································· 3
4.3 作法及びルールの品質特性との関連付け············································································· 3
4.4 作法及びルールの記述形式 ······························································································ 4
5 コーディング規約の作成・運用プロセス ··············································································· 5
5.1 概要 ···························································································································· 5
5.2 コーディング規約の作成・運用の局面················································································ 5
5.3 新規コーディング規約の作成 ··························································································· 5
5.4 コーディング規約の改善 ································································································· 7
5.5 コーディング規約の運用 ································································································· 7
5.6 既存コーディング規約の充実 ··························································································· 8
6 作法一覧························································································································· 8
6.1 はじめに ······················································································································ 8
6.2 (R) 信頼性 ···················································································································· 8
6.3 (M) 保守性 ·················································································································· 10
6.4 (P) 移植性 ··················································································································· 11
6.5 (E) 効率性 ··················································································································· 12
附属書A(参考)C言語対応コーディング規約作成方法······························································ 13
附属書B(参考)C言語文法によるルール分類 ·········································································· 78
附属書C(参考)C言語処理系定義文書化テンプレート······························································ 87
附属書D(参考)ソースコード品質の捉え方 ············································································ 94
附属書E(参考)参考文献 ···································································································· 97
X 0180:2011
(2)
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
まえがき
この規格は,工業標準化法第12条第1項の規定に基づき,独立行政法人情報処理推進機構(IPA)及び
財団法人日本規格協会(JSA)から,工業標準原案を具して日本工業規格を制定すべきとの申出があり,
日本工業標準調査会の審議を経て,経済産業大臣が制定した日本工業規格である。
この規格は,著作権法で保護対象となっている著作物である。
この規格の一部が,特許権,出願公開後の特許出願又は実用新案権に抵触する可能性があることに注意
を喚起する。経済産業大臣及び日本工業標準調査会は,このような特許権,出願公開後の特許出願及び実
用新案権に関わる確認について,責任はもたない。
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
日本工業規格 JIS
X 0180:2011
組込みソフトウェア向けコーディング規約の
作成方法
Framework of establishing coding guidelines for
embedded system development
序文
この規格は,業界,組織又はプロジェクトの特性に応じて組込みソフトウェア向けに開発されるソフト
ウェアのソースコードの品質をより良いものとすることを目的として,コーディングのときに用いること
が望ましい規約を定める場合の,プログラム言語に共通した,規約作成方法の基本を規定したものである。
また,開発されるソフトウェアのソースコードの作法を統一することによって,ソースコードの容易な理
解,ソフトウェア作成の能率向上なども目的としている。
組込みソフトウェアを開発する場合,ソースコードを実装する作業(コード実装)は避けて通ることが
できない。この作業の出来不出来はその後のソフトウェアの品質を大きく左右する。一方で,組込みソフ
トウェア開発で最も多く利用されているC言語の場合,記述の自由度が高く,技術者の経験の差が出やす
い言語といわれている。技術者の技量,経験の差によって,作られるソースコードの出来不出来に差が生
じてしまうのは好ましくない。先進的な企業の中にはこうした事態を防ぐために,組織として,又はグル
ープとして守ることが望ましいコーディングの基準又はコーディング規約を定め,ソースコードの標準化
を進めているケースもある。
次に,この規格制定に至った目的,規格の想定する読者など,この規格の基本的な立脚点について示す。
a) コーディング規約に関する課題 通常,コーディング規約とは“品質を保つために守ることが望まし
いコードの書き方[コーディングルール(以後,単にルールということがある。)]を整理したもの”
となっているが,現在利用されているコーディング規約に関しては,次のような課題が存在している。
1) ルールの必要性が理解されない。又は,ルール違反に対する正しい対処方法が理解されていない。
2) ルールが多すぎて覚えきれない。又は,ルールが少なくて品質が保てない。
3) ルールの遵守状況を確認するための高精度のツールがなく,確認を技術者が目視で行うレビューに
頼っており負担が大きい。また,この結果として,既にコーディング規約がある業界,組織又はプ
ロジェクトにおいても,それらが形骸化して守られていないといった状況も散見されている。
さらに,どのような形であれコーディング規約が用意されていればまだよく,コーディング規約
自体が決められずに,依然として個々の担当者の判断に任せたコーディングが中心となっている組
織も少なくない。
b) コーディング作法とは コーディング作法(以下,単に作法という。)とは,このようなコーディング
規約に関する現場の問題を解決することを目的として,様々なコーディングの場面で守ることが望ま
しい基本的な考え方(基本概念)をソフトウェアの品質の視点を考慮して作法として整理したもので
ある。この規格ではこうした作法及びこれに関連するコーディングルールを提示する。
2
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
この規格の利用者は,これらの情報を参考に,“自部門における具体的なコーディング規約を策定す
る”といった作業を行うことで,前述したコーディング規約に関する課題を解決することができる。
c) 想定する利用者 この規格は,次の利用者を想定して作成している。
1) コーディング規約を作成する人 この規格を参考にして新規のコーディング規約を作成することが
できる。また,既にあるコーディング規約の確認,整理ができる。
2) プログラマ及びプログラムレビューをする人 この規格の作法及びルールを理解・修得することに
よって,信頼性の高い,保守しやすいコードの作成が無理なくできるようになる。
d) 得られる効果 この規格を利用することで利用者には前述のような効果のほかに,次のような効果が
期待できる。
1) ソフトウェアの品質面で大きなボトルネックとなっている実装面での技術者による出来不出来のば
らつきを解消できる。
2) ソースコード上の明らかな誤りなどをコーディング段階,その後のレビューなどで早期に除去する
ことができる。
e) コーディング作法の特徴 この規格を参考とすることにより,次に示すような特徴をもつコーディン
グ作法を作成することができる。
1) 体系化された作法及びルール この規格では,ソフトウェアの品質と同様に,コードの品質も信頼
性,保守性,移植性及び効率性の品質特性で分類できると考え,作法及びルールをJIS X 0129-1を
基に体系化している。この規格における作法とは,ソースコードの品質を保つための慣習及び実装
の考え方で,個々のルールの基本的な概念を示す。作法及びルールを品質特性で分類することで,
それらがどの品質を保つことを主たる目的としているのかを理解できるようにしている。
2) ルールの提示 コーディング規約作成のために参考となるC言語用のルールを附属書Aに示す。こ
ので提示するルールは,世の中に存在する多くのコーディング規約を十分に吟味した上でまとめた
ものであり,この規格の利用者はそれぞれの状況(言語仕様,処理系の実情など)に合わせて取捨
選択し,作法に対応させる形でそしゃく(咀嚼)し,理解することにより参考とすることができる。
1
適用範囲
この規格は,業界,組織又はプロジェクトの特性に応じて組込みソフトウェアのコーディング規約を定
める場合のプログラム言語に共通な作成方法を規定するとともに,その共通な作成方法に基づくC言語の
場合の具体的コーディング規約の作成方法も規定する。この規格は附属書を追加することによって,他の
プログラム言語の場合にも拡張可能である。この規格によって適合性評価を行うことは,意図していない。
なお,対応国際規格はこの規格の制定時点で発行されていない。
2
引用規格
次に掲げる規格は,この規格に引用されることによって,この規格の規定の一部を構成する。これらの
引用規格は,記載の年の版を適用し,その後の改正版(追補を含む。)は適用しない。
JIS X 0129-1:2003 ソフトウェア製品の品質−第1部:品質モデル
注記 対応国際規格:ISO/IEC 9126-1:2001,Software engineering−Product quality−Part 1: Quality
model(IDT)
JIS X 3010:2003 プログラム言語C
注記 対応国際規格:ISO/IEC 9899:1999,Programming languages−C(IDT)
3
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
3
用語及び定義
この規格で用いる主な用語及び定義は,次による。
3.1
コーディング作法(coding convention)
ソースコードの品質を保つための慣習及び実装の考え方。個々のルールの基本概念を示す。この規格で
は誤解のおそれがない場合,単に作法ともいう。
3.2
コーディング規約(coding guideline)
業界,組織又はプロジェクトにおいて,品質を保つために守ることが望ましいソースコードの書き方(ル
ール)を整理したもの。
3.3
コーディングルール(coding rule)
コーディング規約を構成する,具体的な一つ一つの決めごと。誤解のおそれがない場合,単にルールと
もいう。
4
概要
この箇条では,この規格の取り扱う範囲に関する制限事項,この規格の全体の構成,作法一覧の記述形
式などについて示す。
4.1
この規格の取り扱う範囲の制限
次のものは,この規格の作法及びルールの対象外とする。
a) ライブラリ関数。
b) メトリクス(関数の行数・複雑度など。)。
c) コーディングミスに分類されると思われる記述誤り。
4.2
規格の全体構成
a) 箇条5に,コーディング規約の作成・運用プロセスを示す。
b) 箇条6に,コーディング作法を列挙して示す。
c) 附属書Aには,C言語の場合のコーディング規約作成方法を示す。また,この規格で用いている略語
の意味を,更に,この規格を読みやすくするために示している。
d) 附属書Bには,附属書AのコーディングルールをC言語の文法の観点から分類し直して示す。
e) 附属書Cには,C言語の言語処理系定義の機能をコーディング作法及びルールの活用の目的で利用す
るために必要な文書化テンプレートを示す。
f)
附属書Dには,JIS X 0129-1が示しているソースコード品質の捉え方を,この規格を活用する上で便
利なように整理して示す。
g) 附属書Eには,この規格の原案作成の際に用いた参考文献を示す。
なお,上記の附属書A〜附属書Dは,コーディング規約策定の際の参考情報として掲載してある。
4.3
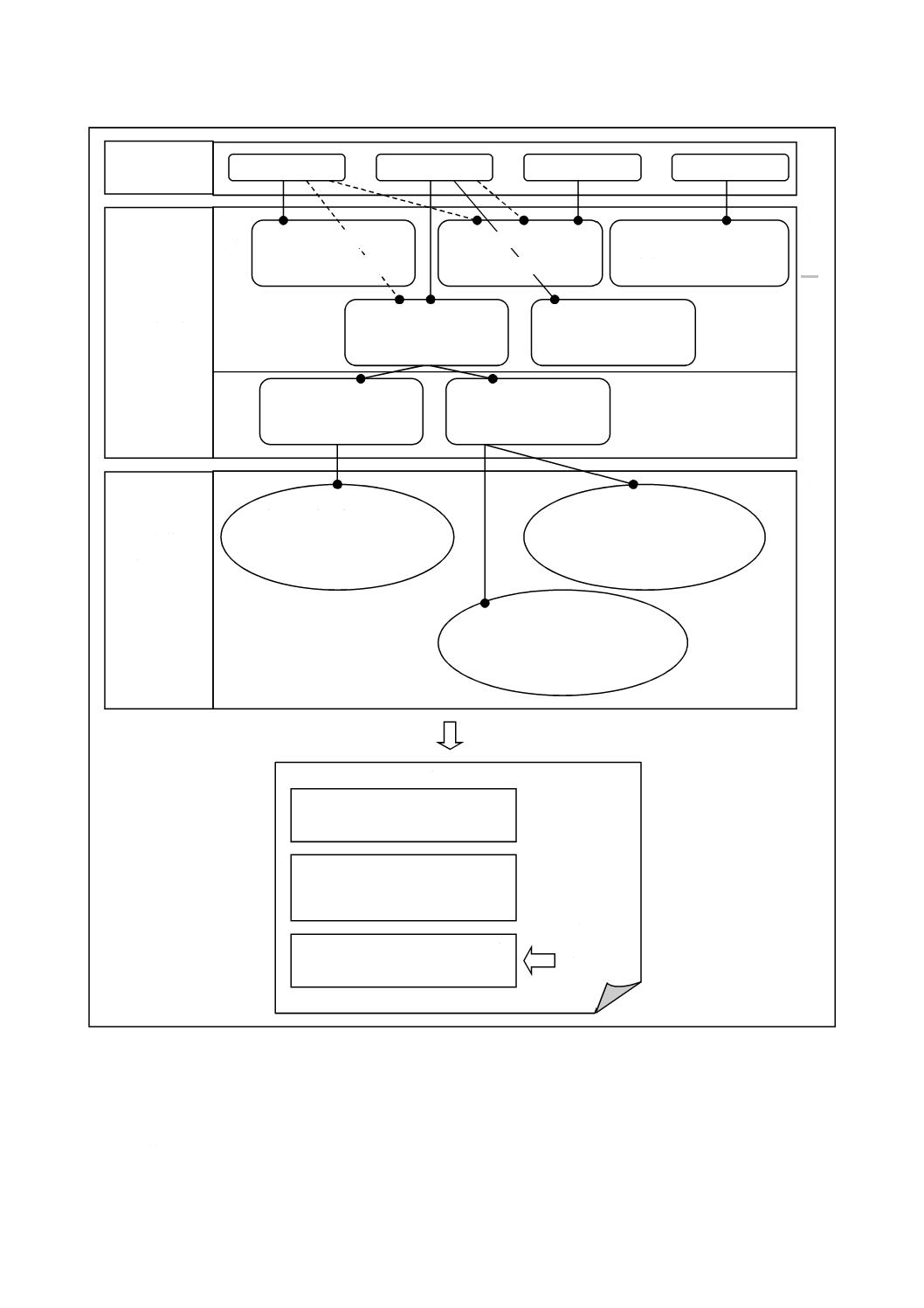
作法及びルールの品質特性との関連付け
この規格では,作法及びルールを,図1に示した四つの品質特性に関連付けて分類・整理している。作
法及びルールの多くは,複数の品質特性に関連するが,最も関連の強い特性に分類している。品質特性と
関連付けることによって,各作法がどのような品質に強く影響するかを理解できる。
4
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
図1−品質特性,作法及びルールの関係
4.4
作法及びルールの記述形式
作法及びルールを記述するに当たって,次の略号及びその表記法を使用する。
a) 品質特性を表すために次の略号を用いる。
信頼性
保守性
移植性
効率性
作法
品質向上のため
に守ることが望
ましい具体的な
実装の考え方
領域は初期化し大きさに
気を付けて使用する。
作
法
概
要
コンパイラに依存しない
書き方にする。
資源及び/又は時間の効率
を考慮した書き方にする。
修正し誤りのないような
書き方にする。
統一した書き方にする。
ブロックは明確化し,省
略しない。
アクセス範囲は局所化す
る。
・・・
・・・
品質特性
作
法
詳
細
ルール
言語依存を考慮
した具体的なコ
ーディングルー
ルの参考情報
if, else if, else, while,
do, for, switch文の本体
はブロック化する。
一つの関数だけで使用する
変数は関数内で宣言する。
同じファイルで定義した関数
だけから呼ばれる関数は
static関数とする。
プロジェクトごとのコーディング規約
一つの関数だけで使用する変数は関
数内で宣言する。
同じファイルで定義した関数だけか
ら呼ばれる関数はstatic関数とする。
一つのファイルの行数は1000行以内
とする。
独
自
に
追
加
ルールを参考にして作成
・・・
・・・
言
語
独
立
(
一
部
依
存
)
言
語
依
存
5
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
R
信頼性
M 保守性
P
移植性
E
効率性
b) 各品質特性に関連する作法及びルールを識別するために次の表記法を用いる。
Xn
Xn.n
Xn.n.n
ここで,Xは品質特性の略号,n,n.n,n.n.nはそれぞれ作法概要,作法詳細,ルールの階層的番号付け
である。箇条6,附属書A及び附属書Bに示す記述で,それぞれ作法又はルールを示す行の先頭に丸括弧
に入れてこの表記法による識別を示した。また,他の箇所でそれら作法又はルールを参照するときは,通
常の文章中では丸括弧を付けた上記の略号で参照し,表の中では括弧なしで参照する。
5
コーディング規約の作成・運用プロセス
5.1
概要
次に示す手順に沿ってコーディング規約を作成し,運用・教育体制を整備し,見直された規約のプロセ
スは,この規格に適合したコーディング規約作成・運用プロセスである。
5.2
コーディング規約の作成・運用の局面
コーディング規約の作成・運用のプロセスが実施される局面には,次の2通りがある。この規格は,こ
れらの局面で活用することによって,有効なコーディング規約の作成・運用に役立つ。
a) 新規コーディング規約の作成 業界,組織又はプロジェクトで守ることが望ましいコーディング規約
が現在まだ整備できていない場合に,それぞれの状況に適したコーディング規約を作成する。
b) 既存コーディング規約の充実 既にコーディング規約が整備されている業界,組織又はプロジェクト
であっても,それらを保守・改定する。
5.3
新規コーディング規約の作成
5.3.1
概要
5.3〜5.5ではコーディング規約を策定していない業界,組織又はプロジェクトが,この規格を用いて新
規にコーディング規約を作成する場合の手順を示す。
5.3.2
作成時期
業界,組織又はプロジェクトの標準的なコーディング規約を作成する場合は,経験の蓄積に基づいて適
切な時期に,関係者間での作成の合意形成を経て,開始する。
プロジェクトでは,コーディング規約は,プロジェクトを開始し,プログラム設計に入る前までに作成
する。コーディング規約は,コーディング時に参照するルールの集まりだが,関数名の命名規約などプロ
グラム設計に関わるルールもある。そのため,プログラム設計以前に作成する必要がある。
5.3.3
作成
5.3.3.1
概要
新規にコーディング規約を策定する場合には,次の順序で作成する。
a) 作成方針の決定。
b) 作法及びルールの選択。
c) プロジェクト依存部分の定義。
6
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
d) 作成したルールのレビュー。
5.3.3.2
作成方針の決定
コーディング規約作成に当たっては,まず,業界,組織又はプロジェクトの特性をよく見極めた上で,
コーディング規約の作成方針を決定する。コーディング規約の作成方針とは,プロジェクトが作成するソ
フトウェア,プロジェクトを構成する人の特性などから,そのプロジェクトで作成されるコードがどのよ
うな書き方となっていることが望ましいかを示す方針のことである。例えば,安全性を重視し,便利であ
っても危険な機能は使用しないという書き方にするのか,危険な機能であっても注意して使用する書き方
にするかなどが,この方針に当たる。
なお,方針の決定に当たっては,プロジェクトで重視したい品質特性,作法,及び次に示す視点などを
考慮する。
a) プログラムを見やすくするコーディング
b) デバッグを考慮したコーディング
c) 障害許容性を考慮したコーディング
5.3.3.3
ルールの選択
ルールは,作成方針で決定した規約作成の方針に従い,世の中で既に存在するルール,業界・組織・プ
ロジェクトで蓄積された経験によるルールなどの中から選択する。この場合,選択するルールがどの品質
特性を保つためのルールであるかを吟味して,方針にふさわしいルールを選択する。C言語では,附属書
Aに示すルール候補の中から選択するのがよい。また,例えば,移植性を重視する方針とした場合,移植
性に該当するルールを多く選ぶなどの工夫をする。このときに,取り上げる作法及びルールを修整し,又
は他のルールを追加してもよい。これらの修整又は追加を行った場合には,その理由を明示するのがよい。
附属書Aでは,ルールの採用指針という特性を表示している。規約として採用しないとそのルールが属
する品質特性を著しく損なうと考えられるルールについては,ルール末尾に採用指針を“必要”という用
語で示している。一方,言語仕様を熟知している人にはあえて規約にする必要がないと思われるルールに
ついては,採用指針を“基本”という用語で示している。これらを参考にルールを選択する。ルール選択
の最も簡便な方法は,“必要”という用語がついているルールだけを選択することである。それによって,
ごく一般的に利用されているルールが選択できる。
5.3.3.4
プロジェクト依存部分の定義
世の中に存在するコーディングルールは,次のように,業界,組織又はプロジェクトでそのまま使える
ルールと変更及び/又は追加記述が必要なルールとがある。
a) ある書き方に対する一般的なルールが一つしかなく規約としてそのまま使えるルール[次のb),c)で
ないもの]
b) ある書き方に対する一般的なルールが複数あり,業界,組織又はプロジェクトの特性に合わせて選択
するルール
この場合は,業界,組織又はプロジェクトの特性に合わせて与えられた候補の中からルールを選択
する。
c) 業界,組織又はプロジェクトの特性に合わせて,ルールを具体化する必要があるルール,又は文書作
成を要求するルール
この場合は,業界,組織又はプロジェクトの特性に合わせて,ルール又は文書を作成する。例えば,
C言語の場合,c)に当たるルールの例としては,それぞれ,附属書Aで“規約”,“文書”の利用特性
が付けられたルールが挙げられる。
7
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
5.3.3.5
作成したルールのレビュー
業界,組織又はプロジェクトで作成したコーディングルールは,レビュー会を開いて検証及び妥当性を
確認する。また,パイロットプロジェクト又は実際のプロジェクトで試用して,その内容が実務的な利用
に際してもつ有効性の観点から検証及び妥当性確認をする。
プロジェクトで作成したルールを変更する必要がある場合は,構成管理プロセスの下で変更を行う。
5.4
コーディング規約の改善
コーディング規約は,対象となるプロジェクトの特性によって変化するものである。異なる特性のプロ
ジェクトではかなり異なるコーディング規約が必要となることがある。しかし,同種のプロジェクトでは
同種のコーディング規約となることが期待され,その場合には継続的に安定的なコーディング規約を運用
することが可能となる。
個別のプロジェクトばかりでなく,業界,組織又はプロジェクトが継続的に安定したコーディング規約
を運用できるかどうかも検討しなければならない。可能な場合は,組織のもつソフトウェアプロセスの一
環としてコーディング規約の活用を制度化していくことが有効である。
業界,組織又はプロジェクトの特性の変化は,プロジェクト要員の変化,対象業務の変化,技術的な環
境の変化,事業環境の変化など多くの要因からもたらされる。コーディング規約を最適化し,安定させる
と同時に,特性の変化に対応して適切なコーディング規約を改定・運用することが必要である。
業界,組織又はプロジェクトが制度化されたコーディング規約をもつ場合には,それらは定期的にレビ
ューし,必要な改善を提起・計画・実装・周知しなければならない。レビューするための体制を維持する
のがよい。改善を提起する根拠となる指標データを収集するのがよい。
5.5
コーディング規約の運用
5.5.1
運用
コーディング規約は,単に作成し,周知させればよいというものではなく,実際の開発において漏れな
く,適切に利用されることが重要である。このためには,プロジェクト管理において,コーディング規約
を徹底させるための教育・訓練及び組織的な点検・報告といったコミュニケーションが必要となる。また,
コーディング規約の徹底を支援するソフトウェアツールの活用も有効である可能性がある。
5.5.2
運用時のルール適用除外及びその手順
プロジェクトで対象とするソフトウェアが実現する機能に応じて,コーディング時に注目することが望
ましい品質特性が異なる場合がある(例えば,保守性よりも効率性を重視しなければならないなど。)。こ
の場合,定めたルールどおりに記述すると,目的が達せられないなどの不具合になる可能性がある。この
ような場合に対応するべく,部分的に,ルールを適用除外として認めることを手順化しておく必要がある。
重要なことは,ルールどおりに記述することによってどのような不具合になるかを明記し,これを有識
者にレビューしてもらい,その結果を記録に残すことである。安易にルール適用除外を許してしまい,ル
ールが形骸化するのを防止する。
次に,適用除外を認める手順の例を示す。
a) 適用除外の理由書を作成する[理由書の項目例:“ルール番号”“発生箇所(ファイル名,行番号)”“ル
ール遵守の問題点”“ルール逸脱の影響など”]。
b) 有識者のレビューを受け,レビュー結果を理由書に追記する。
c) コーディング工程の責任者の承認を受け,承認記録を理由書に記載する。
5.5.3
教育
コーディング規約は,開発に従事する要員に対して,制度的に教育し,理解させる必要がある。コーデ
8
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
ィング規約は単に業界,組織又はプロジェクトで作成するルールというだけではなく,開発要員が自ら積
極的にその必要性を理解し,実施し,また,改善を提起するものでなければならない。そのためには,開
発要員がコーディング作法,ルールの背景及び制定理由をよく理解し,趣旨を生かしていけるのでなけれ
ばならない。
開発要員が信頼性,保守性,移植性,効率性などの観点から分類されたこの規格の下で制定されたコー
ディング作法・ルールを活用することによって,次のコーディングを適切に行えるようになる可能性があ
る。
a) 信頼性を高くするコーディング
b) バグを作り込まないようにするコーディング
c) デバッグ・テストがしやすいようにするコーディング
5.6
既存コーディング規約の充実
5.6.1
概要
この規格は,コーディング規約が既に存在する業界,組織又はプロジェクトに対しては,既存のコーデ
ィング規約を更に充実したものとするための基準として利用できる。
5.6.2
有効利用の視点
既存のコーディング規約を更に充実したものとする視点として,次の点に留意する。
a) 抜け漏れの防止 この規格の作法概念を用いて,既存のコーディング規約をカテゴライズすることに
よって,抜けている観点及び漏れているルールを補い充実させることができ,また,自プロジェクト
が何に重点を置いて作業していたか再認識することができる。
b) ルール必要性の明確化 この規格の作法,ルールの適合例などを参照することによって,理由も明示
されず制定されていた規則の必要性を認識するためのツールとして利用できる。
6
作法一覧
6.1
はじめに
信頼できる組込みソフトウェア開発では,この箇条に示す作法を満たすことが望ましい。この規格に適
合するコーディング規約は,次に示す作法を基準として採用し,これらの作法との異同を明示しなければ
ならない。これらの作法は,実際に作成・運用するコーディングルールのメタルールであり,ルールは実
際の状況に応じて取捨選択することが望ましいものである。C言語の場合のルールの例について,附属書
Aに示す。
6.2
(R) 信頼性
6.2.1
概要
組込みソフトウェアの多くは製品に組み込まれて,我々の生活の中の様々な場面で利用されている。こ
のため,組込みソフトウェアの中には極めて高い信頼性が求められるものも少なくない。ソフトウェアの
信頼性では,ソフトウェアとしての誤った動作(障害の発生)をしないこと,誤動作をしてもソフトウェ
ア全体及びシステム全体の機能動作に影響を及ぼさないこと,誤動作が発生しても正常動作に速やかに復
帰できることなどが求められる。
ソースコードを記述する上で,ソフトウェアの信頼性について気を付けることが望ましいこととして,
このような誤動作を引き起こすような記述を極力避けることがある。ここでは,そのための作法を次のよ
うに示す。
・ (R1) 領域は初期化し,大きさに気を付けて使用する。
9
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
・ (R2) データは範囲,大きさ,内部表現などに気を付けて使用する。
・ (R3) 動作が保証された書き方にする。
6.2.2
領域の信頼性
a) 作法概要
(R1)
領域は初期化し,大きさに気を付けて使用する。
コンピュータ上で確保する領域を意識し,領域の初期化などを確実にしておかないと,思わぬ誤動
作の元になる。領域の初期化及び大きさには,特に注意して利用する必要がある。
b) 作法詳細
(R1.1)
領域は,初期化してから使用する。
(R1.2)
初期化は過不足ないことが分かるように記述する。
(R1.3)
領域へのポインタは,大きさ(指す範囲)に気を付けて使用する。
6.2.3
データの安全性
a) 作法概要
(R2)
データは範囲,大きさ,内部表現などに気を付けて使用する。
データを記述するときに,データの精度,データの大きさなどに注意をしないと,思わぬ誤動作の
元になりかねない。扱うデータの範囲,大きさ,内部表現などを意識する必要がある。
b) 作法詳細
(R2.1)
内部表現に依存しない比較を行う。
(R2.2)
論理値などが区間として定義されている場合,その中の一点(代表的な実装値)と等しいか
どうかで判定を行ってはならない。
(R2.3)
データ型をそろえた演算・比較を行う。
(R2.4)
演算精度を考慮して記述する。
(R2.5)
情報損失の危険のある演算は使用しない。
(R2.6)
対象データが表現可能な型を使用する。
(R2.7)
ポインタの型に気を付ける。
(R2.8)
宣言,使用及び定義に矛盾がないことをコンパイラが検査できる書き方にする。
6.2.4
障害許容性
a) 作法概要
(R3)
動作が保証された書き方にする。
高い信頼性を実現させるためには,誤動作につながる記述を極力避け,できるだけ動作が保証され
た安全な書き方をすることが望ましい。
b) 作法詳細
(R3.1)
領域の大きさを意識した書き方にする。
(R3.2)
実行時にエラーになる可能性のある演算に対しては,エラーケースをう(迂)回させる。
(R3.3)
関数呼出しではインタフェースの制約を検査する。
(R3.4)
再帰呼出しは行わない。
(R3.5)
分岐の条件に気を付け,所定の条件以外が発生した場合の処理を記述する。
(R3.6)
評価順序に気を付ける。
10
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
6.3
(M) 保守性
6.3.1
概要
多くの組込みソフトウェア開発では,ひとたび作成したソフトウェアに手を加えるといった保守作業も
必要になる。
保守の原因は様々であるが,例えば,次の場合などが考えられる。
・ リリースしたソフトウェアの一部に不具合などが見つかり修正をする場合
・ 製品に対する市場からの要求などに応じて,既存ソフトウェアをベースに,新たな機能を追加する
場合
このように作成したソフトウェアに何らかの手を加える場合,その作業をできるだけ誤りなく効率的に
行えるかどうかが重要な特質になる。システムの世界では,これを保守性と呼ぶ。
ここでは,組込みソフトウェアのソースコードに関して,保守性を維持し,向上させるための作法を整
理して示す。
・ (M1) 他人が読むことを意識する。
・ (M2) 修正誤りのないような書き方にする。
・ (M3) プログラムはシンプルに書く。
・ (M4) 統一した書き方にする。
・ (M5) 試験しやすい書き方にする。
6.3.2
解析性
a) 作法概要
(M1)
他人が読むことを意識する。
ソースコードは,将来,第三者が読むことを考慮して,分かりやすく表現する必要がある。
b) 作法詳細
(M1.1) 使用しない記述を残さない。
(M1.2) 紛らわしい書き方をしない。
(M1.3) 特殊な書き方はしない。
(M1.4) 演算の実行順序が分かりやすいように記述する。
(M1.5) 誤解を招きやすいある種の演算については,言語仕様で省略可能になっている場合でも,省
略せずに明示的に記述する。
(M1.6) 領域は一つの利用目的に使用する。
(M1.7) 名前を再使用しない。
(M1.8) 勘違いしやすい言語仕様を使用しない。
(M1.9) 特殊な書き方は意図を明示する。
(M1.10) マジックナンバーを埋め込まない。
(M1.11) 領域の属性は明示する。
(M1.12) コンパイルされない文でも正しい記述を行う。
6.3.3
変更性
a) 作法概要
(M2)
修正誤りのないような書き方にする。
不具合を修正する場合に,別の不具合を埋め込んでしまうことがある。こうした修正ミスをできる
だけ少なくするような書き方にする必要がある。
11
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
b) 作法詳細
(M2.1) 構造化されたデータ及びブロックは,まとまりを明確化する。
(M2.2) アクセス範囲及び関連するデータは局所化する。
6.3.4
プログラムの簡潔性
a) 作法概要
(M3)
プログラムはシンプルに書く。
保守のしやすさという観点では,ソースコードをシンプルな書き方にする必要がある。
b) 作法詳細
(M3.1) 構造化プログラミングを行う。
(M3.2) 一つの文で一つの副作用とする。
(M3.3) 目的の違う式は,分離して記述する。
(M3.4) 複雑なポインタ演算は使用しない。
6.3.5
コーディングスタイルの統一性
a) 作法概要
(M4)
統一した書き方にする。
複数人による分業開発が定着している。このような場合,プロジェクト内では,極力,ソースコー
ドの書き方を統一する必要がある。
b) 作法詳細
(M4.1) コーディングスタイルを統一する。
(M4.2) 注釈の書き方を統一する。
(M4.3) 名前の付け方を統一する。
(M4.4) ファイル内の記述内容及び記述順序を統一する。
(M4.5) 宣言の書き方を統一する。
(M4.6) 空ポインタの書き方を統一する。
(M4.7) 前処理指令の書き方を統一する。
6.3.6
試験性
a) 作法概要
(M5)
試験しやすい書き方にする。
ソースコードを記述する場合に,問題原因分析のしやすさなどまで考慮しておくことが必要である。
b) 作法詳細
(M5.1) 問題発生時の原因を調査しやすい書き方にする。
(M5.2) 動的なメモリ割当ての使用に気を付ける。
6.4
(P) 移植性
6.4.1
概要
組込みソフトウェアの特徴の一つとしては,それが動作するプラットフォームの選択肢が多様である点
が挙げられる。すなわち,ハードウェアプラットフォームとしてのCPUの選択,ソフトウェアプラットフ
ォームであるOSの選択など様々な組合せが考えられる。そして,組込みソフトウェアで実現する機能の
増大とともに,一つのソフトウェアを様々なプラットフォームに対応させる形で,既存のソフトウェアを
別のプラットフォームに移植する機会が増えてきている。
こうした中で,ソフトウェアの移植性は,ソースコードレベルでも極めて重要な要素になりつつある。
12
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
特に,利用するコンパイラなどに依存する書き方などは日常的にも犯しやすい誤りの一つである。ここで
は,そのような誤りを避けるための作法を示す。
・ (P1) コンパイラに依存しない書き方にする。
・ (P2) 移植性に問題のあるコードは局所化する。
6.4.2
処理系からの独立性
a) 作法概要
(P1)
コンパイラに依存しない書き方にする。
世の中には様々な処理系が提供されているが,処理系に依存しない書き方にする必要である。
b) 作法詳細
(P1.1)
拡張機能及び処理系定義の機能は使用しない。
(P1.2)
言語規格で定義されている文字及び拡張表記だけを使用する。
(P1.3)
データ型の表現,動作仕様の拡張機能,及び処理系依存部分を確認し,文書化する。
(P1.4)
ソースファイル取込みについて,処理系依存部分を確認し,依存しない書き方にする。
(P1.5)
コンパイル環境に依存しない書き方にする。
6.4.3
コードの局所性
a) 作法概要
(P2)
移植性に問題のあるコードは局所化する。
処理系に依存する記述を避けられない場合には,その部分をできるだけ局所化しておく必要がある。
b) 作法詳細
(P2.1)
移植性に問題のあるコードは局所化する。
6.5
(E) 効率性
6.5.1
概要
組込みソフトウェアは,製品に組み込まれてハードウェアとともに,実世界で動作する点が特徴である。
製品コストをより安価にするためのCPU,メモリなどの様々な制約が,ソフトウェアにも課せられる。
また,リアルタイム性の要求などから,厳しい時間制約をクリアしなければならない。組込みソフトウ
ェアでは,メモリなどの資源効率性及び/又は時間性能を考慮した時間効率性に注意しながらコーディン
グする必要がある。
・ (E1) 資源及び/又は時間の効率を考慮した書き方にする。
6.5.2
資源及び/又は時間の効率性
a) 作法概要
(E1)
資源及び/又は時間の効率を考慮した書き方にする。
メモリサイズ及び/又は処理時間に制約がある場合には,それらを意識したソースコードの書き方
を工夫する必要がある。
b) 作法詳細
(E1.1)
資源及び/又は時間の効率を考慮した書き方にする。
13
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書A
(参考)
C言語対応コーディング規約作成方法
この附属書は,本体に規定したコーディング規約作成方法に基づき,具体的なコーディング規約の作成
方法をC言語の場合を例として示している。
ここでは,品質特性ごとに,コーディング作法(作法概要・作法詳細)に従って,コーディングルール,
及びルールに適合する(又は適合しない)C言語のプログラムコードの例を示す。
なお,本例は,独立行政法人情報処理推進機構が策定したコーディング作法ガイドを参考として整理し
たものである。コーディング作法ガイドはその作成の過程において,英国MIRA Ltdが策定したMISRA C
Standardを参考としている。このためこの規格の附属書として掲載するに当たり,MIRA Ltdと使用許諾を
もって,MISRA Cルールに類似するものについては,その番号を明示している。MISRA規約に関しての
著作権は,英国The Motor Industry Software Reliability Association(MISRA)にある。
実際にコーディング規約を策定する場合に,MISRA Cそのものを利用したいと考えるとき,又はこの規
格及び附属書に記載されていないMISRA Cルールを利用したいと考えるときには,事前に利用者より
MISRAから許諾を得なければならない。
A.1 はじめに
A.1.1 ルールの利用特性を示す用語
ルールの利用における特性を示すために,次の用語を用い,それぞれのルールを記述する文の末尾に付
記している。附属書Bに関しても,同様の用語を用いる。
この規格を用いてコーディング規約を作成する場合に,この規格に示したルールを適切に選択するため
の指針(これを採用指針という。)を次の用語によって示す。
a) プロジェクトの特性に合わせて選択すればよいと思われるルールは,用語を無表示とする。
b) 基本 言語仕様を熟知している人にはあえて規約にする必要がないと思われるルールである。経験の
あるプログラマには当たり前なことを示す。
c) 必要 守らないと著しく品質特性を損なうと考えられるルールである。
また,ルールが,そのまま使えるものか,更に具体的な状況に合わせて工夫を要するものかを示すため
に,すなわちルールの選択,規約作成作業又は文書作成作業の必要性の有無を示す(この区分を規約化の
特性による区分という。)ために,次の用語を用いる。
a) 規約としてそのまま使えるルールは,用語を無表示とする。
b) 選択 選択を意味する。複数のルールの中から選択する必要があることを示す。選択肢は片括弧付き
の数字[1),2)など]で示す。
c) 規約 プロジェクトごとに具体的なルールを規約として定める必要があることを示す。規約化するこ
とが望ましい部分は“<<”,“>>”で囲んで示す。
d) 文書 文書作成を指示するルールであることを示す。文書を作成することが望ましい部分は“<<”,
“>>”で囲んで示す。
A.1.2 この規格におけるルールの扱い
14
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
この附属書で列挙するコーディングルールは例示として示すものであり,個々のルールは規定の一部で
はない。
A.1.3 対象とするC言語仕様
この附属書では,C90(表A.1参照)を対象言語仕様とする。
A.1.4 略語及び用語
A.1.4.1 略語の説明
この附属書で用いる引用及び参照に用いる略語は,次による。
表A.1−引用及び参照している略語の説明
用語
説明
C90
ISO/IEC 9899:1990が規定し,広く普及しているC言語仕様。ISO/IEC 9899:1990自体及びそれ
に対する一致規格であった“JIS X 3010:1996 プログラム言語C”は,規格としては廃止され
ているが,参考文献(10)をはじめとする多数の教科書・解説書類が現在も入手可能であり,組込
みソフトウェアのための処理系のほとんどは,この言語仕様に基づいている。1990年に発行さ
れたため,C90と一般的に呼んでいる。
C99
“JIS X 3010:2003プログラム言語C”が規定するC言語仕様。対応国際一致規格のISO/IEC
9899:1999が1999年に発行されたため,この略語が一般に使用されている。C90からC99への
変更の概要については,“JIS X 3010:2003 プログラム言語C”の解説(“ISO/IEC 9899:1999,
Programming Language−C”では序文)などに示されている。
C++
“JIS X 3014:2003 プログラム言語C++”で規定されるC++言語仕様のことである。
MISRA
MISRA-Cの規約には,英国The Motor Industry Software Reliability Association(MISRA)によっ
て定められた,MISRA-C:1998及びMISRA-C:2004がある。この規格における“MISRA”は,
参考文献(5)のMISRA-C:2004規約を指す。それを引用した場合は,(MISRA 11.5)のように表示
している。
A.1.4.2 用語の説明
この附属書で用いる留意することが望ましい用語の説明は,表A.2による。用語の正確な定義はC99を
参照するのがよい。
表A.2−留意することが望ましい用語の説明
用語
説明
アクセス
変数の参照及び変更を含む参照のことである。
オブジェクト
その内容によって,値を表現することができる実行環境中の記憶域のことである。
型指定子
データの型を指定するもの。char,int,floatなどの基本的な型を指定するものと,プログラマ
が独自にtypedef で定義した型を指定するものである。
型修飾子
型に特定の性質を付け加えるもの。次の二つがある。
const,volatile
記憶クラス指定子
データが記憶される場所を指定するもの。次の四つがある。
auto,register,static,extern
境界調整
コンパイラがデータをメモリに配置するときの方法を示す。例えば,int型が2バイトの場合,
必ずメモリの偶数アドレスから配置するようにし,奇数アドレスから配置しないようにするこ
とである。
空ポインタ
いかなるデータ,関数へのポインタと比較しても等しくないポインタのことである。
3文字表記
“??=”,“??/”,“??(”のように決められた3文字をコンパイラが特定の1文字に解釈する文字
表記のことである。
“??=”,“??/”,“??(”は,それぞれ“#”,“\”,“[”に変換される。
生存期間
変数(オブジェクト)が生成されてから,プログラムからの参照が保証されている期間をいう。
15
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
多バイト文字
2バイト以上のデータで表現される文字。漢字,ひらがななどの全角文字,Unicodeで表現され
る文字などがある。
ナル文字
文字列の最後を表現する文字。“\0”で表現される。
ファイルスコープ
有効範囲が,ファイルの終わりまでのことである。
副作用
実行環境の状態に変化を起こす処理。次の処理が該当する。
volatileデータの参照及び変更,データの変更,ファイルの変更,及びこれらの操作を行う関数
呼出し処理である。
ブロック
データ宣言,プログラムなどにおいて波括弧“{”,“}”で囲んだ範囲をいう。
有効範囲
変数などを使用できる範囲のこと。スコープともいう。
列挙型
enum型。幾つかの列挙されたメンバで構成される。
列挙子
列挙型(enum型)のメンバのことである。
A.1.4.3 文字コードの注意点
情報交換用符号の規格JIS X 0201に従う端末表示又は印刷結果では,逆斜線(“\”),チルダ(“~”)は,
それぞれ円記号(“¥”),オーバライン(“̅”)で表示されることがある。
A.2 (R) 信頼性
A.2.1 概要
組込みソフトウェアの多くは製品に組み込まれて,我々の日常生活の中の様々な場面で利用されている。
このため,組込みソフトウェアには極めて高い信頼性が求められるものも少なくない。
信頼性の高い組込みソフトウェアを開発する上では,次のような作法に留意する。
・ (R1) 領域は初期化し,大きさに気を付けて使用する。
・ (R2) データは範囲,大きさ,内部表現に気を付けて使用する。
・ (R3) 動作が保証された書き方にする。
A.2.2 領域の信頼性
A.2.2.1
(R1) 領域は初期化し,大きさに気を付けて使用する。
C言語を用いたプログラムでは,様々な変数が利用される。こうした変数などについては,コンピュー
タ上で確保する領域を意識し,領域の初期化などを確実にしておかないと,思わぬ誤動作の元になる。
また,C言語のポインタはポイントする先の領域を意識して利用しなければならない。ポインタの使い
方を誤るとシステム全体に重大な問題を引き起こす危険があるため,特に注意して利用する必要がある。
・ (R1.1) 領域は,初期化してから使用する。
・ (R1.2) 初期化は過不足ないことが分かるように記述する。
・ (R1.3) 領域へのポインタは,大きさ(指す範囲)に気を付けて使用する。
A.2.2.2
(R1.1) 領域は,初期化してから使用する。
ルールは,次による。
a) (R1.1.1) 自動変数は宣言時に初期化するか,又は値を使用する直前に初期値を代入する。[採用指針:
基本] [規約化: ]
適合例
不適合例
void func() {
int var1 = 0;
/* 宣言時に初期化する */
void func() {
int var1;
var1++;
16
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
int i;
var1++;
/* 使用する直前に初期値を代入 */
for (i = 0; i < 10; i++) {
…
}
}
…
}
注記 自動変数を初期化しないと,その値は不定となり,環境によって演算結果が異なる現象が発
生する。初期化のタイミングは宣言時,又は値を使用する直前とする。
b) (R1.1.2) const型変数は,宣言時に初期化する。[採用指針:基本] [規約化: ]
適合例
不適合例
const int N = 10;
const int N;
注記 const型変数は後から代入ができないので,宣言時に初期化する。初期化しないと外部変数の
場合は0,自動変数の場合は不定となるので,意図しない動作となる可能性がある。宣言時
に未初期化でもコンパイルエラーにならないため,注意が必要である。
なお,C++ではconst型変数の未初期化はコンパイルエラーとなる。
A.2.2.3
(R1.2) 初期化は過不足ないことが分かるように記述する。
ルールは,次による。
a) (R1.2.1) 要素数を指定した配列の初期化では,初期値の数は,指定した要素数と一致させる。[採用指
針:基本] [規約化: ]
適合例
不適合例
char var[] = "abc";
又は
char var[4] = "abc";
char var[3] = "abc";
注記 配列を文字列で初期化する際に,配列の大きさとしてナル文字分を確保せずとも宣言時には
エラーにならない。もし意図した記述であれば問題ないが,文字列操作関数などの引数とし
て使用すると文字列の最後を示すナル文字がないため,意図しない動作となる可能性が高い。
文字列の初期化の際には,最後のナル文字分まで確保する必要がある。
b) (R1.2.2) 列挙型(enum型)のメンバの初期化は,定数を全く指定しない,全て指定する,又は最初の
メンバだけを指定する,のいずれかとする。[採用指針: ] [規約化: ]
適合例
不適合例
/* E1からE4までには異なる値が割り付けられる */
enum etag { E1=9, E2, E3, E4 };
enum etag var1;
var1 = E3;
/* var1に入れたE3とE4とが等しくなること
はない */
if (var1 == E4)
/* 意図せずにE3とE4とがいずれも11になる */
enum etag { E1, E2=10, E3, E4=11 };
enum etag var1;
var1 = E3;
/* E3とE4とは等しいので,意図に反して真に
なる */
if (var1 == E4)
注記 列挙型のメンバに初期値を指定しない場合,直前のメンバの値に1を加えた値になる(最初
17
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
のメンバの値は0である。)。初期値を指定したり,指定しなかったりすると,不用意に同じ
値を割り当ててしまい,意図しない動作となる可能性がある。使い方にも依存するが,メン
バの初期化は,定数を全く指定しない,全て指定する,又は最初のメンバだけを指定する,
のいずれかとし,同じ値が割り振られるのを防止する。
A.2.2.4
(R1.3) 領域へのポインタは,大きさ(指す範囲)に気を付けて使用する。
ルールは,次による。
a) (R1.3.1) 次のいずれかを選択する。[採用指針:基本] [規約化:選択]
1) ポインタへの整数の加減算(++及び--も含む。)は使用せず,確保した領域への参照・代入は[ ]を用
いる配列形式にする。
2) ポインタへの整数の加減算(++及び--も含む。)は,ポインタが配列を指している場合だけとし,結
果は,配列の範囲内を指すようにする。
適合例
不適合例
#define N 10
int data[N];
int *p;
int i;
p = data;
i = 1;
1),2)の例
data[i] = 10; /* 適切 */
data[i+3] = 20; /* 適切 */
2)の例
*(p + 1) = 10;
#define N 10
int data[N];
int *p;
p = data;
1)の例
*(p + 1) = 10; /* 不適切 */
p += 2; /* 不適切 */
2)の例
*(p + 20) = 10; /* 不適切 */
注記 ポインタに対する演算は,ポインタの指している先を分かりにくくする原因となる。すな
わち,確保していない領域を参照したり,領域に書き込んだりするバグを埋め込む可能性
が高くなる。領域の先頭を指している配列名を使った配列の添え字によって,配列要素を
アクセスする方が,安全なプログラムとなる。mallocなどによって獲得した動的メモリは
配列と判断し,先頭ポインタを配列名と同等に扱う。
なお,2)のルールにおいて,配列の最後の要素を一つ超えたところについては,配列要
素にアクセスしない限り指してもよい。すなわち,int arr[N],p=data として,p+Nを,配
列要素のアクセスに利用しない場合はルールに適合しており,*(p+N)のように配列要素の
アクセスに利用する場合は不適合である。
b) (R1.3.2) ポインタ同士の減算は,同じ配列の要素を指すポインタだけに使用する。[採用指針:基本] [規
約化: ]
適合例
不適合例
ptrdiff̲t off;
/* ptrdiff̲tはstddef.hにて定義さ
れているポインタ減算結果の型 */
int var1[10];
ptrdiff̲t off;
/* ptrdiff̲tはstddef.hにて定義さ
れているポインタ減算結果の型 */
int var1[10], var2[10];
18
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
int *p1, *p2;
p1 = &var1[5];
p2 = &var1[2];
off = p1−p2; /* 適切 */
int *p1, *p2;
p1 = &var1[5];
p2 = &var2[2];
off = p1−p2; /* 不適切 */
注記 C言語では,ポインタ同士の減算を行った場合,各ポインタが指している要素の間に幾つ要
素があるかが求められる。このとき,各ポインタが別の配列を指していると,その間にどの
ような変数が配置されるかは,コンパイラ依存であり,実行結果は保証されない。このよう
にポインタ同士の減算は,同じ配列内の要素を指している場合にだけ意味がある。したがっ
て,ポインタ減算を行う場合には,同じ配列を指しているポインタ同士であることをプログ
ラマが確認して行う。
c) (R1.3.3) ポインタ同士の比較は,同じ配列の要素,又は同じ構造体のメンバを指すポインタだけに使
用する。[採用指針: ] [規約化: ]
適合例
不適合例
#define N 10
char var1[N];
void func(int i, int j) {
if (&var1[i] < &var1[j]) {
…
}
}
#define N 10
char var1[N];
char var2[N];
void func(int i, int j) {
if (&var1[i] < &var2[j]) {
…
}
}
注記 異なる変数のアドレスを比較してもコンパイルエラーにならないが,変数の配置はコンパイ
ラ依存なので意味のない比較となる。また,このような比較の動作は,定義されていない(未
定義の動作である。)。
A.2.3 データの安全性
A.2.3.1
(R2) データは範囲,大きさ,内部表現などに気を付けて使用する。
プログラム内で扱う様々なデータは,その種類によって内部的な表現が異なり,扱えるデータの範囲も
異なる。こうした様々なデータを利用して演算などの処理を行った場合,データを記述するときに,例え
ば,データの精度,データの大きさなどに注意をしないと,思わぬ誤動作の元になりかねない。このよう
にデータを扱う場合には,その範囲,大きさ,内部表現などを意識する。
・ (R2.1) 内部表現に依存しない比較を行う。
・ (R2.2) 論理値などが区間として定義されている場合,その中の一点(代表的な実装値)と等しいか
どうかで判定を行ってはならない。
・ (R2.3) データ型をそろえた演算・比較を行う。
・ (R2.4) 演算精度を考慮して記述する。
・ (R2.5) 情報損失の危険のある演算は使用しない。
・ (R2.6) 対象データが表現可能な型を使用する。
・ (R2.7) ポインタの型に気を付ける。
・ (R2.8) 宣言,使用及び定義に矛盾がないことをコンパイラが検査できる書き方にする。

19
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
A.2.3.2
(R2.1) 内部表現に依存しない比較を行う。
ルールは,次による。
a) (R2.1.1) 浮動小数点式は,等価又は非等価の比較をしない。[採用指針:基本] [規約化: ]
適合例
不適合例
#define LIMIT 1.0e-4
void func(double d1, double d2) {
double diff = d1−d2;
if (-LIMIT <= diff &&
diff <= LIMIT) {
…
}
}
void func(double d1, double d2) {
if (d1 == d2) {
…
}
}
注記 浮動小数点型は,ソースコード上に書かれた値と実装された値とは完全に一致していないの
で,比較は許容誤差を考慮して判定する。
b) (R2.1.2) 浮動小数点型変数は繰返しカウンタとして使用しない。[採用指針:基本] [規約化: ]
適合例
不適合例
void func() {
int i;
for (i = 0; i < 10; i++) {
…
}
}
void func() {
double d;
for (d = 0.0; d < 1.0; d += 0.1) {
…
}
}
注記 浮動小数点型は,繰返しカウンタとして演算が繰り返されると,誤差が累積し,意図した結
果が得られないことがある。このため,繰返しカウンタには整数型(int型)を使用する。
c) (R2.1.3) 構造体又は共用体の比較にmemcmpを使用しない。[採用指針:基本] [規約化: ]
適合例
不適合例
struct TAG {
char c;
long ln;
};
TAG var1, var2;
void func() {
if (var1.c == var2.c &&
var1.ln == var2.ln) {
…
}
}
struct TAG {
char c;
long ln;
};
TAG var1, var2;
void func() {
if (memcmp(&var1, &var2,
sizeof(var1)) == 0) { …
}
}
注記 構造体又は共用体のメモリには,未使用の領域が含まれる可能性がある。その領域には何が
入っているか分からないので,memcmpは使用しない。比較する場合は,メンバ同士で比較

20
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
する。
A.2.3.3
(R2.2) 論理値などが区間として定義されている場合,その中の一点(代表的な実装値)と等しいかどう
かで判定を行ってはならない。
ルールは,次による。
a) (R2.2.1) 真偽を求める式の中で,真として定義した値と比較しない。[採用指針: ] [規約化: ]
適合例
不適合例
#define FALSE 0
/* func1は0又は1以外を返す可能性がある */
void func2() {
if (func1() != FALSE) {
又は
if (func1()) {
}
}
#define TRUE 1
/* func1は0又は1以外を返す可能性がある */
void func2() {
if (func1() == TRUE) {
}
}
注記 C言語では,真は0ではない値で示され,1とは限らない。
A.2.3.4
(R2.3) データ型をそろえた演算・比較を行う。
ルールは,次による。
a) (R2.3.1) 符号なし整数定数式は,結果の型で表現できる範囲内で記述する。[採用指針: ] [規約化: ]
適合例
不適合例
#define MAX 0xffffUL
/* long型を指定する */
unsigned int i = MAX;
if (i < MAX + 1) {
/* long が 32bitの場合,
intの bit 数が違っても問題ない */
}
#define MAX 0xffffU
unsigned int i = MAX;
if (i < MAX + 1) {
/* int が 16bit か 32bit かで
結果が異なる。intが16bitの場合,
演算結果はラップアラウンドして比較
結果は偽になる。int が32 bitの場合,
演算結果はintの範囲内に収まり,比較
結果は真になる */
}
注記 C言語の符号なし整数演算は,オーバフローせずにラップアラウンドする(表現可能な最大
数の剰余となる。)。このため,演算結果が意図と異なっていることに気が付かない場合があ
る。例えば,同じ定数式でも,intのビット数が異なる環境では,演算結果がその型で表現で
きる範囲を超えた場合と超えない場合とで結果が異なる。
b) (R2.3.2) 条件演算子(?: 演算子)では,論理式は括弧で囲み,戻り値は二つとも同じ型にする。[採用
指針: ] [規約化: ]
適合例
不適合例
void func(int i1, int i2, long l1) {
i1 = (i1 > 10) ? i2 : (int)l1;
void func(int i1, int i2, long l1) {
i1 = (i1 > 10) ? i2 : l1;
21
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
}
}
注記 型が異なる記述を行った場合は,結果はいずれの型を期待しているかを明示するためにキャ
ストする。
c) (R2.3.3) 繰返しカウンタとループ継続条件との比較に使用する変数は,同じ型にする。[採用指針:基
本] [規約化: ]
適合例
不適合例
void func(int arg) {
int i;
for (i = 0; i < arg; i++) {
}
}
void func(int arg) {
unsigned char i;
for (i = 0; i < arg; i++) {
}
}
注記 ループの継続条件に,表現できる値の範囲が違う変数の比較を使用すると,意図した結果に
ならず,無限ループになる場合がある。
A.2.3.5
(R2.4) 演算精度を考慮して記述する。
ルールは,次による。
a) (R2.4.1) 演算の型と演算結果の代入先の型とが異なる場合は,期待する演算精度の型へキャストして
から演算する。[採用指針:基本] [規約化: ]
適合例
不適合例
int i1, i2;
long l;
double d;
void func() {
d = (double)i1 / (double)i2;
/* 浮動小数点型での除算 */
l = ((long)i1) << i2;
/* longでのシフト */
}
int i1, i2;
long l;
double d;
void func() {
d = i1 / i2;
/* 整数型での除算 */
l = i1 << i2;
/* intでのシフト */
}
注記 演算の型は演算に使用する式(オペランド)の型によって決まり,代入先の型は考慮されな
い。演算の型と代入先の型とが異なる場合,誤って代入先の型での演算を期待していること
がある。オペランドの型とは異なる型の演算を行いたい場合は,期待する型にキャストして
から演算する。
b) (R2.4.2) 符号付きの式と符号なしの式との混在した算術演算又は比較を行う場合は,期待する型に明
示的にキャストする。[採用指針: ] [規約化: ]
適合例
不適合例
long l;
unsigned int ui;
void func() {
l = l / (long)ui;
又は
long l;
unsigned int ui;
void func() {
l = l / ui;
if (l < ui) {

22
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
l = (unsigned int)l / ui;
if (l < (long)ui) {
又は
if ((unsigned int)l < ui) {
}
}
…
}
}
注記 大小比較,乗除算など,演算を符号付きで行うか,符号なしで行うかによって結果が異なる
演算もある。符号付き,符号なしを混在して記述した場合,どちらで行われるかは,それぞ
れのデータのサイズも考慮して決定されるため,常に符号なしで行われるとは限らない。こ
のため,混在した算術演算を行う場合は,期待する演算が符号付きか符号なしかを確認し,
期待した演算になるように,明示的にキャストする。機械的にキャストするのでなく,使用
するデータ型を変更した方がよい場合が多いので,まずデータ型の変更を検討する。
A.2.3.6
(R2.5) 情報損失の危険のある演算は使用しない。
ルールは,次による。
a) (R2.5.1) 情報損失を起こす可能性のあるデータ型への代入(=演算,関数呼出しの実引数渡し,又は
関数復帰)又は演算を行う場合は,問題がないことを確認し,問題がないことを明示するためにキャ
ストを行う。[採用指針:必要] [規約化: ]
適合例
不適合例
/* 代入の例 */
short s; /* 16ビット */
long l; /* 32ビット */
void func() {
s = (short)l;
s = (short)(s + 1);
}
/* 演算の例 */
unsigned int var1, var2;
/* intサイズが16ビット */
var1 = 0x8000;
var2 = 0x8000;
if ((long)var1 + var2 > 0xffff) {
/* 判定結果は真 */
}
/* 代入の例 */
short s; /* 16ビット */
long l; /* 32ビット */
void func() {
s = l;
s = s + 1;
}
/* 演算の例 */
unsigned int var1, var2;
/* intサイズが16ビット */
var1 = 0x8000;
var2 = 0x8000;
if (var1 + var2 > 0xffff) {
/* 判定結果は偽 */
}
注記 値をその型と異なる型の変数に代入すると,値が変わる(情報損失する)可能性がある。も
し可能であれば,代入先は同じ型とする。情報損失のおそれはない,損失してもよいなど,
意図的に異なる型へ代入する場合は,その意図を明示するためにキャストを行う。
演算では,演算結果が,その型で表現できる値の範囲を超えた場合,意図しない値になる
可能性がある。安全のためには,演算結果がその型で表現できる値の範囲にあることを確認
23
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
してから,演算する。又は,より大きな値を扱える型に変換してから演算する。
機械的にキャストするのでなく,使用するデータ型を変更した方がよい場合が多いので,
まずデータ型の変更を検討する。
b) (R2.5.2) 単項演算子“-”は符号なしの式に使用しない。[採用指針:基本] [規約化: ]
適合例
不適合例
int i;
void func() {
i = -i;
}
unsigned int ui;
void func() {
ui = -ui;
}
注記 符号なしの式に単項“-”を使用することで,演算結果が元の符号なしの型で表現できる範囲
外になった場合,予期しない動作となる可能性がある。
例えば,上記例でif (-ui < 0) と記述した場合,このifは真にはならない。
c) (R2.5.3) unsigned char型,又はunsigned short型のデータをビット反転(~),又は左シフト(<<)する
場合,結果の型に明示的にキャストする。[採用指針:必要] [規約化: ]
適合例
不適合例
uc = 0x0f;
if ((unsigned char)(~uc) >= 0x0f)
uc = 0x0f;
if ((~uc) >= 0x0f) /* 真にならない */
注記 unsigned char又はunsigned shortの演算結果はsigned intとなる。演算によって,符号ビット
がオンになると,期待した演算結果にならない場合がある。このため,期待する演算の型へ
のキャストを明示する。不適合例では,〜ucは負の値となるので,必ず偽となる。
d) (R2.5.4) シフト演算子の右辺(右オペランド)の項はゼロ以上,左辺(左オペランド)の項のビット
幅未満にする。[採用指針:基本] [規約化: ]
適合例
不適合例
unsigned char a;
/* 8ビット */
unsigned short b;
/* 16ビット */
b = (unsigned short)a << 12;
/* 16ビットとして処理していることが明示的 */
unsigned char a;
/* 8ビット */
unsigned short b;
/* 16ビット */
b = a << 12;
/* シフト数に誤りの可能性あり */
注記 シフト演算子の右辺[右オペランド(シフト数)]の指定が,負の値の場合及び左辺[左オペ
ランド(シフトされる値)]のビット幅(intよりサイズが小さい場合はintのビット幅)以上
の場合の動作は,C言語規格で定義されておらず,コンパイラによって異なる。
左辺[左オペランド(シフトされる値)]がintより小さいサイズの型の場合に,シフト数
としてintのビット幅までの値を指定することは,言語規格で動作が定義されているが,意
図が分かりにくい。
A.2.3.7
(R2.6) 対象データが表現可能な型を使用する。
ルールは,次による。
a) (R2.6.1) ビットフィールドに使用する型はsigned int又はunsigned intだけとし,1ビット幅のビットフ
ィールドが必要な場合はsigned int型でなく,unsigned int型を使用する。[採用指針:必要] [規約化: ]

24
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
struct S {
signed int m1:2;
unsigned int m2:1;
unsigned int m3:4;
};
struct S {
int m1:2;
/* 符号指定がない */
signed int m2:1;
/* signedで1bit */
char m3:4;
/* int以外の型 */
};
注記 符号指定のないintをビットフィールドに使用した場合,符号付き,符号なしのいずれで使用
されるかはコンパイラによって異なる。そのため,符号指定のないint型はビットフィールド
には使用しない。また,コンパイラが機能をもっていても,char,short,longの型をビット
フィールドに使用することはC言語規格外であるので,移植性を考慮する場合は使用しない。
また,1ビットのsigned intのビットフィールドが表現できる値は-1及び0だけとなるので,
1ビットのビットフィールドにはunsigned intを使用する。
b) (R2.6.2) ビット列として使用するデータは,符号付き型ではなく,符号なし型で定義する。[採用指
針: ] [規約化: ]
適合例
不適合例
unsigned int flags;
void set̲x̲on() {
flags |= 0x01;
}
signed int flags;
void set̲x̲on() {
flags |= 0x01;
}
注記 符号付き型に対するビット単位の演算(~,<<,>>,&,^,| )の結果は,コンパイラによ
って異なる可能性がある。
A.2.3.8
(R2.7) ポインタの型に気を付ける。
ルールは,次による。
a) (R2.7.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) ポインタ型は,他のポインタ型,及び整数型に変換しない。また,逆もしない。ただし,データへ
のポインタ型におけるvoid*型との変換は除く。
2) ポインタ型は,他のポインタ型,及びポインタ型のデータ幅未満の整数型に変換しない。ただし,
データへのポインタ型におけるvoid*型との変換は除く。
3) データへのポインタ型は,他のデータ型へのポインタ型に変換してよいが,関数型へのポインタは,
他の関数型及びデータ型へのポインタ型に変換しない。ポインタ型を整数型に変換する場合,ポイ
ンタ型のデータ幅未満の整数型への変換はしない。
適合例
不適合例
int *ip;
int (*fp)(void);
char *cp;
int i;
int *ip;
int (*fp)(void);
char c;
char *cp;
25
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
void *vp;
1) の例
ip = (int*)vp;
2) の例
i = (int)ip;
1) の例
i = (int)fp;
cp = (char*)ip;
1) の例
ip = (int*)cp;
2) の例
c = (char)ip;
3) の例
ip = (int*)fp;
注記 ポインタ型の変数を他のポインタ型にキャスト又は代入をすると,ポインタの指す先の領域
がどのようなデータなのかが分かりにくくなる。CPUによっては,ワード境界を指さないポ
インタを使ってポインタの指す先をint型でアクセスすると,実行時エラーが発生するものも
あり,ポインタの型を変更すると,思わぬバグになる危険がある。ポインタ型の変数は,他
のポインタ型にキャスト又は代入をしない方が安全である。ポインタ型を整数型に変換する
ことも,前述の問題と同じ危険性があり,必要な場合は,経験者を交えたレビューを行う。
さらに,int型の扱う値の範囲とポインタ型の扱う値の範囲とに対する注意も必要である。int
型サイズが32ビットにもかかわらず,ポインタ型サイズが64ビットということもあるので,
事前に,コンパイラの仕様を確認しておく。
b) (R2.7.2) ポインタで指し示された型からconst修飾又はvolatile修飾を取り除くキャストをしない
(MISRA 11.5)。[採用指針:必要] [規約化: ]
適合例
不適合例
void func(const char *);
const char *str;
void x() {
func(str);
…
}
void func(char *);
const char *str;
void x() {
func((char*)str);
…
}
注記 const修飾又はvolatile修飾された領域は,参照だけしかされない領域であったり,最適化を
してはならない領域なので,その領域に対するアクセスに注意しなければならない。これら
の領域を指すポインタに対し,const修飾又はvolatile修飾を取り除くキャストを行ってしま
うと,前述の注意項目が見えなくなり,コンパイラは,プログラムの誤った記述に対し,何
も検査できなくなる。
c) (R2.7.3) ポインタが負かどうかの比較をしない。[採用指針:基本] [規約化: ]
適合例
不適合例
̲
int * func1() {
…
return -1;
}
26
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
int func2() {
…
if (func1() < 0) {
/* 負かどうかの比較のつもり */
…
}
return 0;
}
注記 ポインタと0との大小比較は意味がないので注意が必要である。
0は,比較の対象がポインタの場合,コンパイラによって空ポインタに変換される。した
がって,それはポインタ同士の比較であり,期待する動作にならない可能性がある。
A.2.3.9
(R2.8) 宣言,使用及び定義に矛盾がないことをコンパイラが検査できる書き方にする。
ルールは,次による。
a) (R2.8.1) 引数をもたない関数は,引数の型をvoidとして宣言する。[採用指針:必要] [規約化: ]
適合例
不適合例
int func(void);
int func();
注記 int func(); は,引数がない関数の宣言ではなく,旧式[K&R C形式。参考文献(11)で規定され
ている。]の宣言で引数の数と型とが不明という意味である。引数がない関数を宣言する場合
はvoidを明記する。
b) (R2.8.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択,文書]
1) 可変個引数をもつ関数を定義しない(MISRA 16.1)。
2) 可変個引数をもつ関数を使用する場合は,《処理系での動作を文書化し,使用する》。
適合例
不適合例
1)の例
int func(int a, char b);
1)の例
int func(int a, char b, ... );
注記 可変個引数関数が,使用する処理系でどのような動作をするかを理解した上で使用しないと
期待する動作をしない可能性がある。また,引数を可変とした場合,引数の個数及び型が明
確に定義されないので,可読性が低下する。
c) (R2.8.3) 関数呼出し及び関数定義の前に関数原型宣言を行い,さらに,同じ宣言が関数呼出しと定義
とで参照されるようにする。[採用指針:必要 ] [規約化: ]
適合例
不適合例
-- file1.h --
void f(int i);
-- file1.c --
#include "file1.h"
void f(int i) {
…
}
-- file1.c --
void f(int i);/* それぞれのファイルで宣言 */
void f(int i) {
…
}
27
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
-- file2.c --
#include "file1.h"
void g(void) {
f(10);
}
-- file2.c --
void f(int i);/* それぞれのファイルで宣言 */
void g(void) {
f(10);
}
注記 関数宣言には,K&R C形式と関数原型形式とがある。K&R C形式“参考文献(11)で規定され
ている。”は,関数の引数の型検査をコンパイラが行えないため,プログラマのミスが見つか
りにくくなる。よって,関数原型宣言を使用する。また,一つの関数の定義と宣言とに関数
原型形式とK&R C形式とを混在させると思わぬ問題が発生するため,混在は避ける。
A.2.4 障害許容性
A.2.4.1
(R3) 動作が保証された書き方にする。
プログラムの仕様上,あり得ないケースについても,想定外の事象が起こることを考慮し,エラー処理
を漏れなく記述することも必要となる。また,演算子の優先順位付けなど,言語仕様に頼らない書き方も
安全性を高める。高い信頼性を実現させるためには,誤動作につながる記述を極力避け,できるだけ動作
が保証された安全な書き方をすることが望まれる。
・ (R3.1) 領域の大きさを意識した書き方にする。
・ (R3.2) 実行時にエラーになる可能性のある演算に対しては,エラーケースをう(迂)回させる。
・ (R3.3) 関数呼出しではインタフェースの制約を検査する。
・ (R3.4) 再帰呼出しは行わない。
・ (R3.5) 分岐の条件に気を付け,所定の条件以外が発生した場合の処理を記述する。
・ (R3.6) 評価順序に気を付ける。
A.2.4.2
(R3.1) 領域の大きさを意識した書き方にする。
ルールは,次による。
a) (R3.1.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) 配列のextern宣言の要素数は必ず指定する。
2) 要素数が省略された初期化付き配列定義に対応した配列のextern宣言を除き,配列のextern宣言の
要素数は必ず指定する。
適合例
不適合例
1)の例
extern char *mes[3];
…
char *mes[] = {"abc", "def", NULL};
2)の例
extern char *mes[];
…
char *mes[] = {"abc", "def", NULL};
1)の例
extern char *mes[];
…
char *mes[] = {"abc", "def", NULL};
1),2)の例
extern int var1[];
int var1[MAX];
28
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1),2)の例
extern int var1[MAX];
…
int var1[MAX];
注記 配列の大きさを省略してextern宣言しても,エラーにはならない。しかし,大きさが省略さ
れていると,配列の範囲外の検査に支障が生じる場合がある。このため,配列の大きさは明
示して宣言した方がよい。ただし,初期値の個数で配列の大きさを決定し,宣言時に大きさ
が決まらない場合などは,宣言時の配列の大きさを省略した方がよい場合もある。
b) (R3.1.2) 配列を順次にアクセスするループの継続条件には,配列の範囲内であるかの判定を入れる。
[採用指針: ] [規約化: ]
適合例
不適合例
char var1[MAX];
for (i = 0; i < MAX && var1[i] != 0;
i++) {
/* var1配列に0が未設定の場合でも,
配列の範囲外へのアクセスの危険なし */
…
}
char var1[MAX];
for (i = 0; var1[i] != 0;
i++) {
/* var1配列に0が未設定の場合,
配列の範囲外へのアクセスの危険あり */
…
}
注記 領域外へのアクセスを防ぐためのルールである。
A.2.4.3
(R3.2) 実行時にエラーになる可能性のある演算に対しては,エラーケースをう(迂)回させる。
ルールは,次による。
a) (R3.2.1) 除算及び剰余算の右辺式は,0でないことを確認してから演算をする。[採用指針: ] [規約
化: ]
適合例
不適合例
if (y != 0) {
ans = x/y;
}
ans = x/y;
注記 明らかに0でない場合を除き,除算及び剰余算の右辺(右オペランド)が0でないことを確
認してから演算する。そうしない場合,実行時に0除算のエラーが発生する可能性がある。
b) (R3.2.2) ポインタは,空ポインタでないことを確認してからポインタの指す先を参照する。[採用指
針: ] [規約化: ]
適合例
不適合例
if (p != NULL) {
*p = 1;
}
*p = 1;
A.2.4.4
(R3.3) 関数呼出しではインタフェースの制約を検査する。
ルールは,次による。
29
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
a) (R3.3.1) 関数がエラー情報を戻す場合,エラー情報をテストする(MISRA 16.10)。[採用指針: ] [規
約化: ]
適合例
不適合例
p = malloc(BUFFERSIZE);
if (p == NULL) {
/* 異常処理 */
} else {
*p = '\0';
}
p = malloc(BUFFERSIZE);
*p = '\0';
b) (R3.3.2) 関数に渡す引数に制限がある場合,関数呼出しの前に,制限値でないことを確認してから関
数を呼び出す。[採用指針: ] [規約化: ]
適合例
不適合例
if ((MIN <= para) && (para <= MAX)) {
ret = func(para);
}
ret = func(para);
A.2.4.5
(R3.4) 再帰呼出しは行わない。
ルールは,次による。
a) (R3.4.1) 関数は,直接的か間接的かにかかわらず,その関数自体を呼び出さないほうがよい(MISRA
16.2)。[採用指針: ] [規約化: ]
適合例
不適合例
̲
unsigned int calc(unsigned int n) {
if (n <= 1) {
return 1;
}
return n * calc(n-1);
}
注記 再帰呼出しは実行時の利用スタックサイズが予測できないため,スタックオーバフローの危
険がある。
A.2.4.6
(R3.5) 分岐の条件に気を付け,所定の条件以外が発生した場合の処理を記述する。
ルールは,次による。
a) (R3.5.1) if-else if文は,最後にelse節を置く。通常,else条件が発生しないことが分かっている場合は,
次のいずれかの記述とする。[採用指針:必要] [規約化:規約]
1) else節には,例外発生時の処理を記述する。
2) else節には,プロジェクトで規定した注釈を入れる。
適合例
不適合例
/* else条件が通常発生しない場合の
if-else if文のelse節 */
if (var1 == 0) {
/* else節のないif-else if文 */
if (var1 == 0) {
…
30
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…
} else if (0 < var1) {
…
} else {
/* 例外処理を記述する */
…
}
…
if (var1 == 0) {
…
} else if (0 < var1) {
…
} else {
/* NOT REACHED */
}
} else if (0 < var1) {
…
}
注記 else節がないと,else節を書き忘れているのか,else節が発生しないif-else if文なのかが分か
らなくなる。通常,else条件が発生しないことが分かっている場合でも次のようにelse節を
書くことによって想定外の条件が発生した場合のプログラムの動作を予測することができる。
・ else条件に想定外の条件に対する動作を記述する(万が一,else条件が発生した場合
のプログラムの動作を決めておく。)。また,else条件が発生しない注釈を記述するだ
けでも,プログラムが分かりやすくなる。
・ /* NOT REACHED */ のように,プロジェクトで規定したelse条件が発生しないこと
を明示する注釈を記述し,else節の書き漏れではないことを表現する。
b) (R3.5.2) switch文は,最後にdefault節を置く。通常,default条件が発生しないことが分かっている場
合は,次のいずれかの記述とする。[採用指針:必要] [規約化:規約]
1) default節には,例外発生時の処理を記述する。
2) default節には,プロジェクトで規定した注釈を入れる。
適合例
不適合例
/* default条件が通常発生しない
switch文のdefault節 */
switch(var1) {
case 0:
…
break;
case 1:
…
break;
default:
/* 例外処理を記述する */
…
/* default節のないswitch文 */
switch(var1) {
case 0:
…
break;
case 1:
…
break;
}
31
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
break;
}
…
switch(var1) {
case 0:
…
break;
case 1:
…
break;
default:
/* NOT REACHED */
break;
}
注記 default節がないと,default節を書き忘れているのか,default節が発生しないswitch文なのか
が分からなくなる。
通常,default条件が発生しないことが分かっている場合でも,次のようにdefault節を書く
ことによって想定外の条件が発生した場合のプログラムの動作を予測することができる。
・ default条件に想定外の条件に対する動作を記述する(万が一,default条件が発生した
場合のプログラムの動作を決めておく。)。また,default条件が発生しない注釈を記述
するだけでも,プログラムが分かりやすくなる。
・ /* NOT REACHED */ のように,プロジェクトで規定したdefault条件が発生しないこ
とを明示する注釈を記述し,default節の書き漏れではないことを表現する。
c) (R3.5.3) 繰返しカウンタの比較に等式及び不等式は使用しない(<=,>=,<,又は >を使用する。)。[採
用指針: ] [規約化: ]
適合例
不適合例
void func() {
int i;
for (i = 0; i < 9; i += 2) {
…
}
}
void func() {
int i;
for (i = 0; i != 9; i += 2) {
…
}
}
注記 繰返しカウンタの変化量が1 でない場合,無限ループになる可能性があるので,ループ回数
を判定する比較では,等式及び不等式は使用しない。
A.2.4.7
(R3.6) 評価順序に気を付ける。
ルールは,次による。
a) (R3.6.1) 変数の値を変更する記述をした同じ式内で,その変数を参照,変更しない。[採用指針:基本]
[規約化: ]
32
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
f(x, x);
x++;
又は
f(x + 1, x);
x++;
f(x, x++);
注記 複数の引数をもつ関数の各実引数の実行(評価)順序は,コンパイラは保証していない。引
数は右から実行されたり,左から実行されたりする。また,+演算のような2項演算の左式
と右式との実行の順序も,コンパイラは保証していない。このため,引数並び又は2項演算
式内で,一つのオブジェクトの更新又は参照を行うと,その実行結果が保証されない。実行
結果が保証されないこのような問題を副作用問題と呼んでいる。副作用問題が発生する記述
はしない。
このルールでは副作用問題の発生しない次のような記述については,禁止していない。
x = x + 1;
x = f(x);
b) (R3.6.2) 実引数並び,又は2項演算式に,副作用をもつ関数呼出し又はvolatile 変数を,複数記述し
ない。[採用指針:必要] [規約化: ]
適合例
不適合例
例1
extern int G̲a;
x = func1();
x += func2();
…
int func1(void) {
G̲a += 10;
…
}
int func2(void) {
G̲a -= 10;
…
}
例2
volatile int v;
y = v;
f(y, v);
例1
extern int G̲a;
x = func1() + func2(); /* 副作用問題あり */
…
int func1(void) {
G̲a += 10;
…
}
int func2(void) {
G̲a -= 10;
…
}
例2
volatile int v;
f(v, v);
注記 複数の引数をもつ関数の各実引数の実行(評価)の順序は,コンパイラは保証していない。
引数は右から実行されたり,左から実行されたりする。また,+演算のような2項演算の左
式と右式との実行の順序も,コンパイラは保証していない。このため,引数並び又は2項演
33
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
算式内で,副作用をもつ関数呼出し又はvolatile 変数を複数記述すると,その実行結果が保
証されない場合がある。このような危険な記述は避ける。
A.3 (M) 保守性
A.3.1 概要
多くの組込みソフトウェア開発では,ひとたび作成したソフトウェアに手を加えるといった保守作業も
必要になる。組込みソフトウェアのソースコードの保守性を維持,向上させるためには,次のような作法
に留意する。
・ (M1) 他人が読むことを意識する。
・ (M2) 修正誤りのないような書き方にする。
・ (M3) プログラムはシンプルに書く。
・ (M4) 統一した書き方にする。
・ (M5) 試験しやすい書き方にする。
A.3.2 解析性
A.3.2.1
(M1) 他人が読むことを意識する。
ソースコードは,実際に作成した技術者以外の技術者が再利用したり,保守したりといった場合も十分
に考えられる。このため,ソースコードは,将来,第三者が読むことを考慮して,分かりやすく表現する。
・ (M1.1) 使用しない記述を残さない。
・ (M1.2) 紛らわしい書き方をしない。
・ (M1.3) 特殊な書き方はしない。
・ (M1.4) 演算の実行順序が分かりやすいように記述する。
・ (M1.5) 誤解を招きやすいある種の演算については,言語仕様で省略可能になっている場合でも,省
略せずに明示的に記述する。
・ (M1.6) 領域は一つの利用目的に使用する。
・ (M1.7) 名前を再使用しない。
・ (M1.8) 勘違いしやすい言語仕様を使用しない。
・ (M1.9) 特殊な書き方は意図を明示する。
・ (M1.10) マジックナンバーを埋め込まない。
・ (M1.11) 領域の属性は明示する。
・ (M1.12) コンパイルされない文でも正しい記述を行う。
A.3.2.2
(M1.1) 使用しない記述を残さない。
ルールは,次による。
a) (M1.1.1) 使用しない関数,変数,引数,ラベルなどは宣言(定義)しない。[採用指針:必要] [規約化: ]
適合例
不適合例
void func(void) {
…
}
void func(int arg) {
/* arg未使用 */
…
}
34
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
注記 使用しない関数,変数,引数,ラベルなどの宣言(定義)は,削除し忘れたのか,記述を誤
っているかの判断が難しいため,保守性を損なう。
b) (M1.1.2) コードの一部を“コメントアウト”しない(MISRA 2.4)。[採用指針:必要] [規約化: ]
適合例
不適合例
…
#if 0 /* 〜のため,無効化 */
a++;
#endif
…
…
/* a++; */
…
注記 無効としたコード部を残すことは,コードを読みにくくするため,本来避けることが望まし
い。
ただし,コード部の無効化が必要な場合は,コメントアウトせず,#if 0で囲むなど,無効
化したコード部を明示するルールを決めておく。
A.3.2.3
(M1.2) 紛らわしい書き方をしない。
ルールは,次による。
a) (M1.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 一つの宣言文で宣言する変数は,一つとする(複数宣言しない。)。
2) 同じような目的で使用する同じ型の自動変数は,一つの宣言文で複数宣言してもよいが,初期化す
る変数と初期化しない変数とを混在させない。
適合例
不適合例
1)の例
int i;
int j;
2)の例
int i, j;
int k = 0;
int *p;
int i;
1)の例
int i, j;
2)の例
int i, j, k = 0;
/* 初期化のあるものないものが混在(不適切)*/
int *p, i;
/* 型の異なる変数が混在(不適切)*/
注記 int *p; と宣言した場合,pの型はint * であるが,int *p, q; と宣言した場合,qの型はint * で
はなく,int となる。
b) (M1.2.2) 適切な型を示す接尾語が使用できる定数記述には,接尾語を付けて記述する。long型整数定
数を示す接尾語は大文字の“L”だけを使用する。[採用指針: ] [規約化: ]
適合例
不適合例
void func(long int);
…
float f;
long int l;
void func(long int);
…
float f;
long int l;

35
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
unsigned int ui;
f = f + 1.0F;
/* floatの演算であることを明示する*/
func(1L); /* Lは大文字で記述する */
if (ui < 0x8000U) {
/* unsignedの比較であることを明示する */
…
}
unsigned int ui;
f = f + 1.0;
func(1l); /* 1lは11と紛らわしい */
if (ui < 0x8000) {
…
}
注記 基本的に接尾語がない場合は,整数定数はint型,浮動小数点定数はdouble型となる。ただ
し,整数定数でint型で表現できない値を記述した場合はその値を表現できる型になる。この
ため,0x8000はint が16bitの場合はunsigned intであるが,intが32bitの場合はsigned intと
なる。unsignedとして使用したい場合は,接尾語として“U”を明記する必要がある。また,
浮動小数点数のfloat型とdouble型との演算速度が異なるターゲットシステムの場合,float
型の変数と浮動小数点定数との演算を行う場合に,浮動小数点定数に接尾語“F”がないと,
その演算はdouble型の演算になるので注意が必要である。
浮動小数点定数は,小数点の左右に少なくとも一つの数字を記述するなど,浮動小数点定
数であることを見分けやすくする工夫が必要である。
c) (M1.2.3) 長い文字列リテラルを表現する場合には,文字列リテラル内で改行を使用せず,連続した文
字列リテラルの連結を使用する。[採用指針: ] [規約化: ]
適合例
不適合例
char abc[] = "aaaaaaaa\n"
"bbbbbbbb\n"
"ccccccc\n";
char abc[] = "aaaaaaaa\n\
bbbbbbbb\n\
ccccccc\n";
注記 複数行にわたる長い文字列を表現したい場合,複数の文字列リテラルを連結した書き方の方
が見やすい。
A.3.2.4
(M1.3) 特殊な書き方はしない。
ルールは,次による。
a) (M1.3.1) switch(式)の式には,真偽結果を求める式を記述しない。[採用指針:基本] [規約化: ]
適合例
不適合例
if (i̲var1 == 0) {
i̲var2 = 0;
} else {
i̲var2 = 1;
}
switch (i̲var1 == 0) {
case 0:
i̲var2 = 1;
break;
default:
i̲var2 = 0;
break;
}
注記1 真偽結果を求める式をswitch文に使用すると,分岐数は二つになり,多分岐命令である
36
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
switch文を使用する必要性は低くなる。switch文は,default節の誤記又はbreak文の記述漏
れなど,if文と比較して間違いが発生する可能性が高いので,3 分岐以上にならない場合
は,if文を使用することを推奨する。
注記2 関連ルール (E1.1.4) 参照。
b) (M1.3.2) switch文のcase ラベル及びdefault ラベルは,switch文本体の複合文(その中に入れ子にな
った複合文は除く。)だけに記述する。[採用指針: ] [規約化: ]
適合例
不適合例
switch (x) {
case 1:
{
…
}
…
break;
case 2:
…
break;
default:
…
break;
}
switch (x) { /* switch文本体の複合文 */
case 1:
{ /* 入れ子になった複合文 */
case 2:
/* 入れ子になった複合文にcaseラベルを
記述しない */
…
}
…
break;
default:
…
break;
}
c) (M1.3.3) 関数,変数の定義及び宣言では型を明示的に記述する。[採用指針:基本] [規約化: ]
適合例
不適合例
extern int global;
int func(void) {
…
}
extern global;
func(void) {
…
}
注記 関数,変数の定義及び宣言で,データ型を記述しない場合,int型と解釈されるが,明示的に
データ型を記述した方が見やすくなる。
A.3.2.5
(M1.4) 演算の実行順序が分かりやすいように記述する。
ルールは,次による。
a) (M1.4.1) &&演算及び || 演算の右式及び左式は単純な変数又は ( ) で囲まれた式を記述する。ただし,
&&演算が連続して結合している場合,及び|| 演算が連続して結合している場合は,&& 式又は || 式
を ( ) で囲まない。[採用指針: ] [規約化: ]
適合例
不適合例
if ((x > 0) && (x < 10))
if ((!x) || y)
if ((flag̲tb[i]) && status)
if ((x != 1) && (x != 4) && (x != 10))
if (x > 0 && x < 10)
if (! x || y)
if (flag̲tb[i] && status)
if (x != 1 && x != 4 && x != 10)
37
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
注記 変数,定数式,文字列リテラル,( ) で囲まれた式を一次式という。&&及び || の各項は,一
次式にするというのがこのルールである。演算子が含まれる式に対し( ) で囲むことによって,
&&及び || 演算の各項の演算を目立たせ,可読性を向上させることが目的である。
b) (M1.4.2) 《演算の実行順序を明示するための括弧の付け方を規定する。》[採用指針: ] [規約化:規
約]
適合例
不適合例
a = (b << 1) + c;
又は
a = b << (1 + c);
a = b << 1 + c;
/* 優先順位間違いしている可能性あり */
注記 C言語の演算子の優先順位は見間違いやすいため,例えば次のようなルールを決めるのがよ
い。式中に優先順位の異なる複数の2項演算子を含む場合には優先順位を明示するための括
弧を付ける。ただし,四則演算に関しては括弧を省略してもよい。
A.3.2.6
(M1.5) 誤解を招きやすいある種の演算については,言語仕様で省略可能になっている場合でも,省略せ
ずに明示的に記述する。
ルールは,次による。
a) (M1.5.1) 関数識別子(関数名)には,前に &を付けるか,括弧付きの仮引数並び(空でも可)を指定
して使用する(MISRA 16.9)。[採用指針: ] [規約化: ]
適合例
不適合例
void func(void);
void (*fp)(void) = &func;
if (func()) {
…
}
void func(void);
void (*fp)(void) = func; /* &がない */
if (func) {
/* 関数呼出しではなく,アドレスを取得して
いる。引数のない関数呼出しと勘違いして
記述されている場合がある */
}
注記 C言語では,関数名を単独で記述すると関数呼出しではなく,関数アドレス取得となる。す
なわち,関数アドレスの取得に&を付ける必要はない。しかしながら,&を付けない場合,関
数呼出しと勘違いすることがある(Adaなど,引数のないサブプログラム呼出しに名前だけ
を記述する言語を利用している場合など)。関数のアドレスを求める場合に&を付ける規則を
守ることで,&が付かず,()も続かない関数名の出現を検査でき,勘違い(ミス)を見付け
られる。
b) (M1.5.2) ゼロとの比較は明示的にする。[採用指針: ] [規約化: ]
適合例
不適合例
int x = 5;
if (x != 0) {
…
}
int x = 5;
if (x) {
…
}

38
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
注記 条件判定では,式の結果が0の場合は偽,0以外は真と判断される。このため,条件を判定
する式では != 0を省略可能である。ただし,プログラムを明示的にするためには,省略しな
い。
A.3.2.7
(M1.6) 領域は一つの利用目的に使用する。
ルールは,次による。
a) (M1.6.1) 目的ごとに変数を用意する。[採用指針: ] [規約化: ]
適合例
不適合例
/* カウンタ変数と入替え用作業変数とは
別変数 */
for (i = 0; i < MAX; i++) {
data[i] = i;
}
if (min > max) {
wk = max;
max = min;
min = wk;
}
/* カウンタ変数と入替え用作業変数とは
同じ変数 */
for (i = 0; i < MAX; i++) {
data[i] = i;
}
if (min > max) {
i = max;
max = min;
min = i;
}
注記 変数の再利用は可読性を損ない,修正時に正しく修正されない危険性が増すので行わない。
b) (M1.6.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 共用体は使用しない(MISRA 18.4)。
2) 共用体を使用する場合は,書き込んだメンバで参照する。
適合例
不適合例
2)の例
/* typeがINT→i̲var,
CHAR→c̲var[4] */
struct stag {
int type;
union utag {
char c̲var[4];
int i̲var;
} u̲var;
} s̲var;
…
int i;
…
if (s̲var.type == INT) {
s̲var.u̲var.i̲var = 1;
}
…
2)の例
/* typeがINT→i̲var,
CHAR→c̲var[4] */
struct stag {
int type;
union utag {
char c̲var[4];
int i̲var;
} u̲var;
} s̲var;
…
int i;
…
if (s̲var.type == INT) {
s̲var.u̲var.c̲var[0] = 0;
s̲var.u̲var.c̲var[1] = 0;
s̲var.u̲var.c̲var[2] = 0;
39
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
i = s̲var.u̲var.i̲var;
s̲var.u̲var.c̲var[3] = 1;
}
…
i = s̲var.u̲var.i̲var;
注記 共用体は,一つの領域を異なる大きさの領域で宣言できるが,メンバ間のビットの重なり方
が処理系に依存するため,期待する動作にならない可能性がある。使用する場合はルール2)
のような注意が必要である。
A.3.2.8
(M1.7) 名前を再使用しない。
ルールは,次による。
a) (M1.7.1) 名前の一意性は,次の規則に従う。[採用指針:必要] [規約化: ]
1) 外部有効範囲の識別子が隠蔽されることになるため,内部有効範囲の識別子には外部有効範囲の同
じ名前を使用しない(MISRA 5.2)。
2) typedef 名は固有の識別子とする(MISRA 5.3)。
3) タグ名は固有の識別子とする(MISRA 5.4)。
4) 静的記憶域期間をもつオブジェクト又は関数識別子は再使用しない(MISRA 5.5)。
5) 構造体及び共用体のメンバ名を除いて,ある名前空間の識別子を,他の名前空間の識別子と同じつ
づりにしない(MISRA 5.6)。
適合例
不適合例
int var1;
void func(int arg1) {
int var2;
var2 = arg1;
{
int var3;
var3 = var2;
…
}
}
int var1;
void func(int arg1) {
int var1;
/* 関数の外側の変数名と同じ名前を使用 */
var1 = arg1;
{
int var1;
/* 外側の有効範囲にある変数名と同じ名前
を使用 */
…
var1 = 0;
/* どのvar1に代入する意図か分からない */
…
}
}
注記 名前は,自動変数など有効範囲が限られている場合を除き,できる限りプログラムで一意と
することで,プログラムを読みやすくすることができる。
C言語では,名前はファイル,ブロックなどによる有効範囲のほかに,それが属するカテ
ゴリによって次の四つの名前空間をもっている。
1. ラベル 2. タグ 3. 構造体・共用体のメンバ 4. その他の識別子
マクロは,名前空間をもたない。

40
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
名前空間が異なれば,言語仕様的には同じ名前を付けてもよいが,このルールはそれを制
限することで読みやすいプログラムとすることを目的としている。
b) (M1.7.2) 標準ライブラリの関数名,変数名及びマクロ名は再定義・再利用しない。また,定義を解除
しない。[採用指針:必要] [規約化: ]
適合例
不適合例
#include <string.h>
void *my̲memcpy(void *arg1,
const void *arg2, size̲t size) {
…
}
#undef NULL
#define NULL ((void *)0)
#include <string.h>
void *memcpy(void *arg1,
const void *arg2, size̲t size) {
…
}
注記 標準ライブラリで定義されている関数名,変数名及びマクロ名を独自に定義すると,プログ
ラムの可読性を低下させる。
c) (M1.7.3) 下線で始まる名前(変数)は定義しない。[採用指針:必要] [規約化: ]
適合例
不適合例
̲
int ̲Max1; /* 予約されている */
int ̲̲max2; /* 予約されている */
int ̲max3; /* 予約されている */
struct S {
int ̲mem1;
/* 予約されていないが使用しない */
};
注記1 C言語規格では,次の名前を予約済みとしている。
1) 下線に続き英大文字1 字,又は下線に続きもう一つの下線で始まる名前。
この名前は,いかなる使用に対しても常に予約済みである。
例: ̲Abc, ̲̲abc
2) 一つの下線で始まる全ての名前。
この名前は,ファイル有効範囲をもつ変数,関数の名前及びタグ名に対して,予
約済みである。予約済みの名前を再定義した場合,コンパイラの動作が保証されて
いない。
注記2 一つの下線で始まり,小文字が続く名前は,ファイル有効範囲以外の部分では予約されて
いないが,覚えやすいルールとするため,下線で始まる名前全てを使用しないというルー
ルとしている。
A.3.2.9
(M1.8) 勘違いしやすい言語仕様を使用しない。
ルールは,次による。
a) (M1.8.1) 論理演算子 &&又は || の右側のオペランドには,副作用がないようにする(MISRA 12.4)。
[採用指針: ] [規約化: ]
41
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
a = *p;
p++;
/* pの指す内容に依存せずにpはカウント
アップ済み */
if ((MIN < a) && (a < MAX)) {
…
}
/* pの指す内容がMINより小さい場合とMIN
以上の場合とでpがカウントアップされている
か否か異なる(難解) */
if ((MIN < *p) && (*p++ < MAX)) {
…
}
注記 &&及び || 演算子の右式は,左式の条件結果によって,実行されない場合がある。増分など
の副作用のある式を右式に記述すると,左式の条件によって増分される場合とされない場合
が生じ,分かりにくくなるため,&&及び || 演算子の右式には副作用のある式を記述しない。
b) (M1.8.2) Cマクロは,波括弧で囲まれた初期化子,定数,括弧で囲まれた式,型修飾子,記憶域クラ
ス指定子,又はdo-while-zero構造だけに展開する(MISRA 19.4)。[採用指針: ] [規約化: ]
適合例
不適合例
#define START 0x0410
#define STOP 0x0401
#define BEGIN {
#define END }
#define LOOP̲STAT for(;;) {
#define LOOP̲END }
注記 マクロ定義を駆使することによって,C言語以外で書かれたコーディングのように見せかけ
たり,コーディング量を大幅に減らすことも可能である。しかしながら,このような用途の
ためにマクロを使用すると可読性が低下する。コーディングミス又は変更ミスを防止できる
箇所に絞って使用することが重要である。
do-while-zero については,MISRA-C:2004を参照。
c) (M1.8.3) #lineは,ツールによる自動生成以外では使用しない。[採用指針: ] [規約化: ]
注記 #lineは,コンパイラが出す警告,エラーメッセージのファイル名及び行番号を意図的に変更
するための機能である。ツールによるコード生成を想定して提供されており,プログラマが,
直接使うものではない。
d) (M1.8.4) ??で始まる3文字以上の文字の並びは使用しない。[採用指針: ] [規約化: ]
適合例
不適合例
s = "abc?(x)";
s = "abc??(x)";
/* 3文字表記が可能なコンパイラでは
"abc[x)"と解釈される */
注記 C言語規格は,コーディング時に必要な文字が,使用している開発環境で利用できない場合
を想定して,?? で始まる3文字表記を規定している。次の九つの3文字のパター
ン,??=,??(,??/,??),??',??<,??!,??>,??- は,対応する次の1文字,#,[,\,],^,{,
|,},~に置き換えられる。
ただし,利用頻度は低いため,コンパイラオプション指定で機能をもっているコンパイラ
も多い。
e) (M1.8.5) (0以外の)8進定数及び8進拡張表記は使用しない(MISRA 7.1)。[採用指針: ] [規約化: ]
42
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
a = 0;
b = 10;
c = 100;
a = 000;
b = 010; /* これは8進表記となり,10進の8と
なる。したがって,10進の10を意図する
ならばこれは誤り。また,8進を意図した
としても誤解を避けるため,このように書
かないのがよい。*/
c = 100;
注記 0で始まる定数は8進数として解釈される。10進数の見た目の桁をそろえるために,0を前
に付けることはできない。
A.3.2.10
(M1.9) 特殊な書き方は意図を明示する。
ルールは,次による。
a) (M1.9.1) 意図的に何もしない文を記述しなければならない場合は,注釈,空になるマクロなどを利用
し,目立たせる。[採用指針:必要] [規約化: ]
適合例
不適合例
for (;;) {
/* 割込み待ち */
}
#define NO̲STATEMENT
while ((--i) > 0) {
NO̲STATEMENT;
}
for (;;) {
}
while ((--i) > 0);
b) (M1.9.2) 《無限ループの書き方を規定する。》[採用指針:必要] [規約化:規約]
注記 無限ループの書き方は,例えば次のような書き方に統一する。
・ 無限ループは,for(;;) で統一する。
・ 無限ループは,while(1) で統一する。
・ マクロ化した無限ループを使用する。
A.3.2.11
(M1.10) マジックナンバーを埋め込まない。
ルールは,次による。
(M1.10.1) 意味のある定数はマクロとして定義して使用する。[採用指針:必要] [規約化: ]
適合例
不適合例
#define MAXCNT 8
if (cnt == MAXCNT) {
…
}
if (cnt == 8) {
…
}
43
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
注記 マクロ化することによって,定数の意味を明確に示すことができ,定数が複数箇所で使われて
いるプログラムの変更時も一つのマクロを変更すれば済み,変更ミスが防げる。
ただし,データの大きさは,マクロではなく,sizeofを使用する。
A.3.2.12
(M1.11) 領域の属性は明示する。
ルールは,次による。
a) (M1.11.1) 参照しかしない領域はconstであることを示す宣言をする。[採用指針:必要] [規約化: ]
適合例
不適合例
const volatile int read̲only̲mem;
/* 参照だけのメモリ */
const int constant̲data = 10;
/* メモリ割付け不要な参照だけのデータ */
/* argの指す内容を参照するだけ */
void func(const char *arg, int n) {
int i;
for (i = 0; i < n; i++) {
put(*arg++);
}
}
int read̲only̲mem;
/* 参照だけのメモリ */
int constant̲data = 10;
/* メモリ割付け不要な参照だけのデータ */
/* argの指す内容を参照するだけ */
void func(char *arg, int n) {
int i;
for (i = 0; i < n; i++) {
put(*arg++);
}
}
注記 参照するだけで変更しない変数は,const型で宣言することで,変更しないことが明確になる。
また,コンパイラの最適化処理でオブジェクトサイズが小さくなる可能性もある。このため,
参照しかしない変数はconst型にするのがよい。また,プログラムからは参照しかしないが,
他の実行単位からは変更されるメモリは,const volatile型で宣言することによって,プログ
ラムで誤って更新することをコンパイラが検査できる。このほか,関数処理内で,引数で示
される領域を参照しかしない場合にも,constを付けることで,関数インタフェースを明示す
ることができる。
b) (M1.11.2) 他の実行単位によって更新される可能性のある領域はvolatile であることを示す宣言をす
る。[採用指針:必要] [規約化: ]
適合例
不適合例
volatile int x = 1;
…
while (x == 1) {
/* xはループ内で変更されずに他の
実行単位から変更される */
}
int x = 1;
…
while (x == 1) {
/* xはループ内で変更されずに他の
実行単位から変更される */
}
注記 volatile修飾された領域は,コンパイラに対し,最適化を禁止する。最適化禁止とは,論理上
は無駄な処理とされる記述に対しても忠実に,実行オブジェクトを生成させるという意味で
ある。例えば,x; という記述があったとする。論理的には,変数xを参照するだけで意味の
ない文のため,volatile修飾されていなければ,通常,コンパイラはこのような記述は無視し,
44
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
実行オブジェクトは生成しない。
volatile修飾されていた場合は,変数xの参照(レジスタにロード)だけを行う。この記述
の意味するところとしては,メモリをリードするとリセットするようなインタフェースのIO
レジスタ(メモリにマッピング)が考えられる。組込みソフトウェアでは,ハードウェアを
制御するためのIOレジスタがあり,IOレジスタの特性に応じて,適宜volatile修飾するのが
よい。
c) (M1.11.3) 《ROM化するための変数宣言及び定義のルールを規定する。》[採用指針: ] [規約化:規
約]
適合例
不適合例
const int x = 100; /* ROMに配置 */
int x = 100;
注記 const修飾された変数はROM化の対象となる領域に配置することができる。ROM化を行う
プログラムを開発する場合には,例えば参照しかしない変数に対して,const修飾し,#pragma
などで配置するセクション名を指定する。
A.3.2.13
(M1.12) コンパイルされない文でも正しい記述を行う。
ルールは,次による。
(M1.12.1) 前処理系が削除する部分でも正しい記述をする。[採用指針: ] [規約化: ]
適合例
不適合例
#if 0
/* */
#endif
#if 0
…
#else
int var;
#endif
#if 0
/* I don't know */
#endif
#if 0
/*
#endif
#if 0
…
#else1
int var;
#endif
#if 0
I don't know
#endif
A.3.3 変更性
A.3.3.1
(M2) 修正誤りのないような書き方にする。
プログラムに不具合が入り込むパターンの一つとして,不具合を修正する場合に,別の不具合を埋め込
んでしまうことがある。特に,ソースコードを書いてから日時がたっていたり,別の技術者の書いたソー
スコードを修正する場合,思わぬ勘違いなどが発生することがある。
こうした修正ミスをできるだけ少なくするための作法を,次に示す。
・ (M2.1) 構造化されたデータ及びブロックは,まとまりを明確化する。
・ (M2.2) アクセス範囲及び関連するデータは局所化する。

45
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
A.3.3.2
(M2.1) 構造化されたデータ及びブロックは,まとまりを明確化する。
ルールは,次による。
a) (M2.1.1) 配列及び構造体を0 以外で初期化する場合は,構造を示し,それに合わせるために波括弧
“{ }”を使用する。また,全て0 以外の場合を除き,データは漏れなく記述する。[採用指針:必要]
[規約化: ]
適合例
不適合例
int arr1[2][3] = {{0, 1, 2}, {3, 4, 5}};
int arr2[3] = {1, 1, 0};
int arr1[2][3] = {0, 1, 2, 3, 4, 5};
int arr2[3] = {1, 1};
注記 配列及び構造体の初期化では,最低限,波括弧が一対もしあればよいが,どのように初期化
データが設定されるかが分かりにくくなる。構造に合わせてブロック化し,初期化データを
漏れなく記述した方が,安全である。
b) (M2.1.2) if,else if,else,while,do,for及びswitchの各文の本体はブロック化する。[採用指針: ] [規
約化: ]
適合例
不適合例
if (x == 1) {
func();
}
if (x == 1)
func();
注記 if文などで制御される文(本体)が複数の文である場合,ブロックで囲む必要がある。制御
される文が一つの場合は,ブロック化する必要はないが,プログラムの変更時に一つの文か
ら複数の文に変更したとき,ブロックで囲み忘れてしまうことがある。変更時のミスを未然
に防ぐためには,各制御文の本体をブロックで囲むようにする。
A.3.3.3
(M2.2) アクセス範囲及び関連するデータは局所化する。
ルールは,次による。
a) (M2.2.1) 一つの関数内でだけ使用する変数は関数内で変数宣言する。[採用指針:基本] [規約化: ]
適合例
不適合例
void func1(void) {
static int x = 0;
if (x != 0) {
/* 前回呼ばれたときの値を参照する */
x++;
}
…
}
void func2(void) {
int y = 0; /* 毎回初期設定する */
int x = 0;
/* xはfunc1からしかアクセスされない */
int y = 0;
/* yはfunc2からしかアクセスされない */
void func1(void) {
if ( x != 0 ) {
/* 前回呼ばれたときの値を参照する */
x++;
}
…
}
void func2(void) {
y = 0; /* 毎回初期設定する */
46
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…
}
…
}
注記 関数内で変数宣言する場合,static記憶クラス指定子を付けると有効な場合もある。staticを
付けた場合,次の特徴がある。
・ 静的領域が確保され,領域はプログラム終了時まで有効(staticを付けないと通常はス
タック領域で,関数終了まで有効。)。
・ 初期化は,プログラム開始後1度だけで,関数が複数回呼び出される場合,1回前に
呼び出されたときの値が保持されている。
このため,その関数内だけでアクセスされる変数のうち,関数終了後も値を保持し
たいものは,staticを付けて宣言する。また,自動変数に大きな領域を宣言するとスタ
ックオーバフローの危険がある。
そのような場合,関数終了後の値保持が必要なくとも,静的領域を確保する目的で,
staticを付けることもある。ただし,この利用方法に対しては,注釈などで意図を明示
することを推奨する(間違えてstaticを付けたと誤解される危険があるため。)。
b) (M2.2.2) 同一ファイル内で定義された複数の関数からアクセスされる変数は,ファイル内が有効範囲
のstatic変数宣言する。[採用指針:必要] [規約化: ]
適合例
不適合例
/* xは他のファイルからアクセスされない*/
static int x;
void func1(void) {
…
x = 0;
…
}
void func2(void) {
…
if (x == 0) {
x++;
}
…
}
/* xは他のファイルからアクセスされない */
int x;
void func1(void) {
…
x = 0;
…
}
void func2(void) {
…
if (x == 0) {
x++;
}
…
}
注記 グローバルな変数の数が少ないほど,プログラム全体を理解する場合の可読性は向上する。
グローバルな変数が増えないように,できるだけstaticを付ける。
c) (M2.2.3) 同じファイルで定義した関数からだけ呼ばれる関数は,static 関数とする。[採用指針:必要]
[規約化: ]
適合例
不適合例
/* func1は他のファイルの関数から呼ばれない */
static void func1(void) {
…
}
/* func1は他のファイルの関数から呼ばれない */
void func1(void) {
…
}
47
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
void func2(void) {
…
func1();
…
}
void func2(void) {
…
func1();
…
}
注記 グローバルな関数の数が少ないほど,プログラム全体を理解する場合の可読性は向上する。
グローバルな関数が増えないように,できるだけstaticを付ける。
d) (M2.2.4) 関連する整数定数を定義するときは,#defineよりenumを使用する。[採用指針: ] [規約
化: ]
適合例
不適合例
enum ecountry {
ENGLAND, FRANCE, …
} country;
enum eweek {
SUNDAY, MONDAY, …
} day;
…
if ( country == ENGLAND ) {
}
if ( day == MONDAY ) {
}
if ( country == SUNDAY ) {
/* ツールで検査可能 */
}
#define ENGLAND 0
#define FRANCE 1
#define SUNDAY 0
#define MONDAY 1
int country, day;
…
if ( country == ENGLAND ) {
}
if ( day == MONDAY ) {
}
if ( country == SUNDAY ) {
/* ツールで検査不可 */
}
注記 列挙型は,集合のように関連する整数定数を定義するときに使用する。関連する整数定数ご
とにenum型で定義しておくと,誤った使い方に対し,ツールが検査できるようになる。#define
で定義されたマクロ名は,前処理段階でマクロ展開され,コンパイラが処理する名前となら
ないが,enum宣言で定義されたenum 定数は,コンパイラが処理する名前となる。コンパイ
ラが処理する名前は,シンボリックデバッグ時に参照できるためデバッグしやすくなる。
A.3.4 プログラムの簡潔性
A.3.4.1
(M3) プログラムはシンプルに書く。
ソフトウェアの保守しやすさという点に関しては,とにかくソフトウェアがシンプルな書き方になって
いるに越したことはない。
C言語は,ファイルに分割する,関数に分割するなどによって,ソフトウェアの構造化が行える。順次・
選択・反復の三つによってプログラム構造を表現する構造化プログラミングもソフトウェアをシンプルに
書く技法の一つである。ソフトウェアの構造化を活用して,ソフトウェアはシンプルに記述する。また,
繰返し処理,代入,演算などについても,書き方によっては保守しにくい形になってしまう。
・ (M3.1) 構造化プログラミングを行う。
・ (M3.2) 一つの文で一つの副作用とする。

48
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
・ (M3.3) 目的の違う式は,分離して記述する。
・ (M3.4) 複雑なポインタ演算は使用しない。
A.3.4.2
(M3.1) 構造化プログラミングを行う。
ルールは,次による。
a) (M3.1.1) 繰返し文では,ループを終了させるためのbreak文の使用を最大でも一つだけにする
(MISRA14.6)。[採用指針: ] [規約化: ]
適合例
不適合例
end = 0;
for (i = 0; ループの継続条件 && !end; i++) {
繰り返す処理1;
if (終了条件1 || 終了条件2) {
end = 1;
} else {
繰り返す処理2;
}
}
又は
for (i = 0; ループの継続条件; i++) {
繰り返す処理1;
if (終了条件1 || 終了条件2) {
break;
}
繰り返す処理2;
}
for (i = 0; ループの継続条件; i++) {
繰り返す処理1;
if (終了条件1) {
break;
}
if (終了条件2) {
break;
}
繰り返す処理2;
}
注記 プログラム論理が複雑にならないようにするための工夫である。break文をなくすためだけの
フラグを用意しなければならない場合は,フラグは用意せずに,breakを使用した方がよいこ
ともある(適合例の,endフラグを使う例は,プログラムを複雑にしてしまう危険がある。)。
b) (M3.1.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) goto文を使用しない。
2) goto文は,多重ループを抜ける場合又はエラー処理に分岐する場合だけに使用する。
適合例
不適合例
1),2)の例
for (i = 0; ループの継続条件; i++) {
繰り返す処理;
}
2)の例
if (err != 0) {
goto ERR̲RET;
1),2)の例
i = 0;
LOOP:
繰り返す処理;
i++;
if (ループの継続条件) {
goto LOOP;
}
49
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
}
…
ERR̲RET:
end̲proc();
return err;
}
注記 プログラム論理が複雑にならないようにするための工夫である。goto文をなくすことが目的
ではなく,プログラムが複雑になる(上から下へ読めなくなる。)ことを避けるための手段と
して,不要なgotoをなくす,ということが重要である。goto文を用いることによって,可読
性が向上することもある。いかに論理をシンプルに表現できるかを考えて,プログラミング
する。
c) (M3.1.3) continue文を使用しない(MISRA 14.5)。[採用指針: ] [規約化: ]
適合例
不適合例
for (i = 0; ループの継続条件1; i++) {
繰り返す処理1;
if (!継続条件2) {
繰り返す処理2;
}
}
for (i = 0; ループの継続条件1; i++) {
繰り返す処理1;
if (継続条件2) {
continue;
}
繰り返す処理2;
}
注記 プログラム論理が複雑にならないようにするための工夫である。continue文をなくすことが
目的ではなく,プログラムが複雑になる(上から下へ読めなくなる。)ことを避けるための手
段として,不要なcontinueをなくす,ということが重要である。continue文を用いることに
よって,可読性が向上することもある。いかに論理をシンプルに表現できるかを考えて,プ
ログラミングする。
d) (M3.1.4) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,規約]
1) switch文のcase節及びdefault節は,必ずbreak文で終了する。
2) switch文のcase節及びdefault節をbreak文で終了させない場合は,《プロジェクトで注釈を規定し》
その注釈を挿入する。
適合例
不適合例
1),2)の例
switch (week) {
case A:
code = MON;
break;
case B:
code = TUE;
break;
case C:
code = WED;
1),2)の例
/* weekがどんな値でも,codeはELSEにな
ってしまう ==>バグ */
switch (week) {
case A:
code = MON;
case B:
code = TUE;
case C:
code = WED;
50
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
break;
default:
code = ELSE;
break;
}
2)の例
dd = 0;
switch (status) {
case A:
dd++;
/* FALL THROUGH */
case B:
default:
code = ELSE;
}
/* case Bの処理を継続してよい場合だが,注釈
がないので1)だけでなく2)にも不適合 */
dd = 0;
switch (status) {
case A:
dd++;
case B:
注記 C言語のswitch文におけるbreak忘れは,コーディングミスしやすい代表例の一つである。
不用意にbreak文なしのcaseを使用することは避けるのがよい。break文なしに次のcaseに
処理を継続させる場合は,break文がなくても問題のないことを明示する注釈を,必ず入れる
ようにする。どのような注釈を入れるかは,コーディング規約で定める。例えば,/* FALL
THROUGH */などがよく利用される。
e) (M3.1.5) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 関数は,一つのreturn文で終了する。
2) 処理の途中で復帰するreturn文は,異常復帰の場合だけとする。
A.3.4.3
(M3.2) 一つの文で一つの副作用とする。
ルールは,次による。
a) (M3.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) コンマ式は使用しない。
2) コンマ式はfor文の初期化式又は更新式以外では使用しない。
適合例
不適合例
1),2)の例
a = 1;
b = 1;
j = 10;
for (i = 0; i < 10; i++) {
…
j--;
}
2)の適合例
for (i = 0, j = 10; i < 10; i++, j--) {
1),2)の例
a = 1, b = 1;
1)の例
for (i = 0, j = 10; i < 10; i++, j--) {
…
}
51
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…
}
注記 コンマ式を利用すると複雑になる。ただし,for文の初期化式及び更新式は,ループの前後に
実施することが望ましい処理をまとめて記述する場所であり,コンマ式を利用してまとめて
記述する方が分かりやすいこともある。
b) (M3.2.2) 一つの文に,代入を複数記述しない。ただし,同じ値を複数の変数に代入する場合を除く。
[採用指針:必要] [規約化: ]
適合例
不適合例
x = y = 0;
y = (x += 1) + 2;
y = (a++) + (b++);
注記 代入には,単純代入(=)のほかに,複合代入(+=,-=など)がある。一つの文に複数の代
入を記述できるが,可読性を低下させるため,一つの文では,一つの代入に止めることが望
ましい。
ただし,次の“よく使用される習慣的な記述”については,可読性を損なわない場合も多
い。例外として許すルールとしてもよい。
c = *p++;
*p++ = *q++;
A.3.4.4
(M3.3) 目的の違う式は,分離して記述する。
ルールは,次による。
a) (M3.3.1) for文の三つの式には,ループ制御に関わるものだけを記述する(MISRA 13.5)。[採用指針: ]
[規約化: ]
適合例
不適合例
for (i = 0; i < MAX; i++) {
…
j++;
}
for (i = 0; i < MAX; i++, j++) {
…
}
b) (M3.3.2) forループの中で繰返しカウンタとして用いる数値変数は,ループの本体内で変更しない
(MISRA 13.6)。[採用指針: ] [規約化: ]
適合例
不適合例
for (i = 0; i < MAX; i++) {
…
}
for (i = 0; i < MAX; ) {
…
i++;
}
c) (M3.3.3) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 真偽を求める式の中で代入演算子を使用しない。
2) 真偽を求める式の中で代入演算子を使用しない。ただし,慣習的に使う表現は除く。
適合例
不適合例
1),2)の例
p = top̲p;
1),2)の例
if (p = top̲p) {

52
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
if (p != NULL) {
…
}
1)の例
c = *p++;
while (c != '\0') {
…
c = *p++;
}
…
}
1)の例
while (c = *p++) {
…
}
/* 慣習的に使う表現なのでこれでよい(開発
者のスキルに依存するので要注意) */
注記 真偽を求める式は,次の式である。
if(式),for( ;式; ),while(式),(式)? : ,式 && 式,式 || 式
A.3.4.5
(M3.4) 複雑なポインタ演算は使用しない。
ルールは,次による。
(M3.4.1) 3段階以上のポインタ指定は使用しない。[採用指針: ] [規約化: ]
適合例
不適合例
int **p;
typedef char **strptr̲t;
strptr̲t q;
int ***p;
typedef char **strptr̲t;
strptr̲t *q;
注記 3段階以上のポインタの値の変化を理解することは難しいため,保守性を損なう。
A.3.5 コーディングスタイルの統一性
A.3.5.1
(M4) 統一した書き方にする。
最近のプログラム開発では,複数人による分業開発が定着している。このような場合,開発者それぞれ
が異なったソースコードの書き方をしていると,それぞれの内容確認を目的としたレビューなどがしづら
いといった問題が発生する。また,変数の名前の付け方,ファイル内の情報の記載内容,記載順序などが
ばらばらだと,思わぬ誤解又は誤りの元になりかねない。このため,一つの業界,組織又はプロジェクト
内では,極力,ソースコードの書き方を統一するのがよい。
・ (M4.1) コーディングスタイルを統一する。
・ (M4.2) 注釈の書き方を統一する。
・ (M4.3) 名前の付け方を統一する。
・ (M4.4) ファイル内の記述内容及び記述順序を統一する。
・ (M4.5) 宣言の書き方を統一する。
・ (M4.6) 空ポインタの書き方を統一する。
・ (M4.7) 前処理指令の書き方を統一する。
A.3.5.2
(M4.1) コーディングスタイルを統一する。
ルールは,次による。
(M4.1.1) 《波括弧({),字下げ,空白の入れ方などのスタイルに関する規約を規定する。》[採用指針:
53
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
必要] [規約化:規約]
注記 コードの見やすさのために,コーディングスタイルをプロジェクトで統一することは重要であ
る。
スタイルの規約をプロジェクトで新規に決定する場合,世の中で既に存在するコーディング
スタイルから選択することを推奨する。既存のコーディングスタイルには,幾つかの流派があ
るが,多くのプログラマがそのいずれかに沿ってプログラムを作成している。それらのスタイ
ルを選択することで,エディタ,プログラムの整形コマンドなどで簡単に指定できるといった
恩恵も受けられる。一方,既存のプロジェクトでコーディングスタイルが明確に示されていな
い場合,現状のソースコードに一番近い形で規約を作成することを推奨する。
スタイル規約の決定において,最も重要なことは“決定して統一する”ことであり,“どのよ
うなスタイルに決定するか”ではないことに注意する。
次に,決めることが望ましい項目について説明する。
a) 波括弧({ })の位置 波括弧の位置は,ブロックの始まりと終わりとを見やすくするた
めに統一する[e)の“代表的なスタイル”参照]。
b) 字下げ(インデンテーション) 字下げは,宣言又は処理のまとまりを見やすくするため
に行う。字下げの統一で規定することは,次のとおり。
・ 字下げに,空白を使用するか,タブを使用するか。
・ 空白の場合,空白を何文字とするか,タブの場合,1タブを何文字とするか。
c) 空白の入れ方 空白は,コードを見やすくし,また,コーディングミスを発見しやすく
するために,挿入する。例えば,次のようなルールを規定する。
・ 2項演算子,及び3項演算子の前後に,空白を入れる。ただし,次の演算子を除
く。
[ ], ->, .(ピリオド),,(コンマ演算子)
・ 単項演算子と演算項との間には,空白を入れない。
これらのルールは,複合代入演算子のコーディングミスを発見しやすくする。
[例]
x=-1; /* x-=1 と書くのを誤って書いてしまった。 見付けにくい */
x =- 1; /* x-=1 と書くのを誤って書いてしまった。 見付けやすい */
上記のほかに,次のようなルールを定めることもある。
・ コンマの後に,空白を入れる(ただし,マクロ定義時の引数のコンマを除く。)。
・ if,forなどの制御式を囲む左括弧の前に空白を入れる。関数呼出しの左括弧の前
には空白を入れない。このルールは,関数呼出しを探しやすくする。
d) 継続行における改行の位置 式が長くなり,見やすい1行の長さを超える場合,適切な
位置で改行する。改行に当たっては,次の二つの方式のいずれかを選択することを推奨
する。重要なことは,継続行は字下げして記述することである。
[方式1]演算子を行の最後に書く。
例:
x = var1 + var2 + var3 + var4 +
var5 + var6 + var7 + var8 + var9;
54
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
if ((var1 == var2) &&
(var3 == var4))
[方式2]演算子を継続行の先頭に書く。
例:
x = var1 + var2 + var3 + var4
+ var5 + var6 + var7 + var8 + var9;
if ((var1 == var2)
&& (var3 == var4))
e) 代表的なスタイル
1) K&Rスタイル 書籍“プログラミング言語C”(略称K&R本)で用いられたコ
ーディングスタイルである。この本の2 人の著者のイニシャルから,本の略称同
様,このように呼ばれている。K&Rスタイルにおける,波括弧の位置及び字下げ
を次に示す。
・ 波括弧の位置:関数定義の波括弧は,改行して行の先頭に記述する。その
他(構造体,if,for,whileなどの制御文など)は,改行なしでその行に記
述する(例参照)。
・ 字下げ:1タブ。初版である参考文献(11)では,5だったが,第2版である
参考文献(10)では4。
2) BSDスタイル 多くのBSDのユーティリティを記述したEric Allman氏の記述ス
タイルで,Allmanスタイルとも呼ばれている。BSDスタイルにおける,波括弧の
位置及び字下げを次に示す。
・ 波括弧の位置:関数定義,if,for,whileなど全て改行し,波括弧は,前の
行とそろえたカラムに置く(例参照)。
・ 字下げ:8。4も多い。
3) GNUスタイル GNUパッケージを記述するためのコーディングスタイルである。
Richard Stallman氏及びGNUプロジェクトのボランティアの人々によって書かれ
た“GNUコーディング規約”で定められている。GNUスタイルにおける,波括
弧の位置及び字下げを次に示す。
・ 波括弧の位置:関数定義,if,for,whileなど全て,改行し,記述する。関
数定義の波括弧は,カラム0に置き,それ以外は,2文字分の空白を入れ
たインデントとする(例参照)。
・ 字下げ:2。波括弧,本体共に,2 インデントする。
K&Rスタイルの例:
void func(int arg1)
{ /* 関数の { は改行して記述する */
/* インデントは1タブ */
if (arg1) {
...
}
55
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
...
}
BSDスタイルの例:
void
func(int arg1)
{ /* 関数の { は改行して記述する */
if (arg1)
{
...
}
...
}
GNUスタイルの例:
void
func(int arg1)
{ /* 関数の { は改行してカラム0に記述する */
if (arg1)
{
...
}
...
}
A.3.5.3
(M4.2) 注釈の書き方を統一する。
ルールは,次による。
(M4.2.1) 《ファイルヘッダ注釈,関数ヘッダ注釈,行末注釈,ブロック注釈,著作権表示などの書き方
に関する規約を規定する。》[採用指針:必要] [規約化:規約]
注記 注釈を上手に記述することで,プログラムの可読性が向上する。更に見やすくするためには,
統一した書き方が必要となる。また,ソースコードから保守・調査用ドキュメントを生成する
ドキュメント生成ツールがある。このようなツールを活用する場合,その仕様に沿った書き方
が必要になる。ドキュメント生成ツールは,一般的には,変数又は関数の説明を一定の注釈規
約の下で記述すると,ソースコードからドキュメントに反映される。ツールの仕様を調査して,
注釈規約を定めるのがよい。
次に,既存のコーディング規約,書籍などから,注釈の書き方に関するものを紹介する。
1) Indian Hillコーディング規約[参考文献(6)] Indian Hillコーディング規約では,次のよ
うな注釈ルールが記述されている。
・ ブロック注釈
データ構造又はアルゴリズムを記述する場合に利用する。形式は,1桁目に / を
56
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
おき,全て2桁目に * を書き,最後は,2桁目と3桁目とに */ を書く(grep ^.\*
でブロック注釈が抽出可能。)。
例:
/* 注釈を書く
* 注釈を書く
*/
・ 注釈の位置
− 関数中のブロック注釈
次の行の字下げ位置にそろえるなど,ふさわしい位置に書く。
− 行末の注釈
タブで遠く離して書く。複数のそのような注釈がある場合は,同じ字下
げ位置にそろえる。
2) GNUコーディング規約[参考文献(9)] GNUコーディング規約では,次のような注釈ル
ールが記述されている。
・ 記述言語 英語。
・ 記述場所及び内容
− プログラムの先頭
全てのプログラムは,何をするプログラムかを簡潔に説明する注釈で始
める。
− 関数
関数ごとに次の注釈を書く。
何をする関数か,引数の説明(値,意味,用途),戻り値
− #endif
入れ子になっていない短い条件を除いて,#endifは全て,行末に注釈を
入れ,条件を明確にする。
− ツール用の記法
注釈のセンテンスの終わりには,空白を2文字置く。
3) “プログラミング作法”[参考文献(13)] “プログラミング作法”では,次のような注
釈ルールが記述されている。
・ 記述場所 関数及びグローバルデータに対して記述する。
・ その他の作法
− 当たり前のことはいちいち書かない。
− コードと矛盾させない。
− あくまでも明快に,混乱を招く記述をしない。
4) その他
・ 著作権表示を注釈に入れる。
・ break なしcase文に対する注釈を決める。
例:
switch (status) {
case CASE1:
57
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
処理;
/* FALL THROUGH */
case CASE2:
…
・ 処理なしに対する注釈を決める。
例:
if (条件1) {
処理;
} else if (条件2) {
処理;
} else {
/* DO NOTHING */
}
A.3.5.4
(M4.3) 名前の付け方を統一する。
ルールは,次による。
a) (M4.3.1) 《外部変数,内部変数などの命名に関する規約を規定する。》[採用指針:必要] [規約化:規
約]
b) (M4.3.2) 《ファイル名の命名に関する規約を規定する。》[採用指針:必要] [規約化:規約]
注記 プログラムの読みやすさは,名前の付け方に大きく左右される。名前の付け方にも,様々な
方式があるが,重要なことは統一性であり,分かりやすさである。
名前の付け方では,次のような項目を規定する。
・ 名前全体に対する指針
・ ファイル名(フォルダ名又はディレクトリ名を含む。)の付け方
・ グローバルな名前及びローカルな名前の付け方
・ マクロ名の付け方
次に,既存のコーディング規約,書籍などから紹介されている名前の付け方に関する指針
及びルールの幾つかを紹介する。プロジェクトで新規に命名規約を作成する場合の参考にす
るとよい。既存のプロジェクトで命名規約が明確に示されていない場合,現状のソースコー
ドに一番近い規約を作成することを推奨する。
1) Indian Hillコーディング規約
・ 下線が前後に付いた名前はシステム用に確保してあるので,使用しない。
・ #defineされる定数名は全て大文字にする。
・ enumで定義する定数は,先頭文字だけ大文字にするか,又は全ての文字を大文
字にする。
・ 大文字と小文字との差しかない二つの名前は使用しない(fooとFooなど)。
・ グローバルなものには,どのモジュールに属するのか分かるように,共通の接
頭辞を付ける。
・ ファイル名のはじめの文字は英字,その後の文字は英数字で8文字以下(拡張
子を除く。)とする。
58
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
・ ライブラリのヘッダファイルと同じ名前のファイル名は避ける。
全体
・ 下線が前後に付いた名前は使用しない。
・ 大文字と小文字との差しかない二つの名前は利用しない。
例:fooとFoo
変数名
関数名
グローバル モジュール名の接頭辞を付ける。
ローカル
特になし。
その他
・ マクロ名は,全てを大文字とする。
例:#define MACRO
・ enumメンバは,先頭文字だけ大文字にするか,又は全ての文
字を大文字とする。
2) GNUコーディング規約
・ グローバル変数及び関数の名前は,短すぎる名前を付けない。英語で意味をも
つような名前にする。
・ 名前の中で語を分けるのには下線を使う。
・ 大文字は,マクロとenum定数と一定の規約に従った名前の接頭辞だけに使用
する。通常は,英小文字だけの名前を使用する。
全体
・ 名前の中で語を分けるのに下線を使う。
例:get̲name
・ 大文字は,マクロ,enum定数,及び一定の規約に従った名前
の接頭辞にだけ使用する。通常は,英小文字だけの名前を使用
する。
変数名
関数名
グローバル 短すぎる名前を付けない。英語で意味をもつ名前とする。
ローカル
特になし。
その他
・ マクロ名は,全てを大文字とする。
例:#define MACRO ....
・ enumメンバは,全ての文字を大文字とする。
3) “プログラミング作法”
・ グローバルには分かりやすい名前を,ローカルには短い名前を付ける。
・ 関連性のあるものには,関連性のある名前を付けて,違いを際立たせるように
する。
・ 関数名は能動的な動詞を基本にし,特に問題がなければその後に名詞を付ける。
全体
関連性のあるものには,関連性のある名前を付ける。
変数名
関数名
グローバル 分かりやすい名前を付ける。
ローカル
短い名前を付ける。
その他
関数名は,能動的な動詞を基本にし,特に問題がなければその後
に名詞を付ける。
4) その他
・ 名前の区切り方
複数の単語で構成される名前の単語の区切りは,下線で区切るか,又は単語
59
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
の1文字目を大文字にして区切るか,どちらかに統一する。
・ ハンガリアン記法
変数の型を明示的にするためのハンガリアン記法などもある。
・ ファイル名の付け方
接頭辞として,例えばサブシステムを示す名前を付ける。
A.3.5.5
(M4.4) ファイル内の記述内容及び記述順序を統一する。
ルールは,次による。
a) (M4.4.1) 《ヘッダファイルに記述する内容(宣言,定義など)とその記述順序を規定する。》[採用指
針:必要] [規約化:規約]
注記 複数の箇所に記述すると変更ミスの危険があるため,共通に使用するものはヘッダファイル
に記述する。ヘッダファイルには,複数のソースファイルで共通に使用するマクロの定義,
構造体・共用体・列挙型のタグ宣言,typedef宣言,外部変数宣言及び関数原型宣言を記述す
る。
例えば,次の順序で記述する。
1) ファイルヘッダ注釈
2) システムヘッダの取込み
3) 利用者作成ヘッダの取込み
4) #defineマクロ
5) #define関数形式マクロ
6) typedef定義(int,charといった基本型に対する型定義)
7) enumタグ定義(typedefを同時に行う。)
8) struct/unionタグ定義(typedefを同時に行う。)
9) extern 変数宣言
10) 関数原型宣言
b) (M4.4.2) 《ソースファイルに記述する内容(宣言,定義など)とその記述順序を規定する。》[採用指
針:必要] [規約化:規約]
注記 ソースファイルには,変数及び関数の定義又は宣言のほかに,個々のソースファイルだけで
使用する,マクロ,タグ及び型(typedef型)の定義又は宣言を記述する。
例えば,次の順序で記述する。
1) ファイルヘッダ注釈
2) システムヘッダの取込み
3) 利用者作成ヘッダの取込み
4) 自ファイル内だけで使用する#defineマクロ
5) 自ファイル内だけで使用する#define関数形式マクロ
6) 自ファイル内だけで使用するtypedef定義
7) 自ファイル内だけで使用するenumタグ定義
8) 自ファイル内だけで使用するstruct/unionタグ定義
9) ファイル内で共有するstatic変数宣言
10) static関数宣言

60
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
11) 変数定義
12) 関数定義
c) (M4.4.3) 外部変数又は関数(ファイル内でだけ使用する関数を除く。)を使用又は定義する場合,宣
言を記述したヘッダファイルを取り込む。[採用指針:必要] [規約化: ]
適合例
不適合例
--- my̲inc.h ---
extern int x;
int func(int);
--------------
#include "my̲inc.h"
int x;
int func(int in) {
…
}
/* 変数x及び関数funcの宣言がない */
int x;
int func(int in) {
…
}
注記 C言語では,変数は使用前に宣言か定義が必要である。一方,関数は宣言も定義もなくても
使用できる。
しかしながら,宣言と定義との整合性を保つために,宣言をヘッダファイルに記述し,そ
のヘッダファイルを取り込むことを推奨する。
d) (M4.4.4) 外部変数は,複数箇所で定義しない。[採用指針:基本] [規約化: ]
適合例
不適合例
int x;
/* 一つの外部変数定義は,一つにする */
int x;
int x;
/* 外部変数定義は複数箇所でもコンパイルエラー
にならない */
注記 外部変数は,初期化なしの定義を複数記述できる。ただし,複数ファイルで初期化を行った
場合の動作は保証されない。
e) (M4.4.5) ヘッダファイルには,変数定義及び関数定義を記述しない。[採用指針:必要] [規約化: ]
適合例
不適合例
--- file1.h ---
extern int x; /* 変数宣言 */
int func(void); /* 関数宣言 */
--- file1.c ---
#include "file1.h"
int x; /* 変数定義 */
int func(void) {
/* 関数定義 */
…
--- file1.h ---
int x; /* 外部変数定義 */
static int func(void) {
/* 関数定義 */
…
}
61
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
}
注記 ヘッダファイルは,複数のソースファイルに取り込まれる可能性がある。このため,ヘッダ
ファイルに変数定義又は関数定義を記述すると,コンパイル後に生成されるオブジェクトコ
ードのサイズが不要に大きくなる危険がある。ヘッダファイルは,基本的に宣言,型の定義
などだけを記述する。
f)
(M4.4.6) ヘッダファイルは重複取込みに耐え得る作りとする。《そのための記述方法を規定する。》[採
用指針:必要] [規約化:規約]
適合例
不適合例
--- myheader.h ---
#ifndef MYHEADER̲H
#define MYHEADER̲H
ヘッダファイルの内容
#endif /* MYHEADER̲H */
--- myheader.h ---
void func(void);
/* end of file */
注記 ヘッダファイルは,重複して取り込む必要がないようにできる限り整理しておくことが望ま
しい。しかしながら,重複して取り込まれる場合もある。そのときのために,重複取込みに
耐え得る作りとすることも必要である。
例えば,次のルールとする。
ルールの例:
ヘッダファイルの先頭で,ヘッダを取り込み済みか否かを判定する #ifndefマクロを
記述し,2回目の取込みでは,以降の記述がコンパイル対象にならないようにする。こ
のときのマクロ名は,ヘッダファイルの名前を全て大文字にした名前で,ピリオドを̲
(下線)に変更した名前を付ける。
A.3.5.6
(M4.5) 宣言の書き方を統一する。
ルールは,次による。
a) (M4.5.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) 関数原型(function prototype)宣言では,全ての引数に名前を付けない(型だけとする。)。
2) 関数原型宣言では,全ての引数に名前を付ける。さらに,引数の型及び名前,並びに戻り型は,関
数定義と文字どおりに同じにする。
適合例
不適合例
1)の例
int func1(int, int);
int func1(int x, int y) {
/* 関数の処理 */
}
2)の例
int func1(int x, int y);
int func2(float x, int y);
1),2)の例
int func1(int x, int y);
int func2(float x, int y);
int func1(int y, int x) {
/* 引数の名前が関数原型宣言と異なる */
/* 関数の処理 */
}

62
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
int func1(int x, int y) {
/* 関数の処理 */
}
int func2(float x, int y) {
/* 関数の処理 */
}
typedef int INT;
int func2(float x, INT y) {
/* yの型が関数原型宣言と文字どおりに
同じでない */
/* 関数の処理 */
}
注記 関数原型宣言では引数の名前を省略できるが,適切な引数名の記述は,関数インタフェース
情報として価値がある。引数名を記述する場合,定義と同じ名前を利用し,無用な混乱を避
けることが望ましい。型についても,関数定義と文字どおりに同じ方が理解しやすく,同じ
にすることを推奨する。
b) (M4.5.2) 構造体タグの宣言と変数の宣言とは別々にする。[採用指針: ] [規約化: ]
適合例
不適合例
struct TAG {
int mem1;
int mem2;
};
struct TAG x;
struct TAG {
int mem1;
int mem2;
} x;
c) (M4.5.3) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 構造体・共用体・配列の初期値式の並び,及び列挙子並びの最後の“}”の前に“,”を記述しない。
2) 構造体・共用体・配列の初期値式の並び,及び列挙子並びの最後の“}”の前に“,”を記述しない。
ただし,配列の初期化の初期値並びの最後の“}”の前に“,”を書くことは許す。
適合例
不適合例
1)の例
struct tag data[] = {
{ 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 }/* 最後の要素にコンマはない */
};
2)の例
struct tag data[] = {
{ 1, 2, 3 },
{ 4, 5, 6 },
{ 7, 8, 9 },/* 最後の要素にコンマがある */
};
1),2)の例
struct tag x = { 1, 2, };
/* メンバが二つだけなのか,三つ以上あ
るのか不明確 */
注記 複数のデータの初期化では,初期化の最後を明示するために,最後の初期値にコンマを付け
ない流派と,初期値の追加・削除のしやすさを考慮し,最後にコンマを付ける流派とがある。
いずれを重視するかを検討し,ルールを決定する。
63
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
なお,C90の仕様では,列挙子並びの最後を示す“}”の直前のコンマは許されなかったが,
C99の規格ではコンマが許されるようになった。
A.3.5.7
(M4.6) 空ポインタの書き方を統一する。
ルールは,次による。
(M4.6.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) 空ポインタには0を使用する。NULLはいかなる場合にも使用しない。
2) 空ポインタにはNULLを使用する。NULLは空ポインタ以外に使用しない。
適合例
不適合例
1)の例
char *p;
int dat[10];
p = 0;
dat[0] = 0;
2)の例
char *p;
int dat[10];
p = NULL;
dat[0] = 0;
1)の例
char *p;
int dat[10];
p = NULL;
dat[0] = NULL;
2)の例
char *p;
int dat[10];
p = 0;
dat[0] = NULL;
注記 NULLは空ポインタとして従来使用されてきた表現だが,実行環境によって空ポインタの表
現は異なる。このため,0を使うほうが安全だと考える人もいる。
A.3.5.8
(M4.7) 前処理指令の書き方を統一する。
ルールは,次による。
a) (M4.7.1) 演算子を含むマクロは,マクロ本体及びマクロ引数を括弧で囲む。[採用指針:必要] [規約
化: ]
適合例
不適合例
#define M̲SAMPLE(a, b) ((a)+(b))
#define M̲SAMPLE(a, b) a+b
注記 マクロ本体,マクロ引数を括弧で囲っていない場合,マクロ展開後にマクロに隣接する演算
子と,マクロ内の演算子との優先順位によって,期待する演算順序にならず,バグになる可
能性がある。
b) (M4.7.2) #ifdef,#ifndef,#ifに対応する #else,#endifは,同一ファイル内に記述し,プロジェクトで
規定した注釈を入れ,対応関係を明確にする。[採用指針:必要] [規約化:規約]
適合例
不適合例
#ifdef AAA
…
#else /* not AAA */
#ifdef AAA
…
#else
64
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…
#endif /* end AAA */
…
#endif
注記 #ifdefなどマクロによる処理の切分けにおいて,#else,#endif が離れた場所に記述されたり,
入れ子にすると,対応が分かりにくくなる。#ifdefなどと対応する #else,#endifなどに注釈
を付け,対応を分かりやすくする。
c) (M4.7.3) #ifで,マクロ名が定義済みかを調べる場合は,defined(マクロ名)によって定義済みかを調
べる。#ifマクロ名 という書き方をしない。[採用指針:基本] [規約化: ]
適合例
不適合例
#if defined(AAA)
…
#endif
#if AAA
…
#endif
注記 #ifマクロ名としても,マクロが定義されているかどうかの判定にはならない。マクロが定義
されていない場合だけでなく,マクロが定義されその値が0の場合も判定は偽となる。マク
ロが定義されているかどうかを検査するには,definedを利用する。
d) (M4.7.4) #if ,#elifで使用するdefined 演算子は,defined(マクロ名)又はdefinedマクロ名 という書
き方以外は書かない。[採用指針: ] [規約化: ]
適合例
不適合例
#if defined(AAA)
…
#endif
#define DD(x) defined(x)
#if DD(AAA)
…
#endif
注記 C言語規格では,defined(マクロ名) 又はdefinedマクロ名 以外の書き方をした場合,どのよ
うに処理されるか定義されていない(未定義)。コンパイラによってエラーにしたり,独自の
解釈をしている場合があるため,使用しないようにする。
e) (M4.7.5) マクロは,ブロック内で#define,又は#undef しない(MISRA 19.5)。[採用指針: ] [規約化: ]
適合例
不適合例
#define AAA 0
#define BBB 1
#define CCC 2
struct stag {
int mem1;
char *mem2;
};
/* 設定される値に制限があるメンバが存在する */
struct stag {
int mem1; /* 次の値が設定可能 */
#define AAA 0
#define BBB 1
#define CCC 2
char *mem2;
};
注記 マクロ定義(#define)は,一般的にファイルの先頭にまとめて記述する。ブロック内に記述
するなど,分散させると可読性が低下する。また,ブロック内で定義を解除(#undef)する
ことも可読性を低下させる。マクロ定義は,変数と違い,有効範囲は,ファイルの終わりま
でになることにも注意。不適合例のプログラムは,次のように変更することも考えられる。
enum etag { AAA, BBB, CCC };
65
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
struct stag {
enum etag mem1;
char *mem2;
};
f)
(M4.7.6) #undefは使用しない(MISRA 19.6)。[採用指針: ] [規約化: ]
注記 #defineしたマクロ名は,#undefすることによって,定義されていない状態にすることが可能
であるが,マクロ名が参照されている箇所によって,解釈が異なる危険があり,可読性を低
下させる。
A.3.6 試験性
A.3.6.1
(M5) 試験しやすい書き方にする。
組込みソフトウェア開発で欠くことのできない作業の一つが動作確認(テスト)である。しかし,近年
の複雑な組込みソフトウェアでは,テスト時に検出された不具合,誤動作が再現できないなどの問題が発
生する場合がある。このため,ソースコードを記述する場合に,問題原因分析のしやすさなどまで考慮し
ておくことが望ましい。また,特に動的メモリの利用などは,メモリリークなどの危険があるため,特別
な注意を払う必要がある。
・ (M5.1) 問題発生時の原因を調査しやすい書き方にする。
・ (M5.2) 動的なメモリ割当ての使用に気を付ける。
A.3.6.2
(M5.1) 問題発生時の原因を調査しやすい書き方にする。
ルールは,次による。
a) (M5.1.1) 《デバッグオプション設定時のコーディング方法及びリリースモジュールにログを残すため
のコーディング方法を規定する。》[採用指針:必要] [規約化:規約]
注記 プログラムは,所定の機能を実装するだけではなく,デバッグ及び問題発生時の調査のしや
すさを考慮に入れて,コーディングする必要がある。問題を調査しやすくするための記述に
は,リリース用モジュールには反映されないデバッグ用記述と,リリース用モジュールにも
反映するリリース後のログ出力の記述とがある。次に,それぞれに関する規約の決め方につ
いて説明する。
1) デバッグ用記述 プログラム開発中に利用するprint文など,デバッグ用の記述は,リ
リース用モジュールには反映しないように記述する。ここでは,デバッグ用記述の方
法として,マクロ定義を利用した切分け及びassertマクロの利用について説明する。
1.1)
デバッグ処理記述の切分けに,マクロ定義を利用する方法 デバッグ用の記述を提
供モジュールに反映しないようにするためには,コンパイル対象の有無を切り分け
るマクロ定義を利用する。マクロ名には,文字列 "DEBUG","MODULEA̲DEBUG"
など"DEBUG" を含む名前がよく用いられる。
ルール定義の例:
デバッグ用のコードは,#ifdef DEBUG で切り分ける(DEBUGマクロは,コ
ンパイル時に指定する。)。
[コード例]
#ifdef DEBUG
66
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
fprintf(stderr, "var1 = %d\n", var1);
#endif
さらに,次のようなマクロ定義を利用する方法もある。
ルール定義の例:
デバッグ用のコードは,#ifdef DEBUG で切り分ける(DEBUGマクロは,コ
ンパイル時に指定する。)。
さらに,デバッグ情報出力では,次のマクロを利用する。
DEBUG̲PRINT(str); /* strを標準出力に出力する */
このマクロは,プロジェクトの共通ヘッダdebug̲macros.h に定義しているため,
利用時には,そのヘッダをインクルードする。
-- debug̲macros.h --
#ifdef DEBUG
#define DEBUG̲PRINT(str) fputs(str, stderr)
#else
#define DEBUG̲PRINT(str) ((void) 0) /* no action */
#endif /* DEBUG */
[コード例]
void func(void) {
DEBUG̲PRINT(">> func\n");
…
DEBUG̲PRINT("<< func\n");
}
1.2)
assertマクロを使用する方法 C言語規格では,プログラム診断機能として,assert
マクロが用意されている。assertマクロはデバッグ時にプログラムミスを見付けやす
くするために有用である。どのような場所でassertマクロを使用するのかを規定し,
プロジェクト内で統一させておくと,結合テストなどのときに一貫したデバッグ情
報が収集でき,デバッグしやすくなる。
次に,assertマクロの使用方法について簡単に説明する。例えば,引数として渡さ
れるポインタに,空ポインタが渡されることはないという前提条件のもとに書かれ
た関数定義では,次のようにコーディングしておく。
void func(int *p) {
assert(p != NULL);
*p = INIT̲DATA;
…
}
コンパイル時に,NDEBUGマクロが定義された場合,assertマクロは何もしない。
一方,NDEBUGマクロが定義されない場合は,assertマクロに渡した式が偽の場合,
ソースのファイル名及び行位置を標準エラーに吐き出した後,異常終了する。マク
ロ名がDEBUGではなく,NDEBUGであることに注意する。
67
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
assertマクロは,コンパイラがassert.hで用意するマクロである。次を参考に,プ
ロジェクトで異常終了のさせ方を検討し,コンパイラが用意しているマクロを利用
するか,独自のassert関数を用意するかを決定する。
#ifdef NDEBUG
#define assert(exp) ((void) 0)
#else
#define assert(exp) (void) ((exp)) || (̲assert(#exp, ̲̲FILE̲̲,
̲̲LINE̲̲)))
#endif
void ̲assert(char *mes, char *fname, unsigned int lno) {
fprintf(stderr, "Assert:%s:%s(%d)\n", mes, fname, lno);
fflush(stderr);
abort();
}
2) リリース後のログ出力 デバッグのための記述を含まないリリース用モジュールに
も,問題調査のための記述を入れておくと有用である。よくある方法は,調査情報を
ログとして残すことである。ログ情報は,リリースモジュールに対する妥当性確認の
テスト,又は顧客に提供したシステムで発生した問題の調査に役立つ。
ログ情報を残す場合,次のような項目を決定し,規約として規定する。
・ タイミング
ログを残すタイミングは,異常状態発見時だけでなく,外部システムとの送
受信のタイミングなど,どうして異常状態が発生したのかの過去の履歴が追え
るようなタイミングを設定する。
・ ログに残す情報
直前に実行していた処理,データの値,メモリのトレース情報など,どうし
て異常状態が発生したのかの過去の履歴が追えるような情報を残す。
・ 情報出力用マクロ又は関数
ログ情報の出力は,マクロ又は関数として局所化する。ログの出力先は変更
できる方が好ましいことが多いためである。
b) (M5.1.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 前処理演算子 #及び ##は使用しない(MISRA 19.13)。
2) 一つのマクロ定義内で#又は## 前処理演算子を複数回使用しない(MISRA 19.12)。
適合例
不適合例
2)の例
#define AAA(a, b) a#b
#define BBB(x, y) x##y
1),2)の例
#define XXX(a, b, c) a#b##c
注記 # 演算子と ## 演算子との評価順序は規定されていないので,# 演算子と ## 演算子とを
混在させない,及びそれぞれを2回以上使用しない。
68
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
c) (M5.1.3) 関数形式のマクロよりも,関数を使用する。[採用指針: ] [規約化: ]
適合例
不適合例
int func(int arg1, int arg2) {
return arg1 + arg2;
}
#define func(arg1, arg2) (arg1 + arg2)
注記 関数形式のマクロではなく関数にすることで,デバッグ時に関数の先頭でストップするなど,
処理を追いやすくなる。また,コンパイラによる型検査が行われるため,コーディングミス
を見付けやすくなる。
A.3.6.3
(M5.2) 動的なメモリ割当ての使用に気を付ける。
ルールは,次による。
(M5.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択,規約]
1) 動的メモリは使用しない。
2) 動的メモリを使用する場合は,《使用するメモリ量の上限,メモリ不足の場合の処理,デバッグ方法
などを規定する。》
注記 動的メモリを使用すると,不当なメモリをアクセスしたり,メモリをシステムに返却し忘
れたりすることによって,システム資源がなくなるメモリリークの危険がある。動的メモ
リを使用せざるを得ない場合は,デバッグしやすくするためのルールを決めておくとよい。
コンパイラによっては,次のようなデバッグ用の関数が用意されているものもある。ま
ずは使用しているコンパイラを確認する。また,オープンソースの中にもデバッグ用のソ
ースコードがあるので,自作する場合は,これらを参考に,作成するとよい。
ルール定義の例:
動的メモリ獲得・返却は,malloc,freeなどの標準関数は使用せずに,プロジェクトで用
意した,X̲MALLOC,X̲FREE関数を使用する。デバッグ用のコードは,-DDEBUGでコ
ンパイルして作成する。
-- X̲MALLOC.h --
#ifdef DEBUG
void *log̲malloc(size̲t size, char*, char*);
void log̲free(void*);
#define X̲MALLOC(size) log̲malloc(size, ̲̲FILE̲̲, ̲̲LINE̲̲)
#define X̲FREE(p) log̲free(p, ̲̲FILE̲̲, ̲̲LINE̲̲)
#else
#include <stdlib.h>
#define X̲MALLOC(size) malloc(size)
#define X̲FREE(p) free(p)
#endif
[コード例]
#include "X̲MALLOC.h"
69
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
…
p = X̲MALLOC(sizeof(*p) * NUM);
if (p == NULL) {
return (MEM̲NOTHING);
}
…
X̲FREE(p);
return (OK);
注意(動的メモリ使用時の問題点)
動的メモリを使用する場合に起こしがちな問題を,次に挙げる。
・ バッファオーバフロー
獲得したメモリの範囲を超えて,参照又は更新を行うことである。特に,範囲外
を更新してしまった場合,更新した箇所で障害が発生する訳ではなく,更新によっ
て破壊されたメモリを参照した箇所で障害が発生する。厄介なのは,動的メモリの
場合,どこでメモリを破壊しているかを見付けるのが,非常に困難なことである。
・ 初期化漏れ
通常の動的メモリ関数で獲得したメモリの初期化は行われていない(一部の動的
メモリ獲得関数では初期化を行っているものもある。)。自動変数と同様に,プログ
ラムで初期化してから使用しなければならない。
・ メモリリーク
返却し忘れているメモリのことである。1回1回終わってしまうプログラムの場
合は問題ないが,動作し続けるプログラムの場合,メモリリークの存在は,メモリ
が枯渇し,システム異常が発生する危険の原因となる。
・ 返却後使用
free関数などでメモリを返却すると,そのメモリは,その後に呼ばれるmalloc関
数などで再利用される可能性がある。このため,freeしたメモリのアドレスを使っ
て更新した場合,別用途で利用しているメモリを破壊することになる。バッファオ
ーバフローでも説明したように,この問題は非常にデバッグが困難である。
これらの問題を起こすコードは,コンパイルエラーにならない。また,問題を埋め込ん
だ場所で障害が発生しないため,通常の仕様を確認するテストでは発見できない。デバッ
グする場合には,コードレビューを行ったり,これらの問題を発見するためのテストコー
ドを挿入し,又は特別なライブラリを組み込んだりしてテストを実施する。
A.4 (P) 移植性
A.4.1 概要
組込みソフトウェアの特徴の一つは,それが動作するプラットフォームの選択肢が多様である点が挙げ
られる。こうした中で,組込みソフトウェアの移植性は,ソースコードレベルでも極めて重要な要素とな
りつつある。ソフトウェアの移植性を向上させるためには,次のような作法に留意する。
・ (P1) コンパイラに依存しない書き方にする。
70
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
・ (P2) 移植性に問題のあるコードは局所化する。
A.4.2 処理系からの独立性
A.4.2.1
(P1) コンパイラに依存しない書き方にする。
C言語でプログラミングをする場合,コンパイラ(処理系)の利用は避けて通れない。世の中には様々
な処理系が提供されているが,それぞれ,若干の癖をもっている。そして,ソースコードを作成する場合
に下手な書き方をすると,この処理系の癖に依存する形となってしまい,別の処理系を用いた場合に思わ
ぬ事態となる。
このため,プログラミングをする場合には,処理系に依存しない書き方にするといった注意が必要であ
る。
・ (P1.1) 拡張機能及び処理系定義の機能は使用しない。
・ (P1.2) 言語規格で定義されている文字及び拡張表記だけを使用する。
・ (P1.3) データ型の表現,動作仕様の拡張機能,及び処理系依存部分を確認し,文書化する。
・ (P1.4) ソースファイル取込みについて,処理系依存部分を確認し,依存しない書き方にする。
・ (P1.5) コンパイル環境に依存しない書き方にする。
A.4.2.2
(P1.1) 拡張機能及び処理系定義の機能は使用しない。
ルールは,次による。
a) (P1.1.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択,文書]
1) C90の仕様外の機能は使用しない。
2) C90の仕様外の機能を使用する場合は,《使用する機能とその使い方を文書化する。》
注記 C90では,// コメント,long long型など,最近のコンパイラでは提供されC99の規格で定
義されている機能が許されていない。
2)のルールを選択し,C99の規格で定義されている機能について利用を認めるというル
ールも現実的である。
b) (P1.1.2) 《使用する処理系定義の動作は全て文書化する。》(MISRA 3.1)[採用指針:必要] [規約化:
文書]
注記 C90では,ライブラリ部分を除くと41個の処理系定義項目がある。例えば,次は処理系定義
であり,使用する場合には文書化の対象となる。
・ 浮動小数点の表現方法
・ 整数除算の剰余の符号の扱い
・ インクルード指令のファイル検索順序
・ #pragma
附属書Cも参照。
c) (P1.1.3) 他言語で書かれたプログラムを利用する場合,《そのインタフェースを文書化し,使用方法を
規定する。》[採用指針: ] [規約化:文書,規約]
注記 C言語規格では,他の言語で書かれたプログラムをC言語プログラムから利用するためのイ
ンタフェースを定めていない。すなわち,他言語で書かれたプログラムを利用する場合は,
拡張機能を利用することとなり,移植性に欠ける。使用する場合は,移植の可能性の有無に
かかわらず,コンパイラの仕様を文書化するとともに使用方法を規定する。
71
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
A.4.2.3
(P1.2) 言語規格で定義されている文字及び拡張表記だけを使用する。
ルールは,次による。
a) (P1.2.1) プログラムの記述において,C90で規定している文字以外の文字を使用する場合,コンパイ
ラの仕様を確認し《その使い方を規定する。》[採用指針: ] [規約化:規約]
注記 C90でソースコードに使用できる文字として最低限定義しているのは,アルファベット26文
字の大文字及び小文字,10個の10進数字,29個の図形文字,空白文字,水平タブ,垂直タ
ブ,並びに書式送りを表す制御文字である。日本では,多くのコンパイラが日本語の文字列
及び/又はコメント記述を許しているが,問題を起こす場合もあり注意が必要である。
例えば,シフトJISの“表”という文字は2バイト目がASCIIコードの“\”になり,// コ
メントを利用した場合,行連結と思われることがある。
int index̲arr[10]; // インデックス表
int *index̲ptr = index̲arr; // この行が前の行に連結されることがある。
C90で規定していない文字(例えば,日本語)を使用する場合には,次の場所に使用でき
るかを確認し,その使い方を規定する。
・ コメント
・ 文字列リテラル
− 文字列の文字コード中に \ が存在した場合の処理(特別な配慮が必要か,コン
パイル時のオプション指定が必要か,など)
− ワイド文字列リテラル(L"文字列" のようにLという接頭語)で記述する必要
性
・ 文字定数
− その文字定数のビット長
− ワイド文字定数(L'あ' のようにLという接頭語)で記述する必要性
・ #includeのファイル名
例えば,次のようなルールを規定する。
・ コメントに日本語を使用してよい。使用する日本語のコードはシフトJIS とする。半
角カナは使用しない。
・ 文字列,文字定数,#includeのファイル名には,日本語を使用してはならない。
b) (P1.2.2) 言語規格で定義されている英字逆斜線表記(エスケープシーケンス)だけを使用する。[採用
指針: ] [規約化: ]
適合例
不適合例
char c = '\t'; /* 適切 */
char c = '\x';
/* 不適切。言語規格で定義されていない英字
逆斜線表記。
多くの処理系はxと解釈するが移植性はない */
注記 英字逆斜線表記は,C90では改行(\n)など,次の七つが規定されている。
\a,\b,\f,\n,\r,\t,\v
72
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
規定されていない英字逆斜線表記が文字定数,又は文字列リテラルの中に現れる場合,動
作は規定されていない。
A.4.2.4
(P1.3) データ型の表現,動作仕様の拡張機能,及び処理系依存部分を確認し,文書化する。
ルールは,次による。
a) (P1.3.1) 単なる(符号の有無の指定のない)char型は,文字の値の格納(処理)だけに使用し,符号
の有無(処理系定義)に依存する処理が必要な場合は,符号を明記したunsigned char又はsigned char
を利用する。[採用指針:必要] [規約化: ]
適合例
不適合例
char c = 'a'; /* 文字の格納に利用 */
int8̲t i8 = -1;
/* 8bitのデータとして利用したい場合は,
例えばtypedefした型を使用する */
char c = -1;
if (c > 0) { … }
/* 不適切。処理系によってcharは符号付き
の場合と符号なしの場合とがあり,その違いで,
比較の結果が異なる */
注記 符号の有無を指定しないcharは,intなどの他の整数型と違い,符号付きか否かがコンパイラ
によって異なる(intはsigned intと同じ。)。このため,符号の有無に依存する使用は移植性
がない。これは,符号の有無の指定のないcharが,文字の格納のために用意された独立した
型(char,unsigned char,signed charは,三つの型である。)であり,言語規格は,そのため
に利用することを想定しているためである。符号の有無に依存する処理が必要であるなど小
さい整数型として使用する場合には,符号の有無を指定したunsigned char又はsigned charを
使用する。その場合,移植時の修正範囲を局所化するため,その型をtypedefして使用するこ
とが望ましい。
このルールと似ている問題に,標準関数のgetcの返す型がintであり,charで受けてはい
けないというものがあるがこれは関数インタフェース(情報損失の可能性のある代入)の問
題である。
b) (P1.3.2) 列挙型(enum型)のメンバは,int型で表現可能な値で定義する。[採用指針: ] [規約化: ]
適合例
不適合例
/* int 16bit,long32bitの場合 */
enum largenum {
LARGE = INT̲MAX
};
/* int 16bit,long32bitの場合 */
enum largenum {
LARGE = INT̲MAX+1
};
注記 C言語規格では,列挙型のメンバはint型で表現できる範囲の値でなければならない。しかし
ながら,コンパイラによっては,機能を拡張しint型の範囲を超えていてもエラーにならない
可能性がある。
なお,C++ ではlong型の範囲の値が許されている。
c) (P1.3.3) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,文書]
1) ビットフィールドは使用しない。
2) ビット位置が意識されたデータに対してはビットフィールドは使用しない。
3) ビットフィールドの処理系定義の動作又はパッキングに(プログラムが)依存している場合,《それ
は文書化する。》(MISRA 3.5)
73
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
2)の例
struct S {
unsigned int bit1:1;
unsigned int bit2:1;
};
extern struct S *p;
/* 例えばpは,単なるフラグの集合を指して
いるなど,pが指すデータ中,bit1がどのビット
であってもよい場合は,これでよい*/
p->bit1 = 1;
2)の例
struct S {
unsigned int bit1:1;
unsigned int bit2:1;
};
extern struct S *p;
/* 例えばpがIOポートを指しているなど
ビット位置が意味をもつ,すなわち,bit1
がデータの最低位ビットを指すか,最高位
ビットを指すかに意味がある場合は,移植
性がない */
p->bit1 = 1;
/* pが指しているデータのどのビットに
設定されるかは処理系依存 */
注記 ビットフィールドは,次の動作がコンパイラによって異なる。
1) 符号の有無の指定のないint型のビットフィールドが符号付きと扱われるかどうか
2) 単位内のビットフィールドの割付け順序
3) ビットフィールドの記憶域単位の境界
例えばIO ポートへのアクセスのように,ビット位置が意味をもつデータのアクセスに使
用すると,2)及び3)の点から移植性に問題がある。そのため,そのような場合にはビットフ
ィールドは利用せず,& ,| などのビット単位の演算を使用する。
A.4.2.5
(P1.4) ソースファイル取込みについて,処理系依存部分を確認し,依存しない書き方にする。
ルールは,次による。
a) (P1.4.1) #include指令の後には,<filename> 又は "filename" を続ける(MISRA 19.3)。[採用指針:基
本] [規約化: ]
適合例
不適合例
#include <stdio.h>
#include "myheader.h"
#if VERSION == 1
#define INCFILE "vers1.h"
#elif VERSION == 2
#define INCFILE "vers2.h"
#endif
#include INCFILE
#include stdio.h
/* < > も,""も付いていない */
#include "myheader.h" 1
/* 最後に1が指定されている */
注記 C言語規格では,#include指令をマクロ展開した後の形がヘッダ名の二つの形式(<…>又は
"…")のいずれとも一致しない場合の動作は定義されていない(未定義)。ほとんどのコンパ
イラが,いずれの形式にも一致しない場合をエラーにするが,エラーにしない場合もあるの
で,いずれかの形式で記述する。
74
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
b) (P1.4.2) 《#includeのファイル指定で,<> 形式と"" 形式との使い分け方を規定する。》[採用指針: ]
[規約化:規約]
適合例
不適合例
#include <stdio.h>
#include "myheader.h"
#include "stdio.h"
#include <myheader.h>
注記 #includeの書き方には2種類ある。使い方を統一するために,例えば次のようなルールを規
定する。
・ コンパイラの提供するヘッダは,<> で囲んで指定する。
・ プロジェクトで作成したヘッダは," " で囲んで指定する。
・ 購入ソフトの提供するヘッダは," " で囲んで指定する。
c) (P1.4.3) #includeのファイル指定では,文字 ',\,",/*,及び : は使用しない。[採用指針:必要] [規
約化: ]
適合例
不適合例
#include "inc/my̲header.h" /* 適切 */
#include "inc\my̲header.h" /* 不適切 */
注記 これらの文字を使用する(正確には次に示す。)場合,C言語規格では,動作が定義されてい
ない。すなわち,どのような動作となるか不定であり,移植性がない。
・ 文字 ',\,",又は /* が <> の間の文字列中に現れた場合
・ 文字 ',\,又は /* が " の間の文字列中に現れた場合
その他,文字:(コロン)は処理系によって動作が異なるため,移植性がない。
A.4.2.6
(P1.5) コンパイル環境に依存しない書き方にする。
ルールは,次による。
(P1.5.1) #includeのファイル指定では,絶対パスは記述しない。 [採用指針: ] [規約化: ]
適合例
不適合例
#include "h1.h"
#include "/project1/module1/h1.h"
注記 絶対パスで記述すると,ディレクトリを変更してコンパイルするときに修正が必要となる。
A.4.3 コードの局所性
A.4.3.1
(P2) 移植性に問題のあるコードは局所化する。
処理系に依存するソースコードは極力書かないようにすることが原則であるが,場合によっては,その
ような記述を避けられない場合がある。代表的なものとしては,C言語からアセンブリ言語のプログラム
を呼び出す場合などがそれに当たる。このような場合には,その部分をできるだけ局所化しておくのがよ
い。
・ (P2.1) 移植性に問題のあるコードは局所化する。
A.4.3.2
(P2.1) 移植性に問題のあるコードは局所化する。
ルールは,次による。
a) (P2.1.1) C言語からアセンブリ言語のプログラムを呼び出す場合,インラインアセンブリ言語だけが含
まれるC言語の関数として表現する,マクロで記述するなど,《局所化する方法を規定する。》[採用指
針:必要] [規約化:規約]

75
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
#define SET̲PORT1 asm(" st.b 1, port1")
void f() {
…
SET̲PORT1;
…
}
void f() {
…
asm(" st.b 1,port1");
…
}
/* asmと他の処理とが混在している */
注記 アセンブラを取り込む方式としてasm(文字列) の形式を拡張機能としてもっている処理系が
多い。しかしながら,機能をもっていない処理系もあり,また,同じ形式でも違う動作とな
る場合もあり,移植性はない。
b) (P2.1.2) 処理系が拡張しているキーワードは,《マクロを規定して》局所化して使用する。[採用指針:
必要] [規約化:規約]
適合例
不適合例
/* interruptはある処理系が機能拡張している
キーワードとする */
#define INTERRUPT interrupt
INTERRUPT void int̲handler (void) {
…
}
/* interruptはある処理系が機能拡張している
キーワードとする。マクロ化せずに利用して
いる */
interrupt void int̲handler(void) {
…
}
注記 コンパイラによっては,#pragma指令を用いず,拡張したキーワードを提供している場合が
あるが,そのようなキーワードの使用は移植性がない。使用する場合は,マクロ化するなど
局所化することが重要である。マクロ名は,例に示すように,キーワードを大文字にしたも
のを利用することが多い。
c) (P2.1.3) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,規約]
1) char,int,long,float及びdoubleという基本型は使用しない。代わりにtypedefした型を使用する。
《プロジェクトで利用するtypedefした型を規定する。》
2) char,int,long,float及びdoubleという基本型を,そのサイズに依存する形式で使用する場合,各
基本型をtypedefした型を使用する。《プロジェクトで利用するtypedef型を規定する。》
適合例
不適合例
1),2)の例
uint32̲t flag32;
/* 32bitを仮定する場合,uint32̲tを利用 */
2)の例
int i;
for (i = 0; i < 10; i++) { … }
/* iはインデックスとして利用。8bitで
も,16bitでも,32bitでも適切であり,
言語仕様の基本型を利用しているのでこれ
1),2)の例
unsigned int flag32;
/* intを32bitと仮定して利用 */
76
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
でよい */
注記 char,short,int,longの各整数型のサイズ及び内部表現は組込み系の処理系によって異なる。
組込みシステムでは,言語規格に合わないものが使われている可能性がある。
C99 では,言語規格として次のtypedefを提供することが任意選択機能として規定されて
いるため,typedef する名前として参考にするとよい。
int8̲t,int16̲t,int32̲t,int64̲t,uint8̲t,uint16̲t,uint32̲t,uint64̲t
A.5 (E) 効率性
A.5.1 概要
組込みソフトウェアは,製品に組み込まれてハードウェアとともに,実世界で動作する点が特徴である。
そのために,組込みソフトウェアでは,特にメモリなどの資源効率性及び/又は時間性能を考慮した時間
効率性に注意しながらコーディングする必要がある。そのためには次のような作法に留意する。
・ (E1) 資源及び/又は時間の効率を考慮した書き方にする。
A.5.2 資源及び/又は時間の効率性
A.5.2.1
(E1) 資源及び/又は時間の効率を考慮した書き方にする。
ソースコードの書き方によって,オブジェクトサイズが増加してしまったり,実行速度が低下してしま
うことがある。メモリサイズ及び/又は処理時間に制約がある場合には,それらを意識したソースコード
の書き方を工夫する。
・ (E1.1) 資源及び/又は時間の効率を考慮した書き方にする。
A.5.2.2
(E1.1) 資源及び/又は時間の効率を考慮した書き方にする。
ルールは,次による。
a) (E1.1.1) 関数形式マクロは,速度性能に関わる部分に閉じて使用する。[採用指針:基本] [規約化: ]
適合例
不適合例
extern void func1(int, int); /* 関数 */
#define func2(arg1, arg2) /* 関数形式マクロ */
func1(arg1, arg2);
for (i = 0; i < 10000; i++) {
func2(arg1, arg2);
/* 速度性能が重要な処理 */
}
#define func1(arg1, arg2) /* 関数形式マクロ */
extern void func2(int, int); /* 関数 */
func1(arg1, arg2);
for (i = 0; i < 10000; i++) {
func2(arg1, arg2);
/* 速度性能が重要な処理 */
}
注記1 関数形式マクロよりも関数の方が安全であり,なるべく関数を使用することが望ましい。
しかし,関数は呼出しの処理と復帰の処理とで速度性能が劣化する場合がある。このため,
速度性能を上げたい場合,関数形式マクロを使用する。ただし,関数形式マクロを多用す
ると,使用した場所にコードが展開されオブジェクトサイズが増加する可能性がある。
注記2 関連ルールとして(M5.1.3)を参照。
b) (E1.1.2) 繰返し処理内で,変化のない処理をしない。[採用指針:基本] [規約化: ]
77
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
適合例
不適合例
var1 = func();
for (i = 0; (i + var1) < MAX; i++) {
…
}
/* 関数funcは,同じ結果を返す */
for (i = 0; (i + func()) < MAX; i++) {
…
}
注記 同じ結果が返される場合に,同じ処理を複数回実施すると非効率である。コンパイラの最適
化に頼れることも多いが,例のように,コンパイラでは分からない場合は注意する。
c) (E1.1.3) 関数の引数として構造体ではなく構造体ポインタを使用する。[採用指針: ] [規約化: ]
適合例
不適合例
typedef struct stag {
int mem1;
int mem2;
…
} STAG;
int func (const STAG *p) {
return p->mem1 + p->mem2;
}
typedef struct stag {
int mem1;
int mem2;
…
} STAG;
int func (STAG x) {
return x.mem1 + x.mem2;
}
注記 関数の引数として構造体を渡すと,関数呼出し時に構造体のデータを全て実引数のための領
域にコピーする処理が行われ,構造体のサイズが大きいと,速度性能を劣化させる原因とな
る。
参照しかしない構造体を渡す場合は,単に構造体ポインタにするだけでなく,const修飾を
行う。
d) (E1.1.4) 《switch文とするかif文とするかは,可読性及び効率性を考えて選択方針を決定し,規定す
る。》[採用指針: ] [規約化:規約]
注記1 switch文はif文より可読性に優れることが多い。また,最近のコンパイラは,switch文に
対して,テーブルジャンプ,バイナリサーチなどの最適化したコードを出力することが多
い。このことを考慮してルールを規定する。
注記2 関連ルール(M1.3.1)を参照。
ルールの例:
式の値(整数値)によって処理を分岐する場合,分岐の数が3 以上である場合,if
文ではなくswitch文を使用する。ただし,プログラムの性能向上において,switch文
の効率が問題となる場合には,この限りではない。
78
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書B
(参考)
C言語文法によるルール分類
この附属書は,この規格の附属書Aに示したルールをC言語の文法項目によって分類したものである。
ただし,ルールの利用特性に関する採用指針及び規約化の用語は,附属書Aの記法に従う。
B.1
スタイル
B.1.1 構文スタイル
(M4.1.1) 《波括弧({),字下げ,空白の入れ方などのスタイルに関する規約を規定する。》[採用指針:
必要] [規約化:規約]
B.1.2 注釈
(M4.2.1) 《ファイルヘッダ注釈,関数ヘッダ注釈,行末注釈,ブロック注釈,著作権表示などの書き方
に関する規約を規定する。》[採用指針:必要] [規約化:規約]
B.1.3 名前付け
a) (M4.3.1) 《外部変数,内部変数などの命名に関する規約を規定する。》[採用指針:必要] [規約化:規
約]
b) (M4.3.2) 《ファイル名の命名に関する規約を規定する。》[採用指針:必要] [規約化:規約]
c) (M1.7.1) 名前の一意性は,次の規則に従う。[採用指針:必要] [規約化: ]
1) 外部有効範囲の識別子が隠蔽されることになるため,内部有効範囲の識別子には外部有効範囲の同
じ名前を使用しない(MISRA 5.2)。
2) typedef 名は固有の識別子とする(MISRA 5.3)。
3) タグ名は固有の識別子とする(MISRA 5.4)。
4) 静的記憶域期間をもつオブジェクト又は関数識別子は再使用しない(MISRA 5.5)。
5) 構造体及び共用体のメンバ名を除いて,ある名前空間の識別子を,他の名前空間の識別子と同じつ
づりにしない(MISRA 5.6)。
d) (M1.7.2) 標準ライブラリの関数名,変数名及びマクロ名は再定義・再利用しない。また,定義を解除
しない。[採用指針:必要] [規約化: ]
e) (M1.7.3) 下線で始まる名前(変数)は定義しない。[採用指針:必要] [規約化: ]
B.1.4 ファイル内の構成
a) (M4.4.1) 《ヘッダファイルに記述する内容(宣言,定義など)とその記述順序を規定する。》[採用指
針:必要] [規約化:規約]
b) (M4.4.5) ヘッダファイルには,変数定義及び関数定義を記述しない。[採用指針:必要] [規約化: ]
c) (M4.4.6) ヘッダファイルは重複取込みに耐え得る作りとする。《そのための記述方法を規定する。》[採
用指針:必要] [規約化:規約]
d) (M4.4.2) 《ソースファイルに記述する内容(宣言,定義など)とその記述順序を規定する。》[採用指
針:必要] [規約化:規約]
e) (M4.4.3) 外部変数又は関数(ファイル内でだけ使用する関数を除く。)を使用,又は定義する場合,
宣言を記述したヘッダファイルを取り込む。[採用指針:必要] [規約化: ]
79
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
B.1.5 定数
a) (M1.2.2) 適切な型を示す接尾語が使用できる定数記述には,接尾語を付けて記述する。long型整数定
数を示す接尾語は大文字の“L”だけを使用する。[採用指針: ] [規約化: ]
b) (M1.8.5) (0以外の)8進定数及び8 進拡張表記は使用しない(MISRA 7.1)。[採用指針: ] [規約化: ]
c) (M1.2.3) 長い文字列リテラルを表現する場合には,文字列リテラル内で改行を使用せず,連続した文
字列リテラルの連結を使用する。[採用指針: ] [規約化: ]
d) (M1.10.1) 意味のある定数はマクロとして定義して使用する。[採用指針:必要] [規約化: ]
B.1.6 その他(スタイル)
a) (M1.1.2) コードの一部を“コメントアウト”しない(MISRA 2.4)。[採用指針:必要] [規約化: ]
b) (M1.9.1) 意図的に何もしない文を記述しなければならない場合は,注釈又は空になるマクロなどを利
用し,目立たせる。[採用指針:必要] [規約化: ]
c) (M1.8.4) ??で始まる3文字以上の文字の並びは使用しない。[採用指針: ] [規約化: ]
d) (M5.1.3) 関数形式のマクロよりも,関数を使用する。[採用指針: ] [規約化: ]
B.2
型
B.2.1 基本型
a) (P2.1.3) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,規約]
1) char,int,long,float及びdoubleという基本型は使用しない。代わりにtypedefした型を使用する。
《プロジェクトで利用するtypedefした型を規定する。》
2) char,int,long,float及びdoubleという基本型を,そのサイズに依存する形式で使用する場合,各
基本型をtypedefした型を使用する。《プロジェクトで利用するtypedef型を規定する。》
b) (P1.3.1) 単なる(符号の有無の指定のない)char型は,文字の値の格納(処理)だけに使用し,符号
の有無(処理系定義)に依存する処理が必要な場合は,符号を明記したunsigned char又はsigned char
を利用する。[採用指針:必要] [規約化: ]
c) (R2.6.2) ビット列として使用するデータは,符号付き型ではなく,符号なし型で定義する。[採用指
針: ] [規約化: ]
B.2.2 構造体・共用体
a) (M4.5.2) 構造体タグの宣言と変数の宣言とは別々にする。[採用指針: ] [規約化: ]
b) (M1.6.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 共用体は使用しない(MISRA 18.4)。
2) 共用体を使用する場合は,書き込んだメンバで参照する。
c) (R2.1.3) 構造体又は共用体の比較にmemcmpを使用しない。[採用指針:基本] [規約化: ]
B.2.3 ビットフィールド
a) (P1.3.3) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,文書]
1) ビットフィールドは使用しない。
2) ビット位置が意識されたデータに対してはビットフィールドは使用しない。
3) ビットフィールドの処理系定義の動作又はパッキングに(プログラムが)依存している場合,《それ
は文書化する。》(MISRA 3.5)
b) (R2.6.1) ビットフィールドに使用する型はsigned int又はunsigned intだけとし,1ビット幅のビットフ
ィールドが必要な場合はsigned int型でなく,unsigned int型を使用する。[採用指針:必要] [規約化: ]
80
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
B.2.4 列挙型
a) (R1.2.2) 列挙型(enum型)のメンバの初期化は,定数を全く指定しない,全て指定する,又は最初の
メンバだけを指定する,のいずれかとする。[採用指針: ] [規約化: ]
b) (M2.2.4) 関連する整数定数を定義するときは,#defineよりenumを使用する。[採用指針: ] [規約
化: ]
c) (P1.3.2) 列挙型(enum型)のメンバは,int型で表現可能な値で定義する。[採用指針: ] [規約化: ]
B.3
宣言・定義
B.3.1 初期化
a) (R1.1.1) 自動変数は宣言時に初期化するか,又は値を使用する直前に初期値を代入する。[採用指針:
基本] [規約化: ]
b) (R1.1.2) const型変数は,宣言時に初期化する。[採用指針:基本] [規約化: ]
c) (R1.2.1) 要素数を指定した配列の初期化では,初期値の数は,指定した要素数と一致させる。[採用指
針:基本] [規約化: ]
d) (M2.1.1) 配列及び構造体を0 以外で初期化する場合は,構造を示し,それに合わせるために波括弧
“{ }”を使用する。また,全て0 以外の場合を除き,データは漏れなく記述する。[採用指針:必要]
[規約化: ]
e) (M4.5.3) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 構造体・共用体・配列の初期値式の並び,及び列挙子並びの最後の“}”の前に“,”を記述しない。
2) 構造体・共用体・配列の初期値式の並び,及び列挙子並びの最後の“}”の前に“,”を記述しない。
ただし,配列の初期化の初期値並びの最後の“}”の前に“,”を書くことは許す。
B.3.2 変数宣言・定義
a) (M1.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 一つの宣言文で宣言する変数は,一つとする(複数宣言しない。)。
2) 同じような目的で使用する同じ型の自動変数は,一つの宣言文で複数宣言してもよいが,初期化す
る変数と初期化しない変数とを混在させない。
b) (M1.11.1) 参照しかしない領域はconstであることを示す宣言をする。[採用指針:必要] [規約化: ]
c) (M1.11.2) 他の実行単位によって更新される可能性のある領域はvolatile であることを示す宣言をす
る。[採用指針:必要] [規約化: ]
d) (M2.2.1) 一つの関数内でだけ使用する変数は関数内で変数宣言する。[採用指針:基本] [規約化: ]
e) (M2.2.2) 同一ファイル内で定義された複数の関数からアクセスされる変数は,ファイル内が有効範囲
のstatic変数宣言する。[採用指針:必要] [規約化: ]
f)
(M4.4.4) 外部変数は,複数箇所で定義しない。[採用指針:基本] [規約化: ]
g) (M1.6.1) 目的ごとに変数を用意する。[採用指針: ] [規約化: ]
h) (M1.11.3) 《ROM化するための変数宣言及び定義のルールを規定する。》[採用指針: ] [規約化:規
約]
B.3.3 関数宣言・定義
a) (R2.8.3) 関数呼出し及び関数定義の前に関数原型宣言を行い,さらに,同じ宣言が関数呼出しと定義
とで参照されるようにする。[採用指針:必要] [規約化: ]
b) (M4.5.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
81
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
1) 関数原型宣言では,全ての引数に名前を付けない(型だけとする。)。
2) 関数原型宣言では,全ての引数に名前を付ける。さらに,引数の型及び名前,並びに戻り型は,関
数定義と文字どおりに同じにする。
c) (R2.8.1) 引数をもたない関数は,引数の型をvoidとして宣言する。[採用指針:必要] [規約化: ]
d) (R2.8.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択,文書]
1) 可変個引数をもつ関数を定義しない(MISRA 16.1)。
2) 可変個引数をもつ関数を使用する場合は,《処理系での動作を文書化し,使用する》。
e) (M2.2.3) 同じファイルで定義した関数からだけ呼ばれる関数は,static関数とする。[採用指針:必要]
[規約化: ]
B.3.4 配列宣言・定義
(R3.1.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) 配列のextern宣言の要素数は必ず指定する。
2) 要素数が省略された初期化付き配列定義に対応した配列のextern宣言を除き,配列のextern宣言の
要素数は必ず指定する。
B.3.5 その他(宣言・定義)
a) (M1.1.1) 使用しない関数,変数,引数,ラベルなどは宣言(定義)しない。[採用指針:必要] [規約化: ]
b) (M1.3.3) 関数,変数の定義及び宣言では型を明示的に記述する。[採用指針:基本] [規約化: ]
B.4
式
B.4.1 関数呼出し
a) (R3.3.2) 関数に渡す引数に制限がある場合,関数呼出しの前に,制限値でないことを確認してから関
数を呼び出す。[採用指針: ] [規約化: ]
b) (R3.3.1) 関数がエラー情報を戻す場合,エラー情報をテストする(MISRA 16.10)。[採用指針: ] [規
約化: ]
c) (R3.4.1) 関数は,直接的か間接的かにかかわらず,その関数自体を呼び出さないほうがよい(MISRA
16.2)。[採用指針: ] [規約化: ]
B.4.2 ポインタ
a) (R2.7.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) ポインタ型は,他のポインタ型及び整数型に変換しない。また,逆もしない。ただし,データへの
ポインタ型におけるvoid*型との変換は除く。
2) ポインタ型は,他のポインタ型,及びポインタ型のデータ幅未満の整数型に変換しない。ただし,
データへのポインタ型におけるvoid*型との変換は除く。
3) データへのポインタ型は,他のデータ型へのポインタ型に変換してよいが,関数型へのポインタは,
他の関数型及びデータ型へのポインタ型に変換しない。ポインタ型を整数型に変換する場合,ポイ
ンタ型のデータ幅未満の整数型への変換はしない。
b) (R1.3.1) 次のいずれかを選択する。[採用指針:基本] [規約化:選択]
1) ポインタへの整数の加減算(++及び--も含む。)は使用せず,確保した領域への参照・代入は[ ]を用
いる配列形式にする。
2) ポインタへの整数の加減算(++及び--も含む。)は,ポインタが配列を指している場合だけとし,結
果は,配列の範囲内を指すようにする。
82
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
c) (R1.3.2) ポインタ同士の減算は,同じ配列の要素を指すポインタだけに使用する。[採用指針:基本] [規
約化: ]
d) (R1.3.3) ポインタ同士の比較は,同じ配列の要素,又は同じ構造体のメンバを指すポインタだけに使
用する。[採用指針: ] [規約化: ]
e) (R2.7.3) ポインタが負かどうかの比較をしない。[採用指針:基本] [規約化: ]
f)
(R3.2.2) ポインタは,空ポインタでないことを確認してからポインタの指す先を参照する。[採用指
針: ] [規約化: ]
g) (M3.4.1) 3段階以上のポインタ指定は使用しない。[採用指針: ] [規約化: ]
h) (M4.6.1) 次のいずれかを選択する。[採用指針:必要] [規約化:選択]
1) 空ポインタには0を使用する。NULLはいかなる場合にも使用しない。
2) 空ポインタにはNULLを使用する。NULLは空ポインタ以外に使用しない。
B.4.3 キャスト
a) (R2.4.2) 符号付きの式と符号なしの式との混在した算術演算又は比較を行う場合は,期待する型に明
示的にキャストする。[採用指針: ] [規約化: ]
b) (R2.7.2) ポインタで指し示された型からconst修飾又はvolatile修飾を取り除くキャストをしない
(MISRA 11.5)。[採用指針:必要] [規約化: ]
B.4.4 単項演算
a) (R2.5.2) 単項演算子 '-' は符号なしの式に使用しない。[採用指針:基本] [規約化: ]
b) (M1.5.1) 関数識別子(関数名)には,前に &を付けるか,括弧付きの仮引数並び(空でも可)を指定
して使用する(MISRA 16.9)。[採用指針: ] [規約化: ]
B.4.5 加減乗除
(R3.2.1) 除算及び剰余算の右辺式は,0でないことを確認してから演算をする。[採用指針: ] [規約
化: ]
B.4.6 シフト
a) (R2.5.4) シフト演算子の右辺(右オペランド)の項はゼロ以上,左辺(左オペランド)の項のビット
幅未満にする。[採用指針:基本] [規約化: ]
B.4.7 比較
a) (R2.1.1) 浮動小数点式は,等価又は非等価の比較をしない。[採用指針:基本] [規約化: ]
b) (R2.2.1) 真偽を求める式の中で,真として定義した値と比較しない。[採用指針: ] [規約化: ]
c) (M1.5.2) ゼロとの比較は明示的にする。[採用指針: ] [規約化: ]
B.4.8 ビット演算
(R2.5.3) unsigned char型,又はunsigned short型のデータをビット反転(~),又は左シフト(<<)する場
合,結果の型に明示的にキャストする。[採用指針:必要] [規約化: ]
B.4.9 論理演算
a) (M1.4.1) &&演算及び || 演算の右式及び左式は単純な変数又は ( ) で囲まれた式を記述する。ただし,
&& 演算が連続して結合している場合,及び|| 演算が連続して結合している場合は,&& 式又は || 式
を ( ) で囲まない。[採用指針: ] [規約化: ]
b) (M1.8.1) 論理演算子 &&又は || の右側のオペランドには,副作用がないようにする(MISRA 12.4)。
[採用指針: ] [規約化: ]
83
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
B.4.10 3項演算
(R2.3.2) 条件演算子(?: 演算子)では,論理式は括弧で囲み,戻り値は二つとも同じ型にする。[採用指
針: ] [規約化: ]
B.4.11 代入
a) (R2.5.1) 情報損失を起こす可能性のあるデータ型への代入(=演算,関数呼出しの実引数渡し,又は
関数復帰)又は演算を行う場合は,問題がないことを確認し,問題がないことを明示するためにキャ
ストする。[採用指針:必要] [規約化: ]
b) (R2.4.1) 演算の型と演算結果の代入先の型とが異なる場合は,期待する演算精度の型へキャストして
から演算する。[採用指針:基本] [規約化: ]
c) (M3.3.3) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 真偽を求める式の中で代入演算子を使用しない。
2) 真偽を求める式の中で代入演算子を使用しない。ただし,慣習的に使う表現は除く。
B.4.12 コンマ
(M3.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) コンマ式は使用しない。
2) コンマ式はfor文の初期化式又は更新式以外では使用しない。
B.4.13 優先順位及び副作用
a) (R3.6.1) 変数の値を変更する記述をした同じ式内で,その変数を参照,変更しない。[採用指針:基本]
[規約化: ]
b) (R3.6.2) 実引数並び,又は2項演算式に,副作用をもつ関数呼出し又はvolatile 変数を,複数記述し
ない。[採用指針:必要] [規約化: ]
c) (M1.4.2) 《演算の実行順序を明示するための括弧の付け方を規定する。》[採用指針: ] [規約化:規
約]
B.4.14 その他(式)
(R2.3.1) 符号なし整数定数式は,結果の型で表現できる範囲内で記述する。[採用指針: ] [規約化: ]
B.5
文
B.5.1 if文
(R3.5.1) if-else if文は,最後にelse節を置く。通常,else条件が発生しないことが分かっている場合は,
次のいずれかの記述とする。[採用指針:必要] [規約化:規約]
1) else節には,例外発生時の処理を記述する。
2) else節には,プロジェクトで規定した注釈を入れる。
B.5.2 switch文
a) (M3.1.4) 次のいずれかを選択する。[採用指針:必要] [規約化:選択,規約]
1) switch文のcase節及びdefault節は,必ずbreak文で終了する。
2) switch文のcase節及びdefault節をbreak文で終了させない場合は,《プロジェクトで注釈を規定し》
その注釈を挿入する。
b) (R3.5.2) switch文は,最後にdefault節を置く。通常,default条件が発生しないことが分かっている場
合は,次のいずれかの記述とする。[採用指針:必要] [規約化:規約]
1) default節には,例外発生時の処理を記述する。
84
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
2) default節には,プロジェクトで規定した注釈を入れる。
c) (M1.3.1) switch(式)の式には,真偽結果を求める式を記述しない。[採用指針:基本] [規約化: ]
d) (M1.3.2) switch文のcase ラベル及びdefault ラベルは,switch文本体の複合文(その中に入れ子にな
った複合文は除く。)だけに記述する。[採用指針: ] [規約化: ]
B.5.3 for・while文
a) (R2.1.2) 浮動小数点型変数は繰返しカウンタとして使用しない。[採用指針:基本] [規約化: ]
b) (R2.3.3) 繰返しカウンタとループ継続条件との比較に使用する変数は,同じ型にする。[採用指針:基
本] [規約化: ]
c) (R3.5.3) 繰返しカウンタの比較に等式及び不等式は使用しない(<=,>=,<,又は >を使用する。)。[採
用指針: ] [規約化: ]
d) (M3.3.1) for文の三つの式には,ループ制御に関わるものだけを記述する(MISRA 13.5)。[採用指針: ]
[規約化: ]
e) (M3.3.2) for ループの中で繰返しカウンタとして用いる数値変数は,ループの本体内で変更しない
(MISRA 13.6)。[採用指針: ] [規約化: ]
f)
(M3.1.1) 繰返し文では,ループを終了させるためのbreak文の使用を最大でも一つだけにする
(MISRA14.6)。[採用指針: ] [規約化: ]
g) (M3.1.3) continue文を使用しない(MISRA 14.5)。[採用指針: ] [規約化: ]
h) (R3.1.2) 配列を順次にアクセスするループの継続条件には,配列の範囲内であるかの判定を入れる。
[採用指針: ] [規約化: ]
i)
(M1.9.2) 《無限ループの書き方を規定する。》[採用指針:必要] [規約化:規約]
B.5.4 その他(文)
a) (M2.1.2) if,else if,else,while,do,for及びswitchの各文の本体はブロック化する。[採用指針: ] [規
約化: ]
b) (M3.1.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) goto文を使用しない。
2) goto文は,多重ループを抜ける場合又はエラー処理に分岐する場合だけに使用する。
c) (M3.1.5) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 関数は,一つのreturn文で終了する。
2) 処理の途中で復帰するreturn文は,異常復帰の場合だけとする。
d) (M3.2.2) 一つの文に,代入を複数記述しない。ただし,同じ値を複数の変数に代入する場合を除く。
[採用指針:必要] [規約化: ]
B.6
マクロ及び前処理系
B.6.1 #if系
a) (M4.7.2) #ifdef,#ifndef,#ifに対応する #else,#endifは,同一ファイル内に記述し,プロジェクトで
規定した注釈を入れ,対応関係を明確にする。[採用指針:必要] [規約化:規約]
b) (M4.7.3) #ifで,マクロ名が定義済みかを調べる場合は,defined(マクロ名)によって定義済みかを調
べる。#ifマクロ名 という書き方をしない。[採用指針:基本] [規約化: ]
c) (M4.7.4) #if ,#elifで使用するdefined 演算子は,defined(マクロ名)又はdefinedマクロ名という書
き方以外は書かない。[採用指針: ] [規約化: ]
85
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
B.6.2 #include
a) (P1.4.1) #include 指令の後には,<filename> 又は "filename" を続ける(MISRA 19.3)。[採用指針:基
本] [規約化: ]
b) (P1.4.2) 《#includeのファイル指定で,<> 形式と"" 形式との使い分け方を規定する。》[採用指針: ]
[規約化:規約]
c) (P1.4.3) #includeのファイル指定では,文字 ',\,",/*,及び : は使用しない。[採用指針:必要] [規
約化: ]
d) (P1.5.1) #includeのファイル指定では,絶対パスは記述しない。[採用指針: ] [規約化: ]
B.6.3 マクロ
a) (M4.7.1) 演算子を含むマクロは,マクロ本体及びマクロ引数を括弧で囲む。[採用指針:必要] [規約
化: ]
b) (M1.8.2) Cマクロは,波括弧で囲まれた初期化子,定数,括弧で囲まれた式,型修飾子,記憶域クラ
ス指定子,又はdo-while-zero 構造だけに展開する(MISRA 19.4)。[採用指針: ] [規約化: ]
c) (M4.7.5) マクロは,ブロック内で#define,又は#undefしない(MISRA 19.5)。[採用指針: ] [規約化: ]
d) (M4.7.6) #undefは使用しない(MISRA 19.6)。[採用指針: ] [規約化: ]
B.6.4 その他(前処理系)
a) (M1.12.1) 前処理系が削除する部分でも正しい記述をする。[採用指針: ] [規約化: ]
b) (M1.8.3) #lineは,ツールによる自動生成以外では使用しない。[採用指針: ] [規約化: ]
c) (M5.1.2) 次のいずれかを選択する。[採用指針: ] [規約化:選択]
1) 前処理演算子 #及び ##は使用しない(MISRA 19.13)。
2) 一つのマクロ定義内で#又は## 前処理演算子を複数回使用しない(MISRA 19.12)。
B.7
その他(環境など)
B.7.1 移植性
a) (P1.1.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択,文書]
1) C90の仕様外の機能は使用しない。
2) C90の仕様外の機能を使用する場合は,《使用する機能とその使い方を文書化する。》
b) (P1.1.2) 《使用する処理系定義の動作は全て文書化する。》(MISRA 3.1)[採用指針:必要] [規約化:
文書]
c) (P1.2.1) プログラムの記述において,C90で規定している文字以外の文字を使用する場合,コンパイ
ラの仕様を確認し《その使い方を規定する。》[採用指針: ] [規約化:規約]
d) (P1.2.2) 言語規格で定義されている英字逆斜線表記(エスケープシーケンス)だけを使用する。[採用
指針: ] [規約化: ]
e) (P1.1.3) 他言語で書かれたプログラムを利用する場合,《そのインタフェースを文書化し,使用方法を
規定する。》[採用指針: ] [規約化:文書,規約]
f)
(P2.1.1) C言語からアセンブリ言語のプログラムを呼び出す場合,インラインアセンブリ言語だけが含
まれるC言語の関数として表現する,マクロで記述するなど,《局所化する方法を規定する。》[採用指
針:必要] [規約化:規約]
g) (P2.1.2) 処理系が拡張しているキーワードは,《マクロを規定して》局所化して使用する。[採用指針:
必要] [規約化:規約]
86
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
B.7.2 性能
a) (E1.1.1) 関数形式マクロは,速度性能に関わる部分に閉じて使用する。[採用指針:基本] [規約化: ]
b) (E1.1.2) 繰返し処理内で,変化のない処理をしない。[採用指針:基本] [規約化: ]
c) (E1.1.3) 関数の引数として構造体ではなく構造体ポインタを使用する。[採用指針: ] [規約化: ]
d) (E1.1.4) 《switch文とするかif文とするかは,可読性及び効率性を考えて選択方針を決定し,規定す
る。》[採用指針: ] [規約化:規約]
B.7.3 デバッグ用記述
(M5.1.1) 《デバッグオプション設定時のコーディング方法及びリリースモジュールにログを残すための
コーディング方法を規定する。》[採用指針:必要] [規約化:規約]
B.7.4 その他
(M5.2.1) 次のいずれかを選択する。[採用指針: ] [規約化:選択,規約]
1) 動的メモリは使用しない。
2) 動的メモリを使用する場合は,《使用するメモリ量の上限,メモリ不足の場合の処理,デバッグ方法
などを規定する。》
87
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書C
(参考)
C言語処理系定義文書化テンプレート
この附属書は,本体の規定を補足するものであって,規定の一部ではない。
C.1 処理系定義文書化テンプレート
処理系定義の機能を利用する場合には,採用した処理系の仕様を文書化しなければならない。
そのための文書化テンプレートを,表C.1から表C.4までを含む次の記述で示す。
表C.1−処理系定義文書化テンプレート
処理系名
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
1
診断メッセ
ージ
どのような方法で診断メ
ッセージを識別するか
P1.1.2
多くの場合記述不要(問
題にならない。)。
2
開始
main関数への実引数の意
味
P1.1.2
main関数への実引数を
利用する。
3
対話型装置 対話型装置がどのような
もので構成されるか
P1.1.2
多くの場合記述不要。
4
名前の識別 外部結合でない識別子に
おいて(31以上の)意味
がある先頭の文字列
P1.1.2
32文字以上の名前を付
ける(C90では外部識別
子は,5文字までで識別
できる必要があるが,現
在の処理系で31文字機
能をもっていないコン
パイラはないに等しく,
また,C99では,外部も
最低31文字意味がある
となっているため,外部
も32以上の場合だけ,
処理系の動作検査を必
須とした。)。
( )文字
5
外部結合の識別子におい
て(6以上の)意味がある
先頭の文字列
P1.1.2
( )文字
6
外部結合である識別子に
おいて英小文字と英大文
字との区別に意味がある
か否か
P1.1.2
必須(命名規約で大文字
小文字の区別に注意す
ること。)
参考:C99では,言語規
格で区別することとな
っている。
□ 区別する
□ 区別しない
88
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.1−処理系定義文書化テンプレート(続き)
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
7
ソース及び
実行文字
ソース及び実行文字集合
の要素で,言語仕様で明示
的に規定しているもの以
外の要素
P1.2.1
基本ソース文字集合又
は基本実行文字集合以
外の文字を利用する。
注記:基本ソース文字集
合とは,アルファベット
26文字の大文字,小文
字,10進数字,29個の
図形文字(!,",など),
空白,水平タブ,垂直タ
ブ,書式送りを示す制御
文字である。基本実行文
字集合は,基本ソース文
字集合に加えて,5個の
制御文字(\0,\a,\b,\r,
\n)を加えたものであ
る。
注釈に日本語を記述す
る場合,この項目に該当
する。
ソース文字:
日本語文字,エンコードは
シフトJIS
実行文字:
日本語文字,エンコードは
EUC
8
多バイト文字のコード化
のために使用されるシフ
ト状態
P1.1.2
上記7で利用文字(実行
文字)を明確化すれば,
必要なし。
9
実行文字集合の文字にお
けるビット数
P1.1.2
8bitのことが多い。16bit
の場合は記す。
□ 8bit
□ 16bit
□ その他
( )
10
(文字定数内及び文字列
リテラル内の)ソース文字
集合の要素と実行文字集
合の要素との対応付け
P1.1.2
7 でほぼ説明される。特
別なことがもしあれば
記す。
11
基本実行文字集合で表現
できない文字若しくは英
字逆斜線表記を含む単純
文字定数の値,又はワイド
文字定数に対しては拡張
文字集合で表現できない
文字若しくは英字逆斜線
表記を含むワイド文字定
数の値
P1.1.2
次のいずれかを利用す
る。
・ 基本実行文字集合
で表現できない文
字
・ 英字逆斜線表記を
含む単純文字定数
・ ワイド文字定数
− 拡張文字集合で
表現できない文
字
− 英字逆斜線表記
注記:定義は利用すると
した部分だけでよい。
・ 基本実行文字集合で
表現できない文字
・ 英字逆斜線表記を含
む単純文字定数
・ ワイド文字定数
− 拡張文字集合で表
現できない文字
− 英字逆斜線表記

89
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.1−処理系定義文書化テンプレート(続き)
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
12 ソース及び
実行文字
(続き)
2文字以上の文字を含む単
純文字定数又は2文字以
上の多バイト文字を含む
ワイド文字定数の値
P1.1.2
2文字以上の文字を含
む文字定数を利用する。
例:'ab' '漢' L'ab'
・ 2文字以上の文字を含
む単純文字定数の値
・ 2文字以上の多バイト
文字を含むワイド文
字定数の値
13
ワイド文字定数に対して,
多バイト文字を対応する
ワイド文字(コード)に変
換するために使用される
ロケール
P1.1.2
多バイト文字を利用す
る。
14 データ型の
範囲
“単なる(符号指定のな
い)”charがsigned charと
同じ値の範囲をもつか,
unsigned charと同じ値の
範囲をもつか
P1.1.2
単なるcharを利用する。
□ signed charと同じ
□ unsigned charと同じ
15
整数の様々な型の表現方
法及び値の集合
P2.1.3
必須である。
表C.2参照。
16
整数をより短い符号付き
整数に変換した結果,又は
符合なし整数を長さの等
しい符号付き整数に変換
した結果で,値が表現でき
ない場合の変換結果
P1.1.2
より短い符号付きの型
への変換,又は長さの等
しい符号なしから符号
付きへの変換を実施す
る。
より短い符号付きの型へ
の変換
□ ビット列イメージその
まま(上位ビット切捨て)
□ その他
( )
符号なしから符号付きへ
の変換
□ ビット列イメージその
まま
□ その他
( )
17 演算結果
符号付き整数に対してビ
ット単位の演算(~,<<,
>>,&,^,|)を行った結
果
R2.6.2 符号付き整数にビット
単位の演算(~,<<,>>,
&,^,|)を実施する。
表C.3参照。
18
整数除算における剰余の
符号
P1.1.2
負の値の除算(/),剰余
算(%)を実施する
(C99では,除算の結果
は処理系依存ではなく
0方向に切捨てと決め
られている。)。
□ 被除数に一致
(除算の結果を0 方向に
切捨て)
□ 除数に一致
□ その他
( )
19
負の値をもつ符号付き汎
整数型の右シフトの結果
R2.5.4 負の値の符号付き汎整
数型に右シフトを実施
する。

90
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.1−処理系定義文書化テンプレート(続き)
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
20 浮動小数点 浮動小数点数の様々な型
の表現方法及び値の集合
R2.1.1
R2.1.2
浮動小数点を利用する。
21
汎整数の値を,元の値に正
確に表現することができ
ない浮動小数点数に変換
する場合の切捨ての方向
22
浮動小数点の値をより狭
い浮動小数点数に変換す
る場合の切捨ての方向
R2.1.1
R2.1.2
浮動小数点を利用する。
23 size̲t
配列の大きさの最大値を
保持するために必要な整
数の型,すなわちsizeof演
算子の型size̲t
P1.1.2
size̲tを利用する。
□ unsigned int
□ int
□ その他
( )
24 型変換
(ポインタ
及び整数)
ポインタを整数へキャス
トした結果,及びその逆の
場合の結果
R2.7.1 ポインタ又は整数のキ
ャストを利用する。
1. ポインタ->整数
□ ビットを保持する
□ その他
( )
2. 整数->ポインタ
□ ビットを保持する
□ その他
( )
25 ptrdiff̲t
同じ配列内の,二つの要素
へのポインタ間の差を保
持するために必要な整数
の型,すなわちptrdiff̲t
P1.1.2
ptrdiff̲tを利用する。
□ unsigned int
□ int
□ その他
( )
26 Register
指定
レジスタ記憶域クラス指
定子を使用することによ
って実際にオブジェクト
をレジスタに置くことが
できる範囲
P1.1.2
register指定を利用す
る。
27 共用体メン
バアクセス
共用体オブジェクトのメ
ンバを異なる型のメンバ
を用いてアクセスする場
合
M1.6.2 基本的に禁止する。
28 構造体メン
バの境界整
列
構造体のメンバの詰め物,
及び境界調整(これはある
処理系によって書かれた
バイナリデータを他の処
理系で読まない限り問題
にならない。)。
R2.1.3 構造体を利用し,そのバ
イナリデータを他の処
理系で読むことがある
(メモリのオーバレイ
使用はないとしている。
オーバレイ使用する場
合は,記述が必要であ
る。)。

91
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.1−処理系定義文書化テンプレート(続き)
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
29 ビットフィ
ールド
“単なる(符号指定のな
い)”int型のビットフィー
ルドが,signed intのビット
フィールドと扱われるか,
unsigned intのビットフィ
ールドとして扱われるか
P1.3.3
符号指定のないint型の
ビットフィールドを利
用する。
□ signed int
□ unsigned int
30
単位内のビットフィール
ドの割付け順序
P1.3.3
ビットフィールドをデ
ータ中のビット位置が
意味をもつ形で利用す
る。
(注:メモリのオーバレ
イ使用はないとしてい
る。オーバレイ使用する
場合は,記述が必要であ
る。)
□ 上位から下位
□ 下位から上位
31
ビットフィールドを記憶
域単位の境界をまたがっ
て割付け得るか否か
□ 境界をまたぐ
□ 次の単位に割付け
32 enumの型
列挙型の値を表現するた
めに選択される整数型
P1.3.2
列挙型を利用する。
□ int
□ その他
( )
33 volatile へ
のアクセス
volatile修飾型へのアクセ
スをどのように構成する
か
P1.1.2
volatile 指定を利用す
る。
34 宣言子の最
大個数
算術型,構造体型又は共用
体型を修飾する宣言子の
最大数
P1.1.2
多くの場合記述不要で
ある(問題になるほど少
ない処理系はほとんど
ない。)。
35 caseの最大
個数
switch文におけるcase値
の最大数
P1.1.2
多くの場合記述不要(問
題になるほど少ない処
理系はほとんどない。)。
36 条件取込み
における文
字定数
条件付き取込みを制御す
る定数式中の単一文字か
らなる文字定数の値が実
行文字集合中の同じ文字
定数の値に一致するか否
か,このような文字定数が
負の値をもつことがある
か否か。
P1.1.2
条件取込みの定数式中
に単一文字からなる文
字定数を使用する。
92
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.1−処理系定義文書化テンプレート(続き)
C言語仕様 処理系定義項目
関連
ルール
利用
対象処理系の仕様(利用欄
に○がある場合,仕様を明
示する。)
番
号
カテゴリ
内容
利用の意味
利用す
る場合
○
37 ソースファ
イル取込み
(#include)
取込み可能なソースファ
イルを探すための方法(こ
の項目は,<>に対するもの
と解釈する。)
P1.4.2
必須である[使用しない
ことはまれ(稀)であ
る。]。
<> で指定された取込みフ
ァイルの探索方法の例:
次の順序で探索する。
1) オプションで指定され
たディレクトリ
2) システムで規定されて
いるディレクトリ
38
取込み可能なソースファ
イルに対する"で囲まれた
名前の探索
P1.4.2
次の順序で探索する例:
1) ソースファイルのある
ディレクトリ
2) <>と同様の方法
39
ソースファイル名と文字
列との対応付け
P1.4.2
例:
文字どおりの指定とする。
40 #pragma
認識される#pragma指令の
動作
P1.1.2
#pragmaを利用する。
表C.4参照。
41 ̲̲DATE̲̲,
̲̲TIME̲̲
翻訳日付,及び翻訳時刻が
それぞれ有効でない場合
における̲̲DATE̲̲,及び
̲̲TIME̲̲の定義
P1.1.2
この機能はほとんど利
用しないと思われる。利
用する場合は記述する。
(1)基本型,ポインタ
注記 ルール (P2.1.3) を参照。基本型を利用しない場合(あるかないかも含む。)をプロジェクトで
決定し,簡単に説明する。プロジェクトで言語が定義している型に対して別の型名を定義しな
い場合は,先頭の型名欄を削除する。この注記は,テンプレートの一部ではない。
表C.2−基本型,ポインタ
プロジェクト
定義の型名
C言語の型
ビット数
最小値
最大値
境界整列
char
signed char
unsigned char
short
unsigned short
int
unsigned int
long
unsigned long
ポインタ
(2)符号付けのデータに対するビット単位演算子の動作
93
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表C.3−ビット単位演算子の動作
ビット単位演算子
動作
~
<<
>>
&
^
|
(3)#pragma一覧
このプロジェクトで使用してよいpragmaを示す。
表C.4−pragma一覧
pragma名
機能概略
94
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書D
(参考)
ソースコード品質の捉え方
この附属書は,本体の規定を補足するものであって,規定の一部ではない。
D.1 品質特性
ソフトウェアの品質というと,一般的に“バグ”を思い浮かべる場合もある。しかし,ソフトウェアエ
ンジニアリングの世界では,ソフトウェアの製品としての品質はより広い概念で捉えられている。このソ
フトウェア製品の品質概念を整理したものが,ISO/IEC 9126-1であり,これをJIS化したものがJIS X
0129-1である。
D.2 JIS X 0129-1とソースコードの品質との関係
JIS X 0129-1では,ソフトウェア製品の品質に関わる特性(品質特性)に関しては,信頼性,保守性,
移植性,効率性,機能性及び使用性の6特性を規定している。
このうち,機能性及び使用性の2特性については,より上流の設計段階以前に作り込むことが望ましい
と考えられている。これに対し,ソースコード段階では信頼性,保守性,移植性及び効率性の4特性が深
く関係すると考えられている。
このため,記述方法で提供する作法については,その大分類として,これらの4特性を採用している。
表D.1に,JIS X 0129-1の品質特性とこの規格が想定しているコードの品質との関係を品質副特性ととも
に示す。
95
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表D.1−ソフトウェアの品質特性とコードとの品質
品質特性(JIS X 0129-1)
品質副特性(JIS X 0129-1)
コードの品質
信
頼
性
指定された条件下で利
用するとき,指定され
た達成水準を維持する
ソフトウェア製品の能
力
成熟性
ソフトウェアに潜在する障害の結果として生じる故
障を回避するソフトウェア製品の能力
使い込んだとき
のバグの少なさ
障害許容性
ソフトウェアの障害部分を実行した場合,又は仕様化
されたインタフェース条件に違反が発生した場合に,
指定された達成水準を維持するソフトウェア製品の
能力
バグ,インタフ
ェース違反など
に対する許容性
回復性
故障時に,指定された達成水準を再確立し,直接に影
響を受けたデータを回復するソフトウェア製品の能
力
−
信頼性標準
適合性
信頼性に関連する規格,規約又は規則を遵守するソフ
トウェア製品の能力
−
保
守
性
修正のしやすさに関す
るソフトウェア製品の
能力
解析性
ソフトウェアにある欠陥の診断又は故障原因の追及,
及びソフトウェアの修正箇所の識別を行うためのソ
フトウェア製品の能力
コードの理解し
やすさ
変更性
指定された修正を行うことができるソフトウェア製
品の能力
コードの修正し
やすさ
安定性
ソフトウェアの修正による,予期せぬ影響を避けるソ
フトウェア製品の能力
修正による影響
の少なさ
試験性
修正したソフトウェアの妥当性確認ができるソフト
ウェア製品の能力
修正したコード
のテスト,デバ
ッグのしやすさ
保守性標準
適合性
保守性に関連する規格又は規約を遵守するソフトウ
ェア製品の能力
−
移
植
性
ある環境から他の環境
に移すためのソフトウ
ェア製品の能力
環境適応性
ソフトウェアにあらかじめ用意された以外の付加的
な作業又は手段なしに指定された異なる環境にソフ
トウェアを適応させるためのソフトウェア製品の能
力
異なる環境への
適応のしやす
さ。標準規格へ
の適合性も含む
設置性
指定された環境に設置するためのソフトウェア製品
の能力
−
共存性
共通の資源を共有する共通の環境の中で,他の独立し
たソフトウェアと共存するためのソフトウェア製品
の能力
−
置換性
同じ環境で,同じ目的のために,他の指定されたソフ
トウェア製品から置き換えて使用することができる
ソフトウェア製品の能力
−
移植性標準
適合性
移植性に関連する規格又は規約を遵守するソフトウ
ェア製品の能力
−
効
率
性
明示的な条件の下で,
使用する資源の量に対
比して適切な性能を提
供するソフトウェア製
品の能力
時間効率性
明示的な条件の下で,ソフトウェアの機能を実行する
際の,適切な応答時間,処理時間及び処理能力を提供
するソフトウェア製品の能力
処理時間に関す
る効率性
資源効率性
明示的な条件の下で,ソフトウェア機能を実行する際
の,資源の量及び資源の種類を適切に使用するソフト
ウェア製品の能力
資源に関する効
率性
効率性標準
適合性
効率性に関連する規格又は規約を遵守するソフトウ
ェア製品の能力
−
96
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
表D.1−ソフトウェアの品質特性とコードとの品質(続き)
品質特性(JIS X 0129-1)
品質副特性(JIS X 0129-1)
コードの品質
機
能
性
ソフトウェアが,指定
された条件の下で利用
されるときに,明示的
及び暗示的必要性に合
致する機能を提供する
ソフトウェア製品の能
力
合目的性
指定された作業及び利用者の具体的目標に対して適
切な機能の集合を提供するソフトウェア製品の能力
−
正確性
必要とされる精度で,正しい結果若しくは正しい効
果,又は同意できる結果若しくは同意できる効果をも
たらすソフトウェア製品の能力
−
相互運用性
一つ以上の指定されたシステムと相互作用するソフ
トウェア製品の能力
−
セキュリティ 許可されていない人又はシステムが,情報又はデータ
を読んだり,修正したりすることができないように,
及び許可された人又はシステムが,情報又はデータへ
のアクセスを拒否されないように,情報又はデータを
保護するソフトウェア製品の能力(JIS X 0160)
−
機能性標準
適合性
機能性に関連する規格,規約又は法律上及び類似の法
規上の規則を遵守するソフトウェア製品の能力
−
使
用
性
指定された条件の下で
利用するとき,理解,
習得,利用でき,利用
者にとって魅力的であ
るソフトウェア製品の
能力
理解性
ソフトウェアが特定の作業に特定の利用条件で適用
できるかどうか,及びどのように利用できるかを利用
者が理解できるソフトウェア製品の能力
−
習得性
ソフトウェアの適用を利用者が習得できるソフトウ
ェア製品の能力
−
運用性
利用者がソフトウェアの運用及び運用管理を行うこ
とができるソフトウェア製品の能力
−
魅力性
利用者にとって魅力的であるためのソフトウェア製
品の能力
−
使用性標準
適合性
使用性に関連する規格,規約,スタイルガイド又は規
則を遵守するソフトウェア製品の能力
−
97
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
附属書E
(参考)
参考文献
E.1
参考文献
(1)
JIS X 0201 7ビット及び8ビットの情報交換用符号化文字集合
注記 対応国際規格:ISO/IEC 646:1991,Information technology−ISO 7-bit coded character set for
information interchange(MOD)
(2)
JIS X 0160 ソフトウェアライフサイクルプロセス
注記 対応国際規格:ISO/IEC 12207:1995,Information technology−Software life cycle processes
(IDT)
(3)
JIS X 3014:2003 プログラム言語C++
注記 対応国際規格:ISO/IEC 14882:2003,Programming languages−C++(IDT)
(4)
"MISRA Guidelines For The Use Of The C Language In Vehicle Based Software", Motor Industry Software
Reliability Association, ISBN 0-9524156-9-0, Motor Industry Research Association, Nuneaton, April 1998
注記 www.misra-c.com
(5)
"MISRA-C:2004 Guidelines for the use of the C language in critical systems", Motor Industry Software
Reliability Association, ISBN 0-9524156-2-3, Motor Industry Research Association, Nuneaton, October 2004
注記 www.misra-c.com
(6)
"Indian Hill C Style and Coding Standards", ftp://ftp.cs.utoronto.ca/doc/programming/ihstyle.ps
(7)
"comp.lang.c Frequently Asked Questions", http://www.c-faq.com/
(8)
“組込み開発者におくるMISRA-C 組込みプログラミングの高信頼化ガイド”,MISRA-C研究会編,
ISBN 4-542-50334-8,日本規格協会,2004年5月
(9)
"GNU coding standards", Free Software Foundation, http://www.gnu.org/prep/standards/
(10)
"The C Programming Language, Second Edition", Brian W. Kernighan and Dennis Ritchie, ISBN
0-13-110362-8, Prentice Hall PTR, March 1988
注記 “プログラミング言語C 第2版(訳書訂正版)”,B.W.Kernighan,D.M.Ritchie著/石田晴
久訳,ISBN 4-320-02692-6,共立出版,1993年3月が翻訳書である。
(11)
"The C Programming Language", Brian W. Kernighan and Dennis Ritchie, ISBN 0-13-110163-3, Prentice
Hall PTR, September 1978
(12)
"Writing Solid Code: Microsoft's Techniques for Developing Bug-Free C Programs", Steve Maguire, ISBN
1-55615-551-4,Microsoft Press, May 1993
注記 “ライティング ソリッドコード”,Steve Maguire著/関本健太郎訳,ISBN 4-7561-0364-2,
アスキー,1995年3月が翻訳書である。
(13)
"The Practice of Programming", Brian W. Kernighan and Rob Pike, ISBN 0-201-61586-X, Addison Wesley
Professional, Feb 1999
注記 “プログラミング作法”,Brian W. Kernighan,Rob Pike著/福崎俊博訳,ISBN 4-7561-3649-4,
アスキー,2000年11月が翻訳書である。
(14)
"Linux kernel coding style", http://www.linux.or.jp/JF/JFdocs/kernel-docs-2.2/CodingStyle.html
98
X 0180:2011
2019年7月1日の法改正により名称が変わりました。まえがきを除き,本規格中の「日本工業規格」を「日本産業規格」に読み替えてください。
(15)
"C Style: Standards and Guidelines: Defining Programming Standards for Professional C Programmers",
David Straker, ISBN0-1311-6898-3, Prentice Hall, Jan 1992
注記 “Cスタイル標準とガイドライン”,David Straker著/奥田正人訳,ISBN 4-3037-2480-7,
海文堂出版,1993年2月が翻訳書である。
(16)
"C Programming FAQs: Frequently Asked Questions", ISBN0-2018-4519-9, Steve Summit
注記 “CプログラミングFAQ Cプログラミングの良く尋ねられる質問”,Steve Summit著/北
野欽一訳,ISBN 4-7753-0250-7,新紀元社,1997年3月が翻訳書である。
(17)
"C STYLE GUIDE (SOFTWARE ENGINEERING LABORATORY SERIES SEL-94-003)", NASA, Aug
1994, http://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/19950022400̲1995122400.pdf
(18)
TP-01002:2005,自動車用C言語利用のガイドライン(第2版),社団法人自動車技術会規格委員会